


















 Download code from GitHub
Download code from GitHub
Introducing Redash
Nowadays, every business creates vast amounts of data. Whether it’s plain logs, usage statistics, or user data, businesses tend to store it.
But without proper analysis and usage, this data just occupies space (S3s, self-hosted Hadoop clusters, regular RDBMS, and so on) and resources (someone must maintain the servers; otherwise, the data is lost).
The ultimate goal is to try to make the data work for the benefit of the company.
Data analysis rapidly expands beyound the domain of enclosed research departments and penetrates almost every department along the company's verticals.
The trend is that data insights move from business-supporting to business-generating roles.
In this chapter, we will cover the following topics:
- Data challenges experienced by companies on a daily basis
- Ideal tools to target challenges
- Meeting Redash
- Redash architecture
Data challenges experienced by companies on a daily basis
Let's have a look at an abstract example of a social gaming company and it's use of data:
- CEO/SVPs use generic knowledge of company revenues, pre-defined KPIs (new daily users/daily active users/churn rate)
- The marketing/business development departments use conversion funnels/campaign traction/pre-defined KPIs/growth rate/revenues (usually also sliced by department/game type/geolocation).
- The finance department uses various revenue breakdowns (by department/by external clients, and so on)
- The sales department uses revenues by campaigns breakdown (for better campaign evaluation)
- The product department uses statistics/growth rate/feature popularity/new daily users (to find out whether a specific feature attracts more users/revenue (with at least the same slicing as marketing)
- Customer support/QA/developers deal with bug rates/user reviews/usage statistics
- Data analytics/data scientists require data on usage statistics
- IT/DBAs/operations/infrastructure need information regarding load statistics/uptime/response SLAs/disk usage/CPU/memory (and other various system stats)
- External (contractors/clients/partners) require daily/weekly/monthly reports of various business metrics
As you can see, all the different departments rely on data and have their own specific data needs.
We can also note that if we treat each need as a building block, we can reuse them across departments.
But data is not only about numbers. People like to get a real feel, and that's where visualization can come in handy, especially when there is a need to discover trends or spot anomalies. Most of the time, it's much easier to track everything through charts and graphs, even if they represent an abstract trend.
Needless to say, each visualization forms a building block too.
All the preceding points can be joined by a dashboard (or, in most cases, dashboards), where every department has at least one of their own.
Moreover, good visualizations, which are tied together to make an understandable and meaningful user journey through the data (like dashboards), are almost mandatory for data-driven decision making (instead of decision making based on a gut feeling).
This data usage pattern is not unique to social gaming companies. In fact, you can easily define a starter pack of KPIs/metrics that are crucial to track the growth of any company.
An example dashboard
(image source: redash.io)
Suppose we want to provide our product department with a Redash usage dashboard (based on real Redash usage data), that consists of several metrics:

The preceding diagram is a Usage chart. Usage can be any form of interaction with Redash. This chart shows us the total amount of interactions with Redash per day over a 30-day period:

In the preceding chart, we can see that the different events have been broken down into types, which allows us to gain a better understanding of the main use cases of Redash:
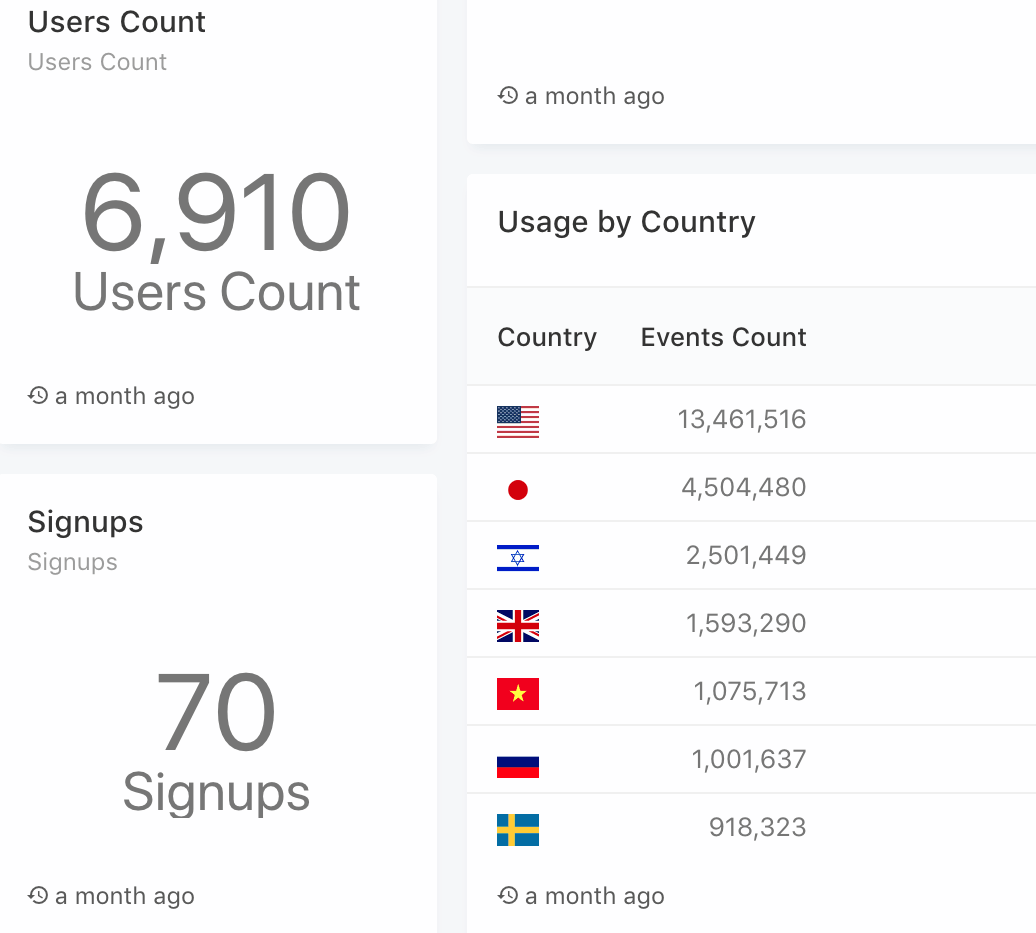
Along with a further breakout of events by Country (gives us a distribution of events in different countries), using IP2Location transformation. In addition to this, there are the new signups and the total user count metrics.
Every single one of these metrics can tell us something valuable, but when combined with a single dashboard (as you can see in the following diagram), a metric can tell us a whole different kind of story (which we will cover in upcoming chapters):

Ideal tools for targeting challenges
Based on the previous example, let’s summarize a set of features for an ideal tool that help the company as a whole make the most of its data:
- Easy to use: Not everyone in every department is a rocket scientist, so we need the tool to be as simple as possible.
- Easy to collaborate on: Since we have already defined the building blocks, it would be great if it can be used and, more importantly, re-used and extended.
It would be great if person A from marketing were to start to create a query and person B from sales were able to see it while it's being created, and then comment/modify and create a separate version of it.
The same goes for query visualizations and dashboards.
- Shareable: Preferably online, as there is no need to force anyone to install extra tools on their laptop. It must be flexible in terms of what to share, since we might want to expose it to someone outside the company (contractors/clients/partners).
- Should support a variety of Data Sources: Every department has its own Data Sources (the marketing department might have Oracle/MySQL/PostgreSQL, while the IT department might have InfluxDB/ElasticSearch, and so on), and it would be great to have a tool that connects to them all or, even better, a tool that can mix different Data Sources in the same dashboard.
- Query scheduling/auto-refresh: We want the dashboards to be up to date every time we look at them.
- Easily extendable: The data world changes rapidly; new Data Sources are being created, businesses demand new visualizations, new integrations pop up, and so on. We want to ensure that all of these factors are easily incorporated into our tool.
- Alerts: It would be very handy to be able to define critical thresholds for KPIs or metrics and receive an email/slack alert/custom notification if this occurs.
- API for external integrations: To fully unleash the power of company data, you can't skip the API part; every developer who has an idea of how to tailor the analytical tool to their own need must be provided with an easy way to do it. The same goes for integrations with external clients/partners who want to access the data programmatically—and what can be easier than the REST API?
- Fast: In a rapidly changing world and businesses that grow quickly, speed is king. When we say speed, we mean both tool response time and tool-get-the-task-done time. What is the tool worth if it takes half an hour just to create and visualize a single KPI?
Meeting Redash
Back in 2013, a company named EverythingMe was facing all the preceding challenges and yearned for a tool that would have an ideal set of features and fit in with our well-established data-driven culture.
After trying several legacy BI suites, a decision was made to create an easier, more collaborative, and faster tool having JSFiddle as inspiration.
These conditions stimulated the creation of Redash to target those requirements.
Redash was created during a hackathon by Arik Fraimovich, who then became the founder and lead developer of Redash.
While initially built to allow rapidly querying and visualizing data from Amazon Redshift (hence the name Re:Dash = Redshift + Dashboard), Redash quickly grew to become the company’s main data analysis, visualization, and dashboarding tool, serving all of the departments in the company.
More Data Sources and visualization types were added, people started to contribute to the source code, and eventually Redash was released as an open source tool, and later developed into a separate independent company, with Redash as its main product. Its main goal was to help other companies to become more data-driven with little to no effort, just as we did back in the days at EverythingMe.
What exactly is Redash?
In this paragraph, we will go over the key features of Redash to understand its possibilities and how it can fit into various departments within the company:
- Redash is an open source tool that is used to create, visualize, and share queries and dashboards.
- It works in the browser, so there's no need to install anything on a user’s computer: just click the link and log in.
- It's easy to set up and can provide any team member with the immediate power to analyze data.
- Redash is very easy and intuitive to use.
Even if a team member is not familiar with SQL syntax, they can utilize query parameters that they can easily modify to get the desired results, alternatively they can easily Fork (Duplicate—exactly as you would in GitHub), an existing query/visualization, and modify it according to their needs.
Both the query parameters and Forking work best as a quick intro into the Redash world.
- Redash allows you to share and embed queries/visualizations/dashboards, which is as easy as sending a URL.
- Redash supports many Data Sources. Whether it's RDBMS, BigData NoSQL, or REST API, you’ve got them all (a full list and further details are available in Chapter 4, Connecting to Data Sources). You can even define a query result as a separate datasource and use it later in other queries.
- There are a handful of various visualizations, so everyone in the company will find one that suits their mission best.
- Visualizations can be exported as PNGs, PDFs, and so on.
- Data can be exported as CSV/JSON and Excel.
- Redash includes query scheduling and an auto refresh mechanism.
- Redash provides you with an alerting mechanism, where you can define alerts (for example, if the new daily user numbers are below a certain threshold), and then get notifications about it via email/chat/a custom defined webhook.
- Redash provides live auto complete in the query editor and keyboard shortcuts.
- Automatic schema discovery for all Data Sources.
- Results are cached for minimal running times and rapid response. Results from the same query are reused; there is no resource wasting and needless query execution!
- There's SSO, access control, and many other great features for enterprise-friendly workflows, in regard to user management.
- Regarding the API, Redash provides a REST API that allows you to access all of its features programmatically, as well as pass dynamic parameters to queries. This can be used to extend functionality and tailor it to your own department's specific needs.
One example of this concerns data export for external clients, such as sending an automatic daily revenue report. Another great example of API usage is slack chatbot integration, which allows you to easily bring data into team conversations. A proper example of self-service is where any team member can fetch data insights from within a chat window, no coding is required, and there is no need to open tickets to the BI team: just type your request inside the chat and get the results!
- In addition to the API, Redash is open source, which means that you can extend any part you want (this will be covered in Chapter 8, Customizing Redash).
What if you need a different visualization type? You got it! You need a new datasource? This is a piece of cake. You need a new alert or a new API call? Everything is at your fingertips.
- With over 200 contributors and over 10,000 stars on GitHub, Redash has got a strong and vibrant community, and the project constantly evolves.
In summary, Redash improves—and makes more transparent to peers —a company's decision-making process, based on an easy and speedy creation of deep-dive dashboards over a company's Data Sources.
This speed comes from several aspects:
- There's no entry level barrier, as literally every team member can log in to Redash and start getting insights.
- There are suitable solutions across all the verticals and departments within the company, which eliminates the need to wait for other departments to get the data ready. This is tailored to your needs.
- Self-service is king, as you can fork the queries and modify them as required. You are in full control of your data and visualizations.
- You can query all the possible Data Sources from a single place, and join multiple Data Sources into a single dashboard.
- You can create crucial business alerts to keep you posted as they happen.
- Results are cached for faster retrieving and avoid the generation of useless loads on your Data Sources.
- Instant sharing! Just send the link and you're set.
Redash has two options that you can use: hosted (with monthly subscription plans) or self-hosted Open Source version (free, and you get to maintain it yourself).
The hosted version is suitable for companies who don't want the hassle of hosting and managing the Redash service (and the surrounding components such as Redis/PostgreSQL/Celery) by themselves (usually, this requires at least one or two dedicated employees, and not everyone has them available immediately).
The self-hosted version suits you best when you have the necessary resources (both machine and human) and:
- You want to extend Redash to your own specific needs
- You want to contribute to the open source community
- You want full control over your own data
The hosted and self-hosted versions are identical, and you can always switch back and forth.
It is recommended, however, to try the self-hosted Redash in development mode at the very least, as this way you can gain a better understanding of the internals of the tool that is about to change your company's data culture!
This book will cover only the self-hosted version of Redash (v5), all the covered themes are identical to the hosted version of Redash. Most of the themes are fully backwards compatible to versions older than v5, please refer to Redash official website to check the difference.
- Redash's official website can be found at https://redash.io/
- Redash's official Git repository can be found at https://github.com/getredash/redash
- Redash's knowledge base can be found at https://redash.io/help/
Redash architecture
Redash is a single-page web app, with JS frontend and backend.
Originally having the frontend written in AngularJS, since V5, it's in transition to React:
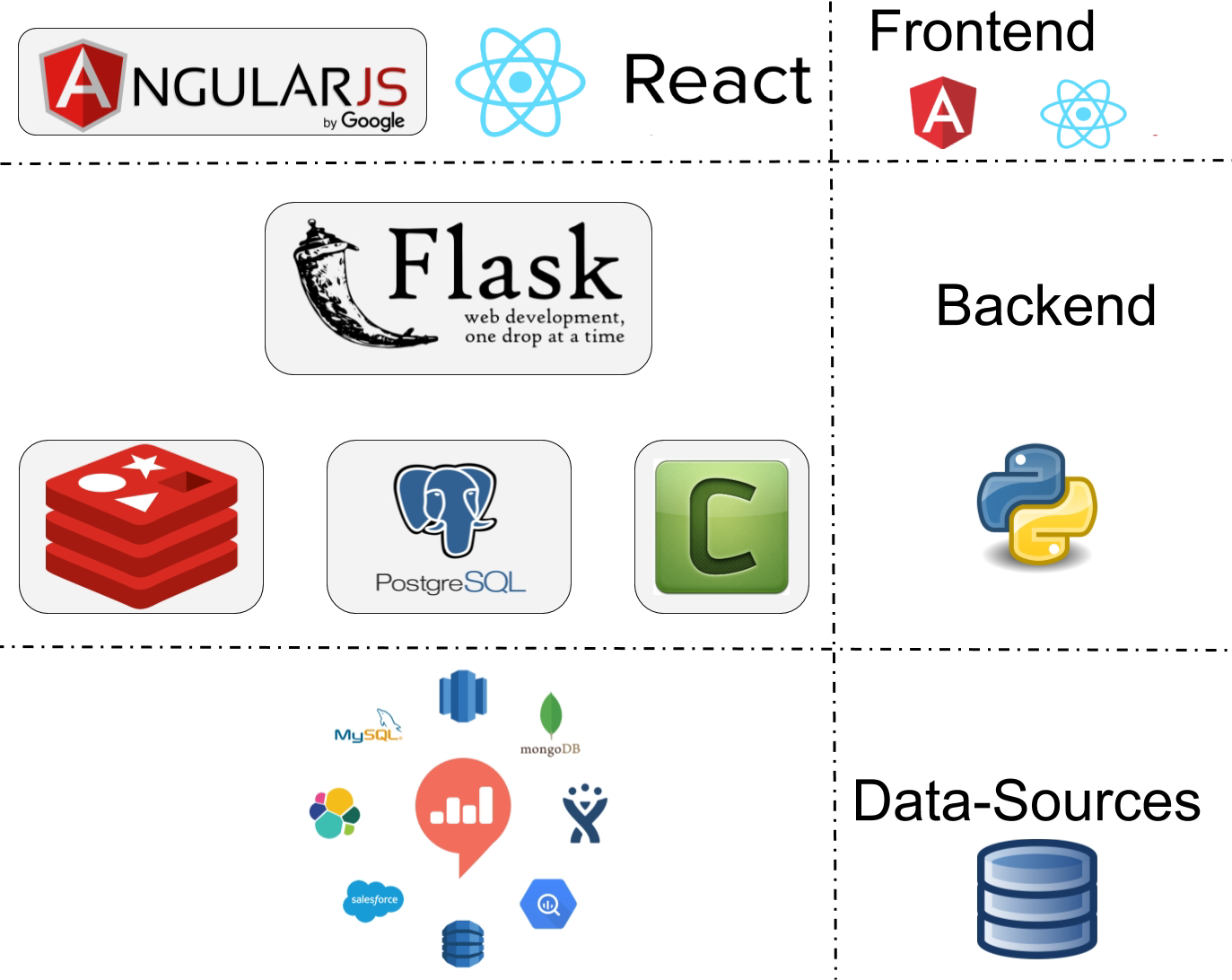
Redash itself is written in Python.
The UI (frontend) is AngularJS, which is responsible for all the visualizations, dashboards, and the query editor. The regular user interacts with this the most.
The server (backend) is a Flask App, which uses the Celery Distributed Task Queue as its task worker engine (Celery workers are responsible for query execution).
The server handles the actual query execution requests on various Data Sources, such as dashboard refresh requests, both from the frontend and from API calls (for example, slack bots, advanced user's webhooks, and so on).
The PostgreSQL database is used to store all the necessary application metadata and configurations (users/groups/datasource definitions/queries/dashboards).
Redis in the memory datastore serves as both the Celery Message Broker (Celery requires a message broker service to send and receive messages).
Summary
In this chapter, we've covered the challenges that every data-driven business should expect to come across, and how Redash comes in handy to target those challenges and help shorten the time between questions and answers by allowing the user to query all of their Data Sources from a single place, without moving the data anywhere.
Redash allows you to combine queries and visualizations from different Data Sources in a single dashboard to provide the business department with the most comprehensive overview possible.
In the sections that followed, we went over the main features of Redash, as well as its architecture in brief. In the next chapter, we will cover the installation options and a step-by-step guide to Redash.
If you're planning to use Redash as a hosted service, or if the installation of the software will be undertaken by another department, you can skip the next chapter.
