Elasticsearch is often described as a distributed search engine that can be used to search through and aggregate enormous amounts of data. Some describe Elasticsearch as an analytics engine, while others have used the term document store or NoSQL database. The reason for the wide-ranging definitions for Elasticsearch is that it is quite a flexible product. It can be used to store JSON documents, with or without a predefined schema (allowing for unstructured data); it can be used to compute aggregations on document values (to calculate metrics or group data into buckets), and it can be used to implement relevant, free text search functionality across a large corpus.
Elasticsearch builds on top of Apache Lucene, a popular and fast full-text search library for Java applications. Lucene is not distributed in any way and does not manage resources/handle requests natively. At its core, Elasticsearch abstracts away the complexities and intricacies of working directly with a library such as Lucene by providing user-friendly APIs to help index, search for, and aggregate data. It also introduces concepts such as the following:
- A method to organize and group related data as indices
- Replica shards to improve search performance and add redundancy in the case of hardware failure
- Thread pools for managing node resources while servicing several types of requests and cluster tasks
- Features such as Index Lifecycle Management (ILM) and data streams to manage the size and movement of indices on a cluster
Elasticsearch exposes RESTful APIs using JSON format, allowing for interoperability between different programming languages and technology stacks.
Elasticsearch today is a feature-rich and complex piece of software. Do not worry if you do not fully understand or appreciate some of the terms used to explain Elasticsearch. We will dive into these, as well as the features on offer, in Chapter 3, Indexing and Searching for Data.
When to use Elasticsearch
Selecting the right tool for the job is an important aspect of any project. This section describes some scenarios where Elasticsearch may be suited for use.
Ingesting, storing, and searching through large volumes of data
Elasticsearch is a horizontally scalable data store where additional nodes can easily be added to a cluster to increase the available resources. Each node can store multiple primary shards on data, and each shard can be replicated (as replica shards) on other nodes. Primary shards handle read and write requests, while replica shards only handle read requests.
The following diagram shows how primary and replica shards are distributed across Elasticsearch nodes to achieve scalable and redundant reading and writing of data:
Figure 1.2 – Shards of data distributed across nodes
The preceding diagram shows the following:
- Three Elasticsearch nodes: node A, node B, and node C
- Two indices: index A and index B
- Each index with two primary and two replica shards
High volume ingest can mean either of the following things:
- A singular index or data source with a large number of events Emitted Per Second (EPS)
- A group of indices or data sources receiving a large number of aggregate events per second
Elasticsearch can also store large volumes of data for search and aggregation. To retain data costs efficiently over long retention periods, clusters can be architected with hot, warm, and cold tiers of data. During its life cycle, data can be moved across nodes with different disk or Input/Output Operations Per Second (IOPS) specifications to take advantage of slower disk drives and their associated lower costs. We will look at these sorts of architectures in Chapter 3, Indexing and Searching for Data and Chapter 13, Architecting Workloads on the Elastic Stack.
Some examples of where you need to handle large volumes of data include the following:
- Centralized logging platforms (ingesting various application, security, event, and audit logs from multiple sources)
- When handling metrics/traces/telemetry data from many devices
- When ingesting data from large document repositories or crawling a large number of web pages
Getting relevant search results from textual data
As we discussed previously, Elasticsearch leverages Lucene for indexing and searching operations. As documents are ingested into Elasticsearch, unstructured textual components from the document are analyzed to extract some structure in the form of terms. Terms are maintained in an inverted index data structure. In simple terms, an index (such as the table of contents in a book) is a list of topics (or documents) and the corresponding page numbers for each topic. An index is great for retrieving page content, given you already know what the chapter is called. An inverted index, however, is a collection of words (or terms) in topics and a corresponding list of pages that contain them. Therefore, an inverted index can make it easier to find all the relevant pages, given the search term you are interested in.
The following table visualizes an inverted index for a collection of documents containing recipes:
Table 1.1 – Visualization of an inverted index
A search string containing multiple terms goes through a similar process of analysis to extract terms, to then look up all the matching terms and their occurrences in the inverted index. A score is calculated for each field match based on the similarity module. By default, the BM25 ranking function (based on term frequency/inverse document frequency) is used to estimate the relevance of a document for a search query. Elasticsearch then returns a union of the results if an OR operator is used (by default) or an intersection of the results if an AND operator is used. The results are sorted by score, with the highest score appearing first.
Aggregating data
Elasticsearch can aggregate large volumes of data with speed thanks to its distributed nature. There are primarily two types of aggregations:
- Bucket aggregations: Bucket aggregations allow you to group (and sub-group) documents based on the values of fields or where the value sits in a range.
- Metrics aggregations: Metrics aggregations can calculate metrics based on the values of fields in documents. Supported metrics aggregations include
avg, min, max, count, and cardinality, among others. Metrics can be computed for buckets/groups of data.
Tools such as Kibana heavily use aggregations to visualize the data on Elasticsearch. We will dive deeper into aggregations in Chapter 4, Leveraging Insights and Managing Data on Elasticsearch.
Acting on data in near real time
One of the benefits of quickly ingesting and retrieving data is the ability to respond to the latest information quickly. Imagine a scenario where uptime information for business-critical services is ingested into Elasticsearch. Alerting would work by continually querying Elasticsearch (at a predefined interval) to return any documents that indicate degrading service performance or downtime. If the query returns any results, actions can be configured to alert a Site Reliability Engineer (SRE) or trigger automated remediation processes as appropriate.
Watcher and Kibana alerting are two ways in which this can be achieved; we will look at this in detail in Chapter 4, Leveraging Insights and Managing Data on Elasticsearch, and Chapter 8, Interacting with Your Data on Kibana.
Working with unstructured/semi-structured data
Elasticsearch does not require predefined schemas for documents you want to work with. Schemas on indices can be preconfigured if they're known to control storage/memory consumption and know how the data will be used later on. Schemas (also known as index mappings) can be dynamically or strictly configured, depending on your flexibility and the maturity of your document's structure.
By default, Elasticsearch will dynamically update these index mappings based on the documents that have been ingested. Where no mapping exists for a field, Elasticsearch will guess the data type based on its value. This flexibility makes it extremely easy for developers to get up and running, while also making it suitable for use in environments where document schemas may evolve over time.
We'll look at index mappings in Chapter 3, Indexing and Searching for Data.
Architectural characteristics of Elasticsearch
Elasticsearch can be configured to work as a distributed system where groups of nodes (Elasticsearch instances) work together to form a cluster. Clusters can be set up for the various architectural characteristics when deployed in mission-critical environments. We will take a look at some of these in this section.
Horizontally scalable
As we mentioned previously, Elasticsearch is a horizontally scalable system. Read/write throughput, as well as storage capacity, can be increased almost linearly by adding additional nodes to the Elasticsearch cluster. Adding nodes to a cluster is relatively effortless and can be done without any downtime. The cluster can automatically redistribute shards evenly across nodes (subject to shard allocation filtering rules) as the number of nodes available changes to optimize performance and improve resource utilization across nodes.
Highly available and resilient
A primary shard in Elasticsearch can handle both read and write operations, while a replica shard is a read-only copy of a primary shard. By default, Elasticsearch will allocate one replica for every primary shard on different nodes in the cluster, making Elasticsearch a highly available system where requests can still be completed when one or more nodes experience failures.
If a node holding a primary shard is lost, a replica shard will be selected and promoted to become a primary shard, and a replica shard will be allocated to another node in the cluster.
If a node holding a replica shard is lost, the replica shard will simply be allocated to another node in the cluster.
Indexing and search requests can be handled seamlessly while shards are being allocated, with clients experiencing little to no downtime. Even if a search request fails, subsequent search requests will likely succeed because of this architecture.
Shard allocation on Elasticsearch can also consider node attributes to help us make more informed allocation decisions. For example, a cluster deployed in a cloud region with three availability zones can be configured so that replicas are always allocated on a different availability zone (or even a server rack in an on-premises data center) to the primary shard to protect against failures at the zone level.
Recoverable from disasters
Elasticsearch allows us to persistently store or snapshot data, making it a recoverable system in the event of a disaster. Snapshots can be configured to write data to a traditional filesystem or an object store such as AWS S3. Snapshots are a point-in-time copy of the data and must be taken at regular intervals, depending on your Recovery Point Objective (RPO), for an effective disaster recovery plan to be created.
Cross-cluster operations
Elasticsearch can search for and replicate data across remote clusters to enable more sophisticated architectural patterns.
Cross-Cluster Search (CCS) is a feature that allows you to search data that resides on an external or remote Elasticsearch cluster. A single search request can be run on the local cluster, as well as one or more remote clusters. Each cluster will run the search independently on its own data before returning a response to the coordinator node (the node handling the search request). The coordinator nodes then combine the results from the different clusters into a single response for the client. The local node does not join remote clusters, allowing for higher network latencies for inter-cluster communication, compared to intracluster communication. This is useful in scenarios where multiple independent clusters in different geographic regions need to search on each other to have a unified search capability.
The following diagram shows how Elasticsearch clusters can search across multiple clusters and combine results into a single search response for the user:
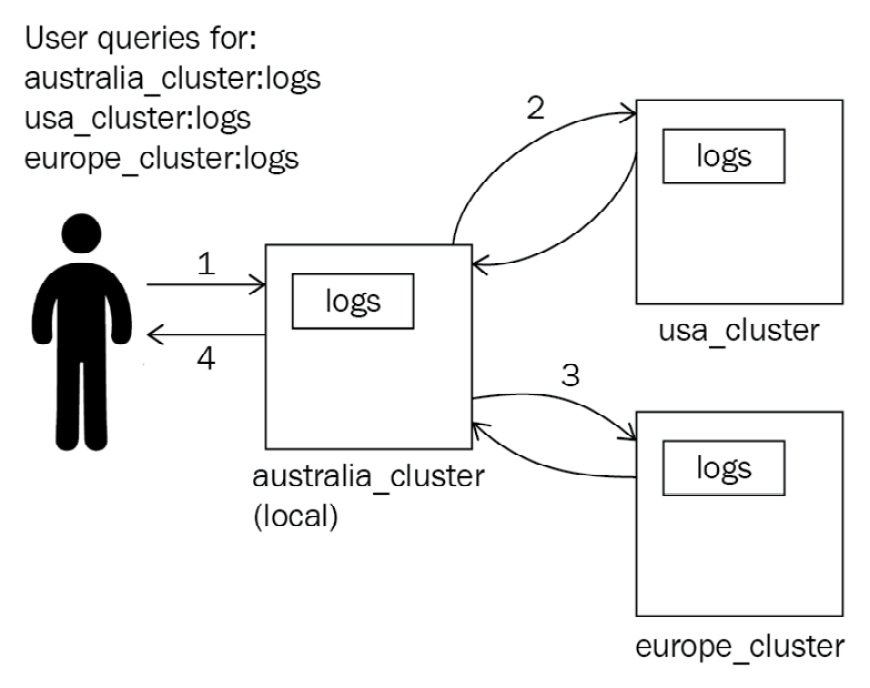
Figure 1.3 – How CCS requests are handled
Cross-cluster replication (CCR) allows an index to be replicated in a local cluster to a remote cluster. CCR implements a leader/follower model, where all the changes that have been made to a leader index are replicated on the follower index. This feature allows for fast searching on the same dataset in different geographical regions by replicating data closer to where it will be consumed. CCR is also sometimes used for cross-region redundancy requirements:
Figure 1.4 – How CCR works
CCS and CCR enable more complex use cases where multiple regional clusters can be used to independently store and search for data, while also allowing unified search and geographical redundancy.
Security
Elasticsearch offers security features to help authenticate and authorize user requests, as well as encrypting network communications to and within the cluster:
- Encryption in transit: TLS can be used to encrypt inter-node communications, as well as REST API requests.
- Access control: Role-Based Access Control (RBAC) or Attribute-Based Access Control (ABAC) can be used to control access to the data and functionality on Elasticsearch:
- RBAC works by associating a user with a role, where a role contains a list of privileges (such as read/write/update), as well as the resources these privileges can be applied to (such as an index; for example,
my-logs-1).
- ABAC works by using attributes the user has (such as their location, security clearance, or job role) in conjunction with an access policy to determine what the user can do or access on the cluster. ABAC is generally a more fine-grained authorization control compared to RBAC.
- Document security: A security role in Elasticsearch can specify what subset of data a user can access on an index. A role can also specify what fields in a document a user can or cannot access. For example, an employee with security clearance of baseline can only access documents where the value of the classification field is either
UNOFFICIAL or OFFICIAL.
- Field security: Elasticsearch can also control what fields a user has access to as part of a document. Building on the example in the previous point, field-level security can be used so that the user can only view fields that start with the
metadata- string.
- Authentication providers: In addition to local/native authentication, Elasticsearch can use external services such as Active Directory, LDAP, SAML, and Kerberos for user authentication. API keys-based authentication is also available for system accounts and programmatic access.
When Elasticsearch may not be the right tool
It is also important to understand the limitations of Elasticsearch. This section describes some scenarios where Elasticsearch alone may not be the best tool for the job.
Handling relational datasets
Elasticsearch, unlike databases such as MySQL, was not designed to handle relational data. Elasticsearch allows you to have simple relationships in your data, such as parent-child and nested relationships, at a performance cost (at search time and indexing time, respectively). Data on Elasticsearch must be de-normalized (duplicating or adding redundant fields to documents, to avoid having to join data) to improve search and indexing/update performance.
If you need to have the database manage relationships and enforce rules of consistency across different types of linked data, as well as maintaining normalized records of data, Elasticsearch may not be the right tool for the job.
Performing ACID transactions
Individual requests in Elasticsearch support ACID properties. However, Elasticsearch does not have the concept of transactions, so it does not offer ACID transactions.
At the individual request level, ACID properties can be achieved as follows:
- Atomicity is achieved by sending a write request, which will either succeed on all active shards or fail. There is no way for the request to partially succeed.
- Consistency is achieved by writing to the primary shard. Data replication happens synchronously before a success response is returned. This means that all the read requests on all shards after a write request will see the same response.
- Isolation is offered since concurrent writes or updates (which are deletes and writes) can be handled successfully without any interference.
- Durability is achieved since once a document is written into Elasticsearch, it will persist, even in the case of a system failure. Writes on Elasticsearch are not immediately persisted onto Lucene segments on disk as Lucene commits are relatively expensive operations. Instead, documents are written to a transaction log (referred to as a translog) and flushed into the disk periodically. If a node crashes before the data is flushed, operations from the translog will be recovered into the Lucene index upon startup.
If ACID transactions are important to your use case, Elasticsearch may not be suitable for you.
Important Note
In the case of relational data or ACID transaction requirements, Elasticsearch is often used alongside a traditional RDBMS solution such as MySQL. In such architectures, the RDBMS would act as the source of truth and handle writes/updates from the application. These updates can then be replicated to Elasticsearch using tools such as Logstash for fast/relevant searches and visualization/analytics use cases.
With that, we have explored some of the core concepts of Elasticsearch and the role it plays in ingesting and storing our data. Now, let's look at how we can interact with the data on Elasticsearch using Kibana.

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Singapore
Singapore
 Canary Islands
Canary Islands
 Hungary
Hungary
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 South Korea
South Korea
 Turkey
Turkey
 Switzerland
Switzerland
 Colombia
Colombia
 Taiwan
Taiwan
 Chile
Chile
 Norway
Norway
 Ecuador
Ecuador
 Indonesia
Indonesia
 New Zealand
New Zealand
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 Austria
Austria
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 South Africa
South Africa
 Malaysia
Malaysia
 Japan
Japan
 Slovakia
Slovakia
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand




















