


















 Download code from GitHub
Download code from GitHub
Chapter 1: Designing and Architecting the Enterprise Application
Enterprise applications are software solutions designed to solve large and complex problems for enterprise organizations. They enable Order-to-Fulfillment capabilities for enterprise customers in the IT, government, education, and public sectors and empower them to digitally transform their businesses with capabilities such as product purchase, payment processing, automated billing, and customer management. The number of integrations when it comes to enterprise applications is quite high, and the volume of users is also very high as such applications are typically targeted at a global audience. To ensure that enterprise systems remain highly reliable, highly available, and highly performant, getting the design and architecture right is very important. Design and architecture form the foundation of any good software. They form the basis for the rest of the software development life cycle and therefore are very important to get right and avoid any rework later, which could prove very costly depending on the changes needed. So, you need a flexible, scalable, extensible, and maintainable design and architecture.
In this chapter, we will cover the following topics:
- A primer on common design principles and patterns
- Understanding common enterprise architectures
- Identifying enterprise application requirements (business and technical)
- Architecting an enterprise application
- Solution structuring for an enterprise application
By the end of the chapter, you will be able to design and architect applications by following the right design principles.
A primer on common design principles and patterns
Every piece of software in the world solves one real-world problem or another. As time goes by, things change, including what we expect from any specific software. To manage this change and deal with various aspects of software, engineers have developed a number of programming paradigms, frameworks, tools, techniques, processes, and principles. These principles and patterns, proven over time, have become guiding stars for engineers to use to collaborate and build quality software.
We will be discussing object-oriented programming (OOP) in this chapter, a paradigm based on the concepts of "objects" and their states, behaviors, and interactions with each other. We will also cover some common design principles and patterns.
Principles are high-level abstract guidelines to be followed while designing; they are applicable regardless of the programming language being used. They do not provide implementation guidelines.
Patterns are low-level specific implementation guidelines that are proven, reusable solutions for recurring problems. Let's first start with design principles.
Design principles
Techniques become principles if they are widely accepted, practiced, and proven to be useful in any industry. Those principles become solutions to make software designs more understandable, flexible, and maintainable. We will cover the SOLID, KISS, and DRY design principles in this section.
SOLID
The SOLID principles are a subset of many principles promoted by American software engineer and instructor Robert C. Martin. These principles have become de facto standard principles in the OOP world and have become part of the core philosophy for other methodologies and paradigms.
SOLID is an acronym for the following five principles:
- Single responsibility principle (SRP): An entity or software module should only have a single responsibility. You should avoid granting one entity multiple responsibilities:

Figure 1.1 – SRP
- Open-closed principle (OCP): Entities should be designed in such a way that they are open for extension but closed for modification. This means regression testing of existing behaviors can be avoided; only extensions need to be tested:

Figure 1.2 – OCP
- Liskov substitution principle (LSP): Parent or base class instances should be replaceable with instances of their derived classes or subtypes without altering the sanity of the program:

Figure 1.3 – LSP
- Interface segregation principle (ISP): Instead of one common large interface, you should plan multiple, scenario-specific interfaces for better decoupling and change management:

Figure 1.4 – ISP
- Dependency inversion principle (DIP): You should avoid having any direct dependency on concrete implementations. High-level modules and low-level modules should not depend on each other directly, and instead, both should depend on abstractions as much as possible. Abstraction should not depend on details and details should depend on abstractions.
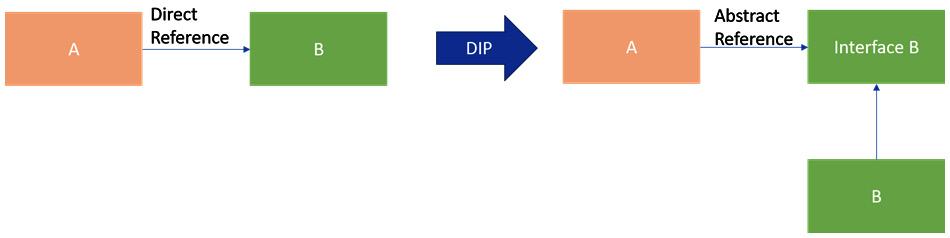
Figure 1.5 – DIP
Don't repeat yourself (DRY)
With DRY, a system should be designed in such a way that the implementation of a feature or a pattern should not be repeated in multiple places. This would result in maintenance overhead as a change in requirements would result in modification being needed at multiple places. If you fail to make a necessary update in one place by mistake, the behavior of the system will become inconsistent. Rather, the feature should be wrapped into a package and should be reused in all places. In the case of a database, you should look at using data normalization to reduce redundancy:
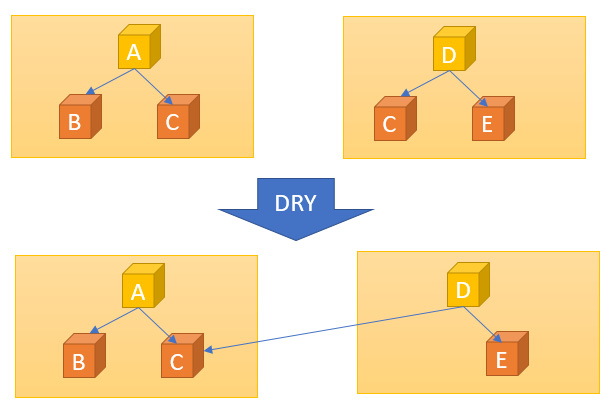
Figure 1.6 – DRY
This strategy helps in reducing redundancy and promoting reuse. This principle helps an organization's culture as well, encouraging more collaboration.
Keep it simple, stupid (KISS)
With KISS, a system should be designed as simply as possible, avoiding complicated designs, algorithms, new untried technologies, and so on. You should focus on leveraging the right OOP concepts and reusing proven patterns and principles. Include new or non-simple things only if it is necessary and adds value to the implementation.
When you keep it simple, you will be able to do the following better:
- Avoid mistakes while designing/developing
- Keep the train running (there is always a team whose job is to maintain the system, although they are not the team that developed the system in the first place)
- Read and understand your system and code (your system and code need to be understandable to people new to it or people using it far in the future)
- Do better and less error-prone change management
With this, we are done with our primer on common design principles; we have learned about SOLID, DRY, and KISS. In the next section, we'll look at some common design patterns in the context of real-world examples to help you understand the difference between principles and patterns and when to leverage which pattern, a skill that's essential for good design and architecture.
Design patterns
While following design principles in the OOP paradigm, you may see the same structures and patterns repeating over and again. These repeating structures and techniques are proven solutions to common problems and are known as design patterns. Proven design patterns are easy to reuse, implement, change, and test. The well-known book Design Patterns: Elements of Reusable Object-Oriented Software, comprising what are known as the Gang of Four (GOF) design patterns, is considered as the bible of patterns.
We can categorize the GOF patterns as follows:
- Creative: Helpful in creating objects
- Structural: Helpful in dealing with the composition of objects
- Behavioral: Helpful in defining the interactions between objects and distributing responsibility
Let's look at the patterns with some real-life examples.
Creational design patterns
Let's have a look at some creational design patterns along with relevant examples in the following table:
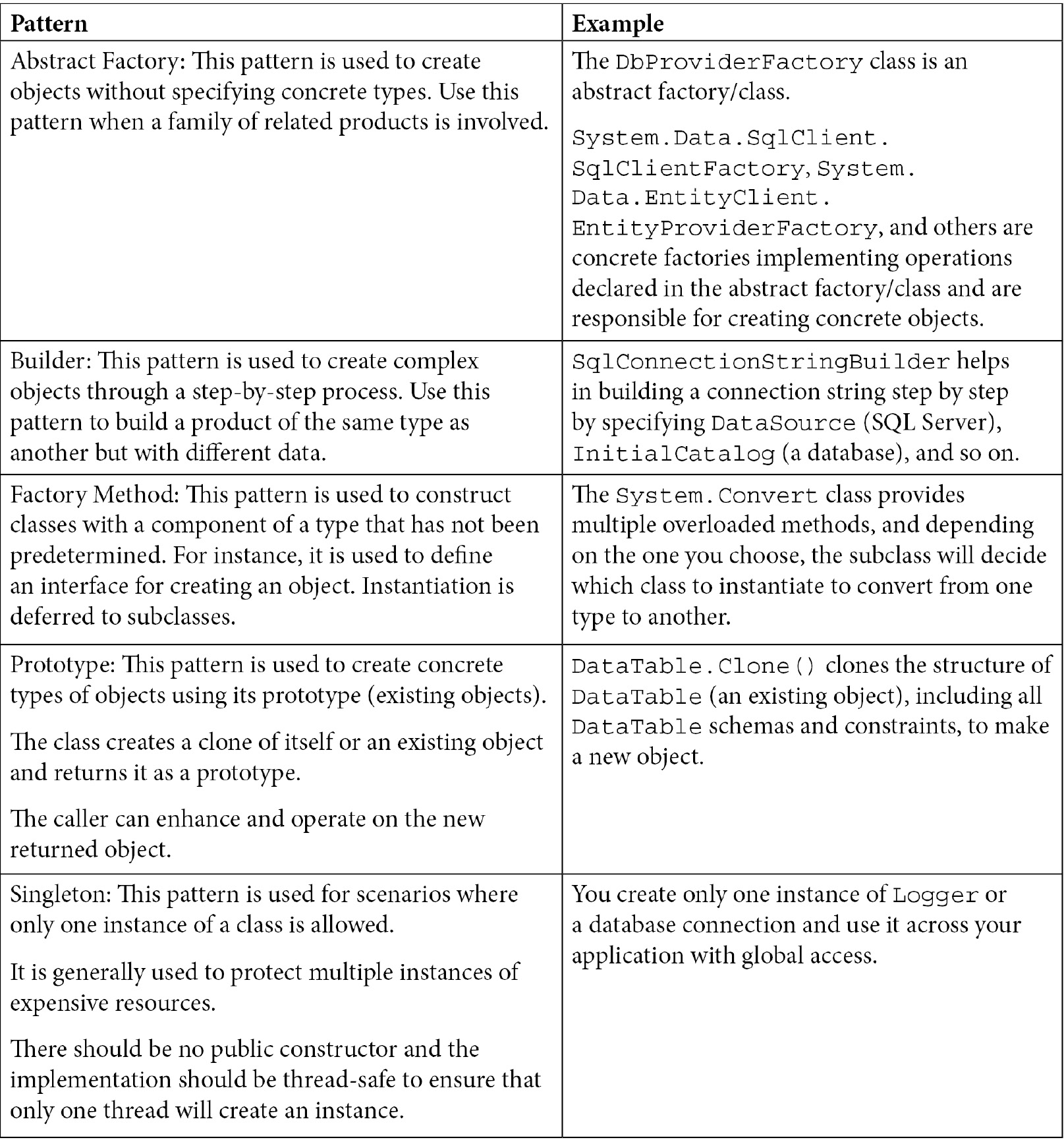
Table 1.1
Structural design patterns
The following table includes some examples of structural design patterns:

Table 1.2
Behavior design patterns
The following table includes some examples of behavioral design patterns:

Table 1.3
Sometimes, you can become overwhelmed by all these patterns being on the table, but really, any design is a good design until it violates the basic principles. One rule of thumb that we can use is to go back to basics, and in design, principles are the basics.
Figure 1.7 – Pattern versus principles
With this, we are done with our primer on common design principles and patterns. By now, you should have a good understanding of the different principles and patterns, where to use them, and what it takes to build a great solution. Let's now spend some time looking at common enterprise architectures.
Understanding common enterprise architectures
There are a few principles and architectures that are commonly practiced when designing enterprise applications. First and foremost, the goal of any architecture is to support business needs at the lowest cost possible (costs being time and resources). A business wants software to enable it rather than acting as a bottleneck. In today's world, availability, reliability, and performance are the three KPIs of any system.
In this section, we will first look at the issues with monolithic architecture and then we will see how to avoid them using widely adopted and proven architectures for developing enterprise applications.
Consider a classical monolithic e-commerce website application, such as the one shown in the following diagram, with all the business providers and functionality in a single app and data being stored in a classical SQL database:
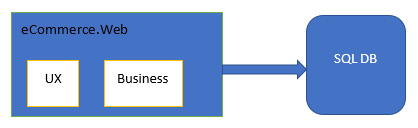
Figure 1.8 – Monolithic application
The monolithic architecture was widely adopted 15-20 years ago, but plenty of problems arose for software engineering teams when systems grew and business needs expanded over time. Let's look at some of the common issues with this approach.
Common issues with monolithic apps
Let's have a look at the scaling issues:
- In a monolithic app, the only way to horizontally scale is by adding more compute to the system. This leads to higher operational costs and unoptimized resource utilization. Sometimes, scaling becomes impossible due to conflicting needs in terms of resources.
- As all the features mostly use single storage, there is the possibility of locks leading to high latency, and there will also be physical limits as to how far a single storage instance can scale.
Here are some issues associated with availability, reliability, and performance:
- Any changes in the system will require the redeployment of all components, leading to downtime and low availability.
- Any non-persistent state, such as sessions stored in a web app, will be lost after every deployment. This will lead to the abandonment of all workflows that were triggered by users.
- Any bugs in a module, such as memory leaks or security bugs, make all the modules vulnerable and have the potential to impact the whole system.
- Due to the highly coupled nature and sharing of resources within modules, there will always be unoptimized use of resources, leading to high latency in the system.
Lastly, let's see what the impact on the business and engineering teams is:
- The impact of a change is difficult to quantify and needs extensive testing. Hence, it slows down the rate of delivery to production. Even a small change will require the entire system to be deployed again.
- In a single highly coupled system, there will always be physical limits on collaboration across teams to deliver any feature.
- New scenarios such as mobile apps, chatbots, and analysis engines will take more effort as there are no independent reusable components or services.
- Continuous deployment is almost impossible.
Let's try to solve these common problems by adopting some proven principles/architectures.
Separation of concerns/single responsibility architecture
Software should be divided into components or modules based on the kind of work it performs. Every module or component should have a single responsibility. Interaction between components should be via interfaces or messaging systems. Let's look at the n-tier and microservices architecture and how the separation of concerns is taken care of.
N-tier architecture
N-tier architecture divides the application of a system into three (or n) tiers:
- Presentation (known as the UX layer, the UI layer, or the work surface)
- Business (known as the business rules layer or the services layer)
- Data (known as the data storage and access layer)

Figure 1.9 – N-tier architecture
These tiers can be owned/managed/deployed separately. For example, multiple presentation layers, such as web, mobile, and bot layers, can leverage the same business and data tier.
Microservices architecture
Microservices architecture consists of small, loosely coupled, independent, and autonomous services. Let's look at their benefits:
- Services can be deployed and scaled independently. An issue in one service will have a local impact and can be fixed by just deploying the impacted service. There is no need to share a technology or framework.
- Services communicate with each other via well-defined APIs or a messaging system such as Azure Service Bus:
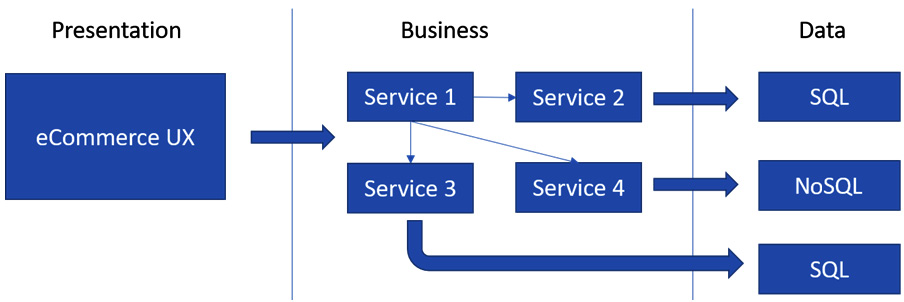
Figure 1.10 – Microservices architecture
As seen in the preceding figure, a service can be owned by independent teams and can have its own cycle. Services are responsible for managing their own data stores. Scenarios demanding lower latency can be optimized by bringing in a cache or high-performance NoSQL stores.
Domain-driven architecture
Each logical module should not have a direct dependency on another module. Each module or component should serve a single domain.
Modeling services around a domain prevents service explosion. Modules should be loosely coupled and modules that are likely to change together can be clubbed together.
Stateless services architecture
Services should not have any state. State and data should be managed independently from services, that is, externally. By delegating state externally, services will have the resources to serve more requests with high reliability.
Session affinity should not be enabled as it leads to sticky session issues and will stop you from getting the benefits of load balancing, scalability, and the distribution of traffic.
Event-driven architecture
The main features of event-driven architecture are as follows:
- In event-driven architecture, communication, which is generally known as (publisher-subscriber communication) between modules, is primarily asynchronous and achieved via events. Producers and consumers are totally decoupled from each other. The structure of the event is the only contract that is exchanged between them.
- There can be multiple consumers of the same event taking care of their specific operations; ideally, they won't even be aware of each other. Producers can continuously push events without worrying about the availability of the consumers.
- Publishers publish events via a messaging infrastructure such as queues or a service bus. Once an event is published, the messaging infrastructure is responsible for sending the event to eligible subscribers:

Figure 1.11 – Event-driven architecture
This architecture is best suited for scenarios that are asynchronous in nature. For example, long-running operations can be queued for processing. A client might poll for a status or even act as a subscriber for an event.
Data storage and access architecture
Data storage and access architecture play a vital role in the scaling, availability, and reliability of an overall system:
- A service should decide the type of data storage depending on the needs of the operation.
- Data should be partitioned and modeled according to the needs of the given operation. Hot partitions should be avoided at any cost. Replication should be opted for if you need more than one type of structure from the same data.
- The correct consistency model should be chosen for lower latency. For example, an operation that can afford to have stale data for some time should use weak/eventual consistency. Operations that have the potential to change the state and need real-time data should opt for stronger consistency.
- Caching data that is appropriate to services helps the performance of services. Areas should be identified where data can be cached. Depending on the given need, an in-memory or out-of-memory cache can be chosen.
Resiliency architecture
As the communication between components increases, so does the possibility of failures. A system should be designed to recover from any kind of failure. We will cover a few strategies for building a fault-tolerant system that can heal itself in the case of failures.
If you are familiar with Azure, you'll know that applications, services, and data should be replicated globally in at least two Azure regions for planned downtime and unplanned transient or permanent failures. Choosing Azure App Service to host web applications, using REST APIs, and choosing a globally distributed database service such as Azure Cosmos DB, is wise in these scenarios. Choosing Azure paired regions will help in business continuity and disaster recovery (BCDR), as at least one region in each pair will be prioritized for recovery if an outage affects multiple regions. Now, let's see how to tackle different types of faults.
Transient faults can occur in any type of communication or service. You need to have a strategy to recover from transient faults, such as the following:
- Identify the operation and type of a transient fault, then determine the appropriate retry count and interval.
- Avoid anti-patterns such as endless retry mechanisms with a finite number of retries or circuit breakers.
If a failure is not transient, you should respond to the failure gracefully by choosing some of the following options:
- Failing over
- Compensating for any failed operations
- Throttling/blocking the bad client/actor
- Using a leader election to select a leader in the case of a failure
Telemetry plays a big role here; you should have custom metrics to keep a tab on the health of any component. Alerts can be raised when a custom event occurs or a specific metric reaches a certain threshold.
Evolution and operations architecture
Evolution and operations play a vital role in continuous integration, deployment, staged feature rollout, and reducing downtime and costs:
- Services should be deployed independently.
- Designing an ecosystem that can scale enables a business to grow and change over time.
- A loosely coupled system is best for a business, as any change or feature can be delivered with good velocity and quality. Changes can be managed and scoped to individual components.
- Elasticity in scale leads to the better management of resources, which in turn reduces operation costs.
- A continuous build and release pipeline alongside a blue-green deployment strategy can help in identifying issues early in a system. This also enables the testing of certain hypotheses with a reduced amount of production traffic.
With this, we are done with our coverage of common enterprise architectures. Next, we will look at enterprise application requirements and different architectures through the lens of the design principles and common architectures we have learned about.
Identifying enterprise application requirements (business and technical)
In the next few chapters, we will build a working e-commerce application. It will be a three-tier application consisting of a UI layer, a service layer, and a database. Let's look at the requirements for this e-commerce application.
The solution requirements are the capabilities to be implemented and made available in the product to solve a problem or achieve an objective.
The business requirements are simply the end customer's needs. In the IT world, "business" generally refers to "customers." These requirements are collected from various stakeholders and documented as a single source of truth for everyone's reference. This eventually becomes the backlog and scope of work to be completed.
The technical requirements are the technology aspects that a system should implement, such as reliability, availability, performance, and BCDR. These are also known as quality of service (QOS) requirements.
Let's break the typical business requirements for an e-commerce application site down into the following categories: Epic, Feature, and User Story.
The application's business requirements
The following screenshot from Azure DevOps shows a summary of the backlog for our business requirements. You can see the different features expected in our application along with the user stories:
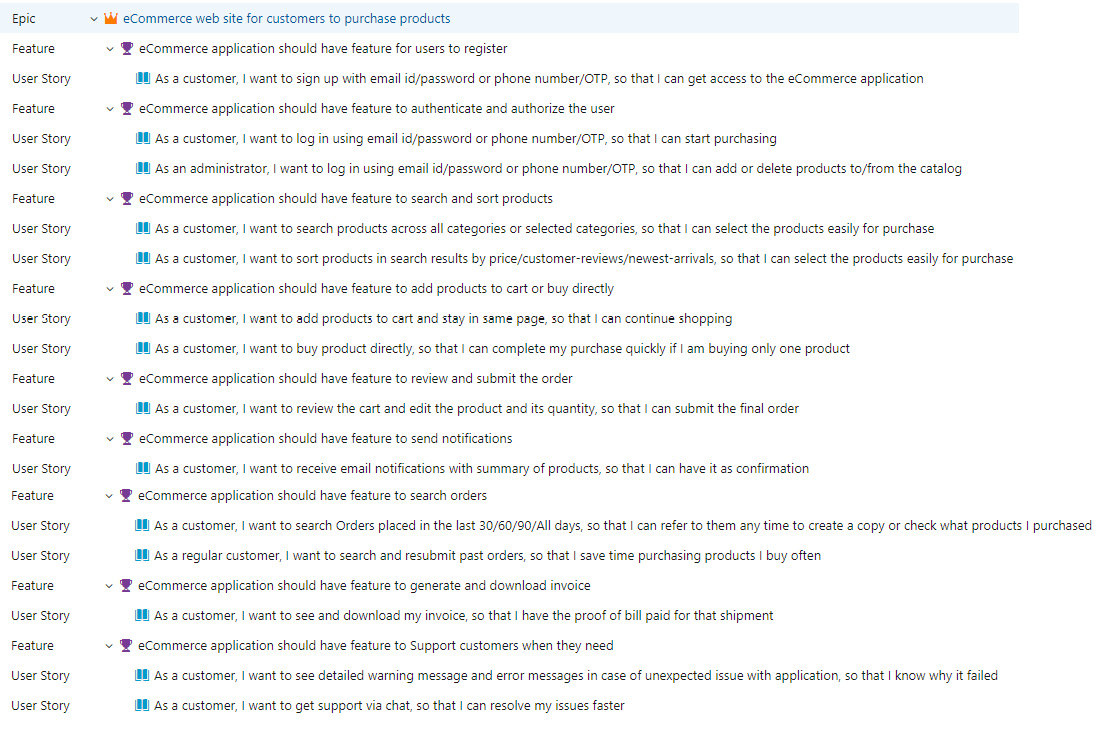
Figure 1.12 – Requirements backlog from Azure DevOps
The application's technical requirements
Having seen the business requirements, let's now go through the technical requirements:
- The e-commerce application should be highly available, that is, available for 99.99% of the time for any 24-hour period.
- The e-commerce application should be highly reliable, that is, reliable 99.99% of the time for any 24-hour period.
- The e-commerce application should be highly performant: 95% of the operations should take less than or equal to 3 seconds.
- The e-commerce application should be highly scalable: it should automatically scale up/down based on the varying load.
- The e-commerce application should have monitoring and alerts: an alert should be sent to a support engineer in the case of any system failure.
Here are the technical aspects identified for the e-commerce application and its requirements:
Frontend
Core components
Middle tier
- An Azure API gateway to implement authentication
- A user management service through an ASP.NET 5.0 web API to add/remove users
- Product and pricing services through an ASP.NET 5.0 web API to get products from the data store
- A domain data service through an ASP.NET 5.0 web API to get the domain data, such as country data.
- A payment service through an ASP.NET 5.0 web API to complete payments
- An order processing service through an ASP.NET 5.0 web API to submit and search orders
- An invoice processing service through an ASP.NET 5.0 web API to generate invoices
- A notification service through an ASP.NET 5.0 web API to send notifications such as emails
Data tier
- A data access service through an ASP.NET 5.0 web API to talk to Azure Cosmos DB to read/write data
- Entity Framework Core to access data
Azure Stack
- Azure Cosmos DB as a backend data store
- Azure Service Bus for asynchronous message processing
- Azure App Service to host the web application and web APIs
- Azure Traffic Manager for high availability and responsiveness
- Azure Application Insights for diagnostics and telemetry
- Azure paired regions for better resiliency
- Azure resource groups to create Azure Resource Manager (ARM) templates and deploy to the Azure subscription
- Azure Pipelines for continuous integration and continuous deployment (CI/CD)
We are now done with the enterprise application requirements. Next, we will look at architecting an enterprise application.
Architecting an enterprise application
The following architecture diagram depicts what we are building. We need to keep in mind all of the design principles, patterns, and requirements we saw in this chapter when we are architecting and developing the application. The next figure shows the proposed architecture diagram for our e-commerce enterprise application:

Figure 1.13 – Our e-commerce application's three-tier architecture diagram
Separation of concerns/SRP has been taken care of at each tier. The presentation tier containing the UI is separated from the services tier containing the business logic, which is again separated from the data access tier containing the data store.
The high-level components are unaware of the low-level components consuming them. The data access tier is unaware of the services consuming it, and services are unaware of the UX tier consuming them.
Each service is separated based on the business logic and functionality it is supposed to perform.
Encapsulation has been taken care of at the architecture level and should be taken care of during development as well. Each component in the architecture will be interacting with other components through well-defined interfaces and contracts. We should be able to replace any component in the diagram without worrying about its internal implementation if it adheres to the contracts.
The loosely coupled architecture here also helps in faster development and faster deployment to market for customers. Multiple teams can work in parallel on each of their components independently. They share the contracts and timelines for integration testing at the start, and once the internal implementation and unit tests are done, they can start with integration testing.
Refer to the following figure:

Figure 1.14 – Our e-commerce application components, broken down by chapter
From the figure, we identify the chapters in which different parts of the e-commerce application that we will build will be covered, which are explained as follows:
- Creating an ASP.NET web application (our e-commerce portal) will be covered as part of Chapter 11, Creating an ASP.NET Core 5 Web Application.
- Authentication will be covered as part of Chapter 12, Understanding Authentication.
- The order processing service and the invoice processing service are the two core services for generating orders and invoicing. They will be the heart of the e-commerce application as they are the ones that are responsible for the revenue. Creating an ASP.NET Core web API will be covered as part of Chapter 10, Creating an ASP.NET Core 5 Web API, and cross-cutting concerns will be covered as part of Chapter 5, Dependency Injection in .NET, Chapter 6, Configuration in .NET Core, and Chapter 7, Logging in .NET 5, respectively. The DRY principle will be taken care of by reusing core components and cross-cutting concerns instead of repeating implementations.
- Caching will be covered as part of the product pricing service in Chapter 8, Understanding Caching. Caching will help to improve the performance and scalability of our system, with temporary copies of frequently accessed data being available in memory.
- Data storage, access, and providers will be covered as part of the data access layer in Chapter 9, Working with Data in .NET 5. The kind of architecture that we have adopted, where data and access to it is separate from the rest of the application, gives us better maintenance. Azure Cosmos DB is our choice to scale throughput and storage elastically and independently across any number of Azure regions worldwide. It is also secure by default and enterprise-ready.
This concludes our discussion on architecting our enterprise application. Next, we will look at the solution structure for our enterprise application.
Solution structuring for an enterprise application
We will go with a single solution for all our projects to keep things simple, as shown in the following figure. The other approach of having separate solutions for the UI, shared components, web APIs, and so on can also be considered when the number of projects in the solution explodes and causes maintenance issues. The following screenshot shows our application's solution structure:
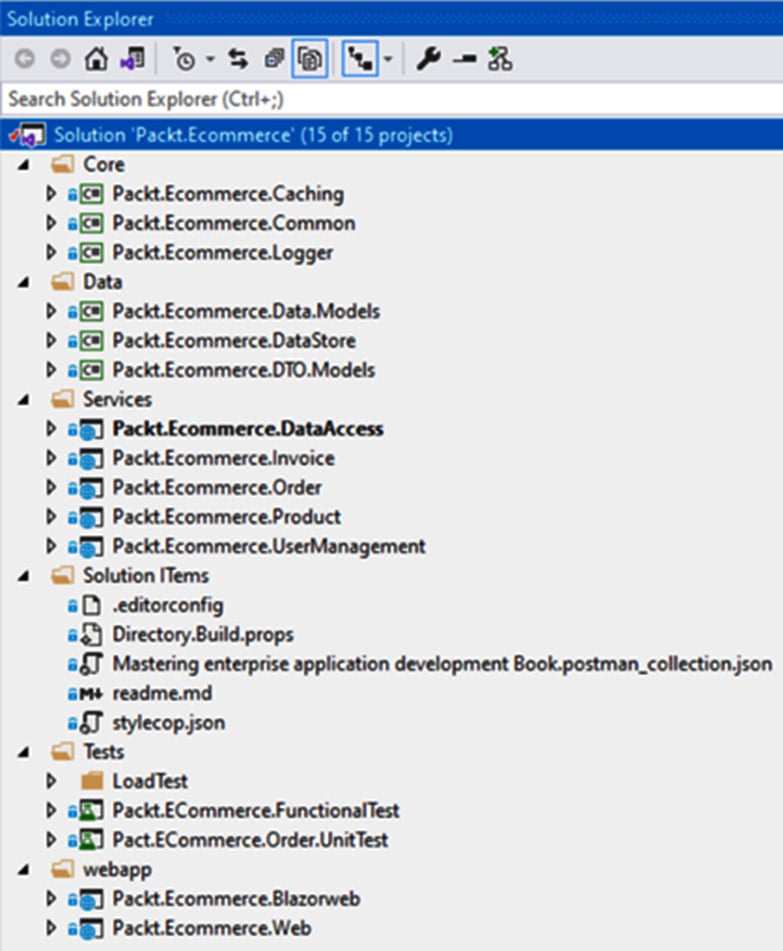
Figure 1.15 – Solution structure for the e-commerce application
Summary
In this chapter, we learned about common design principles such as SOLID, DRY, and KISS. We also looked at various design patterns with real-world examples. Then, we looked at different enterprise architectures, identified requirements for the e-commerce application that we are going to build, and applied what we learned in order to architect our e-commerce application. You can now apply what you have learned here when you design any application. In the next chapter, we will learn about .NET 5 Core and Standard.
Questions
- What is the LSP?
a. Base class instances should be replaceable with instances of their derived type.
b. Derived class instances should be replaceable with instances of their base type.
c. Designing for generics that can work with any data type.
- What is the SRP?
a. Instead of having one common large interface, plan for multiple scenario-specific interfaces for better decoupling and change management.
b. You should avoid having direct dependencies on a concrete implementation; instead, you should depend on abstractions as much as possible.
c. An entity should only have a single responsibility. You should avoid giving one entity multiple responsibilities.
d. Entities should be designed in such a way that they should be open for extension but closed for modification.
- What is the OCP?
a. Entities should be open to modification but closed for extension.
b. Entities should be open to extension but closed for modification.
c. Entities should be open to composition but closed for extension.
d. Entities should be open to abstraction but closed for inheritance.
- Which pattern is used to make two incompatible interfaces work together?
a. Proxy
b. Bridge
c. Iterator
d. Adapter
- Which principle ensures that services can be deployed and scaled independently and that an issue in one service will have a local impact and can be fixed by just redeploying the impacted service?
a. The domain-driven design principle
b. The Single Responsibility Principle
c. The stateless service principle
d. The resiliency principle






