


















Claude Monet, one of the founders of French Impressionist painting, taught his students to paint only what they saw, not what they knew. He even went as far as to say:
"I wish I had been born blind and then suddenly gained my sight so that I could begin to paint without knowing what the objects were that I could see before me."
Monet rejected traditional artistic subjects, which tended to be mystical, heroic, militaristic, or revolutionary. Instead, he relied on his own observations of middle-class life: of social excursions; of sunny gardens, lily ponds, rivers, and the seaside; of foggy boulevards and train stations; and of private loss. With deep sadness, he told his friend, Georges Clemenceau (the future President of France):
"I one day found myself looking at my beloved wife's dead face and just systematically noting the colors according to an automatic reflex!"
Monet painted everything according to his personal impressions. Late in life, he even painted the symptoms of his own deteriorating eyesight. He adopted a reddish palette while he suffered from cataracts and a brilliant bluish palette after cataract surgery left his eyes more sensitive, possibly to the near ultraviolet range.
Like Monet's students, we as scholars of computer vision must confront a distinction between seeing and knowing and likewise between input and processing. Light, a lens, a camera, and a digital imaging pipeline can grant a computer a sense of sight. From the resulting image data, machine-learning (ML) algorithms can extract knowledge or at least a set of meta-senses such as detection, recognition, and reconstruction (scanning). Without proper senses or data, a system's learning potential is limited, perhaps even nil. Thus, when designing any computer vision system, we must consider the foundational requirements in terms of lighting conditions, lenses, cameras, and imaging pipelines.
What do we require in order to clearly see a given subject? This is the central question of our first chapter. Along the way, we will address five subquestions:
What do we require to see fast motion or fast changes in light?
What do we require to see distant objects?
What do we require to see with depth perception?
What do we require to see in the dark?
How do we obtain good value-for-money when purchasing lenses and cameras?
Tip
For many practical applications of computer vision, the environment is not a well-lit, white room, and the subject is not a human face at a distance of 0.6m (2')!
The choice of hardware is crucial to these problems. Different cameras and lenses are optimized for different imaging scenarios. However, software can also make or break a solution. On the software side, we will focus on the efficient use of OpenCV. Fortunately, OpenCV's videoio module supports many classes of camera systems, including the following:
Webcams in Windows, Mac, and Linux via the following frameworks, which come standard with most versions of the operating system:
Windows: Microsoft Media Foundation (MSMF), DirectShow, or Video for Windows (VfW)
Mac: QuickTime
Linux: Video4Linux (V4L), Video4Linux2 (V4L2), or libv4l
Built-in cameras in iOS and Android devices
OpenNI-compliant depth cameras via OpenNI or OpenNI2, which are open-source under the Apache license
Other depth cameras via the proprietary Intel Perceptual Computing SDK
Photo cameras via libgphoto2, which is open source under the GPL license. For a list of libgphoto2's supported cameras, see http://gphoto.org/proj/libgphoto2/support.php.
IIDC/DCAM-compliant industrial cameras via libdc1394, which is open-source under the LGPLv2 license
For Linux, unicap can be used as an alternative interface for IIDC/DCAM-compliant cameras, but unicap is GPL-licensed and thus not appropriate for use in closed-source software.
Other industrial cameras via the following proprietary frameworks:
Allied Vision Technologies (AVT) PvAPI for GigE Vision cameras
Smartek Vision Giganetix SDK for GigE Vision cameras
XIMEA API
Note
The videoio module is new in OpenCV 3. Previously, in OpenCV 2, video capture and recording were part of the highgui module, but in OpenCV 3, the highgui module is only responsible for GUI functionality. For a complete index of OpenCV's modules, see the official documentation at http://docs.opencv.org/3.0.0/.
However, we are not limited to the features of the videoio module; we can use other APIs to configure cameras and capture images. If an API can capture an array of image data, OpenCV can readily use the data, often without any copy operation or conversion. As an example, we will capture and use images from depth cameras via OpenNI2 (without the videoio module) and from industrial cameras via the FlyCapture SDK by Point Grey Research (PGR).
Note
An industrial camera or machine vision camera typically has interchangeable lenses, a high-speed hardware interface (such as FireWire, Gigabit Ethernet, USB 3.0, or Camera Link), and a complete programming interface for all camera settings.
Most industrial cameras have SDKs for Windows and Linux. PGR's FlyCapture SDK supports single-camera and multi-camera setups on Windows as well as single-camera setups on Linux. Some of PGR's competitors, such as Allied Vision Technologies (AVT), offer better support for multi-camera setups on Linux.
We will learn about the differences among categories of cameras, and we will test the capabilities of several specific lenses, cameras, and configurations. By the end of the chapter, you will be better qualified to design either consumer-grade or industrial-grade vision systems for yourself, your lab, your company, or your clients. I hope to surprise you with the results that are possible at each price point!
The human eye is sensitive to certain wavelengths of electromagnetic radiation. We call these wavelengths "visible light", "colors", or sometimes just "light". However, our definition of "visible light" is anthropocentric as different animals see different wavelengths. For example, bees are blind to red light, but can see ultraviolet light (which is invisible to humans). Moreover, machines can assemble human-viewable images based on almost any stimulus, such as light, radiation, sound, or magnetism. To broaden our horizons, let's consider eight kinds of electromagnetic radiation and their common sources. Here is the list, in order of decreasing wavelength:
Radio waves radiate from certain astronomical objects and from lightning. They are also generated by wireless electronics (radio, Wi-Fi, Bluetooth, and so on).
Microwaves radiated from the Big Bang and are present throughout the Universe as background radiation. They are also generated by microwave ovens.
Far infrared (FIR) light is an invisible glow from warm or hot things such as warm-blooded animals and hot-water pipes.
Near infrared (NIR) light radiates brightly from our sun, from flames, and from metal that is red-hot or nearly red-hot. However, it is a relatively weak component in commonplace electric lighting. Leaves and other vegetation brightly reflect NIR light. Skin and certain fabrics are slightly transparent to NIR.
Visible light radiates brightly from our sun and from commonplace electric light sources. Visible light includes the colors red, orange, yellow, green, blue, and violet (in order of decreasing wavelength).
Ultraviolet (UV) light, too, is abundant in sunlight. On a sunny day, UV light can burn our skin and can become slightly visible to us as a blue-gray haze in the distance. Commonplace, silicate glass is nearly opaque to UV light, so we do not suffer sunburn when we are behind windows (indoors or in a car). For the same reason, UV camera systems rely on lenses made of non-silicate materials such as quartz. Many flowers have UV markings that are visible to insects. Certain bodily fluids such as blood and urine are more opaque to UV than to visible light.
X-rays radiate from certain astronomical objects such as black holes. On Earth, radon gas, and certain other radioactive elements are natural X-ray sources.
Gamma rays radiate from nuclear explosions, including supernovae. To lesser extents the sources of gamma rays also include radioactive decay and lightning strikes.
NASA provides the following visualization of the wavelength and temperature associated with each kind of light or radiation:
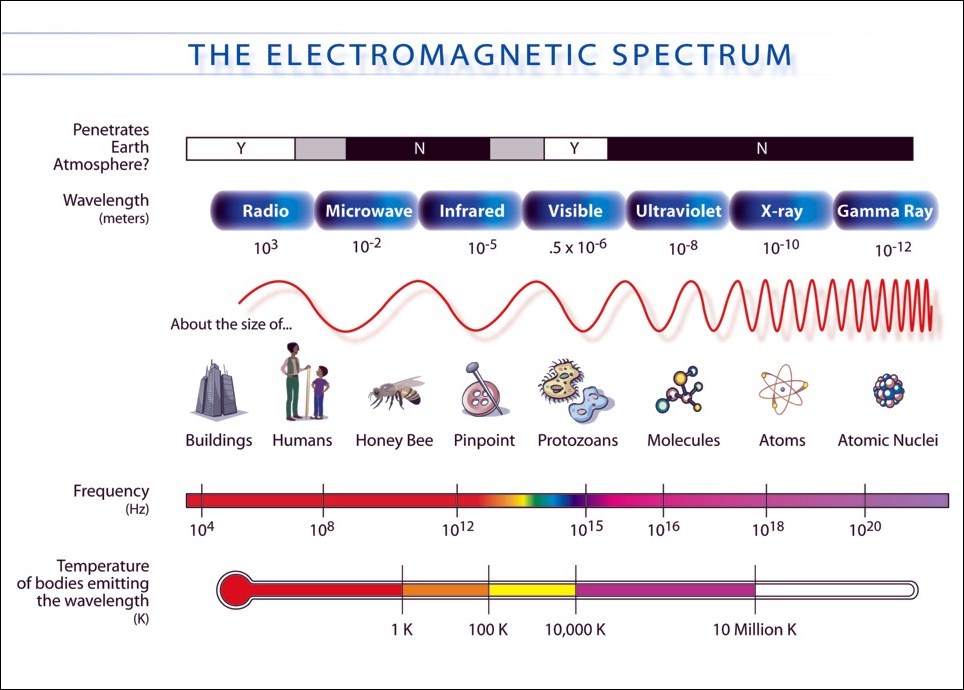
Passive imaging systems rely on ambient (commonplace) light or radiation sources as described in the preceding list. Active imaging systems include sources of their own so that the light or radiation is structured in more predictable ways. For example, an active night vision scope might use a NIR camera plus a NIR light.
For astronomy, passive imaging is feasible across the entire electromagnetic spectrum; the vast expanse of the Universe is flooded with all kinds of light and radiation from sources old and new. However, for terrestrial (Earth-bound) purposes, passive imaging is mostly limited to the FIR, NIR, visible, and UV ranges. Active imaging is feasible across the entire spectrum, but the practicalities of power consumption, safety, and interference (between our use case and others) limit the extent to which we can flood an environment with excess light and radiation.
Whether active or passive, an imaging system typically uses a lens to bring light or radiation into focus on the surface of the camera's sensor. The lens and its coatings transmit some wavelengths while blocking others. Additional filters may be placed in front of the lens or sensor to block more wavelengths. Finally, the sensor itself exhibits a varying spectral response, meaning that for some wavelengths, the sensor registers a strong (bright) signal, but for other wavelengths, it registers a weak (dim) signal or no signal. Typically, a mass-produced digital sensor responds most strongly to green, followed by red, blue, and NIR. Depending on the use case, such a sensor might be deployed with a filter to block a range of light (whether NIR or visible) and/or a filter to superimpose a pattern of varying colors. The latter filter allows for the capture of multichannel images, such as RGB images, whereas the unfiltered sensor would capture monochrome (gray) images.
The sensor's surface consists of many sensitive points or photosites. These are analogous to pixels in the captured digital image. However, photosites and pixels do not necessarily correspond one-to-one. Depending on the camera system's design and configuration, the signals from several photosites might be blended together to create a neighborhood of multichannel pixels, a brighter pixel, or a less noisy pixel.
Consider the following pair of images. They show a sensor with a Bayer filter, which is a common type of color filter with two green photosites per red or blue photosite. To compute a single RGB pixel, multiple photosite values are blended. The left-hand image is a photo of the filtered sensor under a microscope, while the right-hand image is a cut-away diagram showing the filter and underlying photosites:
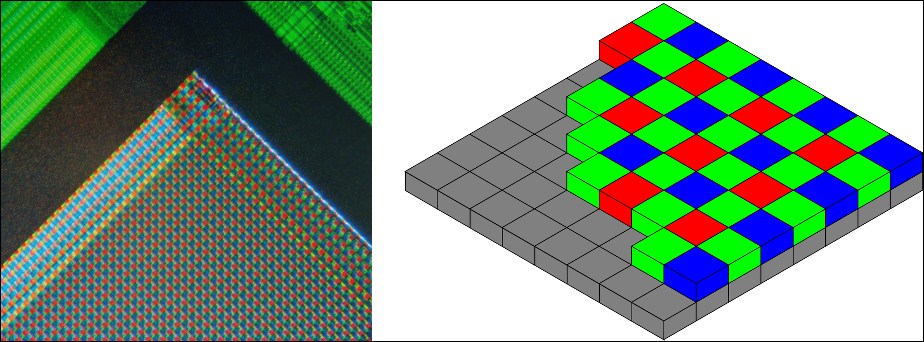
Note
The preceding images come from Wikimedia. They are contributed by the users Natural Philo, under the Creative Commons Attribution-Share Alike 3.0 Unported license (left), and Cburnett, under the GNU Free Documentation License (right).
As we see in this example, a simplistic model (an RGB pixel) might hide important details about the way data are captured and stored. To build efficient image pipelines, we need to think about not just pixels, but also channels and macropixels—neighborhoods of pixels that share some channels of data and are captured, stored, and processed in one block. Let's consider three categories of image formats:
A raw image is a literal representation of the photosites' signals, scaled to some range such as 8, 12, or 16 bits. For photosites in a given row of the sensor, the data are contiguous but for photosites in a given column, they are not.
A packed image stores each pixel or macropixel contiguously in memory. That is to say, data are ordered according to their neighborhood. This is an efficient format if most of our processing pertains to multiple color components at a time. For a typical color camera, a raw image is not packed because each neighborhood's data are split across multiple rows. Packed color images usually use RGB channels, but alternatively, they may use YUV channels, where Y is brightness (grayscale), U is blueness (versus greenness), and V is redness (also versus greenness).
A planar image stores each channel contiguously in memory. That is to say, data are ordered according to the color component they represent. This is an efficient format if most of our processing pertains to a single color component at a time. Packed color images usually use YUV channels. Having a Y channel in a planar format is efficient for computer vision because many algorithms are designed to work on grayscale data alone.
An image from a monochrome camera can be efficiently stored and processed in its raw format or (if it must integrate seamlessly into a color imaging pipeline) as the Y plane in a planar YUV format. Later in this chapter, in the sections Supercharging the PlayStation Eye and Supercharging the GS3-U3-23S6M-C and other Point Grey Research cameras, we will discuss code samples that demonstrate efficient handling of various image formats.
Until now, we have covered a brief taxonomy of light, radiation, and color—their sources, their interaction with optics and sensors, and their representation as channels and neighborhoods. Now, let's explore some more dimensions of image capture: time and space.
Robert Capa, a photojournalist who covered five wars and shot images of the first wave of D-Day landings at Omaha Beach, gave this advice:
"If your pictures aren't good enough, you're not close enough."
Like a computer vision program, a photographer is the intelligence behind the lens. (Some would say the photographer is the soul behind the lens.) A good photographer continuously performs detection and tracking tasks—scanning the environment, choosing the subject, predicting actions and expressions that will create the right moment for the photo, and choosing the lens, settings, and viewpoint that will most effectively frame the subject.
By getting "close enough" to the subject and the action, the photographer can observe details quickly with the naked eye and can move to other viewpoints quickly because the distances are short and because the equipment is typically light (compared to a long lens on a tripod for a distant shot). Moreover, a close-up, wide-angle shot pulls the photographer, and viewer, into a first-person perspective of events, as if we become the subject or the subject's comrade for a single moment.
Photographic aesthetics concern us further in Chapter 2, Photographing Nature and Wildlife with an Automated Camera. For now, let's just establish two cardinal rules: don't miss the subject and don't miss the moment! Poor visibility and unfortunate timing are the worst excuses a photographer or a practitioner of computer vision can give. To hold ourselves to account, let us define some measurements that are relevant to these cardinal rules.
Resolution is the finest level of detail that the lens and camera can see. For many computer vision applications, recognizable details are the subject of the work, and if the system's resolution is poor, we might miss this subject completely. Resolution is often expressed in terms of the sensor's photosite counts or the captured image's pixel counts, but at best these measurements only tell us about one limiting factor. A better, empirical measurement, which reflects all characteristics of the lens, sensor, and setup, is called line pairs per millimeter (lp/mm). This means the maximum density of black-on-white lines that the lens and camera can resolve, in a given setup. At any higher density than this, the lines in the captured image blur together. Note that lp/mm varies with the subject's distance and the lens's settings, including the focal length (optical zoom) of a zoom lens. When you approach the subject, zoom in, or swap out a short lens for a long lens, the system should of course capture more detail! However, lp/mm does not vary when you crop (digitally zoom) a captured image.
Lighting conditions and the camera's ISO speed setting also have an effect on lp/mm. High ISO speeds are used in low light and they boost both the signal (which is weak in low light) and the noise (which is as strong as ever). Thus, at high ISO speeds, some details are blotted out by the boosted noise.
To achieve anything near its potential resolution, the lens must be properly focused. Dante Stella, a contemporary photographer, describes a problem with modern camera technology:
"For starters, it lacks … thought-controlled predictive autofocus."
That is to say, autofocus can fail miserably when its algorithm is mismatched to a particular, intelligent use or a particular pattern of evolving conditions in the scene. Long lenses are especially unforgiving with respect to improper focus. The depth of field (the distance between the nearest and farthest points in focus) is shallower in longer lenses. For some computer vision setups—for example, a camera hanging over an assembly line—the distance to the subject is highly predictable and in such cases manual focus is an acceptable solution.
Field of view (FOV) is the extent of the lens's vision. Typically, FOV is measured as an angle, but it can be measured as the distance between two peripherally observable points at a given depth from the lens. For example, a FOV of 90 degrees may also be expressed as a FOV of 2m at a depth of 1m or a FOV of 4m at a depth of 2m. Where not otherwise specified, FOV usually means diagonal FOV (the diagonal of the lens's vision), as opposed to horizontal FOV or vertical FOV. A longer lens has a narrower FOV. Typically, a longer lens also has higher resolution and less distortion. If our subject falls outside the FOV, we miss the subject completely! Toward the edges of the FOV, resolution tends to decrease and distortion tends to increase, so preferably the FOV should be wide enough to leave a margin around the subject.
The camera's throughput is the rate at which it captures image data. For many computer vision applications, a visual event might start and end in a fleeting moment and if the throughput is low, we might miss the moment completely or our image of it might suffer from motion blur. Typically, throughput is measured in frames per second (FPS), though measuring it as a bitrate can be useful, too. Throughput is limited by the following factors:
Shutter speed (exposure time): For a well-exposed image, the shutter speed is limited by lighting conditions, the lens's aperture setting, and the camera's ISO speed setting. (Conversely, a slower shutter speed allows for a narrower aperture setting or slower ISO speed.) We will discuss aperture settings after this list.
The type of shutter: A global shutter synchronizes the capture across all photosites. A rolling shutter does not; rather, the capture is sequential such that photosites at the bottom of the sensor register their signals later than photosites at the top. A rolling shutter is inferior because it can make an object appear skewed when the object or the camera moves rapidly. (This is sometimes called the "Jell-O effect" because of the video's resemblance to a wobbling mound of gelatin.) Also, under rapidly flickering lighting, a rolling shutter creates light and dark bands in the image. If the start of the capture is synchronized but the end is not, the shutter is referred to as a rolling shutter with global reset.
The camera's onboard image processing routines, such as conversion of raw photosite signals to a given number of pixels in a given format. As the number of pixels and bytes per pixel increase, the throughput decreases.
The interface between the camera and host computer: Common camera interfaces, in order of decreasing bit rates, include CoaXPress full, Camera Link full, USB 3.0, CoaXPress base, Camera Link base, Gigabit Ethernet, IEEE 1394b (FireWire full), USB 2.0, and IEEE 1394 (FireWire base).
A wide aperture setting lets in more light to allow for a faster exposure, a lower ISO speed, or a brighter image. However, a narrower aperture has the advantage of offering a greater depth of field. A lens supports a limited range of aperture settings. Depending on the lens, some aperture settings exhibit higher resolution than others. Long lenses tend to exhibit more stable resolution across aperture settings.
A lens's aperture size is expressed as an f-number or f-stop, which is the ratio of the lens's focal length to the diameter of its aperture. Roughly speaking, focal length is related to the length of the lens. More precisely, it is the distance between the camera's sensor and the lens system's optical center when the lens is focused at an infinitely distant target. The focal length should not be confused with the focus distance—the distance to objects that are in focus. The following diagram illustrates the meanings of focal length and focal distance as well as FOV:

With a higher f-number (a proportionally narrower aperture), a lens transmits a smaller proportion of incoming light. Specifically, the intensity of the transmitted light is inversely proportional to the square of the f-number. For example, when comparing the maximum apertures of two lenses, a photographer might write, "The f/2 lens is twice as fast as the f/2.8 lens." This means that the former lens can transmit twice the intensity of light, allowing an equivalent exposure to be taken in half the time.
A lens's efficiency or transmittance (the proportion of light transmitted) depends on not only the f-number but also non-ideal factors. For example, some light is reflected off the lens elements instead of being transmitted. The T-number or T-stop is an adjustment to the f-number based on empirical findings about a given lens's transmittance. For example, regardless of its f-number, a T/2.4 lens has the same transmittance as an ideal f/2.4 lens. For cinema lenses, manufacturers often provide T-number specifications but for other lenses, it is much more common to see only f-number specifications.
The sensor's efficiency is the proportion of the lens-transmitted light that reaches photosites and gets converted to a signal. If the efficiency is poor, the sensor misses much of the light! A more efficient sensor will tend to take well-exposed images for a broader range of camera settings, lens settings, and lighting conditions. Thus, efficiency gives the system more freedom to auto-select settings that are optimal for resolution and throughput. For the common type of sensor described in the previous section, Coloring the light, the choice of color filters has a big effect on efficiency. A camera designed to capture visible light in grayscale has high efficiency because it can receive all visible wavelengths at each photosite. A camera designed to capture visible light in multiple color channels typically has much lower efficiency because some wavelengths are filtered out at each photosite. A camera designed to capture NIR alone, by filtering out all visible light, typically has even lower efficiency.
Efficiency is a good indication of the system's ability to form some kind of image under diverse lighting (or radiation) conditions. However, depending on the subject and the real lighting, a relatively inefficient system could have higher contrast and better resolution. The advantages of selectively filtering wavelengths are not necessarily reflected in lp/mm, which measures black-on-white resolution.
By now, we have seen many quantifiable tradeoffs that complicate our efforts to capture a subject in a moment. As Robert Capa's advice implies, getting close with a short lens is a relatively robust recipe. It allows for good resolution with minimal risk of completely missing the framing or the focus. On the other hand, such a setup suffers from high distortion and, by definition, a short working distance. Moving beyond the capabilities of cameras in Capa's day, we have also considered the features and configurations that allow for high-throughput and high-efficiency video capture.
Having primed ourselves on wavelengths, image formats, cameras, lenses, capture settings, and photographers' common sense, let us now select several systems to study.
This chapter's demo applications are tested with three cameras, which are described in the following table. The demos are also compatible with many additional cameras; we will discuss compatibility later as part of each demo's detailed description. The three chosen cameras differ greatly in terms of price and features but each one can do things that an ordinary webcam cannot!
|
Name |
Price |
Purposes |
Modes |
Optics |
|---|---|---|---|---|
|
Sony PlayStation Eye |
$10 |
Passive, color imaging in visible light |
640x480 @ 60 FPS 320x240 @ 187 FPS |
FOV: 75 degrees or 56 degrees (two zoom settings) |
|
ASUS Xtion PRO Live |
$230 |
Passive, color imaging in visible light Active, monochrome imaging in NIR light Depth estimation |
Color or NIR: 1280x1024 @ 60 FPS Depth: 640x480 @ 30 FPS |
FOV: 70 degrees |
|
PGR Grasshopper 3 GS3-U3-23S6M-C |
$1000 |
Passive, monochrome imaging in visible light |
1920x1200 @ 162 FPS |
C-mount lens (not included) |
Note
For examples of lenses that we can use with the GS3-U3-23S6M-C camera, refer to the Shopping for glass section, later in this chapter.
We will try to push these cameras to the limits of their capabilities. Using multiple libraries, we will write applications to access unusual capture modes and to process frames so rapidly that the input remains the bottleneck. To borrow a term from the automobile designers who made 1950s muscle cars, we might say that we want to "supercharge" our systems; we want to supply them with specialized or excess input to see what they can do!
Sony developed the Eye camera in 2007 as an input device for PlayStation 3 games. Originally, no other system supported the Eye. Since then, third parties have created drivers and SDKs for Linux, Windows, and Mac. The following list describes the current state of some of these third-party projects:
For Linux, the gspca_ov534 driver supports the PlayStation Eye and works out of the box with OpenCV's videoio module. This driver comes standard with most recent Linux distributions. Current releases of the driver support modes as fast as 320x240 @ 125 FPS and 640x480 @ 60 FPS. An upcoming release will add support for 320x240 @187 FPS. If you want to upgrade to this future version today, you will need to familiarize yourself with the basics of Linux kernel development, and build the driver yourself.
Note
See the driver's latest source code at https://github.com/torvalds/linux/blob/master/drivers/media/usb/gspca/ov534.c. Briefly, you would need to obtain the source code of your Linux distribution's kernel, merge the new
ov534.cfile, build the driver as part of the kernel, and finally, load the newly built gspca_ov534 driver.For Mac and Windows, developers can add PlayStation Eye support to their applications using an SDK called PS3EYEDriver, available from https://github.com/inspirit/PS3EYEDriver. Despite the name, this project is not a driver; it supports the camera at the application level, but not the OS level. The supported modes include 320x240 @ 187 FPS and 640x480 @ 60 FPS. The project comes with sample application code. Much of the code in PS3EYEDriver is derived from the GPL-licensed gspca_ov534 driver, and thus, the use of PS3EYEDriver is probably only appropriate to projects that are also GPL-licensed.
For Windows, a commercial driver and SDK are available from Code Laboratories (CL) at https://codelaboratories.com/products/eye/driver/. At the time of writing, the CL-Eye Driver costs $3. However, the driver does not work with OpenCV 3's videoio module. The CL-Eye Platform SDK, which depends on the driver, costs an additional $5. The fastest supported modes are 320x240 @ 187 FPS and 640x480 @ 75 FPS.
For recent versions of Mac, no driver is available. A driver called macam is available at http://webcam-osx.sourceforge.net/, but it was last updated in 2009 and does not work on Mac OS X Mountain Lion and newer versions.
Thus, OpenCV in Linux can capture data directly from an Eye camera, but OpenCV in Windows or Mac requires another SDK as an intermediary.
First, for Linux, let us consider a minimal example of a C++ application that uses OpenCV to record a slow-motion video based on high-speed input from an Eye. Also, the program should log its frame rate. Let's call this application Unblinking Eye.
Note
Unblinking Eye's source code and build files are in this book's GitHub repository at https://github.com/OpenCVBlueprints/OpenCVBlueprints/tree/master/chapter_1/UnblinkingEye.
Note that this sample code should also work with other OpenCV-compatible cameras, albeit at a slower frame rate compared to the Eye.
Unblinking Eye can be implemented in a single file, UnblinkingEye.cpp, containing these few lines of code:
#include <stdio.h>
#include <time.h>
#include <opencv2/core.hpp>
#include <opencv2/videoio.hpp>
int main(int argc, char *argv[]) {
const int cameraIndex = 0;
const bool isColor = true;
const int w = 320;
const int h = 240;
const double captureFPS = 187.0;
const double writerFPS = 60.0;
// With MJPG encoding, OpenCV requires the AVI extension.
const char filename[] = "SlowMo.avi";
const int fourcc = cv::VideoWriter::fourcc('M','J','P','G');
const unsigned int numFrames = 3750;
cv::Mat mat;
// Initialize and configure the video capture.
cv::VideoCapture capture(cameraIndex);
if (!isColor) {
capture.set(cv::CAP_PROP_MODE, cv::CAP_MODE_GRAY);
}
capture.set(cv::CAP_PROP_FRAME_WIDTH, w);
capture.set(cv::CAP_PROP_FRAME_HEIGHT, h);
capture.set(cv::CAP_PROP_FPS, captureFPS);
// Initialize the video writer.
cv::VideoWriter writer(
filename, fourcc, writerFPS, cv::Size(w, h), isColor);
// Get the start time.
clock_t startTicks = clock();
// Capture frames and write them to the video file.
for (unsigned int i = 0; i < numFrames;) {
if (capture.read(mat)) {
writer.write(mat);
i++;
}
}
// Get the end time.
clock_t endTicks = clock();
// Calculate and print the actual frame rate.
double actualFPS = numFrames * CLOCKS_PER_SEC /
(double)(endTicks - startTicks);
printf("FPS: %.1f\n", actualFPS);
}Note that the camera's specified mode is 320x240 @ 187 FPS. If our version of the gspca_ov534 driver does not support this mode, we can expect it to fall back to 320x240 @ 125 FPS. Meanwhile, the video file's specified mode is 320x240 @ 60 FPS, meaning that the video will play back at slower-than-real speed as a special effect. Unblinking Eye can be built using a Terminal command such as the following:
$ g++ UnblinkingEye.cpp -o UnblinkingEye -lopencv_core -lopencv_videoio
Build Unblinking Eye, run it, record a moving subject, observe the frame rate, and play back the recorded video, SlowMo.avi. How does your subject look in slow motion?
On a machine with a slow CPU or slow storage, Unblinking Eye might drop some of the captured frames due to a bottleneck in video encoding or file output. Do not be fooled by the low resolution! The rate of data transfer for a camera in 320x240 @ 187 FPS mode is greater than for a camera in 1280x720 @ 15 FPS mode (an HD resolution at a slightly choppy frame rate). Multiply the pixels by the frame rate to see how many pixels per second are transferred in each mode.
Suppose we want to reduce the amount of data per frame by capturing and recording monochrome video. Such an option is available when OpenCV 3 is built for Linux with libv4l support. (The relevant CMake definition is WITH_LIBV4L, which is turned on by default.) By changing the following line in the code of Unblinking Eye and then rebuilding it, we can switch to grayscale capture:
const bool isColor = false;
Note that the change to this Boolean affects the highlighted portions of the following code:
cv::VideoCapture capture(cameraIndex); if (!isColor) { capture.set(cv::CAP_PROP_MODE, cv::CAP_MODE_GRAY); } capture.set(cv::CAP_PROP_FRAME_WIDTH, w); capture.set(cv::CAP_PROP_FRAME_HEIGHT, h); capture.set(cv::CAP_PROP_FPS, captureFPS); cv::VideoWriter writer( filename, fourcc, writerFPS, cv::Size(w, h), isColor);
Behind the scenes, the VideoCapture and VideoWriter objects are now using a planar YUV format. The captured Y data are copied to a single-channel OpenCV Mat and are ultimately stored in the video file's Y channel. Meanwhile, the video file's U and V color channels are just filled with the mid-range value, 128, for gray. U and V use a lower resolution than Y, so at the time of capture, the YUV format has only 12 bits per pixel (bpp), compared to 24 bpp for OpenCV's default BGR format.
Note
The libv4l interface in OpenCV's videoio module currently supports the following values for cv::CAP_PROP_MODE:
cv::CAP_MODE_BGR(the default) captures 24 bpp color in BGR format (8 bpp per channel).cv::CAP_MODE_RGBcaptures 24 bpp color in RGB format (8 bpp per channel).cv::CAP_MODE_GRAYextracts 8 bpp grayscale from a 12 bpp planar YUV format.cv::CAP_MODE_YUYVcaptures 16 bpp color in a packed YUV format (8 bpp for Y and 4 bpp each for U and V).
For Windows or Mac, we should instead capture data using PS3EYEDriver, CL-Eye Platform SDK, or another library, and then create an OpenCV Mat that references the data. This approach is illustrated in the following partial code sample:
int width = 320, height = 240; int matType = CV_8UC3; // 8 bpp per channel, 3 channels void *pData; // Use the camera SDK to capture image data. someCaptureFunction(&pData); // Create the matrix. No data are copied; the pointer is copied. cv::Mat mat(height, width, matType, pData);
Indeed, the same approach applies to integrating almost any source of data into OpenCV. Conversely, to use OpenCV as a source of data for another library, we can get a pointer to the data stored in a matrix:
void *pData = mat.data;
Later in this chapter, in Supercharging the GS3-U3-23S6M-C and other Point Grey Research cameras, we cover a nuanced example of integrating OpenCV with other libraries, specifically FlyCapture2 for capture and SDL2 for display. PS3EYEDriver comes with a comparable sample, in which the pointer to captured data is passed to SDL2 for display. As an exercise, you might want to adapt these two examples to build a demo that integrates OpenCV with PS3EYEDriver for capture and SDL2 for display.
Hopefully, after some experimentation, you will conclude that the PlayStation Eye is a more capable camera than its $10 price tag suggests. For fast-moving subjects, its high frame rate is a good tradeoff for its low resolution. Banish motion blur!
If we are willing to invest in hardware modifications, the Eye has even more tricks hidden up its sleeve (or in its socket). The lens and IR blocking filter are relatively easy to replace. An aftermarket lens and filter can allow for NIR capture. Furthermore, an aftermarket lens can yield higher resolution, a different FOV, less distortion, and greater efficiency. Peau Productions sells premodified Eye cameras as well as do-it-yourself (DIY) kits, at http://peauproductions.com/store/index.php?cPath=136_1. The company's modifications support interchangeable lenses with an m12 mount or CS mount (two different standards of screw mounts). The website offers detailed recommendations based on lens characteristics such as distortion and IR transmission. Peau's price for a premodified NIR Eye camera plus a lens starts from approximately $85. More expensive options, including distortion-corrected lenses, range up to $585. However, at these prices, it is advisable to compare lens prices across multiple vendors, as described later in this chapter's Shopping for glass section.
Next, we will examine a camera that lacks high-speed modes, but is designed to separately capture visible and NIR light, with active NIR illumination.
ASUS introduced the Xtion PRO Live in 2012 as an input device for motion-controlled games, natural user interfaces (NUIs), and computer vision research. It is one of six similar cameras based on sensors designed by PrimeSense, an Israeli company that Apple acquired and shut down in 2013. For a brief comparison between the Xtion PRO Live and the other devices that use PrimeSense sensors, see the following table:
|
Name |
Price and Availability |
Highest Res NIR Mode |
Highest Res Color Mode |
Highest Res Depth Mode |
Depth Range |
|---|---|---|---|---|---|
|
Microsoft Kinect for Xbox 360 |
$135 Available |
640x480 @ 30 FPS? |
640x480 @ 30 FPS |
640x480 @ 30 FPS |
0.8m to 3.5m? |
|
ASUS Xtion PRO |
$200 Discontinued |
1280x1024 @ 60 FPS? |
None |
640x480 @ 30 FPS |
0.8m to 3.5m |
|
ASUS Xtion PRO Live |
$230 Available |
1280x1024 @ 60 FPS |
1280x1024 @ 60 FPS |
640x480 @ 30 FPS |
0.8m to 3.5m |
|
PrimeSense Carmine 1.08 |
$300 Discontinued |
1280x960 @ 60 FPS? |
1280x960 @ 60 FPS |
640x480 @ 30 FPS |
0.8m to 3.5m |
|
PrimeSense Carmine 1.09 |
$325 Discontinued |
1280x960 @ 60 FPS? |
1280x960 @ 60 FPS |
640x480 @ 30 FPS |
0.35m to 1.4m |
|
Structure Sensor |
$380 Available |
640x480 @ 30 FPS? |
None |
640x480 @ 30 FPS |
0.4m to 3.5m |
All of these devices include a NIR camera and a source of NIR illumination. The light source projects a pattern of NIR dots, which might be detectable at a distance of 0.8m to 3.5m, depending on the model. Most of the devices also include an RGB color camera. Based on the appearance of the active NIR image (of the dots) and the passive RGB image, the device can estimate distances and produce a so-called depth map, containing distance estimates for 640x480 points. Thus, the device has up to three modes: NIR (a camera image), color (a camera image), and depth (a processed image).
Note
For more information on the types of active illumination or structured light that are useful in depth imaging, see the following paper:
David Fofi, Tadeusz Sliwa, Yvon Voisin, "A comparative survey on invisible structured light", SPIE Electronic Imaging - Machine Vision Applications in Industrial Inspection XII, San José, USA, pp. 90-97, January, 2004.
The paper is available online at http://www.le2i.cnrs.fr/IMG/publications/fofi04a.pdf.
The Xtion, Carmine, and Structure Sensor devices as well as certain versions of the Kinect are compatible with open source SDKs called OpenNI and OpenNI2. Both OpenNI and OpenNI2 are available under the Apache license. On Windows, OpenNI2 comes with support for many cameras. However, on Linux and Mac, support for the Xtion, Carmine, and Structure Sensor devices is provided through an extra module called PrimeSense Sensor, which is also open source under the Apache license. The Sensor module and OpenNI2 have separate installation procedures and the Sensor module must be installed first. Obtain the Sensor module from one of the following URLs, depending on your operating system:
After downloading this archive, decompress it and run install.sh (inside the decompressed folder).
Note
For Kinect compatibility, instead try the SensorKinect fork of the Sensor module. Downloads for SensorKinect are available at https://github.com/avin2/SensorKinect/downloads. SensorKinect only supports Kinect for Xbox 360 and it does not support model 1473. (The model number is printed on the bottom of the device.) Moreover, SensorKinect is only compatible with an old development build of OpenNI (and not OpenNI2). For download links to the old build of OpenNI, refer to http://nummist.com/opencv/.
Now, on any operating system, we need to build the latest development version of OpenNI2 from source. (Older, stable versions do not work with the Xtion PRO Live, at least on some systems.) The source code can be downloaded as a ZIP archive from https://github.com/occipital/OpenNI2/archive/develop.zip or it can be cloned as a Git repository using the following command:
$ git clone –b develop https://github.com/occipital/OpenNI2.git
Let's refer to the unzipped directory or local repository directory as <openni2_path>. This path should contain a Visual Studio project for Windows and a Makefile for Linux or Mac. Build the project (using Visual Studio or the make command). Library files are generated in directories such as <openni2_path>/Bin/x64-Release and <openni2_path>/Bin/x64-Release/OpenNI2/Drivers (or similar names for another architecture besides x64). On Windows, add these two folders to the system's Path so that applications can find the dll files. On Linux or Mac, edit your ~/.profile file and add lines such as the following to create environment variables related to OpenNI2:
export OPENNI2_INCLUDE="<openni2_path>/Include" export OPENNI2_REDIST="<openni2_path>/Bin/x64-Release"
At this point, we have set up OpenNI2 with support for the Sensor module, so we can create applications for the Xtion PRO Live or other cameras that are based on the PrimeSense hardware. Source code, Visual Studio projects, and Makefiles for several samples can be found in <openni2_path>/Samples.
Note
Optionally, OpenCV's videoio module can be compiled with support for capturing images via OpenNI or OpenNI2. However, we will capture images directly from OpenNI2 and then convert them for use with OpenCV. By using OpenNI2 directly, we gain more control over the selection of camera modes, such as raw NIR capture.
The Xtion devices are designed for USB 2.0 and their standard firmware does not work with USB 3.0 ports. For USB 3.0 compatibility, we need an unofficial firmware update. The firmware updater only runs in Windows, but after the update is applied, the device is USB 3.0-compatible in Linux and Mac, too. To obtain and apply the update, take the following steps:
Download the update from https://github.com/nh2/asus-xtion-fix/blob/master/FW579-RD1081-112v2.zip?raw=true and unzip it to any destination, which we will refer to as
<xtion_firmware_unzip_path>.Ensure that the Xtion device is plugged in.
Open Command Prompt and run the following commands:
> cd <xtion_firmware_unzip_path>\UsbUpdate > !Update-RD108x!
If the firmware updater prints errors, these are not necessarily fatal. Proceed to test the camera using our demo application shown here.
To understand the Xtion PRO Live's capabilities as either an active or passive NIR camera, we will build a simple application that captures and displays images from the device. Let's call this application Infravision.
Note
Infravision's source code and build files are in this book's GitHub repository at https://github.com/OpenCVBlueprints/OpenCVBlueprints/tree/master/chapter_1/Infravision.
This project needs just one source file, Infravision.cpp. From the C standard library, we will use functionality for formatting and printing strings. Thus, our implementation begins with the following import statements:
#include <stdio.h> #include <stdlib.h>
Infravision will use OpenNI2 and OpenCV. From OpenCV, we will use the core and imgproc modules for basic image manipulation as well as the highgui module for event handling and display. Here are the relevant import statements:
#include <opencv2/core.hpp> #include <opencv2/highgui.hpp> #include <opencv2/imgproc.hpp> #include <OpenNI.h>
Note
The documentation for OpenNI2 as well as OpenNI can be found online at http://structure.io/openni.
The only function in Infravision is a main function. It begins with definitions of two constants, which we might want to configure. The first of these specifies the kind of sensor data to be captured via OpenNI. This can be SENSOR_IR (monochrome output from the IR camera), SENSOR_COLOR (RGB output from the color camera), or SENSOR_DEPTH (processed, hybrid data reflecting the estimated distance to each point). The second constant is the title of the application window. Here are the relevant definitions:
int main(int argc, char *argv[]) {
const openni::SensorType sensorType = openni::SENSOR_IR;
// const openni::SensorType sensorType = openni::SENSOR_COLOR;
// const openni::SensorType sensorType = openni::SENSOR_DEPTH;
const char windowName[] = "Infravision";Based on the capture mode, we will define the format of the corresponding OpenCV matrix. The IR and depth modes are monochrome with 16 bpp. The color mode has three channels with 8 bpp per channel, as seen in the following code:
int srcMatType;
if (sensorType == openni::SENSOR_COLOR) {
srcMatType = CV_8UC3;
} else {
srcMatType = CV_16U;
}Let's proceed by taking several steps to initialize OpenNI2, connect to the camera, configure it, and start capturing images. Here is the code for the first step, initializing the library:
openni::Status status;
status = openni::OpenNI::initialize();
if (status != openni::STATUS_OK) {
printf(
"Failed to initialize OpenNI:\n%s\n",
openni::OpenNI::getExtendedError());
return EXIT_FAILURE;
}Next, we will connect to any available OpenNI-compliant camera:
openni::Device device;
status = device.open(openni::ANY_DEVICE);
if (status != openni::STATUS_OK) {
printf(
"Failed to open device:\n%s\n",
openni::OpenNI::getExtendedError());
openni::OpenNI::shutdown();
return EXIT_FAILURE;
}We will ensure that the device has the appropriate type of sensor by attempting to fetch information about that sensor:
const openni::SensorInfo *sensorInfo =
device.getSensorInfo(sensorType);
if (sensorInfo == NULL) {
printf("Failed to find sensor of appropriate type\n");
device.close();
openni::OpenNI::shutdown();
return EXIT_FAILURE;
}We will also create a stream but not start it yet:
openni::VideoStream stream;
status = stream.create(device, sensorType);
if (status != openni::STATUS_OK) {
printf(
"Failed to create stream:\n%s\n",
openni::OpenNI::getExtendedError());
device.close();
openni::OpenNI::shutdown();
return EXIT_FAILURE;
}We will query the supported video modes and iterate through them to find the one with the highest resolution. Then, we will select this mode:
// Select the video mode with the highest resolution.
{
const openni::Array<openni::VideoMode> *videoModes =
&sensorInfo->getSupportedVideoModes();
int maxResolutionX = -1;
int maxResolutionIndex = 0;
for (int i = 0; i < videoModes->getSize(); i++) {
int resolutionX = (*videoModes)[i].getResolutionX();
if (resolutionX > maxResolutionX) {
maxResolutionX = resolutionX;
maxResolutionIndex = i;
}
}
stream.setVideoMode((*videoModes)[maxResolutionIndex]);
}We will start streaming images from the camera:
status = stream.start();
if (status != openni::STATUS_OK) {
printf(
"Failed to start stream:\n%s\n",
openni::OpenNI::getExtendedError());
stream.destroy();
device.close();
openni::OpenNI::shutdown();
return EXIT_FAILURE;
}To prepare for capturing and displaying images, we will create an OpenNI frame, an OpenCV matrix, and a window:
openni::VideoFrameRef frame; cv::Mat dstMat; cv::namedWindow(windowName);
Next, we will implement the application's main loop. On each iteration, we will capture a frame via OpenNI, convert it to a typical OpenCV format (either grayscale with 8 bpp or BGR with 8 bpp per channel), and display it via the highgui module. The loop ends when the user presses any key. Here is the implementation:
// Capture and display frames until any key is pressed.
while (cv::waitKey(1) == -1) {
status = stream.readFrame(&frame);
if (frame.isValid()) {
cv::Mat srcMat(
frame.getHeight(), frame.getWidth(), srcMatType,
(void *)frame.getData(), frame.getStrideInBytes());
if (sensorType == openni::SENSOR_COLOR) {
cv::cvtColor(srcMat, dstMat, cv::COLOR_RGB2BGR);
} else {
srcMat.convertTo(dstMat, CV_8U);
}
cv::imshow(windowName, dstMat);
}
}Note
OpenCV's highgui module has many shortcomings. It does not allow for handling of a standard quit event, such as the clicking of a window's X button. Thus, we quit based on a keystroke instead. Also, highgui imposes a delay of at least 1ms (but possibly more, depending on the operating system's minimum time to switch between threads) when polling events such as keystrokes. This delay should not matter for the purpose of demonstrating a camera with a low frame rate, such as the Xtion PRO Live with its 30 FPS limit. However, in the next section, Supercharging the GS3-U3-23S6M-C and other Point Gray Research cameras, we will explore SDL2 as a more efficient alternative to highgui.
After the loop ends (due to the user pressing a key), we will clean up the window and all of OpenNI's resources, as shown in the following code:
cv::destroyWindow(windowName); stream.stop(); stream.destroy(); device.close(); openni::OpenNI::shutdown(); }
This is the end of the source code. On Windows, Infravision can be built as a Visual C++ Win32 Console Project in Visual Studio. Remember to right-click on the project and edit its Project Properties so that C++ | General | Additional Include Directories lists the path to OpenCV's and OpenNI's include directories. Also, edit Linker | Input | Additional Dependencies so that it lists the paths to opencv_core300.lib and opencv_imgproc300.lib (or similarly named lib files for other OpenCV versions besides 3.0.0) as well as OpenNI2.lib. Finally, ensure that OpenCV's and OpenNI's dll files are in the system's Path.
On Linux or Mac, Infravision can be compiled using a Terminal command such as the following (assuming that the OPENNI2_INCLUDE and OPENNI2_REDIST environment variables are defined as described earlier in this section):
$ g++ Infravision.cpp -o Infravision \ -I include -I $OPENNI2_INCLUDE -L $OPENNI2_REDIST \ -Wl,-R$OPENNI2_REDIST -Wl,-R$OPENNI2_REDIST/OPENNI2 \ -lopencv_core -lopencv_highgui -lopencv_imgproc -lOpenNI2
Note
The -Wl,-R flags specify an additional path where the executable should search for library files at runtime.
After building Infravision, run it and observe the pattern of NIR dots that the Xtion PRO Live projects onto nearby objects. When reflected from distant objects, the dots are sparsely spaced, but when reflected from nearby objects, they are densely spaced or even indistinguishable. Thus, the density of dots is a predictor of distance. Here is a screenshot showing the effect in a sunlit room where NIR light is coming from both the Xtion and the windows:

Alternatively, if you want to use the Xtion as a passive NIR camera, simply cover up the camera's NIR emitter. Your fingers will not block all of the emitter's light, but a piece of electrical tape will. Now, point the camera at a scene that has moderately bright NIR illumination. For example, the Xtion should be able to take a good passive NIR image in a sunlit room or beside a campfire at night. However, the camera will not cope well with a sunlit outdoor scene because this is vastly brighter than the conditions for which the device was designed. Here is a screenshot showing the same sunlit room as in the previous example but this time, the Xtion's NIR emitter is covered up:

Note that all the dots have disappeared and the new image looks like a relatively normal black-and-white photo. However, do any objects appear to have a strange glow?
Feel free to modify the code to use SENSOR_DEPTH or SENSOR_COLOR instead of SENSOR_IR. Recompile, rerun the application, and observe the effects. The depth sensor provides a depth map, which appears bright in nearby regions and dark in faraway regions or regions of unknown distance. The color sensor provides a normal-looking image based on the visible spectrum, as seen in the following screenshot of the same sunlit room:

Compare the previous two screenshots. Note that the leaves of the roses are much brighter in the NIR image. Moreover, the printed pattern on the footstool (beneath the roses) is invisible in the NIR image. (When designers choose pigments, they usually do not think about how the object will look in NIR!)
Perhaps you want to use the Xtion as an active NIR imaging device—capable of night vision at short range—but you do not want the pattern of NIR dots. Just cover the illuminator with something to diffuse the NIR light, such as your fingers or a piece of fabric.
As an example of this diffused lighting, look at the following screenshot, showing a woman's wrists in NIR:

Note that the veins are more distinguishable than they would be in visible light. Similarly, active NIR cameras have a superior ability to capture identifiable details in the iris of a person's eye, as demonstrated in Chapter 6, Efficient Person Identification Using Biometric Properties. Can you find other examples of things that look much different in the NIR and visible wavelengths?
By now, we have seen that OpenNI-compatible cameras can be configured (programmatically and physically) to take several kinds of images. However, these cameras are designed for a specific task—depth estimation in indoor scenes—and they do not necessarily cope well with alternative uses such as outdoor NIR imaging. Next, we will look at a more diverse, more configurable, and more expensive family of cameras.
Point Grey Research (PGR), a Canadian company, manufactures industrial cameras with a wide variety of features. A few examples are listed in the following table:
|
Family and Model |
Price |
Color Sensitivity |
Highest Res Mode |
Sensor Format and Lens Mount |
Interface |
Shutter |
|---|---|---|---|---|---|---|
|
Firefly MV FMVU-03MTC-CS |
$275 |
Color |
752x480 @ 60 FPS |
1/3" CS mount |
USB 2.0 |
Global |
|
Firefly MV FMVU-03MTM-CS |
$275 |
Gray from visible light |
752x480 @ 60 FPS |
1/3" CS mount |
USB 2.0 |
Global |
|
Flea 3 FL3-U3-88S2C-C |
$900 |
Color |
4096x2160 @ 21 FPS |
1/2.5" C mount |
USB 3.0 |
Rolling with global reset |
|
Grasshopper 3 GS3-U3-23S6C-C |
$1,000 |
Color |
1920x1200 @ 162 FPS |
1/1.2" C mount |
USB 3.0 |
Global |
|
Grasshopper 3 GS3-U3-23S6M-C |
$1,000 |
Gray from visible light |
1920x1200 @ 162 FPS |
1/1.2" C mount |
USB 3.0 |
Global |
|
Grasshopper 3 GS3-U3-41C6C-C |
$1,300 |
Color |
2048x2048 @ 90 FPS |
1" C mount |
USB 3.0 |
Global |
|
Grasshopper 3 GS3-U3-41C6M-C |
$1,300 |
Gray from visible light |
2048x2048 @ 90 FPS |
1" C mount |
USB 3.0 |
Global |
|
Grasshopper 3 GS3-U3-41C6NIR-C |
$1,300 |
Gray from NIR light |
2048x2048 @ 90 FPS |
1" C mount |
USB 3.0 |
Global |
|
Gazelle GZL-CL-22C5M-C |
$1,500 |
Gray from visible light |
2048x1088 @ 280 FPS |
2/3" C mount |
Camera Link |
Global |
|
Gazelle GZL-CL-41C6M-C |
$2,200 |
Gray from visible light |
2048x2048 @ 150 FPS |
1" C mount |
Camera Link |
Global |
Note
To browse the features of many more PGR cameras, see the company's Camera Selector tool at http://www.ptgrey.com/Camera-selector. For performance statistics about the sensors in PGR cameras, see the company's series of Camera Sensor Review publications such as the ones posted at http://www.ptgrey.com/press-release/10545.
For more information on sensor formats and lens mounts, see the Shopping for glass section, later in this chapter.
Some of PGR's recent cameras use the Sony Pregius brand of sensors. This sensor technology is notable for its combination of high resolution, high frame rate, and efficiency, as described in PGR's white paper at http://ptgrey.com/white-paper/id/10795. For example, the GS3-U3-23S6M-C (a monochrome camera) and GS3-U3-23S6C-C (a color camera) use a Pregius sensor called the Sony IMX174 CMOS. Thanks to the sensor and a fast USB 3.0 interface, these cameras are capable of capturing 1920x1200 @ 162 FPS.
The code in this section is tested with the GS3-U3-23S6M-C camera. However, it should work with other PGR cameras, too. Being a monochrome camera, the GS3-U3-23S6M-C allows us to see the full potential of the sensor's resolution and efficiency, without any color filter.
The GS3-U3-23S6M-C, like most PGR cameras, does not come with a lens; rather, it uses a standard C mount for interchangeable lenses. Examples of low-cost lenses for this mount are discussed later in this chapter, in the section Shopping for glass.
The GS3-U3-23S6M-C requires a USB 3.0 interface. For a desktop computer, a USB 3.0 interface can be added via a PCIe expansion card, which might cost between $15 and $60. PGR sells PCIe expansion cards that are guaranteed to work with its cameras; however, I have had success with other brands, too.
Once we are armed with the necessary hardware, we need to obtain an application called FlyCapture2 for configuring and testing our PGR camera. Along with this application, we will obtain FlyCapture2 SDK, which is a complete programming interface for all the functionality of our PGR camera. Go to http://www.ptgrey.com/support/downloads and download the relevant installer. (You will be prompted to register a user account if you have not already done so.) At the time of writing, the relevant download links have the following names:
FlyCapture 2.8.3.1 SDK - Windows (64-bit)
FlyCapture 2.8.3.1 SDK- Windows (32-bit)
FlyCapture 2.8.3.1 SDK- Linux Ubuntu (64-bit)
FlyCapture 2.8.3.1 SDK- Linux Ubuntu (32-bit)
FlyCapture 2.8.3.1 SDK- ARM Hard Float
Note
PGR does not offer an application or SDK for Mac. However, in principle, third-party applications or SDKs might be able use PGR cameras on Mac, as most PGR cameras are compliant with standards such as IIDC/DCAM.
For Windows, run the installer that you downloaded. If in doubt, choose a Complete installation when prompted. A shortcut, Point Grey FlyCap2, should appear in your Start menu.
For Linux, decompress the downloaded archive. Follow the installation instructions in the README file (inside the decompressed folder). A launcher, FlyCap2, should appear in your applications menu.
After installation, plug in your PGR camera and open the application. You should see a window entitled FlyCapture2 Camera Selection, as in the following screenshot:

Ensure that your camera is selected and then click the Configure Selected button. Another window should appear. Its title includes the camera name, such as Point Grey Research Grasshopper3 GS3-U3-23S6M. All the camera's settings can be configured in this window. I find that the Camera Video Modes tab is particularly useful. Select it. You should see options relating to the capture mode, pixel format, cropped region (called region of interest or ROI), and data transfer, as shown in the following screenshot:

For more information about the available modes and other settings, refer to the camera's Technical Reference Manual, which can be downloaded from http://www.ptgrey.com/support/downloads. Do not worry that you might permanently mess up any settings; they are reset every time you unplug the camera. When you are satisfied with the settings, click Apply and close the window. Now, in the Camera Selection window, click the OK button. On Linux, the FlyCapture2 application exits now. On Windows, we should see a new window, which also has the camera's name in its title bar. This window displays a live video feed and statistics. To ensure that the whole video is visible, select the menu option View | Stretched To Fit. Now, you should see the video letterboxed inside the window, as in the following screenshot:

If the video looks corrupted (for example, if you see pieces of multiple frames at one time), the most likely reason is that the host computer is failing to handle the data transfer at a sufficiently high speed. There are two possible approaches to solving this problem:
We can transfer less data. For example, go back to the Camera Video Modes tab of the configuration window and select either a smaller region of interest or a mode with a lower resolution.
We can configure the operating system and BIOS to give high priority to the task of processing incoming data. For details, see the following Technical Application Note (TAN) by PGR: http://www.ptgrey.com/tan/10367.
Feel free to experiment with other features of the FlyCapture2 application, such as video recording. When you are done, close the application.
Now that we have seen a PGR camera in action, let us write our own application to capture and display frames at high speed. It will support both Windows and Linux. We will call this application LookSpry. ("Spry" means quick, nimble, or lively, and a person who possesses these qualities is said to "look spry". If our high-speed camera application were a person, we might describe it this way.)
Note
LookSpry's source code and build files are in this book's GitHub repository at https://github.com/OpenCVBlueprints/OpenCVBlueprints/tree/master/chapter_1/LookSpry.
Like our other demos in this chapter, LookSpry can be implemented in a single source file, LookSpry.cpp. To begin the implementation, we need to import some of the C standard library's functionality, including string formatting and timing:
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <time.h>
LookSpry will use three additional libraries: FlyCapture2 SDK (FC2), OpenCV, and Simple DirectMedia Layer 2 (SDL2). (SDL2 is a cross-platform hardware abstraction layer for writing multimedia applications.) From OpenCV, we will use the core and imgproc modules for basic image manipulation, as well as the objdetect module for face detection. The role of face detection in this demo is simply to show that we can perform a real computer vision task with high-resolution input and a high frame rate. Here are the relevant import statements:
#include <flycapture/C/FlyCapture2_C.h> #include <opencv2/core.hpp> #include <opencv2/imgproc.hpp> #include <opencv2/objdetect.hpp> #include <SDL2/SDL.h>
Note
FC2 is closed-source but owners of PGR cameras receive a license to use it. The library's documentation can be found in the installation directory.
SDL2 is open-source under the zlib license. The library's documentation can be found online at https://wiki.libsdl.org.
Throughout LookSpry, we use a string formatting function—either sprintf_s in the Microsoft Visual C libraries or snprintf in standard C libraries. For our purposes, the two functions are equivalent. We will use the following macro definition so that snprintf is mapped to sprintf_s on Windows:
#ifdef _WIN32 #define snprintf sprintf_s #endif
At several points, the application can potentially encounter an error while calling functions in FlyCapture2 or SDL2. Such an error should be shown in a dialog box. The two following helper functions get and show the relevant error message from FC2 or SDL2:
void showFC2Error(fc2Error error) {
if (error != FC2_ERROR_OK) {
SDL_ShowSimpleMessage(SDL_MESSAGEBOX_ERROR,
"FlyCapture2 Error",
fc2ErrorToDescription(error), NULL);
}
}
void showSDLError() {
SDL_ShowSimpleMessageBox(
SDL_MESSAGEBOX_ERROR, "SDL2 Error", SDL_GetError(), NULL);
}The rest of LookSpry is simply implemented in a main function. At the start of the function, we will define several constants that we might want to configure, including the parameters of image capture, face detection, frame rate measurement, and display:
int main(int argc, char *argv[]) {
const unsigned int cameraIndex = 0u;
const unsigned int numImagesPerFPSMeasurement = 240u;
const int windowWidth = 1440;
const int windowHeight = 900;
const char cascadeFilename[] = "haarcascade_frontalface_alt.xml";
const double detectionScaleFactor = 1.25;
const int detectionMinNeighbours = 4;
const int detectionFlags = CV_HAAR_SCALE_IMAGE;
const cv::Size detectionMinSize(120, 120);
const cv::Size detectionMaxSize;
const cv::Scalar detectionDrawColor(255.0, 0.0, 255.0);
char strBuffer[256u];
const size_t strBufferSize = 256u;We will declare an image format, which will help OpenCV interpret captured image data. (A value will be assigned to this variable later, when we start capturing images.) We will also declare an OpenCV matrix that will store an equalized, grayscale version of the captured image. The declarations are as follows:
int matType; cv::Mat equalizedGrayMat;
Note
Equalization is a kind of contrast adjustment that makes all levels of brightness equally common in the output image. This adjustment makes a subject's appearance more stable with respect to variations in lighting. Thus, it is common practice to equalize an image before attempting to detect or recognize subjects (such as faces) in it.
For face detection, we will create a CascadeClassifier object (from OpenCV's objdetect module). The classifier loads a cascade file, for which we must specify an absolute path on Windows or a relative path on Unix. The following code constructs the path, the classifier, and a vector in which face detection results will be stored:
#ifdef _WIN32
snprintf(strBuffer, strBufferSize, "%s/../%s", argv[0], cascadeFilename);
cv::CascadeClassifier detector(strBuffer);
#else
cv::CascadeClassifier detector(cascadeFilename);
#endif
if (detector.empty()) {
snprintf(strBuffer, strBufferSize, "%s could not be loaded.",
cascadeFilename);
SDL_ShowSimpleMessageBox(
SDL_MESSAGEBOX_ERROR, "Failed to Load Cascade File", strBuffer,NULL);
return EXIT_FAILURE;
}
std::vector<cv::Rect> detectionRects;Now, we must set up several things related to FlyCapture2. First, the following code creates an image header that will receive captured data and metadata:
fc2Error error;
fc2Image image;
error = fc2CreateImage(&image);
if (error != FC2_ERROR_OK) {
showFC2Error(error);
return EXIT_FAILURE;
}The following code creates an FC2 context, which is responsible for querying, connecting to, and capturing from available cameras:
fc2Context context;
error = fc2CreateContext(&context);
if (error != FC2_ERROR_OK) {
showFC2Error(error);
return EXIT_FAILURE;
}The following lines use the context to fetch the identifier of the camera with the specified index:
fc2PGRGuid cameraGUID;
error = fc2GetCameraFromIndex(context, cameraIndex, &cameraGUID);
if (error != FC2_ERROR_OK) {
showFC2Error(error);
return EXIT_FAILURE;
} error = fc2Connect(context, &cameraGUID);
if (error != FC2_ERROR_OK) {
showFC2Error(error);
return EXIT_FAILURE;
}We finish our initialization of FC2 variables by starting the capture session:
error = fc2StartCapture(context);
if (error != FC2_ERROR_OK) {
fc2Disconnect(context);
showFC2Error(error);
return EXIT_FAILURE;
}Our use of SDL2 also requires several initialization steps. First, we must load the library's main module and video module, as seen in the following code:
if (SDL_Init(SDL_INIT_VIDEO) < 0) {
fc2StopCapture(context);
fc2Disconnect(context);
showSDLError();
return EXIT_FAILURE;
}Next, in the following code, we create a window with a specified title and size:
SDL_Window *window = SDL_CreateWindow(
"LookSpry", SDL_WINDOWPOS_UNDEFINED, SDL_WINDOWPOS_UNDEFINED,
windowWidth, windowHeight, 0u);
if (window == NULL) {
fc2StopCapture(context);
fc2Disconnect(context);
showSDLError();
return EXIT_FAILURE;
}We will create a renderer that is capable of drawing textures (image data) to the window's surface. The parameters in the following code permit SDL2 to select any rendering device and any optimizations:
SDL_Renderer *renderer = SDL_CreateRenderer(window, -1, 0u);
if (renderer == NULL) {
fc2StopCapture(context);
fc2Disconnect(context);
SDL_DestroyWindow(window);
showSDLError();
return EXIT_FAILURE;
}Next, we will query the renderer to see which rendering backend was selected by SDL2. The possibilities include Direct3D, OpenGL, and software rendering. Depending on the back-end, we might request a high-quality scaling mode so that the video does not appear pixelated when we scale it. Here is the code for querying and configuring the renderer:
SDL_RendererInfo rendererInfo;
SDL_GetRendererInfo(renderer, &rendererInfo);
if (strcmp(rendererInfo.name, "direct3d") == 0) {
SDL_SetHint(SDL_HINT_RENDER_SCALE_QUALITY, "best");
} else if (strcmp(rendererInfo.name, "opengl") == 0) {
SDL_SetHint(SDL_HINT_RENDER_SCALE_QUALITY, "linear");
}To provide feedback to the user, we will display the name of the rendering backend in the window's title bar:
snprintf(strBuffer, strBufferSize, "LookSpry | %s",
rendererInfo.name);
SDL_SetWindowTitle(window, strBuffer);We will declare variables relating to the image data rendered each frame. SDL2 uses a texture as an interface to these data:
SDL_Texture *videoTex = NULL; void *videoTexPixels; int pitch;
We will also declare variables relating to frame rate measurements:
clock_t startTicks = clock(); clock_t endTicks; unsigned int numImagesCaptured = 0u;
Three more variables will track the application's state—whether it should continue running, whether it should be detecting faces, and whether it should be mirroring the image (flipping it horizontally) for display. Here are the relevant declarations:
bool running = true; bool detecting = true; bool mirroring = true;
Now, we are ready to enter the application's main loop. On each iteration, we poll the SDL2 event queue for any and all events. A quit event (which arises, for example, when the window's close button is clicked) causes the running flag to be cleared and the main loop to exit at the iteration's end. When the user presses D or M, respectively, the detecting or mirroring flag is negated. The following code implements the event handling logic:
SDL_Event event;
while (running) {
while (SDL_PollEvent(&event)) {
if (event.type == SDL_QUIT) {
running = false;
break;
} else if (event.type == SDL_KEYUP) {
switch(event.key.keysym.sym) {
// When 'd' is pressed, start or stop [d]etection.
case SDLK_d:
detecting = !detecting;
break;
// When 'm' is pressed, [m]irror or un-mirror the video.
case SDLK_m:
mirroring = !mirroring;
break;
default:
break;
}
}
}Still in the main loop, we attempt to retrieve the next image from the camera. The following code does this synchronously:
error = fc2RetrieveBuffer(context, &image);
if (error != FC2_ERROR_OK) {
fc2Disconnect(context);
SDL_DestroyTexture(videoTex);
SDL_DestroyRenderer(renderer);
SDL_DestroyWindow(window);
showFC2Error(error);
return EXIT_FAILURE;
}Tip
Given the high throughput of the GS3-U3-23S6M-C and many other Point Grey cameras, synchronous capture is justifiable here. Images are coming in so quickly that we can expect zero or negligible wait time until a buffered frame is available. Thus, the user will not experience any perceptible lag in the processing of events. However, FC2 also offers asynchronous capture, with a callback, via the fc2SetCallbck function. The asynchronous option might be better for low-throughput cameras and, in this case, capture and rendering would not occur in the same loop as event polling.
If we have just captured the first frame in this run of the application, we still need to initialize several variables; for example, the texture is NULL. Based on the captured image's dimensions, we can set the size of the equalized matrix and of the renderer's (pre-scaling) buffer, as seen in the following code:
if (videoTex == NULL) {
equalizedGrayMat.create(image.rows, image.cols, CV_8UC1);
SDL_RenderSetLogicalSize(renderer, image.cols, image.rows);Based on the captured image's pixel format, we can select closely matching formats for OpenCV matrices and for the SDL2 texture. For monochrome capture—and raw capture, which we assume to be monochrome—we will use single-channel matrices and a YUV texture (specifically, the Y channel). The following code handles the relevant cases:
Uint32 videoTexPixelFormat;
switch (image.format) {
// For monochrome capture modes, plan to render captured data
// to the Y plane of a planar YUV texture.
case FC2_PIXEL_FORMAT_RAW8:
case FC2_PIXEL_FORMAT_MONO8:
videoTexPixelFormat = SDL_PIXELFORMAT_YV12;
matType = CV_8UC1;
break;For color capture in YUV, RGB, or BGR format, we select a matching texture format and a number of matrix channels based on the format's bytes per pixel:
// For color capture modes, plan to render captured data
// to the entire space of a texture in a matching color
// format.
case FC2_PIXEL_FORMAT_422YUV8:
videoTexPixelFormat = SDL_PIXELFORMAT_UYVY;
matType = CV_8UC2;
break;
case FC2_PIXEL_FORMAT_RGB:
videoTexPixelFormat = SDL_PIXELFORMAT_RGB24;
matType = CV_8UC3;
break;
case FC2_PIXEL_FORMAT_BGR:
videoTexPixelFormat = SDL_PIXELFORMAT_BGR24;
matType = CV_8UC3;
break;Some capture formats, including those with 16 bpp per channel, are not currently supported in LookSpry and are considered failure cases, as seen in the following code:
default:
fc2StopCapture(context);
fc2Disconnect(context);
SDL_DestroyTexture(videoTex);
SDL_DestroyRenderer(renderer);
SDL_DestroyWindow(window);
SDL_ShowSimpleMessageBox(
SDL_MESSAGEBOX_ERROR,
"Unsupported FlyCapture2 Pixel Format",
"LookSpry supports RAW8, MONO8, 422YUV8, RGB, and BGR.",
NULL);
return EXIT_FAILURE;
}We will create a texture with the given format and the same size as the captured image:
videoTex = SDL_CreateTexture(
renderer, videoTexPixelFormat, SDL_TEXTUREACCESS_STREAMING,
image.cols, image.rows);
if (videoTex == NULL) {
fc2StopCapture(context);
fc2Disconnect(context);
SDL_DestroyRenderer(renderer);
SDL_DestroyWindow(window);
showSDLError();
return EXIT_FAILURE;
}Using the following code, let's update the window's title bar to show the pixel dimensions of the captured image and the rendered image, in pixels:
snprintf(
strBuffer, strBufferSize, "LookSpry | %s | %dx%d --> %dx%d",
rendererInfo.name, image.cols, image.rows, windowWidth,
windowHeight);
SDL_SetWindowTitle(window, strBuffer);
}Next, if the application is in its face detection mode, we will convert the image to an equalized, grayscale version, as seen in the following code:
cv::Mat srcMat(image.rows, image.cols, matType, image.pData,
image.stride);
if (detecting) {
switch (image.format) {
// For monochrome capture modes, just equalize.
case FC2_PIXEL_FORMAT_RAW8:
case FC2_PIXEL_FORMAT_MONO8:
cv::equalizeHist(srcMat, equalizedGrayMat);
break;
// For color capture modes, convert to gray and equalize.
cv::cvtColor(srcMat, equalizedGrayMat,
cv::COLOR_YUV2GRAY_UYVY);
cv::equalizeHist(equalizedGrayMat, equalizedGrayMat);
break;
case FC2_PIXEL_FORMAT_RGB:
cv::cvtColor(srcMat, equalizedGrayMat, cv::COLOR_RGB2GRAY);
cv::equalizeHist(equalizedGrayMat, equalizedGrayMat);
break;
case FC2_PIXEL_FORMAT_BGR:
cv::cvtColor(srcMat, equalizedGrayMat, cv::COLOR_BGR2GRAY);
cv::equalizeHist(equalizedGrayMat, equalizedGrayMat);
break;
default:
break;
}We will perform face detection on the equalized image. Then, in the original image, we will draw rectangles around any detected faces:
// Run the detector on the equalized image.
detector.detectMultiScale(
equalizedGrayMat, detectionRects, detectionScaleFactor,
detectionMinNeighbours, detectionFlags, detectionMinSize,
detectionMaxSize);
// Draw the resulting detection rectangles on the original image.
for (cv::Rect detectionRect : detectionRects) {
cv::rectangle(srcMat, detectionRect, detectionDrawColor);
}
}At this stage, we have finished our computer vision task for this frame and we need to consider our output task. The image data are destined to be copied to the texture and then rendered. First, we will lock the texture, meaning that we will obtain write access to its memory. This is accomplished in the following SDL2 function call:
SDL_LockTexture(videoTex, NULL, &videoTexPixels, &pitch);
Remember, if the camera is in a monochrome capture mode (or a raw mode, which we assume to be monochrome), we are using a YUV texture. We need to fill the U and V channels with the mid-range value, 128, to ensure that the texture is gray. The following code accomplishes this efficiently by using the memset function from the C standard library:
switch (image.format) {
case FC2_PIXEL_FORMAT_RAW8:
case FC2_PIXEL_FORMAT_MONO8:
// Make the planar YUV video gray by setting all bytes in its U
// and V planes to 128 (the middle of the range).
memset(((unsigned char *)videoTexPixels + image.dataSize), 128,
image.dataSize / 2u);
break;
default:
break;
}Now, we are ready to copy the image data to the texture. If the mirroring flag is set, we will copy and mirror the data at the same time. To accomplish this efficiently, we will wrap the destination array in an OpenCV Mat and then use OpenCV's flip function to flip and copy the data simultaneously. Alternatively, if the mirroring flag is not set, we will simply copy the data using the standard C memcpy function. The following code implements these two alternatives:
if (mirroring) {
// Flip the image data while copying it to the texture.
cv::Mat dstMat(image.rows, image.cols, matType, videoTexPixels,
image.stride);
cv::flip(srcMat, dstMat, 1);
} else {
// Copy the image data, as-is, to the texture.
// Note that the PointGrey image and srcMat have pointers to the
// same data, so the following code does reference the data that
// we modified earlier via srcMat.
memcpy(videoTexPixels, image.pData, image.dataSize);
}Tip
Typically, the memcpy function (from the C standard library) compiles to block transfer instructions, meaning that it provides the best possible hardware acceleration for copying large arrays. However, it does not support any modification or reordering of data while copying. An article by David Nadeau benchmarks memcpy against four other copying techniques, using four compilers for each technique , and can be found at: http://nadeausoftware.com/articles/2012/05/c_c_tip_how_copy_memory_quickly.
Now that we have written the frame's data to the texture, we will unlock the texture (potentially causing data to be uploaded to the GPU) and we will tell the renderer to render it:
SDL_UnlockTexture(videoTex);
SDL_RenderCopy(renderer, videoTex, NULL, NULL);
SDL_RenderPresent(renderer);After a specified number of frames, we will update our FPS measurement and display it in the window's title bar, as seen in the following code:
numImagesCaptured++;
if (numImagesCaptured >= numImagesPerFPSMeasurement) {
endTicks = clock();
snprintf(
strBuffer, strBufferSize,
"LookSpry | %s | %dx%d --> %dx%d | %ld FPS",
rendererInfo.name, image.cols, image.rows, windowWidth,
windowHeight,
numImagesCaptured * CLOCKS_PER_SEC /
(endTicks - startTicks));
SDL_SetWindowTitle(window, strBuffer);
startTicks = endTicks;
numImagesCaptured = 0u;
}
}There is nothing more in the application's main loop. Once the loop ends (as a result of the user closing the window), we will clean up FC2 and SDL2 resources and exit:
fc2StopCapture(context); fc2Disconnect(context); SDL_DestroyTexture(videoTex); SDL_DestroyRenderer(renderer); SDL_DestroyWindow(window); return EXIT_SUCCESS; }
On Windows, LookSpry can be built as a Visual C++ Win32 Console Project in Visual Studio. Remember to right-click on the project and edit its Project Properties so that C++ | General | Additional Include Directories lists the paths to OpenCV's, FlyCapture 2's, and SDL 2's include directories. Similarly, edit Linker | Input | Additional Dependencies so that it lists the paths to opencv_core300.lib, opencv_imgproc300.lib, and opencv_objdetect300.lib (or similarly named lib files for other OpenCV versions besides 3.0.0) as well as FlyCapture2_C.lib, SDL2.lib, and SDL2main.lib. Finally, ensure that OpenCV's dll files are in the system's Path.
On Linux, a Terminal command such as the following should succeed in building LookSpry:
$ g++ LookSpry.cpp -o LookSpry `sdl2-config --cflags --libs` \ -lflycapture-c -lopencv_core -lopencv_imgproc -lopencv_objdetect
Ensure that the GS3-U3-23S6M-C camera (or another PGR camera) is plugged in and that it is properly configured using the FlyCap2 GUI application. Remember that the configuration is reset whenever the camera is unplugged.
Note
All the camera settings in the FlyCap2 GUI application can also be set programmatically via the FlyCapture2 SDK. Refer to the official documentation and samples that come with the SDK.
When you are satisfied with the camera's configuration, close the FlyCap2 GUI application and run LookSpry. Try different image processing modes by pressing M to un-mirror or mirror the video and D to stop or restart detection. How many frames per second are processed in each mode? How is the frame rate in detection mode affected by the number of faces?

Hopefully, you have observed that in some or all modes, LookSpry processes frames at a much faster rate than a typical monitor's 60Hz refresh rate. The real-time video would look even smoother if we viewed it on a high-quality 144Hz gaming monitor. However, even if the refresh rate is a bottleneck, we can still appreciate the low latency or responsiveness of this real-time video.
Since the GS3-U3-23S6M-C and other PGR cameras take interchangeable, C-mount lenses, we should now educate ourselves about the big responsibility of buying a lens!
There is nothing quite like a well-crafted piece of glass that has survived many years and continued to sparkle because someone cared for it. On the mantle at home, my parents have a few keepsakes like this. One of them—a little, colorful glass flower—comes from a Parisian shopping mall where my brother and I ate many cheap but good meals during our first trip away from home and family. Other pieces go back earlier than I remember.
Some of the secondhand lenses that I use are 30 or 40 years old; their country of manufacture no longer exists; yet their glass and coatings are in perfect condition. I like to think that these lenses earned such good care by taking many fine pictures for previous owners and that they might still be taking fine pictures for somebody else 40 years from now.
Glass lasts. So do lens designs. For example, the Zeiss Planar T* lenses, one of the most respected names in the trade, are based on optical designs from the 1890s and coating processes from the 1930s. Lenses have gained electronic and motorized components to support autoexposure, autofocus, and image stabilization. However, the evolution of optics and coatings has been relatively slow. Mechanically, many old lenses are excellent.
Tip
Chromatic and spherical aberrations
An ideal lens causes all incoming rays of light to converge at one focal point. However, real lenses suffer from aberrations, such that the rays do not converge at precisely the same point. If different colors or wavelengths converge at different points, the lens suffers from chromatic aberrations, which are visible in the image as colorful haloes around high-contrast edges. If rays from the center and edge of the lens converge at different points, the lens suffers from spherical aberrations, which appear in the image as bright haloes around high-contrast edges in out-of-focus regions.
Starting in the 1970s, new manufacturing techniques have allowed for better correction of chromatic and spherical aberrations in high-end lenses. Apochromatic or "APO" lenses use highly refractive materials (often, rare earth elements) to correct chromatic aberrations. Aspherical or "ASPH" lenses use complex curves to correct spherical aberrations. These corrected lenses tend to be more expensive, but you should keep an eye out for them as they may sometimes appear at bargain prices.
Due to shallow depth of field, wide apertures produce the most visible aberrations. Even with non-APO and non-ASPH lenses, aberrations may be insignificant at most aperture settings, and in most scenes.
With a few bargain-hunting skills, we can find half a dozen good lenses from the 1960s to 1980s for the price of one good, new lens. Moreover, even recent lens models might sell at a 50 percent discount on the secondhand market. Before discussing specific examples of bargains, let's consider five steps we might follow when shopping for any secondhand lens:
Understand the requirements. As we discussed earlier in the Capturing the subject in the moment section, many parameters of the lens and camera interact to determine whether we can take a clear and timely picture. At minimum, we should consider the appropriate focal length, f-number or T-number, and nearest focusing distance for a given application and given camera. We should also attempt to gauge the importance of high resolution and low distortion to the given application. Wavelengths of light matter, too. For example, if a lens is optimized for visible light (as most are), it is not necessarily efficient at transmitting NIR.
Study the supply. If you live in a large city, perhaps local merchants have a good stock of used lenses at low prices. Otherwise, the lowest prices can typically be found on auction sites such as eBay. Search based on the requirements that we defined in step 1, such as "100 2.8 lens" if we are looking for a focal length of 100mm and an f-number or T-number of 2.8. Some of the lenses you find will not have the same type of mount as your camera. Check whether adapters are available. Adapting a lens is often an economical option, especially in the case of long lenses, which tend not to be mass-produced for cameras with a small sensor. Create a shortlist of the available lens models that seem to meet the requirements at an attractive price.
Study the lens models. Online, have users published detailed specifications, sample images, test data, comparisons, and opinions? MFlenses (http://www.mflenses.com/) is an excellent source of information on old, manual focus lenses. It offers numerous reviews and an active forum. Image and video hosting sites such as Flickr (https://www.flickr.com/) are also good places to search for reviews and sample output of old and unusual lenses, including cine (video) lenses, nightvision scopes, and more! Find out about variations in each lens model over the years of its manufacture. For example, early versions of a given lens might be single-coated, while newer versions would be multicoated for better transmittance, contrast, and durability.
Pick an item in good condition. The lens should have no fungus or haze. Preferably, it should have no scratches or cleaning marks (smudges in the coatings), though the effect on image quality might be small if the damage is to the front lens element (the element farthest from the camera).
A little dust inside the lens should not affect image quality. The aperture and focusing mechanism should move smoothly and, preferably, there should be no oil on the aperture blades.
Bid, make an offer, or buy at the seller's price. If you think the bidding or negotiation is reaching too high a price, save your money for another deal. Remember, despite what sellers might tell you, most bargain items are not rare and most bargain prices will occur again. Keep looking!
Some brands enjoy an enduring reputation for excellence. Between the 1860s and 1930s, German manufacturers such as Carl Zeiss, Leica, and Schneider Kreuznach solidified their fame as creators of premium optics. (Schneider Kreuznach is best known for cine lenses.) Other, venerable European brands include Alpa (of Switzerland) and Angéniuex (of France), which are both best known for cine lenses. By the 1950s, Nikon began to gain recognition as the first Japanese manufacturer to rival the quality of German lenses. Subsequently, Fuji and Canon became regarded as makers of high-end lenses for both cine and photo cameras.
Although Willy Loman (from Arthur Miller's play Death of a Salesman) might advise us to buy "a well-advertised machine", this is not necessarily the best bargain. Assuming we are buying lenses for their practical value and not their collectible value, we would be delighted if we found excellent quality in a mass-produced, no-name lens. Some lenses come reasonably close to this ideal.
East Germany and the Soviet Union mass-produced good lenses for photo cameras, cine cameras, projectors, microscopes, night vision scopes, and other devices. Optics were also important in major projects ranging from submarines to spacecraft! East German manufacturers included Carl Zeiss Jena, Meyer, and Pentacon. Soviet (later Russian, Ukrainian, and Belarusian) manufacturers included KMZ, BelOMO, KOMZ, Vologda, LOMO, Arsenal, and many others. Often, lens designs and manufacturing processes were copied and modified by multiple manufacturers in the Eastern Bloc, giving a recognizable character to lenses of this region and era.
Note
Many lenses from the Eastern Bloc were no-name goods insofar as they did not bear a manufacturer's name. Some models, for export, were simply labeled "MADE IN USSR" or "aus JENA" (from Jena, East Germany). However, most Soviet lenses bear a symbol and serial number that encode the location and date of manufacture. For a catalogue of these markings and a description of their historical significance, see Nathan Dayton's article, "An Attempt to Clear the FOG", at http://www.commiecameras.com/sov/.
Some of the lesser-known Japanese brands tend to be bargains, too. For example, Pentax makes good lenses but it has never commanded quite the same premium as its competitors do. The company's older photo lenses come in an M42 mount, and these are especially plentiful at low prices. Also, search for the company's C-mount cine lenses, which were formerly branded Cosmicar.
Let's see how we can couple some bargain lenses with the GS3-U3-23S6M-C to produce fine images. Remember that the GS3-U3-23S6M-C has a C mount and a sensor whose format is 1/1.2". For C-mount and CS-mount cameras, the name of the sensor format does not refer to any actual dimension of the sensor! Rather, for historical reasons, the measurement such as 1/1.2" refers to the diameter that a vacuum tube would have if video cameras still used vacuum tubes! The following table lists the conversions between common sensors formats and the actual dimensions of the sensor:
|
Format Name |
Typical Lens Mounts |
Typical Uses |
Diagonal (mm) |
Width (mm) |
Height (mm) |
Aspect Ratio |
|---|---|---|---|---|---|---|
|
1/4" |
CS |
Machine vision |
4.0 |
3.2 |
2.4 |
4:3 |
|
1/3" |
CS |
Machine vision |
6.0 |
4.8 |
3.6 |
4:3 |
|
1/2.5" |
C |
Machine vision |
6.4 |
5.1 |
3.8 |
4:3 |
|
1/2" |
C |
Machine vision |
8.0 |
6.4 |
4.8 |
4:3 |
|
1/1.8" |
C |
Machine vision |
9.0 |
7.2 |
5.4 |
4:3 |
|
2/3" |
C |
Machine vision |
11.0 |
8.8 |
6.6 |
4:3 |
|
16mm |
C |
Cine |
12.7 |
10.3 |
7.5 |
4:3 |
|
1/1.2" |
C |
Machine vision |
13.3 |
10.7 |
8.0 |
4:3 |
|
Super 16 |
C |
Cine |
14.6 |
12.5 |
7.4 |
5:3 |
|
1" |
C |
Machine vision |
16.0 |
12.8 |
9.6 |
4:3 |
|
Four Thirds |
Four Thirds Micro Four Thirds |
Photography Cine |
21.6 |
17.3 |
13.0 |
4:3 |
|
APS-C |
Various proprietary such as Nikon F |
Photography |
27.3 |
22.7 |
15.1 |
3:2 |
|
35mm ("Full Frame") |
M42 Various proprietary such as Nikon F |
Photography Machine vision |
43.3 |
36.0 |
24.0 |
3:2 |
Note
For more information about typical sensor sizes in machine vision cameras, see the following article from Vision-Doctor.co.uk: http://www.vision-doctor.co.uk/camera-technology-basics/sensor-and-pixel-sizes.html.
A lens casts a circular image, which needs to have a large enough diameter to cover the diagonal of the sensor. Otherwise, the captured image will suffer from vignetting, meaning that the corners will be blurry and dark. For example, vignetting is obvious in the following image of a painting, Snow Monkeys, by Janet Howse. The image was captured using a 1/1.2" sensor, but the lens was designed for a 1/2" sensor, and therefore the image is blurry and dark, except for a circular region in the center:

A lens designed for one format can cover any format that is approximately the same size or smaller, without vignetting; however, we might need an adapter to mount the lens. The system's diagonal field of view, in degrees, depends on the sensor's diagonal size and the lens's focal length, according to the following formula:
diagonalFOVDegrees = 2 * atan(0.5 * sensorDiagonal / focalLength) * 180/pi
For example, if a lens has the same focal length as the sensor's diagonal, the diagonal FOV is 53.1 degrees. Such a lens is called a normal lens (with respect to the given sensor format) and a FOV of 53.1 degrees is considered neither wide nor narrow.
Consulting the table above, we see that the 1/1.2" format is similar to the 16mm and Super 16 formats. Thus, the GS3-U3-23S6M-C (and similar cameras) should be able to use most C-mount cine lenses without vignetting, without an adapter, and with approximately the same FOV as the lens designers intended.
Suppose we want a narrow FOV to capture a subject at a distance. We might need a long focal length that is not commonly available in C-mount. Comparing diagonal sizes, note that the 35mm format is larger than the 1/1.2" format by a factor of 3.25. A normal lens for 35mm format becomes a long lens with a 17.5 degree FOV when mounted for 1/1.2" format! An M42 to C mount adapter might cost $30 and lets us use a huge selection of lenses!
Suppose we want to take close-up pictures of a subject but none of our lenses can focus close enough. This problem has a low-tech solution—an extension tube, which increases the distance between the lens and camera. For C-mount, a set of several extension tubes, of various lengths, might cost $30. When the lens's total extension (from tubes plus its built-in focusing mechanism) is equal to the focal length, the subject is projected onto the sensor at 1:1 magnification. For example, a 13.3mm subject would fill the 13.3mm diagonal of a 1/1.2" sensor. The following formula holds true:
magnificationRatio = totalExtension / focalLength
However, for a high magnification ratio, the subject must be very close to the front lens element in order to come into focus. Sometimes, the use of extension tubes creates an impractical optical system that cannot even focus as far as its front lens element! Other times, parts of the subject and lens housing (such as a built-in lens shade) might bump into each other. Some experimentation might be required in order to determine the practical limits of extending the lens.
The following table lists some of the lenses and lens accessories that I have recently purchased for use with the GS3-U3-23S6M-C:
|
Name |
Price |
Origin |
Mount and Intended Format |
Focal Length (mm) |
FOV for 1/1.2" Sensor (degrees) |
Max f-number or T-number |
|---|---|---|---|---|---|---|
|
Cosmicar TV Lens 12.5mm 1:1.8 |
$41 |
Japan 1980s? |
C Super 16 |
12.5 |
56.1 |
T/1.8 |
|
Vega-73 |
$35 |
LZOS factory Lytkarino, USSR 1984 |
C Super 16 |
20.0 |
36.9 |
T/2.0 |
|
Jupiter-11A |
$50 |
KOMZ factory Kazan, USSR 1975 |
M42 35mm |
135.0 |
5.7 |
f/4.0 |
|
C-mount extension tubes: 10mm, 20mm, and 40mm |
$30 |
Japan New |
C |
- |
- |
- |
|
Fotodiox M42 to C adapter |
$30 |
USA New |
M42 to C |
- |
- |
- |
For comparison, consider the following table, which gives examples of new lenses that are specifically intended for the machine vision:
|
Name |
Price |
Origin |
Mount and Intended Format |
Focal Length (mm) |
FOV for 1/1.2" Sensor (degrees) |
Max f-number or T-number |
|---|---|---|---|---|---|---|
|
Fujinon CF12.5HA-1 |
$268 |
Japan New |
C 1" |
12.5 |
56.1 |
T/1.4 |
|
Fujinon CF25HA-1 |
$270 |
Japan New |
C 1" |
25.0 |
29.9 |
T/1.4 |
|
Fujinon CF50HA-1 |
$325 |
Japan New |
C 1" |
50.0 |
15.2 |
T/1.8 |
|
Fujinon CF75HA-1 |
$320 |
Japan New |
C 1" |
75.0 |
10.2 |
T/1.4 |
Note
Prices in the preceding table are from B&H (http://www.bhphotovideo.com), a major photo and video supplier in the United States. It offers a good selection of machine vision lenses, often at lower prices than listed by industrial suppliers.
These new, machine vision lenses are probably excellent. I have not tested them. However, let's look at a few sample shots from our selection of old, used, photo and cine lenses that are cheaper by a factor of six or more. All the images are captured at a resolution of 1920x1200 using FlyCapture2, but they are resized for inclusion in this book.
First, let's try the Cosmicar 12.5mm lens. For a wide-angle lens such as this, a scene with many straight lines can help us judge the amount of distortion. The following sample shot shows a reading room with many bookshelves:

To better see the detail, such as the text on books' spines, look at the following crop of 480x480 pixels (25 percent of the original width) from the center of the image:

The following image is a close-up of blood vessels in my eye, captured with the Vega-73 lens and a 10mm extension tube:
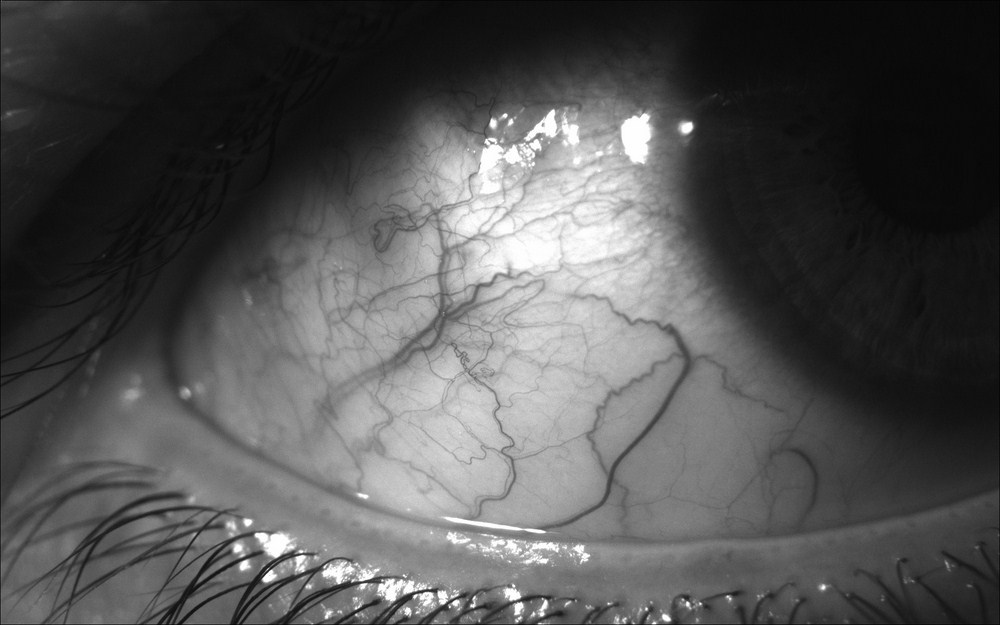
Again, the detail can be better appreciated in a 480x480 crop from the center, as shown here:

Finally, let's capture a distant subject with the Jupiter-11A. Here is the Moon on a clear night:

Once more, let's examine a 480x480 crop from the image's center in order to see the level of detail captured by the lens:

By now, our discussion of bargain lenses has spanned many decades and the distance from here to the Moon! I encourage you to explore even further on your own. What are the most interesting and capable optical systems that you can assemble within a given budget?
This chapter has been an opportunity to consider the inputs of a computer vision system at the hardware and software levels. Also, we have addressed the need to efficiently marshal image data from the input stage to the processing and output stages. Our specific accomplishments have included the following:
Understanding differences among various wavelengths of light and radiation
Understanding various properties of sensors, lenses, and images
Capturing and recording slow-motion video with the PlayStation Eye camera and OpenCV's videoio module
Comparing subjects' appearance in visible and NIR light using the ASUS Xtion PRO Live camera with OpenNI2 and OpenCV's highgui module
Capturing and rendering HD video at high speed while detecting faces, using FlyCapture2, OpenCV, SDL2, and the GS3-U3-23S6M-C camera
Shopping for cheap, old, used lenses that are surprisingly good!
Next, in Chapter 2, Photographing Nature and Wildlife with an Automated Camera, we will deepen our appreciation of high-quality images as we build a smart camera that captures and edits documentary footage of a natural environment!


