


















In this chapter, you'll learn about common hardware solutions that you can find on the market, and which ones are slower or faster for MariaDB. You'll be able to properly tune your operating system to optimize your hardware and see how to reserve resources. Finally, you'll learn how to migrate from MySQL to MariaDB and have an overview of the available engines.
What is MariaDB? If you have bought this book, you probably already know; anyway, a quick reminder and a short introduction helps us to understand certain things.
MariaDB is a fork (drop-in replacement) of MySQL. MySQL was acquired by Sun Microsystems in 2008. Then, Oracle acquired Sun Microsystems in 2010 with MySQL included.
For several reasons, Michael Monty Widenius (the founder of MySQL) decided to fork MySQL and create a company for it called Monty Program AB. Thus, MariaDB (Maria is the name of the second daughter of Michael Monty Widenius) was born.
In December 2012, the MariaDB foundation was created to avoid any company acquisition like what had happened in the past for MySQL.
SkySQL is a company comprising of ex-MySQL executives and investors who deliver services around MySQL/MariaDB. In April 2013, there was a merger between SkySQL and Monty Program AB. For a company that may have wanted to switch to MariaDB without support, it was problematic. However, since the merger, it has been possible.
MariaDB has new interesting features: better testing, performance improvements, and bug fixes that are unfortunately not available in MySQL. For example, some optimizations come from Google, Facebook, Twitter, and so on.
Choosing the correct hardware is not an easy task. MariaDB has the following hardware requirements:
Disk performance
RAID and acceleration cards
RAM
CPU
Some types of software do not require so many important resources, but this is not the case for MariaDB. Of course, it depends on what you want to use your MariaDB instance for. For example, for a small website with poor access, you do not really need a huge configuration; a 10-year-old PC should really be enough. However, for a high-load website, requests should be analyzed to know which kind of hardware should be taken into consideration.
The disk is one of the biggest parts as several kinds of elements should be taken into consideration, and the storage is, in most cases, the bottleneck. Everything will depend on the write access you will need of course. That's why you're going to see several solutions that exist for speedy access to sensitive and reactive requirements.
SATA Hard Disk Drives (HDDs) are the slowest solution that can be commonly found on some servers. Generally, there are two kinds of rotation-per-minute drives:
10K HDDs exist but are not designed for production usages. A good solution to win access time is to have the highest disk cache size.
We can find disk caches with 2,5' and 3,5' sizes on the market. Servers are now generally shipped with 2,5' drives as we could add more than 3,5'. For instance, it's common to see 1U servers with eight arrays plugged to 2,5' disks. On 3U servers, constructors can add up to 25 disks. With Redundant Array of Independent Disks (RAID) mechanisms, it becomes interesting to get as many drives as possible to speed up the storage.
SAS magnetic drives are faster drives than SATA and are generally used with a specific PCI-X RAID card to enhance performance. Like the SATA HDDs, there are two kinds of rotation speeds:
The disk choice is important, but there is another thing to take into account. Like SATA drives, 3,5' drives exist, but they are hard to find now. Let's stick with 2,5' drives instead.
Hybrid drives are more common because their performances are similar to that of Solid State Drives (SSDs) with the size of SATA HDDs. This is a real good alternative to the high cost of SSDs. Hybrid drives are bridging the gap between SSDs and SATA drives.
Hybrid drives combine NAND flash drives (SSDs) with HDDs. The NAND flash of the drive is used to store data as cache to quickly deliver often-accessed files. The HDD part of the drive stores all the information, but the access is slower.
The hybrid drives that we can find on the market today have, for example, 1 TB of magnetic storage with 8 GB, 16 GB, or 24 GB of NAND flash.
Having an overview of what kinds of disks exist is generally not enough to get maximum fault tolerance and speed performance. That's why additional mechanisms such as RAID and acceleration cards exist. We'll see their pros and cons in the following sections.
I have already talked about PCI-X RAID cards—cards where disks are plugged embed fast cache memory. Today, we can commonly find 512 MB, 1 GB, or 2 GB flash cache. The more flash cache the PCI-X card has, the faster the transactions. You generally, depending on the card model, configure two kinds of cache: read and write caches.
There are two types of read cache:
Demand caching: This helps to quickly serve the same information if requested multiple times. In this case, it significantly improves disk I/O performance.
Look-ahead caching: If the required data is sequentially stored in blocks, this will store the next requested blocks in the cache to serve them faster when they are asked for.
The best performance solution for MariaDB is demand caching, as data is not sequential when reading.
There are two types of write cache:
Write-back caching: When a write request is issued, data is quickly written to the cache and the system is informed about the correct write. When it's free time for the bus or when the buffer does not have enough space to store new data, the data cache is written to the disk.
Write-through caching: This is the same as the write-back caching method, except the data is immediately transferred from the cache to the disk before informing the system.
In the case of a system crash, the write-back caching method is of course the most dangerous option. To avoid losing data, a Battery Backup Unit (BBU) is present on the cards to preserve data during a power cut. For example, when the system powers up and the SAS RAID card boots, the battery writes the cache information to disk.
When using BBU, it is recommend to disable the learning cycle. During a learning cycle, the battery is unloaded/reloaded and the write cache method switches from write-back to write-through.
Depending on the card manufacturer, some other options can be configured to customize those cache types.
Regarding the RAID levels, multiple solutions exist, and here are the common ones:
RAID 0 is not really the best solution for production use as there is no security. If a disk crashes, there is no way to recover it. In RAID 1, it's only mirroring! Even if we add more than two disks, the same information will be replicated. So, it is not good to use with MariaDB, but it generally answers OS disk problems. RAID 5 has been a really good solution for several years because of its good security guarantee. But we're losing performance here because of the parity calculation and storage, which corresponds to one disk. It's not recommended to create a very big RAID 5 solution, because if you lose more than one disk, all your data is lost. RAID 6 permits to lose up to two disks at once! However, the parity calculation is double and performance is not what we expect.
RAID 10 is a better solution! RAID 10 stripes mirrors; it's as simple as that! We have security as we could lose more than one disk (with mirroring) and have speed (with striping). The major problem of this solution is the cost, as you would only be able to use half of the total capacity of your disks. For example, if I have 12 disks in a server, you can consider that six disks are mirrored against the other six. Each of the six groups are stripped or they can be divided once again to get smaller (three) stripes.
Fusion-io direct acceleration cards are PCI-X cards that permit the drives to be faster than classic SSD solutions, with a better and consistent I/O throughput to give up to 85 percent more transactions. How? Simply because it requires less hardware components to access data and uses high speed hardware to achieve it.
When you use SSD/HDD SAS drives, CPU transactions need to pass through the RAID card and are then transferred to the disks. This is the bottleneck! On a high load charge on the SAS RAID card, the performance degrades gradually because of the connectivity to the disks.
To avoid it, Fusion-io direct access cards embed NAND flash directly on the PCI-X card to permit the drive to have a big cache system (up to 5 TB per card). The high bus bandwidth of the PCI-X permits the drive to quickly access information from the CPU and reduce a lot of latency.
The Fusion-io company provides other cheaper solutions to speed up server performance, but the fastest solution remains the Fusion-io direct access card anyway. Moreover, MariaDB is a partner with Fusion-io and has created special parameters to double the I/O capacity on those cards (available since MariaDB 5.5.31).
Disk arrays have been the solution to get maximum performance, and the only way to have a huge data size solution. The information that comes from the server(s) to the disk array (DAS, NAS, and SAN) takes too much time to process requests as it passes through several kinds of components such as networks in the worst case.
Even if it's a good solution in several cases, it's unfortunately not the fastest one. The recommendation for high performance is to store data locally. Multiple solutions exist for replication and high availability, so you don't have to worry about it.
In MariaDB, RAM availability is very important. The more RAM you have, the more data from your database can be kept in memory. For instance, on the InnoDB/XtraDB engine, to get maximum performance, it's recommended to get the database size equal to the free RAM size. It's also used to store table caches and so on.
Of course, if you have terabits of database data, it will be hard to get that much RAM. However, solutions exist to avoid those problems.
Another important thing is to look at your server architecture. You should take care of the motherboard's bus frequency and keep it as high as possible. In a major case, if you fill all the RAM slots that the motherboard can take, the bus frequency will decrease and the result will be a higher latency communication between the CPU and RAM. If you want to get the maximum RAM capacity of your server without losing any performance, look at the server constructor documentation to fill the correct amount of RAM slots with the highest RAM size per slot.
The latest important thing is not related to MariaDB: the Error-Correcting Code memory (ECC memory). It's a type of RAM that can detect and correct the most common kinds of internal data corruption. You may lower memory performance by around two to three percent. This is not a big performance loss, but you'll be sure that your data will be best protected from corruption.
Depending on the CPU model and constructor, having a lot of cores is of course interesting for multi-threading operations. A high processor clock speed allows faster calculation.
The L1, L2, and L3 processor cache sizes are very important as well. More memory allocation can be used to store on the processor; the fewer round trips made, faster the transactions will be.
To get maximum dedicated performance, you have to use the Linux cgroup feature to bind CPUs/cores to a MariaDB instance. This is also called CPU pinning.
MariaDB is able to run on multiple kinds of operating systems:
Microsoft Windows x86 and x64
Oracle Solaris 10 and 11 x64
Linux x86 and x64
Tip
MariaDB has a special thread-pool implementation that allows it to perform much better than MySQL under heavy loads (lots of connections).
In this book, every exercise will be on Debian GNU/Linux Wheezy amd64 version. Of course, all MariaDB tuning will be portable to any operating system, so you won't be lost. For the operating system performance tuning, we'll focus on Linux amd64 (Debian GNU/Linux), as it's free and open source, and of course MariaDB works very well on it.
To easily test the following parameters, you can use the following Vagrant file that provides you with the necessary virtual machine with MariaDB installed. The requirements are as follows:
Four cores
512 MB of RAM
8 GB of disk space
Here is the associated Vagrant file:
# -*- mode: ruby -*-
# vi: set ft=ruby :
# Vagrantfile API/syntax version. Don't touch unless you know what you're doing!
#
VAGRANTFILE_API_VERSION = "2"
# Insert all your Vms with configs
boxes = [
{ :name => :mariadb },
]
$install = <<INSTALL
aptitude update
DEBIAN_FRONTEND=noninteractive aptitude -y -o Dpkg::Options::="--force-confdef" -o Dpkg::Options::="--force-confold" install python-software-properties
apt-key adv --recv-keys --keyserver keyserver.ubuntu.com 0xcbcb082a1bb943db
add-apt-repository 'deb http://ftp.igh.cnrs.fr/pub/mariadb/repo/10.0/debian wheezy main'
aptitude update
DEBIAN_FRONTEND=noninteractive aptitude -y -o Dpkg::Options::="--force-confdef" -o Dpkg::Options::="--force-confold" install mariadb-server
INSTALL
Vagrant::Config.run do |config|
# Default box OS
vm_default = proc do |boxcnf|
boxcnf.vm.box = "deimosfr/debian-wheezy"
end
# For each VM, add a public and private card. Then install Ceph
boxes.each do |opts|
vm_default.call(config)
config.vm.define opts[:name] do |config|
config.vm.customize ["modifyvm", :id, "--cpus", 4]
config.vm.host_name = "%s.vm" % opts[:name].to_s
file_to_disk = 'ext4-journal_' + opts[:name].to_s + '.vdi'
config.vm.customize ['createhd', '--filename', file_to_disk, '--size', 250]
config.vm.customize ['storageattach', :id, '--storagectl', 'SATA Controller', '--port', 1, '--device', 0, '--type', 'hdd', '--medium', file_to_disk]
config.vm.provision "shell", inline: $install
end
end
endBy default, new servers are configured for low consumption power (green energy). This is a really good point for the environment! However, reducing electric power implies reducing computation power.
The CPU is the main component that directly affects performance because of its wake up time during sleep states. CPU power management should be disabled as much as possible. However, depending on the hardware manufacturer, multiple options may change.
If you're wondering what the effects are of that power management, it's simple. If the activity of the processor is reduced too much, a standard action that takes 1 second could take more than 2 seconds in that period. During this period of 1 or more seconds, CPU power management techniques are changing the CPU state (lowering frequency, lowering voltage, and deactivating some subsystems, and so on).
When the workload increases, subsystems are reactivated, but C-State reactivation implies some latency (milliseconds to seconds) before being at maximum performance.
C-States are idle CPU states. C0 is the working processor while C1 is the first idle level of the processor. The problem is no instructions are executed during the C1 state, as the CPU manufacturer introduced new C-States to reduce power consumption during an idle period.
P-States are different levels of the operation state of the processor. Each level differs from the others by different working voltages/frequencies. For example, at P0, a processor can run at 3 GHz, but at P1 it can run at only 1.5 GHz. Voltage is also scaled to reduce power consumption.
In a P-State, the CPU is working, performing operations and executing instructions. This is not an idle state.
Depending on the CPU constructor, power management technologies do not have the same name. Here is a list of functionalities that should be disabled. For Intel, they are called:
Speedstep
Turbo boost
C1E
QPI Power Management
For AMD, the functionalities are as follows:
PowerNow!
Cooln'Quiet
Turbo Core
Some constructors have enabled extra power management features that are keyboard tricks (for example, with HP hardware, a Ctrl + A in the BIOS shows an additional Services Options menu).
Most of the following power management commands may not work under virtual machines. So, you should consider having a physical machine to test and run them.
cpufreq allows the OS to control P-States. This means that the OS-based idleness can lower the frequency of the CPU to reduce power consumption.
To get cpufreq information on a specified core, look at the cpufreq folder by running the following command:
> ls -1 /sys/devices/system/cpu/cpu0/cpufreq affected_cpus bios_limit cpuinfo_cur_freq cpuinfo_max_freq cpuinfo_min_freq cpuinfo_transition_latency freqdomain_cpus related_cpus scaling_available_frequencies scaling_available_governors scaling_cur_freq scaling_driver scaling_governor scaling_max_freq scaling_min_freq scaling_setspeed
When enabled in the BIOS, cpufreq drivers are loaded and the cpufreq directory in sysfs is available. You can look at the used governor (power management mechanism using the following command):
> cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor ondemand
If the BIOS settings are disabled, no drivers are loaded and no scaling frequency is allowed. That means your server works at maximum performance. However, you can also tune the scaling governor for performance purposes.
To always get the maximum performance without disabling the options in the BIOS, we'll install a package that will configure all the cores on your machine:
aptitude install cpufrequtils cp /usr/share/doc/cpufrequtils/examples/cpufrequtils.loadcpufreq.sample /etc/default/cpufrequtils
Then, edit the configuration file (/etc/default/cpufrequtils) and set the new configuration:
# /etc/default/loadcpufreq sample file # # Use this file to override the CPUFreq kernel module to # be loaded or disable loading at all ENABLE=true FREQDRIVER=performance
You can get all the available governors with the following command:
> cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_available_governors ondemand performance
Then, you can restart the cpufrequtils service and your governors' cores will be updated to performance.
cpuidle allows the OS to control the CPU C-states (control how the CPU goes into idle/sleep state). Depending on the CPU constructor and model, several C-States are available. Standard ones are C0 and C1. C0 is a running state while C1 is an idle state.
Even if C-States have been disabled in the BIOS settings, the cpuidle driver can be loaded and managed. To look at the loaded driver, run the following command:
> cat /sys/devices/system/cpu/cpuidle/current_driver intel_idle
The intel_idle driver handles more C-States and aggressively puts the CPU into a lower idle mode. Since we have significant latency to wake up from lower C-States, this can affect performance.
When the intel_idle driver is loaded, specific cpuidle configurations are available for each CPU:
> ls -1R /sys/devices/system/cpu/cpu0/cpuidle/ /sys/devices/system/cpu/cpu0/cpuidle/: state0 state1 state2 state3 /sys/devices/system/cpu/cpu0/cpuidle/state0: desc latency name power time usage [...] /sys/devices/system/cpu/cpu0/cpuidle/state3: desc latency name power time usage
Each of the C-States are described here with the latency to wake up. To know the time it takes a C-State to wake up and check the latency file, run the following command:
> cat /sys/devices/system/cpu/cpu0/cpuidle/state3/latency 150
In the preceding command, the time for C-State 3 to wake up is 150 ms! To avoid having all the C-States enabled, change the grub boot configuration and add the following option (in the /etc/default/grub location):
GRUB_CMDLINE_LINUX_DEFAULT="quiet intel_idle.max_cstate=0"
To make it work, upgrade the grub configuration and reboot:
update-grub
For disks and filesystems, there are multiple factors that can slow down your MariaDB instance:
Magnetic drives' rotation per minute
Magnetic drives with data at the beginning of the disk
Partitions not aligned to the disk
Small partitions at the end of the disk
Disk bus speed
Magnetic drives' seek time
Active SWAP partitions
Some of these factors can only be resolved by changing the hardware, but others can be changed by tuning the operating system.
The kernel I/O scheduler permits us to change the way we read and write data on the disk. There are three kinds of schedulers. You can select a disk and look at the currently used scheduler using the following command:
# cat /sys/block/sda/queue/scheduler noop deadline [cfq]
The I/O scheduler used here is Completely Fair Queuing (CFQ).
The noop scheduler queues requests as they are sent to the I/O.
The deadline scheduler prevents excessive seek movement by serving I/O requests that are near to the new location on the disk. This is the best solution for SSDs.
The CFQ scheduler is the default scheduler on most Linux distributions. The goal of this scheduler is to minimize seek head movements. This is the best solution for magnetic disks if there is no other mechanism above it (such as RAID, Fusion-io, and so on). In the case of SSDs, you have to use the deadline scheduler.
To change the disk I/O scheduler with deadline, use the following command:
echo deadline > /sys/block/device/queue/scheduler
You have to replace the device with the device name (such as sda).
Another solution to avoid changing the disk I/O scheduler manually is to install sysfsutils by using the following command:
aptitude install sysfsutils
Then, you have to configure it in /etc/sysfs.conf:
block/sdb/queue/scheduler = deadline
Easy to use and understand, sysfsutils is a daemon that permits us to make changes in /sys automatically (as there is no sysctl for /sys).
Now, it could be a problem if you have a lot of disks on your machine and want to set the same I/O scheduler on all devices. Simply change the grub boot settings (/etc/default/grub) with the elevetor option:
GRUB_CMDLINE_LINUX_DEFAULT="quiet elevator=deadline"
To make the preceding setting work, upgrade the grub configuration and reboot:
update-grub
If you want to go ahead, there are several options for each I/O scheduler, and there is no optimal configuration. For example, on MyISAM, you need to increase nr_requests to multiply the throughput. You have to test them and look at the better solution corresponding to your needs.
In the latest version of CFQ, it automatically detects if it's a magnetic disk and adapts itself to avoid changing the elevator value. You can find all the required information on the Linux kernel website (http://www.kernel.org).
The goal of partition alignment is to match logical block partitions with physical blocks to limit the number of disk operations. You must make the first partition begin from the disk sector 2048. However, it can be done automatically if you're using the parted command. First of all, install the package:
aptitude install parted
Here is an example:
device=/dev/sdb parted -s -a optimal $device mklabel gpt parted -s -a optimal $device mkpart primary ext4 0% 100%
In the preceding example, we set /dev/sdb as the disk device, then created a gpt table partition, and finally created a single partition that takes the full disk size. 0% means the beginning of the disk (which in fact starts at 2M) and goes to the end (100%). The optimal option means we want the best partition alignment to get the best performance.
From the 2.6.33 version of kernel, you can enable TRIM support. Btrfs, Ext4, JFS, and XFS are optimized for TRIM when you activate this option. The TRIM feature blocks data that is no longer considered in use and that can be wiped internally. It allows the SSDs to handle garbage collection overhead that otherwise slows down future operations on the blocks.
Ext4 is one of the best solutions for high performance. To enable TRIM on it, modify your fstab (/etc/fstab) configuration to add the discard option:
/dev/sda2 / ext4 rw,discard,errors=remount-ro 0 1
Now, remount your partition to enable TRIM support for Ext4:
mount -o remount /
On LVM, you can also enable TRIM for all the logical volumes by changing the issue_discards option in your LVM configuration file (/etc/lvm/lvm.conf):
issue_discards = 1
Finally, we want to limit needless utilization of SSD, and this can be done by setting temporary folders in the RAM using the tmpfs filesystem. To achieve this, edit the fstab file at /etc/fstab and add the following three lines:
tmpfs /tmp tmpfs defaults,noatime,mode=1777 0 0 tmpfs /var/lock tmpfs defaults,noatime,mode=1777 0 0 tmpfs /var/run tmpfs defaults,noatime,mode=1777 0 0
Several kinds of filesystems exist and their performances generally depend on their usage. For MariaDB, I've performed several tests against XFS. My conclusion is the same as what we can find on most of the specialized websites on the Internet: XFS is a good solution but Ext4 is slightly faster.
On Ext4, you can add several interesting options to limit write access on the disk. You can, for example, disable the access time on all files and folders. This will avoid writing the last access time information to any acceded files on partition. As MariaDB often needs to access the same files, they are updated on each MariaDB modification (insert/update/delete), which is disk I/O consuming.
This could be a problem in some cases (for example, if you absolutely need these updates), but most of the time, it can be disabled by adding the following options in the fstab configuration (/etc/fstab):
/dev/sda2 / ext4 rw,noatime,nodiratime,data=writeback,discard 0 1
On a high disk I/O system, you will reduce the disk's access significantly.
You've also noticed that we used data=writeback. This option means that only metadata writes are journalized. It works well with InnoDB and is safe. Why? Because InnoDB has its own transaction logs, there is no need to duplicate the same action. This is the fastest solution, but if you prefer a safer one, you can use data=ordered instead to get data written before metadata.
Another interesting filesystem performance solution is to separate the Ext4 journal from the data disk (as in journaling, the filesystem writes data twice). Place the journal on a separate fast drive such as SSD. By default, the journal occupies between 2.5 percent and 5 percent of the filesystem size. It's suggested to keep the size at minimum for performance (it could be reduced on a very large data size).
First of all, check your current filesystem block size (here /dev/mapper/vg-home):
> dumpe2fs /dev/mapper/vg-home | grep "^Block" dumpe2fs 1.42.5 (29-Jul-2012) Block count: 1327104 Block size: 4096 Blocks per group: 32768
Here, we've got a 4096 block size and the journal needs to have the same block size as well.
To dedicate a journal to a current partition, we need to unmount it. To be sure that there is no access, remove the current journal from the partition, create the journal partition on the dedicated device (partition size * 5 / 100), attach it to the wished partition, and then remount it:
> umount /home > dumpe2fs /dev/mapper/vg-home | grep "Journal" Journal inode: 8 Journal backup: inode blocks Journal features: (none) Journal size: 128M Journal length: 32768 Journal sequence: 0x0000002f Journal start: 0 > tune2fs -f -O ^has_journal /dev/mapper/vg-home > mke2fs -O journal_dev -b 4096 /dev/sdb1 > tune2fs -j -J device=/dev/sdb1 /dev/mapper/vg-home > mount /home
Now, you check on your partition to see whether the journal is located on another partition:
> dumpe2fs /dev/mapper/vg-home | grep "Journal" Journal UUID: 8a3c6cec-2d45-4aa9-ac2f-4a181093a92e Journal device: 0x0811 Journal backup: inode blocks
To locate it, use the following command:
> blkid | grep 8a3c6cec-2d45-4aa9-ac2f-4a181093a92e /dev/mapper/vg-home: UUID="6b8f2604-e1ac-4bea-a5c9-e7acf08cec8c" TYPE="ext4" EXT_JOURNAL="8a3c6cec-2d45-4aa9-ac2f-4a181093a92e" /dev/sdb1: UUID="8a3c6cec-2d45-4aa9-ac2f-4a181093a92e" TYPE="jbd"
As you now have a dedicated journal for your partition, add two other options to /etc/fstab (journal_async_commit). The advantage is that the commit block can be written to disk without waiting for the descriptor blocks. This option will boost performance. The code is as follows:
/dev/mapper/vg-home /home ext4 rw,noatime,nodiratime,data=writeback,discard,journal_async_commit 0 2
Another option exists for Ext4: barrier=0. It will boost performance as well. Do not use it if you have a standalone server, because it will delay journal data writes and you may not be able to recover your data if your system crashes. You only have to use barrier=0 if you're using a RAID car with a BBU.
As SWAP is used on a physical disk (magnetic or SSD), it's slower than RAM. Linux, by default, likes swapping for several reasons. To avoid your MariaDB data being SWAP instead of RAM, you have to play with a kernel parameter called swappiness.
A swappiness value is used to change the balance between swapping out runtime memory and dropping pages from the system page cache. The higher the value, the more the system will swap. The lower the value, the less the system will swap. The maximum value is 100, the minimum is 0, and 60 is the default. To change this parameter in the persistence mode, add this line to your sysctl.conf file in /etc/sysctl.conf:
vm.swappiness = 0
To avoid a system reboot to get this value set on the running system, you can launch the following command:
sysctl -w vm.swappiness=0
And now check the value to be sure it has been applied:
> sysctl vm.swappiness vm.swap piness = 0
Linux kernel brings features that permit the isolation of a process from others, called cgroups (since version 2.6.24). If we want to dedicate CPU, RAM, or disk I/O, we can use cgroups to do it (it also provides other interesting features if you want to go ahead). With this solution, you can be sure to dedicate hardware to your MariaDB instance.
To start using cgroups, we must start preparing the environment. In fact, cgroups needs a specific folder hierarchy to work, but you'll see the advantages when we use it. So, edit the fstab file in /etc/fstab to mount cgroups at each machine startup, and add the following line:
cgroup /sys/fs/cgroup cgroup defaults 0 0
Mount cgroup now to make cgroups available:
mount /sys/fs/cgroup
To get all the CPU and memory features enabled, you need to change the grub configuration by adding two new features in /etc/default/grub (cgroup_enable and swapaccount):
GRUB_CMDLINE_LINUX_DEFAULT="quiet cgroup_enable=memory swapaccount=1"
Then, upgrade your grub settings and reboot:
update-grub
After the machine has rebooted, you can check whether your cgroup hierarchy exists:
> mount | grep ^cgroup cgroup on /sys/fs/cgroup type cgroup (rw,relatime,perf_event,blkio,net_cls,freezer,devices,memory,cpuacct ,cpu,cpuset)
Let's create our first cgroup, the MariaDB one! Create a folder with a name of your choice in the cgroup folder:
mkdir /sys/fs/cgroup/mariadb_cgroup
If we now look at the mariadb_cgroup content, you can see all the limitations that the cgroup features are able to offer:
> ls -1 /sys/fs/cgroup/mariadb_cgroup/ [...] cpuset.cpu_exclusive cpuset.cpus cpuset.mem_exclusive cpuset.mem_hardwall cpuset.memory_migrate cpuset.memory_pressure cpuset.memory_spread_page cpuset.memory_spread_slab cpuset.mems [...] tasks
You can see that there's a lot of stuff! Ok, now let's look at your processor information to see how many cores you've got:
> cat /proc/cpuinfo | grep ^processor processor : 0 processor : 1 processor : 2 processor : 3
I can see that I've got four cores available on this machine. For example, let's say I want to dedicate two cores to my MariaDB instance. The first thing to do is to assign two cores to the mariadb_cgroup cgroup:
echo 2,3 > /sys/fs/cgroup/mariadb_cgroup/cpuset.cpus
You can set multiple cores separated by commas or with the minus character if you want a CPU range (0-3 to set from C0 to C3).
In case of multiple cores, I've just asked the cgroup to be bound to the last two cores. That means this cgroup is only able to use those two cores and that doesn't mean it is the only one able to use them. Those cores are still sharable with other processes. To make them dedicated to this cgroup, simply use the following command:
echo 1 > /sys/fs/cgroup/mariadb_cgroup/cpuset.cpu_exclusive
You can check the configuration of your cgroup simply with cat:
> cat /sys/fs/cgroup/mariadb_cgroup/cpuset.cpu* 1 2-3
We also need to specify the memory nodes that the tasks will be allowed to access. First, let's get a look at the available memory nodes:
> numactl --hardware | grep ^available available: 1 nodes (0)
Then, set to the wished memory node (here 0):
echo 0 > /sys/fs/cgroup/mariadb_cgroup/cpuset.mems
Now, the cgroup is ready to dedicate cores to a process ID:
echo $(pidof mysqld) > /sys/fs/cgroup/mariadb_cgroup/tasks
That is it! If you want to be sure that you've correctly configured your cgroups, you can add another PID in that cgroup that will burst the two cores and check with the top or htop command, for example.
You can check your configuration using a PID in the following way:
> cat /proc/$(pidof mysqld)/status | grep _allowed Cpus_allowed: c Cpus_allowed_list: 2-3 Mems_allowed: 00000000,00000001 Me ms_allowed_list: 0
It's preferable to be able to manage the manual solution before the automatic solution to check whether your configuration works as expected.
Now, if you want to have it enabled on boot and automatically configured correctly, you will need to use the cgconfig daemon. It will load a configuration and then watch all the launched processes. If one matches its set configuration, it will automatically apply the defined rules.
To get cgconfig, you'll need to install the following package:
aptitude install cgroup-bin daemon
The cgroup-bin package in Debian wheezy is a little bit young, so we need to manually set up the init file and the configuration from the package documentation.
Unfortunately, you need to do a little hack with the init skeleton file to be able to use the update-rc.d command for the cgconfig services because the original init files are not 100 percent Debian-compliant yet:
cd /etc/init.d cp skeleton cgconfig cp skeleton cgred chmod 755 cgconfig cgred sed -i 's/skeleton/cgconfig/' cgconfig sed -i 's/skeleton/cgred/' cgred update-rc.d cgconfig defaults update-rc.d cgred defaults cd /usr/share/doc/cgroup-bin/examples/ cp cgred.conf /etc/default/ cp cgconfig.conf cgrules.conf /etc/ gzip -d cgconfig.gz cp cgconfig cgred /etc/init.d/ cd /etc/init.d/ sed -i 's/sysconfig/defaults/' cgred cgconfig sed -i 's/\/etc\/rc.d\/init.d\/functions/\/lib\/init\/vars.sh/' cgred sed -i 's/--check/--name/' cgred sed -i 's/killproc.*/kill $(cat $pidfile)/' cgred sed -i 's/touch "$lockfile"/test -d \/var\/lock\/subsys || mkdir \/var\/lock\/subsys\n\t&/' cgconfig chmod 755 cgconfig cgred
In the meantime, we've updated a Red Hat path to a Debian one (sysconfig | defaults), modified the folder to store the lock file of the daemon, and changed the default cgred init to correct some bugs.
Regarding the configuration files, let's start with /etc/cgconfig.conf:
#
# Copyright IBM Corporation. 2007
#
# Authors: Balbir Singh <balbir@linux.vnet.ibm.com>
# This program is free software; you can redistribute it and/or modify it
# under the terms of version 2.1 of the GNU Lesser General Public License
# as published by the Free Software Foundation.
#
# This program is distributed in the hope that it would be useful, but
# WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
#
group mariadb_cgroup {
perm {
admin {
uid = mysql;
}
task {
uid = mysql;
}
}
cpuset {
cpuset.mems = 0;
cpuset.cpus = "2,3";
cpuset.cpu_exclusive = 1;
}
}Here, we've got the cgroup name mariadb_cgroup. When a user, mysql, launches an operation, the cpuset configuration will be applied. In the same way as in the manual method, we've limited the mysql user process to the second and third cores.
The last thing to configure is the cgrules.conf file in /etc/cgrules.conf, which will indicate which process belongs to which cgroup. You need to add the user mysql to modify the cpu information and the cgroup folder name where it should be placed:
mysql cpu mariadb_cgroup/
Of course, you can check your configuration in /sys/fs/cgroup when you want.
When you've finished configuring your cgroup and want the new configuration to be active, restart the services in the following order:
/etc/init.d/cgred stop/etc/init.d/cgconfig stopumount /sys/fs/cgroup 2>/dev/nullrmdir /sys/fs/cgroup/* /sys/fs/cgroup 2>/dev/nullmount /sys/fs/cgroup/etc/init.d/cgconfig start/etc/init.d/cgred start
With large InnoDB databases (~ >32G), it becomes important to take a look at this kind of optimization.
In old/classic Uniform Memory Architecture (UMA), all the memory was shared among all the processors with equal access. There wasn't any affinity and performances were equal among all cores to the memory bank. With the Non-Uniform Memory Access (NUMA) architecture (starting with Intel Nehalem and AMD Opteron), this is totally different:
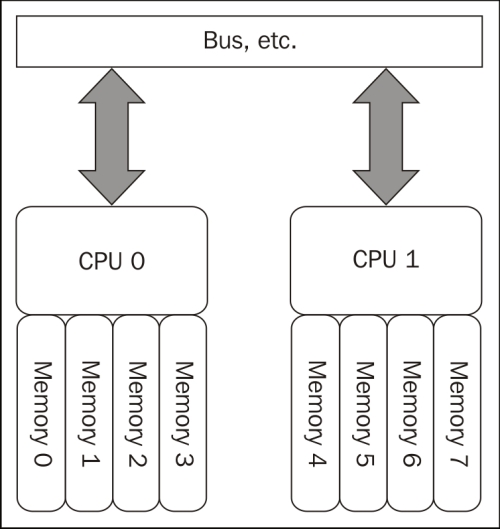
Each core has a local memory bank that gives closer access and thus reduces the latency. Of course, the whole system is visible as one unit, but optimization can be done to restrict a processor to its local memory bank. If there is no NUMA optimization, a core can ask for memory outside its local memory, which will increase the latency and lower the global performances.
By default, Linux automatically knows when it runs on a NUMA architecture and performs the following kind of operations natively:
Collects hardware information to understand the running architecture
Binds the correct memory module to the local core it belongs to
Splits physical processors to nodes
Collects cost information regarding inter-node communication
To look at the NUMA hardware on a running system, you can use the numactl command (install it first if not present):
> numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30
node 0 size: 65490 MB
node 0 free: 56085 MB
node 1 cpus: 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31
node 1 size: 65536 MB
node 1 free: 35150 MB
node distances:
node 0 1
0: 10 20
1: 20 10
We can see two different nodes here that indicate two different physical CPUs and the physical allocated RAM.
The node distances represent the cost of interconnect access. The weight for node 0 to access its local bank is 10, and for node 1, it's 20. This is the same constraint for node 1 to access node 0.
You can see the NUMA policy and information using the following command:
> numactl --show
policy: default
preferred node: current
physcpubind: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
cpubind: 0 1
nodebind: 0 1
membind: 0 1
Now, if you want to bind a process to a CPU, use the following command:
numactl –physcpubind=0,1 <PID>
To allocate the local memory of a NUMA node, use the following command:
numactl --physcpubind=0 --localalloc <PID>
Now, if you want to get stats and see how your NUMA system works when the interleave has been hit and so on, use the numastat command:
> numastat
node0 node1
numa_hit 407467513 656867541
numa_miss 0 0
numa_foreign 0 0
interleave_hit 32442 32470
local_node 407037248 656824235
other_node 430265 43306
First of all, MariaDB is a fork of MySQL. So, if you're using a version from 5.1 to 5.5, the migration will be really easy. To make it clear and simple, if you're running a MySQL version under 5.1, upgrade it first to 5.1 at least and 5.5 at max.
Then, it will be easy to migrate. First of all, you need to understand the best compatibility version, as shown in the following table:
|
MySQL version |
MariaDB version |
|---|---|
|
5.1 |
5.1, 5.2, 5.3 |
|
5.5 |
5.5 |
|
5.6 |
10 |
It is recommended, for example, to switch from the 5.1 version of MySQL to the 5.1 version of MariaDB. Then test it, see if everything is fine, and then you can upgrade to a higher version of MariaDB.
There is something that you should consider: starting from the 5.6 version of MySQL, MariaDB will start to number the version from 10. Why? Because MariaDB developers want to be clear on the features portability from MySQL to MariaDB. All the features won't be ported in version 10. They may be done later or not at all. Some features will be fully rewritten for several reasons, and MariaDB developers will try to keep compatibility with MySQL. That's why for a migration, it's preferable to migrate a MySQL version from 5.1 to 5.5. If you don't use advanced features, it shouldn't be a problem as incompatibilities are very low.
Since 5.5 is really stable, you can skip the upgrade to 5.3 (the latest branch of MariaDB based on 5.1) and go straight to 5.5. Of course, complete regression testing of the application is recommended.
To get more information on the compatibility list from one version to another, I strongly recommend following the official MariaDB compatibility information page available on the main site: https://mariadb.com/kb/en/mariadb-versus-mysql-compatibility/.
Now that you've understood how to migrate, we'll perform a migration using a virtual machine. You'll need the following:
1 CPU
512 MB of RAM
8 GB of disk space
This is the code you need to run:
# -*- mode: ruby -*-
# vi: set ft=ruby :
ENV['LANG'] = 'C'
# Vagrantfile API/syntax version. Don't touch unless you know what you're doing!
VAGRANTFILE_API_VERSION = "2"
# Insert all your Vms with configs
boxes = [
{ :name => :mysqlserver },
]
$install = <<INSTALL
aptitude update
DEBIAN_FRONTEND=noninteractive aptitude -y -o Dpkg::Options::="--force-confdef" -o Dpkg::Options::="--force-confold" install mysql-server
INSTALL
Vagrant::Config.run do |config|
# Default box OS
vm_default = proc do |boxcnf|
boxcnf.vm.box = "deimosfr/debian-wheezy"
end
# For each VM, add a public and private card. Then install Ceph
boxes.each do |opts|
vm_default.call(config)
config.vm.define opts[:name] do |config|
config.vm.host_name = "%s.vm" % opts[:name].to_s
config.vm.provision "shell", inline: $install
end
end
endInstall on this virtual machine the application of your choice (WordPress, MediaWiki, and so on) to confirm the migration doesn't break anything.
You will see that the migration is an easy step. First of all, remove the current MySQL version, but keep the data:
apt-get remove mysql-server
Then, your database will still be available in the data directory (/var/lib/mysql by default) but no binary will be present.
It's time to install MariaDB. First add the MariaDB repository (for version 5.5 here):
apt-get install python-software-properties apt-key adv --recv-keys --keyserver keyserver.ubuntu.com 0xcbcb082a1bb943db add-apt-repository 'deb http://mirrors.linsrv.net/mariadb/repo/5.5/debian wheezy main'
Now install MariaDB:
apt-get update apt-get install mariadb-server
It should have started without any issues. Take a look at the logs in /var/log/syslog if this is not the case.
When you use MariaDB, you may not know all of the engines, what they can do, which one is more efficient, and in which situation, and so on.
Comparing all the available engines of MariaDB could take a whole book. So, we're going to cover them here, but just an introduction with some additional information to help you to choose some of them for testing.
The classic engines that can also be found on MySQL are as follows:
MariaDB introduces several new engines and is still adding some more for different usages and performances:
In the future, more and more NoSQL engines will be integrated.
This chapter gave you an overview of the hardware that exists for MariaDB and which one is better than the others. You also now know how to take advantage of some hardware and operating systems for MariaDB. You've seen a quick overview of which MariaDB engines are available and which ones are faster. Selecting the correct hardware is a very important thing, and to know how it works is a completely different topic. Take time to understand how to optimize and how your environment works to avoid misunderstood slowdowns. As a rule, try to keep yourself updated on the new CPU features / power management and how Linux evolves with it.


