


















Learning Objectives
By the end of this lesson, you will be able to:
Describe high availability and disaster recovery
Explain the different HA and DR concepts and terminology
Describe the different HA and DR solutions available in SQL Server
Describe replication concepts and terminology
Describe the different types of replication
Configure and troubleshoot snapshot replication
This lesson will discuss the common concepts related to high availability and disaster recovery. We will then see how to configure snapshot replication.
Business continuity is of utmost importance in today's world. An application downtime that's even as low as a few minutes may result in potential revenue loss for companies such as Amazon and Flipkart. Downtime not only results in direct revenue loss as transactions are dropped as and when downtime happens, it also contributes to a bad user experience.
Often, application downtime because of programming or functional issues doesn't affect the entire application and can be fixed by the developers quickly. However, downtime caused by infrastructure or system failure affects the entire application and can't be controlled functionally (by the developers).
This is where high availability (HA) and disaster recovery (DR) are required. In this lesson, you'll learn about high availability and disaster recovery concepts and terminology, and the different solutions that are available in Microsoft SQL Server to achieve HA and DR.
The type of HA and DR solution implemented by a business depends majorly on the service level agreement (SLA). The SLA defines the recovery point objective (RPO) and recovery time objective (RTO), which will be discussed in detail later in this lesson.
High availability refers to providing an agreed level of system or application availability by minimizing the downtime caused by infrastructure or hardware failure.
When the hardware fails, there's not much you can do other than switch the application to a different computer so as to make sure that the hardware failure doesn't cause application downtime.
Business continuity and disaster recovery, though used interchangeably, are different concepts.
Disaster recovery refers to re-establishing the application or system connectivity or availability on an alternate site, commonly known as a DR site, after an outage in the primary site. The outage can be caused by a site-wide (data center) wide infrastructure outage or a natural disaster.
Business continuity is a strategy that ensures that a business is up and running with minimal or zero downtime or service outage. For example, as a part of business continuity, an organization may plan to decouple an application into small individual standalone applications and deploy each small application across multiple regions. Let's say that a financial application is deployed on region one and the sales application is deployed on region two. Therefore, if a disaster hits region one, the finance application will go down, and the company will follow the disaster recovery plan to recover the financial application. However, the sales application in region two will be up and running.
High availability and disaster recovery are not only required during hardware failures; you also need them in the following scenarios:
System upgrades: Critical system upgrades such as software, hardware, network, or storage require the system to be rebooted and may even cause application downtime after being upgraded because of configuration changes. If there is an HA setup present, this can be done with zero downtime.
Human errors: As it's rightly said, to err is human. We can't avoid human errors; however, we can have a system in place to recover from human errors. An error in deployment or an application configuration or bad code can cause an application to fail. An example of this is the GitLab outage on January 31, 2017, which was caused by the accidental removal of customer data from the primary database server, resulting in an overall downtime of 18 hours.
Note
You can read more about the GitLab outage post-mortem here: https://about.gitlab.com/2017/02/10/postmortem-of-database-outage-of-january-31/.
Security breaches: Cyber-attacks are a lot more common these days and can result in downtime while you find and fix the issue. Moving the application to a secondary database server may help reduce the downtime while you fix the security issue in most cases.
Let's look at an example of how high availability and disaster recovery work to provide business continuity in the case of outages.
Consider the following diagram:

Figure 1.1: A simple HA and DR example
The preceding diagram shows a common HA and DR implementation with the following configuration:
The primary and secondary servers (SQL Server instance) are in Virginia. This is for high availability (having an available backup system).
The primary and secondary servers are in the same data center and are connected over LAN.
A DR server (a third SQL Server instance) is in Ohio, which is far away from Virginia. The third SQL Server instance is used as a DR site.
The DR site is connected over the internet to the primary site. This is mostly a private network for added security.
The primary SQL Server (node 1) is active and is currently serving user transactions.
The secondary and DR servers are inactive or passive and are not serving user transactions.
Let's say there is a motherboard failure on node 1 and it crashes. This causes node 2 to be active automatically and it starts serving user transactions. This is shown in the following diagram:

Figure 1.2: A simple HA and DR example – Node 1 crashes
This is an example of high availability where the system automatically switches to the secondary node within the same data center or a different data center in the same region (Virginia here).
The system can fall back to the primary node once it's fixed and up and running.
Note
A data center is a facility that's typically owned by a third-party organization, allowing customers to rent or lease out infrastructure. A node here refers to a standalone physical computer. A disaster recovery site is a data center in a different geographical region than that of the primary site.
Now, let's say that while the primary server, node 1, was being recovered, there was a region-wide failure that caused the secondary server, node 2, to go down. At this point, the region is down; therefore, the system will fail over to the DR server, node 3, and it'll start serving user transactions, as shown in the following diagram:

Figure 1.3: A simple HA and DR example – Nodes 1 and 2 crash
This is an example of disaster recovery. Once the primary and secondary servers are up and running, the system can fall back to the primary server.
The following terms are important in the world of HA and DR so that you can correctly choose the best possible HA and DR solutions and for the better understanding of HA and DR concepts.
Availability or uptime is defined as the percentage that a system or an application should be available for in a given year. Availability is expressed as Number of Nines.
For example, a 90%, one nine, availability means that a system can tolerate a downtime of 36.5 hours in a year, and a 99.999%, five nines, availability means that a system can tolerate a downtime of 5.26 minutes per year.
The following table, taken from https://en.wikipedia.org/wiki/High_availability#"Nines", describes the availability percentages and the downtime for each percentage:
Note
This link also talks about how this is calculated. You can look at it, but a discussion on calculation is out of the scope of this book.

Figure 1.4: Availability table
In the preceding table, you can see that as the Number of Nines increases, the downtime decreases. The business decides the availability, the Number of Nines, required for the system. This plays a vital role in selecting the type of HA and DR solution required for any given system. The higher the Number of Nines, the more rigorous or robust the required solution.
Recovery time objective, or RTO, is essentially the downtime a business can tolerate without any substantial loss. For example, an RTO of one hour means that an application shouldn't be down for more than one hour. A downtime of more than an hour would result in critical financial, reputation, or data loss.
The choice of HA and DR solution depends on the RTO. If an application has a four-hour RTO, you can recover the database using backups (if backups are being done every two hours or so), and you may not need any HA and DR solution. However, if the RTO is 15 minutes, then backups won't work, and an HA and DR solution will be needed.
Recovery point objective, or RPO, defines how much data loss a business can tolerate during an outage. For example, an RPO of two hours would mean a data loss of two hours won't cost anything to the business; however, if it goes beyond that, it would have significant financial or reputation impacts.
Essentially, this is the time difference between the last transaction committed before downtime and the first transaction committed after recovery.
The choice of HA and DR solution also depends on the RPO. If an application has 24 hours of RPO, daily full backups are good enough; however, for a business with four hours of RPO, daily full backups are not enough.
To differentiate between RTO and RPO, let's consider a scenario. A company has an RTO of one hour and an RPO of four hours. There's no HA and DR solution, and backups are being done every 12 hours.
In the case of an outage, the company was able to restore the database from the last full backup in one hour, which is within the given RTO of one hour; however, they suffered a data loss as the backups are being done every 12 hours and the RPO is of four hours.
The following are the most commonly used HA and DR solutions available in Microsoft SQL Server.
Commonly known as FCI, this requires SQL Server to be installed as a cluster service on top of the Windows failover cluster.
The SQL Server service is managed by a Windows cluster resource. The example we took to explain HA and DR earlier in this lesson was largely based on this.
This book covers creating a Windows Server Failover Cluster; however, it doesn't cover troubleshooting a failover cluster.
Log shipping is one of the oldest SQL Server solutions, and is mostly used for DR and SQL Server migration. It takes transaction log backups from the primary server and restores them on one or more secondary servers. It is implemented using SQL Agent jobs.
Log shipping is covered in more detail later in this book.
Introduced in SQL Server 2012, AlwaysOn AG is one of the newest and most impressive HA and DR features in SQL Server. When launched, it worked on top of Windows Server Failover Cluster; however, this restriction has been removed in Windows Server 2016 and SQL Server 2016.
AlwaysOn Availability Groups allows you to manually or automatically fail over one or more databases to a secondary instance if the primary instance is unavailable. This book talks about AlwaysOn in detail in a later lesson.
Replication is one of the oldest SQL Server features that replicates data from one database (commonly known as a publisher) to one or more databases (known as subscribers) in the same or different SQL Server instances.
Replication is commonly used for load balancing read and write workloads. The writes are done on the publisher and reads are done on the subscriber. However, as it replicates data, it is also used as an HA and DR solution.
The solutions described here can be used together as well. Using one feature doesn't restrict you from using others. Consider a scenario where a company has a transactional database and logging database. The transactional database is of more importance and has stringent RTO and RPO compared to the logging database. A company can choose AlwaysOn for the transactional database and log shipping/replication for the logging database.
Note
There are other solutions such as database mirroring and third-party solutions. Database mirroring is deprecated and will be removed in future SQL Server versions. This book only talks about SQL Server features and not any third-party HA and DR solutions.
In this section, you have learned about high availability and disaster recovery concepts and terminology.
The next section talks about replication and how it can be used as an HA and DR solution.
Replication is one of the oldest features in SQL Server. It allows you to sync or replicate data from one or more databases on the same or different SQL Server instances. In this section, we will cover replication concepts and terminology. We will also talk about the different types of replications available in SQL Server. We will then cover snapshot replication in detail.
Replication is a SQL Server feature that synchronizes data from a database (known as a publisher) to one or more databases (known as subscribers) on the same or different SQL Server instances.
Consider the following diagram:

Figure 1.5: Replication example
The preceding diagram depicts a typical implementation of replication. A replication has a number of components that work together to synchronize data between databases.
Let's look at these components in detail:
Publisher: A publisher is a database that facilitates the data for replication.
Publication: A publication is a set of objects and data to replicate. A publisher (database) can have one or more publications. For example, a database has two schemas,
financeandsales. There's one publication that has objects and data for thefinanceschema and another publication that has objects and data for thesalesschema.Articles: Articles are the database objects that are to be replicated such as tables and stored procedures. A publication can include one or more selected database objects and data.
Distributor: A distributor is a database (distribution database) that stores the data to be replicated from one or more publishers. The distribution database can be on the same instance as the publisher (which happens in most cases) or can be on a different SQL Server instance. Created as part of the replication database, it also stores the replication metadata such as publisher and subscriber details.
A better understanding of distribution databases is crucial in troubleshooting replication.
Subscriber: A subscriber is a database that subscribes to one or more publications from the one or more publishers in order to get the replicated data. A subscriber can also update the publisher data in case of merge or peer-to-peer transactional replication. A subscriber database can be on the same SQL Server instance as the publisher or on a different SQL Server instance.
Subscription: Subscription is the opposite of publication. The subscriber connects to the publisher by creating a subscription for the given publication.
There are two types of subscriptions, push and pull subscriptions. In the case of a push subscription, the distributor updates the subscriber as and when data is received (distribution agent is at distributor). In a pull subscription, the subscriber asks the distributor for any new data changes, as scheduled (distribution agent is at the subscriber).
If we now look at the preceding diagram, the publisher database has two publications, one for finance and one for the sales schema. The replication agent gets the changes from the publisher and inserts them into the distribution database.
The distribution agent then applies the changes to the relevant subscribers. There are two subscribers: one has a subscription to the finance publication and another subscribes to the sales publication.
Replication agents are the standalone executables that are responsible for replicating the data from a publisher to a subscriber. In this section, we will cover replication agents in brief, and we will look at them in detail later in this book.
Snapshot Agent
The snapshot agent creates the selected articles and copies all of the data from the publisher to the subscriber whenever executed. An important thing to note here is that the subsequent execution of the agent doesn't copy the differential data; rather, each run clears out the existing schema and data at the subscriber and copies the schema and data from the publisher.
The snapshot agent is run at the distributor and is used via snapshot replication. It is also used in transactional and merge replication to initialize the subscriber with the initial data.
Log Reader Agent
The log reader agent scans the transaction log for the transactions marked for replication and inserts them into the distribution database. It is used only in transactional replication and provides continuous replication from the publisher to the subscriber.
Each publication has its own log reader agent; that is, if there are two different databases with transactional replication, there will be two log reader agents, one for each database.
The log reader agent runs at the distributor.
Distribution Agent
As the name suggests, the distribution agent distributes (applies) the data that's inserted into the distribution database by the log reader agent to the subscribers.
The distribution agent runs at the subscriber if it's a pull subscription and at the distributor if it's a push subscription.
Note
There's also a queue reader agent that's used in bidirectional transactional replication. Bidirectional transactional replication is now obsolete.
Merge Agent
Used in merge replication, the merge agent applies the initial snapshot to the subscriber (generated by the snapshot agent) and then replicates the changes from the publisher to the subscriber and from the subscriber to the publisher as and when they occur, or when the subscriber is online and available for replication.
There is one merge agent for one merge subscription.
SQL Server has snapshot, transactional, and merge replication. Each replication type is best suited for one or more sets of scenarios. This section discusses different types of replication and scenarios in which they should be used.
Transactional replication, as the name suggests, replicates the transactions as and when they are committed at the publisher to the subscribers.
It's one of the most commonly used replications to load balance read-write workloads. The writes are done at the publisher and the reads (or reporting) are done at the subscriber, thereby eliminating read-write blocking. Moreover, the subscriber database can be better indexed to speed up the reads and the publisher database can be optimized for Data Manipulation Language (DML) operations.
The log reader and distribution agent carry out the transactional replication, as stated earlier. The agents are implemented as SQL agent jobs, that is, there's a SQL agent job for a log reader agent and a SQL agent job for the distribution agent.
There are two other transactional replications that allow changes to flow from subscriber to publisher: transactional replication with updatable subscription (bidirectional transactional replication) and peer-to-peer transactional replication.
Transaction replication is discussed in detail in Lesson 2, Transactional Replication.
Merge replication, as the name suggests, replicates changes from publishers to subscribers and from subscribers to publishers. This sometimes results in conflict in cases where the same row is updated with different values from the publisher and subscriber.
Merge replication has a built-in mechanism to detect and resolve conflicts; however, in some cases, it may get difficult to troubleshoot conflicts. This makes it the most complex replication type available in SQL Server.
Merge replication uses the merge agent to initialize subscribers and merge changes. Unlike transaction replication, where the snapshot agent is used to initialize subscribers, in merge replication, the snapshot agent only creates the snapshot. The merge agent applies that snapshot and starts replicating the changes thereafter.
Merge replication isn't covered in this book as it's not used as an HA and DR solution anymore.
Snapshot replication generates a snapshot of the articles to be replicated and applies it to the subscriber. The snapshot replication can be run on demand or as per schedule. It's the simplest form of replication and is also used to initialize transactional and merge replication.
Consider the following diagram:

Figure 1.6: Snapshot replication example
The preceding diagram demonstrates how snapshot replication works. The finance database is replicated from publisher to subscriber. Here's how it works:
A publication for the
financedatabase is created at the publisher.The snapshot agent creates the snapshot (
.schfiles for object schema and.bcpfiles for data). The snapshot files are kept at a shared folder that's accessible by the publisher and the distributor.A subscription for the
financepublication is created at the subscriber.The distribution agent applies the snapshot at the subscriber's
financedatabase.
Throughout this book, we will be using SQL Server Management Studio. You should already be familiar with this. Installation instructions are available in the preface, and all exercises can be completed on the free tier.
Configuring snapshot replication is a two-step process: the first step is to create the publication and the second step is to create the subscription. We will first create the publication.
In this exercise, we will create a publication for our snapshot replication:
Open SQL Server Management Studio and connect to the Object Explorer (press F8 to open and connect to Object Explorer).
Find and expand the Replication node and right-click on the Local Publication node. In the context menu, select New Publication:

Figure 1.7: Select New Publication
In the New Publication Wizard introduction page, click Next to continue:

Figure 1.8: The New Publication Wizard window
The New Publication Wizard | Distributor page defines where the distribution database will be created. The first option specifies that the publisher server will act as the distribution server and will host the distribution database and distributor jobs.
The second option allows you to add a new server to act as the distribution server.
Leave the first option checked and click Next to continue:

Figure 1.9: The Distributor window
In the New Publication Wizard | Snapshot Folder window, specify the location where snapshots (schema:
.schfiles and data) are stored. This needs to be a network path, and both the distributor and the subscriber should have access to this path.Create a new folder in any location on your computer and share it with everyone by modifying the sharing settings of the new folder that's been created.
Copy the shared path in the Snapshot folder box, as shown in the following screenshot. Click Next to continue:

Figure 1.10: The Snapshot Folder window
In the New Publication Wizard | Publication Database window, choose the database you wish to publish or replicate. Click Next to continue:

Figure 1.11: The Publication Database window
In the New Publication Wizard | Publication Type window, select Snapshot publication and click Next to continue:

Figure 1.12: The Publication Type window
In the New Publication Wizard | Articles window, select the database objects to be replicated.
Expand Tables and select the required tables, as shown in the following screenshot:

Figure 1.13: The Articles window
Note
Make sure you don't select any temporal tables. Temporal tables aren't supported for replication at the time of writing this book. Temporal tables are the ones with the
_archivepostfix, for example,Customers_Archive.Do not select any other objects for now.
Select the
BuyingGroupstable and then click Article Properties. Then, select Set properties of Highlighted Table Article.The Article Properties window lists multiple article properties that you may have to change as and when required. For example, you can change the table name and owner at the subscriber database or you can copy the non-clustered
Columnstoreindex from the publisher to the subscriber. This property is disabled by default:
Figure 1.14: The Articles Properties window
The New Publication Wizard | Filter Table Rows window allows you to filter out data to be replicated to the subscriber:

Figure 1.15: The Filter Table Rows window
In the Filter Table Rows window, click on the Add button to add filters. In the Add Filter window, add the filter, as shown in the following screenshot:

Figure 1.16: The Add Filter window
The shown filter will filter out any order with an order year of less than 2016 and will replicate all orders made after the year 2016.
Click OK to go back to the Filter Table Rows window:

Figure 1.17: The Filter Table Rows window
Observe that the filter has been added.
You can't add filters by joining one or more tables. The filter only works on a single table. It is therefore advised that you add the filter to other tables as well. Otherwise, all tables other than the
Orderstable will have data for all the years. This example, however, applies the filter on theOrderstable only.Click Next to continue.
In the New Publication Wizard | Snapshot Agent window, check the Create a snapshot immediately and keep the snapshot available to initialize subscriptions option.
This will generate the snapshot in the snapshot folder that's specified:

Figure 1.18: The Snapshot Agent window
Click Next to continue.
In the New Publication Wizard | Agent Security window, specify the service account under which the snapshot agent process will run and how it connects to the publisher:

Figure 1.19: The Agent Security window
Click on Security Settings to continue.
In the Snapshot Agent Security window, choose options, as shown in the following screenshot:

Figure 1.20: The Snapshot Agent Security window
Note
Running the snapshot agent process under a SQL agent service account isn't a good practice on production environments as a SQL agent service account has more privileges than required by the snapshot agent. However, we are only using it for demonstrative purposes.
The minimum permissions required by the Windows account under which the snapshot agent process runs are
db_ownerrights on the distribution database,db_ownerrights on the publisher database, and read, write, and modify rights on the shared snapshot folder.Click OK to continue. You'll be redirected to the Agent Security window. In this window, click Next to continue:

Figure 1.21: The Agent Security window with account selected
In the Wizard Actions window, select Create the publication, and then click Next to continue:

Figure 1.22: The Agent Security window with account selected
In the Complete the Wizard window, provide the publication name, as shown in the following screenshot, and then click on Finish to complete the wizard and create the publication:

Figure 1.23: The Complete the Wizard window
The wizard creates the publication, adds the selected articles, and creates and starts the snapshot agent job:

Figure 1.24: The Creating Publication window
After the publication is created, click on Close to exit the wizard.
Now, let's look at the objects or components that are created as part of creating the publication.
In step 4 of the previous exercise, we specified that the publisher will act as its own distributor. This results in the creation of a distribution database and snapshot agent job on the publisher itself. We can also use a different instance for distribution, however, let's keep it simple for this demonstration.
In SQL Server Management Studio, connect to the Object Explorer, expand Databases, and then expand System Database. Observe that a new system database distribution has been added as a result of the previous exercise:
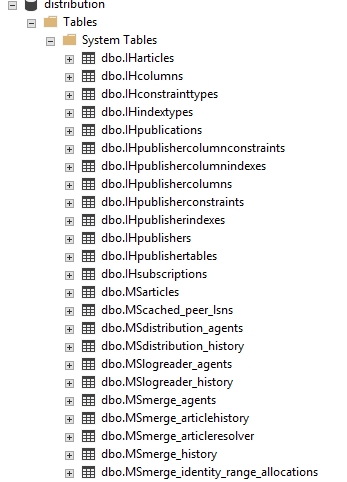
Figure 1.25: System tables
The distribution database has system tables that keep track of replication metadata. Let's explore the metadata tables that are related to snapshot replication.
Open a new query window in SSMS and execute the following queries one by one:
To get publication information, run this query:
SELECT [publisher_id] ,[publisher_db] ,[publication] ,[publication_id] ,[publication_type] ,[thirdparty_flag] ,[independent_agent] ,[immediate_sync] ,[allow_push] ,[allow_pull] ,[allow_anonymous] ,[description] ,[vendor_name] ,[retention] ,[sync_method] ,[allow_subscription_copy] ,[thirdparty_options] ,[allow_queued_tran] ,[options] ,[retention_period_unit] ,[allow_initialize_from_backup] ,[min_autonosync_lsn] FROM [distribution].[dbo].[MSpublications]You should see the following output:

Figure 1.26: Publication information
You can get the publication details from Object Explorer as well:

Figure 1.27: Publication details from the Object Explorer
To get the article information, run this query:
SELECT [publisher_id] ,[publisher_db] ,[publication_id] ,[article] ,[article_id] ,[destination_object] ,[source_owner] ,[source_object] ,[description] ,[destination_owner] FROM [distribution].[dbo].[MSarticles]You should get the following output:

Figure 1.28: Article information
To get the snapshot agent information, run this query:
SELECT [id] ,[name] ,[publisher_id] ,[publisher_db] ,[publication] ,[publication_type] ,[local_job] ,[job_id] ,[profile_id] ,[dynamic_filter_login] ,[dynamic_filter_hostname] ,[publisher_security_mode] ,[publisher_login] ,[publisher_password] ,[job_step_uid] FROM [distribution].[dbo].[MSsnapshot_agents]You should get the following output:

Figure 1.29: Snapshot agent information
To get the snapshot agent's execution history, run this query:
SELECT [agent_id] ,[runstatus] ,[start_time] ,[time] ,[duration] ,[comments] ,[delivered_transactions] ,[delivered_commands] ,[delivery_rate] ,[error_id] ,[timestamp] FROM [distribution].[dbo].[MSsnapshot_history]You should get the following output:

Figure 1.30: Snapshot agent execution history
You can also get the snapshot agent and its history from the Object Explorer under the SQL Server Agent node:

Figure 1.31: Snapshot agent history from the object explorer
Right-click on the snapshot agent job and select View History from the context menu.
Navigate to the snapshot folder (WideWorldImporters-Snapshot) that was provided in step 5 of the previous exercise. This contains the snapshot files for the articles that were selected for replication.
Observe that this folder acts as a base and has a subfolder named WIN2012R2$SQL2016_WIDEWORLDIMPORTERS_WWI-SNAPSHOT. The subfolder is named by concatenating the SQL Server instance name and the publication name to the base snapshot folder. This is done to separate out snapshots for different publications; the base snapshot folder can therefore have snapshots from multiple publications.
Every time a snapshot agent is run, a new folder is created inside WIN2012R2$SQL2016_WIDEWORLDIMPORTERS_WWI-SNAPSHOT. This is named by the timestamp when the snapshot agent ran and contains the schema and data files. This is shown in the following screenshot:
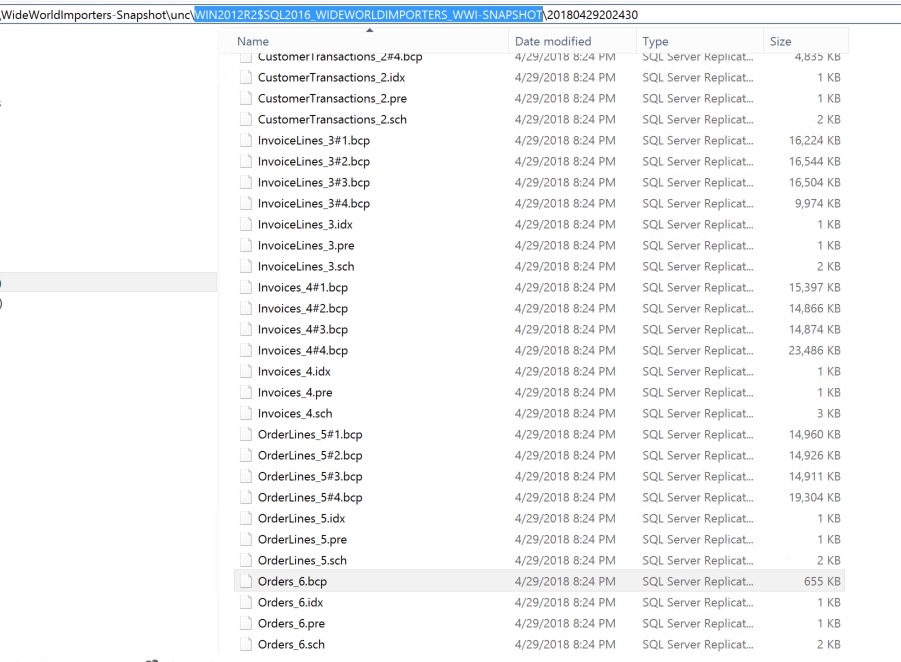
Figure 1.32: Snapshot folder
Observe that the snapshot folder has .sch, .idx, .pre, and .bcp files. Let's see what these files are used for.
.pre Files
The .pre files are the pre-snapshot scripts that drop the object at the subscriber if it exists. This is because every time a snapshot runs, it initializes the tables from scratch. Therefore, the objects are first dropped at the subscriber. Let's look at an example:
SET QUOTED_IDENTIFIER ON
go
if object_id('sys.sp_MSrestoresavedforeignkeys') < 0 exec sys.sp_MSdropfkreferencingarticle @destination_object_name = N'CustomerTransactions', @destination_owner_name = N'Sales'
go
drop Table [Sales].[CustomerTransactions]
goThe preceding query is from the customertransactions.pre file. It first drops foreign keys, if any, for the CustomerTransactions table and then drops the CustomerTransactions table.
Note
Another way to do this is to set the Action if name is in use option in the Article Properties window to the value Drop existing object and create a new one.
.sch Files
The .sch files contain the creation script for the articles to be replicated. Let's look at an example:
drop Table [Sales].[CustomerTransactions] go SET ANSI_PADDING ON go SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [Sales].[CustomerTransactions]( [CustomerTransactionID] [int] NOT NULL, [CustomerID] [int] NOT NULL, [TransactionTypeID] [int] NOT NULL, [InvoiceID] [int] NULL, [PaymentMethodID] [int] NULL, [TransactionDate] [date] NOT NULL, [AmountExcludingTax] [decimal](18, 2) NOT NULL, [TaxAmount] [decimal](18, 2) NOT NULL, [TransactionAmount] [decimal](18, 2) NOT NULL, [OutstandingBalance] [decimal](18, 2) NOT NULL, [FinalizationDate] [date] NULL, [IsFinalized] AS (case when [FinalizationDate] IS NULL then CONVERT([bit],(0)) else CONVERT([bit],(1)) end) PERSISTED, [LastEditedBy] [int] NOT NULL, [LastEditedWhen] [datetime2](7) NOT NULL ) GO
This query is from the customertransactions.sch file.
.idx Files
The .idx files contain the indexes and constraints on the tables to be created at the subscriber. Let's look at an example:
CREATE CLUSTERED INDEX [CX_Sales_CustomerTransactions] ON [Sales].[CustomerTransactions]([TransactionDate]) go ALTER TABLE [Sales].[CustomerTransactions] ADD CONSTRAINT [PK_Sales_CustomerTransactions] PRIMARY KEY NONCLUSTERED ([CustomerTransactionID]) Go
This query is from the customertransactions.idx file.
.bcp Files
The .bcp files contain the table data to be inserted into the tables at the subscriber. There can be multiple .bcp files, depending on the table size.
The snapshot agent job is a SQL Server agent job that executes snapshot.exe to generate the snapshot (these are the files we discussed earlier: .sch, .pre, .idx, and .bcp).
The snapshot agent job is created as part of creating the snapshot publication. You can locate the job in Object Explorer under the SQL Server Agent | Jobs node:
Figure 1.33: Snapshot agent job location
Double-click on the job to open it.
In the Job Properties window, click on Steps on the left-hand side in the Select a page pane:
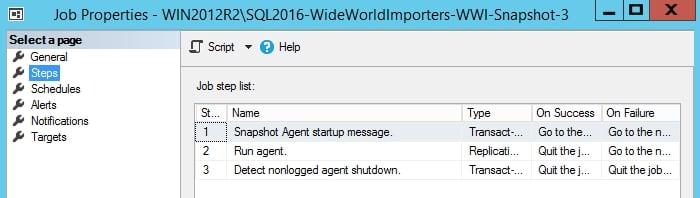
Figure 1.34: The Job Properties window
This job has three steps.
Step 1 - Snapshot Agent startup message: This inserts the Starting Agent message in the
Msnapshot_historytable in thedistributiondatabase:
Figure 1.35: The Snapshot Agent startup message window
It uses the system-stored
sp_MSadd_snapshot_historyprocedure to insert a row in theMsnapshot_historytable, indicating the start of the snapshot agent.Step 2 - Run agent: This runs the
snapshot.execommand with the required parameters to generate the snapshot:
Figure 1.36: The Run agent window
Observe that the Type parameter shows Replication Snapshot (this points to
snapshot.exe). The Command text is the list of parameters that are passed to thesnapshot.exeprocess. Similar to the previous step, where the Starting Agent status is written to theMSsnapshot_historytable,snapshot.exealso logs the progress to theMSsnapshot_historytable.Step 3 - Detect nonlogged agent shutdown: This step uses the systems-stored
sp_MSdetect_nonlogged_shutdownprocedure to check if the agent is shut down without logging any message to theMSsnapshot_historytable. It then checks and logs a relevant message for the agent that was shut down to theMSsnapshot_historytable:
Figure 1.37: The Detect nonlogged agent shutdown window
This completes the objects and components that were created as part of creating a publication.
We'll now look into the snapshot.exe process in detail.
The snapshot.exe process is installed with SQL Server (if you choose to install replication when installing SQL Server) and is stored in the C:\Program Files\Microsoft SQL Server\130\COM folder (for SQL Server 2016 installation).
The snapshot.exe process accepts quite a few parameters that are used to generate snapshots and to tune snapshot generation.
Note
This book covers the most important parameters, and not all parameters. For a complete list of parameters, go to https://docs.microsoft.com/en-us/sql/relational-databases/replication/agents/replication-snapshot-agent?view=sql-server-2017.
The snapshot.exe process can be run independently from the command line by passing the relevant parameters.
Execute the following commands in a command-line window to run snapshot.exe with the default parameters, as specified in step 2 of the snapshot agent job that we discussed previously:
REM -- Change the variable values as per your environment SET Publisher=WIN2012R2\SQL2016 SET PublisherDB=WideWorldImporters SET Publication=WWI-Snapshot "C:\Program Files\Microsoft SQL Server\130\COM\SNAPSHOT.EXE" -Publisher %Publisher% -PublisherDB %PublisherDB% -Distributor %Publisher% -Publication %Publication% -DistributorSecurityMode 1
You will have to change the Publisher variable with the SQL Server instance you created in the snapshot publication. You may have to change the PublisherDB and Publication parameters if you chose a different database and publication name when creating the snapshot publication in Exercise 1: Creating a Publication.
Once it runs successfully, it generates the following output:
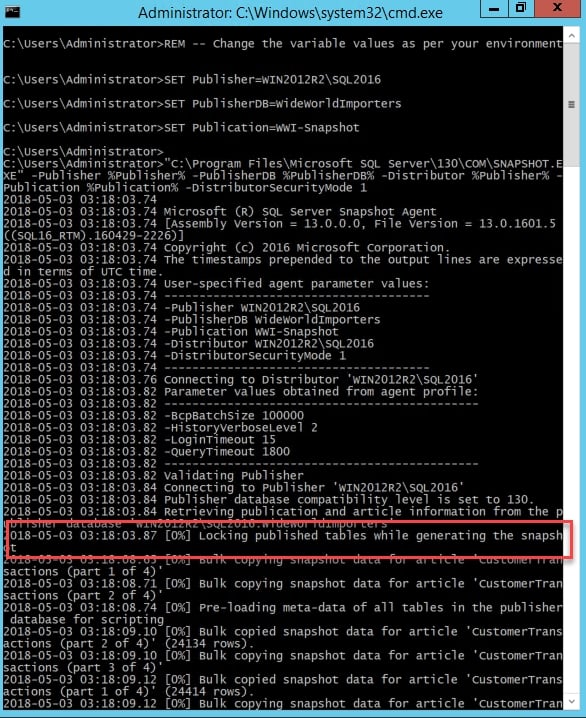
Figure 1.38: Running snapshot.exe
The snapshot agent also logs the progress status in the distribution.dbo.MSsnapshot_history table. You can query the table to verify these steps.
An important thing to note here is that the snapshot agent locks the published tables (schema lock and exclusive locks) while generating the snapshot. This is to make sure that no changes are made to the schema when a snapshot is being generated. Any changes to the schema during snapshot generation will leave the snapshot in an inconsistent state and it will error out when applying the snapshot to the subscriber.
For example, when the snapshot agent generated a .sch file, a table had two columns; however, when it exports the data for that table, another transaction modifies the table by adding one more column to it. Therefore, the table creation script, .sch, has two columns and .bcp, which is the data file, has three columns. This will error out when applied to the subscriber.
This also means that for large databases, generating snapshots may result in blocking issues.
To review the locks being applied during snapshot generation, run the snapshot.exe process, as described earlier. Then, quickly switch to SQL Server Management Studio and execute the following query to get lock details:
select resource_type, db_name(resource_database_id) As resource_database_name, resource_description, request_mode, request_type, request_status, request_session_id from sys.dm_tran_locks
You should get an output similar to what is shown in the following screenshot:
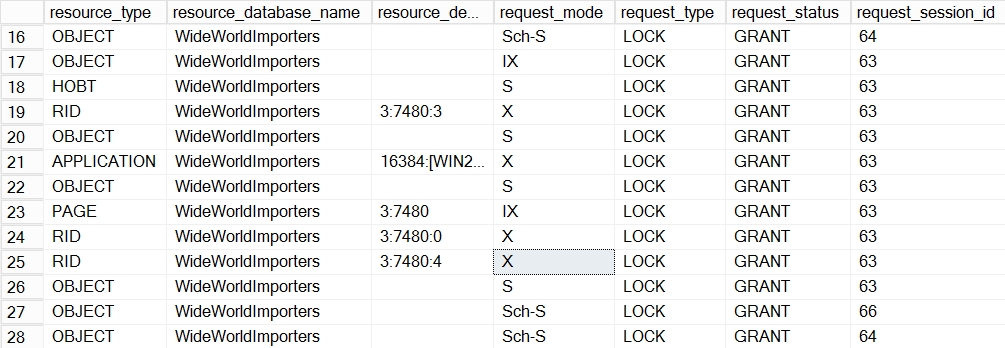
Figure 1.39: Reviewing the applied locks
Observe that the IX, X, and Sch-S locks are applied on the WideWorldImporters database during snapshot generation.
This section explores existing publication properties and how to modify an existing publication so that you can add or remove articles, change agent security settings, and more.
To view publication properties, connect to Object Explorer, expand Replication, and then expand Local Publications.
Right-click on the snapshot (WWI-Snapshot) and select Properties from the context menu:
Figure 1.40: Selecting Properties from the context menu
This opens the Publication Properties window:
Figure 1.41: The Publication Properties | General window
The Publication Properties window has different options on the left-hand side (Select a page) pane to modify or change publication properties. We'll now look at these options in detail.
Articles
The Articles page allows you to add or remove an article to or from the publication. Once you add or remove one, you'll have to generate a snapshot for the changes to take effect:
Figure 1.42: The Articles window
Adding or removing an article is very simple. Uncheck the Show only checked articles in the list option to display all database objects.
Note
When adding a new article, the article properties can be changed if required using the Article Properties dropdown, as shown earlier. The article properties can, however, be changed later if required.
Then, select or remove the objects as required and click on OK to apply the changes.
Filter Rows
The Filter Rows page allows you to add or remove row filters to the tables. This is similar to step 9 of Exercise 1: Creating a Publication:
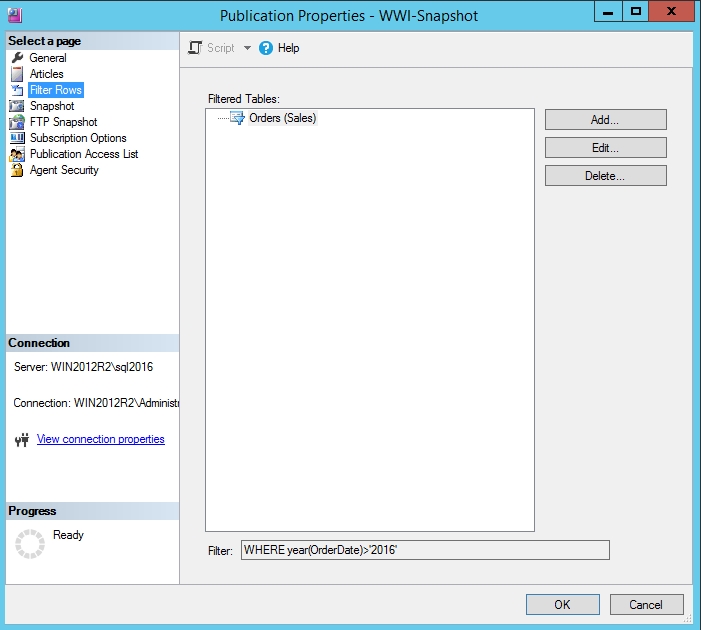
Figure 1.43: The Filter Rows window
Snapshot
The Snapshot page allows you to do the following:
Modify the snapshot format to Native SQL Server or Character.
Modify the location of the snapshot folder.
Compress the snapshot files in the snapshot folder. This saves storage for large publications. When compression is specified, a single cabinet (compressed) file is generated. However, if an article file size exceeds 2 GB, cab compression can't be used.
Run additional scripts before and after applying the snapshot at the subscriber:

Figure 1.44: The Snapshot window
FTP Snapshot
The FTP Snapshot page allows subscribers to download snapshots using FTP. You'll have to specify the FTP folder as the snapshot folder:
Figure 1.45: The FTP Snapshot window
You'll have to set up the FTP by specifying the connection details so that the snapshot agent can then push and pull snapshot files to and from the specified FTP folder.
Subscription Options
The Subscription Options page lets you control subscriber-level settings:
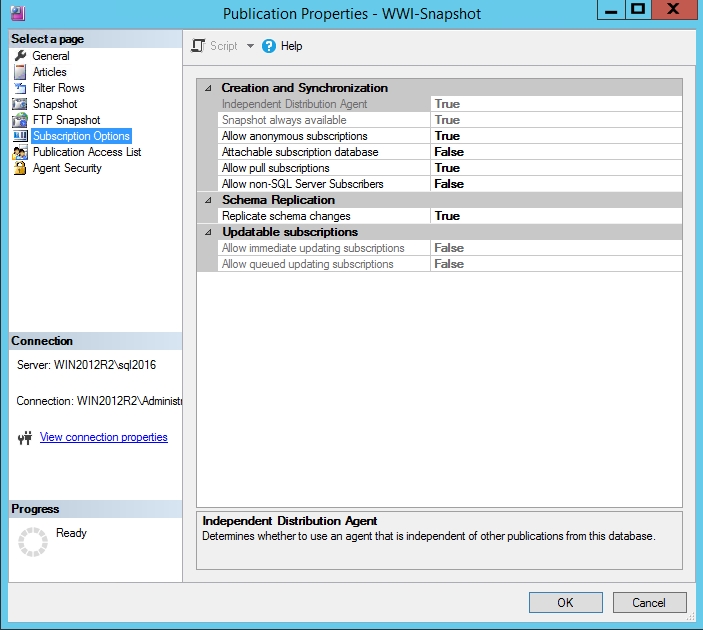
Figure 1.46: The Subscription Options window
The important settings for snapshot replication are as follows:
Allow pull subscriptions: This determines whether or not to allow pull subscriptions. The default value is True. Pull subscription is the only option available when an FTP snapshot is used.
Allow non-SQL Server Subscribers: This determines whether or not to allow non-SQL Server, that is, Oracle, MySQL, and so on, subscribers. The default value is False.
Replication schema changes: This determines whether or not to replicate schema changes to the published articles. The default value is True.
Publication Access List
The Publication Access List (PAL) page is a list of logins that have permission to create and synchronize subscriptions. Any login that has access to the publication database (WideWorldImporter) and is defined in both the publisher and distributor can be added to PAL:

Figure 1.47: The Publication Access List window
Agent Security
In the Agent Security page, you can modify the agent security settings, as defined in step 11 of Exercise 1: Creating a Publication:
Figure 1.48: The Agent Security window
To change or modify security settings, click on the Security Settings button and change as required.
In this exercise, we'll create the subscription at the subscriber end. A subscriber is usually a separate SQL Server instance.
To create a new subscription for the publication, follow these steps:
Connect to Object Explorer in SSMS. Expand Replication | Local Publications.
Right-click on the [WideWorldImporters]: WWI-Snapshot publication and select New Subscriptions:

Figure 1.49: The New Subscriptions option in the Object Explorer
This will open the New Subscription Wizard. Click Next to continue:

Figure 1.50: The New Subscriptions Wizard window
In the Publication window, under the Publisher dropdown, select the publisher server and then the publication:

Figure 1.51: The Publication window
Click on Next to continue.
In the Distribution Agent Location window, select pull subscriptions:

Figure 1.52: The Distribution Agent Location window
Pull subscriptions will create the distribution job at the subscriber server. This option reduces overhead at the distributor, and this becomes more important when the publisher acts as the distributor.
Note
We are using pull subscription as this will cause jobs to be created at the subscriber, making it easy to understand different jobs.
Moreover, if you have a lot of published databases and the publisher is being used as a distributor, it's advised to use pull subscription so as to offload jobs from the publisher, that is, the distributor, to subscribers.
Click Next to continue.
In the Subscribers window, click on Add SQL Server Subscriber to connect to the subscriber server. This is the server where the data will be replicated:

Figure 1.53: The Subscribers window
In the Connect to Server window, enter the subscriber server name and credentials. Click on Connect to continue:

Figure 1.54: The Connect to Server window
You'll be taken back to the Subscribers window:

Figure 1.55: The Subscribers window after connecting to the subscriber server
Under Subscription Database, select WideWorldImporters. Although you can replicate data to a different database name, it's advised that you use the same database name.
If the database doesn't exist at the subscriber, create one.
Click Next to continue.
In the Distribution Agent Security window, you can specify the distribution agent process account and how the distribution agent connects to the distributor and the subscriber. Select the button with three dots:

Figure 1.56: The Distribution Agent Security window
This opens the following window:

Figure 1.57: The Distribution Agent Security properties window
Select Run under the SQL Server Agent service account as the distribution agent process account.
Select By impersonating the process account under Connect to the Distributor and Connect to the Subscriber.
The By impersonating the process account option uses the SQL Server service account to connect to the distributor. However, as discussed earlier, this should not be done in production as the process account has the maximum set of privileges on the SQL Server instance.
The minimum set of permissions required by a Windows account under which the distribution agent runs are as follows.
The account that connects to the distributor should have the following permissions: be a part of the
db_ownerfixed database role on the distribution database, be a member of the publication access list, have read permission on the shared snapshot folder, and have write permission on theC:\Program Files\Microsoft SQL Server\InstanceID\COMfolder for replication LOB data.The account that connects to the subscriber should be a member of the
db_ownerfixed database role on the subscriber database.Click OK to continue.
You'll be taken back to the Distribution Agent Security window:

Figure 1.58: The Distribution Agent Security window after applying the settings
Click Next to continue.
In the Synchronization Schedule window, select Run on demand only under Agent Schedule.
The synchronization schedule specifies the schedule at which the distribution agent will run to replicate the changes:

Figure 1.59: The Synchronization Schedule window
Click Next to continue.
In the Initialize Subscriptions window, check the Initialize box and then select At first synchronization under the Initialize When option:

Figure 1.60: The Initialize Subscriptions window
The initialize process applies the snapshot to the subscriber to bring it in sync with the publisher. If the Initialize checkbox is left unchecked, the subscription isn't initialized. If it's checked, then there are two options available: Immediately and At first synchronization. The Immediately option will start the initialization as soon as the wizard is complete, and the At first synchronization option will start the initialization when the distribution agent runs for the first time.
In the Wizard Actions window, check the Create the subscription(s) option and click on Next to continue:

Figure 1.61: The Wizard Actions window
In the Complete the Wizard window, review the subscription settings and click on Finish to create the subscription:

Figure 1.62: The Complete the Wizard window
This ends the wizard. The wizard creates the subscription and the distributor agent job. At this point, the snapshot is not yet applied to the subscriber as we chose to run the distribution agent on demand.
Now, let's look at the objects that were created as part of creating the subscription.
Let's look at the changes that are made to the distribution tables after creating the subscription.
Open SSMS and connect to the distribution database on the publisher server. You can execute the following queries to find out how the subscription details are stored:
Subscriber information is stored in the
distribution.dbo.subscriber_infotable. Execute the following query to return the subscriber details:SELECT [publisher] ,[subscriber] ,[type] ,[login] ,[description] ,[security_mode] FROM [distribution].[dbo].[MSsubscriber_info]You should get a similar output to the following:

Figure 1.63: Subscriber information
The publisher and subscriber will be different in your case.
Execute the following query to get all of the information about the articles being replicated:
SELECT [publisher_database_id] ,[publisher_id] ,[publisher_db] ,[publication_id] ,[article_id] ,[subscriber_id] ,[subscriber_db] ,[subscription_type] ,[sync_type] ,[status] ,[subscription_seqno] ,[snapshot_seqno_flag] ,[independent_agent] ,[subscription_time] ,[loopback_detection] ,[agent_id] ,[update_mode] ,[publisher_seqno] ,[ss_cplt_seqno] ,[nosync_type] FROM [distribution].[dbo].[MSsubscriptions]You should get a similar output to the following:

Figure 1.64: Replicated articles
Execute the following query to get the distribution run history:
SELECT [agent_id] ,[runstatus] ,[start_time] ,[time] ,[duration] ,[comments] ,[xact_seqno] ,[current_delivery_rate] ,[current_delivery_latency] ,[delivered_transactions] ,[delivered_commands] ,[average_commands] ,[delivery_rate] ,[delivery_latency] ,[total_delivered_commands] ,[error_id] ,[updateable_row] ,[timestamp] FROM [distribution].[dbo].[MSdistribution_history]You should get a similar output to the following:

Figure 1.65: Distribution run history
Observe that the duration is 0 as the agent hasn't run until now.
The distribution agent job that was created at the subscriber (pull subscription) runs the distribution.exe process to apply the snapshot that was created by the snapshot agent on the subscriber database.
To view the job, you can open SSMS and connect to the subscriber server using Object Explorer. Then, you can expand the SQL Server Agent node.
You should see a job similar to what is shown in the following screenshot:
Figure 1.66: The distribution agent job
Note
The job name includes the publisher server, published database, and the publication name. This helps in identifying the publication the job is for. The job name also includes the subscriber server and database, as well as the job ID. This helps in identifying the publisher and subscriber when the job is on the distributor server and multiple replications have been configured.
You can double-click on the job to open its Job Properties window:
Figure 1.67: The Job Properties window
The Job Properties window lists out the general information about the job. You can select the Steps page from the Select a page pane on the left-hand side of the Job Properties window:
Figure 1.68: The Steps page
This job has only one step. You can double-click on the step name or select Edit at the bottom of the window to check the step details:
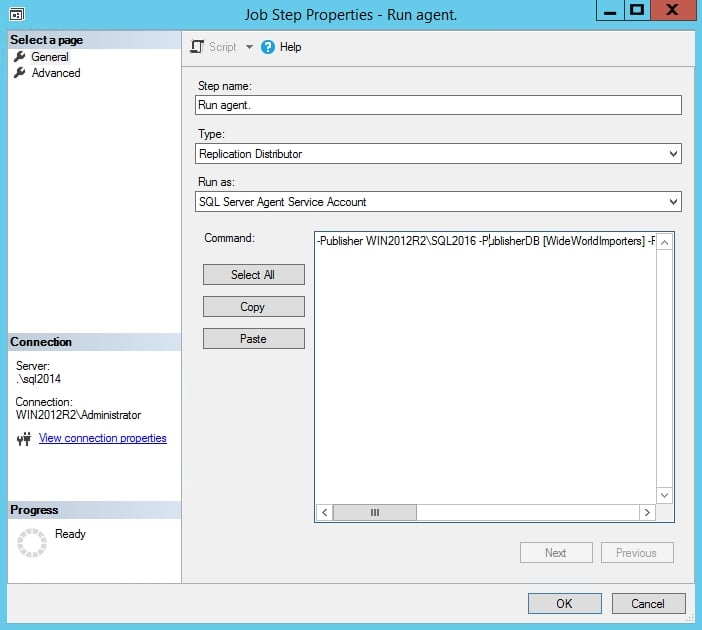
Figure 1.69: The Run agent window
Observe that the Run agent step calls the distributor.exe executable with a set of parameters.
Note
The parameters are self-explanatory. It's advised to go through the parameters and understand what the distributor agent is doing.
The job wasn't run until now as we opted for Run on Demand when configuring the subscription. Close the Job Properties window.
Now, let's run the job and replicate the data from the publisher to the subscriber. To run the job manually, navigate to the job on the Object Explorer, as mentioned earlier:
Right-click on the job and select Start Job at Step:

Figure 1.70: The Start Job at Step option
Once the job is successful, you'll get a Success message on the Start Jobs window, as shown in the following screenshot:

Figure 1.71: The Start Jobs window
Click Close to close the Start Jobs window.
Right-click on the job under the SQL Server Agent | Jobs node and select View History from the context menu:

Figure 1.72: The View History option
This opens the job's history:

Figure 1.73: The View History window
Observe that the agent has completed successfully. An important thing to observe is the values for the
distribution.exeparameters (highlighted in red). We'll discuss these later in this lesson.The job history is also a good place to start troubleshooting snapshot replication. Errors, if any, show up in the job history, and we can then fix these issues based on the errors.
Note
You can also start/stop snapshot view history by right-clicking on Replication | Local Publications | Publication name (on publisher server) and selecting View Snapshot Agent Status.
Similarly, to start/stop the distribution agent and to view history, right-click on Replication | Local Subscription | Subscription Name and then select View Synchronization Status from the context menu.
In the Object Explorer, navigate to the Databases node and expand the WideWorldImporters database on the
subscriberserver.Observe that it now has the replicated tables:

Figure 1.74: The replicated tables
distrib.exe is the executable that does the actual work of replicating the data from the publisher to the subscriber:
Note
This section discusses the parameters that are relevant for snapshot replication. For a complete list of parameters, refer to https://docs.microsoft.com/en-us/sql/relational-databases/replication/agents/replication-distribution-agent?view=sql-server-2017.
First, let's run the distribution agent from the command line (similar to how we ran
snapshot.exe) and get familiar with the common parameters. As we have already applied the snapshot, let's modify theorderstable and generate a new snapshot.Execute the following query to update the
orderstable on thepublisherdatabase:UPDATE [Sales].Orders SET ExpectedDeliveryDate = '2017-12-10' WHERE Customerid = 935 and Year(OrderDate)>2016
The preceding query will update four rows.
Generate the snapshot by running the following on the command line:
REM -- Change the variable values as per your environment SET Publisher=WIN2012R2\SQL2016 SET PublisherDB=WideWorldImporters SET Publication=WWI-Snapshot "C:\Program Files\Microsoft SQL Server\130\COM\SNAPSHOT.EXE" -Publisher %Publisher% -PublisherDB %PublisherDB% -Distributor %Publisher% -Publication %Publication% -DistributorSecurityMode 1
You should get an output similar to the following screenshot:

Figure 1.75: Generating the snapshot
You can also verify the new snapshot generation by looking into the snapshot folder for the snapshot files dated to the date you ran the command. Moreover, you can query the
MSsnapshot_historytable in thedistributiondatabase for the run status.We have a fresh snapshot now. Run
distrib.exeto apply the snapshot to thesubscriberdatabase:"C:\Program Files\Microsoft SQL Server\130\COM\DISTRIB.EXE" -Publisher WIN2012R2\SQL2016 -PublisherDB [WideWorldImporters] -Publication [WWI-Snapshot] -Distributor [WIN2012R2\SQL2016] -SubscriptionType 1 -Subscriber [WIN2012R2\SQL2014] -SubscriberSecurityMode 1 -SubscriberDB [WideWorldImporters]
You'll have to replace the publisher and subscriber SQL Server instance name in this command. If you are replicating a database other than
WideWorldImportersand have a different publication name, replace those parameters as well.You should get a similar output to what's shown in the following screenshot:

Figure 1.76: Applying the snapshot
The distribution agent runs and applies the snapshot on the subscriber. Note that the replication agent runs under the security context of the administrator. This is because the command-line console is open as an administrator.
Now, query the
orderstable at thesubscriberdatabase to verify the changes made at thepublisherdatabase:SELECT ExpectedDeliveryDate FROM WideWorldImporters.Sales.Orders WHERE Customerid = 935 and YEAR(OrderDate)>2016
You should get the following output.

Figure 1.77: Querying the Orders table
The changes are therefore replicated.
In this section, we'll discuss optimizing snapshot replication by following best practices and tuning the snapshot and distributor agent parameters.
Let's look at a few of the best practices you should consider when working with snapshot replication.
Minimizing Logging at Subscriber
Snapshot replication uses bcp to bulk insert data from the publisher to the subscriber database. It's therefore advised to switch to a bulk-logged or simple recovery model to minimize logging and optimize bulk insert performance.
Note
To find out more about recovery models, refer to https://docs.microsoft.com/en-us/sql/relational-databases/backup-restore/recovery-models-sql-server?view=sql-server-2017.
Minimizing Locking
As we discussed earlier, snapshot generation applies exclusive locks on tables until the snapshot is generated. This stops any other applications from accessing the tables, resulting in blocking. You can look at the following options to minimize blocking:
Change the isolation level to read-committed snapshot to avoid read-write blocking. You'll have to research and find out how the read-committed snapshot will not affect any other application or functionality of your environment.
Another way to avoid read-write blocking is to selectively use the NoLock query hint. This is not a good practice; however, it's being used in many applications to fix read-write blocking.
Schedule snapshot generation at off-peak hours when there is less workload on the server.
Replicating Only Required Articles
Understand the business requirements and replicate only what is required. Replicating all articles in a large database will take time and resources for snapshot generation.
Using Pull Subscription
Consider using pull subscription. In pull subscription, the distribution agent is on the subscriber and not on the distributor. This reduces workload on the distributor. Moreover, if the publisher is acting as its own distributor, its workload is reduced.
Compressing the Snapshot Folder
As discussed earlier, there is an option to compress snapshot files in the .cab format. This reduces the size of the snapshot files and speeds up network transfer. However, it takes time to compress the files by the snapshot agent and decompress by the distribution agent.
The following table discusses snapshot and distribution agent parameters that can be modified so as to optimize snapshot replication:

Figure 1.78: The Agent Parameters table
In this activity, we'll troubleshoot snapshot replication.
You have been asked to set up snapshot replication for the WideWorldImporters database. The subscriber database will be used to run daily reports. You configured the replication so that the initial snapshot is applied successfully. You schedule it to occur daily at 12:00 AM, as directed by the business. However, the next day you are informed that the data isn't synced.
In this activity, you'll find and fix the issue.
Setup Steps
To simulate the error, follow these steps:
Use the existing snapshot replication that was configured in this lesson. You do not need to configure it again. If you didn't configure it, then follow the previous exercises to configure the snapshot replication.
Open a PowerShell console and run the following PowerShell script on the
subscriberdatabase:C:\Code\Lesson01\1_Activity1B.ps1 -SubscriberServer .\sql2014 -SubscriberDB WideWorldImporters -SQLUserName sa -SQLUserPassword sql@2014
Modify the parameters as per your environment before running the script.
Generating a New Snapshot
Follow these steps to generate a new snapshot:
Open SQL Server Management Studio and connect to the
publisherserver in the Object Explorer.Expand Replication | Local Publication. Right-click on the
[WideWorldImporters]:WWI-Snapshotpublication and select View Snapshot Agent Status from the context menu:
Figure 1.79: The View Snapshot Agent Status option
In the View Snapshot Agent Status window, select Start to generate a new snapshot. This is another way to generate the snapshot:

Figure 1.80: The View Snapshot Agent Status window
Once the snapshot is generated, you'll get a success message, as shown in the preceding screenshot.
You can further verify this by checking the snapshot folder or querying the
MSsnapshot_historytable in thedistributiondatabase.
Applying the Snapshot to the Subscriber
You'll now apply the generated snapshot to the subscriber. To apply the snapshot, follow these steps:
In the Object Explorer in SSMS, connect to the
subscriberserver. Expand Replication | Local Subscriptions.Right-click on the
[WideWorldImporters] – [WIN2012R2\SQL2016].[WideWorldImporters]:WWI-Snapshotsubscription and select View Synchronization Status from the context menu.This is another way to run the distributor agent:

Figure 1.81: The View Synchronization Status option
In the View Synchronization Status window, select Start to start the distributor agent. The agent will error out and the snapshot won't be applied to the subscriber:

Figure 1.82: The View Synchronization Status window
To find out what the error is, click on View Job History in the View Synchronization Status window.
This will open the SQL Server agent job history for the distributor job. You should see the following error in the agent history:

Figure 1.83: The job history
The distribution agent fails to drop the
Sales.OrdersandSales.Orderlinestables because they are referenced by a view,vw_orders.
An easy solution to this problem is to drop the view at the subscriber database. However, the business tells you that the view can't be dropped as it's being used by the daily report.
Another solution to this problem is to modify the publication properties to include pre- and post-snapshot scripts so that you can delete and create the view, respectively.
In this lesson, we have learned about high availability and disaster recovery concepts, as well as the terminology and the different solutions available in SQL Server to achieve HA and DR. We have discussed the importance of RTO and RPO and the role they play in selecting an HA and DR strategy or solution.
We have also learned about replication concepts and terminology, and different types of replications that are available in SQL Server. We looked at how to configure and troubleshoot snapshot replication.
In the next lesson, we'll learn about transactional replication.


