


















Functional programming is a style of constructing the elements and structure of computer program which treats computations like evaluations in mathematical functions. Although there are some specifically designed languages for creating functional programming, such as Haskell or Scala, we can also use C# to accomplish designing functional programming.
In the first chapter of this book, we are going to explore the functional programming by testing it. We will use the power of C# to construct some functional code. We will also deal with the features in C# that are mostly used in developing functional programs. By the end of this chapter, we will have an idea of what the functional approach in C# will be like. Here are the topics we will cover in this chapter:
Introduction to functional programming concepts
Comparison between the functional and imperative approach
The concepts of functional programming
Using the mathematical approach to understand functional programming
Refactoring imperative code to functional code
The advantages and disadvantages of functional programming
In functional programming, we write functions without side effects the way we write in Mathematics. The variable in the code function represents the value of the function parameter, and it similar to the mathematical function. The idea is that a programmer defines the functions that contain the expression, definition, and the parameters that can be expressed by a variable in order to solve problems.
After a programmer builds the function and sends the function to the computer, it's the computer's turn to do its job. In general, the role of the computer is to evaluate the expression in the function and return the result. We can imagine that the computer acts like a calculator since it will analyze the expression from the function and yield the result to the user in a printed format. The calculator will evaluate a function which are composed of variables passed as parameters and expressions which form the body of the function. Variables are substituted by their values in the expression. We can give simple expression and compound expressions using algebraic operators. Since expressions without assignments never alter the value, sub expressions needs to be evaluated only once.
Suppose we have the expression 3 + 5 inside a function. The computer will definitely return 8 as the result right after it completely evaluates it. However, this is just a simple example of how the computer acts in evaluating an expression. In fact, a programmer can increase the ability of the computer by creating a complex definition and expression inside the function. Not only can the computer evaluate the simple expression, but it can also evaluate the complex calculation and expression.
As we discussed earlier about a calculator that will analyze the expression from the function, let's imagine we have a calculator that has a console panel like a computer does. The difference between that and a conventional calculator is that we have to press Enter instead of = (equal to) in order to run the evaluation process of the expression. Here, we can type the expression and then press Enter . Now, imagine that we type the following expression:
3 x 9
Immediately after pressing
Enter
, the computer will print 27 in the console, and that's what we are expecting. The computer has done a great job of evaluating the expression we gave. Now, let's move to analyzing the following definitions. Imagine that we type them on our functional calculator:
square a = a * a
max a b = a, if a >= b
= b, if b > a
We have defined the two definitions, square and max. We can call the list of definitions script. By calling the square function followed by any number representing variable a, we will be given the square of that number. Also, in the max definition, we serve two numbers to represent variables a and b, and then the computer will evaluate this expression to find out the biggest number between the variables.
By defining these two definitions, we can use them as a function, which we can call session, as follows:
square (1 + 2)
The computer will definitely print 9 after evaluating the preceding function. The computer will also be able to evaluate the following function:
max 1 2
It will return 2 as the result based on the definition we defined earlier. This is also possible if we provide the following expression:
square (max 2 5)
Then, 25 will be displayed in our calculator console panel.
We can also modify a definition using the previous definition. Suppose we want to quadruple an integer number and take advantage of the definition of the square function; here is what we can send to our calculator:
quad q = square q * square q quad 10
The first line of the preceding expression is a definition of the quad function. In the second line, we call that function, and we will be provided with 10000 as the result.
The script can define the variable value; for instance, take a look at the following:
radius = 20
So, we should expect the computer to be able to evaluate the following definition:
area = (22 / 7) * square (radius)
Using a mathematical method called reduction, we can evaluate expressions by substitution variables or expressions to simplify the expressions until no more substitution on reduction is possible. Let's take our preceding expression, square (1 + 2) , and look at the following reduction process:
square (1 + 2) -> square 3 (addition)
-> 3 x 3 (square)
-> 9 (multiply)
First, we have the symbol -> to indicate the reduction. From the sequence, we can discover the reduction process-in other words, the evaluation process. In the first line, the computer will run the 1 + 2 expression and substitute it with 3 in order to reduce the expression. Then, it will reduce the expression in the second line by simplifying square 3 to 3 x 3 expressions. Lastly, it will simplify 3 x 3 and substitute it with 9, which is the result of that expression.
Actually, an expression can have more than one possibility in the reduction. The preceding reduction process is one of the possibilities of a reduction process. We can also create other possibilities, like the following:
square (1 + 2) -> (1 + 2) x (1 + 2) (square)
-> 3 x (1 + 2) (addition)
-> 3 x 3 (addition)
-> 9 (multiply)
In the preceding sequence, firstly, we can see that the rule for a square is applied. The computer then substitutes 1 + 2 in line 2 and line 3. Lastly, it multiplies the number in the expression.
From the preceding two examples, we can conclude that the expression can be evaluated using simple substitution and simplification, the basic rule of mathematics. We can also see that the expression is a representation of the value, not the value itself. However, the expression will be in the normal form if it can't be reduced anymore.
Functional programming uses a technique of emphasizing functions and their application instead of commands and their execution. Most values in functional programming are function values. Let's take a look at the following mathematical notation:
f :: A -> B
From the preceding notation, we can say that function f is a relation of each element stated there, which is A and B. We call A, the source type, and B, the target type. In other words, the notation of A -> B states that A is an argument where we have to input the value, and B is a return value or the output of the function evaluation.
Consider that x denotes an element of A and x + 2 denotes an element of B, so we can create the mathematical notation as follows:
f(x) = x + 2
In mathematics, we use f(x) to denote a functional application. In functional programming, the function will be passed as an argument and will return the result after the evaluation of the expression.
We can construct many definitions for one and the same function. The following two definitions are similar and will triple the input passed as an argument:
triple y = y + y + y triple' y = 3 * y
As we can see, triple and triple' have different expressions. However, they are the same functions, so we can say that triple = triple'. Although we have many definitions to express one function, we will find that there is only one definition that will prove to be the most efficient in the procedure of evaluation in the sense of the reducing the expression we discussed previously. Unfortunately, we cannot determine which one is the most efficient from our preceding two definitions since that depends on the characteristic of the evaluation mechanism.
Now, let's go back to our discussion on definitions at the beginning of this chapter. We have the following definition in order to retrieve the value from the case analysis:
max a b = a, if a >= b
= b, if b > a
There are two expressions in this definition, distinguished by a Boolean-value expression. This distinguisher is called guards, and we use them to evaluate the value of True or False. The first line is one of the alternative result values for this function. It states that the return value will be a if the expression a >= b is True. In contrast, the function will return value b if the expression b >= a is True. Using these two cases, a >= b and b >= a, the max value depends on the value of a and b. The order of the cases doesn't matter. We can also define the max function using the special word otherwise. This word ensures that the otherwise case will be executed if no expression results in a True value. Here, we will refactor our max function using the word otherwise:
max a b = a, if a >= b
= b, otherwise
From the preceding function definition, we can see that if the first expression is False, the function will return b immediately without performing any evaluation. In other words, the otherwise case will always return True if all previous guards return False.
Another special word usually used in mathematical notations is where. This word is used to set the local definition for the expression of the function. Let's take a look at the following example:
f x y = (z + 2) * (z + 3)
where z = x + y
In the preceding example, we have a function f with variable z, whose value is determined by x and y. There, we introduce a local z definition to the function. This local definition can also be used along with the case analysis we have discussed earlier. Here is an example of the conjunction local definition with the case analysis:
f x y = x + z, if x > 100
= x - z, otherwise
where z = triple(y + 3)
In the preceding function, there is a local z definition, which qualifies for both x + z and x - z expressions. As we discussed earlier, although the function has two equal to (=) signs, only one expression will return the value.
Currying is a simple technique of changing structure arguments by sequence. It will transform a n-ary function into n unary function. It is a technique which was created to circumvent limitations of Lambda functions which are unary functions. Let's go back to our max function again and get the following definition:
max a b = a, if a >= b
= b, if b > a
We can see that there is no bracket in the max a b function name. Also, there is no comma-separated a and b in the function name. We can add a bracket and a comma to the function definition, as follows:
max' (a,b) = a, if a >= b
= b, if b > a
At first glance, we find the two functions to be the same since they have the same expression. However, they are different because of their different types. The max' function has a single argument, which consists of a pair of numbers. The type of max' function can be written as follows:
max' :: (num, num) -> num
On the other hand, the max function has two arguments. The type of this function can be written as follows:
max :: num -> (num -> num)
The max function will take a number and then return a function from single number to many numbers. From the preceding max function, we pass the variable a to the max function, which returns a value. Then, that value is compared to variable b in order to find the maximum number.
The main difference between functional and imperative programming is that imperative programming produces side effects while functional programming doesn't. In imperative programming, the expressions are evaluated and its resulting value is assigned to variables. So, when we group series of expressions into a function, the resulting value depends upon the state of variables at that point in time. This is called side effects. Because of the continuous changes in state, the order of evaluation matters. In functional programming world, destructive assignment is forbidden and each time an assignment happens a new variable is induced.
For the rest of the discussion in this chapter, we are going to create some code in C#. In order we have the same environment, let's define what we will use in configuration settings. We will use Visual Studio 2015 Community Edition and .NET Framework 4.6.2 in all of the source code we discuss in this book. We will also choose the console application project in order to ease the development of our code since it doesn't need many changes to the settings.
Here is the screenshot of the setting in creating Visual Studio projects we will use:
When we are discussing a source code that has a csproj filename-for instance, FuncObject.csproj-we can find it in one of solution files provided in the sample code. It will be in the Program.cs file. The following is a screenshot of the structure of the project in Visual Studio:
However, sometimes, we have more than one .cs file inside the project file. In this case, we can find the code we are discussing in one of the .cs files inside the project file. For instance, we have a project file named FunctionalCode.csproj. So, when we discuss any source code related to this project file, we can find it from the .cs files inside the project file. The structure of a project file consisting of more than one .cs files is as follows:
As we can see, inside the FunctionalCode.csproj file, not only do we have the Program.cs file, but also Disposable.cs, FunctionalExtension.cs, StringBuilderExtension.cs, and Utility.cs.
We will also find the partial keyword to the classes name in most of our code even though we write the classes in the same file. The purpose is to make the code snippet in this book easy to find in the sample code. By knowing the class name, it will be easier to find the source code in the file.
Note
We also need to install Visual Studio Community 2017 RC since we will use a new feature of C# 7 in Chapter 9, Working with Pattern.
We can also distinguish functional programming from imperative programming by the concepts. The core ideas of functional programming are encapsulated in the constructs such as first class functions, higher order functions, purity, recursion over loops, and partial functions. We will discuss the concepts in this topic.
In imperative programming, the given data is more important and are passed through series of functions (with side effects). Functions are special constructs with their own semantics. In effect, functions do not have the same place as variables and constants. Since a function cannot be passed as a parameter or returned as a result, they are regarded as second class citizens of the programming world. In the functional programming world, we can pass a function as a parameter and return function as a result. They obey the same semantics as variables and their values. Thus, they are first class citizens. We can also create function of functions called second order function through composition. There is no limit imposed on the composability of functions and they are called higher order functions.
Fortunately, the C# language supports these two concepts since it has a feature called function object, which has types and values. To discuss more details about the function object, let's take a look at the following code:
class Program
{
static void Main(string[] args)
{
Func<int, int> f = (x) => x + 2;
int i = f(1);
Console.WriteLine(i);
f = (x) => 2 * x + 1;
i = f(1);
Console.WriteLine(i);
}
}
We can find the code in FuncObject.csproj, and if we run it, it will display the following output on the console screen:

Why do we display it? Let's continue the discussion on function types and function values.
Tip
Hit Ctrl + F5 instead of F5 in order to run the code in debug mode but without the debugger. It's useful to stop the console from closing on the exit.
As with other objects in C#, function objects have a type as well. We can initialize the types in the function declaration. Here is the syntax to declare function objects:
Func<T1, T2, T3, T4, ..., T16, TResult>
Note that we have T1 until T16, which are the types that correspond to input parameters, and TResult is a type that corresponds to the return type. If we need to convert our previous mathematical function, f(x) = x + 2, we can write it as follows:
Func<int, int> f = (x) => x + 2;
We now have a function f, which has one argument-typed integer and the integer return type as well. Here, we use a lambda expression to define a delegate to be assigned to the object named f with the Func type. Don't worry if you are not familiar with delegate and lambda expressions yet. We will discuss them further in our next chapters.
To assign a value to function variable, there are the following possibilities:
A function variable can be assigned to an existing method inside a class by its name using a reference. We can use delegate as reference. Let's take a look at the following code snippet:
class Program { delegate int DoubleAction(int inp); static void Main(string[] args) { DoubleAction da = Double; int doubledValue = da(2); } static int Double(int input) { return input * 2; } }As we can see in the preceding code, we assign
davariable to existingDouble()method usingdelegate.A function variable can be assigned to an anonymous function using a lambda expression. Let's look at the following code snippet:
class Program { static void Main(string[] args) { Func<int, int> da = input => input * 2; int doubledValue = da(2); } }As we can see, the
davariable is assigned using lambda expression and we can use thedavariable like we use in previous code snippet.
Now we have a function variable and can assign a variable-integer-typed variable, for instance, to this function variable, as follows:
int i = f(1);
After executing the preceding code, the value of variable i will be 3 since we pass 1 as the argument, and it will return 1 + 2. We can also assign the function variable with another function, as follows:
f = (x) => 2 * x + 1; i = f(1);
We assign a new function, 2 * x + 1, to variable f, so we will retrieve 3 if we run the preceding code.
In the functional programming, most of the functions do not have side effects. In other words, the function doesn't change any variables outside the function itself. Also, it is consistent, which means that it always returns the same value for the same input data. The following are example actions that will generate side effects in programming:
Modifying a global variable or static variable since it will make a function interact with the outside world.
Modifying the argument in a function. This usually happens if we pass a parameter as a reference.
Raising an exception.
Taking input and output outside-for instance, get a keystroke from the keyboard or write data to the screen.
Note
Although it does not satisfy the rule of a pure function, we will use many Console.WriteLine() methods in our program in order to ease our understanding in the code sample.
The following is the sample non-pure function that we can find in NonPureFunction1.csproj:
class Program
{
private static string strValue = "First";
public static void AddSpace(string str)
{
strValue += ' ' + str;
}
static void Main(string[] args)
{
AddSpace("Second");
AddSpace("Third");
Console.WriteLine(strValue);
}
}
If we run the preceding code, as expected, the following result will be displayed on the console:

In this code, we modify the strValue global variable inside the AddSpace function. Since it modifies the variable outside, it's not considered a pure function.
Let's take a look at another non-pure function example in NonPureFunction2.csproj:
class Program
{
public static void AddSpace(StringBuilder sb, string str)
{
sb.Append(' ' + str);
}
static void Main(string[] args)
{
StringBuilder sb1 = new StringBuilder("First");
AddSpace(sb1, "Second");
AddSpace(sb1, "Third");
Console.WriteLine(sb1);
}
}
We see the AddSpace function again but this time with the addition of an argument-typed StringBuilder argument. In the function, we modify the sb argument with hyphen and str. Since we pass the sb variable by reference, it also modifies the sb1 variable in the Main function. Note that it will display the same output as NonPureFunction2.csproj.
To convert the preceding two examples of non-pure function code into pure function code, we can refactor the code to be the following. This code can be found at PureFunction.csproj:
class Program
{
public static string AddSpace(string strSource, string str)
{
return (strSource + ' ' + str);
}
static void Main(string[] args)
{
string str1 = "First";
string str2 = AddSpace(str1, "Second");
string str3 = AddSpace(str2, "Third");
Console.WriteLine(str3);
}
}
Running PureFunction.csproj, we will get the same output compared to the two previous non-pure function code. However, in this pure function code, we have three variables in the Main function. This is because in functional programming, we cannot modify the variable we have initialized earlier. In the AddSpace function, instead of modifying the global variable or argument, it now returns a string value to satisfy the the functional rule.
The following are the advantages we will have if we implement the pure function in our code:
Our code will be easy to be read and maintain because the function does not depend on external state and variables. It is also designed to perform specific tasks that increase maintainability.
The design will be easier to be changed since it is easier to refactor.
Testing and debugging will be easier since it's quite easy to isolate the pure function.
In an imperative programming world, we have got destructive assignments to mutate the state if a variable. By using loops, one can change multiple variables to achieve the computational objective. In the functional programming world, since variables cannot be destructively assigned, we need a recursive function call to achieve the objective of looping.
Let's create a factorial function. In mathematical terms, the factorial of the nonnegative integer N is the multiplication of all positive integers less than or equal to N. This is usually denoted by N!. We can denote the factorial of 7 as follows:
7! = 7 x 6 x 5 x 4 x 3 x 2 x 1 = 5040
If we look deeper at the preceding formula, we will discover that the pattern of the formula is as follows:
N! = N * (N-1) * (N-2) * (N-3) * (N-4) * (N-5) ...
Now, let's take a look at the following factorial function in C#. It's an imperative approach and can be found in the RecursiveImperative.csproj file:
public partial class Program
{
private static int GetFactorial(int intNumber)
{
if (intNumber == 0)
{
return 1;
}
return intNumber * GetFactorial(intNumber - 1);
}
}
As we can see, we invoke the GetFactorial() function from the GetFactorial() function itself. This is what we call a recursive function. We can use this function by creating a Main() method containing the following code:
public partial class Program
{
static void Main(string[] args)
{
Console.WriteLine(
"Enter an integer number (Imperative approach)");
int inputNumber = Convert.ToInt32(Console.ReadLine());
int factorialNumber = GetFactorial(inputNumber);
Console.WriteLine(
"{0}! is {1}",
inputNumber,
factorialNumber);
}
}
We invoke the GetFactorial() method and pass our desired number to the argument. The method will then multiply our number with what's returned by the GetFactorial() method, in which the argument has been subtracted by 1. The iteration will last until intNumber - 1 is equal to 0, which will return 1.
Now, let's compare the preceding recursive function in the imperative approach with one in the functional approach. We will use the power of the Aggregate operator in the LINQ feature to achieve this goal. We can find the code in the RecursiveFunctional.csproj file. The code will look like what is shown in the following:
class Program
{
static void Main(string[] args)
{
Console.WriteLine(
"Enter an integer number (Functional approach)");
int inputNumber = Convert.ToInt32(Console.ReadLine());
IEnumerable<int> ints = Enumerable.Range(1, inputNumber);
int factorialNumber = ints.Aggregate((f, s) => f * s);
Console.WriteLine(
"{0}! is {1}",
inputNumber,
factorialNumber);
}
}
We initialize the ints variable, which contains a value from 1 to our desired integer number in the preceding code, and then we iterate ints using the Aggregate operator. The output of RecursiveFunctional.csproj will be completely the same compared to the output of RecursiveImperative.csproj. However, we use the functional approach in the code in RecursiveFunctional.csproj.
This section will discuss about functional programming in C#. We will be discussing both the conceptual aspects of functional programming and write code in C#, as well. We will be kick-starting the discussion by discussing about currying, pipelining, and method chaining.
In functional programming, functions behave the way a mathematical function behaves by returning the same value for a given argument regardless of the context in which it is invoked. This is called Referential Transparency. To understand this in more detail, consider that we have the following mathematical function notation, and we want to turn it into functional programming in C#:
f(x) = 4x2-14x-8
The functional programming in C# is as follows:
public partial class Program
{
public static int f(int x)
{
return (4 * x * x - 14 * x - 8);
}
}
From the preceding function, which we can find in the FunctionF.csproj file, if x is 5, we will obtain f of 5, which is 22. The notation will be as follows:
f(5) = 22
We can also invoke the f function in C#, as follows:
public partial class Program
{
static void Main(string[] args)
{
int i = f(5);
Console.WriteLine(i);
}
}
Every time we run the function with 5 as the argument, which means that x is equal to 5, we always receive 22 as the return value.
Now, compare this with the imperative approach. Let's take a look at the following code, which will be stored in the ImperativeApproach.csproj file:
public partial class Program
{
static int i = 0;
static void increment()
{
i++;
}
static void set(int inpSet)
{
i = inpSet;
}
}
We describe the following code in the Main() method:
public partial class Program
{
static void Main(string[] args)
{
increment();
Console.WriteLine("First increment(), i = {0}", i);
set(6);
increment();
Console.WriteLine("Second increment(), i = {0}", i);
set(2);
increment();
Console.WriteLine("Last increment(), i = {0}", i);
return;
}
}
If we run ImperativeApproach.csproj, the console screen should be like what is shown in the following screenshot:
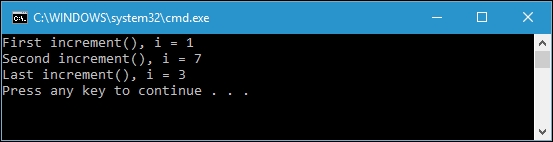
In the preceding imperative approach code, we will get the different i output in every invocation of increment or set although we pass the identical argument. Here, we find the so-called side effect problem of the imperative approach. The increment or set functions are said to have a side effect since they modify the state of i and interact with the outside world.
That was about side effects, and now, we have the following code in C#:
public partial class Program
{
public static string GetSign(int val)
{
string posOrNeg;
if (val > 0)
posOrNeg = "positive";
else
posOrNeg = "negative";
return posOrNeg;
}
}
The preceding code is statement style code, and we can find it in the StatementStyle.csproj file. It is an imperative programming technique that defines actions rather than producing results. We tell the computer what to do. We ask the computer to compare the value of the value variable with zero and then assign the posOrNeg variable to the associated value. We can try the preceding function by adding the following code to the project:
public partial class Program
{
static void Main(string[] args)
{
Console.WriteLine(
"Sign of -15 is {0}",
GetSign(-15));
}
}
The output in the console will be as follow:

And it agrees with our preceding discussion.
We can turn it into a functional approach by modifying it to expression style code. In C#, we can use the conditional operator to achieve this goal. The following is the code we have refactored from the StatementStyle.csproj code, and we can find it in the ExpressionStyle.csproj file:
public partial class Program
{
public static string GetSign(int val)
{
return val > 0 ? "positive" : "negative";
}
}
Now we have compact code that has the same behavior as our preceding many lines of code. However, as we discussed previously, the preceding code has no side-effect since it only returns the string value with no need to prepare the variable first. While in the statement style approach, we have to assign the posOrNeg variable twice. In other words, we can say that the functional approach will produce a side-effect-free function.
In contrast to imperative programming, in functional programming, we describe what we want as the result rather than specifying how to receive the result. Suppose we have a list of data and want to create a new list containing the Nth element from the source list. The imperative approach to achieve this is as follows:
public partial class Program
{
static List<int> NthImperative(List<int> list, int n)
{
var newList = new List<int>();
for (int i = 0; i < list.Count; i++)
{
if (i % n == 0) newList.Add(list[i]);
}
return newList;
}
}
The preceding code can be found in the NthElementImperative.csproj file. As we can see, to retrieve the Nth element from the list in C#, we have to initialize the first element so that we define i as 0. We then iterate through the list element and decide whether the current element is the Nth element. If so, we add newList the new data from the source list. Here, we find that the preceding source code is not a functional approach because the newList variable is assigned more than once when adding the new data. It also contains the loop process, which the functional approach doesn't have. However, we can turn the code into a functional approach as follows:
public partial class Program
{
static List<int> NthFunctional(List<int> list, int n)
{
return list.Where((x, i) => i % n == 0).ToList();
}
}
Again, we have compact code in the functional approach since we are using the power of the LINQ feature. If we want to try the preceding two functions, we can inset the following code to the Main() function:
public partial class Program
{
static void Main(string[] args)
{
List<int> listing =
new List<int>() {
0, 1, 2, 3, 4, 5,
6, 7, 8, 9, 10, 11,
12, 13, 14, 15, 16 };
var list3rd_imper = NthImperative(listing, 3);
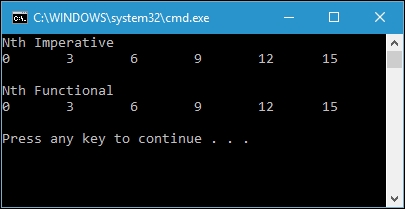
PrintIntList("Nth Imperative", list3rd_imper);
var list3rd_funct = NthFunctional(listing, 3);
PrintIntList("Nth Functional", list3rd_funct);
}
}
For the PrintIntList() method, the implementation is as follows:
public partial class Program
{
static void PrintIntList(
string titleHeader,
List<int> list)
{
Console.WriteLine(
String.Format("{0}",
titleHeader));
foreach (int i in list)
{
Console.Write(String.Format("{0}\t", i));
}
Console.WriteLine("\n");
}
}
Although we run the two functions with different approaches, we are still given the same output, as follows:
In .NET Framework 4, Tuples is introduced as a new set of generic classes to store a set of different typed elements. Tuples is immutable so it can be applied to functional programming. It is used to represent a data structure when we need the different data type in an object. Here is the available syntax to declare tuple objects:
public class Tuple <T1> public class Tuple <T1, T2> public class Tuple <T1, T2, T3> public class Tuple <T1, T2, T3, T4> public class Tuple <T1, T2, T3, T4, T5> public class Tuple <T1, T2, T3, T4, T5, T6> public class Tuple <T1, T2, T3, T4, T5, T6, T7> public class Tuple <T1, T2, T3, T4, T5, T6, T7, T8>
As we can see in the preceding syntaxes, we can create a tuple with a maximum eight item type (T1, T2, and so on). Tuple has read-only properties that’s why it’s immutable. Let’s look at the following code snippet we can find in Tuple.csproj project:
public partial class Program
{
Tuple<string, int, int> geometry1 =
new Tuple<string, int, int>(
"Rectangle",
2,
3);
Tuple<string, int, int> geometry2 =
Tuple.Create(
"Square",
2,
2);
}To create Tuple, we have two different ways based on the preceding code. The former, we instantiate a new Tuple to a variable. The latter, we use Tuple.Create(). To consume the Tuple data, we can use its Item like the following code snippet:
public partial class Program
{
private static void ConsumeTuple()
{
Console.WriteLine(
"{0} has size {1} x {2}",
geometry1.Item1,
geometry1.Item2,
geometry1.Item3);
Console.WriteLine(
"{0} has size {1} x {2}",
geometry2.Item1,
geometry2.Item2,
geometry2.Item3);
}
}If we run ConsumeTuple() method above, we will get the following on the console:

We can also return a tuple data type like we do in the following code snippet:
public partial class Program
{
private static Tuple<int, int> (
string shape)
{ GetSize
if (shape == "Rectangle")
{
return Tuple.Create(2, 3);
}
else if (shape == "Square")
{
return Tuple.Create(2, 2);
}
else
{
return Tuple.Create(0, 0);
}
}
}As we can see, GetSize() method will return Tuple data type. We can add the following ReturnTuple() method:
public partial class Program
{
private static void ReturnTuple()
{
var rect = GetSize("Rectangle");
Console.WriteLine(
"Rectangle has size {0} x {1}",
rect.Item1,
rect.Item2);
var square = GetSize("Square");
Console.WriteLine(
"Square has size {0} x {1}",
square.Item1,
square.Item2);
}
}And if we run ReturnTuple() method above, we will be displayed exactly same output as ConsumeTuple() method.
Fortunately, in C# 7, we can return Tuple data type without having to state the Tuple like the following code snippet:
public partial class Program
{
(int, int) GetSizeInCS7(
string shape)
{
if (shape == "Rectangle")
{
return (2, 3);
}
else if (shape == "Square")
{
return (2, 2);
}
else
{
return (0, 0);
}
}
}And if we want to name all items in the Tuple, we can now do it in C# 7 by using the technique like the following code snippet:
public partial class Program
{
private static (int x, int y) GetSizeNamedItem(
string shape)
{
if (shape == "Rectangle")
{
return (2, 3);
}
else if (shape == "Square")
{
return (2, 2);
}
else
{
return (0, 0);
}
}
}And now it will be clearer when we access the Tuple items like the following code:
public partial class Program
{
private static void ConsumeTupleByItemName()
{
var rect = GetSizeNamedItem("Rectangle");
Console.WriteLine(
"Rectangle has size {0} x {1}",
rect.x,
rect.y);
var square = GetSizeNamedItem("Square");
Console.WriteLine(
"Square has size {0} x {1}",
square.x,
square.y);
}
}We no longer call the Item1 and Item2, instead we call the x and y name.
In order to gain all new feature of Tuple in C# 7, we have to download System.ValueTuple NuGet package from https://www.nuget.org/packages/System.ValueTuple.
We have theoretically discussed currying at the beginning of this chapter. We apply currying when we split a function that takes multiple arguments into a sequence of functions that occupy part of the argument. In other words, when we pass fewer arguments into a function, it will expect that we get back another function to complete the original function using the sequence of functions. Let's take a look at the following code from the NonCurriedMethod.csproj file:
public partial class Program
{
public static int NonCurriedAdd(int a, int b) => a + b;
}
The preceding function will add the a and b arguments and then return the result. The usage of this function is commonly used in our daily programming; for instance, take a look at the following code snippet:
public partial class Program
{
static void Main(string[] args)
{
int add = NonCurriedAdd(2, 3);
Console.WriteLine(add);
}
}
Now, let's move on to the curried method. The code will be found in the CurriedMethod.csproj file, and the function declaration will be as follows:
public partial class Program
{
public static Func<int, int> CurriedAdd(int a) => b => a + b;
}
We use the Func<> delegate to create the CurriedAdd() method. We can invoke the preceding method in two ways, and the first is as follows:
public partial class Program
{
public static void CurriedStyle1()
{
int add = CurriedAdd(2)(3);
Console.WriteLine(add);
}
}
In the preceding invocation of the CurriedAdd() method, we pass the argument with two brackets, which it might not be familiar with. In fact, we can also curry our CurriedAdd() method by passing one argument only. The code will be as follows:
public partial class Program
{
public static void CurriedStyle2()
{
var addition = CurriedAdd(2);
int x = addition(3);
Console.WriteLine(x);
}
}
From the preceding code, we supply one argument to the CurriedAdd() method in the following:
var addition = CurriedAdd(2);
Then, it waits for the other addition expression, which we provide in the following code:
int x = addition(3);
The result of the preceding code will be completely the same as the NonCurried() method.
Pipelining is a technique used to pass the output of one function as an input to the next function. The data in the operation will flow like the flow of water in a pipe. We usually find this technique in command-line interfaces. Let's take a look at the following command line:
C:\>dir | more
The preceding command line will pass the output of the dir command to the input of the more command. Now, let's take a look at the following C# code that we can find in the NestedMethodCalls.csproj file:
class Program
{
static void Main(string[] args)
{
Console.WriteLine(
Encoding.UTF8.GetString(
new byte[] { 0x70, 0x69, 0x70, 0x65, 0x6C,
0x69, 0x6E, 0x69, 0x6E, 0x67 }
)
);
}
}
In the previous code, we used the nested method calls technique to write pipelining in console screen. If we want to refactor it to the pipelining approach, we can take a look at the following code that we can find in the Pipelining.csproj file:
class Program
{
static void Main(string[] args)
{
var bytes = new byte[] {
0x70, 0x69, 0x70, 0x65, 0x6C,
0x69, 0x6E, 0x69, 0x6E, 0x67 };
var stringFromBytes = Encoding.UTF8.GetString(bytes);
Console.WriteLine(stringFromBytes);
}
}
If run the preceding code, we will get exactly the same pipelining output, but this time, it will be in the pipelining style.
Method chaining is process of chaining multiple methods in one code line. The return from one method will be the input of the next method, and so on. Using method chaining, we don't need to declare many variables to store every method return. Instead, the return of the method will be passed to the next method argument. The following is the traditional method, which doesn't apply method chaining, and we can find the code at TraditionalMethod.csproj:
class Program
{
static void Main(string[] args)
{
var sb = new StringBuilder("0123", 10);
sb.Append(new char[] { '4', '5', '6' });
sb.AppendFormat("{0}{1}{2}", 7, 8, 9);
sb.Insert(0, "number: ");
sb.Replace('n', 'N');
var str = sb.ToString();
Console.WriteLine(str);
}
}
There are five methods of StringBuilder invoked inside the Main function and two variables: sb is used to initialize StringBuilder and str is used to store StringBuilder in the string format. Unfortunately, the five methods we invoked there modify the sb variable. We can refactor the code to apply method chaining in order to make it functional. The following is the functional code, and we can find it at ChainingMethod.csproj:
class Program
{
static void Main(string[] args)
{
var str =
new StringBuilder("0123", 10)
.Append(new char[] { '4', '5', '6' })
.AppendFormat("{0}{1}{2}", 7, 8, 9)
.Insert(0, "number: ")
.Replace('n', 'N')
.ToString();
Console.WriteLine(str);
}
}
The same output will be displayed if we run both types of code. However, we now have functional code by chaining all the invoking methods.
In this section, we will transform imperative code to functional code by leveraging method chaining. Suppose we want to create an HTML-ordered list containing the list of the planets in our solar system; the HTML will look as follows:
<ol id="thePlanets"> <li>The Sun/li> <li value="0">Mercury</li> <li value="1">Venus</li> <li value="2">Earth</li> <li value="3">Mars</li> <li value="4">Jupiter</li> <li value="5">Saturn</li> <li value="6">Uranus</li> <li value="7">Neptune</li> </ol>
We are going to list the name of planets, including the Sun. We will also mark the order of the planets with the value attribute in each li element. The preceding HTML code will be displayed in the console. We will create the list in ImperativeCode.csproj; here you go:
class Program
{
static void Main(string[] args)
{
byte[] buffer;
using (var stream = Utility.GeneratePlanetsStream())
{
buffer = new byte[stream.Length];
stream.Read(buffer, 0, (int)stream.Length);
}
var options = Encoding.UTF8
.GetString(buffer)
.Split(new[] { Environment.NewLine, },
StringSplitOptions.RemoveEmptyEntries)
.Select((s, ix) => Tuple.Create(ix, s))
.ToDictionary(k => k.Item1, v => v.Item2);
var orderedList = Utility.GenerateOrderedList(
options, "thePlanets", true);
Console.WriteLine(orderedList);
}
}
In the Main() method, we create a byte array, buffer, containing the planet stream we generate in other classes. The code snippet is as follows:
byte[] buffer;
using (var stream = Utility.GeneratePlanetsStream())
{
buffer = new byte[stream.Length];
stream.Read(buffer, 0, (int)stream.Length);
}
We can see that there is a class named Utility, containing the GeneratePlanetStream() method. This method is used to generate the list of planets in the solar system in a stream format. Let's take a look at the following code in order to find what is inside the method:
public static partial class Utility
{
public static Stream GeneratePlanetsStream()
{
var planets =
String.Join(
Environment.NewLine,
new[] {
"Mercury", "Venus", "Earth",
"Mars", "Jupiter", "Saturn",
"Uranus", "Neptune"
});
var buffer = Encoding.UTF8.GetBytes(planets);
var stream = new MemoryStream();
stream.Write(buffer, 0, buffer.Length);
stream.Position = 0L;
return stream;
}
}
Firstly, it creates a variable named planets, containing eight planets named separately on a new line. We get the bytes of the ASCII using the GetBytes method, and then it is converted into a stream. This stream will be returned to the caller function.
In the main function, we also have variable options, as follows:
var options = Encoding.UTF8
.GetString(buffer)
.Split(new[] { Environment.NewLine, },
StringSplitOptions.RemoveEmptyEntries)
.Select((s, ix) => Tuple.Create(ix, s))
.ToDictionary(k => k.Item1, v => v.Item2);
This will create a dictionary-typed variable, which contains the name of the planet and its order in the solar system. We use LINQ here, but we will discuss it deeper in the next chapter.
Then, we invoke the GenerateOrderedList() method inside the Utility class. This method is used to generate an HTML-ordered list containing the order of the planets in the solar system. The code snippet is as follows:
var orderedList = Utility.GenerateOrderedList(
options, "thePlanets", true);
If we take a look at the GenerateOrderedList() method, we will find the following code:
public static partial class Utility
{
public static string GenerateOrderedList(
IDictionary<int, string> options,
string id,
bool includeSun)
{
var html = new StringBuilder();
html.AppendFormat("<ol id="{0}">", id);
html.AppendLine();
if (includeSun)
{
html.AppendLine("\t<li>The Sun/li>");
}
foreach (var opt in options)
{
html.AppendFormat("\t<li value="{0}">{1}</li>",
opt.Key,
opt.Value);
html.AppendLine();
}
html.AppendLine("</ol>");
return html.ToString();
}
}
First, in this method, we create a StringBuilder function named html and add an opening ol tag, which means an ordered list. The code snippet is as follows:
var html = new StringBuilder();
html.AppendFormat("<ol id="{0}">", id);
html.AppendLine();
We also have Boolean variable, includeSun, to define whether we need to include Sun in the list. We get the value of this variable from the argument of the method. After that, we iterate the content of the dictionary we get from argument. This dictionary is generated by LINQ in the Main() method. We list the content by adding the li tag. The foreach keyword is used to achieve this goal. Here is the code snippet:
foreach (var opt in options)
{
html.AppendFormat("\t<li value="{0}">{1}</li>",
opt.Key,
opt.Value);
html.AppendLine();
}
We can see that AppendFormat in the StringBuilder class is similar to String.Format, and we can pass Key and Value from dictionary. Do not forget to insert a new line for each li tag using the AppendLine method.
Lastly, we close the ol tag with the </ol> tag, which we define in the following snippet:
html.AppendLine("</ol>");
Then, we invoke the ToString() method to get a bunch of strings from StringBuilder. Now if we run the code, we will get the output on the console screen, as we discussed earlier.
We have already developed imperative code in order to construct an HTML-ordered list of planet names, as discussed earlier. Now, from this imperative code, we are going to refactor it to functional code using method chaining. The functional code we build will be at FunctionalCode.csproj.
We start with the GenerateOrderedList() method since we will modify its first three lines. It looks like the following in ImperativeCode.csproj:
var html = new StringBuilder();
html.AppendFormat("<ol id="{0}">", id);
html.AppendLine();
We can refactor the preceding code to this:
var html =
new StringBuilder()
.AppendFormat("<ol id="{0}">", id)
.AppendLine();
The code becomes more natural now since it applies method chaining. However, we are still able to join the AppendFormat() method with the AppendLine() method in order to make it simple. To achieve this goal, we need help from method extension. We can create a method extension for StringBuilder as follows:
public static partial class StringBuilderExtension
{
public static StringBuilder AppendFormattedLine(
this StringBuilder @this,
string format,
params object[] args) =>
@this.AppendFormat(format, args).AppendLine();
}
Now, because we have the AppendFormattedLine() method in the StringBuilder class, we can refactor our previous code snippet to the following:
var html =
new StringBuilder()
.AppendFormattedLine("<ol id="{0}">", id);
The code snippet becomes much simpler than earlier. We also have the invocation of AppendFormat() following AppendLine() inside the foreach loop, as follows:
foreach (var opt in options)
{
html.AppendFormat("\t<li value="{0}">{1}</li>",
opt.Key,
opt.Value);
html.AppendLine();
}
Therefore, we can also refactor the preceding code snippet using the AppendFormattedLine() function we added inside the StringBuilder class, as follows:
foreach (var opt in options)
{
html.AppendFormattedLine(
"\t<li value="{0}">{1}</li>",
opt.Key,
opt.Value);
}
Next, we have AppendLine() inside the conditional keyword if. We also need to refactor it to apply method chaining using the extension method. We can create the extension method for StringBuilder named AppendLineWhen(). The use of this method is to compare the condition we provide, and then it should decide whether or not it needs to be written. The extension method will be as follows:
public static partial class StringBuilderExtension
{
public static StringBuilder AppendLineWhen(
this StringBuilder @this,
Func<bool> predicate,
string value) =>
predicate()
? @this.AppendLine(value)
: @this;
}
Since we now have the AppendLineWhen() method, we can chain it to the previous code snippet, as follows:
var html =
new StringBuilder()
.AppendFormattedLine("<ol id="{0}">", id)
.AppendLineWhen(() => includeSun, "\t<li>The Sun/li>");
Thus, we are now confident about removing the following code from the GenerateOrderedList() method:
if (includeSun)
{
html.AppendLine("\t<li>The Sun/li>");
}
We are also able to make the AppendLineWhen() method more general so that it not only accepts a string, but also takes a function as an argument. Let's modify the AppendLineWhen() method to the AppendWhen() method, as follows:
public static partial class StringBuilderExtension
{
public static StringBuilder AppendWhen(
this StringBuilder @this,
Func<bool> predicate,
Func<StringBuilder, StringBuilder> fn) =>
predicate()
? fn(@this)
: @this;
}
As we can see, the function now takes Func<StringBuilder, StringBuilder> fn as an argument to replace the string value. So, it now uses the function to decide the conditional with fn(@this). We can refactor var html again with our new method, as follows:
var html =
new StringBuilder()
.AppendFormattedLine("<ol id="{0}">", id)
.AppendWhen(
() => includeSun,
sb => sb.AppendLine("\t<li>The Sun/li>"));
We have chained two methods so far; they are AppendFormattedLine() and AppendWhen() methods. The remaining function we have is foreach loop that we need to chain to the StringBuilder object named html. For this purpose, we create an extension method to a StringBuilder named AppendSequence() again, as follows:
public static partial class StringBuilderExtension
{
public static StringBuilder AppendSequence<T>(
this StringBuilder @this,
IEnumerable<T> sequence,
Func<StringBuilder, T, StringBuilder> fn) =>
sequence.Aggregate(@this, fn);
}
We use the IEnumerable interface to make this function iterate over the sequence. It also invokes the Aggregate method in IEnumerable as an accumulator that counts the increasing sequence.
Now, using AppendSequence(), we can refactor the foreach loop and chain the methods to var html, as follows:
var html =
new StringBuilder()
.AppendFormattedLine("<ol id="{0}">", id)
.AppendWhen(
() => includeSun,
sb => sb.AppendLine("\t<li>The Sun/li>"))
.AppendSequence(
options,
(sb, opt) =>
sb.AppendFormattedLine(
"\t<li value="{0}">{1}</li>",
opt.Key,
opt.Value));
The AppendSequence() method we add takes the options variable as the dictionary input and function of sb and opt. This method will iterate the dictionary content and then append the formatted string into StringBuilder sb. Now, the following foreach loop can be removed from the code:
foreach (var opt in options)
{
html.AppendFormattedLine(
"\t<li value="{0}">{1}</li>",
opt.Key,
opt.Value);
}
Next is the html.AppendLine("</ol>") function invocation we want to chain to the var html variable. This is quite simple because we just need to chain it without making many changes. Now let's take a look at a change in the var html assignment:
var html =
new StringBuilder()
.AppendFormattedLine("<ol id="{0}">", id)
.AppendWhen(
() => includeSun,
sb => sb.AppendLine("\t<li>The Sun/li>"))
.AppendSequence(
options,
(sb, opt) =>
sb.AppendFormattedLine(
"\t<li value="{0}">{1}</li>",
opt.Key,
opt.Value))
.AppendLine("</ol>");
As we can see in the preceding code, we refactor the AppendLine() method, so it is now chained to the StringBuilder declaration.
In the GenerateOrderedList() method, we have the following line of code:
return html.ToString();
We can also refactor the line so that it will be chained to the StringBuilder declaration in var html. If we chain it, we will have the following var html initialization:
var html =
new StringBuilder()
.AppendFormattedLine("<ol id="{0}">", id)
.AppendWhen(
() => includeSun,
sb => sb.AppendLine("\t<li>The Sun/li>"))
.AppendSequence(
options,
(sb, opt) =>
sb.AppendFormattedLine(
"\t<li value="{0}">{1}</li>",
opt.Key,
opt.Value))
.AppendLine("</ol>")
.ToString();
Unfortunately, if we compile the code now, it will yield the CS0161 error with the following explanation:
'Utility.GenerateOrderedList(IDictionary<int, string>, string, bool)': not all code paths return a value
The error occurs because the method doesn't return any value when it's expected to return a string value. However, since it is functional programming, we can refactor this method in an expression member. The complete GenerateOrderedList() method will be as follows:
public static partial class Utility
{
public static string GenerateOrderedList(
IDictionary<int, string> options,
string id,
bool includeSun) =>
new StringBuilder()
.AppendFormattedLine("<ol id="{0}">", id)
.AppendWhen(
() => includeSun,
sb => sb.AppendLine("\t<li>The Sun/li>"))
.AppendSequence(
options,
(sb, opt) =>
sb.AppendFormattedLine(
"\t<li value="{0}">{1}</li>",
opt.Key,
opt.Value))
.AppendLine("</ol>")
.ToString();
}
We have removed the return keyword from the preceding code. We have also removed the html variable. We now have a function that has bodies as lambda-like expressions instead of statement blocks. This feature was announced in .NET Framework 4.6.
The Main() method in FunctionalCode.csproj is a typical method we usually face when programming in C#. The method flow is as follows: it reads data from the stream into the byte array and then converts those bytes into strings. After that, it performs a transformation to modify that string before passing it to the GenerateOrderedList() method.
If we look at the starting code lines, we get the following code snippet:
byte[] buffer;
using (var stream = Utility.GeneratePlanetsStream())
{
buffer = new byte[stream.Length];
stream.Read(buffer, 0, (int)stream.Length);
}
We need to refactor the preceding code to be able to be chained. For this purpose, we create a new class named Disposable, containing the Using() method. The Using() method inside the Disposable class is as follows:
public static class Disposable
{
public static TResult Using<TDisposable, TResult>
(
Func<TDisposable> factory,
Func<TDisposable, TResult> fn)
where TDisposable : IDisposable
{
using (var disposable = factory())
{
return fn(disposable);
}
}
}
In the preceding Using() method, we take two arguments: factory and fn. The function to which the IDisposable interface applies is factory, and fn is the function that will be executed after declaring the factory function. Now we can refactor the starting lines in the Main() method as follows:
var buffer =
Disposable
.Using(
Utility.GeneratePlanetsStream,
stream =>
{
var buff = new byte[stream.Length];
stream.Read(buff, 0, (int)stream.Length);
return buff;
});
Compared to imperative code, we have now refactored the code that reads the stream and stores it in a byte array with the help of the Dispose.Using() method. We ask the lambda stream function to return the buff content. Now, we have a buffer variable to be passed to the next phase, which is the UTF8.GetString(buffer) method. What we actually do in the GetString(buffer) method is transforming and then mapping the buffer to a string. In order to chain this method, we need to create the Map method extension. The method will look as follows:
public static partial class FunctionalExtensions
{
public static TResult Map<TSource, TResult>(
this TSource @this,
Func<TSource, TResult> fn) =>
fn(@this);
}
Since we need to make it a general method, we use a generic type in the arguments of the method. We also use a generic type in the returning value so that it won't return only the string value. Using the generic types, this Map extension method will be able to transform any static type value into another static type value. We need to use an expression body member for this method, so we use the lambda expression here. Now we can use this Map method for the UTF8.GetString() method. The var buffer initialization will be as follows:
var buffer =
Disposable
.Using(
Utility.GeneratePlanetsStream,
stream =>
{
var buff = new byte[stream.Length];
stream.Read(buff, 0, (int)stream.Length);
return buff;
})
.Map(Encoding.UTF8.GetString)
.Split(new[] { Environment.NewLine, },
StringSplitOptions.RemoveEmptyEntries)
.Select((s, ix) => Tuple.Create(ix, s))
.ToDictionary(k => k.Item1, v => v.Item2);
By applying the Map method like the preceding code snippet, we don't need the following code anymore:
var options =
Encoding
.UTF8
.GetString(buffer)
.Split(new[] { Environment.NewLine, },
StringSplitOptions.RemoveEmptyEntries)
.Select((s, ix) => Tuple.Create(ix, s))
.ToDictionary(k => k.Item1, v => v.Item2);
However, the problem occurs since the next code needs variable options as arguments to the GenerateOrderedList() method, which we can see in following code snippet:
var orderedList = Utility.GenerateOrderedList( options, "thePlanets", true);
To solve this problem, we can use the Map methods as well to chain the GenerateOrderedList() method to the buffer variable initialization so that we can remove the orderedList variable. Now, the code will be look like what is shown in the following:
var buffer =
Disposable
.Using(
Utility.GeneratePlanetsStream,
stream =>
{
var buff = new byte[stream.Length];
stream.Read(buff, 0, (int)stream.Length);
return buff;
})
.Map(Encoding.UTF8.GetString)
.Split(new[] { Environment.NewLine, },
StringSplitOptions.RemoveEmptyEntries)
.Select((s, ix) => Tuple.Create(ix, s))
.ToDictionary(k => k.Item1, v => v.Item2)
.Map(options => Utility.GenerateOrderedList(
options, "thePlanets", true));
Since the last line of code is the Console.WriteLine() method, which takes the orderedList variable as an argument, we can modify the buffer variable to orderedList. The change will be as follows:
var orderedList =
Disposable
.Using(
Utility.GeneratePlanetsStream,
stream =>
{
var buff = new byte[stream.Length];
stream.Read(buff, 0, (int)stream.Length);
return buff;
})
.Map(Encoding.UTF8.GetString)
.Split(new[] { Environment.NewLine, },
StringSplitOptions.RemoveEmptyEntries)
.Select((s, ix) => Tuple.Create(ix, s))
.ToDictionary(k => k.Item1, v => v.Item2)
.Map(options => Utility.GenerateOrderedList(
options, "thePlanets", true));
The last line in the GenerateOrderedList() method is the Console.WriteLine() method. We will also chain this method to the orderedList variable. For this purpose, we need to extend a method called Tee, containing the pipelining technique we discussed earlier. Let's take a look at the following Tee method extension:
public static partial class FunctionalExtensions
{
public static T Tee<T>(
this T @this,
Action<T> action)
{
action(@this);
return @this;
}
}
From the preceding code, we can see that the output of Tee will be passed to the input of the Action function. Then, we can chain the last line using Tee, as follows:
Disposable
.Using(
Utility.GeneratePlanetsStream,
stream =>
{
var buff = new byte[stream.Length];
stream.Read(buff, 0, (int)stream.Length);
return buff;
})
.Map(Encoding.UTF8.GetString)
.Split(new[] { Environment.NewLine, },
StringSplitOptions.RemoveEmptyEntries)
.Select((s, ix) => Tuple.Create(ix, s))
.ToDictionary(k => k.Item1, v => v.Item2)
.Map(options => Utility.GenerateOrderedList(
options, "thePlanets", true))
.Tee(Console.WriteLine);
Tee can return the HTML generated by the GenerateOrderedList() method so that we can remove the orderedList variable from the code.
We can also implement the Tee method to the lambda expression in the preceding code. We will refactor the following code snippet using Tee:
stream =>
{
var buff = new byte[stream.Length];
stream.Read(buff, 0, (int)stream.Length);
return buff;
}
Let's understand what the preceding code snippet is actually doing. First, we initialize the byte array variable buff to store as many bytes as the length of the stream. It then populates this byte array using the stream.Read method before returning the byte array. We can also ask the Tee method to do this job. The code will be as follows:
Disposable
.Using(
Utility.GeneratePlanetsStream,
stream => new byte[stream.Length]
.Tee(b => stream.Read(
b, 0, (int)stream.Length)))
.Map(Encoding.UTF8.GetString)
.Split(new[] { Environment.NewLine, },
StringSplitOptions.RemoveEmptyEntries)
.Select((s, ix) => Tuple.Create(ix, s))
.ToDictionary(k => k.Item1, v => v.Item2)
.Map(options => Utility.GenerateOrderedList(
options, "thePlanets", true))
.Tee(Console.WriteLine);
Now, we have a new Main() method, applying method chaining to approach functional programming.
So far, we have had to deal with functional programming by creating code using functional approach. Now, we can look at the advantages of the functional approach, such as the following:
The order of execution doesn't matter since it is handled by the system to compute the value we have given rather than the one defined by programmer. In other words, the declarative of the expressions will become unique. Because functional programs have an approach toward mathematical concepts, the system will be designed with the notation as close as possible to the mathematical way of concept.
Variables can be replaced by their value since the evaluation of expression can be done any time. The functional code is then more mathematically traceable because the program is allowed to be manipulated or transformed by substituting equals with equals. This feature is called referential transparency.
Immutability makes the functional code free of side effects. A shared variable, which is an example of a side effect, is a serious obstacle for creating parallel code and result in non-deterministic execution. By removing the side effect, we can have a good coding approach.
The power of lazy evaluation will make the program run faster because it only provides what we really required for the queries result. Suppose we have a large amount of data and want to filter it by a specific condition, such as showing only the data that contains the word Name. In imperative programming, we will have to evaluate each operation of all the data. The problem is that when the operation takes a long time, the program will need more time to run as well. Fortunately, the functional programming that applies LINQ will perform the filtering operation only when it is needed. That's why functional programming will save much of our time using lazy evaluation.
We have a solution for complex problems using composability. It is a rule principle that manages a problem by dividing it, and it gives pieces of the problem to several functions. The concept is similar to a situation when we organize an event and ask different people to take up a particular responsibility. By doing this, we can ensure that everything will done properly by each person.
Beside the advantages of functional programming, there are several disadvantages as well. Here are some of them:
Since there's no state and no update of variables is allowed, loss of performance will take place. The problem occurs when we deal with a large data structure and it needs to perform a duplication of any data even though it only changes a small part of the data.
Compared to imperative programming, much garbage will be generated in functional programming due to the concept of immutability, which needs more variables to handle specific assignments. Because we cannot control the garbage collection, the performance will decrease as well.
So far, we have been acquainted with the functional approach by discussing the introduction of functional programming. We also have compared the functional approach to the mathematical concept when we create functional program. It's now clear that the functional approach uses the mathematical approach to compose a functional program.
There are three important points in constructing the function; they are definition, script, and session. The definition is the equation between particular expressions that describe the mathematical function. Script is a collection of definitions that are supplied by the programmer. Session is a situation where the program submits the expressions that can contain references to the function defined in the script to the computer for evaluation.
The comparison between functional and imperative programming also led us to the important point of distinguishing the two. It's now clear that in functional programming, the programmer focuses on the kind of desired information and the kind of required transformation, while in the imperative approach, the programmer focuses on the way of performing the task and tracking changes in the state.
We also explored several concepts of functional programming, such as first-class and higher-order functions, pure functions, and recursive functions. The first-class and higher-order functions concept treats the functions as values so that we can assign it to a variable and pass it to the argument of the function. The pure functions concept makes the function have no side-effect. Recursive functions help us iterate the function itself with the power of aggregate in LINQ. Also, functions in functional programming have several characteristics that we need to know, such as the following:
It always returns the same value every time it is given the same set of inputs.
It never references a variable defined outside the function.
It cannot change the value of the variable since it applies the immutable concept.
It doesn't contain any I/O, such as a fancy output or a keyboard stroke, since no side-effect occurrence is allowed.
When we test functional program in C#, we take the mathematical approach to find out how to compose a function in C# from a mathematical function. We learn how to curry the curried function to pass the second argument after we assign the first argument alone. Also, we now know how to make the program functional using pipelining and the method chaining technique.
After finishing with learning the techniques for creating functional programming, we translate the imperative approach code into the functional approach code. Here, we compose the imperative code from scratch and then refactor it into functional code.
Lastly, after we become more familiar with functional programming, we can grasp the advantages and disadvantages of functional programming itself. This will be the reason why we need to learn functional programming.
In the next chapter, we will talk about delegate data type to encapsulates a method that has particular parameters and return type. It is useful when we need create a cleaner and an easier function pointer.

