


















 Download code from GitHub
Download code from GitHub
Chapter 1: Architecture for the Cloud
Before we examine the detailed knowledge that the AZ-304 exam tests, this chapter discusses some general principles of solution architecture and how the advent of cloud computing has changed the role of the architect. As applications have moved toward ever more sophisticated constructs, the role of the architect has, in turn, become more critical to ensure security, reliability, and scalability.
It is useful to agree on what architecture means today, how we arrived here, and what we need to achieve when documenting requirements and producing designs.
In this chapter, we're going to cover the following main topics:
- Introducing architecture
- Exploring the transition from monolithic to microservices
- Migrating to the cloud from on-premises
- Understanding infrastructure and platform services
- Moving from waterfall to Agile projects
Introducing architecture
It may seem a strange question to ask in a book about solution architecture—after all, it could be assumed that if you are reading this book, then you already know the answer to that question.
In my experience, many architects I have worked with all have a very different view of what architecture is or, to be more precise, what falls into the realms of architecture and what falls into other workstreams such as engineering or operational support.
These differing views usually depend on an architect's background. Infrastructure engineers concern themselves with the more physical aspects such as servers, networking, and storage. Software developers see solutions in terms of communication layers, interactions, and lower-level data schemas. Finally, former business analysts are naturally more focused on operations, processes, and support tiers.
For me, as someone involved across disciplines, architecture is about all these aspects, and we need to realize that a solution's components aren't just technical—they also cover business, operations, and security.
Some would argue that actually, these would typically be broken down into infrastructure, application, or business architecture, with enterprise architecture sitting over the top of all three, providing strategic direction. In a more traditional, on-premises world, this indeed makes sense; however, as business has embraced and adopted cloud, how software is designed, built, and deployed has changed radically.
Where once there was a clear line between all these fields, today they are all treated the same. Every part of a solution's components, from servers to code, must be created and implemented as part of a single set of tasks.
Software is no longer shaped by hardware; quite the opposite—the supporting systems that run code are now smaller, more agile, and more dynamic.
With so much change, cloud architects must now comprehend the entire stack, from storage to networking, code patterns to project management, and everything in between.
Let's now look at how systems are transitioned from monolithic to microservices.
Exploring the transition from monolithic to microservices
I've often felt that it helps to understand what has led us to where we are in terms of what we're trying to achieve—that is, well-designed solutions that provide business value and meet all technical and non-technical requirements.
When we architect a system, we must consider many aspects—security, resilience, performance, and more. But why do we need to think of these? At some point, something will go wrong, and therefore we must accommodate that eventuality in our designs.
For this reason, I want to go through a brief history of how technology has changed over the years, how it has affected system design, what new issues have arisen, and—most importantly—how it has changed the role of an IT architect.
We will start in the 1960s when big businesses began to leverage computers to bring efficiencies to their operating models.
Mainframe computing
Older IT systems were monolithic. The first business systems consisted of a large mainframe computer that users interacted with through dumb terminals—simple screens and keyboards with no processing power of their own.
The software that ran on them was often built similarly—they were often unwieldy chunks of code. There is a particularly famous photograph of the National Aeronautics and Space Administration (NASA) computer scientist Margaret Hamilton standing by a stack of printed code that is as tall as she is—this was the code that ran the Apollo Guidance Computer (AGC).
In these systems, the biggest concern was computing resources, and therefore architecture was about managing these resources efficiently. Security was primarily performed by a single user database contained within this monolithic system. While the internet did exist in a primitive way, external communications and, therefore, the security around them didn't come into play. In other words, as the entire solution was essentially one big computer, there was a natural security boundary.
If we examine the following diagram, we can see that in many ways, the role of an architect dealt with fewer moving parts than today, and many of today's complexities, such as security, didn't exist because so much was intrinsic to the mainframe itself:

Figure 1.1 – Mainframe computing
Mainframe computing slowly gave way to personal computing, so next, we will look at how the PC revolution changed systems, and therefore design requirements.
Personal computing
The PC era brought about a business computing model in which you had lower-powered servers that delivered one or two duties—for example, a file server, a print server, or an internal email server.
PCs now connected to these servers over a local network and performed much of the processing themselves.
Early on, each of these servers might have had a user database to control access. However, this was very quickly addressed. The notion of a directory server quickly became the norm so that now we still have a single user database, as in the days of the mainframe; however, the information in that database must control access to services running on other servers.
Security had now become more complex as the resources were distributed, but there was still a naturally secure boundary—that of the local network.
Software also started to become more modular in that individual programs were written to run on single servers that performed discrete tasks; however, these servers and programs might have needed to communicate with each other.
The following diagram shows a typical server-based system whereby individual servers provide discrete services, but all within a corporate network:
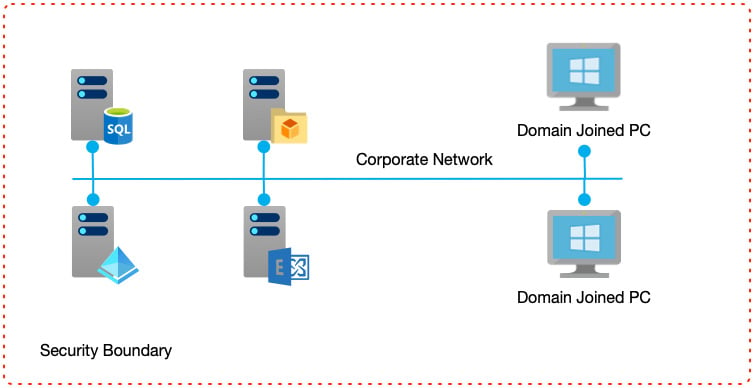
Figure 1.2 – The personal computing era
Decentralizing applications into individual components running on their own servers enabled a new type of software architecture to emerge—that of N-tier architecture. N-tier architecture is a paradigm whereby the first tier would be the user interface, and the second tier the database. Each was run on a separate server and was responsible for providing those specific services.
As systems developed, additional tiers were added—for example, in a three-tier application the database moved to the third tier, and the middle tier encapsulated business logic—for example, performing calculations, or providing a façade over the database layer, which in turn made the software easier to update and expand.
As PCs effectively brought about a divergence in hardware and software design, so too did the role of an architect also split. It now became more common to see architects who specialized in hardware and networking, with responsibilities for communication protocols and role-based security, and software architects who were more concerned with development patterns, data models, and user interfaces.
The lower-cost entry for PCs also vastly expanded their use; now, smaller businesses could start to leverage technologies. Greater adoption led to greater innovation—and one such advancement was to make more efficient use of hardware—through the use of virtualization.
Virtualization
As the software that ran on servers started to become more complex and take on more diverse tasks, it began to become clear that having a server that ran internal emails during the day but was unused in the evening and at the weekend was not very efficient.
Conversely, a backup or report-building server might only be used in the evening and not during the day.
One solution to this problem was virtualization, whereby multiple servers—even those with a different underlying operating system—could be run on the same physical hardware. The key was that physical resources such as random-access memory (RAM) and compute could be dynamically reassigned to the virtual servers running on them.
So, in the preceding example, more resources would be given to the email server during core hours, but would then be reduced and given to backup and reporting servers outside of core hours.
Virtualization also enabled better resilience as the software was no longer tied to hardware. It could move across physical servers in response to an underlying problem such as a power cut or a hardware failure. However, to truly leverage this, the software needed to accommodate it and automatically recover if a move caused a momentary communications failure.
From an architectural perspective, the usual issues remained the same—we still used a single user database directory; virtual servers needed to be able to communicate; and we still had the physically secure boundary of a network.
Virtualization technologies presented different capabilities to design around—centrally shared disks rather than dedicated disks communicating over an internal data bus; faster and more efficient communications between physical servers; the ability to detect and respond to a physical server failing, and moving its resources to another physical server that has capacity.
In the following diagram, we see that discrete servers such as databases, file services, and email servers run as separate virtual services, but now they share hardware. However, from a networking point of view, and arguably a software and security point of view, nothing has changed. A large role of the virtualization layer is to abstract away the underlying complexity so that the operating systems and applications they run are entirely unaware:
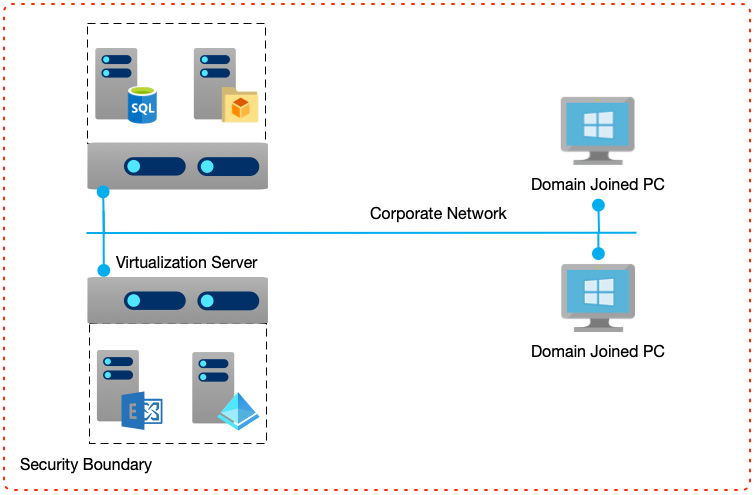
Figure 1.3 – Virtualization of servers
We will now look at web apps, mobile apps, and application programming interfaces (APIs).
Web apps, mobile apps, and APIs
At around the same time, virtualization was starting to grow, and the internet began to mature beyond an academic and military tool. Static, informational websites built purely in HTML gave way to database-driven dynamic content that enabled small start-ups to sell on a worldwide platform with minimal infrastructure.
Websites started to become ever more complex, and slowly the developer community began to realize that full-blown applications could be run as web apps within a browser window, rather than having to control and deploy software directly to a user's PC.
Processing requirements now moved to the backend server—dynamic web pages were generated on the fly by the web server, with the user's PC only rendering the HTML.
With all this reliance on the backend, those designing applications had to take into account how to react to failures automatically. The virtualization layer, and the software running on top, had to be able to respond to issues in a way that made the user completely unaware of them.
Architects had to design solutions to be able to cope with an unknown number of users that may vary over time, coming from different countries. Web farms helped spread the load across multiple servers, but this in itself meant a new way of maintaining state or remembering what a user was doing from one page request to the next, keeping in mind that they might be running on a different server from one request to the next.
As the mobile world exploded, more and more mobile apps needed a way of using a centralized data store—one that could be accessed over the internet. Thus, a new type of web app, the API app, started serving raw data as RESTful services (where REST stands for REpresentational State Transfer) using formats such as Extensible Markup Language (XML) or JavaScript Object Notation (JSON).
Information
A RESTful service is an architectural pattern that uses web services to expose data that other systems can then consume. REST allows systems to interchange data in a pre-defined way. As opposed to an application that communicates directly with a database using database-specific commands and connection types, RESTful services use HTTP/HTTPS with standard methods (GET, POST, DELETE, and so on). This allows the underlying data source to be independent of the actual implementation—in other words, the consuming application does not need to know what the source database is, and in fact could be changed without the need to update the consumer.
Eventually, hosted web sites also started using these APIs, with JavaScript-based frameworks to provide a more fluid experience to users. Ironically, this moved the compute requirements back to the user's PC.
Now, architects have to consider both the capabilities of a backend server and the potential power of a user's device—be it a phone, tablet, laptop, or desktop.
Security now starts to become increasingly problematic for many different reasons.
The first-generation apps mainly used form-based authentication backed by the same database running the app, which worked well for applications such as shopping sites. But as web applications started to serve businesses, users had to remember multiple logins and passwords for all the different systems they use.
As web applications became more popular—being used by corporates, small businesses, and retail customers—ensuring security became equally more difficult. There was no longer a natural internal barrier—systems needed to be accessible from anywhere. As apps themselves needed to be able to communicate to their respective backend APIs, or even APIs from other businesses providing complementary services, it was no longer just users we had to secure, but additional services too.
Having multiple user databases will no longer do the job, and therefore new security mechanisms must be designed and built. OpenID, OAuth2.0, SAML (which stands for Security Assertion Markup Language), and others have been created to address these needs; however, each has its own nuances, and each needs to be considered when architecting solutions. The wrong decision no longer means it won't work; it could mean a user's data being exposed, which in turn leads to massive reputational and financial risk.
From an architectural point of view, solutions are more complex, and as the following diagram shows, the number of components required also increases to accommodate this:
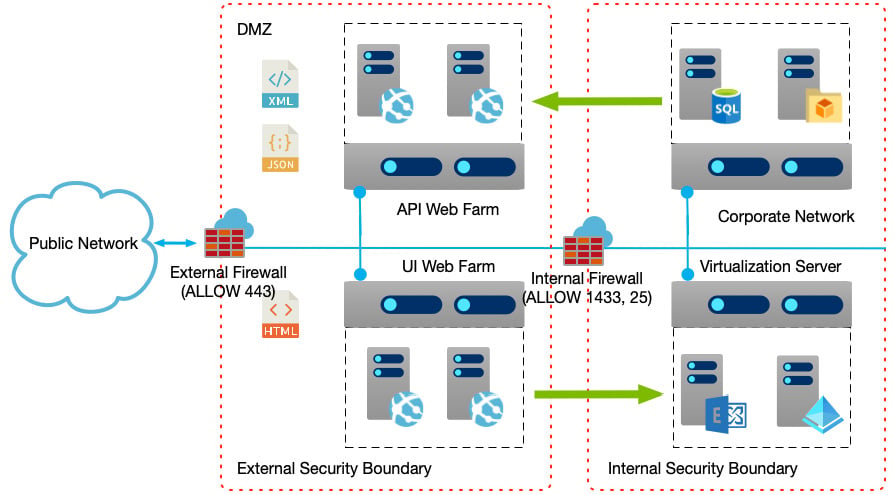
Figure 1.4 – Web apps and APIs increase complexity
Advancements in hardware to support this new era and provide ever more stable and robust systems meant networking, storage, and compute required roles focused on these niche, but highly complex components.
In many ways, this complexity of the underlying hosting platforms led to businesses struggling to cope with or afford the necessary systems and skills. This, in turn, led to our next and final step—cloud computing.
Cloud computing
Cloud platforms such as Azure sought to remove the difficulty and cost of maintaining the underlying hardware by providing pure compute and storage services on a pay-as-you-go or operational expenditure (OpEx) model rather than a capital expenditure (CapEx) model.
So, instead of providing hardware hosting, they offered Infrastructure as a Service (IaaS) components such as VMs, networking and storage, and Platform as a Service (PaaS) components such as Azure Web Apps and Azure SQL Databases. The latter is the most interesting. Azure Web Apps and Azure SQL Databases were the first PaaS offerings. The key difference is that they are services that are fully managed by Microsoft.
Under the hood, these services run on VMs; however, whereas with VMs you are responsible for the maintenance and management of them—patching, backups, resilience—with PaaS, the vendor takes over these tasks and just offers the basic service you want to consume.
Over time, Microsoft has developed and enhanced its service offerings and built many new ones as well. But as an architect, it is vital that you understand the differences and how each type of service has its own configurations, and what impact these have.
Many see Azure as "easy to use", and to a certain extent, one of the marketing points around Microsoft's service is just that—it's easy. Billions of dollars are spent on securing the platform, and a central feature is that the vendor takes responsibility for ensuring the security of its services.
A common mistake made by many engineers, developers, system administrators, and architects is that this means you can just start up a service, such as Azure Web Apps or Azure SQL Databases, and that it is inherently secure "out of the box".
While to a certain extent this may be true, by the very nature of cloud, many services are open to the internet. Every component has its own configuration options, and some of these revolve around securing communications and how they interact with other Azure services.
Now, more than ever, with security taking center stage, an architect must be vigilant of all these aspects and ensure they are taken into consideration. So, whereas the requirement to design underlying hardware is no longer an issue, the correct configuration of higher-level services is critical.
As we can see in the following diagram, the designs of our solutions to a certain extent become more complex in that we must now consider how services communicate between our corporate and cloud networks. However, the need to worry about VMs and hardware disappears—at least when purely using PaaS:

Figure 1.5 – Cloud integration
As we have moved from confined systems such as mainframes to distributed systems with the cloud provider taking on more responsibility, our role as an architect has evolved. Certain aspects may no longer be required, such as hardware design, which has become extremely specialized. However, a cloud architect must simultaneously broaden their range of skills to handle software, security, resilience, and scalability.
For many enterprises, the move to the cloud provides a massive opportunity, but due to existing assets, moving to a provider such as Azure will not necessarily be straightforward. Therefore, let's consider which additional challenges may face an architect when considering migration.
Migrating to the cloud from on-premises
A new company starting up today can build its IT services as cloud native from day one. These born-in-the-cloud enterprises arguably have a much simpler route.
For existing businesses, especially larger ones, they must consider how any cloud-based service operates with existing applications currently running within their infrastructure.
Even when a corporation chooses to migrate to the cloud, this is rarely performed in a single big-bang approach. Tools exist to perform a lift-and-shift copy of existing servers to VMs, but even this takes time and lots of planning.
For such companies, consideration at each step of the way is crucial. Individual services don't always run on a single piece of hardware—even websites are generally split into at least two tiers: a frontend user interface running on an Internet Information Services (IIS), with a backend database running on a separate SQL server.
Other services may also communicate with each other—a payroll system will most likely need to interface with an HR database. At the very least, many systems share a standard user directory such as Microsoft Active Directory (AD) for user authentication and authorization.
An architect must decide which servers and systems should be migrated together to ensure these communication lines aren't impacted by adverse latency and can move independently with adequate cloud-to-on-premises network links. Should we use dedicated connectivity such as ExpressRoute, or will a virtual private network (VPN) channel running over the internet suffice?
As already discussed, as we move to the cloud, we change from an inherently secure platform whereby services are firewalled off by default, to an open one whereby connectivity is exposed to the internet by default. Any new communication channels from the cloud to your on-premises network, required to support a potentially long drawn-out migration, effectively provide an entry point from the internet back into your corporate system.
To alleviate business concerns, a strong governance and monitoring model must be in place, and this needs to be well designed from the outset. Will additional teams be required to support this? Will these tasks be added to existing teams' responsibilities? What tooling is used? Will it be your current compliance monitoring and reporting software, or will you have a different set for the cloud?
There are many different ways to achieve this, all depending on the answers to these specific questions. However, for those who wish to embrace a cloud-first solution, this may involve the following technologies:
- Azure Policy and Azure Blueprints for build control
- Azure Recovery Services
- Azure Update Management for VM patching
- Azure Security Center for alerting and compliance reporting
- Azure Monitor Agent installed on VMs
- Azure Monitor
- Azure Log Analytics and Azure Monitor Workbooks
Although these are Azure solutions, they can, however, also be integrated with on-premises infrastructure as well. The following diagram shows an example of this:
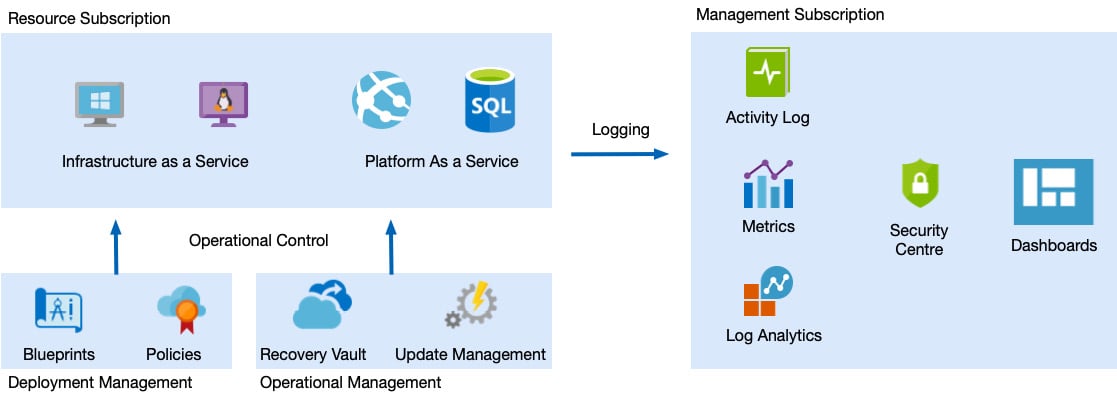
Figure 1.6 – Cloud compliance and monitoring tooling
As you can see, having a well-architected framework in place is crucial for ensuring the health and safety of your platform, and this in turn feeds into your strategies and overall solution design when considering a migration into the cloud.
Once we have decided how our integration with an on-premises system might look, we can then start to consider whether we perform a simple "lift and shift" or take the opportunity to re-platform. Before making these choices, we need to understand the main differences between IaaS and PaaS, and when one might be better than the other.
Understanding infrastructure and platform services
One of the big differences between IaaS and PaaS is about how the responsibility of components shifts.
The simplest examples of this are with websites and Structured Query Language (SQL) databases. Before we look at IaaS, let's consider an on-premise implementation.
When hosted in your own data center, you might have a server running IIS, upon which your website is hosted, and a database server running SQL. In this traditional scenario, you own full responsibility for the hardware, Basic Input/Output System (BIOS) updates, operating system (OS) patching, security updates, resilience, inbound and outbound traffic—often via a centralized firewall—and all physical security.
IaaS
The first step in migrating to cloud might be via a lift-and-shift approach using virtual networks (VNETs) and VMs—again, running IIS and SQL. Because you are running in Microsoft's data centers, you no longer need to worry about the physical aspects of the underlying hardware.
Microsoft ensures their data centers have all the necessary physical security systems, including personnel, monitoring, and access processes. They also worry about hardware maintenance and BIOS updates, as well as the resilience of the underlying hypervisor layer that all the VMs run on.
You must still, however, maintain the software and operating systems of those VMs. You need to ensure they are patched regularly with the latest security and improvement updates. You must architect your solution to provide application-level resilience, perhaps by building your SQL database as a failover cluster over multiple VMs; similarly, your web application may be load-balanced across a farm of IIS servers.
Microsoft maintains network access in general, through its networking and firewall hardware. However, you are still responsible for configuring certain aspects to ensure only the correct ports are open to valid sources and destinations.
A typical example of this split in responsibility is around access to an application. Microsoft ensures protection around the general Azure infrastructure, but it provides the relevant tools and options to allow you to set which ports are exposed from your platform. Through the use of network security groups (NSGs) and firewall appliances, you define source and destination firewall rules just as you would with a physical firewall device in your data center. If you misconfigure a rule, you're still open to attack—and that's your responsibility.
PaaS
As we move toward PaaS, accountability shifts again. With Azure SQL databases and Azure web apps, Microsoft takes full responsibility for ensuring all OS-level patches are applied; it ensures the platforms that run Azure SQL databases and Azure web apps are resilient against hardware failure.
Your focus now moves toward the configuration of these appliances. Again, for many services, this includes setting the appropriate firewalls. However, depending on your corporate governance rules, this needs to be well planned.
By default, communications from a web app to a backend Azure SQL database are over the public network. Although it is, of course, contained within Microsoft's network, it is technically open. To provide more secure connectivity, Azure provides the option to use service connections—direct communication over its internal backbone—but this needs specifically configuring at the web app, the SQL service, and the VNET level.
As the methods of those who wish to circumvent these systems become increasingly sophisticated, further controls are required. For web applications, the use of Web Application Firewall (WAF) is an essential part of this—as the architect, you must ensure they are included in your designs and configured correctly; they are not included by default.
Important note
Even though Microsoft spends billions of dollars a year on securing the Azure platform, unless you carefully architect your solutions, you are still vulnerable to attack. Making an incorrect assumption about where your responsibility lies leads to designing systems that are exposed—remember, many cloud platforms' networking is open by default; it has to be, and you need to ensure you fully understand where the lines are drawn.
Throughout this chapter, we have covered how changing technologies have significantly impacted how we design and build solutions; however, so far, the discussion has been around the technical implementation.
As software and infrastructure become closely aligned, teams implementing solutions have started to utilize the same tools as developers, which has changed the way projects are managed.
This doesn't just affect the day-to-day life of an architect; it has yet another impact on the way we design those solutions as well.
Moving from Waterfall to Agile projects
As we move into the cloud, other new terms around working practices come to the fore. DevOps, DevSecOps, and Agile are becoming ingrained in those responsible for building software and infrastructure.
If you come from a software or a DevOps background, there is a good chance you already understand these concepts, but if not, it helps to understand them.
Waterfall
Traditional waterfall project delivery has distinct phases to manage and control the build. In the past, it has often been considered crucial that much effort goes into planning and designing a solution before any engineering or building work commences.
A typical example is that of building a house. Before a single brick is laid, a complete architectural blueprint is produced. Next, foundations must be put in place, followed by the walls, roof, and interiors. The idea is that should you change your mind halfway through, it would be challenging to change anything. If you decide a house needs to be larger after the roof is built, you would need to tear everything down and start again.
With a waterfall approach, every step must be well planned and agreed at the outset. The software industry developed a bad reputation for delivering projects late and over budget. Businesses soon realized that this was not necessarily because of mismanagement but because it is difficult to articulate a vision for something that does not yet exist and, in many cases, has never existed before.
If we take the building metaphor, houses can be built as they are because, in many cases, they are merely copying elements of another house. Each house has a lot in common—walls, floors, and a roof, and there are set ways of building each of these.
The following diagram shows a typical setup of a waterfall project, with well-defined steps completed in turn:

Figure 1.7 – Typical waterfall process
With software, this is not always the case. We often build new applications to address a need that has never been considered or addressed before. Trying to follow a waterfall approach has led to many failed projects, mainly because it's impossible to design or even articulate the requirements upfront fully.
Agile
Thus, Agile was born. The concept is to break down a big project into lots of smaller projects that each deliver a particular facet of the entire solution. Each mini-project is called a sprint, and each sprint runs through a complete project life cycle—design, plan, build, test, and review.
The following diagram shows that in many ways, Agile is lots of mini-waterfall projects:
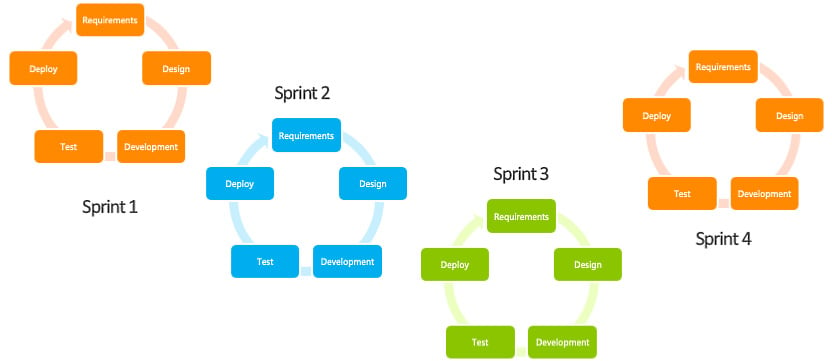
Figure 1.8 – Agile process
Sprints are also short-lived, usually 1 or 2 weeks, but at the end of each one, something is delivered. A waterfall project may last months or years before anything is provided to a customer—thus, there is a high margin for error. A small misunderstanding of a single element along the way results in an end state that does not meet requirements.
A particular tenet of Agile is "fail fast"—it is better to know something is wrong and correct it as soon as possible than have that problem exacerbate over time.
This sprint-led delivery mechanism can only be achieved if solutions are built in a particular manner. The application must be modular, and those modules designed in such a way that they can be easily swapped out or modified in response to changing requirements. An application architect must consider this when designing systems.
At this point, you may be wondering how this relates to the cloud. Agile suits software delivery because solutions can be built in small increments, creating lots of small modules combined into an entire solution. To support this, DevOps tooling provides automated mechanisms that deploy code in a repeatable, consistent manner.
As infrastructure in the cloud is virtualized, deployments can now be scripted and therefore automated—this is known as Infrastructure as Code (IaC).
IaC
In Azure, components can be created either in the portal using the graphical user interface (GUI) with PowerShell or by using JSON templates. In other words, you can deploy infrastructure in Azure purely with code.
IaC provides many benefits, such as the ability to define VMs, storage, databases, or any Azure component in a way that promotes reusability, automation, and testing.
Tools such as Azure DevOps provide a central repository for all your code that can be controlled and built upon in an iterative process by multiple engineers. DevOps also builds, tests, and releases your infrastructure using automated pipelines—again, in the same way that modern software is deployed.
The DevOps name embodies the fact that operational infrastructure can now be built using development methodologies and can follow the same Agile principles.
DevSecOps takes this even further and includes codifying security components into release pipelines. Security must be designed and built hand in hand with infrastructure and security at every level, as opposed to merely being a perimeter or gateway device.
Cloud architects must, therefore, be fully conversant with the taxonomy, principles, and benefits of Agile, DevOps, and DevSecOps, incorporating them into working practices and designs.
Microsoft provides a range of tools and components to support your role and provides best-in-class solutions that are reliable, resilient, scalable, and—of course—secure.
As we have seen, architecture in the cloud involves many more areas than you might traditionally have gotten involved in. Hopefully, you will appreciate the reasons why these changes have occurred.
From changes in technology to new ways of working, your role has changed in different ways—although challenging, this can also be very exciting as you become involved across various disciplines and work closely with business users.
Summary
During this chapter, we have defined what we mean by architecture in the context of the AZ-304 exam, which is an important starting point to ensure we agree on what the role entails and precisely what is expected for the Azure certification.
We have walked through a brief history of business computing and how this has changed architecture over the years, from monolithic systems through to the era of personal computing, virtualization, the web, and ultimately to the cloud. We examined how each period changed the responsibilities and design requirements for the solutions built on top.
Finally, we had a brief introduction to modern working practices with IaC and project management methodologies, moving from waterfall to Agile, and how this has also changed how we as architects must think about systems.
In the next chapter, we will explore specific areas of architectural principles, specifically those aligned to the Microsoft Azure Well-Architected Framework.




