


















 Download code from GitHub
Download code from GitHub
A Gentle Introduction to Machine Learning
In the last few years, machine learning has become one of the most important and prolific IT and artificial intelligence branches. It's not surprising that its applications are becoming more widespread day by day in every business sector, always with new and more powerful tools and results. Open source, production-ready frameworks, together with hundreds of papers published every month, are contributing to one of the most pervasive democratization processes in IT history. But why is machine learning so important and valuable?
In this chapter, we are going to discuss the following:
- The difference between classic systems and adaptive ones
- The general concept of learning, proving a few examples of different approaches
- Why bio-inspired systems and computational neuroscience allowed a dramatic improvement in performances
- The relationship between big data and machine learning
Introduction – classic and adaptive machines
Since time immemorial, human beings have built tools and machines to simplify their work and reduce the overall effort needed to complete many different tasks. Even without knowing any physical law, they invented levers (formally described for the first time by Archimedes), instruments, and more complex machines to carry out longer and more sophisticated procedures. Hammering a nail became easier and more painless thanks to a simple trick, and so did moving heavy stones or wood using a cart. But, what's the difference between these two examples? Even if the latter is still a simple machine, its complexity allows a person to carry out a composite task without thinking about each step. Some fundamental mechanical laws play a primary role in allowing a horizontal force to contrast gravity efficiently, but neither human beings, nor horses or oxen, knew anything about them. The primitive people simply observed how a genial trick (the wheel) could improve their lives.
The lesson we've learned is that a machine is never efficient or trendy without a concrete possibility to use it with pragmatism. A machine is immediately considered useful and destined to be continuously improved if its users can easily understand what tasks can be completed with less effort or automatically. In the latter case, some intelligence seems to appear next to cogs, wheels, or axles. So, a further step can be added to our evolution list: automatic machines, built (nowadays, we'd say programmed) to accomplish specific goals by transforming energy into work. Wind or watermills are some examples of elementary tools that are able to carry out complete tasks with minimal (compared to a direct activity) human control.
In the following diagram, there's a generic representation of a classical system that receives some input values, processes them, and produces output results:
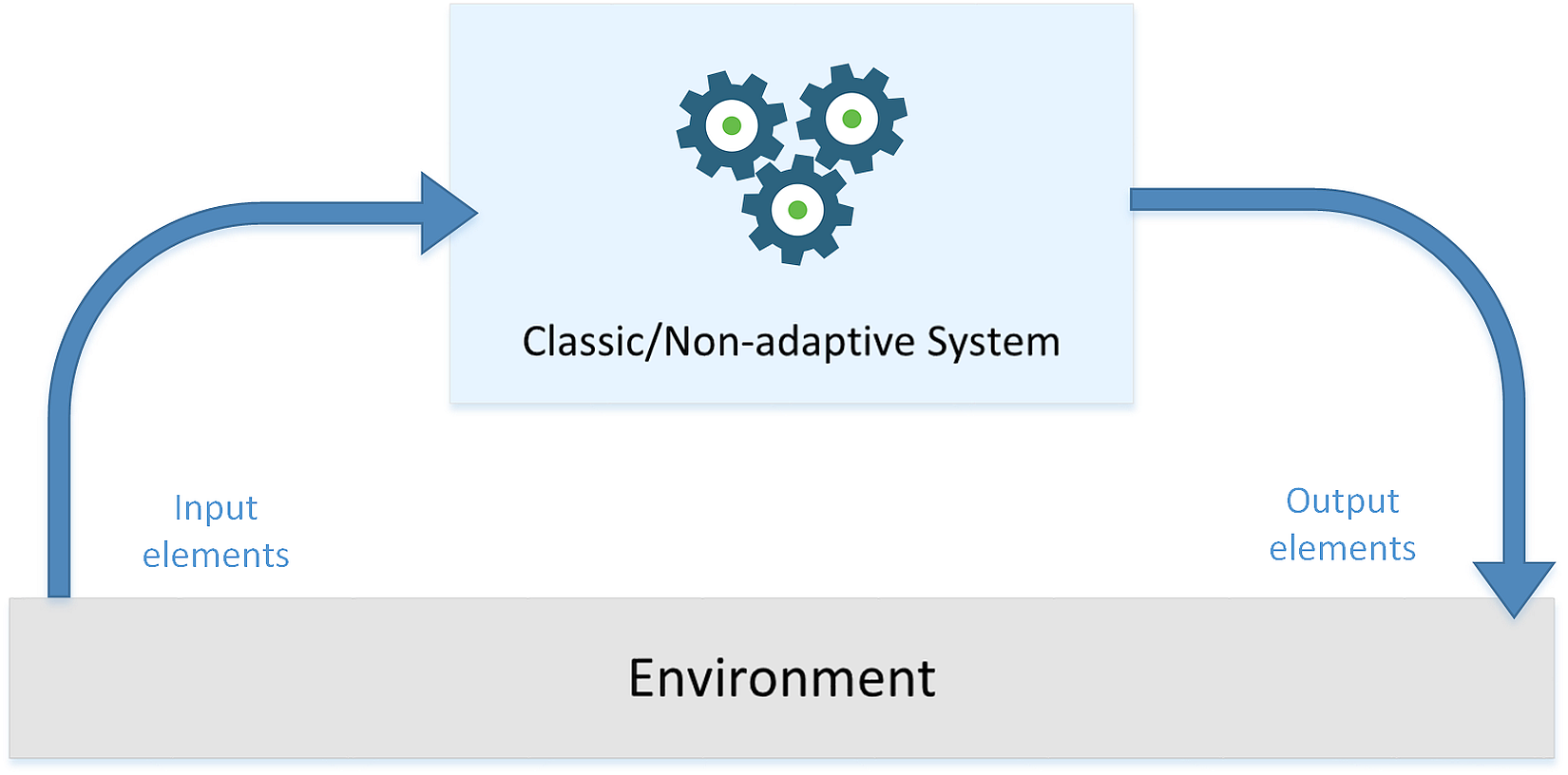
But again, what's the key to the success of a mill? It's not hasty at all to say that human beings have tried to transfer some intelligence into their tools since the dawn of technology. Both the water in a river and the wind show a behavior that we can simply call flowing. They have a lot of energy to give us free of any charge, but a machine should have some awareness to facilitate this process. A wheel can turn around a fixed axle millions of times, but the wind must find a suitable surface to push on. The answer seems obvious, but you should try to think about people without any knowledge or experience; even if implicitly, they started a brand new approach to technology. If you prefer to reserve the word intelligence to more recent results, it's possible to say that the path started with tools, moved first to simple machines, and then moved to smarter ones.
Without further intermediate (but no less important) steps, we can jump into our epoch and change the scope of our discussion. Programmable computers are widespread, flexible, and more and more powerful instruments; moreover, the diffusion of the internet allowed us to share software applications and related information with minimal effort. The word-processing software that I'm using, my email client, a web browser, and many other common tools running on the same machine, are all examples of such flexibility. It's undeniable that the IT revolution dramatically changed our lives and sometimes improved our daily jobs, but without machine learning (and all its applications), there are still many tasks that seem far out of the computer domain. Spam filtering, Natural Language Processing (NLP), visual tracking with a webcam or a smartphone, and predictive analysis are only a few applications that revolutionized human-machine interaction and increased our expectations. In many cases, they transformed our electronic tools into actual cognitive extensions that are changing the way we interact with many daily situations. They achieved this goal by filling the gap between human perception, language, reasoning, and model and artificial instruments.
Here's a schematic representation of an adaptive system:

Such a system isn't based on static or permanent structures (model parameters and architectures), but rather on a continuous ability to adapt its behavior to external signals (datasets or real-time inputs) and, like a human being, to predict the future using uncertain and fragmentary pieces of information.
Before moving on with a more specific discussion, let's briefly define the different kinds of system analysis that can be performed. These techniques are often structured as a sequence of specific operations whose goal is increasing the overall domain knowledge and allowing answering specific questions, however, in some cases, it's possible to limit the process to a single step in order to meet specific business needs. I always suggest to briefly consider them all, because many particular operations make sense only when some conditions are required. A clear understanding of the problem and its implications is the best way to make the right decisions, also taking into consideration possible future developments.
Descriptive analysis
Before trying any machine learning solution, it's necessary to create an abstract description of the context. The best way to achieve this goal is to define a mathematical model, which has the advantage of being immediately comprehensible by anybody (assuming the basic knowledge). However, the goal of descriptive analysis is to find out an accurate description of the phenomena that are observed and validate all the hypothesis. Let's suppose that our task is to optimize the supply chain of a large store. We start collecting data about purchases and sales and, after a discussion with a manager, we define the generic hypotheses that the sales volume increases during the day before the weekend. This means that our model should be based on a periodicity. A descriptive analysis has the task to validate it, but also to discover all those other particular features that were initially neglected.
At the end of this stage, we should know, for example, if the time series (let's suppose we consider only a variable) is periodic, if it has a trend, if it's possible to find out a set of standard rules, and so forth. A further step (that I prefer to consider as whole with this one) is to define a diagnostic model that must be able to connect all the effects with precise causes. This process seems to go in the opposite direction, but its goal is very close to the descriptive analysis one. In fact, whenever we describe a phenomenon, we are naturally driven to finding a rational reason that justifies each specific step. Let's suppose that, after having observed the periodicity in our time series, we find a sequence that doesn't obey this rule. The goal of diagnostic analysis is to give a suitable answer (that is, the store is open on Sunday). This new piece of information enriches our knowledge and specializes it: now, we can state that the series is periodic only when there is a day off, and therefore (clearly, this is a trivial example) we don't expect an increase in the sales before a working day. As many machine learning models have specific prerequisites, a descriptive analysis allows us to immediately understand whether a model will perform poorly or if it's the best choice considering all the known factors. In all of the examples we will look at, we are going to perform a brief descriptive analysis by defining the features of each dataset and what we can observe. As the goal of this book is to focus on adaptive systems, we don't have space for a complete description, but I always invite the reader to imagine new possible scenarios, performing a virtual analysis before defining the models.
Predictive analysis
The goal of machine learning is almost related to this precise stage. In fact, once we have defined a model of our system, we need to infer its future states, given some initial conditions. This process is based on the discovery of the rules that underlie the phenomenon so as to push them forward in time (in the case of a time series) and observe the results. Of course, the goal of a predictive model is to minimize the error between actual and predictive value, considering all possible interfering factors.
In the example of the large store, a good model should be able to forecast a peak before a day off and a normal behavior in all the other cases. Moreover, once a predictive model has been defined and trained, it can be used as a fundamental part of a decision-based process. In this case, the prediction must be turned into a suggested prescription. For example, the object detector of a self-driving car can be extremely accurate and detect an obstacle on time. However, which is the best action to perform in order to achieve a specific goal? According to the prediction (position, size, speed, and so on), another model must be able to pick the action that minimizes the risk of damage and maximizes the probability of a safe movement. This is a common task in reinforcement learning, but it's also extremely useful whenever a manager has to make a decision in a context where there are many factors. The resultant model is, hence, a pipeline that is fed with raw inputs and uses the single outcomes as inputs for subsequent models. Returning to our initial example, the store manager is not interested in discovering the hidden oscillations, but in the right volumes of goods that he has to order every day. Therefore, the first step is predictive analysis, while the second is a prescriptive one, which can take into account many factors that are discarded by the previous model (that is, different suppliers can have shorter or longer delivery times or they can apply discounts according to the volume).
So, the manager will probably define a goal in terms of a function to maximize (or minimize), and the model has to find the best amount of goods to order so as to fulfill the main requirement (that, of course, is the availability, and it depends on the sales prediction). In the remaining part of this book, we are going to discuss many solutions to specific problems, focusing on the predictive stage. But, in order to move on, we need to define what learning means and why it's so important in more and more different business contexts.
Only learning matters
What does learning exactly mean? Simply, we can say that learning is the ability to change according to external stimuli and remember most of our previous experiences. So, machine learning is an engineering approach that gives maximum importance to every technique that increases or improves the propensity for changing adaptively. A mechanical watch, for example, is an extraordinary artifact, but its structure obeys stationary laws and becomes useless if something external is changed. This ability is peculiar to animals and, in particular, to human beings; according to Darwin’s theory, it's also a key success factor for the survival and evolution of all species. Machines, even if they don't evolve autonomously, seem to obey the same law.
Therefore, the main goal of machine learning is to study, engineer, and improve mathematical models that can be trained (once or continuously) with context-related data (provided by a generic environment) to infer the future and to make decisions without complete knowledge of all influencing elements (external factors). In other words, an agent (which is a software entity that receives information from an environment, picks the best action to reach a specific goal, and observes the results of it) adopts a statistical learning approach, trying to determine the right probability distributions, and use them to compute the action (value or decision) that is most likely to be successful (with the fewest errors).
I do prefer using the term inference instead of prediction, but only to avoid the weird (but not so uncommon) idea that machine learning is a sort of modern magic. Moreover, it's possible to introduce a fundamental statement: an algorithm can extrapolate general laws and learn their structure with relatively high precision, but only if they affect the actual data. So, the term prediction can be freely used, but with the same meaning adopted in physics or system theory. Even in the most complex scenarios, such as image classification with convolutional neural networks, every piece of information (geometry, color, peculiar features, contrast, and so on) is already present in the data and the model has to be flexible enough to extract and learn it permanently.
In the following sections, we will give you a brief description of some common approaches to machine learning. Mathematical models, algorithms, and practical examples will be discussed in later chapters.
Supervised learning
A supervised scenario is characterized by the concept of a teacher or supervisor, whose main task is to provide the agent with a precise measure of its error (directly comparable with output values). With actual algorithms, this function is provided by a training set made up of couples (input and expected output). Starting from this information, the agent can correct its parameters so as to reduce the magnitude of a global loss function. After each iteration, if the algorithm is flexible enough and data elements are coherent, the overall accuracy increases and the difference between the predicted and expected values becomes close to zero. Of course, in a supervised scenario, the goal is training a system that must also work with samples that have never been seen before. So, it's necessary to allow the model to develop a generalization ability and avoid a common problem called overfitting, which causes overlearning due to an excessive capacity (we're going to discuss this in more detail in the following chapters, however, we can say that one of the main effects of such a problem is the ability to only correctly predict the samples used for training, while the error rate for the remaining ones is always very high).
In the following graph, a few training points are marked with circles, and the thin blue line represents a perfect generalization (in this case, the connection is a simple segment):

Two different models are trained with the same datasets (corresponding to the two larger lines). The former is unacceptable because it cannot generalize and capture the fastest dynamics (in terms of frequency), while the latter seems a very good compromise between the original trend, and has a residual ability to generalize correctly in a predictive analysis.
Formally, the previous example is called regression because it's based on continuous output values. Instead, if there is only a discrete number of possible outcomes (called categories), the process becomes a classification. Sometimes, instead of predicting the actual category, it's better to determine its probability distribution. For example, an algorithm can be trained to recognize a handwritten alphabetical letter, so its output is categorical (in English, there'll be 26 allowed symbols). On the other hand, even for human beings, such a process can lead to more than one probable outcome when the visual representation of a letter isn't clear enough to belong to a single category. This means that the actual output is better described by a discrete probability distribution (for example, with 26 continuous values normalized so that they always sum up to 1).
In the following graph, there's an example of classification of elements with two features. The majority of algorithms try to find the best separating hyperplane (in this case, it's a linear problem) by imposing different conditions. However, the goal is always the same: reducing the number of misclassifications and increasing the noise-robustness. For example, look at the triangular point that is closest to the plane (its coordinates are about [5.1 - 3.0]). If the magnitude of the second feature were affected by noise and so the value were quite smaller than 3.0, a slightly higher hyperplane could wrongly classify it. We're going to discuss some powerful techniques to solve these problems in later chapters:

Common supervised learning applications include the following:
- Predictive analysis based on regression or categorical classification
- Spam detection
- Pattern detection
- NLP
- Sentiment analysis
- Automatic image classification
- Automatic sequence processing (for example, music or speech)
Unsupervised learning
This approach is based on the absence of any supervisor and therefore of absolute error measures. It's useful when it's necessary to learn how a set of elements can be grouped (clustered) according to their similarity (or distance measure). For example, looking at the previous graph, a human being can immediately identify two sets without considering the colors or the shapes. In fact, the circular dots (as well as the triangular ones) determine a coherent set; it is separate from the other one much more than how its points are internally separated. Using a metaphor, an ideal scenario is a sea with a few islands that can be separated from each other, considering only their mutual position and internal cohesion. Clearly, unsupervised learning provides an implicit descriptive analysis because all the pieces of information discovered by the clustering algorithm can be used to obtain a complete insight of the dataset. In fact, all objects share a subset of features, while they are different under other viewpoints. The aggregation process is also aimed to extend the characteristics of some points to their neighbors, assuming that the similarity is not limited to some specific features. For example, in a recommendation engine, a group of users can be clustered according to the preference expressed for some books. If the chosen criteria detected some analogies between users A and B, we can share the non-overlapping elements between the users. Therefore, if A has read a book that can be suitable for B, we are implicitly authorized to recommend it. In this case, the decision is made by considering a goal (sharing the features) and a descriptive analysis. However, as the model can (and should) manage unknown users too, its purpose is also predictive.
In the following graph, each ellipse represents a cluster and all the points inside its area can be labeled in the same way. There are also boundary points (such as the triangles overlapping the circle area) that need a specific criterion (normally a trade-off distance measure) to determine the corresponding cluster. Just as for classification with ambiguities (P and malformed R), a good clustering approach should consider the presence of outliers and treat them so as to increase both the internal coherence (visually, this means picking a subdivision that maximizes the local density) and the separation among clusters.
For example, it's possible to give priority to the distance between a single point and a centroid, or the average distance among points belonging to the same cluster and different ones. In this graph, all boundary triangles are close to each other, so the nearest neighbor is another triangle. However, in real-life problems, there are often boundary areas where there's a partial overlap, meaning that some points have a high degree of uncertainty due to their feature values:

Another interpretation can be expressed by using probability distributions. If you look at the ellipses, they represent the area of multivariate Gaussians bound between a minimum and maximum variance. Considering the whole domain, a point (for example, a blue star) could potentially belong to all clusters, but the probability given by the first one (lower-left corner) is the highest, and so this determines the membership. Once the variance and mean (in other words, the shape) of all Gaussians become stable, each boundary point is automatically captured by a single Gaussian distribution (except in the case of equal probabilities). Technically, we say that such an approach maximizes the likelihood of a Gaussian mixture given a certain dataset. This is a very important statistical learning concept that spans many different applications, so it will be examined in more depth in the next chapter, Chapter 2, Important Elements in Machine Learning. Moreover, we're going to discuss some common clustering methodologies, considering both strong and weak points, and compare their performances for various test distributions.
Other important techniques involve the use of both labeled and unlabeled data. This approach is therefore called semi-supervised and can be adopted when it's necessary to categorize a large amount of data with a few complete (labeled) examples or when there's the need to impose some constraints to a clustering algorithm (for example, assigning some elements to a specific cluster or excluding others).
Commons unsupervised applications include the following:
- Object segmentation (for example, users, products, movies, songs, and so on)
- Similarity detection
- Automatic labeling
- Recommendation engines
Semi-supervised learning
There are many problems where the amount of labeled samples is very small compared with the potential number of elements. A direct supervised approach is infeasible because the data used to train the model couldn't be representative of the whole distribution, so therefore it's necessary to find a trade-off between a supervised and an unsupervised strategy. Semi-supervised learning has been mainly studied in order to solve these kinds of problems. The topic is a little bit more advanced and won't be covered in this book (the reader who is interested can check out Mastering Machine Learning Algorithms, Bonaccorso G., Packt Publishing). However, the main goals that a semi-supervised learning approach pursues are as follows:
- The propagation of labels to unlabeled samples considering the graph of the whole dataset. The samples with labels become attractors that extend their influence to the neighbors until an equilibrium point is reached.
- Performing a classification training model (in general, Support Vector Machines (SVM); see Chapter 7, Support Vector Machines, for further information) using the labeled samples to enforce the conditions necessary for a good separation while trying to exploit the unlabeled samples as balancers, whose influence must be mediated by the labeled ones. Semi-supervised SVMs can perform extremely well when the dataset contains only a few labeled samples and dramatically reduce the burden of building and managing very large datasets.
- Non-linear dimensionality reduction considering the graph structure of the dataset. This is one of most challenging problems due to the constraints existing in high-dimensional datasets (that is, images). Finding a low-dimensional distribution that represents the original one minimizing the discrepancy is a fundamental task necessary to visualize structures with more than three dimensions. Moreover, the ability to reduce the dimensionality without a significant information loss is a key element whenever it's necessary to work with simpler models. In this book, we are going to discuss some common linear techniques (such as Principal Component Analysis (PCA) that the reader will be able to understand when some features can be removed without impacting the final accuracy but with a training speed gain.
It should now be clear that semi-supervised learning exploits the ability of finding out separating hyperplanes (classification) together with the auto-discovery of structural relationships (clustering). Without a loss of generality, we could say that the real supervisor, in this case, is the data graph (representing the relationships) that corrects the decisions according to the underlying informational layer. To better understand the logic, we can imagine that we have a set of users, but only 1% of them have been labeled (for simplicity, let's suppose that they are uniformly distributed). Our goal is to find the most accurate labels for the remaining part. A clustering algorithm can rearrange the structure according to the similarities (as the labeled samples are uniform, we can expect to find unlabeled neighbors whose center is a labeled one). Under some assumptions, we can propagate the center's label to the neighbors, repeating this process until every sample becomes stable. At this point, the whole dataset is labeled and it's possible to employ other algorithms to perform specific operations. Clearly, this is only an example, but in real life, it's extremely common to find scenarios where the cost of labeling millions of samples is not justified considering the accuracy achieved by semi-supervised methods.
Reinforcement learning
Even if there are no actual supervisors, reinforcement learning is also based on feedback provided by the environment. However, in this case, the information is more qualitative and doesn't help the agent in determining a precise measure of its error. In reinforcement learning, this feedback is usually called reward (sometimes, a negative one is defined as a penalty), and it's useful to understand whether a certain action performed in a state is positive or not. The sequence of most useful actions is a policy that the agent has to learn in order to be able to always make the best decision in terms of the highest immediate and cumulative (future) reward. In other words, an action can also be imperfect, but in terms of a global policy, it has to offer the highest total reward. This concept is based on the idea that a rational agent always pursues the objectives that can increase his/her wealth. The ability to see over a distant horizon is a distinctive mark for advanced agents, while short-sighted ones are often unable to correctly evaluate the consequences of their immediate actions and so their strategies are always sub-optimal.
Reinforcement learning is particularly efficient when the environment is not completely deterministic, when it's often very dynamic, and when it's impossible to have a precise error measure. During the last few years, many classical algorithms have been applied to deep neural networks to learn the best policy for playing Atari video games and to teach an agent how to associate the right action with an input representing the state (usually, this is a screenshot or a memory dump).
In the following diagram, there's a schematic representation of a deep neural network that's been trained to play a famous Atari game:

As input, there are one or more subsequent screenshots (this can often be enough to capture the temporal dynamics as well). They are processed using different layers (discussed briefly later) to produce an output that represents the policy for a specific state transition. After applying this policy, the game produces a feedback (as a reward-penalty), and this result is used to refine the output until it becomes stable (so the states are correctly recognized and the suggested action is always the best one) and the total reward overcomes a predefined threshold.
We're going to discuss some examples of reinforcement learning in the Chapter 15, Introducing Neural Networks, and Chapter 16, Advanced Deep Learning Models, dedicated to introducing deep learning and TensorFlow. However, some common examples are as follows:
- Automatic robot control
- Game solving
- Stock trade analysis based on feedback signals
Computational neuroscience
It's not surprising that many machine learning algorithms have been defined and refined thanks to the contribution of research in the field of computational neuroscience. On the other hand, the most diffused adaptive systems are the animals, thanks to their nervous systems, that allow an effective interaction with the environment. From a mechanistic viewpoint, we need to assume that all the processes working inside the gigantic network of neurons are responsible for all computational features, starting from low-level perception and progressing until the highest abstractions, like language, logic reasoning, artistic creation, and so forth.
At the beginning of 1900, Ramón y Cajal and Golgi discovered the structure of the nerve cells, the neurons, but it was necessary to fully understand that their behavior was purely computational. Both scientists drew sketches representing the input units (dendrites), the body (soma), the main channel (axon) and the output gates (synapses), however neither the dynamic nor the learning mechanism of a cell group was fully comprehended. The neuroscientific community was convinced that learning was equivalent to a continuous and structural change, but they weren't able to define exactly what was changing during a learning process. In 1949, the Canadian psychologist Donald Hebb proposed his famous rule (a broader discussion can be found in Mastering Machine Learning Algorithms, Bonaccorso G., Packt Publishing, 2018 and Theoretical Neuroscience, Dayan P., Abbott L. F., The MIT Press, 2005) that is focused on the synaptic plasticity of the neurons. In other words, the changing element is the number and the nature of the output gates which connect a unit to a large number of other neurons. Hebb understood that if a neuron produces a spike and a synapse propagates it to another neuron which behaves in the same way, the connection is strengthened, otherwise, it's weakened. This can seem like a very simplistic explanation, but it allows you to understand how elementary neural aggregates can perform operations such as detecting the borders of an object, denoising a signal, or even finding the dimensions with maximum variance (PCA).
The research in this field has continued until today, and many companies, together with high-level universities, are currently involved in studying the computational behavior of the brain using the most advanced neuroimaging technologies available. The discoveries are sometimes surprising, as they confirm what was only imagined and never observed. In particular, some areas of the brain can easily manage supervised and unsupervised problems, while others exploit reinforcement learning to predict the most likely future perceptions. For example, an animal quickly learns to associate the sound of steps to the possibility of facing a predator, and learns how to behave consequently. In the same way, the input coming from its eyes are manipulated so as to extract all those pieces of information that are useful to detect the objects. This denoising procedure is extremely common in machine learning and, surprisingly, many algorithms achieve the same goal that an animal brain does! Of course, the complexity of human minds is beyond any complete explanation, but the possibility to double-check these intuitions using computer software has dramatically increased the research speed. At the end of this book, we are going to discuss the basics of deep learning, which is the most advanced branch of machine learning. However, I invite the reader to try to understand all the dynamics (even when they seem very abstract) because the underlying logic is always based on very simple and natural mechanisms, and your brain is very likely to perform the same operations that you're learning while you read!
Beyond machine learning – deep learning and bio-inspired adaptive systems
During the last few years, thanks to more powerful and cheaper computers, many researchers started adopting complex (deep) neural architectures to achieve goals that were unimaginable only two decades ago. Since 1957, when Rosenblatt invented the first perceptron, interest in neural networks has grown more and more. However, many limitations (concerning memory and CPU speed) prevented massive research and hid lots of potential applications of these kinds of algorithms.
In the last decade, many researchers started training bigger and bigger models, built with several different layers (that's why this approach is called deep learning), in order to solve new challenging problems. The availability of cheap and fast computers allowed them to get results in acceptable timeframes and to use very large datasets (made up of images, texts, and animations). This effort led to impressive results, in particular for classification based on photo elements and real-time intelligent interaction using reinforcement learning.
The idea behind these techniques is to create algorithms that work like a brain, and many important advancements in this field have been achieved thanks to the contribution of neurosciences and cognitive psychology. In particular, there's a growing interest in pattern recognition and associative memories whose structure and functioning are similar to what happens in the neocortex. Such an approach also allows simpler algorithms called model-free; these aren't based on any mathematical-physical formulation of a particular problem, but rather on generic learning techniques and repeating experiences.
Of course, testing different architectures and optimization algorithms is rather simpler (and it can be done with parallel processing) than defining a complex model (which is also more difficult to adapt to different contexts). Moreover, deep learning showed better performance than other approaches, even without a context-based model. This suggests that, in many cases, it's better to have a less precise decision made with uncertainty than a precise one determined by the output of a very complex model (often not so fast). For animals, this is often a matter of life and death, and if they succeed, it is thanks to an implicit renounce of some precision.
Common deep learning applications include the following:
- Image classification
- Real-time visual tracking
- Autonomous car driving
- Robot control
- Logistic optimization
- Bioinformatics
- Speech recognition and Natural Language Understanding (NLU)
- Natural Language Generation (NLG) and speech synthesis
Many of these problems can also be solved by using classic approaches that are sometimes much more complex, but deep learning outperformed them all. Moreover, it allowed extending their application to contexts initially considered extremely complex, such as autonomous cars or real-time visual object identification.
This book covers, in detail, only some classical algorithms; however, there are many resources that can be read both as an introduction and for a more advanced insight.
Machine learning and big data
Another area that can be exploited using machine learning is big data. After the first release of Apache Hadoop, which implemented an efficient MapReduce algorithm, the amount of information managed in different business contexts grew exponentially. At the same time, the opportunity to use it for machine learning purposes arose and several applications such as mass collaborative filtering became a reality.
Imagine an online store with 1 million users and only 1,000 products. Consider a matrix where each user is associated with every product by an implicit or explicit ranking. This matrix will contain 1,000,000 x 1,000 cells, and even if the number of products is very limited, any operation performed on it will be slow and memory-consuming. Instead, using a cluster, together with parallel algorithms, such a problem disappears, and operations with a higher dimensionality can be carried out in a very short time.
Think about training an image classifier with 1 million samples. A single instance needs to iterate several times, processing small batches of pictures. Even if this problem can be performed using a streaming approach (with a limited amount of memory), it's not surprising to wait even for a few days before the model begins to perform well. Adopting a big data approach instead, it's possible to asynchronously train several local models, periodically share the updates, and re-synchronize them all with a master model. This technique has also been exploited to solve some reinforcement learning problems, where many agents (often managed by different threads) played the same game, providing their periodical contribution to a global intelligence.
Not every machine learning problem is suitable for big data, and not all big datasets are really useful when training models. However, their conjunction in particular situations can lead to extraordinary results by removing many limitations that often affect smaller scenarios. Unfortunately, both machine learning and big data are topics subject to continuous hype, hence one of the tasks that an engineer/scientist has to accomplish is understanding when a particular technology is really helpful and when its burden can be heavier than the benefits. Modern computers often have enough resources to process datasets that, a few years ago, were easily considered big data. Therefore, I invite the reader to carefully analyze each situation and think about the problem from a business viewpoint as well. A Spark cluster has a cost that is sometimes completely unjustified. I've personally seen clusters of two medium machines running tasks that a laptop could have carried out even faster. Hence, always perform a descriptive/prescriptive analysis of the problem and the data, trying to focus on the following:
- The current situation
- Objectives (what do we need to achieve?)
- Data and dimensionality (do we work with batch data? Do we have incoming streams?)
- Acceptable delays (do we need real-time? Is it possible to process once a day/week?)
Big data solutions are justified, for example, when the following is the case:
- The dataset cannot fit in the memory of a high-end machine
- The incoming data flow is huge, continuous, and needs prompt computations (for example, clickstreams, web analytics, message dispatching, and so on)
- It's not possible to split the data into small chunks because the acceptable delays are minimal (this piece of information must be mathematically quantified)
- The operations can be parallelized efficiently (nowadays, many important algorithms have been implemented in distributed frameworks, but there are still tasks that cannot be processed by using parallel architectures)
In the chapter dedicated to recommendation systems, Chapter 12, Introduction to Recommendation Systems, we're going to discuss how to implement collaborative filtering using Apache Spark. The same framework will also be adopted for an example of Naive Bayes classification.
Summary
In this chapter, we introduced the concept of adaptive systems; they can learn from their experiences and modify their behavior in order to maximize the possibility of reaching a specific goal. Machine learning is the name given to a set of techniques that allow you to implement adaptive algorithms to make predictions and auto-organize input data according to their common features.
The three main learning strategies are supervised, unsupervised, and reinforcement. The first one assumes the presence of a teacher that provides a precise feedback on errors. The algorithm can, therefore, compare its output with the right one and correct its parameters accordingly. In an unsupervised scenario, there are no external teachers, so everything is learned directly from the data. An algorithm will try to find out all of the features that are common to a group of elements so that it's able to associate new samples with the right cluster. Examples of the former type are provided by all the automatic classifications of objects into a specific category according to some known features, while common applications of unsupervised learning are the automatic groupings of items with a subsequent labeling or processing. The third kind of learning is similar to supervised, but it only receives an environmental feedback about the quality of its actions. It doesn't know exactly what is wrong or the magnitude of its error, but receives generic information that helps it in deciding whether to continue to adopt a policy or to pick another one.
In the next chapter, Chapter 2, Important Elements in Machine Learning, we're going to discuss some fundamental elements of machine learning, with particular focus on the mathematical notation and the main definitions that we'll need in the rest of the chapters. We'll also discuss important statistical learning concepts and some theory about learnability and its limits.





