


















 Download code from GitHub
Download code from GitHub
Qlik Sense Self-Service Model
Considering this book is called Mastering Qlik Sense, you have probably already been exposed to Qlik Sense and are familiar with its capabilities and functionalities. While you probably have experience on how to install the tool on a small scale, you ask yourself whether Qlik Sense is viable to be deployed on an enterprise level. This book takes the next step with you and will show and teach you how to take Qlik Sense to the next level. What needs to be considered to successfully deploy to enterprises? In order to answer that question, firstly the newly introduced self-service approach within the business intelligence (BI) world needs to be analyzed.
Self-service BI, abbreviated as SS BI throughout this chapter, is a new approach to data analytics in which users get access to the IT platform to load their data and create their own data-driven analytic reports. This model differs significantly from how traditional BI tools are deployed.
Qlik has recognized the need for self-service in the market and has decided to develop a wholly new product called Qlik Sense, which is also the main topic of this book. This chapter aims to take a step back from focusing on the new technology and educate and inform the reader about the new self-service approach that Qlik Sense is taking.
We will begin this chapter with a discussion on the historical background of Qlik Sense as narrated by Qlik itself (yes, the company itself!). The self-service model will be introduced with its key four focus points. A small excursion will be taken to the so-called IKEA effect and why it is relevant to Qlik Sense. With the self-service model, different user types within this space emerge, which will be described and summarized. This will allow the reader to not only identify those user types but also approach them appropriately.
To ensure the business and the organization are best advised on Qlik Sense and self-service BI, a list of benefits and challenges will be described. They will help assess whether Qlik Sense is fit for purpose in the examined use case and what can be done to mitigate the risks in order to make self-service BI a success within the organization.
Last but not least, the reader will be equipped with lots of recommendations on how to best champion Qlik Sense, all coming from the distilled professional experience of the authors deploying the same in large-scale organizations.
The goal of this chapter is for the reader to be able to understand the dynamics of self-service, how to correctly leverage them with Qlik Sense to identify good use cases for using the technology, and advising the business on how and why to invest in self-service BI.
The chapter is structured into the following sections:
- A review of Qlik Sense
- The self-service model
- The IKEA effect
- User types in self-service
- Benefits and challenges of self-service
- Recommendations on deploying self-service with Qlik Sense
A review of Qlik Sense
With the release of Qlik Sense, QlikTech decided to address a new trend in BI – the emergence of self-service BI and the need for business users to become more self-reliant. Business users wish to be in more control and get faster access to BI and their business data.
Based on their Qlik associative analytics engine, which successfully promoted the ability for data discovery in QlikView, Qlik decided to reinvent itself by building a next-generation BI tool which addressed five themes to capture the new trend:
- Gorgeous and genius: Within the theme, Qlik focused on making QS as slick and visually beautiful as possible, enabling the user to leverage the full power of the associative engine model and allowing for a seamless experience across all devices.
- Mobility with agility: Moving away from a local installed client, Qlik Sense is 100 percent web-based and therefore can be accessed by any device that supports web browsers. The same applies to the enterprise platform, which with the release of Qlik Sense Cloud will ensure the whole environment will be hosted outside of your users' premises, making it accessible at all times from anywhere in the world.
- Compulsive collaboration: With the focus on collaboration, new ways of consuming data can be explored if users have real-time capabilities to either modify or enrich existing reports or easily share insights with each other by sharing bookmarks or stories of their data.
- The premier platform: Short development and deployment time to market – the platform focuses on simplifying and speeding up the SS BI supply chain from data access to development, with access through broadened API under one unified platform interface.
- Enabling new enterprise: By unifying the whole platform, Qlik is offering its capabilities, including security, reliability, and scalability, not only for large enterprises but also for smaller companies. With their Qlik cloud offering, they aim to even increase the flexibility to address a new market: small companies or teams which do not have the resources or the time to invest in an infrastructure before deploying Qlik Sense.
Addressing the five themes earlier was not possible by releasing a new version of QlikView. Qlik had to disrupt itself and create a wholly new product almost from scratch, retaining their market-leading in-memory calculation engine and their expertise and vision around data discovery and business intelligence.
Qlik Sense is fundamentally different from QlikView in its approach to BI and the development process, as well as the user experience. What stays the same is the security model called section access, Qlik’s associative engine (the driver of data discovery) and most of the front end expressions to aggregate your data, including set analysis. However, the whole approach to developing apps and dashboards is different as all of a sudden the user becomes an integral part of the process. Qlik Sense’s easy-to-use approach gives them capabilities to significantly contribute to their own content even to the extent that all of the development can be done by them. This will be elaborated in Chapter 2, Transitioning from QlikView to Qlik Sense; however, it is important to understand Qlik Sense is not an evolution of QlikView, but a whole new concept on how to offer BI and data insights to the business.
The most common fallacy among Qlik customers is to believe an existing QlikView environment can simply be migrated to Qlik Sense, leveraging its new technology and implementing new cutting-edge visualizations. This is not the case, as guided analytics dashboards, a dominant development concept in QlikView, are not directly supported in Qlik Sense in the same way. For those who are not familiar with QlikView, its guided analytics aspect takes the user on a pre-canned journey through the dashboard with sometimes restricted views and constrained ways to interact and explore the data, hence guided.
While it is not impossible to implement something similar to the API using the approach of mashups and advanced extensions, this would require IT and the user to enter the world of web development, which is the absolute opposite of a business-friendly self-service environment. In there, possibilities are unlimited; however, new skills are required and the very value-add of sped-up dashboard development that QlikView provides gets lost in Qlik Sense when it comes to guided analytics dashboards. On the other hand, building simple visualizations is much easier in Qlik Sense, supported by the sheet canvas, the drag and drop functionality, and the suggestive dimensions and measure which is all hosted on the web, requiring no installation on the client side other than access to the platform. Also, the data loading process has been significantly simplified by offering a huge variety of connectors and user-friendly data processing interfaces.
The next section will focus on explaining the self-service BI model in Qlik Sense, its advantages, and disadvantages, as well as classic user types and working models, finishing with some considerations and recommendations on how to best deploy self-service within your organization.
The Self-Service model
Transforming data with intelligence (TDWI), an organization providing educational research material on data and BI, did extensive work in 2011 in researching and describing the dynamics of the newly emerging phenomenon of self-service BI. This is how its published report describes it:
Self-reliance and reduced dependency are key here, as a shift from the classic BI model is evident, where the responsibilities of developing data analytics dashboards move away from IT and closer to the business. And this makes sense as the business itself is the body within the organization that best understands how to extract value from its own data and what insights it hopes to get out of its analytics. Also, by being able to modify BI dashboards themselves, not only can users personalize their own reports but time to market is reduced significantly.
TDWI identifies four key objectives self-service BI focuses on:
- Simpler and customizable end-user interfaces: Communicating data in an effective way to get the insight across efficiently is key and arguably the most important objective of self-service BI. Compelling visualizations, uncomplicated dashboards, and clear presentation of data are paramount for any BI tool. Qlik Sense does exactly that and takes the user experience to another level by leveraging its associative engine and allowing the user to explore the data in their own way through filtering and truly embracing data discovery.
- Easy access to source data: The best analytics solution or platform will not be of any use if the user can’t access the data. A big difference to traditional BI tools, though, is that not all data needs to be stored in one database in order to be consumed. Qlik Sense allows users to easily connect to various data sources using drag and drop as well as following user-friendly load wizards. Qlik’s acquisition of QVSource in 2016, a third-party tool which has a collection of data connectors to plenty of platforms, underlines the importance of being able to connect data from disparate sources into one dashboard for reporting and analysis purposes. Also, by opening up the sourcing of data, new reports and dashboards can be built, which may not have been possible with an earlier architecture of technologies. Think of combining data from different departments, linking them by cost center, and being able to draw new insights of how costs are directly associated with revenue. All in all, being able to easily connect to its own data, the business can build its own bespoke reports, to its own requirements, and at its own pace:
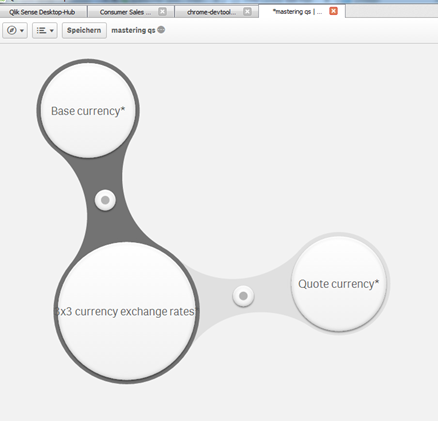
- Easy-to-use BI tools: Similar to the first point, this one focuses on the simplicity of building these dashboards. Even if it is expected that the business upskills itself to become more IT-savvy, self-service BI tools will only be adapted to the organization if they are easy to use for the layman. Hence, Qlik has focused a lot on developing a very user-friendly interface in Qlik Sense, which allows the user to create their own dashboards simply by dragging and dropping certain items to a canvas, rearranging them to their own liking, and selecting the dimensions and measures they wish to analyze. Qlik Sense is incredibly easy to use for simple analytics, with sophisticated data load and processing editors on the back end too. The capturing of this objective is best demonstrated with Qlik's release of the visual management of data associations, the so-called data load bubbles depicted in the diagram that precedes this bulleted list. It allows the user to create connections between different tables, creating a logical link based on the suggested key, which will then associate on the front end when filtering.
- Quick-to-deploy and easy-to-manage architecture: Albeit very technical, self-service BI should be as easy on the back end as it is on the front end. As will be discussed in later chapters, the management of the Qlik Sense environment has been simplified a lot, the same as the licensing model and many other things in the back end. This is done to support a fast release cycle and deployment to business users, decreasing the time to market of new apps and enabling IT and users to work in an agile way iteratively, without time-consuming release processes. The same principles have been applied to the deployment of the whole architecture: Qlik Sense is fairly easy to scale horizontally across multiple nodes if the user base increases. Installation of the technology is also well supported in cloud platforms such as Amazon Web Services, Microsoft Azure, or Google Cloud. The simplicity on the back end makes it very attractive too for the IT department to deploy self-service BI without massive training, making the technology much more cost-effective.
The relationship between those four key objectives is depicted in the following diagram:

The ecosystem of self-service BI shows that there are four interdependent areas where its principles need to apply to aggregate to one successful solution. While it is the front end that is predominantly being advertised, all other aspects are equally important and need to be taken into account when taking the whole into consideration.
The freedom that comes with self-service BI, though, stands in strong opposition to IT governance principles: standards, data quality, consistency of terms and definitions, and consistency of look and feel. IT departments often resist allowing the business user to venture into the data analytics world all by themselves, believing this will lead to data anarchy and loss of control and governance over the BI environment.
For it to be successful, a strict framework needs to be introduced to successfully deploy Qlik Sense. The key there, however, will be to introduce governance which is user-enabling and not an IT dictatorship. IT governance in Qlik Sense without impairing the users will be at the forefront of this book.
The IKEA effect
The name IKEA derives from the Swedish furniture manufacturer and relates to their business model that allows the consumer to compile and build their furniture themselves at home, based on instructions. A working paper by Harvard Business School points out that traditional economic thinking would suggest a consumer or customer would subtract their own labor from the overall final cost of the product. In fact, the opposite effect can readily be observed and the perceived value of the product is increased the more individual labor is put into it, suggesting there is love in our own labor.
This relates well to a similar story about cakes. Since 1931, Betty Crocker had been espousing speed and ease in the kitchen to facilitate the life of women living in the city. Part of that was to also invent the famous cake mixture which allowed a person to promptly bake a fresh cake themselves by adding a couple of ingredients. Having to go to the bakery or confectionery to buy a cake was too simple and certainly did not impress the dinner guests. The initial cake mixture required the customer to only add water to the mix and put it in the oven. Betty Crocker struggled to get traction with their new product, even though it ticked off all the economic boxes. It was self-made, could be baked on demand, was very easy, and little could go wrong. Experimenting with variations, Betty Crocker eventually discovered that taking away the milk and the eggs from the mix, effectively asking the customers to put more effort into the baking, made the product a hit. This is where they discovered that people wanted to put their own personal touch to the cake they baked, effectively increasing the home-made authenticity of what they made.
This story shows two things where a clear link can be drawn between cake mixture and self-service BI:
- Firstly, there is also the presence of a cognitive bias in self-service BI, which allows the user to perceive their own reports they build as being qualitatively higher than they are in reality. This bias is a powerful aspect of successful adoption and plays a significant role in promoting self-service BI within the organization. Users will be keener to sell and promote the analytics work they create and will naturally be keen to share all insights they discover. This can eventually lead to having the self-service BI tool promoting itself, almost going viral.
- Secondly, the approach Betty Crocker eventually took is not just designing for ease and speed but focusing on designing an entire user experience. This is important in self-service BI as the architect or developer should not only focus on delivering results but put equal focus on the fashion in which the results and insights are delivered to the end user.
The fact is that with self-service BI and the close involvement of the end user in the development process, new psychological dynamics are introduced to the classic IT development process which need to be taken into account. It also reiterates the importance of forgetting some best practices in IT development in order be able to harness the new possibilities and the new approach to data analytics which come with self-service BI.
User types in self-service
With the introduction of self-service to BI, there is a segmentation of various levels and breaths on how self-service is conducted and to what extent. There are, quite frankly, different user types that differ from each other in level of interest, technical expertise, and the way in which they consume the data. While each user will almost be unique in the way they use self-service, the user base can be divided into four different groups:
- Power Users or Data Champions: Power users are the most tech-savvy business users, who show a great interest in self-service BI. They produce and build dashboards themselves and know how to load data and process it to create a logical data model. They tend to be self-learning and carry a hybrid set of skills, usually a mixture of business knowledge and some advanced technical skills. This user group is often frustrated with existing reporting or BI solutions and finds IT inadequate in delivering the same. As a result, especially in the past, they take away data dumps from IT solutions and create their own dashboards in Excel, using advanced skills such as VBA, Visual Basic for Applications. They generally like to participate in the development process but have been unable to do so due to governance rules and a strict old-school separation of IT from the business. Self-service BI is addressing this group in particular, and identifying those users is key in reaching adoption within an organization. Within an established self-service environment, power users generally participate in committees revolving around the technical environments and represent the business interest. They also develop the bulk of the first versions of the apps, which, as part of a naturally evolving process, are then handed over to more experienced IT for them to be polished and optimized. Power users advocate the self-service BI technology and often not only demo the insights and information they achieved to extract from their data, but also the efficiency and timeliness of doing so. At the same time, they also serve as the first point of contact for other users and consumers when it comes to questions about their apps and dashboards. Sometimes they also participate in a technical advisory capacity on whether other projects are feasible to be implemented using the same technology. Within a self-service BI environment, it is safe to say that those power users are the pillars of a successful adoption.
- Business Users or Data Visualizers: Users are frequent users of data analytics, with the main goal to extract value from the data they are presented with. They represent the group of the user base which is interested in conducting data analysis and data discovery to better understand their business in order to make better-informed decisions. Presentation and ease of use of the application are key to this type of user group and they are less interested in building new analytics themselves. That being said, some form of creating new charts and loading data is sometimes still of interest to them, albeit on a very basic level. Timeliness, the relevance of data, and the user experience are most relevant to them. They are the ones who are slicing and dicing the data and drilling down into dimensions, and who are keen to click around in the app to obtain valuable information. Usually, a group of users belong to the same department and have a power user overseeing them with regard to questions but also in receiving feedback on how the dashboard can be improved even more. Their interaction with IT is mostly limited to requesting access and resolving unexpected technical errors.
- Consumers or Data Readers: Consumers usually form the largest user group of a self-service BI analytics solution. They are the end recipients of the insights and data analytics that have been produced and, normally, are only interested in distilled information which is presented to them in a digested form. They are usually the kind of users who are happy with a report, either digital or in printed form, which summarizes highlights and lowlights in a few pages, requiring no interaction at all. Also, they are most sensitive to the timeliness and availability of their reports. While usually the largest audience, at the same time this user group leverages the self-service capabilities of a BI tool the least. This poses a licensing challenge, as those users don’t take full advantage of the functionality on offer, but are costing the full amount in order to access the reports. It is therefore not uncommon to assign this type of user group a bucket of login access passes or not give them access to the self-service BI platform at all and give them the information they need in (digitally) printed format or within presentations, prepared by users.
- IT or Data Overseers: IT represents the technical user group within this context, who sit in the background and develop and manage the framework within which the self-service BI solution operates. They are the backbone of the deployment and ensure the environment is set up correctly to cater for the various use cases required by the above-described user groups. At the same time, they ensure a security policy is in place and maintained and they introduce a governance framework for deployment, data quality, and best practices. They are in effect responsible for overseeing the power users and helping them with technical questions, but at the same time ensuring terms and definition as well as the look and feel is consistent and maintained across all apps. With self-service BI, IT plays a lesser role in actually developing the dashboards but assumes a more mentoring position, where training, consultation, and advisory in best practices are conducted. While working closely with power users, IT also provides technical support to users and liaises with the IT infrastructure to ensure the server infrastructure is fit for purpose and up and running to serve the users. This also includes upgrading the platform where required and enriching it with additional functionality if and when available.
The previous four groups can be distinguished within a typical enterprise environment; however, this is not to say hybrid or fewer user groups are not viable models for self-service BI. It is an evolutionary process in how an organization adapts self-service data analytics with a lot of dependencies on available skills, competing established solutions, culture, and appetite on new technologies. It usually begins with IT being the first users in a newly deployed self-service environment, not only setting up the infrastructure but also developing the first apps for a couple of consumers. Power users then follow up; generally, they are the business sponsors themselves who are often big fans of data analytics, modifying the app to their liking and promoting it to their users. The user base emerges with the success of the solution, where analytics are integrated into their business as the usual process. The last group, the consumers, is mostly the last type of user group that is established, which more often than not doesn’t have actual access to the platform itself, but rather receives printouts, email summaries with screenshots, or PowerPoint presentations. Due to licensing cost and the size of the consumer audience, it is not always easy to give them access to the self-service platform; hence, most of the time, an automated and streamlined PDF printing process is the most elegant solution to cater for this type of user group.
At the same time, the size of the deployment also determines the number of various user groups. In small enterprise environments, it will be mostly power users and IT who will be using self-service. This greatly simplifies the approach as well as the setup considerations.
Benefits and challenges of self-service
Knowing the advantages and disadvantages of self-service BI is fundamental to its success within the organization. It is important when you plan to introduce self-service BI and prepare a business case to assess whether it actually achieves what you hope it will. Also, organizational blockers can be recognized in time to prevent them having an adverse effect on the environment. Disadvantages are good to know because they will add credibility to the tool if you establish beforehand what it’s supposed to be used for. If users only expected printed PDF files en masse, Qlik Sense might end up becoming an inadequate tool and far too expensive, disappointing stakeholders and users.
Benefits
There are several online blogs and articles discussing the benefits and challenges of self-service BI and more of them are expected to be released after publication of this book. This section will summarize the most relevant benefits which are applicable to Qlik Sense. The order of points is arbitrary and, to some extent, they reiterate content that has already been elaborated in this chapter:
- Empowering users: Users become self-reliant and empowered by the ability to create business intelligence apps all by themselves with little to no help from IT. They know best what they want to see and extract from their data. Self-service BI allows them to build their own personalized analytics, to their own requirements, at their own pace.
- The speed of development: If a proper framework is in place with setup access to various data sources and a controlled environment where publication of new and enriched apps is streamlined and automated, app development and the subsequent delivery of new insights can be significantly sped up. This not only delivers results and information in a timely fashion but also allows for a more agile and iterative approach to developing analytics with a short feedback cycle.
- The IKEA effect: The cognitive bias described earlier in this chapter lets users perceive the apps in which they had significant input as being much more valuable. While biased, this greatly encourages users to get involved and promotes the adoption of data analytics within the organization. As most organizations are investing to become digital and more data-driven, the adaptation of data analytics is an integral part of it and the IKEA effect certainly helps.
- Relieving IT: As organizations become more data-driven, the pressure on IT to deliver faster becomes evident. With applications deployed and used by the business, an inconvenient overhead emerges to support these applications, which prevents IT from doing any further development of new ideas and data sources. This bottleneck not only puts pressure on IT but also frustrates the business, which has to wait longer for the realization of its projects. With self-service BI, power users from the business can become an integral part of the development, relieving the pressure on IT. This frees them to think about more strategically and technically challenging tasks and focus on value-added development for the company rather than just keeping the lights on.
- Becoming proactive rather than reactive: By having the data readily available, and with the possibility of creating new analytics being easy, the business can start becoming more proactive in its culture. Rather than receiving reports, agreeing on actions, and getting a feedback report within the next cycles to confirm whether its strategy was the right one, the business can become more data-driven and not only receive a faster feedback but also spend more time investigating the data to make better-informed decisions. While this sounds like a sound generic benefit, it is only with self-service BI that this becomes possible in its most efficient way.
- Reduced technology costs: It is possible to cut down on technology costs on various ends by deploying self-service BI. For example, by reducing the involvement of IT and handing over the bulk of the development to the business user, it is not necessary to spend as much money on getting consultants on board for development purposes as with traditional BI tools. At the same time, self-service BI (with its ease of use) allows for an increased speed of development and subsequent decreased time to market, which also reduces the costs associated with deploying the technology. Lastly, due to the speed of development and the possibility of integrating agile project management with lots of iteration, as well as involving the business end user into the process, self-service BI projects can have a much higher success rate, which also effectively brings down the overall technology costs within the organization.
- Mobile: This is possible and a novelty. If Qlik Sense is set up correctly and the user has had some basic training, it is possible to create analytics and basic dashboards on mobile devices such as the iPad. Qlik Sense's ease to use and capability to create compelling dashboards allows for a pioneering way to develop on the go, something which has rarely been possible so far and only in a limited capacity.
Challenges and risks
Following are the challenges and risks that are involved:
- Data Literacy: Just as literacy is the ability to derive meaning from the written word, data literacy is the ability to derive meaning from data. In more technical terms, data literacy can be referred to as the ability to "consume for knowledge, produce coherently and think critically about data." Qlik Sense has put significant effort into making the new self-service BI technology as simple to use for the business end user as possible. Dragging and dropping functionality is omnipresent, limiting the use of keyboards required as well as the necessity of writing of code at all. While this works for very basic and simple solutions, there is no way around having to upskill in basic concepts of data modeling, data aggregation, and data presentation within Qlik Sense, or for that matter any other self-service BI tool. Qlik Sense, in particular, has a very powerful associative in-memory calculation engine, which, however, requires the data model to be set up correctly, with underlying tables linking or the right keys, for the front end to aggregate the numbers correctly. At the same time, summing, averaging, or obtaining the max or min value is easy but writing more sophisticated aggregations, for example, based on dates, deltas, or totals, requires training in set analysis. Data modeling techniques very quickly become relevant if the user wishes to load more than two or three data sources. For the user or power user, as a matter of fact, to create more than basic dashboards, the organization needs to invest in training.
- Data quality: Qlik Sense boasts about its capabilities to bring together various data sources into one dashboard in a user-friendly way. While powerful, it presumes the data loaded into Qlik Sense is of the highest quality, has been validated, and is coherent, and excludes the possibility of invalid combinations of the data models. This assumes the perfect scenario where the user picks various data tables like in a shop and can immediately derive insights from what has been loaded. While hypothetically possible, if the organization started using Qlik Sense since its inception, it is quite frankly unrealistic. There are disparate systems producing data, different teams have a diverse understanding of the same business and dissimilar ways of capturing meaningful and correct data across the organization. Bringing it together into one place without any validation process creates a mess and chaos which will not produce any meaningful analytics. If a proper data governance, ideally within a data warehouse, is not in place, self-service BI will not work, and will at best only be loading one data source at a time, diminishing the value-return of the technology investment.
This risk, however, is an ongoing problem of poor data management within organizations and not specifically related to Qlik Sense; Qlik Sense only brings this issue to the surface. To mitigate this risk, there needs to be an organizational layer between data within the organization and the data available for Qlik Sense to control, validate, and clean the data made available for self-service BI.
- A constant struggle for governance: Qlik Sense promotes empowering the user to create their very own data analytics with little to no limits. With no limits also comes no control, which is a source of chaos and frustration not only with IT but also with the users of self-service BI. Governance is required for two reasons:
- Firstly, IT needs to guarantee that the user, while building their own dashboards, is in no position to break the system for everybody else who is using it. The bulletproof solution would be to limit the user from doing anything but this would defeat the purpose of self-service BI and diminish the value of Qlik Sense. This introduces a constant struggle between freedom and value versus control, which not only raises a lot of discussions but can initiate conflict or tension within the departments in an organization. There are a couple of areas of middle ground in this issue which will be presented in later chapters, but getting to that point will require educating both sides of the fence.
- Secondly, with limited governance, there is a lack of testing and validation of the reports produced by the users. Using different aggregation logic and terminologies, or simply making errors, Qlik Sense is error-prone and it is dangerous if a dashboard is distributed to a wide audience, who then possibly use the results and insight to support their decisions and actions. By misrepresenting information, it is possible for a BI tool to do more damage to an organization than it could ever bring in value. Users need to be critical thinkers and now even more so. This is especially applicable to self-service BI where looser governance is required. To provide you with a suitable analogy by Karl Pover, it's like going from reading news from a few, established news organizations to reading news from your social media feed.
- Basic dashboards and data analytics: Whether or not this is a challenge depends on how the organization is looking to utilize Qlik Sense. Qlik Sense predominantly produces very basic dashboards with uncomplicated aggregations where a simple idea can be presented and analyzed. Doing more sophisticated analysis, even to the extent of bringing in machine learning elements, requires either training, hiring a specialist resource, or integration with external systems. This then takes self-service BI back to becoming normal BI, where the users are not able to do these things themselves. The same applies to Qlik Sense’s advertised unlimited possibilities with the QS API, where compelling and super amazing mashups can be created. But this is not self-service, this is old-school web development, which not only requires a specific set of skills but also has a longer time to market and a more complicated development process.
- Inconsistent design principles and terminology: If everyone is able to build their own reports and dashboards in Qlik Sense, it is not unreasonable to suggest that everyone will design their apps to their own liking and style as well as use their own terminology in describing business insights. This possible inconsistency can be annoying to users and makes it difficult promote the brand of data analytics within the organization. Inconsistencies, especially in terminology, can also lead to misunderstandings. To overcome this risk, a design principle and terminology framework need to be in place and monitored by IT.
Recommendations on deploying self-service with Qlik Sense
This section summarizes various recommendations which have been captured and collected by the authors in the course of their deployments.
As part of a successful deployment of Qlik Sense, it is important IT recognizes self-service BI has its own dynamics and adoption rules–the various use cases and subsequent user groups need to be assessed and captured. For a strong adoption of the tool, IT needs to prepare the environment and identify the key power users in the organization and win them over to using the technology. It is important they are intensively supported, especially in the beginning, and they are allowed to drive how the technology should be used rather than having principles imposed on them. Governance should always be present but power users should never get the feeling they are restricted by it. Because once they are won over, the rest of the traction and the adoption of other user types is very easy.
Here are a few of the important points on deploying self-service with Qlik Sense:
- Qlik Sense is not QlikView: Not even nearly. The biggest challenge and fallacy is that the organization was sold, by Qlik or someone else, just the next version of the tool. It did not help at all that Qlik itself was working for years on Qlik Sense under the initial product name Qlik.Next. Whatever you are being told, however, it is being sold to you, Qlik Sense is at best the cousin of QlikView. Same family, but no blood relation. Thinking otherwise sets the wrong expectation so the business gives the wrong message to stakeholders and does not raise awareness to IT that self-service BI cannot be deployed in the same fashion as guided analytics, QlikView in this case. Disappointment is imminent when stakeholders realize Qlik Sense cannot replicate their QlikView dashboards.
- Don’t assume that simply installing Qlik Sense creates a self-service BI environment: Installing Qlik Sense and giving users access to the tool is a start but there is more to it than simply installing it. The infrastructure requires design and planning, data quality processing, data collection, and determining who intends to use the platform to consume what type of data. If data is not available and accessible to the user, data analytics serve no purpose. Make sure a data warehouse or similar is in place and the business has a use case for self-service data analytics. A good indicator for this is when the business or project works with a lot of data, and there are business users who have lots of Excel spreadsheets lying around analyzing it in different ways. That’s your best case candidate for Qlik Sense.
- IT needs to take a step back and monitor the Qlik Sense environment rather than controlling it: IT needs to unlearn to learn new things and the same applies when it comes to deploying self-service. Create a framework with guidelines and principles and monitor that users are following it, rather than limiting them in their capabilities. This framework needs to have the input of the users as well and to be elastic. Also, not many IT professionals agree with giving away too much power to the user in the development process, believing this leads to chaos and anarchy. While the risk is there, this fear needs to be overcome. Users love data analytics, and they are keen to get the help of IT to create the most valuable dashboard possible and ensure it will be well received by a wide audience.
- Identify the key users and user groups: For a strong adoption of the tool, IT needs to prepare the environment and identify the key power users in the organization and to win them over to using the technology. It is important they are intensively supported, especially in the beginning, and they are allowed to drive how the technology should be used rather than having principles imposed on them. Governance should always be present but power users should never get the feeling they are restricted by it. Because once they are won over, the rest of the traction and the adoption of other user types are very easy.
- Qlik Sense sells well–do a lot of demos: Data analytics, compelling visualizations, and the interactivity of Qlik Sense is something almost everyone is interested in. The business wants to see its own data aggregated and distilled in a cool and glossy dashboard. Utilize the momentum and do as many demos as you can to win advocates of the technology and promote a consciousness of becoming a data-driven culture in the organization. Even the simplest Qlik Sense dashboards amaze people and boost their creativity for use cases where data analytics in their area could apply and create value.
- Promote collaboration: Sharing is caring. This not only applies to insights, which naturally are shared with the excitement of having found out something new and valuable, but also to how the new insight has been derived. People keep their secrets on the approach and methodology to themselves, but this is counterproductive. It is important that applications, visualizations, and dashboards created with Qlik Sense are shared and demonstrated to other Qlik Sense users as frequently as possible. This not only promotes a data-driven culture but also encourages the collaboration of users and teams across various business functions, which would not have happened otherwise. They could either be sharing knowledge, tips, and tricks or even realizing they look at the same slices of data and could create additional value by connecting them together.
- Market the successes of Qlik Sense within the organization: If Qlik Sense has had a successful achievement in a project, tell others about it. Create a success story and propose doing demos of the dashboard and its analytics. IT has been historically very bad in promoting their work, which is counterproductive. Data analytics creates value and there is nothing embarrassing about boasting about its success; as Muhammad Ali suggested, it’s not bragging if it’s true.
- Introduce guidelines on design and terminology: Avoiding the pitfalls of having multiple different-looking dashboards by promoting a consistent branding look across all Qlik Sense dashboards and applications, including terminology and best practices. Ensure the document is easily accessible to all users. Also, create predesigned templates with some sample sheets so the users duplicate them and modify them to their liking and extend them, applying the same design.
- Protect less experienced users from complexities: Don’t overwhelm users if they have never developed in their life. Approach less technically savvy users in a different way by providing them with sample data and sample templates, including a library of predefined visualizations, dimensions, or measures (so-called Master Key Items). Be aware that what is intuitive to Qlik professionals or power users is not necessarily intuitive to other users – be patient and appreciative of their feedback, and try to understand how a typical business user might think.
Summary
Qlik struck a new path with the development of a new product called Qlik Sense. Unlike QlikView, the new technology focuses on bringing self-service BI capabilities to business users, empowering them to create their very own data analytics, to their requirements, at their own pace. The self-service BI model differs significantly from traditional BI tools in the way that it incorporates the end user into the development process and, as such, needs to be approached in its own way.
The self-service model has its own goals, aims, and dynamics. Its four main focus points are simple and customizable end-user interfaces, easy access to source data, easy-to-use BI tools, and quick-to-deploy and easy-to-manage architecture. It sets up a business-friendly environment where the users themselves enjoy the freedom of doing development in their own way. While self-service offers lots of functionality, not all users are either able or willing to leverage all of it.
Some users have a high interest in self-service while others are more interested in getting an answer in a digested and timely fashion. The different user groups can be summarized and ordered by level of sophistication into IT, power users, users, and consumers. Identifying those groups plays an important aspect in designing the architecture for a self-service environment with Qlik Sense. Especially power users are not only the most active users but they also need to be won over as advocates for the technology: they build the dashboards and promote them and the technology to the business without much input from IT. This can make Qlik Sense as a BI solution very cost-effective. This, sped-up development time, empowerment of users, the IKEA effect, and mobile capabilities are all great benefits of Qlik Sense which allow organizations to become more data-driven to be able to make better, timely, and informed decisions for their business. The challenges and risks are predominantly the lack of governance that comes along with the self-service aspect of Qlik Sense, including the required investment into training, and also that, while easy to install, reliable data sources need to be in place in order to extract the most value from Qlik Sense.
Without meaningful data, data analytics will not be much of a value-add to the business. It is, therefore, important to take into account various organizational considerations before deciding to deploy Qlik Sense. Recommendations are summarized in this chapter, with the top three being: don’t assume Qlik Sense can be deployed in the same way as QlikView; introduce governance but not a governance dictatorship, and promote collaboration to create a data-driven culture with advocates of Qlik Sense.






