


















 Download code from GitHub
Download code from GitHub
Chapter 1: An Introduction to Distributed Applications
In today's world of digital platforms, all applications are expected to be highly scalable, available, and reliable with world-class performance. Many IT companies use the term ARP, which stands for availability, reliability, performance, and have a guaranteed service-level agreement (SLA) for each. Any SLA below 99.99% (four nines) is not acceptable for an application given the challenging and highly competitive world we are in. Some mission-critical applications guarantee a higher SLA of >=99.999% (five nines). To meet increasing user demands and requirements, an application needs to be highly scalable and distributed.
Distributed applications are applications/programs that run on multiple computers and communicate with each other through a well-defined interface over a network to process data and achieve the desired output. While they appear to be one application from the end user's perspective, distributed applications typically have multiple components.
This chapter will cover the following:
- Monolithic applications versus distributed applications
- Challenges with distributed applications
- Designing your application for scalability
- Designing your application for high availability
Monolithic applications versus distributed applications
In the following diagram, we have a classic monolithic hotel booking application with all the UX and business processing services deployed in a single application server tightly coupled together with the database on the left side. We have a basic N-tier distributed hotel booking application with UX, business processing services, and a database all decoupled and deployed in separate servers on the right side.

Figure 1.1 – Monolithic application (left) versus an N-tier distributed application (right)
Monolithic architecture was widely adopted 15-20 years ago, but plenty of problems arose for software engineering teams when systems grew and business needs expanded with time. Let's see some of the common issues with this approach.
Common issues with monolithic apps
Let's have a look at the scaling issues:
- In a monolithic app, there will be no option to scale up UX and services separately as they are tightly coupled. Sometimes scaling doesn't help due to conflicting needs of the resources.
- As most components use a common backend storage, there will be a possibility of locks when everyone tries to access the data at the same time leading to high latency. You can scale up but there will be physical limits to what a single instance of storage can scale.
Here are some issues associated with availability, reliability, and performance SLAs:
- Any changes in the system will need the deployment of all UX and business components, leading to downtime and low availability.
- Any non-persistent state-like session stored in a web app will be lost after every deployment. This will lead to abandoning all the workflows that were triggered by the user.
- Any bugs such as memory leaks or any security bugs in any module make all the modules vulnerable and have the potential to impact the whole system.
- Due to the highly coupled nature and the sharing of resources within modules, there will always be resource starvation or unoptimized usage of resources, leading to high latency in the system.
Lastly, let's see what the impacts are on the business and engineering team:
- The impact of a change is difficult to quantify and needs extensive testing. Hence, it slows down the rate of delivery to production. Even a small change would need the entire system to be deployed.
- Given a single highly coupled system, there will always be physical limits on collaboration across teams to deliver a feature.
- New scenarios such as mobile apps, chatbots, and analysis engines will take more effort as there are no independent reusable components and services.
- Continuous deployment is almost impossible.
Let's see how these issues are addressed in a distributed application.
N-tier distributed applications
N-tier architecture divides the application into n tiers:
- Presentation (known as the UX layer, UI layer, and the work surface)
- Business (known as the business rules layer and services layer)
- Data (known as the data storage and access layer)
Let's have a look at the advantages of a distributed application:
- These tiers can be owned, managed, and deployed separately. For example, any bug fixes or changes in the UX or service will need regression testing and deployment of only that portion.
- Multiple presentation layers, such as web, mobile, and bots, can leverage the same business and data tiers as they are decoupled.
- Better scalability: I can scale up my UX, services, and database independently. For example, in the following diagram, I have horizontally scaled out each of the tiers independently.

Figure 1.2 – N-tier Distributed application scaled out
- The separation of concerns has been taken care of. The presentation tier containing the user interface is separated from the services tier containing business logic, which is again separated from the data access tier containing the data store. High-level components are unaware of the low-level components consuming them. The data access tier is unaware of the services consuming it, and the services are unaware of the UX consuming them. Each service is separated based on business logic and the functionality it is supposed to provide.
- Encapsulation has been taken care of. Each component in the architecture will interact with other components through a well-defined interface and contracts. We should be able to replace any component in the diagram without worrying about its internal implementation if it adheres to the contract. The loosely coupled architecture here also helps in faster development and deployment to the market for customers. Multiple teams can work in parallel on each of their components independently. They share the contract and timelines for integration testing at the beginning of the project with each other and once internal implementation and unit tests are done, they can start with integration testing.
In this section, we discussed the advantages of distributed applications over monolithic applications and how easy it is to scale each of the tiers independently. In the next section, we will see challenges with distributed applications.
Challenges with distributed applications
When you start developing distributed applications, you will run into the following common set of challenges that all developers face:
- Design and implementation
- Data management
- Messaging
Design and implementation
The decisions made during the design and implementation phase are very important. There are several challenges, such as designing for high availability and scalability. Some design changes in the later stages of the project might incur huge costs in terms of changes to development, testing, and so on, depending on the nature of the change. Hence, it is very important to arrive at the right design choices at the beginning.
Data management
As data is spread across different regions and servers in distributed applications, there are several challenges, such as data availability, maintaining data consistency in different locations across multiple servers, optimizing your queries and data store for good performance, caching, security, and many more.
Messaging
As all components are loosely coupled in distributed applications, asynchronous messaging will be widely used for functionalities such as sending emails, uploading files, and so on. The user doesn't have to wait for these operations to be completed as these can happen asynchronously in the background and then send notifications to the user on completion. While there are several benefits, such as high performance, better scaling, and so on, there are several challenges as well with asynchronous messaging, such as handling large messages, processing messages in a defined order, idempotency, handling failed messages, and many more.
In the next section, we will see how to design applications for scalability.
Designing applications for scalability
Scalability is the ability of a system to adapt itself to handle a growing number of incoming requests successfully by increasing the resources available to the system. Scalability is measured by the total number of requests your application can process and respond to successfully. How do you know your application has reached its threshold of the maximum capacity limit? When it is busy processing current requests in the pipeline and can no longer take any incoming requests and process them successfully. Also, your application may not perform as expected, resulting in performance issues, and some requests will start to fail by timing out. At this stage, we must scale our application for business continuity. Let's look at the options available.
Vertical scaling or scaling up
Vertical scaling or scaling up means adding more resources to individual application servers and increasing the hardware capacity. Users send requests and the application processes the requests, reads/writes to the database, and sends responses back to the users. If the user base grows and the number of incoming requests becomes high, the application server will be overloaded, resulting in longer processing times and latency in responding to users. In this case, we can scale up the application server hardware to a higher hardware capacity, as shown in the following diagram.

Figure 1.3 – Vertical scaling (scaling up)
Horizontal scaling or scaling out
Horizontal scaling or scaling out means adding more processing servers/machines to a system. Let's say my application is running on one server and can process up to 1,000 requests per minute. I could scale out by adding 4 more servers and could process 4,000 more requests per minute, as shown in the following screenshot.

Figure 1.4 – Horizontal scaling (scaling out)
Tip
Having a single server is always a bottleneck beyond a certain load, no matter how many CPU cores and memory you have. That's when horizontal scaling or scaling out may help.
Load balancers
Load balancers help in increasing scalability by distributing incoming traffic to healthy servers within a region when the amount of simultaneous traffic increases. Load balancers have health probe monitors to monitor a given port on each of the servers to check the health, and if they're found to be unhealthy, the server is disabled from the load balancer and incoming traffic. When the next health probe test passes, the server is added back to the load balancer.
Caching
Caching is one of the key system design patterns that help in scaling any application, along with improving response times. Any application typically involves reading and writing data from and to a data store, which is usually a relational database such as SQL Server or a NoSQL database such as Cosmos DB. However, reading data from the database for every request is not efficient, especially when data is not changing, because databases usually persist data to disk and it's a costly operation to load the data from disk and send it back to the browser client (or device in the case of mobile/desktop applications) or user. This is where caching comes into play. Cache stores can be used as a primary source for retrieving data and falling back to the original data store only when data is not available in the cache, thus giving a faster response to the consuming application. While doing this, we also need to ensure that the cached data is expired/refreshed as and when data in the original data store is updated.
Distributed caching
As we know, in a distributed system, the data store is split across multiple servers; similarly, distributed caching is an extension of traditional caching in which cached data is stored in more than one server in a network. Before we get into distributed caching, here's a quick recap of the CAP theorem:
- C: Stands for consistency, meaning the data is consistent across all the nodes and has the same copy of data
- A: Stands for availability, meaning the system is available, and failure of one node doesn't cause the system to go down
- P: Stands for partition tolerant, meaning the system doesn't go down even if the communication between nodes goes down
As per the CAP theorem, any distributed system can only achieve two of the preceding principles, and as distributed systems must be partition-tolerant (P), we can only achieve either the consistency (C) of data or the high availability (A) of data.
So, distributed caching is a cache strategy in which data is stored in multiple servers/nodes/shards outside the application server. Since data is distributed across multiple servers, if one server goes down, another server can be used as a backup to retrieve data. For example, if our system wanted to cache countries, states, and cities, and if there were three caching servers in a distributed caching system, hypothetically there would be a possibility that one of the cache servers would cache countries, another one would cache states, and one would cache cities (of course, in a real-time application, data is split in a much more complex way). Also, each server would additionally act as a backup for one or more entities. So, on a high level, one type of distributed cache system looks as shown:

Figure 1.5 – Distributed caching high-level representation
As you can see, while reading data, it is read from the primary server, and if the primary server is not available, the caching system will fall back to the secondary server. Similarly, for writes, write operations are not complete until data is written to the primary as well as the secondary server, and until this operation is completed, read operations can be blocked, hence compromising the availability of the system. Another strategy for writes could be background synchronization, which will result in the eventual consistency of data, hence compromising the consistency of data until synchronization is completed. Going back to the CAP theorem, most distributed caching systems fall under the category of CP or AP.
Sharding
Sharding can improve scalability when storing and accessing large data from data stores. This is achieved by splitting a single data store into multiple horizontal partitions or shards. As the data is split across a cluster of databases, the system will be able to store a large amount of data and at the same time, the system can handle additional requests. We can continue to scale the system out by adding further shards.
Here are a few important considerations:
- Keep shards balanced for even load distribution. Periodically rebalance shards as data is updated and removed from each shard.
- Avoid queries that retrieve data from multiple shards as they are not efficient and cause a performance bottleneck. You can use parallel tasks to fetch data from different shards for better efficiency but it adds complexity.
- Creating a large number of smaller shards is better for load balancing than a small number of large shards.
In the next section, we will see how to design applications for high availability.
Designing applications for high availability
High availability ensures business continuity by reducing outages and disruption for customers even when some components fail in a distributed application. Let's look at some of the ways to achieve high availability.
In a scaled-out N-tier distributed application, we can add more servers to all the tiers, but I did not mention anything about Azure data centers, Azure regions, Azure Load Balancer, Azure Traffic Manager, Azure availability sets, Azure availability zones, or SQL Always On availability groups. Let's discuss each of these offerings from Microsoft Azure and see what benefits it gives to our distributed application to make it highly available.
Azure data centers
Azure data centers are physical infrastructures or buildings located all over the world where Microsoft Azure servers/VMs and services are managed.
Azure regions
An Azure region is a set of data centers connected through a dedicated low-latency network. Microsoft has 60+ Azure regions all over the world – more than any other cloud provider – from which customers can choose to deploy their applications.
Azure paired regions
An Azure paired region, as the name suggests, is a set of two regions and each region consists of a set of data centers connected through a dedicated low-latency network. The main benefit of going with paired regions is where there is a broader Azure outage affecting multiple regions, at least one region in each pair will be prioritized by Azure for quicker recovery. Planned Azure system patches and updates are rolled out sequentially to one region after another in paired regions to minimize outages or downtime in the rare case of bugs or issues with updates being rolled out.
Tip
You can read in detail about paired regions here: https://docs.microsoft.com/en-us/azure/best-practices-availability-paired-regions, which will help you understand the best practices, different regional pairs available across the globe for you to choose from, and their benefits.
Azure Traffic Manager
Azure Traffic Manager is a DNS-based load balancer to distribute traffic to internet-facing endpoints across global regions.
Traffic Manager provides a wide range of options to route traffic. Let's look at some of the frequently used routing options that can be configured in your Traffic Manager profile:
- Priority: This option enables you to set a primary service endpoint to which all traffic is routed and provides the option to configure backup endpoints that will take traffic when the primary endpoint is not available. This routing option is very useful in scenarios where you want to provide reliable services to your customers by having backup endpoints.
- Weighted: This option enables you to distribute traffic across a set of endpoints based on pre-defined weights. The weight is an integer and the higher the weight, the higher the priority. You can configure the same weight across all endpoints to distribute traffic evenly. This routing option is very useful in scenarios where you want to gradually increase the traffic to a new endpoint or provide specific weightage to certain endpoints when you are horizontally scaling up.
- Performance: This option enables you to distribute traffic to the "closest" endpoint for the user. The closest endpoint is not measured by geographic distance but based on the lowest network latency. Traffic Manager maintains a lookup latency table for the closest endpoint between different source IP address ranges and the Azure data center. This routing option is very useful in scenarios where you want to improve the responsiveness of your applications.
Traffic Manager provides endpoint monitoring and automatic endpoint failover as well. Let's look at important settings to be configured in your Traffic Manager profile for endpoint monitoring:
- Protocol: You can set HTTP, HTTPS, or TCP as the protocol that Traffic Manager can use to probe your endpoints' health. Please note that HTTPS monitoring just checks whether a certificate is present or not and doesn't check whether a certificate is valid or not.
- Port: You can set the port that Traffic Manager can use to send a request.
- Expected status code ranges: You can set success status code ranges in the format 200-299, 301-301. When these status codes are received as a response once a health check is done, Traffic Manager marks those endpoints as healthy. If you don't set anything, a default value of 200 is defined as the success status code.
- Probing interval: You can set an interval to specify the frequency of endpoint monitoring health check runs from Traffic Manager. You have options to set 30 seconds (normal probing) and 10 seconds (fast probing). If you don't set anything, a default value of 30 seconds is defined as the probing interval.
- Tolerated number of failures: You can set the total number of failures Traffic Manager can consider before making an endpoint unhealthy. You have options to set it between 0 and 9. A value of 0 means the endpoint will be marked as unhealthy for even a single failure. If you don't set anything, a default value of 3 is considered.
- Probe timeout: You can set the timeout value Traffic Manager can consider before making an endpoint unhealthy when no response is received. You can set the timeout value between 5 and 10 seconds when the probing interval is 30 seconds. If you don't set anything, a default value of 9 seconds is set for probe timeout.
A Traffic Manager probe initiates a GET request to the endpoint to be monitored using the protocol, port, and relative path given. If the probing agent receives a 200-OK response or any of the responses configured in the expected status code ranges, it marks the endpoint as healthy. If the response is different from any of the responses configured in the expected status code ranges or no response is received within the timeout period, the probing agent reattempts till the tolerated number of failures is reached. The endpoint is marked unhealthy once the consecutive failures count is higher than the Tolerated number of failures setting.
You can configure the routing and endpoint monitoring settings in your Traffic manager profile as shown in the following screenshot. The following are just sample values; you can set them based on your application's requirements.
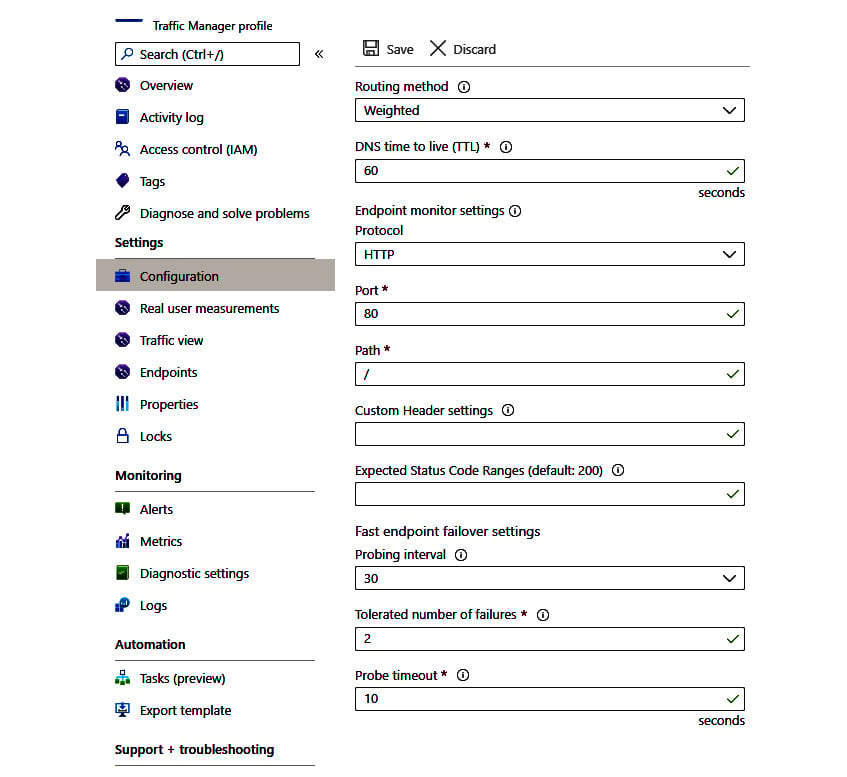
Figure 1.6 – Traffic Manager profile settings
Availability sets and availability zones
An availability set is a logical group of VMs within a data center in an Azure region and promises availability of 99.95%. They don't provide resiliency and high availability in the event of an entire data center outage.
An availability zone is made up of one or more data centers with independent power, cooling, and networking. It's a physical location within an Azure region and provides high availability (99.99%) even in the event of data center failures.
SQL Always On availability groups
SQL Always On availability groups were introduced in SQL Server 2012 to increase database availability. Availability groups support a set of read-write primary databases and one to eight sets of secondary databases to which we can fail over. These sets of databases are also called availability databases. Having primary databases and secondary databases in different Azure regions will give us high availability and resiliency against data center and Azure region failure. You can create a listener for an availability group and share that connection string for clients to connect to a database. Commit mode and failover are two important factors to consider in this list:
- Synchronous commit mode: In this mode, confirmations are not sent back to the client until the data is committed to a secondary database. In a way, this provides a 100% guarantee that every transaction that is committed on a given primary database has also been committed on the corresponding secondary database. Hence, this is the preferred option to sync data between databases within the same region but not for databases across regions due to latency.
- Asynchronous commit mode: In this mode, confirmations are sent back to the client as soon as the data is committed to the primary database without waiting to commit it to a secondary database. This mode is suitable when you want to reduce the response latency or in scenarios where primary and secondary databases are distributed over a considerable distance. Hence, this is the preferred option to sync data between databases across two different regions.
- Automatic failover: An automatic failover enables a secondary database to automatically transition to the primary database when the primary database becomes unavailable. Automatic failover is the preferred option when the primary database and secondary database reside within the same region with data always synchronized between the two databases. For cross region manual failover is the preferred option to avoid data loss as data is usually asynchronously committed.
Architecture for high availability
Let's extend the N-tier scaled-out distributed application to be highly available based on the options we discussed, as shown in the following screenshot.
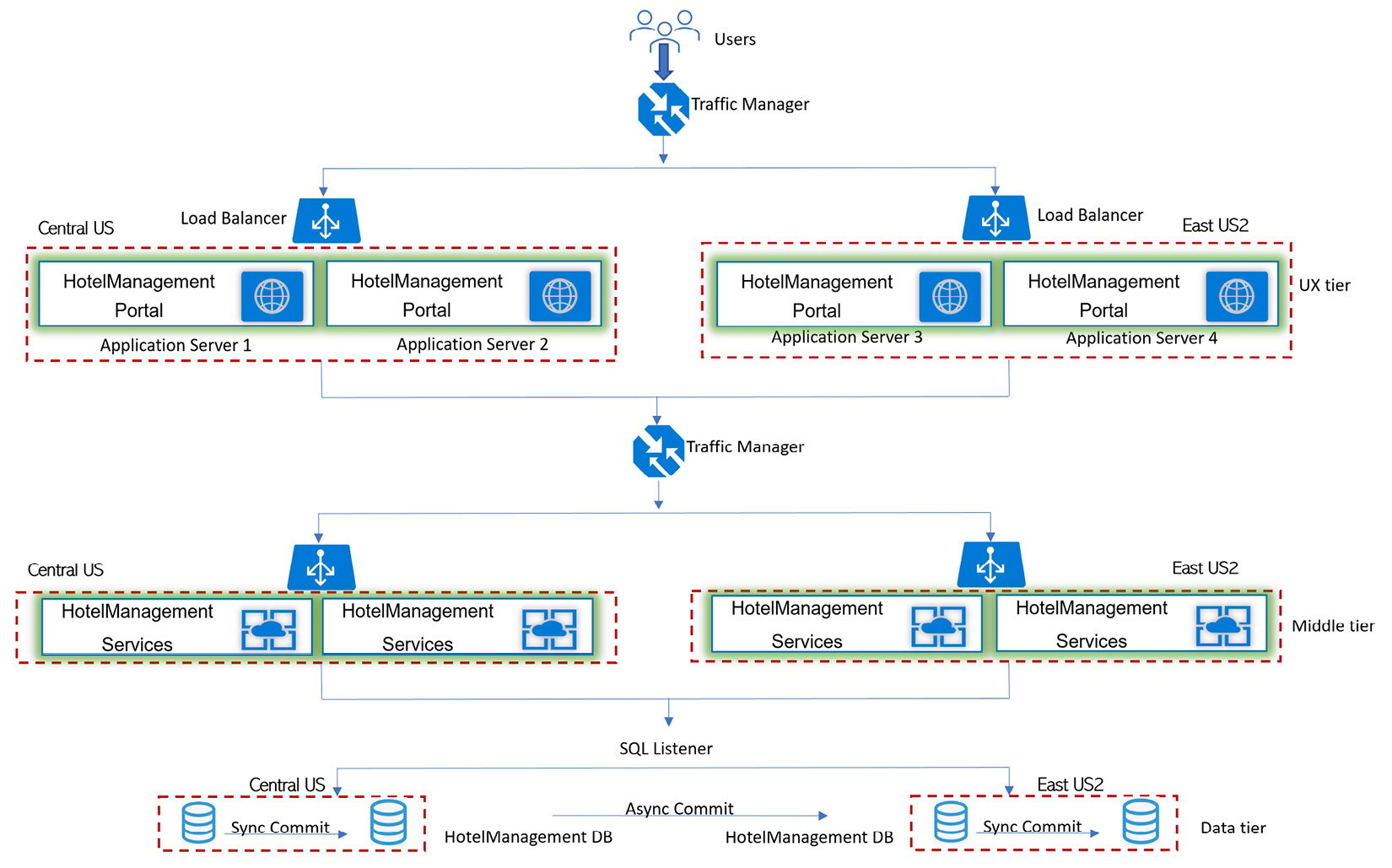
Figure 1.7 – N-tier distributed application scaled out and highly available
- Leverage Azure paired regions for high availability for your UX tier, middle tier, and data tier. One region will be the primary region and the other region will be the secondary region. If one region goes down, the other region will be available as a backup region. In this case, I have gone with the
Americanregions, with the primary region as Central US and East US 2 as the secondary region. You have regional pairs available in Asia, Europe, and Africa as well. Depending upon the customer's location base, you can select regional pairs appropriately. When you combine Azure Traffic Manager with Azure Load Balancer, you get global traffic management combined with a local failover option. - Leverage stateless services as any of the servers in your application can handle incoming requests and processes. Stateful services maintain contextual information during transactions and subsequent requests within a transaction need to hit the same server, hence designing for high availability and scalability becomes a challenge.
- Leverage Active-Active mode, which enables traffic to be routed to both regions and to load-balanced incoming requests. If one region becomes unavailable, it is automatically taken out of rotation. Active-Passive mode enables traffic to be routed to only one region at a time and would require manual failover to a secondary region when the primary region goes down, hence is not the right option for high availability unless your service is stateful and needs to maintain a sticky session where requests need to hit the same server every time for the active user session.
- Leverage deployment of multiple instances of your service in each region: The DNS names of these two instances are
eCommerce-CUS.cloudapp.netandeCommerce-EUS2.cloudapp.net. Create a Traffic Manager profile with the nameeCommerce-trafficmanager.netand configure it to use a weighted routing method across two endpoints,eCommerce-CUS.cloudapp.netandeCommerce-EUS2.cloudapp.net. Configure the domain nameeCommerce.comto point toeCommerce-trafficmanager.netusing a DNS CNAME record. - Leverage availability zones to get high availability (99.99%) and resiliency against data center failures. Each of the two endpoints
eCommerce-CUS.cloudapp.netandeCommerce-EUS2.cloudapp.netare configured to run on multiple servers within each region and all the servers run under the availability zone. - Leverage SQL Always On high availability set up with sync commit and auto failover between databases/nodes in the same region and async commit and manual failover across the regions, as shown in the following screenshot, which is a magnified view of the database from an architecture diagram. When the application connects to a SQL availability group listener, calls will be routed to the Node 1 (N1) part of Datacenter 1 (DC1), which is the primary region and primary read/write database.
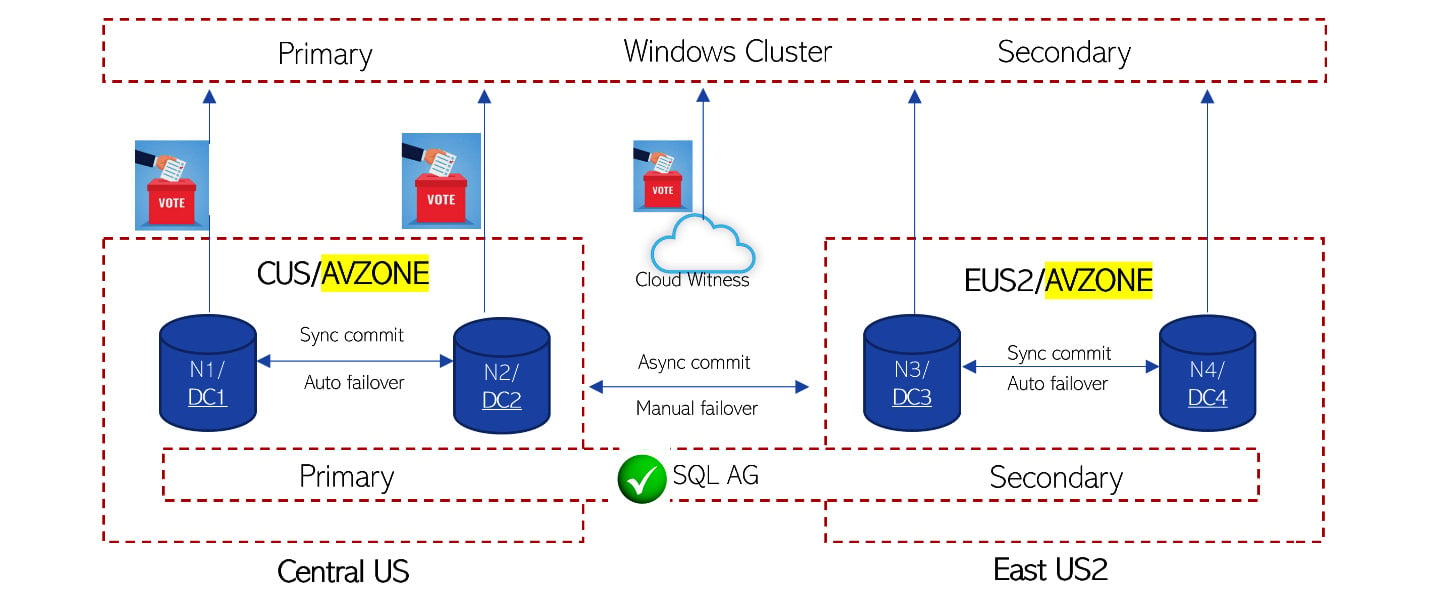
Figure 1.8 – SQL high availability setup
Let's look at two different scenarios when there is an outage and how this setup will help with high availability:
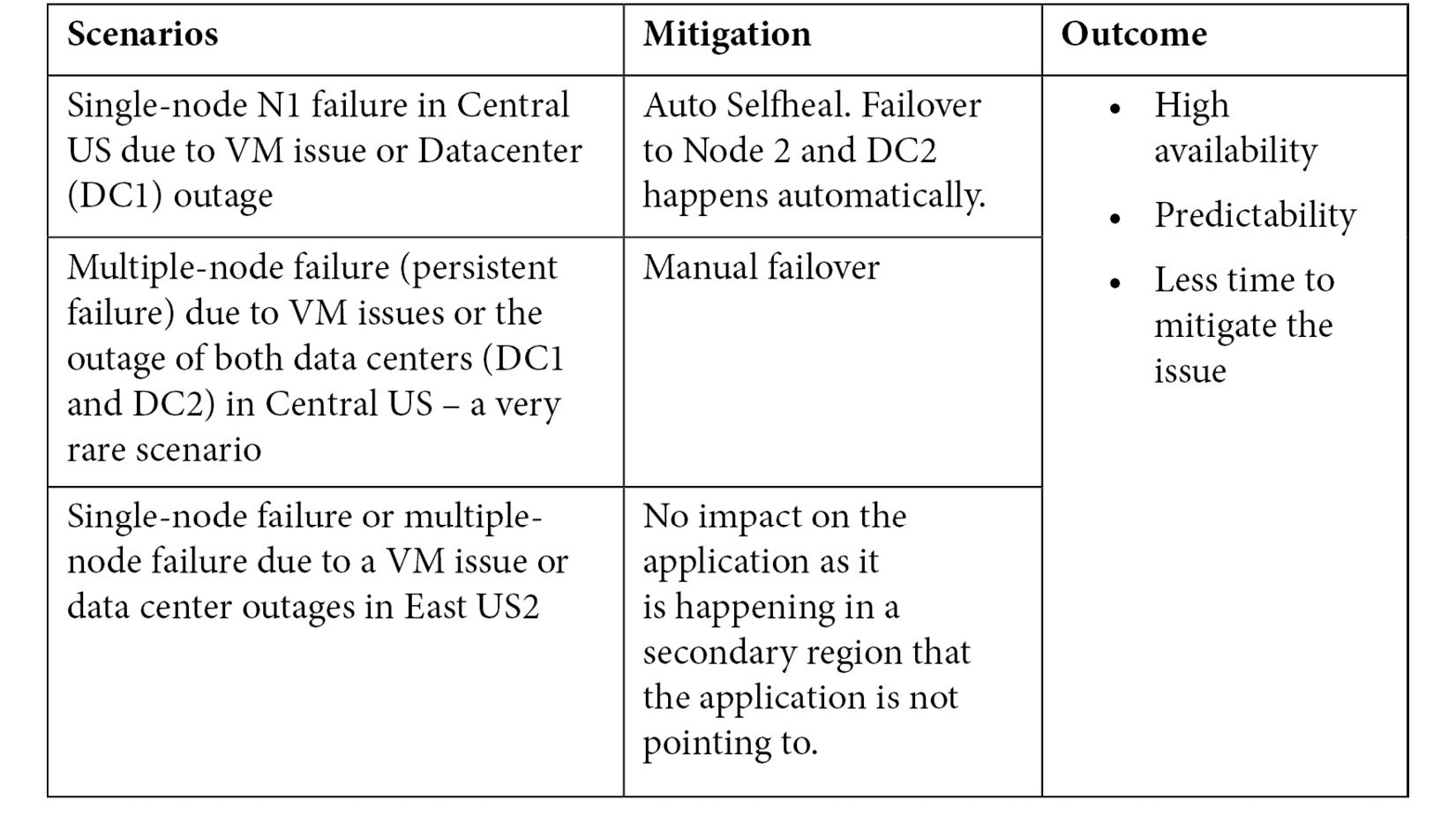
Summary
In this chapter, we discussed the difference between monolithic and distributed applications and why distributed applications are the way forward. We also discussed challenges with distributed applications and how to architect your distributed applications for high availability and scalability. In the next chapter, we will learn in detail about proven design patterns and principles to handle the different challenges with design, data management, and messaging in distributed applications.
Questions
- What are the options available to increase the scalability of the system?
A. Vertical scaling or scaling up
B. Horizontal scaling or scaling out
C. Both
D. None of the above
Answer – C
- What is vertical scaling or scaling up?
A. Vertical scaling or scaling up means adding more resources to a single application server and increasing its hardware capacity, typically achieved by increasing the capacity of the CPU or memory.
B. Vertical scaling or scaling up means adding more processing servers/machines to a system.
C. Vertical scaling or scaling up means adding caching to your system to avoid database calls for frequently used objects.
D. None of the above.
Answer – A
- What is an availability zone?
A. An availability zone is a logical group of VMs within a data center in an Azure region and promises availability of 99.95%. They don't provide resiliency and high availability in the event of the outage of an entire data center.
B. An availability zone is made up of one or more data centers with independent power, cooling, and networking. It's a physical location within an Azure region and provides high availability (99.99%) even in the case of data center failures.
C. An availability zone is a pair of regions and each region consists of a set of data centers connected through a dedicated low-latency network.
D. An availability zone is a DNS-based load balancer to distribute traffic to internet-facing endpoints across global regions.
Answer – B
- Which of the following statements is correct?
A. SQL Always On availability groups support a set of read-write primary databases and 1 to 12 sets of secondary databases to which we can fail over.
B. SQL Always On availability groups support a set of read-write primary databases and one to four sets of secondary databases to which we can fail over.
C. SQL Always On availability groups support a set of read-write primary databases and one set of secondary databases to which we can fail over.
D. SQL Always On availability groups support a set of read-write primary databases and one to eight sets of secondary databases to which we can fail over.
Answer – D
- Services can be deployed and scaled independently. Issues in one service will have a local impact and can be fixed by just deploying the impacted service.
A. Domain-driven design principle
B. Single-responsibility principle
C. Stateless service principle
D. Resiliency principle
Answer – B
- What are stateful services?
A. Stateful services maintain contextual information during transactions and subsequent requests within a transaction need to hit the same server, hence designing for high availability and scalability becomes a challenge.
B. Stateful services do not maintain contextual information during transactions and subsequent requests within a transaction can hit any server, hence designing for high availability and scalability is not a challenge.
C. Stateful services are the right approach to build your services for a highly scalable distributed application.
Answer – A
