


















A common use of data mining is to detect patterns or rules in data.
The points of interest are the non-obvious patterns that can only be detected using a large dataset. The detection of simpler patterns, such as market basket analysis for purchasing associations or timings, has been possible for some time. Our interest in R programming is in detecting unexpected associations that can lead to new opportunities.
Some patterns are sequential in nature, for example, predicting faults in systems based on past results that are, again, only obvious using large datasets. These will be explored in the next chapter.
This chapter discusses the use of R to discover patterns in datasets' various methods:
Cluster analysis: This is the process of examining your data and establishing groups of data points that are similar. Cluster analysis can be performed using several algorithms. The different algorithms focus on using different attributes of the data distribution, such as distance between points, density, or statistical ranges.
Anomaly detection: This is the process of looking at data that appears to be similar but shows differences or anomalies for certain attributes. Anomaly detection is used frequently in the field of law enforcement, fraud detection, and insurance claims.
Association rules: These are a set of decisions that can be made from your data. Here, we are looking for concrete steps so that if we find one data point, we can use a rule to determine whether another data point will likely exist. Rules are frequently used in market basket approaches. In data mining, we are looking for deeper, non-obvious rules that are present in the data.
Cluster analysis can be performed using a variety of algorithms; some of them are listed in the following table:
Within an algorithm, there are finer levels of granularity as well, including:
In R programming, we have clustering tools for:
K-means clustering
K-medoids clustering
Hierarchical clustering
Expectation-maximization
Density estimation
K-means clustering is a method of partitioning the dataset into k clusters. You need to predetermine the number of clusters you want to divide the dataset into. The k-means algorithm has the following steps:
Select k random rows (centroids) from your data (you have a predetermined number of clusters to use).
We are using Lloyd's algorithm (the default) to determine clusters.
Assign each data point according to its closeness to a centroid.
Recalculate each centroid as an average of all the points associated with it.
Reassign each data point as closest to a centroid.
Continue with steps 3 and 4 until data points are no longer assigned or you have looped some maximum number of times.
This is a heuristic algorithm, so it is a good idea to run the process several times. It will normally run quickly in R, as the work in each step is not difficult. The objective is to minimize the sum of squares by constant refining of the terms.
Predetermining the number of clusters may be problematic. Graphing the data (or its squares or the like) should present logical groupings for your data visually. You can determine group sizes by iterating through the steps to determine the cutoff for selection (we will use that later in this chapter). There are other R packages that will attempt to compute this as well. You should also verify the fit of the clusters selected upon completion.
Using an average (in step 3) shows that k-means does not work well with fairly sparse data or data with a larger number of outliers. Furthermore, there can be a problem if the cluster is not in a nice, linear shape. Graphical representation should prove whether your data fits this algorithm.
K-means clustering is performed in R programming with the
kmeans function. The R programming usage of k-means clustering follows the convention given here (note that you can always determine the conventions for a function using the inline help function, for example, ?kmeans, to get this information):
kmeans(x,
centers,
iter.max = 10,
nstart = 1,
algorithm = c("Hartigan-Wong",
"Lloyd",
"Forgy",
"MacQueen"),
trace=FALSE)The various parameters are explained in the following table:
Calling the kmeans function returns a kmeans object with the following properties:
|
Property |
Description |
|---|---|
|
| |
|
| |
|
| |
|
| |
|
| |
|
| |
|
| |
|
| |
|
|
First, generate a hundred pairs of random numbers in a normal distribution and assign it to the matrix x as follows:
>x <- rbind(matrix(rnorm(100, sd = 0.3), ncol = 2),
matrix(rnorm(100, mean = 1, sd = 0.3), ncol = 2))We can display the values we generate as follows:
>x
[,1] [,2]
[1,] 0.4679569701 -0.269074028
[2,] -0.5030944919 -0.393382748
[3,] -0.3645075552 -0.304474590
…
[98,] 1.1121388866 0.975150551
[99,] 1.1818402912 1.512040138
[100,] 1.7643166039 1.339428999The the resultant kmeans object values can be determined and displayed (using 10 clusters) as follows:
> fit <- kmeans(x,10)
> fit
K-means clustering with 10 clusters of sizes 4, 12, 10, 7, 13, 16, 8, 13, 8, 9
Cluster means:
[,1] [,2]
1 0.59611989 0.77213527
2 1.09064550 1.02456563
3 -0.01095292 0.41255130
4 0.07613688 -0.48816360
5 1.04043914 0.78864770
6 0.04167769 -0.05023832
7 0.47920281 -0.05528244
8 1.03305030 1.28488358
9 1.47791031 0.90185427
10 -0.28881626 -0.26002816
Clustering vector:
[1] 7 10 10 6 7 6 3 3 7 10 4 7 4 7 6 7 6 6 4 3 10 4 3 6 10 6 6 3 6 10 3 6 4 3 6 3 6 6 6 7 3 4 6 7 6 10 4 10 3 10 5 2 9 2
[55] 9 5 5 2 5 8 9 8 1 2 5 9 5 2 5 8 1 5 8 2 8 8 5 5 8 1 1 5 8 9 9 8 5 2 5 8 2 2 9 2 8 2 8 2 8 9
Within cluster sum of squares by cluster:
[1] 0.09842712 0.23620192 0.47286373 0.30604945 0.21233870 0.47824982 0.36380678 0.58063931 0.67803464 0.28407093
(between_SS / total_SS = 94.6 %)
Available components:
[1] "cluster" "centers" "totss" "withinss" "tot.withinss" "betweenss" "size" "iter" "ifault"If we look at the results, we find some interesting data points:
The
Cluster meansshows the breakdown of the means used for the cluster assignments.The
Clustering vectorshows which cluster each of the 100 numbers was assigned to.The
Cluster sum of squaresshows thetotssvalue, as described in the output.The percentage value is the
betweenssvalue divided as a percentage of thetotssvalue. At 94.6 percent, we have a very good fit.
We chose an arbitrary cluster size of 10, but we should verify that this is a good number to use. If we were to run the kmeans function a number of times using a range of cluster sizes, we would end up with a graph that looks like the one in the following example.
For example, if we ran the following code and recorded the results, the output will be as follows:
results <- matrix(nrow=14, ncol=2, dimnames=list(2:15,c("clusters","sumsquares")))
for(i in 2:15) {
fit <- kmeans(x,i)
results[i-1,1] <- i
results[i-1,2] <- fit$totss
}
plot(results)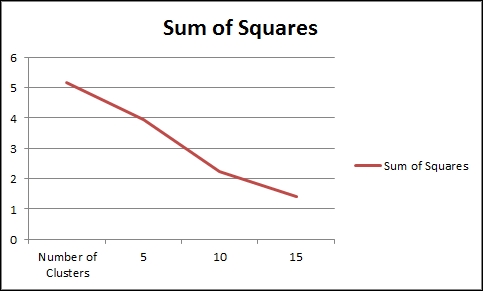
If the data were more distributed, there would be a clear demarcation about the maximum number of clusters, as further clustering will show no improvement in the sum of squares. However, since we used very smooth data for the test, the number of clusters could be allowed to increase.
Once your clusters have been determined, you should be able to gather a visual representation, as shown in the following plot:
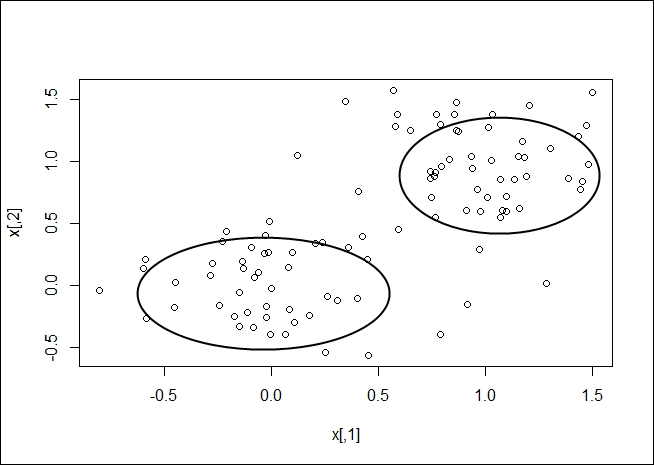
K-medoids clustering is another method of determining the clusters in a dataset. A medoid is an entity of the dataset that represents the group to which it was inserted. K-means works with centroids, which are artificially created to represent a cluster. So, a medoid is actually part of the dataset. A centroid is a derived amount.
When partitioning around medoids, make sure that the following points are taken care of:
Each entity is assigned to only one cluster
Each entity is assigned to the medoid that defines its cluster
Exactly k clusters are defined
The algorithm has two phases with several steps:
Build phase: During the build phase, we come up with initial estimates for the clusters:
Swap phase: In the swap phase, we fine-tune our initial estimates given the rough clusters determined in the build phase:
Search each cluster for the entity that lowers the average dissimilarity coefficient the most and therefore makes it the medoid for the cluster.
If any medoid has changed, start from step 3 of the build phase again.
K-medoid clustering is calculated in R programming with the pam function:
pam(x, k, diss, metric, medoids, stand, cluster.only, do.swap, keep.diss, keep.data, trace.lev)
The various parameters of the pam function are explained in the following table:
The results returned from the pam function can be displayed, which is rather difficult to interpret, or the results can be plotted, which is intuitively more understandable.
Using a simple set of data with two (visually) clear clusters as follows, as stored in a file named medoids.csv:
|
Object |
x |
y |
|---|---|---|
|
1 |
1 |
10 |
|
2 |
2 |
11 |
|
3 |
1 |
10 |
|
4 |
2 |
12 |
|
5 |
1 |
4 |
|
6 |
3 |
5 |
|
7 |
2 |
6 |
|
8 |
2 |
5 |
|
9 |
3 |
6 |
Let's use the pam function on the medoids.csv file as follows:
# load pam function
> library(cluster)
#load the table from a file
> x <- read.table("medoids.csv", header=TRUE, sep=",")
#execute the pam algorithm with the dataset created for the example
> result <- pam(x, 2, FALSE, "euclidean")
Looking at the result directly we get:
> result
Medoids:
ID Object x y
[1,] 2 2 2 11
[2,] 7 7 2 6
Clustering vector:
[1] 1 1 1 1 2 2 2 2 2
Objective function:
build swap
1.564722 1.564722
Available components:
[1] "medoids" "id.med" "clustering" "objective" "isolation"
[6] "clusinfo" "silinfo" "diss" "call" "data"Evaluating the results we can see:
We specified the use of two medoids, and row 3 and 6 were chosen
The rows were clustered as presented in the
clustering vector(as expected, about half in the first medoid and the rest in the other medoid)The function did not change greatly from the
buildphase to theswapphase (looking at theObjective functionvalues for build and swap of 1.56 versus 1.56)
Using a summary for a clearer picture, we see the following result:
> summary(result)
Medoids:
ID Object x y
[1,] 2 2 2 11
[2,] 7 7 2 6
Clustering vector:
[1] 1 1 1 1 2 2 2 2 2
Objective function:
build swap
1.564722 1.564722
Numerical information per cluster:
sizemax_dissav_diss diameter separation
[1,] 4 2.236068 1.425042 3.741657 5.744563
[2,] 5 3.000000 1.676466 4.898979 5.744563
Isolated clusters:
L-clusters: character(0)
L*-clusters: [1] 1 2
Silhouette plot information:
cluster neighbor sil_width
2 1 2 0.7575089
3 1 2 0.6864544
1 1 2 0.6859661
4 1 2 0.6315196
8 2 1 0.7310922
7 2 1 0.6872724
6 2 1 0.6595811
9 2 1 0.6374808
5 2 1 0.5342637
Average silhouette width per cluster:
[1] 0.6903623 0.6499381
Average silhouette width of total data set:
[1] 0.6679044
36 dissimilarities, summarized :
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.4142 2.3961 6.2445 5.2746 7.3822 9.1652
Metric : euclidean
Number of objects : 9
Available components:
[1] "medoids" "id.med" "clustering" "objective" "isolation"
[6] "clusinfo" "silinfo" "diss" "call" "data" Tip
Downloading the example code
You can download the example code files from your account at http://www.packtpub.com for all the Packt Publishing books you have purchased. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
The summary presents more details on the medoids and how they were selected. However, note the dissimilarities as well.
Plotting the data, we can see the following output:
#plot a graphic showing the clusters and the medoids of each cluster > plot(result$data, col = result$clustering)
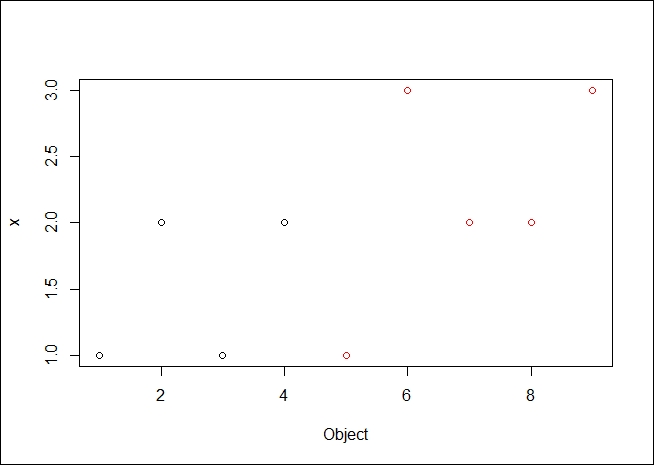
The resulting plot is as we expected it to be. It is good to see the data clearly broken into two medoids, both spatially and by color demarcation.
Hierarchical clustering is a method to ascertain clusters in a dataset that are in a hierarchy.
Using hierarchical clustering, we are attempting to create a hierarchy of clusters. There are two approaches of doing this:
The resulting hierarchy is normally displayed using a tree/graph model of a dendogram.
Hierarchical clustering is performed in R programming with the hclust function.
The hclust function is called as follows:
hclust(d, method = "complete", members = NULL)
The various parameters of the hclust function are explained in the following table:
We start by generating some random data over a normal distribution using the following code:
> dat <- matrix(rnorm(100), nrow=10, ncol=10)
> dat
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 1.4811953 -1.0882253 -0.47659922 0.22344983 -0.74227899 0.2835530
[2,] -0.6414931 -1.0103688 -0.55213606 -0.48812235 1.41763706 0.8337524
[3,] 0.2638638 0.2535630 -0.53310519 2.27778665 -0.09526058 1.9579652
[4,] -0.50307726 -0.3873578 -1.54407287 -0.1503834
Then, we calculate the hierarchical distribution for our data as follows:
> hc <- hclust(dist(dat))
> hc
Call:
hclust(d = dist(dat))
Cluster method : complete
Distance : euclidean
Number of objects: 10The resulting data object is very uninformative. We can display the hierarchical cluster using a dendogram, as follows:
>plot(hc)
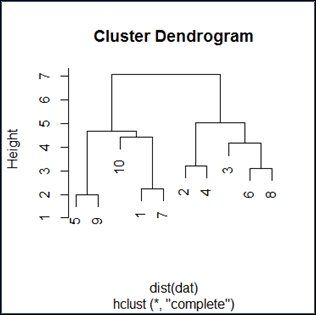
The dendogram has the expected shape. I find these diagrams somewhat unclear, but if you go over them in detail, the inference will be as follows:
Reading the diagram in a top-down fashion, we see it has two distinct branches. The implication is that there are two groups that are distinctly different from one another. Within the two branches, we see 10 and 3 as distinctly different from the rest. Generally, it appears that we have determined there are an even group and an odd group, as expected.
Reading the diagram bottom up, we see closeness and similarity over a number of elements. This would be expected from a simple random distribution.
Expectation-maximization (EM) is the process of estimating the parameters in a statistical model.
For a given model, we have the following parameters:
X: This is a set of observed dataZ: This is a set of missing valuesT: This is a set of unknown parameters that we should apply to our model to predictZ
The steps to perform expectation-maximization are as follows:
Initialize the unknown parameters (
T) to random values.Compute the best missing values (
Z) using the new parameter values.Use the best missing values (
Z), which were just computed, to determine a better estimate for the unknown parameters (T).Iterate over steps 2 and 3 until we have a convergence.
This version of the algorithm produces hard parameter values (Z). In practice, soft values may be of interest where probabilities are assigned to various values of the parameters (Z). By hard values, I mean we are selecting specific Z values. We could instead use soft values where Z varies by some probability distribution.
We use EM in R programming with the Mclust function from the mclust library. The full description of Mclust is the normal mixture modeling fitted via EM algorithm for model-based clustering, classification, and density estimation, including Bayesian regularization.
The Mclust function is as follows:
Mclust(data, G = NULL, modelNames = NULL,
prior = NULL, control = emControl(),
initialization = NULL, warn = FALSE, ...)The various parameters of the Mclust function are explained in the following table:
The Mclust function uses a model when trying to decide which items belong to a cluster. There are different model names for univariate, multivariate, and single component datasets. In each, the idea is to select a model that describes the data, for example, VII will be used for data that is spherically displaced with equal volume across each cluster.
|
Model |
Type of dataset |
|---|---|
|
Univariate mixture | |
|
E |
equal variance (one-dimensional) |
|
V |
variable variance (one-dimensional) |
|
Multivariate mixture | |
|
EII |
spherical, equal volume |
|
VII |
spherical, unequal volume |
|
EEI |
diagonal, equal volume and shape |
|
VEI |
diagonal, varying volume, equal shape |
|
EVI |
diagonal, equal volume, varying shape |
|
VVI |
diagonal, varying volume and shape |
|
EEE |
ellipsoidal, equal volume, shape, and orientation |
|
EEV |
ellipsoidal, equal volume and equal shape |
|
VEV |
ellipsoidal, equal shape |
|
VVV |
ellipsoidal, varying volume, shape, and orientation |
|
Single component | |
|
X |
univariate normal |
|
XII | |
|
XXI |
diagonal multivariate normal |
|
XXX |
ellipsoidal multivariate normal |
First, we must load the library that contains the mclust function (we may need to install it in the local environment) as follows:
> install.packages("mclust")
> library(mclust)We will be using the iris data in this example, as shown here:
> data <- read.csv("http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data")Now, we can compute the best fit via EM (note capitalization of Mclust) as follows:
> fit <- Mclust(data)
We can display our results as follows:
> fit
'Mclust' model object:
best model: ellipsoidal, equal shape (VEV) with 2 components
> summary(fit)
----------------------------------------------------
Gaussian finite mixture model fitted by EM algorithm
----------------------------------------------------
Mclust VEV (ellipsoidal, equal shape) model with 2 components:
log.likelihood n df BIC ICL
-121.1459 149 37 -427.4378 -427.4385
Clustering table:
1 2
49 100Simple display of the fit data object doesn't tell us very much, it shows just what was used to compute the density of the dataset.
The summary command presents more detailed information about the results, as listed here:
log.likelihood (-121): This is the log likelihood of the BIC valuen (149): This is the number of data pointsdf (37): This is the distributionBIC (-427): This is the Bayesian information criteria; this is an optimal valueICL (-427): Integrated Complete Data Likelihood—a classification version of the BIC. As we have the same value for ICL and BIC we classified the data points.
We can plot the results for a visual verification as follows:
> plot(fit)
You will notice that the plot command for EM produces the following four plots (as shown in the graph):
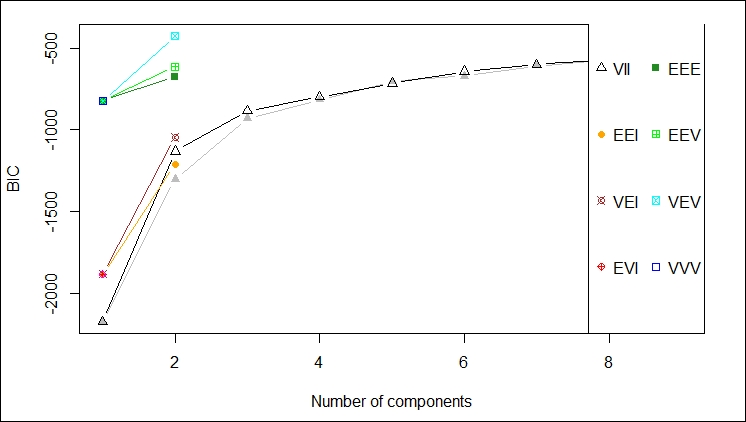
The BIC values used for choosing the number of clusters
A plot of the clustering
A plot of the classification uncertainty
The orbital plot of clusters
The following graph depicts the plot of density.
The first plot gives a depiction of the BIC ranges versus the number of components by different model names; in this case, we should probably not use VEV, for example:
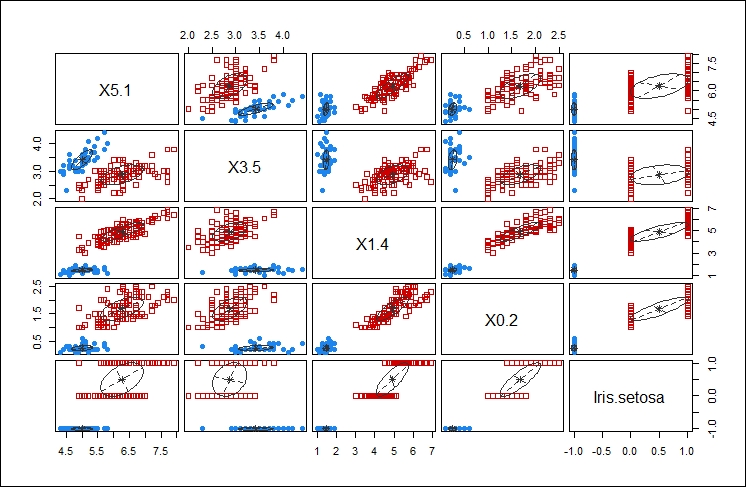
This second plot shows the comparison of using each of the components of the data feed against every other component of the data feed to determine the clustering that would result. The idea is to select the components that give you the best clustering of your data. This is one of those cases where your familiarity with the data is key to selecting the appropriate data points for clustering.
In this case, I think selecting X5.1 and X1.4 yield the tightest clusters, as shown in the following graph:
.
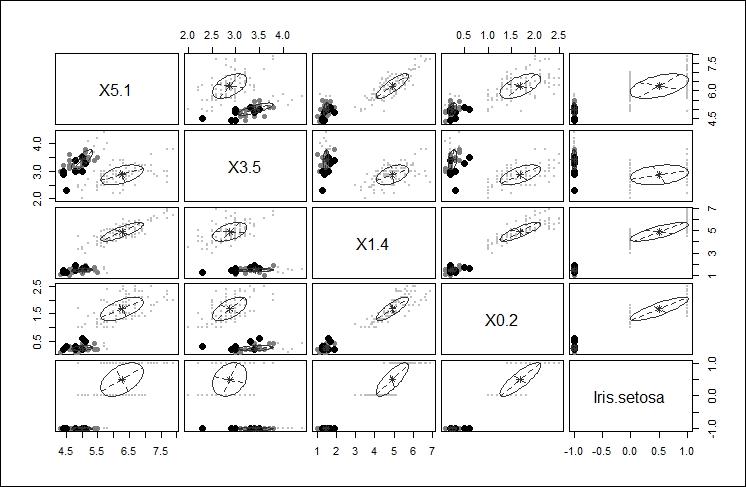
The third plot gives another iteration of the clustering affects of the different choices highlighting the main cluster by eliminating any points from the plot that would be applied to the main cluster, as shown here:
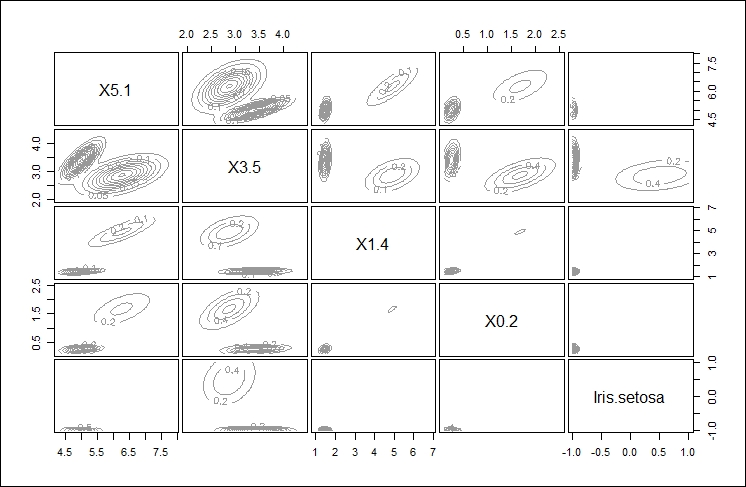
The final, fourth plot gives an orbital view of each of the clusters giving a highlight display of where the points might appear relative to the center of each cluster, as shown here:
Density estimation is the process of estimating the probability density function of a population given in an observation set. The density estimation process takes your observations, disperses them across a number of data points, runs a FF transform to determine a kernel, and then runs a linear approximation to estimate density.
Density estimation produces an estimate for the unobservable population distribution function. Some approaches that are used to produce the density estimation are as follows:
Parzen windows: In this approach, the observations are placed in a window and density estimates are made based on proximity
Vector quantization: This approach lets you model the probability density functions as per the distribution of observations
Histograms: With a histogram, you get a nice visual showing density (size of the bars); the number of bins chosen while developing the histogram decide your density outcome
Density estimation is performed via the density function in R programming. Other functions for density evaluation in R are:
|
Function |
Description |
|---|---|
|
|
This function determines clustering for fixed point clusters |
|
|
This function determines clustering for wide distribution clusters |
The
density function is invoked as follows:
density(x, bw = "nrd0", adjust = 1,
kernel = c("gaussian", "epanechnikov",
"rectangular",
"triangular", "biweight",
"cosine", "optcosine"),
weights = NULL, window = kernel, width,
give.Rkern = FALSE,
n = 512, from, to, na.rm = FALSE, ...) The various parameters of the density function are explained in the following table:
The available bandwidths can be found using the following commands:
bw.nrd0(x)
bw.nrd(x)
bw.ucv(x, nb = 1000, lower = 0.1 * hmax, upper = hmax, tol = 0.1 * lower)
bw.bcv(x, nb = 1000, lower = 0.1 * hmax, upper = hmax, tol = 0.1 * lower)
bw.SJ(x, nb = 1000, lower = 0.1 * hmax, upper = hmax, method =
c("ste", "dpi"), tol = 0.1 * lower)The various parameters of the bw function are explained in the following table:
We can use the iris dataset as follows:
> data <- read.csv("http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data")
The density of the X5.1 series (sepal length) can be computed as follows:
> d <- density(data$X5.1)
> d
Call:
density.default(x = data$X5.1)
Data: data$X5.1 (149 obs.); Bandwidth 'bw' = 0.2741
x y
Min.:3.478 Min. :0.0001504
1st Qu.:4.789 1st Qu.:0.0342542
Median :6.100 Median :0.1538908
Mean :6.100 Mean :0.1904755
3rd Qu.:7.411 3rd Qu.:0.3765078
Max. :8.722 Max. :0.3987472 We can plot the density values as follows:
> plot(d)
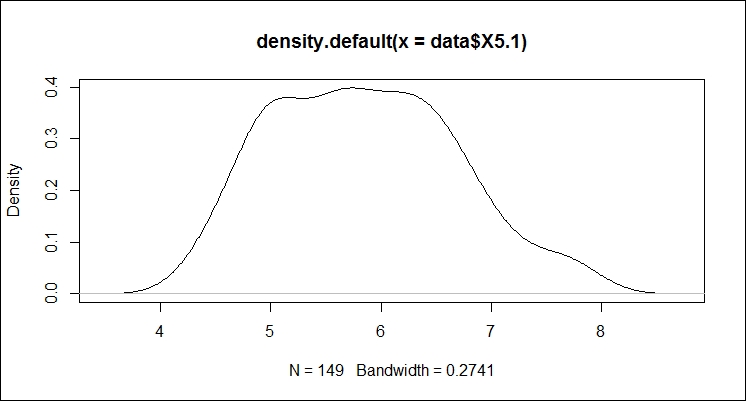
The plot shows most of the data occurring between 5 and 7. So, sepal length averages at just under 6.
We can use R programming to detect anomalies in a dataset. Anomaly detection can be used in a number of different areas, such as intrusion detection, fraud detection, system health, and so on. In R programming, these are called outliers. R programming allows the detection of outliers in a number of ways, as listed here:
Statistical tests
Depth-based approaches
Deviation-based approaches
Distance-based approaches
Density-based approaches
High-dimensional approaches
R programming has a function to display outliers: identify (in boxplot).
The boxplot function produces a box-and-whisker plot (see following graph). The boxplot function has a number of graphics options. For this example, we do not need to set any.
The identify function is a convenient method for marking points in a scatter plot. In R programming, box plot is a type of scatter plot.
In this example, we need to generate a 100 random numbers and then plot the points in boxes.
Then, we mark the first outlier with it's identifier as follows:
> y <- rnorm(100) > boxplot(y) > identify(rep(1, length(y)), y, labels = seq_along(y))
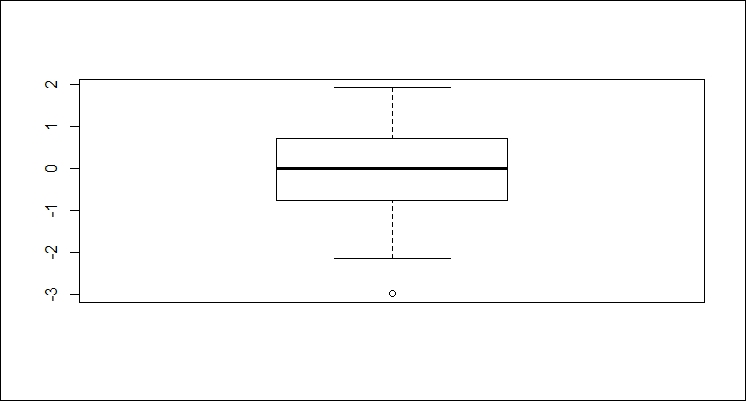
The boxplot function automatically computes the outliers for a set as well.
First, we will generate a 100 random numbers as follows (note that this data is randomly generated, so your results may not be the same):
> x <- rnorm(100)
We can have a look at the summary information on the set using the following code:
> summary(x)
Min. 1st Qu. Median Mean 3rd Qu. Max.
-2.12000 -0.74790 -0.20060 -0.01711 0.49930 2.43200Now, we can display the outliers using the following code:
> boxplot.stats(x)$out [1] 2.420850 2.432033
The following code will graph the set and highlight the outliers:
> boxplot(x)
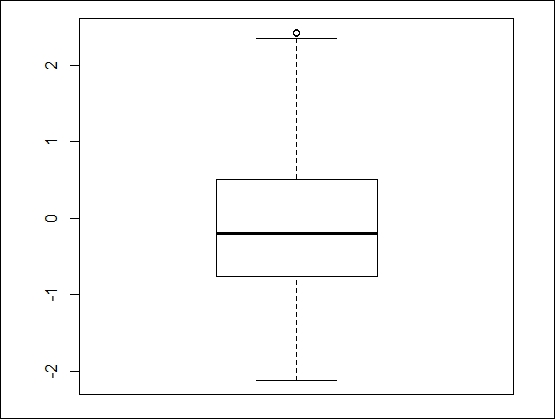
We can generate a box plot of more familiar data showing the same issue with outliers using the built-in data for cars, as follows:
boxplot(mpg~cyl,data=mtcars, xlab="Cylinders", ylab="MPG")
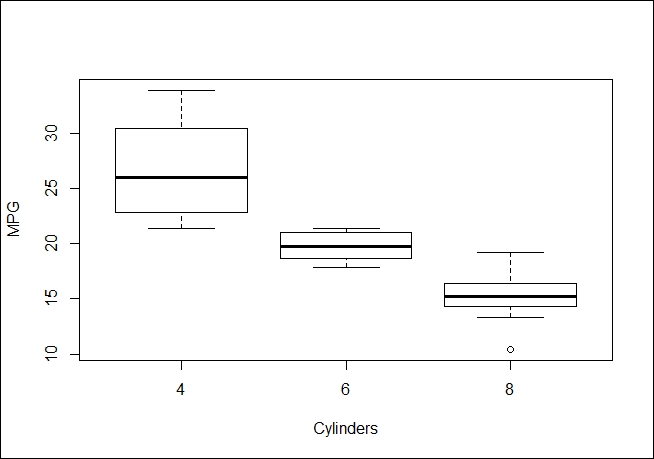
We can also use box plot's outlier detection when we have two dimensions. Note that we are forcing the issue by using a union of the outliers in x and y rather than an intersection. The point of the example is to display such points. The code is as follows:
> x <- rnorm(1000) > y <- rnorm(1000) > f <- data.frame(x,y) > a <- boxplot.stats(x)$out > b <- boxplot.stats(y)$out > list <- union(a,b) > plot(f) > px <- f[f$x %in% a,] > py <- f[f$y %in% b,] > p <- rbind(px,py) > par(new=TRUE) > plot(p$x, p$y,cex=2,col=2)
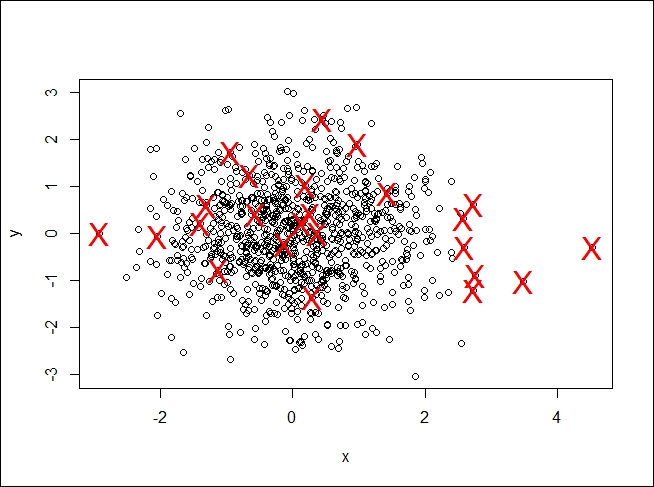
While R did what we asked, the plot does not look right. We completely fabricated the data; in a real use case, you would need to use your domain expertise to determine whether these outliers were correct or not.
Given the variety of what constitutes an anomaly, R programming has a mechanism that gives you complete control over it: write your own function that can be used to make a decision.
We can use the name function to create our own anomaly as shown here:
name <- function(parameters,…) {
# determine what constitutes an anomaly
return(df)
}Here, the parameters are the values we need to use in the function. I am assuming we return a data frame from the function. The function could do anything.
We will be using the iris data in this example, as shown here:
> data <- read.csv("http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data")If we decide an anomaly is present when sepal is under 4.5 or over 7.5, we could use a function as shown here:
> outliers <- function(data, low, high) {
> outs <- subset(data, data$X5.1 < low | data$X5.1 > high)
> return(outs)
>}Then, we will get the following output:
> outliers(data, 4.5, 7.5)
X5.1 X3.5 X1.4 X0.2 Iris.setosa
8 4.4 2.9 1.4 0.2 Iris-setosa
13 4.3 3.0 1.1 0.1 Iris-setosa
38 4.4 3.0 1.3 0.2 Iris-setosa
42 4.4 3.2 1.3 0.2 Iris-setosa
105 7.6 3.0 6.6 2.1 Iris-virginica
117 7.7 3.8 6.7 2.2 Iris-virginica
118 7.7 2.6 6.9 2.3 Iris-virginica
122 7.7 2.8 6.7 2.0 Iris-virginica
131 7.9 3.8 6.4 2.0 Iris-virginica
135 7.7 3.0 6.1 2.3 Iris-virginicaThis gives us the flexibility of making slight adjustments to our criteria by passing different parameter values to the function in order to achieve the desired results.
Another popular package is DMwR. It contains the lofactor function that can also be used to locate outliers. The DMwR package can be installed using the following command:
> install.packages("DMwR")
> library(DMwR)We need to remove the species column from the data, as it is categorical against it data. This can be done by using the following command:
> nospecies <- data[,1:4]
Now, we determine the outliers in the frame:
> scores <- lofactor(nospecies, k=3)
Next, we take a look at their distribution:
> plot(density(scores))
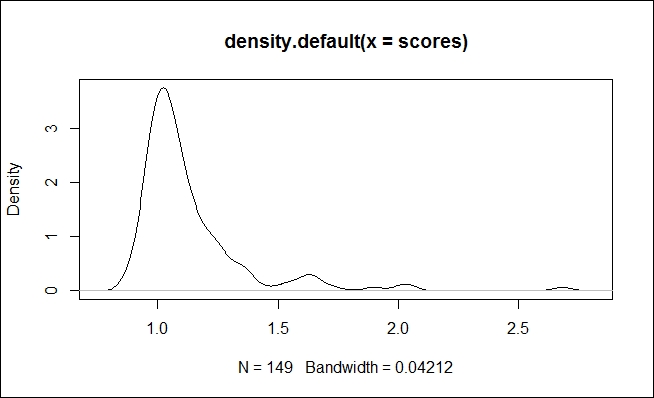
One point of interest is if there is some close equality amongst several of the outliers (that is, density of about 4).
Association rules describe associations between two datasets. This is most commonly used in market basket analysis. Given a set of transactions with multiple, different items per transaction (shopping bag), how can the item sales be associated? The most common associations are as follows:
Support: This is the percentage of transactions that contain A and B.
Confidence: This is the percentage (of time that rule is correct) of cases containing A that also contain B.
Lift: This is the ratio of confidence to the percentage of cases containing B. Please note that if lift is 1, then A and B are independent.
The most widely used tool in R from association rules is apriori.
The apriori rules library can be called as follows:
apriori(data, parameter = NULL, appearance = NULL, control = NULL)
The various parameters of the apriori library are explained in the following table:
You will need to load the apriori rules library as follows:
> install.packages("arules")
> library(arules)The market basket data can be loaded as follows:
> data <- read.csv("http://www.salemmarafi.com/wp-content/uploads/2014/03/groceries.csv")Then, we can generate rules from the data as follows:
> rules <- apriori(data)
parameter specification:
confidenceminvalsmaxaremavaloriginalSupport support minlenmaxlen target
0.8 0.1 1 none FALSE TRUE 0.1 1 10 rules
ext
FALSE
algorithmic control:
filter tree heap memopt load sort verbose
0.1 TRUE TRUE FALSE TRUE 2 TRUE
apriori - find association rules with the apriori algorithm
version 4.21 (2004.05.09) (c) 1996-2004 Christian Borgelt
set item appearances ...[0 item(s)] done [0.00s].
set transactions ...[655 item(s), 15295 transaction(s)] done [0.00s].
sorting and recoding items ... [3 item(s)] done [0.00s].
creating transaction tree ... done [0.00s].
checking subsets of size 1 2 3 done [0.00s].
writing ... [5 rule(s)] done [0.00s].
creating S4 object ... done [0.00s].There are several points to highlight in the results:
As you can see from the display, we are using the default settings (confidence 0.8, and so on)
We found 15,000 transactions for three items (picked from the 655 total items available)
We generated five rules
We can examine the rules that were generated as follows:
> rules
set of 5 rules
> inspect(rules)
lhsrhs support confidence lift
1 {semi.finished.bread=} => {margarine=} 0.2278522 1 2.501226
2 {semi.finished.bread=} => {ready.soups=} 0.2278522 1 1.861385
3 {margarine=} => {ready.soups=} 0.3998039 1 1.861385
4 {semi.finished.bread=,
margarine=} => {ready.soups=} 0.2278522 1 1.861385
5 {semi.finished.bread=,
ready.soups=} => {margarine=} 0.2278522 1 2.501226The code has been slightly reformatted for readability.
Looking over the rules, there is a clear connection between buying bread, soup, and margarine—at least in the market where and when the data was gathered.
If we change the parameters (thresholds) used in the calculation, we get a different set of rules. For example, check the following code:
> rules <- apriori(data, parameter = list(supp = 0.001, conf = 0.8))
This code generates over 500 rules, but they have questionable meaning as we now have the rules with 0.001 confidence.
Factual
How do you decide whether to use
kmeansorkdemoids?What is the significance of the boxplot layout? Why does it look that way?
Describe the underlying data produced in the outliers for the
irisdata, given the density plot.What are the extract rules for other items in the market dataset?
When, how, and why?
What is the risk of not vetting the outliers that are detected for the specific domain? Shouldn't the calculation always work?
Why do we need to exclude the
iriscategory column from the outlier detection algorithm? Can it be used in some way when determining outliers?Can you come up with a scenario where the market basket data and rules we generated were not applicable to the store you are working with?
Challenges
I found it difficult to develop test data for outliers in two dimensions that both occurred in the same instance using random data. Can you develop a test that would always have several outliers in at least two dimensions that occur in the same instance?
There is a good dataset on the Internet regarding passenger data on the Titanic. Generate the rules regarding the possible survival of the passengers.
In this chapter, we discussed cluster analysis, anomaly detection, and association rules. In cluster analysis, we use k-means clustering, k-medoids clustering, hierarchical clustering, expectation-maximization, and density estimation. In anomaly detection, we found outliers using built-in R functions and developed our own specialized R function. For association rules, we used the apriori package to determine the associations amongst datasets.
In the next chapter, we will cover data mining for sequences.

