


















 Download code from GitHub
Download code from GitHub
Advanced Introduction to Concurrent and Parallel Programming
This first chapter of Mastering Concurrency in Python will provide an overview of what concurrent programming is (in contrast to sequential programming). We will briefly discuss the differences between a program that can be made concurrent and one that cannot. We will go over the history of concurrent engineering and programming, and we will provide a number of examples of how concurrent programming is used in the present day. Finally, we will give a brief introduction to the approach that will be taken in this book, including an outline of the chapter structure and detailed instructions for how to download the code and create a working Python environment.
The following topics will be covered in this chapter:
- The concept of concurrency
- Why some programs cannot be made concurrent, and how to differentiate them from programs that can
- The history of concurrency in computer science: how it is used in the industry today, and what can be expected in the future
- The specific topics that will be covered in each section/chapter of the book
- How to set up a Python environment, and how to check out/download code from GitHub
Technical requirements
Check out the following video to see the Code in Action: http://bit.ly/2TAMAeR
What is concurrency?
It is estimated that the amount of data that needs to be processed by computer programs doubles every two years. The International Data Corporation (IDC), for example, estimates that, by 2020, there will be 5,200 GB of data for every person on earth. With this staggering volume of data come insatiable demands for computing power, and, while numerous computing techniques are being developed and utilized every day, concurrent programming remains one of the most prominent ways to effectively and accurately process data.
While some might be intimidated when the word concurrency appears, the notion behind it is quite intuitive, and it is very common, even in a non-programming context. However, this is not to say that concurrent programs are as simple as sequential ones; they are indeed more difficult to write and understand. Yet, once a correct and effective concurrent structure is achieved, significant improvement in execution time will follow, as you will see later on.
Concurrent versus sequential
Perhaps the most obvious way to understand concurrent programming is to compare it to sequential programming. While a sequential program is in one place at a time, in a concurrent program, different components are in independent, or semi-independent, states. This means that components in different states can be executed independently, and therefore at the same time (as the execution of one component does not depend on the result of another). The following diagram illustrates the basic differences between these two types:
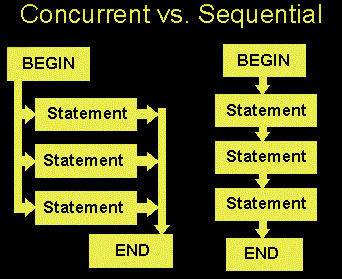
One immediate advantage of concurrency is an improvement in execution time. Again, since some tasks are independent and can therefore be completed at the same time, less time is required for the computer to execute the whole program.
Example 1 – checking whether a non-negative number is prime
Let's consider a quick example. Suppose that we have a simple function that checks whether a non-negative number is prime, as follows:
# Chapter01/example1.py
from math import sqrt
def is_prime(x):
if x < 2:
return False
if x == 2:
return True
if x % 2 == 0:
return False
limit = int(sqrt(x)) + 1
for i in range(3, limit, 2):
if x % i == 0:
return False
return True
Also, suppose that we have a list of significantly large integers (1013 to 1013 + 500), and we want to check whether each of them is prime by using the preceding function:
input = [i for i in range(10 ** 13, 10 ** 13 + 500)]
A sequential approach would be to simply pass one number after another to the is_prime() function, as follows:
# Chapter01/example1.py
from timeit import default_timer as timer
# sequential
start = timer()
result = []
for i in input:
if is_prime(i):
result.append(i)
print('Result 1:', result)
print('Took: %.2f seconds.' % (timer() - start))
Copy the code or download it from the GitHub repository and run it (using the python example1.py command). The first section of your output will be something similar to the following:
> python example1.py
Result 1: [10000000000037, 10000000000051, 10000000000099, 10000000000129, 10000000000183, 10000000000259, 10000000000267, 10000000000273, 10000000000279, 10000000000283, 10000000000313, 10000000000343, 10000000000391, 10000000000411, 10000000000433, 10000000000453]
Took: 3.41 seconds.
You can see that the program took around 3.41 seconds to process all of the numbers; we will come back to this number soon. For now, it will also be beneficial for us to check how hard the computer was working while running the program. Open an Activity Monitor application in your operating system, and run the Python script again; the following screenshot shows my results:

Evidently, the computer was not working too hard, as it was nearly 83% idle.
Now, let's see if concurrency can actually help us to improve our program. The is_prime() function contains a lot of heavy computation, and therefore it is a good candidate for concurrent programming. Since the process of passing one number to the is_prime() function is independent from passing another, we could potentially apply concurrency to our program, as follows:
# Chapter01/example1.py
# concurrent
start = timer()
result = []
with concurrent.futures.ProcessPoolExecutor(max_workers=20) as executor:
futures = [executor.submit(is_prime, i) for i in input]
for i, future in enumerate(concurrent.futures.as_completed(futures)):
if future.result():
result.append(input[i])
print('Result 2:', result)
print('Took: %.2f seconds.' % (timer() - start))
Roughly speaking, we are splitting the tasks into different, smaller chunks, and running them at the same time. Don't worry about the specifics of the code for now, as we will discuss this use of a pool of processes in greater detail later on.
When I executed the function, the execution time was noticeably better, and the computer also used more of its resources, being only 37% idle:
> python example1.py
Result 2: [10000000000183, 10000000000037, 10000000000129, 10000000000273, 10000000000259, 10000000000343, 10000000000051, 10000000000267, 10000000000279, 10000000000099, 10000000000283, 10000000000313, 10000000000391, 10000000000433, 10000000000411, 10000000000453]
Took: 2.33 seconds
The output of the Activity Monitor application will look something like the following:

Concurrent versus parallel
At this point, if you have had some experience in parallel programming, you might be wondering whether concurrency is any different from parallelism. The key difference between concurrent and parallel programming is that, while in parallel programs there are a number of processing flows (mainly CPUs and cores) working independently all at once, there might be different processing flows (mostly threads) accessing and using a shared resource at the same time in concurrent programs.
Since this shared resource can be read and overwritten by any of the different processing flows, some form of coordination is required at times, when the tasks that need to be executed are not entirely independent from one another. In other words, it is important for some tasks to be executed after the others, to ensure that the programs will produce the correct results.
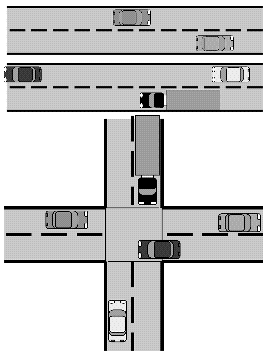
The preceding figure illustrates the difference between concurrency and parallelism: while in the upper section, parallel activities (in this case, cars) that do not interact with each other can run at the same time, in the lower section, some tasks have to wait for others to finish before they can be executed.
We will look at more examples of these distinctions later on.
A quick metaphor
Concurrency is a quite difficult concept to fully grasp immediately, so let's consider a quick metaphor, in order to make concurrency and its differences from parallelism easier to understand.
Although some neuroscientists might disagree, let's briefly assume that different parts of the human brain are responsible for performing separate, exclusive body part actions and activities. For example, the left hemisphere of the brain controls the right side of the body, and hence, the right hand (and vice versa); or, one part of the brain might be responsible for writing, while another solely processes speaking.
Now, let's consider the first example, specifically. If you want to move your left hand, the right side of your brain (and only the right side) has to process that command to move, which means that the left side of your brain is free to process other information. So, it is possible to move and use the left and right hands at the same time, in order to do different things. Similarly, it is possible to be writing and talking at the same time.
That is parallelism: where different processes don't interact with, and are independent of, each other. Remember that concurrency is not quite like parallelism. Even though there are instances where processes are executed together, concurrency also involves sharing the same resources. If parallelism is similar to using your left and right hands for independent tasks at the same time, concurrency can be associated with juggling, where the two hands perform different tasks simultaneously, but they also interact with the same object (in this case, the juggling balls), and some form of coordination between the two hands is therefore required.
Not everything should be made concurrent
Not all programs are created equal: some can be made parallel or concurrent relatively easily, while others are inherently sequential, and thus cannot be executed concurrently, or in parallel. An extreme example of the former is embarrassingly parallel programs, which can be divided into different parallel tasks, between which there is little or no dependency or need for communication.
Embarrassingly parallel
A common example of an embarrassingly parallel program is the 3D video rendering handled by a graphics processing unit, where each frame or pixel can be processed with no interdependency. Password cracking is another embarrassingly parallel task that can easily be distributed on CPU cores. In a later chapter, we will tackle a number of similar problems, including image processing and web scraping, which can be made concurrent/parallel intuitively, resulting in significantly improved execution times.
Inherently sequential
In opposition to embarrassingly parallel tasks, the execution of some tasks depends heavily on the results of others. In other words, those tasks are not independent, and thus, cannot be made parallel or concurrent. Furthermore, if we were to try to implement concurrency into those programs, it could cost us more execution time to produce the same results. Let's go back to our prime-checking example from earlier; the following is the output that we saw:
> python example1.py
Result 1: [10000000000037, 10000000000051, 10000000000099, 10000000000129, 10000000000183, 10000000000259, 10000000000267, 10000000000273, 10000000000279, 10000000000283, 10000000000313, 10000000000343, 10000000000391, 10000000000411, 10000000000433, 10000000000453]
Took: 3.41 seconds.
Result 2: [10000000000183, 10000000000037, 10000000000129, 10000000000273, 10000000000259, 10000000000343, 10000000000051, 10000000000267, 10000000000279, 10000000000099, 10000000000283, 10000000000313, 10000000000391, 10000000000433, 10000000000411, 10000000000453]
Took: 2.33 seconds.
Pay close attention, and you will see that the two results from the two methods are not identical; the primes in the second result list are out of order. (Recall that, in the second method, to apply concurrency we specified splitting the tasks into different groups to be executed simultaneously, and the order of the results we obtained is the order in which each task finished being executed.) This is a direct result of using concurrency in our second method: we split the tasks to be executed by the program into different groups, and our program processed the tasks in these groups at the same time.
Since tasks across different groups were executed simultaneously, there were tasks that were behind other tasks in the input list, and yet were executed before those other tasks. For example, the number 10000000000183 was behind the number 10000000000129 in our input list, but was processed prior to, and therefore in front of, the number 10000000000129 in our output list. In fact, if you execute the program again and again, the second result will vary in almost every run.
Evidently, this situation is not desirable if the result we'd like to obtain needs to be in the order of the input we originally had. Of course, in this example, we can simply modify the result by using some form of sorting, but it will cost us extra execution time in the end, which might make it even more expensive than the original sequential approach.
A concept that is commonly used to illustrate the innate sequentiality of some tasks is pregnancy: the number of women will never reduce the length of pregnancy. As opposed to parallel or concurrent tasks, where an increase in the number of processing entities will improve the execution time, adding more processors in inherently sequential tasks will not. Famous examples of inherent sequentiality include iterative algorithms: Newton's method, iterative solutions to the three-body problem, or iterative numerical approximation methods.
Example 2 – inherently sequential tasks
Let us consider a quick example:
Computing f1000(3), with f(x) = x2 - x + 1, and fn + 1(x) = f(fn(x)).
With complicated functions like f (where it is relatively difficult to find a general form of fn(x)), the only obviously reasonable way to compute f1000(3) or similar values is to iteratively compute f2(3) = f( f(3)), f3(3) = f( f2(3)), ... , f999(3) = f( f998(3)), and, finally, f1000(3) = f( f999(3)).
Since it will take significant time to actually compute f1000(3), even when using a computer, we will only consider f20(3) in our code (my laptop actually started heating up after f25(3)):
# Chapter01/example2.py
def f(x):
return x * x - x + 1
# sequential
def f(x):
return x * x - x + 1
start = timer()
result = 3
for i in range(20):
result = f(result)
print('Result is very large. Only printing the last 5 digits:', result % 100000)
print('Sequential took: %.2f seconds.' % (timer() - start))
Run it (or use python example2.py); the following code shows the output I received:
> python example2.py
Result is very large. Only printing the last 5 digits: 35443
Sequential took: 0.10 seconds.
Now, if we were to attempt to apply concurrency to this script, the only possible way would be through a for loop. One solution might be as follows:
# Chapter01/example2.py
# concurrent
def concurrent_f(x):
global result
result = f(result)
result = 3
with concurrent.futures.ThreadPoolExecutor(max_workers=20) as exector:
futures = [exector.submit(concurrent_f, i) for i in range(20)]
_ = concurrent.futures.as_completed(futures)
print('Result is very large. Only printing the last 5 digits:', result % 100000)
print('Concurrent took: %.2f seconds.' % (timer() - start))
The output I received is shown as follows:
> python example2.py
Result is very large. Only printing the last 5 digits: 35443
Concurrent took: 0.19 seconds.
Even though both methods produced the same result, the concurrent method took almost twice as long as the sequential method. This is due to the fact that every time a new thread (from ThreadPoolExecutor) was spawned, the function conconcurrent_f(), inside that thread, needed to wait for the variable result to be processed by the previous thread completely, and the program as a whole was thus executed in a sequential manner, nonetheless.
So, while there was no actual concurrency involved in the second method, the overhead cost of spawning new threads contributed to the significantly worse execution time. This is one example of inherently sequential tasks, where concurrency or parallelism should not be applied to attempt an improvement in execution time.
I/O bound
Another way to think about sequentiality is the concept (in computer science) of a condition called I/O bound, in which the time it takes to complete a computation is mainly determined by the time spent waiting for input/output (I/O) operations to be completed. This condition arises when the rate at which data is requested is slower than the rate at which it is consumed, or, in short, more time is spent requesting data than processing it.
In an I/O bound state, the CPU must stall its operation, waiting for data to be processed. This means that, even if the CPU gets faster at processing data, processes tend to not increase in speed in proportion to the increased CPU speed, since they get more I/O-bound. With faster computation speed being the primary goal of new computer and processor designs, I/O bound states are becoming undesirable, yet more and more common, in programs.
As you have seen, there are a number of situations in which the application of concurrent programming results in decreased processing speed, and they should thus be avoided. It is therefore important for us to not see concurrency as a golden ticket that can produce unconditionally better execution times, and to understand the differences between the structures of programs that benefit from concurrency and programs that do not.
The history, present, and future of concurrency
In the following sub-topics, we will discuss the past, present, and future of concurrency.
The field of concurrent programming has enjoyed significant popularity since the early days of computer science. In this section, we will discuss how concurrent programming started and evolved throughout its history, its current usage in the industry, and some predictions regarding how concurrency will be used in the future.
The history of concurrency
The concept of concurrency has been around for quite some time. The idea developed from early work on railroads and telegraphy in the nineteenth and early twentieth centuries, and some terms have even survived to this day (such as semaphore, which indicates a variable that controls access to a shared resource in concurrent programs). Concurrency was first applied to address the question of how to handle multiple trains on the same railroad system, in order to avoid collisions and maximize efficiency, and how to handle multiple transmissions over a given set of wires in early telegraphy.
A significant portion of the theoretical groundwork for concurrent programming was actually laid in the 1960s. The early algorithmic language ALGOL 68, which was first developed in 1959, includes features that support concurrent programming. The academic study of concurrency officially started with a seminal paper in 1965 from Edsger Dijkstra, who was a pioneer in computer science, best known for the path-finding algorithm that was named after him.
That seminal paper is considered the first paper in the field of concurrent programming, in which Dijkstra identified and solved the mutual exclusion problem. Mutual exclusion, which is a property of concurrency control that prevents race conditions (which we will discuss later on), went on to become one of the most discussed topics in concurrency.
Yet, there was no considerable interest after that. From around 1970 to early 2000, processors were said to double in executing speed every 18 months. During this period, programmers did not need to concern themselves with concurrent programming, as all they had to do to have their programs run faster was wait. However, in the early 2000s, a paradigm shift in the processor business took place; instead of making increasingly big and fast processors for computers, manufacturers started focusing on smaller, slower processors, which were put together in groups. This was when computers started to have multicore processors.
Nowadays, an average computer has more than one core. So, if a programmer writes all of their programs to be non-concurrent in any way, they will find that their programs utilize only one core or one thread to process data, while the rest of the CPU sits idle, doing nothing (as we saw in the Example 1 – Checking whether a non-negative number is prime section). This is one reason for the recent push in concurrent programming.
Another reason for the increasing popularity of concurrency is the growing field of graphical, multimedia, and web-based application development, in which the application of concurrency is widely used to solve complex and meaningful problems. For example, concurrency is a major player in web development: each new request made by a user typically comes in as its own process (this is called multiprocessing; see Chapter 6, Working with Processes in Python) or asynchronously coordinated with other requests (this is called asynchronous programming; see Chapter 9, Introduction to Asynchronous Programming); if any of those requests need to access a shared resource (a database, for example) where data can be changed, concurrency should be taken into consideration.
The present
Considering the present day, where an explosive growth the internet and data sharing happens every second, concurrency is more important than ever. The current use of concurrent programming emphasizes correctness, performance, and robustness.
Some concurrent systems, such as operating systems or database management systems, are generally designed to operate indefinitely, including automatic recovery from failure, and not terminate unexpectedly. As mentioned previously, concurrent systems use shared resources, and thus they require some form of semaphore in their implementation, to control and coordinate access to those resources.
Concurrent programming is quite ubiquitous in the field of software development. Following are a few examples where concurrency is present:
- Concurrency plays an important role in most common programming languages: C++, C#, Erlang, Go, Java, Julia, JavaScript, Perl, Python, Ruby, Scala, and so on.
- Again, since almost every computer today has more than one core in its CPU, desktop applications need to be able to take advantage of that computing power, in order to provide truly well-designed software.

- The iPhone 4S, which was released in 2011, has a dual-core CPU, so mobile development also has to stay connected to concurrent applications.
- As for video games, two of the biggest players on the current market are the Xbox 360, which is a multi-CPU system, and Sony's PS3, which is essentially a multicore system.
- Even the current iteration of the $35 Raspberry Pi is built around a quad-core system.
- It is estimated that on average, Google processes over 40,000 search queries every second, which equates to over 3.5 billion searches per day, and 1.2 trillion searches per year, worldwide. Apart from having massive machines with incredible processing power, concurrency is the best way to handle that amount of data requests.
A large percentage of today's data and applications are stored in the cloud. Since computing instances on the cloud are relatively small in size, almost every web application is therefore forced to be concurrent, processing different small jobs simultaneously. As it gains more customers and has to process more requests, a well-designed web application can simply utilize more servers while keeping the same logic; this corresponds to the property of robustness that we mentioned earlier.
Even in the increasingly popular fields of artificial intelligence and data science, major advances have been made, in part due to the availability of high-end graphics cards (GPUs), which are used as parallel computing engines. In every notable competition on the biggest data science website (https://www.kaggle.com/), almost all prize-winning solutions feature some form of GPU usage during the training process. With the sheer amount of data that big data models have to comb through, concurrency provides an effective solution. Some AI algorithms are even designed to break their input data down into smaller portions and process them independently, which is a perfect opportunity to apply concurrency in order to achieve better model-training time.
The future
In this day and age, computer/internet users expect instant output, no matter what applications they are using, and developers often find themselves struggling with the problem of providing better speed for their applications. In terms of usage, concurrency will continue to be one of the main players in the field of programming, providing unique and innovative solutions to those problems. As mentioned earlier, whether it be video game design, mobile apps, desktop software, or web development, concurrency is, and will be, omnipresent in the near future.
Given the need for concurrency support in applications, some might argue that concurrent programming will also become more standard in academia. Even though specific topics in concurrency and parallelism are being covered in computer science courses, in-depth, complex subjects on concurrent programming (both theoretical and applied subjects) will be implemented in undergraduate and graduate courses, to better prepare students for the industry, where concurrency is being used every day. Computer science courses on building concurrent systems, studying data flows, and analyzing concurrent and parallel structures will only be the beginning.
Others might have a more skeptical view of the future of concurrent programming. Some say that concurrency is really about dependency analysis: a sub-field of compiler theory that analyzes execution-order constraints between statements/instructions, and determines whether it is safe for a program to reorder or parallelize its statements. Furthermore, since only a very small number of programmers truly understand concurrency and all of its intricacies, there will be a push for compilers, along with support from the operating system, to take on the responsibility of actually implementing concurrency into the programs they compile on their own.
Specifically, in the future programmers will not have to concern themselves with the concepts and problems of concurrent programming, nor should they. An algorithm implemented on the compiler-level should look at the program being compiled, analyze the statements and instructions, produce a dependency graph to determine the optimal order of execution for those statements and instructions, and apply concurrency/parallelism where it is appropriate and efficient. In short, the combination of the low number of programmers understanding and being able to effectively work with concurrent systems and the possibility of automating the design of concurrency will lead to a decrease in interest in concurrent programming.
In the end, only time will tell what the future holds for concurrent programming. We programmers can only look at how concurrency is currently being used in the real world, and determine whether it is worth learning or not: which, as we have seen in this case, it is. Furthermore, even though there are strong connections between designing concurrent programs and dependency analysis, I personally see concurrent programming as a more intricate and involved process, which might be very difficult to achieve through automation.
Concurrent programming is indeed extremely complicated and very hard to get right, but that also means the knowledge gained through the process will be beneficial and useful to any programmer, and I see that as a good enough reason to learn about concurrency. The ability to analyze the problems of program speedup, restructure your programs into different independent tasks, and coordinate those tasks to use the same resources, are the main skills that programmers build while working with concurrency, and knowledge of these topics will help them with other programming problems, as well.
A brief overview of mastering concurrency in Python
Python is one of the most popular programming languages out there, and for good reason. The language comes with numerous libraries and frameworks that facilitate high-performance computing, whether it be software development, web development, data analysis, or machine learning. Yet, there have been discussions among developers criticizing Python, which often revolve around the Global Interpreter Lock (GIL) and the difficulty of implementing concurrent and parallel programs that it leads to.
While concurrency and parallelism do behave differently in Python than in other common programming languages, it is still possible for programmers to implement Python programs that run concurrently or in parallel, and achieve significant speedup for their programs.
Mastering Concurrency in Python will serve as a comprehensive introduction to various advanced concepts in concurrent engineering and programming in Python. This book will also provide a detailed overview of how concurrency and parallelism are being used in real-world applications. It is a perfect blend of theoretical analyses and practical examples, which will give you a full understanding of the theories and techniques regarding concurrent programming in Python.
This book will be divided into six main sections. It will start with the idea behind concurrency and concurrent programming—the history, how it is being used in the industry today, and finally, a mathematical analysis of the speedup that concurrency can potentially provide. Additionally, the last section in this chapter (which is our next section) will cover instructions for how to follow the coding examples in this book, including setting up a Python environment on your own computer, downloading/cloning the code included in this book from GitHub, and running each example from your computer.
The next three sections will cover three of the main implementation approaches in concurrent programming: threads, processes, and asynchronous I/O, respectively. These sections will include theoretical concepts and principles for each of these approaches, the syntax and various functionalities that the Python language provides to support them, discussions of best practices for their advanced usage, and hands-on projects that directly apply these concepts to solve real-world problems.
Section five will introduce readers to some of the most common problems that engineers and programmers face in concurrent programming: deadlock, starvation, and race conditions. Readers will learn about the theoretical foundations and causes for each problem, analyze and replicate each of them in Python, and finally implement potential solutions. The last chapter in this section will discuss the aforementioned GIL, which is specific to the Python language. It will cover the GIL's integral role in the Python ecosystem, some challenges that the GIL poses for concurrent programming, and how to implement effective workarounds.
In the last section of the book, we will be working on various advanced applications of concurrent Python programming. These applications will include the design of lock-free and lock-based concurrent data structures, memory models and operations on atomic types, and how to build a server that supports concurrent request processing from scratch. The section will also cover the the best practices when testing, debugging, and scheduling concurrent Python applications.
Throughout this book, you will be building essential skills for working with concurrent programs, just through following the discussions, the example code, and the hands-on projects. You will understand the fundamentals of the most important concepts in concurrent programming, how to implement them in Python programs, and how to apply that knowledge to advanced applications. By the end of Mastering Concurrency in Python, you will have a unique combination of extensive theoretical knowledge regarding concurrency, and practical know-how of the various applications of concurrency in the Python language.
Why Python?
As mentioned previously, one of the difficulties that developers face while working with concurrency in the Python programming language (specifically, CPython—a reference implementation of Python written in C) is its GIL. The GIL is a mutex that protects access to Python objects, preventing multiple threads from executing Python byte codes at once. This lock is necessary mainly because CPython's memory management is not thread-safe. CPython uses reference counting to implement its memory management. This results in the fact that multiple threads can access and execute Python code simultaneously; this situation is undesirable, as it can cause an incorrect handling of data, and we say that this type of memory management is not thread-safe. To address this problem, the GIL is, as the name suggests, a lock that allows only one thread to access Python code and objects. However, this also means that, to implement multithreading programs in CPython, developers need to be aware of the GIL and work around it. That is why many have problems with implementing concurrent systems in Python.
So, why use Python for concurrency at all? Even though the GIL prevents multithreaded CPython programs from taking full advantage of multiprocessor systems in certain situations, most blocking or long-running operations, such as I/O, image processing, and NumPy number crunching, happen outside the GIL. Therefore, the GIL only becomes a potential bottleneck for multithreaded programs that spend significant time inside the GIL. As you will see in future chapters, multithreading is only a form of concurrent programming, and, while the GIL poses some challenges for multithreaded CPython programs that allow more than one thread to access shared resources, other forms of concurrent programming do not have this problem. For example, multiprocessing applications that do not share any common resources among processes, such as I/O, image processing, or NumPy number crunching, can work seamlessly with the GIL. We will discuss the GIL and its place in the Python ecosystem in greater depth in Chapter 15, The Global Interpret Lock.
Aside from that, Python has been gaining increasing popularity from the programming community. Due to its user-friendly syntax and overall readability, more and more people have found it relatively straightforward to use Python in their development, whether it is beginners learning a new programming language, intermediate users looking for the advanced functionalities of Python, or experienced programmers using Python to solve complex problems. It is estimated that the development of Python code can be up to 10 times faster than C/C++ code.
The large number of developers using Python has resulted in a strong, ever-growing support community. Libraries and packages in Python are being developed and released every day, tackling different problems and technologies. Currently, the Python language supports an incredibly wide range of programming—namely, software development, desktop GUIs, video game design, web and internet development, and scientific and numeric computing. In recent years, Python has also been growing as one of the top tools in data science, big data, and machine learning, competing with the long-time player in the field, R.
The sheer number of development tools available in Python has encouraged more developers to start programming with Python, making Python even more popular and easy to use; I call this the vicious circle of Python. David Robinson, chief data scientist at DataCamp, wrote a blog (https://stackoverflow.blog/2017/09/06/incredible-growth-python/) about the incredible growth of Python, and called it the most popular programming language.
However, Python is slow, or at least slower than other popular programming languages. This is due to the fact that Python is a dynamically typed, interpreted language, where values are stored not in dense buffers, but in scattered objects. This is a direct result of Python's readability and user-friendliness. Luckily, there are various options regarding how to make your Python program run faster, and concurrency is one of the most complex of them; that is what we are going to master throughout this book.
Setting up your Python environment
Before we move any further, let's go through a number of specifications regarding how to set up the necessary tools that you will be using throughout this book. In particular, we will discuss the process of obtaining a Python distribution for your system and an appropriate development environment, as well as how to download the code used in the examples included in the chapters of this book.
General setup
Let's look at the process of obtaining a Python distribution for your system and an appropriate development environment:
- Any developer can obtain their own Python distribution from https://www.python.org/downloads/.
- Even though both Python 2 and Python 3 are being supported and maintained, throughout this book we will be using Python 3.
- The choice of an integrated development environment (IDE) is flexible for this book. Although it is technically possible to develop Python applications using a minimal text editor, such as Notepad or TextEdit, it is usually much easier to read and write code with IDEs designed specifically for Python. These include IDLE (https://docs.python.org/3/library/idle.html), PyCharm (https://www.jetbrains.com/pycharm/), Sublime Text (https://www.sublimetext.com/), and Atom (https://atom.io/).
Downloading example code
To obtain the code used throughout this book, you can download a repository from GitHub, which includes all of the example and project code covered in this book:
- First, visit https://github.com/PacktPublishing/Mastering-Concurrency-in-Python.
- To download the repository, simply click on the Clone or download button in the top right corner of your window. Choose Download ZIP to download the compressed repository to your computer:
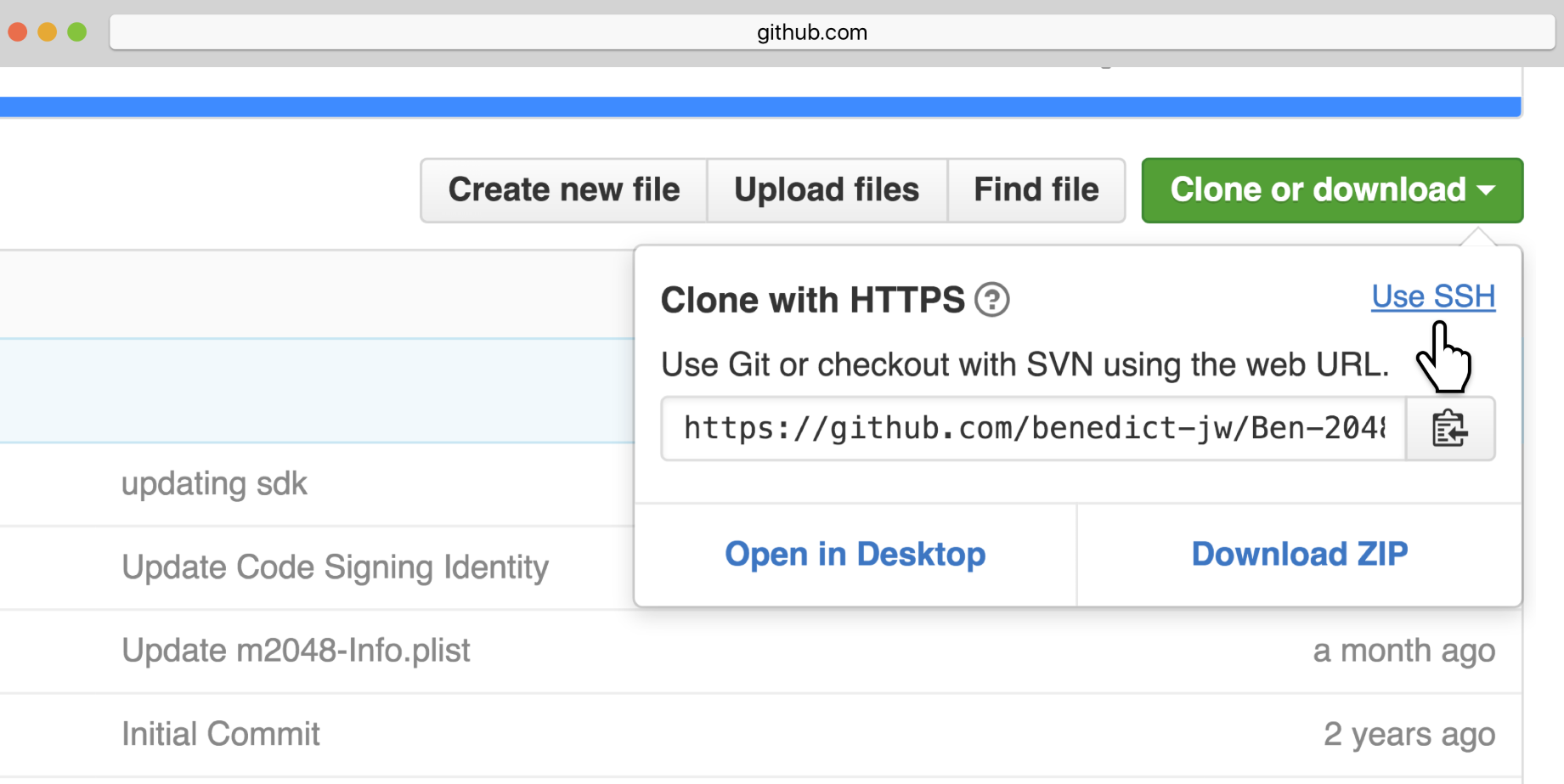
- Uncompress the downloaded file to create the folder that we are looking for. The folder should have the name Mastering-Concurrency-in-Python.
Separate folders, titled ChapterXX, are inside the folder, indicating the chapter that covers the code in that folder. For example, the Chapter03 folder contains the example and project code covered in Chapter 3, Working with Threads in Python. In each subfolder, there are various Python scripts; as you go through each code example in the book, you will know which script to run at a specific point in each chapter.
Summary
You have now been introduced to the concept of concurrent and parallel programming. It is about designing and structuring programming commands and instructions, so that different sections of the program can be executed in an efficient order, while sharing the same resources. Since time is saved when some commands and instructions are executed at the same time, concurrent programming provides significant improvements in program execution time, as compared to traditional sequential programming.
However, various factors need to be taken into consideration while designing a concurrent program. While there are specific tasks that can easily be broken down into independent sections that can be executed in parallel (embarrassingly parallel tasks), others require different forms of coordination between the program commands, so that shared resources are used correctly and efficiently. There are also inherently sequential tasks, in which no concurrency and parallelism can be applied to achieve program speedup. You should know the fundamental differences between these tasks, so that you can design your concurrent programs appropriately.
Recently, there was a paradigm shift that facilitated the implementation of concurrency into most aspects of the programming world. Now, concurrency can be found almost everywhere: desktop and mobile applications, video games, web and internet development, AI, and so on. Concurrency is still growing, and it is expected to keep growing in the future. It is therefore crucial for any experienced programmer to understand concurrency and its relevant concepts, and to know how to integrate those concepts into their applications.
Python, on the other hand, is one of the most (if not the most) popular programming languages. It provides powerful options in most sub-fields of programming. The combination of concurrency and Python is therefore one of the topics most worth learning and mastering in programming.
In the next chapter, on Amdahl's Law, we will discuss how significant the improvements in speedup that concurrency provides for our programs are. We will analyze the formula for Amdahl's Law, discussing its implications and considering Python examples.
Questions
- What is the idea behind concurrency, and why is it useful?
- What are the differences between concurrent programming and sequential programming?
- What are the differences between concurrent programming and parallel programming?
- Can every program be made concurrent or parallel?
- What are embarrassingly parallel tasks?
- What are inherently sequential tasks?
- What does I/O bound mean?
- How is concurrent processing currently being used in the real world?
Further reading
For more information you can refer to the following links:
- Python Parallel Programming Cookbook, by Giancarlo Zaccone, Packt Publishing Ltd, 2015
- Learning Concurrency in Python: Build highly efficient, robust, and concurrent applications (2017), by Forbes, Elliot
- "The historical roots of concurrent engineering fundamentals." IEEE Transactions on Engineering Management 44.1 (1997): 67-78, by Robert P. Smith
- Programming language pragmatics, Morgan Kaufmann, 2000, by Michael Lee Scott





