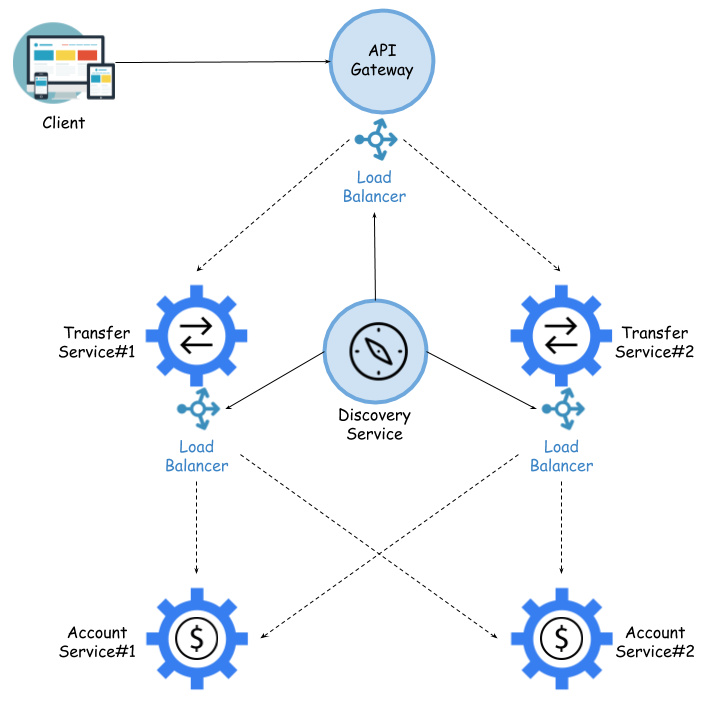
In order to guarantee the system's reliability, we cannot allow a situation where each service would have only one instance running. We usually aim to have a minimum of two running instances in case one of them experiences a failure. Of course, there could be more, but we'll keep it low for performance reasons. Anyway, multiple instances of the same service make it necessary to use load balancing for incoming requests. Firstly, the load balancer is usually built into an API gateway. This load balancer should get the list of registered instances from the discovery server. If there is no reason not to, then we usually use a round-robin rule that balances incoming traffic 50/50 between all running instances. The same rule also applies to load balancers on the microservices side.
The following diagram illustrates the most important components that are involved in interservice communication between multiple instances of two sample microservices:
Most people, when they hear about microservices, consider it to consist of RESTful web services with JSON notation, but that's just one of the possibilities. We can use some other interaction styles, which, of course, apply not only to microservices-based architecture. The first categorization that should be performed is one-to-one or one-to-many communication. In one-to-one interaction, every incoming request is processed by exactly one service instance while, in one-to-many, it is processed by multiple service instances. But the most popular division criterion is whether the call is synchronous or asynchronous. Additionally, asynchronous communication can be divided into notifications. When a client sends a request to a service, but a reply is not expected, it can just perform a simple asynchronous call, which does not block a thread and replies asynchronously.
Furthermore, it is worth mentioning reactive microservices. Now, from version 5, Spring also supports this type of programming. There are also libraries with Reactive support for interaction with NoSQL databases, such as MongoDB or Cassandra. The last well-known communication type is publish-subscribe. This is a one-to-many interaction type where a client publishes a message that is then consumed by all listening services. Typically, this model is realized using message brokers, such as Apache Kafka, RabbitMQ, and ActiveMQ.

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Singapore
Singapore
 Canary Islands
Canary Islands
 Hungary
Hungary
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 South Korea
South Korea
 Turkey
Turkey
 Switzerland
Switzerland
 Colombia
Colombia
 Taiwan
Taiwan
 Chile
Chile
 Norway
Norway
 Ecuador
Ecuador
 Indonesia
Indonesia
 New Zealand
New Zealand
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 Austria
Austria
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 South Africa
South Africa
 Malaysia
Malaysia
 Japan
Japan
 Slovakia
Slovakia
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand



















