While a more detailed discussion of learning algorithms will be addressed in Chapter 4, Learning from Data, in this section, we will deal with the fundamental concept of a neural network and the developments that led to deep learning.
The model of a neuron
The human brain has input connections from other neurons (synapses) that receive stimuli in the form of electric charges, and then has a nucleus that depends on how the input stimulates the neuron that can trigger the neuron's activation. At the end of the neuron, the output signal is propagated to other neurons through dendrites, thus forming a network of neurons.
The analogy of the human neuron is depicted in Figure 1.3, where the input is represented with the vector x, the activation of the neuron is given by some function z(.), and the output is y. The parameters of the neuron are w and b:
Figure 1.3 - The basic model of a neuron
The trainable parameters of a neuron are w and b, and they are unknown. Thus, we can use training data  to determine these parameters using some learning strategy. From the picture, x1 multiplies w1, then x2 multiplies w2, and b is multiplied by 1; all these products are added, which can be simplified as follows:
to determine these parameters using some learning strategy. From the picture, x1 multiplies w1, then x2 multiplies w2, and b is multiplied by 1; all these products are added, which can be simplified as follows:
The activation function operates as a way to ensure the output is within the desired output range. Let's say that we want a simple linear activation, then the function z(.) is non-existing or can be bypassed, as follows:
This is usually the case when we want to solve a regression problem and the output data can have a range from -∞ to +∞. However, we may want to train the neuron to determine whether a vector x belongs to one of two classes, say -1 and +1. Then we would be better suited using a function called a sign activation:
Where the sign(.) function is denoted as follows:
There are many other activation functions, but we will introduce those later on. For now, we will briefly show one of the simplest learning algorithms, the perceptron learning algorithm (PLA).
The perceptron learning algorithm
The PLA begins from the assumption that you want to classify data, X, into two different groups, the positive group (+) and the negative group (-). It will find some w and b by training to predict the corresponding correct labels y. The PLA uses the sign( . ) function as the activation. Here are the steps that the PLA follows:
- Initialize w to zeros, and iteration counter t = 0
- While there are any incorrectly classified examples:
- Pick an incorrectly classified example, call it x*, whose true label is y*
- Update w as follows: wt+1 = wt + y*x*
- Increase iteration counter t++ and repeat
Notice that, for the PLA to work as we want, we have to make an adjustment. What we want is for 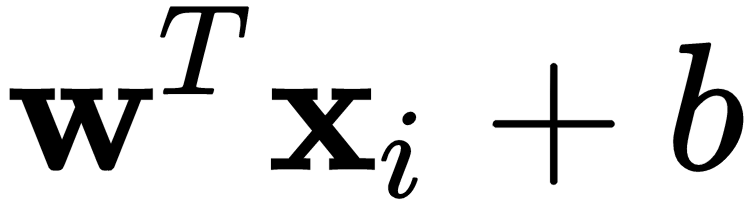 to be implied in the expression
to be implied in the expression 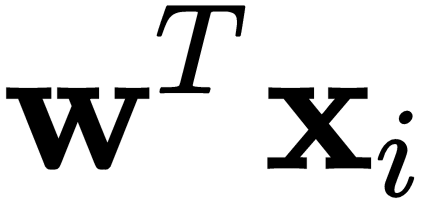 . The only way this could work is if we set
. The only way this could work is if we set 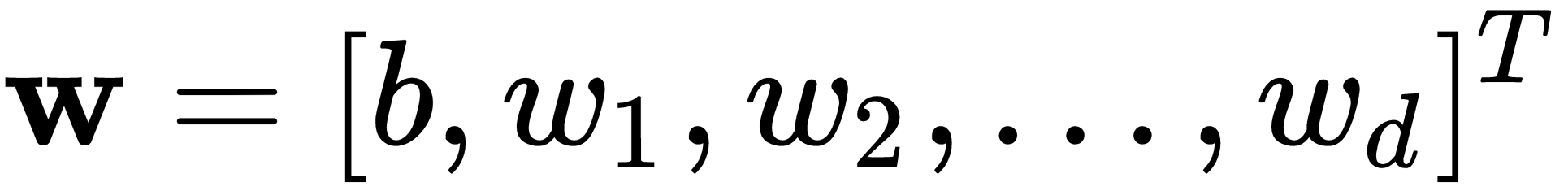 and
and 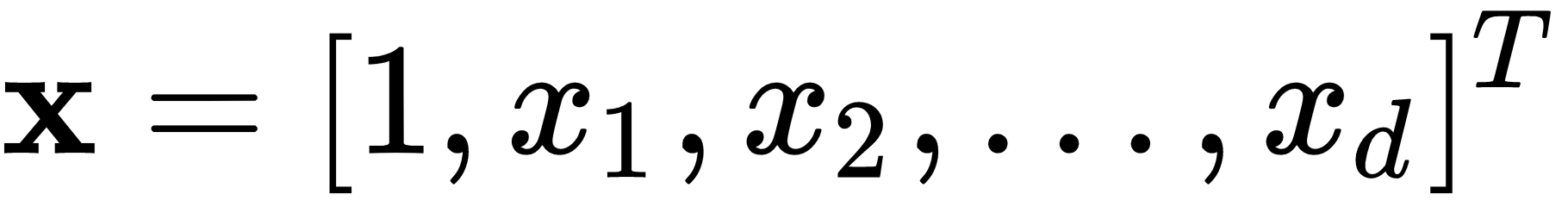 . The previous rule seeks w, which implies the search for b.
. The previous rule seeks w, which implies the search for b.
To illustrate the PLA, consider the case of the following linearly separable dataset:
A linearly separable dataset is one whose data points are sufficiently apart such that at least one hypothetical line exists that can be used to separate the data groups into two. Having a linearly separable dataset is the dream of all ML scientists, but it is seldom the case that we will find such datasets naturally. In further chapters, we will see that neural networks transform the data into a new feature space where such a line may exist.
This two-dimensional dataset was produced at random using Python tools that we will discuss later on. For now, it should be self-evident that you can draw a line between the two groups and divide them.
Following the steps outlined previously, the PLA can find a solution, that is, a separating line that satisfies the training data target outputs completely in only four iterations in this particular case. The plots after each update are depicted in the following plots with the corresponding line found at every update:
At iteration zero, all 100 points are misclassified, but after randomly choosing one misclassified point to make the first update, the new line only misses four points:
After the second update, the line only misses one data point:
Finally, after update number three, all data points are correctly classified. This is just to show that a simple learning algorithm can successfully learn from data. Also, the perceptron model led to much more complicated models such as a neural network. We will now introduce the concept of a shallow network and its basic complexities.
Shallow networks
A neural network consists of multiple networks connected in different layers. In contrast, a perceptron has only one neuron and its architecture consists of an input layer and an output layer. In neural networks, there are additional layers between the input and output layer, as shown in Figure 1.4, and they are known as hidden layers:
Figure 1.4 - Example of a shallow neural network
The example in the figure shows a neural network that has a hidden layer with eight neurons in it. The input size is 10-dimensional, and the output layer has four dimensions (four neurons). This intermediate layer can have as many neurons as your system can handle during training, but it is usually a good idea to keep things to a reasonable number of neurons.
If this is your first time using neural networks, it is recommended that your hidden layer size, that is, the number of neurons, is greater than or equal to the input layer, and less than or equal to the output size. However, although this is good advice for absolute beginners, this is not an absolute scientific fact since finding the optimal number of neurons in neural networks is an art, rather than a science, and it is usually determined through a great deal of experimentation.
Neural networks can solve more difficult problems than without a network, for example, with a single neural unit such as the perceptron. This must feel intuitive and must be easy to conceive. A neural network can solve problems including and beyond those that are linearly separable. For linearly separable problems, we can use both the perceptron model and a neural network. However, for more complex and non-linearly separable problems, the perceptron cannot offer a high-quality solution, while a neural network does.
For example, if we consider the sample two-class dataset and we bring the data groups closer together, the perceptron will fail to terminate with a solution and some other strategy can be used to stop it from going forever. Or, we can switch to a neural network and train it to find the best solution it can possibly find. Figure 1.5 shows an example of training a neural network with 100 neurons in the hidden layer over a two-class dataset that is not linearly separable:
Figure 1.5 - Non-separable data and a non-linear solution using a neural network with 100 neurons in the hidden layer
This neural network has 100 neurons in the hidden layer. This was a choice done by experimentation and you will learn strategies on how to find such instances in further chapters. However, before we go any further, there are two new terms introduced that require further explanation: non-separable data and non-linear models, which are defined as follows:
- Non-separable data is such that there is no line that can separate groups of data (or classes) into two groups.
- Non-linear models, or solutions, are those that naturally and commonly occur when the best solution to a classification problem is not a line. For example, it can be some curve described by some polynomial of any degree greater than one. For an example, see Figure 1.5.
A non-linear model is usually what we will be working with throughout this book, and the reason is that this is most likely what you will encounter out there in the real world. Also, it is non-linear, in a way, because the problem is non-separable. To achieve this non-linear solution, the neural network model goes through the following mathematical operations.
The input-to-hidden layer
In a neural network, the input vector x is connected to a number of neurons through weights w for each neuron, which can be now thought of as a number of weight vectors forming a matrix W. The matrix W has as many columns as neurons as the layer has, and as many rows as the number of features (or dimensions) x has. Thus, the output of the hidden layer can be thought of as the following vector:
Where b is a vector of biases, whose elements correspond to one neural unit, and the size of h is proportional to the number of hidden units. For example, eight neurons in Figure 1.4, and 100 neurons in Figure 1.5. However, the activation function z(.) does not have to be the sign(.) function, in fact, it usually never is. Instead, most people use functions that are easily differentiable.
A differentiable activation function is one that has a mathematical derivative that can be computed with traditional numerical methods or that is clearly defined. The opposite would be a function that does not have a defined derivative, it does not exist, or is nearly impossible to calculate.
The hidden-to-hidden layer
In a neural network, we could have more than one single hidden layer, and we will work with this kind a lot in this book. In such case, the matrix W can be expressed as a three-dimensional matrix that will have as many elements in the third dimension and as many hidden layers as the network has. In the case of the i-th layer, we will refer to that matrix as Wi for convenience.
Therefore, we can refer to the output of the i-th hidden layer as follows:
For i = 2, 3, ..., k-1, where k is the total number of layers, and the case of h1 is computed with the equation given for the first layer (see previous section), which uses x directly, and does not go all the way to the last layer, hk, because that is computed as discussed next.
The hidden-to-output layer
The overall output of the network is the output at the last layer:
Here, the last activation function is usually different from the hidden layer activations. The activation function in the last layer (output) traditionally depends on the type of problem we are trying to solve. For example, if we want to solve a regression problem, we would use a linear function, or sigmoid activations for classification problems. We will discuss those later on. For now, it should be evident that the perceptron algorithm will no longer work in the training phase.
While the learning still has to be in terms of the mistakes the neural network makes, the adjustments cannot be in direct proportion to the data point that is incorrectly classified or predicted. The reason is that the neurons in the last layer are responsible for making the predictions, but they depend on a previous layer, and those may depend on more previous layers, and when making adjustments to W and b, the adjustment has to be made differently for each neuron.
One approach to do this is to apply gradient descent techniques on the neural network. There are many of these techniques and we will discuss the most popular of these in further chapters. In general, a gradient descent algorithm is one that uses the notion that, if you take the derivative of a function and that reaches a value of zero, then you have found the maximum (or minimum) value you can get for the set of parameters on which you are taking the derivatives. For the case of scalars, we call them derivatives, but for vectors or matrices (W, b), we call them gradients.
The function we can use is called a loss function.
A loss function is usually one that is differentiable so that we can calculate its gradient using some gradient descent algorithm.
We can define a loss function, for example, as follows:
This loss is known as the mean squared error (MSE); it is meant to measure how different the target output y is from the predicted output in the output layer hk in terms of the square of its elements, and averaged. This is a good loss because it is differentiable and it is easy to compute.
A neural network such as this introduced a great number of possibilities, but relied heavily on a gradient descent technique for learning them called backpropagation (Hecht-Nielsen, R. 1992). Rather than explaining backpropagation here (we will reserve that for later), we rather have to remark that it changed the world of ML, but did not make much progress for a number of years because it had some practical limitations and the solutions to these paved the way for deep learning.
Deep networks
On March 27, 2019, an announcement was published by the ACM saying that three computer scientists were awarded the Nobel Prize in computing, that is, the ACM Turing Award, for their achievements in deep learning. Their names are Yoshua Bengio, Yann LeCun, and Geoffrey Hinton; all are very accomplished scientists. One of their major contributions was in the learning algorithm known as backpropagation.
In the official communication, the ACM wrote the following about Dr. Hinton and one of his seminal papers (Rumelhart, D. E. 1985):
In a 1986 paper, “Learning Internal Representations by Error Propagation,” co-authored with David Rumelhart and Ronald Williams, Hinton demonstrated that the backpropagation algorithm allowed neural nets to discover their own internal representations of data, making it possible to use neural nets to solve problems that had previously been thought to be beyond their reach. The backpropagation algorithm is standard in most neural networks today.
Similarly, they wrote the following about Dr. LeCun's paper (LeCun, Y., et.al., 1998):
LeCun proposed an early version of the backpropagation algorithm (backprop), and gave a clean derivation of it based on variational principles. His work to speed up backpropagation algorithms included describing two simple methods to accelerate learning time.
Dr. Hinton was able to show that there was a way to minimize a loss function in neural networks using biologically inspired algorithms such as the backward and forward adjustment of connections by modifying its importance for particular neurons. Usually, backpropagation is related to feed-forward neural networks, while backward-forward propagation is related to Restricted Boltzmann Machines (covered in Chapter 10, Restricted Boltzmann Machines).
A feed-forward neural network is one whose input is pipelined directly toward the output layer through intermediate layers that have no backward connections, as shown in Figure 1.4, and we will talk about these all the time in this book.
It is usually safe to assume that, unless you are told otherwise, all neural networks have a feed-forward architecture. Most of this book will talk about deep neural networks and the great majority are feed-forward-like, with the exception of Restricted Boltzmann Machines or recurrent neural networks, for example.
Backpropagation enabled people to train neural networks in a way that was never seen before; however, people had problems training neural networks on large datasets, and on larger (deeper) architectures. If you go ahead and look at neural network papers in the late '80s and early '90s, you will notice that architectures were small in size; networks usually had no more than two or three layers, and the number of neurons usually did not exceed the order of hundreds. These are (today) known as shallow neural networks.
The major problems were with convergence time for larger datasets, and convergence time for deeper architectures. Dr. LeCun's contributions were precisely in this area as he envisioned different ways to speed up the training process. Other advances such as vector (tensor) computations over graphics processing units (GPUs) increased training speeds dramatically.
Thus, over the last few years, we have seen the rise of deep learning, that is, the ability to train deeper neural networks, with more than three or four layers, in fact with tens and hundreds of layers. Further, we have a wide variety of architectures that can accomplish things that we were not able in the last decade.
The deep network shown in Figure 1.6 would have been impossible to train 30 years ago, and it is not that deep anyway:
Figure 1.6 - A deep and fully connected feed-forward neural network with eight layers
In this book, we will consider a deep neural network any network that has more than three or four layers overall. However, there is no standard definition as to exactly how deep is considered deep out there. Also, you need to consider that what we consider deep today, at the time of writing this book in 2020, will probably not be considered deep in 20 or 30 years from now.
Regardless of the future of DL, let us now discuss what makes DL so important today.

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Singapore
Singapore
 Canary Islands
Canary Islands
 Hungary
Hungary
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 South Korea
South Korea
 Turkey
Turkey
 Switzerland
Switzerland
 Colombia
Colombia
 Taiwan
Taiwan
 Chile
Chile
 Norway
Norway
 Ecuador
Ecuador
 Indonesia
Indonesia
 New Zealand
New Zealand
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 Austria
Austria
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 South Africa
South Africa
 Malaysia
Malaysia
 Japan
Japan
 Slovakia
Slovakia
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand




















