


















 Download code from GitHub
Download code from GitHub
"Computer language design is just like a stroll in the park. Jurassic Park, that is." | ||
| --Larry Wall | ||
In this chapter, we will cover the following recipes:
- Adding a resource to a node
- Using Facter to describe a node
- Installing a package before starting a service
- Installing, configuring, and starting a service
- Using community Puppet style
- Creating a manifest
- Checking your manifests with Puppet-lint
- Using modules
- Using standard naming conventions
- Using inline templates
- Iterating over multiple items
- Writing powerful conditional statements
- Using regular expressions in if statements
- Using selectors and case statements
- Using the in operator
- Using regular expression substitutions
- Using the future parser
This recipe will introduce the language and show you the basics of writing Puppet code. A beginner may wish to reference Puppet 3: Beginner's Guide, John Arundel, Packt Publishing in addition to this section. Puppet code files are called manifests; manifests declare resources. A resource in Puppet may be a type, class, or node. A type is something like a file or package or anything that has a type declared in the language. The current list of standard types is available on puppetlabs website at https://docs.puppetlabs.com/references/latest/type.html. I find myself referencing this site very often. You may define your own types, either using a mechanism, similar to a subroutine, named
defined types, or you can extend the language using a custom type. Types are the heart of the language; they describe the things that make up a node (node is the word Puppet uses for client computers/devices). Puppet uses resources to describe the state of a node; for example, we will declare the following package resource for a node using a site manifest (site.pp).
Create a site.pp file and place the following code in it:
Tip
You can download the example code files for all Packt books you have purchased from your account at http://www.packtpub.com. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
site.pp file and place the following code in it:
Tip
You can download the example code files for all Packt books you have purchased from your account at http://www.packtpub.com. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
'httpd'. The default keyword is a wildcard to Puppet; it applies anything within the node default definition to any node. When Puppet applies the manifest to a node, it uses a Resource Abstraction Layer (RAL) to translate the package type into the package management system of the target node. What this means is that we can use the same manifest to install the httpd package on any system for which Puppet has a
Provider for the package type. Providers are the pieces of code that do the real work of applying a manifest. When the previous code is applied to a node running on a YUM-based distribution, the YUM provider will be used to install the httpd RPM packages. When the same code is applied to a node running on an APT-based distribution, the APT provider will be used to install the httpd DEB package (which may not exist, most debian-based systems call this package apache2; we'll deal with this sort of naming problem later).
Facter is a separate utility upon which Puppet depends. It is the system used by Puppet to gather information about the target system (node); facter calls the nuggets of information facts. You may run facter from the command line to obtain real-time information from the system.
Variables in Puppet are marked with a dollar sign ($) character. When using variables within a manifest, it is preferred to enclose the variable within braces "${myvariable}" instead of "$myvariable". All of the facts from facter can be referenced as top scope variables (we will discuss scope in the next section). For example, the fully qualified domain name (FQDN) of the node may be referenced by "${::fqdn}". Variables can only contain alphabetic characters, numerals, and the underscore character (_). As a matter of style, variables should start with an alphabetic character. Never use dashes in variable names.
In the variable example explained in the There's more… section, the fully qualified domain name was referred to as ${::fqdn} rather than ${fqdn}; the double colons are how Puppet differentiates scope. The highest level scope, top scope or global, is referred to by two colons (::) at the beginning of a variable identifier. To reduce namespace collisions, always use fully scoped variable identifiers in your manifests. For a Unix user, think of top scope variables as the / (root) level. You can refer to variables using the double colon syntax similar to how you would refer to a directory by its full path. For the developer, you can think of top scope variables as global variables; however, unlike global variables, you must always refer to them with the double colon notation to guarantee that a local variable isn't obscuring the top scope variable.
facter to find
Variables in Puppet are marked with a dollar sign ($) character. When using variables within a manifest, it is preferred to enclose the variable within braces "${myvariable}" instead of "$myvariable". All of the facts from facter can be referenced as top scope variables (we will discuss scope in the next section). For example, the fully qualified domain name (FQDN) of the node may be referenced by "${::fqdn}". Variables can only contain alphabetic characters, numerals, and the underscore character (_). As a matter of style, variables should start with an alphabetic character. Never use dashes in variable names.
In the variable example explained in the There's more… section, the fully qualified domain name was referred to as ${::fqdn} rather than ${fqdn}; the double colons are how Puppet differentiates scope. The highest level scope, top scope or global, is referred to by two colons (::) at the beginning of a variable identifier. To reduce namespace collisions, always use fully scoped variable identifiers in your manifests. For a Unix user, think of top scope variables as the / (root) level. You can refer to variables using the double colon syntax similar to how you would refer to a directory by its full path. For the developer, you can think of top scope variables as global variables; however, unlike global variables, you must always refer to them with the double colon notation to guarantee that a local variable isn't obscuring the top scope variable.
facter is installed (as a dependency for puppet), several fact definitions are installed by default. You can reference each of these facts by name from the command line.
Variables in Puppet are marked with a dollar sign ($) character. When using variables within a manifest, it is preferred to enclose the variable within braces "${myvariable}" instead of "$myvariable". All of the facts from facter can be referenced as top scope variables (we will discuss scope in the next section). For example, the fully qualified domain name (FQDN) of the node may be referenced by "${::fqdn}". Variables can only contain alphabetic characters, numerals, and the underscore character (_). As a matter of style, variables should start with an alphabetic character. Never use dashes in variable names.
In the variable example explained in the There's more… section, the fully qualified domain name was referred to as ${::fqdn} rather than ${fqdn}; the double colons are how Puppet differentiates scope. The highest level scope, top scope or global, is referred to by two colons (::) at the beginning of a variable identifier. To reduce namespace collisions, always use fully scoped variable identifiers in your manifests. For a Unix user, think of top scope variables as the / (root) level. You can refer to variables using the double colon syntax similar to how you would refer to a directory by its full path. For the developer, you can think of top scope variables as global variables; however, unlike global variables, you must always refer to them with the double colon notation to guarantee that a local variable isn't obscuring the top scope variable.
facter without any arguments causes facter to print all the facts known about the system. We will see in later chapters that facter can be extended with your own custom facts. All facts are available for you to use as variables; variables are discussed in the next section.
Variables in Puppet are marked with a dollar sign ($) character. When using variables within a manifest, it is preferred to enclose the variable within braces "${myvariable}" instead of "$myvariable". All of the facts from facter can be referenced as top scope variables (we will discuss scope in the next section). For example, the fully qualified domain name (FQDN) of the node may be referenced by "${::fqdn}". Variables can only contain alphabetic characters, numerals, and the underscore character (_). As a matter of style, variables should start with an alphabetic character. Never use dashes in variable names.
In the variable example explained in the There's more… section, the fully qualified domain name was referred to as ${::fqdn} rather than ${fqdn}; the double colons are how Puppet differentiates scope. The highest level scope, top scope or global, is referred to by two colons (::) at the beginning of a variable identifier. To reduce namespace collisions, always use fully scoped variable identifiers in your manifests. For a Unix user, think of top scope variables as the / (root) level. You can refer to variables using the double colon syntax similar to how you would refer to a directory by its full path. For the developer, you can think of top scope variables as global variables; however, unlike global variables, you must always refer to them with the double colon notation to guarantee that a local variable isn't obscuring the top scope variable.
in Puppet are marked with a dollar sign ($) character. When using variables within a manifest, it is preferred to enclose the variable within braces "${myvariable}" instead of "$myvariable". All of the facts from facter can be referenced as top scope variables (we will discuss scope in the next section). For example, the fully qualified domain name (FQDN) of the node may be referenced by "${::fqdn}". Variables can only contain alphabetic characters, numerals, and the underscore character (_). As a matter of style, variables should start with an alphabetic character. Never use dashes in variable names.
In the variable example explained in the There's more… section, the fully qualified domain name was referred to as ${::fqdn} rather than ${fqdn}; the double colons are how Puppet differentiates scope. The highest level scope, top scope or global, is referred to by two colons (::) at the beginning of a variable identifier. To reduce namespace collisions, always use fully scoped variable identifiers in your manifests. For a Unix user, think of top scope variables as the / (root) level. You can refer to variables using the double colon syntax similar to how you would refer to a directory by its full path. For the developer, you can think of top scope variables as global variables; however, unlike global variables, you must always refer to them with the double colon notation to guarantee that a local variable isn't obscuring the top scope variable.
${::fqdn} rather than ${fqdn}; the double colons are how Puppet differentiates
To show how ordering works, we'll create a manifest that installs httpd and then ensures the httpd package service is running.
In this example, the package will be installed before the service is started. Using require within the definition of the httpd service ensures that the package is installed first, regardless of the order within the manifest file.
Capitalization is important in Puppet. In our previous example, we created a package named httpd. If we wanted to refer to this package later, we would capitalize its type (package) as follows:
When you have a defined type, for example the following defined type:
All the manifests that will be used to define a node are compiled into a catalog. A catalog is the code that will be applied to configure a node. It is important to remember that manifests are not applied to nodes sequentially. There is no inherent order to the application of manifests. With this in mind, in the previous httpd example, what if we wanted to ensure that the httpd process started after the httpd package was installed?
The before and require metaparameters specify a direct ordering; notify implies before and subscribe implies require. The notify metaparameter is only applicable to services; what notify does is tell a service to restart after the notifying resource has been applied to the node (this is most often a package or file resource). In the case of files, once the file is created on the node, a notify parameter will restart any services mentioned. The subscribe metaparameter has the same effect but is defined on the service; the service will subscribe to the file.
The relationship between package and service previously mentioned is an important and powerful paradigm of Puppet. Adding one more resource-type file into the fold, creates what puppeteers refer to as the trifecta. Almost all system administration tasks revolve around these three resource types. As a system administrator, you install a package, configure the package with files, and then start the service.

A key concept of Puppet is that the state of the system when a catalog is applied to a node cannot affect the outcome of Puppet run. In other words, at the end of Puppet run (if the run was successful), the system will be in a known state and any further application of the catalog will result in a system that is in the same state. This property of Puppet is known as idempotency. Idempotency is the property that no matter how many times you do something, it remains in the same state as the first time you did it. For instance, if you had a light switch and you gave the instruction to turn it on, the light would turn on. If you gave the instruction again, the light would remain on.
service {'httpd':
ensure => running,
require => Package['httpd'],
}httpd; we now need to define that resource: package {'httpd':
ensure => 'installed',
}In this example, the package will be installed before the service is started. Using require within the definition of the httpd service ensures that the package is installed first, regardless of the order within the manifest file.
Capitalization is important in Puppet. In our previous example, we created a package named httpd. If we wanted to refer to this package later, we would capitalize its type (package) as follows:
When you have a defined type, for example the following defined type:
All the manifests that will be used to define a node are compiled into a catalog. A catalog is the code that will be applied to configure a node. It is important to remember that manifests are not applied to nodes sequentially. There is no inherent order to the application of manifests. With this in mind, in the previous httpd example, what if we wanted to ensure that the httpd process started after the httpd package was installed?
The before and require metaparameters specify a direct ordering; notify implies before and subscribe implies require. The notify metaparameter is only applicable to services; what notify does is tell a service to restart after the notifying resource has been applied to the node (this is most often a package or file resource). In the case of files, once the file is created on the node, a notify parameter will restart any services mentioned. The subscribe metaparameter has the same effect but is defined on the service; the service will subscribe to the file.
The relationship between package and service previously mentioned is an important and powerful paradigm of Puppet. Adding one more resource-type file into the fold, creates what puppeteers refer to as the trifecta. Almost all system administration tasks revolve around these three resource types. As a system administrator, you install a package, configure the package with files, and then start the service.
A key concept of Puppet is that the state of the system when a catalog is applied to a node cannot affect the outcome of Puppet run. In other words, at the end of Puppet run (if the run was successful), the system will be in a known state and any further application of the catalog will result in a system that is in the same state. This property of Puppet is known as idempotency. Idempotency is the property that no matter how many times you do something, it remains in the same state as the first time you did it. For instance, if you had a light switch and you gave the instruction to turn it on, the light would turn on. If you gave the instruction again, the light would remain on.
package will be installed before the service is started. Using require within the definition of the httpd service ensures that the package is installed first, regardless of the order within the manifest file.
Capitalization is important in Puppet. In our previous example, we created a package named httpd. If we wanted to refer to this package later, we would capitalize its type (package) as follows:
When you have a defined type, for example the following defined type:
All the manifests that will be used to define a node are compiled into a catalog. A catalog is the code that will be applied to configure a node. It is important to remember that manifests are not applied to nodes sequentially. There is no inherent order to the application of manifests. With this in mind, in the previous httpd example, what if we wanted to ensure that the httpd process started after the httpd package was installed?
The before and require metaparameters specify a direct ordering; notify implies before and subscribe implies require. The notify metaparameter is only applicable to services; what notify does is tell a service to restart after the notifying resource has been applied to the node (this is most often a package or file resource). In the case of files, once the file is created on the node, a notify parameter will restart any services mentioned. The subscribe metaparameter has the same effect but is defined on the service; the service will subscribe to the file.
The relationship between package and service previously mentioned is an important and powerful paradigm of Puppet. Adding one more resource-type file into the fold, creates what puppeteers refer to as the trifecta. Almost all system administration tasks revolve around these three resource types. As a system administrator, you install a package, configure the package with files, and then start the service.
A key concept of Puppet is that the state of the system when a catalog is applied to a node cannot affect the outcome of Puppet run. In other words, at the end of Puppet run (if the run was successful), the system will be in a known state and any further application of the catalog will result in a system that is in the same state. This property of Puppet is known as idempotency. Idempotency is the property that no matter how many times you do something, it remains in the same state as the first time you did it. For instance, if you had a light switch and you gave the instruction to turn it on, the light would turn on. If you gave the instruction again, the light would remain on.
When you have a defined type, for example the following defined type:
All the manifests that will be used to define a node are compiled into a catalog. A catalog is the code that will be applied to configure a node. It is important to remember that manifests are not applied to nodes sequentially. There is no inherent order to the application of manifests. With this in mind, in the previous httpd example, what if we wanted to ensure that the httpd process started after the httpd package was installed?
The before and require metaparameters specify a direct ordering; notify implies before and subscribe implies require. The notify metaparameter is only applicable to services; what notify does is tell a service to restart after the notifying resource has been applied to the node (this is most often a package or file resource). In the case of files, once the file is created on the node, a notify parameter will restart any services mentioned. The subscribe metaparameter has the same effect but is defined on the service; the service will subscribe to the file.
The relationship between package and service previously mentioned is an important and powerful paradigm of Puppet. Adding one more resource-type file into the fold, creates what puppeteers refer to as the trifecta. Almost all system administration tasks revolve around these three resource types. As a system administrator, you install a package, configure the package with files, and then start the service.
A key concept of Puppet is that the state of the system when a catalog is applied to a node cannot affect the outcome of Puppet run. In other words, at the end of Puppet run (if the run was successful), the system will be in a known state and any further application of the catalog will result in a system that is in the same state. This property of Puppet is known as idempotency. Idempotency is the property that no matter how many times you do something, it remains in the same state as the first time you did it. For instance, if you had a light switch and you gave the instruction to turn it on, the light would turn on. If you gave the instruction again, the light would remain on.
used to define a node are compiled into a catalog. A catalog is the code that will be applied to configure a node. It is important to remember that manifests are not applied to nodes sequentially. There is no inherent order to the application of manifests. With this in mind, in the previous httpd example, what if we wanted to ensure that the httpd process started after the httpd package was installed?
The before and require metaparameters specify a direct ordering; notify implies before and subscribe implies require. The notify metaparameter is only applicable to services; what notify does is tell a service to restart after the notifying resource has been applied to the node (this is most often a package or file resource). In the case of files, once the file is created on the node, a notify parameter will restart any services mentioned. The subscribe metaparameter has the same effect but is defined on the service; the service will subscribe to the file.
The relationship between package and service previously mentioned is an important and powerful paradigm of Puppet. Adding one more resource-type file into the fold, creates what puppeteers refer to as the trifecta. Almost all system administration tasks revolve around these three resource types. As a system administrator, you install a package, configure the package with files, and then start the service.
A key concept of Puppet is that the state of the system when a catalog is applied to a node cannot affect the outcome of Puppet run. In other words, at the end of Puppet run (if the run was successful), the system will be in a known state and any further application of the catalog will result in a system that is in the same state. This property of Puppet is known as idempotency. Idempotency is the property that no matter how many times you do something, it remains in the same state as the first time you did it. For instance, if you had a light switch and you gave the instruction to turn it on, the light would turn on. If you gave the instruction again, the light would remain on.
A key concept of Puppet is that the state of the system when a catalog is applied to a node cannot affect the outcome of Puppet run. In other words, at the end of Puppet run (if the run was successful), the system will be in a known state and any further application of the catalog will result in a system that is in the same state. This property of Puppet is known as idempotency. Idempotency is the property that no matter how many times you do something, it remains in the same state as the first time you did it. For instance, if you had a light switch and you gave the instruction to turn it on, the light would turn on. If you gave the instruction again, the light would remain on.
We will need the same definitions as our last example; we need the package and service installed. We now need two more things. We need the configuration file and index page (index.html) created. For this, we follow these steps:
- As in the previous example, we ensure the service is running and specify that the service requires the
httpdpackage:service {'httpd': ensure => running, require => Package['httpd'], } - We then define the package as follows:
package {'httpd': ensure => installed, } - Now, we create the
/etc/httpd/conf.d/cookbook.confconfiguration file; the/etc/httpd/conf.ddirectory will not exist until thehttpdpackage is installed. Therequiremetaparameter tells Puppet that this file requires thehttpdpackage to be installed before it is created:file {'/etc/httpd/conf.d/cookbook.conf': content => "<VirtualHost *:80>\nServernamecookbook\nDocumentRoot/var/www/cookbook\n</VirtualHost>\n", require => Package['httpd'], notify => Service['httpd'], } - We then go on to create an
index.htmlfile for our virtual host in/var/www/cookbook. This directory won't exist yet, so we need to create this as well, using the following code:file {'/var/www/cookbook': ensure => directory, } file {'/var/www/cookbook/index.html': content => "<html><h1>Hello World!</h1></html>\n", require => File['/var/www/cookbook'], }
definitions as our last example; we need the package and service installed. We now need two more things. We need the configuration file and index page (index.html) created. For this, we follow these steps:
- As in the previous example, we ensure the service is running and specify that the service requires the
httpdpackage:service {'httpd': ensure => running, require => Package['httpd'], } - We then define the package as follows:
package {'httpd': ensure => installed, } - Now, we create the
/etc/httpd/conf.d/cookbook.confconfiguration file; the/etc/httpd/conf.ddirectory will not exist until thehttpdpackage is installed. Therequiremetaparameter tells Puppet that this file requires thehttpdpackage to be installed before it is created:file {'/etc/httpd/conf.d/cookbook.conf': content => "<VirtualHost *:80>\nServernamecookbook\nDocumentRoot/var/www/cookbook\n</VirtualHost>\n", require => Package['httpd'], notify => Service['httpd'], } - We then go on to create an
index.htmlfile for our virtual host in/var/www/cookbook. This directory won't exist yet, so we need to create this as well, using the following code:file {'/var/www/cookbook': ensure => directory, } file {'/var/www/cookbook/index.html': content => "<html><h1>Hello World!</h1></html>\n", require => File['/var/www/cookbook'], }
require attribute to the file resources tell Puppet that we need the /var/www/cookbook directory created before we can create the index.html file. The important concept to remember is that we cannot assume anything about the target system (node). We need to define everything on which the target depends. Anytime you create a file in a manifest, you have to ensure that the directory containing that file exists. Anytime you specify that a service should be running, you have to ensure that the package providing that service is installed.
httpd will be running
VirtualHost
If other people need to read or maintain your manifests, or if you want to share code with the community, it's a good idea to follow the existing style conventions as closely as possible. These govern such aspects of your code as layout, spacing, quoting, alignment, and variable references, and the official puppetlabs recommendations on style are available at http://docs.puppetlabs.com/guides/style_guide.html.
Always quote your resource names, as follows:
We cannot do this as follows though:
Use single quotes for all strings, except when:
Puppet doesn't process variable references or escape sequences unless they're inside double quotes.
However, these values are reserved words and therefore not quoted:
There is only one thing in Puppet that is false, that is, the word false without any quotes. The string "false" evaluates to true and the string "true" also evaluates to true. Actually, everything besides the literal false evaluates to true (when treated as a Boolean):
Always include curly braces ({}) around variable names when referring to them in strings, for example, as follows:
Always quote your resource names, as follows:
We cannot do this as follows though:
Use single quotes for all strings, except when:
Puppet doesn't process variable references or escape sequences unless they're inside double quotes.
However, these values are reserved words and therefore not quoted:
There is only one thing in Puppet that is false, that is, the word false without any quotes. The string "false" evaluates to true and the string "true" also evaluates to true. Actually, everything besides the literal false evaluates to true (when treated as a Boolean):
Always include curly braces ({}) around variable names when referring to them in strings, for example, as follows:
Always quote your resource names, as follows:
We cannot do this as follows though:
Use single quotes for all strings, except when:
Puppet doesn't process variable references or escape sequences unless they're inside double quotes.
However, these values are reserved words and therefore not quoted:
There is only one thing in Puppet that is false, that is, the word false without any quotes. The string "false" evaluates to true and the string "true" also evaluates to true. Actually, everything besides the literal false evaluates to true (when treated as a Boolean):
Always include curly braces ({}) around variable names when referring to them in strings, for example, as follows:
We cannot do this as follows though:
Use single quotes for all strings, except when:
Puppet doesn't process variable references or escape sequences unless they're inside double quotes.
However, these values are reserved words and therefore not quoted:
There is only one thing in Puppet that is false, that is, the word false without any quotes. The string "false" evaluates to true and the string "true" also evaluates to true. Actually, everything besides the literal false evaluates to true (when treated as a Boolean):
Always include curly braces ({}) around variable names when referring to them in strings, for example, as follows:
false without any quotes. The string "false" evaluates to true and the string "true" also evaluates to true. Actually, everything besides the literal
Always include curly braces ({}) around variable names when referring to them in strings, for example, as follows:
If you already have some Puppet code (known as a Puppet manifest), you can skip this section and go on to the next. If not, we'll see how to create and apply a simple manifest.
To create and apply a simple manifest, follow these steps:
- First, install Puppet locally on your machine or create a virtual machine and install Puppet on that machine. For YUM-based systems, use https://yum.puppetlabs.com/ and for APT-based systems, use https://apt.puppetlabs.com/. You may also use gem to install Puppet. For our examples, we'll install Puppet using gem on a Debian Wheezy system (hostname:
cookbook). To use gem, we need therubygemspackage as follows:t@cookbook:~$ sudo apt-get install rubygems Reading package lists... Done Building dependency tree Reading state information... Done The following NEW packages will be installed: rubygems 0 upgraded, 1 newly installed, 0 to remove and 0 not upgraded. Need to get 0 B/597 kB of archives. After this operation, 3,844 kB of additional disk space will be used. Selecting previously unselected package rubygems. (Reading database ... 30390 files and directories currently installed.) Unpacking rubygems (from .../rubygems_1.8.24-1_all.deb) ... Processing triggers for man-db ... Setting up rubygems (1.8.24-1) ...
- Now, use
gemto install Puppet:t@cookbook $ sudo gem install puppet Successfully installed hiera-1.3.4 Fetching: facter-2.3.0.gem (100%) Successfully installed facter-2.3.0 Fetching: puppet-3.7.3.gem (100%) Successfully installed puppet-3.7.3 Installing ri documentation for hiera-1.3.4 Installing ri documentation for facter-2.3.0 Installing ri documentation for puppet-3.7.3 Done installing documentation for hiera, facter, puppet after 239 seconds
- Three gems are installed. Now, with Puppet installed, we can create a directory to contain our Puppet code:
t@cookbook:~$ mkdir -p .puppet/manifests t@cookbook:~$ cd .puppet/manifests t@cookbook:~/.puppet/manifests$
- Within your
manifestsdirectory, create thesite.ppfile with the following content:node default { file { '/tmp/hello': content => "Hello, world!\n", } } - Test your manifest with the
puppet applycommand. This will tell Puppet to read the manifest, compare it to the state of the machine, and make any necessary changes to that state:t@cookbook:~/.puppet/manifests$ puppet apply site.pp Notice: Compiled catalog for cookbook in environment production in 0.14 seconds Notice: /Stage[main]/Main/Node[default]/File[/tmp/hello]/ensure: defined content as '{md5}746308829575e17c3331bbcb00c0898b' Notice: Finished catalog run in 0.04 seconds
- To see if Puppet did what we expected (create the
/tmp/hellofile with theHello, world! content), run the following command:t@cookbook:~/puppet/manifests$ cat /tmp/hello Hello, world! t@cookbook:~/puppet/manifests$
- YUM-based systems, use https://yum.puppetlabs.com/ and for APT-based systems, use https://apt.puppetlabs.com/. You may also use gem to install Puppet. For our examples, we'll install Puppet using gem on a Debian Wheezy system (hostname:
cookbook). To use gem, we need therubygemspackage as follows:t@cookbook:~$ sudo apt-get install rubygems Reading package lists... Done Building dependency tree Reading state information... Done The following NEW packages will be installed: rubygems 0 upgraded, 1 newly installed, 0 to remove and 0 not upgraded. Need to get 0 B/597 kB of archives. After this operation, 3,844 kB of additional disk space will be used. Selecting previously unselected package rubygems. (Reading database ... 30390 files and directories currently installed.) Unpacking rubygems (from .../rubygems_1.8.24-1_all.deb) ... Processing triggers for man-db ... Setting up rubygems (1.8.24-1) ...
- Now, use
gemto install Puppet:t@cookbook $ sudo gem install puppet Successfully installed hiera-1.3.4 Fetching: facter-2.3.0.gem (100%) Successfully installed facter-2.3.0 Fetching: puppet-3.7.3.gem (100%) Successfully installed puppet-3.7.3 Installing ri documentation for hiera-1.3.4 Installing ri documentation for facter-2.3.0 Installing ri documentation for puppet-3.7.3 Done installing documentation for hiera, facter, puppet after 239 seconds
- Three gems are installed. Now, with Puppet installed, we can create a directory to contain our Puppet code:
t@cookbook:~$ mkdir -p .puppet/manifests t@cookbook:~$ cd .puppet/manifests t@cookbook:~/.puppet/manifests$
- Within your
manifestsdirectory, create thesite.ppfile with the following content:node default { file { '/tmp/hello': content => "Hello, world!\n", } } - Test your manifest with the
puppet applycommand. This will tell Puppet to read the manifest, compare it to the state of the machine, and make any necessary changes to that state:t@cookbook:~/.puppet/manifests$ puppet apply site.pp Notice: Compiled catalog for cookbook in environment production in 0.14 seconds Notice: /Stage[main]/Main/Node[default]/File[/tmp/hello]/ensure: defined content as '{md5}746308829575e17c3331bbcb00c0898b' Notice: Finished catalog run in 0.04 seconds
- To see if Puppet did what we expected (create the
/tmp/hellofile with theHello, world! content), run the following command:t@cookbook:~/puppet/manifests$ cat /tmp/hello Hello, world! t@cookbook:~/puppet/manifests$
The puppet-lint tool will automatically check your code against the style guide. The next section explains how to use it.
Here's what you need to do to install Puppet-lint:
- We'll install Puppet-lint using the gem provider because the gem version is much more up to date than the APT or RPM packages available. Create a
puppet-lint.ppmanifest as shown in the following code snippet:package {'puppet-lint': ensure => 'installed', provider => 'gem', } - Run
puppet applyon thepuppet-lint.ppmanifest, as shown in the following command:t@cookbook ~$ puppet apply puppet-lint.pp Notice: Compiled catalog for node1.example.com in environment production in 0.42 seconds Notice: /Stage[main]/Main/Package[puppet-lint]/ensure: created Notice: Finished catalog run in 2.96 seconds t@cookbook ~$ gem list puppet-lint *** LOCAL GEMS *** puppet-lint (1.0.1)
Follow these steps to use Puppet-lint:
- Choose a Puppet manifest file that you want to check with Puppet-lint, and run the following command:
t@cookbook ~$ puppet-lint puppet-lint.pp WARNING: indentation of => is not properly aligned on line 2 ERROR: trailing whitespace found on line 4
- As you can see, Puppet-lint found a number of problems with the manifest file. Correct the errors, save the file, and rerun Puppet-lint to check that all is well. If successful, you'll see no output:
t@cookbook ~$ puppet-lint puppet-lint.pp t@cookbook ~$
You can find out more about Puppet-lint at https://github.com/rodjek/puppet-lint.
Should you follow Puppet style guide and, by extension, keep your code lint-clean? It's up to you, but here are a couple of things to think about:
- It makes sense to use some style conventions, especially when you're working collaboratively on code. Unless you and your colleagues can agree on standards for whitespace, tabs, quoting, alignment, and so on, your code will be messy and difficult to read or maintain.
- If you're choosing a set of style conventions to follow, the logical choice would be that issued by puppetlabs and adopted by the community for use in public modules.
Having said that, it's possible to tell Puppet-lint to ignore certain checks if you've chosen not to adopt them in your codebase. For example, if you don't want Puppet-lint to warn you about code lines exceeding 80 characters, you can run Puppet-lint with the following option:
t@cookbook ~$ puppet-lint --no-80chars-check
Run puppet-lint --help to see the complete list of check configuration commands.
- The Automatic syntax checking with Git hooks recipe in Chapter 2, Puppet Infrastructure
- The Testing your Puppet manifests with rspec-puppet recipe in Chapter 9, External Tools and the Puppet Ecosystem
- We'll install Puppet-lint using the gem provider because the gem version is much more up to date than the APT or RPM packages available. Create a
puppet-lint.ppmanifest as shown in the following code snippet:package {'puppet-lint': ensure => 'installed', provider => 'gem', } - Run
puppet applyon thepuppet-lint.ppmanifest, as shown in the following command:t@cookbook ~$ puppet apply puppet-lint.pp Notice: Compiled catalog for node1.example.com in environment production in 0.42 seconds Notice: /Stage[main]/Main/Package[puppet-lint]/ensure: created Notice: Finished catalog run in 2.96 seconds t@cookbook ~$ gem list puppet-lint *** LOCAL GEMS *** puppet-lint (1.0.1)
Follow these steps to use Puppet-lint:
- Choose a Puppet manifest file that you want to check with Puppet-lint, and run the following command:
t@cookbook ~$ puppet-lint puppet-lint.pp WARNING: indentation of => is not properly aligned on line 2 ERROR: trailing whitespace found on line 4
- As you can see, Puppet-lint found a number of problems with the manifest file. Correct the errors, save the file, and rerun Puppet-lint to check that all is well. If successful, you'll see no output:
t@cookbook ~$ puppet-lint puppet-lint.pp t@cookbook ~$
You can find out more about Puppet-lint at https://github.com/rodjek/puppet-lint.
Should you follow Puppet style guide and, by extension, keep your code lint-clean? It's up to you, but here are a couple of things to think about:
- It makes sense to use some style conventions, especially when you're working collaboratively on code. Unless you and your colleagues can agree on standards for whitespace, tabs, quoting, alignment, and so on, your code will be messy and difficult to read or maintain.
- If you're choosing a set of style conventions to follow, the logical choice would be that issued by puppetlabs and adopted by the community for use in public modules.
Having said that, it's possible to tell Puppet-lint to ignore certain checks if you've chosen not to adopt them in your codebase. For example, if you don't want Puppet-lint to warn you about code lines exceeding 80 characters, you can run Puppet-lint with the following option:
t@cookbook ~$ puppet-lint --no-80chars-check
Run puppet-lint --help to see the complete list of check configuration commands.
- The Automatic syntax checking with Git hooks recipe in Chapter 2, Puppet Infrastructure
- The Testing your Puppet manifests with rspec-puppet recipe in Chapter 9, External Tools and the Puppet Ecosystem
- Choose a Puppet manifest file that you want to check with Puppet-lint, and run the following command:
t@cookbook ~$ puppet-lint puppet-lint.pp WARNING: indentation of => is not properly aligned on line 2 ERROR: trailing whitespace found on line 4
- As you can see, Puppet-lint found a number of problems with the manifest file. Correct the errors, save the file, and rerun Puppet-lint to check that all is well. If successful, you'll see no output:
t@cookbook ~$ puppet-lint puppet-lint.pp t@cookbook ~$
You can find out more about Puppet-lint at https://github.com/rodjek/puppet-lint.
Should you follow Puppet style guide and, by extension, keep your code lint-clean? It's up to you, but here are a couple of things to think about:
- It makes sense to use some style conventions, especially when you're working collaboratively on code. Unless you and your colleagues can agree on standards for whitespace, tabs, quoting, alignment, and so on, your code will be messy and difficult to read or maintain.
- If you're choosing a set of style conventions to follow, the logical choice would be that issued by puppetlabs and adopted by the community for use in public modules.
Having said that, it's possible to tell Puppet-lint to ignore certain checks if you've chosen not to adopt them in your codebase. For example, if you don't want Puppet-lint to warn you about code lines exceeding 80 characters, you can run Puppet-lint with the following option:
t@cookbook ~$ puppet-lint --no-80chars-check
Run puppet-lint --help to see the complete list of check configuration commands.
- The Automatic syntax checking with Git hooks recipe in Chapter 2, Puppet Infrastructure
- The Testing your Puppet manifests with rspec-puppet recipe in Chapter 9, External Tools and the Puppet Ecosystem
Puppet-lint at https://github.com/rodjek/puppet-lint.
Should you follow Puppet style guide and, by extension, keep your code lint-clean? It's up to you, but here are a couple of things to think about:
- It makes sense to use some style conventions, especially when you're working collaboratively on code. Unless you and your colleagues can agree on standards for whitespace, tabs, quoting, alignment, and so on, your code will be messy and difficult to read or maintain.
- If you're choosing a set of style conventions to follow, the logical choice would be that issued by puppetlabs and adopted by the community for use in public modules.
Having said that, it's possible to tell Puppet-lint to ignore certain checks if you've chosen not to adopt them in your codebase. For example, if you don't want Puppet-lint to warn you about code lines exceeding 80 characters, you can run Puppet-lint with the following option:
t@cookbook ~$ puppet-lint --no-80chars-check
Run puppet-lint --help to see the complete list of check configuration commands.
- The Automatic syntax checking with Git hooks recipe in Chapter 2, Puppet Infrastructure
- The Testing your Puppet manifests with rspec-puppet recipe in Chapter 9, External Tools and the Puppet Ecosystem
Modules are self-contained bundles of Puppet code that include all the files necessary to implement a thing. Modules may contain flat files, templates, Puppet manifests, custom fact declarations, augeas lenses, and custom Puppet types and providers.
Following are the steps to create an example module:
- We will use Puppet's module subcommand to create the directory structure for our new module:
t@cookbook:~$ mkdir -p .puppet/modules t@cookbook:~$ cd .puppet/modules t@cookbook:~/.puppet/modules$ puppet module generate thomas-memcached We need to create a metadata.json file for this module. Please answer the following questions; if the question is not applicable to this module, feel free to leave it blank. Puppet uses Semantic Versioning (semver.org) to version modules.What version is this module? [0.1.0] --> Who wrote this module? [thomas] --> What license does this module code fall under? [Apache 2.0] --> How would you describe this module in a single sentence? --> A module to install memcached Where is this module's source code repository? --> Where can others go to learn more about this module? --> Where can others go to file issues about this module? --> ---------------------------------------- { "name": "thomas-memcached", "version": "0.1.0", "author": "thomas", "summary": "A module to install memcached", "license": "Apache 2.0", "source": "", "issues_url": null, "project_page": null, "dependencies": [ { "version_range": ">= 1.0.0", "name": "puppetlabs-stdlib" } ] } ---------------------------------------- About to generate this metadata; continue? [n/Y] --> y Notice: Generating module at /home/thomas/.puppet/modules/thomas-memcached... Notice: Populating ERB templates... Finished; module generated in thomas-memcached. thomas-memcached/manifests thomas-memcached/manifests/init.pp thomas-memcached/spec thomas-memcached/spec/classes thomas-memcached/spec/classes/init_spec.rb thomas-memcached/spec/spec_helper.rb thomas-memcached/README.md thomas-memcached/metadata.json thomas-memcached/Rakefile thomas-memcached/tests thomas-memcached/tests/init.pp
This command creates the module directory and creates some empty files as starting points. To use the module, we'll create a symlink to the module name (memcached).
t@cookbook:~/.puppet/modules$ ln –s thomas-memcached memcached - Now, edit
memcached/manifests/init.ppand change the class definition at the end of the file to the following. Note thatpuppet module generatecreated many lines of comments; in a production module you would want to edit those default comments:class memcached { package { 'memcached': ensure => installed, } file { '/etc/memcached.conf': source => 'puppet:///modules/memcached/memcached.conf', owner => 'root', group => 'root', mode => '0644', require => Package['memcached'], } service { 'memcached': ensure => running, enable => true, require => [Package['memcached'], File['/etc/memcached.conf']], } } - Create the
modules/thomas-memcached/filesdirectory and then create a file namedmemcached.confwith the following contents:-m 64 -p 11211 -u nobody -l 127.0.0.1
- Change your
site.ppfile to the following:node default { include memcached } - We would like this module to install memcached. We'll need to run Puppet with root privileges, and we'll use sudo for that. We'll need Puppet to be able to find the module in our home directory; we can specify this on the command line when we run Puppet as shown in the following code snippet:
t@cookbook:~$ sudo puppet apply --modulepath=/home/thomas/.puppet/modules /home/thomas/.puppet/manifests/site.pp Notice: Compiled catalog for cookbook.example.com in environment production in 0.33 seconds Notice: /Stage[main]/Memcached/File[/etc/memcached.conf]/content: content changed '{md5}a977521922a151c959ac953712840803' to '{md5}9429eff3e3354c0be232a020bcf78f75' Notice: Finished catalog run in 0.11 seconds - Check whether the new service is running:
t@cookbook:~$ sudo service memcached status [ ok ] memcached is running.
All manifest files (those containing Puppet code) live in the manifests directory. In our example, the memcached class is defined in the manifests/init.pp file, which will be imported automatically.
Inside the memcached class, we refer to the memcached.conf file:
The preceding source parameter tells Puppet to look for the file in:
If you need to use a template as a part of the module, place it in the module's templates directory and refer to it as follows:
Modules can also contain custom facts, custom functions, custom types, and providers.
For more information about these, refer to Chapter 9, External Tools and the Puppet Ecosystem.
You can download modules provided by other people and use them in your own manifests just like the modules you create. For more on this, see Using Public Modules recipe in Chapter 7, Managing Applications.
- The Creating custom facts recipe in Chapter 9, External Tools and the Puppet Ecosystem
- The Using public modules recipe in Chapter 7, Managing Applications
- The Creating your own resource types recipe in Chapter 9, External Tools and the Puppet Ecosystem
- The Creating your own providers recipe in Chapter 9, External Tools and the Puppet Ecosystem
- We will use Puppet's module subcommand to create the directory structure for our new module:
t@cookbook:~$ mkdir -p .puppet/modules t@cookbook:~$ cd .puppet/modules t@cookbook:~/.puppet/modules$ puppet module generate thomas-memcached We need to create a metadata.json file for this module. Please answer the following questions; if the question is not applicable to this module, feel free to leave it blank. Puppet uses Semantic Versioning (semver.org) to version modules.What version is this module? [0.1.0] --> Who wrote this module? [thomas] --> What license does this module code fall under? [Apache 2.0] --> How would you describe this module in a single sentence? --> A module to install memcached Where is this module's source code repository? --> Where can others go to learn more about this module? --> Where can others go to file issues about this module? --> ---------------------------------------- { "name": "thomas-memcached", "version": "0.1.0", "author": "thomas", "summary": "A module to install memcached", "license": "Apache 2.0", "source": "", "issues_url": null, "project_page": null, "dependencies": [ { "version_range": ">= 1.0.0", "name": "puppetlabs-stdlib" } ] } ---------------------------------------- About to generate this metadata; continue? [n/Y] --> y Notice: Generating module at /home/thomas/.puppet/modules/thomas-memcached... Notice: Populating ERB templates... Finished; module generated in thomas-memcached. thomas-memcached/manifests thomas-memcached/manifests/init.pp thomas-memcached/spec thomas-memcached/spec/classes thomas-memcached/spec/classes/init_spec.rb thomas-memcached/spec/spec_helper.rb thomas-memcached/README.md thomas-memcached/metadata.json thomas-memcached/Rakefile thomas-memcached/tests thomas-memcached/tests/init.pp
This command creates the module directory and creates some empty files as starting points. To use the module, we'll create a symlink to the module name (memcached).
t@cookbook:~/.puppet/modules$ ln –s thomas-memcached memcached - Now, edit
memcached/manifests/init.ppand change the class definition at the end of the file to the following. Note thatpuppet module generatecreated many lines of comments; in a production module you would want to edit those default comments:class memcached { package { 'memcached': ensure => installed, } file { '/etc/memcached.conf': source => 'puppet:///modules/memcached/memcached.conf', owner => 'root', group => 'root', mode => '0644', require => Package['memcached'], } service { 'memcached': ensure => running, enable => true, require => [Package['memcached'], File['/etc/memcached.conf']], } } - Create the
modules/thomas-memcached/filesdirectory and then create a file namedmemcached.confwith the following contents:-m 64 -p 11211 -u nobody -l 127.0.0.1
- Change your
site.ppfile to the following:node default { include memcached } - We would like this module to install memcached. We'll need to run Puppet with root privileges, and we'll use sudo for that. We'll need Puppet to be able to find the module in our home directory; we can specify this on the command line when we run Puppet as shown in the following code snippet:
t@cookbook:~$ sudo puppet apply --modulepath=/home/thomas/.puppet/modules /home/thomas/.puppet/manifests/site.pp Notice: Compiled catalog for cookbook.example.com in environment production in 0.33 seconds Notice: /Stage[main]/Memcached/File[/etc/memcached.conf]/content: content changed '{md5}a977521922a151c959ac953712840803' to '{md5}9429eff3e3354c0be232a020bcf78f75' Notice: Finished catalog run in 0.11 seconds - Check whether the new service is running:
t@cookbook:~$ sudo service memcached status [ ok ] memcached is running.
All manifest files (those containing Puppet code) live in the manifests directory. In our example, the memcached class is defined in the manifests/init.pp file, which will be imported automatically.
Inside the memcached class, we refer to the memcached.conf file:
The preceding source parameter tells Puppet to look for the file in:
If you need to use a template as a part of the module, place it in the module's templates directory and refer to it as follows:
Modules can also contain custom facts, custom functions, custom types, and providers.
For more information about these, refer to Chapter 9, External Tools and the Puppet Ecosystem.
You can download modules provided by other people and use them in your own manifests just like the modules you create. For more on this, see Using Public Modules recipe in Chapter 7, Managing Applications.
- The Creating custom facts recipe in Chapter 9, External Tools and the Puppet Ecosystem
- The Using public modules recipe in Chapter 7, Managing Applications
- The Creating your own resource types recipe in Chapter 9, External Tools and the Puppet Ecosystem
- The Creating your own providers recipe in Chapter 9, External Tools and the Puppet Ecosystem
thomas-memcached. The name before the hyphen is your username or your username on Puppet forge (an online repository of modules). Since we want Puppet to be able to find the module by the name memcached, we make a symbolic link between thomas-memcached and memcached.
Inside the memcached class, we refer to the memcached.conf file:
The preceding source parameter tells Puppet to look for the file in:
If you need to use a template as a part of the module, place it in the module's templates directory and refer to it as follows:
Modules can also contain custom facts, custom functions, custom types, and providers.
For more information about these, refer to Chapter 9, External Tools and the Puppet Ecosystem.
You can download modules provided by other people and use them in your own manifests just like the modules you create. For more on this, see Using Public Modules recipe in Chapter 7, Managing Applications.
- The Creating custom facts recipe in Chapter 9, External Tools and the Puppet Ecosystem
- The Using public modules recipe in Chapter 7, Managing Applications
- The Creating your own resource types recipe in Chapter 9, External Tools and the Puppet Ecosystem
- The Creating your own providers recipe in Chapter 9, External Tools and the Puppet Ecosystem
If you need to use a template as a part of the module, place it in the module's templates directory and refer to it as follows:
Modules can also contain custom facts, custom functions, custom types, and providers.
For more information about these, refer to Chapter 9, External Tools and the Puppet Ecosystem.
You can download modules provided by other people and use them in your own manifests just like the modules you create. For more on this, see Using Public Modules recipe in Chapter 7, Managing Applications.
- The Creating custom facts recipe in Chapter 9, External Tools and the Puppet Ecosystem
- The Using public modules recipe in Chapter 7, Managing Applications
- The Creating your own resource types recipe in Chapter 9, External Tools and the Puppet Ecosystem
- The Creating your own providers recipe in Chapter 9, External Tools and the Puppet Ecosystem
Modules can also contain custom facts, custom functions, custom types, and providers.
For more information about these, refer to Chapter 9, External Tools and the Puppet Ecosystem.
You can download modules provided by other people and use them in your own manifests just like the modules you create. For more on this, see Using Public Modules recipe in Chapter 7, Managing Applications.
- The Creating custom facts recipe in Chapter 9, External Tools and the Puppet Ecosystem
- The Using public modules recipe in Chapter 7, Managing Applications
- The Creating your own resource types recipe in Chapter 9, External Tools and the Puppet Ecosystem
- The Creating your own providers recipe in Chapter 9, External Tools and the Puppet Ecosystem
custom facts, custom functions, custom types, and providers.
For more information about these, refer to Chapter 9, External Tools and the Puppet Ecosystem.
You can download modules provided by other people and use them in your own manifests just like the modules you create. For more on this, see Using Public Modules recipe in Chapter 7, Managing Applications.
- The Creating custom facts recipe in Chapter 9, External Tools and the Puppet Ecosystem
- The Using public modules recipe in Chapter 7, Managing Applications
- The Creating your own resource types recipe in Chapter 9, External Tools and the Puppet Ecosystem
- The Creating your own providers recipe in Chapter 9, External Tools and the Puppet Ecosystem
other people and use them in your own manifests just like the modules you create. For more on this, see Using Public Modules recipe in Chapter 7, Managing Applications.
- The Creating custom facts recipe in Chapter 9, External Tools and the Puppet Ecosystem
- The Using public modules recipe in Chapter 7, Managing Applications
- The Creating your own resource types recipe in Chapter 9, External Tools and the Puppet Ecosystem
- The Creating your own providers recipe in Chapter 9, External Tools and the Puppet Ecosystem
- The Creating custom facts recipe in Chapter 9, External Tools and the Puppet Ecosystem
- The Using public modules recipe in Chapter 7, Managing Applications
- The Creating your own resource types recipe in Chapter 9, External Tools and the Puppet Ecosystem
- The Creating your own providers recipe in Chapter 9, External Tools and the Puppet Ecosystem
- Chapter 9, External Tools and the Puppet Ecosystem
- The Using public modules recipe in Chapter 7, Managing Applications
- The Creating your own resource types recipe in Chapter 9, External Tools and the Puppet Ecosystem
- The Creating your own providers recipe in Chapter 9, External Tools and the Puppet Ecosystem
Choosing appropriate and informative names for your modules and classes will be a big help when it comes to maintaining your code. This is even truer if other people need to read and work on your manifests.
Here are some tips on how to name things in your manifests:
- Name modules after the software or service they manage, for example,
apacheorhaproxy. - Name classes within modules (subclasses) after the function or service they provide to the module, for example,
apache::vhostsorrails::dependencies. - If a class within a module disables the service provided by that module, name it
disabled. For example, a class that disables Apache should be namedapache::disabled. - Create a roles and profiles hierarchy of modules. Each node should have a single role consisting of one or more profiles. Each profile module should configure a single service.
- The module that manages users should be named
user. - Within the user module, declare your virtual users within the class
user::virtual(for more on virtual users and other resources, see the Using virtual resources recipe in Chapter 5, Users and Virtual Resources). - Within the user module, subclasses for particular groups of users should be named after the group, for example,
user::sysadminsoruser::contractors. - When using Puppet to deploy the config files for different services, name the file after the service, but with a suffix indicating what kind of file it is, for example:
- Apache init script:
apache.init - Logrotate config snippet for Rails:
rails.logrotate - Nginx vhost file for mywizzoapp:
mywizzoapp.vhost.nginx - MySQL config for standalone server:
standalone.mysql
- Apache init script:
- If you need to deploy a different version of a file depending on the operating system release, for example, you can use a naming convention like the following:
memcached.lucid.conf memcached.precise.conf
- You can have Puppet automatically select the appropriate version as follows:
source = > "puppet:///modules/memcached /memcached.${::lsbdistrelease}.conf", - If you need to manage, for example, different Ruby versions, name the class after the version it is responsible for, for example,
ruby192orruby186.
Puppet community maintains a set of best practice guidelines for your Puppet infrastructure, which includes some hints on naming conventions:
http://docs.puppetlabs.com/guides/best_practices.html
Some people prefer to include multiple classes on a node by using a comma-separated list, rather than separate include statements, for example:
node 'server014' inherits 'server' {
include mail::server, repo::gem, repo::apt, zabbix
}This is a matter of style, but I prefer to use separate include statements, one on a line, because it makes it easier to copy and move around class inclusions between nodes without having to tidy up the commas and indentation every time.
I mentioned inheritance in a couple of the preceding examples; if you're not sure what this is, don't worry, I'll explain this in detail in the next chapter.
apache or haproxy.
apache::vhosts or rails::dependencies.
disabled. For example, a class that disables Apache should be named apache::disabled.
user.
user::virtual (for more on virtual users and other resources, see the Using virtual resources recipe in
- Chapter 5, Users and Virtual Resources).
- Within the user module, subclasses for particular groups of users should be named after the group, for example,
user::sysadminsoruser::contractors. - When using Puppet to deploy the config files for different services, name the file after the service, but with a suffix indicating what kind of file it is, for example:
- Apache init script:
apache.init - Logrotate config snippet for Rails:
rails.logrotate - Nginx vhost file for mywizzoapp:
mywizzoapp.vhost.nginx - MySQL config for standalone server:
standalone.mysql
- Apache init script:
- If you need to deploy a different version of a file depending on the operating system release, for example, you can use a naming convention like the following:
memcached.lucid.conf memcached.precise.conf
- You can have Puppet automatically select the appropriate version as follows:
source = > "puppet:///modules/memcached /memcached.${::lsbdistrelease}.conf", - If you need to manage, for example, different Ruby versions, name the class after the version it is responsible for, for example,
ruby192orruby186.
Puppet community maintains a set of best practice guidelines for your Puppet infrastructure, which includes some hints on naming conventions:
http://docs.puppetlabs.com/guides/best_practices.html
Some people prefer to include multiple classes on a node by using a comma-separated list, rather than separate include statements, for example:
node 'server014' inherits 'server' {
include mail::server, repo::gem, repo::apt, zabbix
}This is a matter of style, but I prefer to use separate include statements, one on a line, because it makes it easier to copy and move around class inclusions between nodes without having to tidy up the commas and indentation every time.
I mentioned inheritance in a couple of the preceding examples; if you're not sure what this is, don't worry, I'll explain this in detail in the next chapter.
for your Puppet infrastructure, which includes some hints on naming conventions:
http://docs.puppetlabs.com/guides/best_practices.html
Some people prefer to include multiple classes on a node by using a comma-separated list, rather than separate include statements, for example:
node 'server014' inherits 'server' {
include mail::server, repo::gem, repo::apt, zabbix
}This is a matter of style, but I prefer to use separate include statements, one on a line, because it makes it easier to copy and move around class inclusions between nodes without having to tidy up the commas and indentation every time.
I mentioned inheritance in a couple of the preceding examples; if you're not sure what this is, don't worry, I'll explain this in detail in the next chapter.
Templates are a powerful way of using
Embedded Ruby (ERB) to help build config files dynamically. You can also use ERB syntax directly without having to use a separate file by calling the inline_template function. ERB allows you to use conditional logic, iterate over arrays, and include variables.
Here's an example of how to use inline_template:
Pass your Ruby code to inline_template within Puppet manifest, as follows:
In this example, we use inline_template to compute a different hour for this cron resource (a scheduled job) for each machine, so that the same job does not run at the same time on all machines. For more on this technique, see the Distributing cron jobs efficiently recipe in Chapter 6, Managing Resources and Files.
In ERB code, whether inside a template file or an inline_template string, you can access your Puppet variables directly by name using an @ prefix, if they are in the current scope or the top scope (facts):
To reference variables in another scope, use scope.lookupvar, as follows:
You should use inline templates sparingly. If you really need to use some complicated logic in your manifest, consider using a custom function instead (see the Creating custom functions recipe in Chapter 9, External Tools and the Puppet Ecosystem).
- The Using ERB templates recipe in Chapter 4, Working with Files and Packages
- The Using array iteration in templates recipe in Chapter 4, Working with Files and Packages
In this example, we use inline_template to compute a different hour for this cron resource (a scheduled job) for each machine, so that the same job does not run at the same time on all machines. For more on this technique, see the Distributing cron jobs efficiently recipe in Chapter 6, Managing Resources and Files.
In ERB code, whether inside a template file or an inline_template string, you can access your Puppet variables directly by name using an @ prefix, if they are in the current scope or the top scope (facts):
To reference variables in another scope, use scope.lookupvar, as follows:
You should use inline templates sparingly. If you really need to use some complicated logic in your manifest, consider using a custom function instead (see the Creating custom functions recipe in Chapter 9, External Tools and the Puppet Ecosystem).
- The Using ERB templates recipe in Chapter 4, Working with Files and Packages
- The Using array iteration in templates recipe in Chapter 4, Working with Files and Packages
inline_template is executed as if it were an ERB template. That is, anything inside the <%= and %> delimiters will be executed as Ruby code, and the rest will be treated as a string.
inline_template to compute a different hour for this cron resource (a scheduled job) for each machine, so that the same job does not run at the same time on all machines. For more on this technique, see the Distributing cron jobs efficiently recipe in
Chapter 6, Managing Resources and Files.
In ERB code, whether inside a template file or an inline_template string, you can access your Puppet variables directly by name using an @ prefix, if they are in the current scope or the top scope (facts):
To reference variables in another scope, use scope.lookupvar, as follows:
You should use inline templates sparingly. If you really need to use some complicated logic in your manifest, consider using a custom function instead (see the Creating custom functions recipe in Chapter 9, External Tools and the Puppet Ecosystem).
- The Using ERB templates recipe in Chapter 4, Working with Files and Packages
- The Using array iteration in templates recipe in Chapter 4, Working with Files and Packages
To reference variables in another scope, use scope.lookupvar, as follows:
You should use inline templates sparingly. If you really need to use some complicated logic in your manifest, consider using a custom function instead (see the Creating custom functions recipe in Chapter 9, External Tools and the Puppet Ecosystem).
- The Using ERB templates recipe in Chapter 4, Working with Files and Packages
- The Using array iteration in templates recipe in Chapter 4, Working with Files and Packages
Arrays are a powerful feature in Puppet; wherever you want to perform the same operation on a list of things, an array may be able to help. You can create an array just by putting its content in square brackets:
Although arrays will take you a long way with Puppet, it's also useful to know about an even more flexible data structure: the hash.
A hash is like an array, but each of the elements can be stored and looked up by name (referred to as the key), for example (hash.pp):
When we run Puppet on this, we see the following notify in the output:
You can declare literal arrays using square brackets, as follows:
Now, when we run Puppet on the preceding code, we see the following notice messages in the output:
However, Puppet can also create arrays for you from strings, using the split function, as follows:
Running puppet apply against this new manifest, we see the same messages in the output:
$packages = [ 'ruby1.8-dev',
'ruby1.8',
'ri1.8',
'rdoc1.8',
'irb1.8',
'libreadline-ruby1.8',
'libruby1.8',
'libopenssl-ruby' ]
package { $packages: ensure => installed }Although arrays will take you a long way with Puppet, it's also useful to know about an even more flexible data structure: the hash.
A hash is like an array, but each of the elements can be stored and looked up by name (referred to as the key), for example (hash.pp):
When we run Puppet on this, we see the following notify in the output:
You can declare literal arrays using square brackets, as follows:
Now, when we run Puppet on the preceding code, we see the following notice messages in the output:
However, Puppet can also create arrays for you from strings, using the split function, as follows:
Running puppet apply against this new manifest, we see the same messages in the output:
$packages array, with the same parameters (ensure => installed). This is a very compact way to instantiate many similar resources.
Although arrays will take you a long way with Puppet, it's also useful to know about an even more flexible data structure: the hash.
A hash is like an array, but each of the elements can be stored and looked up by name (referred to as the key), for example (hash.pp):
When we run Puppet on this, we see the following notify in the output:
You can declare literal arrays using square brackets, as follows:
Now, when we run Puppet on the preceding code, we see the following notice messages in the output:
However, Puppet can also create arrays for you from strings, using the split function, as follows:
Running puppet apply against this new manifest, we see the same messages in the output:
A hash is like an array, but each of the elements can be stored and looked up by name (referred to as the key), for example (hash.pp):
When we run Puppet on this, we see the following notify in the output:
You can declare literal arrays using square brackets, as follows:
Now, when we run Puppet on the preceding code, we see the following notice messages in the output:
However, Puppet can also create arrays for you from strings, using the split function, as follows:
Running puppet apply against this new manifest, we see the same messages in the output:
You can declare literal arrays using square brackets, as follows:
Now, when we run Puppet on the preceding code, we see the following notice messages in the output:
However, Puppet can also create arrays for you from strings, using the split function, as follows:
Running puppet apply against this new manifest, we see the same messages in the output:
arrays using square brackets, as follows:
Now, when we run Puppet on the preceding code, we see the following notice messages in the output:
However, Puppet can also create arrays for you from strings, using the split function, as follows:
Running puppet apply against this new manifest, we see the same messages in the output:
Puppet's if statement allows you to change the manifest behavior based on the value of a variable or an expression. With it, you can apply different resources or parameter values depending on certain facts about the node, for example, the operating system, or the memory size.
Optionally, you can add an else branch, which will be executed if the expression evaluates to false.
Optionally, you can add an else branch, which will be executed if the expression evaluates to false.
if keyword as an expression and evaluates it. If the expression evaluates to true, Puppet will execute the code within the curly braces.
if statements.
Another kind of expression you can test in if statements and other conditionals is the regular expression. A regular expression is a powerful way to compare strings using pattern matching.
Puppet treats the text supplied between the forward slashes as a regular expression, specifying the text to be matched. If the match succeeds, the if expression will be true and so the code between the first set of curly braces will be executed. In this example, we used a regular expression because different distributions have different ideas on what to call 64bit; some use amd64, while others use x86_64. The only thing we can count on is the presence of the number 64 within the fact. Some facts that have version numbers in them are treated as strings to Puppet. For instance, $::facterversion. On my test system, this is 2.0.1, but when I try to compare that with 2, Puppet fails to make the comparison:
If you wanted instead to do something if the text does not match, use !~ rather than =~:
You can not only match text using a regular expression, but also capture the matched text and store it in a variable:
The preceding code produces this output:
The variable $0 stores the whole matched text (assuming the overall match succeeded). If you put brackets around any part of the regular expression, it creates a group, and any matched groups will also be stored in variables. The first matched group will be $1, the second $2, and so on, as shown in the preceding example.
Puppet treats the text supplied between the forward slashes as a regular expression, specifying the text to be matched. If the match succeeds, the if expression will be true and so the code between the first set of curly braces will be executed. In this example, we used a regular expression because different distributions have different ideas on what to call 64bit; some use amd64, while others use x86_64. The only thing we can count on is the presence of the number 64 within the fact. Some facts that have version numbers in them are treated as strings to Puppet. For instance, $::facterversion. On my test system, this is 2.0.1, but when I try to compare that with 2, Puppet fails to make the comparison:
If you wanted instead to do something if the text does not match, use !~ rather than =~:
You can not only match text using a regular expression, but also capture the matched text and store it in a variable:
The preceding code produces this output:
The variable $0 stores the whole matched text (assuming the overall match succeeded). If you put brackets around any part of the regular expression, it creates a group, and any matched groups will also be stored in variables. The first matched group will be $1, the second $2, and so on, as shown in the preceding example.
between the forward slashes as a regular expression, specifying the text to be matched. If the match succeeds, the if expression will be true and so the code between the first set of curly braces will be executed. In this example, we used a regular expression because different distributions have different ideas on what to call 64bit; some use amd64, while others use x86_64. The only thing we can count on is the presence of the number 64 within the fact. Some facts that have version numbers in them are treated as strings to Puppet. For instance, $::facterversion. On my test system, this is 2.0.1, but when I try to compare that with 2, Puppet fails to make the comparison:
If you wanted instead to do something if the text does not match, use !~ rather than =~:
You can not only match text using a regular expression, but also capture the matched text and store it in a variable:
The preceding code produces this output:
The variable $0 stores the whole matched text (assuming the overall match succeeded). If you put brackets around any part of the regular expression, it creates a group, and any matched groups will also be stored in variables. The first matched group will be $1, the second $2, and so on, as shown in the preceding example.
You can not only match text using a regular expression, but also capture the matched text and store it in a variable:
The preceding code produces this output:
The variable $0 stores the whole matched text (assuming the overall match succeeded). If you put brackets around any part of the regular expression, it creates a group, and any matched groups will also be stored in variables. The first matched group will be $1, the second $2, and so on, as shown in the preceding example.
regular expression, but also capture the matched text and store it in a variable:
The preceding code produces this output:
The variable $0 stores the whole matched text (assuming the overall match succeeded). If you put brackets around any part of the regular expression, it creates a group, and any matched groups will also be stored in variables. The first matched group will be $1, the second $2, and so on, as shown in the preceding example.
Here are some examples of selector and case statements:
- Add the following code to your manifest:
$systemtype = $::operatingsystem ? { 'Ubuntu' => 'debianlike', 'Debian' => 'debianlike', 'RedHat' => 'redhatlike', 'Fedora' => 'redhatlike', 'CentOS' => 'redhatlike', default => 'unknown', } notify { "You have a ${systemtype} system": } - Add the following code to your manifest:
class debianlike { notify { 'Special manifest for Debian-like systems': } } class redhatlike { notify { 'Special manifest for RedHat-like systems': } } case $::operatingsystem { 'Ubuntu', 'Debian': { include debianlike } 'RedHat', 'Fedora', 'CentOS', 'Springdale': { include redhatlike } default: { notify { "I don't know what kind of system you have!": } } }
In the first example, we used a selector (the ? operator) to choose a value for the $systemtype variable depending on the value of $::operatingsystem. This is similar to the ternary operator in C or Ruby, but instead of choosing between two possible values, you can have as many values as you like.
Unlike selectors, the case statement does not return a value. case statements come in handy when you want to execute different code depending on the value of some expression. In our second example, we used the case statement to include either the debianlike or redhatlike class, depending on the value of $::operatingsystem.
As with if statements, you can use regular expressions with selectors and case statements, and you can also capture the values of the matched groups and refer to them using $1, $2, and so on:
examples of selector and case statements:
- Add the following code to your manifest:
$systemtype = $::operatingsystem ? { 'Ubuntu' => 'debianlike', 'Debian' => 'debianlike', 'RedHat' => 'redhatlike', 'Fedora' => 'redhatlike', 'CentOS' => 'redhatlike', default => 'unknown', } notify { "You have a ${systemtype} system": } - Add the following code to your manifest:
class debianlike { notify { 'Special manifest for Debian-like systems': } } class redhatlike { notify { 'Special manifest for RedHat-like systems': } } case $::operatingsystem { 'Ubuntu', 'Debian': { include debianlike } 'RedHat', 'Fedora', 'CentOS', 'Springdale': { include redhatlike } default: { notify { "I don't know what kind of system you have!": } } }
In the first example, we used a selector (the ? operator) to choose a value for the $systemtype variable depending on the value of $::operatingsystem. This is similar to the ternary operator in C or Ruby, but instead of choosing between two possible values, you can have as many values as you like.
Unlike selectors, the case statement does not return a value. case statements come in handy when you want to execute different code depending on the value of some expression. In our second example, we used the case statement to include either the debianlike or redhatlike class, depending on the value of $::operatingsystem.
As with if statements, you can use regular expressions with selectors and case statements, and you can also capture the values of the matched groups and refer to them using $1, $2, and so on:
case statement, so let's see in detail how each of them works.
In the first example, we used a selector (the ? operator) to choose a value for the $systemtype variable depending on the value of $::operatingsystem. This is similar to the ternary operator in C or Ruby, but instead of choosing between two possible values, you can have as many values as you like.
Unlike selectors, the case statement does not return a value. case statements come in handy when you want to execute different code depending on the value of some expression. In our second example, we used the case statement to include either the debianlike or redhatlike class, depending on the value of $::operatingsystem.
As with if statements, you can use regular expressions with selectors and case statements, and you can also capture the values of the matched groups and refer to them using $1, $2, and so on:
Unlike selectors, the case statement does not return a value. case statements come in handy when you want to execute different code depending on the value of some expression. In our second example, we used the case statement to include either the debianlike or redhatlike class, depending on the value of $::operatingsystem.
As with if statements, you can use regular expressions with selectors and case statements, and you can also capture the values of the matched groups and refer to them using $1, $2, and so on:
case statement does
As with if statements, you can use regular expressions with selectors and case statements, and you can also capture the values of the matched groups and refer to them using $1, $2, and so on:
case statements, you may find the following tips useful.
As with if statements, you can use regular expressions with selectors and case statements, and you can also capture the values of the matched groups and refer to them using $1, $2, and so on:
if statements, you can use
The in operator tests whether one string contains another string. Here's an example:
When in is used with a hash, it tests whether the string is a key of the hash:
The following steps will show you how to use the in operator:
- Add the following code to your manifest:
if $::operatingsystem in [ 'Ubuntu', 'Debian' ] { notify { 'Debian-type operating system detected': } } elseif $::operatingsystem in [ 'RedHat', 'Fedora', 'SuSE', 'CentOS' ] { notify { 'RedHat-type operating system detected': } } else { notify { 'Some other operating system detected': } } - Run Puppet:
t@cookbook:~/.puppet/manifests$ puppet apply in.pp Notice: Compiled catalog for cookbook.example.com in environment production in 0.03 seconds Notice: Debian-type operating system detected Notice: /Stage[main]/Main/Notify[Debian-type operating system detected]/message: defined 'message' as 'Debian-type operating system detected' Notice: Finished catalog run in 0.02 seconds
in operator:
if $::operatingsystem in [ 'Ubuntu', 'Debian' ] {
notify { 'Debian-type operating system detected': }
} elseif $::operatingsystem in [ 'RedHat', 'Fedora', 'SuSE', 'CentOS' ] {
notify { 'RedHat-type operating system detected': }
} else {
notify { 'Some other operating system detected': }
}in expression is Boolean (true or false) so you can assign it to a variable:
Puppet's regsubst function provides an easy way to manipulate text, search and replace expressions within strings, or extract patterns from strings. We often need to do this with data obtained from a fact, for example, or from external programs.
Follow these steps to build the example:
- Add the following code to your manifest:
$class_c = regsubst($::ipaddress, '(.*)\..*', '\1.0') notify { "The network part of ${::ipaddress} is ${class_c}": } - Run Puppet:
t@cookbook:~/.puppet/manifests$ puppet apply ipaddress.pp Notice: Compiled catalog for cookbook.example.com in environment production in 0.02 seconds Notice: The network part of 192.168.122.148 is 192.168.122.0 Notice: /Stage[main]/Main/Notify[The network part of 192.168.122.148 is 192.168.122.0]/message: defined 'message' as 'The network part of 192.168.122.148 is 192.168.122.0' Notice: Finished catalog run in 0.03 seconds
The regsubst function takes at least three parameters: source, pattern, and replacement. In our example, we specified the source string as $::ipaddress, which, on this machine, is as follows:
We specify the pattern function as follows:
We specify the replacement function as follows:
We could have got the same result in other ways, of course, including the following:
- The Importing dynamic information recipe in Chapter 3, Writing Better Manifests
- The Getting information about the environment recipe in Chapter 3, Writing Better Manifests
- The Using regular expressions in if statements recipe in this chapter
$class_c = regsubst($::ipaddress, '(.*)\..*', '\1.0')
notify { "The network part of ${::ipaddress} is ${class_c}": }t@cookbook:~/.puppet/manifests$ puppet apply ipaddress.pp Notice: Compiled catalog for cookbook.example.com in environment production in 0.02 seconds Notice: The network part of 192.168.122.148 is 192.168.122.0 Notice: /Stage[main]/Main/Notify[The network part of 192.168.122.148 is 192.168.122.0]/message: defined 'message' as 'The network part of 192.168.122.148 is 192.168.122.0' Notice: Finished catalog run in 0.03 seconds
The regsubst function takes at least three parameters: source, pattern, and replacement. In our example, we specified the source string as $::ipaddress, which, on this machine, is as follows:
We specify the pattern function as follows:
We specify the replacement function as follows:
We could have got the same result in other ways, of course, including the following:
- The Importing dynamic information recipe in Chapter 3, Writing Better Manifests
- The Getting information about the environment recipe in Chapter 3, Writing Better Manifests
- The Using regular expressions in if statements recipe in this chapter
regsubst function
takes at least three parameters: source, pattern, and replacement. In our example, we specified the source string as $::ipaddress, which, on this machine, is as follows:
We specify the pattern function as follows:
We specify the replacement function as follows:
We could have got the same result in other ways, of course, including the following:
- The Importing dynamic information recipe in Chapter 3, Writing Better Manifests
- The Getting information about the environment recipe in Chapter 3, Writing Better Manifests
- The Using regular expressions in if statements recipe in this chapter
pattern function can be any regular expression, using the same (Ruby) syntax as regular expressions in if statements.
- The Importing dynamic information recipe in Chapter 3, Writing Better Manifests
- The Getting information about the environment recipe in Chapter 3, Writing Better Manifests
- The Using regular expressions in if statements recipe in this chapter
Puppet language is evolving at the moment; many features that are expected to be included in the next major release (4) are available if you enable the future parser.
- Ensure that the
rgengem is installed. - Set
parser = futurein the[main]section of yourpuppet.conf(/etc/puppet/puppet.conffor open source Puppet asroot,/etc/puppetlabs/puppet/puppet.conffor PuppetEnterprise, and~/.puppet/puppet.conffor a non-root user running puppet). - To temporarily test with the future parser, use
--parser=futureon the command line.
You can concatenate arrays with the + operator or append them with the << operator. In the following example, we use the ternary operator to assign a specific package name to the $apache variable. We then append that value to an array using the << operator:
Lambda functions are iterators applied to arrays or hashes. You iterate through the array or hash and apply an iterator function such as each, map, filter, reduce, or slice to each element of the array or key of the hash. Some of the lambda functions return a calculated array or value; others such as each only return the input array or hash.
Reduce is used to reduce the array to a single value. This can be used to calculate the maximum or minimum of the array, or in this case, the sum of the elements of the array:
Filter is used to filter the array or hash based upon a test within the lambda function. For instance to filter our $count array as follows:
When we apply this manifest, we see that only elements 4 and 5 are in the result:
Map is used to apply a function to each element of the array. For instance, if we wanted (for some unknown reason) to compute the square of all the elements of the array, we would use map as follows:
Slice is useful when you have related values stored in the same array in a sequential order. For instance, if we had the destination and port information for a firewall in an array, we could split them up into pairs and perform operations on those pairs:
When applied, this manifest will produce the following notices:
Each is used to iterate over the elements of the array but lacks the ability to capture the results like the other functions. Each is the simplest case where you simply wish to do something with each element of the array, as shown in the following code snippet:
As expected, this executes the notice for each element of the $count array, as follows:
rgen gem is installed.
parser = future in the [main] section of your puppet.conf(/etc/puppet/puppet.conf for open source Puppet as root,/etc/puppetlabs/puppet/puppet.conf for Puppet Enterprise, and~/.puppet/puppet.conf for a non-root user running puppet).
--parser=future on the command line.
You can concatenate arrays with the + operator or append them with the << operator. In the following example, we use the ternary operator to assign a specific package name to the $apache variable. We then append that value to an array using the << operator:
Lambda functions are iterators applied to arrays or hashes. You iterate through the array or hash and apply an iterator function such as each, map, filter, reduce, or slice to each element of the array or key of the hash. Some of the lambda functions return a calculated array or value; others such as each only return the input array or hash.
Reduce is used to reduce the array to a single value. This can be used to calculate the maximum or minimum of the array, or in this case, the sum of the elements of the array:
Filter is used to filter the array or hash based upon a test within the lambda function. For instance to filter our $count array as follows:
When we apply this manifest, we see that only elements 4 and 5 are in the result:
Map is used to apply a function to each element of the array. For instance, if we wanted (for some unknown reason) to compute the square of all the elements of the array, we would use map as follows:
Slice is useful when you have related values stored in the same array in a sequential order. For instance, if we had the destination and port information for a firewall in an array, we could split them up into pairs and perform operations on those pairs:
When applied, this manifest will produce the following notices:
Each is used to iterate over the elements of the array but lacks the ability to capture the results like the other functions. Each is the simplest case where you simply wish to do something with each element of the array, as shown in the following code snippet:
As expected, this executes the notice for each element of the $count array, as follows:
$::facterversion fact with a number, but the value is treated as a string so the code fails to compile. Using the future parser, the value is converted and no error is reported as shown in the following command line output:
You can concatenate arrays with the + operator or append them with the << operator. In the following example, we use the ternary operator to assign a specific package name to the $apache variable. We then append that value to an array using the << operator:
Lambda functions are iterators applied to arrays or hashes. You iterate through the array or hash and apply an iterator function such as each, map, filter, reduce, or slice to each element of the array or key of the hash. Some of the lambda functions return a calculated array or value; others such as each only return the input array or hash.
Reduce is used to reduce the array to a single value. This can be used to calculate the maximum or minimum of the array, or in this case, the sum of the elements of the array:
Filter is used to filter the array or hash based upon a test within the lambda function. For instance to filter our $count array as follows:
When we apply this manifest, we see that only elements 4 and 5 are in the result:
Map is used to apply a function to each element of the array. For instance, if we wanted (for some unknown reason) to compute the square of all the elements of the array, we would use map as follows:
Slice is useful when you have related values stored in the same array in a sequential order. For instance, if we had the destination and port information for a firewall in an array, we could split them up into pairs and perform operations on those pairs:
When applied, this manifest will produce the following notices:
Each is used to iterate over the elements of the array but lacks the ability to capture the results like the other functions. Each is the simplest case where you simply wish to do something with each element of the array, as shown in the following code snippet:
As expected, this executes the notice for each element of the $count array, as follows:
arrays with the + operator or append them with the << operator. In the following example, we use the ternary operator to assign a specific package name to the $apache variable. We then append that value to an array using the << operator:
Lambda functions are iterators applied to arrays or hashes. You iterate through the array or hash and apply an iterator function such as each, map, filter, reduce, or slice to each element of the array or key of the hash. Some of the lambda functions return a calculated array or value; others such as each only return the input array or hash.
Reduce is used to reduce the array to a single value. This can be used to calculate the maximum or minimum of the array, or in this case, the sum of the elements of the array:
Filter is used to filter the array or hash based upon a test within the lambda function. For instance to filter our $count array as follows:
When we apply this manifest, we see that only elements 4 and 5 are in the result:
Map is used to apply a function to each element of the array. For instance, if we wanted (for some unknown reason) to compute the square of all the elements of the array, we would use map as follows:
Slice is useful when you have related values stored in the same array in a sequential order. For instance, if we had the destination and port information for a firewall in an array, we could split them up into pairs and perform operations on those pairs:
When applied, this manifest will produce the following notices:
Each is used to iterate over the elements of the array but lacks the ability to capture the results like the other functions. Each is the simplest case where you simply wish to do something with each element of the array, as shown in the following code snippet:
As expected, this executes the notice for each element of the $count array, as follows:
Reduce is used to reduce the array to a single value. This can be used to calculate the maximum or minimum of the array, or in this case, the sum of the elements of the array:
Filter is used to filter the array or hash based upon a test within the lambda function. For instance to filter our $count array as follows:
When we apply this manifest, we see that only elements 4 and 5 are in the result:
Map is used to apply a function to each element of the array. For instance, if we wanted (for some unknown reason) to compute the square of all the elements of the array, we would use map as follows:
Slice is useful when you have related values stored in the same array in a sequential order. For instance, if we had the destination and port information for a firewall in an array, we could split them up into pairs and perform operations on those pairs:
When applied, this manifest will produce the following notices:
Each is used to iterate over the elements of the array but lacks the ability to capture the results like the other functions. Each is the simplest case where you simply wish to do something with each element of the array, as shown in the following code snippet:
As expected, this executes the notice for each element of the $count array, as follows:
is used to reduce the array to a single value. This can be used to calculate the maximum or minimum of the array, or in this case, the sum of the elements of the array:
Filter is used to filter the array or hash based upon a test within the lambda function. For instance to filter our $count array as follows:
When we apply this manifest, we see that only elements 4 and 5 are in the result:
Map is used to apply a function to each element of the array. For instance, if we wanted (for some unknown reason) to compute the square of all the elements of the array, we would use map as follows:
Slice is useful when you have related values stored in the same array in a sequential order. For instance, if we had the destination and port information for a firewall in an array, we could split them up into pairs and perform operations on those pairs:
When applied, this manifest will produce the following notices:
Each is used to iterate over the elements of the array but lacks the ability to capture the results like the other functions. Each is the simplest case where you simply wish to do something with each element of the array, as shown in the following code snippet:
As expected, this executes the notice for each element of the $count array, as follows:
used to filter the array or hash based upon a test within the lambda function. For instance to filter our $count array as follows:
When we apply this manifest, we see that only elements 4 and 5 are in the result:
Map is used to apply a function to each element of the array. For instance, if we wanted (for some unknown reason) to compute the square of all the elements of the array, we would use map as follows:
Slice is useful when you have related values stored in the same array in a sequential order. For instance, if we had the destination and port information for a firewall in an array, we could split them up into pairs and perform operations on those pairs:
When applied, this manifest will produce the following notices:
Each is used to iterate over the elements of the array but lacks the ability to capture the results like the other functions. Each is the simplest case where you simply wish to do something with each element of the array, as shown in the following code snippet:
As expected, this executes the notice for each element of the $count array, as follows:
is used to apply a function to each element of the array. For instance, if we wanted (for some unknown reason) to compute the square of all the elements of the array, we would use map as follows:
Slice is useful when you have related values stored in the same array in a sequential order. For instance, if we had the destination and port information for a firewall in an array, we could split them up into pairs and perform operations on those pairs:
When applied, this manifest will produce the following notices:
Each is used to iterate over the elements of the array but lacks the ability to capture the results like the other functions. Each is the simplest case where you simply wish to do something with each element of the array, as shown in the following code snippet:
As expected, this executes the notice for each element of the $count array, as follows:
when you have related values stored in the same array in a sequential order. For instance, if we had the destination and port information for a firewall in an array, we could split them up into pairs and perform operations on those pairs:
When applied, this manifest will produce the following notices:
Each is used to iterate over the elements of the array but lacks the ability to capture the results like the other functions. Each is the simplest case where you simply wish to do something with each element of the array, as shown in the following code snippet:
As expected, this executes the notice for each element of the $count array, as follows:
is used to iterate over the elements of the array but lacks the ability to capture the results like the other functions. Each is the simplest case where you simply wish to do something with each element of the array, as shown in the following code snippet:
As expected, this executes the notice for each element of the $count array, as follows:
"Computers in the future may have as few as 1,000 vacuum tubes and weigh only 1.5 tons." | ||
| --Popular Mechanics, 1949 | ||
In this chapter, we will cover:
- Installing Puppet
- Managing your manifests with Git
- Creating a decentralized Puppet architecture
- Writing a papply script
- Running Puppet from cron
- Bootstrapping Puppet with bash
- Creating a centralized Puppet infrastructure
- Creating certificates with multiple DNS names
- Running Puppet from passenger
- Setting up the environment
- Configuring PuppetDB
- Configuring Hiera
- Setting-node specific data with Hiera
- Storing secret data with hiera-gpg
- Using MessagePack serialization
- Automatic syntax checking with Git hooks
- Pushing code around with Git
- Managing environments with Git
We'll configure and use both PuppetDB and Hiera. PuppetDB is used with exported resources, which we will cover in Chapter 5, Users and Virtual Resources. Hiera is used to separate variable data from Puppet code.
Finally, I'll introduce Git and see how to use Git to organize our code and our infrastructure.
Because Linux distributions, such as Ubuntu, Red Hat, and CentOS, differ in the specific details of package names, configuration file paths, and many other things, I have decided that for reasons of space and clarity the best approach for this book is to pick one distribution (Debian 7 named as Wheezy) and stick to that. However, Puppet runs on most popular operating systems, so you should have very little trouble adapting the recipes to your own favorite OS and distribution.
At the time of writing, Puppet 3.7.2 is the latest stable version available, this is the version of Puppet used in the book. The syntax of Puppet commands changes often, so be aware that while older versions of Puppet are still perfectly usable, they may not support all of the features and syntax described in this book. As we saw in Chapter 1, Puppet Language and Style, the future parser showcases features of the language scheduled to become default in Version 4 of Puppet.
In Chapter 1, Puppet Language and Style, we installed Puppet as a rubygem using the gem install. When deploying to several nodes, this may not be the best approach. Using the package manager of your chosen distribution is the best way to keep your Puppet versions similar on all of the nodes in your deployment. Puppet labs maintain repositories for APT-based and YUM-based distributions.
If your Linux distribution uses APT for package management, go to http://apt.puppetlabs.com/ and download the appropriate Puppet labs release package for your distribution. For our wheezy cookbook node, we will use http://apt.puppetlabs.com/puppetlabs-release-wheezy.deb.
If you are using a Linux distribution that uses YUM for package management, go to http://yum.puppetlabs.com/ and download the appropriate Puppet labs release package for your distribution.
- Once you have found the appropriate Puppet labs release package for your distribution, the steps to install Puppet are the same for either APT or YUM:
- Install Puppet labs release package
- Install Puppet package
- Once you have installed Puppet, verify the version of Puppet as shown in the following example:
t@ckbk:~ puppet --version 3.7.2
Now that we have a method to install Puppet on our nodes, we need to turn our attention to keeping our Puppet manifests organized. In the next section, we will see how to use Git to keep our code organized and consistent.
http://apt.puppetlabs.com/ and download the appropriate Puppet labs release package for your distribution. For our wheezy cookbook node, we will use http://apt.puppetlabs.com/puppetlabs-release-wheezy.deb.
If you are using a Linux distribution that uses YUM for package management, go to http://yum.puppetlabs.com/ and download the appropriate Puppet labs release package for your distribution.
- Once you have found the appropriate Puppet labs release package for your distribution, the steps to install Puppet are the same for either APT or YUM:
- Install Puppet labs release package
- Install Puppet package
- Once you have installed Puppet, verify the version of Puppet as shown in the following example:
t@ckbk:~ puppet --version 3.7.2
Now that we have a method to install Puppet on our nodes, we need to turn our attention to keeping our Puppet manifests organized. In the next section, we will see how to use Git to keep our code organized and consistent.
- Install Puppet labs release package
- Install Puppet package
t@ckbk:~ puppet --version 3.7.2
It's a great idea to put your Puppet manifests in a version control system such as Git or Subversion (Git is the de facto standard for Puppet). This gives you several advantages:
- You can undo changes and revert to any previous version of your manifest
- You can experiment with new features using a branch
- If several people need to make changes to the manifests, they can make them independently, in their own working copies, and then merge their changes later
- You can use the
git logfeature to see what was changed, and when (and by whom)
- First, install Git on your Git server (
git.example.comin our example). The easiest way to do this is using Puppet. Create the following manifest, call itgit.pp:package {'git': ensure => installed } - Apply this manifest using
puppet apply git.pp, this will install Git. - Next, create a Git user that the nodes will use to log in and retrieve the latest code. Again, we'll do this with puppet. We'll also create a directory to hold our repository (
/home/git/repos) as shown in the following code snippet:group { 'git': gid => 1111, } user {'git': uid => 1111, gid => 1111, comment => 'Git User', home => '/home/git', require => Group['git'], } file {'/home/git': ensure => 'directory', owner => 1111, group => 1111, require => User['git'], } file {'/home/git/repos': ensure => 'directory', owner => 1111, group => 1111, require => File['/home/git'] } - After applying that manifest, log in as the Git user and create an empty Git repository using the following command:
# sudo -iu git git@git $ cd repos git@git $ git init --bare puppet.git Initialized empty Git repository in /home/git/repos/puppet.git/ - Set a password for the Git user, we'll need to log in remotely after the next step:
[root@git ~]# passwd git Changing password for user git. New password: Retype new password: passwd: all authentication tokens updated successfully.
- Now back on your local machine, create an
sshkey for our nodes to use to update the repository:t@mylaptop ~ $ cd .ssh t@mylaptop ~/.ssh $ ssh-keygen -b 4096 -f git_rsa Generating public/private rsa key pair. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in git_rsa. Your public key has been saved in git_rsa.pub. The key fingerprint is: 87:35:0e:4e:d2:96:5f:e4:ce:64:4a:d5:76:c8:2b:e4 thomas@mylaptop
- Now copy the newly created public key to the
authorized_keysfile. This will allow us to connect to the Git server using this new key:t@mylaptop ~/.ssh $ ssh-copy-id -i git_rsa git@git.example.com git@git.example.com's password: Number of key(s) added: 1
- Now try logging into the machine, with: "ssh 'git@git.example.com'" and check to make sure that only the key(s) you wanted were added.
- Next, configure
sshto use your key when accessing the Git server and add the following to your~/.ssh/configfile:Host git git.example.com User git IdentityFile /home/thomas/.ssh/git_rsa
- Clone the repo onto your machine into a directory named Puppet (substitute your server name if you didn't use
git.example.com):t@mylaptop ~$ git clone git@git.example.com:repos/puppet.git Cloning into 'puppet'... warning: You appear to have cloned an empty repository. Checking connectivity... done.
We've created a Git repository; before we commit any changes to the repository, it's a good idea to set your name and e-mail in Git. Your name and e-mail will be appended to each commit you make.
- When you are working in a large team, knowing who made a change is very important; for this, use the following code snippet:
t@mylaptop puppet$ git config --global user.email"thomas@narrabilis.com" t@mylaptop puppet$ git config --global user.name "ThomasUphill"
- You can verify your Git settings using the following snippet:
t@mylaptop ~$ git config --global --list user.name=Thomas Uphill user.email=thomas@narrabilis.com core.editor=vim merge.tool=vimdiff color.ui=true push.default=simple
- Now that we have Git configured properly, change directory to your repository directory and create a new site manifest as shown in the following snippet:
t@mylaptop ~$ cd puppet t@mylaptop puppet$ mkdir manifests t@mylaptop puppet$ vim manifests/site.pp node default { include base }
- This site manifest will install our base class on every node; we will create the base class using the Puppet module as we did in Chapter 1, Puppet Language and Style:
t@mylaptop puppet$ mkdir modules t@mylaptop puppet$ cd modules t@mylaptop modules$ puppet module generate thomas-base Notice: Generating module at /home/tuphill/puppet/modules/thomas-base thomas-base thomas-base/Modulefile thomas-base/README thomas-base/manifests thomas-base/manifests/init.pp thomas-base/spec thomas-base/spec/spec_helper.rb thomas-base/tests thomas-base/tests/init.pp t@mylaptop modules$ ln -s thomas-base base
- As a last step, we create a symbolic link between the
thomas-basedirectory andbase. Now to make sure our module does something useful, add the following to the body of thebaseclass defined inthomas-base/manifests/init.pp:class base { file {'/etc/motd': content => "${::fqdn}\nManaged by puppet ${::puppetversion}\n" } }
- Now add the new base module and site manifest to Git using
git addandgit commitas follows:t@mylaptop modules$ cd .. t@mylaptop puppet$ git add modules manifests t@mylaptop puppet$ git status On branch master Initial commit Changes to be committed: (use "git rm --cached <file>..." to unstage) new file: manifests/site.pp new file: modules/base new file: modules/thomas-base/Modulefile new file: modules/thomas-base/README new file: modules/thomas-base/manifests/init.pp new file: modules/thomas-base/spec/spec_helper.rb new file: modules/thomas-base/tests/init.pp t@mylaptop puppet$ git commit -m "Initial commit with simple base module" [master (root-commit) 3e1f837] Initial commit with simple base module 7 files changed, 102 insertions(+) create mode 100644 manifests/site.pp create mode 120000 modules/base create mode 100644 modules/thomas-base/Modulefile create mode 100644 modules/thomas-base/README create mode 100644 modules/thomas-base/manifests/init.pp create mode 100644 modules/thomas-base/spec/spec_helper.rb create mode 100644 modules/thomas-base/tests/init.pp
- At this point your changes to the Git repository have been committed locally; you now need to push those changes back to
git.example.comso that other nodes can retrieve the updated files:t@mylaptop puppet$ git push origin master Counting objects: 15, done. Delta compression using up to 4 threads. Compressing objects: 100% (9/9), done. Writing objects: 100% (15/15), 2.15 KiB | 0 bytes/s, done. Total 15 (delta 0), reused 0 (delta 0) To git@git.example.com:repos/puppet.git * [new branch] master -> master
Now that you have a central Git repository for your Puppet manifests, you can check out multiple copies of it in different places and work on them before committing your changes. For example, if you're working in a team, each member can have their own local copy of the repo and synchronize changes with the others via the central server. You may also choose to use GitHub as your central Git repository server. GitHub offers free Git repository hosting for public repositories, and you can pay for GitHub's premium service if you don't want your Puppet code to be publicly available.
- First, install Git on your Git server (
git.example.comin our example). The easiest way to do this is using Puppet. Create the following manifest, call itgit.pp:package {'git': ensure => installed } - Apply this manifest using
puppet apply git.pp, this will install Git. - Next, create a Git user that the nodes will use to log in and retrieve the latest code. Again, we'll do this with puppet. We'll also create a directory to hold our repository (
/home/git/repos) as shown in the following code snippet:group { 'git': gid => 1111, } user {'git': uid => 1111, gid => 1111, comment => 'Git User', home => '/home/git', require => Group['git'], } file {'/home/git': ensure => 'directory', owner => 1111, group => 1111, require => User['git'], } file {'/home/git/repos': ensure => 'directory', owner => 1111, group => 1111, require => File['/home/git'] } - After applying that manifest, log in as the Git user and create an empty Git repository using the following command:
# sudo -iu git git@git $ cd repos git@git $ git init --bare puppet.git Initialized empty Git repository in /home/git/repos/puppet.git/ - Set a password for the Git user, we'll need to log in remotely after the next step:
[root@git ~]# passwd git Changing password for user git. New password: Retype new password: passwd: all authentication tokens updated successfully.
- Now back on your local machine, create an
sshkey for our nodes to use to update the repository:t@mylaptop ~ $ cd .ssh t@mylaptop ~/.ssh $ ssh-keygen -b 4096 -f git_rsa Generating public/private rsa key pair. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in git_rsa. Your public key has been saved in git_rsa.pub. The key fingerprint is: 87:35:0e:4e:d2:96:5f:e4:ce:64:4a:d5:76:c8:2b:e4 thomas@mylaptop
- Now copy the newly created public key to the
authorized_keysfile. This will allow us to connect to the Git server using this new key:t@mylaptop ~/.ssh $ ssh-copy-id -i git_rsa git@git.example.com git@git.example.com's password: Number of key(s) added: 1
- Now try logging into the machine, with: "ssh 'git@git.example.com'" and check to make sure that only the key(s) you wanted were added.
- Next, configure
sshto use your key when accessing the Git server and add the following to your~/.ssh/configfile:Host git git.example.com User git IdentityFile /home/thomas/.ssh/git_rsa
- Clone the repo onto your machine into a directory named Puppet (substitute your server name if you didn't use
git.example.com):t@mylaptop ~$ git clone git@git.example.com:repos/puppet.git Cloning into 'puppet'... warning: You appear to have cloned an empty repository. Checking connectivity... done.
We've created a Git repository; before we commit any changes to the repository, it's a good idea to set your name and e-mail in Git. Your name and e-mail will be appended to each commit you make.
- When you are working in a large team, knowing who made a change is very important; for this, use the following code snippet:
t@mylaptop puppet$ git config --global user.email"thomas@narrabilis.com" t@mylaptop puppet$ git config --global user.name "ThomasUphill"
- You can verify your Git settings using the following snippet:
t@mylaptop ~$ git config --global --list user.name=Thomas Uphill user.email=thomas@narrabilis.com core.editor=vim merge.tool=vimdiff color.ui=true push.default=simple
- Now that we have Git configured properly, change directory to your repository directory and create a new site manifest as shown in the following snippet:
t@mylaptop ~$ cd puppet t@mylaptop puppet$ mkdir manifests t@mylaptop puppet$ vim manifests/site.pp node default { include base }
- This site manifest will install our base class on every node; we will create the base class using the Puppet module as we did in Chapter 1, Puppet Language and Style:
t@mylaptop puppet$ mkdir modules t@mylaptop puppet$ cd modules t@mylaptop modules$ puppet module generate thomas-base Notice: Generating module at /home/tuphill/puppet/modules/thomas-base thomas-base thomas-base/Modulefile thomas-base/README thomas-base/manifests thomas-base/manifests/init.pp thomas-base/spec thomas-base/spec/spec_helper.rb thomas-base/tests thomas-base/tests/init.pp t@mylaptop modules$ ln -s thomas-base base
- As a last step, we create a symbolic link between the
thomas-basedirectory andbase. Now to make sure our module does something useful, add the following to the body of thebaseclass defined inthomas-base/manifests/init.pp:class base { file {'/etc/motd': content => "${::fqdn}\nManaged by puppet ${::puppetversion}\n" } }
- Now add the new base module and site manifest to Git using
git addandgit commitas follows:t@mylaptop modules$ cd .. t@mylaptop puppet$ git add modules manifests t@mylaptop puppet$ git status On branch master Initial commit Changes to be committed: (use "git rm --cached <file>..." to unstage) new file: manifests/site.pp new file: modules/base new file: modules/thomas-base/Modulefile new file: modules/thomas-base/README new file: modules/thomas-base/manifests/init.pp new file: modules/thomas-base/spec/spec_helper.rb new file: modules/thomas-base/tests/init.pp t@mylaptop puppet$ git commit -m "Initial commit with simple base module" [master (root-commit) 3e1f837] Initial commit with simple base module 7 files changed, 102 insertions(+) create mode 100644 manifests/site.pp create mode 120000 modules/base create mode 100644 modules/thomas-base/Modulefile create mode 100644 modules/thomas-base/README create mode 100644 modules/thomas-base/manifests/init.pp create mode 100644 modules/thomas-base/spec/spec_helper.rb create mode 100644 modules/thomas-base/tests/init.pp
- At this point your changes to the Git repository have been committed locally; you now need to push those changes back to
git.example.comso that other nodes can retrieve the updated files:t@mylaptop puppet$ git push origin master Counting objects: 15, done. Delta compression using up to 4 threads. Compressing objects: 100% (9/9), done. Writing objects: 100% (15/15), 2.15 KiB | 0 bytes/s, done. Total 15 (delta 0), reused 0 (delta 0) To git@git.example.com:repos/puppet.git * [new branch] master -> master
Now that you have a central Git repository for your Puppet manifests, you can check out multiple copies of it in different places and work on them before committing your changes. For example, if you're working in a team, each member can have their own local copy of the repo and synchronize changes with the others via the central server. You may also choose to use GitHub as your central Git repository server. GitHub offers free Git repository hosting for public repositories, and you can pay for GitHub's premium service if you don't want your Puppet code to be publicly available.
- Git on your Git server (
git.example.comin our example). The easiest way to do this is using Puppet. Create the following manifest, call itgit.pp:package {'git': ensure => installed } - Apply this manifest using
puppet apply git.pp, this will install Git. - Next, create a Git user that the nodes will use to log in and retrieve the latest code. Again, we'll do this with puppet. We'll also create a directory to hold our repository (
/home/git/repos) as shown in the following code snippet:group { 'git': gid => 1111, } user {'git': uid => 1111, gid => 1111, comment => 'Git User', home => '/home/git', require => Group['git'], } file {'/home/git': ensure => 'directory', owner => 1111, group => 1111, require => User['git'], } file {'/home/git/repos': ensure => 'directory', owner => 1111, group => 1111, require => File['/home/git'] } - After applying that manifest, log in as the Git user and create an empty Git repository using the following command:
# sudo -iu git git@git $ cd repos git@git $ git init --bare puppet.git Initialized empty Git repository in /home/git/repos/puppet.git/ - Set a password for the Git user, we'll need to log in remotely after the next step:
[root@git ~]# passwd git Changing password for user git. New password: Retype new password: passwd: all authentication tokens updated successfully.
- Now back on your local machine, create an
sshkey for our nodes to use to update the repository:t@mylaptop ~ $ cd .ssh t@mylaptop ~/.ssh $ ssh-keygen -b 4096 -f git_rsa Generating public/private rsa key pair. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in git_rsa. Your public key has been saved in git_rsa.pub. The key fingerprint is: 87:35:0e:4e:d2:96:5f:e4:ce:64:4a:d5:76:c8:2b:e4 thomas@mylaptop
- Now copy the newly created public key to the
authorized_keysfile. This will allow us to connect to the Git server using this new key:t@mylaptop ~/.ssh $ ssh-copy-id -i git_rsa git@git.example.com git@git.example.com's password: Number of key(s) added: 1
- Now try logging into the machine, with: "ssh 'git@git.example.com'" and check to make sure that only the key(s) you wanted were added.
- Next, configure
sshto use your key when accessing the Git server and add the following to your~/.ssh/configfile:Host git git.example.com User git IdentityFile /home/thomas/.ssh/git_rsa
- Clone the repo onto your machine into a directory named Puppet (substitute your server name if you didn't use
git.example.com):t@mylaptop ~$ git clone git@git.example.com:repos/puppet.git Cloning into 'puppet'... warning: You appear to have cloned an empty repository. Checking connectivity... done.
We've created a Git repository; before we commit any changes to the repository, it's a good idea to set your name and e-mail in Git. Your name and e-mail will be appended to each commit you make.
- When you are working in a large team, knowing who made a change is very important; for this, use the following code snippet:
t@mylaptop puppet$ git config --global user.email"thomas@narrabilis.com" t@mylaptop puppet$ git config --global user.name "ThomasUphill"
- You can verify your Git settings using the following snippet:
t@mylaptop ~$ git config --global --list user.name=Thomas Uphill user.email=thomas@narrabilis.com core.editor=vim merge.tool=vimdiff color.ui=true push.default=simple
- Now that we have Git configured properly, change directory to your repository directory and create a new site manifest as shown in the following snippet:
t@mylaptop ~$ cd puppet t@mylaptop puppet$ mkdir manifests t@mylaptop puppet$ vim manifests/site.pp node default { include base }
- This site manifest will install our base class on every node; we will create the base class using the Puppet module as we did in Chapter 1, Puppet Language and Style:
t@mylaptop puppet$ mkdir modules t@mylaptop puppet$ cd modules t@mylaptop modules$ puppet module generate thomas-base Notice: Generating module at /home/tuphill/puppet/modules/thomas-base thomas-base thomas-base/Modulefile thomas-base/README thomas-base/manifests thomas-base/manifests/init.pp thomas-base/spec thomas-base/spec/spec_helper.rb thomas-base/tests thomas-base/tests/init.pp t@mylaptop modules$ ln -s thomas-base base
- As a last step, we create a symbolic link between the
thomas-basedirectory andbase. Now to make sure our module does something useful, add the following to the body of thebaseclass defined inthomas-base/manifests/init.pp:class base { file {'/etc/motd': content => "${::fqdn}\nManaged by puppet ${::puppetversion}\n" } }
- Now add the new base module and site manifest to Git using
git addandgit commitas follows:t@mylaptop modules$ cd .. t@mylaptop puppet$ git add modules manifests t@mylaptop puppet$ git status On branch master Initial commit Changes to be committed: (use "git rm --cached <file>..." to unstage) new file: manifests/site.pp new file: modules/base new file: modules/thomas-base/Modulefile new file: modules/thomas-base/README new file: modules/thomas-base/manifests/init.pp new file: modules/thomas-base/spec/spec_helper.rb new file: modules/thomas-base/tests/init.pp t@mylaptop puppet$ git commit -m "Initial commit with simple base module" [master (root-commit) 3e1f837] Initial commit with simple base module 7 files changed, 102 insertions(+) create mode 100644 manifests/site.pp create mode 120000 modules/base create mode 100644 modules/thomas-base/Modulefile create mode 100644 modules/thomas-base/README create mode 100644 modules/thomas-base/manifests/init.pp create mode 100644 modules/thomas-base/spec/spec_helper.rb create mode 100644 modules/thomas-base/tests/init.pp
- At this point your changes to the Git repository have been committed locally; you now need to push those changes back to
git.example.comso that other nodes can retrieve the updated files:t@mylaptop puppet$ git push origin master Counting objects: 15, done. Delta compression using up to 4 threads. Compressing objects: 100% (9/9), done. Writing objects: 100% (15/15), 2.15 KiB | 0 bytes/s, done. Total 15 (delta 0), reused 0 (delta 0) To git@git.example.com:repos/puppet.git * [new branch] master -> master
Now that you have a central Git repository for your Puppet manifests, you can check out multiple copies of it in different places and work on them before committing your changes. For example, if you're working in a team, each member can have their own local copy of the repo and synchronize changes with the others via the central server. You may also choose to use GitHub as your central Git repository server. GitHub offers free Git repository hosting for public repositories, and you can pay for GitHub's premium service if you don't want your Puppet code to be publicly available.
git commit command and annotate with a message.
git.example.com copy, the git push command pushes all changes made since the last sync.
Now that you have a central Git repository for your Puppet manifests, you can check out multiple copies of it in different places and work on them before committing your changes. For example, if you're working in a team, each member can have their own local copy of the repo and synchronize changes with the others via the central server. You may also choose to use GitHub as your central Git repository server. GitHub offers free Git repository hosting for public repositories, and you can pay for GitHub's premium service if you don't want your Puppet code to be publicly available.
repo and synchronize changes with the others via the central server. You may also choose to use GitHub as your central Git repository server. GitHub offers free Git repository hosting for public repositories, and you can pay for GitHub's premium service if you don't want your Puppet code to be publicly available.
Puppet is a configuration management tool. You can use Puppet to configure and prevent configuration drift in a large number of client computers. If all your client computers are easily reached via a central location, you may choose to have a central Puppet server control all the client computers. In the centralized model, the Puppet server is known as the Puppet master. We will cover how to configure a central Puppet master in a few sections.
Create a bootstrap.pp manifest that will perform the following configuration steps on our new node:
- Install Git:
package {'git': ensure => 'installed' } - Install the
sshkey to accessgit.example.comin the Puppet user's home directory (/var/lib/puppet/.ssh/id_rsa):File { owner => 'puppet', group => 'puppet', } file {'/var/lib/puppet/.ssh': ensure => 'directory', } file {'/var/lib/puppet/.ssh/id_rsa': content => " -----BEGIN RSA PRIVATE KEY----- … NIjTXmZUlOKefh4MBilqUU3KQG8GBHjzYl2TkFVGLNYGNA0U8VG8SUJq -----END RSA PRIVATE KEY----- ", mode => 0600, require => File['/var/lib/puppet/.ssh'] } - Download the
sshhost key fromgit.example.com(/var/lib/puppet/.ssh/known_hosts):exec {'download git.example.com host key': command => 'sudo -u puppet ssh-keyscan git.example.com >> /var/lib/puppet/.ssh/known_hosts', path => '/usr/bin:/usr/sbin:/bin:/sbin', unless => 'grep git.example.com /var/lib/puppet/.ssh/known_hosts', require => File['/var/lib/puppet/.ssh'], } - Create a directory to contain the Git repository (
/etc/puppet/cookbook):file {'/etc/puppet/cookbook': ensure => 'directory', } - Clone the Puppet repository onto the new machine:
exec {'create cookbook': command => 'sudo -u puppet git clone git@git.example.com:repos/puppet.git /etc/puppet/cookbook', path => '/usr/bin:/usr/sbin:/bin:/sbin', require => [Package['git'],File['/var/lib/puppet/.ssh/id_rsa'],Exec['download git.example.com host key']], unless => 'test -f /etc/puppet/cookbook/.git/config', } - Now when we run Puppet apply on the new machine, the
sshkey will be installed for the Puppet user. The Puppet user will then clone the Git repository into/etc/puppet/cookbook:root@testnode /tmp# puppet apply bootstrap.pp Notice: Compiled catalog for testnode.example.com in environment production in 0.40 seconds Notice: /Stage[main]/Main/File[/etc/puppet/cookbook]/ensure: created Notice: /Stage[main]/Main/File[/var/lib/puppet/.ssh]/ensure: created Notice: /Stage[main]/Main/Exec[download git.example.com host key]/returns: executed successfully Notice: /Stage[main]/Main/File[/var/lib/puppet/.ssh/id_rsa]/ensure: defined content as '{md5}da61ce6ccc79bc6937bd98c798bc9fd3' Notice: /Stage[main]/Main/Exec[create cookbook]/returns: executed successfully Notice: Finished catalog run in 0.82 seconds
- Now that your Puppet code is available on the new node, you can apply it using
puppet apply, specifying that/etc/puppet/cookbook/moduleswill contain the modules:root@testnode ~# puppet apply --modulepath=/etc/puppet/cookbook/modules /etc/puppet/cookbook/manifests/site.pp Notice: Compiled catalog for testnode.example.com in environment production in 0.12 seconds Notice: /Stage[main]/Base/File[/etc/motd]/content: content changed '{md5}86d28ff83a8d49d349ba56b5c64b79ee' to '{md5}4c4c3ab7591d940318279d78b9c51d4f' Notice: Finished catalog run in 0.11 seconds root@testnode /tmp# cat /etc/motd testnode.example.com Managed by puppet 3.6.2
First, our bootstrap.pp manifest ensures that Git is installed. The manifest then goes on to ensure that the ssh key for the Git user on git.example.com is installed into the Puppet user's home directory (/var/lib/puppet by default). The manifest then ensures that the host key for git.example.com is trusted by the Puppet user. With ssh configured, the bootstrap ensures that /etc/puppet/cookbook exists and is a directory.
We then use an exec to have Git clone the repository into /etc/puppet/cookbook. With all the code in place, we then call puppet apply a final time to deploy the code from the repository. In a production setting, you would distribute the bootstrap.pp manifest to all your nodes, possibly via an internal web server, using a method similar to curl http://puppet/bootstrap.pp >bootstrap.pp && puppet apply bootstrap.pp
testnode for mine. Install Puppet on the machine as we have previously done.
Create a bootstrap.pp manifest that will perform the following configuration steps on our new node:
- Install Git:
package {'git': ensure => 'installed' } - Install the
sshkey to accessgit.example.comin the Puppet user's home directory (/var/lib/puppet/.ssh/id_rsa):File { owner => 'puppet', group => 'puppet', } file {'/var/lib/puppet/.ssh': ensure => 'directory', } file {'/var/lib/puppet/.ssh/id_rsa': content => " -----BEGIN RSA PRIVATE KEY----- … NIjTXmZUlOKefh4MBilqUU3KQG8GBHjzYl2TkFVGLNYGNA0U8VG8SUJq -----END RSA PRIVATE KEY----- ", mode => 0600, require => File['/var/lib/puppet/.ssh'] } - Download the
sshhost key fromgit.example.com(/var/lib/puppet/.ssh/known_hosts):exec {'download git.example.com host key': command => 'sudo -u puppet ssh-keyscan git.example.com >> /var/lib/puppet/.ssh/known_hosts', path => '/usr/bin:/usr/sbin:/bin:/sbin', unless => 'grep git.example.com /var/lib/puppet/.ssh/known_hosts', require => File['/var/lib/puppet/.ssh'], } - Create a directory to contain the Git repository (
/etc/puppet/cookbook):file {'/etc/puppet/cookbook': ensure => 'directory', } - Clone the Puppet repository onto the new machine:
exec {'create cookbook': command => 'sudo -u puppet git clone git@git.example.com:repos/puppet.git /etc/puppet/cookbook', path => '/usr/bin:/usr/sbin:/bin:/sbin', require => [Package['git'],File['/var/lib/puppet/.ssh/id_rsa'],Exec['download git.example.com host key']], unless => 'test -f /etc/puppet/cookbook/.git/config', } - Now when we run Puppet apply on the new machine, the
sshkey will be installed for the Puppet user. The Puppet user will then clone the Git repository into/etc/puppet/cookbook:root@testnode /tmp# puppet apply bootstrap.pp Notice: Compiled catalog for testnode.example.com in environment production in 0.40 seconds Notice: /Stage[main]/Main/File[/etc/puppet/cookbook]/ensure: created Notice: /Stage[main]/Main/File[/var/lib/puppet/.ssh]/ensure: created Notice: /Stage[main]/Main/Exec[download git.example.com host key]/returns: executed successfully Notice: /Stage[main]/Main/File[/var/lib/puppet/.ssh/id_rsa]/ensure: defined content as '{md5}da61ce6ccc79bc6937bd98c798bc9fd3' Notice: /Stage[main]/Main/Exec[create cookbook]/returns: executed successfully Notice: Finished catalog run in 0.82 seconds
- Now that your Puppet code is available on the new node, you can apply it using
puppet apply, specifying that/etc/puppet/cookbook/moduleswill contain the modules:root@testnode ~# puppet apply --modulepath=/etc/puppet/cookbook/modules /etc/puppet/cookbook/manifests/site.pp Notice: Compiled catalog for testnode.example.com in environment production in 0.12 seconds Notice: /Stage[main]/Base/File[/etc/motd]/content: content changed '{md5}86d28ff83a8d49d349ba56b5c64b79ee' to '{md5}4c4c3ab7591d940318279d78b9c51d4f' Notice: Finished catalog run in 0.11 seconds root@testnode /tmp# cat /etc/motd testnode.example.com Managed by puppet 3.6.2
First, our bootstrap.pp manifest ensures that Git is installed. The manifest then goes on to ensure that the ssh key for the Git user on git.example.com is installed into the Puppet user's home directory (/var/lib/puppet by default). The manifest then ensures that the host key for git.example.com is trusted by the Puppet user. With ssh configured, the bootstrap ensures that /etc/puppet/cookbook exists and is a directory.
We then use an exec to have Git clone the repository into /etc/puppet/cookbook. With all the code in place, we then call puppet apply a final time to deploy the code from the repository. In a production setting, you would distribute the bootstrap.pp manifest to all your nodes, possibly via an internal web server, using a method similar to curl http://puppet/bootstrap.pp >bootstrap.pp && puppet apply bootstrap.pp
bootstrap.pp manifest that will perform the following configuration steps on our new node:
package {'git':
ensure => 'installed'
}- the
sshkey to accessgit.example.comin the Puppet user's home directory (/var/lib/puppet/.ssh/id_rsa):File { owner => 'puppet', group => 'puppet', } file {'/var/lib/puppet/.ssh': ensure => 'directory', } file {'/var/lib/puppet/.ssh/id_rsa': content => " -----BEGIN RSA PRIVATE KEY----- … NIjTXmZUlOKefh4MBilqUU3KQG8GBHjzYl2TkFVGLNYGNA0U8VG8SUJq -----END RSA PRIVATE KEY----- ", mode => 0600, require => File['/var/lib/puppet/.ssh'] } - Download the
sshhost key fromgit.example.com(/var/lib/puppet/.ssh/known_hosts):exec {'download git.example.com host key': command => 'sudo -u puppet ssh-keyscan git.example.com >> /var/lib/puppet/.ssh/known_hosts', path => '/usr/bin:/usr/sbin:/bin:/sbin', unless => 'grep git.example.com /var/lib/puppet/.ssh/known_hosts', require => File['/var/lib/puppet/.ssh'], } - Create a directory to contain the Git repository (
/etc/puppet/cookbook):file {'/etc/puppet/cookbook': ensure => 'directory', } - Clone the Puppet repository onto the new machine:
exec {'create cookbook': command => 'sudo -u puppet git clone git@git.example.com:repos/puppet.git /etc/puppet/cookbook', path => '/usr/bin:/usr/sbin:/bin:/sbin', require => [Package['git'],File['/var/lib/puppet/.ssh/id_rsa'],Exec['download git.example.com host key']], unless => 'test -f /etc/puppet/cookbook/.git/config', } - Now when we run Puppet apply on the new machine, the
sshkey will be installed for the Puppet user. The Puppet user will then clone the Git repository into/etc/puppet/cookbook:root@testnode /tmp# puppet apply bootstrap.pp Notice: Compiled catalog for testnode.example.com in environment production in 0.40 seconds Notice: /Stage[main]/Main/File[/etc/puppet/cookbook]/ensure: created Notice: /Stage[main]/Main/File[/var/lib/puppet/.ssh]/ensure: created Notice: /Stage[main]/Main/Exec[download git.example.com host key]/returns: executed successfully Notice: /Stage[main]/Main/File[/var/lib/puppet/.ssh/id_rsa]/ensure: defined content as '{md5}da61ce6ccc79bc6937bd98c798bc9fd3' Notice: /Stage[main]/Main/Exec[create cookbook]/returns: executed successfully Notice: Finished catalog run in 0.82 seconds
- Now that your Puppet code is available on the new node, you can apply it using
puppet apply, specifying that/etc/puppet/cookbook/moduleswill contain the modules:root@testnode ~# puppet apply --modulepath=/etc/puppet/cookbook/modules /etc/puppet/cookbook/manifests/site.pp Notice: Compiled catalog for testnode.example.com in environment production in 0.12 seconds Notice: /Stage[main]/Base/File[/etc/motd]/content: content changed '{md5}86d28ff83a8d49d349ba56b5c64b79ee' to '{md5}4c4c3ab7591d940318279d78b9c51d4f' Notice: Finished catalog run in 0.11 seconds root@testnode /tmp# cat /etc/motd testnode.example.com Managed by puppet 3.6.2
First, our bootstrap.pp manifest ensures that Git is installed. The manifest then goes on to ensure that the ssh key for the Git user on git.example.com is installed into the Puppet user's home directory (/var/lib/puppet by default). The manifest then ensures that the host key for git.example.com is trusted by the Puppet user. With ssh configured, the bootstrap ensures that /etc/puppet/cookbook exists and is a directory.
We then use an exec to have Git clone the repository into /etc/puppet/cookbook. With all the code in place, we then call puppet apply a final time to deploy the code from the repository. In a production setting, you would distribute the bootstrap.pp manifest to all your nodes, possibly via an internal web server, using a method similar to curl http://puppet/bootstrap.pp >bootstrap.pp && puppet apply bootstrap.pp
bootstrap.pp manifest ensures that Git is installed. The manifest then goes on to ensure
We then use an exec to have Git clone the repository into /etc/puppet/cookbook. With all the code in place, we then call puppet apply a final time to deploy the code from the repository. In a production setting, you would distribute the bootstrap.pp manifest to all your nodes, possibly via an internal web server, using a method similar to curl http://puppet/bootstrap.pp >bootstrap.pp && puppet apply bootstrap.pp
We'd like to make it as quick and easy as possible to apply Puppet on a machine; for this we'll write a little script that wraps the puppet apply command with the parameters it needs. We'll deploy the script where it's needed with Puppet itself.
- In your Puppet repo, create the directories needed for a Puppet module:
t@mylaptop ~$ cd puppet/modules t@mylaptop modules$ mkdir -p puppet/{manifests,files}
- Create the
modules/puppet/files/papply.shfile with the following contents:#!/bin/sh sudo puppet apply /etc/puppet/cookbook/manifests/site.pp \--modulepath=/etc/puppet/cookbook/modules $*
- Create the
modules/puppet/manifests/init.ppfile with the following contents:class puppet { file { '/usr/local/bin/papply': source => 'puppet:///modules/puppet/papply.sh', mode => '0755', } } - Modify your
manifests/site.ppfile as follows:node default { include base include puppet } - Add the Puppet module to the Git repository and commit the change as follows:
t@mylaptop puppet$ git add manifests/site.pp modules/puppet t@mylaptop puppet$ git status On branch master Your branch is up-to-date with 'origin/master'. Changes to be committed: (use "git reset HEAD <file>..." to unstage) modified: manifests/site.pp new file: modules/puppet/files/papply.sh new file: modules/puppet/manifests/init.pp t@mylaptop puppet$ git commit -m "adding puppet module to include papply" [master 7c2e3d5] adding puppet module to include papply 3 files changed, 11 insertions(+) create mode 100644 modules/puppet/files/papply.sh create mode 100644 modules/puppet/manifests/init.pp
- Now remember to push the changes to the Git repository on
git.example.com:t@mylaptop puppet$ git push origin master Counting objects: 14, done. Delta compression using up to 4 threads. Compressing objects: 100% (7/7), done. Writing objects: 100% (10/10), 894 bytes | 0 bytes/s, done. Total 10 (delta 0), reused 0 (delta 0) To git@git.example.com:repos/puppet.git 23e887c..7c2e3d5 master -> master - Pull the latest version of the Git repository to your new node (
testnodefor me) as shown in the following command line:root@testnode ~# sudo -iu puppet puppet@testnode ~$ cd /etc/puppet/cookbook/puppet@testnode /etc/puppet/cookbook$ git pull origin master remote: Counting objects: 14, done. remote: Compressing objects: 100% (7/7), done. remote: Total 10 (delta 0), reused 0 (delta 0) Unpacking objects: 100% (10/10), done. From git.example.com:repos/puppet * branch master -> FETCH_HEAD Updating 23e887c..7c2e3d5 Fast-forward manifests/site.pp | 1 + modules/puppet/files/papply.sh | 4 ++++ modules/puppet/manifests/init.pp | 6 ++++++ 3 files changed, 11 insertions(+), 0 deletions(-) create mode 100644 modules/puppet/files/papply.sh create mode 100644 modules/puppet/manifests/init.pp
- Apply the manifest manually once to install the
papplyscript:root@testnode ~# puppet apply /etc/puppet/cookbook/manifests/site.pp --modulepath /etc/puppet/cookbook/modules Notice: Compiled catalog for testnode.example.com in environment production in 0.13 seconds Notice: /Stage[main]/Puppet/File[/usr/local/bin/papply]/ensure: defined content as '{md5}d5c2cdd359306dd6e6441e6fb96e5ef7' Notice: Finished catalog run in 0.13 seconds
- Finally, test the script:
root@testnode ~# papply Notice: Compiled catalog for testnode.example.com in environment production in 0.13 seconds Notice: Finished catalog run in 0.09 seconds
t@mylaptop ~$ cd puppet/modules t@mylaptop modules$ mkdir -p puppet/{manifests,files}
modules/puppet/files/papply.sh file with the following contents:#!/bin/sh sudo puppet apply /etc/puppet/cookbook/manifests/site.pp \--modulepath=/etc/puppet/cookbook/modules $*
modules/puppet/manifests/init.pp file with the following contents:class puppet {
file { '/usr/local/bin/papply':
source => 'puppet:///modules/puppet/papply.sh',
mode => '0755',
}
}- your
manifests/site.ppfile as follows:node default { include base include puppet } - Add the Puppet module to the Git repository and commit the change as follows:
t@mylaptop puppet$ git add manifests/site.pp modules/puppet t@mylaptop puppet$ git status On branch master Your branch is up-to-date with 'origin/master'. Changes to be committed: (use "git reset HEAD <file>..." to unstage) modified: manifests/site.pp new file: modules/puppet/files/papply.sh new file: modules/puppet/manifests/init.pp t@mylaptop puppet$ git commit -m "adding puppet module to include papply" [master 7c2e3d5] adding puppet module to include papply 3 files changed, 11 insertions(+) create mode 100644 modules/puppet/files/papply.sh create mode 100644 modules/puppet/manifests/init.pp
- Now remember to push the changes to the Git repository on
git.example.com:t@mylaptop puppet$ git push origin master Counting objects: 14, done. Delta compression using up to 4 threads. Compressing objects: 100% (7/7), done. Writing objects: 100% (10/10), 894 bytes | 0 bytes/s, done. Total 10 (delta 0), reused 0 (delta 0) To git@git.example.com:repos/puppet.git 23e887c..7c2e3d5 master -> master - Pull the latest version of the Git repository to your new node (
testnodefor me) as shown in the following command line:root@testnode ~# sudo -iu puppet puppet@testnode ~$ cd /etc/puppet/cookbook/puppet@testnode /etc/puppet/cookbook$ git pull origin master remote: Counting objects: 14, done. remote: Compressing objects: 100% (7/7), done. remote: Total 10 (delta 0), reused 0 (delta 0) Unpacking objects: 100% (10/10), done. From git.example.com:repos/puppet * branch master -> FETCH_HEAD Updating 23e887c..7c2e3d5 Fast-forward manifests/site.pp | 1 + modules/puppet/files/papply.sh | 4 ++++ modules/puppet/manifests/init.pp | 6 ++++++ 3 files changed, 11 insertions(+), 0 deletions(-) create mode 100644 modules/puppet/files/papply.sh create mode 100644 modules/puppet/manifests/init.pp
- Apply the manifest manually once to install the
papplyscript:root@testnode ~# puppet apply /etc/puppet/cookbook/manifests/site.pp --modulepath /etc/puppet/cookbook/modules Notice: Compiled catalog for testnode.example.com in environment production in 0.13 seconds Notice: /Stage[main]/Puppet/File[/usr/local/bin/papply]/ensure: defined content as '{md5}d5c2cdd359306dd6e6441e6fb96e5ef7' Notice: Finished catalog run in 0.13 seconds
- Finally, test the script:
root@testnode ~# papply Notice: Compiled catalog for testnode.example.com in environment production in 0.13 seconds Notice: Finished catalog run in 0.09 seconds
puppet apply command:
modulepath argument:
sudo before everything:
You can do a lot with the setup you already have: work on your Puppet manifests as a team, communicate changes via a central Git repository, and manually apply them on a machine using the papply script.
- Copy the
bootstrap.ppscript to any node you wish to enroll. Thebootstrap.ppmanifest includes the private key used to access the Git repository, it should be protected in a production environment. - Create the
modules/puppet/files/pull-updates.shfile with the following contents:#!/bin/sh cd /etc/puppet/cookbook sudo –u puppet git pull && /usr/local/bin/papply
- Modify the
modules/puppet/manifests/init.ppfile and add the following snippet after thepapplyfile definition:file { '/usr/local/bin/pull-updates': source => 'puppet:///modules/puppet/pull-updates.sh', mode => '0755', } cron { 'run-puppet': ensure => 'present', user => 'puppet', command => '/usr/local/bin/pull-updates', minute => '*/10', hour => '*', } - Commit the changes as before and push to the Git server as shown in the following command line:
t@mylaptop puppet$ git add modules/puppet t@mylaptop puppet$ git commit -m "adding pull-updates" [master 7e9bac3] adding pull-updates 2 files changed, 14 insertions(+) create mode 100644 modules/puppet/files/pull-updates.sh t@mylaptop puppet$ git push Counting objects: 14, done. Delta compression using up to 4 threads. Compressing objects: 100% (7/7), done. Writing objects: 100% (8/8), 839 bytes | 0 bytes/s, done. Total 8 (delta 0), reused 0 (delta 0) To git@git.example.com:repos/puppet.git 7c2e3d5..7e9bac3 master -> master - Issue a Git pull on the test node:
root@testnode ~# cd /etc/puppet/cookbook/ root@testnode /etc/puppet/cookbook# sudo –u puppet git pull remote: Counting objects: 14, done. remote: Compressing objects: 100% (7/7), done. remote: Total 8 (delta 0), reused 0 (delta 0) Unpacking objects: 100% (8/8), done. From git.example.com:repos/puppet 23e887c..7e9bac3 master -> origin/master Updating 7c2e3d5..7e9bac3 Fast-forward modules/puppet/files/pull-updates.sh | 3 +++ modules/puppet/manifests/init.pp | 11 +++++++++++ 2 files changed, 14 insertions(+), 0 deletions(-) create mode 100644 modules/puppet/files/pull-updates.sh
- Run Puppet on the test node:
root@testnode /etc/puppet/cookbook# papply Notice: Compiled catalog for testnode.example.com in environment production in 0.17 seconds Notice: /Stage[main]/Puppet/Cron[run-puppet]/ensure: created Notice: /Stage[main]/Puppet/File[/usr/local/bin/pull-updates]/ensure: defined content as '{md5}04c023feb5d566a417b519ea51586398' Notice: Finished catalog run in 0.16 seconds
- Check that the
pull-updatesscript works properly:root@testnode /etc/puppet/cookbook# pull-updates Already up-to-date. Notice: Compiled catalog for testnode.example.com in environment production in 0.15 seconds Notice: Finished catalog run in 0.14 seconds
- Verify the
cronjob was created successfully:root@testnode /etc/puppet/cookbook# crontab -l -u puppet # HEADER: This file was autogenerated at Tue Sep 09 02:31:00 -0400 2014 by puppet. # HEADER: While it can still be managed manually, it is definitely not recommended. # HEADER: Note particularly that the comments starting with 'Puppet Name' should # HEADER: not be deleted, as doing so could cause duplicate cron jobs. # Puppet Name: run-puppet */10 * * * * /usr/local/bin/pull-updates
When we created the bootstrap.pp manifest, we made sure that the Puppet user can checkout the Git repository using an ssh key. This enables the Puppet user to run the Git pull in the cookbook directory unattended. We've also added the pull-updates script, which does this and runs Puppet if any changes are pulled:
papply script from the Writing a papply script recipe. You'll need to apply the bootstrap.pp manifest we created to install ssh keys to download the latest repository.
- Copy the
bootstrap.ppscript to any node you wish to enroll. Thebootstrap.ppmanifest includes the private key used to access the Git repository, it should be protected in a production environment. - Create the
modules/puppet/files/pull-updates.shfile with the following contents:#!/bin/sh cd /etc/puppet/cookbook sudo –u puppet git pull && /usr/local/bin/papply
- Modify the
modules/puppet/manifests/init.ppfile and add the following snippet after thepapplyfile definition:file { '/usr/local/bin/pull-updates': source => 'puppet:///modules/puppet/pull-updates.sh', mode => '0755', } cron { 'run-puppet': ensure => 'present', user => 'puppet', command => '/usr/local/bin/pull-updates', minute => '*/10', hour => '*', } - Commit the changes as before and push to the Git server as shown in the following command line:
t@mylaptop puppet$ git add modules/puppet t@mylaptop puppet$ git commit -m "adding pull-updates" [master 7e9bac3] adding pull-updates 2 files changed, 14 insertions(+) create mode 100644 modules/puppet/files/pull-updates.sh t@mylaptop puppet$ git push Counting objects: 14, done. Delta compression using up to 4 threads. Compressing objects: 100% (7/7), done. Writing objects: 100% (8/8), 839 bytes | 0 bytes/s, done. Total 8 (delta 0), reused 0 (delta 0) To git@git.example.com:repos/puppet.git 7c2e3d5..7e9bac3 master -> master - Issue a Git pull on the test node:
root@testnode ~# cd /etc/puppet/cookbook/ root@testnode /etc/puppet/cookbook# sudo –u puppet git pull remote: Counting objects: 14, done. remote: Compressing objects: 100% (7/7), done. remote: Total 8 (delta 0), reused 0 (delta 0) Unpacking objects: 100% (8/8), done. From git.example.com:repos/puppet 23e887c..7e9bac3 master -> origin/master Updating 7c2e3d5..7e9bac3 Fast-forward modules/puppet/files/pull-updates.sh | 3 +++ modules/puppet/manifests/init.pp | 11 +++++++++++ 2 files changed, 14 insertions(+), 0 deletions(-) create mode 100644 modules/puppet/files/pull-updates.sh
- Run Puppet on the test node:
root@testnode /etc/puppet/cookbook# papply Notice: Compiled catalog for testnode.example.com in environment production in 0.17 seconds Notice: /Stage[main]/Puppet/Cron[run-puppet]/ensure: created Notice: /Stage[main]/Puppet/File[/usr/local/bin/pull-updates]/ensure: defined content as '{md5}04c023feb5d566a417b519ea51586398' Notice: Finished catalog run in 0.16 seconds
- Check that the
pull-updatesscript works properly:root@testnode /etc/puppet/cookbook# pull-updates Already up-to-date. Notice: Compiled catalog for testnode.example.com in environment production in 0.15 seconds Notice: Finished catalog run in 0.14 seconds
- Verify the
cronjob was created successfully:root@testnode /etc/puppet/cookbook# crontab -l -u puppet # HEADER: This file was autogenerated at Tue Sep 09 02:31:00 -0400 2014 by puppet. # HEADER: While it can still be managed manually, it is definitely not recommended. # HEADER: Note particularly that the comments starting with 'Puppet Name' should # HEADER: not be deleted, as doing so could cause duplicate cron jobs. # Puppet Name: run-puppet */10 * * * * /usr/local/bin/pull-updates
When we created the bootstrap.pp manifest, we made sure that the Puppet user can checkout the Git repository using an ssh key. This enables the Puppet user to run the Git pull in the cookbook directory unattended. We've also added the pull-updates script, which does this and runs Puppet if any changes are pulled:
- Copy the
bootstrap.ppscript to any node you wish to enroll. Thebootstrap.ppmanifest includes the private key used to access the Git repository, it should be protected in a production environment. - Create the
modules/puppet/files/pull-updates.shfile with the following contents:#!/bin/sh cd /etc/puppet/cookbook sudo –u puppet git pull && /usr/local/bin/papply
- Modify the
modules/puppet/manifests/init.ppfile and add the following snippet after thepapplyfile definition:file { '/usr/local/bin/pull-updates': source => 'puppet:///modules/puppet/pull-updates.sh', mode => '0755', } cron { 'run-puppet': ensure => 'present', user => 'puppet', command => '/usr/local/bin/pull-updates', minute => '*/10', hour => '*', } - Commit the changes as before and push to the Git server as shown in the following command line:
t@mylaptop puppet$ git add modules/puppet t@mylaptop puppet$ git commit -m "adding pull-updates" [master 7e9bac3] adding pull-updates 2 files changed, 14 insertions(+) create mode 100644 modules/puppet/files/pull-updates.sh t@mylaptop puppet$ git push Counting objects: 14, done. Delta compression using up to 4 threads. Compressing objects: 100% (7/7), done. Writing objects: 100% (8/8), 839 bytes | 0 bytes/s, done. Total 8 (delta 0), reused 0 (delta 0) To git@git.example.com:repos/puppet.git 7c2e3d5..7e9bac3 master -> master - Issue a Git pull on the test node:
root@testnode ~# cd /etc/puppet/cookbook/ root@testnode /etc/puppet/cookbook# sudo –u puppet git pull remote: Counting objects: 14, done. remote: Compressing objects: 100% (7/7), done. remote: Total 8 (delta 0), reused 0 (delta 0) Unpacking objects: 100% (8/8), done. From git.example.com:repos/puppet 23e887c..7e9bac3 master -> origin/master Updating 7c2e3d5..7e9bac3 Fast-forward modules/puppet/files/pull-updates.sh | 3 +++ modules/puppet/manifests/init.pp | 11 +++++++++++ 2 files changed, 14 insertions(+), 0 deletions(-) create mode 100644 modules/puppet/files/pull-updates.sh
- Run Puppet on the test node:
root@testnode /etc/puppet/cookbook# papply Notice: Compiled catalog for testnode.example.com in environment production in 0.17 seconds Notice: /Stage[main]/Puppet/Cron[run-puppet]/ensure: created Notice: /Stage[main]/Puppet/File[/usr/local/bin/pull-updates]/ensure: defined content as '{md5}04c023feb5d566a417b519ea51586398' Notice: Finished catalog run in 0.16 seconds
- Check that the
pull-updatesscript works properly:root@testnode /etc/puppet/cookbook# pull-updates Already up-to-date. Notice: Compiled catalog for testnode.example.com in environment production in 0.15 seconds Notice: Finished catalog run in 0.14 seconds
- Verify the
cronjob was created successfully:root@testnode /etc/puppet/cookbook# crontab -l -u puppet # HEADER: This file was autogenerated at Tue Sep 09 02:31:00 -0400 2014 by puppet. # HEADER: While it can still be managed manually, it is definitely not recommended. # HEADER: Note particularly that the comments starting with 'Puppet Name' should # HEADER: not be deleted, as doing so could cause duplicate cron jobs. # Puppet Name: run-puppet */10 * * * * /usr/local/bin/pull-updates
When we created the bootstrap.pp manifest, we made sure that the Puppet user can checkout the Git repository using an ssh key. This enables the Puppet user to run the Git pull in the cookbook directory unattended. We've also added the pull-updates script, which does this and runs Puppet if any changes are pulled:
bootstrap.pp manifest, we made sure that the Puppet user can checkout
the Git repository using an ssh key. This enables the Puppet user to run the Git pull in the cookbook directory unattended. We've also added the pull-updates script, which does this and runs Puppet if any changes are pulled:
bootstrap.pp manifest, run Puppet on the repository; the machine will be set up to pull any new changes and apply them automatically.
Previous versions of this book used Rakefiles to bootstrap Puppet. The problem with using Rake to configure a node is that you are running the commands from your laptop; you assume you already have ssh access to the machine. Most bootstrap processes work by issuing an easy to remember command from a node once it has been provisioned. In this section, we'll show how to use bash to bootstrap Puppet with a web server and a bootstrap script.
Now perform the following steps:
- Add the following location definition to your apache configuration:
<Location /bootstrap> AuthType basic AuthName "Bootstrap" AuthBasicProvider file AuthUserFile /var/www/puppet.passwd Require valid-user </Location>
- Reload your web server to ensure the location configuration is operating. Verify with curl that you cannot download from the bootstrap directory without authentication:
[root@bootstrap-test tmp]# curl http://git.example.com/bootstrap/ <!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN"> <html><head> <title>401 Authorization Required</title> </head><body> <h1>Authorization Required</h1>
- Create the password file you referenced in the apache configuration (
/var/www/puppet.passwd):root@git# cd /var/www root@git# htpasswd –cb puppet.passwd bootstrap cookbook Adding password for user bootstrap - Verify that the username and password permit access to the bootstrap directory as follows:
[root@node1 tmp]# curl --user bootstrap:cookbook http://git.example.com/bootstrap/ <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN"> <html> <head> <title>Index of /bootstrap</title>
Now that you have a safe location to store the bootstrap script, create a bootstrap script for each OS you support in the bootstrap directory. In this example, I'll show you how to do this for a Red Hat Enterprise Linux 6-based distribution.
Create a script named el6.sh in the bootstrap directory with the following contents:
The apache configuration only permits access to the bootstrap directory with a username and password combination. We supply these with the --user argument to curl, thereby getting access to the file. We use a pipe (|) to redirect the output of curl into bash. This causes bash to execute the script. We write our bash script like we would any other bash script. The bash script downloads our bootstrap.pp manifest and applies it. Finally, we apply the Puppet manifest from the Git repository and the machine is configured as a member of our decentralized infrastructure.
git.example.com. Start by creating a directory in the root of your web server:
<Location /bootstrap> AuthType basic AuthName "Bootstrap" AuthBasicProvider file AuthUserFile /var/www/puppet.passwd Require valid-user </Location>
[root@bootstrap-test tmp]# curl http://git.example.com/bootstrap/ <!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN"> <html><head> <title>401 Authorization Required</title> </head><body> <h1>Authorization Required</h1>
/var/www/puppet.passwd):root@git# cd /var/www
root@git# htpasswd –cb puppet.passwd bootstrap cookbook
Adding password for user bootstrap
[root@node1 tmp]# curl --user bootstrap:cookbook http://git.example.com/bootstrap/ <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN"> <html> <head> <title>Index of /bootstrap</title>
Now that you have a safe location to store the bootstrap script, create a bootstrap script for each OS you support in the bootstrap directory. In this example, I'll show you how to do this for a Red Hat Enterprise Linux 6-based distribution.
Create a script named el6.sh in the bootstrap directory with the following contents:
The apache configuration only permits access to the bootstrap directory with a username and password combination. We supply these with the --user argument to curl, thereby getting access to the file. We use a pipe (|) to redirect the output of curl into bash. This causes bash to execute the script. We write our bash script like we would any other bash script. The bash script downloads our bootstrap.pp manifest and applies it. Finally, we apply the Puppet manifest from the Git repository and the machine is configured as a member of our decentralized infrastructure.
that you have a safe location to store the bootstrap script, create a bootstrap script for each OS you support in the bootstrap directory. In this example, I'll show you how to do this for a Red Hat Enterprise Linux 6-based distribution.
Create a script named el6.sh in the bootstrap directory with the following contents:
The apache configuration only permits access to the bootstrap directory with a username and password combination. We supply these with the --user argument to curl, thereby getting access to the file. We use a pipe (|) to redirect the output of curl into bash. This causes bash to execute the script. We write our bash script like we would any other bash script. The bash script downloads our bootstrap.pp manifest and applies it. Finally, we apply the Puppet manifest from the Git repository and the machine is configured as a member of our decentralized infrastructure.
apache configuration only permits access to the bootstrap directory with a username and password combination. We supply these with the --user argument to curl, thereby getting access to the file. We use a pipe (|) to redirect the output of curl into bash. This causes bash to execute the script. We write our bash script like we would any other bash script. The bash script downloads our bootstrap.pp manifest and applies it. Finally, we apply the Puppet manifest from the Git repository and the machine is configured as a member of our decentralized infrastructure.
bootstrap.pp manifest, the bootstrap script is quite minimal and easy to port to new operating systems.
A configuration management tool such as Puppet is best used when you have many machines to manage. If all the machines can reach a central location, using a centralized Puppet infrastructure might be a good solution. Unfortunately, Puppet doesn't scale well with a large number of nodes. If your deployment has less than 800 servers, a single Puppet master should be able to handle the load, assuming your catalogs are not complex (take less than 10 seconds to compile each catalog). If you have a larger number of nodes, I suggest a load balancing configuration described in Mastering Puppet, Thomas Uphill, Packt Publishing.
A Puppet master is a Puppet server that acts as an X509 certificate authority for Puppet and distributes catalogs (compiled manifests) to client nodes. Puppet ships with a built-in web server called WEBrick, which can handle a very small number of nodes. In this section, we will see how to use that built-in server to control a very small (less than 10) number of nodes.
- Install Puppet on the new server and then use Puppet to install the Puppet master package:
# puppet resource package puppetmaster ensure='installed' Notice: /Package[puppetmaster]/ensure: created package { 'puppetmaster': ensure => '3.7.0-1puppetlabs1', } - Now start the Puppet master service and ensure it will start at boot:
# puppet resource service puppetmaster ensure=true enable=true service { 'puppetmaster': ensure => 'running', enable => 'true', }
The Puppet master package includes the start and stop scripts for the Puppet master service. We use Puppet to install the package and start the service. Once the service is started, we can point another node at the Puppet master (you might need to disable the host-based firewall on your machine).
- From another node, run
puppet agentto start apuppet agent, which will contact the server and request a new certificate:t@ckbk:~$ sudo puppet agent -t Info: Creating a new SSL key for cookbook.example.com Info: Caching certificate for ca Info: Creating a new SSL certificate request for cookbook.example.com Info: Certificate Request fingerprint (SHA256): 06:C6:2B:C4:97:5D:16:F2:73:82:C4:A9:A7:B1:D0:95:AC:69:7B:27:13:A9:1A:4C:98:20:21:C2:50:48:66:A2 Info: Caching certificate for ca Exiting; no certificate found and waitforcert is disabled
- Now on the Puppet server, sign the new key:
root@puppet:~# puppet cert list pu "cookbook.example.com" (SHA256) 06:C6:2B:C4:97:5D:16:F2:73:82:C4:A9:A7:B1:D0:95:AC:69:7B:27:13:A9:1A:4C:98:20:21:C2:50:48:66:A2 root@puppet:~# puppet cert sign cookbook.example.com Notice: Signed certificate request for cookbook.example.com Notice: Removing file Puppet::SSL::CertificateRequestcookbook.example.com at'/var/lib/puppet/ssl/ca/requests/cookbook.example.com.pem'
- Return to the cookbook node and run Puppet again:
t@ckbk:~$ sudo puppet agent –vt Info: Caching certificate for cookbook.example.com Info: Caching certificate_revocation_list for ca Info: Caching certificate for cookbook.example.comInfo: Retrieving pluginfacts Info: Retrieving plugin Info: Caching catalog for cookbook Info: Applying configuration version '1410401823' Notice: Finished catalog run in 0.04 seconds
puppet master; most Linux distributions have start and stop scripts for the Puppet master in a separate package. To get started, we'll create a new debian server named puppet.example.com.
- Install Puppet on the new server and then use Puppet to install the Puppet master package:
# puppet resource package puppetmaster ensure='installed' Notice: /Package[puppetmaster]/ensure: created package { 'puppetmaster': ensure => '3.7.0-1puppetlabs1', } - Now start the Puppet master service and ensure it will start at boot:
# puppet resource service puppetmaster ensure=true enable=true service { 'puppetmaster': ensure => 'running', enable => 'true', }
The Puppet master package includes the start and stop scripts for the Puppet master service. We use Puppet to install the package and start the service. Once the service is started, we can point another node at the Puppet master (you might need to disable the host-based firewall on your machine).
- From another node, run
puppet agentto start apuppet agent, which will contact the server and request a new certificate:t@ckbk:~$ sudo puppet agent -t Info: Creating a new SSL key for cookbook.example.com Info: Caching certificate for ca Info: Creating a new SSL certificate request for cookbook.example.com Info: Certificate Request fingerprint (SHA256): 06:C6:2B:C4:97:5D:16:F2:73:82:C4:A9:A7:B1:D0:95:AC:69:7B:27:13:A9:1A:4C:98:20:21:C2:50:48:66:A2 Info: Caching certificate for ca Exiting; no certificate found and waitforcert is disabled
- Now on the Puppet server, sign the new key:
root@puppet:~# puppet cert list pu "cookbook.example.com" (SHA256) 06:C6:2B:C4:97:5D:16:F2:73:82:C4:A9:A7:B1:D0:95:AC:69:7B:27:13:A9:1A:4C:98:20:21:C2:50:48:66:A2 root@puppet:~# puppet cert sign cookbook.example.com Notice: Signed certificate request for cookbook.example.com Notice: Removing file Puppet::SSL::CertificateRequestcookbook.example.com at'/var/lib/puppet/ssl/ca/requests/cookbook.example.com.pem'
- Return to the cookbook node and run Puppet again:
t@ckbk:~$ sudo puppet agent –vt Info: Caching certificate for cookbook.example.com Info: Caching certificate_revocation_list for ca Info: Caching certificate for cookbook.example.comInfo: Retrieving pluginfacts Info: Retrieving plugin Info: Caching catalog for cookbook Info: Applying configuration version '1410401823' Notice: Finished catalog run in 0.04 seconds
# puppet resource package puppetmaster ensure='installed' Notice: /Package[puppetmaster]/ensure: created package { 'puppetmaster': ensure => '3.7.0-1puppetlabs1', }
# puppet resource service puppetmaster ensure=true enable=true service { 'puppetmaster': ensure => 'running', enable => 'true', }
The Puppet master package includes the start and stop scripts for the Puppet master service. We use Puppet to install the package and start the service. Once the service is started, we can point another node at the Puppet master (you might need to disable the host-based firewall on your machine).
- From another node, run
puppet agentto start apuppet agent, which will contact the server and request a new certificate:t@ckbk:~$ sudo puppet agent -t Info: Creating a new SSL key for cookbook.example.com Info: Caching certificate for ca Info: Creating a new SSL certificate request for cookbook.example.com Info: Certificate Request fingerprint (SHA256): 06:C6:2B:C4:97:5D:16:F2:73:82:C4:A9:A7:B1:D0:95:AC:69:7B:27:13:A9:1A:4C:98:20:21:C2:50:48:66:A2 Info: Caching certificate for ca Exiting; no certificate found and waitforcert is disabled
- Now on the Puppet server, sign the new key:
root@puppet:~# puppet cert list pu "cookbook.example.com" (SHA256) 06:C6:2B:C4:97:5D:16:F2:73:82:C4:A9:A7:B1:D0:95:AC:69:7B:27:13:A9:1A:4C:98:20:21:C2:50:48:66:A2 root@puppet:~# puppet cert sign cookbook.example.com Notice: Signed certificate request for cookbook.example.com Notice: Removing file Puppet::SSL::CertificateRequestcookbook.example.com at'/var/lib/puppet/ssl/ca/requests/cookbook.example.com.pem'
- Return to the cookbook node and run Puppet again:
t@ckbk:~$ sudo puppet agent –vt Info: Caching certificate for cookbook.example.com Info: Caching certificate_revocation_list for ca Info: Caching certificate for cookbook.example.comInfo: Retrieving pluginfacts Info: Retrieving plugin Info: Caching catalog for cookbook Info: Applying configuration version '1410401823' Notice: Finished catalog run in 0.04 seconds
- From another node, run
puppet agentto start apuppet agent, which will contact the server and request a new certificate:t@ckbk:~$ sudo puppet agent -t Info: Creating a new SSL key for cookbook.example.com Info: Caching certificate for ca Info: Creating a new SSL certificate request for cookbook.example.com Info: Certificate Request fingerprint (SHA256): 06:C6:2B:C4:97:5D:16:F2:73:82:C4:A9:A7:B1:D0:95:AC:69:7B:27:13:A9:1A:4C:98:20:21:C2:50:48:66:A2 Info: Caching certificate for ca Exiting; no certificate found and waitforcert is disabled
- Now on the Puppet server, sign the new key:
root@puppet:~# puppet cert list pu "cookbook.example.com" (SHA256) 06:C6:2B:C4:97:5D:16:F2:73:82:C4:A9:A7:B1:D0:95:AC:69:7B:27:13:A9:1A:4C:98:20:21:C2:50:48:66:A2 root@puppet:~# puppet cert sign cookbook.example.com Notice: Signed certificate request for cookbook.example.com Notice: Removing file Puppet::SSL::CertificateRequestcookbook.example.com at'/var/lib/puppet/ssl/ca/requests/cookbook.example.com.pem'
- Return to the cookbook node and run Puppet again:
t@ckbk:~$ sudo puppet agent –vt Info: Caching certificate for cookbook.example.com Info: Caching certificate_revocation_list for ca Info: Caching certificate for cookbook.example.comInfo: Retrieving pluginfacts Info: Retrieving plugin Info: Caching catalog for cookbook Info: Applying configuration version '1410401823' Notice: Finished catalog run in 0.04 seconds
puppet agent, Puppet looked for a host named puppet.example.com (since our test node is in the example.com domain); if it couldn't find that host, it would then look for a host named Puppet. We can specify the server to contact with the --server option to puppet agent. When we installed the Puppet master package and started the Puppet master service, Puppet created default SSL certificates based on our hostname. In the next section, we'll see how to create an SSL certificate that has multiple DNS names for our Puppet server.
By default, Puppet will create an SSL certificate for your Puppet master that contains the fully qualified domain name of the server only. Depending on how your network is configured, it can be useful for the server to be known by other names. In this recipe, we'll make a new certificate for our Puppet master that has multiple DNS names.
Install the Puppet master package if you haven't already done so. You will then need to start the Puppet master service at least once to create a certificate authority (CA).
- Stop the running Puppet master process with the following command:
# service puppetmaster stop [ ok ] Stopping puppet master.
- Delete (
clean) the current server certificate:# puppet cert clean puppet Notice: Revoked certificate with serial 6 Notice: Removing file Puppet::SSL::Certificate puppet at '/var/lib/puppet/ssl/ca/signed/puppet.pem' Notice: Removing file Puppet::SSL::Certificate puppet at '/var/lib/puppet/ssl/certs/puppet.pem' Notice: Removing file Puppet::SSL::Key puppet at '/var/lib/puppet/ssl/private_keys/puppet.pem'
- Create a new Puppet certificate using Puppet certificate generate with the
--dns-alt-namesoption:root@puppet:~# puppet certificate generate puppet --dns-alt-names puppet.example.com,puppet.example.org,puppet.example.net --ca-location local Notice: puppet has a waiting certificate request true
- Sign the new certificate:
root@puppet:~# puppet cert --allow-dns-alt-names sign puppet Notice: Signed certificate request for puppet Notice: Removing file Puppet::SSL::CertificateRequest puppet at '/var/lib/puppet/ssl/ca/requests/puppet.pem'
- Restart the Puppet master process:
root@puppet:~# service puppetmaster restart [ ok ] Restarting puppet master.
- Stop the running Puppet master process with the following command:
# service puppetmaster stop [ ok ] Stopping puppet master.
- Delete (
clean) the current server certificate:# puppet cert clean puppet Notice: Revoked certificate with serial 6 Notice: Removing file Puppet::SSL::Certificate puppet at '/var/lib/puppet/ssl/ca/signed/puppet.pem' Notice: Removing file Puppet::SSL::Certificate puppet at '/var/lib/puppet/ssl/certs/puppet.pem' Notice: Removing file Puppet::SSL::Key puppet at '/var/lib/puppet/ssl/private_keys/puppet.pem'
- Create a new Puppet certificate using Puppet certificate generate with the
--dns-alt-namesoption:root@puppet:~# puppet certificate generate puppet --dns-alt-names puppet.example.com,puppet.example.org,puppet.example.net --ca-location local Notice: puppet has a waiting certificate request true
- Sign the new certificate:
root@puppet:~# puppet cert --allow-dns-alt-names sign puppet Notice: Signed certificate request for puppet Notice: Removing file Puppet::SSL::CertificateRequest puppet at '/var/lib/puppet/ssl/ca/requests/puppet.pem'
- Restart the Puppet master process:
root@puppet:~# service puppetmaster restart [ ok ] Restarting puppet master.
# service puppetmaster stop [ ok ] Stopping puppet master.
clean) the current server certificate:# puppet cert clean puppet Notice: Revoked certificate with serial 6 Notice: Removing file Puppet::SSL::Certificate puppet at '/var/lib/puppet/ssl/ca/signed/puppet.pem' Notice: Removing file Puppet::SSL::Certificate puppet at '/var/lib/puppet/ssl/certs/puppet.pem' Notice: Removing file Puppet::SSL::Key puppet at '/var/lib/puppet/ssl/private_keys/puppet.pem'
- a new Puppet certificate using Puppet certificate generate with the
--dns-alt-namesoption:root@puppet:~# puppet certificate generate puppet --dns-alt-names puppet.example.com,puppet.example.org,puppet.example.net --ca-location local Notice: puppet has a waiting certificate request true
- Sign the new certificate:
root@puppet:~# puppet cert --allow-dns-alt-names sign puppet Notice: Signed certificate request for puppet Notice: Removing file Puppet::SSL::CertificateRequest puppet at '/var/lib/puppet/ssl/ca/requests/puppet.pem'
- Restart the Puppet master process:
root@puppet:~# service puppetmaster restart [ ok ] Restarting puppet master.
Puppet, they then look for a host called Puppet.[your domain]. If your clients are in different domains, then you need your Puppet master to reply to all the names correctly. By removing the existing certificate and generating a new one, you can have your Puppet master reply to multiple DNS names.
The WEBrick server we configured in the previous section is not capable of handling a large number of nodes. To deal with a large number of nodes, a scalable web server is required. Puppet is a ruby process, so we need a way to run a ruby process within a web server. Passenger is the solution to this problem. It allows us to run the Puppet master process within a web server (apache by default). Many distributions ship with a puppetmaster-passenger package that configures this for you. In this section, we'll use the package to configure Puppet to run within passenger.
- Ensure the Puppet master site is enabled in your apache configuration. Depending on your distribution this may be at
/etc/httpd/conf.dor/etc/apache2/sites-enabled. The configuration file should be created for you and contain the following information:PassengerHighPerformance on PassengerMaxPoolSize 12 PassengerPoolIdleTime 1500 # PassengerMaxRequests 1000 PassengerStatThrottleRate 120 RackAutoDetect Off RailsAutoDetect Off Listen 8140
- These lines are tuning settings for passenger. The file then instructs apache to listen on port 8140, the Puppet master port. Next a
VirtualHostdefinition is created that loads the Puppet CA certificates and the Puppet master's certificate:<VirtualHost *:8140> SSLEngine on SSLProtocol ALL -SSLv2 -SSLv3 SSLCertificateFile /var/lib/puppet/ssl/certs/puppet.pem SSLCertificateKeyFile /var/lib/puppet/ssl/private_keys/puppet.pem SSLCertificateChainFile /var/lib/puppet/ssl/certs/ca.pem SSLCACertificateFile /var/lib/puppet/ssl/certs/ca.pem SSLCARevocationFile /var/lib/puppet/ssl/ca/ca_crl.pem SSLVerifyClient optional SSLVerifyDepth 1 SSLOptions +StdEnvVars +ExportCertData
- Next, a few important headers are set so that the passenger process has access to the SSL information sent by the client node:
RequestHeader unset X-Forwarded-For RequestHeader set X-SSL-Subject %{SSL_CLIENT_S_DN}e RequestHeader set X-Client-DN %{SSL_CLIENT_S_DN}e RequestHeader set X-Client-Verify %{SSL_CLIENT_VERIFY}e
- Finally, the location of the passenger configuration file
config.ruis given with theDocumentRootlocation as follows:DocumentRoot /usr/share/puppet/rack/puppetmasterd/public/ RackBaseURI /
- The
config.rufile should exist at/usr/share/puppet/rack/puppetmasterd/and should have the following content:$0 = "master" ARGV << "--rack" ARGV << "--confdir" << "/etc/puppet" ARGV << "--vardir" << "/var/lib/puppet" require 'puppet/util/command_line' run Puppet::Util::CommandLine.new.execute
- With the passenger apache configuration file in place and the
config.rufile correctly configured, start the apache server and verify that apache is listening on the Puppet master port (if you configured the standalone Puppet master previously, you must stop that process now usingservice puppetmaster stop):root@puppet:~ # service apache2 start [ ok ] Starting web server: apache2 root@puppet:~ # lsof -i :8140 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME apache2 9048 root 8u IPv6 16842 0t0 TCP *:8140 (LISTEN) apache2 9069 www-data 8u IPv6 16842 0t0 TCP *:8140 (LISTEN) apache2 9070 www-data 8u IPv6 16842 0t0 TCP *:8140 (LISTEN)
You can add additional configuration parameters to the config.ru file to further alter how Puppet runs when it's running through passenger. For instance, to enable debugging on the passenger Puppet master, add the following line to config.ru before the run Puppet::Util::CommandLine.new.execute line:
- Ensure the Puppet master site is enabled in your apache configuration. Depending on your distribution this may be at
/etc/httpd/conf.dor/etc/apache2/sites-enabled. The configuration file should be created for you and contain the following information:PassengerHighPerformance on PassengerMaxPoolSize 12 PassengerPoolIdleTime 1500 # PassengerMaxRequests 1000 PassengerStatThrottleRate 120 RackAutoDetect Off RailsAutoDetect Off Listen 8140
- These lines are tuning settings for passenger. The file then instructs apache to listen on port 8140, the Puppet master port. Next a
VirtualHostdefinition is created that loads the Puppet CA certificates and the Puppet master's certificate:<VirtualHost *:8140> SSLEngine on SSLProtocol ALL -SSLv2 -SSLv3 SSLCertificateFile /var/lib/puppet/ssl/certs/puppet.pem SSLCertificateKeyFile /var/lib/puppet/ssl/private_keys/puppet.pem SSLCertificateChainFile /var/lib/puppet/ssl/certs/ca.pem SSLCACertificateFile /var/lib/puppet/ssl/certs/ca.pem SSLCARevocationFile /var/lib/puppet/ssl/ca/ca_crl.pem SSLVerifyClient optional SSLVerifyDepth 1 SSLOptions +StdEnvVars +ExportCertData
- Next, a few important headers are set so that the passenger process has access to the SSL information sent by the client node:
RequestHeader unset X-Forwarded-For RequestHeader set X-SSL-Subject %{SSL_CLIENT_S_DN}e RequestHeader set X-Client-DN %{SSL_CLIENT_S_DN}e RequestHeader set X-Client-Verify %{SSL_CLIENT_VERIFY}e
- Finally, the location of the passenger configuration file
config.ruis given with theDocumentRootlocation as follows:DocumentRoot /usr/share/puppet/rack/puppetmasterd/public/ RackBaseURI /
- The
config.rufile should exist at/usr/share/puppet/rack/puppetmasterd/and should have the following content:$0 = "master" ARGV << "--rack" ARGV << "--confdir" << "/etc/puppet" ARGV << "--vardir" << "/var/lib/puppet" require 'puppet/util/command_line' run Puppet::Util::CommandLine.new.execute
- With the passenger apache configuration file in place and the
config.rufile correctly configured, start the apache server and verify that apache is listening on the Puppet master port (if you configured the standalone Puppet master previously, you must stop that process now usingservice puppetmaster stop):root@puppet:~ # service apache2 start [ ok ] Starting web server: apache2 root@puppet:~ # lsof -i :8140 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME apache2 9048 root 8u IPv6 16842 0t0 TCP *:8140 (LISTEN) apache2 9069 www-data 8u IPv6 16842 0t0 TCP *:8140 (LISTEN) apache2 9070 www-data 8u IPv6 16842 0t0 TCP *:8140 (LISTEN)
You can add additional configuration parameters to the config.ru file to further alter how Puppet runs when it's running through passenger. For instance, to enable debugging on the passenger Puppet master, add the following line to config.ru before the run Puppet::Util::CommandLine.new.execute line:
/etc/httpd/conf.d or /etc/apache2/sites-enabled. The configuration file should be created for you and contain the following information:PassengerHighPerformance on PassengerMaxPoolSize 12 PassengerPoolIdleTime 1500 # PassengerMaxRequests 1000 PassengerStatThrottleRate 120 RackAutoDetect Off RailsAutoDetect Off Listen 8140
VirtualHost definition is created
- that loads the Puppet CA certificates and the Puppet master's certificate:
<VirtualHost *:8140> SSLEngine on SSLProtocol ALL -SSLv2 -SSLv3 SSLCertificateFile /var/lib/puppet/ssl/certs/puppet.pem SSLCertificateKeyFile /var/lib/puppet/ssl/private_keys/puppet.pem SSLCertificateChainFile /var/lib/puppet/ssl/certs/ca.pem SSLCACertificateFile /var/lib/puppet/ssl/certs/ca.pem SSLCARevocationFile /var/lib/puppet/ssl/ca/ca_crl.pem SSLVerifyClient optional SSLVerifyDepth 1 SSLOptions +StdEnvVars +ExportCertData
- Next, a few important headers are set so that the passenger process has access to the SSL information sent by the client node:
RequestHeader unset X-Forwarded-For RequestHeader set X-SSL-Subject %{SSL_CLIENT_S_DN}e RequestHeader set X-Client-DN %{SSL_CLIENT_S_DN}e RequestHeader set X-Client-Verify %{SSL_CLIENT_VERIFY}e
- Finally, the location of the passenger configuration file
config.ruis given with theDocumentRootlocation as follows:DocumentRoot /usr/share/puppet/rack/puppetmasterd/public/ RackBaseURI /
- The
config.rufile should exist at/usr/share/puppet/rack/puppetmasterd/and should have the following content:$0 = "master" ARGV << "--rack" ARGV << "--confdir" << "/etc/puppet" ARGV << "--vardir" << "/var/lib/puppet" require 'puppet/util/command_line' run Puppet::Util::CommandLine.new.execute
- With the passenger apache configuration file in place and the
config.rufile correctly configured, start the apache server and verify that apache is listening on the Puppet master port (if you configured the standalone Puppet master previously, you must stop that process now usingservice puppetmaster stop):root@puppet:~ # service apache2 start [ ok ] Starting web server: apache2 root@puppet:~ # lsof -i :8140 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME apache2 9048 root 8u IPv6 16842 0t0 TCP *:8140 (LISTEN) apache2 9069 www-data 8u IPv6 16842 0t0 TCP *:8140 (LISTEN) apache2 9070 www-data 8u IPv6 16842 0t0 TCP *:8140 (LISTEN)
You can add additional configuration parameters to the config.ru file to further alter how Puppet runs when it's running through passenger. For instance, to enable debugging on the passenger Puppet master, add the following line to config.ru before the run Puppet::Util::CommandLine.new.execute line:
config.ru file.
$0 variable is set to master and the arguments variable is set to --rack --confdir /etc/puppet --vardir /var/lib/puppet; this is equivalent to running the following from the command line:
You can add additional configuration parameters to the config.ru file to further alter how Puppet runs when it's running through passenger. For instance, to enable debugging on the passenger Puppet master, add the following line to config.ru before the run Puppet::Util::CommandLine.new.execute line:
config.ru file to further alter how Puppet
Environments in Puppet are directories holding different versions of your Puppet manifests. Environments prior to Version 3.6 of Puppet were not a default configuration for Puppet. In newer versions of Puppet, environments are configured by default.
- Create a
productiondirectory at/etc/puppet/environmentsthat contains both amodulesandmanifestsdirectory. Then create asite.ppwhich creates a file in/tmpas follows:root@puppet:~# cd /etc/puppet/environments/ root@puppet:/etc/puppet/environments# mkdir -p production/{manifests,modules} root@puppet:/etc/puppet/environments# vim production/manifests/site.pp node default { file {'/tmp/production': content => "Hello World!\nThis is production\n", } }
- Run puppet agent on the master to connect to it and verify that the production code was delivered:
root@puppet:~# puppet agent -vt Info: Retrieving pluginfacts Info: Retrieving plugin Info: Caching catalog for puppet Info: Applying configuration version '1410415538' Notice: /Stage[main]/Main/Node[default]/File[/tmp/production]/ensure: defined content as '{md5}f7ad9261670b9da33a67a5126933044c' Notice: Finished catalog run in 0.04 seconds # cat /tmp/production Hello World! This is production
- Configure another environment
devel. Create a new manifest in thedevelenvironment:root@puppet:/etc/puppet/environments# mkdir -p devel/{manifests,modules} root@puppet:/etc/puppet/environments# vim devel/manifests/site.pp node default { file {'/tmp/devel': content => "Good-bye! Development\n", } }
- Apply the new environment by running the
--environment develpuppet agent using the following command:root@puppet:/etc/puppet/environments# puppet agent -vt --environment devel Info: Retrieving pluginfacts Info: Retrieving plugin Info: Caching catalog for puppet Info: Applying configuration version '1410415890' Notice: /Stage[main]/Main/Node[default]/File[/tmp/devel]/ensure: defined content as '{md5}b6313bb89bc1b7d97eae5aa94588eb68' Notice: Finished catalog run in 0.04 seconds root@puppet:/etc/puppet/environments# cat /tmp/devel Good-bye! Development
environmentpath function of your installation by adding a line to the [main] section of /etc/puppet/puppet.conf as follows:
- Create a
productiondirectory at/etc/puppet/environmentsthat contains both amodulesandmanifestsdirectory. Then create asite.ppwhich creates a file in/tmpas follows:root@puppet:~# cd /etc/puppet/environments/ root@puppet:/etc/puppet/environments# mkdir -p production/{manifests,modules} root@puppet:/etc/puppet/environments# vim production/manifests/site.pp node default { file {'/tmp/production': content => "Hello World!\nThis is production\n", } }
- Run puppet agent on the master to connect to it and verify that the production code was delivered:
root@puppet:~# puppet agent -vt Info: Retrieving pluginfacts Info: Retrieving plugin Info: Caching catalog for puppet Info: Applying configuration version '1410415538' Notice: /Stage[main]/Main/Node[default]/File[/tmp/production]/ensure: defined content as '{md5}f7ad9261670b9da33a67a5126933044c' Notice: Finished catalog run in 0.04 seconds # cat /tmp/production Hello World! This is production
- Configure another environment
devel. Create a new manifest in thedevelenvironment:root@puppet:/etc/puppet/environments# mkdir -p devel/{manifests,modules} root@puppet:/etc/puppet/environments# vim devel/manifests/site.pp node default { file {'/tmp/devel': content => "Good-bye! Development\n", } }
- Apply the new environment by running the
--environment develpuppet agent using the following command:root@puppet:/etc/puppet/environments# puppet agent -vt --environment devel Info: Retrieving pluginfacts Info: Retrieving plugin Info: Caching catalog for puppet Info: Applying configuration version '1410415890' Notice: /Stage[main]/Main/Node[default]/File[/tmp/devel]/ensure: defined content as '{md5}b6313bb89bc1b7d97eae5aa94588eb68' Notice: Finished catalog run in 0.04 seconds root@puppet:/etc/puppet/environments# cat /tmp/devel Good-bye! Development
production directory at /etc/puppet/environments that contains both a modules and manifests directory. Then create a site.pp which creates a file in /tmp as follows:root@puppet:~# cd /etc/puppet/environments/ root@puppet:/etc/puppet/environments# mkdir -p production/{manifests,modules} root@puppet:/etc/puppet/environments# vim production/manifests/site.pp node default { file {'/tmp/production': content => "Hello World!\nThis is production\n", } }
root@puppet:~# puppet agent -vt Info: Retrieving pluginfacts Info: Retrieving plugin Info: Caching catalog for puppet Info: Applying configuration version '1410415538' Notice: /Stage[main]/Main/Node[default]/File[/tmp/production]/ensure: defined content as '{md5}f7ad9261670b9da33a67a5126933044c' Notice: Finished catalog run in 0.04 seconds # cat /tmp/production Hello World! This is production
- another environment
devel. Create a new manifest in thedevelenvironment:root@puppet:/etc/puppet/environments# mkdir -p devel/{manifests,modules} root@puppet:/etc/puppet/environments# vim devel/manifests/site.pp node default { file {'/tmp/devel': content => "Good-bye! Development\n", } }
- Apply the new environment by running the
--environment develpuppet agent using the following command:root@puppet:/etc/puppet/environments# puppet agent -vt --environment devel Info: Retrieving pluginfacts Info: Retrieving plugin Info: Caching catalog for puppet Info: Applying configuration version '1410415890' Notice: /Stage[main]/Main/Node[default]/File[/tmp/devel]/ensure: defined content as '{md5}b6313bb89bc1b7d97eae5aa94588eb68' Notice: Finished catalog run in 0.04 seconds root@puppet:/etc/puppet/environments# cat /tmp/devel Good-bye! Development
PuppetDB is a database for Puppet that is used to store information about nodes connected to a Puppet master. PuppetDB is also a storage area for exported resources. Exported resources are resources that are defined on nodes but applied to other nodes. The simplest way to install PuppetDB is to use the PuppetDB module from Puppet labs. From this point on, we'll assume you are using the puppet.example.com machine and have a passenger-based configuration of Puppet.
Now that our Puppet master has the PuppetDB module installed, we need to apply the PuppetDB module to our Puppet master, we can do this in the site manifest. Add the following to your (production) site.pp:
Run puppet agent to apply the puppetdb class and the puppetdb::master::config class:
puppet module install will install the module to the correct location for your installation with the following command:
Now that our Puppet master has the PuppetDB module installed, we need to apply the PuppetDB module to our Puppet master, we can do this in the site manifest. Add the following to your (production) site.pp:
Run puppet agent to apply the puppetdb class and the puppetdb::master::config class:
puppetdb class to our Puppet master node, Puppet installed and configured postgresql and puppetdb.
puppetdb::master::config class, we set the puppet_service_name variable to apache2, this is because we are running Puppet through passenger. Without this line our agent would try to start the puppetmaster process instead of apache2.
Hiera is an information repository for Puppet. Using Hiera you can have a hierarchical categorization of data about your nodes that is maintained outside of your manifests. This is very useful for sharing code and dealing with exceptions that will creep into any Puppet deployment.
- Hiera is configured from a yaml file,
/etc/puppet/hiera.yaml. Create the file and add the following as a minimal configuration:--- :hierarchy: - common :backends: - yaml :yaml: :datadir: '/etc/puppet/hieradata'
- Create the
common.yamlfile referenced in the hierarchy:root@puppet:/etc/puppet# mkdir hieradata root@puppet:/etc/puppet# vim hieradata/common.yaml --- message: 'Default Message'
- Edit the
site.ppfile and add a notify resource based on the Hiera value:node default { $message = hiera('message','unknown') notify {"Message is $message":} }
- Apply the manifest to a test node:
t@ckbk:~$ sudo puppet agent -t Info: Retrieving pluginfacts Info: Retrieving plugin ... Info: Caching catalog for cookbook-test Info: Applying configuration version '1410504848' Notice: Message is Default Message Notice: /Stage[main]/Main/Node[default]/Notify[Message is Default Message]/message: defined 'message' as 'Message is Default Message' Notice: Finished catalog run in 0.06 seconds
Hiera uses a hierarchy to search through a set of yaml files to find the appropriate values. We defined this hierarchy in hiera.yaml with the single entry for common.yaml. We used the hiera function in site.pp to lookup the value for message and store that value in the variable $message. The values used for the definition of the hierarchy can be any facter facts defined about the system. A common hierarchy is shown as:
- Hiera is configured from a yaml file,
/etc/puppet/hiera.yaml. Create the file and add the following as a minimal configuration:--- :hierarchy: - common :backends: - yaml :yaml: :datadir: '/etc/puppet/hieradata'
- Create the
common.yamlfile referenced in the hierarchy:root@puppet:/etc/puppet# mkdir hieradata root@puppet:/etc/puppet# vim hieradata/common.yaml --- message: 'Default Message'
- Edit the
site.ppfile and add a notify resource based on the Hiera value:node default { $message = hiera('message','unknown') notify {"Message is $message":} }
- Apply the manifest to a test node:
t@ckbk:~$ sudo puppet agent -t Info: Retrieving pluginfacts Info: Retrieving plugin ... Info: Caching catalog for cookbook-test Info: Applying configuration version '1410504848' Notice: Message is Default Message Notice: /Stage[main]/Main/Node[default]/Notify[Message is Default Message]/message: defined 'message' as 'Message is Default Message' Notice: Finished catalog run in 0.06 seconds
Hiera uses a hierarchy to search through a set of yaml files to find the appropriate values. We defined this hierarchy in hiera.yaml with the single entry for common.yaml. We used the hiera function in site.pp to lookup the value for message and store that value in the variable $message. The values used for the definition of the hierarchy can be any facter facts defined about the system. A common hierarchy is shown as:
/etc/puppet/hiera.yaml. Create the file and add the following as a minimal configuration:--- :hierarchy: - common :backends: - yaml :yaml: :datadir: '/etc/puppet/hieradata'
common.yaml file referenced in the hierarchy:root@puppet:/etc/puppet# mkdir hieradata root@puppet:/etc/puppet# vim hieradata/common.yaml --- message: 'Default Message'
site.pp file and add a notify resource based on the Hiera value:node default { $message = hiera('message','unknown') notify {"Message is $message":} }
t@ckbk:~$ sudo puppet agent -t Info: Retrieving pluginfacts Info: Retrieving plugin ... Info: Caching catalog for cookbook-test Info: Applying configuration version '1410504848' Notice: Message is Default Message Notice: /Stage[main]/Main/Node[default]/Notify[Message is Default Message]/message: defined 'message' as 'Message is Default Message' Notice: Finished catalog run in 0.06 seconds
Hiera uses a hierarchy to search through a set of yaml files to find the appropriate values. We defined this hierarchy in hiera.yaml with the single entry for common.yaml. We used the hiera function in site.pp to lookup the value for message and store that value in the variable $message. The values used for the definition of the hierarchy can be any facter facts defined about the system. A common hierarchy is shown as:
cookbook::example with a parameter named publisher, you can include the following in a Hiera yaml file to automatically set this parameter:
environment you may reference the environment of the client node using %{environment} as shown in the following hierarchy:
In our hierarchy defined in hiera.yaml, we created an entry based on the hostname fact; in this section, we'll create yaml files in the hosts subdirectory of Hiera data with information specific to a particular host.
- Create a file at
/etc/puppet/hieradata/hoststhat is the hostname of your test node. For example if your host is namedcookbook-test, then the file would be namedcookbook-test.yaml. - Insert a specific message in this file:
message: 'This is the test node for the cookbook'
- Run Puppet on two different test nodes to note the difference:
t@ckbk:~$ sudo puppet agent -t Info: Caching catalog for cookbook-test Notice: Message is This is the test node for the cookbook [root@hiera-test ~]# puppet agent -t Info: Caching catalog for hiera-test.example.com Notice: Message is Default Message
hosts/%{hostname} entry.
- Create a file at
/etc/puppet/hieradata/hoststhat is the hostname of your test node. For example if your host is namedcookbook-test, then the file would be namedcookbook-test.yaml. - Insert a specific message in this file:
message: 'This is the test node for the cookbook'
- Run Puppet on two different test nodes to note the difference:
t@ckbk:~$ sudo puppet agent -t Info: Caching catalog for cookbook-test Notice: Message is This is the test node for the cookbook [root@hiera-test ~]# puppet agent -t Info: Caching catalog for hiera-test.example.com Notice: Message is Default Message
/etc/puppet/hieradata/hosts that is the hostname of your test node. For example if your host is named cookbook-test, then the file would be named cookbook-test.yaml.
message: 'This is the test node for the cookbook'
t@ckbk:~$ sudo puppet agent -t Info: Caching catalog for cookbook-test Notice: Message is This is the test node for the cookbook [root@hiera-test ~]# puppet agent -t Info: Caching catalog for hiera-test.example.com Notice: Message is Default Message
If you're using Hiera to store your configuration data, there's a gem available called hiera-gpg that adds an encryption backend to Hiera to allow you to protect values stored in Hiera.
To set up hiera-gpg, follow these steps:
- Install the
ruby-devpackage; it will be required to build thehiera-gpggem as follows:root@puppet:~# puppet resource package ruby-dev ensure=installed Notice: /Package[ruby-dev]/ensure: ensure changed 'purged' to 'present' package { 'ruby-dev': ensure => '1:1.9.3', }
- Install the
hiera-gpggem using the gem provider:root@puppet:~# puppet resource package hiera-gpg ensure=installed provider=gem Notice: /Package[hiera-gpg]/ensure: created package { 'hiera-gpg': ensure => ['1.1.0'], }
- Modify your
hiera.yamlfile as follows::hierarchy: - secret - common :backends: - yaml - gpg :yaml: :datadir: '/etc/puppet/hieradata' :gpg: :datadir: '/etc/puppet/secret'
In this example, we'll create a piece of encrypted data and retrieve it using hiera-gpg as follows:
- Create the
secret.yamlfile at/etc/puppet/secretwith the following contents:top_secret: 'Val Kilmer' - If you don't already have a GnuPG encryption key, follow the steps in the Using GnuPG to encrypt secrets recipe in Chapter 4, Working with Files and Packages.
- Encrypt the
secret.yamlfile to this key using the following command (replace thepuppet@puppet.example.comwith the e-mail address you specified when creating the key). This will create thesecret.gpgfile:root@puppet:/etc/puppet/secret# gpg -e -o secret.gpg -r puppet@puppet.example.com secret.yaml root@puppet:/etc/puppet/secret# file secret.gpg secret.gpg: GPG encrypted data
- Remove the plaintext
secret.yamlfile:root@puppet:/etc/puppet/secret# rm secret.yaml - Modify your default node in the
site.ppfile as follows:node default { $message = hiera('top_secret','Deja Vu') notify { "Message is $message": } }
- Now run Puppet on a node:
[root@hiera-test ~]# puppet agent -t Info: Caching catalog for hiera-test.example.com Info: Applying configuration version '1410508276' Notice: Message is Deja Vu Notice: /Stage[main]/Main/Node[default]/Notify[Message is Deja Vu]/message: defined 'message' as 'Message is Deja Vu' Notice: Finished catalog run in 0.08 seconds
When you install hiera-gpg, it adds to Hiera, the ability to decrypt .gpg files. So you can put any secret data into a .yaml file that you then encrypt to the appropriate key with GnuPG. Only machines that have the right secret key will be able to access this data.
You might also like to know about hiera-eyaml, another secret-data backend for Hiera that supports encryption of individual values within a Hiera data file. This could be handy if you need to mix encrypted and unencrypted facts within a single file. Find out more about hiera-eyaml at https://github.com/TomPoulton/hiera-eyaml.
- The Using GnuPG to encrypt secrets recipe in Chapter 4, Working with Files and Packages.
ruby-dev package; it will be required to build the hiera-gpg gem as follows:root@puppet:~# puppet resource package ruby-dev ensure=installed Notice: /Package[ruby-dev]/ensure: ensure changed 'purged' to 'present' package { 'ruby-dev': ensure => '1:1.9.3', }
hiera-gpg gem using the gem provider:root@puppet:~# puppet resource package hiera-gpg ensure=installed provider=gem Notice: /Package[hiera-gpg]/ensure: created package { 'hiera-gpg': ensure => ['1.1.0'], }
hiera.yaml file as follows: :hierarchy:
- secret
- common
:backends:
- yaml
- gpg
:yaml:
:datadir: '/etc/puppet/hieradata'
:gpg:
:datadir: '/etc/puppet/secret'In this example, we'll create a piece of encrypted data and retrieve it using hiera-gpg as follows:
- Create the
secret.yamlfile at/etc/puppet/secretwith the following contents:top_secret: 'Val Kilmer' - If you don't already have a GnuPG encryption key, follow the steps in the Using GnuPG to encrypt secrets recipe in Chapter 4, Working with Files and Packages.
- Encrypt the
secret.yamlfile to this key using the following command (replace thepuppet@puppet.example.comwith the e-mail address you specified when creating the key). This will create thesecret.gpgfile:root@puppet:/etc/puppet/secret# gpg -e -o secret.gpg -r puppet@puppet.example.com secret.yaml root@puppet:/etc/puppet/secret# file secret.gpg secret.gpg: GPG encrypted data
- Remove the plaintext
secret.yamlfile:root@puppet:/etc/puppet/secret# rm secret.yaml - Modify your default node in the
site.ppfile as follows:node default { $message = hiera('top_secret','Deja Vu') notify { "Message is $message": } }
- Now run Puppet on a node:
[root@hiera-test ~]# puppet agent -t Info: Caching catalog for hiera-test.example.com Info: Applying configuration version '1410508276' Notice: Message is Deja Vu Notice: /Stage[main]/Main/Node[default]/Notify[Message is Deja Vu]/message: defined 'message' as 'Message is Deja Vu' Notice: Finished catalog run in 0.08 seconds
When you install hiera-gpg, it adds to Hiera, the ability to decrypt .gpg files. So you can put any secret data into a .yaml file that you then encrypt to the appropriate key with GnuPG. Only machines that have the right secret key will be able to access this data.
You might also like to know about hiera-eyaml, another secret-data backend for Hiera that supports encryption of individual values within a Hiera data file. This could be handy if you need to mix encrypted and unencrypted facts within a single file. Find out more about hiera-eyaml at https://github.com/TomPoulton/hiera-eyaml.
- The Using GnuPG to encrypt secrets recipe in Chapter 4, Working with Files and Packages.
example, we'll create a piece of encrypted data and retrieve it using hiera-gpg as follows:
- Create the
secret.yamlfile at/etc/puppet/secretwith the following contents:top_secret: 'Val Kilmer' - If you don't already have a GnuPG encryption key, follow the steps in the Using GnuPG to encrypt secrets recipe in Chapter 4, Working with Files and Packages.
- Encrypt the
secret.yamlfile to this key using the following command (replace thepuppet@puppet.example.comwith the e-mail address you specified when creating the key). This will create thesecret.gpgfile:root@puppet:/etc/puppet/secret# gpg -e -o secret.gpg -r puppet@puppet.example.com secret.yaml root@puppet:/etc/puppet/secret# file secret.gpg secret.gpg: GPG encrypted data
- Remove the plaintext
secret.yamlfile:root@puppet:/etc/puppet/secret# rm secret.yaml - Modify your default node in the
site.ppfile as follows:node default { $message = hiera('top_secret','Deja Vu') notify { "Message is $message": } }
- Now run Puppet on a node:
[root@hiera-test ~]# puppet agent -t Info: Caching catalog for hiera-test.example.com Info: Applying configuration version '1410508276' Notice: Message is Deja Vu Notice: /Stage[main]/Main/Node[default]/Notify[Message is Deja Vu]/message: defined 'message' as 'Message is Deja Vu' Notice: Finished catalog run in 0.08 seconds
When you install hiera-gpg, it adds to Hiera, the ability to decrypt .gpg files. So you can put any secret data into a .yaml file that you then encrypt to the appropriate key with GnuPG. Only machines that have the right secret key will be able to access this data.
You might also like to know about hiera-eyaml, another secret-data backend for Hiera that supports encryption of individual values within a Hiera data file. This could be handy if you need to mix encrypted and unencrypted facts within a single file. Find out more about hiera-eyaml at https://github.com/TomPoulton/hiera-eyaml.
- The Using GnuPG to encrypt secrets recipe in Chapter 4, Working with Files and Packages.
you install hiera-gpg, it adds to Hiera, the ability to decrypt .gpg files. So you can put any secret data into a .yaml file that you then encrypt to the appropriate key with GnuPG. Only machines that have the right secret key will be able to access this data.
You might also like to know about hiera-eyaml, another secret-data backend for Hiera that supports encryption of individual values within a Hiera data file. This could be handy if you need to mix encrypted and unencrypted facts within a single file. Find out more about hiera-eyaml at https://github.com/TomPoulton/hiera-eyaml.
- The Using GnuPG to encrypt secrets recipe in Chapter 4, Working with Files and Packages.
hiera-eyaml, another secret-data backend for Hiera that supports encryption of individual values within a Hiera data file. This could be handy if you need
to mix encrypted and unencrypted facts within a single file. Find out more about hiera-eyaml at https://github.com/TomPoulton/hiera-eyaml.
- The Using GnuPG to encrypt secrets recipe in Chapter 4, Working with Files and Packages.
- Chapter 4, Working with Files and Packages.
Running Puppet in a centralized architecture creates a lot of traffic between nodes. The bulk of this traffic is JSON and yaml data. An experimental feature of the latest releases of Puppet allow for the serialization of this data using MessagePack (msgpack).
The master will be sent this option when the node begins communicating with the master. Any classes that support serialization with msgpack will be transmitted with msgpack.Serialization of the data between nodes and the master will in theory increase the speed at which nodes communicate by optimizing the data that is travelling between them. This feature is still experimental.
ruby-dev or ruby-devel package on your nodes/server at this point:
The master will be sent this option when the node begins communicating with the master. Any classes that support serialization with msgpack will be transmitted with msgpack.Serialization of the data between nodes and the master will in theory increase the speed at which nodes communicate by optimizing the data that is travelling between them. This feature is still experimental.
preferred_serialization_format to msgpack in the [agent] section of your nodes puppet.conf file:
The master will be sent this option when the node begins communicating with the master. Any classes that support serialization with msgpack will be transmitted with msgpack.Serialization of the data between nodes and the master will in theory increase the speed at which nodes communicate by optimizing the data that is travelling between them. This feature is still experimental.
msgpack will be transmitted with msgpack.Serialization of the data between nodes and the master will in theory increase the speed at which nodes communicate by optimizing the data that is travelling between
It would be nice if we knew there was a syntax error in the manifest before we even committed it. You can have Puppet check the manifest using the puppet parser validate command:
- In your Puppet repo, create a new
hooksdirectory:t@mylaptop:~/puppet$ mkdir hooks - Create the file
hooks/check_syntax.shwith the following contents (based on a script by Puppet Labs):#!/bin/sh syntax_errors=0 error_msg=$(mktemp /tmp/error_msg.XXXXXX) if git rev-parse --quiet --verify HEAD > /dev/null then against=HEAD else # Initial commit: diff against an empty tree object against=4b825dc642cb6eb9a060e54bf8d69288fbee4904 fi # Get list of new/modified manifest and template files to check (in git index) for indexfile in 'git diff-index --diff-filter=AM -- name-only --cached $against | egrep '\.(pp|erb)'' do # Don't check empty files if [ 'git cat-file -s :0:$indexfile' -gt 0 ] then case $indexfile in *.pp ) # Check puppet manifest syntax git cat-file blob :0:$indexfile | puppet parser validate > $error_msg ;; *.erb ) # Check ERB template syntax git cat-file blob :0:$indexfile | erb -x -T - | ruby -c 2> $error_msg > /dev/null ;; esac if [ "$?" -ne 0 ] then echo -n "$indexfile: " cat $error_msg syntax_errors='expr $syntax_errors + 1' fi fi done rm -f $error_msg if [ "$syntax_errors" -ne 0 ] then echo "Error: $syntax_errors syntax errors found, aborting commit." exit 1 fi - Set execute permission for the
hookscript with the following command:t@mylaptop:~/puppet$ chmod a+x hooks/check_syntax.sh - Now either symlink or copy the script to the precommit hook in your hooks directory. If your Git repo is checked out in
~/puppet, then create the symlink at~/puppet/hooks/pre-commitas follows:t@mylaptop:~/puppet$ ln -s ~/puppet/hooks/check_syntax.sh.git/hooks/pre-commit
hooks directory:t@mylaptop:~/puppet$ mkdir hooks
hooks/check_syntax.sh with the following contents (based on a script by Puppet Labs):#!/bin/sh
syntax_errors=0
error_msg=$(mktemp /tmp/error_msg.XXXXXX)
if git rev-parse --quiet --verify HEAD > /dev/null
then
against=HEAD
else
# Initial commit: diff against an empty tree object
against=4b825dc642cb6eb9a060e54bf8d69288fbee4904
fi
# Get list of new/modified manifest and template files
to check (in git index)
for indexfile in 'git diff-index --diff-filter=AM --
name-only --cached $against | egrep '\.(pp|erb)''
do
# Don't check empty files
if [ 'git cat-file -s :0:$indexfile' -gt 0 ]
then
case $indexfile in
*.pp )
# Check puppet manifest syntax
git cat-file blob :0:$indexfile |
puppet parser validate > $error_msg ;;
*.erb )
# Check ERB template syntax
git cat-file blob :0:$indexfile |
erb -x -T - | ruby -c 2> $error_msg >
/dev/null ;;
esac
if [ "$?" -ne 0 ]
then
echo -n "$indexfile: "
cat $error_msg
syntax_errors='expr $syntax_errors + 1'
fi
fi
done
rm -f $error_msg
if [ "$syntax_errors" -ne 0 ]
then
echo "Error: $syntax_errors syntax errors found,
aborting commit."
exit 1
fi- execute permission for the
hookscript with the following command:t@mylaptop:~/puppet$ chmod a+x hooks/check_syntax.sh - Now either symlink or copy the script to the precommit hook in your hooks directory. If your Git repo is checked out in
~/puppet, then create the symlink at~/puppet/hooks/pre-commitas follows:t@mylaptop:~/puppet$ ln -s ~/puppet/hooks/check_syntax.sh.git/hooks/pre-commit
check_syntax.sh script will prevent you from committing any files with syntax errors when it is used as the pre-commit hook for Git:
As we have already seen in the decentralized model, Git can be used to transfer files between machines using a combination of ssh and ssh keys. It can also be useful to have a Git hook do the same on each successful commit to the repository.
Follow these steps to get started:
- Create an
sshkey that can access your Puppet user on your Puppet master and install this key into the Git user's account ongit.example.com:[git@git ~]$ ssh-keygen -f ~/.ssh/puppet_rsa Generating public/private rsa key pair. Your identification has been saved in /home/git/.ssh/puppet_rsa. Your public key has been saved in /home/git/.ssh/puppet_rsa.pub. Copy the public key into the authorized_keys file of the puppet user on your puppetmaster puppet@puppet:~/.ssh$ cat puppet_rsa.pub >>authorized_keys
- Modify the Puppet account to allow the Git user to log in as follows:
root@puppet:~# chsh puppet -s /bin/bash
- Now that the Git user can log in to the Puppet master as the Puppet user, modify the Git user's
sshconfiguration to use the newly createdsshkey by default:[git@git ~]$ vim .ssh/config Host puppet.example.com IdentityFile ~/.ssh/puppet_rsa
- Add the Puppet master as a remote location for the Puppet repository on the Git server with the following command:
[git@git puppet.git]$ git remote add puppetmaster puppet@puppet.example.com:/etc/puppet/environments/puppet.git - On the Puppet master, move the
productiondirectory out of the way and check out your Puppet repository:root@puppet:~# chown -R puppet:puppet /etc/puppet/environments root@puppet:~# sudo -iu puppet puppet@puppet:~$ cd /etc/puppet/environments/ puppet@puppet:/etc/puppet/environments$ mv production production.orig puppet@puppet:/etc/puppet/environments$ git clone git@git.example.com:repos/puppet.git Cloning into 'puppet.git'... remote: Counting objects: 63, done. remote: Compressing objects: 100% (52/52), done. remote: Total 63 (delta 10), reused 0 (delta 0) Receiving objects: 100% (63/63), 9.51 KiB, done. Resolving deltas: 100% (10/10), done.
- Now we have a local bare repository on the Puppet server that we can push to, to remotely clone this into the
productiondirectory:puppet@puppet:/etc/puppet/environments$ git clone puppet.git production Cloning into 'production'... done.
- Now perform a Git push from the Git server to the Puppet master:
[git@git ~]$ cd repos/puppet.git/ [git@git puppet.git]$ git push puppetmaster Everything up-to-date
- Create a post-commit file in the
hooksdirectory of the repository on the Git server with the following contents:[git@git puppet.git]$ vim hooks/post-commit #!/bin/sh git push puppetmaster ssh puppet@puppet.example.com "cd /etc/puppet/environments/production && git pull" [git@git puppet.git]$ chmod 755 hooks/post-commit
- Commit a change to the repository from your laptop and verify that the change is propagated to the Puppet master as follows:
t@mylaptop puppet$ vim README t@mylaptop puppet$ git add README t@mylaptop puppet$ git commit -m "Adding README" [master 8148902] Adding README 1 file changed, 4 deletions(-) t@mylaptop puppet$ git push X11 forwarding request failed on channel 0 Counting objects: 5, done. Delta compression using up to 4 threads. Compressing objects: 100% (3/3), done. Writing objects: 100% (3/3), 371 bytes | 0 bytes/s, done. Total 3 (delta 1), reused 0 (delta 0) remote: To puppet@puppet.example.com:/etc/puppet/environments/puppet.git remote: 377ed44..8148902 master -> master remote: From /etc/puppet/environments/puppet remote: 377ed44..8148902 master -> origin/master remote: Updating 377ed44..8148902 remote: Fast-forward remote: README | 4 ---- remote: 1 file changed, 4 deletions(-) To git@git.example.com:repos/puppet.git 377ed44..8148902 master -> master
We created a bare repository on the Puppet master that we then use as a remote for the repository on git.example.com (remote repositories must be bare). We then clone that bare repository into the production directory. We add the bare repository on puppet.example.com as a remote to the bare repository on git.example.com. We then create a post-receive hook in the repository on git.example.com.
ssh key that can access your Puppet user on your Puppet master and install this key into the Git user's account on git.example.com:[git@git ~]$ ssh-keygen -f ~/.ssh/puppet_rsa Generating public/private rsa key pair. Your identification has been saved in /home/git/.ssh/puppet_rsa. Your public key has been saved in /home/git/.ssh/puppet_rsa.pub. Copy the public key into the authorized_keys file of the puppet user on your puppetmaster puppet@puppet:~/.ssh$ cat puppet_rsa.pub >>authorized_keys
root@puppet:~# chsh puppet -s /bin/bash
- Now that the Git user can log in to the Puppet master as the Puppet user, modify the Git user's
sshconfiguration to use the newly createdsshkey by default:[git@git ~]$ vim .ssh/config Host puppet.example.com IdentityFile ~/.ssh/puppet_rsa
- Add the Puppet master as a remote location for the Puppet repository on the Git server with the following command:
[git@git puppet.git]$ git remote add puppetmaster puppet@puppet.example.com:/etc/puppet/environments/puppet.git - On the Puppet master, move the
productiondirectory out of the way and check out your Puppet repository:root@puppet:~# chown -R puppet:puppet /etc/puppet/environments root@puppet:~# sudo -iu puppet puppet@puppet:~$ cd /etc/puppet/environments/ puppet@puppet:/etc/puppet/environments$ mv production production.orig puppet@puppet:/etc/puppet/environments$ git clone git@git.example.com:repos/puppet.git Cloning into 'puppet.git'... remote: Counting objects: 63, done. remote: Compressing objects: 100% (52/52), done. remote: Total 63 (delta 10), reused 0 (delta 0) Receiving objects: 100% (63/63), 9.51 KiB, done. Resolving deltas: 100% (10/10), done.
- Now we have a local bare repository on the Puppet server that we can push to, to remotely clone this into the
productiondirectory:puppet@puppet:/etc/puppet/environments$ git clone puppet.git production Cloning into 'production'... done.
- Now perform a Git push from the Git server to the Puppet master:
[git@git ~]$ cd repos/puppet.git/ [git@git puppet.git]$ git push puppetmaster Everything up-to-date
- Create a post-commit file in the
hooksdirectory of the repository on the Git server with the following contents:[git@git puppet.git]$ vim hooks/post-commit #!/bin/sh git push puppetmaster ssh puppet@puppet.example.com "cd /etc/puppet/environments/production && git pull" [git@git puppet.git]$ chmod 755 hooks/post-commit
- Commit a change to the repository from your laptop and verify that the change is propagated to the Puppet master as follows:
t@mylaptop puppet$ vim README t@mylaptop puppet$ git add README t@mylaptop puppet$ git commit -m "Adding README" [master 8148902] Adding README 1 file changed, 4 deletions(-) t@mylaptop puppet$ git push X11 forwarding request failed on channel 0 Counting objects: 5, done. Delta compression using up to 4 threads. Compressing objects: 100% (3/3), done. Writing objects: 100% (3/3), 371 bytes | 0 bytes/s, done. Total 3 (delta 1), reused 0 (delta 0) remote: To puppet@puppet.example.com:/etc/puppet/environments/puppet.git remote: 377ed44..8148902 master -> master remote: From /etc/puppet/environments/puppet remote: 377ed44..8148902 master -> origin/master remote: Updating 377ed44..8148902 remote: Fast-forward remote: README | 4 ---- remote: 1 file changed, 4 deletions(-) To git@git.example.com:repos/puppet.git 377ed44..8148902 master -> master
We created a bare repository on the Puppet master that we then use as a remote for the repository on git.example.com (remote repositories must be bare). We then clone that bare repository into the production directory. We add the bare repository on puppet.example.com as a remote to the bare repository on git.example.com. We then create a post-receive hook in the repository on git.example.com.
ssh configuration to use the newly created ssh key by default:[git@git ~]$ vim .ssh/config Host puppet.example.com IdentityFile ~/.ssh/puppet_rsa
[git@git puppet.git]$ git remote add puppetmaster puppet@puppet.example.com:/etc/puppet/environments/puppet.git
production directory out of the way and check out your Puppet repository:root@puppet:~# chown -R puppet:puppet /etc/puppet/environments root@puppet:~# sudo -iu puppet puppet@puppet:~$ cd /etc/puppet/environments/ puppet@puppet:/etc/puppet/environments$ mv production production.orig puppet@puppet:/etc/puppet/environments$ git clone git@git.example.com:repos/puppet.git Cloning into 'puppet.git'... remote: Counting objects: 63, done. remote: Compressing objects: 100% (52/52), done. remote: Total 63 (delta 10), reused 0 (delta 0) Receiving objects: 100% (63/63), 9.51 KiB, done. Resolving deltas: 100% (10/10), done.
- we have a local bare repository on the Puppet server that we can push to, to remotely clone this into the
productiondirectory:puppet@puppet:/etc/puppet/environments$ git clone puppet.git production Cloning into 'production'... done.
- Now perform a Git push from the Git server to the Puppet master:
[git@git ~]$ cd repos/puppet.git/ [git@git puppet.git]$ git push puppetmaster Everything up-to-date
- Create a post-commit file in the
hooksdirectory of the repository on the Git server with the following contents:[git@git puppet.git]$ vim hooks/post-commit #!/bin/sh git push puppetmaster ssh puppet@puppet.example.com "cd /etc/puppet/environments/production && git pull" [git@git puppet.git]$ chmod 755 hooks/post-commit
- Commit a change to the repository from your laptop and verify that the change is propagated to the Puppet master as follows:
t@mylaptop puppet$ vim README t@mylaptop puppet$ git add README t@mylaptop puppet$ git commit -m "Adding README" [master 8148902] Adding README 1 file changed, 4 deletions(-) t@mylaptop puppet$ git push X11 forwarding request failed on channel 0 Counting objects: 5, done. Delta compression using up to 4 threads. Compressing objects: 100% (3/3), done. Writing objects: 100% (3/3), 371 bytes | 0 bytes/s, done. Total 3 (delta 1), reused 0 (delta 0) remote: To puppet@puppet.example.com:/etc/puppet/environments/puppet.git remote: 377ed44..8148902 master -> master remote: From /etc/puppet/environments/puppet remote: 377ed44..8148902 master -> origin/master remote: Updating 377ed44..8148902 remote: Fast-forward remote: README | 4 ---- remote: 1 file changed, 4 deletions(-) To git@git.example.com:repos/puppet.git 377ed44..8148902 master -> master
We created a bare repository on the Puppet master that we then use as a remote for the repository on git.example.com (remote repositories must be bare). We then clone that bare repository into the production directory. We add the bare repository on puppet.example.com as a remote to the bare repository on git.example.com. We then create a post-receive hook in the repository on git.example.com.
created a bare repository on the Puppet master that we then use as a remote for the repository on git.example.com (remote repositories must be bare). We then clone that bare repository into the production directory. We add the bare repository on puppet.example.com as a remote to the bare repository on git.example.com. We then create a post-receive hook in the repository on git.example.com.
Branches are a way of keeping several different tracks of development within a single source repository. Puppet environments are a lot like Git branches. You can have the same code with slight variations between branches, just as you can have different modules for different environments. In this section, we'll show how to use Git branches to define environments on the Puppet master.
The hook now reads in the refname and parses out the branch that is being updated. We use that branch variable to clone the repository into a new directory and check out the branch.
- Create the production branch as shown in the following command line:
t@mylaptop puppet$ git branch production t@mylaptop puppet$ git checkout production Switched to branch 'production'
- Update the production branch and push to the Git server as follows:
t@mylaptop puppet$ vim README t@mylaptop puppet$ git add README t@mylaptop puppet$ git commit -m "Production Branch" t@mylaptop puppet$ git push origin production Counting objects: 7, done. Delta compression using up to 4 threads. Compressing objects: 100% (3/3), done. Writing objects: 100% (3/3), 372 bytes | 0 bytes/s, done. Total 3 (delta 1), reused 0 (delta 0) remote: To puppet@puppet.example.com:/etc/puppet/environments/puppet.git remote: 11db6e5..832f6a9 production -> production remote: Cloning into '/etc/puppet/environments/production'... remote: done. remote: Switched to a new branch 'production' remote: Branch production set up to track remote branch production from origin. remote: Already up-to-date. To git@git.example.com:repos/puppet.git 11db6e5..832f6a9 production -> production
Now whenever we create a new branch, a corresponding directory is created in our environment's directory. A one-to-one mapping is established between environments and branches.
production directory that was based on the master branch; we'll remove that directory now:
The hook now reads in the refname and parses out the branch that is being updated. We use that branch variable to clone the repository into a new directory and check out the branch.
- Create the production branch as shown in the following command line:
t@mylaptop puppet$ git branch production t@mylaptop puppet$ git checkout production Switched to branch 'production'
- Update the production branch and push to the Git server as follows:
t@mylaptop puppet$ vim README t@mylaptop puppet$ git add README t@mylaptop puppet$ git commit -m "Production Branch" t@mylaptop puppet$ git push origin production Counting objects: 7, done. Delta compression using up to 4 threads. Compressing objects: 100% (3/3), done. Writing objects: 100% (3/3), 372 bytes | 0 bytes/s, done. Total 3 (delta 1), reused 0 (delta 0) remote: To puppet@puppet.example.com:/etc/puppet/environments/puppet.git remote: 11db6e5..832f6a9 production -> production remote: Cloning into '/etc/puppet/environments/production'... remote: done. remote: Switched to a new branch 'production' remote: Branch production set up to track remote branch production from origin. remote: Already up-to-date. To git@git.example.com:repos/puppet.git 11db6e5..832f6a9 production -> production
Now whenever we create a new branch, a corresponding directory is created in our environment's directory. A one-to-one mapping is established between environments and branches.
post-receive hook to accept a branch variable. The hook will use this variable to create a directory on the Puppet master as follows:
README file again and push to the repository on git.example.com:
The hook now reads in the refname and parses out the branch that is being updated. We use that branch variable to clone the repository into a new directory and check out the branch.
- Create the production branch as shown in the following command line:
t@mylaptop puppet$ git branch production t@mylaptop puppet$ git checkout production Switched to branch 'production'
- Update the production branch and push to the Git server as follows:
t@mylaptop puppet$ vim README t@mylaptop puppet$ git add README t@mylaptop puppet$ git commit -m "Production Branch" t@mylaptop puppet$ git push origin production Counting objects: 7, done. Delta compression using up to 4 threads. Compressing objects: 100% (3/3), done. Writing objects: 100% (3/3), 372 bytes | 0 bytes/s, done. Total 3 (delta 1), reused 0 (delta 0) remote: To puppet@puppet.example.com:/etc/puppet/environments/puppet.git remote: 11db6e5..832f6a9 production -> production remote: Cloning into '/etc/puppet/environments/production'... remote: done. remote: Switched to a new branch 'production' remote: Branch production set up to track remote branch production from origin. remote: Already up-to-date. To git@git.example.com:repos/puppet.git 11db6e5..832f6a9 production -> production
Now whenever we create a new branch, a corresponding directory is created in our environment's directory. A one-to-one mapping is established between environments and branches.
hook now reads in the refname and parses out the branch that is being updated. We use that branch variable to clone the repository into a new directory and check out the branch.
- Create the production branch as shown in the following command line:
t@mylaptop puppet$ git branch production t@mylaptop puppet$ git checkout production Switched to branch 'production'
- Update the production branch and push to the Git server as follows:
t@mylaptop puppet$ vim README t@mylaptop puppet$ git add README t@mylaptop puppet$ git commit -m "Production Branch" t@mylaptop puppet$ git push origin production Counting objects: 7, done. Delta compression using up to 4 threads. Compressing objects: 100% (3/3), done. Writing objects: 100% (3/3), 372 bytes | 0 bytes/s, done. Total 3 (delta 1), reused 0 (delta 0) remote: To puppet@puppet.example.com:/etc/puppet/environments/puppet.git remote: 11db6e5..832f6a9 production -> production remote: Cloning into '/etc/puppet/environments/production'... remote: done. remote: Switched to a new branch 'production' remote: Branch production set up to track remote branch production from origin. remote: Already up-to-date. To git@git.example.com:repos/puppet.git 11db6e5..832f6a9 production -> production
Now whenever we create a new branch, a corresponding directory is created in our environment's directory. A one-to-one mapping is established between environments and branches.
t@mylaptop puppet$ git branch production t@mylaptop puppet$ git checkout production Switched to branch 'production'
t@mylaptop puppet$ vim README t@mylaptop puppet$ git add README t@mylaptop puppet$ git commit -m "Production Branch" t@mylaptop puppet$ git push origin production Counting objects: 7, done. Delta compression using up to 4 threads. Compressing objects: 100% (3/3), done. Writing objects: 100% (3/3), 372 bytes | 0 bytes/s, done. Total 3 (delta 1), reused 0 (delta 0) remote: To puppet@puppet.example.com:/etc/puppet/environments/puppet.git remote: 11db6e5..832f6a9 production -> production remote: Cloning into '/etc/puppet/environments/production'... remote: done. remote: Switched to a new branch 'production' remote: Branch production set up to track remote branch production from origin. remote: Already up-to-date. To git@git.example.com:repos/puppet.git 11db6e5..832f6a9 production -> production
"Measuring programming progress by lines of code is like measuring aircraft building progress by weight." | ||
| --Bill Gates | ||
In this chapter, we will cover:
- Using arrays of resources
- Using resource defaults
- Using defined types
- Using tags
- Using run stages
- Using roles and profiles
- Passing parameters to classes
- Passing parameters from Hiera
- Writing reusable, cross-platform manifests
- Getting information about the environment
- Importing dynamic information
- Passing arguments to shell commands
Anything that you can do to a resource, you can do to an array of resources. Use this idea to refactor your manifests to make them shorter and clearer.
Here are the steps to refactor using arrays of resources:
- Identify a class in your manifest where you have several instances of the same kind of resource, for example, packages:
package { 'sudo' : ensure => installed } package { 'unzip' : ensure => installed } package { 'locate' : ensure => installed } package { 'lsof' : ensure => installed } package { 'cron' : ensure => installed } package { 'rubygems' : ensure => installed } - Group them together and replace them with a single package resource using an array:
package { [ 'cron', 'locate', 'lsof', 'rubygems', 'sudo', 'unzip' ]: ensure => installed, }
Most of Puppet's resource types can accept an array instead of a single name, and will create one instance for each of the elements in the array. All the parameters you provide for the resource (for example, ensure => installed) will be assigned to each of the new resource instances. This shorthand will only work when all the resources have the same attributes.
- The Iterating over multiple items recipe in Chapter 1, Puppet Language and Style
package { 'sudo' : ensure => installed }
package { 'unzip' : ensure => installed }
package { 'locate' : ensure => installed }
package { 'lsof' : ensure => installed }
package { 'cron' : ensure => installed }
package { 'rubygems' : ensure => installed } package
{
[ 'cron',
'locate',
'lsof',
'rubygems',
'sudo',
'unzip' ]:
ensure => installed,
}Most of Puppet's resource types can accept an array instead of a single name, and will create one instance for each of the elements in the array. All the parameters you provide for the resource (for example, ensure => installed) will be assigned to each of the new resource instances. This shorthand will only work when all the resources have the same attributes.
- The Iterating over multiple items recipe in Chapter 1, Puppet Language and Style
resource types can accept an array instead of a single name, and will create one instance for each of the elements in the array. All the parameters you provide for the resource (for example, ensure => installed) will be assigned to each of the new resource instances. This shorthand will only work when all the resources have the same attributes.
- The Iterating over multiple items recipe in Chapter 1, Puppet Language and Style
- Chapter 1, Puppet Language and Style
To show you how to use resource defaults, we'll create an apache module. Within this module we will specify that the default owner and group are the apache user as follows:
- Create an apache module and create a resource default for the
Filetype:class apache { File { owner => 'apache', group => 'apache', mode => 0644, } } - Create html files within the
/var/www/htmldirectory:file {'/var/www/html/index.html': content => "<html><body><h1><a href='cookbook.html'>Cookbook! </a></h1></body></html>\n", } file {'/var/www/html/cookbook.html': content => "<html><body><h2>PacktPub</h2></body></html>\n", } - Add this class to your default node definition, or use
puppet applyto apply the module to your node. I will use the method we configured in the previous chapter, pushing our code to the Git repository and using a Git hook to have the code deployed to the Puppet master as follows:t@mylaptop ~/puppet $ git pull origin production From git.example.com:repos/puppet * branch production -> FETCH_HEAD Already up-to-date. t@mylaptop ~/puppet $ cd modules t@mylaptop ~/puppet/modules $ mkdir -p apache/manifests t@mylaptop ~/puppet/modules $ vim apache/manifests/init.pp t@mylaptop ~/puppet/modules $ cd .. t@mylaptop ~/puppet $ vim manifests/site.pp t@mylaptop ~/puppet $ git status On branch production Changes not staged for commit: modified: manifests/site.pp Untracked files: modules/apache/ t@mylaptop ~/puppet $ git add manifests/site.pp modules/apache t@mylaptop ~/puppet $ git commit -m 'adding apache module' [production d639a86] adding apache module 2 files changed, 14 insertions(+) create mode 100644 modules/apache/manifests/init.pp t@mylaptop ~/puppet $ git push origin production Counting objects: 13, done. Delta compression using up to 4 threads. Compressing objects: 100% (6/6), done. Writing objects: 100% (8/8), 885 bytes | 0 bytes/s, done. Total 8 (delta 0), reused 0 (delta 0) remote: To puppet@puppet.example.com:/etc/puppet/environments/puppet.git remote: 832f6a9..d639a86 production -> production remote: Already on 'production' remote: From /etc/puppet/environments/puppet remote: 832f6a9..d639a86 production -> origin/production remote: Updating 832f6a9..d639a86 remote: Fast-forward remote: manifests/site.pp | 1 + remote: modules/apache/manifests/init.pp | 13 +++++++++++++ remote: 2 files changed, 14 insertions(+) remote: create mode 100644 modules/apache/manifests/init.pp To git@git.example.com:repos/puppet.git 832f6a9..d639a86 production -> production
- Apply the module to a node or run Puppet:
Notice: /Stage[main]/Apache/File[/var/www/html/cookbook.html]/ensure: defined content as '{md5}493473fb5bde778ca93d034900348c5d' Notice: /Stage[main]/Apache/File[/var/www/html/index.html]/ensure: defined content as '{md5}184f22c181c5632b86ebf9a0370685b3' Notice: Finished catalog run in 2.00 seconds [root@hiera-test ~]# ls -l /var/www/html total 8 -rw-r--r--. 1 apache apache 44 Sep 15 12:00 cookbook.html -rw-r--r--. 1 apache apache 73 Sep 15 12:00 index.html
You can specify resource defaults for any resource type. You can also specify resource defaults in site.pp. I find it useful to specify the default action for Package and Service resources as follows:
With these defaults, whenever you specify a package, the package will be installed. Whenever you specify a service, the service will be started and enabled to run at boot. These are the usual reasons you specify packages and services, most of the time these defaults will do what you prefer and your code will be cleaner. When you need to disable a service, simply override the defaults.
- Create an apache module and create a resource default for the
Filetype:class apache { File { owner => 'apache', group => 'apache', mode => 0644, } } - Create html files within the
/var/www/htmldirectory:file {'/var/www/html/index.html': content => "<html><body><h1><a href='cookbook.html'>Cookbook! </a></h1></body></html>\n", } file {'/var/www/html/cookbook.html': content => "<html><body><h2>PacktPub</h2></body></html>\n", } - Add this class to your default node definition, or use
puppet applyto apply the module to your node. I will use the method we configured in the previous chapter, pushing our code to the Git repository and using a Git hook to have the code deployed to the Puppet master as follows:t@mylaptop ~/puppet $ git pull origin production From git.example.com:repos/puppet * branch production -> FETCH_HEAD Already up-to-date. t@mylaptop ~/puppet $ cd modules t@mylaptop ~/puppet/modules $ mkdir -p apache/manifests t@mylaptop ~/puppet/modules $ vim apache/manifests/init.pp t@mylaptop ~/puppet/modules $ cd .. t@mylaptop ~/puppet $ vim manifests/site.pp t@mylaptop ~/puppet $ git status On branch production Changes not staged for commit: modified: manifests/site.pp Untracked files: modules/apache/ t@mylaptop ~/puppet $ git add manifests/site.pp modules/apache t@mylaptop ~/puppet $ git commit -m 'adding apache module' [production d639a86] adding apache module 2 files changed, 14 insertions(+) create mode 100644 modules/apache/manifests/init.pp t@mylaptop ~/puppet $ git push origin production Counting objects: 13, done. Delta compression using up to 4 threads. Compressing objects: 100% (6/6), done. Writing objects: 100% (8/8), 885 bytes | 0 bytes/s, done. Total 8 (delta 0), reused 0 (delta 0) remote: To puppet@puppet.example.com:/etc/puppet/environments/puppet.git remote: 832f6a9..d639a86 production -> production remote: Already on 'production' remote: From /etc/puppet/environments/puppet remote: 832f6a9..d639a86 production -> origin/production remote: Updating 832f6a9..d639a86 remote: Fast-forward remote: manifests/site.pp | 1 + remote: modules/apache/manifests/init.pp | 13 +++++++++++++ remote: 2 files changed, 14 insertions(+) remote: create mode 100644 modules/apache/manifests/init.pp To git@git.example.com:repos/puppet.git 832f6a9..d639a86 production -> production
- Apply the module to a node or run Puppet:
Notice: /Stage[main]/Apache/File[/var/www/html/cookbook.html]/ensure: defined content as '{md5}493473fb5bde778ca93d034900348c5d' Notice: /Stage[main]/Apache/File[/var/www/html/index.html]/ensure: defined content as '{md5}184f22c181c5632b86ebf9a0370685b3' Notice: Finished catalog run in 2.00 seconds [root@hiera-test ~]# ls -l /var/www/html total 8 -rw-r--r--. 1 apache apache 44 Sep 15 12:00 cookbook.html -rw-r--r--. 1 apache apache 73 Sep 15 12:00 index.html
You can specify resource defaults for any resource type. You can also specify resource defaults in site.pp. I find it useful to specify the default action for Package and Service resources as follows:
With these defaults, whenever you specify a package, the package will be installed. Whenever you specify a service, the service will be started and enabled to run at boot. These are the usual reasons you specify packages and services, most of the time these defaults will do what you prefer and your code will be cleaner. When you need to disable a service, simply override the defaults.
You can specify resource defaults for any resource type. You can also specify resource defaults in site.pp. I find it useful to specify the default action for Package and Service resources as follows:
With these defaults, whenever you specify a package, the package will be installed. Whenever you specify a service, the service will be started and enabled to run at boot. These are the usual reasons you specify packages and services, most of the time these defaults will do what you prefer and your code will be cleaner. When you need to disable a service, simply override the defaults.
resource type. You can also specify resource defaults in site.pp. I find it useful to specify the default action for Package and Service resources as follows:
With these defaults, whenever you specify a package, the package will be installed. Whenever you specify a service, the service will be started and enabled to run at boot. These are the usual reasons you specify packages and services, most of the time these defaults will do what you prefer and your code will be cleaner. When you need to disable a service, simply override the defaults.
In the previous example, we saw how to reduce redundant code by grouping identical resources into arrays. However, this technique is limited to resources where all the parameters are the same. When you have a set of resources that have some parameters in common, you need to use a defined type to group them together.
The following steps will show you how to create a definition:
- Add the following code to your manifest:
define tmpfile() { file { "/tmp/${name}": content => "Hello, world\n", } } tmpfile { ['a', 'b', 'c']: } - Run Puppet:
[root@hiera-test ~]# vim tmp.pp [root@hiera-test ~]# puppet apply tmp.pp Notice: Compiled catalog for hiera-test.example.com in environment production in 0.11 seconds Notice: /Stage[main]/Main/Tmpfile[a]/File[/tmp/a]/ensure: defined content as '{md5}a7966bf58e23583c9a5a4059383ff850' Notice: /Stage[main]/Main/Tmpfile[b]/File[/tmp/b]/ensure: defined content as '{md5}a7966bf58e23583c9a5a4059383ff850' Notice: /Stage[main]/Main/Tmpfile[c]/File[/tmp/c]/ensure: defined content as '{md5}a7966bf58e23583c9a5a4059383ff850' Notice: Finished catalog run in 0.09 seconds [root@hiera-test ~]# cat /tmp/{a,b,c} Hello, world Hello, world Hello, world
You can think of a defined type (introduced with the define keyword) as a cookie-cutter. It describes a pattern that Puppet can use to create lots of similar resources. Any time you declare a tmpfile instance in your manifest, Puppet will insert all the resources contained in the tmpfile definition.
Next, pass values to them when we declare an instance of the resource:
You can declare multiple parameters as a comma-separated list:
This is a powerful technique for abstracting out everything that's common to certain resources, and keeping it in one place so that you don't repeat yourself. In the preceding example, there might be many individual resources contained within webapp: packages, config files, source code checkouts, virtual hosts, and so on. But all of them are the same for every instance of webapp except the parameters we provide. These might be referenced in a template, for example, to set the domain for a virtual host.
define tmpfile() {
file { "/tmp/${name}": content => "Hello, world\n",
}
}
tmpfile { ['a', 'b', 'c']: }[root@hiera-test ~]# vim tmp.pp [root@hiera-test ~]# puppet apply tmp.pp Notice: Compiled catalog for hiera-test.example.com in environment production in 0.11 seconds Notice: /Stage[main]/Main/Tmpfile[a]/File[/tmp/a]/ensure: defined content as '{md5}a7966bf58e23583c9a5a4059383ff850' Notice: /Stage[main]/Main/Tmpfile[b]/File[/tmp/b]/ensure: defined content as '{md5}a7966bf58e23583c9a5a4059383ff850' Notice: /Stage[main]/Main/Tmpfile[c]/File[/tmp/c]/ensure: defined content as '{md5}a7966bf58e23583c9a5a4059383ff850' Notice: Finished catalog run in 0.09 seconds [root@hiera-test ~]# cat /tmp/{a,b,c} Hello, world Hello, world Hello, world
You can think of a defined type (introduced with the define keyword) as a cookie-cutter. It describes a pattern that Puppet can use to create lots of similar resources. Any time you declare a tmpfile instance in your manifest, Puppet will insert all the resources contained in the tmpfile definition.
Next, pass values to them when we declare an instance of the resource:
You can declare multiple parameters as a comma-separated list:
This is a powerful technique for abstracting out everything that's common to certain resources, and keeping it in one place so that you don't repeat yourself. In the preceding example, there might be many individual resources contained within webapp: packages, config files, source code checkouts, virtual hosts, and so on. But all of them are the same for every instance of webapp except the parameters we provide. These might be referenced in a template, for example, to set the domain for a virtual host.
Next, pass values to them when we declare an instance of the resource:
You can declare multiple parameters as a comma-separated list:
This is a powerful technique for abstracting out everything that's common to certain resources, and keeping it in one place so that you don't repeat yourself. In the preceding example, there might be many individual resources contained within webapp: packages, config files, source code checkouts, virtual hosts, and so on. But all of them are the same for every instance of webapp except the parameters we provide. These might be referenced in a template, for example, to set the domain for a virtual host.
name parameter. But we can add whatever parameters we want, so long as we declare them in the definition in parentheses after the name parameter, as follows:
Puppet's tagged function will tell you whether a named class or resource is present in the catalog for this node. You can also apply arbitrary tags to a node or class and check for the presence of these tags. Tags are another metaparameter, similar to require and notify we introduced in Chapter 1, Puppet Language and Style. Metaparameters are used in the compilation of the Puppet catalog but are not an attribute of the resource to which they are attached.
- Add the following code to your
site.ppfile (replacingcookbookwith your machine'shostname):node 'cookbook' { if tagged('cookbook') { notify { 'tagged cookbook': } } } - Run Puppet:
root@cookbook:~# puppet agent -vt Info: Caching catalog for cookbook Info: Applying configuration version '1410848350' Notice: tagged cookbook Notice: Finished catalog run in 1.00 seconds
Nodes are also automatically tagged with the names of all the classes they include in addition to several other automatic tags. You can use
taggedto find out what classes are included on the node. - Modify your
site.ppfile as follows:node 'cookbook' { tag('tagging') class {'tag_test': } } - Add a
tag_testmodule with the followinginit.pp(or be lazy and add the following definition to yoursite.pp):class tag_test { if tagged('tagging') { notify { 'containing node/class was tagged.': } } } - Run Puppet:
root@cookbook:~# puppet agent -vt Info: Caching catalog for cookbook Info: Applying configuration version '1410851300' Notice: containing node/class was tagged. Notice: Finished catalog run in 0.22 seconds
- You can also use tags to determine which parts of the manifest to apply. If you use the
--tagsoption on the Puppet command line, Puppet will apply only those classes or resources tagged with the specific tags you include. For example, we can define ourcookbookclass with two classes:node cookbook { class {'first_class': } class {'second_class': } } class first_class { notify { 'First Class': } } class second_class { notify {'Second Class': } } - Now when we run
puppet agenton thecookbooknode, we see both notifies:root@cookbook:~# puppet agent -t Notice: Second Class Notice: First Class Notice: Finished catalog run in 0.22 seconds
- Now apply the
first_classandadd --tagsfunction to the command line:root@cookbook:~# puppet agent -t --tags first_class Notice: First Class Notice: Finished catalog run in 0.07 seconds
Although we could add a notify => Service["firewall"] function to each snippet resource if our definition of the firewall service were ever to change, we would have to hunt down and update all the snippets accordingly. The tag lets us encapsulate the logic in one place, making future maintenance and refactoring much easier.
Note
What's <| tag == 'firewall-snippet' |> syntax? This is called a resource collector, and it's a way of specifying a group of resources by searching for some piece of data about them; in this case, the value of a tag. You can find out more about resource collectors and the <| |> operator (sometimes known as the spaceship operator) on the Puppet Labs website: http://docs.puppetlabs.com/puppet/3/reference/lang_collectors.html.
tagged to get this information:
site.pp file (replacing cookbook with your machine's hostname): node 'cookbook' {
if tagged('cookbook') {
notify { 'tagged cookbook': }
}
}root@cookbook:~# puppet agent -vt Info: Caching catalog for cookbook Info: Applying configuration version '1410848350' Notice: tagged cookbook Notice: Finished catalog run in 1.00 seconds
- Modify your
site.ppfile as follows:node 'cookbook' { tag('tagging') class {'tag_test': } } - Add a
tag_testmodule with the followinginit.pp(or be lazy and add the following definition to yoursite.pp):class tag_test { if tagged('tagging') { notify { 'containing node/class was tagged.': } } } - Run Puppet:
root@cookbook:~# puppet agent -vt Info: Caching catalog for cookbook Info: Applying configuration version '1410851300' Notice: containing node/class was tagged. Notice: Finished catalog run in 0.22 seconds
- You can also use tags to determine which parts of the manifest to apply. If you use the
--tagsoption on the Puppet command line, Puppet will apply only those classes or resources tagged with the specific tags you include. For example, we can define ourcookbookclass with two classes:node cookbook { class {'first_class': } class {'second_class': } } class first_class { notify { 'First Class': } } class second_class { notify {'Second Class': } } - Now when we run
puppet agenton thecookbooknode, we see both notifies:root@cookbook:~# puppet agent -t Notice: Second Class Notice: First Class Notice: Finished catalog run in 0.22 seconds
- Now apply the
first_classandadd --tagsfunction to the command line:root@cookbook:~# puppet agent -t --tags first_class Notice: First Class Notice: Finished catalog run in 0.07 seconds
Although we could add a notify => Service["firewall"] function to each snippet resource if our definition of the firewall service were ever to change, we would have to hunt down and update all the snippets accordingly. The tag lets us encapsulate the logic in one place, making future maintenance and refactoring much easier.
Note
What's <| tag == 'firewall-snippet' |> syntax? This is called a resource collector, and it's a way of specifying a group of resources by searching for some piece of data about them; in this case, the value of a tag. You can find out more about resource collectors and the <| |> operator (sometimes known as the spaceship operator) on the Puppet Labs website: http://docs.puppetlabs.com/puppet/3/reference/lang_collectors.html.
firewall service should be notified if any file resource tagged firewall-snippet is updated. All we need to do to add a firewall config snippet for any particular application or service is to tag it firewall-snippet, and Puppet will do the rest.
Note
What's <| tag == 'firewall-snippet' |> syntax? This is called a resource collector, and it's a way of specifying a group of resources by searching for some piece of data about them; in this case, the value of a tag. You can find out more about resource collectors and the <| |> operator (sometimes known as the spaceship operator) on the Puppet Labs website: http://docs.puppetlabs.com/puppet/3/reference/lang_collectors.html.
By default, all resources in your manifest are applied in a single stage named main. If you need a resource to be applied before all others, you can assign it to a new run stage that is specified to come before main. Similarly, you could define a run stage that comes after main. In fact, you can define as many run stages as you need and tell Puppet which order they should be applied in.
In this example, we'll use stages to ensure one class is applied first and another last.
Here are the steps to create an example of using run stages:
- Create the file
modules/admin/manifests/stages.ppwith the following contents:class admin::stages { stage { 'first': before => Stage['main'] } stage { 'last': require => Stage['main'] } class me_first { notify { 'This will be done first': } } class me_last { notify { 'This will be done last': } } class { 'me_first': stage => 'first', } class { 'me_last': stage => 'last', } } - Modify your
site.ppfile as follows:node 'cookbook' { class {'first_class': } class {'second_class': } include admin::stages } - Run Puppet:
root@cookbook:~# puppet agent -t Info: Applying configuration version '1411019225' Notice: This will be done first Notice: Second Class Notice: First Class Notice: This will be done last Notice: Finished catalog run in 0.43 seconds
We then declare some classes that we'll later assign to these run stages:
We can now put it all together and include these classes on the node, specifying the run stages for each as we do so:
Gary Larizza has written a helpful introduction to using run stages, with some real-world examples, on his website:
http://garylarizza.com/blog/2011/03/11/using-run-stages-with-puppet/
- The Using tags recipe, in this chapter
- The Drawing dependency graphs recipe in Chapter 10, Monitoring, Reporting, and Troubleshooting
stages:
modules/admin/manifests/stages.pp with the following contents: class admin::stages {
stage { 'first': before => Stage['main'] }
stage { 'last': require => Stage['main'] }
class me_first {
notify { 'This will be done first': }
}
class me_last {
notify { 'This will be done last': }
}
class { 'me_first':
stage => 'first',
}
class { 'me_last':
stage => 'last',
}
}site.pp file as follows: node 'cookbook' {
class {'first_class': }
class {'second_class': }
include admin::stages
}We then declare some classes that we'll later assign to these run stages:
We can now put it all together and include these classes on the node, specifying the run stages for each as we do so:
Gary Larizza has written a helpful introduction to using run stages, with some real-world examples, on his website:
http://garylarizza.com/blog/2011/03/11/using-run-stages-with-puppet/
- The Using tags recipe, in this chapter
- The Drawing dependency graphs recipe in Chapter 10, Monitoring, Reporting, and Troubleshooting
first and last, as follows:
first stage, we've specified that it should come before main. That is, every resource marked as being in the first stage will be applied before any resource in the main stage (the default stage).
last stage requires the main stage, so no resource in the last stage can be applied until after every resource in the main stage.
Gary Larizza has written a helpful introduction to using run stages, with some real-world examples, on his website:
http://garylarizza.com/blog/2011/03/11/using-run-stages-with-puppet/
- The Using tags recipe, in this chapter
- The Drawing dependency graphs recipe in Chapter 10, Monitoring, Reporting, and Troubleshooting
site.pp file instead, so that at the top level of the manifest, it's easy to see what stages are available.
some real-world examples, on his website:
http://garylarizza.com/blog/2011/03/11/using-run-stages-with-puppet/
- The Using tags recipe, in this chapter
- The Drawing dependency graphs recipe in Chapter 10, Monitoring, Reporting, and Troubleshooting
- Chapter 10, Monitoring, Reporting, and Troubleshooting
Well organized Puppet manifests are easy to read; the purpose of a module should be evident in its name. The purpose of a node should be defined in a single class. This single class should include all classes that are required to perform that purpose. Craig Dunn wrote a post about such a classification system, which he dubbed "roles and profiles" (http://www.craigdunn.org/2012/05/239/). In this model, roles are the single purpose of a node, a node may only have one role, a role may contain more than one profile, and a profile contains all the resources related to a single service. In this example, we will create a web server role that uses several profiles.
- Decide on a naming strategy for your roles and profiles. In our example, we will create two modules,
rolesandprofilesthat will contain our roles and profiles respectively:$ puppet module generate thomas-profiles $ ln -s thomas-profiles profiles $ puppet module generate thomas-roles $ ln -s thomas-roles roles
- Begin defining the constituent parts of our
webserverrole as profiles. To keep this example simple, we will create two profiles. First, abaseprofile to include our basic server configuration classes. Second, anapacheclass to install and configure the apache web server (httpd) as follows:$ vim profiles/manifests/base.pp class profiles::base { include base } $ vim profiles/manifests/apache.pp class profiles::apache { $apache = $::osfamily ? { 'RedHat' => 'httpd', 'Debian' => 'apache2', } service { "$apache": enable => true, ensure => true, } package { "$apache": ensure => 'installed', } }
- Define a
roles::webserverclass for ourwebserverrole as follows:$ vim roles/manifests/webserver.pp class roles::webserver { include profiles::apache include profiles::base }
- Apply the
roles::webserverclass to a node. In a centralized installation, you would use either an External Node Classifier (ENC) to apply the class to the node, or you would use Hiera to define the role:node 'webtest' { include roles::webserver }
Breaking down the parts of the web server configuration into different profiles allows us to apply those parts independently. We created a base profile that we can expand to include all the resources we would like applied to all nodes. Our roles::webserver class simply includes the base and apache classes.
profile::base
roles and profiles that will contain our roles and profiles respectively:$ puppet module generate thomas-profiles $ ln -s thomas-profiles profiles $ puppet module generate thomas-roles $ ln -s thomas-roles roles
webserver role as profiles. To keep this example simple, we will create two profiles. First, a base profile to include our basic server configuration classes. Second, an apache class to install and configure the apache web server (httpd) as follows:$ vim profiles/manifests/base.pp class profiles::base { include base } $ vim profiles/manifests/apache.pp class profiles::apache { $apache = $::osfamily ? { 'RedHat' => 'httpd', 'Debian' => 'apache2', } service { "$apache": enable => true, ensure => true, } package { "$apache": ensure => 'installed', } }
roles::webserver class for our webserver role as follows:$ vim roles/manifests/webserver.pp class roles::webserver { include profiles::apache include profiles::base }
roles::webserver class to a node. In a centralized installation, you would use either an External Node Classifier (ENC)
Breaking down the parts of the web server configuration into different profiles allows us to apply those parts independently. We created a base profile that we can expand to include all the resources we would like applied to all nodes. Our roles::webserver class simply includes the base and apache classes.
down the parts of the web server configuration into different profiles allows us to apply those parts independently. We created a base profile that we can expand to include all the resources we would like applied to all nodes. Our roles::webserver class simply includes the base and apache classes.
roles::webserver class, we can use the class instantiation syntax instead of include, and override it with parameters in the classes. For instance, to pass a parameter to the base class, we would use:
Sometimes it's very useful to parameterize some aspect of a class. For example, you might need to manage different versions of a gem package, and rather than making separate classes for each that differ only in the version number, you can pass in the version number as a parameter.
This is a gem package, and we're requesting to install version $version.
Include the class on a node, instead of the usual include syntax:
On doing so, there will be a class statement:
This has the same effect but also sets a value for the parameter as version.
You can specify multiple parameters for a class as:
Then supply them in the same way:
You can also give default values for some of your parameters. When you include the class without setting a parameter, the default value will be used. For instance, if we created a mysql class with three parameters, we could provide default values for any or all of the parameters as shown in the code snippet:
Defaults allow you to use a default value and override that default where you need it.
class eventmachine($version) {
package { 'eventmachine': provider => gem, ensure => $version,
}
} class { 'eventmachine':
version => '1.0.3',
}This is a gem package, and we're requesting to install version $version.
Include the class on a node, instead of the usual include syntax:
On doing so, there will be a class statement:
This has the same effect but also sets a value for the parameter as version.
You can specify multiple parameters for a class as:
Then supply them in the same way:
You can also give default values for some of your parameters. When you include the class without setting a parameter, the default value will be used. For instance, if we created a mysql class with three parameters, we could provide default values for any or all of the parameters as shown in the code snippet:
Defaults allow you to use a default value and override that default where you need it.
class eventmachine($version) { is just like a normal class definition except it specifies that the class takes one parameter: $version. Inside the class, we've defined a package resource:
gem package, and we're requesting to install version $version.
include syntax:
class statement:
You can specify multiple parameters for a class as:
Then supply them in the same way:
You can also give default values for some of your parameters. When you include the class without setting a parameter, the default value will be used. For instance, if we created a mysql class with three parameters, we could provide default values for any or all of the parameters as shown in the code snippet:
Defaults allow you to use a default value and override that default where you need it.
You can also give default values for some of your parameters. When you include the class without setting a parameter, the default value will be used. For instance, if we created a mysql class with three parameters, we could provide default values for any or all of the parameters as shown in the code snippet:
Defaults allow you to use a default value and override that default where you need it.
parameters. When you include the class without setting a parameter, the default value will be used. For instance, if we created a mysql class with three parameters, we could provide default values for any or all of the parameters as shown in the code snippet:
Defaults allow you to use a default value and override that default where you need it.
Like the parameter defaults we introduced in the previous chapter, Hiera may be used to provide default values to classes. This feature requires Puppet Version 3 and higher.
Install and configure hiera as we did in Chapter 2, Puppet Infrastructure. Create a global or common yaml file; this will serve as the default for all values.
- Create a class with parameters and no default values:
t@mylaptop ~/puppet $ mkdir -p modules/mysql/manifests t@mylaptop ~/puppet $ vim modules/mysql/manifests/init.pp class mysql ( $port, $socket, $package ) { notify {"Port: $port Socket: $socket Package: $package": } }
- Update your common
.yamlfile in Hiera with the default values for themysqlclass:--- mysql::port: 3306 mysql::package: 'mysql-server' mysql::socket: '/var/lib/mysql/mysql.sock'
Apply the class to a node, you can add the mysql class to your default node for now.
node default { class {'mysql': } }
- Run
puppet agentand verify the output:[root@hiera-test ~]# puppet agent -t Info: Caching catalog for hiera-test.example.com Info: Applying configuration version '1411182251' Notice: Port: 3306 Socket: /var/lib/mysql/mysql.sock Package: mysql-server Notice: /Stage[main]/Mysql/Notify[Port: 3306 Socket: /var/lib/mysql/mysql.sock Package: mysql-server]/message: defined 'message' as 'Port: 3306 Socket: /var/lib/mysql/mysql.sock Package: mysql-server' Notice: Finished catalog run in 1.75 seconds
hiera as we did in
Chapter 2, Puppet Infrastructure. Create a global or common yaml file; this will serve as the default for all values.
- Create a class with parameters and no default values:
t@mylaptop ~/puppet $ mkdir -p modules/mysql/manifests t@mylaptop ~/puppet $ vim modules/mysql/manifests/init.pp class mysql ( $port, $socket, $package ) { notify {"Port: $port Socket: $socket Package: $package": } }
- Update your common
.yamlfile in Hiera with the default values for themysqlclass:--- mysql::port: 3306 mysql::package: 'mysql-server' mysql::socket: '/var/lib/mysql/mysql.sock'
Apply the class to a node, you can add the mysql class to your default node for now.
node default { class {'mysql': } }
- Run
puppet agentand verify the output:[root@hiera-test ~]# puppet agent -t Info: Caching catalog for hiera-test.example.com Info: Applying configuration version '1411182251' Notice: Port: 3306 Socket: /var/lib/mysql/mysql.sock Package: mysql-server Notice: /Stage[main]/Mysql/Notify[Port: 3306 Socket: /var/lib/mysql/mysql.sock Package: mysql-server]/message: defined 'message' as 'Port: 3306 Socket: /var/lib/mysql/mysql.sock Package: mysql-server' Notice: Finished catalog run in 1.75 seconds
t@mylaptop ~/puppet $ mkdir -p modules/mysql/manifests t@mylaptop ~/puppet $ vim modules/mysql/manifests/init.pp class mysql ( $port, $socket, $package ) { notify {"Port: $port Socket: $socket Package: $package": } }
.yaml file in Hiera with the default values for the mysql class:--- mysql::port: 3306 mysql::package: 'mysql-server' mysql::socket: '/var/lib/mysql/mysql.sock'
Apply the class to a node, you can add the mysql class to your default node for now.
node default { class {'mysql': } }
puppet agent and verify the output:[root@hiera-test ~]# puppet agent -t Info: Caching catalog for hiera-test.example.com Info: Applying configuration version '1411182251' Notice: Port: 3306 Socket: /var/lib/mysql/mysql.sock Package: mysql-server Notice: /Stage[main]/Mysql/Notify[Port: 3306 Socket: /var/lib/mysql/mysql.sock Package: mysql-server]/message: defined 'message' as 'Port: 3306 Socket: /var/lib/mysql/mysql.sock Package: mysql-server' Notice: Finished catalog run in 1.75 seconds
mysql class in our manifest, we provided no values for any of the attributes. Puppet knows to look for a value in Hiera that matches class_name::parameter_name: or ::class_name::parameter_name:.
%{::osfamily} in your hierarchy and have different yaml files based on the osfamily parameter (RedHat, Suse, and Debian).
Every system administrator dreams of a unified, homogeneous infrastructure of identical machines all running the same version of the same OS. As in other areas of life, however, the reality is often messy and doesn't conform to the plan.
Here are some examples of how to make your manifests more portable:
- Where you need to apply the same manifest to servers with different OS distributions, the main differences will probably be the names of packages and services, and the location of config files. Try to capture all these differences into a single class by using selectors to set global variables:
$ssh_service = $::operatingsystem? { /Ubuntu|Debian/ => 'ssh', default => 'sshd', }You needn't worry about the differences in any other part of the manifest; when you refer to something, use the variable with confidence that it will point to the right thing in each environment:
service { $ssh_service: ensure => running, } - Often we need to cope with mixed architectures; this can affect the paths to shared libraries, and also may require different versions of packages. Again, try to encapsulate all the required settings in a single architecture class that sets global variables:
$libdir = $::architecture ? { /amd64|x86_64/ => '/usr/lib64', default => '/usr/lib', }Then you can use these wherever an architecture-dependent value is required in your manifests or even in templates:
This not only results in lots of duplication, but makes the code harder to read. And when a new operating system is added to the mix, you'll need to make changes throughout the whole manifest, instead of just in one place.
If you are writing a module for public distribution (for example, on Puppet Forge), making your module as cross-platform as possible will make it more valuable to the community. As far as you can, test it on many different distributions, platforms, and architectures, and add the appropriate variables so that it works everywhere.
"Always code as if the guy who ends up maintaining your code will be a violent psychopath who knows where you live." | ||
| --Dave Carhart | ||
- The Using public modules recipe in Chapter 7, Managing Applications
- The Configuring Hiera recipe in Chapter 2, Puppet Infrastructure
$ssh_service = $::operatingsystem? { /Ubuntu|Debian/ => 'ssh', default => 'sshd',
}You needn't worry about the differences in any other part of the manifest; when you refer to something, use the variable with confidence that it will point to the right thing in each environment:
service { $ssh_service: ensure => running,
} $libdir = $::architecture ? {
/amd64|x86_64/ => '/usr/lib64', default => '/usr/lib',
}This not only results in lots of duplication, but makes the code harder to read. And when a new operating system is added to the mix, you'll need to make changes throughout the whole manifest, instead of just in one place.
If you are writing a module for public distribution (for example, on Puppet Forge), making your module as cross-platform as possible will make it more valuable to the community. As far as you can, test it on many different distributions, platforms, and architectures, and add the appropriate variables so that it works everywhere.
"Always code as if the guy who ends up maintaining your code will be a violent psychopath who knows where you live." | ||
| --Dave Carhart | ||
- The Using public modules recipe in Chapter 7, Managing Applications
- The Configuring Hiera recipe in Chapter 2, Puppet Infrastructure
case statement everywhere a setting is used:
duplication, but makes the code harder to read. And when a new operating system is added to the mix, you'll need to make changes throughout the whole manifest, instead of just in one place.
If you are writing a module for public distribution (for example, on Puppet Forge), making your module as cross-platform as possible will make it more valuable to the community. As far as you can, test it on many different distributions, platforms, and architectures, and add the appropriate variables so that it works everywhere.
"Always code as if the guy who ends up maintaining your code will be a violent psychopath who knows where you live." | ||
| --Dave Carhart | ||
- The Using public modules recipe in Chapter 7, Managing Applications
- The Configuring Hiera recipe in Chapter 2, Puppet Infrastructure
"Always code as if the guy who ends up maintaining your code will be a violent psychopath who knows where you live." | ||
| --Dave Carhart | ||
- The Using public modules recipe in Chapter 7, Managing Applications
- The Configuring Hiera recipe in Chapter 2, Puppet Infrastructure
Often in a Puppet manifest, you need to know some local information about the machine you're on. Facter is the tool that accompanies Puppet to provide a standard way of getting information (facts) from the environment about things such as these:
To see a complete list of the facts available on your system, run:
Some modules define their own facts; to see any facts that have been defined locally, add the -p (pluginsync) option to facter as follows:
Here's an example of using Facter facts in a manifest:
- Reference a Facter fact in your manifest like any other variable. Facts are global variables in Puppet, so they should be prefixed with a double colon (
::), as in the following code snippet:notify { "This is $::operatingsystem version $::operatingsystemrelease, on $::architecture architecture, kernel version $::kernelversion": } - When Puppet runs, it will fill in the appropriate values for the current node:
[root@hiera-test ~]# puppet agent -t ... Info: Applying configuration version '1411275985'Notice: This is RedHat version 6.5, on x86_64 architecture, kernel version 2.6.32 ... Notice: Finished catalog run in 0.40 seconds
Facter provides a standard way for manifests to get information about the nodes to which they are applied. When you refer to a fact in a manifest, Puppet will query Facter to get the current value and insert it into the manifest. Facter facts are top scope variables.
You can also use facts in ERB templates. For example, you might want to insert the node's hostname into a file, or change a configuration setting for an application based on the memory size of the node. When you use fact names in templates, remember that they don't need a dollar sign because this is Ruby, not Puppet:
- The Creating custom facts recipe in Chapter 9, External Tools and the Puppet Ecosystem
::), as in the following code snippet:notify { "This is $::operatingsystem version $::operatingsystemrelease, on $::architecture architecture, kernel version $::kernelversion": }[root@hiera-test ~]# puppet agent -t ... Info: Applying configuration version '1411275985'Notice: This is RedHat version 6.5, on x86_64 architecture, kernel version 2.6.32 ... Notice: Finished catalog run in 0.40 seconds
Facter provides a standard way for manifests to get information about the nodes to which they are applied. When you refer to a fact in a manifest, Puppet will query Facter to get the current value and insert it into the manifest. Facter facts are top scope variables.
You can also use facts in ERB templates. For example, you might want to insert the node's hostname into a file, or change a configuration setting for an application based on the memory size of the node. When you use fact names in templates, remember that they don't need a dollar sign because this is Ruby, not Puppet:
- The Creating custom facts recipe in Chapter 9, External Tools and the Puppet Ecosystem
You can also use facts in ERB templates. For example, you might want to insert the node's hostname into a file, or change a configuration setting for an application based on the memory size of the node. When you use fact names in templates, remember that they don't need a dollar sign because this is Ruby, not Puppet:
- The Creating custom facts recipe in Chapter 9, External Tools and the Puppet Ecosystem
ERB templates. For example, you might want to insert the node's hostname into a file, or change a configuration setting for an application based on the memory size of the node. When you use fact names in templates, remember that they don't need a dollar sign because this is Ruby, not Puppet:
- The Creating custom facts recipe in Chapter 9, External Tools and the Puppet Ecosystem
- Chapter 9, External Tools and the Puppet Ecosystem
Even though some system administrators like to wall themselves off from the rest of the office using piles of old printers, we all need to exchange information with other departments from time to time. For example, you may want to insert data into your Puppet manifests that is derived from some outside source. The generate function is ideal for this. Functions are executed on the machine compiling the catalog (the master for centralized deployments); an example like that shown here will only work in a masterless configuration.
This example calls the external script we created previously and gets its output:
- Create a
message.ppmanifest containing the following:$message = generate('/usr/local/bin/message.rb') notify { $message: }
- Run Puppet:
$ puppet apply message.pp ... Notice: /Stage[main]/Main/Notify[This runs on the master if you are centralized ]/message: defined 'message' as 'This runs on the master if you are centralized
If you need to pass arguments to the executable called by generate, add them as extra arguments to the function call:
- The Creating custom facts recipe in Chapter 9, External Tools and the Puppet Ecosystem
- The Configuring Hiera recipe in Chapter 2, Puppet Infrastructure
/usr/local/bin/message.rb with the following contents:#!/usr/bin/env ruby puts "This runs on the master if you are centralized"
$ sudo chmod a+x /usr/local/bin/message.rb
This example calls the external script we created previously and gets its output:
- Create a
message.ppmanifest containing the following:$message = generate('/usr/local/bin/message.rb') notify { $message: }
- Run Puppet:
$ puppet apply message.pp ... Notice: /Stage[main]/Main/Notify[This runs on the master if you are centralized ]/message: defined 'message' as 'This runs on the master if you are centralized
If you need to pass arguments to the executable called by generate, add them as extra arguments to the function call:
- The Creating custom facts recipe in Chapter 9, External Tools and the Puppet Ecosystem
- The Configuring Hiera recipe in Chapter 2, Puppet Infrastructure
message.pp manifest containing the following:$message = generate('/usr/local/bin/message.rb') notify { $message: }
$ puppet apply message.pp ... Notice: /Stage[main]/Main/Notify[This runs on the master if you are centralized ]/message: defined 'message' as 'This runs on the master if you are centralized
If you need to pass arguments to the executable called by generate, add them as extra arguments to the function call:
- The Creating custom facts recipe in Chapter 9, External Tools and the Puppet Ecosystem
- The Configuring Hiera recipe in Chapter 2, Puppet Infrastructure
generate function runs the specified script or program and returns the result, in this case, a cheerful message from Ruby.
generate. You can also, of course, run standard UNIX utilities such as cat and grep.
If you need to pass arguments to the executable called by generate, add them as extra arguments to the function call:
- The Creating custom facts recipe in Chapter 9, External Tools and the Puppet Ecosystem
- The Configuring Hiera recipe in Chapter 2, Puppet Infrastructure
- The Creating custom facts recipe in Chapter 9, External Tools and the Puppet Ecosystem
- The Configuring Hiera recipe in Chapter 2, Puppet Infrastructure
If you want to insert values into a command line (to be run by an exec resource, for example), they often need to be quoted, especially if they contain spaces. The shellquote function will take any number of arguments, including arrays, and quote each of the arguments and return them all as a space-separated string that you can pass to commands.
Here's an example of using the shellquote function:
- Create a
shellquote.ppmanifest with the following command:$source = 'Hello Jerry' $target = 'Hello... Newman' $argstring = shellquote($source, $target) $command = "/bin/mv ${argstring}" notify { $command: }
- Run Puppet:
$ puppet apply shellquote.pp ... Notice: /bin/mv "Hello Jerry" "Hello... Newman" Notice: /Stage[main]/Main/Notify[/bin/mv "Hello Jerry" "Hello... Newman"]/message: defined 'message' as '/bin/mv "Hello Jerry" "Hello... Newman"'
shellquote function:
shellquote.pp manifest with the following command:$source = 'Hello Jerry' $target = 'Hello... Newman' $argstring = shellquote($source, $target) $command = "/bin/mv ${argstring}" notify { $command: }
$ puppet apply shellquote.pp ... Notice: /bin/mv "Hello Jerry" "Hello... Newman" Notice: /Stage[main]/Main/Notify[/bin/mv "Hello Jerry" "Hello... Newman"]/message: defined 'message' as '/bin/mv "Hello Jerry" "Hello... Newman"'
$source and $target variables, which are the two filenames we want to use in the command line:
shellquote to
"A writer has the duty to be good, not lousy; true, not false; lively, not dull; accurate, not full of error." | ||
| --E.B. White | ||
In this chapter, we will cover the following recipes:
- Making quick edits to config files
- Editing INI style files with puppetlabs-inifile
- Using Augeas to reliably edit config files
- Building config files using snippets
- Using ERB templates
- Using array iteration in templates
- Using EPP templates
- Using GnuPG to encrypt secrets
- Installing packages from a third-party repository
- Comparing package versions
In this chapter, we'll see how to make small edits to files, how to make larger changes in a structured way using the Augeas tool, how to construct files from concatenated snippets, and how to generate files from templates. We'll also learn how to install packages from additional repositories, and how to manage those repositories. In addition, we'll see how to store and decrypt secret data with Puppet.
When you need to have Puppet change a particular setting in a config file, it's common to simply deploy the whole file with Puppet. This isn't always possible, though; especially if it's a file that several different parts of your Puppet manifest may need to modify.
- Create a manifest named
oneline.ppthat will usefile_lineon a file in/tmp:file {'/tmp/cookbook': ensure => 'file', } file_line {'cookbook-hello': path => '/tmp/cookbook', line => 'Hello World!', require => File['/tmp/cookbook'], } - Run
puppet applyon theoneline.ppmanifest:t@mylaptop ~/.puppet/manifests $ puppet apply oneline.pp Notice: Compiled catalog for mylaptop in environment production in 0.39 seconds Notice: /Stage[main]/Main/File[/tmp/cookbook]/ensure: created Notice: /Stage[main]/Main/File_line[cookbook-hello]/ensure: created Notice: Finished catalog run in 0.02 seconds
- Now verify that
/tmp/cookbookcontains the line we defined:t@mylaptop ~/.puppet/manifests $ cat /tmp/cookbook Hello World!
We installed the puppetlabs-stdlib module into the default module path for Puppet, so when we ran puppet apply, Puppet knew where to find the file_line type definition. Puppet then created the /tmp/cookbook file if it didn't exist. The line Hello World! was not found in the file, so Puppet added the line to the file.
Modify the oneline.pp file and add another file_line resource:
Now apply the manifest again and verify whether the new line is appended to the file:
Verify the contents of /tmp/cookbook before your Puppet run:
Verify that the line has been removed and the goodbye line has been replaced:
t@mylaptop ~/.puppet/manifests $ cat /tmp/cookbook Oh freddled gruntbuggly, thanks for all the fish.
Editing files with file_line works well if the file is unstructured. Structured files may have similar lines in different sections that have different meanings. In the next section, we'll show you how to deal with one particular type of structured file, a file using INI syntax.
puppetlabs-stdlib module
- Create a manifest named
oneline.ppthat will usefile_lineon a file in/tmp:file {'/tmp/cookbook': ensure => 'file', } file_line {'cookbook-hello': path => '/tmp/cookbook', line => 'Hello World!', require => File['/tmp/cookbook'], } - Run
puppet applyon theoneline.ppmanifest:t@mylaptop ~/.puppet/manifests $ puppet apply oneline.pp Notice: Compiled catalog for mylaptop in environment production in 0.39 seconds Notice: /Stage[main]/Main/File[/tmp/cookbook]/ensure: created Notice: /Stage[main]/Main/File_line[cookbook-hello]/ensure: created Notice: Finished catalog run in 0.02 seconds
- Now verify that
/tmp/cookbookcontains the line we defined:t@mylaptop ~/.puppet/manifests $ cat /tmp/cookbook Hello World!
We installed the puppetlabs-stdlib module into the default module path for Puppet, so when we ran puppet apply, Puppet knew where to find the file_line type definition. Puppet then created the /tmp/cookbook file if it didn't exist. The line Hello World! was not found in the file, so Puppet added the line to the file.
Modify the oneline.pp file and add another file_line resource:
Now apply the manifest again and verify whether the new line is appended to the file:
Verify the contents of /tmp/cookbook before your Puppet run:
Verify that the line has been removed and the goodbye line has been replaced:
t@mylaptop ~/.puppet/manifests $ cat /tmp/cookbook Oh freddled gruntbuggly, thanks for all the fish.
Editing files with file_line works well if the file is unstructured. Structured files may have similar lines in different sections that have different meanings. In the next section, we'll show you how to deal with one particular type of structured file, a file using INI syntax.
file_line resource type, we can ensure that a line exists or is absent in a config file. Using file_line we can quickly make edits to files without controlling the entire file.
oneline.pp that will use file_line on a file in /tmp: file {'/tmp/cookbook':
ensure => 'file',
}
file_line {'cookbook-hello':
path => '/tmp/cookbook',
line => 'Hello World!',
require => File['/tmp/cookbook'],
}puppet apply on the oneline.pp manifest:t@mylaptop ~/.puppet/manifests $ puppet apply oneline.pp Notice: Compiled catalog for mylaptop in environment production in 0.39 seconds Notice: /Stage[main]/Main/File[/tmp/cookbook]/ensure: created Notice: /Stage[main]/Main/File_line[cookbook-hello]/ensure: created Notice: Finished catalog run in 0.02 seconds
/tmp/cookbook contains the line we defined:t@mylaptop ~/.puppet/manifests $ cat /tmp/cookbook Hello World!
We installed the puppetlabs-stdlib module into the default module path for Puppet, so when we ran puppet apply, Puppet knew where to find the file_line type definition. Puppet then created the /tmp/cookbook file if it didn't exist. The line Hello World! was not found in the file, so Puppet added the line to the file.
Modify the oneline.pp file and add another file_line resource:
Now apply the manifest again and verify whether the new line is appended to the file:
Verify the contents of /tmp/cookbook before your Puppet run:
Verify that the line has been removed and the goodbye line has been replaced:
t@mylaptop ~/.puppet/manifests $ cat /tmp/cookbook Oh freddled gruntbuggly, thanks for all the fish.
Editing files with file_line works well if the file is unstructured. Structured files may have similar lines in different sections that have different meanings. In the next section, we'll show you how to deal with one particular type of structured file, a file using INI syntax.
the puppetlabs-stdlib module into the default module path for Puppet, so when we ran puppet apply, Puppet knew where to find the file_line type definition. Puppet then created the /tmp/cookbook file if it didn't exist. The line Hello World! was not found in the file, so Puppet added the line to the file.
Modify the oneline.pp file and add another file_line resource:
Now apply the manifest again and verify whether the new line is appended to the file:
Verify the contents of /tmp/cookbook before your Puppet run:
Verify that the line has been removed and the goodbye line has been replaced:
t@mylaptop ~/.puppet/manifests $ cat /tmp/cookbook Oh freddled gruntbuggly, thanks for all the fish.
Editing files with file_line works well if the file is unstructured. Structured files may have similar lines in different sections that have different meanings. In the next section, we'll show you how to deal with one particular type of structured file, a file using INI syntax.
file_line and add more lines to the file; we can have multiple resources modifying a single file.
oneline.pp file
and add another file_line resource:
Now apply the manifest again and verify whether the new line is appended to the file:
Verify the contents of /tmp/cookbook before your Puppet run:
Verify that the line has been removed and the goodbye line has been replaced:
t@mylaptop ~/.puppet/manifests $ cat /tmp/cookbook Oh freddled gruntbuggly, thanks for all the fish.
Editing files with file_line works well if the file is unstructured. Structured files may have similar lines in different sections that have different meanings. In the next section, we'll show you how to deal with one particular type of structured file, a file using INI syntax.
- Create an
initest.ppmanifest with the following contents:ini_setting {'server_true': path => '/tmp/server.conf', section => 'main', setting => 'server', value => 'true', } - Apply the manifest:
t@mylaptop ~/.puppet/manifests $ puppet apply initest.pp Notice: Compiled catalog for burnaby in environment production in 0.14 seconds Notice: /Stage[main]/Main/Ini_setting[server_true]/ensure: created Notice: Finished catalog run in 0.02 seconds
- Verify the contents of the
/tmp/server.conffile:t@mylaptop ~/.puppet/manifests $ cat /tmp/server.conf [main] server = true
The inifile module defines two types, ini_setting and ini_subsetting. Our manifest defines an ini_setting resource that creates a server = true setting within the main section of the ini file. In our case, the file didn't exist, so Puppet created the file, then created the main section, and finally added the setting to the main section.
Using ini_subsetting, you can have several resources added to a setting. For instance, our server.conf file has a server's line, we could have each node append its own hostname to a server's line. Add the following to the end of the initest.pp file:
Now temporarily change your hostname and rerun Puppet:
If your configuration files are not in INI syntax, another tool, Augeas, can be used. In the following section, we will use augeas to modify files.
- Create an
initest.ppmanifest with the following contents:ini_setting {'server_true': path => '/tmp/server.conf', section => 'main', setting => 'server', value => 'true', } - Apply the manifest:
t@mylaptop ~/.puppet/manifests $ puppet apply initest.pp Notice: Compiled catalog for burnaby in environment production in 0.14 seconds Notice: /Stage[main]/Main/Ini_setting[server_true]/ensure: created Notice: Finished catalog run in 0.02 seconds
- Verify the contents of the
/tmp/server.conffile:t@mylaptop ~/.puppet/manifests $ cat /tmp/server.conf [main] server = true
The inifile module defines two types, ini_setting and ini_subsetting. Our manifest defines an ini_setting resource that creates a server = true setting within the main section of the ini file. In our case, the file didn't exist, so Puppet created the file, then created the main section, and finally added the setting to the main section.
Using ini_subsetting, you can have several resources added to a setting. For instance, our server.conf file has a server's line, we could have each node append its own hostname to a server's line. Add the following to the end of the initest.pp file:
Now temporarily change your hostname and rerun Puppet:
If your configuration files are not in INI syntax, another tool, Augeas, can be used. In the following section, we will use augeas to modify files.
/tmp/server.conf file and ensure that the server_true setting is set in that file:
initest.pp manifest with the following contents: ini_setting {'server_true':
path => '/tmp/server.conf',
section => 'main',
setting => 'server',
value => 'true',
}t@mylaptop ~/.puppet/manifests $ puppet apply initest.pp Notice: Compiled catalog for burnaby in environment production in 0.14 seconds Notice: /Stage[main]/Main/Ini_setting[server_true]/ensure: created Notice: Finished catalog run in 0.02 seconds
/tmp/server.conf file:t@mylaptop ~/.puppet/manifests $ cat /tmp/server.conf [main] server = true
The inifile module defines two types, ini_setting and ini_subsetting. Our manifest defines an ini_setting resource that creates a server = true setting within the main section of the ini file. In our case, the file didn't exist, so Puppet created the file, then created the main section, and finally added the setting to the main section.
Using ini_subsetting, you can have several resources added to a setting. For instance, our server.conf file has a server's line, we could have each node append its own hostname to a server's line. Add the following to the end of the initest.pp file:
Now temporarily change your hostname and rerun Puppet:
If your configuration files are not in INI syntax, another tool, Augeas, can be used. In the following section, we will use augeas to modify files.
inifile module defines two types, ini_setting and ini_subsetting. Our manifest defines an ini_setting resource that creates a server = true setting within
the main section of the ini file. In our case, the file didn't exist, so Puppet created the file, then created the main section, and finally added the setting to the main section.
Using ini_subsetting, you can have several resources added to a setting. For instance, our server.conf file has a server's line, we could have each node append its own hostname to a server's line. Add the following to the end of the initest.pp file:
Now temporarily change your hostname and rerun Puppet:
If your configuration files are not in INI syntax, another tool, Augeas, can be used. In the following section, we will use augeas to modify files.
ini_subsetting, you can have
Thankfully, Augeas is here to help. Augeas is a system that aims to simplify working with different config file formats by presenting them all as a simple tree of values. Puppet's Augeas support allows you to create augeas resources that can make the required config changes intelligently and automatically.
Follow these steps to create an example augeas resource:
- Modify your
basemodule as follows:class base { augeas { 'enable-ip-forwarding': incl => '/etc/sysctl.conf', lens => 'Sysctl.lns', changes => ['set net.ipv4.ip_forward 1'], } } - Run Puppet:
[root@cookbook ~]# puppet agent -t Info: Applying configuration version '1412130479' Notice: Augeas[enable-ip-forwarding](provider=augeas): --- /etc/sysctl.conf 2014-09-04 03:41:09.000000000 -0400 +++ /etc/sysctl.conf.augnew 2014-09-30 22:28:03.503000039 -0400 @@ -4,7 +4,7 @@ # sysctl.conf(5) for more details. # Controls IP packet forwarding -net.ipv4.ip_forward = 0 +net.ipv4.ip_forward = 1 # Controls source route verification net.ipv4.conf.default.rp_filter = 1 Notice: /Stage[main]/Base/Augeas[enable-ip-forwarding]/returns: executed successfully Notice: Finished catalog run in 2.27 seconds
- Check whether the setting has been correctly applied:
[root@cookbook ~]# sysctl -p |grep ip_forward net.ipv4.ip_forward = 1
We declare an augeas resource named enable-ip-forwarding:
We specify that we want to make changes in the file /etc/sysctl.conf:
Next we specify the lens to use on this file. Augeas uses files called lenses to translate a configuration file into an object representation. Augeas ships with several lenses, they are located in /usr/share/augeas/lenses by default. When specifying the lens in an augeas resource, the name of the lens is capitalized and has the .lns suffix. In this case, we will specify the Sysctl lens as follows:
In general, Augeas changes take the following form:
In this case, the setting will be translated into a line like this in /etc/sysctl.conf:
For more information about using Puppet and Augeas, see the page on the Puppet Labs website http://projects.puppetlabs.com/projects/1/wiki/Puppet_Augeas.
Another project that uses Augeas is Augeasproviders. Augeasproviders uses Augeas to define several types. One of these types is sysctl, using this type you can make sysctl changes without knowing how to write the changes in Augeas. More information is available on the forge at https://forge.puppetlabs.com/domcleal/augeasproviders.
Learning how to use Augeas can be a little confusing at first. Augeas provides a command line tool, augtool, which can be used to get acquainted with making changes in Augeas.
augeas resource:
base module as follows: class base {
augeas { 'enable-ip-forwarding':
incl => '/etc/sysctl.conf',
lens => 'Sysctl.lns',
changes => ['set net.ipv4.ip_forward 1'],
}
}[root@cookbook ~]# puppet agent -t Info: Applying configuration version '1412130479' Notice: Augeas[enable-ip-forwarding](provider=augeas): --- /etc/sysctl.conf 2014-09-04 03:41:09.000000000 -0400 +++ /etc/sysctl.conf.augnew 2014-09-30 22:28:03.503000039 -0400 @@ -4,7 +4,7 @@ # sysctl.conf(5) for more details. # Controls IP packet forwarding -net.ipv4.ip_forward = 0 +net.ipv4.ip_forward = 1 # Controls source route verification net.ipv4.conf.default.rp_filter = 1 Notice: /Stage[main]/Base/Augeas[enable-ip-forwarding]/returns: executed successfully Notice: Finished catalog run in 2.27 seconds
[root@cookbook ~]# sysctl -p |grep ip_forward net.ipv4.ip_forward = 1
We declare an augeas resource named enable-ip-forwarding:
We specify that we want to make changes in the file /etc/sysctl.conf:
Next we specify the lens to use on this file. Augeas uses files called lenses to translate a configuration file into an object representation. Augeas ships with several lenses, they are located in /usr/share/augeas/lenses by default. When specifying the lens in an augeas resource, the name of the lens is capitalized and has the .lns suffix. In this case, we will specify the Sysctl lens as follows:
In general, Augeas changes take the following form:
In this case, the setting will be translated into a line like this in /etc/sysctl.conf:
For more information about using Puppet and Augeas, see the page on the Puppet Labs website http://projects.puppetlabs.com/projects/1/wiki/Puppet_Augeas.
Another project that uses Augeas is Augeasproviders. Augeasproviders uses Augeas to define several types. One of these types is sysctl, using this type you can make sysctl changes without knowing how to write the changes in Augeas. More information is available on the forge at https://forge.puppetlabs.com/domcleal/augeasproviders.
Learning how to use Augeas can be a little confusing at first. Augeas provides a command line tool, augtool, which can be used to get acquainted with making changes in Augeas.
augeas
resource named enable-ip-forwarding:
We specify that we want to make changes in the file /etc/sysctl.conf:
Next we specify the lens to use on this file. Augeas uses files called lenses to translate a configuration file into an object representation. Augeas ships with several lenses, they are located in /usr/share/augeas/lenses by default. When specifying the lens in an augeas resource, the name of the lens is capitalized and has the .lns suffix. In this case, we will specify the Sysctl lens as follows:
In general, Augeas changes take the following form:
In this case, the setting will be translated into a line like this in /etc/sysctl.conf:
For more information about using Puppet and Augeas, see the page on the Puppet Labs website http://projects.puppetlabs.com/projects/1/wiki/Puppet_Augeas.
Another project that uses Augeas is Augeasproviders. Augeasproviders uses Augeas to define several types. One of these types is sysctl, using this type you can make sysctl changes without knowing how to write the changes in Augeas. More information is available on the forge at https://forge.puppetlabs.com/domcleal/augeasproviders.
Learning how to use Augeas can be a little confusing at first. Augeas provides a command line tool, augtool, which can be used to get acquainted with making changes in Augeas.
/etc/sysctl.conf as the example because it can contain a wide variety of kernel settings and you may want to change these settings for all sorts of different purposes and in different Puppet classes. You might want to enable IP forwarding, as in the example, for a router class but you might also want to tune the value of net.core.somaxconn for a load-balancer class.
/etc/sysctl.conf file and distributing it as a text file won't work because you might have several different and conflicting versions depending on the setting you want to modify. Augeas is the right solution here because you can define augeas resources in different places, which modify the same file and they won't conflict.
Augeas, see the page on the Puppet Labs website http://projects.puppetlabs.com/projects/1/wiki/Puppet_Augeas.
Another project that uses Augeas is Augeasproviders. Augeasproviders uses Augeas to define several types. One of these types is sysctl, using this type you can make sysctl changes without knowing how to write the changes in Augeas. More information is available on the forge at https://forge.puppetlabs.com/domcleal/augeasproviders.
Learning how to use Augeas can be a little confusing at first. Augeas provides a command line tool, augtool, which can be used to get acquainted with making changes in Augeas.
Sometimes you can't deploy a whole config file in one piece, yet making line by line edits isn't enough. Often, you need to build a config file from various bits of configuration managed by different classes. You may run into a situation where local information needs to be imported into the file as well. In this example, we'll build a config file using a local file as well as snippets defined in our manifests.
In your Git repository create an environment.conf file with the following contents:
Create the public directory and download the module into that directory as follows:
Now that we have the concat module available on our server, we can create a concat container resource in our base module:
Create a concat::fragment module for the header of the new file:
Create a concat::fragment that includes a local file:
Create a concat::fragment module that will go at the end of the file:
On the node, create /etc/hosts.allow.local with the following contents:
The concat resource defines a container that will hold all the subsequent concat::fragment resources. Each concat::fragment resource references the concat resource as the target. Each concat::fragment also includes an order attribute. The order attribute is used to specify the order in which the fragments are added to the final file. Our /etc/hosts.allow file is built with the header line, the contents of the local file, and finally the in.tftpd line we defined.
concat module. We will start by installing the concat module, in a previous example we installed the module to our local machine. In this example, we'll modify the Puppet server configuration and download the module to the Puppet server.
environment.conf file with the following contents:
Now that we have the concat module available on our server, we can create a concat container resource in our base module:
Create a concat::fragment module for the header of the new file:
Create a concat::fragment that includes a local file:
Create a concat::fragment module that will go at the end of the file:
On the node, create /etc/hosts.allow.local with the following contents:
The concat resource defines a container that will hold all the subsequent concat::fragment resources. Each concat::fragment resource references the concat resource as the target. Each concat::fragment also includes an order attribute. The order attribute is used to specify the order in which the fragments are added to the final file. Our /etc/hosts.allow file is built with the header line, the contents of the local file, and finally the in.tftpd line we defined.
the concat module available on our server, we can create a concat container resource in our base module:
Create a concat::fragment module for the header of the new file:
Create a concat::fragment that includes a local file:
Create a concat::fragment module that will go at the end of the file:
On the node, create /etc/hosts.allow.local with the following contents:
The concat resource defines a container that will hold all the subsequent concat::fragment resources. Each concat::fragment resource references the concat resource as the target. Each concat::fragment also includes an order attribute. The order attribute is used to specify the order in which the fragments are added to the final file. Our /etc/hosts.allow file is built with the header line, the contents of the local file, and finally the in.tftpd line we defined.
concat resource defines
a container that will hold all the subsequent concat::fragment resources. Each concat::fragment resource references the concat resource as the target. Each concat::fragment also includes an order attribute. The order attribute is used to specify the order in which the fragments are added to the final file. Our /etc/hosts.allow file is built with the header line, the contents of the local file, and finally the in.tftpd line we defined.
While you can deploy config files easily with Puppet as simple text files, templates are much more powerful. A template file can do calculations, execute Ruby code, or reference the values of variables from your Puppet manifests. Anywhere you might deploy a text file using Puppet, you can use a template instead.
In this example, we'll use an ERB template to insert a password into a backup script:
- Create the file
modules/admin/templates/backup-mysql.sh.erbwith the following contents:#!/bin/sh /usr/bin/mysqldump -uroot \ -p<%= @mysql_password %> \ --all-databases | \ /bin/gzip > /backup/mysql/all-databases.sql.gz
- Modify your
site.ppfile as follows:node 'cookbook' { $mysql_password = 'secret' file { '/usr/local/bin/backup-mysql': content => template('admin/backup-mysql.sh.erb'), mode => '0755', } } - Run Puppet:
[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1412140971' Notice: /Stage[main]/Main/Node[cookbook]/File[/usr/local/bin/backup-mysql]/ensure: defined content as '{md5}c12af56559ef36529975d568ff52dca5' Notice: Finished catalog run in 0.31 seconds
- Check whether Puppet has correctly inserted the password into the template:
[root@cookbook ~]# cat /usr/local/bin/backup-mysql #!/bin/sh /usr/bin/mysqldump -uroot \ -psecret \ --all-databases | \ /bin/gzip > /backup/mysql/all-databases.sql.gz
Wherever a variable is referenced in the template, for example <%= @mysql_password %>, Puppet will replace it with the corresponding value, secret.
modules/admin/templates/backup-mysql.sh.erb with the following contents:#!/bin/sh /usr/bin/mysqldump -uroot \ -p<%= @mysql_password %> \ --all-databases | \ /bin/gzip > /backup/mysql/all-databases.sql.gz
site.pp file as follows:node 'cookbook' {
$mysql_password = 'secret'
file { '/usr/local/bin/backup-mysql':
content => template('admin/backup-mysql.sh.erb'),
mode => '0755',
}
}[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1412140971' Notice: /Stage[main]/Main/Node[cookbook]/File[/usr/local/bin/backup-mysql]/ensure: defined content as '{md5}c12af56559ef36529975d568ff52dca5' Notice: Finished catalog run in 0.31 seconds
[root@cookbook ~]# cat /usr/local/bin/backup-mysql #!/bin/sh /usr/bin/mysqldump -uroot \ -psecret \ --all-databases | \ /bin/gzip > /backup/mysql/all-databases.sql.gz
Wherever a variable is referenced in the template, for example <%= @mysql_password %>, Puppet will replace it with the corresponding value, secret.
In the previous example, we saw that you can use Ruby to interpolate different values in templates depending on the result of an expression. But you're not limited to getting one value at a time. You can put lots of them in a Puppet array and then have the template generate some content for each element of the array using a loop.
Follow these steps to build an example of iterating over arrays:
- Modify your
site.ppfile as follows:node 'cookbook' { $ipaddresses = ['192.168.0.1', '158.43.128.1', '10.0.75.207' ] file { '/tmp/addresslist.txt': content => template('base/addresslist.erb') } } - Create the file
modules/base/templates/addresslist.erbwith the following contents:<% @ipaddresses.each do |ip| -%> IP address <%= ip %> is present <% end -%>
- Run Puppet:
[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1412141917' Notice: /Stage[main]/Main/Node[cookbook]/File[/tmp/addresslist.txt]/ensure: defined content as '{md5}073851229d7b2843830024afb2b3902d' Notice: Finished catalog run in 0.30 seconds
- Check the contents of the generated file:
[root@cookbook ~]# cat /tmp/addresslist.txt IP address 192.168.0.1 is present. IP address 158.43.128.1 is present. IP address 10.0.75.207 is present.
In the first line of the template, we reference the array ipaddresses, and call its each method:
site.pp file as follows: node 'cookbook' {
$ipaddresses = ['192.168.0.1', '158.43.128.1', '10.0.75.207' ]
file { '/tmp/addresslist.txt':
content => template('base/addresslist.erb')
}
}modules/base/templates/addresslist.erb with the following contents:<% @ipaddresses.each do |ip| -%> IP address <%= ip %> is present <% end -%>
[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1412141917' Notice: /Stage[main]/Main/Node[cookbook]/File[/tmp/addresslist.txt]/ensure: defined content as '{md5}073851229d7b2843830024afb2b3902d' Notice: Finished catalog run in 0.30 seconds
[root@cookbook ~]# cat /tmp/addresslist.txt IP address 192.168.0.1 is present. IP address 158.43.128.1 is present. IP address 10.0.75.207 is present.
In the first line of the template, we reference the array ipaddresses, and call its each method:
template, we reference the array ipaddresses, and call its each method:
EPP templates are a new feature in Puppet 3.5 and newer versions. EPP templates use a syntax similar to ERB templates but are not compiled through Ruby. Two new functions are defined to call EPP templates, epp, and inline_epp. These functions are the EPP equivalents of the ERB functions template and inline_template, respectively. The main difference with EPP templates is that variables are referenced using the Puppet notation, $variable instead of @variable.
- Create an EPP template in
~/puppet/epp-test.eppwith the following content:This is <%= $message %>.
- Create an
epp.ppmanifest, which uses theeppandinline_eppfunctions:$message = "the message" file {'/tmp/epp-test': content => epp('/home/thomas/puppet/epp-test.epp') } notify {inline_epp('Also prints <%= $message %>'):} - Apply the manifest making sure to use the future parser (the future parser is required for the
eppandinline_eppfunctions to be defined):t@mylaptop ~/puppet $ puppet apply epp.pp --parser=future Notice: Compiled catalog for mylaptop in environment production in 1.03 seconds Notice: /Stage[main]/Main/File[/tmp/epp-test]/ensure: defined content as '{md5}999ccc2507d79d50fae0775d69b63b8c' Notice: Also prints the message
- Verify that the template worked as intended:
t@mylaptop ~/puppet $ cat /tmp/epp-test This is the message.
Both epp and inline_epp allow for variables to be overridden within the function call. A second parameter to the function call can be used to specify values for variables used within the scope of the function call. For example, we can override the value of $message with the following code:
Now when we run Puppet and verify the output we see that the value of $message has been overridden:
~/puppet/epp-test.epp with the following content:This is <%= $message %>.
epp.pp manifest, which uses the epp and inline_epp functions:$message = "the message"
file {'/tmp/epp-test':
content => epp('/home/thomas/puppet/epp-test.epp')
}
notify {inline_epp('Also prints <%= $message %>'):}epp and inline_epp functions to be defined):t@mylaptop ~/puppet $ puppet apply epp.pp --parser=future Notice: Compiled catalog for mylaptop in environment production in 1.03 seconds Notice: /Stage[main]/Main/File[/tmp/epp-test]/ensure: defined content as '{md5}999ccc2507d79d50fae0775d69b63b8c' Notice: Also prints the message
t@mylaptop ~/puppet $ cat /tmp/epp-test This is the message.
Both epp and inline_epp allow for variables to be overridden within the function call. A second parameter to the function call can be used to specify values for variables used within the scope of the function call. For example, we can override the value of $message with the following code:
Now when we run Puppet and verify the output we see that the value of $message has been overridden:
epp and inline_epp functions are defined. The main difference between EPP templates and ERB templates is that variables are referenced in the same way they are within Puppet manifests.
Both epp and inline_epp allow for variables to be overridden within the function call. A second parameter to the function call can be used to specify values for variables used within the scope of the function call. For example, we can override the value of $message with the following code:
Now when we run Puppet and verify the output we see that the value of $message has been overridden:
epp and inline_epp allow
for variables to be overridden within the function call. A second parameter to the function call can be used to specify values for variables used within the scope of the function call. For example, we can override the value of $message with the following code:
Now when we run Puppet and verify the output we see that the value of $message has been overridden:
It's a common requirement for third-party developers and contractors to be able to make changes via Puppet, but they definitely shouldn't see any confidential information. Similarly, if you're using a distributed Puppet setup like that described in Chapter 2, Puppet Infrastructure, every machine has a copy of the whole repo, including secrets for other machines that it doesn't need and shouldn't have. How can we prevent this?
One answer is to encrypt the secrets using the GnuPG tool, so that any secret information in the Puppet repo is undecipherable (for all practical purposes) without the appropriate key. Then we distribute the key securely to the people or machines that need it.
First you'll need an encryption key, so follow these steps to generate one. If you already have a GnuPG key that you'd like to use, go on to the next section. To complete this section, you will need to install the gpg command:
- Use
puppetresource to install gpg:# puppet resource package gnupg ensure=installed - Run the following command. Answer the prompts as shown, except to substitute your name and e-mail address for mine. When prompted for a passphrase, just hit Enter:
t@mylaptop ~/puppet $ gpg --gen-key gpg (GnuPG) 1.4.18; Copyright (C) 2014 Free Software Foundation, Inc. This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Please select what kind of key you want: (1) RSA and RSA (default) (2) DSA and Elgamal (3) DSA (sign only) (4) RSA (sign only) Your selection? 1 RSA keys may be between 1024 and 4096 bits long. What keysize do you want? (2048) 2048 Requested keysize is 2048 bits Please specify how long the key should be valid. 0 = key does not expire <n> = key expires in n days <n>w = key expires in n weeks <n>m = key expires in n months <n>y = key expires in n years Key is valid for? (0) 0 Key does not expire at all Is this correct? (y/N) y You need a user ID to identify your key; the software constructs the user ID from the Real Name, Comment and Email Address in this form: "Heinrich Heine (Der Dichter) <heinrichh@duesseldorf.de>" Real name: Thomas Uphill Email address: thomas@narrabilis.com Comment: <enter> You selected this USER-ID: "Thomas Uphill <thomas@narrabilis.com>" Change (N)ame, (C)omment, (E)mail or (O)kay/(Q)uit? o You need a Passphrase to protect your secret key.
Hit enter twice here to have an empty passphrase
You don't want a passphrase - this is probably a *bad* idea! I will do it anyway. You can change your passphrase at any time, using this program with the option "--edit-key". gpg: key F1C1EE49 marked as ultimately trusted public and secret key created and signed. gpg: checking the trustdb gpg: 3 marginal(s) needed, 1 complete(s) needed, PGP trust model gpg: depth: 0 valid: 1 signed: 0 trust: 0-, 0q, 0n, 0m, 0f, 1u pub 2048R/F1C1EE49 2014-10-01 Key fingerprint = 461A CB4C 397F 06A7 FB82 3BAD 63CF 50D8 F1C1 EE49 uid Thomas Uphill <thomas@narrabilis.com> sub 2048R/E2440023 2014-10-01
- You may see a message like this if your system is not configured with a source of randomness:
We need to generate a lot of random bytes. It is a good idea to perform some other action (type on the keyboard, move the mouse, utilize the disks) during the prime generation; this gives the random number generator a better chance to gain enough entropy.
- In this case, install and start a random number generator daemon such as
havegedorrng-tools. Copy the gpg key you just created into thepuppetuser's account on your Puppet master:t@mylaptop ~ $ scp -r .gnupg puppet@puppet.example.com: gpg.conf 100% 7680 7.5KB/s 00:00 random_seed 100% 600 0.6KB/s 00:00 pubring.gpg 100% 1196 1.2KB/s 00:00 secring.gpg 100% 2498 2.4KB/s 00:00 trustdb.gpg 100% 1280 1.3KB/s 00:00
With your encryption key installed on the puppet user's keyring (the key generation process described in the previous section will do this for you), you're ready to set up Puppet to decrypt secrets.
- Create the following directory:
t@cookbook:~/puppet$ mkdir -p modules/admin/lib/puppet/parser/functions - Create the file
modules/admin/lib/puppet/parser/functions/secret.rbwith the following contents:module Puppet::Parser::Functions newfunction(:secret, :type => :rvalue) do |args| 'gpg --no-tty -d #{args[0]}' end end - Create the file
secret_messagewith the following contents:For a moment, nothing happened. Then, after a second or so, nothing continued to happen.
- Encrypt this file with the following command (use the e-mail address you supplied when creating the GnuPG key):
t@mylaptop ~/puppet $ gpg -e -r thomas@narrabilis.com secret_message - Move the resulting encrypted file into your Puppet repo:
t@mylaptop:~/puppet$ mv secret_message.gpg modules/admin/files/ - Remove the original (plaintext) file:
t@mylaptop:~/puppet$ rm secret_message - Modify your
site.ppfile as follows:node 'cookbook' { $message = secret('/etc/puppet/environments/production/ modules/admin/files/secret_message.gpg') notify { "The secret message is: ${message}": } } - Run Puppet:
[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1412145910' Notice: The secret message is: For a moment, nothing happened. Then, after a second or so, nothing continued to happen. Notice: Finished catalog run in 0.27 seconds
First, we've created a custom function to allow Puppet to decrypt the secret files using GnuPG:
Having set up the secret function and the required key, we now encrypt a message to this key:
We then call the secret function to decrypt this file and get the contents:
You should use the secret function, or something like it, to protect any confidential data in your Puppet repo: passwords, AWS credentials, license keys, even other secret keys such as SSL host keys.
You may decide to use a single key, which you push to machines as they're built, perhaps as part of a bootstrap process like that described in the Bootstrapping Puppet with Bash recipe in Chapter 2, Puppet Infrastructure. For even greater security, you might like to create a new key for each machine, or group of machines, and encrypt a given secret only for the machines that need it.
For example, your web servers might need a certain secret that you don't want to be accessible on any other machine. You could create a key for web servers, and encrypt the data only for this key.
If you want to use encrypted data with Hiera, there is a GnuPG backend for Hiera available at http://www.craigdunn.org/2011/10/secret-variables-in-puppet-with-hiera-and-gpg/.
- The Configuring Hiera recipe in Chapter 2, Puppet Infrastructure
- The Storing secret data with hiera-gpg recipe in Chapter 2, Puppet Infrastructure
encryption key, so follow these steps to generate one. If you already have a GnuPG key that you'd like to use, go on to the next section. To complete this section, you will need to install the gpg command:
- Use
puppetresource to install gpg:# puppet resource package gnupg ensure=installed - Run the following command. Answer the prompts as shown, except to substitute your name and e-mail address for mine. When prompted for a passphrase, just hit Enter:
t@mylaptop ~/puppet $ gpg --gen-key gpg (GnuPG) 1.4.18; Copyright (C) 2014 Free Software Foundation, Inc. This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Please select what kind of key you want: (1) RSA and RSA (default) (2) DSA and Elgamal (3) DSA (sign only) (4) RSA (sign only) Your selection? 1 RSA keys may be between 1024 and 4096 bits long. What keysize do you want? (2048) 2048 Requested keysize is 2048 bits Please specify how long the key should be valid. 0 = key does not expire <n> = key expires in n days <n>w = key expires in n weeks <n>m = key expires in n months <n>y = key expires in n years Key is valid for? (0) 0 Key does not expire at all Is this correct? (y/N) y You need a user ID to identify your key; the software constructs the user ID from the Real Name, Comment and Email Address in this form: "Heinrich Heine (Der Dichter) <heinrichh@duesseldorf.de>" Real name: Thomas Uphill Email address: thomas@narrabilis.com Comment: <enter> You selected this USER-ID: "Thomas Uphill <thomas@narrabilis.com>" Change (N)ame, (C)omment, (E)mail or (O)kay/(Q)uit? o You need a Passphrase to protect your secret key.
Hit enter twice here to have an empty passphrase
You don't want a passphrase - this is probably a *bad* idea! I will do it anyway. You can change your passphrase at any time, using this program with the option "--edit-key". gpg: key F1C1EE49 marked as ultimately trusted public and secret key created and signed. gpg: checking the trustdb gpg: 3 marginal(s) needed, 1 complete(s) needed, PGP trust model gpg: depth: 0 valid: 1 signed: 0 trust: 0-, 0q, 0n, 0m, 0f, 1u pub 2048R/F1C1EE49 2014-10-01 Key fingerprint = 461A CB4C 397F 06A7 FB82 3BAD 63CF 50D8 F1C1 EE49 uid Thomas Uphill <thomas@narrabilis.com> sub 2048R/E2440023 2014-10-01
- You may see a message like this if your system is not configured with a source of randomness:
We need to generate a lot of random bytes. It is a good idea to perform some other action (type on the keyboard, move the mouse, utilize the disks) during the prime generation; this gives the random number generator a better chance to gain enough entropy.
- In this case, install and start a random number generator daemon such as
havegedorrng-tools. Copy the gpg key you just created into thepuppetuser's account on your Puppet master:t@mylaptop ~ $ scp -r .gnupg puppet@puppet.example.com: gpg.conf 100% 7680 7.5KB/s 00:00 random_seed 100% 600 0.6KB/s 00:00 pubring.gpg 100% 1196 1.2KB/s 00:00 secring.gpg 100% 2498 2.4KB/s 00:00 trustdb.gpg 100% 1280 1.3KB/s 00:00
With your encryption key installed on the puppet user's keyring (the key generation process described in the previous section will do this for you), you're ready to set up Puppet to decrypt secrets.
- Create the following directory:
t@cookbook:~/puppet$ mkdir -p modules/admin/lib/puppet/parser/functions - Create the file
modules/admin/lib/puppet/parser/functions/secret.rbwith the following contents:module Puppet::Parser::Functions newfunction(:secret, :type => :rvalue) do |args| 'gpg --no-tty -d #{args[0]}' end end - Create the file
secret_messagewith the following contents:For a moment, nothing happened. Then, after a second or so, nothing continued to happen.
- Encrypt this file with the following command (use the e-mail address you supplied when creating the GnuPG key):
t@mylaptop ~/puppet $ gpg -e -r thomas@narrabilis.com secret_message - Move the resulting encrypted file into your Puppet repo:
t@mylaptop:~/puppet$ mv secret_message.gpg modules/admin/files/ - Remove the original (plaintext) file:
t@mylaptop:~/puppet$ rm secret_message - Modify your
site.ppfile as follows:node 'cookbook' { $message = secret('/etc/puppet/environments/production/ modules/admin/files/secret_message.gpg') notify { "The secret message is: ${message}": } } - Run Puppet:
[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1412145910' Notice: The secret message is: For a moment, nothing happened. Then, after a second or so, nothing continued to happen. Notice: Finished catalog run in 0.27 seconds
First, we've created a custom function to allow Puppet to decrypt the secret files using GnuPG:
Having set up the secret function and the required key, we now encrypt a message to this key:
We then call the secret function to decrypt this file and get the contents:
You should use the secret function, or something like it, to protect any confidential data in your Puppet repo: passwords, AWS credentials, license keys, even other secret keys such as SSL host keys.
You may decide to use a single key, which you push to machines as they're built, perhaps as part of a bootstrap process like that described in the Bootstrapping Puppet with Bash recipe in Chapter 2, Puppet Infrastructure. For even greater security, you might like to create a new key for each machine, or group of machines, and encrypt a given secret only for the machines that need it.
For example, your web servers might need a certain secret that you don't want to be accessible on any other machine. You could create a key for web servers, and encrypt the data only for this key.
If you want to use encrypted data with Hiera, there is a GnuPG backend for Hiera available at http://www.craigdunn.org/2011/10/secret-variables-in-puppet-with-hiera-and-gpg/.
- The Configuring Hiera recipe in Chapter 2, Puppet Infrastructure
- The Storing secret data with hiera-gpg recipe in Chapter 2, Puppet Infrastructure
installed on the puppet user's keyring (the key generation process described in the previous section will do this for you), you're ready to set up Puppet to decrypt secrets.
- Create the following directory:
t@cookbook:~/puppet$ mkdir -p modules/admin/lib/puppet/parser/functions - Create the file
modules/admin/lib/puppet/parser/functions/secret.rbwith the following contents:module Puppet::Parser::Functions newfunction(:secret, :type => :rvalue) do |args| 'gpg --no-tty -d #{args[0]}' end end - Create the file
secret_messagewith the following contents:For a moment, nothing happened. Then, after a second or so, nothing continued to happen.
- Encrypt this file with the following command (use the e-mail address you supplied when creating the GnuPG key):
t@mylaptop ~/puppet $ gpg -e -r thomas@narrabilis.com secret_message - Move the resulting encrypted file into your Puppet repo:
t@mylaptop:~/puppet$ mv secret_message.gpg modules/admin/files/ - Remove the original (plaintext) file:
t@mylaptop:~/puppet$ rm secret_message - Modify your
site.ppfile as follows:node 'cookbook' { $message = secret('/etc/puppet/environments/production/ modules/admin/files/secret_message.gpg') notify { "The secret message is: ${message}": } } - Run Puppet:
[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1412145910' Notice: The secret message is: For a moment, nothing happened. Then, after a second or so, nothing continued to happen. Notice: Finished catalog run in 0.27 seconds
First, we've created a custom function to allow Puppet to decrypt the secret files using GnuPG:
Having set up the secret function and the required key, we now encrypt a message to this key:
We then call the secret function to decrypt this file and get the contents:
You should use the secret function, or something like it, to protect any confidential data in your Puppet repo: passwords, AWS credentials, license keys, even other secret keys such as SSL host keys.
You may decide to use a single key, which you push to machines as they're built, perhaps as part of a bootstrap process like that described in the Bootstrapping Puppet with Bash recipe in Chapter 2, Puppet Infrastructure. For even greater security, you might like to create a new key for each machine, or group of machines, and encrypt a given secret only for the machines that need it.
For example, your web servers might need a certain secret that you don't want to be accessible on any other machine. You could create a key for web servers, and encrypt the data only for this key.
If you want to use encrypted data with Hiera, there is a GnuPG backend for Hiera available at http://www.craigdunn.org/2011/10/secret-variables-in-puppet-with-hiera-and-gpg/.
- The Configuring Hiera recipe in Chapter 2, Puppet Infrastructure
- The Storing secret data with hiera-gpg recipe in Chapter 2, Puppet Infrastructure
custom function to allow Puppet to decrypt the secret files using GnuPG:
Having set up the secret function and the required key, we now encrypt a message to this key:
We then call the secret function to decrypt this file and get the contents:
You should use the secret function, or something like it, to protect any confidential data in your Puppet repo: passwords, AWS credentials, license keys, even other secret keys such as SSL host keys.
You may decide to use a single key, which you push to machines as they're built, perhaps as part of a bootstrap process like that described in the Bootstrapping Puppet with Bash recipe in Chapter 2, Puppet Infrastructure. For even greater security, you might like to create a new key for each machine, or group of machines, and encrypt a given secret only for the machines that need it.
For example, your web servers might need a certain secret that you don't want to be accessible on any other machine. You could create a key for web servers, and encrypt the data only for this key.
If you want to use encrypted data with Hiera, there is a GnuPG backend for Hiera available at http://www.craigdunn.org/2011/10/secret-variables-in-puppet-with-hiera-and-gpg/.
- The Configuring Hiera recipe in Chapter 2, Puppet Infrastructure
- The Storing secret data with hiera-gpg recipe in Chapter 2, Puppet Infrastructure
You may decide to use a single key, which you push to machines as they're built, perhaps as part of a bootstrap process like that described in the Bootstrapping Puppet with Bash recipe in Chapter 2, Puppet Infrastructure. For even greater security, you might like to create a new key for each machine, or group of machines, and encrypt a given secret only for the machines that need it.
For example, your web servers might need a certain secret that you don't want to be accessible on any other machine. You could create a key for web servers, and encrypt the data only for this key.
If you want to use encrypted data with Hiera, there is a GnuPG backend for Hiera available at http://www.craigdunn.org/2011/10/secret-variables-in-puppet-with-hiera-and-gpg/.
- The Configuring Hiera recipe in Chapter 2, Puppet Infrastructure
- The Storing secret data with hiera-gpg recipe in Chapter 2, Puppet Infrastructure
Most often you will want to install packages from the main distribution repo, so a simple package resource will do:
In this example, we'll use the popular Percona APT repo (Percona is a MySQL consulting firm who maintain and release their own specialized version of MySQL, more information is available at http://www.percona.com/software/repositories):
- Create the file
modules/admin/manifests/percona_repo.ppwith the following contents:# Install Percona APT repo class admin::percona_repo { exec { 'add-percona-apt-key': unless => '/usr/bin/apt-key list |grep percona', command => '/usr/bin/gpg --keyserver hkp://keys.gnupg.net --recv-keys 1C4CBDCDCD2EFD2A && /usr/bin/gpg -a --export CD2EFD2A | apt-key add -', notify => Exec['percona-apt-update'], } exec { 'percona-apt-update': command => '/usr/bin/apt-get update', require => [File['/etc/apt/sources.list.d/percona.list'], File['/etc/apt/preferences.d/00percona.pref']], refreshonly => true, } file { '/etc/apt/sources.list.d/percona.list': content => 'deb http://repo.percona.com/apt wheezy main', notify => Exec['percona-apt-update'], } file { '/etc/apt/preferences.d/00percona.pref': content => "Package: *\nPin: release o=Percona Development Team\nPin-Priority: 1001", notify => Exec['percona-apt-update'], } } - Modify your
site.ppfile as follows:node 'cookbook' { include admin::percona_repo package { 'percona-server-server-5.5': ensure => installed, require => Class['admin::percona_repo'], } } - Run Puppet:
root@cookbook-deb:~# puppet agent -t Info: Caching catalog for cookbook-deb Notice: /Stage[main]/Admin::Percona_repo/Exec[add-percona-apt-key]/returns: executed successfully Info: /Stage[main]/Admin::Percona_repo/Exec[add-percona-apt-key]: Scheduling refresh of Exec[percona-apt-update] Notice: /Stage[main]/Admin::Percona_repo/File[/etc/apt/sources.list.d/percona.list]/ensure: defined content as '{md5}b8d479374497255804ffbf0a7bcdf6c2' Info: /Stage[main]/Admin::Percona_repo/File[/etc/apt/sources.list.d/percona.list]: Scheduling refresh of Exec[percona-apt-update] Notice: /Stage[main]/Admin::Percona_repo/File[/etc/apt/preferences.d/00percona.pref]/ensure: defined content as '{md5}1d8ca6c1e752308a9bd3018713e2d1ad' Info: /Stage[main]/Admin::Percona_repo/File[/etc/apt/preferences.d/00percona.pref]: Scheduling refresh of Exec[percona-apt-update] Notice: /Stage[main]/Admin::Percona_repo/Exec[percona-apt-update]: Triggered 'refresh' from 3 events
In order to install any Percona package, we first need to have the repository configuration installed on the machine. This is why the percona-server-server-5.5 package (Percona's version of the standard MySQL server) requires the admin::percona_repo class:
So, what does the admin::percona_repo class do? It:
First of all, we install the APT key:
The unless parameter checks the output of apt-key list to make sure that the Percona key is not already installed, in which case we need not do anything. Assuming it isn't, the command runs:
Having installed the key, we add the repo configuration:
Then run apt-get update to update the system's APT cache with the metadata from the new repo:
Finally, we configure the APT pin priority for the repo:
This ensures that packages installed from the Percona repo will never be superseded by packages from somewhere else (the main Ubuntu distro, for example). Otherwise, you could end up with broken dependencies and be unable to install the Percona packages automatically.
The APT package framework is specific to the Debian and Ubuntu systems. There is a forge module for managing apt repos, https://forge.puppetlabs.com/puppetlabs/apt. If you're on a Red Hat or CentOS-based system, you can use the yumrepo resources to manage RPM repositories directly:
http://docs.puppetlabs.com/references/latest/type.html#yumrepo
the popular Percona APT repo (Percona is a MySQL consulting firm who maintain and release their own specialized version of MySQL, more information is available at http://www.percona.com/software/repositories):
- Create the file
modules/admin/manifests/percona_repo.ppwith the following contents:# Install Percona APT repo class admin::percona_repo { exec { 'add-percona-apt-key': unless => '/usr/bin/apt-key list |grep percona', command => '/usr/bin/gpg --keyserver hkp://keys.gnupg.net --recv-keys 1C4CBDCDCD2EFD2A && /usr/bin/gpg -a --export CD2EFD2A | apt-key add -', notify => Exec['percona-apt-update'], } exec { 'percona-apt-update': command => '/usr/bin/apt-get update', require => [File['/etc/apt/sources.list.d/percona.list'], File['/etc/apt/preferences.d/00percona.pref']], refreshonly => true, } file { '/etc/apt/sources.list.d/percona.list': content => 'deb http://repo.percona.com/apt wheezy main', notify => Exec['percona-apt-update'], } file { '/etc/apt/preferences.d/00percona.pref': content => "Package: *\nPin: release o=Percona Development Team\nPin-Priority: 1001", notify => Exec['percona-apt-update'], } } - Modify your
site.ppfile as follows:node 'cookbook' { include admin::percona_repo package { 'percona-server-server-5.5': ensure => installed, require => Class['admin::percona_repo'], } } - Run Puppet:
root@cookbook-deb:~# puppet agent -t Info: Caching catalog for cookbook-deb Notice: /Stage[main]/Admin::Percona_repo/Exec[add-percona-apt-key]/returns: executed successfully Info: /Stage[main]/Admin::Percona_repo/Exec[add-percona-apt-key]: Scheduling refresh of Exec[percona-apt-update] Notice: /Stage[main]/Admin::Percona_repo/File[/etc/apt/sources.list.d/percona.list]/ensure: defined content as '{md5}b8d479374497255804ffbf0a7bcdf6c2' Info: /Stage[main]/Admin::Percona_repo/File[/etc/apt/sources.list.d/percona.list]: Scheduling refresh of Exec[percona-apt-update] Notice: /Stage[main]/Admin::Percona_repo/File[/etc/apt/preferences.d/00percona.pref]/ensure: defined content as '{md5}1d8ca6c1e752308a9bd3018713e2d1ad' Info: /Stage[main]/Admin::Percona_repo/File[/etc/apt/preferences.d/00percona.pref]: Scheduling refresh of Exec[percona-apt-update] Notice: /Stage[main]/Admin::Percona_repo/Exec[percona-apt-update]: Triggered 'refresh' from 3 events
In order to install any Percona package, we first need to have the repository configuration installed on the machine. This is why the percona-server-server-5.5 package (Percona's version of the standard MySQL server) requires the admin::percona_repo class:
So, what does the admin::percona_repo class do? It:
First of all, we install the APT key:
The unless parameter checks the output of apt-key list to make sure that the Percona key is not already installed, in which case we need not do anything. Assuming it isn't, the command runs:
Having installed the key, we add the repo configuration:
Then run apt-get update to update the system's APT cache with the metadata from the new repo:
Finally, we configure the APT pin priority for the repo:
This ensures that packages installed from the Percona repo will never be superseded by packages from somewhere else (the main Ubuntu distro, for example). Otherwise, you could end up with broken dependencies and be unable to install the Percona packages automatically.
The APT package framework is specific to the Debian and Ubuntu systems. There is a forge module for managing apt repos, https://forge.puppetlabs.com/puppetlabs/apt. If you're on a Red Hat or CentOS-based system, you can use the yumrepo resources to manage RPM repositories directly:
http://docs.puppetlabs.com/references/latest/type.html#yumrepo
Percona package, we first need to have the repository configuration installed on the machine. This is why the percona-server-server-5.5 package (Percona's version of the standard MySQL server) requires the admin::percona_repo class:
So, what does the admin::percona_repo class do? It:
First of all, we install the APT key:
The unless parameter checks the output of apt-key list to make sure that the Percona key is not already installed, in which case we need not do anything. Assuming it isn't, the command runs:
Having installed the key, we add the repo configuration:
Then run apt-get update to update the system's APT cache with the metadata from the new repo:
Finally, we configure the APT pin priority for the repo:
This ensures that packages installed from the Percona repo will never be superseded by packages from somewhere else (the main Ubuntu distro, for example). Otherwise, you could end up with broken dependencies and be unable to install the Percona packages automatically.
The APT package framework is specific to the Debian and Ubuntu systems. There is a forge module for managing apt repos, https://forge.puppetlabs.com/puppetlabs/apt. If you're on a Red Hat or CentOS-based system, you can use the yumrepo resources to manage RPM repositories directly:
http://docs.puppetlabs.com/references/latest/type.html#yumrepo
for managing apt repos, https://forge.puppetlabs.com/puppetlabs/apt. If you're on a Red Hat or CentOS-based system, you can use the yumrepo resources to manage RPM repositories directly:
http://docs.puppetlabs.com/references/latest/type.html#yumrepo
Package version numbers are odd things. They look like decimal numbers, but they're not: a version number is often in the form of 2.6.4, for example. If you need to compare one version number with another, you can't do a straightforward string comparison: 2.6.4 would be interpreted as greater than 2.6.12. And a numeric comparison won't work because they're not valid numbers.
Puppet's versioncmp function comes to the rescue. If you pass two things that look like version numbers, it will compare them and return a value indicating which is greater:
Here's an example using the versioncmp function:
- Modify your
site.ppfile as follows:node 'cookbook' { $app_version = '1.2.2' $min_version = '1.2.10' if versioncmp($app_version, $min_version) >= 0 { notify { 'Version OK': } } else { notify { 'Upgrade needed': } } } - Run Puppet:
[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Notice: Upgrade needed
- Now change the value of
$app_version:$app_version = '1.2.14'
- Run Puppet again:
[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Notice: Version OK
versioncmp function:
site.pp file as follows:node 'cookbook' {
$app_version = '1.2.2'
$min_version = '1.2.10'
if versioncmp($app_version, $min_version) >= 0 {
notify { 'Version OK': }
} else {
notify { 'Upgrade needed': }
}
}[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Notice: Upgrade needed
$app_version:$app_version = '1.2.14'
$min_version) is 1.2.10. So, in the first example, we want to compare it with $app_version of 1.2.2. A simple alphabetic comparison of these two strings (in Ruby, for example) would give the wrong result, but versioncmp correctly determines that 1.2.2 is less than 1.2.10 and alerts us that we need to upgrade.
$app_version is now 1.2.14, which versioncmp correctly recognizes as greater than $min_version and so we get the message Version OK.
Virtual resources in Puppet might seem complicated and confusing but, in fact, they're very simple. They're exactly like regular resources, but they don't actually take effect until they're realized (in the sense of "made real"); whereas a regular resource can only be declared once per node (so two classes can't declare the same resource, for example). A virtual resource can be realized as many times as you like.
To clarify this, let's look at a typical situation where virtual resources might come in handy.
You are responsible for two popular web applications: WordPress and Drupal. Both are web apps running on Apache, so they both require the Apache package to be installed. The definition for WordPress might look something like the following:
The definition for Drupal might look like this:
All is well until you need to consolidate both apps onto a single server:
Now Puppet will complain because you tried to define two resources with the same name: httpd.
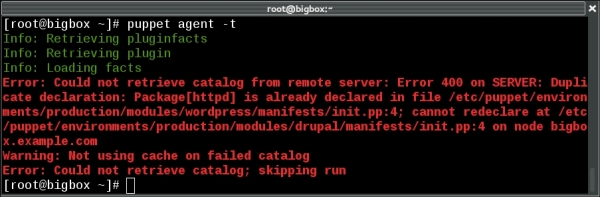
You could remove the duplicate Apache package definition from one of the classes, but then nodes without the class including Apache would fail. You can get around this problem by putting the Apache package in its own class and then using include apache everywhere it's needed; Puppet doesn't mind you including the same class multiple times. In reality, putting Apache in its own class solves most problems but, in general, this method has the disadvantage that every potentially conflicting resource must have its own class.
To create the resource, use the realize function:
Here's how to build the example using virtual resources:
- Create the virtual module with the following contents:
class virtual { @package {'httpd': ensure => installed } @service {'httpd': ensure => running, enable => true, require => Package['httpd'] } } - Create the Drupal module with the following contents:
class drupal { include virtual realize(Package['httpd']) realize(Service['httpd']) } - Create the WordPress module with the following contents:
class wordpress { include virtual realize(Package['httpd']) realize(Service['httpd']) } - Modify your
site.ppfile as follows:node 'bigbox' { include drupal include wordpress } - Run Puppet:
bigbox# puppet agent -t Info: Caching catalog for bigbox.example.com Info: Applying configuration version '1413179615' Notice: /Stage[main]/Virtual/Package[httpd]/ensure: created Notice: /Stage[main]/Virtual/Service[httpd]/ensure: ensure changed 'stopped' to 'running' Info: /Stage[main]/Virtual/Service[httpd]: Unscheduling refresh on Service[httpd] Notice: Finished catalog run in 6.67 seconds
Every class that needs the Apache package can call realize on this virtual resource:
Puppet knows, because you made the resource virtual, that you intended to have multiple references to the same package, and didn't just accidentally create two resources with the same name. So it does the right thing.
class virtual {
@package {'httpd': ensure => installed }
@service {'httpd':
ensure => running,
enable => true,
require => Package['httpd']
}
}class drupal {
include virtual
realize(Package['httpd'])
realize(Service['httpd'])
}
class wordpress {
include virtual
realize(Package['httpd'])
realize(Service['httpd'])
}site.pp file as follows:node 'bigbox' {
include drupal
include wordpress
}Every class that needs the Apache package can call realize on this virtual resource:
Puppet knows, because you made the resource virtual, that you intended to have multiple references to the same package, and didn't just accidentally create two resources with the same name. So it does the right thing.
virtual class. All nodes can include this class and you can put all your virtual services and packages in it. None of the packages will actually be installed on a node or services started until you call realize:
realize on this virtual resource:
Users are a great example of a resource that may need to be realized by multiple classes. Consider the following situation. To simplify administration of a large number of machines, you defined classes for two kinds of users: developers and sysadmins. All machines need to include sysadmins, but only some machines need developers:
Follow these steps to create a user::virtual class:
- Create the file
modules/user/manifests/virtual.ppwith the following contents:class user::virtual { @user { 'thomas': ensure => present } @user { 'theresa': ensure => present } @user { 'josko': ensure => present } @user { 'nate': ensure => present } } - Create the file
modules/user/manifests/developers.ppwith the following contents:class user::developers { realize(User['theresa']) realize(User['nate']) } - Create the file
modules/user/manifests/sysadmins.ppwith the following contents:class user::sysadmins { realize(User['thomas']) realize(User['theresa']) realize(User['josko']) } - Modify your
nodes.ppfile as follows:node 'cookbook' { include user::virtual include user::sysadmins include user::developers } - Run Puppet:
cookbook# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413180590' Notice: /Stage[main]/User::Virtual/User[theresa]/ensure: created Notice: /Stage[main]/User::Virtual/User[nate]/ensure: created Notice: /Stage[main]/User::Virtual/User[thomas]/ensure: created Notice: /Stage[main]/User::Virtual/User[josko]/ensure: created Notice: Finished catalog run in 0.47 seconds
When we include the user::virtual class, all the users are declared as virtual resources (because we included the @ symbol):
That is to say, the resources exist in Puppet's catalog; they can be referred to by and linked with other resources, and they are in every respect identical to regular resources, except that Puppet doesn't actually create the corresponding users on the machine.
Yes, it does, and that's fine. You're explicitly allowed to realize resources multiple times, and there will be no conflict. So long as some class, somewhere, calls realize on Theresa's account, it will be created. Unrealized resources are simply discarded during catalog compilation.
When you use this pattern to manage your own users, every node should include the user::virtual class, as a part of your basic housekeeping configuration. This class will declare all users (as virtual) in your organization or site. This should also include any users who exist only to run applications or services (such as Apache, www-data, or deploy, for example). Then, you can realize them as needed on individual nodes or in specific classes.
For example, see the following code snippet:
In the previous example, only users thomas and theresa would be included.
to create a user::virtual class:
- Create the file
modules/user/manifests/virtual.ppwith the following contents:class user::virtual { @user { 'thomas': ensure => present } @user { 'theresa': ensure => present } @user { 'josko': ensure => present } @user { 'nate': ensure => present } } - Create the file
modules/user/manifests/developers.ppwith the following contents:class user::developers { realize(User['theresa']) realize(User['nate']) } - Create the file
modules/user/manifests/sysadmins.ppwith the following contents:class user::sysadmins { realize(User['thomas']) realize(User['theresa']) realize(User['josko']) } - Modify your
nodes.ppfile as follows:node 'cookbook' { include user::virtual include user::sysadmins include user::developers } - Run Puppet:
cookbook# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413180590' Notice: /Stage[main]/User::Virtual/User[theresa]/ensure: created Notice: /Stage[main]/User::Virtual/User[nate]/ensure: created Notice: /Stage[main]/User::Virtual/User[thomas]/ensure: created Notice: /Stage[main]/User::Virtual/User[josko]/ensure: created Notice: Finished catalog run in 0.47 seconds
When we include the user::virtual class, all the users are declared as virtual resources (because we included the @ symbol):
That is to say, the resources exist in Puppet's catalog; they can be referred to by and linked with other resources, and they are in every respect identical to regular resources, except that Puppet doesn't actually create the corresponding users on the machine.
Yes, it does, and that's fine. You're explicitly allowed to realize resources multiple times, and there will be no conflict. So long as some class, somewhere, calls realize on Theresa's account, it will be created. Unrealized resources are simply discarded during catalog compilation.
When you use this pattern to manage your own users, every node should include the user::virtual class, as a part of your basic housekeeping configuration. This class will declare all users (as virtual) in your organization or site. This should also include any users who exist only to run applications or services (such as Apache, www-data, or deploy, for example). Then, you can realize them as needed on individual nodes or in specific classes.
For example, see the following code snippet:
In the previous example, only users thomas and theresa would be included.
the user::virtual class, all the users are declared as virtual resources (because we included the @ symbol):
That is to say, the resources exist in Puppet's catalog; they can be referred to by and linked with other resources, and they are in every respect identical to regular resources, except that Puppet doesn't actually create the corresponding users on the machine.
Yes, it does, and that's fine. You're explicitly allowed to realize resources multiple times, and there will be no conflict. So long as some class, somewhere, calls realize on Theresa's account, it will be created. Unrealized resources are simply discarded during catalog compilation.
When you use this pattern to manage your own users, every node should include the user::virtual class, as a part of your basic housekeeping configuration. This class will declare all users (as virtual) in your organization or site. This should also include any users who exist only to run applications or services (such as Apache, www-data, or deploy, for example). Then, you can realize them as needed on individual nodes or in specific classes.
For example, see the following code snippet:
In the previous example, only users thomas and theresa would be included.
A sensible approach to access control for servers is to use named user accounts with passphrase-protected SSH keys, rather than having users share an account with a widely known password. Puppet makes this easy to manage thanks to the built-in ssh_authorized_key type.
Follow these steps to extend your virtual users' class to include SSH access:
- Create a new module
ssh_userto contain ourssh_userdefinition. Create themodules/ssh_user/manifests/init.ppfile as follows:define ssh_user($key,$keytype) { user { $name: ensure => present, } file { "/home/${name}": ensure => directory, mode => '0700', owner => $name, require => User["$name"] } file { "/home/${name}/.ssh": ensure => directory, mode => '0700', owner => "$name", require => File["/home/${name}"], } ssh_authorized_key { "${name}_key": key => $key, type => "$keytype", user => $name, require => File["/home/${name}/.ssh"], } } - Modify your
modules/user/manifests/virtual.ppfile, comment out the previous definition for userthomas, and replace it with the following:@ssh_user { 'thomas': key => 'AAAAB3NzaC1yc2E...XaWM5sX0z', keytype => 'ssh-rsa' } - Modify your
modules/user/manifests/sysadmins.ppfile as follows:class user::sysadmins { realize(Ssh_user['thomas']) } - Modify your
site.ppfile as follows:node 'cookbook' { include user::virtual include user::sysadmins } - Run Puppet:
cookbook# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413254461' Notice: /Stage[main]/User::Virtual/Ssh_user[thomas]/File[/home/thomas/.ssh]/ensure: created Notice: /Stage[main]/User::Virtual/Ssh_user[thomas]/Ssh_authorized_key[thomas_key]/ensure: created Notice: Finished catalog run in 0.11 seconds
For each user in our user::virtual class, we need to create:
Next, we need to ensure that the .ssh directory exists within the home directory of the user. We require the home directory, File["/home/${name}"], since that needs to exist before we create this subdirectory. This implies that the user already exists because the home directory required the user:
We passed the $key and $keytype variables when we defined the ssh_user resource for thomas:
Now, with everything defined, we just need to call realize on thomas for all these resources to take effect:
ssh_user to contain our ssh_user definition. Create the modules/ssh_user/manifests/init.pp file as follows:define ssh_user($key,$keytype) {
user { $name:
ensure => present,
}
file { "/home/${name}":
ensure => directory,
mode => '0700',
owner => $name,
require => User["$name"]
}
file { "/home/${name}/.ssh":
ensure => directory,
mode => '0700',
owner => "$name",
require => File["/home/${name}"],
}
ssh_authorized_key { "${name}_key":
key => $key,
type => "$keytype",
user => $name,
require => File["/home/${name}/.ssh"],
}
}modules/user/manifests/virtual.pp file, comment out the previous definition for user thomas, and replace it with the following:@ssh_user { 'thomas':
key => 'AAAAB3NzaC1yc2E...XaWM5sX0z',
keytype => 'ssh-rsa'
}- your
modules/user/manifests/sysadmins.ppfile as follows:class user::sysadmins { realize(Ssh_user['thomas']) } - Modify your
site.ppfile as follows:node 'cookbook' { include user::virtual include user::sysadmins } - Run Puppet:
cookbook# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413254461' Notice: /Stage[main]/User::Virtual/Ssh_user[thomas]/File[/home/thomas/.ssh]/ensure: created Notice: /Stage[main]/User::Virtual/Ssh_user[thomas]/Ssh_authorized_key[thomas_key]/ensure: created Notice: Finished catalog run in 0.11 seconds
For each user in our user::virtual class, we need to create:
Next, we need to ensure that the .ssh directory exists within the home directory of the user. We require the home directory, File["/home/${name}"], since that needs to exist before we create this subdirectory. This implies that the user already exists because the home directory required the user:
We passed the $key and $keytype variables when we defined the ssh_user resource for thomas:
Now, with everything defined, we just need to call realize on thomas for all these resources to take effect:
user::virtual class, we need to create:
.ssh directory
.ssh/authorized_keys file
ssh_user from anywhere (in any scope):
owner => $name:
Next, we need to ensure that the .ssh directory exists within the home directory of the user. We require the home directory, File["/home/${name}"], since that needs to exist before we create this subdirectory. This implies that the user already exists because the home directory required the user:
We passed the $key and $keytype variables when we defined the ssh_user resource for thomas:
Now, with everything defined, we just need to call realize on thomas for all these resources to take effect:
ssh_user definition to have Puppet automatically create them for new users. We'll see an example of this in the next recipe, Managing users' customization files.
Users tend to customize their shell environments, terminal colors, aliases, and so forth. This is usually achieved by a number of dotfiles in their home directory, for example, .bash_profile or .vimrc.
- Create the
admin_userdefined type (define admin_user) in themodules/admin_user/manifests/init.ppfile as follows:define admin_user ($key, $keytype, $dotfiles = false) { $username = $name user { $username: ensure => present, } file { "/home/${username}/.ssh": ensure => directory, mode => '0700', owner => $username, group => $username, require => File["/home/${username}"], } ssh_authorized_key { "${username}_key": key => $key, type => "$keytype", user => $username, require => File["/home/${username}/.ssh"], } # dotfiles if $dotfiles == false { # just create the directory file { "/home/${username}": ensure => 'directory', mode => '0700', owner => $username, group => $username, require => User["$username"] } } else { # copy in all the files in the subdirectory file { "/home/${username}": recurse => true, mode => '0700', owner => $username, group => $username, source => "puppet:///modules/admin_user/${username}", require => User["$username"] } } } - Modify the file
modules/user/manifests/sysadmins.ppas follows:class user::sysadmins { realize(Admin_user['thomas']) } - Alter the definition of
thomasinmodules/user/manifests/virtual.ppas follows:@ssh_user { 'thomas': key => 'AAAAB3NzaC1yc2E...XaWM5sX0z', keytype => 'ssh-rsa', dotfiles => true } - Create a subdirectory in the
admin_usermodule for the file of userthomas:$ mkdir -p modules/admin_user/files/thomas - Create dotfiles for the user
thomasin the directory you just created:$ echo "alias vi=vim" > modules/admin_user/files/thomas/.bashrc $ echo "set tabstop=2" > modules/admin_user/files/thomas/.vimrc
- Make sure your
site.ppfile reads as follows:node 'cookbook' { include user::virtual include user::sysadmins } - Run Puppet:
cookbook# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413266235' Notice: /Stage[main]/User::Virtual/Admin_user[thomas]/User[thomas]/ensure: created Notice: /Stage[main]/User::Virtual/Admin_user[thomas]/File[/home/thomas]/ensure: created Notice: /Stage[main]/User::Virtual/Admin_user[thomas]/File[/home/thomas/.vimrc]/ensure: defined content as '{md5}cb2af2d35b18b5ac2539057bd429d3ae' Notice: /Stage[main]/User::Virtual/Admin_user[thomas]/File[/home/thomas/.bashrc]/ensure: defined content as '{md5}033c3484e4b276e0641becc3aa268a3a' Notice: /Stage[main]/User::Virtual/Admin_user[thomas]/File[/home/thomas/.ssh]/ensure: created Notice: /Stage[main]/User::Virtual/Admin_user[thomas]/Ssh_authorized_key[thomas_key]/ensure: created Notice: Finished catalog run in 0.36 seconds
We created a new admin_user definition, which defines the home directory recursively if $dotfiles is not false (the default value):
Using the recurse option allows us to add as many dotfiles as we wish for each user without having to modify the definition of the user.
- Create the
admin_userdefined type (define admin_user) in themodules/admin_user/manifests/init.ppfile as follows:define admin_user ($key, $keytype, $dotfiles = false) { $username = $name user { $username: ensure => present, } file { "/home/${username}/.ssh": ensure => directory, mode => '0700', owner => $username, group => $username, require => File["/home/${username}"], } ssh_authorized_key { "${username}_key": key => $key, type => "$keytype", user => $username, require => File["/home/${username}/.ssh"], } # dotfiles if $dotfiles == false { # just create the directory file { "/home/${username}": ensure => 'directory', mode => '0700', owner => $username, group => $username, require => User["$username"] } } else { # copy in all the files in the subdirectory file { "/home/${username}": recurse => true, mode => '0700', owner => $username, group => $username, source => "puppet:///modules/admin_user/${username}", require => User["$username"] } } } - Modify the file
modules/user/manifests/sysadmins.ppas follows:class user::sysadmins { realize(Admin_user['thomas']) } - Alter the definition of
thomasinmodules/user/manifests/virtual.ppas follows:@ssh_user { 'thomas': key => 'AAAAB3NzaC1yc2E...XaWM5sX0z', keytype => 'ssh-rsa', dotfiles => true } - Create a subdirectory in the
admin_usermodule for the file of userthomas:$ mkdir -p modules/admin_user/files/thomas - Create dotfiles for the user
thomasin the directory you just created:$ echo "alias vi=vim" > modules/admin_user/files/thomas/.bashrc $ echo "set tabstop=2" > modules/admin_user/files/thomas/.vimrc
- Make sure your
site.ppfile reads as follows:node 'cookbook' { include user::virtual include user::sysadmins } - Run Puppet:
cookbook# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413266235' Notice: /Stage[main]/User::Virtual/Admin_user[thomas]/User[thomas]/ensure: created Notice: /Stage[main]/User::Virtual/Admin_user[thomas]/File[/home/thomas]/ensure: created Notice: /Stage[main]/User::Virtual/Admin_user[thomas]/File[/home/thomas/.vimrc]/ensure: defined content as '{md5}cb2af2d35b18b5ac2539057bd429d3ae' Notice: /Stage[main]/User::Virtual/Admin_user[thomas]/File[/home/thomas/.bashrc]/ensure: defined content as '{md5}033c3484e4b276e0641becc3aa268a3a' Notice: /Stage[main]/User::Virtual/Admin_user[thomas]/File[/home/thomas/.ssh]/ensure: created Notice: /Stage[main]/User::Virtual/Admin_user[thomas]/Ssh_authorized_key[thomas_key]/ensure: created Notice: Finished catalog run in 0.36 seconds
We created a new admin_user definition, which defines the home directory recursively if $dotfiles is not false (the default value):
Using the recurse option allows us to add as many dotfiles as we wish for each user without having to modify the definition of the user.
Using the recurse option allows us to add as many dotfiles as we wish for each user without having to modify the definition of the user.
source attribute of the home directory is a directory where users can place their own dotfiles. This way, each user could modify their own dotfiles and have them transferred to all the nodes in the network without our involvement.
See also
All our recipes up to this point have dealt with a single machine. It is possible with Puppet to have resources from one node affect another node. This interaction is managed with exported resources. Exported resources are just like any resource you might define for a node but instead of applying to the node on which they were created, they are exported for use by all nodes in the environment. Exported resources can be thought of as virtual resources that go one step further and exist beyond the node on which they were defined.
There are many examples that use exported resources; the most common one involves SSH host keys. Using exported resources, it is possible to have every machine that is running Puppet share their SSH host keys with the other connected nodes. The idea here is that each machine exports its own host key and then collects all the keys from the other machines. In our example, we will create two classes; first, a class that exports the SSH host key from every node. We will include this class in our base class. The second class will be a collector class, which collects the SSH host keys. We will apply this class to our Jumpboxes or SSH login servers.
To use exported resources, you will need to enable storeconfigs on your Puppet masters. It is possible to use exported resources with a masterless (decentralized) deployment; however, we will assume you are using a centralized model for this example. In Chapter 2, Puppet Infrastructure, we configured puppetdb using the puppetdb module from the forge. It is possible to use other backends if you desire; however, all of these except puppetdb are deprecated. More information is available at the following link: http://projects.puppetlabs.com/projects/puppet/wiki/Using_Stored_Configuration.
Ensure your Puppet masters are configured to use puppetdb as a storeconfigs container.
- Create the first class,
base::ssh_host, which we will include in our base class:class base::ssh_host { @@sshkey{"$::fqdn": ensure => 'present', host_aliases => ["$::hostname","$::ipaddress"], key => $::sshdsakey, type => 'dsa', } } - Remember to include this class from inside the base class definition:
class base { ... include ssh_host } - Create a definition for
jumpbox, either in a class or within the node definition forjumpbox:node 'jumpbox' { Sshkey <<| |>> } - Now run Puppet on a few nodes to create the exported resources. In my case, I ran Puppet on my Puppet server and my second example node (
node2). Finally, run Puppet onjumpboxto verify that the SSH host keys for our other nodes are collected:[root@jumpbox ~]# puppet agent -t Info: Caching catalog for jumpbox.example.com Info: Applying configuration version '1413176635' Notice: /Stage[main]/Main/Node[jumpbox]/Sshkey[node2.example.com]/ensure: created Notice: /Stage[main]/Main/Node[jumpbox]/Sshkey[puppet]/ensure: created Notice: Finished catalog run in 0.08 seconds
We created an sshkey resource for the node using the facter facts fqdn, hostname, ipaddress, and sshdsakey. We use the fqdn as the title for our exported resource because each exported resource must have a unique name. We can assume the fqdn of a node will be unique within our organization (although sometimes they may not be; Puppet can be good at finding out such things when you least expect it). We then go on to define aliases by which our node may be known. We use the hostname variable for one alias and the main IP address of the machine as the other. If you had other naming conventions for your nodes, you could include other aliases here. We assume that hosts are using DSA keys, so we use the sshdsakey variable in our definition. In a large installation, you would wrap this definition in tests to ensure the DSA keys existed. You would also use the RSA keys if they existed as well.
You could then modify jumpbox to only collect resources for production, for example, as follows:
Two important things to remember when working with exported resources: first, every resource must have a unique name across your installation. Using the fqdn domain name within the title is usually enough to keep your definitions unique. Second, any resource can be made virtual. Even defined types that you created may be exported. Exported resources can be used to achieve some fairly complex configurations that automatically adjust when machines change.
resources, you will need to enable storeconfigs on your Puppet masters. It is possible to use exported resources with a masterless (decentralized) deployment; however, we will assume you are using a centralized model for this example. In Chapter 2, Puppet Infrastructure, we configured puppetdb using the puppetdb module from the forge. It is possible to use other backends if you desire; however, all of these except puppetdb are deprecated. More information is available at the following link: http://projects.puppetlabs.com/projects/puppet/wiki/Using_Stored_Configuration.
Ensure your Puppet masters are configured to use puppetdb as a storeconfigs container.
- Create the first class,
base::ssh_host, which we will include in our base class:class base::ssh_host { @@sshkey{"$::fqdn": ensure => 'present', host_aliases => ["$::hostname","$::ipaddress"], key => $::sshdsakey, type => 'dsa', } } - Remember to include this class from inside the base class definition:
class base { ... include ssh_host } - Create a definition for
jumpbox, either in a class or within the node definition forjumpbox:node 'jumpbox' { Sshkey <<| |>> } - Now run Puppet on a few nodes to create the exported resources. In my case, I ran Puppet on my Puppet server and my second example node (
node2). Finally, run Puppet onjumpboxto verify that the SSH host keys for our other nodes are collected:[root@jumpbox ~]# puppet agent -t Info: Caching catalog for jumpbox.example.com Info: Applying configuration version '1413176635' Notice: /Stage[main]/Main/Node[jumpbox]/Sshkey[node2.example.com]/ensure: created Notice: /Stage[main]/Main/Node[jumpbox]/Sshkey[puppet]/ensure: created Notice: Finished catalog run in 0.08 seconds
We created an sshkey resource for the node using the facter facts fqdn, hostname, ipaddress, and sshdsakey. We use the fqdn as the title for our exported resource because each exported resource must have a unique name. We can assume the fqdn of a node will be unique within our organization (although sometimes they may not be; Puppet can be good at finding out such things when you least expect it). We then go on to define aliases by which our node may be known. We use the hostname variable for one alias and the main IP address of the machine as the other. If you had other naming conventions for your nodes, you could include other aliases here. We assume that hosts are using DSA keys, so we use the sshdsakey variable in our definition. In a large installation, you would wrap this definition in tests to ensure the DSA keys existed. You would also use the RSA keys if they existed as well.
You could then modify jumpbox to only collect resources for production, for example, as follows:
Two important things to remember when working with exported resources: first, every resource must have a unique name across your installation. Using the fqdn domain name within the title is usually enough to keep your definitions unique. Second, any resource can be made virtual. Even defined types that you created may be exported. Exported resources can be used to achieve some fairly complex configurations that automatically adjust when machines change.
ssh_host class to export the ssh keys of a host and ensure that it is included in our base class.
base::ssh_host, which we will include in our base class:class base::ssh_host {
@@sshkey{"$::fqdn":
ensure => 'present',
host_aliases => ["$::hostname","$::ipaddress"],
key => $::sshdsakey,
type => 'dsa',
}
}class base {
...
include ssh_host
}jumpbox, either in a class or within the node definition for jumpbox:node 'jumpbox' {
Sshkey <<| |>>
}node2). Finally, run Puppet on jumpbox to verify that the SSH host keys for our other nodes are collected:[root@jumpbox ~]# puppet agent -t Info: Caching catalog for jumpbox.example.com Info: Applying configuration version '1413176635' Notice: /Stage[main]/Main/Node[jumpbox]/Sshkey[node2.example.com]/ensure: created Notice: /Stage[main]/Main/Node[jumpbox]/Sshkey[puppet]/ensure: created Notice: Finished catalog run in 0.08 seconds
We created an sshkey resource for the node using the facter facts fqdn, hostname, ipaddress, and sshdsakey. We use the fqdn as the title for our exported resource because each exported resource must have a unique name. We can assume the fqdn of a node will be unique within our organization (although sometimes they may not be; Puppet can be good at finding out such things when you least expect it). We then go on to define aliases by which our node may be known. We use the hostname variable for one alias and the main IP address of the machine as the other. If you had other naming conventions for your nodes, you could include other aliases here. We assume that hosts are using DSA keys, so we use the sshdsakey variable in our definition. In a large installation, you would wrap this definition in tests to ensure the DSA keys existed. You would also use the RSA keys if they existed as well.
You could then modify jumpbox to only collect resources for production, for example, as follows:
Two important things to remember when working with exported resources: first, every resource must have a unique name across your installation. Using the fqdn domain name within the title is usually enough to keep your definitions unique. Second, any resource can be made virtual. Even defined types that you created may be exported. Exported resources can be used to achieve some fairly complex configurations that automatically adjust when machines change.
sshkey resource for
You could then modify jumpbox to only collect resources for production, for example, as follows:
Two important things to remember when working with exported resources: first, every resource must have a unique name across your installation. Using the fqdn domain name within the title is usually enough to keep your definitions unique. Second, any resource can be made virtual. Even defined types that you created may be exported. Exported resources can be used to achieve some fairly complex configurations that automatically adjust when machines change.
sshkey resources for each area as shown in the following code snippet:
jumpbox to only collect resources for production, for example, as follows:
fqdn domain name within the title is usually enough to keep your definitions unique. Second, any resource can be made virtual. Even defined types that you created may be exported. Exported resources can be used to
"The art of simplicity is a puzzle of complexity". | ||
| --Douglas Horton | ||
In this chapter, we will cover the following recipes:
When you have many servers executing the same cron job, it's usually a good idea not to run them all at the same time. If all the jobs access a common server (for example, when running backups), it may put too much load on that server, and even if they don't, all the servers will be busy at the same time, which may affect their capacity to provide other services.
As usual, Puppet can help; this time, using the inline_template function to calculate a unique time for each job.
Here's how to have Puppet schedule the same job at a different time for each machine:
- Modify your
site.ppfile as follows:node 'cookbook' { cron { 'run-backup': ensure => present, command => '/usr/local/bin/backup', hour => inline_template('<%= @hostname.sum % 24 %>'), minute => '00', } } - Run Puppet:
[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413730771' Notice: /Stage[main]/Main/Node[cookbook]/Cron[run-backup]/ensure: created Notice: Finished catalog run in 0.11 seconds
- Run
crontabto see how the job has been configured:[root@cookbook ~]# crontab -l # HEADER: This file was autogenerated at Sun Oct 19 10:59:32 -0400 2014 by puppet. # HEADER: While it can still be managed manually, it is definitely not recommended. # HEADER: Note particularly that the comments starting with 'Puppet Name' should # HEADER: not be deleted, as doing so could cause duplicate cron jobs. # Puppet Name: run-backup 0 15 * * * /usr/local/bin/backup
We want to distribute the hour of the cron job runs across all our nodes. We choose something that is unique across all the machines and convert it to a number. This way, the value will be distributed across the nodes and will not change per node.
We can do the conversion using Ruby's sum method, which computes a numerical value from a string that is unique to the machine (in this case, the machine's hostname). The sum function will generate a large integer (in the case of the string cookbook, the sum is 855), and we want values for hour between 0 and 23, so we use Ruby's % (modulo) operator to restrict the result to this range. We should get a reasonably good (though not statistically uniform) distribution of values, depending on your hostnames. Another option here is to use the fqdn_rand() function, which works in much the same way as our example.
Most cron implementations have directories for hourly, daily, weekly, and monthly tasks. The directories /etc/cron.hourly, /etc/cron.daily, /etc/cron.weekly, and /etc/cron.monthly exist on both our Debian and Enterprise Linux machines. These directories hold executables, which will be run on the referenced schedule (hourly, daily, weekly, or monthly). I find it better to describe all the jobs in these folders and push the jobs as file resources. An admin on the box searching for your script will be able to find it with grep in these directories. To use the same trick here, we would push a cron task into /etc/cron.hourly and then verify that the hour is the correct hour for the task to run. To create the cron jobs using the cron directories, follow these steps:
- First, create a
cronclass inmodules/cron/init.pp:class cron { file { '/etc/cron.hourly/run-backup': content => template('cron/run-backup'), mode => 0755, } } - Include the
cronclass in your cookbook node insite.pp:node cookbook { include cron } - Create a template to hold the cron task:
#!/bin/bash runhour=<%= @hostname.sum%24 %> hour=$(date +%H) if [ "$runhour" -ne "$hour" ]; then exit 0 fi echo run-backup
- Then, run Puppet:
[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413732254' Notice: /Stage[main]/Cron/File[/etc/cron.hourly/run-backup]/ensure: defined content as '{md5}5e50a7b586ce774df23301ee72904dda' Notice: Finished catalog run in 0.11 seconds
- Verify that the script has the same value we calculated before,
15:#!/bin/bash runhour=15 hour=$(date +%H) if [ "$runhour" -ne "$hour" ]; then exit 0 fi echo run-backup
This will sleep a maximum of 600 seconds but will sleep a different amount each time it runs (assuming your random number generator is working). This sort of random wait is useful when you have thousands of machines, all running the same task and you need to stagger the runs as much as possible.
- The Running Puppet from cron recipe in Chapter 2, Puppet Infrastructure
site.pp file as follows:node 'cookbook' {
cron { 'run-backup':
ensure => present,
command => '/usr/local/bin/backup',
hour => inline_template('<%= @hostname.sum % 24 %>'),
minute => '00',
}
}[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413730771' Notice: /Stage[main]/Main/Node[cookbook]/Cron[run-backup]/ensure: created Notice: Finished catalog run in 0.11 seconds
crontab to see how the job has been configured:[root@cookbook ~]# crontab -l # HEADER: This file was autogenerated at Sun Oct 19 10:59:32 -0400 2014 by puppet. # HEADER: While it can still be managed manually, it is definitely not recommended. # HEADER: Note particularly that the comments starting with 'Puppet Name' should # HEADER: not be deleted, as doing so could cause duplicate cron jobs. # Puppet Name: run-backup 0 15 * * * /usr/local/bin/backup
We want to distribute the hour of the cron job runs across all our nodes. We choose something that is unique across all the machines and convert it to a number. This way, the value will be distributed across the nodes and will not change per node.
We can do the conversion using Ruby's sum method, which computes a numerical value from a string that is unique to the machine (in this case, the machine's hostname). The sum function will generate a large integer (in the case of the string cookbook, the sum is 855), and we want values for hour between 0 and 23, so we use Ruby's % (modulo) operator to restrict the result to this range. We should get a reasonably good (though not statistically uniform) distribution of values, depending on your hostnames. Another option here is to use the fqdn_rand() function, which works in much the same way as our example.
Most cron implementations have directories for hourly, daily, weekly, and monthly tasks. The directories /etc/cron.hourly, /etc/cron.daily, /etc/cron.weekly, and /etc/cron.monthly exist on both our Debian and Enterprise Linux machines. These directories hold executables, which will be run on the referenced schedule (hourly, daily, weekly, or monthly). I find it better to describe all the jobs in these folders and push the jobs as file resources. An admin on the box searching for your script will be able to find it with grep in these directories. To use the same trick here, we would push a cron task into /etc/cron.hourly and then verify that the hour is the correct hour for the task to run. To create the cron jobs using the cron directories, follow these steps:
- First, create a
cronclass inmodules/cron/init.pp:class cron { file { '/etc/cron.hourly/run-backup': content => template('cron/run-backup'), mode => 0755, } } - Include the
cronclass in your cookbook node insite.pp:node cookbook { include cron } - Create a template to hold the cron task:
#!/bin/bash runhour=<%= @hostname.sum%24 %> hour=$(date +%H) if [ "$runhour" -ne "$hour" ]; then exit 0 fi echo run-backup
- Then, run Puppet:
[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413732254' Notice: /Stage[main]/Cron/File[/etc/cron.hourly/run-backup]/ensure: defined content as '{md5}5e50a7b586ce774df23301ee72904dda' Notice: Finished catalog run in 0.11 seconds
- Verify that the script has the same value we calculated before,
15:#!/bin/bash runhour=15 hour=$(date +%H) if [ "$runhour" -ne "$hour" ]; then exit 0 fi echo run-backup
This will sleep a maximum of 600 seconds but will sleep a different amount each time it runs (assuming your random number generator is working). This sort of random wait is useful when you have thousands of machines, all running the same task and you need to stagger the runs as much as possible.
- The Running Puppet from cron recipe in Chapter 2, Puppet Infrastructure
We can do the conversion using Ruby's sum method, which computes a numerical value from a string that is unique to the machine (in this case, the machine's hostname). The sum function will generate a large integer (in the case of the string cookbook, the sum is 855), and we want values for hour between 0 and 23, so we use Ruby's % (modulo) operator to restrict the result to this range. We should get a reasonably good (though not statistically uniform) distribution of values, depending on your hostnames. Another option here is to use the fqdn_rand() function, which works in much the same way as our example.
Most cron implementations have directories for hourly, daily, weekly, and monthly tasks. The directories /etc/cron.hourly, /etc/cron.daily, /etc/cron.weekly, and /etc/cron.monthly exist on both our Debian and Enterprise Linux machines. These directories hold executables, which will be run on the referenced schedule (hourly, daily, weekly, or monthly). I find it better to describe all the jobs in these folders and push the jobs as file resources. An admin on the box searching for your script will be able to find it with grep in these directories. To use the same trick here, we would push a cron task into /etc/cron.hourly and then verify that the hour is the correct hour for the task to run. To create the cron jobs using the cron directories, follow these steps:
- First, create a
cronclass inmodules/cron/init.pp:class cron { file { '/etc/cron.hourly/run-backup': content => template('cron/run-backup'), mode => 0755, } } - Include the
cronclass in your cookbook node insite.pp:node cookbook { include cron } - Create a template to hold the cron task:
#!/bin/bash runhour=<%= @hostname.sum%24 %> hour=$(date +%H) if [ "$runhour" -ne "$hour" ]; then exit 0 fi echo run-backup
- Then, run Puppet:
[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413732254' Notice: /Stage[main]/Cron/File[/etc/cron.hourly/run-backup]/ensure: defined content as '{md5}5e50a7b586ce774df23301ee72904dda' Notice: Finished catalog run in 0.11 seconds
- Verify that the script has the same value we calculated before,
15:#!/bin/bash runhour=15 hour=$(date +%H) if [ "$runhour" -ne "$hour" ]; then exit 0 fi echo run-backup
This will sleep a maximum of 600 seconds but will sleep a different amount each time it runs (assuming your random number generator is working). This sort of random wait is useful when you have thousands of machines, all running the same task and you need to stagger the runs as much as possible.
- The Running Puppet from cron recipe in Chapter 2, Puppet Infrastructure
hostname.sum resource before taking the modulus. Let's say we want to run the dump_database job at some arbitrary time and the run_backup job an hour later, this can be done using the following code snippet:
hour values for each machine Puppet runs on, but run_backup will always be one hour after dump_database.
/etc/cron.hourly, /etc/cron.daily, /etc/cron.weekly, and /etc/cron.monthly exist on both our Debian and Enterprise Linux machines. These directories hold executables, which will be run on the referenced schedule (hourly, daily, weekly, or monthly). I find it better to describe all the jobs in these folders and push the jobs as file resources. An
- First, create a
cronclass inmodules/cron/init.pp:class cron { file { '/etc/cron.hourly/run-backup': content => template('cron/run-backup'), mode => 0755, } } - Include the
cronclass in your cookbook node insite.pp:node cookbook { include cron } - Create a template to hold the cron task:
#!/bin/bash runhour=<%= @hostname.sum%24 %> hour=$(date +%H) if [ "$runhour" -ne "$hour" ]; then exit 0 fi echo run-backup
- Then, run Puppet:
[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413732254' Notice: /Stage[main]/Cron/File[/etc/cron.hourly/run-backup]/ensure: defined content as '{md5}5e50a7b586ce774df23301ee72904dda' Notice: Finished catalog run in 0.11 seconds
- Verify that the script has the same value we calculated before,
15:#!/bin/bash runhour=15 hour=$(date +%H) if [ "$runhour" -ne "$hour" ]; then exit 0 fi echo run-backup
This will sleep a maximum of 600 seconds but will sleep a different amount each time it runs (assuming your random number generator is working). This sort of random wait is useful when you have thousands of machines, all running the same task and you need to stagger the runs as much as possible.
- The Running Puppet from cron recipe in Chapter 2, Puppet Infrastructure
- Chapter 2, Puppet Infrastructure
So far, we looked at what Puppet can do, and the order that it does things in, but not when it does them. One way to control this is to use the schedule metaparameter. When you need to limit the number of times a resource is applied within a specified period, schedule can help. For example:
In this example, we'll create a custom schedule resource and assign this to the resource:
- Modify your
site.ppfile as follows:schedule { 'outside-office-hours': period => daily, range => ['17:00-23:59','00:00-09:00'], repeat => 1, } node 'cookbook' { notify { 'Doing some maintenance': schedule => 'outside-office-hours', } } - Run Puppet. What you'll see will depend on the time of the day. If it's currently outside the office hours period you defined, Puppet will apply the resource as follows:
[root@cookbook ~]# date Fri Jan 2 23:59:01 PST 2015 [root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413734477' Notice: Doing some maintenance Notice: /Stage[main]/Main/Node[cookbook]/Notify[Doing some maintenance]/message: defined 'message' as 'Doing some maintenance' Notice: Finished catalog run in 0.07 seconds
- If the time is within the office hours period, Puppet will do nothing:
[root@cookbook ~]# date Fri Jan 2 09:59:01 PST 2015 [root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413734289' Notice: Finished catalog run in 0.09 seconds
A schedule consists of three bits of information:
Our custom schedule named outside-office-hours supplies these three parameters:
The period is daily, and range is defined as an array of two time intervals:
- 4 p.m.: It's outside the permitted time range, so Puppet will do nothing
- 5 p.m.: It's inside the permitted time range, and the resource hasn't been run yet in this period, so Puppet will apply the resource
- 6 p.m.: It's inside the permitted time range, but the resource has already been run the maximum number of times in this period, so Puppet will do nothing
custom schedule resource and assign this to the resource:
- Modify your
site.ppfile as follows:schedule { 'outside-office-hours': period => daily, range => ['17:00-23:59','00:00-09:00'], repeat => 1, } node 'cookbook' { notify { 'Doing some maintenance': schedule => 'outside-office-hours', } } - Run Puppet. What you'll see will depend on the time of the day. If it's currently outside the office hours period you defined, Puppet will apply the resource as follows:
[root@cookbook ~]# date Fri Jan 2 23:59:01 PST 2015 [root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413734477' Notice: Doing some maintenance Notice: /Stage[main]/Main/Node[cookbook]/Notify[Doing some maintenance]/message: defined 'message' as 'Doing some maintenance' Notice: Finished catalog run in 0.07 seconds
- If the time is within the office hours period, Puppet will do nothing:
[root@cookbook ~]# date Fri Jan 2 09:59:01 PST 2015 [root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413734289' Notice: Finished catalog run in 0.09 seconds
A schedule consists of three bits of information:
Our custom schedule named outside-office-hours supplies these three parameters:
The period is daily, and range is defined as an array of two time intervals:
- 4 p.m.: It's outside the permitted time range, so Puppet will do nothing
- 5 p.m.: It's inside the permitted time range, and the resource hasn't been run yet in this period, so Puppet will apply the resource
- 6 p.m.: It's inside the permitted time range, but the resource has already been run the maximum number of times in this period, so Puppet will do nothing
Our custom schedule named outside-office-hours supplies these three parameters:
The period is daily, and range is defined as an array of two time intervals:
- 4 p.m.: It's outside the permitted time range, so Puppet will do nothing
- 5 p.m.: It's inside the permitted time range, and the resource hasn't been run yet in this period, so Puppet will apply the resource
- 6 p.m.: It's inside the permitted time range, but the resource has already been run the maximum number of times in this period, so Puppet will do nothing
repeat parameter
It's not always practical or convenient to use DNS to map your machine names to IP addresses, especially in cloud infrastructures, where those addresses may change all the time. However, if you use entries in the /etc/hosts file instead, you then have the problem of how to distribute these entries to all machines and keep them up to date.
Follow these steps to create an example host resource:
- Modify your
site.ppfile as follows:node 'cookbook' { host { 'packtpub.com': ensure => present, ip => '83.166.169.231', } } - Run Puppet:
[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413781153' Notice: /Stage[main]/Main/Node[cookbook]/Host[packtpub.com]/ensure: created Info: Computing checksum on file /etc/hosts Notice: Finished catalog run in 0.12 seconds
Puppet will check the target file (usually /etc/hosts) to see whether the host entry already exists, and if not, add it. If an entry for that hostname already exists with a different address, Puppet will change the address to match the manifest.
host resource:
site.pp file as follows:node 'cookbook' {
host { 'packtpub.com':
ensure => present,
ip => '83.166.169.231',
}
}[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413781153' Notice: /Stage[main]/Main/Node[cookbook]/Host[packtpub.com]/ensure: created Info: Computing checksum on file /etc/hosts Notice: Finished catalog run in 0.12 seconds
Puppet will check the target file (usually /etc/hosts) to see whether the host entry already exists, and if not, add it. If an entry for that hostname already exists with a different address, Puppet will change the address to match the manifest.
admin::dbhosts, which is included by all web servers.
In the previous example, we used the spaceship syntax to collect virtual host resources for hosts of type database or type web. You can use the same trick with exported resources. The advantage to using exported resources is that as you add more database servers, the collector syntax will automatically pull in the newly created exported host entries for those servers. This makes your /etc/hosts entries more dynamic.
We will be using exported resources. If you haven't already done so, set up puppetdb and enable storeconfigs to use puppetdb as outlined in Chapter 2, Puppet Infrastructure.
- Create a new database module,
db:t@mylaptop ~/puppet/modules $ mkdir -p db/manifests - Create a new class for your database servers,
db::server:class db::server { @@host {"$::fqdn": host_aliases => $::hostname, ip => $::ipaddress, tag => 'db::server', } # rest of db class } - Create a new class for your database clients:
class db::client { Host <<| tag == 'db::server' |>> } - Apply the database server module to some nodes, in
site.pp, for example:node 'dbserver1.example.com' { class {'db::server': } } node 'dbserver2.example.com' { class {'db::server': } } - Run Puppet on the nodes with the database server module to create the exported resources.
- Apply the database client module to cookbook:
node 'cookbook' { class {'db::client': } } - Run Puppet:
[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413782501' Notice: /Stage[main]/Db::Client/Host[dbserver2.example.com]/ensure: created Info: Computing checksum on file /etc/hosts Notice: /Stage[main]/Db::Client/Host[dbserver1.example.com]/ensure: created Notice: Finished catalog run in 0.10 seconds
- Verify the host entries in
/etc/hosts:[root@cookbook ~]# cat /etc/hosts # HEADER: This file was autogenerated at Mon Oct 20 01:21:42 -0400 2014 # HEADER: by puppet. While it can still be managed manually, it # HEADER: is definitely not recommended. 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 83.166.169.231 packtpub.com 192.168.122.150 dbserver2.example.com dbserver2 192.168.122.151 dbserver1.example.com dbserver1
Chapter 2, Puppet Infrastructure.
- Create a new database module,
db:t@mylaptop ~/puppet/modules $ mkdir -p db/manifests - Create a new class for your database servers,
db::server:class db::server { @@host {"$::fqdn": host_aliases => $::hostname, ip => $::ipaddress, tag => 'db::server', } # rest of db class } - Create a new class for your database clients:
class db::client { Host <<| tag == 'db::server' |>> } - Apply the database server module to some nodes, in
site.pp, for example:node 'dbserver1.example.com' { class {'db::server': } } node 'dbserver2.example.com' { class {'db::server': } } - Run Puppet on the nodes with the database server module to create the exported resources.
- Apply the database client module to cookbook:
node 'cookbook' { class {'db::client': } } - Run Puppet:
[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413782501' Notice: /Stage[main]/Db::Client/Host[dbserver2.example.com]/ensure: created Info: Computing checksum on file /etc/hosts Notice: /Stage[main]/Db::Client/Host[dbserver1.example.com]/ensure: created Notice: Finished catalog run in 0.10 seconds
- Verify the host entries in
/etc/hosts:[root@cookbook ~]# cat /etc/hosts # HEADER: This file was autogenerated at Mon Oct 20 01:21:42 -0400 2014 # HEADER: by puppet. While it can still be managed manually, it # HEADER: is definitely not recommended. 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 83.166.169.231 packtpub.com 192.168.122.150 dbserver2.example.com dbserver2 192.168.122.151 dbserver1.example.com dbserver1
db:t@mylaptop ~/puppet/modules $ mkdir -p db/manifests
db::server:class db::server {
@@host {"$::fqdn":
host_aliases => $::hostname,
ip => $::ipaddress,
tag => 'db::server',
}
# rest of db class
}class db::client {
Host <<| tag == 'db::server' |>>
}site.pp, for example:node 'dbserver1.example.com' {
class {'db::server': }
}
node 'dbserver2.example.com' {
class {'db::server': }
}- with the database server module to create the exported resources.
- Apply the database client module to cookbook:
node 'cookbook' { class {'db::client': } } - Run Puppet:
[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413782501' Notice: /Stage[main]/Db::Client/Host[dbserver2.example.com]/ensure: created Info: Computing checksum on file /etc/hosts Notice: /Stage[main]/Db::Client/Host[dbserver1.example.com]/ensure: created Notice: Finished catalog run in 0.10 seconds
- Verify the host entries in
/etc/hosts:[root@cookbook ~]# cat /etc/hosts # HEADER: This file was autogenerated at Mon Oct 20 01:21:42 -0400 2014 # HEADER: by puppet. While it can still be managed manually, it # HEADER: is definitely not recommended. 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 83.166.169.231 packtpub.com 192.168.122.150 dbserver2.example.com dbserver2 192.168.122.151 dbserver1.example.com dbserver1
db::server class, we
There's more...
A neat feature of Puppet's file resource is that you can specify multiple values for the source parameter. Puppet will search them in order. If the first source isn't found, it moves on to the next, and so on. You can use this to specify a default substitute if the particular file isn't present, or even a series of increasingly generic substitutes.
This example demonstrates using multiple file sources:
- Create a new greeting module as follows:
class greeting { file { '/tmp/greeting': source => [ 'puppet:///modules/greeting/hello.txt', 'puppet:///modules/greeting/universal.txt'], } } - Create the file
modules/greeting/files/hello.txtwith the following contents:Hello, world.
- Create the file
modules/greeting/files/universal.txtwith the following contents:Bah-weep-Graaaaagnah wheep ni ni bong
- Add the class to a node:
node cookbook { class {'greeting': } } - Run Puppet:
[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413784347' Notice: /Stage[main]/Greeting/File[/tmp/greeting]/ensure: defined content as '{md5}54098b367d2e87b078671fad4afb9dbb' Notice: Finished catalog run in 0.43 seconds
- Check the contents of the
/tmp/greetingfile:[root@cookbook ~]# cat /tmp/greeting Hello, world.
- Now remove the
hello.txtfile from your Puppet repository and rerun the agent:[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413784939' Notice: /Stage[main]/Greeting/File[/tmp/greeting]/content: --- /tmp/greeting 2014-10-20 01:52:28.117999991 -0400 +++ /tmp/puppet-file20141020-4960-1o9g344-0 2014-10-20 02:02:20.695999979 -0400 @@ -1 +1 @@ -Hello, world. +Bah-weep-Graaaaagnah wheep ni ni bong Info: Computing checksum on file /tmp/greeting Info: /Stage[main]/Greeting/File[/tmp/greeting]: Filebucketed /tmp/greeting to puppet with sum 54098b367d2e87b078671fad4afb9dbb Notice: /Stage[main]/Greeting/File[/tmp/greeting]/content: content changed '{md5}54098b367d2e87b078671fad4afb9dbb' to '{md5}933c7f04d501b45456e830de299b5521' Notice: Finished catalog run in 0.77 seconds
You can use this trick anywhere you have a file resource. A common example is a service that is deployed on all nodes, such as rsyslog. The rsyslog configuration is the same on every host except for the rsyslog server. Create an rsyslog class with a file resource for the rsyslog configuration file:
- The Passing parameters to classes recipe in Chapter 3, Writing Better Manifests
class greeting {
file { '/tmp/greeting':
source => [ 'puppet:///modules/greeting/hello.txt',
'puppet:///modules/greeting/universal.txt'],
}
}modules/greeting/files/hello.txt with the following contents:Hello, world.
modules/greeting/files/universal.txt with the following contents:Bah-weep-Graaaaagnah wheep ni ni bong
node cookbook {
class {'greeting': }
}[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413784347' Notice: /Stage[main]/Greeting/File[/tmp/greeting]/ensure: defined content as '{md5}54098b367d2e87b078671fad4afb9dbb' Notice: Finished catalog run in 0.43 seconds
/tmp/greeting file:[root@cookbook ~]# cat /tmp/greeting Hello, world.
hello.txt file from your Puppet repository and rerun the agent:[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413784939' Notice: /Stage[main]/Greeting/File[/tmp/greeting]/content: --- /tmp/greeting 2014-10-20 01:52:28.117999991 -0400 +++ /tmp/puppet-file20141020-4960-1o9g344-0 2014-10-20 02:02:20.695999979 -0400 @@ -1 +1 @@ -Hello, world. +Bah-weep-Graaaaagnah wheep ni ni bong Info: Computing checksum on file /tmp/greeting Info: /Stage[main]/Greeting/File[/tmp/greeting]: Filebucketed /tmp/greeting to puppet with sum 54098b367d2e87b078671fad4afb9dbb Notice: /Stage[main]/Greeting/File[/tmp/greeting]/content: content changed '{md5}54098b367d2e87b078671fad4afb9dbb' to '{md5}933c7f04d501b45456e830de299b5521' Notice: Finished catalog run in 0.77 seconds
You can use this trick anywhere you have a file resource. A common example is a service that is deployed on all nodes, such as rsyslog. The rsyslog configuration is the same on every host except for the rsyslog server. Create an rsyslog class with a file resource for the rsyslog configuration file:
- The Passing parameters to classes recipe in Chapter 3, Writing Better Manifests
You can use this trick anywhere you have a file resource. A common example is a service that is deployed on all nodes, such as rsyslog. The rsyslog configuration is the same on every host except for the rsyslog server. Create an rsyslog class with a file resource for the rsyslog configuration file:
- The Passing parameters to classes recipe in Chapter 3, Writing Better Manifests
- The Passing parameters to classes recipe in Chapter 3, Writing Better Manifests
- Chapter 3, Writing Better Manifests
As we saw in the previous chapter, the file resource has a recurse parameter, which allows Puppet to transfer entire directory trees. We used this parameter to copy an admin user's dotfiles into their home directory. In this section, we'll show how to use recurse and another parameter sourceselect to extend our previous example.
Modify our admin user example as follows:
- Remove the
$dotfilesparameter, remove the condition based on$dotfiles. Add a second source to the home directoryfileresource:define admin_user ($key, $keytype) { $username = $name user { $username: ensure => present, } file { "/home/${username}/.ssh": ensure => directory, mode => '0700', owner => $username, group => $username, require => File["/home/${username}"], } ssh_authorized_key { "${username}_key": key => $key, type => "$keytype", user => $username, require => File["/home/${username}/.ssh"], } # copy in all the files in the subdirectory file { "/home/${username}": recurse => true, mode => '0700', owner => $username, group => $username, source => [ "puppet:///modules/admin_user/${username}", 'puppet:///modules/admin_user/base' ], sourceselect => 'all', require => User["$username"], } }
- Create a base directory and copy all the system default files from
/etc/skel:t@mylaptop ~/puppet/modules/admin_user/files $ cp -a /etc/skel base - Create a new
admin_userresource, one that will not have a directory defined:node 'cookbook' { admin_user {'steven': key => 'AAAAB3N...', keytype => 'dsa', } } - Run Puppet:
[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413787159' Notice: /Stage[main]/Main/Node[cookbook]/Admin_user[steven]/User[steven]/ensure: created Notice: /Stage[main]/Main/Node[cookbook]/Admin_user[steven]/File[/home/steven]/ensure: created Notice: /Stage[main]/Main/Node[cookbook]/Admin_user[steven]/File[/home/steven/.bash_logout]/ensure: defined content as '{md5}6a5bc1cc5f80a48b540bc09d082b5855' Notice: /Stage[main]/Main/Node[cookbook]/Admin_user[steven]/File[/home/steven/.emacs]/ensure: defined content as '{md5}de7ee35f4058681a834a99b5d1b048b3' Notice: /Stage[main]/Main/Node[cookbook]/Admin_user[steven]/File[/home/steven/.bashrc]/ensure: defined content as '{md5}2f8222b4f275c4f18e69c34f66d2631b' Notice: /Stage[main]/Main/Node[cookbook]/Admin_user[steven]/File[/home/steven/.bash_profile]/ensure: defined content as '{md5}f939eb71a81a9da364410b799e817202' Notice: /Stage[main]/Main/Node[cookbook]/Admin_user[steven]/File[/home/steven/.ssh]/ensure: created Notice: /Stage[main]/Main/Node[cookbook]/Admin_user[steven]/Ssh_authorized_key[steven_key]/ensure: created Notice: Finished catalog run in 1.11 seconds
If a file resource has the recurse parameter set on it, and it is a directory, Puppet will deploy not only the directory itself, but all its contents (including subdirectories and their contents). As we saw in the previous example, when a file has more than one source, the first source file found is used to satisfy the request. This applies to directories as well.
By specifying the parameter sourceselect as 'all', the contents of all the source directories will be combined. For example, add thomas admin_user back into your node definition in site.pp for cookbook:
Now run Puppet again on cookbook:
Sometimes you want to deploy files to an existing directory but remove any files which aren't managed by Puppet. A good example would be if you are using mcollective in your environment. The directory holding client credentials should only have certificates that come from Puppet.
The purge parameter will do this for you. Define the directory as a resource in Puppet:
$dotfiles parameter, remove the condition based on $dotfiles. Add a second source to the home directory file resource:define admin_user ($key, $keytype) { $username = $name user { $username: ensure => present, } file { "/home/${username}/.ssh": ensure => directory, mode => '0700', owner => $username, group => $username, require => File["/home/${username}"], } ssh_authorized_key { "${username}_key": key => $key, type => "$keytype", user => $username, require => File["/home/${username}/.ssh"], } # copy in all the files in the subdirectory file { "/home/${username}": recurse => true, mode => '0700', owner => $username, group => $username, source => [ "puppet:///modules/admin_user/${username}", 'puppet:///modules/admin_user/base' ], sourceselect => 'all', require => User["$username"], } }
- base directory and copy all the system default files from
/etc/skel:t@mylaptop ~/puppet/modules/admin_user/files $ cp -a /etc/skel base - Create a new
admin_userresource, one that will not have a directory defined:node 'cookbook' { admin_user {'steven': key => 'AAAAB3N...', keytype => 'dsa', } } - Run Puppet:
[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413787159' Notice: /Stage[main]/Main/Node[cookbook]/Admin_user[steven]/User[steven]/ensure: created Notice: /Stage[main]/Main/Node[cookbook]/Admin_user[steven]/File[/home/steven]/ensure: created Notice: /Stage[main]/Main/Node[cookbook]/Admin_user[steven]/File[/home/steven/.bash_logout]/ensure: defined content as '{md5}6a5bc1cc5f80a48b540bc09d082b5855' Notice: /Stage[main]/Main/Node[cookbook]/Admin_user[steven]/File[/home/steven/.emacs]/ensure: defined content as '{md5}de7ee35f4058681a834a99b5d1b048b3' Notice: /Stage[main]/Main/Node[cookbook]/Admin_user[steven]/File[/home/steven/.bashrc]/ensure: defined content as '{md5}2f8222b4f275c4f18e69c34f66d2631b' Notice: /Stage[main]/Main/Node[cookbook]/Admin_user[steven]/File[/home/steven/.bash_profile]/ensure: defined content as '{md5}f939eb71a81a9da364410b799e817202' Notice: /Stage[main]/Main/Node[cookbook]/Admin_user[steven]/File[/home/steven/.ssh]/ensure: created Notice: /Stage[main]/Main/Node[cookbook]/Admin_user[steven]/Ssh_authorized_key[steven_key]/ensure: created Notice: Finished catalog run in 1.11 seconds
If a file resource has the recurse parameter set on it, and it is a directory, Puppet will deploy not only the directory itself, but all its contents (including subdirectories and their contents). As we saw in the previous example, when a file has more than one source, the first source file found is used to satisfy the request. This applies to directories as well.
By specifying the parameter sourceselect as 'all', the contents of all the source directories will be combined. For example, add thomas admin_user back into your node definition in site.pp for cookbook:
Now run Puppet again on cookbook:
Sometimes you want to deploy files to an existing directory but remove any files which aren't managed by Puppet. A good example would be if you are using mcollective in your environment. The directory holding client credentials should only have certificates that come from Puppet.
The purge parameter will do this for you. Define the directory as a resource in Puppet:
file resource
has the recurse parameter set on it, and it is a directory, Puppet will deploy not only the directory itself, but all its contents (including subdirectories and their contents). As we saw in the previous example, when a file has more than one source, the first source file found is used to satisfy the request. This applies to directories as well.
By specifying the parameter sourceselect as 'all', the contents of all the source directories will be combined. For example, add thomas admin_user back into your node definition in site.pp for cookbook:
Now run Puppet again on cookbook:
Sometimes you want to deploy files to an existing directory but remove any files which aren't managed by Puppet. A good example would be if you are using mcollective in your environment. The directory holding client credentials should only have certificates that come from Puppet.
The purge parameter will do this for you. Define the directory as a resource in Puppet:
parameter sourceselect as 'all', the contents of all the source directories will be combined. For example, add thomas admin_user back into your node definition in site.pp for cookbook:
Now run Puppet again on cookbook:
Sometimes you want to deploy files to an existing directory but remove any files which aren't managed by Puppet. A good example would be if you are using mcollective in your environment. The directory holding client credentials should only have certificates that come from Puppet.
The purge parameter will do this for you. Define the directory as a resource in Puppet:
Puppet's tidy resource will help you clean up old or out-of-date files, reducing disk usage. For example, if you have Puppet reporting enabled as described in the section on generating reports, you might want to regularly delete old report files.
- Modify your
site.ppfile as follows:node 'cookbook' { tidy { '/var/lib/puppet/reports': age => '1w', recurse => true, } } - Run Puppet:
[root@cookbook clients]# puppet agent -t Info: Caching catalog for cookbook.example.com Notice: /Stage[main]/Main/Node[cookbook]/File[/var/lib/puppet/reports/cookbook.example.com/201409090637.yaml]/ensure: removed Notice: /Stage[main]/Main/Node[cookbook]/File[/var/lib/puppet/reports/cookbook.example.com/201409100556.yaml]/ensure: removed Notice: /Stage[main]/Main/Node[cookbook]/File[/var/lib/puppet/reports/cookbook.example.com/201409090631.yaml]/ensure: removed Notice: /Stage[main]/Main/Node[cookbook]/File[/var/lib/puppet/reports/cookbook.example.com/201408210557.yaml]/ensure: removed Notice: /Stage[main]/Main/Node[cookbook]/File[/var/lib/puppet/reports/cookbook.example.com/201409080557.yaml]/ensure: removed Notice: /Stage[main]/Main/Node[cookbook]/File[/var/lib/puppet/reports/cookbook.example.com/201409100558.yaml]/ensure: removed Notice: /Stage[main]/Main/Node[cookbook]/File[/var/lib/puppet/reports/cookbook.example.com/201408210546.yaml]/ensure: removed Notice: /Stage[main]/Main/Node[cookbook]/File[/var/lib/puppet/reports/cookbook.example.com/201408210539.yaml]/ensure: removed Notice: Finished catalog run in 0.80 seconds
Puppet searches the specified path for any files matching the age parameter; in this case, 2w (two weeks). It also searches subdirectories (recurse => true).
site.pp file as follows:node 'cookbook' {
tidy { '/var/lib/puppet/reports':
age => '1w',
recurse => true,
}
}[root@cookbook clients]# puppet agent -t Info: Caching catalog for cookbook.example.com Notice: /Stage[main]/Main/Node[cookbook]/File[/var/lib/puppet/reports/cookbook.example.com/201409090637.yaml]/ensure: removed Notice: /Stage[main]/Main/Node[cookbook]/File[/var/lib/puppet/reports/cookbook.example.com/201409100556.yaml]/ensure: removed Notice: /Stage[main]/Main/Node[cookbook]/File[/var/lib/puppet/reports/cookbook.example.com/201409090631.yaml]/ensure: removed Notice: /Stage[main]/Main/Node[cookbook]/File[/var/lib/puppet/reports/cookbook.example.com/201408210557.yaml]/ensure: removed Notice: /Stage[main]/Main/Node[cookbook]/File[/var/lib/puppet/reports/cookbook.example.com/201409080557.yaml]/ensure: removed Notice: /Stage[main]/Main/Node[cookbook]/File[/var/lib/puppet/reports/cookbook.example.com/201409100558.yaml]/ensure: removed Notice: /Stage[main]/Main/Node[cookbook]/File[/var/lib/puppet/reports/cookbook.example.com/201408210546.yaml]/ensure: removed Notice: /Stage[main]/Main/Node[cookbook]/File[/var/lib/puppet/reports/cookbook.example.com/201408210539.yaml]/ensure: removed Notice: Finished catalog run in 0.80 seconds
Puppet searches the specified path for any files matching the age parameter; in this case, 2w (two weeks). It also searches subdirectories (recurse => true).
specified path for any files matching the age parameter; in this case, 2w (two weeks). It also searches subdirectories (recurse => true).
60s
180m
24h
30d
4w
k, and for bytes, use b.
Dry run mode, using the --noop switch, is a simple way to audit any changes to a machine under Puppet's control. However, Puppet also has a dedicated audit feature, which can report changes to resources or specific attributes.
Here's an example showing Puppet's auditing capabilities:
- Modify your
site.ppfile as follows:node 'cookbook' { file { '/etc/passwd': audit => [ owner, mode ], } } - Run Puppet:
[root@cookbook clients]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413789080' Notice: /Stage[main]/Main/Node[cookbook]/File[/etc/passwd]/owner: audit change: newly-recorded value 0 Notice: /Stage[main]/Main/Node[cookbook]/File[/etc/passwd]/mode: audit change: newly-recorded value 644 Notice: Finished catalog run in 0.55 seconds
This feature is very useful to audit large networks for any changes to machines, either malicious or accidental. It's also very handy to keep an eye on things that aren't managed by Puppet, for example, application code on production servers. You can read more about Puppet's auditing capability here:
http://puppetlabs.com/blog/all-about-auditing-with-puppet/
If you just want to audit everything about a resource, use all:
file { '/etc/passwd':
audit => all,
}- The Noop - the don't change anything option recipe in Chapter 10, Monitoring, Reporting, and Troubleshooting
showing Puppet's auditing capabilities:
- Modify your
site.ppfile as follows:node 'cookbook' { file { '/etc/passwd': audit => [ owner, mode ], } } - Run Puppet:
[root@cookbook clients]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413789080' Notice: /Stage[main]/Main/Node[cookbook]/File[/etc/passwd]/owner: audit change: newly-recorded value 0 Notice: /Stage[main]/Main/Node[cookbook]/File[/etc/passwd]/mode: audit change: newly-recorded value 644 Notice: Finished catalog run in 0.55 seconds
This feature is very useful to audit large networks for any changes to machines, either malicious or accidental. It's also very handy to keep an eye on things that aren't managed by Puppet, for example, application code on production servers. You can read more about Puppet's auditing capability here:
http://puppetlabs.com/blog/all-about-auditing-with-puppet/
If you just want to audit everything about a resource, use all:
file { '/etc/passwd':
audit => all,
}- The Noop - the don't change anything option recipe in Chapter 10, Monitoring, Reporting, and Troubleshooting
audit metaparameter tells Puppet that you want to record and monitor certain things about the resource. The value can be a list of the parameters that you want to audit.
/etc/passwd file. In future runs, Puppet will spot whether either of these has changed. For example, if you run:
This feature is very useful to audit large networks for any changes to machines, either malicious or accidental. It's also very handy to keep an eye on things that aren't managed by Puppet, for example, application code on production servers. You can read more about Puppet's auditing capability here:
http://puppetlabs.com/blog/all-about-auditing-with-puppet/
If you just want to audit everything about a resource, use all:
file { '/etc/passwd':
audit => all,
}- The Noop - the don't change anything option recipe in Chapter 10, Monitoring, Reporting, and Troubleshooting
http://puppetlabs.com/blog/all-about-auditing-with-puppet/
If you just want to audit everything about a resource, use all:
file { '/etc/passwd':
audit => all,
}- The Noop - the don't change anything option recipe in Chapter 10, Monitoring, Reporting, and Troubleshooting
- Chapter 10, Monitoring, Reporting, and Troubleshooting
Sometimes you want to disable a resource for the time being so that it doesn't interfere with other work. For example, you might want to tweak a configuration file on the server until you have the exact settings you want, before checking it into Puppet. You don't want Puppet to overwrite it with an old version in the meantime, so you can set the noop metaparameter on the resource:
This example shows you how to use the noop metaparameter:
- Modify your
site.ppfile as follows:node 'cookbook' { file { '/etc/resolv.conf': content => "nameserver 127.0.0.1\n", noop => true, } } - Run Puppet:
[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413789438' Notice: /Stage[main]/Main/Node[cookbook]/File[/etc/resolv.conf]/content: --- /etc/resolv.conf 2014-10-20 00:27:43.095999975 -0400 +++ /tmp/puppet-file20141020-8439-1lhuy1y-0 2014-10-20 03:17:18.969999979 -0400 @@ -1,3 +1 @@ -; generated by /sbin/dhclient-script -search example.com -nameserver 192.168.122.1 +nameserver 127.0.0.1 Notice: /Stage[main]/Main/Node[cookbook]/File[/etc/resolv.conf]/content: current_value {md5}4c0d192511df253826d302bc830a371b, should be {md5}949343428bded6a653a85910f6bdb48e (noop) Notice: Node[cookbook]: Would have triggered 'refresh' from 1 events Notice: Class[Main]: Would have triggered 'refresh' from 1 events Notice: Stage[main]: Would have triggered 'refresh' from 1 events Notice: Finished catalog run in 0.50 seconds
noop metaparameter:
site.pp file as follows:node 'cookbook' {
file { '/etc/resolv.conf':
content => "nameserver 127.0.0.1\n",
noop => true,
}
}[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1413789438' Notice: /Stage[main]/Main/Node[cookbook]/File[/etc/resolv.conf]/content: --- /etc/resolv.conf 2014-10-20 00:27:43.095999975 -0400 +++ /tmp/puppet-file20141020-8439-1lhuy1y-0 2014-10-20 03:17:18.969999979 -0400 @@ -1,3 +1 @@ -; generated by /sbin/dhclient-script -search example.com -nameserver 192.168.122.1 +nameserver 127.0.0.1 Notice: /Stage[main]/Main/Node[cookbook]/File[/etc/resolv.conf]/content: current_value {md5}4c0d192511df253826d302bc830a371b, should be {md5}949343428bded6a653a85910f6bdb48e (noop) Notice: Node[cookbook]: Would have triggered 'refresh' from 1 events Notice: Class[Main]: Would have triggered 'refresh' from 1 events Notice: Stage[main]: Would have triggered 'refresh' from 1 events Notice: Finished catalog run in 0.50 seconds
noop metaparameter is set to true, so for this particular resource, it's as if you had to run Puppet with the --noop flag. Puppet noted that the resource would have been applied, but otherwise did nothing.
-t) is that Puppet output a diff of what it would have done if the noop was not present (you can tell puppet to show the diff's without using -t with --show_diff; -t implies many different settings):
Everyone knows that debugging is twice as hard as writing a program in the first place. So if you're as clever as you can be when you write it, how will you ever debug it? | ||
| --Brian W. Kernighan. | ||
In this chapter, we will cover the following recipes:
Without applications, a server is just a very expensive space heater. In this chapter, I'll present some recipes to manage some specific software with Puppet: MySQL, Apache, nginx, and Ruby. I hope the recipes will be useful to you in themselves. However, the patterns and techniques they use are applicable to almost any software, so you can adapt them to your own purposes without much difficulty. One thing that is common about these applications, they are common. Most Puppet installations will have to deal with a web server, Apache or nginx. Most, if not all, will have databases and some of those will have MySQL. When everyone has to deal with a problem, community solutions are generally better tested and more thorough than homegrown solutions. We'll use modules from the Puppet Forge in this chapter to manage these applications.
When you are writing your own Apache or nginx modules from scratch, you'll have to pay attention to the nuances of the distributions you support. Some distributions call the apache package httpd, while others use apache2; the same can be said for MySQL. In addition, Debian-based distributions use an enabled folder method to enable custom sites in Apache, which are virtual sites, whereas RPM based distributions do not. For more information on virtual sites, visit http://httpd.apache.org/docs/2.2/vhosts/.
When you write a Puppet module to manage some software or service, you don't have to start from scratch. Community-contributed modules are available at the Puppet Forge site for many popular applications. Sometimes, a community module will be exactly what you need and you can download and start using it straight away. In most cases, you will need to make some modifications to suit your particular needs and environment.
In this example, we'll use the puppet module command to find and install the useful stdlib module, which contains many utility functions to help you develop Puppet code. It is one of the aforementioned supported modules by puppetlabs. I'll download the module into my user's home directory and manually install it in the Git repository. To install puppetlabs stdlib module, follow these steps:
- Run the following command:
t@mylaptop ~ $ puppet module search puppetlabs-stdlib Notice: Searching https://forgeapi.puppetlabs.com ... NAME DESCRIPTION AUTHOR KEYWORDS puppetlabs-stdlib Puppet Module Standard Library @puppetlabs stdlib stages
- We verified that we have the right module, so we'll install it with
module installnow:t@mylaptop ~ $ puppet module install puppetlabs-stdlib Notice: Preparing to install into /home/thomas/.puppet/modules ... Notice: Downloading from https://forgeapi.puppetlabs.com ... Notice: Installing -- do not interrupt ... /home/thomas/.puppet/modules └── puppetlabs-stdlib (v4.3.2)
- The module is now ready to use in your manifests; most good modules come with a
READMEfile to show you how to do this.
You can search for modules that match the package or software you're interested in with the puppet module search command. To install a specific module, use puppet module install. You can add the -i option to tell Puppet where to find your module directory.
You can browse the forge to see what's available at http://forge.puppetlabs.com/.
More information on supported modules is available at https://forge.puppetlabs.com/supported.
The current list of supported modules is available at https://forge.puppetlabs.com/modules?endorsements=supported.
Modules on the Forge include a metadata.json file, which describes the module and which operating systems the module supports. This file also includes a list of modules that are required by the module.
Not all publically available modules are on Puppet Forge. Some other great places to look at on GitHub are:
Though not a collection of modules as such, the Puppet Cookbook website has many useful and illuminating code examples, patterns, and tips, maintained by the admirable Dean Wilson:
puppet module command
to find and install the useful stdlib module, which contains many utility functions to help you develop Puppet code. It is one of the aforementioned supported modules by puppetlabs. I'll download the module into my user's home directory and manually install it in the Git repository. To install puppetlabs stdlib module, follow these steps:
- Run the following command:
t@mylaptop ~ $ puppet module search puppetlabs-stdlib Notice: Searching https://forgeapi.puppetlabs.com ... NAME DESCRIPTION AUTHOR KEYWORDS puppetlabs-stdlib Puppet Module Standard Library @puppetlabs stdlib stages
- We verified that we have the right module, so we'll install it with
module installnow:t@mylaptop ~ $ puppet module install puppetlabs-stdlib Notice: Preparing to install into /home/thomas/.puppet/modules ... Notice: Downloading from https://forgeapi.puppetlabs.com ... Notice: Installing -- do not interrupt ... /home/thomas/.puppet/modules └── puppetlabs-stdlib (v4.3.2)
- The module is now ready to use in your manifests; most good modules come with a
READMEfile to show you how to do this.
You can search for modules that match the package or software you're interested in with the puppet module search command. To install a specific module, use puppet module install. You can add the -i option to tell Puppet where to find your module directory.
You can browse the forge to see what's available at http://forge.puppetlabs.com/.
More information on supported modules is available at https://forge.puppetlabs.com/supported.
The current list of supported modules is available at https://forge.puppetlabs.com/modules?endorsements=supported.
Modules on the Forge include a metadata.json file, which describes the module and which operating systems the module supports. This file also includes a list of modules that are required by the module.
Not all publically available modules are on Puppet Forge. Some other great places to look at on GitHub are:
Though not a collection of modules as such, the Puppet Cookbook website has many useful and illuminating code examples, patterns, and tips, maintained by the admirable Dean Wilson:
You can browse the forge to see what's available at http://forge.puppetlabs.com/.
More information on supported modules is available at https://forge.puppetlabs.com/supported.
The current list of supported modules is available at https://forge.puppetlabs.com/modules?endorsements=supported.
Modules on the Forge include a metadata.json file, which describes the module and which operating systems the module supports. This file also includes a list of modules that are required by the module.
Not all publically available modules are on Puppet Forge. Some other great places to look at on GitHub are:
Though not a collection of modules as such, the Puppet Cookbook website has many useful and illuminating code examples, patterns, and tips, maintained by the admirable Dean Wilson:
metadata.json file, which
Not all publically available modules are on Puppet Forge. Some other great places to look at on GitHub are:
Though not a collection of modules as such, the Puppet Cookbook website has many useful and illuminating code examples, patterns, and tips, maintained by the admirable Dean Wilson:
Apache is the world's favorite web server, so it's highly likely that part of your Puppetly duties will include installing and managing Apache.
- Install the module using
puppet modules install:t@mylaptop ~/puppet $ puppet module install -i modules puppetlabs-apache Notice: Preparing to install into /home/thomas/puppet/modules ... Notice: Downloading from https://forgeapi.puppetlabs.com ... Notice: Installing -- do not interrupt ... /home/thomas/puppet/modules └─┬ puppetlabs-apache (v1.1.1) ├── puppetlabs-concat (v1.1.1) └── puppetlabs-stdlib (v4.3.2)
- Add the modules to your Git repository and push them out:
t@mylaptop ~/puppet $ git add modules/apache modules/concat modules/stdlib t@mylaptop ~/puppet $ git commit -m "adding puppetlabs-apache module" [production 395b079] adding puppetlabs-apache module 647 files changed, 35017 insertions(+), 13 deletions(-) rename modules/{apache => apache.cookbook}/manifests/init.pp (100%) create mode 100644 modules/apache/CHANGELOG.md create mode 100644 modules/apache/CONTRIBUTING.md ... t@mylaptop ~/puppet $ git push origin production Counting objects: 277, done. Delta compression using up to 4 threads. Compressing objects: 100% (248/248), done. Writing objects: 100% (266/266), 136.25 KiB | 0 bytes/s, done. Total 266 (delta 48), reused 0 (delta 0) remote: To puppet@puppet.example.com:/etc/puppet/environments/puppet.git remote: 9faaa16..395b079 production -> production
- Create a web server node definition in
site.pp:node webserver { class {'apache': } }
- Run Puppet to apply the default Apache module configuration:
[root@webserver ~]# puppet agent -t Info: Caching certificate for webserver.example.com Notice: /File[/var/lib/puppet/lib/puppet/provider/a2mod]/ensure: created ... Info: Caching catalog for webserver.example.com ... Info: Class[Apache::Service]: Scheduling refresh of Service[httpd] Notice: /Stage[main]/Apache::Service/Service[httpd]: Triggered 'refresh' from 51 events Notice: Finished catalog run in 11.73 seconds
- Verify that you can reach
webserver.example.com:[root@webserver ~]# curl http://webserver.example.com <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN"> <html> <head> <title>Index of /</title> </head> <body> <h1>Index of /</h1> <table><tr><th><img src="/icons/blank.gif" alt="[ICO]"></th><th><a href="?C=N;O=D">Name</a></th><th><a href="?C=M;O=A">Last modified</a></th><th><a href="?C=S;O=A">Size</a></th><th><a href="?C=D;O=A">Description</a></th></tr><tr><th colspan="5"><hr></th></tr> <tr><th colspan="5"><hr></th></tr> </table> </body></html>
Installing the puppetlabs-Apache module from the Forge causes both puppetlabs-concat and puppetlabs-stdlib to be installed into our modules directory. The concat module is used to stitch snippets of files together in a specific order. It is used by the Apache module to create the main Apache configuration files.
puppetlabs-apache module to install and start Apache. This time, when we run puppet module install, we'll use the -i option to tell Puppet to install the module in our Git repository's module's directory.
puppet modules install:t@mylaptop ~/puppet $ puppet module install -i modules puppetlabs-apache Notice: Preparing to install into /home/thomas/puppet/modules ... Notice: Downloading from https://forgeapi.puppetlabs.com ... Notice: Installing -- do not interrupt ... /home/thomas/puppet/modules └─┬ puppetlabs-apache (v1.1.1) ├── puppetlabs-concat (v1.1.1) └── puppetlabs-stdlib (v4.3.2)
t@mylaptop ~/puppet $ git add modules/apache modules/concat modules/stdlib t@mylaptop ~/puppet $ git commit -m "adding puppetlabs-apache module" [production 395b079] adding puppetlabs-apache module 647 files changed, 35017 insertions(+), 13 deletions(-) rename modules/{apache => apache.cookbook}/manifests/init.pp (100%) create mode 100644 modules/apache/CHANGELOG.md create mode 100644 modules/apache/CONTRIBUTING.md ... t@mylaptop ~/puppet $ git push origin production Counting objects: 277, done. Delta compression using up to 4 threads. Compressing objects: 100% (248/248), done. Writing objects: 100% (266/266), 136.25 KiB | 0 bytes/s, done. Total 266 (delta 48), reused 0 (delta 0) remote: To puppet@puppet.example.com:/etc/puppet/environments/puppet.git remote: 9faaa16..395b079 production -> production
site.pp:node webserver { class {'apache': } }
- the default Apache module configuration:
[root@webserver ~]# puppet agent -t Info: Caching certificate for webserver.example.com Notice: /File[/var/lib/puppet/lib/puppet/provider/a2mod]/ensure: created ... Info: Caching catalog for webserver.example.com ... Info: Class[Apache::Service]: Scheduling refresh of Service[httpd] Notice: /Stage[main]/Apache::Service/Service[httpd]: Triggered 'refresh' from 51 events Notice: Finished catalog run in 11.73 seconds
- Verify that you can reach
webserver.example.com:[root@webserver ~]# curl http://webserver.example.com <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN"> <html> <head> <title>Index of /</title> </head> <body> <h1>Index of /</h1> <table><tr><th><img src="/icons/blank.gif" alt="[ICO]"></th><th><a href="?C=N;O=D">Name</a></th><th><a href="?C=M;O=A">Last modified</a></th><th><a href="?C=S;O=A">Size</a></th><th><a href="?C=D;O=A">Description</a></th></tr><tr><th colspan="5"><hr></th></tr> <tr><th colspan="5"><hr></th></tr> </table> </body></html>
Installing the puppetlabs-Apache module from the Forge causes both puppetlabs-concat and puppetlabs-stdlib to be installed into our modules directory. The concat module is used to stitch snippets of files together in a specific order. It is used by the Apache module to create the main Apache configuration files.
Apache virtual hosts are created with the apache module with the defined type apache::vhost. We will create a new vhost on our Apache webserver called
navajo, one of the apache tribes.
Follow these steps to create Apache virtual hosts:
- Create a navajo
apache::vhostdefinition as follows:apache::vhost { 'navajo.example.com': port => '80', docroot => '/var/www/navajo', } - Create an index file for the new vhost:
file {'/var/www/navajo/index.html': content => "<html>\nnavajo.example.com\nhttp://en.wikipedia.org/wiki/Navajo_people\n</html>\n", mode => '0644', require => Apache::Vhost['navajo.example.com'] } - Run Puppet to create the new vhost:
[root@webserver ~]# puppet agent -t Info: Caching catalog for webserver.example.com Info: Applying configuration version '1414475598' Notice: /Stage[main]/Main/Node[webserver]/Apache::Vhost[navajo.example.com]/File[/var/www/navajo]/ensure: created Notice: /Stage[main]/Main/Node[webserver]/Apache::Vhost[navajo.example.com]/File[25-navajo.example.com.conf]/ensure: created Info: /Stage[main]/Main/Node[webserver]/Apache::Vhost[navajo.example.com]/File[25-navajo.example.com.conf]: Scheduling refresh of Service[httpd] Notice: /Stage[main]/Main/Node[webserver]/File[/var/www/navajo/index.html]/ensure: defined content as '{md5}5212fe215f4c0223fb86102a34319cc6' Notice: /Stage[main]/Apache::Service/Service[httpd]: Triggered 'refresh' from 1 events Notice: Finished catalog run in 2.73 seconds
- Verify that you can reach the new virtual host:
[root@webserver ~]# curl http://navajo.example.com <html> navajo.example.com http://en.wikipedia.org/wiki/Navajo_people </html>
The apache::vhost defined type creates a virtual host configuration file for Apache, 25-navajo.example.com.conf. The file is created with a template; 25 at the beginning of the filename is the "priority level" of this virtual host. When Apache first starts, it reads through its configuration directory and starts executing files in an alphabetical order. Files that begin with numbers are read before files that start with letters. In this way, the Apache module ensures that the virtual hosts are read in a specific order, which can be specified when you define the virtual host. The contents of this file are as follows:
As you can see, the default file has created log files, set up directory access permissions and options, in addition to specifying the listen port and DocumentRoot.
apache::vhost definition as follows:apache::vhost { 'navajo.example.com':
port => '80',
docroot => '/var/www/navajo',
}file {'/var/www/navajo/index.html':
content => "<html>\nnavajo.example.com\nhttp://en.wikipedia.org/wiki/Navajo_people\n</html>\n",
mode => '0644',
require => Apache::Vhost['navajo.example.com']
}[root@webserver ~]# puppet agent -t Info: Caching catalog for webserver.example.com Info: Applying configuration version '1414475598' Notice: /Stage[main]/Main/Node[webserver]/Apache::Vhost[navajo.example.com]/File[/var/www/navajo]/ensure: created Notice: /Stage[main]/Main/Node[webserver]/Apache::Vhost[navajo.example.com]/File[25-navajo.example.com.conf]/ensure: created Info: /Stage[main]/Main/Node[webserver]/Apache::Vhost[navajo.example.com]/File[25-navajo.example.com.conf]: Scheduling refresh of Service[httpd] Notice: /Stage[main]/Main/Node[webserver]/File[/var/www/navajo/index.html]/ensure: defined content as '{md5}5212fe215f4c0223fb86102a34319cc6' Notice: /Stage[main]/Apache::Service/Service[httpd]: Triggered 'refresh' from 1 events Notice: Finished catalog run in 2.73 seconds
[root@webserver ~]# curl http://navajo.example.com <html> navajo.example.com http://en.wikipedia.org/wiki/Navajo_people </html>
The apache::vhost defined type creates a virtual host configuration file for Apache, 25-navajo.example.com.conf. The file is created with a template; 25 at the beginning of the filename is the "priority level" of this virtual host. When Apache first starts, it reads through its configuration directory and starts executing files in an alphabetical order. Files that begin with numbers are read before files that start with letters. In this way, the Apache module ensures that the virtual hosts are read in a specific order, which can be specified when you define the virtual host. The contents of this file are as follows:
As you can see, the default file has created log files, set up directory access permissions and options, in addition to specifying the listen port and DocumentRoot.
apache::vhost defined type
creates a virtual host configuration file for Apache, 25-navajo.example.com.conf. The file is created with a template; 25 at the beginning of the filename is the "priority level" of this virtual host. When Apache first starts, it reads through its configuration directory and starts executing files in an alphabetical order. Files that begin with numbers are read before files that start with letters. In this way, the Apache module ensures that the virtual hosts are read in a specific order, which can be specified when you define the virtual host. The contents of this file are as follows:
As you can see, the default file has created log files, set up directory access permissions and options, in addition to specifying the listen port and DocumentRoot.
apache::virtual and the sheer number of possible arguments.
Nginx is a fast, lightweight web server that is preferred over Apache in many contexts, especially where high performance is important. Nginx is configured slightly differently than Apache; like Apache though, there is a Forge module that can be used to configure nginx for us. Unlike Apache, however, the module that is suggested for use is not supplied by puppetlabs but by James Fryman. This module uses some interesting tricks to configure itself. Previous versions of this module used R.I. Pienaar's module_data package. This package is used to configure hieradata within a module. It's used to supply default values to the nginx module. I wouldn't recommend starting out with this module at this point, but it is a good example of where module configuration may be headed in the future. Giving modules the ability to modify hieradata may prove useful.
- Download the
jfryman-nginxmodule from the Forge:t@mylaptop ~ $ cd ~/puppet t@mylaptop ~/puppet $ puppet module install -i modules jfryman-nginx Notice: Preparing to install into /home/thomas/puppet/modules ... Notice: Downloading from https://forgeapi.puppetlabs.com ... Notice: Installing -- do not interrupt ... /home/thomas/puppet/modules └─┬ jfryman-nginx (v0.2.1) ├── puppetlabs-apt (v1.7.0) ├── puppetlabs-concat (v1.1.1) └── puppetlabs-stdlib (v4.3.2)
- Replace the definition for webserver with an nginx configuration:
node webserver { class {'nginx':} nginx::resource::vhost { 'mescalero.example.com': www_root => '/var/www/mescalero', } file {'/var/www/mescalero': ensure => 'directory''directory', mode => '0755', require => Nginx::Resource::Vhost['mescalero.example.com'], } file {'/var/www/mescalero/index.html': content => "<html>\nmescalero.example.com\nhttp://en.wikipedia.org/wiki/Mescalero\n</html>\n", mode => 0644, require => File['/var/www/mescalero'], } } - If apache is still running on your webserver, stop it:
[root@webserver ~]# puppet resource service httpd ensure=false Notice: /Service[httpd]/ensure: ensure changed 'running' to 'stopped' service { 'httpd': ensure => 'stopped', } Run puppet agent on your webserver node: [root@webserver ~]# puppet agent -t Info: Caching catalog for webserver.example.com Info: Applying configuration version '1414561483' Notice: /Stage[main]/Main/Node[webserver]/Nginx::Resource::Vhost[mescalero.example.com]/Concat[/etc/nginx/sites-available/mescalero.example.com.conf]/File[/etc/nginx/sites-available/mescalero.example.com.conf]/ensure: defined content as '{md5}35bb59bfcd0cf5a549d152aaec284357' Info: /Stage[main]/Main/Node[webserver]/Nginx::Resource::Vhost[mescalero.example.com]/Concat[/etc/nginx/sites-available/mescalero.example.com.conf]/File[/etc/nginx/sites-available/mescalero.example.com.conf]: Scheduling refresh of Class[Nginx::Service] Info: Concat[/etc/nginx/sites-available/mescalero.example.com.conf]: Scheduling refresh of Class[Nginx::Service] Notice: /Stage[main]/Main/Node[webserver]/Nginx::Resource::Vhost[mescalero.example.com]/File[mescalero.example.com.conf symlink]/ensure: created Info: /Stage[main]/Main/Node[webserver]/Nginx::Resource::Vhost[mescalero.example.com]/File[mescalero.example.com.conf symlink]: Scheduling refresh of Service[nginx] Notice: /Stage[main]/Main/Node[webserver]/File[/var/www/mescalero]/ensure: created Notice: /Stage[main]/Main/Node[webserver]/File[/var/www/mescalero/index.html]/ensure: defined content as '{md5}2bd618c7dc3a3addc9e27c2f3cfde294' Notice: /Stage[main]/Nginx::Config/File[/etc/nginx/conf.d/proxy.conf]/ensure: defined content as '{md5}1919fd65635d49653273e14028888617' Info: Computing checksum on file /etc/nginx/conf.d/example_ssl.conf Info: /Stage[main]/Nginx::Config/File[/etc/nginx/conf.d/example_ssl.conf]: Filebucketed /etc/nginx/conf.d/example_ssl.conf to puppet with sum 84724f296c7056157d531d6b1215b507 Notice: /Stage[main]/Nginx::Config/File[/etc/nginx/conf.d/example_ssl.conf]/ensure: removed Info: Computing checksum on file /etc/nginx/conf.d/default.conf Info: /Stage[main]/Nginx::Config/File[/etc/nginx/conf.d/default.conf]: Filebucketed /etc/nginx/conf.d/default.conf to puppet with sum 4dce452bf8dbb01f278ec0ea9ba6cf40 Notice: /Stage[main]/Nginx::Config/File[/etc/nginx/conf.d/default.conf]/ensure: removed Info: Class[Nginx::Config]: Scheduling refresh of Class[Nginx::Service] Info: Class[Nginx::Service]: Scheduling refresh of Service[nginx] Notice: /Stage[main]/Nginx::Service/Service[nginx]: Triggered 'refresh' from 2 events Notice: Finished catalog run in 28.98 seconds
- Verify that you can reach the new virtualhost:
[root@webserver ~]# curl mescalero.example.com <html> mescalero.example.com http://en.wikipedia.org/wiki/Mescalero </html>
Installing the jfryman-nginx module causes the concat, stdlib, and APT modules to be installed. We run Puppet on our master to have the plugins created by these modules added to our running master. The stdlib and concat have facter and Puppet plugins that need to be installed for the nginx module to work properly.
This nginx module is under active development. There are several interesting solutions employed with the module. Previous releases used the ripienaar-module_data module, which allows a module to include default values for its various attributes, via a hiera plugin. Although still in an early stage of development, this system is already usable and represents one of the cutting-edge modules on the Forge.
In the next section, we'll use a supported module to configure and manage MySQL installations.
jfryman-nginx module from the Forge:t@mylaptop ~ $ cd ~/puppet t@mylaptop ~/puppet $ puppet module install -i modules jfryman-nginx Notice: Preparing to install into /home/thomas/puppet/modules ... Notice: Downloading from https://forgeapi.puppetlabs.com ... Notice: Installing -- do not interrupt ... /home/thomas/puppet/modules └─┬ jfryman-nginx (v0.2.1) ├── puppetlabs-apt (v1.7.0) ├── puppetlabs-concat (v1.1.1) └── puppetlabs-stdlib (v4.3.2)
node webserver {
class {'nginx':}
nginx::resource::vhost { 'mescalero.example.com':
www_root => '/var/www/mescalero',
}
file {'/var/www/mescalero':
ensure => 'directory''directory',
mode => '0755',
require => Nginx::Resource::Vhost['mescalero.example.com'],
}
file {'/var/www/mescalero/index.html':
content => "<html>\nmescalero.example.com\nhttp://en.wikipedia.org/wiki/Mescalero\n</html>\n",
mode => 0644,
require => File['/var/www/mescalero'],
}
}- running on your webserver, stop it:
[root@webserver ~]# puppet resource service httpd ensure=false Notice: /Service[httpd]/ensure: ensure changed 'running' to 'stopped' service { 'httpd': ensure => 'stopped', } Run puppet agent on your webserver node: [root@webserver ~]# puppet agent -t Info: Caching catalog for webserver.example.com Info: Applying configuration version '1414561483' Notice: /Stage[main]/Main/Node[webserver]/Nginx::Resource::Vhost[mescalero.example.com]/Concat[/etc/nginx/sites-available/mescalero.example.com.conf]/File[/etc/nginx/sites-available/mescalero.example.com.conf]/ensure: defined content as '{md5}35bb59bfcd0cf5a549d152aaec284357' Info: /Stage[main]/Main/Node[webserver]/Nginx::Resource::Vhost[mescalero.example.com]/Concat[/etc/nginx/sites-available/mescalero.example.com.conf]/File[/etc/nginx/sites-available/mescalero.example.com.conf]: Scheduling refresh of Class[Nginx::Service] Info: Concat[/etc/nginx/sites-available/mescalero.example.com.conf]: Scheduling refresh of Class[Nginx::Service] Notice: /Stage[main]/Main/Node[webserver]/Nginx::Resource::Vhost[mescalero.example.com]/File[mescalero.example.com.conf symlink]/ensure: created Info: /Stage[main]/Main/Node[webserver]/Nginx::Resource::Vhost[mescalero.example.com]/File[mescalero.example.com.conf symlink]: Scheduling refresh of Service[nginx] Notice: /Stage[main]/Main/Node[webserver]/File[/var/www/mescalero]/ensure: created Notice: /Stage[main]/Main/Node[webserver]/File[/var/www/mescalero/index.html]/ensure: defined content as '{md5}2bd618c7dc3a3addc9e27c2f3cfde294' Notice: /Stage[main]/Nginx::Config/File[/etc/nginx/conf.d/proxy.conf]/ensure: defined content as '{md5}1919fd65635d49653273e14028888617' Info: Computing checksum on file /etc/nginx/conf.d/example_ssl.conf Info: /Stage[main]/Nginx::Config/File[/etc/nginx/conf.d/example_ssl.conf]: Filebucketed /etc/nginx/conf.d/example_ssl.conf to puppet with sum 84724f296c7056157d531d6b1215b507 Notice: /Stage[main]/Nginx::Config/File[/etc/nginx/conf.d/example_ssl.conf]/ensure: removed Info: Computing checksum on file /etc/nginx/conf.d/default.conf Info: /Stage[main]/Nginx::Config/File[/etc/nginx/conf.d/default.conf]: Filebucketed /etc/nginx/conf.d/default.conf to puppet with sum 4dce452bf8dbb01f278ec0ea9ba6cf40 Notice: /Stage[main]/Nginx::Config/File[/etc/nginx/conf.d/default.conf]/ensure: removed Info: Class[Nginx::Config]: Scheduling refresh of Class[Nginx::Service] Info: Class[Nginx::Service]: Scheduling refresh of Service[nginx] Notice: /Stage[main]/Nginx::Service/Service[nginx]: Triggered 'refresh' from 2 events Notice: Finished catalog run in 28.98 seconds
- Verify that you can reach the new virtualhost:
[root@webserver ~]# curl mescalero.example.com <html> mescalero.example.com http://en.wikipedia.org/wiki/Mescalero </html>
Installing the jfryman-nginx module causes the concat, stdlib, and APT modules to be installed. We run Puppet on our master to have the plugins created by these modules added to our running master. The stdlib and concat have facter and Puppet plugins that need to be installed for the nginx module to work properly.
This nginx module is under active development. There are several interesting solutions employed with the module. Previous releases used the ripienaar-module_data module, which allows a module to include default values for its various attributes, via a hiera plugin. Although still in an early stage of development, this system is already usable and represents one of the cutting-edge modules on the Forge.
In the next section, we'll use a supported module to configure and manage MySQL installations.
the jfryman-nginx module causes the concat, stdlib, and APT modules to be installed. We run Puppet on our master to have the plugins created by these modules added to our running master. The stdlib and concat have facter and Puppet plugins that need to be installed for the nginx module to work properly.
This nginx module is under active development. There are several interesting solutions employed with the module. Previous releases used the ripienaar-module_data module, which allows a module to include default values for its various attributes, via a hiera plugin. Although still in an early stage of development, this system is already usable and represents one of the cutting-edge modules on the Forge.
In the next section, we'll use a supported module to configure and manage MySQL installations.
ripienaar-module_data module, which allows a
MySQL is a very widely used database server, and it's fairly certain you'll need to install and configure a MySQL server at some point. The puppetlabs-mysql module can simplify your MySQL deployments.
Follow these steps to create the example:
- Install the
puppetlabs-mysqlmodule:t@mylaptop ~/puppet $ puppet module install -i modules puppetlabs-mysql Notice: Preparing to install into /home/thomas/puppet/modules ... Notice: Downloading from https://forgeapi.puppetlabs.com ... Notice: Installing -- do not interrupt ... /home/thomas/puppet/modules └─┬ puppetlabs-mysql (v2.3.1) └── puppetlabs-stdlib (v4.3.2)
- Create a new node definition for your MySQL server:
node dbserver { class { '::mysql::server': root_password => 'PacktPub', override_options => { 'mysqld' => { 'max_connections' => '1024' } } } } - Run Puppet to install the database server and apply the new root password:
[root@dbserver ~]# puppet agent -t Info: Caching catalog for dbserver.example.com Info: Applying configuration version '1414566216' Notice: /Stage[main]/Mysql::Server::Install/Package[mysql-server]/ensure: created Notice: /Stage[main]/Mysql::Server::Service/Service[mysqld]/ensure: ensure changed 'stopped' to 'running' Info: /Stage[main]/Mysql::Server::Service/Service[mysqld]: Unscheduling refresh on Service[mysqld] Notice: /Stage[main]/Mysql::Server::Root_password/Mysql_user[root@localhost]/password_hash: defined 'password_hash' as '*6ABB0D4A7D1381BAEE4D078354557D495ACFC059' Notice: /Stage[main]/Mysql::Server::Root_password/File[/root/.my.cnf]/ensure: defined content as '{md5}87bc129b137c9d613e9f31c80ea5426c' Notice: Finished catalog run in 35.50 seconds
- Verify that you can connect to the database:
[root@dbserver ~]# mysql Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 11 Server version: 5.1.73 Source distribution Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>
The MySQL module installs the MySQL server and ensures that the server is running. It then configures the root password for MySQL. The module does a lot of other things for you as well. It creates a .my.cnf file with the root user password. When we run the mysql client, the .my.cnf file sets all the defaults, so we do not need to supply any arguments.
- Install the
puppetlabs-mysqlmodule:t@mylaptop ~/puppet $ puppet module install -i modules puppetlabs-mysql Notice: Preparing to install into /home/thomas/puppet/modules ... Notice: Downloading from https://forgeapi.puppetlabs.com ... Notice: Installing -- do not interrupt ... /home/thomas/puppet/modules └─┬ puppetlabs-mysql (v2.3.1) └── puppetlabs-stdlib (v4.3.2)
- Create a new node definition for your MySQL server:
node dbserver { class { '::mysql::server': root_password => 'PacktPub', override_options => { 'mysqld' => { 'max_connections' => '1024' } } } } - Run Puppet to install the database server and apply the new root password:
[root@dbserver ~]# puppet agent -t Info: Caching catalog for dbserver.example.com Info: Applying configuration version '1414566216' Notice: /Stage[main]/Mysql::Server::Install/Package[mysql-server]/ensure: created Notice: /Stage[main]/Mysql::Server::Service/Service[mysqld]/ensure: ensure changed 'stopped' to 'running' Info: /Stage[main]/Mysql::Server::Service/Service[mysqld]: Unscheduling refresh on Service[mysqld] Notice: /Stage[main]/Mysql::Server::Root_password/Mysql_user[root@localhost]/password_hash: defined 'password_hash' as '*6ABB0D4A7D1381BAEE4D078354557D495ACFC059' Notice: /Stage[main]/Mysql::Server::Root_password/File[/root/.my.cnf]/ensure: defined content as '{md5}87bc129b137c9d613e9f31c80ea5426c' Notice: Finished catalog run in 35.50 seconds
- Verify that you can connect to the database:
[root@dbserver ~]# mysql Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 11 Server version: 5.1.73 Source distribution Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>
The MySQL module installs the MySQL server and ensures that the server is running. It then configures the root password for MySQL. The module does a lot of other things for you as well. It creates a .my.cnf file with the root user password. When we run the mysql client, the .my.cnf file sets all the defaults, so we do not need to supply any arguments.
Managing a database means more than ensuring that the service is running; a database server is nothing without databases. Databases need users and privileges. Privileges are handled with GRANT statements. We will use the puppetlabs-mysql package to create a database and a user with access to that database. We'll create a MySQL user Drupal and a database called Drupal. We'll create a table named nodes and place data into that table.
Follow these steps to create databases and users:
- Create a database definition within your
dbserverclass:mysql::db { 'drupal': host => 'localhost', user => 'drupal', password => 'Cookbook', sql => '/root/drupal.sql', require => File['/root/drupal.sql'] } file { '/root/drupal.sql': ensure => present, source => 'puppet:///modules/mysql/drupal.sql', } - Allow the Drupal user to modify the nodes table:
mysql_grant { 'drupal@localhost/drupal.nodes': ensure => 'present', options => ['GRANT'], privileges => ['ALL'], table => 'drupal.nodes'nodes', user => 'drupal@localhost', } - Create the
drupal.sqlfile with the following contents:CREATE TABLE users (id INT PRIMARY KEY AUTO_INCREMENT, title VARCHAR(255), body TEXT); INSERT INTO users (id, title, body) VALUES (1,'First Node','Contents of first Node'); INSERT INTO users (id, title, body) VALUES (2,'Second Node','Contents of second Node');
- Run Puppet to have user, database, and
GRANTcreated:[root@dbserver ~]# puppet agent -t Info: Caching catalog for dbserver.example.com Info: Applying configuration version '1414648818' Notice: /Stage[main]/Main/Node[dbserver]/File[/root/drupal.sql]/ensure: defined content as '{md5}780f3946cfc0f373c6d4146394650f6b' Notice: /Stage[main]/Main/Node[dbserver]/Mysql_grant[drupal@localhost/drupal.nodes]/ensure: created Notice: /Stage[main]/Main/Node[dbserver]/Mysql::Db[drupal]/Mysql_user[drupal@localhost]/ensure: created Notice: /Stage[main]/Main/Node[dbserver]/Mysql::Db[drupal]/Mysql_database[drupal]/ensure: created Info: /Stage[main]/Main/Node[dbserver]/Mysql::Db[drupal]/Mysql_database[drupal]: Scheduling refresh of Exec[drupal-import] Notice: /Stage[main]/Main/Node[dbserver]/Mysql::Db[drupal]/Mysql_grant[drupal@localhost/drupal.*]/ensure: created Notice: /Stage[main]/Main/Node[dbserver]/Mysql::Db[drupal]/Exec[drupal-import]: Triggered 'refresh' from 1 events Notice: Finished catalog run in 10.06 seconds
- Verify that the database and table have been created:
[root@dbserver ~]# mysql drupal Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 34 Server version: 5.1.73 Source distribution Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> show tables; +------------------+ | Tables_in_drupal | +------------------+ | users | +------------------+ 1 row in set (0.00 sec)
- Now, verify that our default data has been loaded into the table:
mysql> select * from users; +----+-------------+-------------------------+ | id | title | body | +----+-------------+-------------------------+ | 1 | First Node | Contents of first Node | | 2 | Second Node | Contents of second Node | +----+-------------+-------------------------+ 2 rows in set (0.00 sec)
We start with the definition of the new drupal database:
We then ensure that the user has the appropriate privileges with a mysql_grant statement:
Using the puppetlabs-MySQL and puppetlabs-Apache module, we can create an entire functioning web server. The puppetlabs-Apache module will install Apache, and we can include the PHP module and MySQL module as well. We can then use the puppetlabs-Mysql module to install the MySQL server, and then create the required drupal databases and seed the database with the data.
Deploying a new drupal installation would be as simple as including a class on a node.
dbserver class:mysql::db { 'drupal':
host => 'localhost',
user => 'drupal',
password => 'Cookbook',
sql => '/root/drupal.sql',
require => File['/root/drupal.sql']
}
file { '/root/drupal.sql':
ensure => present,
source => 'puppet:///modules/mysql/drupal.sql',
}mysql_grant { 'drupal@localhost/drupal.nodes':
ensure => 'present',
options => ['GRANT'],
privileges => ['ALL'],
table => 'drupal.nodes'nodes',
user => 'drupal@localhost',
}- the
drupal.sqlfile with the following contents:CREATE TABLE users (id INT PRIMARY KEY AUTO_INCREMENT, title VARCHAR(255), body TEXT); INSERT INTO users (id, title, body) VALUES (1,'First Node','Contents of first Node'); INSERT INTO users (id, title, body) VALUES (2,'Second Node','Contents of second Node');
- Run Puppet to have user, database, and
GRANTcreated:[root@dbserver ~]# puppet agent -t Info: Caching catalog for dbserver.example.com Info: Applying configuration version '1414648818' Notice: /Stage[main]/Main/Node[dbserver]/File[/root/drupal.sql]/ensure: defined content as '{md5}780f3946cfc0f373c6d4146394650f6b' Notice: /Stage[main]/Main/Node[dbserver]/Mysql_grant[drupal@localhost/drupal.nodes]/ensure: created Notice: /Stage[main]/Main/Node[dbserver]/Mysql::Db[drupal]/Mysql_user[drupal@localhost]/ensure: created Notice: /Stage[main]/Main/Node[dbserver]/Mysql::Db[drupal]/Mysql_database[drupal]/ensure: created Info: /Stage[main]/Main/Node[dbserver]/Mysql::Db[drupal]/Mysql_database[drupal]: Scheduling refresh of Exec[drupal-import] Notice: /Stage[main]/Main/Node[dbserver]/Mysql::Db[drupal]/Mysql_grant[drupal@localhost/drupal.*]/ensure: created Notice: /Stage[main]/Main/Node[dbserver]/Mysql::Db[drupal]/Exec[drupal-import]: Triggered 'refresh' from 1 events Notice: Finished catalog run in 10.06 seconds
- Verify that the database and table have been created:
[root@dbserver ~]# mysql drupal Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 34 Server version: 5.1.73 Source distribution Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> show tables; +------------------+ | Tables_in_drupal | +------------------+ | users | +------------------+ 1 row in set (0.00 sec)
- Now, verify that our default data has been loaded into the table:
mysql> select * from users; +----+-------------+-------------------------+ | id | title | body | +----+-------------+-------------------------+ | 1 | First Node | Contents of first Node | | 2 | Second Node | Contents of second Node | +----+-------------+-------------------------+ 2 rows in set (0.00 sec)
We start with the definition of the new drupal database:
We then ensure that the user has the appropriate privileges with a mysql_grant statement:
Using the puppetlabs-MySQL and puppetlabs-Apache module, we can create an entire functioning web server. The puppetlabs-Apache module will install Apache, and we can include the PHP module and MySQL module as well. We can then use the puppetlabs-Mysql module to install the MySQL server, and then create the required drupal databases and seed the database with the data.
Deploying a new drupal installation would be as simple as including a class on a node.
definition of the new drupal database:
We then ensure that the user has the appropriate privileges with a mysql_grant statement:
Using the puppetlabs-MySQL and puppetlabs-Apache module, we can create an entire functioning web server. The puppetlabs-Apache module will install Apache, and we can include the PHP module and MySQL module as well. We can then use the puppetlabs-Mysql module to install the MySQL server, and then create the required drupal databases and seed the database with the data.
Deploying a new drupal installation would be as simple as including a class on a node.
and puppetlabs-Apache module, we can create an entire functioning web server. The puppetlabs-Apache module will install Apache, and we can include the PHP module and MySQL module as well. We can then use the puppetlabs-Mysql module to install the MySQL server, and then create the required drupal databases and seed the database with the data.
Deploying a new drupal installation would be as simple as including a class on a node.
"Rest is not idleness, and to lie sometimes on the grass under trees on a summer's day, listening to the murmur of the water, or watching the clouds float across the sky, is by no means a waste of time." | ||
| --John Lubbock | ||
In this chapter, we will cover the following recipes:
In this chapter, we will begin to configure services that require communication between hosts over the network. Most Linux distributions will default to running a host-based firewall, iptables. If you want your hosts to communicate with each other, you have two options: turn off iptables or configure iptables to allow the communication.
Configuring iptables properly is a complicated task, which requires deep knowledge of networking. The example presented here is a simplification. If you are unfamiliar with iptables, I suggest you research iptables before continuing. More information can be found at http://wiki.centos.org/HowTos/Network/IPTables or https://help.ubuntu.com/community/IptablesHowTo.
In the following examples, we'll be using the Puppet Labs Firewall module to configure iptables. Prepare by installing the module into your Git repository with puppet module install:
- Create a class to contain these rules and call it
myfw::pre:class myfw::pre { Firewall { require => undef, } firewall { '0000 Allow all traffic on loopback': proto => 'all', iniface => 'lo', action => 'accept', } firewall { '0001 Allow all ICMP': proto => 'icmp', action => 'accept', } firewall { '0002 Allow all established traffic': proto => 'all', state => ['RELATED', 'ESTABLISHED'], action => 'accept', } firewall { '0022 Allow all TCP on port 22 (ssh)': proto => 'tcp', port => '22', action => 'accept', } } - When traffic doesn't match any of the previous rules, we want a final rule that will drop the traffic. Create the class
myfw::postto contain the default drop rule:class myfw::post { firewall { '9999 Drop all other traffic': proto => 'all', action => 'drop', before => undef, } } - Create a
myfwclass, which will includemyfw::preandmyfw::postto configure the firewall:class myfw { include firewall # our rulesets include myfw::post include myfw::pre # clear all the rules resources { "firewall": purge => true } # resource defaults Firewall { before => Class['myfw::post'], require => Class['myfw::pre'], } } - Attach the
myfwclass to a node definition; I'll do this to my cookbook node:node cookbook { include myfw } - Run Puppet on cookbook to see whether the firewall rules have been applied:
[root@cookbook ~]# puppet agent -t Info: Retrieving pluginfacts Info: Retrieving plugin Info: Loading facts Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1415512948' Notice: /Stage[main]/Myfw::Pre/Firewall[000 Allow all traffic on loopback]/ensure: created Notice: /File[/etc/sysconfig/iptables]/seluser: seluser changed 'unconfined_u' to 'system_u' Notice: /Stage[main]/Myfw::Pre/Firewall[0001 Allow all ICMP]/ensure: created Notice: /Stage[main]/Myfw::Pre/Firewall[0022 Allow all TCP on port 22 (ssh)]/ensure: created Notice: /Stage[main]/Myfw::Pre/Firewall[0002 Allow all established traffic]/ensure: created Notice: /Stage[main]/Myfw::Post/Firewall[9999 Drop all other traffic]/ensure: created Notice: /Stage[main]/Myfw/Firewall[9003 49bcd611c61bdd18b235cea46ef04fae]/ensure: removed Notice: Finished catalog run in 15.65 seconds
- Verify the new rules with
iptables-save:# Generated by iptables-save v1.4.7 on Sun Nov 9 01:18:30 2014 *filter :INPUT ACCEPT [0:0] :FORWARD ACCEPT [0:0] :OUTPUT ACCEPT [74:35767] -A INPUT -i lo -m comment --comment "0000 Allow all traffic on loopback" -j ACCEPT -A INPUT -p icmp -m comment --comment "0001 Allow all ICMP" -j ACCEPT -A INPUT -m comment --comment "0002 Allow all established traffic" -m state --state RELATED,ESTABLISHED -j ACCEPT -A INPUT -p tcp -m multiport --ports 22 -m comment --comment "022 Allow all TCP on port 22 (ssh)" -j ACCEPT -A INPUT -m comment --comment "9999 Drop all other traffic" -j DROP COMMIT # Completed on Sun Nov 9 01:18:30 2014
This is a great example of how to use metaparameters to achieve a complex ordering with little effort. Our myfw module achieves the following configuration:

Our definition for the myfw class sets up this dependency with resource defaults:
When we defined the myfw::pre class, we removed the require statement in a resource default for Firewall resources. This ensures that the resources within the myfw::pre-class don't require themselves before executing (Puppet will complain that we created a cyclic dependency otherwise):
As we hinted, we can now define firewall resources in our manifests and have them applied to the iptables configuration after the initialization rules (myfw::pre) but before the final drop (myfw::post). For example, to allow http traffic on our cookbook machine, modify the node definition as follows:
Verify that the new rule has been added after the last myfw::pre rule (port 22, ssh):
examples, we'll be using the Puppet Labs Firewall module to configure iptables. Prepare by installing the module into your Git repository with puppet module install:
- Create a class to contain these rules and call it
myfw::pre:class myfw::pre { Firewall { require => undef, } firewall { '0000 Allow all traffic on loopback': proto => 'all', iniface => 'lo', action => 'accept', } firewall { '0001 Allow all ICMP': proto => 'icmp', action => 'accept', } firewall { '0002 Allow all established traffic': proto => 'all', state => ['RELATED', 'ESTABLISHED'], action => 'accept', } firewall { '0022 Allow all TCP on port 22 (ssh)': proto => 'tcp', port => '22', action => 'accept', } } - When traffic doesn't match any of the previous rules, we want a final rule that will drop the traffic. Create the class
myfw::postto contain the default drop rule:class myfw::post { firewall { '9999 Drop all other traffic': proto => 'all', action => 'drop', before => undef, } } - Create a
myfwclass, which will includemyfw::preandmyfw::postto configure the firewall:class myfw { include firewall # our rulesets include myfw::post include myfw::pre # clear all the rules resources { "firewall": purge => true } # resource defaults Firewall { before => Class['myfw::post'], require => Class['myfw::pre'], } } - Attach the
myfwclass to a node definition; I'll do this to my cookbook node:node cookbook { include myfw } - Run Puppet on cookbook to see whether the firewall rules have been applied:
[root@cookbook ~]# puppet agent -t Info: Retrieving pluginfacts Info: Retrieving plugin Info: Loading facts Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1415512948' Notice: /Stage[main]/Myfw::Pre/Firewall[000 Allow all traffic on loopback]/ensure: created Notice: /File[/etc/sysconfig/iptables]/seluser: seluser changed 'unconfined_u' to 'system_u' Notice: /Stage[main]/Myfw::Pre/Firewall[0001 Allow all ICMP]/ensure: created Notice: /Stage[main]/Myfw::Pre/Firewall[0022 Allow all TCP on port 22 (ssh)]/ensure: created Notice: /Stage[main]/Myfw::Pre/Firewall[0002 Allow all established traffic]/ensure: created Notice: /Stage[main]/Myfw::Post/Firewall[9999 Drop all other traffic]/ensure: created Notice: /Stage[main]/Myfw/Firewall[9003 49bcd611c61bdd18b235cea46ef04fae]/ensure: removed Notice: Finished catalog run in 15.65 seconds
- Verify the new rules with
iptables-save:# Generated by iptables-save v1.4.7 on Sun Nov 9 01:18:30 2014 *filter :INPUT ACCEPT [0:0] :FORWARD ACCEPT [0:0] :OUTPUT ACCEPT [74:35767] -A INPUT -i lo -m comment --comment "0000 Allow all traffic on loopback" -j ACCEPT -A INPUT -p icmp -m comment --comment "0001 Allow all ICMP" -j ACCEPT -A INPUT -m comment --comment "0002 Allow all established traffic" -m state --state RELATED,ESTABLISHED -j ACCEPT -A INPUT -p tcp -m multiport --ports 22 -m comment --comment "022 Allow all TCP on port 22 (ssh)" -j ACCEPT -A INPUT -m comment --comment "9999 Drop all other traffic" -j DROP COMMIT # Completed on Sun Nov 9 01:18:30 2014
This is a great example of how to use metaparameters to achieve a complex ordering with little effort. Our myfw module achieves the following configuration:
Our definition for the myfw class sets up this dependency with resource defaults:
When we defined the myfw::pre class, we removed the require statement in a resource default for Firewall resources. This ensures that the resources within the myfw::pre-class don't require themselves before executing (Puppet will complain that we created a cyclic dependency otherwise):
As we hinted, we can now define firewall resources in our manifests and have them applied to the iptables configuration after the initialization rules (myfw::pre) but before the final drop (myfw::post). For example, to allow http traffic on our cookbook machine, modify the node definition as follows:
Verify that the new rule has been added after the last myfw::pre rule (port 22, ssh):
myfw (my firewall) class to configure the firewall module. We will then apply the myfw class to a node to have iptables configured on that node:
myfw::pre:class myfw::pre {
Firewall {
require => undef,
}
firewall { '0000 Allow all traffic on loopback':
proto => 'all',
iniface => 'lo',
action => 'accept',
}
firewall { '0001 Allow all ICMP':
proto => 'icmp',
action => 'accept',
}
firewall { '0002 Allow all established traffic':
proto => 'all',
state => ['RELATED', 'ESTABLISHED'],
action => 'accept',
}
firewall { '0022 Allow all TCP on port 22 (ssh)':
proto => 'tcp',
port => '22',
action => 'accept',
}
}- doesn't match any of the previous rules, we want a final rule that will drop the traffic. Create the class
myfw::postto contain the default drop rule:class myfw::post { firewall { '9999 Drop all other traffic': proto => 'all', action => 'drop', before => undef, } } - Create a
myfwclass, which will includemyfw::preandmyfw::postto configure the firewall:class myfw { include firewall # our rulesets include myfw::post include myfw::pre # clear all the rules resources { "firewall": purge => true } # resource defaults Firewall { before => Class['myfw::post'], require => Class['myfw::pre'], } } - Attach the
myfwclass to a node definition; I'll do this to my cookbook node:node cookbook { include myfw } - Run Puppet on cookbook to see whether the firewall rules have been applied:
[root@cookbook ~]# puppet agent -t Info: Retrieving pluginfacts Info: Retrieving plugin Info: Loading facts Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1415512948' Notice: /Stage[main]/Myfw::Pre/Firewall[000 Allow all traffic on loopback]/ensure: created Notice: /File[/etc/sysconfig/iptables]/seluser: seluser changed 'unconfined_u' to 'system_u' Notice: /Stage[main]/Myfw::Pre/Firewall[0001 Allow all ICMP]/ensure: created Notice: /Stage[main]/Myfw::Pre/Firewall[0022 Allow all TCP on port 22 (ssh)]/ensure: created Notice: /Stage[main]/Myfw::Pre/Firewall[0002 Allow all established traffic]/ensure: created Notice: /Stage[main]/Myfw::Post/Firewall[9999 Drop all other traffic]/ensure: created Notice: /Stage[main]/Myfw/Firewall[9003 49bcd611c61bdd18b235cea46ef04fae]/ensure: removed Notice: Finished catalog run in 15.65 seconds
- Verify the new rules with
iptables-save:# Generated by iptables-save v1.4.7 on Sun Nov 9 01:18:30 2014 *filter :INPUT ACCEPT [0:0] :FORWARD ACCEPT [0:0] :OUTPUT ACCEPT [74:35767] -A INPUT -i lo -m comment --comment "0000 Allow all traffic on loopback" -j ACCEPT -A INPUT -p icmp -m comment --comment "0001 Allow all ICMP" -j ACCEPT -A INPUT -m comment --comment "0002 Allow all established traffic" -m state --state RELATED,ESTABLISHED -j ACCEPT -A INPUT -p tcp -m multiport --ports 22 -m comment --comment "022 Allow all TCP on port 22 (ssh)" -j ACCEPT -A INPUT -m comment --comment "9999 Drop all other traffic" -j DROP COMMIT # Completed on Sun Nov 9 01:18:30 2014
This is a great example of how to use metaparameters to achieve a complex ordering with little effort. Our myfw module achieves the following configuration:
Our definition for the myfw class sets up this dependency with resource defaults:
When we defined the myfw::pre class, we removed the require statement in a resource default for Firewall resources. This ensures that the resources within the myfw::pre-class don't require themselves before executing (Puppet will complain that we created a cyclic dependency otherwise):
As we hinted, we can now define firewall resources in our manifests and have them applied to the iptables configuration after the initialization rules (myfw::pre) but before the final drop (myfw::post). For example, to allow http traffic on our cookbook machine, modify the node definition as follows:
Verify that the new rule has been added after the last myfw::pre rule (port 22, ssh):
example of how to use metaparameters to achieve a complex ordering with little effort. Our myfw module achieves the following configuration:
Our definition for the myfw class sets up this dependency with resource defaults:
When we defined the myfw::pre class, we removed the require statement in a resource default for Firewall resources. This ensures that the resources within the myfw::pre-class don't require themselves before executing (Puppet will complain that we created a cyclic dependency otherwise):
As we hinted, we can now define firewall resources in our manifests and have them applied to the iptables configuration after the initialization rules (myfw::pre) but before the final drop (myfw::post). For example, to allow http traffic on our cookbook machine, modify the node definition as follows:
Verify that the new rule has been added after the last myfw::pre rule (port 22, ssh):
myfw::pre) but before the final drop (myfw::post). For example, to allow http traffic on our cookbook machine, modify the node definition
High-availability services are those that can survive the failure of an individual machine or network connection. The primary technique for high availability is redundancy, otherwise known as throwing hardware at the problem. Although the eventual failure of an individual server is certain, the simultaneous failure of two servers is unlikely enough that this provides a good level of redundancy for most applications.
Follow these steps to build the example:
- Create the file
modules/heartbeat/manifests/init.ppwith the following contents:# Manage Heartbeat class heartbeat { package { 'heartbeat': ensure => installed, } service { 'heartbeat': ensure => running, enable => true, require => Package['heartbeat'], } file { '/etc/ha.d/authkeys': content => "auth 1\n1 sha1 TopSecret", mode => '0600', require => Package['heartbeat'], notify => Service['heartbeat'], } include myfw firewall {'0694 Allow UDP ha-cluster': proto => 'udp', port => 694, action => 'accept', } } - Create the file
modules/heartbeat/manifests/vip.ppwith the following contents:# Manage a specific VIP with Heartbeat class heartbeat::vip($node1,$node2,$ip1,$ip2,$vip,$interface='eth0:1') { include heartbeat file { '/etc/ha.d/haresources': content => "${node1} IPaddr::${vip}/${interface}\n", require => Package['heartbeat'], notify => Service['heartbeat'], } file { '/etc/ha.d/ha.cf': content => template('heartbeat/vip.ha.cf.erb'), require => Package['heartbeat'], notify => Service['heartbeat'], } } - Create the file
modules/heartbeat/templates/vip.ha.cf.erbwith the following contents:use_logd yes udpport 694 autojoin none ucast eth0 <%= @ip1 %> ucast eth0 <%= @ip2 %> keepalive 1 deadtime 10 warntime 5 auto_failback off node <%= @node1 %> node <%= @node2 %>
- Modify your
site.ppfile as follows. Replace theip1andip2addresses with the primary IP addresses of your two nodes,vipwith the virtual IP address you'll be using, andnode1andnode2with the hostnames of the two nodes. (Heartbeat uses the fully-qualified domain name of a node to determine whether it's a member of the cluster, so the values fornode1andnode2should match what's given byfacter fqdnon each machine.):node cookbook,cookbook2 { class { 'heartbeat::vip': ip1 => '192.168.122.132', ip2 => '192.168.122.133', node1 => 'cookbook.example.com', node2 => 'cookbook2.example.com', vip => '192.168.122.200/24', } } - Run Puppet on each of the two servers:
[root@cookbook2 ~]# puppet agent -t Info: Retrieving pluginfacts Info: Retrieving plugin Info: Loading facts Info: Caching catalog for cookbook2.example.com Info: Applying configuration version '1415517914' Notice: /Stage[main]/Heartbeat/Package[heartbeat]/ensure: created Notice: /Stage[main]/Myfw::Pre/Firewall[0000 Allow all traffic on loopback]/ensure: created Notice: /Stage[main]/Myfw::Pre/Firewall[0001 Allow all ICMP]/ensure: created Notice: /File[/etc/sysconfig/iptables]/seluser: seluser changed 'unconfined_u' to 'system_u' Notice: /Stage[main]/Myfw::Pre/Firewall[0022 Allow all TCP on port 22 (ssh)]/ensure: created Notice: /Stage[main]/Heartbeat::Vip/File[/etc/ha.d/haresources]/ensure: defined content as '{md5}fb9f5d9d2b26e3bddf681676d8b2129c' Info: /Stage[main]/Heartbeat::Vip/File[/etc/ha.d/haresources]: Scheduling refresh of Service[heartbeat] Notice: /Stage[main]/Heartbeat::Vip/File[/etc/ha.d/ha.cf]/ensure: defined content as '{md5}84da22f7ac1a3629f69dcf29ccfd8592' Info: /Stage[main]/Heartbeat::Vip/File[/etc/ha.d/ha.cf]: Scheduling refresh of Service[heartbeat] Notice: /Stage[main]/Heartbeat/Service[heartbeat]/ensure: ensure changed 'stopped' to 'running' Info: /Stage[main]/Heartbeat/Service[heartbeat]: Unscheduling refresh on Service[heartbeat] Notice: /Stage[main]/Myfw::Pre/Firewall[0002 Allow all established traffic]/ensure: created Notice: /Stage[main]/Myfw::Post/Firewall[9999 Drop all other traffic]/ensure: created Notice: /Stage[main]/Heartbeat/Firewall[0694 Allow UDP ha-cluster]/ensure: created Notice: Finished catalog run in 12.64 seconds
- Verify that the VIP is running on one of the nodes (it should be on cookbook at this point; note that you will need to use the
ipcommand,ifconfigwill not show the address):[root@cookbook ~]# ip addr show dev eth0 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 52:54:00:c9:d5:63 brd ff:ff:ff:ff:ff:ff inet 192.168.122.132/24 brd 192.168.122.255 scope global eth0 inet 192.168.122.200/24 brd 192.168.122.255 scope global secondary eth0:1 inet6 fe80::5054:ff:fec9:d563/64 scope link valid_lft forever preferred_lft forever
- As we can see, cookbook has the
eth0:1interface active. If you stop heartbeat oncookbook,cookbook2will createeth0:1and take over:[root@cookbook2 ~]# ip a show dev eth0 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 52:54:00:ee:9c:fa brd ff:ff:ff:ff:ff:ff inet 192.168.122.133/24 brd 192.168.122.255 scope global eth0 inet 192.168.122.200/24 brd 192.168.122.255 scope global secondary eth0:1 inet6 fe80::5054:ff:feee:9cfa/64 scope link valid_lft forever preferred_lft forever
We need to install Heartbeat first of all, using the heartbeat class:
Next, we use the heartbeat::vip class to manage a specific virtual IP:
The file is interpreted by Heartbeat as follows:
cookbook.example.com: This is the name of the primary node, which should be the default owner of the resourceIPaddr: This is the type of resource to manage; in this case, an IP address192.168.122.200/24: This is the value for the IP addresseth0:1: This is the virtual interface to configure with the managed IP address
For more information on how heartbeat is configured, please visit the high-availability site at http://linux-ha.org/wiki/Heartbeat.
We will also build the ha.cf file that tells Heartbeat how to communicate between cluster nodes:
file { '/etc/ha.d/ha.cf':
content => template('heartbeat/vip.ha.cf.erb'),
notify => Service['heartbeat'],
require => Package['heartbeat'],
}To do this, we use the template file:
use_logd yes udpport 694 autojoin none ucast eth0 <%= @ip1 %> ucast eth0 <%= @ip2 %> keepalive 1 deadtime 10 warntime 5 auto_failback off node <%= @node1 %> node <%= @node2 %>
The interesting values here are the IP addresses of the two nodes (ip1 and ip2), and the names of the two nodes (node1 and node2).
Finally, we create an instance of heartbeat::vip on both machines and pass it an identical set of parameters as follows:
The auto_failback setting in ha.cf governs what happens next. If auto_failback is set to on, when cookbook becomes available once more, it will automatically take over the IP address. Without auto_failback, the IP will stay where it is until you manually fail it again (by stopping heartbeart on cookbook2, for example).
Heartbeat works great for the previous example but is not in widespread use in this form. Heartbeat only works in two node clusters; for n-node clusters, the newer pacemaker project should be used. More information on Heartbeat, pacemaker, corosync, and other clustering packages can be found at http://www.linux-ha.org/wiki/Main_Page.
Managing cluster configuration is one area where exported resources are useful. Each node in a cluster would export information about itself, which could then be collected by the other members of the cluster. Using the puppetlabs-concat module, you can build up a configuration file using exported concat fragments from all the nodes in the cluster.
Remember to look at the Forge before starting your own module. If nothing else, you'll get some ideas that you can use in your own module. Corosync can be managed with the Puppet labs module at https://forge.puppetlabs.com/puppetlabs/corosync.
cookbook and cookbook2, with cookbook being the primary. We'll add the hosts to the heartbeat configuration.
Follow these steps to build the example:
- Create the file
modules/heartbeat/manifests/init.ppwith the following contents:# Manage Heartbeat class heartbeat { package { 'heartbeat': ensure => installed, } service { 'heartbeat': ensure => running, enable => true, require => Package['heartbeat'], } file { '/etc/ha.d/authkeys': content => "auth 1\n1 sha1 TopSecret", mode => '0600', require => Package['heartbeat'], notify => Service['heartbeat'], } include myfw firewall {'0694 Allow UDP ha-cluster': proto => 'udp', port => 694, action => 'accept', } } - Create the file
modules/heartbeat/manifests/vip.ppwith the following contents:# Manage a specific VIP with Heartbeat class heartbeat::vip($node1,$node2,$ip1,$ip2,$vip,$interface='eth0:1') { include heartbeat file { '/etc/ha.d/haresources': content => "${node1} IPaddr::${vip}/${interface}\n", require => Package['heartbeat'], notify => Service['heartbeat'], } file { '/etc/ha.d/ha.cf': content => template('heartbeat/vip.ha.cf.erb'), require => Package['heartbeat'], notify => Service['heartbeat'], } } - Create the file
modules/heartbeat/templates/vip.ha.cf.erbwith the following contents:use_logd yes udpport 694 autojoin none ucast eth0 <%= @ip1 %> ucast eth0 <%= @ip2 %> keepalive 1 deadtime 10 warntime 5 auto_failback off node <%= @node1 %> node <%= @node2 %>
- Modify your
site.ppfile as follows. Replace theip1andip2addresses with the primary IP addresses of your two nodes,vipwith the virtual IP address you'll be using, andnode1andnode2with the hostnames of the two nodes. (Heartbeat uses the fully-qualified domain name of a node to determine whether it's a member of the cluster, so the values fornode1andnode2should match what's given byfacter fqdnon each machine.):node cookbook,cookbook2 { class { 'heartbeat::vip': ip1 => '192.168.122.132', ip2 => '192.168.122.133', node1 => 'cookbook.example.com', node2 => 'cookbook2.example.com', vip => '192.168.122.200/24', } } - Run Puppet on each of the two servers:
[root@cookbook2 ~]# puppet agent -t Info: Retrieving pluginfacts Info: Retrieving plugin Info: Loading facts Info: Caching catalog for cookbook2.example.com Info: Applying configuration version '1415517914' Notice: /Stage[main]/Heartbeat/Package[heartbeat]/ensure: created Notice: /Stage[main]/Myfw::Pre/Firewall[0000 Allow all traffic on loopback]/ensure: created Notice: /Stage[main]/Myfw::Pre/Firewall[0001 Allow all ICMP]/ensure: created Notice: /File[/etc/sysconfig/iptables]/seluser: seluser changed 'unconfined_u' to 'system_u' Notice: /Stage[main]/Myfw::Pre/Firewall[0022 Allow all TCP on port 22 (ssh)]/ensure: created Notice: /Stage[main]/Heartbeat::Vip/File[/etc/ha.d/haresources]/ensure: defined content as '{md5}fb9f5d9d2b26e3bddf681676d8b2129c' Info: /Stage[main]/Heartbeat::Vip/File[/etc/ha.d/haresources]: Scheduling refresh of Service[heartbeat] Notice: /Stage[main]/Heartbeat::Vip/File[/etc/ha.d/ha.cf]/ensure: defined content as '{md5}84da22f7ac1a3629f69dcf29ccfd8592' Info: /Stage[main]/Heartbeat::Vip/File[/etc/ha.d/ha.cf]: Scheduling refresh of Service[heartbeat] Notice: /Stage[main]/Heartbeat/Service[heartbeat]/ensure: ensure changed 'stopped' to 'running' Info: /Stage[main]/Heartbeat/Service[heartbeat]: Unscheduling refresh on Service[heartbeat] Notice: /Stage[main]/Myfw::Pre/Firewall[0002 Allow all established traffic]/ensure: created Notice: /Stage[main]/Myfw::Post/Firewall[9999 Drop all other traffic]/ensure: created Notice: /Stage[main]/Heartbeat/Firewall[0694 Allow UDP ha-cluster]/ensure: created Notice: Finished catalog run in 12.64 seconds
- Verify that the VIP is running on one of the nodes (it should be on cookbook at this point; note that you will need to use the
ipcommand,ifconfigwill not show the address):[root@cookbook ~]# ip addr show dev eth0 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 52:54:00:c9:d5:63 brd ff:ff:ff:ff:ff:ff inet 192.168.122.132/24 brd 192.168.122.255 scope global eth0 inet 192.168.122.200/24 brd 192.168.122.255 scope global secondary eth0:1 inet6 fe80::5054:ff:fec9:d563/64 scope link valid_lft forever preferred_lft forever
- As we can see, cookbook has the
eth0:1interface active. If you stop heartbeat oncookbook,cookbook2will createeth0:1and take over:[root@cookbook2 ~]# ip a show dev eth0 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 52:54:00:ee:9c:fa brd ff:ff:ff:ff:ff:ff inet 192.168.122.133/24 brd 192.168.122.255 scope global eth0 inet 192.168.122.200/24 brd 192.168.122.255 scope global secondary eth0:1 inet6 fe80::5054:ff:feee:9cfa/64 scope link valid_lft forever preferred_lft forever
We need to install Heartbeat first of all, using the heartbeat class:
Next, we use the heartbeat::vip class to manage a specific virtual IP:
The file is interpreted by Heartbeat as follows:
cookbook.example.com: This is the name of the primary node, which should be the default owner of the resourceIPaddr: This is the type of resource to manage; in this case, an IP address192.168.122.200/24: This is the value for the IP addresseth0:1: This is the virtual interface to configure with the managed IP address
For more information on how heartbeat is configured, please visit the high-availability site at http://linux-ha.org/wiki/Heartbeat.
We will also build the ha.cf file that tells Heartbeat how to communicate between cluster nodes:
file { '/etc/ha.d/ha.cf':
content => template('heartbeat/vip.ha.cf.erb'),
notify => Service['heartbeat'],
require => Package['heartbeat'],
}To do this, we use the template file:
use_logd yes udpport 694 autojoin none ucast eth0 <%= @ip1 %> ucast eth0 <%= @ip2 %> keepalive 1 deadtime 10 warntime 5 auto_failback off node <%= @node1 %> node <%= @node2 %>
The interesting values here are the IP addresses of the two nodes (ip1 and ip2), and the names of the two nodes (node1 and node2).
Finally, we create an instance of heartbeat::vip on both machines and pass it an identical set of parameters as follows:
The auto_failback setting in ha.cf governs what happens next. If auto_failback is set to on, when cookbook becomes available once more, it will automatically take over the IP address. Without auto_failback, the IP will stay where it is until you manually fail it again (by stopping heartbeart on cookbook2, for example).
Heartbeat works great for the previous example but is not in widespread use in this form. Heartbeat only works in two node clusters; for n-node clusters, the newer pacemaker project should be used. More information on Heartbeat, pacemaker, corosync, and other clustering packages can be found at http://www.linux-ha.org/wiki/Main_Page.
Managing cluster configuration is one area where exported resources are useful. Each node in a cluster would export information about itself, which could then be collected by the other members of the cluster. Using the puppetlabs-concat module, you can build up a configuration file using exported concat fragments from all the nodes in the cluster.
Remember to look at the Forge before starting your own module. If nothing else, you'll get some ideas that you can use in your own module. Corosync can be managed with the Puppet labs module at https://forge.puppetlabs.com/puppetlabs/corosync.
modules/heartbeat/manifests/init.pp with the following contents:# Manage Heartbeat
class heartbeat {
package { 'heartbeat':
ensure => installed,
}
service { 'heartbeat':
ensure => running,
enable => true,
require => Package['heartbeat'],
}
file { '/etc/ha.d/authkeys':
content => "auth 1\n1 sha1 TopSecret",
mode => '0600',
require => Package['heartbeat'],
notify => Service['heartbeat'],
}
include myfw
firewall {'0694 Allow UDP ha-cluster':
proto => 'udp',
port => 694,
action => 'accept',
}
}- file
modules/heartbeat/manifests/vip.ppwith the following contents:# Manage a specific VIP with Heartbeat class heartbeat::vip($node1,$node2,$ip1,$ip2,$vip,$interface='eth0:1') { include heartbeat file { '/etc/ha.d/haresources': content => "${node1} IPaddr::${vip}/${interface}\n", require => Package['heartbeat'], notify => Service['heartbeat'], } file { '/etc/ha.d/ha.cf': content => template('heartbeat/vip.ha.cf.erb'), require => Package['heartbeat'], notify => Service['heartbeat'], } } - Create the file
modules/heartbeat/templates/vip.ha.cf.erbwith the following contents:use_logd yes udpport 694 autojoin none ucast eth0 <%= @ip1 %> ucast eth0 <%= @ip2 %> keepalive 1 deadtime 10 warntime 5 auto_failback off node <%= @node1 %> node <%= @node2 %>
- Modify your
site.ppfile as follows. Replace theip1andip2addresses with the primary IP addresses of your two nodes,vipwith the virtual IP address you'll be using, andnode1andnode2with the hostnames of the two nodes. (Heartbeat uses the fully-qualified domain name of a node to determine whether it's a member of the cluster, so the values fornode1andnode2should match what's given byfacter fqdnon each machine.):node cookbook,cookbook2 { class { 'heartbeat::vip': ip1 => '192.168.122.132', ip2 => '192.168.122.133', node1 => 'cookbook.example.com', node2 => 'cookbook2.example.com', vip => '192.168.122.200/24', } } - Run Puppet on each of the two servers:
[root@cookbook2 ~]# puppet agent -t Info: Retrieving pluginfacts Info: Retrieving plugin Info: Loading facts Info: Caching catalog for cookbook2.example.com Info: Applying configuration version '1415517914' Notice: /Stage[main]/Heartbeat/Package[heartbeat]/ensure: created Notice: /Stage[main]/Myfw::Pre/Firewall[0000 Allow all traffic on loopback]/ensure: created Notice: /Stage[main]/Myfw::Pre/Firewall[0001 Allow all ICMP]/ensure: created Notice: /File[/etc/sysconfig/iptables]/seluser: seluser changed 'unconfined_u' to 'system_u' Notice: /Stage[main]/Myfw::Pre/Firewall[0022 Allow all TCP on port 22 (ssh)]/ensure: created Notice: /Stage[main]/Heartbeat::Vip/File[/etc/ha.d/haresources]/ensure: defined content as '{md5}fb9f5d9d2b26e3bddf681676d8b2129c' Info: /Stage[main]/Heartbeat::Vip/File[/etc/ha.d/haresources]: Scheduling refresh of Service[heartbeat] Notice: /Stage[main]/Heartbeat::Vip/File[/etc/ha.d/ha.cf]/ensure: defined content as '{md5}84da22f7ac1a3629f69dcf29ccfd8592' Info: /Stage[main]/Heartbeat::Vip/File[/etc/ha.d/ha.cf]: Scheduling refresh of Service[heartbeat] Notice: /Stage[main]/Heartbeat/Service[heartbeat]/ensure: ensure changed 'stopped' to 'running' Info: /Stage[main]/Heartbeat/Service[heartbeat]: Unscheduling refresh on Service[heartbeat] Notice: /Stage[main]/Myfw::Pre/Firewall[0002 Allow all established traffic]/ensure: created Notice: /Stage[main]/Myfw::Post/Firewall[9999 Drop all other traffic]/ensure: created Notice: /Stage[main]/Heartbeat/Firewall[0694 Allow UDP ha-cluster]/ensure: created Notice: Finished catalog run in 12.64 seconds
- Verify that the VIP is running on one of the nodes (it should be on cookbook at this point; note that you will need to use the
ipcommand,ifconfigwill not show the address):[root@cookbook ~]# ip addr show dev eth0 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 52:54:00:c9:d5:63 brd ff:ff:ff:ff:ff:ff inet 192.168.122.132/24 brd 192.168.122.255 scope global eth0 inet 192.168.122.200/24 brd 192.168.122.255 scope global secondary eth0:1 inet6 fe80::5054:ff:fec9:d563/64 scope link valid_lft forever preferred_lft forever
- As we can see, cookbook has the
eth0:1interface active. If you stop heartbeat oncookbook,cookbook2will createeth0:1and take over:[root@cookbook2 ~]# ip a show dev eth0 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 52:54:00:ee:9c:fa brd ff:ff:ff:ff:ff:ff inet 192.168.122.133/24 brd 192.168.122.255 scope global eth0 inet 192.168.122.200/24 brd 192.168.122.255 scope global secondary eth0:1 inet6 fe80::5054:ff:feee:9cfa/64 scope link valid_lft forever preferred_lft forever
We need to install Heartbeat first of all, using the heartbeat class:
Next, we use the heartbeat::vip class to manage a specific virtual IP:
The file is interpreted by Heartbeat as follows:
cookbook.example.com: This is the name of the primary node, which should be the default owner of the resourceIPaddr: This is the type of resource to manage; in this case, an IP address192.168.122.200/24: This is the value for the IP addresseth0:1: This is the virtual interface to configure with the managed IP address
For more information on how heartbeat is configured, please visit the high-availability site at http://linux-ha.org/wiki/Heartbeat.
We will also build the ha.cf file that tells Heartbeat how to communicate between cluster nodes:
file { '/etc/ha.d/ha.cf':
content => template('heartbeat/vip.ha.cf.erb'),
notify => Service['heartbeat'],
require => Package['heartbeat'],
}To do this, we use the template file:
use_logd yes udpport 694 autojoin none ucast eth0 <%= @ip1 %> ucast eth0 <%= @ip2 %> keepalive 1 deadtime 10 warntime 5 auto_failback off node <%= @node1 %> node <%= @node2 %>
The interesting values here are the IP addresses of the two nodes (ip1 and ip2), and the names of the two nodes (node1 and node2).
Finally, we create an instance of heartbeat::vip on both machines and pass it an identical set of parameters as follows:
The auto_failback setting in ha.cf governs what happens next. If auto_failback is set to on, when cookbook becomes available once more, it will automatically take over the IP address. Without auto_failback, the IP will stay where it is until you manually fail it again (by stopping heartbeart on cookbook2, for example).
Heartbeat works great for the previous example but is not in widespread use in this form. Heartbeat only works in two node clusters; for n-node clusters, the newer pacemaker project should be used. More information on Heartbeat, pacemaker, corosync, and other clustering packages can be found at http://www.linux-ha.org/wiki/Main_Page.
Managing cluster configuration is one area where exported resources are useful. Each node in a cluster would export information about itself, which could then be collected by the other members of the cluster. Using the puppetlabs-concat module, you can build up a configuration file using exported concat fragments from all the nodes in the cluster.
Remember to look at the Forge before starting your own module. If nothing else, you'll get some ideas that you can use in your own module. Corosync can be managed with the Puppet labs module at https://forge.puppetlabs.com/puppetlabs/corosync.
Heartbeat first of all, using the heartbeat class:
Next, we use the heartbeat::vip class to manage a specific virtual IP:
The file is interpreted by Heartbeat as follows:
cookbook.example.com: This is the name of the primary node, which should be the default owner of the resourceIPaddr: This is the type of resource to manage; in this case, an IP address192.168.122.200/24: This is the value for the IP addresseth0:1: This is the virtual interface to configure with the managed IP address
For more information on how heartbeat is configured, please visit the high-availability site at http://linux-ha.org/wiki/Heartbeat.
We will also build the ha.cf file that tells Heartbeat how to communicate between cluster nodes:
file { '/etc/ha.d/ha.cf':
content => template('heartbeat/vip.ha.cf.erb'),
notify => Service['heartbeat'],
require => Package['heartbeat'],
}To do this, we use the template file:
use_logd yes udpport 694 autojoin none ucast eth0 <%= @ip1 %> ucast eth0 <%= @ip2 %> keepalive 1 deadtime 10 warntime 5 auto_failback off node <%= @node1 %> node <%= @node2 %>
The interesting values here are the IP addresses of the two nodes (ip1 and ip2), and the names of the two nodes (node1 and node2).
Finally, we create an instance of heartbeat::vip on both machines and pass it an identical set of parameters as follows:
The auto_failback setting in ha.cf governs what happens next. If auto_failback is set to on, when cookbook becomes available once more, it will automatically take over the IP address. Without auto_failback, the IP will stay where it is until you manually fail it again (by stopping heartbeart on cookbook2, for example).
Heartbeat works great for the previous example but is not in widespread use in this form. Heartbeat only works in two node clusters; for n-node clusters, the newer pacemaker project should be used. More information on Heartbeat, pacemaker, corosync, and other clustering packages can be found at http://www.linux-ha.org/wiki/Main_Page.
Managing cluster configuration is one area where exported resources are useful. Each node in a cluster would export information about itself, which could then be collected by the other members of the cluster. Using the puppetlabs-concat module, you can build up a configuration file using exported concat fragments from all the nodes in the cluster.
Remember to look at the Forge before starting your own module. If nothing else, you'll get some ideas that you can use in your own module. Corosync can be managed with the Puppet labs module at https://forge.puppetlabs.com/puppetlabs/corosync.
cookbook by default. If something happens to interfere with this (for example, if you halt or reboot cookbook, or stop the heartbeat service, or the machine loses network connectivity), cookbook2 will immediately take over the virtual IP.
auto_failback setting
Heartbeat works great for the previous example but is not in widespread use in this form. Heartbeat only works in two node clusters; for n-node clusters, the newer pacemaker project should be used. More information on Heartbeat, pacemaker, corosync, and other clustering packages can be found at http://www.linux-ha.org/wiki/Main_Page.
Managing cluster configuration is one area where exported resources are useful. Each node in a cluster would export information about itself, which could then be collected by the other members of the cluster. Using the puppetlabs-concat module, you can build up a configuration file using exported concat fragments from all the nodes in the cluster.
Remember to look at the Forge before starting your own module. If nothing else, you'll get some ideas that you can use in your own module. Corosync can be managed with the Puppet labs module at https://forge.puppetlabs.com/puppetlabs/corosync.
NFS (Network File System) is a protocol to mount a shared directory from a remote server. For example, a pool of web servers might all mount the same NFS share to serve static assets such as images and stylesheets. Although NFS is generally slower and less secure than local storage or a clustered filesystem, the ease with which it can be used makes it a common choice in the datacenter. We'll use our myfw module from before to ensure the local firewall permits nfs communication. We'll also use the Puppet labs-concat module to edit the list of exported filesystems on our nfs server.
In this example, we'll configure an nfs server to share (export) some filesystem via NFS.
- Create an
nfsmodule with the followingnfs::exportsclass, which defines a concat resource:class nfs::exports { exec {'nfs::exportfs': command => 'exportfs -a', refreshonly => true, path => '/usr/bin:/bin:/sbin:/usr/sbin', } concat {'/etc/exports': notify => Exec['nfs::exportfs'], } } - Create the
nfs::exportdefined type, we'll use this definition for anynfsexports we create:define nfs::export ( $where = $title, $who = '*', $options = 'async,ro', $mount_options = 'defaults', $tag = 'nfs' ) { # make sure the directory exists # export the entry locally, then export a resource to be picked up later. file {"$where": ensure => 'directory', } include nfs::exports concat::fragment { "nfs::export::$where": content => "${where} ${who}(${options})\n", target => '/etc/exports' } @@mount { "nfs::export::${where}::${::ipaddress}": name => "$where", ensure => 'mounted', fstype => 'nfs', options => "$mount_options", device => "${::ipaddress}:${where}", tag => "$tag", } } - Now create the
nfs::serverclass, which will include the OS-specific configuration for the server:class nfs::server { # ensure nfs server is running # firewall should allow nfs communication include nfs::exports case $::osfamily { 'RedHat': { include nfs::server::redhat } 'Debian': { include nfs::server::debian } } include myfw firewall {'2049 NFS TCP communication': proto => 'tcp', port => '2049', action => 'accept', } firewall {'2049 UDP NFS communication': proto => 'udp', port => '2049', action => 'accept', } firewall {'0111 TCP PORTMAP': proto => 'tcp', port => '111', action => 'accept', } firewall {'0111 UDP PORTMAP': proto => 'udp', port => '111', action => 'accept', } firewall {'4000 TCP STAT': proto => 'tcp', port => '4000-4010', action => 'accept', } firewall {'4000 UDP STAT': proto => 'udp', port => '4000-4010', action => 'accept', } } - Next, create the
nfs::server::redhatclass:class nfs::server::redhat { package {'nfs-utils': ensure => 'installed', } service {'nfs': ensure => 'running', enable => true } file {'/etc/sysconfig/nfs': source => 'puppet:///modules/nfs/nfs', mode => 0644, notify => Service['nfs'], } } - Create the
/etc/sysconfig/nfssupport file for RedHat systems in the files directory of ournfsrepo (modules/nfs/files/nfs):STATD_PORT=4000 STATD_OUTGOING_PORT=4001 RQUOTAD_PORT=4002 LOCKD_TCPPORT=4003 LOCKD_UDPPORT=4003 MOUNTD_PORT=4004
- Now create the support class for Debian systems,
nfs::server::debian:class nfs::server::debian { # install the package package {'nfs': name => 'nfs-kernel-server', ensure => 'installed', } # config file {'/etc/default/nfs-common': source => 'puppet:///modules/nfs/nfs-common', mode => 0644, notify => Service['nfs-common'] } # services service {'nfs-common': ensure => 'running', enable => true, } service {'nfs': name => 'nfs-kernel-server', ensure => 'running', enable => true, require => Package['nfs-kernel-server'] } } - Create the nfs-common configuration for Debian (which will be placed in
modules/nfs/files/nfs-common):STATDOPTS="--port 4000 --outgoing-port 4001"
- Apply the
nfs::serverclass to a node and then create an export on that node:node debian { include nfs::server nfs::export {'/srv/home': tag => "srv_home" } } - Create a collector for the exported resource created by the
nfs::serverclass in the preceding code snippet:node cookbook { Mount <<| tag == "srv_home" |>> { name => '/mnt', } } - Finally, run Puppet on the node Debian to create the exported resource. Then, run Puppet on the cookbook node to mount that resource:
root@debian:~# puppet agent -t Info: Caching catalog for debian.example.com Info: Applying configuration version '1415602532' Notice: Finished catalog run in 0.78 seconds [root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1415603580' Notice: /Stage[main]/Main/Node[cookbook]/Mount[nfs::export::/srv/home::192.168.122.148]/ensure: ensure changed 'ghost' to 'mounted' Info: Computing checksum on file /etc/fstab Info: /Stage[main]/Main/Node[cookbook]/Mount[nfs::export::/srv/home::192.168.122.148]: Scheduling refresh of Mount[nfs::export::/srv/home::192.168.122.148] Info: Mount[nfs::export::/srv/home::192.168.122.148](provider=parsed): Remounting Notice: /Stage[main]/Main/Node[cookbook]/Mount[nfs::export::/srv/home::192.168.122.148]: Triggered 'refresh' from 1 events Info: /Stage[main]/Main/Node[cookbook]/Mount[nfs::export::/srv/home::192.168.122.148]: Scheduling refresh of Mount[nfs::export::/srv/home::192.168.122.148] Notice: Finished catalog run in 0.34 seconds
- Verify the mount with
mount:[root@cookbook ~]# mount -t nfs 192.168.122.148:/srv/home on /mnt type nfs (rw)
The nfs::exports class defines an exec, which runs 'exportfs -a', to export all filesystems defined in /etc/exports. Next, we define a concat resource to contain concat::fragments, which we will define next in our nfs::export class. Concat resources specify the file that the fragments are to be placed into; /etc/exports in this case. Our concat resource has a notify for the previous exec. This has the effect that whenever /etc/exports is updated, we run 'exportfs -a' again to export the new entries:
In the definition, we use the attribute $where to define what filesystem we are exporting. We use $who to specify who can mount the filesystem. The attribute $options contains the exporting options such as
rw (read-write),
ro (read-only). Next, we have the options that will be placed in /etc/fstab on the client machine, the mount options, stored in $mount_options. The nfs::exports class is included here so that concat::fragment has a concat target defined.
We reuse our myfw module and include it in the nfs::server class. This class illustrates one of the things to consider when writing your modules. Not all Linux distributions are created equal. Debian and RedHat deal with NFS server configuration quite differently. The nfs::server module deals with this by including OS-specific subclasses:
The nfs::server module opens several firewall ports for NFS communication. NFS traffic is always carried over port 2049 but ancillary systems, such as locking, quota, and file status daemons, use ephemeral ports chosen by the portmapper, by default. The portmapper itself uses port 111. So our module needs to allow 2049, 111, and a few other ports. We attempt to configure the ancillary services to use ports 4000 through 4010.
We use the spaceship syntax (<<| |>>) to collect all the exported mount resources that have the tag we defined earlier (srv_home). We then use a syntax called "override on collect" to modify the name attribute of the mount to specify where to mount the filesystem.
nfs server to share (export) some filesystem via NFS.
nfs module with the following nfs::exports class, which defines a concat resource:class nfs::exports {
exec {'nfs::exportfs':
command => 'exportfs -a',
refreshonly => true,
path => '/usr/bin:/bin:/sbin:/usr/sbin',
}
concat {'/etc/exports':
notify => Exec['nfs::exportfs'],
}
}nfs::export defined type, we'll use this definition for any nfs exports we create:define nfs::export (
$where = $title,
$who = '*',
$options = 'async,ro',
$mount_options = 'defaults',
$tag = 'nfs'
) {
# make sure the directory exists
# export the entry locally, then export a resource to be picked up later.
file {"$where":
ensure => 'directory',
}
include nfs::exports
concat::fragment { "nfs::export::$where":
content => "${where} ${who}(${options})\n",
target => '/etc/exports'
}
@@mount { "nfs::export::${where}::${::ipaddress}":
name => "$where",
ensure => 'mounted',
fstype => 'nfs',
options => "$mount_options",
device => "${::ipaddress}:${where}",
tag => "$tag",
}
}- the
nfs::serverclass, which will include the OS-specific configuration for the server:class nfs::server { # ensure nfs server is running # firewall should allow nfs communication include nfs::exports case $::osfamily { 'RedHat': { include nfs::server::redhat } 'Debian': { include nfs::server::debian } } include myfw firewall {'2049 NFS TCP communication': proto => 'tcp', port => '2049', action => 'accept', } firewall {'2049 UDP NFS communication': proto => 'udp', port => '2049', action => 'accept', } firewall {'0111 TCP PORTMAP': proto => 'tcp', port => '111', action => 'accept', } firewall {'0111 UDP PORTMAP': proto => 'udp', port => '111', action => 'accept', } firewall {'4000 TCP STAT': proto => 'tcp', port => '4000-4010', action => 'accept', } firewall {'4000 UDP STAT': proto => 'udp', port => '4000-4010', action => 'accept', } } - Next, create the
nfs::server::redhatclass:class nfs::server::redhat { package {'nfs-utils': ensure => 'installed', } service {'nfs': ensure => 'running', enable => true } file {'/etc/sysconfig/nfs': source => 'puppet:///modules/nfs/nfs', mode => 0644, notify => Service['nfs'], } } - Create the
/etc/sysconfig/nfssupport file for RedHat systems in the files directory of ournfsrepo (modules/nfs/files/nfs):STATD_PORT=4000 STATD_OUTGOING_PORT=4001 RQUOTAD_PORT=4002 LOCKD_TCPPORT=4003 LOCKD_UDPPORT=4003 MOUNTD_PORT=4004
- Now create the support class for Debian systems,
nfs::server::debian:class nfs::server::debian { # install the package package {'nfs': name => 'nfs-kernel-server', ensure => 'installed', } # config file {'/etc/default/nfs-common': source => 'puppet:///modules/nfs/nfs-common', mode => 0644, notify => Service['nfs-common'] } # services service {'nfs-common': ensure => 'running', enable => true, } service {'nfs': name => 'nfs-kernel-server', ensure => 'running', enable => true, require => Package['nfs-kernel-server'] } } - Create the nfs-common configuration for Debian (which will be placed in
modules/nfs/files/nfs-common):STATDOPTS="--port 4000 --outgoing-port 4001"
- Apply the
nfs::serverclass to a node and then create an export on that node:node debian { include nfs::server nfs::export {'/srv/home': tag => "srv_home" } } - Create a collector for the exported resource created by the
nfs::serverclass in the preceding code snippet:node cookbook { Mount <<| tag == "srv_home" |>> { name => '/mnt', } } - Finally, run Puppet on the node Debian to create the exported resource. Then, run Puppet on the cookbook node to mount that resource:
root@debian:~# puppet agent -t Info: Caching catalog for debian.example.com Info: Applying configuration version '1415602532' Notice: Finished catalog run in 0.78 seconds [root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1415603580' Notice: /Stage[main]/Main/Node[cookbook]/Mount[nfs::export::/srv/home::192.168.122.148]/ensure: ensure changed 'ghost' to 'mounted' Info: Computing checksum on file /etc/fstab Info: /Stage[main]/Main/Node[cookbook]/Mount[nfs::export::/srv/home::192.168.122.148]: Scheduling refresh of Mount[nfs::export::/srv/home::192.168.122.148] Info: Mount[nfs::export::/srv/home::192.168.122.148](provider=parsed): Remounting Notice: /Stage[main]/Main/Node[cookbook]/Mount[nfs::export::/srv/home::192.168.122.148]: Triggered 'refresh' from 1 events Info: /Stage[main]/Main/Node[cookbook]/Mount[nfs::export::/srv/home::192.168.122.148]: Scheduling refresh of Mount[nfs::export::/srv/home::192.168.122.148] Notice: Finished catalog run in 0.34 seconds
- Verify the mount with
mount:[root@cookbook ~]# mount -t nfs 192.168.122.148:/srv/home on /mnt type nfs (rw)
The nfs::exports class defines an exec, which runs 'exportfs -a', to export all filesystems defined in /etc/exports. Next, we define a concat resource to contain concat::fragments, which we will define next in our nfs::export class. Concat resources specify the file that the fragments are to be placed into; /etc/exports in this case. Our concat resource has a notify for the previous exec. This has the effect that whenever /etc/exports is updated, we run 'exportfs -a' again to export the new entries:
In the definition, we use the attribute $where to define what filesystem we are exporting. We use $who to specify who can mount the filesystem. The attribute $options contains the exporting options such as
rw (read-write),
ro (read-only). Next, we have the options that will be placed in /etc/fstab on the client machine, the mount options, stored in $mount_options. The nfs::exports class is included here so that concat::fragment has a concat target defined.
We reuse our myfw module and include it in the nfs::server class. This class illustrates one of the things to consider when writing your modules. Not all Linux distributions are created equal. Debian and RedHat deal with NFS server configuration quite differently. The nfs::server module deals with this by including OS-specific subclasses:
The nfs::server module opens several firewall ports for NFS communication. NFS traffic is always carried over port 2049 but ancillary systems, such as locking, quota, and file status daemons, use ephemeral ports chosen by the portmapper, by default. The portmapper itself uses port 111. So our module needs to allow 2049, 111, and a few other ports. We attempt to configure the ancillary services to use ports 4000 through 4010.
We use the spaceship syntax (<<| |>>) to collect all the exported mount resources that have the tag we defined earlier (srv_home). We then use a syntax called "override on collect" to modify the name attribute of the mount to specify where to mount the filesystem.
nfs::exports class
defines an exec, which runs 'exportfs -a', to export all filesystems defined in /etc/exports. Next, we define a concat resource to contain concat::fragments, which we will define next in our nfs::export class. Concat resources specify the file that the fragments are to be placed into; /etc/exports in this case. Our concat resource has a notify for the previous exec. This has the effect that whenever /etc/exports is updated, we run 'exportfs -a' again to export the new entries:
In the definition, we use the attribute $where to define what filesystem we are exporting. We use $who to specify who can mount the filesystem. The attribute $options contains the exporting options such as
rw (read-write),
ro (read-only). Next, we have the options that will be placed in /etc/fstab on the client machine, the mount options, stored in $mount_options. The nfs::exports class is included here so that concat::fragment has a concat target defined.
We reuse our myfw module and include it in the nfs::server class. This class illustrates one of the things to consider when writing your modules. Not all Linux distributions are created equal. Debian and RedHat deal with NFS server configuration quite differently. The nfs::server module deals with this by including OS-specific subclasses:
The nfs::server module opens several firewall ports for NFS communication. NFS traffic is always carried over port 2049 but ancillary systems, such as locking, quota, and file status daemons, use ephemeral ports chosen by the portmapper, by default. The portmapper itself uses port 111. So our module needs to allow 2049, 111, and a few other ports. We attempt to configure the ancillary services to use ports 4000 through 4010.
We use the spaceship syntax (<<| |>>) to collect all the exported mount resources that have the tag we defined earlier (srv_home). We then use a syntax called "override on collect" to modify the name attribute of the mount to specify where to mount the filesystem.
Load balancers are used to spread a load among a number of servers. Hardware load balancers are still somewhat expensive, whereas software balancers can achieve most of the benefits of a hardware solution.
HAProxy is the software load balancer of choice for most people: fast, powerful, and highly configurable.
In this recipe, I'll show you how to build an HAProxy server to load-balance web requests across web servers. We'll use exported resources to build the haproxy configuration file just like we did for the NFS example.
- Create the file
modules/haproxy/manifests/master.ppwith the following contents:class haproxy::master ($app = 'myapp') { # The HAProxy master server # will collect haproxy::slave resources and add to its balancer package { 'haproxy': ensure => installed } service { 'haproxy': ensure => running, enable => true, require => Package['haproxy'], } include haproxy::config concat::fragment { 'haproxy.cfg header': target => 'haproxy.cfg', source => 'puppet:///modules/haproxy/haproxy.cfg', order => '001', require => Package['haproxy'], notify => Service['haproxy'], } # pull in the exported entries Concat::Fragment <<| tag == "$app" |>> { target => 'haproxy.cfg', notify => Service['haproxy'], } } - Create the file
modules/haproxy/files/haproxy.cfgwith the following contents:global daemon user haproxy group haproxy pidfile /var/run/haproxy.pid defaults log global stats enable mode http option httplog option dontlognull option dontlog-normal retries 3 option redispatch timeout connect 4000 timeout client 60000 timeout server 30000 listen stats :8080 mode http stats uri / stats auth haproxy:topsecret listen myapp 0.0.0.0:80 balance leastconn - Modify your
manifests/nodes.ppfile as follows:node 'cookbook' { include haproxy } - Create the slave server configuration in the
haproxy::slaveclass:class haproxy::slave ($app = "myapp", $localport = 8000) { # haproxy slave, export haproxy.cfg fragment # configure simple web server on different port @@concat::fragment { "haproxy.cfg $::fqdn": content => "\t\tserver ${::hostname} ${::ipaddress}:${localport} check maxconn 100\n", order => '0010', tag => "$app", } include myfw firewall {"${localport} Allow HTTP to haproxy::slave": proto => 'tcp', port => $localport, action => 'accept', } class {'apache': } apache::vhost { 'haproxy.example.com': port => '8000', docroot => '/var/www/haproxy', } file {'/var/www/haproxy': ensure => 'directory', mode => 0755, require => Class['apache'], } file {'/var/www/haproxy/index.html': mode => '0644', content => "<html><body><h1>${::fqdn} haproxy::slave\n</body></html>\n", require => File['/var/www/haproxy'], } } - Create the
concatcontainer resource in thehaproxy::configclass as follows:class haproxy::config { concat {'haproxy.cfg': path => '/etc/haproxy/haproxy.cfg', order => 'numeric', mode => '0644', } } - Modify
site.ppto define the master and slave nodes:node master { class {'haproxy::master': app => 'cookbook' } } node slave1,slave2 { class {'haproxy::slave': app => 'cookbook' } } - Run Puppet on each of the slave servers:
root@slave1:~# puppet agent -t Info: Caching catalog for slave1 Info: Applying configuration version '1415646194' Notice: /Stage[main]/Haproxy::Slave/Apache::Vhost[haproxy.example.com]/File[25-haproxy.example.com.conf]/ensure: created Info: /Stage[main]/Haproxy::Slave/Apache::Vhost[haproxy.example.com]/File[25-haproxy.example.com.conf]: Scheduling refresh of Service[httpd] Notice: /Stage[main]/Haproxy::Slave/Apache::Vhost[haproxy.example.com]/File[25-haproxy.example.com.conf symlink]/ensure: created Info: /Stage[main]/Haproxy::Slave/Apache::Vhost[haproxy.example.com]/File[25-haproxy.example.com.conf symlink]: Scheduling refresh of Service[httpd] Notice: /Stage[main]/Apache::Service/Service[httpd]/ensure: ensure changed 'stopped' to 'running' Info: /Stage[main]/Apache::Service/Service[httpd]: Unscheduling refresh on Service[httpd] Notice: Finished catalog run in 1.71 seconds
- Run Puppet on the master node to configure and run
haproxy:[root@master ~]# puppet agent -t Info: Caching catalog for master.example.com Info: Applying configuration version '1415647075' Notice: /Stage[main]/Haproxy::Master/Package[haproxy]/ensure: created Notice: /Stage[main]/Myfw::Pre/Firewall[0000 Allow all traffic on loopback]/ensure: created Notice: /Stage[main]/Myfw::Pre/Firewall[0001 Allow all ICMP]/ensure: created Notice: /Stage[main]/Haproxy::Master/Firewall[8080 haproxy statistics]/ensure: created Notice: /File[/etc/sysconfig/iptables]/seluser: seluser changed 'unconfined_u' to 'system_u' Notice: /Stage[main]/Myfw::Pre/Firewall[0022 Allow all TCP on port 22 (ssh)]/ensure: created Notice: /Stage[main]/Haproxy::Master/Firewall[0080 http haproxy]/ensure: created Notice: /Stage[main]/Myfw::Pre/Firewall[0002 Allow all established traffic]/ensure: created Notice: /Stage[main]/Myfw::Post/Firewall[9999 Drop all other traffic]/ensure: created Notice: /Stage[main]/Haproxy::Config/Concat[haproxy.cfg]/File[haproxy.cfg]/content: ... +listen myapp 0.0.0.0:80 + balance leastconn + server slave1 192.168.122.148:8000 check maxconn 100 + server slave2 192.168.122.133:8000 check maxconn 100 Info: Computing checksum on file /etc/haproxy/haproxy.cfg Info: /Stage[main]/Haproxy::Config/Concat[haproxy.cfg]/File[haproxy.cfg]: Filebucketed /etc/haproxy/haproxy.cfg to puppet with sum 1f337186b0e1ba5ee82760cb437fb810 Notice: /Stage[main]/Haproxy::Config/Concat[haproxy.cfg]/File[haproxy.cfg]/content: content changed '{md5}1f337186b0e1ba5ee82760cb437fb810' to '{md5}b070f076e1e691e053d6853f7d966394' Notice: /Stage[main]/Haproxy::Master/Service[haproxy]/ensure: ensure changed 'stopped' to 'running' Info: /Stage[main]/Haproxy::Master/Service[haproxy]: Unscheduling refresh on Service[haproxy] Notice: Finished catalog run in 33.48 seconds
- Check the HAProxy stats interface on master port
8080in your web browser (http://master.example.com:8080) to make sure everything is okay (The username and password are inhaproxy.cfg,haproxy, andtopsecret). Try going to the proxied service as well. Notice that the page changes on each reload as the service is redirected from slave1 to slave2 (http://master.example.com).
There are several things going on here. We have the firewall configuration and the Apache configuration in addition to the haproxy configuration. We'll focus on how the exported resources and the haproxy configuration fit together.
In the haproxy::config class, we created the concat container for the haproxy configuration:
We reference this in haproxy::slave:
The rest of the haproxy::master class is concerned with configuring the firewall as we did in previous examples.
HAProxy has a vast range of configuration parameters, which you can explore; see the HAProxy website at http://haproxy.1wt.eu/#docs.
Although it's most often used as a web server, HAProxy can proxy a lot more than just HTTP. It can handle any kind of TCP traffic, so you can use it to balance the load of MySQL servers, SMTP, video servers, or anything you like.
You can use the design we showed to attack many problems of coordination of services between multiple servers. This type of interaction is very common; you can apply it to many configurations for load balancing or distributed systems. You can use the same workflow described previously to have nodes export firewall resources (@@firewall) to permit their own access.
show you how to build an HAProxy server to load-balance web requests across web servers. We'll use exported resources to build the haproxy configuration file just like we did for the NFS example.
- Create the file
modules/haproxy/manifests/master.ppwith the following contents:class haproxy::master ($app = 'myapp') { # The HAProxy master server # will collect haproxy::slave resources and add to its balancer package { 'haproxy': ensure => installed } service { 'haproxy': ensure => running, enable => true, require => Package['haproxy'], } include haproxy::config concat::fragment { 'haproxy.cfg header': target => 'haproxy.cfg', source => 'puppet:///modules/haproxy/haproxy.cfg', order => '001', require => Package['haproxy'], notify => Service['haproxy'], } # pull in the exported entries Concat::Fragment <<| tag == "$app" |>> { target => 'haproxy.cfg', notify => Service['haproxy'], } } - Create the file
modules/haproxy/files/haproxy.cfgwith the following contents:global daemon user haproxy group haproxy pidfile /var/run/haproxy.pid defaults log global stats enable mode http option httplog option dontlognull option dontlog-normal retries 3 option redispatch timeout connect 4000 timeout client 60000 timeout server 30000 listen stats :8080 mode http stats uri / stats auth haproxy:topsecret listen myapp 0.0.0.0:80 balance leastconn - Modify your
manifests/nodes.ppfile as follows:node 'cookbook' { include haproxy } - Create the slave server configuration in the
haproxy::slaveclass:class haproxy::slave ($app = "myapp", $localport = 8000) { # haproxy slave, export haproxy.cfg fragment # configure simple web server on different port @@concat::fragment { "haproxy.cfg $::fqdn": content => "\t\tserver ${::hostname} ${::ipaddress}:${localport} check maxconn 100\n", order => '0010', tag => "$app", } include myfw firewall {"${localport} Allow HTTP to haproxy::slave": proto => 'tcp', port => $localport, action => 'accept', } class {'apache': } apache::vhost { 'haproxy.example.com': port => '8000', docroot => '/var/www/haproxy', } file {'/var/www/haproxy': ensure => 'directory', mode => 0755, require => Class['apache'], } file {'/var/www/haproxy/index.html': mode => '0644', content => "<html><body><h1>${::fqdn} haproxy::slave\n</body></html>\n", require => File['/var/www/haproxy'], } } - Create the
concatcontainer resource in thehaproxy::configclass as follows:class haproxy::config { concat {'haproxy.cfg': path => '/etc/haproxy/haproxy.cfg', order => 'numeric', mode => '0644', } } - Modify
site.ppto define the master and slave nodes:node master { class {'haproxy::master': app => 'cookbook' } } node slave1,slave2 { class {'haproxy::slave': app => 'cookbook' } } - Run Puppet on each of the slave servers:
root@slave1:~# puppet agent -t Info: Caching catalog for slave1 Info: Applying configuration version '1415646194' Notice: /Stage[main]/Haproxy::Slave/Apache::Vhost[haproxy.example.com]/File[25-haproxy.example.com.conf]/ensure: created Info: /Stage[main]/Haproxy::Slave/Apache::Vhost[haproxy.example.com]/File[25-haproxy.example.com.conf]: Scheduling refresh of Service[httpd] Notice: /Stage[main]/Haproxy::Slave/Apache::Vhost[haproxy.example.com]/File[25-haproxy.example.com.conf symlink]/ensure: created Info: /Stage[main]/Haproxy::Slave/Apache::Vhost[haproxy.example.com]/File[25-haproxy.example.com.conf symlink]: Scheduling refresh of Service[httpd] Notice: /Stage[main]/Apache::Service/Service[httpd]/ensure: ensure changed 'stopped' to 'running' Info: /Stage[main]/Apache::Service/Service[httpd]: Unscheduling refresh on Service[httpd] Notice: Finished catalog run in 1.71 seconds
- Run Puppet on the master node to configure and run
haproxy:[root@master ~]# puppet agent -t Info: Caching catalog for master.example.com Info: Applying configuration version '1415647075' Notice: /Stage[main]/Haproxy::Master/Package[haproxy]/ensure: created Notice: /Stage[main]/Myfw::Pre/Firewall[0000 Allow all traffic on loopback]/ensure: created Notice: /Stage[main]/Myfw::Pre/Firewall[0001 Allow all ICMP]/ensure: created Notice: /Stage[main]/Haproxy::Master/Firewall[8080 haproxy statistics]/ensure: created Notice: /File[/etc/sysconfig/iptables]/seluser: seluser changed 'unconfined_u' to 'system_u' Notice: /Stage[main]/Myfw::Pre/Firewall[0022 Allow all TCP on port 22 (ssh)]/ensure: created Notice: /Stage[main]/Haproxy::Master/Firewall[0080 http haproxy]/ensure: created Notice: /Stage[main]/Myfw::Pre/Firewall[0002 Allow all established traffic]/ensure: created Notice: /Stage[main]/Myfw::Post/Firewall[9999 Drop all other traffic]/ensure: created Notice: /Stage[main]/Haproxy::Config/Concat[haproxy.cfg]/File[haproxy.cfg]/content: ... +listen myapp 0.0.0.0:80 + balance leastconn + server slave1 192.168.122.148:8000 check maxconn 100 + server slave2 192.168.122.133:8000 check maxconn 100 Info: Computing checksum on file /etc/haproxy/haproxy.cfg Info: /Stage[main]/Haproxy::Config/Concat[haproxy.cfg]/File[haproxy.cfg]: Filebucketed /etc/haproxy/haproxy.cfg to puppet with sum 1f337186b0e1ba5ee82760cb437fb810 Notice: /Stage[main]/Haproxy::Config/Concat[haproxy.cfg]/File[haproxy.cfg]/content: content changed '{md5}1f337186b0e1ba5ee82760cb437fb810' to '{md5}b070f076e1e691e053d6853f7d966394' Notice: /Stage[main]/Haproxy::Master/Service[haproxy]/ensure: ensure changed 'stopped' to 'running' Info: /Stage[main]/Haproxy::Master/Service[haproxy]: Unscheduling refresh on Service[haproxy] Notice: Finished catalog run in 33.48 seconds
- Check the HAProxy stats interface on master port
8080in your web browser (http://master.example.com:8080) to make sure everything is okay (The username and password are inhaproxy.cfg,haproxy, andtopsecret). Try going to the proxied service as well. Notice that the page changes on each reload as the service is redirected from slave1 to slave2 (http://master.example.com).
There are several things going on here. We have the firewall configuration and the Apache configuration in addition to the haproxy configuration. We'll focus on how the exported resources and the haproxy configuration fit together.
In the haproxy::config class, we created the concat container for the haproxy configuration:
We reference this in haproxy::slave:
The rest of the haproxy::master class is concerned with configuring the firewall as we did in previous examples.
HAProxy has a vast range of configuration parameters, which you can explore; see the HAProxy website at http://haproxy.1wt.eu/#docs.
Although it's most often used as a web server, HAProxy can proxy a lot more than just HTTP. It can handle any kind of TCP traffic, so you can use it to balance the load of MySQL servers, SMTP, video servers, or anything you like.
You can use the design we showed to attack many problems of coordination of services between multiple servers. This type of interaction is very common; you can apply it to many configurations for load balancing or distributed systems. You can use the same workflow described previously to have nodes export firewall resources (@@firewall) to permit their own access.
myfw module to configure the firewall on the slaves and the master to allow communication.
index.html on the website).
several things going on here. We have the firewall configuration and the Apache configuration in addition to the haproxy configuration. We'll focus on how the exported resources and the haproxy configuration fit together.
In the haproxy::config class, we created the concat container for the haproxy configuration:
We reference this in haproxy::slave:
The rest of the haproxy::master class is concerned with configuring the firewall as we did in previous examples.
HAProxy has a vast range of configuration parameters, which you can explore; see the HAProxy website at http://haproxy.1wt.eu/#docs.
Although it's most often used as a web server, HAProxy can proxy a lot more than just HTTP. It can handle any kind of TCP traffic, so you can use it to balance the load of MySQL servers, SMTP, video servers, or anything you like.
You can use the design we showed to attack many problems of coordination of services between multiple servers. This type of interaction is very common; you can apply it to many configurations for load balancing or distributed systems. You can use the same workflow described previously to have nodes export firewall resources (@@firewall) to permit their own access.
website at http://haproxy.1wt.eu/#docs.
Although it's most often used as a web server, HAProxy can proxy a lot more than just HTTP. It can handle any kind of TCP traffic, so you can use it to balance the load of MySQL servers, SMTP, video servers, or anything you like.
You can use the design we showed to attack many problems of coordination of services between multiple servers. This type of interaction is very common; you can apply it to many configurations for load balancing or distributed systems. You can use the same workflow described previously to have nodes export firewall resources (@@firewall) to permit their own access.
Docker is a platform for rapid deployment of containers. Containers are like a lightweight virtual machine that might only run a single process. The containers in Docker are called docks and are configured with files called Dockerfiles. Puppet can be used to configure a node to not only run Docker but also configure and start several docks. You can then use Puppet to ensure that your docks are running and are consistently configured.
Download and install the Puppet Docker module from the Forge (https://forge.puppetlabs.com/garethr/docker):
t@mylaptop ~ $ cd puppet t@mylaptop ~/puppet $ puppet module install -i modules garethr-docker Notice: Preparing to install into /home/thomas/puppet/modules ... Notice: Downloading from https://forgeapi.puppetlabs.com ... Notice: Installing -- do not interrupt ... /home/thomas/puppet/modules └─┬ garethr-docker (v3.3.0) ├── puppetlabs-apt (v1.7.0) ├── puppetlabs-stdlib (v4.3.2) └── stahnma-epel (v1.0.2)
Add these modules to your Puppet repository. The stahnma-epel module is required for Enterprise Linux-based distributions; it contains the Extra Packages for Enterprise Linux YUM repository.
Perform the following steps to manage Docker with Puppet:
- To install Docker on a node, we just need to include the
dockerclass. We'll do more than install Docker; we'll also download an image and start an application on our test node. In this example, we'll create a new machine calledshipyard.Add the following node definition tosite.pp:node shipyard { class {'docker': } docker::image {'phusion/baseimage': } docker::run {'cookbook': image => 'phusion/baseimage', expose => '8080', ports => '8080', command => 'nc -k -l 8080', } }
- Run Puppet on your shipyard node to install Docker. This will also download the
phusion/baseimage dockerimage:[root@shipyard ~]# puppet agent -t Info: Retrieving pluginfacts Info: Retrieving plugin Info: Loading facts Info: Caching catalog for shipyard Info: Applying configuration version '1421049252' Notice: /Stage[main]/Epel/File[/etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6]/ensure: defined content as '{md5}d865e6b948a74cb03bc3401c0b01b785' Notice: /Stage[main]/Epel/Epel::Rpm_gpg_key[EPEL-6]/Exec[import-EPEL-6]/returns: executed successfully ... Notice: /Stage[main]/Docker::Install/Package[docker]/ensure: created ... Notice: /Stage[main]/Main/Node[shipyard]/Docker::Run[cookbook]/File[/etc/init.d/docker-cookbook]/ensure: created Info: /Stage[main]/Main/Node[shipyard]/Docker::Run[cookbook]/File[/etc/init.d/docker-cookbook]: Scheduling refresh of Service[docker-cookbook] Notice: /Stage[main]/Main/Node[shipyard]/Docker::Run[cookbook]/Service[docker-cookbook]: Triggered 'refresh' from 1 events
- Verify that your container is running on shipyard using
docker ps:[root@shipyard ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES f6f5b799a598 phusion/baseimage:0.9.15 "/bin/nc -l 8080" About a minute ago Up About a minute 0.0.0.0:49157->8080/tcp suspicious_hawking
- Verify that the dock is running netcat on port 8080 by connecting to the port listed previously (
49157):[root@shipyard ~]# nc -v localhost 49157 Connection to localhost 49157 port [tcp/*] succeeded!
We began by installing the docker module from the Forge. This module installs the docker-io package on our node, along with any required dependencies.
We then defined a docker::image resource. This instructs Puppet to ensure that the named image is downloaded and available to docker. On our first run, Puppet will make docker download the image. We used phusion/baseimage as our example because it is quite small, well-known, and includes the netcat daemon we used in the example. More information on baseimage can be found at http://phusion.github.io/baseimage-docker/.
We then went on to define a docker::run resource. This example isn't terribly useful; it simply starts netcat in listen mode on port 8080. We need to expose that port to our machine, so we define the expose attribute of our docker::run resource. There are many other options available for the docker::run resource. Refer to the source code for more details.
Docker is a great tool for rapid deployment and development. You can spin as many docks as you need on even the most modest hardware. One great use for docker is having docks act as test nodes for your modules. You can create a docker image, which includes Puppet, and then have Puppet run within the dock. For more information on docker, visit http://www.docker.com/.
module from the Forge (https://forge.puppetlabs.com/garethr/docker):
t@mylaptop ~ $ cd puppet t@mylaptop ~/puppet $ puppet module install -i modules garethr-docker Notice: Preparing to install into /home/thomas/puppet/modules ... Notice: Downloading from https://forgeapi.puppetlabs.com ... Notice: Installing -- do not interrupt ... /home/thomas/puppet/modules └─┬ garethr-docker (v3.3.0) ├── puppetlabs-apt (v1.7.0) ├── puppetlabs-stdlib (v4.3.2) └── stahnma-epel (v1.0.2)
Add these modules to your Puppet repository. The stahnma-epel module is required for Enterprise Linux-based distributions; it contains the Extra Packages for Enterprise Linux YUM repository.
Perform the following steps to manage Docker with Puppet:
- To install Docker on a node, we just need to include the
dockerclass. We'll do more than install Docker; we'll also download an image and start an application on our test node. In this example, we'll create a new machine calledshipyard.Add the following node definition tosite.pp:node shipyard { class {'docker': } docker::image {'phusion/baseimage': } docker::run {'cookbook': image => 'phusion/baseimage', expose => '8080', ports => '8080', command => 'nc -k -l 8080', } }
- Run Puppet on your shipyard node to install Docker. This will also download the
phusion/baseimage dockerimage:[root@shipyard ~]# puppet agent -t Info: Retrieving pluginfacts Info: Retrieving plugin Info: Loading facts Info: Caching catalog for shipyard Info: Applying configuration version '1421049252' Notice: /Stage[main]/Epel/File[/etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6]/ensure: defined content as '{md5}d865e6b948a74cb03bc3401c0b01b785' Notice: /Stage[main]/Epel/Epel::Rpm_gpg_key[EPEL-6]/Exec[import-EPEL-6]/returns: executed successfully ... Notice: /Stage[main]/Docker::Install/Package[docker]/ensure: created ... Notice: /Stage[main]/Main/Node[shipyard]/Docker::Run[cookbook]/File[/etc/init.d/docker-cookbook]/ensure: created Info: /Stage[main]/Main/Node[shipyard]/Docker::Run[cookbook]/File[/etc/init.d/docker-cookbook]: Scheduling refresh of Service[docker-cookbook] Notice: /Stage[main]/Main/Node[shipyard]/Docker::Run[cookbook]/Service[docker-cookbook]: Triggered 'refresh' from 1 events
- Verify that your container is running on shipyard using
docker ps:[root@shipyard ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES f6f5b799a598 phusion/baseimage:0.9.15 "/bin/nc -l 8080" About a minute ago Up About a minute 0.0.0.0:49157->8080/tcp suspicious_hawking
- Verify that the dock is running netcat on port 8080 by connecting to the port listed previously (
49157):[root@shipyard ~]# nc -v localhost 49157 Connection to localhost 49157 port [tcp/*] succeeded!
We began by installing the docker module from the Forge. This module installs the docker-io package on our node, along with any required dependencies.
We then defined a docker::image resource. This instructs Puppet to ensure that the named image is downloaded and available to docker. On our first run, Puppet will make docker download the image. We used phusion/baseimage as our example because it is quite small, well-known, and includes the netcat daemon we used in the example. More information on baseimage can be found at http://phusion.github.io/baseimage-docker/.
We then went on to define a docker::run resource. This example isn't terribly useful; it simply starts netcat in listen mode on port 8080. We need to expose that port to our machine, so we define the expose attribute of our docker::run resource. There are many other options available for the docker::run resource. Refer to the source code for more details.
Docker is a great tool for rapid deployment and development. You can spin as many docks as you need on even the most modest hardware. One great use for docker is having docks act as test nodes for your modules. You can create a docker image, which includes Puppet, and then have Puppet run within the dock. For more information on docker, visit http://www.docker.com/.
docker class. We'll do more than install Docker; we'll also download an image and start an application on our test node. In this example, we'll create a new machine called shipyard. Add the following node definition to site.pp:node shipyard { class {'docker': } docker::image {'phusion/baseimage': } docker::run {'cookbook': image => 'phusion/baseimage', expose => '8080', ports => '8080', command => 'nc -k -l 8080', } }
phusion/baseimage docker image:[root@shipyard ~]# puppet agent -t Info: Retrieving pluginfacts Info: Retrieving plugin Info: Loading facts Info: Caching catalog for shipyard Info: Applying configuration version '1421049252' Notice: /Stage[main]/Epel/File[/etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6]/ensure: defined content as '{md5}d865e6b948a74cb03bc3401c0b01b785' Notice: /Stage[main]/Epel/Epel::Rpm_gpg_key[EPEL-6]/Exec[import-EPEL-6]/returns: executed successfully ... Notice: /Stage[main]/Docker::Install/Package[docker]/ensure: created ... Notice: /Stage[main]/Main/Node[shipyard]/Docker::Run[cookbook]/File[/etc/init.d/docker-cookbook]/ensure: created Info: /Stage[main]/Main/Node[shipyard]/Docker::Run[cookbook]/File[/etc/init.d/docker-cookbook]: Scheduling refresh of Service[docker-cookbook] Notice: /Stage[main]/Main/Node[shipyard]/Docker::Run[cookbook]/Service[docker-cookbook]: Triggered 'refresh' from 1 events
docker ps:[root@shipyard ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES f6f5b799a598 phusion/baseimage:0.9.15 "/bin/nc -l 8080" About a minute ago Up About a minute 0.0.0.0:49157->8080/tcp suspicious_hawking
49157):[root@shipyard ~]# nc -v localhost 49157 Connection to localhost 49157 port [tcp/*] succeeded!
We began by installing the docker module from the Forge. This module installs the docker-io package on our node, along with any required dependencies.
We then defined a docker::image resource. This instructs Puppet to ensure that the named image is downloaded and available to docker. On our first run, Puppet will make docker download the image. We used phusion/baseimage as our example because it is quite small, well-known, and includes the netcat daemon we used in the example. More information on baseimage can be found at http://phusion.github.io/baseimage-docker/.
We then went on to define a docker::run resource. This example isn't terribly useful; it simply starts netcat in listen mode on port 8080. We need to expose that port to our machine, so we define the expose attribute of our docker::run resource. There are many other options available for the docker::run resource. Refer to the source code for more details.
Docker is a great tool for rapid deployment and development. You can spin as many docks as you need on even the most modest hardware. One great use for docker is having docks act as test nodes for your modules. You can create a docker image, which includes Puppet, and then have Puppet run within the dock. For more information on docker, visit http://www.docker.com/.
began by installing the docker module from the Forge. This module installs the docker-io package on our node, along with any required dependencies.
We then defined a docker::image resource. This instructs Puppet to ensure that the named image is downloaded and available to docker. On our first run, Puppet will make docker download the image. We used phusion/baseimage as our example because it is quite small, well-known, and includes the netcat daemon we used in the example. More information on baseimage can be found at http://phusion.github.io/baseimage-docker/.
We then went on to define a docker::run resource. This example isn't terribly useful; it simply starts netcat in listen mode on port 8080. We need to expose that port to our machine, so we define the expose attribute of our docker::run resource. There are many other options available for the docker::run resource. Refer to the source code for more details.
Docker is a great tool for rapid deployment and development. You can spin as many docks as you need on even the most modest hardware. One great use for docker is having docks act as test nodes for your modules. You can create a docker image, which includes Puppet, and then have Puppet run within the dock. For more information on docker, visit http://www.docker.com/.
is a great tool for rapid deployment and development. You can spin as many docks as you need on even the most modest hardware. One great use for docker is having docks act as test nodes for your modules. You can create a docker image, which includes Puppet, and then have Puppet run within the dock. For more information on docker, visit http://www.docker.com/.
"By all means leave the road when you wish. That is precisely the use of a road: to reach individually chosen points of departure." | ||
| --Robert Bringhurst, The Elements of Typographic Style | ||
In this chapter, we will cover the following recipes:
- Creating custom facts
- Adding external facts
- Setting facts as environment variables
- Generating manifests with the Puppet resource command
- Generating manifests with other tools
- Using an external node classifier
- Creating your own resource types
- Creating your own providers
- Creating custom functions
- Testing your Puppet manifests with rspec-puppet
- Using librarian-puppet
- Using r10k
Puppet is a useful tool by itself, but you can get much greater benefits by using Puppet in combination with other tools and frameworks. We'll look at some ways of getting data into Puppet, including custom Facter facts, external facts, and tools to generate Puppet manifests automatically from the existing configuration.
While Facter's built-in facts are useful, it's actually quite easy to add your own facts. For example, if you have machines in different data centers or hosting providers, you could add a custom fact for this so that Puppet can determine whether any local settings need to be applied (for example, local DNS servers or network routes).
Here's an example of a simple custom fact:
- Create the directory
modules/facts/lib/facterand then create the filemodules/facts/lib/facter/hello.rbwith the following contents:Facter.add(:hello) do setcode do "Hello, world" end end - Modify your
site.ppfile as follows:node 'cookbook' { notify { $::hello: } } - Run Puppet:
[root@cookbook ~]# puppet agent -t Notice: /File[/var/lib/puppet/lib/facter/hello.rb]/ensure: defined content as '{md5}f66d5e290459388c5ffb3694dd22388b' Info: Loading facts Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1416205745' Notice: Hello, world Notice: /Stage[main]/Main/Node[cookbook]/Notify[Hello, world]/message: defined 'message' as 'Hello, world' Notice: Finished catalog run in 0.53 seconds
Facter facts are defined in Ruby files that are distributed with facter. Puppet can add additional facts to facter by creating files within the lib/facter subdirectory of a module. These files are then transferred to client nodes as we saw earlier with the puppetlabs-stdlib module. To have the command-line facter use these puppet facts, append the -p option to facter as shown in the following command line:
To reference the fact in your manifests, just use its name like a built-in fact:
The name of the Ruby file that holds the fact definition is irrelevant. You can name this file whatever you wish; the name of the fact comes from the Facter.add() function call. You may also call this function several times within a single Ruby file to define multiple facts as necessary. For instance, you could grep the /proc/meminfo file and return several facts based on memory information as shown in the meminfo.rb file in the following code snippet:
You can extend the use of facts to build a completely nodeless Puppet configuration; in other words, Puppet can decide what resources to apply to a machine, based solely on the results of facts. Jordan Sissel has written about this approach at http://www.semicomplete.com/blog/geekery/puppet-nodeless-configuration.html.
You can find out more about custom facts, including how to make sure that OS-specific facts work only on the relevant systems, and how to weigh facts so that they're evaluated in a specific order at the puppetlabs website:
- The Importing dynamic information recipe in Chapter 3, Writing Better Manifests
- The Configuring Hiera recipe in Chapter 2, Puppet Infrastructure
modules/facts/lib/facter and then create the file modules/facts/lib/facter/hello.rb with the following contents:Facter.add(:hello) do
setcode do
"Hello, world"
end
endsite.pp file as follows:node 'cookbook' {
notify { $::hello: }
}[root@cookbook ~]# puppet agent -t Notice: /File[/var/lib/puppet/lib/facter/hello.rb]/ensure: defined content as '{md5}f66d5e290459388c5ffb3694dd22388b' Info: Loading facts Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1416205745' Notice: Hello, world Notice: /Stage[main]/Main/Node[cookbook]/Notify[Hello, world]/message: defined 'message' as 'Hello, world' Notice: Finished catalog run in 0.53 seconds
Facter facts are defined in Ruby files that are distributed with facter. Puppet can add additional facts to facter by creating files within the lib/facter subdirectory of a module. These files are then transferred to client nodes as we saw earlier with the puppetlabs-stdlib module. To have the command-line facter use these puppet facts, append the -p option to facter as shown in the following command line:
To reference the fact in your manifests, just use its name like a built-in fact:
The name of the Ruby file that holds the fact definition is irrelevant. You can name this file whatever you wish; the name of the fact comes from the Facter.add() function call. You may also call this function several times within a single Ruby file to define multiple facts as necessary. For instance, you could grep the /proc/meminfo file and return several facts based on memory information as shown in the meminfo.rb file in the following code snippet:
You can extend the use of facts to build a completely nodeless Puppet configuration; in other words, Puppet can decide what resources to apply to a machine, based solely on the results of facts. Jordan Sissel has written about this approach at http://www.semicomplete.com/blog/geekery/puppet-nodeless-configuration.html.
You can find out more about custom facts, including how to make sure that OS-specific facts work only on the relevant systems, and how to weigh facts so that they're evaluated in a specific order at the puppetlabs website:
- The Importing dynamic information recipe in Chapter 3, Writing Better Manifests
- The Configuring Hiera recipe in Chapter 2, Puppet Infrastructure
The name of the Ruby file that holds the fact definition is irrelevant. You can name this file whatever you wish; the name of the fact comes from the Facter.add() function call. You may also call this function several times within a single Ruby file to define multiple facts as necessary. For instance, you could grep the /proc/meminfo file and return several facts based on memory information as shown in the meminfo.rb file in the following code snippet:
You can extend the use of facts to build a completely nodeless Puppet configuration; in other words, Puppet can decide what resources to apply to a machine, based solely on the results of facts. Jordan Sissel has written about this approach at http://www.semicomplete.com/blog/geekery/puppet-nodeless-configuration.html.
You can find out more about custom facts, including how to make sure that OS-specific facts work only on the relevant systems, and how to weigh facts so that they're evaluated in a specific order at the puppetlabs website:
- The Importing dynamic information recipe in Chapter 3, Writing Better Manifests
- The Configuring Hiera recipe in Chapter 2, Puppet Infrastructure
Facter.add() function call. You may also call this function several times within a single Ruby file to define multiple facts as necessary. For instance, you could grep the /proc/meminfo file and return several facts based on memory information as shown in the meminfo.rb file
in the following code snippet:
You can extend the use of facts to build a completely nodeless Puppet configuration; in other words, Puppet can decide what resources to apply to a machine, based solely on the results of facts. Jordan Sissel has written about this approach at http://www.semicomplete.com/blog/geekery/puppet-nodeless-configuration.html.
You can find out more about custom facts, including how to make sure that OS-specific facts work only on the relevant systems, and how to weigh facts so that they're evaluated in a specific order at the puppetlabs website:
- The Importing dynamic information recipe in Chapter 3, Writing Better Manifests
- The Configuring Hiera recipe in Chapter 2, Puppet Infrastructure
The Creating custom facts recipe describes how to add extra facts written in Ruby. You can also create facts from simple text files or scripts with external facts instead.
Here's what you need to do to prepare your system to add external facts:
- You'll need Facter Version 1.7 or higher to use external facts, so look up the value of
facterversionor usefacter -v:[root@cookbook ~]# facter facterversion 2.3.0 [root@cookbook ~]# facter -v 2.3.0
- You'll also need to create the external facts directory, using the following command:
[root@cookbook ~]# mkdir -p /etc/facter/facts.d
- Create the file
/etc/facter/facts.d/local.txtwith the following contents:model=ED-209
- Run the following command:
[root@cookbook ~]# facter model ED-209
Well, that was easy! You can add more facts to the same file, or other files, of course, as follows:
model=ED-209 builder=OCP directives=4
However, what if you need to compute a fact in some way, for example, the number of logged-in users? You can create executable facts to do this.
- Create the file
/etc/facter/facts.d/users.shwith the following contents:#!/bin/sh echo users=`who |wc -l`
- Make this file executable with the following command:
[root@cookbook ~]# chmod a+x /etc/facter/facts.d/users.sh - Now check the
usersvalue with the following command:[root@cookbook ~]# facter users 2
In this example, we'll create an external fact by creating files on the node. We'll also show how to override a previously defined fact.
- Current versions of Facter will look into
/etc/facter/facts.dfor files of type.txt,.json, or.yaml. If facter finds a text file, it will parse the file forkey=valuepairs and add the key as a new fact:[root@cookbook ~]# facter model ED-209
- If the file is a YAML or JSON file, then facter will parse the file for
key=valuepairs in the respective format. For YAML, for instance:--- registry: NCC-68814 class: Andromeda shipname: USS Prokofiev
- The resulting output will be as follows:
[root@cookbook ~]# facter registry class shipname class => Andromeda registry => NCC-68814 shipname => USS Prokofiev
- In the case of executable files, Facter will assume that their output is a list of
key=valuepairs. It will execute all the files in thefacts.ddirectory and add their output to the internal fact hash. - In the
usersexample, Facter will execute theusers.shscript, which results in the following output:users=2 - It will then search this output for
usersand return the matching value:[root@cookbook ~]# facter users 2
- If there are multiple matches for the key you specified, Facter determines which fact to return based on a weight property. In my version of facter, the weight of external facts is 10,000 (defined in
facter/util/directory_loader.rbasEXTERNAL_FACT_WEIGHT). This high value is to ensure that the facts you define can override the supplied facts. For example:[root@cookbook ~]# facter architecture x86_64 [root@cookbook ~]# echo "architecture=ppc64">>/etc/facter/facts.d/myfacts.txt [root@cookbook ~]# facter architecture ppc64
If you're having trouble getting Facter to recognize your external facts, run Facter in debug mode to see what's happening:
The X JSON file was parsed but returned an empty data set error, which means Facter didn't find any key=value pairs in the file or (in the case of an executable fact) in its output.
- The Importing dynamic information recipe in Chapter 3, Writing Better Manifests
- The Configuring Hiera recipe in Chapter 2, Puppet Infrastructure
- The Creating custom facts recipe in this chapter
facterversion or use facter -v:[root@cookbook ~]# facter facterversion 2.3.0 [root@cookbook ~]# facter -v 2.3.0
[root@cookbook ~]# mkdir -p /etc/facter/facts.d
- Create the file
/etc/facter/facts.d/local.txtwith the following contents:model=ED-209
- Run the following command:
[root@cookbook ~]# facter model ED-209
Well, that was easy! You can add more facts to the same file, or other files, of course, as follows:
model=ED-209 builder=OCP directives=4
However, what if you need to compute a fact in some way, for example, the number of logged-in users? You can create executable facts to do this.
- Create the file
/etc/facter/facts.d/users.shwith the following contents:#!/bin/sh echo users=`who |wc -l`
- Make this file executable with the following command:
[root@cookbook ~]# chmod a+x /etc/facter/facts.d/users.sh - Now check the
usersvalue with the following command:[root@cookbook ~]# facter users 2
In this example, we'll create an external fact by creating files on the node. We'll also show how to override a previously defined fact.
- Current versions of Facter will look into
/etc/facter/facts.dfor files of type.txt,.json, or.yaml. If facter finds a text file, it will parse the file forkey=valuepairs and add the key as a new fact:[root@cookbook ~]# facter model ED-209
- If the file is a YAML or JSON file, then facter will parse the file for
key=valuepairs in the respective format. For YAML, for instance:--- registry: NCC-68814 class: Andromeda shipname: USS Prokofiev
- The resulting output will be as follows:
[root@cookbook ~]# facter registry class shipname class => Andromeda registry => NCC-68814 shipname => USS Prokofiev
- In the case of executable files, Facter will assume that their output is a list of
key=valuepairs. It will execute all the files in thefacts.ddirectory and add their output to the internal fact hash. - In the
usersexample, Facter will execute theusers.shscript, which results in the following output:users=2 - It will then search this output for
usersand return the matching value:[root@cookbook ~]# facter users 2
- If there are multiple matches for the key you specified, Facter determines which fact to return based on a weight property. In my version of facter, the weight of external facts is 10,000 (defined in
facter/util/directory_loader.rbasEXTERNAL_FACT_WEIGHT). This high value is to ensure that the facts you define can override the supplied facts. For example:[root@cookbook ~]# facter architecture x86_64 [root@cookbook ~]# echo "architecture=ppc64">>/etc/facter/facts.d/myfacts.txt [root@cookbook ~]# facter architecture ppc64
If you're having trouble getting Facter to recognize your external facts, run Facter in debug mode to see what's happening:
The X JSON file was parsed but returned an empty data set error, which means Facter didn't find any key=value pairs in the file or (in the case of an executable fact) in its output.
- The Importing dynamic information recipe in Chapter 3, Writing Better Manifests
- The Configuring Hiera recipe in Chapter 2, Puppet Infrastructure
- The Creating custom facts recipe in this chapter
/etc/facter/facts.d/local.txt with the following contents:model=ED-209
[root@cookbook ~]# facter model ED-209
Well, that was easy! You can add more facts to the same file, or other files, of course, as follows:
model=ED-209 builder=OCP directives=4
However, what if you need to compute a fact in some way, for example, the number of logged-in users? You can create executable facts to do this.
/etc/facter/facts.d/users.sh with the following contents:#!/bin/sh echo users=`who |wc -l`
[root@cookbook ~]# chmod a+x /etc/facter/facts.d/users.sh
users value with the following command:[root@cookbook ~]# facter users 2
In this example, we'll create an external fact by creating files on the node. We'll also show how to override a previously defined fact.
- Current versions of Facter will look into
/etc/facter/facts.dfor files of type.txt,.json, or.yaml. If facter finds a text file, it will parse the file forkey=valuepairs and add the key as a new fact:[root@cookbook ~]# facter model ED-209
- If the file is a YAML or JSON file, then facter will parse the file for
key=valuepairs in the respective format. For YAML, for instance:--- registry: NCC-68814 class: Andromeda shipname: USS Prokofiev
- The resulting output will be as follows:
[root@cookbook ~]# facter registry class shipname class => Andromeda registry => NCC-68814 shipname => USS Prokofiev
- In the case of executable files, Facter will assume that their output is a list of
key=valuepairs. It will execute all the files in thefacts.ddirectory and add their output to the internal fact hash. - In the
usersexample, Facter will execute theusers.shscript, which results in the following output:users=2 - It will then search this output for
usersand return the matching value:[root@cookbook ~]# facter users 2
- If there are multiple matches for the key you specified, Facter determines which fact to return based on a weight property. In my version of facter, the weight of external facts is 10,000 (defined in
facter/util/directory_loader.rbasEXTERNAL_FACT_WEIGHT). This high value is to ensure that the facts you define can override the supplied facts. For example:[root@cookbook ~]# facter architecture x86_64 [root@cookbook ~]# echo "architecture=ppc64">>/etc/facter/facts.d/myfacts.txt [root@cookbook ~]# facter architecture ppc64
If you're having trouble getting Facter to recognize your external facts, run Facter in debug mode to see what's happening:
The X JSON file was parsed but returned an empty data set error, which means Facter didn't find any key=value pairs in the file or (in the case of an executable fact) in its output.
- The Importing dynamic information recipe in Chapter 3, Writing Better Manifests
- The Configuring Hiera recipe in Chapter 2, Puppet Infrastructure
- The Creating custom facts recipe in this chapter
- Current versions of Facter will look into
/etc/facter/facts.dfor files of type.txt,.json, or.yaml. If facter finds a text file, it will parse the file forkey=valuepairs and add the key as a new fact:[root@cookbook ~]# facter model ED-209
- If the file is a YAML or JSON file, then facter will parse the file for
key=valuepairs in the respective format. For YAML, for instance:--- registry: NCC-68814 class: Andromeda shipname: USS Prokofiev
- The resulting output will be as follows:
[root@cookbook ~]# facter registry class shipname class => Andromeda registry => NCC-68814 shipname => USS Prokofiev
- In the case of executable files, Facter will assume that their output is a list of
key=valuepairs. It will execute all the files in thefacts.ddirectory and add their output to the internal fact hash. - In the
usersexample, Facter will execute theusers.shscript, which results in the following output:users=2 - It will then search this output for
usersand return the matching value:[root@cookbook ~]# facter users 2
- If there are multiple matches for the key you specified, Facter determines which fact to return based on a weight property. In my version of facter, the weight of external facts is 10,000 (defined in
facter/util/directory_loader.rbasEXTERNAL_FACT_WEIGHT). This high value is to ensure that the facts you define can override the supplied facts. For example:[root@cookbook ~]# facter architecture x86_64 [root@cookbook ~]# echo "architecture=ppc64">>/etc/facter/facts.d/myfacts.txt [root@cookbook ~]# facter architecture ppc64
If you're having trouble getting Facter to recognize your external facts, run Facter in debug mode to see what's happening:
The X JSON file was parsed but returned an empty data set error, which means Facter didn't find any key=value pairs in the file or (in the case of an executable fact) in its output.
- The Importing dynamic information recipe in Chapter 3, Writing Better Manifests
- The Configuring Hiera recipe in Chapter 2, Puppet Infrastructure
- The Creating custom facts recipe in this chapter
/etc/facter/facts.d directory sets their precedence (with the last one encountered having the highest precedence). To create a fact that will be favored over another, you'll need to have it created in a file that comes last alphabetically:
If you're having trouble getting Facter to recognize your external facts, run Facter in debug mode to see what's happening:
The X JSON file was parsed but returned an empty data set error, which means Facter didn't find any key=value pairs in the file or (in the case of an executable fact) in its output.
- The Importing dynamic information recipe in Chapter 3, Writing Better Manifests
- The Configuring Hiera recipe in Chapter 2, Puppet Infrastructure
- The Creating custom facts recipe in this chapter
The X JSON file was parsed but returned an empty data set error, which means Facter didn't find any key=value pairs in the file or (in the case of an executable fact) in its output.
- The Importing dynamic information recipe in Chapter 3, Writing Better Manifests
- The Configuring Hiera recipe in Chapter 2, Puppet Infrastructure
- The Creating custom facts recipe in this chapter
- The Importing dynamic information recipe in Chapter 3, Writing Better Manifests
- The Configuring Hiera recipe in Chapter 2, Puppet Infrastructure
- The Creating custom facts recipe in this chapter
Another handy way to get information into Puppet and Facter is to pass it using environment variables. Any environment variable whose name starts with FACTER_ will be interpreted as a fact. For example, ask facter the value of hello using the following command:
Now override the value with an environment variable and ask again:
It works just as well with Puppet, so let's run through an example.
In this example we'll set a fact using an environment variable:
- Keep the node definition for cookbook the same as our last example:
node cookbook { notify {"$::hello": } } - Run the following command:
[root@cookbook ~]# FACTER_hello="Hallo Welt" puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1416212026' Notice: Hallo Welt Notice: /Stage[main]/Main/Node[cookbook]/Notify[Hallo Welt]/message: defined 'message' as 'Hallo Welt' Notice: Finished catalog run in 0.27 seconds
set a fact using an environment variable:
- Keep the node definition for cookbook the same as our last example:
node cookbook { notify {"$::hello": } } - Run the following command:
[root@cookbook ~]# FACTER_hello="Hallo Welt" puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1416212026' Notice: Hallo Welt Notice: /Stage[main]/Main/Node[cookbook]/Notify[Hallo Welt]/message: defined 'message' as 'Hallo Welt' Notice: Finished catalog run in 0.27 seconds
If you have a server that is already configured as it needs to be, or nearly so, you can capture that configuration as a Puppet manifest. The Puppet resource command generates Puppet manifests from the existing configuration of a system. For example, you can have puppet resource generate a manifest that creates all the users found on the system. This is very useful to take a snapshot of a working system and get its configuration quickly into Puppet.
Here are some examples of using puppet resource to get data from a running system:
- To generate the manifest for a particular user, run the following command:
[root@cookbook ~]# puppet resource user thomas user { 'thomas': ensure => 'present', comment => 'thomas Admin User', gid => '1001', groups => ['bin', 'wheel'], home => '/home/thomas', password => '!!', password_max_age => '99999', password_min_age => '0', shell => '/bin/bash', uid => '1001', }
- For a particular service, run the following command:
[root@cookbook ~]# puppet resource service sshd service { 'sshd': ensure => 'running', enable => 'true', }
- For a package, run the following command:
[root@cookbook ~]# puppet resource package kernel package { 'kernel': ensure => '2.6.32-431.23.3.el6', }
You can use puppet resource to examine each of the resource types available in Puppet. In the preceding examples, we generated a manifest for a specific instance of the resource type, but you can also use puppet resource to dump all instances of the resource:
This will output the state of each service on the system; this is because each service is an enumerable resource. When you try the same command with a resource that is not enumerable, you get an error message:
Asking Puppet to describe each file on the system will not work; that's something best left to an audit tool such as tripwire (a system designed to look for changes on every file on the system, http://www.tripwire.com).
puppet resource to get data from a running system:
[root@cookbook ~]# puppet resource user thomas user { 'thomas': ensure => 'present', comment => 'thomas Admin User', gid => '1001', groups => ['bin', 'wheel'], home => '/home/thomas', password => '!!', password_max_age => '99999', password_min_age => '0', shell => '/bin/bash', uid => '1001', }
You can use puppet resource to examine each of the resource types available in Puppet. In the preceding examples, we generated a manifest for a specific instance of the resource type, but you can also use puppet resource to dump all instances of the resource:
This will output the state of each service on the system; this is because each service is an enumerable resource. When you try the same command with a resource that is not enumerable, you get an error message:
Asking Puppet to describe each file on the system will not work; that's something best left to an audit tool such as tripwire (a system designed to look for changes on every file on the system, http://www.tripwire.com).
puppet resource to examine each of the
This will output the state of each service on the system; this is because each service is an enumerable resource. When you try the same command with a resource that is not enumerable, you get an error message:
Asking Puppet to describe each file on the system will not work; that's something best left to an audit tool such as tripwire (a system designed to look for changes on every file on the system, http://www.tripwire.com).
If you want to quickly capture the complete configuration of a running system as a Puppet manifest, there are a couple of tools available to help. In this example, we'll look at Blueprint, which is designed to examine a machine and dump its state as Puppet code.
These steps will show you how to run Blueprint:
- Run the following commands:
[root@cookbook ~]# mkdir blueprint && cd blueprint [root@cookbook blueprint]# blueprint create -P blueprint_test # [blueprint] searching for APT packages to exclude # [blueprint] searching for Yum packages to exclude # [blueprint] caching excluded Yum packages # [blueprint] parsing blueprintignore(5) rules # [blueprint] searching for npm packages # [blueprint] searching for configuration files # [blueprint] searching for APT packages # [blueprint] searching for PEAR/PECL packages # [blueprint] searching for Python packages # [blueprint] searching for Ruby gems # [blueprint] searching for software built from source # [blueprint] searching for Yum packages # [blueprint] searching for service dependencies blueprint_test/manifests/init.pp
- Read the
blueprint_test/manifests/init.ppfile to see the generated code:# # Automatically generated by blueprint(7). Edit at your own risk. # class blueprint_test { Exec { path => '/usr/lib64/qt-3.3/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin', } Class['sources'] -> Class['files'] -> Class['packages'] class files { file { '/etc': ensure => directory; '/etc/aliases.db': content => template('blueprint_test/etc/aliases.db'), ensure => file, group => root, mode => 0644, owner => root; '/etc/audit': ensure => directory; '/etc/audit/audit.rules': content => template('blueprint_test/etc/audit/audit.rules'), ensure => file, group => root, mode => 0640, owner => root; '/etc/blkid': ensure => directory; '/etc/cron.hourly': ensure => directory; '/etc/cron.hourly/run-backup': content => template('blueprint_test/etc/cron.hourly/run-backup'), ensure => file, group => root, mode => 0755, owner => root; '/etc/crypttab': content => template('blueprint_test/etc/crypttab'), ensure => file, group => root, mode => 0644, owner => root;
Blueprint just takes a snapshot of the system as it stands; it makes no intelligent decisions, and Blueprint captures all the files on the system and all the packages. It will generate a configuration much larger than you may actually require. For instance, when configuring a server, you may specify that you want the Apache package installed. The dependencies for the Apache package will be installed automatically and you need to specify them. When generating the configuration with a tool such as Blueprint, you will capture all those dependencies and lock the versions that are installed on your system currently. Looking at our generated Blueprint code, we can see that this is the case:
puppet resource here to change the state of the python-pip package:
These steps will show you how to run Blueprint:
- Run the following commands:
[root@cookbook ~]# mkdir blueprint && cd blueprint [root@cookbook blueprint]# blueprint create -P blueprint_test # [blueprint] searching for APT packages to exclude # [blueprint] searching for Yum packages to exclude # [blueprint] caching excluded Yum packages # [blueprint] parsing blueprintignore(5) rules # [blueprint] searching for npm packages # [blueprint] searching for configuration files # [blueprint] searching for APT packages # [blueprint] searching for PEAR/PECL packages # [blueprint] searching for Python packages # [blueprint] searching for Ruby gems # [blueprint] searching for software built from source # [blueprint] searching for Yum packages # [blueprint] searching for service dependencies blueprint_test/manifests/init.pp
- Read the
blueprint_test/manifests/init.ppfile to see the generated code:# # Automatically generated by blueprint(7). Edit at your own risk. # class blueprint_test { Exec { path => '/usr/lib64/qt-3.3/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin', } Class['sources'] -> Class['files'] -> Class['packages'] class files { file { '/etc': ensure => directory; '/etc/aliases.db': content => template('blueprint_test/etc/aliases.db'), ensure => file, group => root, mode => 0644, owner => root; '/etc/audit': ensure => directory; '/etc/audit/audit.rules': content => template('blueprint_test/etc/audit/audit.rules'), ensure => file, group => root, mode => 0640, owner => root; '/etc/blkid': ensure => directory; '/etc/cron.hourly': ensure => directory; '/etc/cron.hourly/run-backup': content => template('blueprint_test/etc/cron.hourly/run-backup'), ensure => file, group => root, mode => 0755, owner => root; '/etc/crypttab': content => template('blueprint_test/etc/crypttab'), ensure => file, group => root, mode => 0644, owner => root;
Blueprint just takes a snapshot of the system as it stands; it makes no intelligent decisions, and Blueprint captures all the files on the system and all the packages. It will generate a configuration much larger than you may actually require. For instance, when configuring a server, you may specify that you want the Apache package installed. The dependencies for the Apache package will be installed automatically and you need to specify them. When generating the configuration with a tool such as Blueprint, you will capture all those dependencies and lock the versions that are installed on your system currently. Looking at our generated Blueprint code, we can see that this is the case:
show you how to run Blueprint:
- Run the following commands:
[root@cookbook ~]# mkdir blueprint && cd blueprint [root@cookbook blueprint]# blueprint create -P blueprint_test # [blueprint] searching for APT packages to exclude # [blueprint] searching for Yum packages to exclude # [blueprint] caching excluded Yum packages # [blueprint] parsing blueprintignore(5) rules # [blueprint] searching for npm packages # [blueprint] searching for configuration files # [blueprint] searching for APT packages # [blueprint] searching for PEAR/PECL packages # [blueprint] searching for Python packages # [blueprint] searching for Ruby gems # [blueprint] searching for software built from source # [blueprint] searching for Yum packages # [blueprint] searching for service dependencies blueprint_test/manifests/init.pp
- Read the
blueprint_test/manifests/init.ppfile to see the generated code:# # Automatically generated by blueprint(7). Edit at your own risk. # class blueprint_test { Exec { path => '/usr/lib64/qt-3.3/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin', } Class['sources'] -> Class['files'] -> Class['packages'] class files { file { '/etc': ensure => directory; '/etc/aliases.db': content => template('blueprint_test/etc/aliases.db'), ensure => file, group => root, mode => 0644, owner => root; '/etc/audit': ensure => directory; '/etc/audit/audit.rules': content => template('blueprint_test/etc/audit/audit.rules'), ensure => file, group => root, mode => 0640, owner => root; '/etc/blkid': ensure => directory; '/etc/cron.hourly': ensure => directory; '/etc/cron.hourly/run-backup': content => template('blueprint_test/etc/cron.hourly/run-backup'), ensure => file, group => root, mode => 0755, owner => root; '/etc/crypttab': content => template('blueprint_test/etc/crypttab'), ensure => file, group => root, mode => 0644, owner => root;
Blueprint just takes a snapshot of the system as it stands; it makes no intelligent decisions, and Blueprint captures all the files on the system and all the packages. It will generate a configuration much larger than you may actually require. For instance, when configuring a server, you may specify that you want the Apache package installed. The dependencies for the Apache package will be installed automatically and you need to specify them. When generating the configuration with a tool such as Blueprint, you will capture all those dependencies and lock the versions that are installed on your system currently. Looking at our generated Blueprint code, we can see that this is the case:
When Puppet runs on a node, it needs to know which classes should be applied to that node. For example, if it is a web server node, it might need to include an apache class. The normal way to map nodes to classes is in the Puppet manifest itself, for example, in your site.pp file:
An ENC could be a simple shell script, for example, or a wrapper around a more complicated program or API that can decide how to map nodes to classes. The ENC provided by Puppet enterprise and The Foreman (http://theforeman.org/) are both simple scripts, which connect to the web API of their respective systems.
In this example, we'll build the most simple of ENCs, a shell script that simply prints a list of classes to include. We'll start by including an enc class, which defines notify that will print a top-scope variable $enc.
- Create the file
/etc/puppet/cookbook.shwith the following contents:#!/bin/bash cat <<EOF --- classes: enc: parameters: enc: $0 EOF
- Run the following command:
root@puppet:/etc/puppet# chmod a+x cookbook.sh - Modify your
/etc/puppet/puppet.conffile as follows:[main] node_terminus = exec external_nodes = /etc/puppet/cookbook.sh
- Restart Apache (restart the master) to make the change effective.
- Ensure your
site.ppfile has the following empty definition for the default node:node default {} - Run Puppet:
[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1416376937' Notice: We defined this from /etc/puppet/cookbook.sh Notice: /Stage[main]/Enc/Notify[We defined this from /etc/puppet/cookbook.sh]/message: defined 'message' as 'We defined this from /etc/puppet/cookbook.sh' Notice: Finished catalog run in 0.17 seconds
Obviously this script is not terribly useful; a more sophisticated script might check a database to find the class list, or look up the node in a hash, or an external text file or database (often an organization's configuration management database, CMDB). Hopefully, this example is enough to get you started with writing your own external node classifier. Remember that you can write your script in any language you prefer.
enc class to include with the enc script:
t@mylaptop ~/puppet $ mkdir -p modules/enc/manifests
modules/enc/manifests/init.pp with the following contents:class enc {
notify {"We defined this from $enc": }
}- Create the file
/etc/puppet/cookbook.shwith the following contents:#!/bin/bash cat <<EOF --- classes: enc: parameters: enc: $0 EOF
- Run the following command:
root@puppet:/etc/puppet# chmod a+x cookbook.sh - Modify your
/etc/puppet/puppet.conffile as follows:[main] node_terminus = exec external_nodes = /etc/puppet/cookbook.sh
- Restart Apache (restart the master) to make the change effective.
- Ensure your
site.ppfile has the following empty definition for the default node:node default {} - Run Puppet:
[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1416376937' Notice: We defined this from /etc/puppet/cookbook.sh Notice: /Stage[main]/Enc/Notify[We defined this from /etc/puppet/cookbook.sh]/message: defined 'message' as 'We defined this from /etc/puppet/cookbook.sh' Notice: Finished catalog run in 0.17 seconds
Obviously this script is not terribly useful; a more sophisticated script might check a database to find the class list, or look up the node in a hash, or an external text file or database (often an organization's configuration management database, CMDB). Hopefully, this example is enough to get you started with writing your own external node classifier. Remember that you can write your script in any language you prefer.
/etc/puppet/cookbook.sh with the following contents:#!/bin/bash cat <<EOF --- classes: enc: parameters: enc: $0 EOF
- following command:
root@puppet:/etc/puppet# chmod a+x cookbook.sh - Modify your
/etc/puppet/puppet.conffile as follows:[main] node_terminus = exec external_nodes = /etc/puppet/cookbook.sh
- Restart Apache (restart the master) to make the change effective.
- Ensure your
site.ppfile has the following empty definition for the default node:node default {} - Run Puppet:
[root@cookbook ~]# puppet agent -t Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1416376937' Notice: We defined this from /etc/puppet/cookbook.sh Notice: /Stage[main]/Enc/Notify[We defined this from /etc/puppet/cookbook.sh]/message: defined 'message' as 'We defined this from /etc/puppet/cookbook.sh' Notice: Finished catalog run in 0.17 seconds
Obviously this script is not terribly useful; a more sophisticated script might check a database to find the class list, or look up the node in a hash, or an external text file or database (often an organization's configuration management database, CMDB). Hopefully, this example is enough to get you started with writing your own external node classifier. Remember that you can write your script in any language you prefer.
puppet.conf, Puppet will call the specified program with the node's fqdn (technically, the certname variable) as the first command-line argument. In our example script, this argument is ignored, and it just outputs a fixed list of classes (actually, just one class).
As you know, Puppet has a bunch of useful built-in resource types: packages, files, users, and so on. Usually, you can do everything you need to do by using either combinations of these built-in resources, or define, which you can use more or less in the same way as a resource (see Chapter 3, Writing Better Manifests for information on definitions).
In the early days of Puppet, creating your own resource type was more common as the list of core resources was shorter than it is today. Before you consider creating your own resource type, I suggest searching the Forge for alternative solutions. Even if you can find a project that only partially solves your problem, you will be better served by extending and helping out that project, rather than trying to create your own. However, if you need to create your own resource type, Puppet makes it quite easy. The native types are written in Ruby, and you will need a basic familiarity with Ruby in order to create your own.
Let's refresh our memory on the distinction between types and providers. A type describes a resource and the parameters it can have (for example, the package type). A provider tells Puppet how to implement a resource type for a particular platform or situation (for example, the apt/dpkg providers implement the package type for Debian-like systems).
A single type (package) can have many providers (APT, YUM, Fink, and so on). If you don't specify a provider when declaring a resource, Puppet will choose the most appropriate one given the environment.
We'll use Ruby in this section; if you are not familiar with Ruby try visiting http://www.ruby-doc.org/docs/Tutorial/ or http://www.codecademy.com/tracks/ruby/.
Custom types can live in any module, in a lib/puppet/type subdirectory and in a file named for the type (in our example, that's modules/cookbook/lib/puppet/type/gitrepo.rb).
The first line of gitrepo.rb tells Puppet to register a new type named gitrepo:
Finally, we tell Puppet that the type accepts the path parameter:
When deciding whether or not you should create a custom type, you should ask a few questions about the resource you are trying to describe such as:
- Is the resource enumerable? Can you easily obtain a list of all the instances of the resource on the system?
- Is the resource atomic? Can you ensure that only one copy of the resource exists on the system (this is particularly important when you want to use
ensure=>absenton the resource)? - Is there any other resource that describes this resource? In such a case, a defined type based on the existing resource would, in most cases, be a simpler solution.
Our example is deliberately simple, but when you move on to developing real custom types for your production environment, you should add documentation strings to describe what the type and its parameters do, for example:
modules/cookbook/lib/puppet/type/gitrepo.rb with the following contents:
Custom types can live in any module, in a lib/puppet/type subdirectory and in a file named for the type (in our example, that's modules/cookbook/lib/puppet/type/gitrepo.rb).
The first line of gitrepo.rb tells Puppet to register a new type named gitrepo:
Finally, we tell Puppet that the type accepts the path parameter:
When deciding whether or not you should create a custom type, you should ask a few questions about the resource you are trying to describe such as:
- Is the resource enumerable? Can you easily obtain a list of all the instances of the resource on the system?
- Is the resource atomic? Can you ensure that only one copy of the resource exists on the system (this is particularly important when you want to use
ensure=>absenton the resource)? - Is there any other resource that describes this resource? In such a case, a defined type based on the existing resource would, in most cases, be a simpler solution.
Our example is deliberately simple, but when you move on to developing real custom types for your production environment, you should add documentation strings to describe what the type and its parameters do, for example:
The first line of gitrepo.rb tells Puppet to register a new type named gitrepo:
Finally, we tell Puppet that the type accepts the path parameter:
When deciding whether or not you should create a custom type, you should ask a few questions about the resource you are trying to describe such as:
- Is the resource enumerable? Can you easily obtain a list of all the instances of the resource on the system?
- Is the resource atomic? Can you ensure that only one copy of the resource exists on the system (this is particularly important when you want to use
ensure=>absenton the resource)? - Is there any other resource that describes this resource? In such a case, a defined type based on the existing resource would, in most cases, be a simpler solution.
Our example is deliberately simple, but when you move on to developing real custom types for your production environment, you should add documentation strings to describe what the type and its parameters do, for example:
resource you are trying to describe such as:
- Is the resource enumerable? Can you easily obtain a list of all the instances of the resource on the system?
- Is the resource atomic? Can you ensure that only one copy of the resource exists on the system (this is particularly important when you want to use
ensure=>absenton the resource)? - Is there any other resource that describes this resource? In such a case, a defined type based on the existing resource would, in most cases, be a simpler solution.
Our example is deliberately simple, but when you move on to developing real custom types for your production environment, you should add documentation strings to describe what the type and its parameters do, for example:
In the previous section, we created a new custom type called gitrepo and told Puppet that it takes two parameters, source and path. However, so far, we haven't told Puppet how to actually check out the repo; in other words, how to create a specific instance of this type. That's where the provider comes in.
We'll add the git provider, and create an instance of a gitrepo resource to check that it all works. You'll need Git installed for this to work, but if you're using the Git-based manifest management setup described in Chapter 2, Puppet Infrastructure, we can safely assume that Git is available.
- Create the file
modules/cookbook/lib/puppet/provider/gitrepo/git.rbwith the following contents:require 'fileutils' Puppet::Type.type(:gitrepo).provide(:git) do commands :git => "git" def create git "clone", resource[:source], resource[:path] end def exists? File.directory? resource[:path] end end - Modify your
site.ppfile as follows:node 'cookbook' { gitrepo { 'https://github.com/puppetlabs/puppetlabs-git': ensure => present, path => '/tmp/puppet', } } - Run Puppet:
[root@cookbook ~]# puppet agent -t Notice: /File[/var/lib/puppet/lib/puppet/type/gitrepo.rb]/ensure: defined content as '{md5}6471793fe2b4372d40289ad4b614fe0b' Notice: /File[/var/lib/puppet/lib/puppet/provider/gitrepo]/ensure: created Notice: /File[/var/lib/puppet/lib/puppet/provider/gitrepo/git.rb]/ensure: defined content as '{md5}f860388234d3d0bdb3b3ec98bbf5115b' Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1416378876' Notice: /Stage[main]/Main/Node[cookbook]/Gitrepo[https://github.com/puppetlabs/puppetlabs-git]/ensure: created Notice: Finished catalog run in 2.59 seconds
Custom providers can live in any module, in a lib/puppet/provider/TYPE_NAME subdirectory in a file named after the provider. (The provider is the actual program that is run on the system; in our example, the program is Git and the provider is in modules/cookbook/lib/puppet/provider/gitrepo/git.rb. Note that the name of the module is irrelevant.)
The method has access to the instance's parameters, which we need to know where to check out the repo from, and which directory to create it in. We get this by looking at resource[:source] and resource[:path].
Our example was very simple, and there is much more to learn about writing your own types. If you're going to distribute your code for others to use, or even if you aren't, it's a good idea to include tests with it. puppetlabs has a useful page on the interface between custom types and providers:
http://docs.puppetlabs.com/guides/custom_types.html
on implementing providers:
http://docs.puppetlabs.com/guides/provider_development.html
and a complete worked example of developing a custom type and provider, a little more advanced than that presented in this book:
http://docs.puppetlabs.com/guides/complete_resource_example.html
git provider, and create an instance of a gitrepo resource to check that it all works. You'll need Git installed for this to work, but if you're using the Git-based manifest management setup described in
Chapter 2, Puppet Infrastructure, we can safely assume that Git is available.
- Create the file
modules/cookbook/lib/puppet/provider/gitrepo/git.rbwith the following contents:require 'fileutils' Puppet::Type.type(:gitrepo).provide(:git) do commands :git => "git" def create git "clone", resource[:source], resource[:path] end def exists? File.directory? resource[:path] end end - Modify your
site.ppfile as follows:node 'cookbook' { gitrepo { 'https://github.com/puppetlabs/puppetlabs-git': ensure => present, path => '/tmp/puppet', } } - Run Puppet:
[root@cookbook ~]# puppet agent -t Notice: /File[/var/lib/puppet/lib/puppet/type/gitrepo.rb]/ensure: defined content as '{md5}6471793fe2b4372d40289ad4b614fe0b' Notice: /File[/var/lib/puppet/lib/puppet/provider/gitrepo]/ensure: created Notice: /File[/var/lib/puppet/lib/puppet/provider/gitrepo/git.rb]/ensure: defined content as '{md5}f860388234d3d0bdb3b3ec98bbf5115b' Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1416378876' Notice: /Stage[main]/Main/Node[cookbook]/Gitrepo[https://github.com/puppetlabs/puppetlabs-git]/ensure: created Notice: Finished catalog run in 2.59 seconds
Custom providers can live in any module, in a lib/puppet/provider/TYPE_NAME subdirectory in a file named after the provider. (The provider is the actual program that is run on the system; in our example, the program is Git and the provider is in modules/cookbook/lib/puppet/provider/gitrepo/git.rb. Note that the name of the module is irrelevant.)
The method has access to the instance's parameters, which we need to know where to check out the repo from, and which directory to create it in. We get this by looking at resource[:source] and resource[:path].
Our example was very simple, and there is much more to learn about writing your own types. If you're going to distribute your code for others to use, or even if you aren't, it's a good idea to include tests with it. puppetlabs has a useful page on the interface between custom types and providers:
http://docs.puppetlabs.com/guides/custom_types.html
on implementing providers:
http://docs.puppetlabs.com/guides/provider_development.html
and a complete worked example of developing a custom type and provider, a little more advanced than that presented in this book:
http://docs.puppetlabs.com/guides/complete_resource_example.html
The method has access to the instance's parameters, which we need to know where to check out the repo from, and which directory to create it in. We get this by looking at resource[:source] and resource[:path].
Our example was very simple, and there is much more to learn about writing your own types. If you're going to distribute your code for others to use, or even if you aren't, it's a good idea to include tests with it. puppetlabs has a useful page on the interface between custom types and providers:
http://docs.puppetlabs.com/guides/custom_types.html
on implementing providers:
http://docs.puppetlabs.com/guides/provider_development.html
and a complete worked example of developing a custom type and provider, a little more advanced than that presented in this book:
http://docs.puppetlabs.com/guides/complete_resource_example.html
define statements and exec resources, you may want to consider replacing these with a custom type. However, as stated previously, it's worth looking around to see if someone else has already done this before implementing your own.
http://docs.puppetlabs.com/guides/custom_types.html
on implementing providers:
http://docs.puppetlabs.com/guides/provider_development.html
and a complete worked example of developing a custom type and provider, a little more advanced than that presented in this book:
http://docs.puppetlabs.com/guides/complete_resource_example.html
If you've read the recipe Using GnuPG to encrypt secrets in Chapter 4, Working with Files and Packages, then you've already seen an example of a custom function (in that example, we created a secret function, which shelled out to GnuPG). Let's look at custom functions in a little more detail now and build an example.
If you've read the recipe Distributing cron jobs efficiently in Chapter 6, Managing Resources and Files, you might remember that we used the inline_template function to set a random time for cron jobs to run, based on the hostname of the node. In this example, we'll take that idea and turn it into a custom function called random_minute:
- Create the file
modules/cookbook/lib/puppet/parser/functions/random_minute.rbwith the following contents:module Puppet::Parser::Functions newfunction(:random_minute, :type => :rvalue) do |args| lookupvar('hostname').sum % 60 end end - Modify your
site.ppfile as follows:node 'cookbook' { cron { 'randomised cron job': command => '/bin/echo Hello, world >>/tmp/hello.txt', hour => '*', minute => random_minute(), } } - Run Puppet:
[root@cookbook ~]# puppet agent -t Info: Retrieving pluginfacts Info: Retrieving plugin Notice: /File[/var/lib/puppet/lib/puppet/parser/functions/random_minute.rb]/ensure: defined content as '{md5}e6ff40165e74677e5837027bb5610744' Info: Loading facts Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1416379652' Notice: /Stage[main]/Main/Node[cookbook]/Cron[custom fuction example job]/ensure: created Notice: Finished catalog run in 0.41 seconds
- Check
crontabwith the following command:[root@cookbook ~]# crontab -l # HEADER: This file was autogenerated at Wed Nov 19 01:48:11 -0500 2014 by puppet. # HEADER: While it can still be managed manually, it is definitely not recommended. # HEADER: Note particularly that the comments starting with 'Puppet Name' should # HEADER: not be deleted, as doing so could cause duplicate cron jobs. # Puppet Name: run-backup 0 15 * * * /usr/local/bin/backup # Puppet Name: custom fuction example job 15 * * * * /bin/echo Hallo, welt >>/tmp/hallo.txt
Custom functions can live in any module, in the lib/puppet/parser/functions subdirectory in a file named after the function (in our example, random_minute.rb).
The function code goes inside a module ... end block like this:
The :rvalue bit simply means that this function returns a value.
recipe Distributing cron jobs efficiently in Chapter 6, Managing Resources and Files, you might remember that we used the inline_template function to set a random time for cron jobs to run, based on the hostname of the node. In this example, we'll take that idea and turn it into a custom function called random_minute:
- Create the file
modules/cookbook/lib/puppet/parser/functions/random_minute.rbwith the following contents:module Puppet::Parser::Functions newfunction(:random_minute, :type => :rvalue) do |args| lookupvar('hostname').sum % 60 end end - Modify your
site.ppfile as follows:node 'cookbook' { cron { 'randomised cron job': command => '/bin/echo Hello, world >>/tmp/hello.txt', hour => '*', minute => random_minute(), } } - Run Puppet:
[root@cookbook ~]# puppet agent -t Info: Retrieving pluginfacts Info: Retrieving plugin Notice: /File[/var/lib/puppet/lib/puppet/parser/functions/random_minute.rb]/ensure: defined content as '{md5}e6ff40165e74677e5837027bb5610744' Info: Loading facts Info: Caching catalog for cookbook.example.com Info: Applying configuration version '1416379652' Notice: /Stage[main]/Main/Node[cookbook]/Cron[custom fuction example job]/ensure: created Notice: Finished catalog run in 0.41 seconds
- Check
crontabwith the following command:[root@cookbook ~]# crontab -l # HEADER: This file was autogenerated at Wed Nov 19 01:48:11 -0500 2014 by puppet. # HEADER: While it can still be managed manually, it is definitely not recommended. # HEADER: Note particularly that the comments starting with 'Puppet Name' should # HEADER: not be deleted, as doing so could cause duplicate cron jobs. # Puppet Name: run-backup 0 15 * * * /usr/local/bin/backup # Puppet Name: custom fuction example job 15 * * * * /bin/echo Hallo, welt >>/tmp/hallo.txt
Custom functions can live in any module, in the lib/puppet/parser/functions subdirectory in a file named after the function (in our example, random_minute.rb).
The function code goes inside a module ... end block like this:
The :rvalue bit simply means that this function returns a value.
The function code goes inside a module ... end block like this:
The :rvalue bit simply means that this function returns a value.
lookupvar as shown in the example. You can also work on arguments, for example, a general purpose hashing function that takes two arguments: the size of the hash table and optionally the thing to hash. Create modules/cookbook/lib/puppet/parser/functions/hashtable.rb with the following contents:
It would be great if we could verify that our Puppet manifests satisfy certain expectations without even having to run Puppet. The rspec-puppet tool is a nifty tool to do this. Based on RSpec, a testing framework for Ruby programs, rspec-puppet lets you write test cases for your Puppet manifests that are especially useful to catch regressions (bugs introduced when fixing another bug), and refactoring problems (bugs introduced when reorganizing your code).
Let's create an example class, thing, and write some tests for it.
- Define the
thingclass:class thing { service {'thing': ensure => 'running', enable => true, require => Package['thing'], } package {'thing': ensure => 'installed' } file {'/etc/thing.conf': content => 'fubar\n', mode => 0644, require => Package['thing'], notify => Service['thing'], } } - Run the following commands:
t@mylaptop ~/puppet]$cd modules/thing t@mylaptop~/puppet/modules/thing $ rspec-puppet-init + spec/ + spec/classes/ + spec/defines/ + spec/functions/ + spec/hosts/ + spec/fixtures/ + spec/fixtures/manifests/ + spec/fixtures/modules/ + spec/fixtures/modules/heartbeat/ + spec/fixtures/manifests/site.pp + spec/fixtures/modules/heartbeat/manifests + spec/fixtures/modules/heartbeat/templates + spec/spec_helper.rb + Rakefile
- Create the file
spec/classes/thing_spec.rbwith the following contents:require 'spec_helper' describe 'thing' do it { should create_class('thing') } it { should contain_package('thing') } it { should contain_service('thing').with( 'ensure' => 'running' ) } it { should contain_file('/etc/things.conf') } end - Run the following commands:
t@mylaptop ~/.puppet/modules/thing $ rspec ...F Failures: 1) thing should contain File[/etc/things.conf] Failure/Error: it { should contain_file('/etc/things.conf') } expected that the catalogue would contain File[/etc/things.conf] # ./spec/classes/thing_spec.rb:9:in `block (2 levels) in <top (required)>' Finished in 1.66 seconds 4 examples, 1 failure Failed examples: rspec ./spec/classes/thing_spec.rb:9 # thing should contain File[/etc/things.conf]
The rspec-puppet-init command creates a framework of directories for you to put your specs (test programs) in. At the moment, we're just interested in the spec/classes directory. This is where you'll put your class specs, one per class, named after the class it tests, for example, thing_spec.rb.
Then, a describe block follows:
Next, we test for the existence of the thing service:
The preceding code actually contains two assertions. First, that the class contains a thing service:
Second, that the service has an ensure attribute with the value running:
You can specify any attributes and values you want using the with method, as a comma-separated list. For example, the following code asserts several attributes of a file resource:
As you can see, we defined the file in our test as /etc/things.conf but the file in the manifests is /etc/thing.conf, so the test fails. Edit thing_spec.rb and change /etc/things.conf to /etc/thing.conf:
You can find more information about rspec-puppet, including complete documentation for the assertions available and a tutorial, at http://rspec-puppet.com/.
When you want to start testing how your code applies to nodes, you'll need to look at another tool, beaker. Beaker works with various virtualization platforms to create temporary virtual machines to which Puppet code is applied. The results are then used for acceptance testing of the Puppet code. This method of testing and developing at the same time is known as Test-driven development (TDD). More information about beaker is available on the GitHub site at https://github.com/puppetlabs/beaker.
- The Checking your manifests with puppet-lint recipe in Chapter 1, Puppet Language and Style
rspec-puppet.
Let's create an example class, thing, and write some tests for it.
- Define the
thingclass:class thing { service {'thing': ensure => 'running', enable => true, require => Package['thing'], } package {'thing': ensure => 'installed' } file {'/etc/thing.conf': content => 'fubar\n', mode => 0644, require => Package['thing'], notify => Service['thing'], } } - Run the following commands:
t@mylaptop ~/puppet]$cd modules/thing t@mylaptop~/puppet/modules/thing $ rspec-puppet-init + spec/ + spec/classes/ + spec/defines/ + spec/functions/ + spec/hosts/ + spec/fixtures/ + spec/fixtures/manifests/ + spec/fixtures/modules/ + spec/fixtures/modules/heartbeat/ + spec/fixtures/manifests/site.pp + spec/fixtures/modules/heartbeat/manifests + spec/fixtures/modules/heartbeat/templates + spec/spec_helper.rb + Rakefile
- Create the file
spec/classes/thing_spec.rbwith the following contents:require 'spec_helper' describe 'thing' do it { should create_class('thing') } it { should contain_package('thing') } it { should contain_service('thing').with( 'ensure' => 'running' ) } it { should contain_file('/etc/things.conf') } end - Run the following commands:
t@mylaptop ~/.puppet/modules/thing $ rspec ...F Failures: 1) thing should contain File[/etc/things.conf] Failure/Error: it { should contain_file('/etc/things.conf') } expected that the catalogue would contain File[/etc/things.conf] # ./spec/classes/thing_spec.rb:9:in `block (2 levels) in <top (required)>' Finished in 1.66 seconds 4 examples, 1 failure Failed examples: rspec ./spec/classes/thing_spec.rb:9 # thing should contain File[/etc/things.conf]
The rspec-puppet-init command creates a framework of directories for you to put your specs (test programs) in. At the moment, we're just interested in the spec/classes directory. This is where you'll put your class specs, one per class, named after the class it tests, for example, thing_spec.rb.
Then, a describe block follows:
Next, we test for the existence of the thing service:
The preceding code actually contains two assertions. First, that the class contains a thing service:
Second, that the service has an ensure attribute with the value running:
You can specify any attributes and values you want using the with method, as a comma-separated list. For example, the following code asserts several attributes of a file resource:
As you can see, we defined the file in our test as /etc/things.conf but the file in the manifests is /etc/thing.conf, so the test fails. Edit thing_spec.rb and change /etc/things.conf to /etc/thing.conf:
You can find more information about rspec-puppet, including complete documentation for the assertions available and a tutorial, at http://rspec-puppet.com/.
When you want to start testing how your code applies to nodes, you'll need to look at another tool, beaker. Beaker works with various virtualization platforms to create temporary virtual machines to which Puppet code is applied. The results are then used for acceptance testing of the Puppet code. This method of testing and developing at the same time is known as Test-driven development (TDD). More information about beaker is available on the GitHub site at https://github.com/puppetlabs/beaker.
- The Checking your manifests with puppet-lint recipe in Chapter 1, Puppet Language and Style
thing, and write some tests for it.
thing class:class thing {
service {'thing':
ensure => 'running',
enable => true,
require => Package['thing'],
}
package {'thing':
ensure => 'installed'
}
file {'/etc/thing.conf':
content => 'fubar\n',
mode => 0644,
require => Package['thing'],
notify => Service['thing'],
}
}- following commands:
t@mylaptop ~/puppet]$cd modules/thing t@mylaptop~/puppet/modules/thing $ rspec-puppet-init + spec/ + spec/classes/ + spec/defines/ + spec/functions/ + spec/hosts/ + spec/fixtures/ + spec/fixtures/manifests/ + spec/fixtures/modules/ + spec/fixtures/modules/heartbeat/ + spec/fixtures/manifests/site.pp + spec/fixtures/modules/heartbeat/manifests + spec/fixtures/modules/heartbeat/templates + spec/spec_helper.rb + Rakefile
- Create the file
spec/classes/thing_spec.rbwith the following contents:require 'spec_helper' describe 'thing' do it { should create_class('thing') } it { should contain_package('thing') } it { should contain_service('thing').with( 'ensure' => 'running' ) } it { should contain_file('/etc/things.conf') } end - Run the following commands:
t@mylaptop ~/.puppet/modules/thing $ rspec ...F Failures: 1) thing should contain File[/etc/things.conf] Failure/Error: it { should contain_file('/etc/things.conf') } expected that the catalogue would contain File[/etc/things.conf] # ./spec/classes/thing_spec.rb:9:in `block (2 levels) in <top (required)>' Finished in 1.66 seconds 4 examples, 1 failure Failed examples: rspec ./spec/classes/thing_spec.rb:9 # thing should contain File[/etc/things.conf]
The rspec-puppet-init command creates a framework of directories for you to put your specs (test programs) in. At the moment, we're just interested in the spec/classes directory. This is where you'll put your class specs, one per class, named after the class it tests, for example, thing_spec.rb.
Then, a describe block follows:
Next, we test for the existence of the thing service:
The preceding code actually contains two assertions. First, that the class contains a thing service:
Second, that the service has an ensure attribute with the value running:
You can specify any attributes and values you want using the with method, as a comma-separated list. For example, the following code asserts several attributes of a file resource:
As you can see, we defined the file in our test as /etc/things.conf but the file in the manifests is /etc/thing.conf, so the test fails. Edit thing_spec.rb and change /etc/things.conf to /etc/thing.conf:
You can find more information about rspec-puppet, including complete documentation for the assertions available and a tutorial, at http://rspec-puppet.com/.
When you want to start testing how your code applies to nodes, you'll need to look at another tool, beaker. Beaker works with various virtualization platforms to create temporary virtual machines to which Puppet code is applied. The results are then used for acceptance testing of the Puppet code. This method of testing and developing at the same time is known as Test-driven development (TDD). More information about beaker is available on the GitHub site at https://github.com/puppetlabs/beaker.
- The Checking your manifests with puppet-lint recipe in Chapter 1, Puppet Language and Style
rspec-puppet-init command creates
a framework of directories for you to put your specs (test programs) in. At the moment, we're just interested in the spec/classes directory. This is where you'll put your class specs, one per class, named after the class it tests, for example, thing_spec.rb.
Then, a describe block follows:
Next, we test for the existence of the thing service:
The preceding code actually contains two assertions. First, that the class contains a thing service:
Second, that the service has an ensure attribute with the value running:
You can specify any attributes and values you want using the with method, as a comma-separated list. For example, the following code asserts several attributes of a file resource:
As you can see, we defined the file in our test as /etc/things.conf but the file in the manifests is /etc/thing.conf, so the test fails. Edit thing_spec.rb and change /etc/things.conf to /etc/thing.conf:
You can find more information about rspec-puppet, including complete documentation for the assertions available and a tutorial, at http://rspec-puppet.com/.
When you want to start testing how your code applies to nodes, you'll need to look at another tool, beaker. Beaker works with various virtualization platforms to create temporary virtual machines to which Puppet code is applied. The results are then used for acceptance testing of the Puppet code. This method of testing and developing at the same time is known as Test-driven development (TDD). More information about beaker is available on the GitHub site at https://github.com/puppetlabs/beaker.
- The Checking your manifests with puppet-lint recipe in Chapter 1, Puppet Language and Style
contain_<resource type>(title). In addition to verifying your classes will apply correctly, you can also test functions and definitions by using the appropriate subdirectories within the spec directory (classes, defines, or functions).
rspec-puppet, including complete documentation for the assertions available
and a tutorial, at http://rspec-puppet.com/.
When you want to start testing how your code applies to nodes, you'll need to look at another tool, beaker. Beaker works with various virtualization platforms to create temporary virtual machines to which Puppet code is applied. The results are then used for acceptance testing of the Puppet code. This method of testing and developing at the same time is known as Test-driven development (TDD). More information about beaker is available on the GitHub site at https://github.com/puppetlabs/beaker.
- The Checking your manifests with puppet-lint recipe in Chapter 1, Puppet Language and Style
- Chapter 1, Puppet Language and Style
When you begin to include modules from the forge in your Puppet infrastructure, keeping track of which versions you installed and ensuring consistency between all your testing areas can become a bit of a problem. Luckily, the tools we will discuss in the next two sections can bring order to your system. We will first begin with librarian-puppet, which uses a special configuration file named Puppetfile to specify the source location of your various modules.
We'll install librarian-puppet to work through the example.
Install librarian-puppet on your Puppet master, using Puppet of course:
We'll use librarian-puppet to download and install a module in this example:
- Create a working directory for yourself; librarian-puppet will overwrite your modules directory by default, so we'll work in a temporary location for now:
root@puppet:~# mkdir librarian root@puppet:~# cd librarian
- Create a new Puppetfile with the following contents:
#!/usr/bin/env ruby #^syntax detection forge "https://forgeapi.puppetlabs.com" # A module from the Puppet Forge mod 'puppetlabs-stdlib'
- Now, run librarian-puppet to download and install the
puppetlabs-stdlibmodule in themodulesdirectory:root@puppet:~/librarian# librarian-puppet install root@puppet:~/librarian # ls modules Puppetfile Puppetfile.lock root@puppet:~/librarian # ls modules stdlib
The first line of the Puppetfile makes the Puppetfile appear to be a Ruby source file. These are completely optional but coerces editors into treating the file as though it was written in Ruby (which it is):
Now, we added a line to include the puppetlabs-stdlib module:
The Puppetfile allows you to pull in modules from sources other than the forge. You may use a local Git url or even a GitHub url to download modules that are not on the Forge. More information on librarian-puppet can be found on the GitHub website at https://github.com/rodjek/librarian-puppet.
Note that librarian-puppet will create the modules directory and remove any modules you placed in there by default. Most installations using librarian-puppet opt to place their local modules in a /local subdirectory (/dist or /companyname are also used).
In the next section, we'll talk about r10k, which goes one step further than librarian and manages your entire environment directory.
librarian-puppet on your Puppet master, using Puppet of course:
We'll use librarian-puppet to download and install a module in this example:
- Create a working directory for yourself; librarian-puppet will overwrite your modules directory by default, so we'll work in a temporary location for now:
root@puppet:~# mkdir librarian root@puppet:~# cd librarian
- Create a new Puppetfile with the following contents:
#!/usr/bin/env ruby #^syntax detection forge "https://forgeapi.puppetlabs.com" # A module from the Puppet Forge mod 'puppetlabs-stdlib'
- Now, run librarian-puppet to download and install the
puppetlabs-stdlibmodule in themodulesdirectory:root@puppet:~/librarian# librarian-puppet install root@puppet:~/librarian # ls modules Puppetfile Puppetfile.lock root@puppet:~/librarian # ls modules stdlib
The first line of the Puppetfile makes the Puppetfile appear to be a Ruby source file. These are completely optional but coerces editors into treating the file as though it was written in Ruby (which it is):
Now, we added a line to include the puppetlabs-stdlib module:
The Puppetfile allows you to pull in modules from sources other than the forge. You may use a local Git url or even a GitHub url to download modules that are not on the Forge. More information on librarian-puppet can be found on the GitHub website at https://github.com/rodjek/librarian-puppet.
Note that librarian-puppet will create the modules directory and remove any modules you placed in there by default. Most installations using librarian-puppet opt to place their local modules in a /local subdirectory (/dist or /companyname are also used).
In the next section, we'll talk about r10k, which goes one step further than librarian and manages your entire environment directory.
root@puppet:~# mkdir librarian root@puppet:~# cd librarian
#!/usr/bin/env ruby #^syntax detection forge "https://forgeapi.puppetlabs.com" # A module from the Puppet Forge mod 'puppetlabs-stdlib'
The first line of the Puppetfile makes the Puppetfile appear to be a Ruby source file. These are completely optional but coerces editors into treating the file as though it was written in Ruby (which it is):
Now, we added a line to include the puppetlabs-stdlib module:
The Puppetfile allows you to pull in modules from sources other than the forge. You may use a local Git url or even a GitHub url to download modules that are not on the Forge. More information on librarian-puppet can be found on the GitHub website at https://github.com/rodjek/librarian-puppet.
Note that librarian-puppet will create the modules directory and remove any modules you placed in there by default. Most installations using librarian-puppet opt to place their local modules in a /local subdirectory (/dist or /companyname are also used).
In the next section, we'll talk about r10k, which goes one step further than librarian and manages your entire environment directory.
The Puppetfile allows you to pull in modules from sources other than the forge. You may use a local Git url or even a GitHub url to download modules that are not on the Forge. More information on librarian-puppet can be found on the GitHub website at https://github.com/rodjek/librarian-puppet.
Note that librarian-puppet will create the modules directory and remove any modules you placed in there by default. Most installations using librarian-puppet opt to place their local modules in a /local subdirectory (/dist or /companyname are also used).
In the next section, we'll talk about r10k, which goes one step further than librarian and manages your entire environment directory.
Puppetfile allows
you to pull in modules from sources other than the forge. You may use a local Git url or even a GitHub url to download modules that are not on the Forge. More information on librarian-puppet can be found on the GitHub website at https://github.com/rodjek/librarian-puppet.
Note that librarian-puppet will create the modules directory and remove any modules you placed in there by default. Most installations using librarian-puppet opt to place their local modules in a /local subdirectory (/dist or /companyname are also used).
In the next section, we'll talk about r10k, which goes one step further than librarian and manages your entire environment directory.
The Puppetfile is a very good format to describe which modules you wish to include in your environment. Building upon the Puppetfile is another tool, r10k. r10k is a total environment management tool. You can use r10k to clone a local Git repository into your environmentpath and then place the modules specified in your Puppetfile into that directory. The local Git repository is known as the master repository; it is where r10k expects to find your Puppetfile. r10k also understands Puppet environments and will clone Git branches into subdirectories of your environmentpath, simplifying the deployment of multiple environments. What makes r10k particularly useful is its use of a local cache directory to speed up deployments. Using a configuration file, r10k.yaml, you can specify where to store this cache and also where your master repository is held.
We'll install r10k on our controlling machine (usually the master). This is where we will control all the modules downloaded and installed.
- Install r10k on your puppet master, or on whichever machine you wish to manage your
environmentpathdirectory:root@puppet:~# puppet resource package r10k ensure=installed provider=gem Notice: /Package[r10k]/ensure: created package { 'r10k': ensure => ['1.3.5'], }
- Make a new copy of your Git repository (optional, do this on your Git server):
[git@git repos]$ git clone --bare puppet.git puppet-r10k.git Initialized empty Git repository in /home/git/repos/puppet-r10k.git/
- Check out the new Git repository (on your local machine) and move the existing modules directory to a new location. We'll use
/localin this example:t@mylaptop ~ $ git clone git@git.example.com:repos/puppet-r10k.git Cloning into 'puppet-r10k'... remote: Counting objects: 2660, done. remote: Compressing objects: 100% (2136/2136), done. remote: Total 2660 (delta 913), reused 1049 (delta 238) Receiving objects: 100% (2660/2660), 738.20 KiB | 0 bytes/s, done. Resolving deltas: 100% (913/913), done. Checking connectivity... done. t@mylaptop ~ $ cd puppet-r10k/ t@mylaptop ~/puppet-r10k $ git checkout production Branch production set up to track remote branch production from origin. Switched to a new branch 'production' t@mylaptop ~/puppet-r10k $ git mv modules local t@mylaptop ~/puppet-r10k $ git commit -m "moving modules in preparation for r10k" [master c96d0dc] moving modules in preparation for r10k 9 files changed, 0 insertions(+), 0 deletions(-) rename {modules => local}/base (100%) rename {modules => local}/puppet/files/papply.sh (100%) rename {modules => local}/puppet/files/pull-updates.sh (100%) rename {modules => local}/puppet/manifests/init.pp (100%)
We'll create a Puppetfile to control r10k and install modules on our master.
- Create a
Puppetfileinto the new Git repository with the following contents:forge "http://forge.puppetlabs.com" mod 'puppetlabs/puppetdb', '3.0.0' mod 'puppetlabs/stdlib', '3.2.0' mod 'puppetlabs/concat' mod 'puppetlabs/firewall'
- Add the
Puppetfileto your new repository:t@mylaptop ~/puppet-r10k $ git add Puppetfile t@mylaptop ~/puppet-r10k $ git commit -m "adding Puppetfile" [production d42481f] adding Puppetfile 1 file changed, 7 insertions(+) create mode 100644 Puppetfile t@mylaptop ~/puppet-r10k $ git push Counting objects: 7, done. Delta compression using up to 4 threads. Compressing objects: 100% (5/5), done. Writing objects: 100% (5/5), 589 bytes | 0 bytes/s, done. Total 5 (delta 2), reused 0 (delta 0) To git@git.example.com:repos/puppet-r10k.git cf8dfb9..d42481f production -> production
- Back to your master, create
/etc/r10k.yamlwith the following contents:--- :cachedir: '/var/cache/r10k' :sources: :plops: remote: 'git@git.example.com:repos/puppet-r10k.git' basedir: '/etc/puppet/environments'
- Run r10k to have the
/etc/puppet/environmentsdirectory populated (hint: create a backup of your/etc/puppet/environmentsdirectory first):root@puppet:~# r10k deploy environment -p - Verify that your
/etc/puppet/environmentsdirectory has a production subdirectory. Within that directory, the/localdirectory will exist and the modules directory will have all the modules listed in thePuppetfile:root@puppet:/etc/puppet/environments# tree -L 2 . ├── master │ ├── manifests │ ├── modules │ └── README └── production ├── environment.conf ├── local ├── manifests ├── modules ├── Puppetfile └── README
We started by creating a copy of our Git repository; this was only done to preserve the earlier work and is not required. The important thing to remember with r10k and librarian-puppet is that they both assume they are in control of the /modules subdirectory. We need to move our modules out of the way and create a new location for the modules.
You can automate the deployment of your environments using r10k. The command we used to run r10k and populate our environments directory can be easily placed inside a Git hook to automatically update your environment. There is also a marionette collective (mcollective) plugin (https://github.com/acidprime/r10k), which can be used to have r10k run on an arbitrary set of servers.
Using either of these tools will help keep your site consistent, even if you are not taking advantage of the various modules available on the Forge.
- Install r10k on your puppet master, or on whichever machine you wish to manage your
environmentpathdirectory:root@puppet:~# puppet resource package r10k ensure=installed provider=gem Notice: /Package[r10k]/ensure: created package { 'r10k': ensure => ['1.3.5'], }
- Make a new copy of your Git repository (optional, do this on your Git server):
[git@git repos]$ git clone --bare puppet.git puppet-r10k.git Initialized empty Git repository in /home/git/repos/puppet-r10k.git/
- Check out the new Git repository (on your local machine) and move the existing modules directory to a new location. We'll use
/localin this example:t@mylaptop ~ $ git clone git@git.example.com:repos/puppet-r10k.git Cloning into 'puppet-r10k'... remote: Counting objects: 2660, done. remote: Compressing objects: 100% (2136/2136), done. remote: Total 2660 (delta 913), reused 1049 (delta 238) Receiving objects: 100% (2660/2660), 738.20 KiB | 0 bytes/s, done. Resolving deltas: 100% (913/913), done. Checking connectivity... done. t@mylaptop ~ $ cd puppet-r10k/ t@mylaptop ~/puppet-r10k $ git checkout production Branch production set up to track remote branch production from origin. Switched to a new branch 'production' t@mylaptop ~/puppet-r10k $ git mv modules local t@mylaptop ~/puppet-r10k $ git commit -m "moving modules in preparation for r10k" [master c96d0dc] moving modules in preparation for r10k 9 files changed, 0 insertions(+), 0 deletions(-) rename {modules => local}/base (100%) rename {modules => local}/puppet/files/papply.sh (100%) rename {modules => local}/puppet/files/pull-updates.sh (100%) rename {modules => local}/puppet/manifests/init.pp (100%)
We'll create a Puppetfile to control r10k and install modules on our master.
- Create a
Puppetfileinto the new Git repository with the following contents:forge "http://forge.puppetlabs.com" mod 'puppetlabs/puppetdb', '3.0.0' mod 'puppetlabs/stdlib', '3.2.0' mod 'puppetlabs/concat' mod 'puppetlabs/firewall'
- Add the
Puppetfileto your new repository:t@mylaptop ~/puppet-r10k $ git add Puppetfile t@mylaptop ~/puppet-r10k $ git commit -m "adding Puppetfile" [production d42481f] adding Puppetfile 1 file changed, 7 insertions(+) create mode 100644 Puppetfile t@mylaptop ~/puppet-r10k $ git push Counting objects: 7, done. Delta compression using up to 4 threads. Compressing objects: 100% (5/5), done. Writing objects: 100% (5/5), 589 bytes | 0 bytes/s, done. Total 5 (delta 2), reused 0 (delta 0) To git@git.example.com:repos/puppet-r10k.git cf8dfb9..d42481f production -> production
- Back to your master, create
/etc/r10k.yamlwith the following contents:--- :cachedir: '/var/cache/r10k' :sources: :plops: remote: 'git@git.example.com:repos/puppet-r10k.git' basedir: '/etc/puppet/environments'
- Run r10k to have the
/etc/puppet/environmentsdirectory populated (hint: create a backup of your/etc/puppet/environmentsdirectory first):root@puppet:~# r10k deploy environment -p - Verify that your
/etc/puppet/environmentsdirectory has a production subdirectory. Within that directory, the/localdirectory will exist and the modules directory will have all the modules listed in thePuppetfile:root@puppet:/etc/puppet/environments# tree -L 2 . ├── master │ ├── manifests │ ├── modules │ └── README └── production ├── environment.conf ├── local ├── manifests ├── modules ├── Puppetfile └── README
We started by creating a copy of our Git repository; this was only done to preserve the earlier work and is not required. The important thing to remember with r10k and librarian-puppet is that they both assume they are in control of the /modules subdirectory. We need to move our modules out of the way and create a new location for the modules.
You can automate the deployment of your environments using r10k. The command we used to run r10k and populate our environments directory can be easily placed inside a Git hook to automatically update your environment. There is also a marionette collective (mcollective) plugin (https://github.com/acidprime/r10k), which can be used to have r10k run on an arbitrary set of servers.
Using either of these tools will help keep your site consistent, even if you are not taking advantage of the various modules available on the Forge.
Puppetfile into the new Git repository with the following contents:forge "http://forge.puppetlabs.com" mod 'puppetlabs/puppetdb', '3.0.0' mod 'puppetlabs/stdlib', '3.2.0' mod 'puppetlabs/concat' mod 'puppetlabs/firewall'
Puppetfile to your new repository:t@mylaptop ~/puppet-r10k $ git add Puppetfile t@mylaptop ~/puppet-r10k $ git commit -m "adding Puppetfile" [production d42481f] adding Puppetfile 1 file changed, 7 insertions(+) create mode 100644 Puppetfile t@mylaptop ~/puppet-r10k $ git push Counting objects: 7, done. Delta compression using up to 4 threads. Compressing objects: 100% (5/5), done. Writing objects: 100% (5/5), 589 bytes | 0 bytes/s, done. Total 5 (delta 2), reused 0 (delta 0) To git@git.example.com:repos/puppet-r10k.git cf8dfb9..d42481f production -> production
- your master, create
/etc/r10k.yamlwith the following contents:--- :cachedir: '/var/cache/r10k' :sources: :plops: remote: 'git@git.example.com:repos/puppet-r10k.git' basedir: '/etc/puppet/environments'
- Run r10k to have the
/etc/puppet/environmentsdirectory populated (hint: create a backup of your/etc/puppet/environmentsdirectory first):root@puppet:~# r10k deploy environment -p - Verify that your
/etc/puppet/environmentsdirectory has a production subdirectory. Within that directory, the/localdirectory will exist and the modules directory will have all the modules listed in thePuppetfile:root@puppet:/etc/puppet/environments# tree -L 2 . ├── master │ ├── manifests │ ├── modules │ └── README └── production ├── environment.conf ├── local ├── manifests ├── modules ├── Puppetfile └── README
We started by creating a copy of our Git repository; this was only done to preserve the earlier work and is not required. The important thing to remember with r10k and librarian-puppet is that they both assume they are in control of the /modules subdirectory. We need to move our modules out of the way and create a new location for the modules.
You can automate the deployment of your environments using r10k. The command we used to run r10k and populate our environments directory can be easily placed inside a Git hook to automatically update your environment. There is also a marionette collective (mcollective) plugin (https://github.com/acidprime/r10k), which can be used to have r10k run on an arbitrary set of servers.
Using either of these tools will help keep your site consistent, even if you are not taking advantage of the various modules available on the Forge.
You can automate the deployment of your environments using r10k. The command we used to run r10k and populate our environments directory can be easily placed inside a Git hook to automatically update your environment. There is also a marionette collective (mcollective) plugin (https://github.com/acidprime/r10k), which can be used to have r10k run on an arbitrary set of servers.
Using either of these tools will help keep your site consistent, even if you are not taking advantage of the various modules available on the Forge.
r10k. The command we used to run r10k and populate our environments directory can be easily placed inside a Git hook to automatically update your environment. There is also a marionette collective (mcollective) plugin
(https://github.com/acidprime/r10k), which can be used to have r10k run on an arbitrary set of servers.
Using either of these tools will help keep your site consistent, even if you are not taking advantage of the various modules available on the Forge.
"Show me a completely smooth operation and I'll show you someone who's covering mistakes. Real boats rock." | ||
| --Frank Herbert, Chapterhouse: Dune | ||
In this chapter, we will cover the following recipes:
To avoid these problems, you can use Puppet's noop mode, which means no operation or do nothing. When run with the noop option, Puppet only reports what it would do but doesn't actually do anything. One caveat here is that even during a noop run, pluginsync still runs and any lib directories in modules will be synced to nodes. This will update external fact definitions and possibly Puppet's types and providers.
You may run noop mode when running puppet agent or puppet apply by appending the --noop switch to the command. You may also create a noop=true line in your puppet.conf file within the [agent] or [main] sections.
- Create a
noop.ppmanifest that creates a file as follows:file {'/tmp/noop': content => 'nothing', mode => 0644, } - Now run puppet agent with the
noopswitch:t@mylaptop ~/puppet/manifests $ puppet apply noop.pp --noop Notice: Compiled catalog for mylaptop in environment production in 0.41 seconds Notice: /Stage[main]/Main/File[/tmp/noop]/ensure: current_value absent, should be file (noop) Notice: Class[Main]: Would have triggered 'refresh' from 1 events Notice: Stage[main]: Would have triggered 'refresh' from 1 events Notice: Finished catalog run in 0.02 seconds
- Now run without the
noopoption to see that the file is created:t@mylaptop ~/puppet/manifests $ puppet apply noop.pp Notice: Compiled catalog for mylaptop in environment production in 0.37 seconds Notice: /Stage[main]/Main/File[/tmp/noop]/ensure: defined content as '{md5}3e47b75000b0924b6c9ba5759a7cf15d'
In the noop mode, Puppet does everything it would normally, with the exception of actually making any changes to the machine (the exec resources, for example, won't run). It tells you what it would have done, and you can compare this with what you expected to happen. If there are any differences, double-check the manifest or the current state of the machine.
You can also use noop mode as a simple auditing tool. It will tell you whether any changes have been made to the machine since Puppet last applied its manifest. Some organizations require all config changes to be made with Puppet, which is one way of implementing a change control process. Unauthorized changes to the resources managed by Puppet can be detected using Puppet in noop mode and you can then decide whether to merge the changes back into the Puppet manifest or undo them.
- The Auditing resources recipe in Chapter 6, Managing Resources and Files
- The Automatic syntax checking with Git hooks recipe in Chapter 2, Puppet Infrastructure
- The Generating reports recipe in this chapter
- The Testing your Puppet manifests with rspec-puppet recipe in Chapter 9, External Tools and the Puppet Ecosystem
- Create a
noop.ppmanifest that creates a file as follows:file {'/tmp/noop': content => 'nothing', mode => 0644, } - Now run puppet agent with the
noopswitch:t@mylaptop ~/puppet/manifests $ puppet apply noop.pp --noop Notice: Compiled catalog for mylaptop in environment production in 0.41 seconds Notice: /Stage[main]/Main/File[/tmp/noop]/ensure: current_value absent, should be file (noop) Notice: Class[Main]: Would have triggered 'refresh' from 1 events Notice: Stage[main]: Would have triggered 'refresh' from 1 events Notice: Finished catalog run in 0.02 seconds
- Now run without the
noopoption to see that the file is created:t@mylaptop ~/puppet/manifests $ puppet apply noop.pp Notice: Compiled catalog for mylaptop in environment production in 0.37 seconds Notice: /Stage[main]/Main/File[/tmp/noop]/ensure: defined content as '{md5}3e47b75000b0924b6c9ba5759a7cf15d'
In the noop mode, Puppet does everything it would normally, with the exception of actually making any changes to the machine (the exec resources, for example, won't run). It tells you what it would have done, and you can compare this with what you expected to happen. If there are any differences, double-check the manifest or the current state of the machine.
You can also use noop mode as a simple auditing tool. It will tell you whether any changes have been made to the machine since Puppet last applied its manifest. Some organizations require all config changes to be made with Puppet, which is one way of implementing a change control process. Unauthorized changes to the resources managed by Puppet can be detected using Puppet in noop mode and you can then decide whether to merge the changes back into the Puppet manifest or undo them.
- The Auditing resources recipe in Chapter 6, Managing Resources and Files
- The Automatic syntax checking with Git hooks recipe in Chapter 2, Puppet Infrastructure
- The Generating reports recipe in this chapter
- The Testing your Puppet manifests with rspec-puppet recipe in Chapter 9, External Tools and the Puppet Ecosystem
noop mode, Puppet
You can also use noop mode as a simple auditing tool. It will tell you whether any changes have been made to the machine since Puppet last applied its manifest. Some organizations require all config changes to be made with Puppet, which is one way of implementing a change control process. Unauthorized changes to the resources managed by Puppet can be detected using Puppet in noop mode and you can then decide whether to merge the changes back into the Puppet manifest or undo them.
- The Auditing resources recipe in Chapter 6, Managing Resources and Files
- The Automatic syntax checking with Git hooks recipe in Chapter 2, Puppet Infrastructure
- The Generating reports recipe in this chapter
- The Testing your Puppet manifests with rspec-puppet recipe in Chapter 9, External Tools and the Puppet Ecosystem
- The Auditing resources recipe in Chapter 6, Managing Resources and Files
- The Automatic syntax checking with Git hooks recipe in Chapter 2, Puppet Infrastructure
- The Generating reports recipe in this chapter
- The Testing your Puppet manifests with rspec-puppet recipe in Chapter 9, External Tools and the Puppet Ecosystem
When you use the exec resources to run commands on the node, Puppet will give you an error message such as the following if a command returns a non-zero exit status:
As you can see, Puppet not only reports that the command failed, but shows its output:
Follow these steps in order to log command output:
- Define an
execresource with thelogoutputparameter as shown in the following code snippet:exec { 'exec with output': command => '/bin/cat /etc/hostname', logoutput => true, } - Run Puppet:
t@mylaptop ~/puppet/manifests $ puppet apply exec.pp Notice: Compiled catalog for mylaptop in environment production in 0.46 seconds Notice: /Stage[main]/Main/Exec[exec with outout]/returns: mylaptop Notice: /Stage[main]/Main/Exec[exec with outout]/returns: executed successfully Notice: Finished catalog run in 0.06 seconds
- As you can see, even though the command succeeds, Puppet prints the output:
mylaptop
Note
Resource defaults: What's this Exec syntax? It looks like an exec resource, but it's not. When you use Exec with a capital E, you're setting the resource default for exec. You may set the resource default for any resource by capitalizing the first letter of the resource type. Anywhere that Puppet see's that resource within the current scope or a nested subscope, it will apply the defaults you define.
If you never want to see the command output, whether it succeeds or fails, use:
More information is available at https://docs.puppetlabs.com/references/latest/type.html#exec.
exec resource with the logoutput parameter as shown in the following code snippet:exec { 'exec with output':
command => '/bin/cat /etc/hostname',
logoutput => true,
}t@mylaptop ~/puppet/manifests $ puppet apply exec.pp Notice: Compiled catalog for mylaptop in environment production in 0.46 seconds Notice: /Stage[main]/Main/Exec[exec with outout]/returns: mylaptop Notice: /Stage[main]/Main/Exec[exec with outout]/returns: executed successfully Notice: Finished catalog run in 0.06 seconds
mylaptop
Note
Resource defaults: What's this Exec syntax? It looks like an exec resource, but it's not. When you use Exec with a capital E, you're setting the resource default for exec. You may set the resource default for any resource by capitalizing the first letter of the resource type. Anywhere that Puppet see's that resource within the current scope or a nested subscope, it will apply the defaults you define.
If you never want to see the command output, whether it succeeds or fails, use:
More information is available at https://docs.puppetlabs.com/references/latest/type.html#exec.
logoutput attribute has three possible settings:
false: This never
Note
Resource defaults: What's this Exec syntax? It looks like an exec resource, but it's not. When you use Exec with a capital E, you're setting the resource default for exec. You may set the resource default for any resource by capitalizing the first letter of the resource type. Anywhere that Puppet see's that resource within the current scope or a nested subscope, it will apply the defaults you define.
If you never want to see the command output, whether it succeeds or fails, use:
More information is available at https://docs.puppetlabs.com/references/latest/type.html#exec.
logoutput to always display command output for all exec resources by defining the following in your site.pp file:
Note
Resource defaults: What's this Exec syntax? It looks like an exec resource, but it's not. When you use Exec with a capital E, you're setting the resource default for exec. You may set the resource default for any resource by capitalizing the first letter of the resource type. Anywhere that Puppet see's that resource within the current scope or a nested subscope, it will apply the defaults you define.
If you never want to see the command output, whether it succeeds or fails, use:
More information is available at https://docs.puppetlabs.com/references/latest/type.html#exec.
It can be very helpful when debugging problems if you can print out information at a certain point in the manifest. This is a good way to tell, for example, if a variable isn't defined or has an unexpected value. Sometimes it's useful just to know that a particular piece of code has been run. Puppet's notify resource lets you print out such messages.
You can refer to variables in the message:
Puppet will interpolate the values in the printout:
The double colon (::) before the fact name tells Puppet that this is a variable in top scope (accessible to all classes) and not local to the class. For more about how Puppet handles variable scope, see the Puppet Labs article:
Puppet compiles your manifests into a catalog; the order in which resources are executed on the client (node) may not be the same as the order of the resources within your source files. When you are using a notify resource for debugging, you should use resource chaining to ensure that the notify resource is executed before or after your failing resource.
If you don't chain the resource or use a metaparameter such as before or require, there is no guarantee your notify statement will be executed near the other resources you are interested in debugging. More information on resource ordering can be found at https://docs.puppetlabs.com/puppet/latest/reference/lang_relationships.html.
For example, to have your notify resource run after 'failing exec' in the preceding code snippet, use:
notify { 'Resource X has been applied':
require => Exec['failing exec'],
}Note, however, that in this case the notify resource will fail to execute since the exec failed. When a resource fails, all the resources that depended on that resource are skipped:
notify {'failed exec failed':
require => Exec['failing exec']
}When we run Puppet, we see that the notify resource is skipped:
t@mylaptop ~/puppet/manifests $ puppet apply fail.pp ... Error: /bin/grepmylaptop /etc/hosts returned 1 instead of one of [0] Error: /Stage[main]/Main/Exec[failing exec]/returns: change from notrun to 0 failed: /bin/grepmylaptop /etc/hosts returned 1 instead of one of [0] Notice: /Stage[main]/Main/Notify[failed exec failed]: Dependency Exec[failing exec] has failures: true Warning: /Stage[main]/Main/Notify[failed exec failed]: Skipping because of failed dependencies Notice: Finished catalog run in 0.06 seconds
notify resource in your manifest at the point you want to investigate:
You can refer to variables in the message:
Puppet will interpolate the values in the printout:
The double colon (::) before the fact name tells Puppet that this is a variable in top scope (accessible to all classes) and not local to the class. For more about how Puppet handles variable scope, see the Puppet Labs article:
Puppet compiles your manifests into a catalog; the order in which resources are executed on the client (node) may not be the same as the order of the resources within your source files. When you are using a notify resource for debugging, you should use resource chaining to ensure that the notify resource is executed before or after your failing resource.
If you don't chain the resource or use a metaparameter such as before or require, there is no guarantee your notify statement will be executed near the other resources you are interested in debugging. More information on resource ordering can be found at https://docs.puppetlabs.com/puppet/latest/reference/lang_relationships.html.
For example, to have your notify resource run after 'failing exec' in the preceding code snippet, use:
notify { 'Resource X has been applied':
require => Exec['failing exec'],
}Note, however, that in this case the notify resource will fail to execute since the exec failed. When a resource fails, all the resources that depended on that resource are skipped:
notify {'failed exec failed':
require => Exec['failing exec']
}When we run Puppet, we see that the notify resource is skipped:
t@mylaptop ~/puppet/manifests $ puppet apply fail.pp ... Error: /bin/grepmylaptop /etc/hosts returned 1 instead of one of [0] Error: /Stage[main]/Main/Exec[failing exec]/returns: change from notrun to 0 failed: /bin/grepmylaptop /etc/hosts returned 1 instead of one of [0] Notice: /Stage[main]/Main/Notify[failed exec failed]: Dependency Exec[failing exec] has failures: true Warning: /Stage[main]/Main/Notify[failed exec failed]: Skipping because of failed dependencies Notice: Finished catalog run in 0.06 seconds
You can refer to variables in the message:
Puppet will interpolate the values in the printout:
The double colon (::) before the fact name tells Puppet that this is a variable in top scope (accessible to all classes) and not local to the class. For more about how Puppet handles variable scope, see the Puppet Labs article:
Puppet compiles your manifests into a catalog; the order in which resources are executed on the client (node) may not be the same as the order of the resources within your source files. When you are using a notify resource for debugging, you should use resource chaining to ensure that the notify resource is executed before or after your failing resource.
If you don't chain the resource or use a metaparameter such as before or require, there is no guarantee your notify statement will be executed near the other resources you are interested in debugging. More information on resource ordering can be found at https://docs.puppetlabs.com/puppet/latest/reference/lang_relationships.html.
For example, to have your notify resource run after 'failing exec' in the preceding code snippet, use:
notify { 'Resource X has been applied':
require => Exec['failing exec'],
}Note, however, that in this case the notify resource will fail to execute since the exec failed. When a resource fails, all the resources that depended on that resource are skipped:
notify {'failed exec failed':
require => Exec['failing exec']
}When we run Puppet, we see that the notify resource is skipped:
t@mylaptop ~/puppet/manifests $ puppet apply fail.pp ... Error: /bin/grepmylaptop /etc/hosts returned 1 instead of one of [0] Error: /Stage[main]/Main/Exec[failing exec]/returns: change from notrun to 0 failed: /bin/grepmylaptop /etc/hosts returned 1 instead of one of [0] Notice: /Stage[main]/Main/Notify[failed exec failed]: Dependency Exec[failing exec] has failures: true Warning: /Stage[main]/Main/Notify[failed exec failed]: Skipping because of failed dependencies Notice: Finished catalog run in 0.06 seconds
notify statements. Additionally, we can treat the notify calls the same as other resources, having them require or be required by other resources.
You can refer to variables in the message:
Puppet will interpolate the values in the printout:
The double colon (::) before the fact name tells Puppet that this is a variable in top scope (accessible to all classes) and not local to the class. For more about how Puppet handles variable scope, see the Puppet Labs article:
Puppet compiles your manifests into a catalog; the order in which resources are executed on the client (node) may not be the same as the order of the resources within your source files. When you are using a notify resource for debugging, you should use resource chaining to ensure that the notify resource is executed before or after your failing resource.
If you don't chain the resource or use a metaparameter such as before or require, there is no guarantee your notify statement will be executed near the other resources you are interested in debugging. More information on resource ordering can be found at https://docs.puppetlabs.com/puppet/latest/reference/lang_relationships.html.
For example, to have your notify resource run after 'failing exec' in the preceding code snippet, use:
notify { 'Resource X has been applied':
require => Exec['failing exec'],
}Note, however, that in this case the notify resource will fail to execute since the exec failed. When a resource fails, all the resources that depended on that resource are skipped:
notify {'failed exec failed':
require => Exec['failing exec']
}When we run Puppet, we see that the notify resource is skipped:
t@mylaptop ~/puppet/manifests $ puppet apply fail.pp ... Error: /bin/grepmylaptop /etc/hosts returned 1 instead of one of [0] Error: /Stage[main]/Main/Exec[failing exec]/returns: change from notrun to 0 failed: /bin/grepmylaptop /etc/hosts returned 1 instead of one of [0] Notice: /Stage[main]/Main/Notify[failed exec failed]: Dependency Exec[failing exec] has failures: true Warning: /Stage[main]/Main/Notify[failed exec failed]: Skipping because of failed dependencies Notice: Finished catalog run in 0.06 seconds
Puppet will interpolate the values in the printout:
The double colon (::) before the fact name tells Puppet that this is a variable in top scope (accessible to all classes) and not local to the class. For more about how Puppet handles variable scope, see the Puppet Labs article:
Puppet compiles your manifests into a catalog; the order in which resources are executed on the client (node) may not be the same as the order of the resources within your source files. When you are using a notify resource for debugging, you should use resource chaining to ensure that the notify resource is executed before or after your failing resource.
If you don't chain the resource or use a metaparameter such as before or require, there is no guarantee your notify statement will be executed near the other resources you are interested in debugging. More information on resource ordering can be found at https://docs.puppetlabs.com/puppet/latest/reference/lang_relationships.html.
For example, to have your notify resource run after 'failing exec' in the preceding code snippet, use:
notify { 'Resource X has been applied':
require => Exec['failing exec'],
}Note, however, that in this case the notify resource will fail to execute since the exec failed. When a resource fails, all the resources that depended on that resource are skipped:
notify {'failed exec failed':
require => Exec['failing exec']
}When we run Puppet, we see that the notify resource is skipped:
t@mylaptop ~/puppet/manifests $ puppet apply fail.pp ... Error: /bin/grepmylaptop /etc/hosts returned 1 instead of one of [0] Error: /Stage[main]/Main/Exec[failing exec]/returns: change from notrun to 0 failed: /bin/grepmylaptop /etc/hosts returned 1 instead of one of [0] Notice: /Stage[main]/Main/Notify[failed exec failed]: Dependency Exec[failing exec] has failures: true Warning: /Stage[main]/Main/Notify[failed exec failed]: Skipping because of failed dependencies Notice: Finished catalog run in 0.06 seconds
If you don't chain the resource or use a metaparameter such as before or require, there is no guarantee your notify statement will be executed near the other resources you are interested in debugging. More information on resource ordering can be found at https://docs.puppetlabs.com/puppet/latest/reference/lang_relationships.html.
For example, to have your notify resource run after 'failing exec' in the preceding code snippet, use:
notify { 'Resource X has been applied':
require => Exec['failing exec'],
}Note, however, that in this case the notify resource will fail to execute since the exec failed. When a resource fails, all the resources that depended on that resource are skipped:
notify {'failed exec failed':
require => Exec['failing exec']
}When we run Puppet, we see that the notify resource is skipped:
t@mylaptop ~/puppet/manifests $ puppet apply fail.pp ... Error: /bin/grepmylaptop /etc/hosts returned 1 instead of one of [0] Error: /Stage[main]/Main/Exec[failing exec]/returns: change from notrun to 0 failed: /bin/grepmylaptop /etc/hosts returned 1 instead of one of [0] Notice: /Stage[main]/Main/Notify[failed exec failed]: Dependency Exec[failing exec] has failures: true Warning: /Stage[main]/Main/Notify[failed exec failed]: Skipping because of failed dependencies Notice: Finished catalog run in 0.06 seconds
If you're managing a lot of machines, Puppet's reporting facility can give you some valuable information on what's actually happening out there.
With reporting enabled, Puppet will generate a report file, containing data such as:
By default, these reports are stored on the node at /var/lib/puppet/reports in a directory named after the hostname, but you can specify a different destination using the reportdir option. You can create your own scripts to process these reports (which are in the standard YAML format). When we run puppet agent on cookbook.example.com, the following file is created on the master:
You won't see any additional output, but a report file will be generated in the report directory.
You can also see some overall statistics about a Puppet run by supplying the --summarize switch:
Puppet can generate different types of reports with the reports option in the [main] or [master] section of puppet.conf on your Puppet master servers. There are several built-in report types listed at https://docs.puppetlabs.com/references/latest/report.html. In addition to the built-in report types, there are some community developed reports that are quite useful. The Foreman (http://theforeman.org), for example, provides a Foreman report type that you can enable to forward your node reports to the Foreman.
- The Auditing resources recipe in Chapter 6, Managing Resources and Files
puppet.conf: within the [main] or [agent] sections:
With reporting enabled, Puppet will generate a report file, containing data such as:
By default, these reports are stored on the node at /var/lib/puppet/reports in a directory named after the hostname, but you can specify a different destination using the reportdir option. You can create your own scripts to process these reports (which are in the standard YAML format). When we run puppet agent on cookbook.example.com, the following file is created on the master:
You won't see any additional output, but a report file will be generated in the report directory.
You can also see some overall statistics about a Puppet run by supplying the --summarize switch:
Puppet can generate different types of reports with the reports option in the [main] or [master] section of puppet.conf on your Puppet master servers. There are several built-in report types listed at https://docs.puppetlabs.com/references/latest/report.html. In addition to the built-in report types, there are some community developed reports that are quite useful. The Foreman (http://theforeman.org), for example, provides a Foreman report type that you can enable to forward your node reports to the Foreman.
- The Auditing resources recipe in Chapter 6, Managing Resources and Files
You won't see any additional output, but a report file will be generated in the report directory.
You can also see some overall statistics about a Puppet run by supplying the --summarize switch:
Puppet can generate different types of reports with the reports option in the [main] or [master] section of puppet.conf on your Puppet master servers. There are several built-in report types listed at https://docs.puppetlabs.com/references/latest/report.html. In addition to the built-in report types, there are some community developed reports that are quite useful. The Foreman (http://theforeman.org), for example, provides a Foreman report type that you can enable to forward your node reports to the Foreman.
- The Auditing resources recipe in Chapter 6, Managing Resources and Files
report_server in the [agent] section of puppet.conf.
--report switch to the command line when you run Puppet agent manually:
report directory.
--summarize switch:
Puppet can generate different types of reports with the reports option in the [main] or [master] section of puppet.conf on your Puppet master servers. There are several built-in report types listed at https://docs.puppetlabs.com/references/latest/report.html. In addition to the built-in report types, there are some community developed reports that are quite useful. The Foreman (http://theforeman.org), for example, provides a Foreman report type that you can enable to forward your node reports to the Foreman.
- The Auditing resources recipe in Chapter 6, Managing Resources and Files
[main] or [master] section of puppet.conf on your Puppet master servers. There are several built-in report types
listed at https://docs.puppetlabs.com/references/latest/report.html. In addition to the built-in report types, there are some community developed reports that are quite useful. The Foreman (http://theforeman.org), for example, provides a Foreman report type that you can enable to forward your node reports to the Foreman.
- The Auditing resources recipe in Chapter 6, Managing Resources and Files
- Chapter 6, Managing Resources and Files
Follow these steps to generate HTML documentation for your manifest:
- Run the following command:
t@mylaptop ~/puppet $ puppet doc --all --outputdir=/tmp/puppet --mode rdoc --modulepath=modules/ - This will generate a set of HTML files at
/tmp/puppet. Open the top-levelindex.htmlfile with your web browser (file:///tmp/puppet/index.html), and you'll see something like the following screenshot:
- Click the classes link on the left and select the Apache module, something similar to the following will be displayed:

The puppet doc command creates a structured HTML documentation tree similar to that produced by RDoc, the popular Ruby documentation generator. This makes it easier to understand how different parts of the manifest relate to one another.
The puppet doc command will generate basic documentation of your manifests as they stand, but you can include more useful information by adding comments to your manifest files, using the standard RDoc syntax. When we created our base class using puppet module generate, these comments were created for us:
After generating the HTML documentation, we can see the result for the base module as shown in the following screenshot:

HTML documentation for your manifest:
- Run the following command:
t@mylaptop ~/puppet $ puppet doc --all --outputdir=/tmp/puppet --mode rdoc --modulepath=modules/ - This will generate a set of HTML files at
/tmp/puppet. Open the top-levelindex.htmlfile with your web browser (file:///tmp/puppet/index.html), and you'll see something like the following screenshot: - Click the classes link on the left and select the Apache module, something similar to the following will be displayed:
The puppet doc command creates a structured HTML documentation tree similar to that produced by RDoc, the popular Ruby documentation generator. This makes it easier to understand how different parts of the manifest relate to one another.
The puppet doc command will generate basic documentation of your manifests as they stand, but you can include more useful information by adding comments to your manifest files, using the standard RDoc syntax. When we created our base class using puppet module generate, these comments were created for us:
After generating the HTML documentation, we can see the result for the base module as shown in the following screenshot:
puppet doc command
creates a structured HTML documentation tree similar to that produced by RDoc, the popular Ruby documentation generator. This makes it easier to understand how different parts of the manifest relate to one another.
The puppet doc command will generate basic documentation of your manifests as they stand, but you can include more useful information by adding comments to your manifest files, using the standard RDoc syntax. When we created our base class using puppet module generate, these comments were created for us:
After generating the HTML documentation, we can see the result for the base module as shown in the following screenshot:
puppet doc command will
generate basic documentation of your manifests as they stand, but you can include more useful information by adding comments to your manifest files, using the standard RDoc syntax. When we created our base class using puppet module generate, these comments were created for us:
After generating the HTML documentation, we can see the result for the base module as shown in the following screenshot:
Dependencies can get complicated quickly, and it's easy to end up with a circular dependency (where A depends on B, which depends on A) that will cause Puppet to complain and stop working. Fortunately, Puppet's --graph option makes it easy to generate a diagram of your resources and the dependencies between them, which can be a big help in fixing such problems.
Follow these steps to generate a dependency graph for your manifest:
- Create the directories for a new
trifectamodule:ubuntu@cookbook:~/puppet$ mkdir modules/trifecta ubuntu@cookbook:~/puppet$ mkdir modules/trifecta/manifests ubuntu@cookbook:~/puppet$ mkdir modules/trifecta/files
- Create the file
modules/trifecta/manifests/init.ppwith the following code containing a deliberate circular dependency (can you spot it?):class trifecta { package { 'ntp': ensure => installed, require => File['/etc/ntp.conf'], } service { 'ntp': ensure => running, require => Package['ntp'], } file { '/etc/ntp.conf': source => 'puppet:///modules/trifecta/ntp.conf', notify => Service['ntp'], require => Package['ntp'], } } - Create a simple
ntp.conffile:t@mylaptop~/puppet $ cd modules/trifecta/files t@mylaptop~/puppet/modules/trifecta/files $ echo "server 127.0.0.1" >ntp.conf
- Since we'll be working locally on this problem, create a
trifecta.ppmanifest that includes the broken trifecta class:include trifecta
- Run Puppet:
t@mylaptop ~/puppet/manifests $ puppet apply trifecta.pp Notice: Compiled catalog for mylaptop in environment production in 1.32 seconds Error: Could not apply complete catalog: Found 1 dependency cycle: (File[/etc/ntp.conf] => Package[ntp] => File[/etc/ntp.conf]) Try the '--graph' option and opening the resulting '.dot' file in OmniGraffle or GraphViz
- Run Puppet with the
--graphoption as suggested:t@mylaptop ~/puppet/manifests $ puppet apply trifecta.pp --graph Notice: Compiled catalog for mylaptop in environment production in 1.26 seconds Error: Could not apply complete catalog: Found 1 dependency cycle: (File[/etc/ntp.conf] => Package[ntp] => File[/etc/ntp.conf]) Cycle graph written to /home/tuphill/.puppet/var/state/graphs/cycles.dot. Notice: Finished catalog run in 0.03 seconds
- Check whether the graph files have been created:
t@mylaptop ~/puppet/manifests $ cd ~/.puppet/var/state/graphs t@mylaptop ~/.puppet/var/state/graphs $ ls -l total 16 -rw-rw-r--. 1 thomasthomas 121 Nov 23 23:11 cycles.dot -rw-rw-r--. 1 thomasthomas 2885 Nov 23 23:11 expanded_relationships.dot -rw-rw-r--. 1 thomasthomas 1557 Nov 23 23:11 relationships.dot -rw-rw-r--. 1 thomasthomas 1680 Nov 23 23:11 resources.dot
- Create a graphic using the
dotcommand as follows:ubuntu@cookbook:~/puppet$ dot -Tpng -o relationships.png /var/lib/puppet/state/graphs/relationships.dot - The graphic will look something like the this:

When you run puppet agent --graph (or enable the graph option in puppet.conf), Puppet will generate three graphs in the DOT format (a graphics language):
resources.dot: This shows the hierarchical structure of your classes and resources, but without dependenciesrelationships.dot: This shows the dependencies between resources as arrows, as shown in the preceding imageexpanded_relationships.dot: This is a more detailed version of the relationships graph
To fix the circular dependency problem, all you need to do is remove one of the dependency lines and break the circle. The following code fixes the problem:

In this graph it is easy to see that Package[ntp] is the first resource to be applied, then File[/etc/ntp.conf], and finally Service[ntp].
Tip
A graph such as that shown previously is known as a Directed Acyclic Graph (DAG). Reducing the resources to a DAG ensures that Puppet can calculate the shortest path of all the vertices (resources) in linear time. For more information on DAGs, look at http://en.wikipedia.org/wiki/Directed_acyclic_graph.
Resource and relationship graphs can be useful even when you don't have a bug to find. If you have a very complex network of classes and resources, for example, studying the resources graph can help you see where to simplify things. Similarly, when dependencies become too complicated to understand from reading the manifest, the graphs can be a useful form of documentation. For instance, a graph will make it readily apparent which resources have the most dependencies and which resources are required by the most other resources. Resources that are required by a large number of other resources will have numerous arrows pointing at them.
- The Using run stages recipe in Chapter 3, Writing Better Manifests
graphviz package to view the diagram files:
Follow these steps to generate a dependency graph for your manifest:
- Create the directories for a new
trifectamodule:ubuntu@cookbook:~/puppet$ mkdir modules/trifecta ubuntu@cookbook:~/puppet$ mkdir modules/trifecta/manifests ubuntu@cookbook:~/puppet$ mkdir modules/trifecta/files
- Create the file
modules/trifecta/manifests/init.ppwith the following code containing a deliberate circular dependency (can you spot it?):class trifecta { package { 'ntp': ensure => installed, require => File['/etc/ntp.conf'], } service { 'ntp': ensure => running, require => Package['ntp'], } file { '/etc/ntp.conf': source => 'puppet:///modules/trifecta/ntp.conf', notify => Service['ntp'], require => Package['ntp'], } } - Create a simple
ntp.conffile:t@mylaptop~/puppet $ cd modules/trifecta/files t@mylaptop~/puppet/modules/trifecta/files $ echo "server 127.0.0.1" >ntp.conf
- Since we'll be working locally on this problem, create a
trifecta.ppmanifest that includes the broken trifecta class:include trifecta
- Run Puppet:
t@mylaptop ~/puppet/manifests $ puppet apply trifecta.pp Notice: Compiled catalog for mylaptop in environment production in 1.32 seconds Error: Could not apply complete catalog: Found 1 dependency cycle: (File[/etc/ntp.conf] => Package[ntp] => File[/etc/ntp.conf]) Try the '--graph' option and opening the resulting '.dot' file in OmniGraffle or GraphViz
- Run Puppet with the
--graphoption as suggested:t@mylaptop ~/puppet/manifests $ puppet apply trifecta.pp --graph Notice: Compiled catalog for mylaptop in environment production in 1.26 seconds Error: Could not apply complete catalog: Found 1 dependency cycle: (File[/etc/ntp.conf] => Package[ntp] => File[/etc/ntp.conf]) Cycle graph written to /home/tuphill/.puppet/var/state/graphs/cycles.dot. Notice: Finished catalog run in 0.03 seconds
- Check whether the graph files have been created:
t@mylaptop ~/puppet/manifests $ cd ~/.puppet/var/state/graphs t@mylaptop ~/.puppet/var/state/graphs $ ls -l total 16 -rw-rw-r--. 1 thomasthomas 121 Nov 23 23:11 cycles.dot -rw-rw-r--. 1 thomasthomas 2885 Nov 23 23:11 expanded_relationships.dot -rw-rw-r--. 1 thomasthomas 1557 Nov 23 23:11 relationships.dot -rw-rw-r--. 1 thomasthomas 1680 Nov 23 23:11 resources.dot
- Create a graphic using the
dotcommand as follows:ubuntu@cookbook:~/puppet$ dot -Tpng -o relationships.png /var/lib/puppet/state/graphs/relationships.dot - The graphic will look something like the this:
When you run puppet agent --graph (or enable the graph option in puppet.conf), Puppet will generate three graphs in the DOT format (a graphics language):
resources.dot: This shows the hierarchical structure of your classes and resources, but without dependenciesrelationships.dot: This shows the dependencies between resources as arrows, as shown in the preceding imageexpanded_relationships.dot: This is a more detailed version of the relationships graph
To fix the circular dependency problem, all you need to do is remove one of the dependency lines and break the circle. The following code fixes the problem:
In this graph it is easy to see that Package[ntp] is the first resource to be applied, then File[/etc/ntp.conf], and finally Service[ntp].
Tip
A graph such as that shown previously is known as a Directed Acyclic Graph (DAG). Reducing the resources to a DAG ensures that Puppet can calculate the shortest path of all the vertices (resources) in linear time. For more information on DAGs, look at http://en.wikipedia.org/wiki/Directed_acyclic_graph.
Resource and relationship graphs can be useful even when you don't have a bug to find. If you have a very complex network of classes and resources, for example, studying the resources graph can help you see where to simplify things. Similarly, when dependencies become too complicated to understand from reading the manifest, the graphs can be a useful form of documentation. For instance, a graph will make it readily apparent which resources have the most dependencies and which resources are required by the most other resources. Resources that are required by a large number of other resources will have numerous arrows pointing at them.
- The Using run stages recipe in Chapter 3, Writing Better Manifests
generate a dependency graph for your manifest:
- Create the directories for a new
trifectamodule:ubuntu@cookbook:~/puppet$ mkdir modules/trifecta ubuntu@cookbook:~/puppet$ mkdir modules/trifecta/manifests ubuntu@cookbook:~/puppet$ mkdir modules/trifecta/files
- Create the file
modules/trifecta/manifests/init.ppwith the following code containing a deliberate circular dependency (can you spot it?):class trifecta { package { 'ntp': ensure => installed, require => File['/etc/ntp.conf'], } service { 'ntp': ensure => running, require => Package['ntp'], } file { '/etc/ntp.conf': source => 'puppet:///modules/trifecta/ntp.conf', notify => Service['ntp'], require => Package['ntp'], } } - Create a simple
ntp.conffile:t@mylaptop~/puppet $ cd modules/trifecta/files t@mylaptop~/puppet/modules/trifecta/files $ echo "server 127.0.0.1" >ntp.conf
- Since we'll be working locally on this problem, create a
trifecta.ppmanifest that includes the broken trifecta class:include trifecta
- Run Puppet:
t@mylaptop ~/puppet/manifests $ puppet apply trifecta.pp Notice: Compiled catalog for mylaptop in environment production in 1.32 seconds Error: Could not apply complete catalog: Found 1 dependency cycle: (File[/etc/ntp.conf] => Package[ntp] => File[/etc/ntp.conf]) Try the '--graph' option and opening the resulting '.dot' file in OmniGraffle or GraphViz
- Run Puppet with the
--graphoption as suggested:t@mylaptop ~/puppet/manifests $ puppet apply trifecta.pp --graph Notice: Compiled catalog for mylaptop in environment production in 1.26 seconds Error: Could not apply complete catalog: Found 1 dependency cycle: (File[/etc/ntp.conf] => Package[ntp] => File[/etc/ntp.conf]) Cycle graph written to /home/tuphill/.puppet/var/state/graphs/cycles.dot. Notice: Finished catalog run in 0.03 seconds
- Check whether the graph files have been created:
t@mylaptop ~/puppet/manifests $ cd ~/.puppet/var/state/graphs t@mylaptop ~/.puppet/var/state/graphs $ ls -l total 16 -rw-rw-r--. 1 thomasthomas 121 Nov 23 23:11 cycles.dot -rw-rw-r--. 1 thomasthomas 2885 Nov 23 23:11 expanded_relationships.dot -rw-rw-r--. 1 thomasthomas 1557 Nov 23 23:11 relationships.dot -rw-rw-r--. 1 thomasthomas 1680 Nov 23 23:11 resources.dot
- Create a graphic using the
dotcommand as follows:ubuntu@cookbook:~/puppet$ dot -Tpng -o relationships.png /var/lib/puppet/state/graphs/relationships.dot - The graphic will look something like the this:
When you run puppet agent --graph (or enable the graph option in puppet.conf), Puppet will generate three graphs in the DOT format (a graphics language):
resources.dot: This shows the hierarchical structure of your classes and resources, but without dependenciesrelationships.dot: This shows the dependencies between resources as arrows, as shown in the preceding imageexpanded_relationships.dot: This is a more detailed version of the relationships graph
To fix the circular dependency problem, all you need to do is remove one of the dependency lines and break the circle. The following code fixes the problem:
In this graph it is easy to see that Package[ntp] is the first resource to be applied, then File[/etc/ntp.conf], and finally Service[ntp].
Tip
A graph such as that shown previously is known as a Directed Acyclic Graph (DAG). Reducing the resources to a DAG ensures that Puppet can calculate the shortest path of all the vertices (resources) in linear time. For more information on DAGs, look at http://en.wikipedia.org/wiki/Directed_acyclic_graph.
Resource and relationship graphs can be useful even when you don't have a bug to find. If you have a very complex network of classes and resources, for example, studying the resources graph can help you see where to simplify things. Similarly, when dependencies become too complicated to understand from reading the manifest, the graphs can be a useful form of documentation. For instance, a graph will make it readily apparent which resources have the most dependencies and which resources are required by the most other resources. Resources that are required by a large number of other resources will have numerous arrows pointing at them.
- The Using run stages recipe in Chapter 3, Writing Better Manifests
resources.dot: This shows the hierarchical structure of your classes and resources, but without dependenciesrelationships.dot: This shows the dependencies between resources as arrows, as shown in the preceding imageexpanded_relationships.dot: This is a more detailed version of the relationships graph
To fix the circular dependency problem, all you need to do is remove one of the dependency lines and break the circle. The following code fixes the problem:
In this graph it is easy to see that Package[ntp] is the first resource to be applied, then File[/etc/ntp.conf], and finally Service[ntp].
Tip
A graph such as that shown previously is known as a Directed Acyclic Graph (DAG). Reducing the resources to a DAG ensures that Puppet can calculate the shortest path of all the vertices (resources) in linear time. For more information on DAGs, look at http://en.wikipedia.org/wiki/Directed_acyclic_graph.
Resource and relationship graphs can be useful even when you don't have a bug to find. If you have a very complex network of classes and resources, for example, studying the resources graph can help you see where to simplify things. Similarly, when dependencies become too complicated to understand from reading the manifest, the graphs can be a useful form of documentation. For instance, a graph will make it readily apparent which resources have the most dependencies and which resources are required by the most other resources. Resources that are required by a large number of other resources will have numerous arrows pointing at them.
- The Using run stages recipe in Chapter 3, Writing Better Manifests
and relationship graphs can be useful even when you don't have a bug to find. If you have a very complex network of classes and resources, for example, studying the resources graph can help you see where to simplify things. Similarly, when dependencies become too complicated to understand from reading the manifest, the graphs can be a useful form of documentation. For instance, a graph will make it readily apparent which resources have the most dependencies and which resources are required by the most other resources. Resources that are required by a large number of other resources will have numerous arrows pointing at them.
- The Using run stages recipe in Chapter 3, Writing Better Manifests
- Chapter 3, Writing Better Manifests
Here are some of the most common errors you might encounter, and what to do about them.
The source file may not be present or may not be in the right location in the Puppet repo:
This one has caused me a bit of puzzlement in the past. Puppet's complaining about a duplicate definition, and normally if you have two resources with the same name, Puppet will helpfully tell you where they are both defined. But in this case, it's indicating the same file and line number for both. How can one resource be a duplicate of itself?
When we run Puppet, the same error is printed twice:
The double quotes are required when you want Puppet to interpolate the value of a variable into a string.
XXX is a file resource, you may have accidentally typed puppet://modules... in a file source instead of puppet:///modules... (note the triple slash):
--debug switch, to get more useful information:
puppet -verbose instead of puppet --verbose. This kind of error can be hard to see:
You probably know that Puppet's configuration settings are stored in puppet.conf, but there are many parameters, and those that aren't listed in puppet.conf will take a default value. How can you see the value of any configuration parameter, regardless of whether or not it's explicitly set in puppet.conf? The answer is to use the puppet config print command.
less if you'd like to browse the available configuration settings):
puppet config print will


