There can be as many distinct questions that can be asked about any given chunk of code as there are chunks of code to ask about—even very simple code, living in a complex system, can raise questions in response to questions, and more questions in response to those questions.
If there isn't an obvious starting point, starting with the following really basic questions is a good first step:
- Who will be using the functionality?
- What will they be doing with it?
- When, and where, will they have access to it?
- What problem is it trying to solve? For example, why do they need it?
- How does it have to work? If detail is lacking, breaking this one down into two separate questions is useful:
- What should happen if it executes successfully?
- What should happen if the execution fails?
Teasing out more information about the whole system usually starts with something as basic as the following questions:
- What other parts of the system does this code interact with?
- How does it interact with them?
Having identified all of the moving parts, thinking about "What happens if…" scenarios is a good way to identify potential points where things will break, risks, and dangerous interactions. You can ask questions such as the following:
- What happens if this argument, which expects a number, is handed a string?
- What happens if that property isn't the object that's expected?
- What happens if some other object tries to change this object while it's already being changed?
Whenever one question has been answered, simply ask, What else? This can be useful for verifying whether the current answer is reasonably complete.
Let's see this process in action. To provide some context, a new function is being written for a system that keeps track of mineral resources on a map-grid, for three resources: gold, silver, and copper. Grid locations are measured in meters from a common origin point, and each grid location keeps track of a floating-point number, from 0.0 to 1.0, which indicates how likely it is that resource will be found in the grid square. The developmental dataset already includes four default nodes - at (0,0), (0,1), (1,0), and (1,1) - with no values, as follows:
The system already has some classes defined to represent individual map nodes, and functions to provide basic access to those nodes and their properties, from whatever central data store they live in:
Constants, exceptions, and functions for various purposes already exist, as follows:
- node_resource_names: This contains all of the resource names that the system is concerned with, and can be thought of and treated as a list of strings: ['gold','silver','copper']
- NodeAlreadyExistsError: An exception that will be raised if an attempt is made to create a MapNode that already exists
- NonexistentNodeError: An exception that will be raised if a request is made for a MapNode that doesn't exist
- OutOfMapBoundsError: An exception that will be raised if a request is made for a MapNode that isn't allowed to exist in the map area
- create_node(x,y): Creates and returns a new, default MapNode, registering it in the global dataset of nodes in the process
- get_node(x,y): Finds and returns a MapNode at the specified (x, y) coordinate location in the global dataset of available nodes
A developer makes an initial attempt at writing the code to set a value for a single resource at a given node, as a part of a project. The resulting code looks as follows (assume that all necessary imports already exist):
def SetNodeResource(x, y, z, r, v):
n = get_node(x,y)
n.z = z
n.resources.add(r, v)
This code is functional, from the perspective that it will do what it's supposed to (and what the developer expected) for a set of simple tests; for example, executing, as follows:
SetNodeResource(0,0,None,'gold',0.25) print(get_node(0,0)) SetNodeResource(0,0,None,'silver',0.25) print(get_node(0,0)) SetNodeResource(0,0,None,'copper',0.25) print(get_node(0,0))
The results are in the following output:
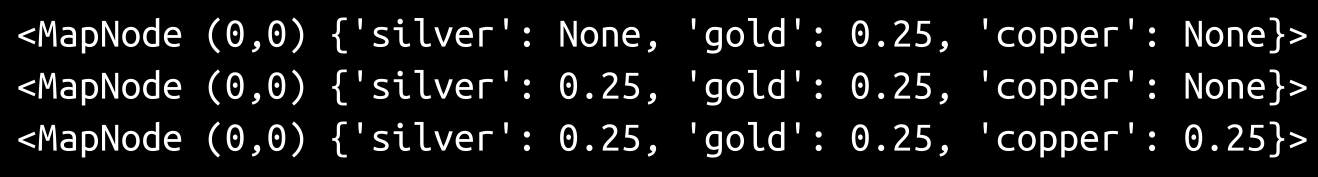
By that measure, there's nothing wrong with the code and its functions, after all. Now, let's ask some of our questions, as follows:
- Who will be using this functionality?: The function may be called, by either of two different application front-ends, by on-site surveyors, or by post-survey assayers. The surveyors probably won't use it often, but if they see obvious signs of a deposit during the survey, they're expected to log it with a 100% certainty of finding the resource(s) at that grid location; otherwise, they'll leave the resource rating completely alone.
- What will they be doing with it?: Between the base requirements (to set a value for a single resource at a given node) and the preceding answer, this feels like it's already been answered.
- When, and where, do they have access to it?: Through a library that's used by the surveyor and assayer applications. No one will use it directly, but it will be integrated into those applications.
- How should it work?: This has already been answered, but raises the question: Will there ever be a need to add more than one resource rating at a time? That's probably worth nothing, if there's a good place to implement it.
- What other parts of the system does this code interact with?: There's not much here that isn't obvious from the code; it uses MapNode objects, those objects' resources, and the get_node function.
- What happens if an attempt is made to alter an existing MapNode?: With the code as it was originally written, this behaves as expected. This is the happy path that the code was written to handle, and it works.
- What happens if a node doesn't already exist?: The fact that there is a NonexistentNodeError defined is a good clue that at least some map operations require a node to exist before they can complete. Execute a quick test against that by calling the existing function, as follows:
SetNodeResource(0,6,None,'gold',0.25)
The preceding command results in the following:

This is the result because the development data doesn't have a MapNode at that location yet.
- What happens if a node can't exist at a given location?: Similarly, there's an OutOfMapBoundsError defined. Since there are no out-of-bounds nodes in the development data, and the code won't currently get past the fact that an out-of-bounds node doesn't exist, there's no good way to see what happens if this is attempted.
- What happens if the z-value isn't known at the time?: Since the create_node function doesn't even expect a z-value, but MapNode instances have one, there's a real risk that calling this function on an existing node would overwrite an existing z-altitude value, on an existing node. That, in the long run, could be a critical bug.
- Does this meet all of the various developmental standards that apply?: Without any details about standards, it's probably fair to assume that any standards that were defined would probably include, at a minimum, the following:
- Naming conventions for code elements, such as function names and arguments; an existing function at the same logical level as get_node, using SetNodeResources as the name of the new function, while perfectly legal syntactically, may be violating a naming convention standard.
- At least some of the effort towards documentation, of which there's none.
- Some inline comments (maybe), if there is a need to explain parts of the code to future readers—there are none of these also, although, given the amount of code in this version and the relatively straightforward approach, it's arguable whether there would be any need.
- What should happen if the execution fails?: It should probably throw explicit errors, with reasonably detailed error messages, if something fails during execution.
- What happens if an invalid value is passed for any of the arguments?: Some of them can be tested by executing the current function (as was done previously), while supplying invalid arguments—an out-of -range number first, then an invalid resource name.
Consider the following code, executed with an invalid number:
SetNodeResource(0,0,'gold',2)
The preceding code results in the following output:

Also, consider the following code, with an invalid resource type:
SetNodeResource(0,0,'tin',0.25)
The preceding code results in the following:

The function itself can either succeed or raise an error during execution, judging by these examples; so, ultimately, all that really needs to happen is that those potential errors have to be accounted for, in some fashion.
Other questions may come to mind, but the preceding questions are enough to implement some significant changes. The final version of the function, after considering the implications of the preceding answers and working out how to handle the issues that those answers exposed, is as follows:
def set_node_resource(x, y, resource_name,
resource_value, z=None):
"""
Sets the value of a named resource for a specified
node, creating that node in the process if it doesn't
exist.
Returns the MapNode instance.
Arguments:
- x ................ (int, required, non-negative) The
x-coordinate location of the node
that the resource type and value is
to be associated with.
- y ................ (int, required, non-negative) The
y-coordinate location of the node
that the resource type and value is
to be associated with.
- z ................ (int, optional, defaults to None)
The z-coordinate (altitude) of the
node.
- resource_name .... (str, required, member of
node_resource_names) The name of the
resource to associate with the node.
- resource_value ... (float, required, between 0.0 and 1.0,
inclusive) The presence of the
resource at the node's location.
Raises
- RuntimeError if any errors are detected.
"""
# Get the node, if it exists
try:
node = get_node(x,y)
except NonexistentNodeError:
# The node doesn't exist, so create it and
# populate it as applicable
node = create_node(x, y)
# If z is specified, set it
if z != None:
node.z = z
# TODO: Determine if there are other exceptions that we can
# do anything about here, and if so, do something
# about them. For example:
# except Exception as error:
# # Handle this exception
# FUTURE: If there's ever a need to add more than one
# resource-value at a time, we could add **resources
# to the signature, and call node.resources.add once
# for each resource.
# All our values are checked and validated by the add
# method, so set the node's resource-value
try:
node.resources.add(resource_name, resource_value)
# Return the newly-modified/created node in case
# we need to keep working with it.
return node
except Exception as error:
raise RuntimeError(
'set_node_resource could not set %s to %0.3f '
'on the node at (%d,%d).'
% (resource_name, resource_value, node.x,
node.y)
)
Stripping out the comments and documentation for the moment, this may not look much different from the original code—only nine lines of code were added—but the differences are significant, as follows:
- It doesn't assume that a node will always be available.
- If the requested node doesn't exist, it creates a new one to operate on, using the existing function defined for that purpose.
- It doesn't assume that every attempt to add a new resource will succeed.
- When such an attempt fails, it raises an error that shows what happened.
All of these additional items are direct results of the questions asked earlier, and of making conscious decisions on how to deal with the answers to those questions. That kind of end result is where the difference between the programming and software engineering mindsets really appears.

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Singapore
Singapore
 Canary Islands
Canary Islands
 Hungary
Hungary
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 South Korea
South Korea
 Turkey
Turkey
 Switzerland
Switzerland
 Colombia
Colombia
 Taiwan
Taiwan
 Chile
Chile
 Norway
Norway
 Ecuador
Ecuador
 Indonesia
Indonesia
 New Zealand
New Zealand
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 Austria
Austria
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 South Africa
South Africa
 Malaysia
Malaysia
 Japan
Japan
 Slovakia
Slovakia
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand



















