


















 Download code from GitHub
Download code from GitHub
Chapter 1: Google Cloud Platform Developer Fundamentals
In this first chapter, you will learn about the fundamentals and best practices of developing in Google Cloud, and how these differ from traditional on-premises application development. You will learn about concepts that allow you to take your developments to decoupled, resilient, highly available, and scalable architectures, in addition to delegating the most significant responsibilities to Google's self-managed services in a secure way.
In this chapter, we're going to cover the following main topics:
- The differences between IaaS, CaaS, PaaS, and serverless
- The fundamentals of a microservices ecosystem
- Delegating responsibilities to Google Cloud services
The basics that every developer should know about Google Cloud infrastructure
There are many people who think that programming in the cloud is simply a matter of programming in another environment, but I could not disagree more with that statement.
Depending on which cloud service you use, for example, a virtual machine, Platform as a Service (PaaS), or Function as a Service (FaaS), your code could need to handle life cycles and unexpected program terminations.
When you program in the cloud, you should pay attention not only to good coding but also to which platform or service you are using, since many things can change depending on this factor.
For example, programming in an IaaS service is different from programming in a CaaS or FaaS service. (We will explain what these acronyms mean very shortly.)
In this section, you will learn about the most important differences between the different services offered in the cloud, what the regions and zones are, and why concepts such as high availability and latency are so important in a cloud solution.
Regions and zones
A region is a specific location where you can choose to host your services and computing resources with one or more zones.
A compute cluster (a layer between regions and zones) is a physical infrastructure in a data center with independent power, cooling, network, and security services.
A zone can be hosted in one or more clusters and allows the resource load to be handled and balanced within a region.
Choosing multiple zones and regions allows the application to reduce latency to final users and handle failures, transforming your application into a high-availability service.
If a specific zone presents an outage, your application can keep operating using another zone.
If a specific region presents an outage, your application can keep operating using another zone in another region.
Having instances of your application in multiple regions and zones increases your costs as well as your application's availability.
What is X as a Service?
One of the most important things before starting development in the cloud is to understand what the different types of service are and how the shared responsibility model works. But when we start working in the cloud, we see acronyms everywhere, such as the following:
- IaaS: Infrastructure as a Service
- CaaS: Container as a Service
- PaaS: Platform as a Service
- FaaS: Function as a Service
- SaaS: Software as a Service
We will start with IaaS. In this case, the cloud provider gives you an infrastructure, generally represented as a virtual machine with an operating system based on a virtualized image. In this kind of service, there is a charge for use. An example of IaaS on Google Cloud Platform (GCP) is GCE, or Google Compute Engine.
In the case of CaaS, the cloud provider gives us an environment where we can deploy our application images. In this kind of service, there is a charge for use.
With PaaS, the cloud provider will provide us with a platform where we can load a previously compiled artifact and configure exposure rules for services and versions. In this kind of service, there is a charge for use. An example of PaaS on GCP is Google App Engine.
If we decide to use FaaS, the cloud provider will give us a platform where we will only have to code and configure the corresponding dependencies, without the need to compile or generate an image. In this kind of service, there is a charge for the number of executions and the time of these executions. An example of FaaS on GCP is Cloud Functions.
And finally, in the case of SaaS, the cloud provider will deliver the software in such a way that the user can directly consume the functionality. For this kind of service, there may be a charge for use or a subscription. An example of SaaS on GCP is Data Studio:

Figure 1.1 – From IaaS to SaaS
When you choose to code using IaaS, you should take care of operating system patches and updates, accepting more responsibilities but also having more options to customize your server. That means more management tasks.
When you choose to code using PaaS, you only need to take care of the business logic of your application, accepting fewer infrastructure responsibilities but also having fewer options to customize your server.
As explained in the introduction to this chapter, each service involves different considerations when we start programming.
Among the most important concepts from the preceding list of services is the control of the execution life cycle of our applications. This was not a concept we needed when we programmed on IaaS, because normally, the servers were always on and it was not necessary to worry about telling the server that our asynchronous executions had finished successfully to turn it off.
This is just one of many points that we will review in this chapter and that will help you to program applications in the different GCP services.
How to reduce latency to your end users
Generally, when we have to solve a problem through coding, the first thing we worry about is that the code does what it has to do, no matter how we achieve it. After this, we focus on ensuring that the code does not have any security vulnerabilities, and finally, we might try to optimize or refactor various methods or functions in the interest of efficiency.
In some cases, this is not enough, and we must plan not only how our code will run in the cloud but also where it will run.
You will probably wonder why some streaming or video services are so fast and others so slow. Various factors may be responsible, such as the speed of the user's internet connection, which unfortunately is not something we can control. However, there is a factor that we can control, and that is how close we can bring the content to our end users.
When a user enters a web page to consume content, and in this particular case we are going to assume that the user decides to consume a video, the user has to go to the source, in this case, the server, to access the content.
Depending on how far the user is from the server where the video is stored, the speed with which they download the content to their computer may be higher or lower. This is known as latency.
The distance between the source and the consumer directly affects the latency, and that is why the closer we bring the source to the consumer, the lower the latency and the higher the speed of consumption of the information.
In GCP (and in most clouds), there is the concept of a Content Delivery Network (CDN), which acts as a content cache. This means that the content is replicated on a different server than the originating one, in order to reduce the requests to the original server and also, in this case, to bring the content closer to the end consumer in order to increase performance.
When content is consumed for the first time, Cloud CDN, the Google Cloud solution CDN implementation, will consult the content on the server to find the source of origin and will replicate it in its nodes so that in future requests, the content is available to be delivered directly to users.
For this feature, Cloud CDN uses a cache key, based on the query URL, to determine whether or not the content the user is trying to access is already replicated on the CDN nodes. This is called a cache hit. When the content is not found, this action is called a cache miss. If you need to configure how long the cache content will exist on the CDN node before revalidating the content at the origin, you can use the Time to Live (TTL) configuration in seconds. The default TTL for content caching is 3,600 seconds (1 hour) and the maximum allowed value is 1 year:
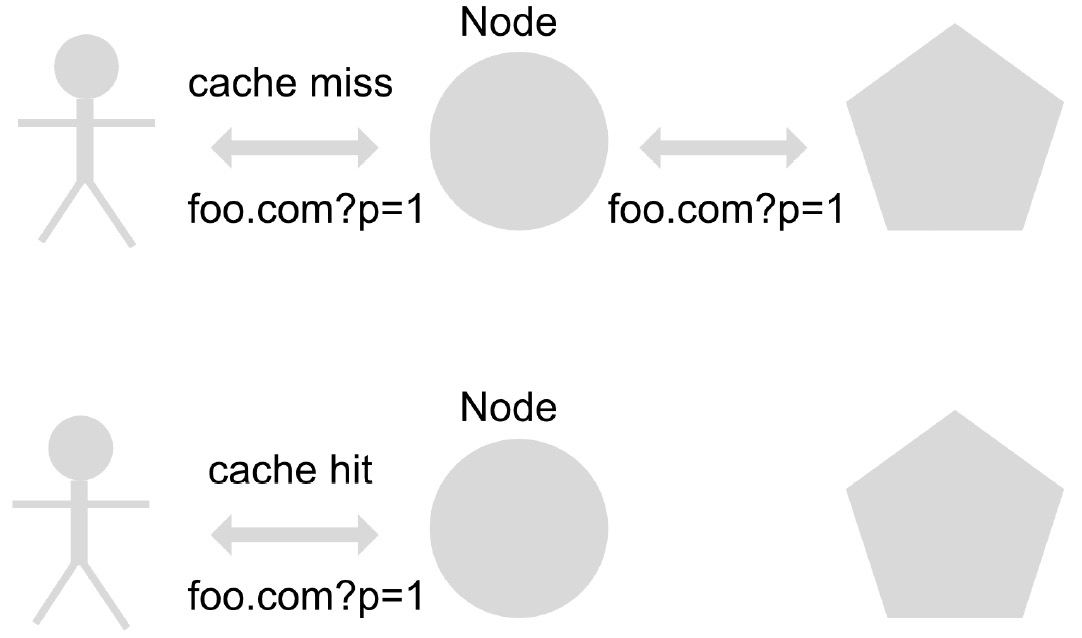
Figure 1.2 – CDN workflow
In summary, Cloud CDN is a solution that allows us to bring content efficiently from the source to consumers, such as images, videos, and files, by replicating the content in different nodes worldwide in order to reduce response times for the final consumer.
Graceful shutdowns
In the world of microservices applications, containerized applications controlled by an orchestrator are generally used. The best-known one is Kubernetes. Kubernetes has the ability to shut down any of the existing microservices (called pods in a Kubernetes cluster) at any time in order to free up resources or maintain the health of the application.
If the design of the application does not support graceful shutdowns, we could run into problems, such as the execution of a call to our application not being completed. That is why it is important to control shutdowns gracefully via the SIGTERM execution termination code.
When our application receives the termination code from SIGTERM execution, our application must close all the connections it has open at that moment and save any information that is useful for maintaining the current state prior to the end of execution.
In Kubernetes, this can be done with the preStop hook, which we will explore in Chapter 5, Virtual Machines and Container Applications on Google Cloud Platform.
But Kubernetes workloads are not the only case where we need to handle graceful shutdowns. For example, GCP has a GCE virtual machine type called a preemptible VM instance. A preemptible VM instance can be purchased with a discount of up to 80% as long as you accept that the instance will terminate after 24 hours.
In that case, you can handle a graceful shutdown using a shutdown script. This script will be executed right before a virtual machine instance is stopped or restarted, allowing instances to perform tasks such as syncing with other applications or exporting logs.
You can also use a shutdown script when you are using other GCP solutions, such as Managed Instance Groups (MIGs), in order to gracefully shut down your instances when the MIG performs a scale-out operation (deleting instances inside the group).
Top tips for developing and implementing resilient and scalable applications
Having presented some of the fundamentals of programming in the cloud, it is important to now address one of the topics that is probably the most mentioned but least understood: microservices. In this section, we briefly introduce the microservices ecosystem and explain how to correctly manage user sessions, create traceability logs in order to detect and solve errors, implement retries in order to make our solution reliable, support consumption peaks through autoscaling, and reduce server consumption through information caching.
Microservice ecosystems
Microservices are an architectural design pattern that allows the separation of responsibilities into smaller applications, which can be programmed in different programming languages, can be independent of each other, and have the possibility of scaling both vertically (increasing CPU and memory) and horizontally (creating more instances) independently in order to optimize the cluster resources.
Although microservices have been widely accepted by both start-ups and established organizations, on account of their great advantages, such as decoupling business logic and better code intelligibility, they also have their disadvantages, which are mostly focused on problems of communication management, networking, and observability.
It is therefore important to decide whether the use of a microservices pattern is really necessary. The size of the solution and clarity in the separation of responsibilities are fundamental factors when making this decision. For simpler or smaller solutions, it is perfectly acceptable to use a monolithic-type architecture pattern, where instead of having many small, orchestrated applications, you have just one large application with full responsibility for the solution.
In Chapter 3, Application Modernization using Google Cloud, we will go into greater detail on the technologies used in GCP in order to support an ecosystem of microservices, mitigating the disadvantages mentioned previously:
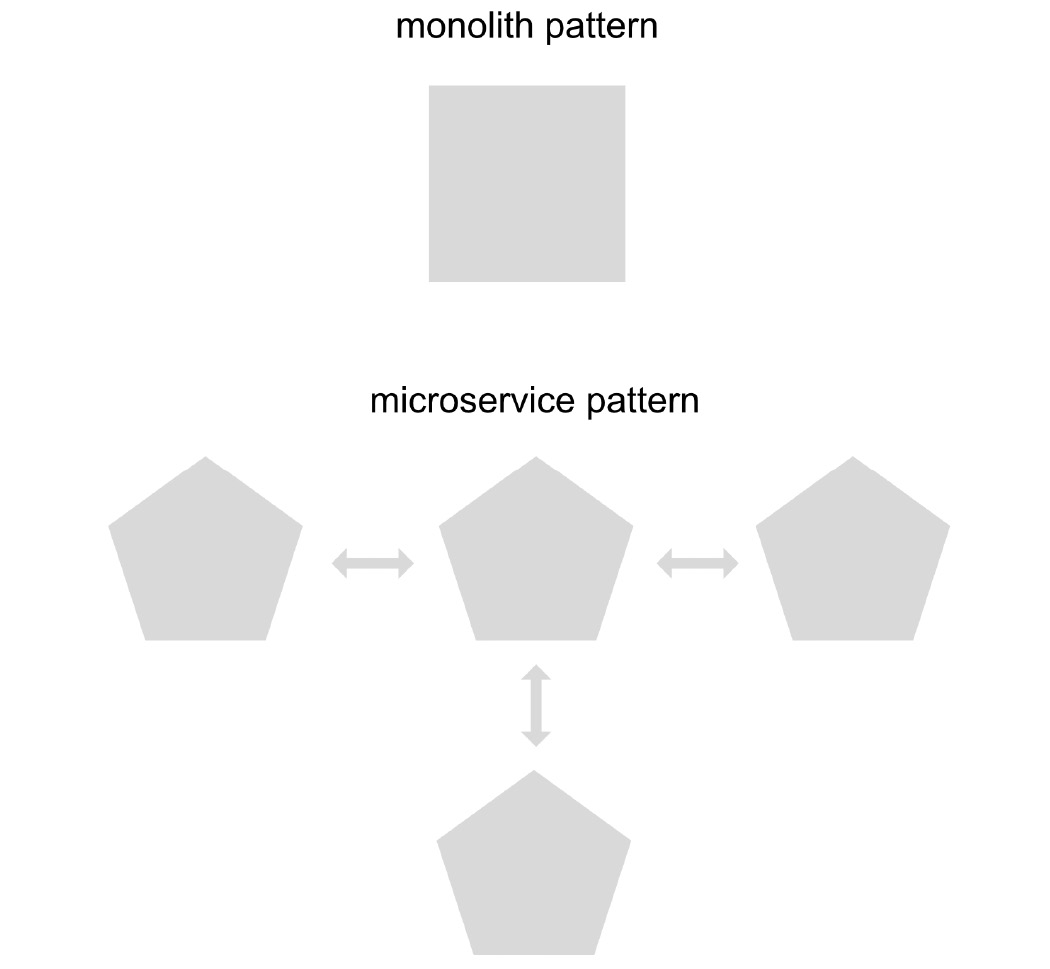
Figure 1.3 – Monolith versus microservice pattern
Handling user sessions and the importance of stateless applications in the autoscaling world
Probably, if you are a developer who comes from an old-school background, you will be familiar with managing user sessions on the server side. For a long time, this was how you knew whether or not a user was already authenticated in an application, consulting the server for this information. These types of applications are called stateful.
With the advent of the cloud and the ease of being able to create and destroy instances, horizontal autoscaling became very popular, but it also brought with it a big problem for applications that already existed and were based on querying the server status.
Horizontal scaling consists of the ability to create and destroy instances of our application to deal with high demand at peak times. One example of a trigger for horizontal scaling could be the number of calls received in a specific period of time.
Stateful applications don't work well using horizontal scaling because in this kind of application, the state information is stored in the instance itself, leaving all the other instances inside the horizontal scaling group without the state information. One example of this is when a user with a user session created and stored in one instance of the application accesses another instance of the group without the information from this user session.
To solve this problem, we can use access tokens, which enable session information to be maintained by the user, not by the server. Applications that store state information outside the instance itself are called stateless.
When a user logs in for the first time, an access token is generated, which is signed by an authorizing entity with a private key (which is only stored in that server or instance) and is verified in each of the other instances or servers with a public key, to verify that the access token has been effectively generated by our application and not by a third party:
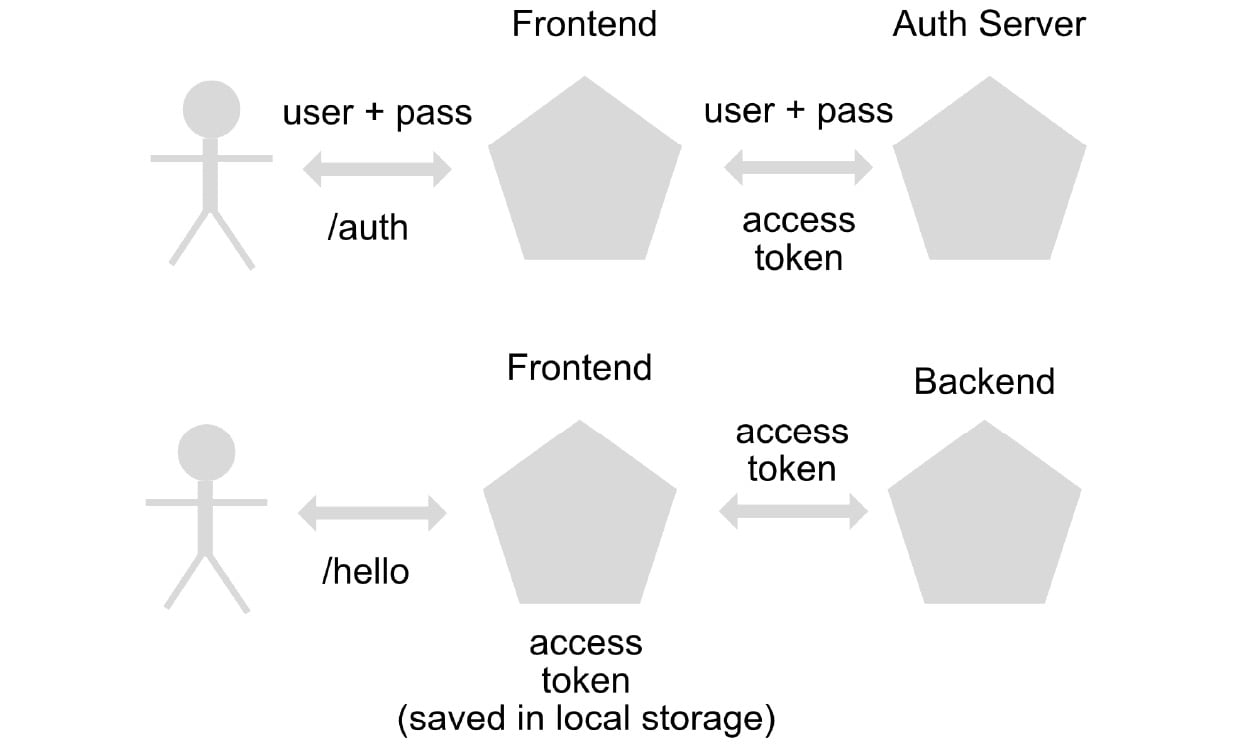
Figure 1.4 – Authentication flow
There are also access tokens of the JSON Web Token (JWT) type, which, in addition to having information about the signature of the token, can contain non-sensitive information such as the user's name, email, and roles, among other things.
In conclusion, although there are still applications that maintain their states based on the server, if an application requires horizontal scaling capabilities, it is necessary to adopt an authentication strategy using access tokens that are stored on the client side, using a stateless application solution.
Application logging, your best friend in error troubleshooting
Before the advent of microservices, there were only monolithic applications, in which the complete solution was kept in a single instance. This allowed application debugging and troubleshooting to be much simpler, since all the logs were stored in one place.
With the advent of microservices, solutions stopped relying on just one instance and this began to make debugging and troubleshooting activities more complex.
Now we need to be able to stream the logs generated by the various microservices to a centralized logging service in order to analyze all the information in one place, transforming our application to stateless.
We need also to revise the way in which logs are generated in our applications to facilitate debugging.
Now the logs have to not only indicate whether or not an error existed, but also somehow allow the generation of a trace from whichever service the call was initiated because an error now depends not only on a single instance but also on multiple actions executed on different servers.
Among the most common solutions to address these problems is the addition of custom headers to each of the calls that are generated between microservices, resulting in the traceability of the origin of the system and unique event codes:
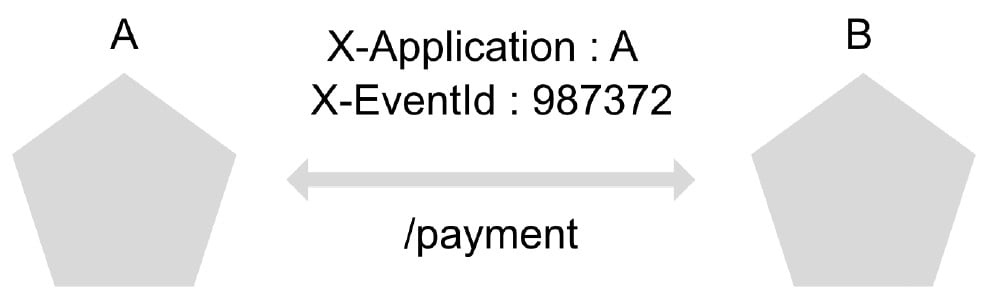
Figure 1.5 – Trace example
These options are an excellent element in microservices ecosystems to facilitate both the debugging and troubleshooting of applications.
Why should your microservices handle retries?
In any computer system, anything can fail and that is why our application has to be prepared to control these errors. In the world of microservices, this problem is even greater since, unlike an application built with the monolithic pattern, where all communications are generated in the same instance, each of the calls between microservices can fail. This makes it necessary to implement retry policies and error handling in each of the calls that are made.
When retrying a call to a microservice, there are some important factors to consider, such as the number of times we are going to retry the call and how long to wait between each retry.
In addition, it is necessary to allow the microservice to recover in the event that it is not available due to call saturation. In this case, the truncated exponential backoff strategy is used, which consists of increasing the time between each of the retry calls to the microservice in order to allow its recovery, with a maximum upper limit of growth of the time between calls.
Some service mesh solutions (a dedicated layer to handle service-to-service communications) such as Istio come with automatic retry functionality, so there is no need to code the retry logic. However, if your microservices ecosystem does not have a service mesh solution, you can use one of the available open source libraries, depending on which programming language you are using.
Understanding that service-to-service communication can sometimes fail, you should always consider implementing retries in applications that work with microservices ecosystems, along with the truncated exponential backoff algorithm, to make your solutions more reliable.
How to handle high traffic with autoscaling
Before the arrival of the cloud, it was necessary, when starting a computer project, to first evaluate the resources that would be required before buying the server on which the application would live. The problem with this was, and still is, that estimating the resources needed to run an application is very complex. Real load tests are generally necessary to effectively understand how many resources an application will use.
Furthermore, once the server was purchased, the resources could not be changed, meaning that in the event of an error in the initial estimate, or some increase in traffic due to a special event such as Cyber Day, the application could not obtain more resources. The result could be a bad experience for users and lost sales.
This is why most of the applications that are still deployed on on-premises servers have problems when high-traffic events arise. However, thanks to the arrival of the cloud, and the ease of creating and destroying instances, we have the arrival of autoscaling.
Autoscaling is the ability of an application under a load balancer to scale its instances horizontally depending on a particular metric. Among the most common metrics to manage autoscaling in an application are the number of calls made to the application and the percentage of CPU and RAM usage:
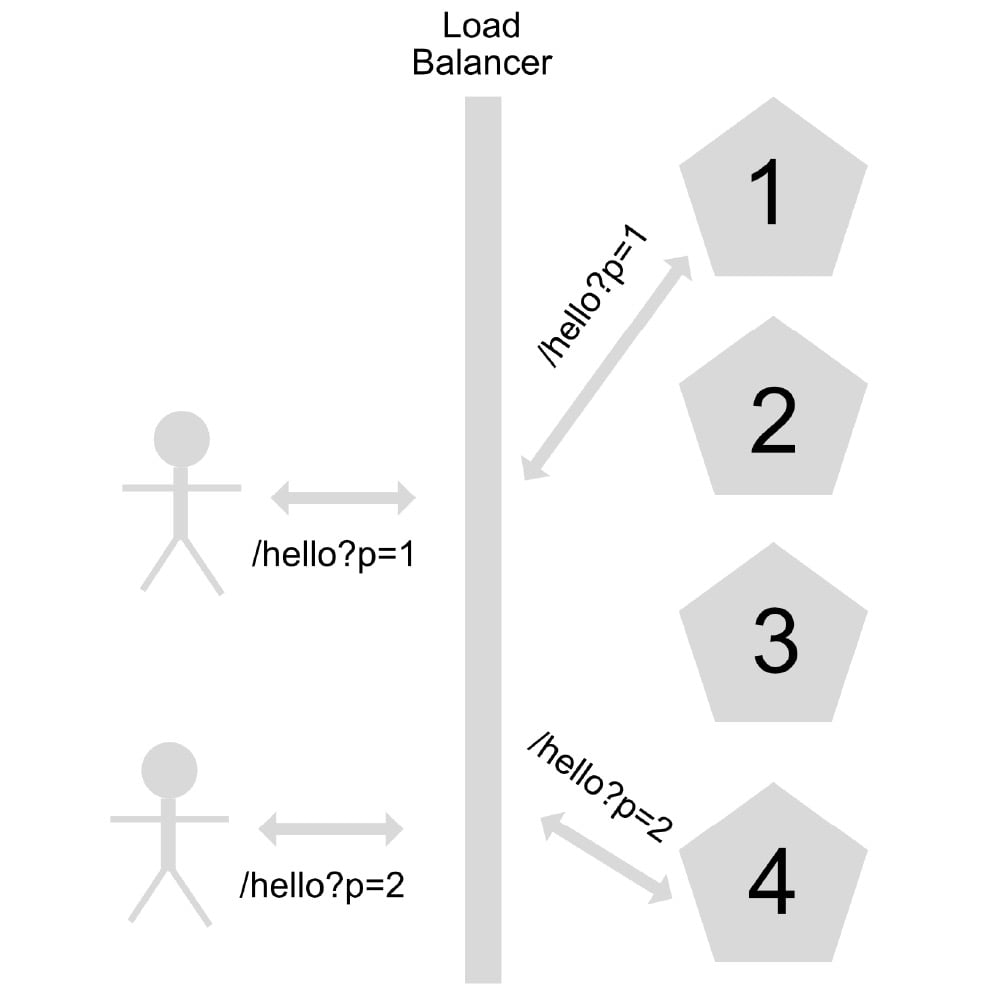
Figure 1.6 – Scaling out or horizontal scaling
For applications implemented in services of the IaaS or CaaS type, it is necessary to consider, for the correct management of the applications' autoscaling, the warm-up and cool-down time, in addition to application health checks.
Warm-up is the time it takes for the application to be available to receive post-deployment calls. This time must be configured to avoid an application receiving calls when it is not yet available.
Cool-down is the period of time where the rules defined in the autoscaling metrics are ignored. This configuration helps avoid the unwanted creation and destruction of instances due to short variations in defined metrics such as CPU, memory, and user concurrency calls.
For example, if you have a 60-second cool-down configuration, all the metrics received in that period of time, after the creation of new instances, will not be considered to trigger the autoscaling policy. If you don't have a cool-down configuration, the autoscaling policy could trigger the creation of new instances before the warm-up of the application in those first created instances, generating the unwanted triggering of the autoscaling policy.
The health check is a status verification used for determining whether a service is available to receive calls (it is related to warming up) so that the load balancer has the possibility of sending traffic only to instances that are able to receive traffic at that time.
For applications implemented as serverless-type services, no special configuration is required, since they support the ability to auto-scale automatically.
Depending on the services supported by the cloud provider you use to implement your application, it may be necessary to perform additional configuration steps to correctly control autoscaling policies.
Avoiding overload caching your data
Although it is possible to control an increase in traffic by autoscaling the application, this action is not free, since it means both the temporary creation of new instances to be able to support this load and, in the case of serverless services, an increase in costs for each call made.
To reduce costs and also increase the performance of the calls made, it is therefore necessary to use a data caching strategy:
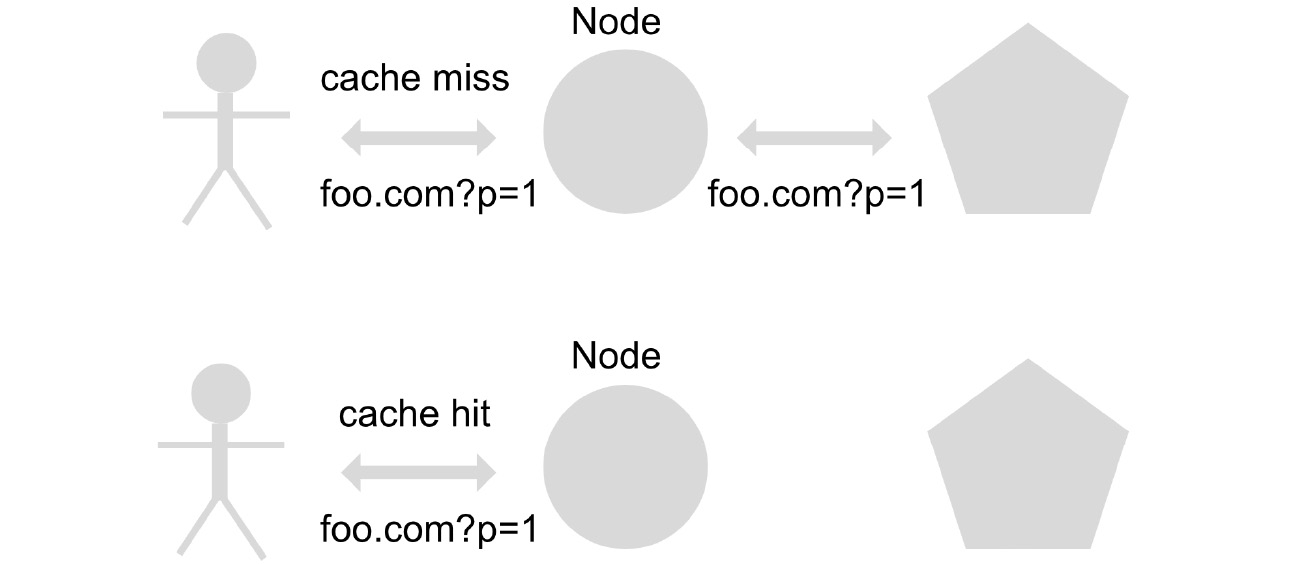
Figure 1.7 – Caching example
Implementing a caching strategy consists of saving in a database, in memory, queries that are made recurrently (using a key that corresponds to the query). To see whether a user returns to make a query that was made previously, it is saved in the database and thus there is no need to re-process the request, thereby reducing both response times and costs.
The first thing to do before implementing a caching strategy is to evaluate whether the scenario allows this strategy to be implemented. For this, it is necessary to identify the frequency with which changes are made to the data source that the application service consults. If the data change frequency of the source is 0 or very low, this is the ideal scenario to implement a caching strategy. Otherwise, if the data change frequency of the source is very high, it is recommended not to implement this caching strategy since the user could get outdated data.
Depending on the frequency with which the data changes in the source, it will be necessary to configure the lifetime of the cache. This is to avoid the data in the cache becoming outdated relative to the data in the source due to modification of the source, in which case users would get outdated information.
This strategy allows us to optimize our application to achieve better use of resources, increase responsiveness for users, and reduce the costs associated with both the use of resources and money for serverless solutions.
Loosely coupled microservices with topics
When designing a microservices architecture, it is important to ensure that calls made between each of the applications are reliable. This means that the information sent between microservices has retry policies and is not lost in cases of failure. It is also important to design the application solution so that if a microservice needs to be replaced, this does not affect the other microservices. This concept is known as loose coupling.
To implement a loosely coupled strategy, and also to ensure that messages sent between microservices are not lost due to communication failures or micro-cuts, there are messaging services.
In GCP, we have a messaging service based on the publisher/subscriber pattern called Pub/Sub, where the publisher makes a publication of the message to be sent to a topic, and the subscriber subscribes to a topic in order to obtain this message. There are also two types of subscriptions: pull-type subscriptions, in which the subscriber must constantly consult the topic if there is a new message, and push-type subscriptions, where the subscriber receives a notification with the message through an HTTP call:

Figure 1.8 – Loosely coupled microservices
In a loosely coupled ecosystem of microservices, each microservice should publish its calls using messages on a topic, and the microservices that are interested in receiving these calls as messages must subscribe. In Pub/Sub, upon receiving a message, the subscriber must inform the topic with an ACK, or acknowledge, code to inform the topic that the message was received correctly. If the subscriber cannot receive or process the message correctly, the topic will resend the message to the subscriber for up to 7 days in order to ensure delivery.
Each microservice that acts as a subscriber must have the ability to filter duplicate messages and execute tasks idempotently, which means having the ability to identify whether a message has already been delivered previously, so as not to process it in a duplicate way.
The use of messaging services in microservices ecosystems allows us to have robust solution designs, loosely coupled and tolerant of communication errors.
Don't waste your time – use cloud management services and securely run your applications
In this section, we review some of the existing services to which we can delegate specific responsibilities so that we can focus development efforts on what really matters, which is business logic.
We will also review how we can communicate with these services in a secure way through service accounts, and how to ensure communication between services.
Don't reinvent the wheel
GCP offers multiple services that allow us to perform tasks just by invoking the available APIs without having to code a solution completely from scratch.
In this section, we will review 10 of the most used services in GCP. In later chapters, we will review each of these services in detail. The services are as follows:
- Cloud storage
- Pub/Sub
- Cloud SQL
- Firestore
- Memorystore
- Compute Engine
- Google Kubernetes Engine
- Google Secret Manager
- Cloud logging
- Cloud monitoring
Cloud Storage is an object store that allows unlimited storage of information in different regions, storage classes (the possibility of reducing costs, changing the pricing model, and the availability of the objects required by the solution), and life cycle policy configuration for existing files. It also allows access to information in a granular way and the hosting of static data web applications.
Pub/Sub is a serverless messaging service under the publisher/subscriber pattern, used for communication between two services in a reliable and decoupled way. It has automatic autoscaling and allows messages to be stored for up to 7 days in case of subscriber failures.
Cloud SQL is a self-managed solution for Online Transactional Processing (OLTP) databases such as MySQL, PostgreSQL, and SQL Server. It allows you to configure the type of machine on which the databases will run, create read-only replicas, and generate backups on a scheduled basis.
Firestore is a serverless NoSQL database solution that allows you to store information in the form of documents based on keys and values, allowing you to access the information very quickly.
Memorystore is an in-memory database solution for technologies such as Redis and Memcached, used when you want to optimize the use of resources, reduce costs, and increase performance in calls to data sources that have zero or very low modification frequency.
Compute Engine is the IaaS solution for getting virtual machines on-demand using the GCP infrastructure.
Google Kubernetes Engine is the self-managed solution for Kubernetes clusters. It offers management of the master node in a totally self-administered way, and provides a host of configuration and monitoring options through the GCP console.
Google Secret Manager is a secret storage solution. It is used in order to comply with security standards, obtaining the secrets to use in on-demand applications instead of hardcoded values.
Cloud Logging is the logging and visualization solution. It allows you to store an unlimited number of logs and query the logs.
Cloud Monitoring is the solution for viewing metrics and scheduling alerts.
These are some of the most used services on GCP. In all, over 100 services are available for delegating different responsibilities within the solution design of your application, allowing you to focus on the development of business logic and the delivery of value to the end user.
Accessing services in a secure way
When we delegate the responsibilities of our solution to one or more services, we must have a way of communicating securely from our application to each of those services.
For the consumption of services and APIs in GCP, two types of authentication are used.
If the application needs to consume GCP services such as Cloud Storage, authentication is carried out through OIDC, or OpenID Connect, an identity layer that utilizes the OAuth 2.0 protocol for authorization, allowing the identity of the consumer to be verified.
If the application is to consume any of the Google APIs hosted on googleapis.com, OAuth 2.0 is used, the standard protocol to manage authentication and authorization.
However, in most cases, it will not be necessary to use either of these protocols and connecting to any of the services will be possible simply by using the libraries of the available programming languages and a service account with the necessary permissions.
A service account is an account that is used by services to consume other services, unlike users who use a username and password. Roles are assigned to the service account (this process is called binding), which has one or more permissions already defined in order to facilitate the consumption of services.
If it is necessary to consume a service from a resource in a GCP project, simply access the project's metadata and select the service account to use. This will allow the service to have access to the service account private key path through the GOOGLE_APPLICATION_CREDENTIALS environment variable and the client library will handle the authentication using the private key and sign the access token.
On the other hand, if the application needs to consume a GCP service and the application is not inside a GCP project, it is necessary to generate a private key of that particular service account, download it, and save it safely in the resource. You can then expose it in your application through the GOOGLE_APPLICATION_CREDENTIALS environment variable:

Figure 1.9 – Service account
In this way, it is possible to consume the different GCP services both for resources within the platform itself and as resources in other clouds or in environments within their own data centers.
Summary
In this chapter, we learned about the differences between the different types of services offered by GCP, from IaaS-type services, which offer the greatest flexibility but, at the same time, impose greater responsibilities, to SaaS-type services, which provide direct access to functionalities without the need to code the solution. We also reviewed concepts such as region, zone, high availability, and latency, and discussed what types of solutions we can apply to our designs in order to meet the needs in these areas.
We had a general introduction to the world of microservices, understanding the importance of structuring and writing logs that allow the traceability of unique events so that debugging and troubleshooting can be carried out. We understood that it is necessary to create tasks within our applications in an idempotent way in order to allow retries and anticipate the failure of calls between microservices.
We reviewed concepts that are key to implementing an auto-scalable solution, such as stateful versus stateless, and were able to understand the importance of designing a loosely coupled solution. In the next chapter, we will learn about security concepts and best practices to protect your applications in the cloud.
