


















 Download code from GitHub
Download code from GitHub
Why Deep Learning?
This chapter will give an overview of deep learning, the history of deep learning, the rise of deep learning, and its recent advances in certain fields. Also, we will talk about challenges, as well as its future potential.
We will answer a few key questions often raised by a practical user of deep learning who may not possess a machine learning background. These questions include:
- What is artificial intelligence (AI) and deep learning?
- What’s the history of deep learning or AI?
- What are the major breakthroughs of deep learning?
- What is the main reason for its recent rise?
- What’s the motivation of deep architecture?
- Why should we resort to deep learning and why can't the existing machine learning algorithms solve the problem at hand?
- In which fields can it be applied?
- Successful stories of deep learning
-
What’s the potential future of deep learning and what are the current challenges?
What is AI and deep learning?
The dream of creating certain forms of intelligence that mimic ourselves has long existed. While most of them appear in science fiction, over recent decades we have gradually been making progress in actually building intelligent machines that can perform certain tasks just like a human. This is an area called artificial intelligence. The beginning of AI can perhaps be traced back to Pamela McCorduck’s book, Machines Who Think, where she described AI as an ancient wish to forge the gods.
Deep learning is a branch of AI, with the aim specified as moving machine learning closer to its original goals: AI.
The path it pursues is an attempt to mimic the activity in layers of neurons in the neocortex, which is the wrinkly 80% of the brain where thinking occurs. In a human brain, there are around 100 billion neurons and 100 ~ 1000 trillion synapses.
It learns hierarchical structures and levels of representation and abstraction to understand the patterns of data that come from various source types, such as images, videos, sound, and text.
Higher level abstractions are defined as the composition of lower-level abstraction. It is called deep because it has more than one state of nonlinear feature transformation. One of the biggest advantages of deep learning is its ability to automatically learn feature representation at multiple levels of abstraction. This allows a system to learn complex functions mapped from the input space to the output space without many dependencies on human-crafted features. Also, it provides the potential for pre-training, which is learning the representation on a set of available datasets, then applying the learned representations to other domains. This may have some limitations, such as being able to acquire good enough quality data for learning. Also, deep learning performs well when learning from a large amount of unsupervised data in a greedy fashion.
The following figure shows a simplified Convolutional Neural Network (CNN):

The deep learning model, that is, the learned deep neural network often consists of multiple layers. Together they work hierarchically to build an improved feature space. The first layer learns the first order features, such as color and edges. The second layer learns higher-order features, such as corners. The third layer learns about small patches or texture. Layers often learn in an unsupervised mode and discover general features of the input space. Then the final layer features are fed into a supervised layer to complete the task, such as classification or regression.
Between layers, nodes are connected through weighted edges. Each node, which can be seen as a simulated neocortex, is associated with an activation function, where its inputs are from the lower layer nodes. Building such large, multi-layer arrays of neuron-like information flow is, however, a decade-old idea. From its creation to its recent successes, it has experienced both breakthroughs and setbacks.
With the newest improvements in mathematical formulas, increasingly powerful computers, and large-scale datasets, finally, spring is around the corner. Deep learning has become a pillar of today’s tech world and has been applied in a wide range of fields. In the next section, we will trace its history and discuss the ups and downs of its incredible journey.
The history and rise of deep learning
The earliest neural network was developed in the 1940s, not long after the dawn of AI research. In 1943, a seminal paper called A Logical Calculus of Ideas Immanent in Nervous Activity was published, which proposed the first mathematical model of a neural network . The unit of this model is a simple formalized neuron, often referred to as a McCulloch–Pitts neuron. It is a mathematical function conceived as a model of biological neurons, a neural network. They are elementary units in an artificial neural network. An illustration of an artificial neuron can be seen from the following figure. Such an idea looks very promising indeed, as they attempted to simulate how a human brain works, but in a greatly simplified way:

These early models consist of only a very small set of virtual neurons and a random number called weights are used to connect them. These weights determine how each simulated neuron transfers information between them, that is, how each neuron responds, with a value between 0 and 1. With this mathematical representation, the neural output can feature an edge or a shape from the image, or a particular energy level at one frequency in a phoneme. The previous figure, An illustration of an artificial neuron model, illustrates a mathematically formulated artificial neuron, where the input corresponds to the dendrites, an activation function controls whether the neuron fires if a threshold is reached, and the output corresponds to the axon. However, early neural networks could only simulate a very limited number of neurons at once, so not many patterns can be recognized by using such a simple architecture. These models languished through the 1970s.
The concept of backpropagation, the use of errors in training deep learning models, was first proposed in the 1960s. This was followed by models with polynomial activation functions. Using a slow and manual process, the best statistically chosen features from each layer were then forwarded on to the next layer. Unfortunately, then the first AI winter kicked in, which lasted about 10 years. At this early stage, although the idea of mimicking the human brain sounded very fancy, the actual capabilities of AI programs were very limited. Even the most impressive one could only deal with some toy problems. Not to mention that they had a very limited computing power and only small size datasets available. The hard winter occurred mainly because the expectations were raised so high, then when the results failed to materialize AI received criticism and funding disappeared:

Slowly, backpropagation evolved significantly in the 1970s but was not applied to neural networks until 1985. In the mid-1980s, Hinton and others helped spark a revival of interest in neural networks with so-called deep models that made better use of many layers of neurons, that is, with more than two hidden layers. An illustration of a multi-layer perceptron neural network can be seen in the previous figure, Illustration of an artificial neuron in a multi-layer perceptron neural network. By then, Hinton and their co-authors (https://www.iro.umontreal.ca/~vincentp/ift3395/lectures/backprop_old.pdf) demonstrated that backpropagation in a neural network could result in interesting representative distribution. In 1989, Yann LeCun (http://yann.lecun.com/exdb/publis/pdf/lecun-89e.pdf) demonstrated the first practical use of backpropagation at Bell Labs. He brought backpropagation to convolutional neural networks to understand handwritten digits, and his idea eventually evolved into a system that reads the numbers of handwritten checks.
This is also the time of the 2nd AI winter (1985-1990). In 1984, two leading AI researchers Roger Schank and Marvin Minsky warned the business community that the enthusiasm for AI had spiraled out of control. Although multi-layer networks could learn complicated tasks, their speed was very slow and results were not that impressive. Therefore, when another simpler but more effective methods, such as support vector machines were invented, government and venture capitalists dropped their support for neural networks. Just three years later, the billion dollar AI industry fell apart.
However, it wasn’t really the failure of AI but more the end of the hype, which is common in many emerging technologies. Despite the ups and downs in its reputation, funding, and interests, some researchers continued their beliefs. Unfortunately, they didn't really look into the actual reason for why the learning of multi-layer networks was so difficult and why the performance was not amazing. In 2000, the vanishing gradient problem was discovered, which finally drew people’s attention to the real key question: Why don’t multi-layer networks learn? The reason is that for certain activation functions, the input is condensed, meaning large areas of input mapped over an extremely small region. With large changes or errors computed from the last layer, only a small amount will be reflected back to front/lower layers. This means little or no learning signal reaches these layers and the learned features at these layers are weak.
Note that many upper layers are fundamental to the problem as they carry the most basic representative pattern of the data. This gets worse because the optimal configuration of an upper layer may also depend on the configuration of the following layers, which means the optimization of an upper layer is based on a non-optimal configuration of a lower layer. All of this means it is difficult to train the lower layers and produce good results.
Two approaches were proposed to solve this problem: layer-by-layer pre-training and the Long Short-Term Memory (LSTM) model. LSTM for recurrent neural networks was first proposed by Sepp Hochreiter and Juergen Schmidhuber in 1997.
In the last decade, many researchers made some fundamental conceptual breakthroughs, and there was a sudden burst of interest in deep learning, not only from the academic side but also from the industry. In 2006, Professor Hinton at Toronto University in Canada and others developed a more efficient way to teach individual layers of neurons, called A fast learning algorithm for deep belief nets (https://www.cs.toronto.edu/~hinton/absps/fastnc.pdf.). This sparked the second revival of the neural network. In his paper, he introduced Deep Belief Networks (DBNs), with a learning algorithm that greedily trains one layer at a time by exploiting an unsupervised learning algorithm for each layer, a Restricted Boltzmann Machine (RBM). The following figure, The layer-wise pre-training that Hinton introduced shows the concept of layer-by-layer training for this deep belief networks.
The proposed DBN was tested using the MNIST database, the standard database for comparing the precision and accuracy of each image recognition method. This database includes 70,000, 28 x 28 pixel, hand-written character images of numbers from 0 to 9 (60,000 is for training and 10,000 is for testing). The goal is to correctly answer which number from 0 to 9 is written in the test case. Although the paper did not attract much attention at the time, results from DBM had considerably higher precision than a conventional machine learning approach:

Fast-forward to 2012 and the entire AI research world was shocked by one method. At the world competition of image recognition, ImageNet Large Scale Visual Recognition Challenge (ILSVRC), a team called SuperVision (http://image-net.org/challenges/LSVRC/2012/supervision.pdf) achieved a winning top five- test error rate of 15.3%, compared to 26.2% achieved by the second-best entry. The ImageNet has around 1.2 million high-resolution images belonging to 1000 different classes. There are 10 million images provided as learning data, and 150,000 images are used for testing. The authors, Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton from Toronto University, built a deep convolutional network with 60 million parameters, 650,000 neurons, and 630 million connections, consisting of seven hidden layers and five convolutional layers, some of which were followed by max-pooling layers and three fully-connected layers with a final 1000-way softmax. To increase the training data, the authors randomly sampled 224 x 224 patches from available images. To speed up the training, they used non-saturating neurons and a very efficient GPU implementation of the convolution operation. They also used dropout to reduce overfitting in the fully connected layers that proved to be very effective.
Since then deep learning has taken off, and today we see many successful applications not only in image classification, but also in regression, dimensionality reduction, texture modeling, action recognition, motion modeling, object segmentation, information retrieval, robotics, natural language processing, speech recognition, biomedical fields, music generation, art, collaborative filtering, and so on:

It’s interesting that when we look back, it seems that most theoretical breakthroughs had already been made by the 1980s-1990s, so what else has changed in the past decade? A not-too-controversial theory is that the success of deep learning is largely a success of engineering. Andrew Ng once said:
Indeed, faster processing, with GPUs processing pictures, increased computational speeds by 1000 times over a 10-year span.
Almost at the same time, the big data era arrived. Millions, billions, or even trillions of bytes of data are collected every day. Industry leaders are also making an effort in deep learning to leverage the massive amounts of data they have collected. For example, Baidu has 50,000 hours of training data for speech recognition and is expected to train about another 100,000 hours of data. For facial recognition, 200 million images were trained. The involvement of large companies greatly boosted the potential of deep learning and AI overall by providing data at a scale that could hardly have been imagined in the past.
With enough training data and faster computational speed, neural networks can now extend to deep architecture, which has never been realized before. On the one hand, the occurrence of new theoretical approaches, massive data, and fast computation have boosted progress in deep learning. On the other hand, the creation of new tools, platforms, and applications boosted academic development, the use of faster and more powerful GPUs, and the collection of big data. This loop continues and deep learning has become a revolution built on top of the following pillars:
- Massive, high-quality, labeled datasets in various formats, such as images, videos, text, speech, audio, and so on.
- Powerful GPU units and networks that are capable of doing fast floating-point calculations in parallel or in distributed ways.
- Creation of new, deep architectures: AlexNet (Krizhevsky and others, ImageNet Classification with Deep Convolutional Neural Networks, 2012), Zeiler Fergus Net (Zeiler and others, Visualizing and Understanding Convolutional Networks, 2013), GoogleLeNet (Szegedy and others, Going Deeper with Convolutions, 2015), Network in Network (Lin and others, Network In Network, 2013), VGG (Simonyan and others, Very deep convolutional networks for large-scale image recognition, 2015) for Very Deep CNN, ResNets (He and others, Deep Residual Learning for Image Recognition, 2015), inception modules, and Highway networks, MXNet, Region-Based CNNs (R-CNN, Girshick and others, Rich feature hierarchies for accurate object detection and semantic segmentation; Girshick, Fast R-CNN, 2015; Ren and others Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, 2016), Generative Adversarial Networks (Goodfellow and others 2014).
- Open source software platforms, such as TensorFlow, Theano, and MXNet provide easy-to-use, low level or high-level APIs for developers or academics so they are able to quickly implement and iterate their ideas and applications.
- Approaches to improve the vanishing gradient problem, such as using non-saturating activation functions like ReLU rather than tanh and the logistic functions.
- Approaches help to avoid overfitting:
- New regularizer, such as Dropout which keeps the network sparse, maxout, batch normalization.
- Data-augmentation that allows training larger and larger networks without (or with less) overfitting.
- Robust optimizers—modifications of the SGD procedure including momentum, RMSprop, and ADAM have helped eke out every last percentage of your loss function.
Why deep learning?
So far we discussed what is deep learning and the history of deep learning. But why is it so popular now? In this section, we talk about advantages of deep learning over traditional shallow methods and its significant impact in a couple of technical fields.
Advantages over traditional shallow methods
Traditional approaches are often considered shallow machine learning and often require the developer to have some prior knowledge regarding the specific features of input that might be helpful, or how to design effective features. Also, shallow learning often uses only one hidden layer, for example, a single layer feed-forward network. In contrast, deep learning is known as representation learning, which has been shown to perform better at extracting non-local and global relationships or structures in the data. One can supply fairly raw formats of data into the learning system, for example, raw image and text, rather than extracted features on top of images (for example, SIFT by David Lowe's Object Recognition from Local Scale-Invariant Features and HOG by Dalal and their co-authors, Histograms of oriented gradients for human detection), or IF-IDF vectors for text. Because of the depth of the architecture, the learned representations form a hierarchical structure with knowledge learned at various levels. This parameterized, multi-level, computational graph provides a high degree of the representation. The emphasis on shallow and deep algorithms are significantly different in that shallow algorithms are more about feature engineering and selection, while deep learning puts its emphasis on defining the most useful computational graph topology (architecture) and the ways of optimizing parameters/hyperparameters efficiently and correctly for good generalization ability of the learned representations:
Deep learning algorithms are shown to perform better at extracting non-local and global relationships and patterns in the data, compared to relatively shallow learning architectures. Other useful characteristics of learnt abstract representations by deep learning include:
- It tries to explore most of the abundant huge volume of the dataset, even when the data is unlabeled.
- The advantage of continuing to improve as more training data is added.
- Automatic data representation extraction, from unsupervised data or supervised data, distributed and hierarchical, usually best when input space is locally structured; spatial or temporal—for example, images, language, and speech.
- Representation extraction from unsupervised data enables its broad application to different data types, such as image, textural, audio, and so on.
- Relatively simple linear models can work effectively with the knowledge obtained from the more complex and more abstract data representations. This means with the advanced feature extracted, the following learning model can be relatively simple, which may help reduce computational complexity, for example, in the case of linear modeling.
- Relational and semantic knowledge can be obtained at higher levels of abstraction and representation of the raw data (Yoshua Bengio and Yann LeCun, Scaling Learning Algorithms towards AI, 2007, source: https://journalofbigdata.springeropen.com/articles/10.1186/s40537-014-0007-7).
- Deep architectures can be representationally efficient. This sounds contradictory, but its a great benefit because of the distributed representation power by deep learning.
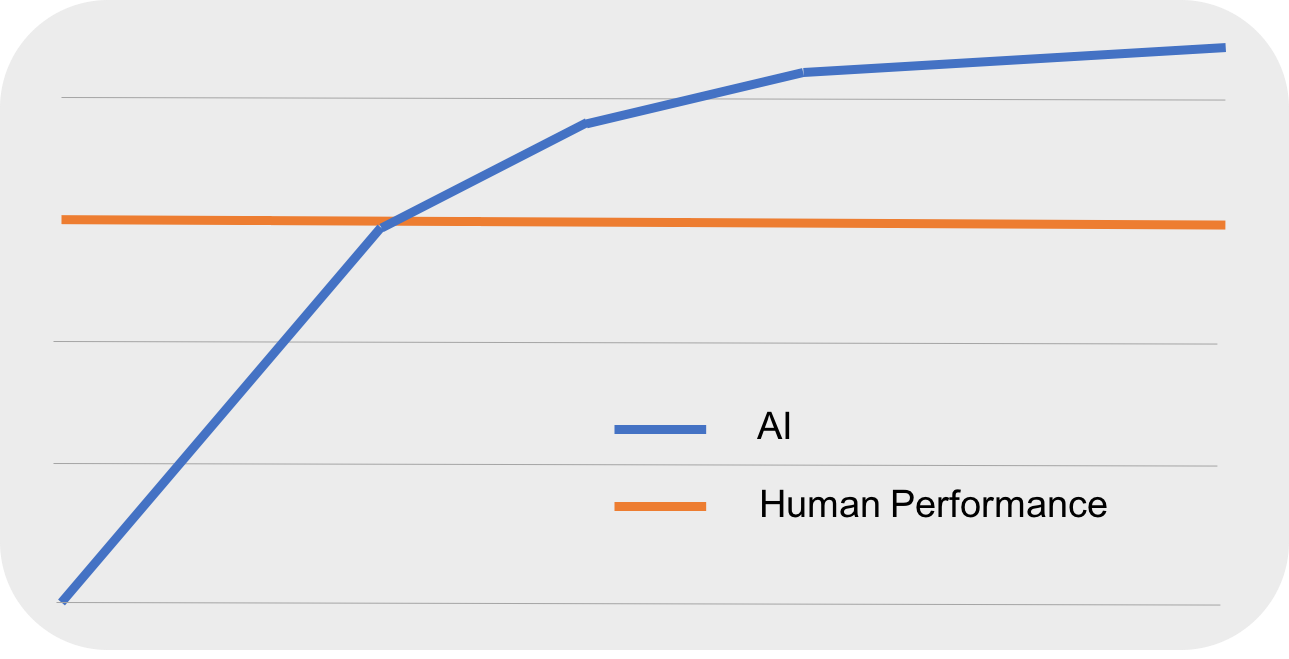
- The learning capacity of deep learning algorithms is proportional to the size of data, that is, performance increases as the input data increases, whereas, for shallow or traditional learning algorithms, the performance reaches a plateau after a certain amount of data is provided as shown in the following figure, Learning capability of deep learning versus traditional machine learning:

Impact of deep learning
To show you some of the impacts of deep learning, let’s take a look at two specific areas: image recognition and speed recognition.
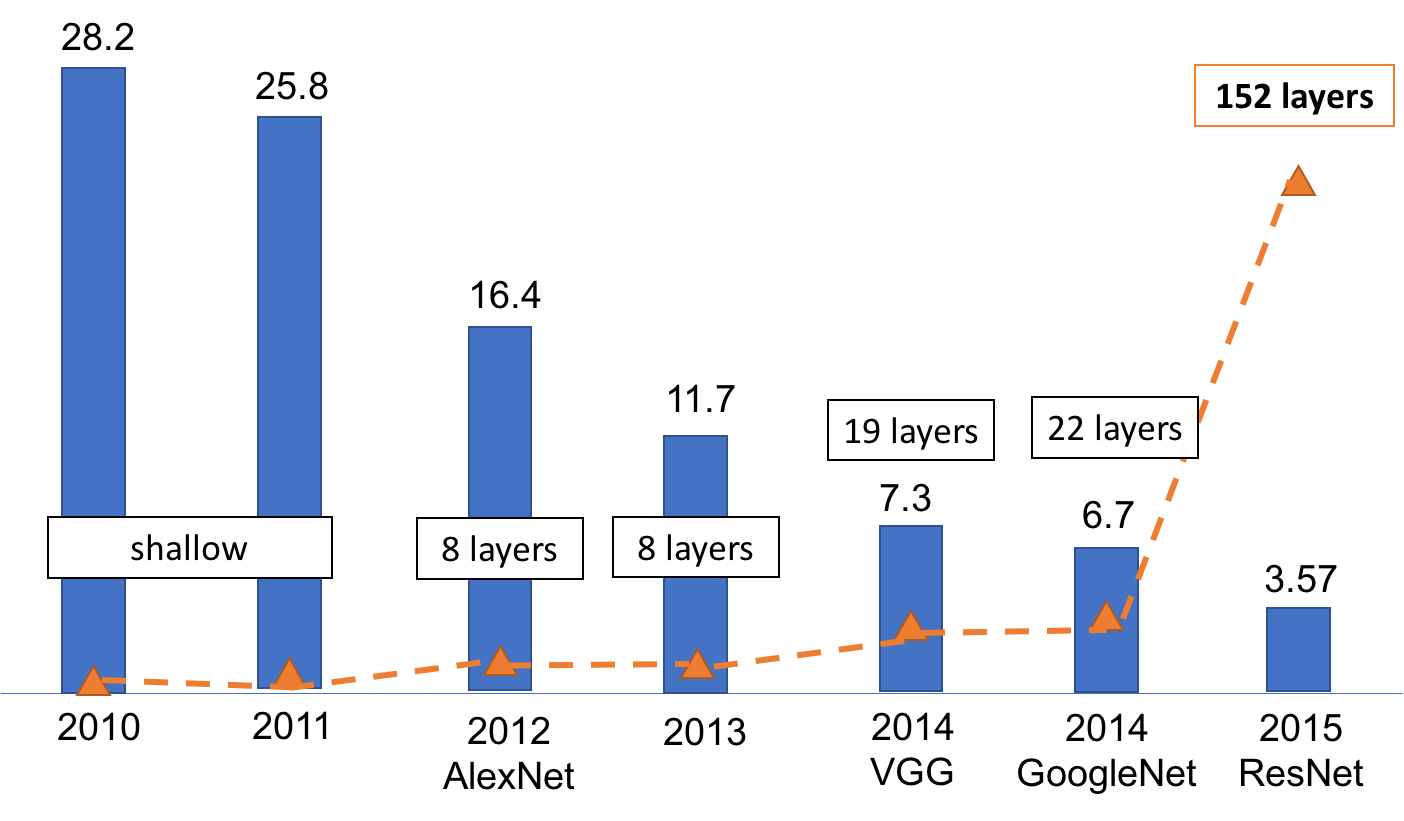
The following figure, Performance on ImageNet classification over time, shows the top five error rate trends for ILSVRC contest winners over the past several years. Traditional image recognition approaches employ hand-crafted computer vision classifiers trained on a number of instances of each object class, for example, SIFT + Fisher vector. In 2012, deep learning entered this competition. Alex Krizhevsky and Professor Hinton from Toronto university stunned the field with around 10% drop in the error rate by their deep convolutional neural network (AlexNet). Since then, the leaderboard has been occupied by this type of method and its variations. By 2015, the error rate had dropped below human testers:
The following figure, Speech recognition progress depicts recent progress in the area of speech recognition. From 2000-2009, there was very little progress. Since 2009, the involvement of deep learning, large datasets, and fast computing has significantly boosted development. In 2016, a major breakthrough was made by a team of researchers and engineers in Microsoft Research AI (MSR AI). They reported a speech recognition system that made the same or fewer errors than professional transcriptionists, with a word error rate (WER) of 5.9%. In other words, the technology could recognize words in a conversation as well as a person does:

A natural question to ask is, what are the advantages of deep learning over traditional approaches? Topology defines functionality. But why do we need expensive deep architecture? Is this really necessary? What are we trying to achieve here? It turns out that there are both theoretical and empirical pieces of evidence in favor of multiple levels of representation. In the next section, let’s dive into more details about the deep architecture of deep learning.
The motivation of deep architecture
The depth of the architecture refers to the number of levels of the composition of non-linear operations in the function learned. These operations include weighted sum, product, a single neuron, kernel, and so on. Most current learning algorithms correspond to shallow architectures that have only 1, 2, or 3 levels. The following table shows some examples of both shallow and deep algorithms:
|
Levels |
Example |
Group |
|
1-layer |
Logistic regression, Maximum Entropy Classifier Perceptron, Linear SVM |
Linear classifier |
|
2-layers |
Multi-layer Perceptron, SVMs with kernels Decision trees |
Universal approximator |
|
3 or more layers |
Deep learning Boosted decision trees |
Compact universal approximator |
There are mainly two viewpoints of understanding the deep architecture of deep learning algorithms: the neural point view and the feature representation view. We will talk about each of them. Both of them may come from different origins, but together they can help us to better understand the mechanisms and advantages deep learning has.
The neural viewpoint
From a neural viewpoint, an architecture for learning is biologically inspired. The human brain has deep architecture, in which the cortex seems to have a generic learning approach. A given input is perceived at multiple levels of abstraction. Each level corresponds to a different area of the cortex. We process information in hierarchical ways, with multi-level transformation and representation. Therefore, we learn simple concepts first then compose them together. This structure of understanding can be seen clearly in a human’s vision system. As shown in the following figure, Signal path from the retina to human lateral occipital cortex (LOC), which finally recognizes the object, the ventral visual cortex comprises a set of areas that process images in increasingly more abstract ways, from edges, corners and contours, shapes, object parts to object, allowing us to learn, recognize, and categorize three-dimensional objects from arbitrary two-dimensional views:

The representation viewpoint
For most traditional machine learning algorithms, their performance depends heavily on the representation of the data they are given. Therefore, domain prior knowledge, feature engineering, and feature selection are critical to the performance of the output. But hand-crafted features lack the flexibility of applying to different scenarios or application areas. Also, they are not data-driven and cannot adapt to new data or information comes in. In the past, it has been noticed that a lot of AI tasks could be solved by using a simple machine learning algorithm on the condition that the right set of features for the task are extracted or designed. For example, an estimate of the size of a speaker’s vocal tract is considered a useful feature, as it’s a strong clue as to whether the speaker is a man, woman, or child. Unfortunately, for many tasks, and for various input formats, for example, image, video, audio, and text, it is very difficult to know what kind of features should be extracted, let alone their generalization ability for other tasks that are beyond the current application. Manually designing features for a complex task requires a great deal of domain understanding, time, and effort. Sometimes, it can take decades for an entire community of researchers to make progress in this area. If one looks back at the area of computer vision, for over a decade researchers have been stuck because of the limitations of the available feature extraction approaches (SIFT, HOG, and so on). A lot of work back then involved trying to design complicated machine learning schema given such base features, and the progress was very slow, especially for large-scale complicated problems, such as recognizing 1000 objects from images. This is a strong motivation for designing flexible and automated feature representation approaches.
One solution to this problem is to use the data driven type of approach, such as machine learning to discover the representation. Such representation can represent the mapping from representation to output (supervised), or simply representation itself (unsupervised). This approach is known as representation learning. Learned representations often result in much better performance as compared to what can be obtained with hand-designed representations. This also allows AI systems to rapidly adapt to new areas, without much human intervention. Also, it may take more time and effort from a whole community to hand-craft and design features. While with a representation learning algorithm, we can discover a good set of features for a simple task in minutes or a complex task in hours to months.
This is where deep learning comes to the rescue. Deep learning can be thought of as representation learning, whereas feature extraction happens automatically when the deep architecture is trying to process the data, learning, and understanding the mapping between the input and the output. This brings significant improvements in accuracy and flexibility since human designed feature/feature extraction lacks accuracy and generalization ability.
In addition to this automated feature learning, the learned representations are both distributed and with a hierarchical structure. Such successful training of intermediate representations helps feature sharing and abstraction across different tasks.
The following figure shows its relationship as compared to other types of machine learning algorithms. In the next section, we will explain why these characteristics (distributed and hierarchical) are important:

Distributed feature representation
A distributed representation is dense, whereas each of the learned concepts is represented by multiple neurons simultaneously, and each neuron represents more than one concept. In other words, input data is represented on multiple, interdependent layers, each describing data at different levels of scale or abstraction. Therefore, the representation is distributed across various layers and multiple neurons. In this way, two types of information are captured by the network topology. On the one hand, for each neuron, it must represent something, so this becomes a local representation. On the other hand, so-called distribution means a map of the graph is built through the topology, and there exists a many-to-many relationship between these local representations. Such connections capture the interaction and mutual relationship when using local concepts and neurons to represent the whole. Such representation has the potential to capture exponentially more variations than local ones with the same number of free parameters. In other words, they can generalize non-locally to unseen regions. They hence offer the potential for better generalization because learning theory shows that the number of examples needed (to achieve the desired degree of generalization performance) to tune O (B) effective degrees of freedom is O (B). This is referred to as the power of distributed representation as compared to local representation (http://www.iro.umontreal.ca/~pift6266/H10/notes/mlintro.html).
An easy way to understand the example is as follows. Suppose we need to represent three words, one can use the traditional one-hot encoding (length N), which is commonly used in NLP. Then at most, we can represent N words. The localist models are very inefficient whenever the data has componential structure:
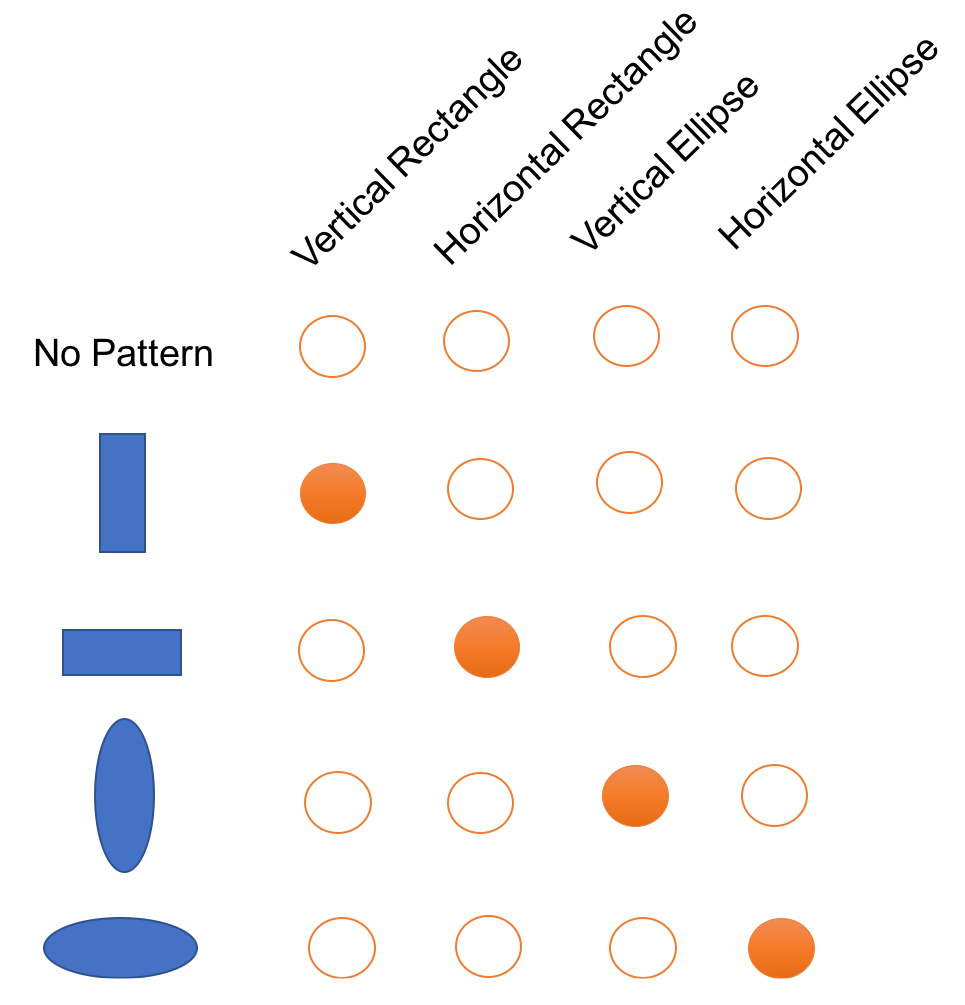
A distributed representation of a set of shapes would look like this:
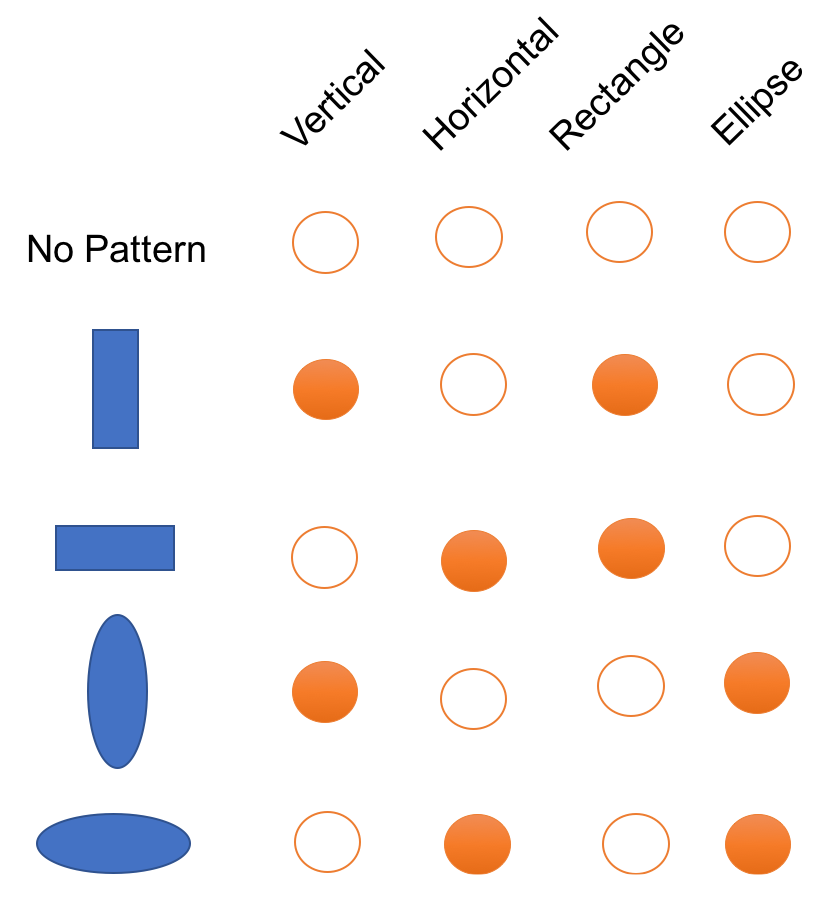
If we wanted to represent a new shape with a sparse representation, such as one-hot-encoding, we would have to increase the dimensionality. But what’s nice about a distributed representation is we may be able to represent a new shape with the existing dimensionality. An example using the previous example is as follows:
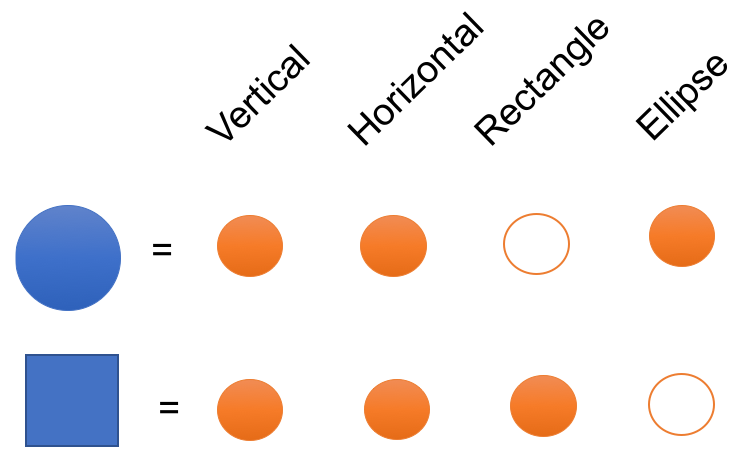
Therefore, non-mutually exclusive features/attributes create a combinatorially large set of distinguishable configurations and the number of distinguishable regions grows almost exponentially with the number of parameters.
One more concept we need to clarify is the difference between distributed and distributional. Distributed is represented as continuous activation levels in a number of elements, for example, a dense word embedding, as opposed to one-hot encoding vectors.
On the other hand, distributional is represented by contexts of use. For example, Word2Vec is distributional, but so are count-based word vectors, as we use the contexts of the word to model the meaning.
Hierarchical feature representation
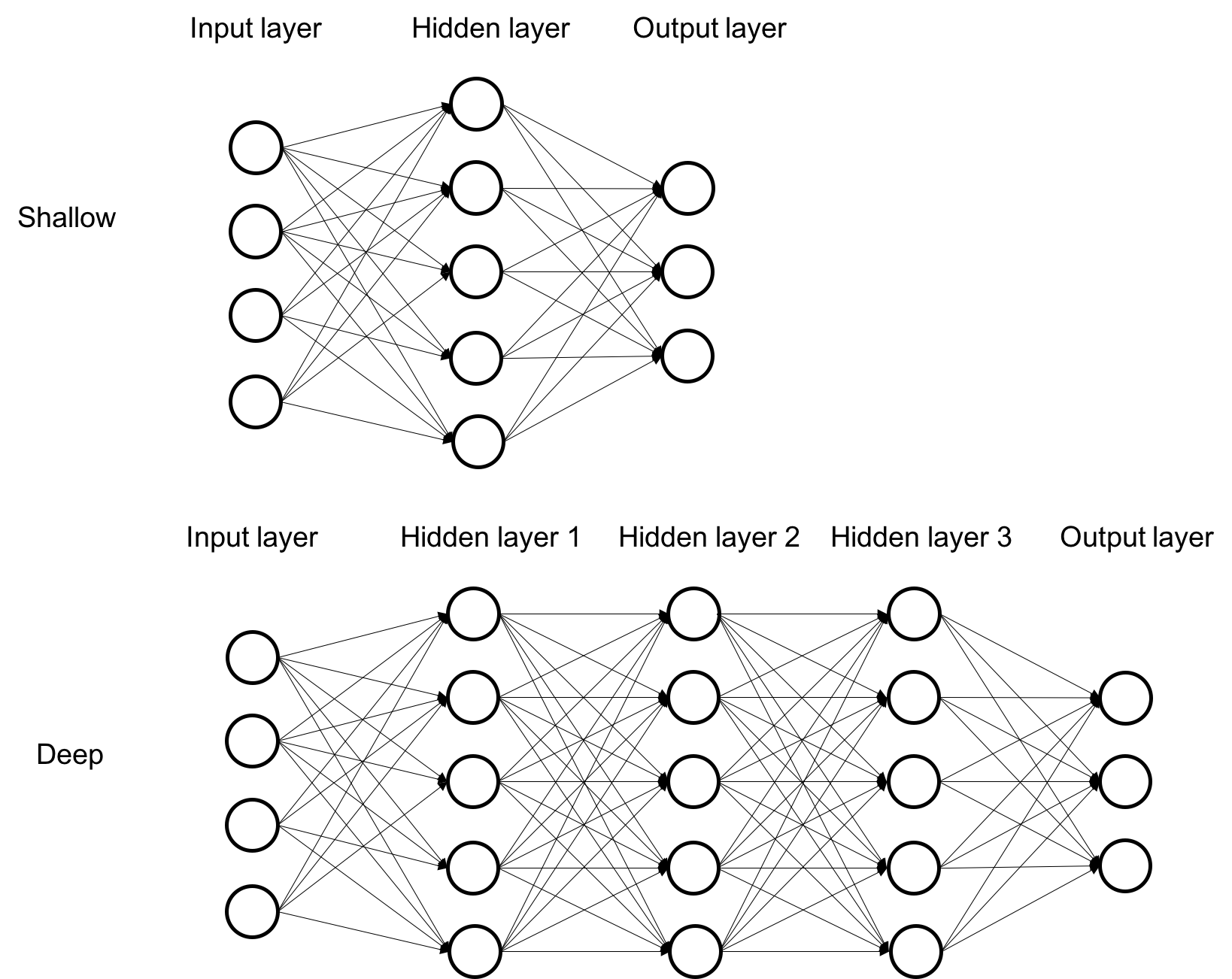
The learnt features capture both local and inter-relationships for the data as a whole, it is not only the learnt features that are distributed, the representations also come hierarchically structured. The previous figure, Comparing deep and shallow architecture. It can be seen that shallow architecture has a more flat topology, while deep architecture has many layers of hierarchical topology compares the typical structure of shallow versus deep architectures, where we can see that the shallow architecture often has a flat structure with one layer at most, whereas the deep architecture structures have multiple layers, and lower layers are composited that serve as input to the higher layer. The following figure uses a more concrete example to show what information has been learned through layers of the hierarchy.
As shown in the image, the lower layer focuses on edges or colors, while higher layers often focus more on patches, curves, and shapes. Such representation effectively captures part-and-whole relationships from various granularity and naturally addresses multi-task problems, for example, edge detection or part recognition. The lower layer often represents the basic and fundamental information that can be used for many distinct tasks in a wide variety of domains. For example, Deep Belief networks have been successfully used to learn high-level structures in a wide variety of domains, including handwritten digits and human motion capture data. The hierarchical structure of representation mimics the human understanding of concepts, that is, learning simple concepts first and then successfully building up more complex concepts by composing the simpler ones together. It is also easier to monitor what is being learnt and to guide the machine to better subspaces. If one treats each neuron as a feature detector, then deep architectures can be seen as consisting of feature detector units arranged in layers. Lower layers detect simple features and feed into higher layers, which in turn detect more complex features. If the feature is detected, the responsible unit or units generate large activations, which can be picked up by the later classifier stages as a good indicator that the class is present:

The above figure illustrates that each feature can be thought of as a detector, which tries to the detector a particular feature (blob, edges, nose, or eye) on the input image.
Applications
Now we have a general understanding of deep learning and its technical advantages over traditional methods. But how do we benefit from it in reality? In this section, we will introduce how deep learning makes tremendous impact in some practical applications across a variety of fields.
Lucrative applications
In the past few years, the number of researchers and engineers in deep learning has grown at an exponential rate. Deep learning breaks new ground in almost every domain it touches using novel neural networks architectures and advanced machine learning frameworks. With significant hardware and algorithmic developments, deep learning has revolutionized the industry and has been highly successful in tackling many real-world AI and data mining problems.
We have seen an explosion in new and lucrative applications using deep learning frameworks in areas as diverse as image recognition, image search, object detection, computer vision, optical character recognition, video parsing, face recognition, pose estimation (Cao and others, Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields, 2016), speech recognition, spam detection, text to speech or image caption, translation, natural language processing, chatbots, targeted online advertising serving, click-through optimization, robotics, computer vision, energy optimization, medicine, art, music, physics, autonomous car driving, data mining of biological data, bioinformatics (protein sequence prediction, phylogenetic inferences, multiple sequence alignment) big data analytics, semantic indexing, sentiment analysis, web search/information retrieval, games (Atari (http://karpathy.github.io/2016/05/31/rl/) and AlphaGo (https://deepmind.com/research/alphago/)), and beyond.
Success stories
In this section, we will enumerate a few major application areas and their success stories.
In the area of computer vision, image recognition/object recognition refers to the task of using an image or a patch of an image as input and predicting what the image or patch contains. For example, an image can be labeled dog, cat, house, bicycle, and so on. In the past, researchers were stuck at how to design good features to tackle challenging problems such as scale-invariant, orientation invariant, and so on. Some of the well-known feature descriptors are Haar-like, Histogram of Oriented Gradient (HOG), Scale-Invariant Feature Transform (SIFT), and Speeded-Up Robust Feature (SURF). While human designed features are good at certain tasks, such as HOG for human detection, it is far from ideal.
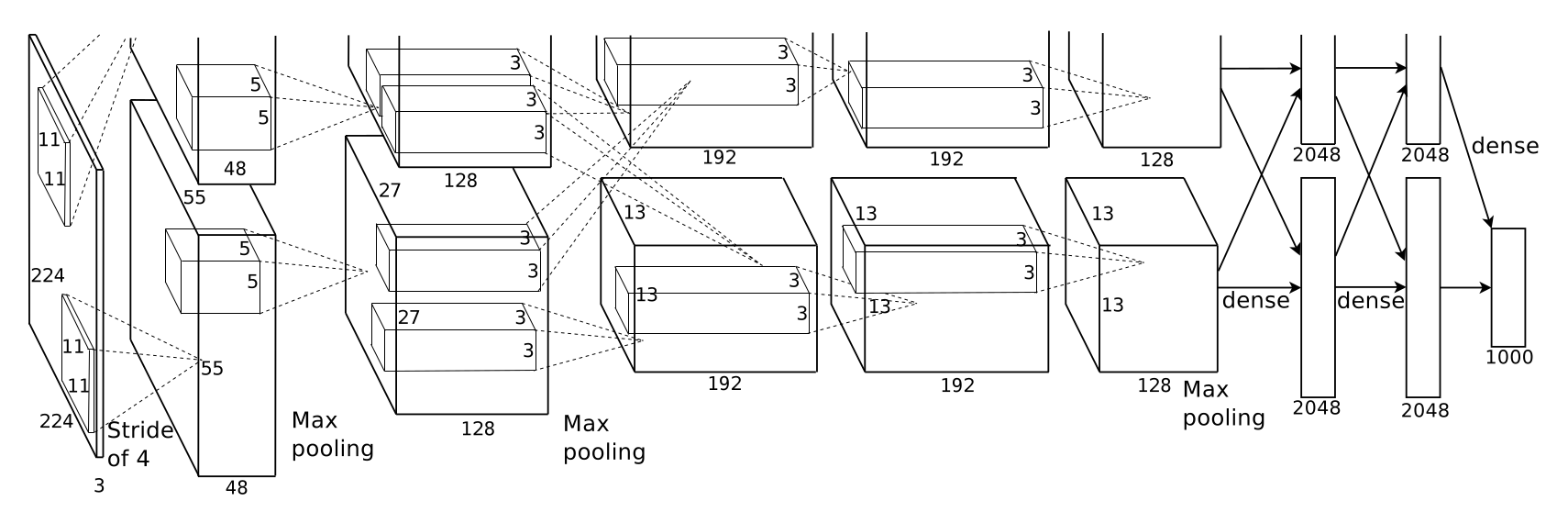
Until 2012, deep learning stunned the field with its resounding success at the ImageNet Large Scale Visual Recognition Challenge (ILSVRC). In that competition, a convolutional neural network (often called AlexNet, see the following figure), developed by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton won 1st place with an astounding 85% accuracy—11% better than the algorithm that won the second place! In 2013, all winning entries were based on deep learning, and by 2015 multiple CNN-based algorithms had surpassed the human recognition rate of 95%. Details can be found at their publication Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification:
In other areas of computer vision, deep learning also shows surprising and interesting power in mimicking human intelligence. For example, deep learning cannot only identify various elements in the picture accurately (and locate them), it can also understand interesting areas such as humans and organize words/phrases into sentences to describe what’s happening in the picture. For more details, one can refer to the work presented by Andrej Karpathy and Fei-Fei Li at http://cs.stanford.edu/people/karpathy/deepimagesent/. They trained a deep learning network to identify dozens of interesting areas and objects, and described the subjects and movements in the picture with correct English grammar. This involves training on both image information and language information to make the right connection between them.
As a further progress, Justin Johnson, Andrej Karpathy and Feifei Li published a new work in 2016 called DenseCap: Fully Convolutional Localization Networks for Dense Captioning. Their proposed fully Convolutional Localization Network (FCLN) architecture can localize and describe salient regions in images in natural language. Some examples are shown in the following figure:

Recently, attention-based neural encoder-decoder frameworks have been widely adopted for image captioning, where novel adaptive attention models with a visual sentinel have been incorporated and better performance has been achieved. Details can be found at their work of Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning.
Early in 2017, Ryan Dahl and others from the Google Brain team proposed a deep learning network called Pixel Recursive Super Resolution to take very low-resolution images of faces and enhance their resolution significantly. It can predict what each face most likely looks like. For example, in the following figure, in the left-hand column, you can see the original 8 x 8 photos, the prediction results in the middle can be found fairly close to the ground truth (in the very right column):

In the area of semantic indexing for search engines, given the advantages of automated feature representation by deep learning, data in various formats can now be represented in a more efficient and useful manner. This provides a powerful source of knowledge discovery and comprehension in addition to increased speed and efficiency. Microsoft Audio Video Indexing Service (MAVIS) is an example that uses deep learning (ANN)-based speech recognition to enable searching for audio and video files with speech.
In the area of natural language processing (NLP), word/character representation learning (such as Word2Vec) and machine translation are great practical examples. In fact, in the past two or three years, deep learning has almost replaced traditional machine translation.
Machine translation is automated translation, which typically refers to statistical inference-based systems that deliver more fluent-sounding but less consistent translations for speech or text between various languages. In the past, popular methods have been statistical techniques that learn the translation rules from a large corpus, as a replacement for a language expert. While cases like this overcome the bottleneck of data acquisition, many challenges exist. For example, hand-crafted features may not be ideal as they cannot cover all possible linguistic variations. It is difficult to use global features, the translation module heavily relies on pre-processing steps including word alignment, word segmentation, tokenization, rule-extraction, syntactic parsing, and so on. The recent development of deep learning provides solutions to these challenges. A machine translator that translates through one large neural network is often called Neural Machine Translation (NMT). Essentially, it’s a sequence to sequence learning problem, where the goal of the neural networks is to learn a parameterized function of P (yT | x1..N, y1..T-1) that maps from the input sequence/source sentence to the output sequence/target sentence. The mapping function often contains two stages: encoding and decoding. The encoder maps a source sequence x1..N to one or more vectors to produce hidden state representations. The decoder predicts a target sequence y1..M symbol by symbol using the source sequence vector representations and previously predicted symbols.
As illustrated by the the following figure, this vase-like shape produces good representation/embeddings at the middle hidden layer:
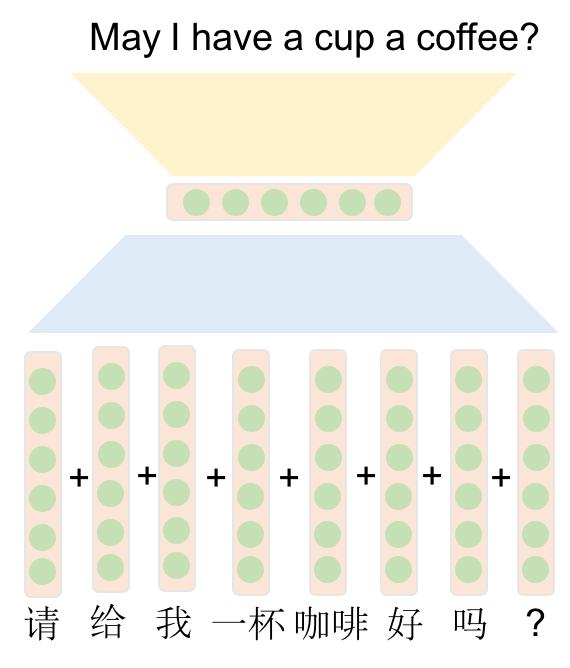
However, NMT systems are known to be computationally expensive both in training and in translation inference. Also, most NMT systems have difficulty with rare words. Some recent improvements include the attention mechanism (Bahdanau and others, Neural Machine Translation by Jointly Learning to Align and Translate, 2014), Subword level modelling (Sennrich and others, Neural Machine Translation of Rare Words with Subword Units, 2015) and character level translation, and the improvements of loss function (Chung and others, A Character-Level Decoder without Explicit Segmentation for Neural Machine Translation 2016). In 2016, Google launched their own NMT system to work on a notoriously difficult language pair, Chinese to English and tried to overcome these disadvantages.
Google’s NMT system (GNMT) conducts about 18 million translations per day from Chinese to English. The production deployment is built on top of the publicly available machine learning toolkit TensorFlow (https://www.tensorflow.org/) and Google’s Tensor Processing Units (TPUs), which provide sufficient computational power to deploy these powerful GNMT models while meeting the stringent latency requirements. The model itself is a deep LSTM model with eight encoder and eight decoder layers using attention and residual connections. On the WMT'14 English-to-French and English-to-German benchmarks, GNMT achieves competitive results. Using a human side-by-side evaluation on a set of isolated simple sentences, it reduces translation errors by an average of 60% compared to Google's phrase-based production system. For more details, one can refer to their tech blog (https://research.googleblog.com/2016/09/a-neural-network-for-machine.html) or paper (Wu and others, Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation, 2016). The following figure shows the improvements per language pairs by the deep learning system. One can see that for French -> English, it is almost as good as a human translator:
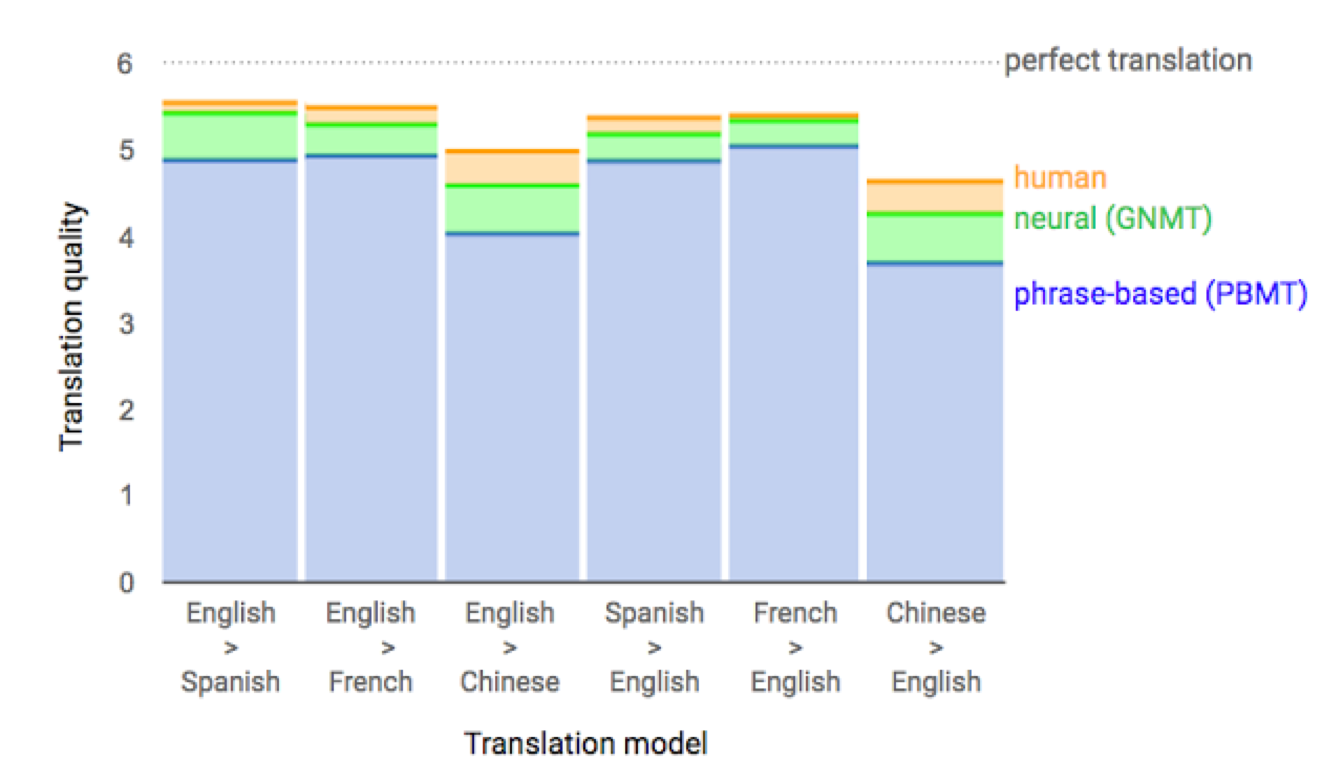
In 2016, Google released WaveNet (https://deepmind.com/blog/wavenet-generative-model-raw-audio/) and Baidu released deep speech, both are deep learning networks that generated voice automatically. The systems learn to mimic human voices by themselves and improve over time, and it is getting harder and harder for an audience to differentiate them from a real human speaking. Why is this important? Although Siri (https://www.wikiwand.com/en/Siri) and Alexa (https://www.wikiwand.com/en/Amazon_Alexa) can talk well, in the past, text2voice systems were mostly manually trained, which was not in a completely autonomous way to create new voices.
While there is still some gap before computers can speak like humans, we are definitely a step closer to realizing automatic voice generation. In addition, deep learning has shown its impressive abilities in music composition and sound generation from videos, for example Owens and their co-authors work Visually Indicated Sounds, 2015.
Deep learning has been applied extensively in self-driving cars, from perception to localization, to path planning. In perception, deep learning is often used to detect cars and pedestrians, for example using the Single Shot MultiBox Detector (Liu and others, SSD: Single Shot MultiBox Detector, 2015) or YOLO Real-Time Object Detection (Redmon and others, You Only Look Once: Unified, Real-Time Object Detection, 2015). People can also use deep learning to understand the scene the car is seeing, for example, the SegNet (Badrinarayanan, SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation, 2015), segmenting the scene into pieces with semantic meaning (sky, building, pole, road, fence, vehicle, bike, pedestrian, and so on). In localization, deep learning can be used to perform odometry, for example, VINet (Clark and others, VINet: Visual-Inertial Odometry as a Sequence-to-Sequence Learning Problem, 2017), which estimates the exact location of the car and its pose (yaw, pitch, roll). In path planning where it is often formulated as an optimization problem, deep learning, specifically reinforcement learning, can also be applied, for example, the work by Shalev-Shwartz, and its co-authors (Safe, Multi-Agent, Reinforcement Learning for Autonomous Driving, 2016). In addition to its applications in different stages of the self-driving pipeline, deep learning has also been used to perform end-to-end learning, mapping raw pixels from the camera to steering commands (Bojarski and others, End to End Learning for Self-Driving Cars, 2016).
Deep learning for business
To leverage the power of deep learning for business, the first question would be how to choose the problems to solve? In an interview with Andrew Ng, he talked about his opinion, the rule of thumb is:
If we look around, we can easily find that companies today, large or small, have already applied deep learning to production with impressive performance and speed. Think about Google, Microsoft, Facebook, Apple, Amazon, IBM, and Baidu. It turns out we are using deep learning based applications and services on a daily basis.
Nowadays, Google can caption your uploaded images with multiple tags and descriptions. Its translation system is almost as good as a human translator. Its image search engine can return related images by either image queries or language-based semantic queries. Project Sunroof (https://www.google.com/get/sunroof) has been helping homeowners explore whether they should go solar - offering solar estimates for over 43 million houses across 42 states.
Apple is working hard to invest in machine learning and computer vision technologies, including the CoreML framework on iOS, Siri, and ARKit (augmented reality platform) on iOS, and their autonomous solutions including self-driving car applications.
Facebook can now automatically tag your friends. Researchers from Microsoft have won the ImageNet competition with better performance than a human annotator and improved their speech recognition system, which has now surpassed humans.
Industry leading companies have also contributed their large-scale deep learning platforms or tools in some way. For example, TensorFlow from Google, MXNet from Amazon, PaddlePaddle from Baidu, and Torch from Facebook. Just recently, Facebook and Microsoft introduced a new open ecosystem for interchangeable AI frameworks. All these toolkits provide useful abstractions for neural networks: routines for n-dimensional arrays (Tensors), simple use of different linear algebra backends (CPU/GPU), and automatic differentiation.
With so many resources and good business models available, it can be foreseen that the process from theoretical development to practical industry realization will be shortened over time.
Future potential and challenges
Despite the exciting past and promising prospects, challenges are still there. As we open this Pandora's box of AI, one of the key questions is, where are we going? What can it do? This question has been addressed by people from various backgrounds. In one of the interviews with Andrew Ng, he posed his point of view that while today’s AI is making rapid progress, such momentum will slow down up until AI reaches a human level of performance. There are mainly three reasons for this, the feasibility of the things a human can do, the massive size of data, and the distinctive human ability called insight. Still, it sounds very impressive, and might be a bit scary, that one day AI will surpass humans and perhaps replace humans in many areas:
There are basically two main streams of AI, the positive ones, and the passive ones. As the creator of Paypal, SpaceX, and Tesla Elon Musk commented one-day:
But right now, most AI technology can only do limited work in certain domains. In the area of deep learning, there are perhaps more challenges than the successful adoptions in people's life. Until now, most of the progress in deep learning has been made by exploring various architectures, but we still lack the fundamental understanding of why and how deep learning has achieved such success. Additionally, there are limited studies on why and how to choose structural features and how to efficiently tune hyper-parameters. Most of the current approaches are still based on validation or cross-validation, which is far from being theoretically grounded and is more on the side of experimental and ad hoc (Plamen Angelov and Alessandro Sperduti, Challenges in Deep Learning, 2016). From a data source perspective, how to deal with fast moving and streamed data, high dimensional data, structured data in the form of sequences (time series, audio and video signals, DNA, and so on), trees (XML documents, parse trees, RNA, and so on), graphs (chemical compounds, social networks, parts of an image, and so on) is still in development, especially when concerning their computational efficiency.
Additionally, there is a need for multi-task unified modeling. As the Google DeepMind’s research scientist Raia Hadsell summed it up:
Until now, many trained models have specialized in just one or two areas, such as recognizing faces, cars, human actions, or understanding speech, which is far from true AI. Whereas a truly intelligent module would not only be able to process and understand multi-source inputs, but also make decisions for various tasks or sequences of tasks. The question of how to best apply the knowledge learned from one domain to other domains and adapt quickly remains unanswered.
While many optimization approaches have been proposed in the past, such as Gradient Descent or Stochastic Gradient Descent, Adagrad, AdaDelta, or Adma (Adaptive Moment Estimation), some known weaknesses, such as trap at local minima, lower performance, and high computational time still occur in deep learning. New research in this direction would yield fundamental impacts on deep learning performance and efficiency. It would be interesting to see whether global optimization techniques can be used to assist deep learning regarding the aforementioned problems.
Last but not least, there are perhaps more opportunities than challenges to be faced when applying deep learning or even developing new types of deep learning algorithms to fields that so far have not yet been benefited from. From finance to e-commerce, social networks to bioinformatics, we have seen tremendous growth in the interest of leveraging deep learning. Powered by deep learning, we are seeing applications, startups, and services which are changing our life at a much faster pace.
Summary
In this chapter, we have introduced the high-level concept of deep learning and AI in general. We talked about the history of deep learning, the up and downs, and its recent rise. From there, we dived deeper to discuss the differences between shallow algorithms and deep algorithms. We specifically discussed the two aspects of understanding deep learning: the neural point view and feature representation learning point of view. We then gave several successful applications across various fields. In the end, we talked about challenges that deep learning still faces and the potential future for machine-based AI.
In the next chapter, we will help you set up the development environment and get our hands dirty.

