


















 Download code from GitHub
Download code from GitHub
In this chapter, we will give a brief introduction on Domain Specific Languages (DSL) and the issues concerning their implementation, especially in the context of an IDE. The initial part of the chapter is informal: we will sketch the main tasks for implementing a DSL and its integration in an IDE. At the end of the chapter, we will also show you how to install Xtext and will give you a glimpse of what you can do with Xtext. Xtext is an Eclipse framework for the development of DSLs that covers all aspects of a language implementation, including its integration in the Eclipse IDE.
Domain Specific Languages, abbreviated as DSL, are programming languages or specification languages that target a specific problem domain. They are not meant to provide features for solving all kinds of problems; you probably will not be able to implement all programs you can implement with, for instance, Java or C (which are known as General Purpose Languages). But if your problem's domain is covered by a particular DSL, you will be able to solve that problem easier and faster by using that DSL instead of a general purpose language.
Some examples of DSLs are SQL (for querying relational databases), Mathematica (for symbolic mathematics), HTML, and many others you have probably used in the past. A program or specification written in a DSL can then be interpreted or compiled into a general purpose language; in other cases, the specification can represent simply data that will be processed by other systems.
For a wider introduction to DSLs, you should refer to Fowler 2010, Ghosh 2010, and Voelter 2013.
You may now wonder why you need to introduce a new DSL for describing specific data, for example, models or applications, instead of using XML, which allows you to describe data in a machine in human-readable form. There are so many tools now that, starting from an XML schema definition, allow you to read, write, or exchange data in XML without having to parse such data according to a specific syntax. There is basically only one syntax to learn (the XML tag syntax) and then all data can be represented with XML.
Of course, this is also a matter of taste, but many people (including the author himself) find that XML is surely machine-readable, but not so much human-readable. It is fine to exchange data in XML if the data in that format is produced by a program. But often, people (programmers and users) are requested to specify data in XML manually; for instance, for specifying an application's specific configuration.
If writing an XML file can be a pain, reading it back can be even worse. In fact, XML tends to be verbose, and it fills documents with too much additional syntax noise due to all the tags. The tags help a computer to process XML, but they surely distract people when they have to read and write XML files.
Consider a very simple example of an XML file describing people:
<people>
<person>
<name>James</name>
<surname>Smith</surname>
<age>50</age>
</person>
<person employed="true">
<name>John</name>
<surname>Anderson</surname>
<age>40</age>
</person>
</people>It is not straightforward for a human to grasp the actual information about a person from such a specification: a human is distracted by all those tags. Also, writing such a specification may be a burden. An editor might help with some syntax highlighting and early user feedback concerning validation, but still there are too many additional details.
How about this version written in an ad-hoc DSL?:
person {
name=James
surname=Smith
age=50
}
person employed {
name=John
surname=Anderson
age=40
}This contains less noise and the information is easier to grasp. We could even do better and have a more compact specification:
James Smith (50) John Anderson (40) employed
After all, since this DSL only lets users describe the name and age of people, why not design it to make the description both compact and easy to read?
For the end user, using a DSL is surely easier than writing XML code; however, the developer of the DSL is now left with the task of implementing it.
Implementing a DSL means developing a program that is able to read text written in that DSL, parse it, process it, and then possibly interpret it or generate code in another language. Depending on the aim of the DSL, this may require several phases, but most of these phases are typical of all implementations.
In this section we only hint at the main concepts of implementing a DSL.
Note
From now on, throughout the book we will not distinguish, unless strictly required by the context, between DSL and programming language.
First of all, when reading a program written in a programming language, the implementation has to make sure that the program respects the syntax of that language.
To this aim, we need to break the program into tokens. Each token is a single atomic element of the language; this can be a keyword (such as class in Java), an identifier (such as a Java class name), or symbol name (such as a variable name in Java).
For instance, in the preceding example, employed is a keyword; the parentheses are operators (which can be seen as special kinds of keywords as well). All the other elements are literals (James is a string literal and 50 is an integer literal).
The process of converting a sequence of characters into a sequence of tokens is called lexical analysis, and the program or procedure that performs such analysis is called a lexical analyzer, lexer, or simply a scanner. This analysis is usually implemented by using regular expressions syntax.
Having the sequence of tokens from the input file is not enough: we must make sure that they form a valid statement in our language, that is, they respect the syntactic structure expected by the language.
This phase is called parsing or syntactic analysis.
Let us recall the DSL to describe the name and age of various people and a possible input text:
James Smith (50) John Anderson (40) employed
In this example each line of the input must respect the following structure:
two string literals
the operator
(one integer literal
the operator
)the optional keyword
employed
In our language, tokens are separated by white spaces, and lines are separated by a newline character.
You can now deduce that the parser relies on the lexer.
If you have never implemented a programming language, you might be scared at this point by the task of implementing a parser, for instance, in Java. You are probably right, since it is not an easy task. The DSL we just used as an example is very small (and still it would require some effort to implement), but if we think about a DSL that has to deal also with, say, arithmetic expressions? In spite of their apparently simple structure, arithmetic expressions are recursive by their own nature, thus a parser implemented in Java would have to deal with recursion as well (and, in particular, it should avoid endless loops).
There are tools to deal with parsing so that you do not have to implement a parser by hand. In particular, there are DSLs to specify the grammar of the language, and from this specification they automatically generate the code for the lexer and parser (for this reason, these tools are called parser generators or compiler-compilers). In this context, such specifications are called grammars. A grammar is a set of rules that describe the form of the elements that are valid according to the language syntax.
Here are some examples of tools for specifying grammars.
Bison and Flex (Levine 2009) are the most famous in the C context: from a high level specification of the syntactic structure (Bison) and lexical structure (Flex) of a language, they generate the parser and lexer in C, respectively. Bison is an implementation of Yacc (Yet Another Compiler-compiler, Brown et al. 1995), and there are variants for other languages as well, such as Racc for Ruby.
In the Java world, the most well-known is probably ANTLR (pronounced Antler, ANother Tool for Language Recognition) (Parr 2007). ANTLR allows the programmer to specify the grammar of the language in one single file (without separating the syntactic and lexical specifications in different files), and then it automatically generates the parser in Java.
Just to have an idea of what the specification of grammars looks like in ANTLR, here is the (simplified) grammar for an expression language for arithmetic expressions (with sum and multiplication):
expression : INT | expression '*' expression | expression '+' expression ;
Even if you do not understand all the details, it should be straightforward to get its meaning: an expression is either an integer literal, or (recursively) two expressions with an operator in between (either * or +).
From such a specification, you automatically get the Java code that will parse such expressions.
Parsing a program is only the first stage in a programming language implementation. Once the program is checked as correct from the syntactic point of view, the implementation will have to do something with the elements of the program.
First of all, the overall correctness of a program cannot always be determined during parsing. One of the correctness checks that usually cannot be performed during parsing is type checking, that is, checking that the program is correct with respect to types. For instance, in Java, you cannot assign a string value to an integer variable, or, you can only assign instances of a variable's declared type or subclasses thereof.
Trying to embed type checking in a grammar specification could either make the specification more complex, or it could be simply impossible, since some type checks can be performed only when other program parts have already been parsed.
Type checking is part of the semantic analysis of a program. This often includes managing the symbol table, that is, for instance, handling the variables that are declared and that are visible only in specific parts of the program (think of fields in a Java class and their visibility in methods).
For these reasons, during parsing, we should also build a representation of the parsed program and store it in memory so that we can perform the semantic analysis on the memory representation without needing to parse the same text over and over again. A convenient representation in memory of a program is a tree structure called the Abstract Syntax Tree (or AST). The AST represents the abstract syntactic structure of the program. In this tree, each node represents a construct of the program.
Once the AST is stored in memory, the DSL implementation will not need to parse the program anymore, and it can perform all the additional semantic checks on the AST, and if they all succeed, it can use the AST for the final stage of the implementation, which can be the interpretation of the program or code generation.
In order to build the AST we need two additional things.
We need the code for representing the nodes of such a tree; if we are using Java, this means that we need to write some Java classes, typically one for each language construct. For instance, for the expression language we might write one class for the integer literal and one for the binary expression. Remember that since the grammar is recursive, we need a base class for representing the abstract concept of an expression. For example,
interface Expression { }
class Literal implements Expression {
Integer value;
// constructor and set methods...
}
class BinaryExpression implements Expression {
Expression left, right;
String operator;
// constructor and set methods...
}Then, we need to annotate the grammar specification with actions that construct the AST during the parsing; these actions are basically Java code blocks embedded in the grammar specification itself; the following is just a (simplified) example and it does not necessarily respect the actual ANTLR syntax:
expression:
INT { $value = new Literal(Integer.parseInt($INT.text)); }
| left=expression '*' right=expression {
$value = new BinaryExpression($left.value, $right.value);
$value.setOperator("*");
}
| left=expression '+' right=expression {
$value = new BinaryExpression($left.value, $right.value);
$value.setOperator("+");
}
;Even once you have implemented your DSL, that is, the mechanisms to read, validate, and execute programs written in your DSL, your work cannot really be considered finished.
Nowadays, a DSL should be shipped with good IDE support: all the IDE tooling that programmers are used to could really make the adoption of your DSL successful.
If your DSL is supported by all the powerful features in an IDE such as a syntax-aware editor, immediate feedback, incremental syntax checking, suggested corrections, auto-completion, and so on, then it will be easier to learn, use, and maintain.
In the following sections we will see the most important features concerning IDE integration; in particular, we will assume Eclipse as the underlying IDE (since Xtext is an Eclipse framework).
The ability to see the program colored and formatted with different visual styles according to the elements of the language (for example, comments, keywords, strings, and so on) is not just "cosmetic".
First of all, it gives immediate feedback concerning the syntactic correctness of what you are writing. For instance, if string constants (typically enclosed in quotes) are rendered as red, and you see that at some point in the editor the rest of your program is all red, you may soon get an idea that somewhere in between you forgot to insert the closing quotation mark.
Moreover, colors and fonts will help the programmer to see the structure of the program directly, making it easier to visually separate the parts of the program.
The programming cycle consisting of writing a program with a text editor, saving it, shifting to the command line, running the compiler, and, in case of errors, shifting back to the text editor is surely not productive.
The programming environment should not let the programmer realize about errors too late; on the contrary, it should continuously check the program in the background while the programmer is writing, even if the current file has not been saved yet. The sooner the environment can tell the programmer about errors the better. The longer it takes to realize that there is an error, the higher the cost in terms of time and mental effort to correct.
When your DSL parser and checker issue some errors, the programmer should not have to go to the console to discover such errors; your implementation should highlight the parts of the program with errors directly in the editor by underlining (for instance, in red) only the parts that actually contain the errors; it should also put some error markers (with an explicit message) on the left of the editor in correspondence to the lines with errors, and should also fill the Problem view with all these errors. The programmer will then have the chance to easily spot the parts of the program that need to be fixed.
It is nice to have the editor propose some content when you write your programs in Eclipse. This is especially true when the proposed content makes sense in that particular program context. Content assist is the feature that automatically, or on demand, provides suggestions on how to complete the statement/expression the programmer just typed. For instance, when editing a Java file, after the keyword new, Eclipse proposes only Java class names as possible completions.
Again, this has to do with productivity; it does not make much sense to be forced to know all the syntax of a programming language by heart (especially for DSLs, which are not common languages such as Java), neither to know all the language's library classes and functions.
It is much better to let the editor help you with contextualized proposals.
In Eclipse the content assist is usually accessed with the keyboard shortcut Ctrl + Space bar.
Hyperlinking is a feature that makes it possible to navigate between references in a program; for example, from a variable to its declaration, or from a function call to where the function is defined. If your DSL provides declarations of any sort (for instance, variable declarations or functions) and a way to refer to them (for instance, referring to a variable or invoking a declared function), then it should also provide Hyperlinking: from a token referring to a declaration, it should be possible to directly jump to the corresponding declaration. This is particularly useful if the declaration is in a file different from the one being edited. In Eclipse this corresponds to pressing F3 or using Ctrl + click.
This functionality really helps a lot if the programmer needs to inspect a specific declaration. For instance, when invoking a Java method, the programmer may need to check what that method actually does.
Hovering is a similar IDE feature: if you need some information about a specific program element, just hovering on that element should display a pop-up window with some documentation about that element.
If the programmer made a mistake and your DSL implementation is able to fix it somehow, why not help the programmer by offering suggested quickfixes?
As an example, in the Eclipse Java editor, if you invoke a method that does not exist in the corresponding class, you are provided with some quickfixes (try to experiment with this); for instance, you are given a chance to fix this problem by actually creating such a method. This is typically implemented by a context menu available from the error marker.
In a test driven scenario this is actually a methodology. Since you write tests before the actual code to test, you can simply write the test that invokes a method that does not exist yet, and then employ the quickfix to let the IDE create that method for you.
If a program is big, it is surely helpful to have an outline of it showing only the main components; clicking on an element of the outline should bring the programmer directly to the corresponding source line in the editor.
Think about the outline view you get in Eclipse when editing a Java source file. The outline shows, in a compact form, all the classes and the corresponding methods of the currently edited Java file without the corresponding method bodies. Therefore, it is easy to have a quick overview of the contents of the file and to quickly jump to a specific class or method through the outline view.
Furthermore, the outline can also include other pieces of information such as types and structure that are not immediately understood by just looking at the program text. It is handy to have a view that is organized differently, perhaps sorted alphabetically to help with navigation.
In Eclipse, you have a Java project, and when you modify one Java file and save it, you know that Eclipse will automatically compile that file and, consequently, all the files that depend on the file you have just modified.
Having such functionality for your DSL will make its users happier.
In this section we briefly and informally introduced the main steps to implement a DSL.
The IDE tooling can be implemented on top of Eclipse, which already provides a comprehensive framework.
Indeed, all the features of the Eclipse Java editor (which is part of the project JDT, Java Development Tools ) are based on the Eclipse framework, thus, you can employ all the functionalities offered by Eclipse to implement the same features for your own DSL.
Unfortunately, this task is not really easy: it certainly requires a deep knowledge of the internals of the Eclipse framework and lot of programming.
Finally, the parser will have to be connected to the Eclipse editing framework.
To make things a little bit worse, if you learned how to use all these tools (and this requires time) for implementing a DSL, when it comes to implement a new DSL, your existing knowledge will help you, but the time to implement the new DSL will still be huge.
All these learning and timing issues might push you to stick with XML, since the effort to produce a new DSL does not seem to be worthwhile. Indeed, there are many existing parsing and processing technologies for XML for different platforms that can be used, not to mention existing editors and IDE tooling for XML.
But what if there was a framework that lets you achieve all these tasks in a very quick way? What if this framework, once learned (yes, you cannot avoid learning new things), will let you implement new DSLs even quicker than the previous ones?
Xtext is an Eclipse framework for implementing programming languages and DSLs. It lets you implement languages quickly, and most of all, it covers all aspects of a complete language infrastructure, starting from the parser, code generator, or interpreter, up to a complete Eclipse IDE integration (with all the typical IDE features we discussed previously).
The really amazing thing about Xtext is that to start a DSL implementation, it only needs a grammar specification similar to ANTLR; it does not need to annotate the rules with actions to build the AST, since the creation of the AST (and the Java classes to store the AST) is handled automatically by Xtext itself. Starting from this specification, Xtext will automatically generate all the mechanisms sketched previously. It will generate the lexer, the parser, the AST model, the construction of the AST to represent the parsed program, and the Eclipse editor with all the IDE features!
Xtext comes with good and smart default implementations for all these aspects, and indeed most of these defaults will surely fit your needs. However, every single aspect can be customized by the programmer.
With all these features, Xtext is easy to use, it produces a professional result quickly, and it is even fun to use.
Xtext is an Eclipse framework, thus it can be installed into your Eclipse installation using the update site as follows:
http://download.eclipse.org/modeling/tmf/xtext/updates/composite/releases
Just copy this URL into the dialog you get when you navigate to Help | Install new software... in the textbox Work with and press Enter; after some time (required to contact the update site), you will be presented with lots of possible features to install. The important features to install are Xtend SDK 2.4.2 and Xtext SDK 2.4.2.
Alternatively, an Eclipse distribution for DSL developers based on Xtext is also available from the main Eclipse downloads page, http://www.eclipse.org/downloads, called Eclipse IDE for Java and DSL Developers.
Hopefully, by now you should be eager of seeing for yourself what Xtext can do! In this section we will briefly present the steps to write your first Xtext project and see what you get. Do not worry if you have no clue about most of the things you will see in this demo; they will be explained in the coming chapters.
Start Eclipse and navigate to File | New | Project...; in the dialog, navigate to the Xtext category and select Xtext Project.

In the next dialog you can leave all the defaults, but uncheck the option Create SDK feature project (we will use the Create SDK feature project feature later in Chapter 11, Building and Releasing).

The wizard will create three projects and will open the file
MyDsl.xtext, which is the grammar definition of the new DSL we are about to implement. You do not need to understand all the details of this file's contents for the moment. But if you understood how the grammar definitions work from the examples in the previous sections, you might have an idea of what this DSL does. It accepts lines starting with the keywordHellofollowed by an identifier, then followed by!.
Now it is time to start the first Xtext generation, so navigate to the file
MyDsl.xtextin the projectorg.xtext.example.mydsl, right-click on it, and navigate to Run As | Generate Xtext Artifacts. The output of the generation will be shown in the Console view. You will note that (only for the first invocation) you will be prompted with a question in the console:*ATTENTION* It is recommended to use the ANTLR 3 parser generator (BSD licence - http://www.antlr.org/license.html).Do you agree to download it (size 1MB) from 'http://download.itemis.com/antlr-generator-3.2.0.jar'? (type 'y' or 'n' and hit enter)
You should type
yand press Enter so that this JAR will be downloaded and stored in your project once and for all (this file cannot be delivered together with Xtext installation: due to license problems, it is not compatible with the Eclipse Public License). Wait for that file to be downloaded, and once you read Done in the console, the code generation phase is finished, and you will note that the three projects now contain much more code. Of course, you will have to wait for Eclipse to build the projects.Your DSL implementation is now ready to be tested! Since what the wizard created for you are Eclipse plug-in projects, you need to start a new Eclipse instance to see your implementation in action. Before you start the new Eclipse instance, you must make sure that the launch configuration has enough PermGen size, otherwise you will experience " out of memory " errors. You need to specify this VM argument in your launch configuration:
-XX:MaxPermSize=256m;alternatively, you can simply use the launch configuration that Xtext created for you in your projectorg.xtext.example.mydsl, so right-click on that project and navigate to Run As | Run Configurations...; in the dialog, you can see Launch Runtime Eclipse under Eclipse Application; select that and click on Run.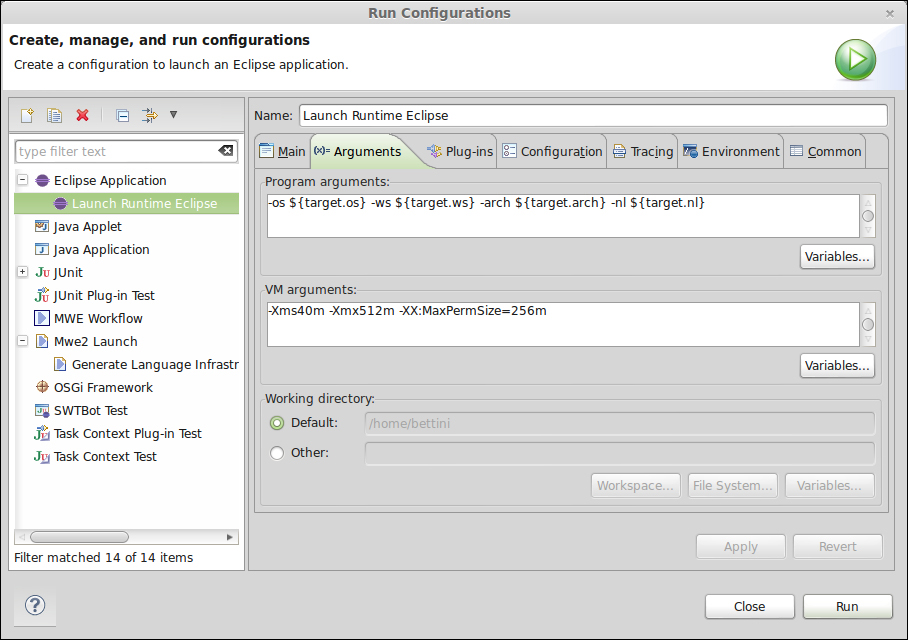
A new Eclipse instance will be run and a new workbench will appear. In this instance, your DSL implementation is available; so let's create a new General project (call it, for instance,
sample). Inside this project create a new file; the name of the file is not important, but the file extension must bemydsl(remember that this was the extension we chose in the Xtext new project wizard). As soon as the file is created it will also be opened in a text editor and you will be asked to add the Xtext nature to your project. You should accept that to make your DSL editor work correctly in Eclipse.Now try all the things that Xtext created for you! The editor features syntax highlighting (you can see that by default Xtext DSLs are already set up to deal with Java-like comments like
//and/* */), immediate error feedback (with error markers only in the relevant parts of the file), outline view (which is automatically synchronized with the elements in the text editor), and code completion. All of these features automatically generated starting from a grammar specification file.
This short demo should have convinced you about the powerful features of Xtext (implementing the same features manually would require a huge amount of work). The result of the code generated by Xtext is so close to what Eclipse provides you for Java that your DSLs implemented in Xtext will be of high quality and will provide the users with all the IDE benefits.
Xtext comes with some nice documentation; you can find such documentation in your Eclipse help system or online at http://www.eclipse.org/Xtext/documentation.html, where a PDF version of the whole documentation is available.
This book aims at being complementary to the official documentation, trying to give you enough information to start being productive in implementing DLSs with Xtext. This book will try to teach you some methodologies and best practices when using Xtext, filling some bits of information that are not present in the official documentation. Most chapters will have a tutorial nature and will provide you with enough information to make sure you understand what is going on. However, the official documentation should be kept at hand to learn more details about the mechanisms we will use throughout the book.
In this chapter we introduced the main concepts related to implementing a DSL, including IDE features.
At this point, you should also have an idea of what Xtext can do for you.
In the next chapter, we will use an uncomplicated DSL to demonstrate the main mechanisms and to get you familiar with the Xtext development workflow.


