


















The Fundamentals of Cloud Security
This chapter, being the first chapter of this book, aims at establishing the base of cloud security, based on which we will discuss all the subsequent chapters in detail. Most chapters in this book will cover specific topics and challenges that one might face in implementing security in the cloud. In this chapter, however, we will cover the basics of cloud computing and the associated security aspect that will help us get started.
We can think of this chapter as the basic principles on which the security practices need to be applied.
Getting started
Cloud computing is basically delivering computing as a service. In this approach, infrastructure, applications, and software platforms are all available as a service to consumers to use anytime, ideally with a pay-to-go-based model.
Let's understand the cloud with a use case. Many years back, when we needed a dedicated server, we had to initially pay up-front for the entire month to the hosting provider and after this, we had to wait for servers to get provisioned. Meanwhile, if we wanted to resize the server, we needed to raise a support ticket, and the hosting provider would manually resize the server, which sometimes would take up to 24 hours.
Cloud computing is a model in which computing resources (for example, servers, storage, and networks) are available as a service that can be rapidly provisioned on the go with minimal intervention from the hosting provider.
Now that we've gone through a simple use case, let's go ahead and understand the three important characteristics of a cloud computing environment:
- On demand and self serviced: The consumer should be able to demand a provision of servers whenever he needs and the deployment should be automatic, without any manual intervention from any hosting provider.
For example, if John needs a 16 GB RAM server in the middle of the night, he should be able to do it in a few clicks of a button without any intervention of the cloud service provider (CSP).
- Elasticity: Consumers can scale the resources upwards or downwards to meet the end user's demands whenever required. This capability is largely dependent on the concept of virtualization, which is tightly integrated with the cloud computing approach.
For example, if John wants to increase or decrease the capacity of a server, he should be able to do it anytime he needs.
- Measured service: Cloud computing providers should monitor the usage of the service used by the consumer and charge according to what customers use. Typically, a cloud computing provider charges on an hourly basis; however, newer plans support payment based on 5 minutes intervals.
For example, if John uses a 16 GB RAM server only for 3 hours and terminates it, he should be charged for 3 hours only.
Service models
There are three major service models in the cloud computing environment, and depending on the use case of the organization, one of them is generally chosen:
- Software as a service (SaaS)
- Platform as a service (PaaS)
- Infrastructure as a service (IaaS)
Let's spend some time understanding each of these service models which will in turn help us decide the ideal one for our requirements. Depending on the service models that we choose, the security implementation varies considerably.
Software as a service
In its simplest terms, SaaS means a hosted application on the internet. A SaaS provider will provide the application on their servers that consumers will be able to use.
The entirety of installing, managing, security, and troubleshooting related to the application is the responsibility of the SaaS provider.
One of the disadvantages of the SaaS-based approach is that if the SaaS provider needs downtime for any reason, then the organizations using the application have no choice but to wait, which leads to less productivity.
For example, Google Docs is a famous SaaS service. We use Google Docs (similar to Microsoft Word) and Google Sheets (similar to Microsoft Excel) online.
Microsoft Word is also ported to the cloud through a service called Office 365. We can access Word, Excel, and PowerPoint all from a browser.
The following is an example of PowerPoint that is available online as a part of the Office 365 suite, where you can run various software, such as Word, Excel, and PowerPoint from your browser without installation:

Platform as a service
In a PaaS-based offering, the provider will allow consumers to host their own application onto their cloud infrastructure.
The PaaS provider, in turn, handles the backend support of the programming languages, libraries, and associated tools that allow a consumer to upload and manage their application. The consumer does not have to worry about underlying servers, OS, networks, and platform security as they're handled by the PaaS provider.
However, the hosted application's security and configuration is still the responsibility of the customer.
Google App Engine, which is part of the Google Cloud Platform, is one famous example. All we have to do is to upload our code and all backend stuff will be managed by them. However, if the code itself is vulnerable, then it is the responsibility of the customer and not the PaaS provider:
Infrastructure as a service
In IaaS, the hosting provider will host the virtual machine (VM) on behalf of the consumer at their end.
The consumer, with just a few clicks on the resources that are needed (RAM, CPU, and network), will be provided a server on the cloud.
The consumer does not control the underlying infrastructure, such as virtualization software, physical security, and hardware. It is the cloud provider's responsibility to handle the reliability of hardware and virtualization software used and the physical security of the servers, and the client is responsible for the VM configuration and its associated security:

For example, as shown in the previous figure, Amazon EC2 is one of the well-known examples for IaaS. Clients can launch an EC2 instance with customized configurations, such as operating systems, associated resources (CPU, RAM, and network), IP addresses, and even the firewall rules (security groups).
Deployment models
This approach generally appears when an organization is planning to use an IaaS-based service model. In such cases, before selecting a CSP, we need to understand what type of cloud service model we are looking for. Many of the organizations decide to create their own data center and launch a cloud environment with the help of OpenStack. One of the advantages in the long term would be the cost benefit, but this approach does take a large amount of investment.
Having said this, as illustrated in the following diagram, there are three deployment models for the cloud, based on which an organization has to decide which one to choose from:

Let's briefly look into each of them:
- Public cloud: In this type of offering, the CSP opens up the service for everyone and anyone willing to pay for the service. This is one of the most common models that is being preferred by startups and mid-sized organizations. One of the benefits of this approach is that the initial investment needed is far less as, the organization will pay as per their resource usage in the cloud environments.
- Private cloud: As the name suggests, private cloud is meant to be used within organizations. In this type of approach, the services are not being offered in public, instead are made to be used for resources within the organization itself. Thus, entire responsibility related to the governance and security maintenance becomes the responsibility of the organization. Organizations choosing this approach generally use OpenStack for their environments.
- Hybrid cloud: In this type, some of the assets are being managed in the internal private cloud while others are moved to the public cloud. Servers can be managed internally, but for data storage, we can use Amazon S3 or Amazon Glacier. Thus, an organization can plan out which assets are costly to handle internally and if the cloud is a cheaper option, then those assets are migrated to the cloud. Many organizations also decide to use a multi-cloud-based approach where services such as servers can be managed by cloud providers such as Linode and DigitalOcean, which are quite cheap and reliable, while other services such as storage, message broker, and much more rely on the AWS platform.
Relying on a single cloud provider such as AWS might prove to be expensive and you will always have your finance team chasing you up over high cost. From what I have observed over the course of many years as a part of cost optimization projects, I prefer to use the hybrid cloud, where servers and services are distributed among different cloud providers such as AWS, DigitalOcean, and Linode. This approach is great but you will need a good amount of time to do all configurations. This approach is generally not preferred by startups that have limited bandwidth and might not have dedicated solutions/DevOps architects to take care of the infrastructure.
Cloud security
Now that we have covered the basics of the cloud computing environment, we can go ahead and start with the security aspect pertaining to cloud environments. Cloud security is generally considered a challenge and there are special certifications such as Certificate of Cloud Security Knowledge (CCSK) being released that are specific to cloud security-based knowledge.
The real reason why cloud security is a different challenge is because of the loss of control of the backend infrastructure and things related to the visibility of the underlying network. The scope of controls associated with the cloud platform differs depending on the service model being used.
The following diagram denotes how the scope would vary:
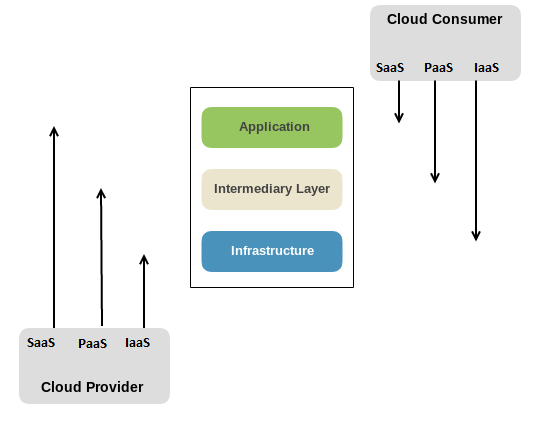
If we look at the preceding diagram, the responsibility of the consumer and security will vary differently depending upon the model that is being chosen. Let's look at an overview based on this aspect:
- In a SaaS-based model, the Cloud Provider is responsible for Infrastructure, Intermediary Layer, and partial part of Application Layer; however, it is the Cloud Consumer who is responsible for data stored in the Application and its associated configuration
- In a PaaS-based model, the Cloud Provider is responsible for Infrastructure and certain aspects of Intermediary Layer, while the Cloud Consumer is responsible for the Application and its associated security along with certain aspects of Intermediary Layer
- In an IaaS-based model, the Cloud Provider is responsible for the underlying backend Infrastructure such as the virtualization layer, backend switches, hardware, and others while the Cloud Consumer is responsible for all the other aspects except server security, firewalls, and routing configurations
Why is cloud security considered hard?
One of the main reasons why cloud security is considered challenging is potentially due to the lack of full control of the environment. Along with the lack of control, lack of visibility is also one of the challenges as we don't really know how things look behind the scenes.
Since cloud environment is a giant resource pool, we generally share the underlying resources with multiple other users belonging to different organizations. This is often referred as multi-tenancy.
Since the resource is generally not dedicated to us, we are not allowed to do various things, such as performing external scans on our websites, that might affect the performance of other customers. There are many such reasons that causes a bit of limitations in terms of flexibility and visibility in cloud environments.
Our security posture
The tools, technologies, and approach that are used between data centers can be different from that of cloud environment. This is because of the limited visibility and control of the infrastructure in cloud.
Thus the way in which security posture of your organization is cannot always be the way it will be when you migrate to cloud environments.
A typical data center environment can have the following things:
- Stateful firewall
- Log and security information and event management (SIEM) solutions
- IDS connected with Switched Port Analyzer (SPAN) port
- Anti-malware at network level
We cannot have everything in the cloud. We need to assess risks and make a decision.
Virtualization – cloud's best friend
One of the very simple and best-known features of virtualization is that it allows us to run multiple operating systems together on a single hardware.
So, essentially, we can run Windows and Linux together simultaneously in a single box without having to worry about much.
I still remember my senior saying that I was very lucky to be born in the days of virtualization as earlier if they messed up their system during testing, they had to spend 2-3 hours re-creating it, while in virtualization, once the snapshot is taken, it takes just 2 minutes to go back to its original state. The snapshot and restore features have been one of the most preferred and useful features, specifically when doing testing related to compiling kernel.
In the following screenshot, I have run the latest version of CentOS 7 on my Macintosh with the help of VMware Fusion, which is a virtualization software:

Understanding the ring architecture
In x86-based computers, user applications have very limited privileges, where certain tasks can only be performed by the operating system code.
In this type of architecture, the OS and the CPU work together to restrict what a user level program can do in the system.
As illustrated in the following diagram, there are four privilege levels that start from 0 (Most privileged) to 3 (Least privileged) and there are three important resources that are protected, which are memory, I/O ports, and ability to run certain machine-level instructions:

It's important to remember that even having a root account means that you are still in user code - that is, Ring 3. It's very simple; all user code runs on Ring 3 and all kernel code runs on Ring 0.
Due to this strict restriction, specifically to memory and I/O ports, the user can do a minimal number of things directly and would thus need to call through the Kernel.
For example, if a user wants to open files, transfer data over the network, and allocate memory for the program, it will have to ask the Kernel (which is running on Ring 0) to allow it, and this is why the Kernel has full control over the program, which leads to more stability in the operating system as a whole.
Hardware virtualization
The x86-based operating systems are designed to run directly on hardware, so they assume that they have full control of the hardware on which they are running.
As discussed, x86 architecture generally offers four levels of privileges, namely Ring 0, Ring 1, Ring 2, and Ring 3, as is described in the following diagram:

These levels of privileges are assigned to operating systems and applications that allow them to manage access to underlying hardware on which they are running. Generally, User Application runs on Ring 3, and the OS must run on Ring 0, which typically has, full privilege over the System Hardware.
Virtualization requires placing a new virtualized layer between the OS and the hardware that will control and manage the guest OS running on top of it, and this is the reason why the virtualization software typically needs higher privileges than that of a guest OS. There are three types of virtualization.
Full virtualization with binary translation
Based on this approach, any OS can be virtualized with the help of Binary Translation and direct execution-based technique. In this approach, the Guest OS is placed on a higher ring and the kernel code is translated by the hypervisor (virtualization software) to have the effect on the virtual hardware on which it is running. The hypervisor translates all the OS instructions on the fly:
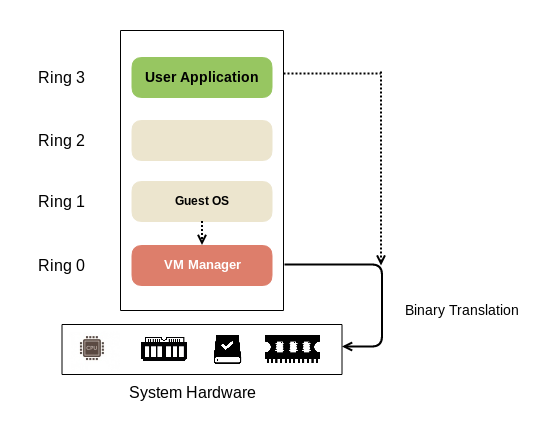
The hypervisor gives virtual machines all the services provided by the hardware such as virtual BIOS, virtual memory, and access to virtual devices. The user code that typically runs on Ring 3 is directly executed to lead to higher performance. The Guest OS is not aware that it is being virtualized and does not require any modification.
Paravirtualization
This is also sometimes referred to as OS assisted virtualization. In this type of technique, the OS code is modified to replace the non-virtualizable instructions with the hypervisor calls. The difference between full virtualization and paravirtualization is that in full virtualization, OS is not aware that it is running on a virtualization layer, and sensitive OS calls are trapped and modified with the help of binary translations.
Paravirtualization can sometimes become overhead as it requires deep OS level code modification.
Building sophisticated binary translation codes are challenging for modern environments, and this is the reason why directly modifying OS code is sometimes considered easy.
Hardware-assisted virtualization
CPU hardware vendors such as Intel and AMD are quickly embracing the need for virtualization and are developing new hardware to support and enhance virtualization.
The initial enhancement includes Intel VT-x and AMD-V that allow Virtual Machine Manager (VMM) to run in a new ROOT Mode below the Ring 0:
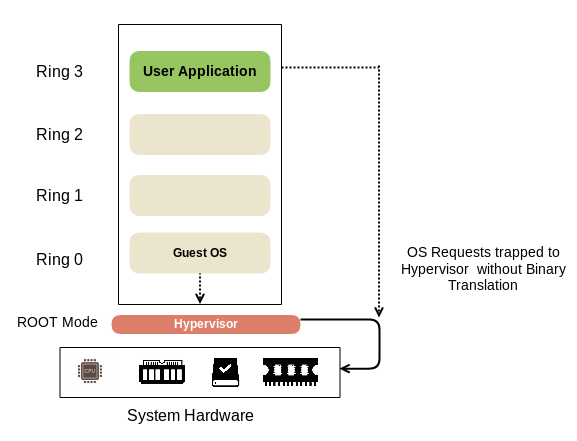
Thus, the privileged instructions and sensitive calls are automatically trapped by the Hypervisor and there is no need for Binary Translation or paravirtualization—for example, Xen.
Now that you have understood different types of virtualization, let's look into one of the enterprise virtualization softwares and understand the benefits and features it brings.
Distributed architecture in virtualization
If we have an understanding of how virtualization works and its best practices, we can understand cloud environments in a more detailed way. Let's understand some of the aspects related to the architecture of virtualized environments.
In a typical server, we have major components such as CPU, memory, storage, and network. This is indicated in the following diagram:

One challenge is that hardware components can fail at any moment, and for organizations that have thousands of servers, this scenario is pretty common on a daily basis. In such a scenario, there is one important aspect that must be protected from these failures, which is the storage device on which customer data resides.
If the CPU or memory fails, then new chips can be replaced, and it might not be a big issue as a restart might be all that's needed but if the hard disk fails, then the entire data gets lost and it can be disastrous for the organization, especially if it's critical data.
This is one of the reasons for having a separately dedicated storage cluster. This is ideally done in a network-attached storage (NAS) environment and then disks are mounted over the Network to a compute instance:

Since the storage volumes are mounted over the network to a server, we can easily attach and detach the storage disks from one virtual machine to another. Let's look into how this works in AWS.
In AWS, we have a dedicated page, where we can see all the storage volumes that are being used in our account. In our case, we have three volumes, each of 8 GiB each:
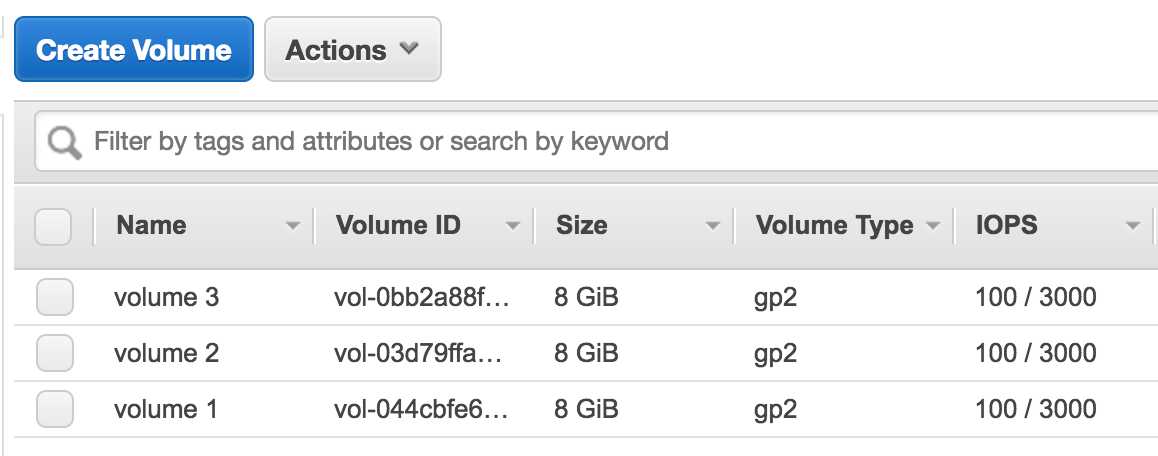
If we click on the volume and select Actions, there is an option of Detach Volume. Once this is done, the storage volume will be detached from an EC2 instance:

We can also attach the volumes to different EC2 instances by clicking on Attach Volume and selecting the instance that we want to mount on:

Enterprise virtualization with oVirt
oVirt is one of the open-source virtualization management platforms available and it was founded by Red Hat as a community project. As discussed, virtualization is generally one of the fundamental parts of most cloud environments, and we will look into some of the features of one of the virtualization applications.
There are four main components of a typical setup of virtualization software used for large-scale applications:
- Virtualization engine: The virtualization engine is responsible for deployment, monitoring followed by start and stop, the creation of virtual machines along with configuration related to storage, network, and many more.
- Hosts and guests: Hosts are basically physical hardware on which the actual VM (guests) reside. There is a minimal OS specially designed for virtualization called a hypervisor, installed on top of hosts. This hypervisor is controlled by the virtualization engine.
- Storage: Storage is used for storing VM disk images, snapshots, ISO files, and many more. The storage can be NFS, iSCSI, GlusterFS, and many more POSIX-compatible network filesystems.
- Network: Network components on the physical layer are Network Interface Cards (NIC); however, there are virtual NICs created to allow communication between virtual machines. These virtual NICs are also assigned IP address for seamless communication. Since they are virtual, we can detach and attach virtual NIC from one VM to another:
It's a large shared pool of resources. As a benefit that virtualization provides, cloud providers generally have a large pool of resources, which are then shared by their customers.
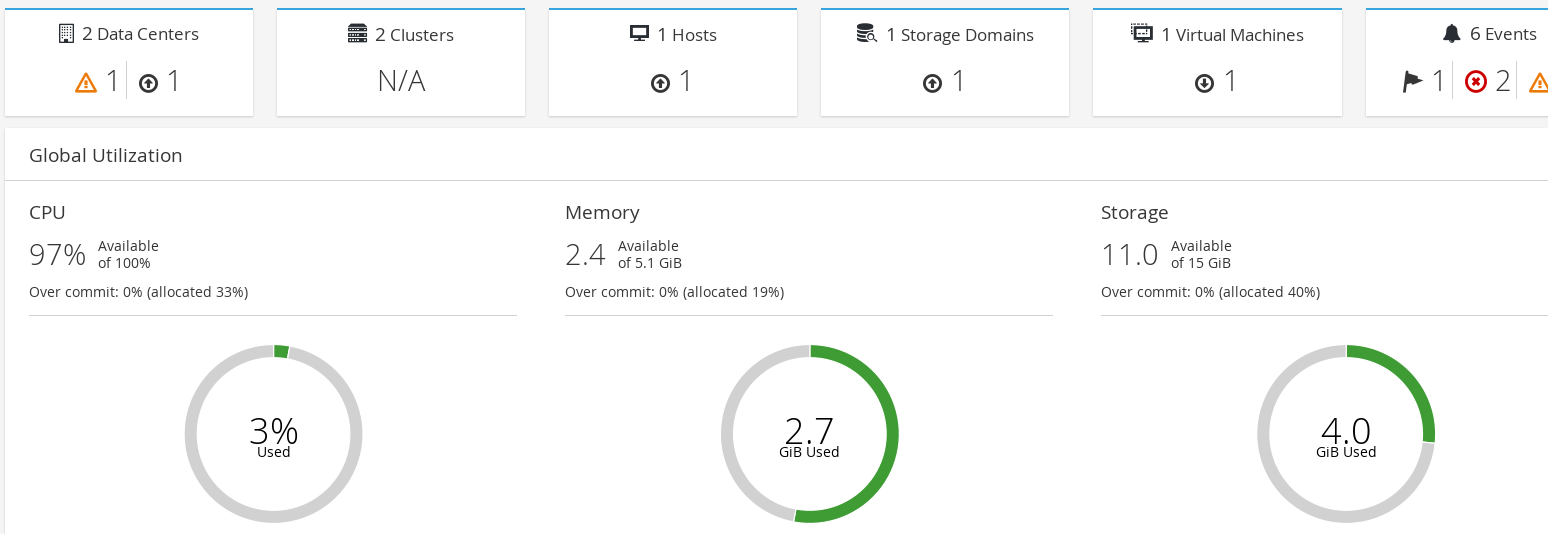
Let's look at how the admin panel might look. The following screenshot is of the admin panel of the oVirt. As we can see, it displays details related to:
- The number of Data Centers available
- The number of Hosts available
- The number of Storage Domains
- Total number of Virtual Machines
It also displays graphical information related to CPU, Memory, and Storage consumed by the virtual machines while running:
It is the CSP's responsibility to ensure that this pool of resources is available so that new users will be able to provision new VMs whenever they are required.
There are several other important benefits that virtualization provides; let's explore them.
Encapsulation
All the data in the virtual machine are stored in terms of file-based format. They are typically stored in their VM directories.
In the following image, we have three VM's: Base, Ubuntu 16, and Windows 10, and each of them has a separate directory:
If we go inside one of these directories, you will see virtual disk files as shown in the following image:

Since virtual disks are stored as files inside directories, it is very easy to take backup of these and store it in safe storage locations. Along with this, sharing of these files is also easy.
Point in time snapshots
A snapshot can be taken of the virtual machine's disk at a given point in time. Modern virtualization software also supports live snapshot, which takes a snapshot of a running virtual machine. AWS also has the snapshotting feature available for users to use:
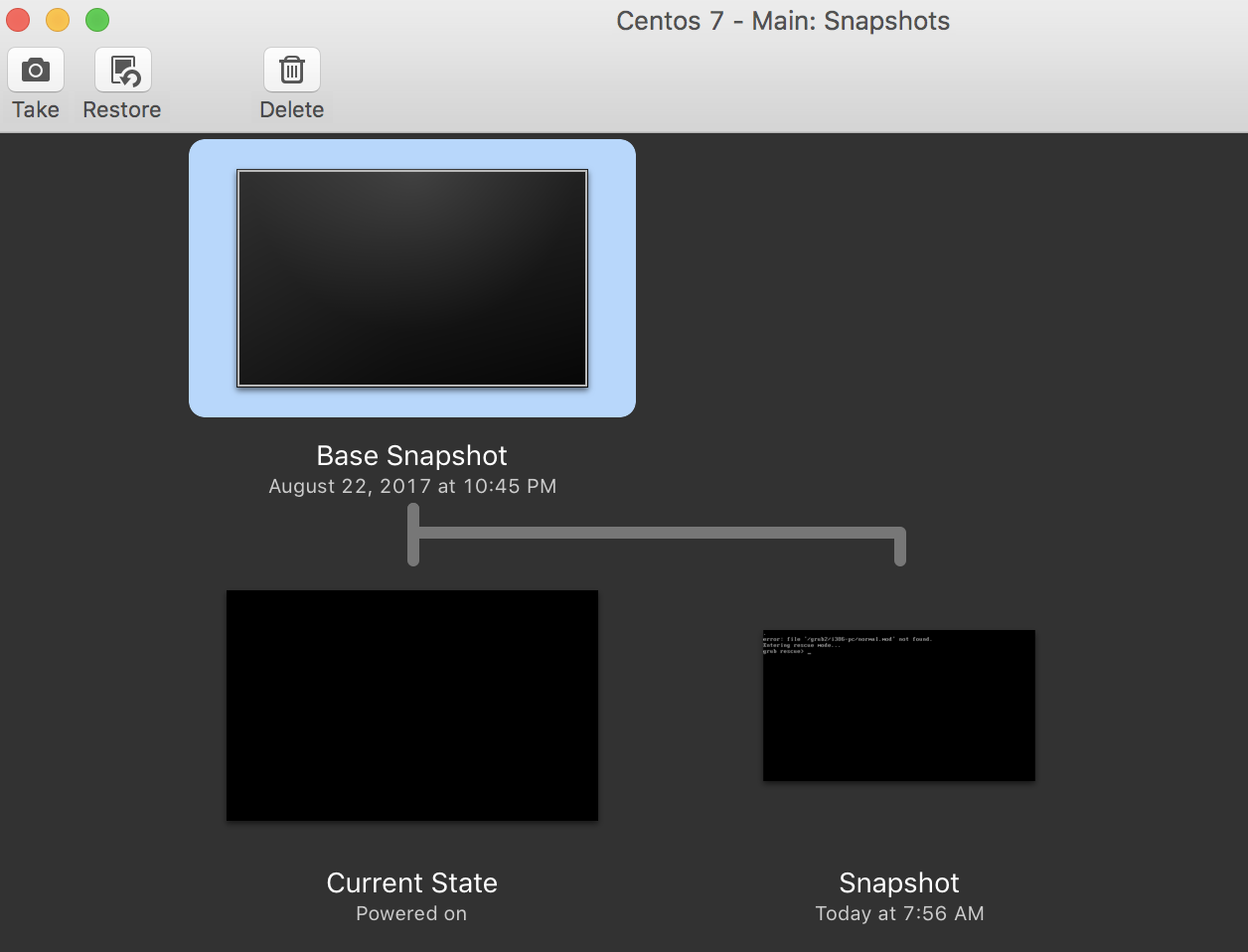
We will discuss this more in the later sections.
Isolation
Virtual machines running on the physical servers are isolated from each other by default. This is a very important security feature as well.
Due to the isolation feature, VMs are used for testing of malicious files such as viruses and Trojans.
Now that we have an overview of virtualization and its associated benefits, we will go ahead and understand how an organization can go about selecting the right cloud provider.
Risk assessment in cloud
As with most environments, even cloud environment comes with its associated risks. The European Union Agency for Network and Information Security (ENISA) framework is designed for organizations who are planning to evaluate risks related to the adoption of cloud computing technology.
It also helps cloud computing providers to follow a list of steps mentioned in the framework as a part of their compliance program. The main aim of ENISA is to improve the overall network and information security in the European Union.
The fourteen points mentioned in the ENISA framework will help an organization to evaluate an appropriate cloud provider. This point acts as a question and answer where points will act as questions and we need to evaluate the answer to that question from the cloud provider.
Let's look into some of the important points that are a part of the ENISA framework:
- Personnel security: Many points are formed as a questionnaire that an auditor assessing the cloud environment can ask and get the appropriate response in terms of yes or no:
- What are the policies and procedures in place, while hiring IT administrators or others who will have a system's access?
- There must be employee verification in place that checks background information related to employees such as criminal records, nationality, and employment history. You don't want a person who was part of a hacking scandal to be employed or have system access as a part of the new job for cloud providers.
- It also talks about giving strong educational-based security training to employees for protecting the customer data.
- Supply chain assurance: All cloud providers in one way or another rely on some outsourcing company for certain tasks that would be done on behalf of the cloud provider. This applies specifically to cloud providers who outsource certain tasks that are important to security for third-party providers:
- CSP should define what services are being outsourced to sub-contractors. It may happen that some cloud providers might outsource certain operations that might be key to security.
- Are there any audits performed on these contractors? If yes, what kind of audit and how often?
Let's consider an use case. There is an organization that deals with payments. When handling sensitive information, security operations monitoring is an integral part. There needs to be a huge investment in purchasing a SIEM solution, and on top of this, an organization has to hire many security analysts, security engineers, and incident response team members, which would lead to additional cost. This is the reason why many organizations decide to outsource their security operations center (SOC) operations to manage service provider. At the point of supply chain assurance, it is important to know whether audits are performed on these contractors to ensure that they are not leaking any information.
- Operational security: One of the important areas to assess a CSP is the operational security. There are specific areas of operational security that are classified under the ENISA framework:
- Change control.
- Remote access policy that determines who can access and what type of access is granted.
- Operating procedures that basically deal with installing and managing various types of OS.
- Staged environment determines if there are Dev, staging, or production environments and how are they separated. It also tell us how the new code update is tested. Ideally, it should be first tested in Dev, then in staging, and then moved to production.
- Host and network controls should be employed to protect the system hosting the application and information related to the customer. These controls can be IDS/IPS systems, traffic filtering devices, and other appropriate measures.
- Malicious code protection to protect against unwanted malicious code such as viruses. The measures include anti-viruses, anti-malware, and other mechanisms.
- Backup policies and procedures related to audit logs in case any unwanted event has occurred and needs investigation. It also talks about how long these audit logs are stored, how is it protected from unwanted access, and how it maintains the integrity.
- Software assurance: It basically defines how a CSP validates that the new software that will be released and put into production is fit for purpose and does not contain any backdoor or Trojan. It verifies if there is any penetration test conducted on the new software. If new vulnerabilities are discovered, it checks how are they remediated. These tests should be based on industry standards such as OWASP.
- Patch management: CSP should be able to describe the procedure they follow for patch management activity. It also dictates that patch management should cover all the areas such as OS, networking, applications, routers, switches, firewalls, and IDS/IPS.
- Network architecture controls: What are the controls to protect against DDoS attacks? Is the virtual network infrastructure protected against both external as well as internal attacks such as MAC spoofing and ARP poisoning, and are the following isolation measures such as VM isolation and segmentation with help of VLAN, traffic shaping controls?
- Host architecture: Are VM images hardened? Generally, hardening guidelines should follow the best practices specified in various industry standard benchmarks such as CIS. Along with this, hardened VM should also be protected against any unauthorized access, both internally and externally.
- Resource provisioning: Since the resources are generally shared, in case of resource overload (CPU, memory, network, and storage) how will CSP prioritize the requests? How fast can a CSP scale when needed? What are the constraints related to maximum available resources at a given point in time?
- Identity and Access Management (IAM): IAM deals with the access control-related policies and procedures to ensure that any access given to the system is controlled, up to a point, and is justified according to the business requirement. There are a few important points to be assessed as far as IAM is concerned; it can be classified as:
- Are there any accounts with system-level privileges for the entire cloud system?
- How are these system-level accounts with high privileges authenticated? Is there a Multi-factor authentication (MFA)?
- Are there any controls for allowing customers to add new users with specific control to customer environment?
- What are the processes in de-provisioning the credentials?
- Business Continuity Management (BCM): BCM deals with ensuring how, in case of any disaster, a CSP will ensure that the services are backed up. It also defines various things related to SLA, recovery timing, and similar things. Points related to this section are as follows:
- CSP should have a sound procedure and guidelines to survive the event of a disaster to ensure continuity of business. It includes:
- How will CSP inform customers in the case of disruptions?
- What are RPO and RTO?
- Does CSP have priority of recovery? Typically, high, medium, and low.
- CSP should have a sound procedure and guidelines to survive the event of a disaster to ensure continuity of business. It includes:
Apart from the 10 points for the ENISA framework that we covered, there are various other controls which are present; these controls include:
- Data and service portability
- Physical security
- Incident management and response
- Environmental controls
- Legal controls
If you are interested in studying the entire ENISA framework, then I would recommend you to go to their official website, where the entire documentation related to all the points is covered.
We had a high-level overview of the ENISA framework and how it helps an organization select an appropriate cloud provider. We will continue further with understanding in detail some of the important aspects of the selection.
Service Level Agreement
The Service Level Agreement (SLA) is between a service provider and client and it basically defines the level of service that is expected from the service provider. SLA is also different for different services such as VM and storage. SLA document size really varies depending upon the criticality and the complexity of the service.
Let's look at a use case. API Corp. is an organization that hosts various API services related to customer's behavior on the client's website. Whenever an application makes requests, the response time is generally less than 5 minutes. They have an SLA of a response time of 10 minutes. Whenever a customer registers and pays for the services of API Corp., the API Corp. is responsible for maintaining the response time within a given SLA document. If it fails to do so, it is the responsibility of the organization to compensate and take ownership of the failure.
Sometimes, service providers have clauses such as beyond our control to compensate for disasters or events beyond their control, so customers have to be very careful while reading the SLA and if they find it acceptable, then they can sign up for the service.
In the SLA, there is also a term called as indemnification. In order to understand this, let's take an example. ISP has an SLA of 99.9999% uptime to the customers. A customer was going to make a bid of 10,000$ on a very crucial online platform, and on that day, the ISP was down the entire day and he was not able to make the bid and hence incurred heavy losses. Now, the question is, who is responsible to give a payback? This is why the term indemnification is used, which states, if the customer has faced any loss because of the service provider, then how much % of that indemnification a customer can put on the service provider.
Normally, in the SLA, there is a line that states that indemnification cannot exceed more than 90% of the annual charges of the services.
The SLA is generally specific to four major aspects:
- Availability
- Performance/Maximum Response Time (MRT)
- Mean time between failures (MTBF)
- Mean time to repair (MTTR)
Here are some of the SLAs for various cloud providers for the compute services:
|
Cloud providers |
Service Level Agreement |
|
Amazon EC2 |
99.95% |
|
Rackspace |
100% |
|
Microsoft Azure |
99.95% |
|
DigialOcean |
99.99% |
|
Linode |
99.99% |
It's always recommended to get the technical staff and internal auditor to go through the SLA. There can be some kind of caveat that you must be aware of. Along with this, always have a contingency plan to prepare for the worst-case scenario.
Business Continuity Planning – Disaster Recovery (BCP/DR)
Business Continuity Planning and Disaster Recovery are two terms that are generally interrelated for the purpose of recovering in the event of any disaster. Let's understand both the terms in individual sections.
Business Continuity Planning
BCP refers to how business should continue its operations in case of any disaster that takes place. In general, it refers to how a business should plan in advance to continue its key operations and services even in the event of disaster.
Disaster Recovery
DR, on the other hand, refers to how it should recover in case of any disaster that took place. It talks more about what needs to be done immediately to recover from the disaster once it has taken place. Thus, incident response, damage assessment, business impact analysis, and so on are all part of the DR.
If you have architected the BCP/DR plan well, there is a good chance that your business will survive any disaster related to cloud providers. While we cannot predict when things will go down, we can be well prepared if we have an effective BCP.
When we talk about BCP, there are are many important metrics to consider; however, among them, two of them play a crucial role, which are Recovery Time Objective (RTO) and Recovery Point Objective (RPO).
Recovery Time Objective
RTO is basically the amount of time it takes for you to recover your infrastructure and business operations after a disaster has struck. The main aim is how quickly we need to recover; this, in turn, can help you on how to prepare for failover as well as telling us more on how much of our budget can be assigned to it.
For example, if our RTO is 3 hours, then we need to invest quite a good amount of money in making sure that the DR region is always ready in case our main region goes down due to disaster. Similarly, if our RTO is 3 weeks, then we need not spend much money and instead we can wait for the failed data center to get back up and resume the operations.
Recovery Point Objective
RPO is more concerned about the data and maximum tolerance period in which data might be lost. It helps in determining how well you should be designing your infrastructure.
For example, if RPO is 5 hours for a database, then you need to make a backup of your database every 5 hours.
Relation between RTO and RPO
RTO covers a broader scope and covers entire business and systems involved, while on the other hand, RPO is more directly related to an interval of backups to make, to avoid data loss beyond what's expected. This is further illustrated in the following diagram:

Real world use case of Disaster Recovery
Generally, in an organization, for every server, the system admin makes a Disaster Recovery plan document.
Let's assume that Suresh is the owner of a log monitoring tool, where developers log in to see the application logs. Once Suresh has written the DR plan document, there would be a schedule where on Wednesday, from 8 am to 10 am, the server would be shut down and this document would be given to the help desk person to restore the server. If the help desk person is able to recover the server by reading the document, then the document will be transitioned from a draft version to the final version.
This is how an organization's DR plan works properly.
I was always a bit too lazy to prepare lengthy disaster recovery plan documents. After all, if we prepare a proper lengthy DR plan document, it would take a long time to read and follow for the person recovering it. So, I would always associate a video tutorial along with the document and almost all the time, the help desk person used to watch the video tutorial and recovery was much faster and more efficient.
Use case to understand BCP/DR
Learning Corp. is a learning platform that teaches various subjects, from Linux to security, to a lot of students at a particular institute in Mumbai. Now, let's assume that some disaster such as heavy rains and heavy flooding has struck, and due to this, the entire network was down. Due to this, Learning Corp. went for plan B, where trainers will take lectures online through an online platform such as Cisco WebEx and has also asked all students to connect online so that classes can go on and students are not affected.
Now, after the heavy rains and flooding have stopped, we need to rebuild the network that was destroyed, and the rebuilding has started. This process is called as Disaster Recovery.
So, in this case:
- BCP: Making sure that the education training goes on and students are not affected
- DR: Rebuilding the network and infrastructure after disaster has passed
I hope this has given you a high-level overview of the BCP/DR.
Policies and governance in cloud
Governance is basically a set of rules and policies through which an organization is directed and controlled so that it is focused towards its goals.
As an overview, if the management is about running the business, governance is about seeing that it runs properly. Before we move further, we need to understand it with a few use cases; otherwise, it will just remain theoretical concepts.
Let's understand this with an example. Small Corp. has started to deal with delivery services. There are three deliveries that are currently pending. Let's look into the management and governance perspective:
- Management:
- Matt will pick up the first and second deliveries at 8 am and deliver them by 11 am
- Alen will pick up the third deliver it by afternoon 3 pm and deliver by 7 pm
- Governance:
- Are all the deliveries being delivered on time?
- Is everything being done is perfect as per as legal and regulatory laws?
When we speak about information security governance, the board members of the organization should be briefed about it and should:
- Be informed about the current information security readiness in organization
- Set direction to add policies and strategies, and to make sure that security is a part of new policies
- Provide resources for security efforts
- Obtain assurance from internal as well as external auditors
- Assign management responsibilities
Let's look into some of the real-world use cases that may be part.
In one of the organizations that I have worked with, although the security posture was good, the board members used to stress and get the audit done by external auditors. So, the external auditors used to come and check every control. Their firewall admin used to sit with our firewall admin and look into individual rules and so on.
All that the board members wanted to hear from the external auditor was: all OK or bad?
When we speak about briefing board members or the CEO about information security governance, it is important to speak their language.
Let's say, a firewall admin cannot say that there are advanced persistent threats and for this, we need next-generation firewalls. They might fire him even though he might be the best firewall admin in the organization.
Thus, the representative must speak their language, and thus CISO, CIO, or others should represent the current security threats, current preparedness level, and future plans for which the board can approve new budgets and discuss further:
- It is the responsibility of the senior executives to respond to the concerns raised by the information security expert
- In order to effectively exercise enterprise governance, the board and senior executives must have a clear vision of what is expected from the information security program
- IT security governance is different from that of IT security management as security management is more focused on how to mitigate the risks associated to security, and governance is more concerned about who in the organization is authorized and responsible for making decisions:
|
Governance |
Management |
|
Overseeing the operations |
Deals with the implementation aspect |
|
Making policies |
Enforcing policies |
|
Allocating the resources |
Utilizing of the resources |
|
Strategic |
Tactical |
- Nowadays, increased corporate governance requirements have caused organizations to look into their internal controls more closely to ensure that the required controls are in place and are operating effectively.
Let's understand this with an example. John is a new CISO and has joined Medium Corp.. After joining, John realized that most things that the organization had been doing were incomplete. At the end of the year, when the auditor came, more than half of the things didn't work, backups were failing, audit trails were not being recorded across many servers, and so on.
So, John decided to implement the NIST Cybersecurity Framework, and as an overview, if you follow the industry standards frameworks such as NIST, you can be sure that your organization is in great shape with respect to security.
Audit challenges in the cloud
An audit can be defined as conducting an official inspection of a particular service or a product.
In order to audit, there needs to be a well-defined document that contains a clear view of what exactly needs to be audited, how it needs to be audited, and that also defines the success and failure criteria for the audit.
During the times where an organization had on-premise servers, auditors had full visibility of the servers and networks and, also, the accountability. However, in the cloud, one doesn't really have any visibility about the underlying network and even the accountability is challenging. This makes auditing in the cloud a challenge for the auditors:
- Visibility: This is one of the major challenges for customers and auditors whenever they have their servers hosted in a cloud environment. Customer or auditor might want to evaluate the state of security of the data centers of CSP as well other security controls; however, CSP doesn't provide access to customers to their actual servers or data center facility.
- Transparency and accountability: In cloud environments, customers generally do not have any proper tracking of where exactly their data resides within a CSP environment. Customers would also like to understand the accountability of the protection of the customer's data and thus would need to understand the boundary between the CSP responsibility and customer's responsibility for the protection of data. There has to be a clear document stating who is responsible for what. This typically changes according to environments, as follows:
- SaaS: CSP is responsible for the infrastructure, software, and back end data storage
- PaaS: CSP responsible for infrastructure and platform but not application security
- IaaS: Underlying infrastructure such as hypervisor is the responsibility of CSP, while OS is customer's responsibility
It is also important to understand how exactly CSP will protect the data and respond to the legal inquiry that might occur.
Implementation challenges for controls on CSP side
Every customer might have different requirements for controls and if they move to a cloud environment, they need to also make sure that the CSP has implemented those controls.
For example, for an organization that stores sensitive cardholder data (debit card / credit card), they need to be PCI compliant. As a part of the compliance program, if you are hosted in a cloud environment, you have to ensure that the cloud provider also has PCI DSS certification and generally user need to submit AOC document provided by the CSP to the auditors.
AWS is a PCI DSS level 1 service provider:
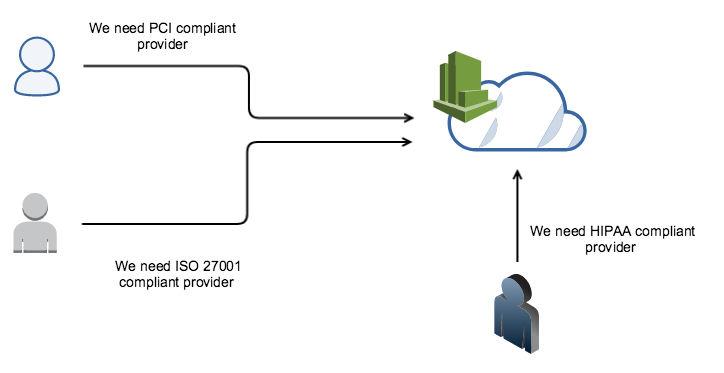
Similarly, there might be other customers who might need ISO 27001 or HIPAA compliant provider and so CSP needs to make sure to have controls in place and to be in compliance with those certifications.
Vulnerability assessment and penetration testing in the cloud
Organizations hosted on a cloud cannot readily perform vulnerability assessment activity or penetration testing activity since the infrastructure belongs to the cloud and it might be a shared resource with other customers as well.
This is one of the reasons that you need to get a prior approval from the CSP before doing activities such as penetration tests or external ASV scans.
In AWS, before doing any such VA/PT activities, you need to fill out a VA/PT form and get prior authorization before you begin to scan or perform any PT activities:

One important thing to remember is that you are not allowed to do all open testing for certain instance types such as t2.nano and m1.small in AWS.
Similarly, there are different challenges related to VA/PT depending on the cloud environments (IaaS, SaaS, or PaaS) which customers are subscribed to.
Use case of a hacked server
One fine evening, my friend called and informed me that he got an email from his cloud hosting provider related to an abuse complaint. It stated that the server was found to be one of the spam emitters and has been blacklisted by spam bots and email services:
It was a very strange email because that website never really used to send emails. Once we logged in to the server, we analyzed that every day there were thousands of emails which were being sent from the server. Postfix was also installed and tens of thousands of emails were in the queue. In fact, there were so many messages in the email queue that entire inodes for the server were full and no new files were getting created:

The first thing to check was who logged in to the server in the past 30 days, and it was concluded that no one from any suspicious IP/username logged in. Only the authorized user had logged in from his office IP.
The second thing to check was which script was calling the Postfix service and creating email queues in the server. During this phase, we had an interesting finding and found that index.php of his website had been calling Postfix. When I opened the index.php file, it was full of obfuscated PHP functions and it was definitely suspicious. Having verified with the developer, it was confirmed that the file had been modified and this was the file placed by the attacker:

With this said, we did a vulnerability assessment on the server as well as the application and found that there were a lot of high-level vulnerabilities present on both the application and the server sides. I decided to patch up the server-based vulnerabilities and asked the developer to look into the application-based vulnerabilities and fix them as soon as possible.
In conclusion, there were two important findings:
- The startup themselves were not capable of detecting that their website was hacked. They had to rely on third-party websites, which reported that their website was hacked.
- There were no security tools or services present which would protect or detect against such attacks. If there had been FIM, the core website file change would have been detected within a minute; if there was a firewall with both inbound/outbound rules, then email would never have been sent; if there was HIDS, then they could have detected the new package installation such as Postfix; had there been SELinux, then they could have confined their Apache process, so it could never have put emails in queue. This list grows long and more refined.
This is something that you find in many organizations nowadays; some might argue that they do have a firewall in place, but when we ask if they have outbound rule restrictions and a firewall justification document, then the answer is generally no. Similarly, there needs to be a systematic approach while dealing with security, and at every layer there needs to be detective or preventive mechanisms in place so that we can identify and prevent against unauthorized users or attacks.
Summary
In this chapter, we revised the basics about the cloud as well as having an overview of the security challenges when infrastructure is moved to cloud environments.
