


















This chapter will provide an overview of Apache Hadoop and Microsoft big data strategy, where Microsoft HDInsight plays an important role. We will cover the following topics:
The era of big data
Hadoop concepts
Hadoop distributions
HDInsight overview
Hadoop on Windows deployment options
We live in a digital era and are always connected with friends and family using social media and smartphones. In 2014, every second over 5,700 tweets were sent and 800 links were shared using Facebook and the digital universe was about 1.7 MB per minute for every person on Earth (source: IDC 2014 report). This amount of data sharing and storing is unprecedented and is contributing to what is known as big data.
The following infographic shows you the details of our current use of the top social media sites (source https://leveragenewagemedia.com/):

Other contributors to big data are the smart connected devices such as smartphones, appliances, cars, sensors, and pretty much everything that we use today and is connected to the Internet. These devices, which will soon be in trillions, continuously collect data and communicate with each other about their environment to make intelligent decisions and help us live better. This digitization of the world has added to the exponential growth of big data.
The following figure depicts the trend analysis done by Microsoft Azure, which shows the evolution of big data "internet of things". In the period 1980 to 1990, IT systems ERM/CRM primarily generated data in a well-structured format with volume in GBs. In the period between 1990 and 2000, the Web and mobile applications emerged and now the data volumes increased to terabytes. After the year 2000, social networking sites, Wikis, blogs, and smart devices emerged and now we are dealing with petabytes of data. The section in blue highlights the big data era that includes social media, sensors, and images where Volume, Velocity, and Variety are the norms. One related key trend is the price of hardware, which dropped from $190/GB in 1980 to $0.07/GB in 2010. This has been a key enabler in big data adoption.
According to the 2014 IDC digital universe report, the growth trend will continue and double in size every two years. In 2013, about 4.4 zettabytes were created and in 2020 the forecast is 44 zettabytes, which is 44 trillion gigabytes (source: http://www.emc.com/leadership/digital-universe/2014iview/executive-summary.htm).

Source: Microsoft TechEd North America 2014 From Zero to Data Insights from HDInsight on Microsoft Azure
While we generated 4.4 zettabytes of data in 2013, only five percent of it was actually analyzed and this is the real opportunity of big data. The IDC report forecasts that by 2020, we will analyze over 35 percent of generated data by making smarter sensors and devices. This data will drive new consumer and business behavior that will drive trillions of dollars in opportunity for IT vendors and organizations analyzing this data.
Let's look at some real use cases that have benefited from Big Data:
IT systems in all major banks are constantly monitoring fraudulent activities and alerting customers within milliseconds. These systems apply complex business rules and analyze historical data, geography, type of vendor, and other parameters based on the customer to get accurate results.
Commercial drones are transforming agriculture by analyzing real-time aerial images and identifying the problem areas. These drones are cheaper and more efficient than satellite imagery, as they fly under the clouds and can take images anytime. They identify irrigation issues related to water, pests, or fungal infections, which thereby, increases the crop productivity and quality. These drones are equipped with technology to capture high quality images every second and transfer them to a cloud hosted big data system for further processing. (You can refer to http://www.technologyreview.com/featuredstory/526491/agricultural-drones/.)
Developers of the blockbuster Halo 4 game were tasked to analyze player preferences and support an online tournament in the cloud. The game attracted over 4 million players in its first five days after the launch. The development team had to also design a solution that kept track of leader board for the global Halo 4 Infinity Challenge, which was open to all players. The development team chose the Azure HDInsight service to analyze the massive amounts of unstructured data in a distributed manner. The results from HDInsight were reported using Microsoft SQL Server PowerPivot and Sharepoint, and business was extremely happy with the response times for their queries, which was a few hours, or less (source: http://www.microsoft.com/casestudies/Windows-Azure/343-Industries/343-Industries-Gets-New-User-Insights-from-Big-Data-in-the-Cloud/710000002102).
Apache Hadoop is the leading open source big data platform that can store and analyze massive amounts of structured and unstructured data efficiently and can be hosted on low cost commodity hardware. There are other technologies that complement Hadoop under the big data umbrella such as MongoDB, a NoSQL database; Cassandra, a document database; and VoltDB, an in-memory database. This section describes Apache Hadoop core concepts and its ecosystem.
Doug Cutting created Hadoop; he named it after his kid's stuffed yellow elephant and it has no real meaning. In 2004, the initial version of Hadoop was launched as Nutch Distributed Filesystem (NDFS). In February 2006, Apache Hadoop project was officially started as a standalone development for MapReduce and HDFS. By 2008, Yahoo adopted Hadoop as the engine of its Web search with a cluster size of around 10,000. In the same year, 2008, Hadoop graduated at top-level Apache project confirming its success. In 2012, Hadoop 2.x was launched with YARN, enabling Hadoop to take on various types of workloads.
Today, Hadoop is known by just about every IT architect and business executive as the open source big data platform and is used across all industries and sizes of organizations.
In this section, we will explore what Hadoop actually comprises. At the basic-level, Hadoop consists of the following four layers:
Hadoop Common: A set of common libraries and utilities used by Hadoop modules.
Hadoop Distributed File System (HDFS): A scalable and fault tolerant distributed filesystem to data in any form. HDFS can be installed on commodity hardware and replicates the data three times (which is configurable) to make the filesystem robust and tolerate partial hardware failures.
Yet Another Resource Negotiator (YARN): From Hadoop 2.0, YARN is the cluster management layer to handle various workloads on the cluster.
MapReduce: MapReduce is a framework that allows parallel processing of data in Hadoop. It breaks a job into smaller tasks and distributes the load to servers that have the relevant data. The framework effectively executes tasks on nodes where data is present thereby reducing the network and disk I/O required to move data.
The following figure shows you the high-level Hadoop 2.0 core components:
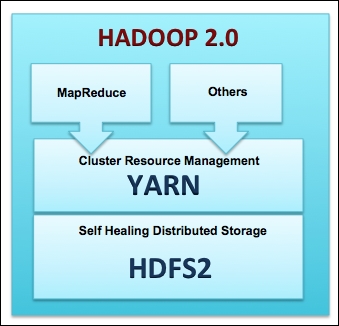
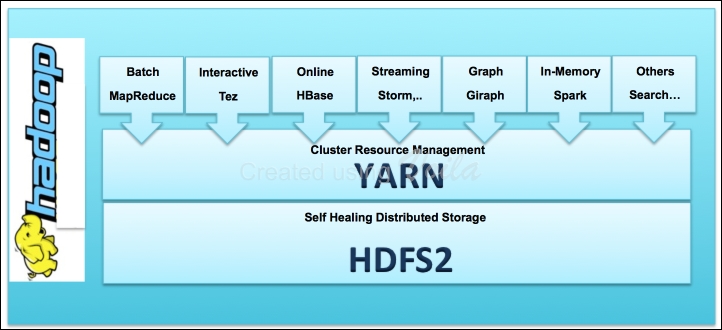
The preceding figure shows you the components that form the basic Hadoop framework. In past few years, a vast array of new components have emerged in the Hadoop ecosystem that take advantage of YARN making Hadoop faster, better, and suitable for various types of workloads. The following figure shows you the Hadoop framework with these new components:
Each Hadoop cluster has the following two types of machines:
A network switch interconnects the master and worker nodes.
Note
It is recommended that you have separate servers for each of the master nodes; however, it is possible to deploy all the master nodes onto a single server for development or testing environments.
The following figure shows you the typical Hadoop cluster layout:
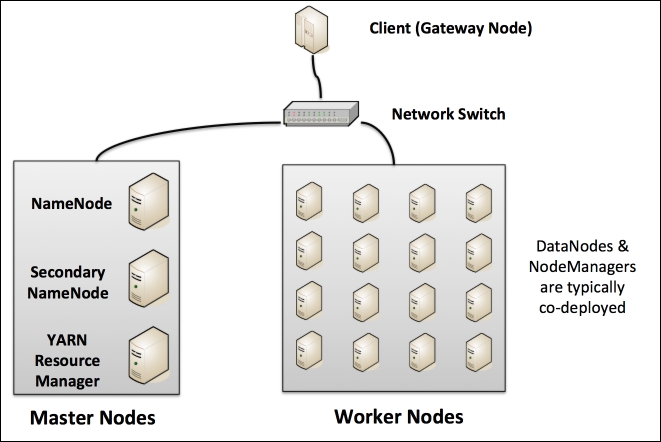
Let's review the key functions of the master and worker nodes:
NameNode: This is the master for the distributed filesystem and maintains metadata. This metadata has the listing of all the files and the location of each block of a file, which are stored across the various slaves. Without a NameNode, HDFS is not accessible. From Hadoop 2.0 onwards, NameNode HA (High Availability) can be configured with active and standby servers.
Secondary NameNode: This is an assistant to NameNode. It communicates only with NameNode to take snapshots of HDFS metadata at intervals that is configured at cluster level.
YARN ResourceManager: This server is a scheduler that allocates available resources in the cluster among the competing applications.
Worker nodes: The Hadoop cluster will have several worker nodes that handle two types of functions: HDFS DataNode and YARN NodeManager. It is typical that each worker node handles both these functions for optimal data locality. This means that processing happens on the data that is local to the node and follows the principle "move code and not data".
This section will look into the distributed filesystem in detail. The following figure shows you a Hadoop cluster with four data nodes and NameNode in HA mode. The NameNode is the bookkeeper for HDFS and keeps track of the following details:
List of all files in HDFS
Blocks associated with each file
Location of each block including the replicated blocks
Starting with HDFS 2.0, NameNode is no longer a single point of failure that eliminates any business impact in case of hardware failures.
Note
Secondary NameNode is not required in NameNode HA configuration, as the Standby NameNode performs the tasks of the Secondary NameNode.
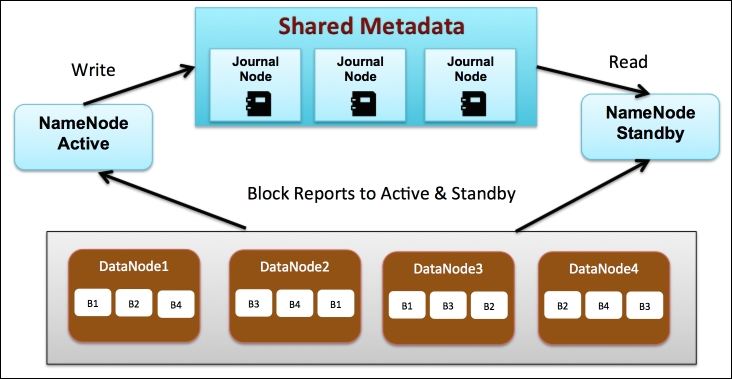
Next, let's review how data is written and read from HDFS.
When a file is ingested to Hadoop, it is first divided into several blocks where each block is typically 64 MB in size that can be configured by administrators. Next, each block is replicated three times onto different data nodes for business continuity so that even if one data node goes down, the replicas come to the rescue. The replication factor is configurable and can be increased or decreased as desired. The preceding figure shows you an example of a file called MyBigfile.txt that is split into four blocks B1, B2, B3, and B4. Each block is replicated three times across different data nodes.
The active NameNode is responsible for all client operations and writes information about the new file and blocks the shared metadata and the standby NameNode reads from this shared metadata. The shared metadata requires a group of daemons called journal nodes.
When a request to read a file is made, the active NameNode refers to the shared metadata in order to identify the blocks associated with the file and the locations of those blocks. In our example, the large file, MyBigfile.txt, the NameNode will return a location for each of the four blocks B1, B2, B3, and B4. If a particular data node is down, then the nearest and not so busy replica's block is loaded.
Let's look at the commonly used Hadoop commands used to access the distributed filesystem:
|
Command |
Syntax |
|---|---|
|
Listing of files in a directory |
|
|
Create a new directory |
|
|
Copy a file from a local machine to Hadoop |
|
|
Copy a file from Hadoop to a local machine |
|
|
Tail last few lines of a large file in Hadoop |
|
|
View the complete contents of a file in Hadoop |
|
|
Remove a complete directory from Hadoop |
|
|
Check the Hadoop filesystem space utilization |
|
Note
For a complete list of Hadoop commands, refer to the link http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/FileSystemShell.html.
Now that we are able to save the large file, the next obvious need would be to process this file and get something useful out of it such as a summary report. Hadoop YARN, which stands for Yet Another Resource Manager, is designed for distributed data processing and is the architectural center of Hadoop. This area in Hadoop has gone through a major rearchitecturing in Version 2.0 of Hadoop and YARN has enabled Hadoop to be a true multiuse data platform that can handle batch processing, real-time streaming, interactive SQL, and is extensible for other custom engines. YARN is flexible, efficient, provides resource sharing, and is fault-tolerant.
YARN consists of a central ResourceManager that arbitrates all available cluster resources and per-node NodeManagers that take directions from the ResourceManager and are responsible for managing resources available on a single node. NodeManagers have containers that perform the real computation.
ResourceManager has the following main components:
Scheduler: This is responsible for allocating resources to various running applications, subject to constraints of capacities and queues that are configured
Applications Manager: This is responsible for accepting job submissions, negotiating the first container for executing the application, which is called "Application Master"
NodeManager is the worker bee and is responsible for managing containers, monitoring their resource usage (CPU, memory, disk, and network), and reporting the same to the ResourceManager. The two types of containers present are as follows:
Application Master: This is one per application and has the responsibility of negotiating with appropriate resource containers from the ResourceManager, tracking their status, and monitoring their progress.
Application Containers: This gets launched as per the application specifications. An example of an application is MapReduce, which is used for batch processing.
Let's understand how the various components in YARN actually interact with a walkthrough of an application lifecycle. The following figure shows you a Hadoop cluster with one master ResourceManager and four worker NodeManagers:
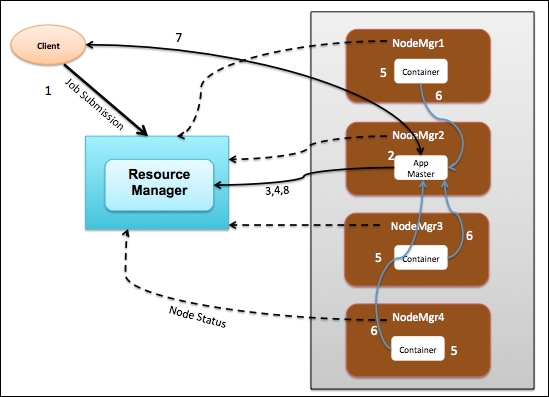
Let's walkthrough the sequence of events in a life of an application such as MapReduce job:
The client program submits an application request to the ResourceManager and provides the necessary specifications to launch the application.
The ResourceManager takes over the responsibility to identify a container to be started as an Application Master and then launches the Application Master, which in our case is NodeManager 2 (NodeMgr2).
The Application Master on boot-up registers with the ResourceManager. This allows the client program to get visibility on which Node is handling the Application Master for further communication.
The Application Master negotiates with the ResourceManager for containers to perform the actual tasks. In the preceding figure, the application master requested three resource containers.
On successful container allocations, the Application Master launches the container by providing the specifications to the NodeManager.
The application code executing within the container provides status and progress information to the Application Master.
During the application execution, the client who submits the program communicates directly with the Application Master to get status, progress, and updates.
After the application is complete, the Application Master deregisters with the ResourceManager and shuts down, allowing all the containers associated with that application to be repurposed.
Prior to Hadoop 2.0, MapReduce was the standard approach to process data on Hadoop. With the introduction of YARN, which has a flexible architecture, various other types of workload are now supported and are now great alternatives to MapReduce with better performance and management. Here is a list of commonly used workloads on top of YARN:
The combination of HDFS, which is a distributed data store, and YARN, which is a flexible data operating system, make Hadoop a true multiuse data platform enabling modern data architecture.
Apache Hadoop is an open source software, and is repackaged and distributed by vendors who offer enterprise support and additional applications to manage Hadoop. The following is the listing of popular commercial distributions:
Amazon Elastic MapReduce (http://aws.amazon.com/elasticmapreduce/)
Cloudera (http://www.cloudera.com/content/cloudera/en/home.html)
EMC PivotalHD (http://gopivotal.com/)
Hortonworks HDP (http://hortonworks.com/)
IBM BigInsights (http://www-01.ibm.com/software/data/infosphere/biginsights/)
MapR (http://mapr.com/)
Microsoft HDInsight (cloud: http://azure.microsoft.com/en-us/services/hdinsight/)
HDInsight is an enterprise-ready distribution of Hadoop that runs on Windows servers and on Azure HDInsight cloud service (PaaS). It is a 100 percent Apache Hadoop-based service in the cloud. HDInsight was developed in partnership with Hortonworks and Microsoft. Enterprises can now harness the power of Hadoop on Windows servers and Windows Azure cloud service.
The following are the key differentiators for HDInsight distribution:
Enterprise-ready Hadoop: HDInsight is backed by Microsoft support, and runs on standard Windows servers. IT teams can leverage Hadoop with the Platform as a Service (PaaS) reducing the operations overhead.
Analytics using Excel: With Excel integration, your business users can visualize and analyze Hadoop data in compelling new ways with an easy to use familiar tool. The Excel add-ons PowerBI, PowerPivot, PowerQuery, and PowerMap integrate with HDInsight.
Develop in your favorite language: HDInsight has powerful programming extensions for languages, including .NET, C#, Java, and more.
Scale using cloud offering: Azure HDInsight service enables customers to scale quickly as per the project needs and have a seamless interface between HDFS and Azure Blob storage.
Connect on-premises Hadoop cluster with the cloud: With HDInsight, you can move Hadoop data from an on-site data center to the Azure cloud for backup, dev/test, and cloud bursting scenarios.
Includes NoSQL transactional capabilities: HDInsight also includes Apache HBase, a columnar NoSQL database that runs on top of Hadoop and allows large online transactional processing (OLTP).
HDInsight Emulator: The HDInsight Emulator provides a local development environment for Azure HDInsight without the need for a cloud subscription. This can be installed using the Microsoft Web Platform installer.
HDInsight is an Apache Hadoop-based service. Let's review the stack in detail. The following figure shows you the stacks that make HDInsight:

The various components are as follows:
Apache Hadoop: This is an open source software that allows distributed storage and computation. Hadoop is reliable and scalable.
Hortonworks Data Platform (HDP): This is an open source Apache Hadoop data platform, architected for the enterprise on Linux and Windows servers. It has a comprehensive set of capabilities aligned to the following functional areas: data management, data access, data governance, security, and operations. The following are the key Apache Software Foundation (ASF) projects have been led and are included in HDP:
Apache Falcon: Falcon is a framework used for simplifying data management and pipeline processing in Hadoop. It also enables disaster recovery and data retention use cases.
Apache Tez: Tez is an extensible framework used for building YARN-based, high performance batch, and interactive data processing applications in Hadoop. Projects such as Hive and Pig can leverage Tez and get an improved performance.
Apache Knox: Knox is a system that provides a single point of authentication and access for Hadoop services in a cluster.
Apache Ambari: Ambari is an operational framework used for provisioning; managing, and monitoring Apache Hadoop clusters.
Azure HDInsight: This has been built in partnership with Hortonworks on top of HDP for Microsoft Servers and Azure cloud service. It has the following key additional value added services provided by Microsoft:
Integration with Azure Blob storage Excel, PowerBI, SQL Server, .Net, C#, Java, and others
Azure PowerShell, which is a powerful scripting environment that can be used to control, automate, and develop workloads in HDInsight
Apache Hadoop can be deployed on Windows either on physical servers or in the cloud. This section reviews the various options for Hadoop on Windows.
Microsoft Azure is a cloud solution that allows one to rent, compute, and store resources on-demand for the duration of a project. HDInsight is a service that utilizes these elastic services and allows us to quickly create a Hadoop cluster for big data processing. HDInsight cluster is completely integrated with low-cost Blob storage and allows other programs to directly leverage data in Blob storage.
Microsoft HDInsight Emulator for Azure is a single node Hadoop cluster with key components installed and configured that is great for development, initial prototyping, and promoting code to production cluster.
HDInsight Emulator requires a 64-bit version of Windows and one of the following operating systems will suffice: Windows 7 Service Pack 1, Windows Server 2008 R2 Service Pack1, Windows 8, or Windows Server 2012.
HDP for Windows can be deployed on multiple servers. With this option, you have complete control over the servers and can scale as per your project needs in your own data center. This option, however, does not have the additional value added features provided by HDInsight.
HDP 2.2 requires a 64-bit version of Windows Server 2008 or Windows Server 2012.
We live in a connected digital era and are witnessing unprecedented growth of data. Organizations that are able to analyze Big Data are demonstrating significant return on investment by detecting fraud, improved operations, and reduced time to analyze a scale-out architecture. Apache Hadoop is the leading open source big data platform with strong and diverse ecosystem projects that enable organizations to build a modern data architecture. At the core, Hadoop has two key components—Hadoop Distributed File System also known as HDFS and a cluster resource manager known as YARN. YARN has enabled Hadoop to be a true multiuse data platform that can handle batch processing, real-time streaming, interactive SQL, and others.
Microsoft HDInsight is an enterprise-ready distribution of Hadoop on the cloud that has been developed in partnership with Hortonworks and Microsoft. Key benefits of HDInsight include: scale up/down as required, analysis using Excel, connect on-premise Hadoop cluster with the cloud, and flexible programming and support for NoSQL transactional database.
In the next chapter, we will take a look at how to build an Enterprise Data Lake using HDInsight.
