


















In this chapter, we will cover the following recipes:
Tokenizing text into sentences
Tokenizing sentences into words
Tokenizing sentences using regular expressions
Training a sentence tokenizer
Filtering stopwords in a tokenized sentence
Looking up Synsets for a word in WordNet
Looking up lemmas and synonyms in WordNet
Calculating WordNet Synset similarity
Discovering word collocations
Natural Language ToolKit (NLTK) is a comprehensive Python library for natural language processing and text analytics. Originally designed for teaching, it has been adopted in the industry for research and development due to its usefulness and breadth of coverage. NLTK is often used for rapid prototyping of text processing programs and can even be used in production applications. Demos of select NLTK functionality and production-ready APIs are available at http://text-processing.com.
This chapter will cover the basics of tokenizing text and using WordNet. Tokenization is a method of breaking up a piece of text into many pieces, such as sentences and words, and is an essential first step for recipes in the later chapters. WordNet is a dictionary designed for programmatic access by natural language processing systems. It has many different use cases, including:
Looking up the definition of a word
Finding synonyms and antonyms
Exploring word relations and similarity
Word sense disambiguation for words that have multiple uses and definitions
NLTK includes a WordNet corpus reader, which we will use to access and explore WordNet. A corpus is just a body of text, and corpus readers are designed to make accessing a corpus much easier than direct file access. We'll be using WordNet again in the later chapters, so it's important to familiarize yourself with the basics first.
Tokenization is the process of splitting a string into a list of pieces or tokens. A token is a piece of a whole, so a word is a token in a sentence, and a sentence is a token in a paragraph. We'll start with sentence tokenization, or splitting a paragraph into a list of sentences.
Installation instructions for NLTK are available at http://nltk.org/install.html and the latest version at the time of writing this is Version 3.0b1. This version of NLTK is built for Python 3.0 or higher, but it is backwards compatible with Python 2.6 and higher. In this book, we will be using Python 3.3.2. If you've used earlier versions of NLTK (such as version 2.0), note that some of the APIs have changed in Version 3 and are not backwards compatible.
Once you've installed NLTK, you'll also need to install the data following the instructions at http://nltk.org/data.html. I recommend installing everything, as we'll be using a number of corpora and pickled objects. The data is installed in a data directory, which on Mac and Linux/Unix is usually /usr/share/nltk_data, or on Windows is C:\nltk_data. Make sure that tokenizers/punkt.zip is in the data directory and has been unpacked so that there's a file at tokenizers/punkt/PY3/english.pickle.
Finally, to run the code examples, you'll need to start a Python console. Instructions on how to do so are available at http://nltk.org/install.html. For Mac and Linux/Unix users, you can open a terminal and type python.
Once NLTK is installed and you have a Python console running, we can start by creating a paragraph of text:
>>> para = "Hello World. It's good to see you. Thanks for buying this book."
Note
Downloading the example code
You can download the example code files for all Packt books you have purchased from your account at http://www.packtpub.com. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
Now we want to split the paragraph into sentences. First we need to import the sentence tokenization function, and then we can call it with the paragraph as an argument:
>>> from nltk.tokenize import sent_tokenize >>> sent_tokenize(para) ['Hello World.', "It's good to see you.", 'Thanks for buying this book.']
So now we have a list of sentences that we can use for further processing.
The sent_tokenize function uses an instance of PunktSentenceTokenizer from the nltk.tokenize.punkt module. This instance has already been trained and works well for many European languages. So it knows what punctuation and characters mark the end of a sentence and the beginning of a new sentence.
The instance used in sent_tokenize() is actually loaded on demand from a pickle file. So if you're going to be tokenizing a lot of sentences, it's more efficient to load the PunktSentenceTokenizer class once, and call its tokenize() method instead:
>>> import nltk.data
>>> tokenizer = nltk.data.load('tokenizers/punkt/PY3/english.pickle')
>>> tokenizer.tokenize(para)
['Hello World.', "It's good to see you.", 'Thanks for buying this book.']If you want to tokenize sentences in languages other than English, you can load one of the other pickle files in tokenizers/punkt/PY3 and use it just like the English sentence tokenizer. Here's an example for Spanish:
>>> spanish_tokenizer = nltk.data.load('tokenizers/punkt/PY3/spanish.pickle')
>>> spanish_tokenizer.tokenize('Hola amigo. Estoy bien.')
['Hola amigo.', 'Estoy bien.']You can see a list of all the available language tokenizers in /usr/share/nltk_data/tokenizers/punkt/PY3 (or C:\nltk_data\tokenizers\punkt\PY3).
In this recipe, we'll split a sentence into individual words. The simple task of creating a list of words from a string is an essential part of all text processing.
Basic word tokenization is very simple; use the word_toke
nize() function:
>>> from nltk.tokenize import word_tokenize
>>> word_tokenize('Hello World.')
['Hello', 'World', '.']The word_tokenize() function is a wrapper function that calls tokenize() on an instance of the TreebankWordTokenizer class. It's equivalent to the following code:
>>> from nltk.tokenize import TreebankWordTokenizer
>>> tokenizer = TreebankWordTokenizer()
>>> tokenizer.tokenize('Hello World.')
['Hello', 'World', '.']It works by separating words using spaces and punctuation. And as you can see, it does not discard the punctuation, allowing you to decide what to do with it.
Ignoring the obviously named WhitespaceTokenizer and SpaceTokenizer, there are two other word tokenizers worth looking at: PunktWordTokenizer and WordPunctTokenizer. These differ from TreebankWordTokenizer by how they handle punctuation and contractions, but they all inherit from TokenizerI. The inheritance tree looks like what's shown in the following diagram:
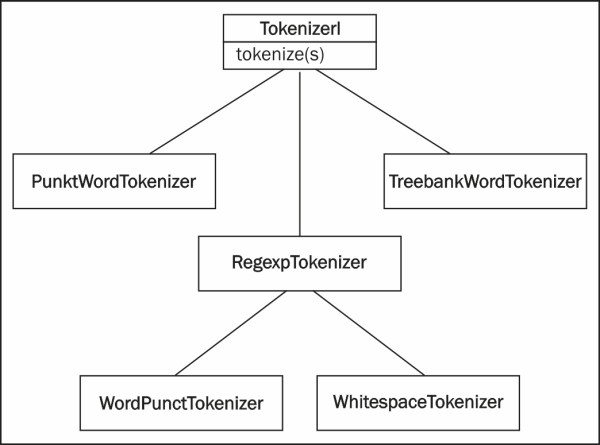
The TreebankWordTokenizer class uses conventions found in the Penn Treebank corpus. This corpus is one of the most used corpora for natural language processing, and was created in the 1980s by annotating articles from the Wall Street Journal. We'll be using this later in Chapter 4, Part-of-speech Tagging, and Chapter 5, Extracting Chunks.
One of the tokenizer's most significant conventions is to separate contractions. For example, consider the following code:
>>> word_tokenize("can't")
['ca', "n't"]If you find this convention unacceptable, then read on for alternatives, and see the next recipe for tokenizing with regular expressions.
An alternative word tokenizer is PunktWordTokenizer. It splits on punctuation, but keeps it with the word instead of creating separate tokens, as shown in the following code:
>>> from nltk.tokenize import PunktWordTokenizer
>>> tokenizer = PunktWordTokenizer()
>>> tokenizer.tokenize("Can't is a contraction.")
['Can', "'t", 'is', 'a', 'contraction.']For more control over word tokenization, you'll want to read the next recipe to learn how to use regular expressions and the RegexpTokenizer for tokenization. And for more on the Penn Treebank corpus, visit http://www.cis.upenn.edu/~treebank/.
Regular expressions can be used if you want complete control over how to tokenize text. As regular expressions can get complicated very quickly, I only recommend using them if the word tokenizers covered in the previous recipe are unacceptable.
First you need to decide how you want to tokenize a piece of text as this will determine how you construct your regular expression. The choices are:
Match on the tokens
Match on the separators or gaps
We'll start with an example of the first, matching alphanumeric tokens plus single quotes so that we don't split up contractions.
We'll create an instance of RegexpTokenizer, giving it a regular expression string to use for matching tokens:
>>> from nltk.tokenize import RegexpTokenizer
>>> tokenizer = RegexpTokenizer("[\w']+")
>>> tokenizer.tokenize("Can't is a contraction.")
["Can't", 'is', 'a', 'contraction']There's also a simple helper function you can use if you don't want to instantiate the class, as shown in the following code:
>>> from nltk.tokenize import regexp_tokenize
>>> regexp_tokenize("Can't is a contraction.", "[\w']+")
["Can't", 'is', 'a', 'contraction']Now we finally have something that can treat contractions as whole words, instead of splitting them into tokens.
The RegexpTokenizer class works by compiling your pattern, then calling re.findall() on your text. You could do all this yourself using the re module, but RegexpTokenizer implements the TokenizerI interface, just like all the word tokenizers from the previous recipe. This means it can be used by other parts of the NLTK package, such as corpus readers, which we'll cover in detail in Chapter 3, Creating Custom Corpora. Many corpus readers need a way to tokenize the text they're reading, and can take optional keyword arguments specifying an instance of a TokenizerI subclass. This way, you have the ability to provide your own tokenizer instance if the default tokenizer is unsuitable.
RegexpTokenizer can also work by matching the gaps, as opposed to the tokens. Instead of using re.findall(), the RegexpTokenizer class will use re.split(). This is how the BlanklineTokenizer class in nltk.tokenize is implemented.
The following is a simple example of using RegexpT
okenizer to tokenize on whitespace:
>>> tokenizer = RegexpTokenizer('\s+', gaps=True)
>>> tokenizer.tokenize("Can't is a contraction.")
["Can't", 'is', 'a', 'contraction.']Notice that punctuation still remains in the tokens. The gaps=True parameter means that the pattern is used to identify gaps to tokenize on. If we used gaps=False, then the pattern would be used to identify tokens.
NLTK's default sentence tokenizer is general purpose, and usually works quite well. But sometimes it is not the best choice for your text. Perhaps your text uses nonstandard punctuation, or is formatted in a unique way. In such cases, training your own sentence tokenizer can result in much more accurate sentence tokenization.
For this example, we'll be using the webtext corpus, specifically the overheard.txt file, so make sure you've downloaded this corpus. The text in this file is formatted as dialog that looks like this:
White guy: So, do you have any plans for this evening? Asian girl: Yeah, being angry! White guy: Oh, that sounds good.
As you can see, this isn't your standard paragraph of sentences formatting, which makes it a perfect case for training a sentence tokenizer.
NLTK provides a PunktSentenceTokenizer class that you can train on raw text to produce a custom sentence tokenizer. You can get raw text either by reading in a file, or from an NLTK corpus using the raw() method. Here's an example of training a sentence tokenizer on dialog text, using overheard.txt from the webtext corpus:
>>> from nltk.tokenize import PunktSentenceTokenizer
>>> from nltk.corpus import webtext
>>> text = webtext.raw('overheard.txt')
>>> sent_tokenizer = PunktSentenceTokenizer(text)Let's compare the results to the default sentence tokenizer, as follows:
>>> sents1 = sent_tokenizer.tokenize(text) >>> sents1[0] 'White guy: So, do you have any plans for this evening?' >>> from nltk.tokenize import sent_tokenize >>> sents2 = sent_tokenize(text) >>> sents2[0] 'White guy: So, do you have any plans for this evening?' >>> sents1[678] 'Girl: But you already have a Big Mac...' >>> sents2[678] 'Girl: But you already have a Big Mac...\\nHobo: Oh, this is all theatrical.'
While the first sentence is the same, you can see that the tokenizers disagree on how to tokenize sentence 679 (this is the first sentence where the tokenizers diverge). The default tokenizer includes the next line of dialog, while our custom tokenizer correctly thinks that the next line is a separate sentence. This difference is a good demonstration of why it can be useful to train your own sentence tokenizer, especially when your text isn't in the typical paragraph-sentence structure.
The PunktSentenceTokenizer class uses an unsupervised learning algorithm to learn what constitutes a sentence break. It is unsupervised because you don't have to give it any labeled training data, just raw text. You can read more about these kinds of algorithms at https://en.wikipedia.org/wiki/Unsupervised_learning. The specific technique used in this case is called sentence boundary detection and it works by counting punctuation and tokens that commonly end a sentence, such as a period or newline, then using the resulting frequencies to decide what the sentence boundaries should actually look like.
This is a simplified description of the algorithm—if you'd like more details, take a look at the source code of the nltk.tokenize.punkt.PunktTrainer class, which can be found online at http://www.nltk.org/_modules/nltk/tokenize/punkt.html#PunktSentenceTokenizer.
The PunktSentenceTokenizer class learns from any string, which means you can open a text file and read its content. Here is an example of reading overheard.txt directly instead of using the raw() corpus method. This assumes that the webtext corpus is located in the standard directory at /usr/share/nltk_data/corpora. We also have to pass a specific encoding to the open() function, as follows, because the file is not in ASCII:
>>> with open('/usr/share/nltk_data/corpora/webtext/overheard.txt', encoding='ISO-8859-2') as f:
... text = f.read()
>>> sent_tokenizer = PunktSentenceTokenizer(text)
>>> sents = sent_tokenizer.tokenize(text)
>>> sents[0]
'White guy: So, do you have any plans for this evening?'
>>> sents[678]
'Girl: But you already have a Big Mac...'Once you have a custom sentence tokenizer, you can use it for your own corpora. Many corpus readers accept a sent_tokenizer parameter, which lets you override the default sentence tokenizer object with your own sentence tokenizer. Corpus readers are covered in more detail in Chapter 3, Creating Custom Corpora.
Stopwords are common words that generally do not contribute to the meaning of a sentence, at least for the purposes of information retrieval and natural language processing. These are words such as the and a. Most search engines will filter out stopwords from search queries and documents in order to save space in their index.
NLTK comes with a stopwords corpus that contains word lists for many languages. Be sure to unzip the data file, so NLTK can find these word lists at nltk_data/corpora/stopwords/.
We're going to create a set of all English stopwords, then use it to filter stopwords from a sentence with the help of the following code:
>>> from nltk.corpus import stopwords
>>> english_stops = set(stopwords.words('english'))
>>> words = ["Can't", 'is', 'a', 'contraction']
>>> [word for word in words if word not in english_stops]
["Can't", 'contraction']The stopwords corpus is an instance of nltk.corpus.reader.WordListCorpusReader. As such, it has a words() method that can take a single argument for the file ID, which in this case is 'english', referring to a file containing a list of English stopwords. You could also call stopwords.words() with no argument to get a list of all stopwords in every language available.
You can see the list of all English stopwords using stopwords.words('english') or by examining the word list file at nltk_data/corpora/stopwords/english. There are also stopword lists for many other languages. You can see the complete list of languages using the fileids method as follows:
>>> stopwords.fileids() ['danish', 'dutch', 'english', 'finnish', 'french', 'german', 'hungarian', 'italian', 'norwegian', 'portuguese', 'russian', 'spanish', 'swedish', 'turkish']
Any of these fileids can be used as an argument to the words() method to get a list of stopwords for that language. For example:
>>> stopwords.words('dutch')
['de', 'en', 'van', 'ik', 'te', 'dat', 'die', 'in', 'een', 'hij', 'het', 'niet', 'zijn', 'is', 'was', 'op', 'aan', 'met', 'als', 'voor', 'had', 'er', 'maar', 'om', 'hem', 'dan', 'zou', 'of', 'wat', 'mijn', 'men', 'dit', 'zo', 'door', 'over', 'ze', 'zich', 'bij', 'ook', 'tot', 'je', 'mij', 'uit', 'der', 'daar', 'haar', 'naar', 'heb', 'hoe', 'heeft', 'hebben', 'deze', 'u', 'want', 'nog', 'zal', 'me', 'zij', 'nu', 'ge', 'geen', 'omdat', 'iets', 'worden', 'toch', 'al', 'waren', 'veel', 'meer', 'doen', 'toen', 'moet', 'ben', 'zonder', 'kan', 'hun', 'dus', 'alles', 'onder', 'ja', 'eens', 'hier', 'wie', 'werd', 'altijd', 'doch', 'wordt', 'wezen', 'kunnen', 'ons', 'zelf', 'tegen', 'na', 'reeds', 'wil', 'kon', 'niets', 'uw', 'iemand', 'geweest', 'andere']If you'd like to create your own stopwords corpus, see the Creating a wordlist corpus recipe in Chapter 3, Creating Custom Corpora, to learn how to use WordListCorpusReader. We'll also be using stopwords in the Discovering word collocations recipe later in this chapter.
WordNet is a lexical database for the English language. In other words, it's a dictionary designed specifically for natural language processing.
NLTK comes with a simple interface to look up words in WordNet. What you get is a list of Synset instances, which are groupings of synonymous words that express the same concept. Many words have only one Synset, but some have several. In this recipe, we'll explore a single Synset, and in the next recipe, we'll look at several in more detail.
Be sure you've unzipped the wordnet corpus at nltk_data/corpora/wordnet. This will allow WordNetCorpusReader to access it.
Now we're going to look up the Synset for cookbook, and explore some of the properties and methods of a Synset using the following code:
>>> from nltk.corpus import wordnet
>>> syn = wordnet.synsets('cookbook')[0]
>>> syn.name()
'cookbook.n.01'
>>> syn.definition()
'a book of recipes and cooking directions'You can look up any word in WordNet using wordnet.synsets(word) to get a list of Synsets. The list may be empty if the word is not found. The list may also have quite a few elements, as some words can have many possible meanings, and, therefore, many Synsets.
Each Synset in the list has a number of methods you can use to learn more about it. The name() method will give you a unique name for the Synset, which you can use to get the Synset directly:
>>> wordnet.synset('cookbook.n.01')
Synset('cookbook.n.01')The definition() method should be self-explanatory. Some Synsets also have an examples() method, which contains a list of phrases that use the word in context:
>>> wordnet.synsets('cooking')[0].examples()
['cooking can be a great art', 'people are needed who have experience in cookery', 'he left the preparation of meals to his wife']Synsets are organized in a structure similar to that of an inheritance tree. More abstract terms are known as hypernyms and more specific terms are hyponyms. This tree can be traced all the way up to a root hypernym.
Hypernyms provide a way to categorize and group words based on their similarity to each other. The Calculating WordNet Synset similarity recipe details the functions used to calculate the similarity based on the distance between two words in the hypernym tree:
>>> syn.hypernyms()
[Synset('reference_book.n.01')]
>>> syn.hypernyms()[0].hyponyms()
[Synset('annual.n.02'), Synset('atlas.n.02'), Synset('cookbook.n.01'), Synset('directory.n.01'), Synset('encyclopedia.n.01'), Synset('handbook.n.01'), Synset('instruction_book.n.01'), Synset('source_book.n.01'), Synset('wordbook.n.01')]
>>> syn.root_hypernyms()
[Synset('entity.n.01')]As you can see, reference_book is a hypernym of cookbook, but cookbook is only one of the many hyponyms of reference_book. And all these types of books have the same root hypernym, which is entity, one of the most abstract terms in the English language. You can trace the entire path from entity down to cookbook using the hypernym_paths() method, as follows:
>>> syn.hypernym_paths()
[[Synset('entity.n.01'), Synset('physical_entity.n.01'), Synset('object.n.01'), Synset('whole.n.02'), Synset('artifact.n.01'), Synset('creation.n.02'), Synset('product.n.02'), Synset('work.n.02'), Synset('publication.n.01'), Synset('book.n.01'), Synset('reference_book.n.01'), Synset('cookbook.n.01')]]The hypernym_paths() method returns a list of lists, where each list starts at the root hypernym and ends with the original Synset. Most of the time, you'll only get one nested list of Synsets.
You can also look up a simplified part-of-speech tag as follows:
>>> syn.pos() 'n'
There are four common part-of-speech tags (or POS tags) found in WordNet, as shown in the following table:
|
Part of speech |
Tag |
|---|---|
|
Noun |
n |
|
Adjective |
a |
|
Adverb |
r |
|
Verb |
v |
These POS tags can be used to look up specific Synsets for a word. For example, the word 'great' can be used as a noun or an adjective. In WordNet, 'great' has 1 noun Synset and 6 adjective Synsets, as shown in the following code:
>>> len(wordnet.synsets('great'))
7
>>> len(wordnet.synsets('great', pos='n'))
1
>>> len(wordnet.synsets('great', pos='a'))
6These POS tags will be referenced more in the Using WordNet for tagging recipe in Chapter 4, Part-of-speech Tagging.
In the next two recipes, we'll explore lemmas and how to calculate Synset similarity. And in Chapter 2, Replacing and Correcting Words, we'll use WordNet for lemmatization, synonym replacement, and then explore the use of antonyms.
Building on the previous recipe, we can also look up lemmas in WordNet to find synonyms of a word. A lemma (in linguistics), is the canonical form or morphological form of a word.
In the following code, we'll find that there are two lemmas for the cookbook Synset using the lemmas() method:
>>> from nltk.corpus import wordnet
>>> syn = wordnet.synsets('cookbook')[0]
>>> lemmas = syn.lemmas()
>>> len(lemmas)
2
>>> lemmas[0].name()
'cookbook'
>>> lemmas[1].name()
'cookery_book'
>>> lemmas[0].synset() == lemmas[1].synset()
TrueAs you can see, cookery_book and cookbook are two distinct lemmas in the same Synset. In fact, a lemma can only belong to a single Synset. In this way, a Synset represents a group of lemmas that all have the same meaning, while a lemma represents a distinct word form.
Since all the lemmas in a Synset have the same meaning, they can be treated as synonyms. So if you wanted to get all synonyms for a Synset, you could do the following:
>>> [lemma.name() for lemma in syn.lemmas()] ['cookbook', 'cookery_book']
As mentioned earlier, many words have multiple Synsets because the word can have different meanings depending on the context. But, let's say you didn't care about the context, and wanted to get all the possible synonyms for a word:
>>> synonyms = []
>>> for syn in wordnet.synsets('book'):
... for lemma in syn.lemmas():
... synonyms.append(lemma.name())
>>> len(synonyms)
38As you can see, there appears to be 38 possible synonyms for the word 'book'. But in fact, some synonyms are verb forms, and many synonyms are just different usages of 'book'. If, instead, we take the set of synonyms, there are fewer unique words, as shown in the following code:
>>> len(set(synonyms)) 25
Some lemmas also have antonyms. The word good, for example, has 27 Synsets, five of which have lemmas with antonyms, as shown in the following code:
>>> gn2 = wordnet.synset('good.n.02')
>>> gn2.definition()
'moral excellence or admirableness'
>>> evil = gn2.lemmas()[0].antonyms()[0]
>>> evil.name
'evil'
>>> evil.synset().definition()
'the quality of being morally wrong in principle or practice'
>>> ga1 = wordnet.synset('good.a.01')
>>> ga1.definition()
'having desirable or positive qualities especially those suitable for a thing specified'
>>> bad = ga1.lemmas()[0].antonyms()[0]
>>> bad.name()
'bad'
>>> bad.synset().definition()
'having undesirable or negative qualities'The antonyms() method returns a list of lemmas. In the first case, as we can see in the previous code, the second Synset for good as a noun is defined as moral excellence, and its first antonym is evil, defined as morally wrong. In the second case, when good is used as an adjective to describe positive qualities, the first antonym is bad, which describes negative qualities.
In the next recipe, we'll learn how to calculate Synset similarity. Then in Chapter 2, Replacing and Correcting Words, we'll revisit lemmas for lemmatization, synonym replacement, and antonym replacement.
Synsets are organized in a hypernym tree. This tree can be used for reasoning about the similarity between the Synsets it contains. The closer the two Synsets are in the tree, the more similar they are.
If you were to look at all the hyponyms of reference_book (which is the hypernym of cookbook), you'd see that one of them is instruction_book. This seems intuitively very similar to a cookbook, so let's see what WordNet similarity has to say about it with the help of the following code:
>>> from nltk.corpus import wordnet
>>> cb = wordnet.synset('cookbook.n.01')
>>> ib = wordnet.synset('instruction_book.n.01')
>>> cb.wup_similarity(ib)
0.9166666666666666So they are over 91% similar!
The wup_similarity method is short for
Wu-Palmer Similarity, which is a scoring method based on how similar the word senses are and where the Synsets occur relative to each other in the hypernym tree. One of the core metrics used to calculate similarity is the shortest path distance between the two Synsets and their common hypernym:
>>> ref = cb.hypernyms()[0] >>> cb.shortest_path_distance(ref) 1 >>> ib.shortest_path_distance(ref) 1 >>> cb.shortest_path_distance(ib) 2
So cookbook and instruction_book must be very similar, because they are only one step away from the same reference_book hypernym, and, therefore, only two steps away from each other.
Let's look at two dissimilar words to see what kind of score we get. We'll compare dog with cookbook, two seemingly very different words.
>>> dog = wordnet.synsets('dog')[0]
>>> dog.wup_similarity(cb)
0.38095238095238093Wow, dog and cookbook are apparently 38% similar! This is because they share common hypernyms further up the tree:
>>> sorted(dog.common_hypernyms(cb))
[Synset('entity.n.01'), Synset('object.n.01'), Synset('physical_entity.n.01'), Synset('whole.n.02')]The previous comparisons were all between nouns, but the same can be done for verbs as well:
>>> cook = wordnet.synset('cook.v.01')
>>> bake = wordnet.0('bake.v.02')
>>> cook.wup_similarity(bake)
00.6666666666666666The previous Synsets were obviously handpicked for demonstration, and the reason is that the hypernym tree for verbs has a lot more breadth and a lot less depth. While most nouns can be traced up to the hypernym object, thereby providing a basis for similarity, many verbs do not share common hypernyms, making WordNet unable to calculate the similarity. For example, if you were to use the Synset for bake.v.01 in the previous code, instead of bake.v.02, the return value would be None. This is because the root hypernyms of both the Synsets are different, with no overlapping paths. For this reason, you also cannot calculate the similarity between words with different parts of speech.
Two other similarity comparisons are the path similarity and the LCH similarity, as shown in the following code:
>>> cb.path_similarity(ib) 0.3333333333333333 >>> cb.path_similarity(dog) 0.07142857142857142 >>> cb.lch_similarity(ib) 2.538973871058276 >>> cb.lch_similarity(dog) 0.9985288301111273
As you can see, the number ranges are very different for these scoring methods, which is why I prefer the wup_similarity method.
Collocations are two or more words that tend to appear frequently together, such as United States. Of course, there are many other words that can come after United, such as United Kingdom and United Airlines. As with many aspects of natural language processing, context is very important. And for collocations, context is everything!
In the case of collocations, the context will be a document in the form of a list of words. Discovering collocations in this list of words means that we'll find common phrases that occur frequently throughout the text. For fun, we'll start with the script for Monty Python and the Holy Grail.
The script for Monty Python and the Holy Grail is found in the webtext corpus, so be sure that it's unzipped at nltk_data/corpora/webtext/.
We're going to create a list of all lowercased words in the text, and then produce BigramCollocationFinder, which we can use to find bigrams, which are pairs of words. These bigrams are found using association measurement functions in the nltk.met
rics package, as follows:
>>> from nltk.corpus import webtext
>>> from nltk.collocations import BigramCollocationFinder
>>> from nltk.metrics import BigramAssocMeasures
>>> words = [w.lower() for w in webtext.words('grail.txt')]
>>> bcf = BigramCollocationFinder.from_words(words)
>>> bcf.nbest(BigramAssocMeasures.likelihood_ratio, 4)
[("'", 's'), ('arthur', ':'), ('#', '1'), ("'", 't')]Well, that's not very useful! Let's refine it a bit by adding a word filter to remove punctuation and stopwords:
>>> from nltk.corpus import stopwords
>>> stopset = set(stopwords.words('english'))
>>> filter_stops = lambda w: len(w) < 3 or w in stopset
>>> bcf.apply_word_filter(filter_stops)
>>> bcf.nbest(BigramAssocMeasures.likelihood_ratio, 4)
[('black', 'knight'), ('clop', 'clop'), ('head', 'knight'), ('mumble', 'mumble')]Much better, we can clearly see four of the most common bigrams in Monty Python and the Holy Grail. If you'd like to see more than four, simply increase the number to whatever you want, and the collocation finder will do its best.
BigramCollocationFinder constructs two frequency distributions: one for each word, and another for bigrams. A frequency distribution, or FreqDist in NLTK, is basically an enhanced Python dictionary where the keys are what's being counted, and the values are the counts. Any filtering functions that are applied reduce the size of these two FreqDists by eliminating any words that don't pass the filter. By using a filtering function to eliminate all words that are one or two characters, and all English stopwords, we can get a much cleaner result. After filtering, the collocation finder is ready to accept a generic scoring function for finding collocations.
In addition to BigramCollocationFinder, there's also TrigramCollocationFinder, which finds triplets instead of pairs. This time, we'll look for trigrams in Australian singles advertisements with the help of the following code:
>>> from nltk.collocations import TrigramCollocationFinder
>>> from nltk.metrics import TrigramAssocMeasures
>>> words = [w.lower() for w in webtext.words('singles.txt')]
>>> tcf = TrigramCollocationFinder.from_words(words)
>>> tcf.apply_word_filter(filter_stops)
>>> tcf.apply_freq_filter(3)
>>> tcf.nbest(TrigramAssocMeasures.likelihood_ratio, 4)
[('long', 'term', 'relationship')]Now, we don't know whether people are looking for a long-term relationship or not, but clearly it's an important topic. In addition to the stopword filter, I also applied a frequency filter, which removed any trigrams that occurred less than three times. This is why only one result was returned when we asked for four because there was only one result that occurred more than two times.
There are many more scoring functions available besides likelihood_ratio(). But other than raw_freq(), you may need a bit of a statistics background to understand how they work. Consult the NLTK API documentation for NgramAssocMeasures in the nltk.metrics package to see all the possible scoring functions.
In addition to the nbest() method, there are two other ways to get ngrams (a generic term used for describing bigrams and trigrams) from a collocation finder:
above_score(score_fn, min_score): This can be used to get all ngrams with scores that are at leastmin_score. Themin_scorevalue that you choose will depend heavily on thescore_fnyou use.score_ngrams(score_fn): This will return a list with tuple pairs of (ngram, score). This can be used to inform your choice formin_score.
The nltk.metrics module will be used again in the Measuring precision and recall of a classifier and Calculating high information words recipes in Chapter 7, Text Classification.


