


















 Download code from GitHub
Download code from GitHub
This chapter provides a detailed exploration of the architecture and design of how Ansible goes about performing tasks on your behalf. We will cover the basic concepts of inventory parsing and how the data is discovered, and then dive into playbook parsing. We will take a walk through module preparation, transportation, and execution. Lastly, we will detail variable types and find out where variables can be located, the scope they can be used in, and how precedence is determined when variables are defined in more than one location. All these things will be covered in order to lay the foundation for mastering Ansible!
In this chapter, we will cover the following topics:
Ansible version and configuration
Inventory parsing and data sources
Playbook parsing
Execution strategies
Module transport and execution
Variable types and locations
Variable precedence
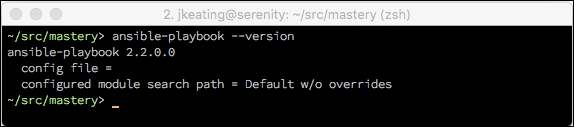
It is assumed that you have Ansible installed on your system. There are many documents out there that cover installing Ansible in a way that is appropriate for the operating system and version that you might be using. This book will assume the use of the Ansible 2.2.x.x version. To discover the version in use on a system with Ansible already installed, make use of the version argument, that is, either ansible or ansible-playbook:
Note
Note that ansible is the executable for doing adhoc one-task executions and ansible-playbook is the executable that will process playbooks for orchestrating many tasks.
The configuration for Ansible can exist in a few different locations, where the first file found will be used. The search order changed slightly in version 1.5, with the new order being:
ANSIBLE_CFG: This is an environment variable~/ansible.cfg: This is in the current directoryansible.cfg: This is in the user's home directory./etc/ansible/ansible.cfg
Some installation methods may include placing a config file in one of these locations. Look around to check whether such a file exists and see what settings are in the file to get an idea of how Ansible operation may be affected. This book will assume no settings in the ansible.cfg file that would affect the default operation of Ansible.
In Ansible, nothing happens without an inventory. Even ad hoc actions performed on localhost require an inventory, even if that inventory consists just of the localhost. The inventory is the most basic building block of Ansible architecture. When executing ansible or ansible-playbook, an inventory must be referenced. Inventories are either files or directories that exist on the same system that runs ansible or ansible-playbook. The location of the inventory can be referenced at runtime with the --inventory-file (-i) argument, or by defining the path in an Ansible config file.
Inventories can be static or dynamic, or even a combination of both, and Ansible is not limited to a single inventory. The standard practice is to split inventories across logical boundaries, such as staging and production, allowing an engineer to run a set of plays against their staging environment for validation, and then follow with the same exact plays run against the production inventory set.
Variable data, such as specific details on how to connect to a particular host in your inventory, can be included along with an inventory in a variety of ways as well, and we'll explore the options available to you.
The static inventory is the most basic of all the inventory options. Typically, a static inventory will consist of a single file in the ini format. Here is an example of a static inventory file describing a single host, mastery.example.name:
mastery.example.name
That is all there is to it. Simply list the names of the systems in your inventory. Of course, this does not take full advantage of all that an inventory has to offer. If every name were listed like this, all plays would have to reference specific hostname, or the special all group. This can be quite tedious when developing a playbook that operates across different sets of your infrastructure. At the very least, hosts should be arranged into groups. A design pattern that works well is to arrange your systems into groups based on expected functionality. At first, this may seem difficult if you have an environment where single systems can play many different roles, but that is perfectly fine. Systems in an inventory can exist in more than one group, and groups can even consist of other groups! Additionally, when listing groups and hosts, it's possible to list hosts without a group. These would have to be listed first, before any other group is defined. Let's build on our previous example and expand our inventory with a few more hosts and some groupings:
[web] mastery.example.name [dns] backend.example.name [database] backend.example.name [frontend:children] web [backend:children] dns database
What we have created here is a set of three groups with one system in each, and then two more groups, which logically group all three together. Yes, that's right; you can have groups of groups. The syntax used here is [groupname:children], which indicates to Ansible's inventory parser that this group by the name of groupname is nothing more than a grouping of other groups. The children in this case are the names of the other groups. This inventory now allows writing plays against specific hosts, low-level role-specific groups, or high-level logical groupings, or any combination.
By utilizing generic group names, such as dns and database, Ansible plays can reference these generic groups rather than the explicit hosts within. An engineer can create one inventory file that fills in these groups with hosts from a preproduction staging environment and another inventory file with the production versions of these groupings. The playbook content does not need to change when executing on either staging or production environment because it refers to the generic group names that exist in both inventories. Simply refer to the right inventory to execute it in the desired environment.
Inventories provide more than just system names and groupings. Data about the systems can be passed along as well. This can include:
Host-specific data to use in templates
Group-specific data to use in task arguments or conditionals
Behavioral parameters to tune how Ansible interacts with a system
Variables are a powerful construct within Ansible and can be used in a variety of ways, not just the ways described here. Nearly every single thing done in Ansible can include a variable reference. While Ansible can discover data about a system during the setup phase, not all data can be discovered. Defining data with the inventory is how to expand the dataset. Note that variable data can come from many different sources, and one source may override another source. Variable precedence order is covered later in this chapter.
Let's improve upon our existing example inventory and add to it some variable data. We will add some host-specific data as well as group-specific data:
[web] mastery.example.name ansible_host=192.168.10.25 [dns] backend.example.name [database] backend.example.name [frontend:children] web [backend:children] dns database [web:vars] http_port=88 proxy_timeout=5 [backend:vars] ansible_port=314 [all:vars] ansible_ssh_user=otto
In this example, we defined ansible_host for mastery.example.name to be the IP address of 192.168.10.25. The ansible_host variable is a behavioral inventory variable, which is intended to alter the way Ansible behaves when operating with this host. In this case, the variable instructs Ansible to connect to the system using the provided IP address rather than performing a DNS lookup on the name mastery.example.name. There are a number of other behavioral inventory variables, which are listed at the end of this section along with their intended use.
Note
As of version 2.0, the longer form of some behavioral inventory parameters has been deprecated. The ssh part of ansible_ssh_host, ansible_ssh_user, and ansible_ssh_port is no longer required. A future release may ignore the longer form of these variables.
Our new inventory data also provides group-level variables for the web and backend groups. The web group defines http_port, which may be used in an nginx configuration file, and proxy_timeout, which might be used to determine HAProxy behavior. The backend group makes use of another behavioral inventory parameter to instruct Ansible to connect to the hosts in this group using port 314 for SSH, rather than the default of 22.
Finally, a construct is introduced that provides variable data across all the hosts in the inventory by utilizing a built-in all group. Variables defined within this group will apply to every host in the inventory. In this particular example, we instruct Ansible to log in as the otto user when connecting to the systems. This is also a behavioral change, as the Ansible default behavior is to log in as a user with the same name as the user executing ansible or ansible-playbook on the control host.
Here is a table of behavior inventory variables and the behavior they intend to modify:
|
Inventory parameters |
Behaviour |
|
|
This is the DNS name or IP address used to connect to the host, if different from the inventory name, or the name of the Docker container to connect to. |
|
|
This is the SSH port number, if not |
|
|
This is the default SSH username or user inside a Docker container to use. |
|
|
This is the SSH password to use (this is insecure; we strongly recommend using |
|
|
This is the private key file used by SSH. This is useful if you use multiple keys and you don't want to use SSH agent. |
|
|
This defines SSH arguments to append to the default arguments for |
|
|
This setting is always appended to the default |
|
|
This setting is always appended to the default |
|
|
This setting is always appended to the default |
|
|
This setting uses a Boolean to define whether or not SSH pipelining should be used for this host. |
|
|
This setting overrides the path to the SSH executable for this host. |
|
|
This defines whether privilege escalation ( |
|
|
The method to use for privilege escalation. One of |
|
|
This is the user to become through privilege escalation. |
|
|
This is the password to use for privilege escalation. |
|
|
This is the sudo password to use (this is insecure; we strongly recommend using |
|
|
This is the connection type of the host. Candidates are |
|
|
This is a string of any extra arguments that can be passed to Docker. This is mainly used to define a remote Docker daemon to use. |
|
|
This is the shell type of the target system. By default, commands are formatted using the |
|
|
This sets the shell tool that will be used on the target system. This should only be used if the default of |
|
|
This is the target host Python path. This is useful for systems with more than one Python, systems that are not located at |
|
|
This works for anything such as Ruby or Perl and works just like |
A static inventory is great and enough for many situations. But there are times when a statically written set of hosts is just too unwieldy to manage. Consider situations where inventory data already exists in a different system, such as LDAP, a cloud computing provider, or an in-house CMDB (inventory, asset tracking, and data warehousing) system. It would be a waste of time and energy to duplicate that data, and in the modern world of on-demand infrastructure, that data would quickly grow stale or disastrously incorrect.
Another example of when a dynamic inventory source might be desired is when your site grows beyond a single set of playbooks. Multiple playbook repositories can fall into the trap of holding multiple copies of the same inventory data, or complicated processes have to be created to reference a single copy of the data. An external inventory can easily be leveraged to access the common inventory data stored outside of the playbook repository to simplify the setup. Thankfully, Ansible is not limited to static inventory files.
A dynamic inventory source (or plugin) is an executable script that Ansible will call at runtime to discover real-time inventory data. This script may reach out into external data sources and return data, or it can just parse local data that already exists but may not be in the Ansible inventory ini format. While it is possible and easy to develop your own dynamic inventory source, which we will cover this in a later chapter, Ansible provides a number of example inventory plugins, including but not limited to:
OpenStack Nova
Rackspace Public Cloud
DigitalOcean
Linode
Amazon EC2
Google Compute Engine
Microsoft Azure
Docker
Vagrant
Many of these plugins require some level of configuration, such as user credentials for EC2 or authentication endpoint for OpenStack Nova. Since it is not possible to configure additional arguments for Ansible to pass along to the inventory script, the configuration for the script must either be managed via an ini
config file read from a known location or environment variables read from the shell environment used to execute ansible or ansible-playbook.
When ansible or ansible-playbook is directed at an executable file for an inventory source, Ansible will execute that script with a single argument, --list. This is so that Ansible can get a listing of the entire inventory in order to build up its internal objects to represent the data. Once that data is built up, Ansible will then execute the script with a different argument for every host in the data to discover variable data. The argument used in this execution is --host <hostname>, which will return any variable data specific to that host.
In Chapter 8, Extending Ansible, we will develop our own custom inventory plugin to demonstrate how they operate.
Just like static inventory files, it is important to remember that Ansible will parse this data once, and only once, per ansible or ansible-playbook execution. This is a fairly common stumbling point for users of cloud dynamic sources, where frequently a playbook will create a new cloud resource and then attempt to use it as if it were part of the inventory. This will fail, as the resource was not part of the inventory when the playbook launched. All is not lost though! A special module is provided that allows a playbook to temporarily add inventory to the in-memory inventory object, the add_host module.
The add_host module takes two options, name and groups. The name should be obvious, it defines the hostname that Ansible will use when connecting to this particular system. The groups option is a comma-separated list of groups to add this new system to. Any other option passed to this module will become the host variable data for this host. For example, if we want to add a new system, name it newmastery.example.name, add it to the web group, and instruct Ansible to connect to it by way of IP address 192.168.10.30, we will create a task same as this:
- name: add new node into runtime inventory
add_host:
name: newmastery.example.name
groups: web
ansible_host: 192.168.10.30
This new host will be available to use, by way of the name provided, or by way of the web group, for the rest of the ansible-playbook execution. However, once the execution has completed, this host will not be available unless it has been added to the inventory source itself. Of course, if this were a new cloud resource created, the next ansible or ansible-playbook execution that sourced inventory from that cloud would pick up the new member.
As mentioned earlier, every execution of ansible or ansible-playbook will parse the entire inventory it has been directed at. This is even true when a limit has been applied. A limit is applied at runtime by making use of the --limit runtime argument to ansible or ansible-playbook. This argument accepts a pattern, which is basically a mask to apply to the inventory. The entire inventory is parsed, and at each play the supplied limit mask further limits the host pattern listed for the play.
Let's take our previous inventory example and demonstrate the behavior of Ansible with and without a limit. If you recall, we have the special group all that we can use to reference all the hosts within an inventory. Let's assume that our inventory is written out in the current working directory in a file named mastery-hosts, and we will construct a playbook to demonstrate the host on which Ansible is operating. Let's write this playbook out as mastery.yaml:
---
- name: limit example play
hosts: all
gather_facts: false
tasks:
- name: tell us which host we are on
debug:
var: inventory_hostname
The debug module is used to print out text, or values of variables. We'll use this module a lot in this book to simulate actual work being done on a host.
Now, let's execute this simple playbook without supplying a limit. For simplicity's sake, we will instruct Ansible to utilize a local connection method, which will execute locally rather than attempting to SSH to these nonexistent hosts. Let's take a look at the following screenshot:

As we can see, both hosts, backend.example.name and mastery.example.name, were operated on. Let's see what happens if we supply a limit, specifically to limit our run to only frontend systems:
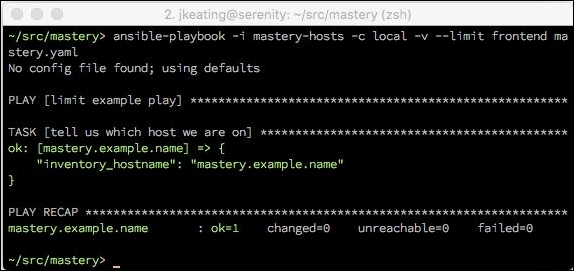
We can see that only mastery.example.name was operated in this time. While there are no visual clues that the entire inventory was parsed, if we dive into the Ansible code and examine the inventory object, we will indeed find all the hosts within, and see how the limit is applied every time the object is queried for items.
It is important to remember that regardless of the host's pattern used in a play, or the limit supplied at runtime, Ansible will still parse the entire inventory set during each run. In fact, we can prove this by attempting to the access host variable data for a system that would otherwise be masked by our limit. Let's expand our playbook slightly and attempt to access the ansible_port variable from backend.example.name:
---
- name: limit example play
hosts: all
gather_facts: false
tasks:
- name: tell us which host we are on
debug:
var: inventory_hostname
- name: grab variable data from backend
debug:
var: hostvars['backend.example.name']['ansible_port']
We will still apply our limit, which will restrict our operations to just mastery.example.name:

We have successfully accessed the host variable data (by way of group variables) for a system that was otherwise limited out. This is a key skill to understand, as it allows for more advanced scenarios, such as directing a task at a host that is otherwise limited out. Delegation can be used to manipulate a load balancer to put a system into maintenance mode while being upgraded without having to include the load balancer system in your limit mask.
The whole purpose of an inventory source is to have systems to manipulate. The manipulation comes from playbooks (or in the case of ansible ad hoc execution, simple single-task plays). You should already have a base understanding of playbook construction so we won't spend a lot of time covering that; however, we will delve into some specifics of how a playbook is parsed. Specifically, we will cover the following:
Order of operations
Relative path assumptions
Play behavior keys
Host selection for plays and tasks
Play and task names
Ansible is designed to be as easy as possible for a human to understand. The developers strive to strike the best balance of human comprehension and machine efficiency. To that end, nearly everything in Ansible can be assumed to be executed in a top to bottom order; that is, the operation listed at the top of a file will be accomplished before the operation listed at the bottom of a file. Having said that, there are a few caveats and even a few ways to influence the order of operations.
A playbook has only two main operations it can accomplish. It can either run a play, or it can include another playbook from somewhere on the filesystem. The order in which these are accomplished is simply the order in which they appear in the playbook file, from top to bottom. It is important to note that while the operations are executed in order, the entire playbook and any included playbooks are completely parsed before any executions. This means that any included playbook file has to exist at the time of the playbook parsing. They cannot be generated in an earlier operation. This is specific to playbook includes, not necessarily to task includes that may appear within a play, which will be covered in a later chapter.
Within a play, there are a few more operations. While a playbook is strictly ordered from top to bottom, a play has a more nuanced order of operations. Here is a list of the possible operations and the order in which they will happen:
Variable loading
Fact gathering
The
pre_tasksexecutionHandlers notified from the
pre_tasksexecutionRoles execution
Tasks execution
Handlers notified from roles or tasks execution
The
post_tasksexecutionHandlers notified from
post_tasksexecution
Here is an example play with most of these operations shown:
---
- hosts: localhost
gather_facts: false
vars:
- a_var: derp
pre_tasks:
- name: pretask
debug:
msg: "a pre task"
changed_when: true
notify: say hi
roles:
- role: simple
derp: newval
tasks:
- name: task
debug:
msg: "a task"
changed_when: true
notify: say hi
post_tasks:
- name: posttask
debug:
msg: "a post task"
changed_when: true
notify: say hi
Regardless of the order in which these blocks are listed in a play, the order detailed above is the order in which they will be processed. Handlers (the tasks that can be triggered by other tasks that result in a change) are a special case. There is a utility module, meta, which can be used to trigger handler processing at a specific point:
- meta: flush_handlers
This will instruct Ansible to process any pending handlers at that point before continuing on with the next task or next block of actions within a play. Understanding the order and being able to influence the order with flush_handlers is another key skill to have when there is a need for orchestrate complicated actions, where things such as service restarts are very sensitive to order. Consider the initial rollout of a service. The play will have tasks that modify config files and indicate that the service should be restarted when these files change. The play will also indicate that the service should be running. The first time this play happens, the config file will change and the service will change from not running to running. Then, the handlers will trigger, which will cause the service to restart immediately. This can be disruptive to any consumers of the service. It would be better to flush the handlers before a final task to ensure the service is running. This way, the restart will happen before the initial start, and thus, the service will start up once and stay up.
When Ansible parses a playbook, there are certain assumptions that can be made about the relative paths of items referenced by the statements in a playbook. In most cases, paths for things such as variable files to include, task files to include, playbook files to include, files to copy, templates to render, scripts to execute, and so on, are all relative to the directory where the file referencing them lives. Let's explore this with an example playbook and directory listing to show where the things are:
Directory structure:
. ├── a_vars_file.yaml ├── mastery-hosts ├── relative.yaml └── tasks ├── a.yaml └── b.yamlContents of
_vars_file.yaml:--- something: "better than nothing"
Contents of
relative.yaml:--- - name: relative path play hosts: localhost gather_facts: false vars_files: - a_vars_file.yaml tasks: - name: who am I debug: msg: "I am mastery task" - name: var from file debug: var: something - include: tasks/a.yamlContents of
tasks/a.yaml:--- - name: where am I debug: msg: "I am task a" - include: b.yamlContents of
tasks/b.yaml:--- - name: who am I debug: msg: "I am task b"
Execution of the playbook is shown as follows:

We can clearly see the relative reference to paths and how they are relative to the file referencing them. When using roles, there are some additional relative path assumptions; however, we'll cover that in detail in a later chapter.
When Ansible parses a play, there are a few directives it looks for to define various behaviors for a play. These directives are written at the same level as the hosts: directive. Here are subset of the keys that can be used is described:
any_errors_fatal: This Boolean directive is used to instruct Ansible to treat any failure as a fatal error to prevent any further tasks from being attempted. This changes the default where Ansible will continue until all the tasks are complete or all the hosts have failed.connection: This string directive defines which connection system to use for a given play. A common choice to make here is local, which instructs Ansible to do all the operations locally, but with the context of the system from the inventory.gather_facts: This Boolean directive controls whether or not Ansible will perform the fact gathering phase of operation, where a special task will run on a host to discover various facts about the system. Skipping fact gathering, when you are sure that you do not need any of the discovered data, can be a significant time-saver in a larger environment.max_fail_percentage: This number directive is similar toany_errors_fatal, but is more fine-grained. This allows you to define just what percentage of your hosts can fail before the whole operation is halted.no_log: This is a Boolean directive to control whether or not Ansible will log (to the screen and/or a configuredlogfile) the command given or the results received from a task. This is important if your task or return deals with secrets. This key can also be applied to a task directly.port: This is a number directive to define what port SSH (or other remote connection plugin) should use to connect unless otherwise configured in inventory data.remote_user: This is a string directive that defines which user to log in with on the remote system. The default is to connect as the same user thatansible-playbookwas started with.serial: This directive takes a number and controls how many systems Ansible will execute a task on before moving to the next task in a play. This is a drastic change from the normal order of operation where a task is executed across every system in a play before moving to the next. This is very useful in rolling update scenarios, which will be detailed in later chapters.become: This is a Boolean directive used to configure whether privilege escalation (sudo or otherwise) should be used on the remote host to execute tasks. This key can also be defined at a task level. Related directives includebecome_user,become_method, andbecome_flags. These can be used to configure how the escalation will occur.strategy: This directive sets the execution strategy to be used for the play.
Many of these keys will be used in example playbooks through this book.
Note
For a full list of available play directives, see the online documentation at: https://docs.ansible.com/ansible/playbooks_directives.html#play.
With the release of Ansible 2.0, a new way to control play execution behavior was introduced, strategy. A strategy defines how Ansible coordinates each task across the set of hosts. Each strategy is a plugin, and two come with Ansible, linear and free. The linear strategy, which is the default strategy, is how Ansible has always behaved. As a play is executed, all the hosts for a given play execute the first task. Once all are complete, Ansible moves to the next task. The serial directive can create batches of hosts to operate in this way, but the base strategy remains the same. All the targets for a given batch must complete a task before the next task is executed. The free strategy breaks from this traditional behavior. When using the free strategy, as soon as a host completes a task, Ansible will execute the next task for that host, without waiting for any other hosts to complete. This will happen for every host in the set, for every task in the play. The hosts will complete the tasks as fast as each are able to, minimizing the execution time of each specific host. While most playbooks will use the default linear strategy, there are situations where the free strategy would be advantageous. For example, upgrading a service across a large set of hosts. If the play has numerous tasks to perform the upgrade, which starts with shutting down the service, then it would be more important for each host to suffer as little downtime as possible. Allowing each host to independently move through the play as fast as it is able too will ensure that each host is down only for as long as necessary. Without using free, the entire fleet will be down for as long as the slowest host in the fleet takes to complete the tasks.
Note
As the free strategy does not coordinate task completion across hosts, it is not possible to depend on the data that is generated during a task on one host to be available for use in a later task on a different host. There is no guarantee that the first host will have completed the task that generates the data.
Execution strategies are implemented as a plugin, and as such, custom strategies can be developed to extend Ansible behavior. Development of such plugins is beyond the scope of this book.
The first thing most plays define (after a name, of course) is a host pattern for the play. This is the pattern used to select hosts out of the inventory object to run the tasks on. Generally, this is straightforward; a host pattern contains one or more blocks indicating a host, group, wildcard pattern, or regex to use for the selection. Blocks are separated by a colon, wildcards are just an asterisk, and regex patterns start with a tilde:
hostname:groupname:*.example:~(web|db)\.example\.com
Advanced usage can include group index selection or even ranges within a group:
Webservers[0]:webservers[2:4]
Each block is treated as an inclusion block, that is, all the hosts found in the first pattern are added to all the hosts found in the next pattern, and so on. However, this can be manipulated with control characters to change their behavior. The use of an ampersand allows an inclusion selection (all the hosts that exist in both patterns). The use of an exclamation point allows exclusion selection (all the hosts that exist in the previous patterns that are NOT in the exclusion pattern):
Webservers:&dbservers Webservers:!dbservers
Once Ansible parses the patterns, it will then apply restrictions, if any. Restrictions come in the form of limits or failed hosts. This result is stored for the duration of the play, and it is accessible via the play_hosts variable. As each task is executed, this data is consulted and an additional restriction may be placed upon it to handle serial operations. As failures are encountered, either failure to connect or a failure in execute tasks, the failed host is placed in a restriction list so that the host will be bypassed in the next task. If, at any time, a host selection routine gets restricted down to zero hosts, the play execution will stop with an error. A caveat here is that if the play is configured to have a max_fail_precentage or any_errors_fatal parameter, then the playbook execution stops immediately after the task where this condition is met.
While not strictly necessary, it is a good practice to label your plays and tasks with names. These names will show up in the command-line output of ansible-playbook, and will show up in the log file if ansible-playbook is directed to log to a file. Task names also come in handy to direct ansible-playbook to start at a specific task and to reference handlers.
There are two main points to consider when naming plays and tasks:
Names of plays and tasks should be unique
Beware of what kind of variables can be used in play and task names
Naming plays and tasks uniquely is a best practice in general that will help to quickly identify where a problematic task may reside in your hierarchy of playbooks, roles, task files, handlers, and so on. Uniqueness is more important when notifying a handler or when starting at a specific task. When task names have duplicates, the behavior of Ansible may be nondeterministic or at least nonobvious.
With uniqueness as a goal, many playbook authors will look to variables to satisfy this constraint. This strategy may work well but authors need to take care as to the source of the variable data they are referencing. Variable data can come from a variety of locations (which we will cover later in this chapter), and the values assigned to variables can be defined at a variety of times. For the sake of play and task names, it is important to remember that only variables for which the values can be determined at playbook parse time will parse and render correctly. If the data of a referenced variable is discovered via a task or other operation, the variable string will be displayed unparsed in the output. Let's look at an example playbook that utilizes variables for play and task names:
---
- name: play with a {{ var_name }}
hosts: localhost
gather_facts: false
vars:
- var_name: not-mastery
tasks:
- name: set a variable
set_fact:
task_var_name: "defined variable"
- name: task with a {{ task_var_name }}
debug:
msg: "I am mastery task"
- name: second play with a {{ task_var_name }}
hosts: localhost
gather_facts: false
tasks:
- name: task with a {{ runtime_var_name }}
debug:
msg: "I am another mastery task"
At first glance, one might expect at least var_name and task_var_name to render correctly. We can clearly see task_var_name being defined before its use. However, armed with our knowledge that playbooks are parsed in their entirety before execution, we know better:

As we can see, the only variable name that is properly rendered is var_name, as it was defined as a static play variable.
Once a playbook is parsed and the hosts are determined, Ansible is ready to execute a task. Tasks are made up of a name (optional, but please don't skip it), a module reference, module arguments, and task control directives. A later chapter will cover task control directives in detail, so we will only concern ourselves with the module reference and arguments.
Every task has a module reference. This tells Ansible which bit of work to do. Ansible is designed to easily allow for custom modules to live alongside a playbook. These custom modules can be a wholly new functionality, or it can replace modules shipped with Ansible itself. When Ansible parses a task and discovers the name of the module to use for a task, it looks into a series of locations in order to find the module requested. Where it looks also depends on where the task lives, whether in a role or not.
If a task is in a role, Ansible will first look for the module within a directory tree named library within the role the task resides in. If the module is not found there, Ansible looks for a directory named library at the same level as the main playbook (the one referenced by the ansible-playbook execution). If the module is not found there, Ansible will finally look in the configured library path, which defaults to /usr/share/ansible/. This library path can be configured in an Ansible config file, or by way of the ANSIBLE_LIBRARY environment variable.
This design, allowing modules to be bundled with roles and playbooks, allows for adding functionality, or quickly repairing problems very easily.
Arguments to a module are not always required; the help output of a module will indicate which models are required and which are not. Module documentation can be accessed with the ansible-doc command:

Arguments can be templated with Jinja2, which will be parsed at module execution time, allowing for data discovered in a previous task to be used in later tasks; this is a very powerful design element.
Arguments can be supplied in a key
=
value format, or in a complex format that is more native to YAML. Here are two examples of arguments being passed to a module showcasing the two formats:
- name: add a keypair to nova
os_keypair: cloud={{ cloud_name }} name=admin-key wait=yes
- name: add a keypair to nova
os_keypair:
cloud: "{{ cloud_name }}"
name: admin-key
wait: yes
Both formats will lead to the same result in this example; however, the complex format is required if you wish to pass complex arguments into a module. Some modules expect a list object or a hash of data to be passed in; the complex format allows for this. While both formats are acceptable for many tasks, the complex format is the format used for the majority of examples in this book.
Once a module is found, Ansible has to execute it in some way. How the module is transported and executed depends on a few factors; however, the common process is to locate the module file on the local filesystem and read it into memory, and then add in the arguments passed to the module. Then the boilerplate module code from core Ansible is added to the file object in memory. This collection is zip compressed and base64 encoded, and then wrapped in a script. What happens next really depends on the connection method and runtime options (such as leaving the module code on the remote system for review).
The default connection method is smart, which most often resolves to the ssh connection method. With a default configuration, Ansible will open an SSH connection to the remote host, create a temporary directory, and close the connection. Ansible will then open another SSH connection in order to write out the wrapped ZIP file from memory (the result of local module file, task module arguments, and Ansible boilerplate code) into a file within the temporary directory that we just created and close the connection.
Finally, Ansible will open a third connection in order to execute the script and delete the temporary directory and all its contents. The module results are captured from stdout in the JSON format, which Ansible will parse and handle appropriately. If a task has an async control, Ansible will close the third connection before the module is complete, and SSH back in to the host to check the status of the task after a prescribed period until the module is complete or a prescribed timeout has been reached.
The above description of how Ansible connects to hosts results in three connections to the host for every task. In a small fleet with a small number of tasks, this may not be a concern; however, as the task set grows and the fleet size grows, the time required to create and tear down SSH connections increases. Thankfully, there are a couple ways to mitigate this.
The first is an SSH feature, ControlPersist, which provides a mechanism to create persistent sockets when first connecting to a remote host that can be reused in subsequent connections to bypass some of the handshaking required when creating a connection. This can drastically reduce the amount of time Ansible spends on opening new connections. Ansible automatically utilizes this feature if the host platform where Ansible is run from supports it. To check whether your platform supports this feature, check the SSH main page for ControlPersist.
The second performance enhancement that can be utilized is an Ansible feature called pipelining. Pipelining is available to SSH-based connection methods and is configured in the Ansible configuration file within the ssh_connection section:
[ssh_connection] pipelining=true
This setting changes how modules are transported. Instead of opening an SSH connection to create a directory, another to write out the composed module, and a third to execute and clean up, Ansible will instead open an SSH connection on the remote host. Then, over that live connection, Ansible will pipe in the zipped composed module code and script for execution. This reduces the connections from three to one, which can really add up. By default, pipelining is disabled.
Utilizing the combination of these two performance tweaks can keep your playbooks nice and fast even as you scale your fleet. However, keep in mind that Ansible will only address as many hosts at once as the number of forks Ansible is configured to run. Forks are the number of processes Ansible will split off as a worker to communicate with remote hosts. The default is five forks, which will address up to five hosts at once. Raise this number to address more hosts as your fleet grows by adjusting the forks= parameter in an Ansible configuration file, or by using the --forks (-f) argument with ansible or ansible-playbook.
Variables are a key component to the Ansible design. Variables allow for dynamic play content and reusable plays across different sets of an inventory. Anything beyond the very basic of Ansible use will utilize variables. Understanding the different variable types and where they can be located, as well as learning how to access external data or prompt users to populate variable data, is the key to mastering Ansible.
Before diving into the precedence of variables, we must first understand the various types and subtypes of variables available to Ansible, their location, and where they are valid for use.
The first major variable type is inventory variables. These are the variables that Ansible gets by way of the inventory. These can be defined as variables that are specific to host_vars to individual hosts or applicable to entire groups as group_vars. These variables can be written directly into the inventory file, delivered by the dynamic inventory plugin, or loaded from the host_vars/<host> or group_vars/<group> directories.
These types of variables might be used to define Ansible behavior when dealing with these hosts or site-specific data related to the applications that these hosts run. Whether a variable comes from host_vars or group_vars, it will be assigned to a host's hostvars, and it can be accessible from the playbooks and template files. Accessing a host's own variables can be done just by referencing the name, such as {{ foobar }}, and accessing another host's variables can be accomplished by accessing hostvars. For example, to access the foobar variable for examplehost: {{ hostvars['examplehost']['foobar'] }}. These variables have global scope.
The second major variable type is role variables. These are variables specific to a role and are utilized by the role tasks and have scope only within the role that they are defined in, which is to say that they can only be used within the role. These variables are often supplied as a role default, which are meant to provide a default value for the variable but can easily be overridden when applying the role. When roles are referenced, it is possible to supply variable data at the same time, either by overriding role defaults or creating wholly new data. We'll cover roles in depth in a later chapter. These variables apply to all hosts within the role and can be accessed directly much like a host's own hostvars.
The third major variable type is play variables. These variables are defined in the control keys of a play, either directly by the vars key or sourced from external files via the vars_files key. Additionally, the play can interactively prompt the user for variable data using vars_prompt. These variables are to be used within the scope of the play and in any tasks or included tasks of the play. The variables apply to all hosts within the play and can be referenced as if they are hostvars.
The fourth variable type is task variables. Task variables are made from data discovered while executing tasks or in the facts gathering phase of a play. These variables are host-specific and are added to the host's hostvars and can be used as such, which also means they have global scope after the point in which they were discovered or defined. Variables of this type can be discovered via gather_facts and fact modules (modules that do not alter state but rather return data), populated from task return data via the register task key, or defined directly by a task making use of the set_fact or add_host modules. Data can also be interactively obtained from the operator using the prompt argument to the pause module and registering the result:
- name: get the operators name
pause:
prompt: "Please enter your name"
register: opname
There is one last variable type, the extra variables, or extra-vars type. These are variables supplied on the command-line when executing ansible-playbook via --extra-vars. Variable data can be supplied as a list of key=value pairs, a quoted JSON data, or a reference to a YAML-formatted file with variable data defined within:
--extra-vars "foo=bar owner=fred"
--extra-vars '{"services":["nova-api","nova-conductor"]}'
--extra-vars @/path/to/data.yaml
Extra variables are considered global variables. They apply to every host and have scope throughout the entire playbook.
Data for role variables, play variables, and task variables can also come from external sources. Ansible provides a mechanism to access and evaluate data from the control machine (the machine running ansible-playbook). The mechanism is called a lookup plugin, and a number of them come with Ansible. These plugins can be used to lookup or access data by reading files, generate and locally store passwords on the Ansible host for later reuse, evaluate environment variables, pipe data in from executables, access data in the Redis or etcd systems, render data from template files, query dnstxt records, and more. The syntax is as follows:
lookup('<plugin_name>', 'plugin_argument')
For example, to use the mastery value from etcd in a debug task:
- name: show data from etcd
debug:
msg: "{{ lookup('etcd', 'mastery') }}"
Lookups are evaluated when the task referencing them is executed, which allows for dynamic data discovery. To reuse a particular lookup in multiple tasks and reevaluate it each time, a playbook variable can be defined with a lookup value. Each time the playbook variable is referenced, the lookup will be executed, potentially providing different values over time.
As you learned in the previous section, there are a few major types of variables that can be defined in a myriad of locations. This leads to a very important question: what happens when the same variable name is used in multiple locations? Ansible has a precedence for loading variable data, and thus it has an order and a definition to decide which variable will win. Variable value overriding is an advanced usage of Ansible, so it is important to fully understand the semantics before attempting such a scenario.
Ansible defines the precedence order as follows:
Extra
vars(from command-line) always win.Task
vars(only for the specific task).Block
vars(only for the tasks within the block).Role and include
vars.Vars created with
set_fact.Vars created with the
registertask directive.Play
vars_files.Play
vars_prompt.Play
vars.Host facts.
Playbook
host_vars.Playbook
group_vars.Inventory
host_vars.Inventory
group_vars.Inventory
vars.Role defaults.
In the previous section, we focused on the precedence in which variables will override each other. The default behavior of Ansible is that any overriding definition for a variable name will completely mask the previous definition of that variable. However, that behavior can be altered for one type of variable, the hash. A hash variable (a dictionary in Python terms) is a dataset of keys and values. Values can be of different types for each key, and can even be hashes themselves for complex data structures.
In some advanced scenarios, it is desirable to replace just one bit of a hash or add to an existing hash rather than replacing the hash altogether. To unlock this ability, a configuration change is necessary in an Ansible config file. The config entry is hash_behavior, which takes one of replace, or merge. A setting of merge will instruct Ansible to merge or blend the values of two hashes when presented with an override scenario rather than the default of replace, which will completely replace the old variable data with the new data.
Let's walk through an example of the two behaviors. We will start with a hash loaded with data and simulate a scenario where a different value for the hash is provided as a higher priority variable.
Starting data:
hash_var:
fred:
home: Seattle
transport: Bicycle
New data loaded via include_vars:
hash_var:
fred:
transport: Bus
With the default behavior, the new value for hash_var will be as follows:
hash_var:
fred:
transport: Bus
However, if we enable the merge behavior, we will get the following result:
hash_var:
fred:
home: Seattle
transport: Bus
There are even more nuances and undefined behaviors when using merge, and as such, it is strongly recommended to only use this setting if absolutely needed.
While the design of Ansible focuses on simplicity and ease of use, the architecture itself is very powerful. In this chapter, we covered key design and architecture concepts of Ansible, such as version and configuration, playbook parsing, module transport and execution, variable types and locations, and variable precedence.
You learned that playbooks contain variables and tasks. Tasks link bits of code called modules with arguments, which can be populated by variable data. These combinations are transported to selected hosts from provided inventory sources. The fundamental understanding of these building blocks is the platform on which you can build a mastery of all things Ansible!
In the next chapter, you will learn how to secure secret data while operating Ansible.


