


















 Download code from GitHub
Download code from GitHub
Planning for Ceph
The first chapter of this book covers all the areas you need to consider when looking to deploy a Ceph cluster from initial planning stages to hardware choices. Topics covered in this chapter are as follows:
- What Ceph is and how it works
- Good use cases for Ceph and important considerations
- Advice and best practices on infrastructure design
- Ideas around planning a Ceph project
What is Ceph?
Ceph is an open source, distributed, scale-out, software-defined storage (SDS) system, which can provide block, object, and file storage. Through the use of the Controlled Replication Under Scalable Hashing (CRUSH) algorithm, Ceph eliminates the need for centralized metadata and can distribute the load across all the nodes in the cluster. Since CRUSH is an algorithm, data placement is calculated rather than being based on table lookups and can scale to hundreds of petabytes without the risk of bottlenecks and the associated single points of failure. Clients also form direct connections with the server storing the requested data and so their is no centralised bottleneck in the data path.
Ceph provides the three main types of storage, being block via RADOS Block Devices (RBD), file via Ceph Filesystem (CephFS), and object via the Reliable Autonomous Distributed Object Store (RADOS) gateway, which provides Simple Storage Service (S3) and Swift compatible storage.
Ceph is a pure SDS solution and as such means that you are free to run it on commodity hardware as long as it provides the correct guarantees around data consistency. More information on the recommended types of hardware can be found later on in this chapter. This is a major development in the storage industry which has typically suffered from strict vendor lock-in. Although there have been numerous open source projects to provide storage services. Very few of them have been able to offer the scale and high resilience of Ceph, without requiring propriety hardware.
It should be noted that Ceph prefers consistency as per the CAP theorem and will try at all costs to make protecting your data the biggest priority over availability in the event of a partition.
How Ceph works?
The core storage layer in Ceph is RADOS, which provides, as the name suggests, an object store on which the higher level storage protocols are built and distributed. The RADOS layer in Ceph comprises a number of OSDs. Each OSD is completely independent and forms peer-to-peer relationships to form a cluster. Each OSD is typically mapped to a single physical disk via a basic host bus adapter (HBA) in contrast to the traditional approach of presenting a number of disks via a Redundant Array of Independent Disks (RAID) controller to the OS.
The other key component in a Ceph cluster are the monitors; these are responsible for forming cluster quorum via the use of Paxos. By forming quorum the monitors can be sure that are in a state where they are allowed to make authoritative decisions for the cluster and avoid split brain scenarios. The monitors are not directly involved in the data path and do not have the same performance requirements as OSDs. They are mainly used to provide a known cluster state including membership, configuration, and statistics via the use of various cluster maps. These cluster maps are used by both Ceph cluster components and clients to describe the cluster topology and enable data to be safely stored in the right location.
Due to the scale that Ceph is intended to be operated at, one can appreciate that tracking the state and placement of every single object in the cluster would become computationally very expensive. Ceph solves this problem using CRUSH to place the objects into groups of objects named placement groups (PGs). This reduces the need to track millions of objects to a much more manageable number in the thousands range.
Librados is a Ceph library that can be used to build applications that interact directly with the RADOS cluster to store and retrieve objects.
For more information on how the internals of Ceph work, it would be strongly recommended to read the official Ceph documentation and also the thesis written by Sage Weil, the creator and primary architect of Ceph.
Ceph use cases
Before jumping into a specific use case, let's cover some key points that should be understood and considered before thinking about deploying a Ceph cluster.
Replacing your storage array with Ceph
Ceph should not be compared with a traditional scale-up storage array. It is fundamentally different, and trying to shoehorn Ceph into that role using existing knowledge, infrastructure, and expectation will lead to disappointment. Ceph is Software Defined Storage (SDS) whose internal data movements operate over TCP/IP networking. This introduces several extra layers of technology and complexity compared with a SAS cable at the rear of a traditional storage array.
Performance
Due to Ceph's distributed approach, it can offer unrestrained performance compared with scale-up storage arrays, which typically have to funnel all I/O through a pair of controller heads. Although technology has constantly been providing new faster CPUs and faster network speeds, there is still a limit to the performance you can expect to achieve with just a pair of controllers. With recent advances in flash technology combined with new interfaces such as Non-volatile Memory Express (NVMe), the scale-out nature of Ceph provides a linear increase in CPU and network resource with every added OSD node.
Let us also consider where Ceph is not a good fit for performance, and this is mainly around use cases where extremely low latency is desired. For the very reason that enables Ceph to become a scale-out solution, it also means that low latency performance will suffer. The overhead of software and additional network hops means that latency will tend to be about double that of a traditional storage array and 10 times that of local storage. A thought should be given to selecting the best technology for given performance requirements. That said, a well-designed and tuned Ceph cluster should be able to meet performance requirements in all but the most extreme cases.
Reliability
Ceph is designed to provide a highly fault-tolerant storage system by the scale-out nature of its components. Although no individual component is highly available, when clustered together any component should be able to fail without causing an inability to service client requests. In fact, as your Ceph cluster grows, the failure of individual components should be expected and become part of normal operating conditions. However, Ceph's ability to provide a resilient cluster should not be an invitation to compromise on hardware or design choice. Doing so will likely lead to failure. There are several factors that Ceph assumes your hardware will meet, which are covered later in this chapter.
Unlike RAID where disk rebuilds with larger disks can now stretch into time periods measured in weeks, Ceph will often recover from single disk failures in a matter of hours. With the increasing trend of larger capacity disks, Ceph offers numerous advantages to both the reliability and degraded performance when compared with a traditional storage array.
The use of commodity hardware
Ceph is designed to be run on commodity hardware, which gives the ability to be able to design and build a cluster without the premium demanded by traditional tier 1 storage and server vendors. This can be both a blessing and a curse. Be able to choose your own hardware that allows you to build your Ceph infrastructure to exactly match your requirements. However, one thing branded hardware does offer is compatibility testing; it's not unknown for strange exotic firmware bugs to be discovered, which can cause very confusing symptoms. A thought should be applied to whether your IT teams have the time and skills to cope with any obscure issues that may crop up with untested hardware solutions.
The use of commodity hardware also protects against the traditional fork lift upgrade model, where the upgrade of a single component often requires the complete replacement of the whole storage array. With Ceph you can replace individual components in a very granular nature, and with automatic data balancing, lengthy data migration periods are avoided. The distributed nature of Ceph means that hardware replacement or upgrades can be done during working hours without effecting service availability.
Specific use cases
We will now cover some of the more common uses cases for Ceph and discuss some of the reasons behind them.
OpenStack- or KVM-based virtualization
Ceph is the perfect match to provide storage to an OpenStack environment. In fact, Ceph currently is the most popular choice. OpenStack Cinder block driver uses Ceph RBDs to provision block volumes for VMs and OpenStack Manila, the Shared File System service (FaaS), integrates well with CephFS. There are a number of reasons why Ceph is such a good solution for OpenStack:
- Both are open source projects with commercial offerings
- Both have a proven track record in large-scale deployments
- Ceph can provide block, CephFS, and object storage, all of which OpenStack can use
- It is possible to deploy a hyper converged cluster with careful planning
If you are not using OpenStack or have no plans to use it, Ceph also integrates very well with KVM virtualization.
Large bulk block storage
Due to the ability to design and build cost-effective OSD nodes, Ceph enables you to build large high-performance storage clusters that are very cost-effective compared with alternative options. However, due to the recommended 3x replication, storage efficiency as calculated against raw storage cannot match traditional RAID JBOD (short for Just a Bunch of Disks) on price or power consumption. However, a lot of the benefits surrounding availability and performance may still make this use case attractive. Erasure coding support for use with RBD's, which should be available by the Luminous release, will close this gap greatly. If your archival requirement allows you to store data in objects, then erasure pools will enable you to match RAID on price and is a very attractive solution.
Object storage
By the very fact that the core RADOS layer is an object store means that Ceph excels at providing object storage either via the S3 or Swift protocols. If cost, latency, or data security are a concern over using public cloud object storage solutions, running your own Ceph cluster to provide object storage can be an ideal use case.
Object storage with custom application
Using librados, you can get your in-house application to directly talk to the underlying Ceph RADOS layer. This can greatly simplify the development of your application and gives you direct access to highly performant reliable storage. Some of the more advanced features of librados, which allow you to bundle a number of operations into a single atomic operation, are also very hard to do with existing storage solutions.
Distributed filesystem - web farm
A farm of web servers all need to access the same files so that they can all serve the same content no matter which one the client connects to. Traditionally, a high-availability (HA) NFS solution would be used to provide distributed file access but can start to hit several limitations at scale. CephFS can provide a distributed filesystem to store the web content and allow it to be mounted across all the web servers in the farm.
Distributed filesystem -SMB file server replacement
There are several interactions between CephFS and Samba, which have not been refined, meaning that the end solution would not work as well as expected. Samba can successfully be used to present a CephFS filesystem, but the lack of HA and stable snapshots means that it will often be a poor replacement. As of the publication of this book, this is not currently a recommended use case for Ceph.
Infrastructure design
While considering infrastructure design we need to take care of certain components. We will now briefly look at this components.
SSDs
SSDs are great. They have come down enormously in price over the past 10 years, and every evidence suggests that they will continue to do so. They have the ability to offer access times several orders of magnitude lower than rotating disks and consume less power.
One important concept to understand about SSDs is that although their read and write latencies are typically measured in 10's of microseconds, to overwrite an existing data in a flash block, it requires the entire flash block to be erased before the write can happen. A typical flash block size in SSD may be 128 KB, and even a 4 KB write I/O would require the entire block to be read, erased and then the existing data and new I/O to be finally written. The erase operation can take several milliseconds and without clever routines in the SSD firmware, would make writes painfully slow. To get around this limitation, SSDs are equipped with a RAM buffer, so they can acknowledge writes instantly, whereas the firmware internally moves data around flash blocks to optimize the overwrite process and wear leveling. However, the RAM buffer is volatile memory and would normally result in the possibility of data loss and corruption in the event of sudden power loss. To protect against this, SSDs can have power loss protection, which is accomplished by having a large capacitor on board, to store enough power to flush any outstanding writes to flash.
One of the biggest trends in recent years is the different tiers of SSDs that have become available. Broadly speaking, these can be broken down into the following categories.
Consumer
These are the cheapest you can buy and are pitched at the average PC user. They provide a lot of capacity very cheaply and offer fairly decent performance. They will likely offer no power loss protection and will either demonstrate extremely poor performance when asked to do synchronous writes or lie about stored data integrity. They will also likely have very poor write endurance, but still more than enough for standard use.
Prosumer
These are a step up from the consumer models and will typically provide better performance and have higher write endurance although still far off what enterprise SSDs provide.
Before moving on to the enterprise models, it is worth just covering why you should not under any condition use the earlier-mentioned models of SSDs for Ceph:
- Lack of proper power loss protection will either result in extremely poor performance or not ensure proper data consistency
- Firmware is not as heavily tested as enterprise SSDs often revealing data corrupting bugs
- Low write endurance will mean that they will quickly wear out, often ending in sudden failure
- Due to high wear and failure rates, their initial cost benefits rapidly disappear
The use of consumer SSDs with Ceph will result in poor performance and increase the chance of catastrophic data loss.
Enterprise SSDs
The biggest difference between consumer and enterprise SSDs is that an enterprise SSD should provide the guarantee that when it responds to the host system confirming that data has been safely stored, it actually is. That is to say, that if power is suddenly removed from a system all data that the operating system believes was committed to disk will be safely stored in flash. Furthermore, it should also be expected that in order to accelerate writes but maintain the data safety condition, the SSDs will contain super capacitors to provide just enough power to flush the SSDs RAM buffer to flash in the event of a power loss condition.
Enterprise SSDs are normally provided in a number of different flavors to provide a wide cost per GB options balanced against write endurance.
Enterprise -read intensive
Read intensive SSDs are a bit of a marketing term. All SSDs will easily handle reads, but the name is referring to the lower write endurance. They will, however, provide the best cost per GB. These SSDs will often only have a write endurance of around 0.3-1 over a 5 year period drive writes per day (DWPD). That is to say you should be able to write 400 GB a day to a 400 GB SSD and expect it to still be working in 5 years' time. If you write 800 GB a day to it, it will only be guaranteed to last 2.5 years. In general, for most Ceph workloads, these ranges of SSDs are normally deemed to not have enough write endurance.
Enterprise - general usage
General usage SSDs will normally provide 3-5 DWPD and are a good balance of cost and write endurance. For using in Ceph, they will normally be a good choice for a SSD-based OSD assuming that the workload on the Ceph cluster is not planned to be overly write heavy.
Enterprise -write intensive
Write intensive SSDs are the most expensive type; they will often offer write endurances up to and over 10 DWPD. They should be used for journals for spinning disks in Ceph clusters or also for SSD-only OSDs if very heavy write workloads are planned.
Currently, Ceph uses filestore as its method of storing objects on disks. The details of how and why filestore works is covered later in Chapter 3, BlueStore. For now, it's important to understand that due to the limitations in normal POSIX filesystems to be able to provide atomic transactions to the several pieces of data Ceph needs to write a journal is used. If no separate SSD is used for the journal, a separate partition is created for it. Every write that the OSD handles will first be written to the journal and then flushed to the main storage area on the disk. This is the main reason why using SSD for a journal for spinning disks is advised. The double write severely impacts spinning disk performance, which is mainly caused by the random nature of the disk heads moving between the journal and data areas.
Likewise, SSD OSD still requires a journal, and so it will experience approximately double the number of writes and thus provide half the client performance expected.
As can now be seen, not all models of SSDs are equal, and Ceph's requirements can make choosing the correct one a tough process. Fortunately, a quick test can be carried out to establish SSD's potential for use as a Ceph journal.
Memory
Official recommendations are for 1 GB of memory for every 1 TB of storage. In truth, there are a number of variables that lead to this recommendation, but suffice to say that you never want to find yourself where your OSDs are running low on memory and any excess memory will be used to improve performance.
Aside from the baseline memory usage of OSD, the main variable effecting memory usage is the number of PGs running on OSD. Although total data size does have an impact on memory usage, it is dwarfed by the effect of the number of PGs. A healthy cluster running within the recommendations of 200 PGs per OSD will probably use less than 2 GB of RAM per OSD. However, in a cluster where the number of PGs has been set higher against best practice, memory usage will be higher. It is also worth noting that when OSD is removed from a cluster, extra PGs will be placed on remaining OSDs to rebalance the cluster; this will also increase memory usage as well as the recovery operation itself. This spike in memory usage can sometimes be the cause of cascading failures if insufficient ram has been provisioned. A large swap partition on SSD should always be provisioned to reduce the risk of the Linux out-of-memory (OOM) killer randomly killing OSD processes in the event of a low memory situation.
As a minimum, look to provision around 2 GB per OSD + OS overheads, but this should be treated as the bare minimum and 4 GB per OSD would be recommended.
Depending on your workload and size of spinning disks being used for the Ceph OSDs, extra memory may be required to ensure that the operating system can sufficiently cache the directory entries and file nodes from the filesystem used to store the Ceph objects. This may have a bearing on the RAM you wish to configure your nodes with and is covered in more detail in the tuning section of the book.
Regardless of the configured memory size, ECC memory should be used at all times.
CPU
Ceph's official recommendations are for 1 GHz of CPU power per OSD. Unfortunately, in real life, it's not quite as simple as this. What the official recommendations don't point out is that a certain amount of CPU power is required per I/O, and it's not just a static figure. Thinking about it, this makes sense; the CPU is only used when there is something to be done. No I/O, no CPU is required. This, however, scales the other way, more I/O, more CPUs are required. The official recommendation is a good safe bet for spinning disk-based OSDs. An OSD node equipped with fast SSDs can often find itself consuming several times this recommendation. To complicate things further, the CPU requirements vary depending on I/O size as well with larger I/Os requiring more CPU.
If the OSD node starts to struggle for CPU resource, it can lead to OSDs to start timing out and get marked out from the cluster, often to rejoin several seconds later. This continual loss and recovery tends to place more strain on the already limited CPU resource causing cascading failures.
A good figure to aim for would be around 1-10 MHz per I/O, corresponding to 4 KB-4 MB I/Os, respectively. As always, testing should be carried out before going live to confirm that CPU requirements are met both in normal and stressed I/O loads.
Another aspect of CPU selection, which is key to determine performance in Ceph, is the clock speed of the cores. A large proportion of the I/O path in Ceph is single threaded and so a faster clocked core will run through this code path faster leading to lower latency. Due to the limited thermal design of most CPUs, there is often a trade-off of clock speed as the number of cores increases. High core count CPUs with high clock speeds also tend to be placed at the top of the pricing structure. Therefore, it is beneficial to understand your I/O and latency requirements to choose the best CPU.
A small experiment was done to find the effect of CPU clock speed against write latency. A Linux workstation running Ceph had its CPU clock manually adjusted using the userspace governor. The following results clearly show the benefit of high-clocked CPUs:
| CPU MHz | 4 KB write I/O | Average latency (microseconds) |
| 1600 | 797 | 1250 |
| 2000 | 815 | 1222 |
| 2400 | 1161 | 857 |
| 2800 | 1227 | 812 |
| 3300 | 1320 | 755 |
| 4300 | 1548 | 644 |
If low latency and especially low write latency is important, then go for the highest clocked CPUs you can get, ideally at least higher than 3 GHz. This may require a compromise in SSD only nodes on how many cores are available and thus how many SSDs each node can support. For nodes with 12 spinning disks and SSD journals, single socket quad core processors make an excellent choice as they are often available with very high clock speeds and are very aggressively priced.
Where latency is not as important, for example, object workloads, look at entry-level processors with well-balanced core counts and clock speeds.
Another consideration around CPU and motherboard choice should be around the number of sockets. In Dual socket designs, the memory, disk controllers, and network interface controllers (NICs) are shared between the sockets. When data required by one CPU is required from a resource located on another CPU's socket, it must cross the interlink bus between the two CPUs. Modern CPUs have high-speed interconnects, but they do introduce some performance penalty and thought should be given to whether a single socket design is achievable. There are some options given in the tuning section on how to work around some of these possible performance penalties.
Disks
When choosing the disks to build a Ceph cluster with, there is always the temptation to go with the biggest disks you can, as the figures look great on paper. Unfortunately, in reality, this is often not a great choice. Although disks have dramatically increased in capacity over the past 20 years, their performance hasn't. First, ignore any sequential MBps figures, and you will never see them in enterprise workloads. There is always something making the I/O pattern nonsequential enough that it might as well be random. Second, remember these figures:
7.2k disks = 70-80 4k IOPS
10k disks = 120-150 4k IOPS
15k disks = You should be using SSDs
As a general rule, if you are designing a cluster that will offer active workloads rather than bulk inactive/archive storage. Design for the required Input/Output Operations Per Second (IOPS), not capacity. If your cluster will contain largely spinning disks with the intention of providing storage for an active workload, an increased number of smaller capacity disks are normally preferred over the use of larger disks. With the decrease in cost of SSD capacity, serious thought should be given to using them in your cluster, either as a cache tier or even for a full SSD cluster.
A thought should also be given to the use of SSDs as either journals with Ceph's filestore or for storing the DB and write-ahead log (WAL) when using BlueStore. Filestore performance is dramatically improved when using SSD journals and would not be recommended to be used without unless the cluster is designed to be used with very cold data.
Also, consider that the default replication level of 3 will mean that each client write I/O will generate at least 3x the I/O on the backend disks. In reality, due to the internal mechanisms in Ceph, this number in some instances will be nearer six times write amplification. If no SSD journals are to be used in the cluster, then this number might be nearer 12 times write amplification in the worst case scenarios.
Understand that although Ceph enables much more rapid recovery from a failed disk as every disk in the cluster will take part in the recovery. However, larger disks still pose a challenge, particularly when looking at having to recover from a node failure. In a cluster comprising 10 1 TB disks each 50% full, in the event of a disk failure, the remaining disks would have to recover 500 GB of data between them or around 55 GB each. At an average recovery speed of 20 MBps, recovery would be expected in around 45 minutes. A cluster with a hundred 1 TB disks would still only have to recover 500 GB of data, but this time, that task is shared between 99 disks. In theory for the larger cluster to recover from a single disk failure, it would take around four minutes. In reality, these recovery times will be higher as there are additional mechanisms at work, which increases recovery time. In smaller clusters, recovery times should be a key factor when selecting disk capacity.
Networking
The network is a key and often overlooked component in a Ceph cluster; a poorly designed network can often lead to a number of problems that manifest themselves in peculiar ways and make for a confusing troubleshooting session.
10G networking requirement
10G networking is strongly recommended for building a Ceph cluster, while 1G networking will work; latency will be pushing on the bounds of being unacceptable and will limit you to the size of nodes you can deploy. A thought should also be given to recovery; in the event of a disk or node failure, large amounts of data will need to be moved around the cluster. Not only will a 1G network be able to provide sufficient performance for this, but normal I/O traffic will be impacted. In the very worst of cases, this may lead to OSDs timing out causing cluster instabilities.
As mentioned, one of the main benefits of 10G networking is the lower latency. Quite often a cluster will never push enough traffic to make full use of the 10G bandwidth; however, the latency improvement is realized, no matter the load on the cluster. The round time trip for a 4k packet over a 10G network might take around 90 microseconds, and the same 4k packet over 1G networking will take over 1 milliseconds. In the tuning section of this book, you will learn that latency has a direct effect on the performance of a storage system, particularly when performing direct or synchronous I/O.
If your OSD node will come equipped with dual NICs, strongly look into a network design that allows you to use them active/active for both transmit and receive. It's wasteful to leave a 10G link in a passive state and will help to lower latency under load.
Network design
A good network design is an important step to bringing a Ceph cluster online. If your networking is handled by another team, make sure that they are included at all stages of the design as often an existing network will not be designed to handle Ceph's requirements, leading to both poor Ceph performance as well as impacting existing systems.
It's recommended that each Ceph node be connected via redundant links to two separate switches so that in the event of a switch failure, the Ceph node is still accessible. Stacking switches should be avoided if possible, as they can introduce single points of failure and in some cases are both required to be offline to carry out firmware upgrades.
If your Ceph cluster will be contained purely in one set of switches, feel free to skip this next section.
Traditional networks were mainly designed around a North-South access path, where clients at the North, access data through the network to servers at the South. If a server connected to an access switch needed to talk to another server connected to another access switch, the traffic would be routed through the core switch. Due to this access pattern, the access and aggregation layers that feed into the core layer were not designed to handle a lot of intraserver traffic, which is fine for the environment they were designed to support. Server-to-server traffic is named East-West traffic and is becoming more prevalent in the modern data center as applications become less isolated and require data from several other servers.
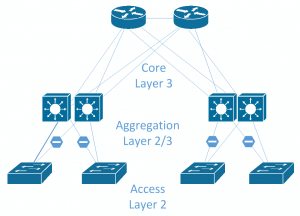
Ceph generates a lot of East-West traffic, not only from internal cluster replication traffic, but also from other servers consuming Ceph storage. In large environments, the traditional core, aggregation, and access layer design may struggle to cope as large amounts of traffic will be expected to be routed through the core switch. Faster switches can be obtained, and faster or more uplinks can be added; however, the underlying problem is that you are trying to run a scale-out storage system on a scale-up network design. Following image shows a typical network design with Core, Aggregation and Access layers. Typically only a single link from the access to the aggregation layer will be active.
A design that is becoming very popular in data centers is leaf-spine design. This approach completely gets rid of the traditional model and instead replaces it with two layers of switches: the spine layer and the leaf layer. The core concept is that each leaf switch connects to every spine switch so that any leaf switch is only one hop anyway from any other leaf switch. This provides consistent hop latency and bandwidth. Following is an example of a leaf spine toplogy. Depending on failure domains you may wish to have single or multiple leaf switches per rack for redundancy.

The leaf layer is where the servers connect into and is typically made up of a large number of 10G ports and a handful of 40G or faster uplink ports to connect into the spine layer.
The spine layer won't normally connect directly into servers, unless there are certain special requirements and will just serve as an aggregation point for all the leaf switches. The spine layer will often have higher port speeds to reduce any possible contention of the traffic coming out of the leaf switches.
Leaf spine networks are typically moving away from pure layer 2 topology, where layer 2 domain is terminated on the leaf switches and layer 3 routing is done between the leaf and spine layer. This is advised to be done using dynamic routing protocols, such as Border Gateway Protocol (BGP) or Open Shortest Path First (OSPF), to establish the routes across the fabric. This brings numerous advantages over large layer 2 networks. Spanning tree, which is typically used in layer 2 networks to stop switching loops, works by blocking an uplink, when using 40G uplinks; this is a lot of bandwidth to lose. When using dynamic routing protocols with a layer 3 design, Equal-cost multi-path (ECMP) routing can be used to fairly distribute data over all uplinks to maximize the available bandwidth. In the example of a leaf switch connected to two spine switches via a 40G uplink, there would be 80G of bandwidth available to any other leaf switch in the topology, no matter where it resides.
Some network designs take this even further and push the layer 3 boundary down to the servers by actually running these routing protocols on servers as well so that ECMP can be used to simplify the use of both NICs on the server in an active/active fashion. This is named Routing on the Host.
OSD node sizes
A common approach when designing nodes for use with Ceph is to pick a large capacity server, which contains large numbers of disks slots. In certain designs, this may be a good choice, but for most scenarios with Ceph, smaller nodes are more preferable. To decide on the number of disks each node in your Ceph cluster should contain, there are a number of things you should consider, some of the main considerations are listed as follows.
Failure domains
If your cluster will have less than 10 nodes, this is probably the most important point.
With legacy scale-up storage, the hardware is expected to be 100% reliable. All components are redundant, and the failure of a complete component such as a system board or disk JBOD would likely cause an outage. Therefore, there is no real knowledge of how such a failure might impact the operation of the system, just the hope that it doesn't happen! With Ceph, there is an underlying assumption that complete failure of a section of your infrastructure, be that a disk, node, or even rack should be considered as normal and should not make your cluster unavailable.
Let's take two Ceph clusters both comprising 240 disks. Cluster A comprises 20x12 disk nodes; Cluster B comprises 4x60 disk nodes. Now, let's take a scenario where for whatever reason a Ceph OSD node goes offline. It could be due to planned maintenance or unexpected failure, but that node is now down and any data on it is unavailable. Ceph is designed to mask this situation and will even recover from it whilst maintaining full data access.
In the case of cluster A, we have now lost 5% of our disks and in the event of a permanent loss would have to reconstruct 72 TB of data. Cluster B has lost 25% of its disks and would have to reconstruct 360 TB. The latter would severely impact the performance of the cluster, and in the case of data reconstruction, this period of degraded performance could last for many days.
It's clear that on smaller sized clusters, these very large dense nodes are not a good idea. A 10 Ceph node cluster is probably the minimum size if you want to reduce the impact of node failure, and so in the case of 60 drive JBODs, you would need a cluster that at minimum is measured in petabytes.
Price
One often cited reason for wanting to go with large dense nodes is to try and drive down the cost of the hardware purchase. This is often a false economy as dense nodes tend to require premium parts that often end up costing more per GB than less dense nodes.
For example, a 12 disk node may only require a single quad processor to provide enough CPU resource for OSDs. A 60 bay enclosure may require dual 10 core processors or greater, which are a lot more expensive per GHz provided. You may also need larger Dual In-line Memory Modules (DIMMs), which demand a premium and perhaps even increased numbers of 10G or even 40G NICs.
The bulk of the cost of the hardware will be made up of the CPUs, memory, networking, and disks. As we have seen, all of these hardware resource requirements scale linearly with the number and size of disks. The only area that larger nodes may have an advantage in is requiring fewer motherboards and power supplies, which is not a large part of the overall cost.
Power supplies
Servers can be configured with either single or dual redundant power supplies. Traditional workloads normally demand dual power supplies to protect against downtime in the case of a power supply or feed failure. If your Ceph cluster is large enough, then you may be able to look into the possibility of running single PSUs in your OSD nodes and allow Ceph to provide the availability in case of a power failure. Consideration should be given to the benefits of running a single power supply versus the worst case situation where an entire feed goes offline at DC.
How to plan a successful Ceph implementation
In order to be certain your Ceph implementation will be succesfull, there are a number of rules you should follow:
- Use 10G networking as a minimum
- Research and test the correctly sized hardware you wish to use
- Don't use the nobarrier mount option
- Don't configure pools with size=2 or minsize=1
- Don't use consumer SSDs
- Don't use RAID controllers in writeback without battery protection
- Don't use configuration options you don't understand
- Implement some form of change management
- Do carry out power loss testing
- Do have an agreed backup and recovery plan
Understanding your requirements and how it relates to Ceph
As we have discussed, Ceph is not always the right choice for every storage requirement. Hopefully, this chapter has given you the knowledge to be able to help you identify your requirements and match them to Ceph's capabilities. Hopefully though, Ceph is a good fit for your use case and you can proceed with the project.
Care should be taken to understand the requirements of the project including the following:
- Who are the key stakeholders of the project, they will likely be the same people that will be able to detail how Ceph will be used.
- Collect details of what systems Ceph will need to interact with. If it becomes apparent, for example, that unsupported operating systems are expected to be used with Ceph, this needs to be flagged at an early stage.
Defining goals so that you can gauge if the project is a success
Every project should have a series of goals that can help identify if the project has been a success. Example goals may be:
- Cost no more than X
- Provide X IOPS or MBps of performance
- Survive certain failure scenarios
- Reduce ownership costs of storage by X
These goals will need to be revisited throughout the life of the project to make sure that it is on track.
Choosing your hardware
The infrastructure section of this chapter will have given you a good idea on the hardware requirements of Ceph and the theory behind selecting the correct hardware for the project. The second biggest cause of outages with a Ceph cluster is caused by poor hardware choices, making the right choices early on in the design stage crucial.
If possible, check with your hardware vendor to see if they have any reference designs, these are often certified by Red Hat and will take a lot of the hard work off your shoulders in trying to determine if your hardware choices are valid. You can also ask Red Hat or your chosen Ceph support vendor to validate your hardware; they will have had previous experience and will be able to guide you around any questions you may have.
Finally, if you are planning on deploying and running your Ceph cluster entirely in-house without any third-party involvement or support, consider reaching out to the Ceph community. The Ceph-users mailing list is participated in by individuals from vastly different backgrounds stretching right round the globe. There is a high chance that someone somewhere will be doing something similar to you and will be able to advise you on hardware choice.
Training yourself and your team to use Ceph
As with all technologies, it's essential that Ceph administrators receive some sort of training. Once the Ceph cluster goes live and becomes a business dependency, unexperienced administrators are a risk to stability. Depending on your reliance on third-party support, various levels of training may be required and may also determine if you look for a training course or self teach.
Running PoC to determine if Ceph has met the requirements
A proof of concept (PoC) cluster should be deployed to test the design and identify any issues early on before proceeding with full-scale hardware procurement. This should be treated as a decision point in the project; don't be afraid to revisit goals or start design from fresh if any serious issues are uncovered. If you have existing hardware of similar specifications, then it should be fine to use it in the proof of concept, but the aim should be to try and test hardware that is as similar as possible to what you intend to build the production cluster with, so as to be able to fully test the design.
As well as testing for stability, the PoC cluster should also be used to forecast if it looks likely that the goals you have set for the project will be met.
The proof of concept stage is also a good time to firm up your knowledge on Ceph, practice day-to-day operations and test out features. This will be of benefit further down the line. You should also take this opportunity to be as abusive as possible to your PoC cluster. Randomly pull out disks, power off nodes, and disconnect network cables. If designed correctly, Ceph should be able to withstand all of these events. Carrying out this testing now will give you the confidence to operate Ceph at larger scale where these events will happen and also help you understand how to troubleshoot them more easily if needed.
Following best practices to deploy your cluster
When deploying your cluster, attention should be paid to understanding the process rather than following guided examples. This will give you better knowledge of the various components that make up Ceph and should you encounter any errors during deployment or operation, you will be much better placed to solve them. The next chapter of this book goes into more detail on deployment of Ceph, including the use of orchestration tools.
Initially, it is recommended that the default options for both the operating system and Ceph are used. It is better to start from a known state should any issues arise during deployment and initial testing.
RADOS pools replication level should be left at the default of 3 and the minimum replication level of 2. This corresponds to the pool variables of size and min_size, respectively. Unless there is both a good understanding and reason for the impact of lowering these values, it would be unwise to change them. The replication size determines how many copies of data will be stored in the cluster, and the effects of lowering it should be obvious in terms of protection against data loss. Less understood is the effect of min_size in relation to data loss and is a common reason for it.
The min_size variable controls how many copies the cluster must write to acknowledge the write back to a client. A min_size of 2 means that the cluster must be able to write two copies of data; this can mean in a severely degraded scenario that write operations are blocked if the PG has only one remaining copy and will continue to do so until the PG is recovered to have two copies of the object. This is the reason that there may be a desire to decrease min_size to 1 so that in this event, cluster operations can still continue and if availability is more important than consistency, then this can be a valid decision. However, with a min_size of 1, data may be written to only one OSD and there is no guarantee that the number of desired copies will be met anytime soon. During that period, any component failure will likely result in loss of data written in the degraded state. If summary downtime is bad, data loss is typically worse and these two settings will probably have one of the biggest impacts on the probability of data loss.
Defininga change management process
The biggest cause of data loss and outages with a Ceph cluster is normally human error, whether it be by accidently running the wrong command or changing configuration options, which may have unintended consequences. These incidents will likely become more common as the number of people in the team administering Ceph grows. A good way of reducing the risk of human error causing service interruptions or data loss is to implement some form of change control. This is covered in the next chapter in more detail.
Creating a backup and recovery plan
Ceph is highly redundant and when properly designed should have no single point of failure and be resilient to many types of hardware failures. However, one in a million situations do occur and as we have also discussed, human error can be very unpredictable. In both cases, there is a chance that the Ceph cluster may enter a state where it is unavailable or data loss occurs. In many cases, it may be possible to recover some or all of the data and return the cluster to full operation. However, in all cases, a full backup and recovery plan should be discussed before putting any live data onto a Ceph cluster. Many businesses have gone out of business or lost faith from customers when it's revealed that not only has there been an extended period of downtime, but critical data has also been lost. It may be that as a result of discussion it is agreed that a backup and recovery plan is not required; this is fine. As long as risks and possible outcomes have been discussed and agreed, that is the important part.
Summary
In this chapter, you learned all the necessary steps to allow you to successfully plan and implement a Ceph project. You learned about the available hardware choices, how they relate to Ceph's requirements, and how they affect both Ceph's performance and reliability.
Finally, you will have awareness of the importance of the processes and procedures that should be in place to ensure a healthy operating environment for your Ceph cluster.


