


















 Download code from GitHub
Download code from GitHub
Chapter 1: Getting Started with Alteryx
In the current century, one of the core functions of all companies is to retrieve data from its source and get it into the hands of your company's analysts, decision makers, and data scientists. This data flow allows businesses to make decisions, supported by empirical evidence, quickly and with confidence. The capability also gives businesses a robust process for delivering the data flows with a significant advantage over their competition.
Creating robust data flows requires that end users find the datasets and trust the raw data source. End users need to know what transformations were applied to the dataset to build trust. They also need to know who to talk to if their needs change. Alteryx gives data engineers and end users a single unified place to create data pipelines and discover data resources. It also provides the context that gives end users confidence when making decisions based on any of those datasets.
This book will describe how to build and deploy data engineering pipelines with Alteryx. We will learn how to examine to apply DataOps methods to build high-quality datasets. We will also learn the techniques required for monitoring the pipelines when they are running in an automated production environment.
This chapter will introduce the Alteryx platform as a whole and the major software components within the platform. Then, we will see how those components fit together to create a data pipeline, and how Alteryx can improve your development speed and build confidence throughout your data team.
Once we understand the Alteryx platform, we will look into Alteryx Designer and familiarize ourselves with the interface. Next, we will set a baseline for building an Alteryx workflow and use Alteryx to create standalone data pipelines.
Next, we will investigate the server-based components of the Alteryx platform, Alteryx Server, and Alteryx Connect. We will learn how Alteryx Server can automate the pipeline execution, scale the efforts and work of your data engineering team, and serve as a central location where workflows are stored and shared. We will also learn how Alteryx Connect is used to find data sources throughout an enterprise, build user confidence with data cataloging, and build trust in the data sources by maintaining the lineage.
Finally, we will see how this book can help your data engineering work and link each part of the data engineering pipeline with the Alteryx platform applications.
In this chapter, we will cover the following topics:
- Understanding the Alteryx platform
- Using Alteryx Designer
- Leveraging Alteryx Server and Alteryx Connect
- Using this book in your data engineering work
Understanding the Alteryx platform
The Alteryx platform is the Alteryx software suite that combines processing, managing datasets, and analysis. While a lot of focus in the Alteryx community tends to be on the business user analyst, a data engineer's benefits are extensive. Alteryx as a whole allows for both code-free and code-friendly workflow development, giving it the flexibility to quickly transform a dataset while having the depth to make complex transformations using whatever tool or process makes the most sense.
In this section, we will learn about the following:
- What software is offered in the Alteryx platform
- How Alteryx can be used with an example business case
The software that makes the Alteryx platform
The Alteryx platform is a collection of four software products:
- Alteryx Designer: Designer is the desktop workflow creation tool. It is a Graphical User Interface (GUI) for building workflows that interact with the Alteryx Engine, which executes the workflow when run. Designer also enables automated and guided Machine Learning (ML) with the Intelligence Suite add-on. This is in addition to building your own ML data pipelines, and we will discuss both methods in Chapter 8, Beginning Advanced Analytics.
- Alteryx Server: We publish a workflow to Server when created to run the workflows on-demand or on a time-based schedule. It also holds a simple version history for referencing which version of a workflow ran a particular transformation. Finally, Server makes provision for the sharing of workflows between different users throughout a company.
- Alteryx Connect: The Connect catalog allows users to find and trace datasets and lineage. The population process is completed by running the Connect Apps, a series of Alteryx workflows with a user input for parameters that identify the different locations where the datasets reside. These apps will extract all the data catalog information and upload it to the connect database for exploration in the web browser. When the source data doesn't contain context information such as field descriptions, you can add them manually to enrich the catalog.
- Alteryx Promote: Promote is a data science model management tool. It provides a way to manage a model's life cycle, monitor performance and model drift, orchestrate model iterations' movements between environments, and provide an API endpoint to deploy the models to other applications.
Important Note
Alteryx software products have Alteryx as part of the name. Generally, the name Alteryx is dropped from the name in discussions and that will often happen throughout this book.
Because the data science deployment falls into Machine Learning Operations (MLOps), it isn't a core component of the Data Operations (DataOps) process. Thus, while you might have some interactions with the model deployment as a data engineer, we will be focusing on extracting and processing the raw datasets rather than the model management and implementation that Promote supports. As such, the Promote software will be beyond the scope of this book.
Now that we know what the Alteryx platform is and what software is available, we can look at how Alteryx will fit into a business case.
Using the Alteryx platform in a business scenario
The Alteryx platform is all about creating a process where iteration is easy. All too often, when integrating a new data source, you won't always know the answer to the following questions until late in the process:
- What is the final form of that data?
- What transformations need to take place?
- Are there additional resources that are required to enrich the data source?
Trying to develop a workflow to answer these questions with a pipeline focused on writing code, common areas of frustration appear when trying to iterate through ideas and tests. These frustrations include the following:
- Knowing when to refactor a part of the pipeline
- Identifying exactly when a particular transformation happens in the pipeline
- Debugging the process for logical errors where the error is in the data output but not caused by a coding error
The visual nature of Alteryx lets you quickly think through the pipeline, and see what transformation is happening where. When errors appear in the process, the tool will highlight the error in context.
It is also easy to trace specific records back through the process visually. This tracing renders straightforward the process of identifying when a transformation takes place that results in a logical error.
How Alteryx benefits data engineers
The Alteryx platform's key benefits to a data engineer arise in three major cases:
- Speed of development
- Iterative workflow development
- Self-documentation (which you can supplement with additional information)
These benefits fall under an overarching theme of making it easier to get new datasets to the end user. For example, suppose the development time, debugging, and documentation can all be made simpler. In that case, responding to requests from analysts and data scientists becomes something to take pride in rather than dreading.
Speed of development
The Alteryx platform supports the speed of development with two fundamental features:
- The visual development process
- The performance of the Alteryx Engine
The visual development process helps a data engineer by allowing them to lay out the pipeline onto the Alteryx canvas. Of course, you can create the pipeline from scratch, which is often the case if little information about the end destination is available. Still, you can build the pipeline from a data flow chart with the principal steps preplanned.
This translation process uses the transformation tools that provide the building blocks for a workflow. By aligning those tools with a logical grid across (or down) the Designer canvas, you can see each step in the pipeline. Such an arrangement allows you to focus on each step to identify when the data might diverge for a particular process and add any intermediate checks.
The other benefit is speed – the fact that the Alteryx engine performs the operations quickly. One of the reasons for this performance is that transformations take place in memory and with the minimum memory footprint required for any particular change.
For example, when a column with millions of records has a formula applied, only the cells (the row and column combination) that are processed are needed in memory. The result is that the transformations that Alteryx does are fast.
The location of the dataset is often the only limit to Alteryx's in-memory performance. For example, opening a large Snowflake or Microsoft SQL Server table in Alteryx can become bottlenecked by network transfers. In these cases, the InDB tools can perform calculations on the remote database to minimize the problem and reduce the volume of data transferred locally.
Iterative development workflow
The next significant benefit is the inherent iterative workflow that Alteryx development uses. When building a data pipeline, the sequencing of the transformations is vital to the dataset result.
This iterative process allows you to do the following:
- Check what the data looks like using browse tools and browse anywhere samples.
- Make modifications and establish the impact that those modifications create.
- Backtrack along the pipeline and insert new changes.
The iterative process allows the data engineer to test changes quickly without worrying about how long it will take to compile or if you haven't noticed a typo in the SQL script.
Self-documenting with additional supplementing of specific notes
Each tool in Alteryx will automatically document itself with annotations. For example, a formula tool will list the calculations taking place.
This self-documenting provides a good starting point for the documentation of the overall workflow. You can supplement these annotations by adding additional context. The further context can be renaming specific tools to reflect what they are doing (which also appears in the workflow logs). Add comment sections to the canvas or grouping processes with tool containers.
We now understand why the Alteryx platform is a powerful tool for data engineering and some of its key benefits. Next, we need to gain a deeper insight into the benefits that using Alteryx Designer can bring to your data engineering development.
Using Alteryx Designer
We have covered at a high level what the benefits of the Alteryx platform are. This section will look a bit closer at Alteryx Designer and why it is suitable for data engineering.
As mentioned previously, Designer is the desktop workflow creation tool in the Alteryx platform. You create the data pipelines and perform advanced analytics in Designer. Designer can also create preformatted reports, upload datasets to API endpoints, or load data into your database of choice.
Here, we will answer some of the questions that revolve around Designer:
- Why is Alteryx Designer suitable for data engineering
- How to start building a workflow in Designer
- How you can leverage the InDB tools for large databases
- And explain some workflow best practices
Answering the preceding questions will give you a basic understanding of why Designer is a good tool for building your data pipelines and the basis for the DataOps principles we will talk about later.
Why is Alteryx Designer suitable for data engineering?
Alteryx Designer utilizes a drag-and-drop interface for building a workflow. Each tool represents a specific transformation or process. This action and visibility of the process allow for a high development speed and emphasize an iterative workflow to get the best results. Throughout the workflow, you can check the impact of the tool's changes on the records and compare them to the tool's input records.
Building a workflow in Designer
If you open a new Designer workflow, you will see the following main interface components:
- Tool Pallet
- Configuration Page
- Workflow Canvas
- Results Window
These components are shown in the following screenshot:
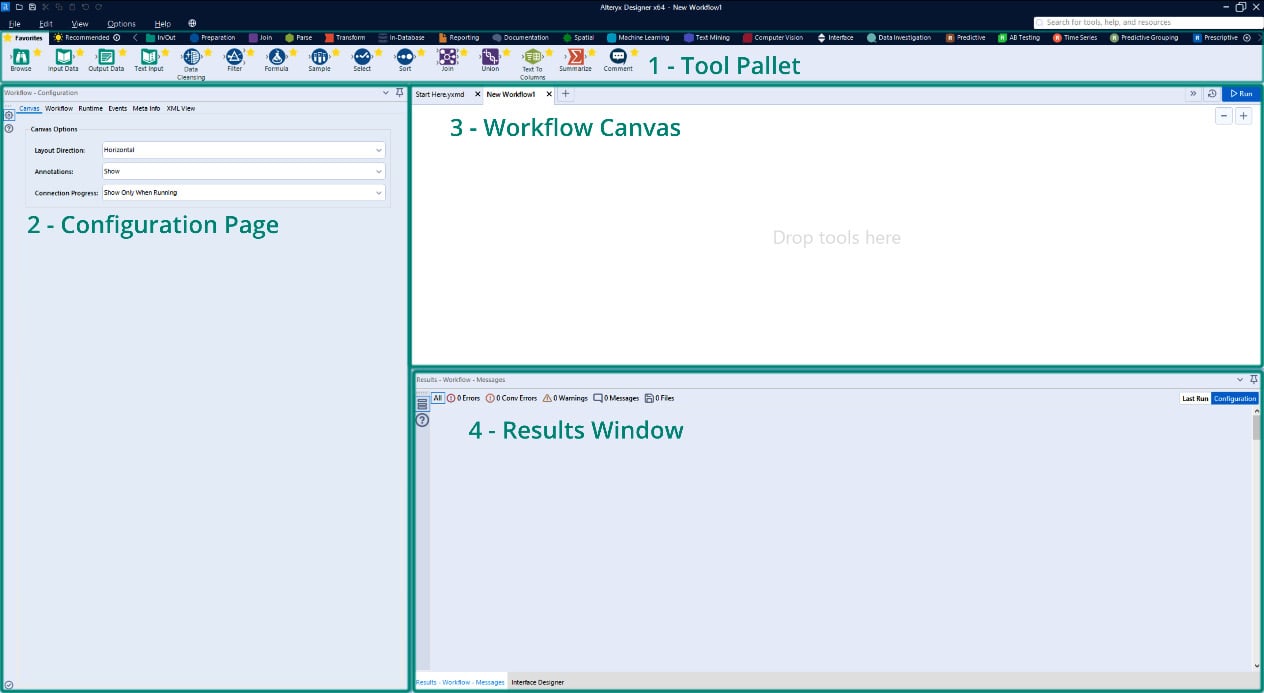
Figure 1.1 – Alteryx Designer interface
Each of these sections provides a different set of information to you while building a workflow.
The Canvas gives a visual representation of the progress of a workflow, the configuration page allows for quick reference and the changing of any settings, and the results window provides a preview of the changes made to the dataset.
This easy viewing of the entire pipeline in the canvas, the data changes at each transformation, and the speedy confirmation of settings in the workflow allow for rapid iteration and testing. As a data engineer, getting a dataset to the stakeholder accurately and quickly is the central goal of your efforts. These Designer features are focused on making that possible.
The default orientation for a workflow is left to right, but you can also customize this to work from top to bottom. Throughout this book, I will describe everything in this context, but be aware that you can change it.
Accessing Online Help
When working in the Designer interface, you can access the online help by pushing the F1 button on your keyboard. Additionally, if you have a particular tool selected when you push the F1 button, you will navigate to the help menu for that specific tool.
Let's build a simple workflow using the tools in the Favorites tool bin. We will complete the following steps and create the completed workflow shown in Figure 1.2:
- Connect to a dataset.
- Perform a calculation.
- Summarize the results.
- Write the results to an Alteryx
yxdbfile:
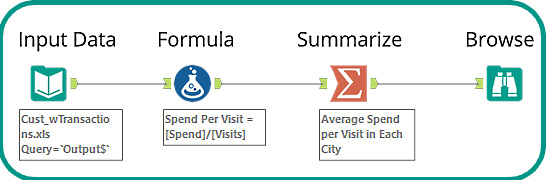
Figure 1.2 – Introduction workflow
You can look at the example workflow in the book's GitHub repository here: https://github.com/PacktPublishing/Data-Engineering-with-Alteryx/tree/main/Chapter%2001.
Using an Input Data tool, we can connect to the Cust_wTransactions.xls dataset. This dataset is one of the Alteryx Sample datasets, and you can find this in the Alteryx Program folder, located at C:\ProgramFiles\Alteryx\Samples\data\SampleData\Cust_wTransactions.xls.
In step 2 of the process, we create a field with the following steps:
- Create a new field with a Formula tool: When creating a formula, you always go through the following steps: Create a new Output Column (or select an existing column).
- Set the data type: Set the data type for a new column (you cannot change an existing column's data type).
- Write the formula: Alteryx has field and formula autocompletion, so that will also help for speeding up your development.
The workflow of the preceding steps can be seen in the following screenshot:
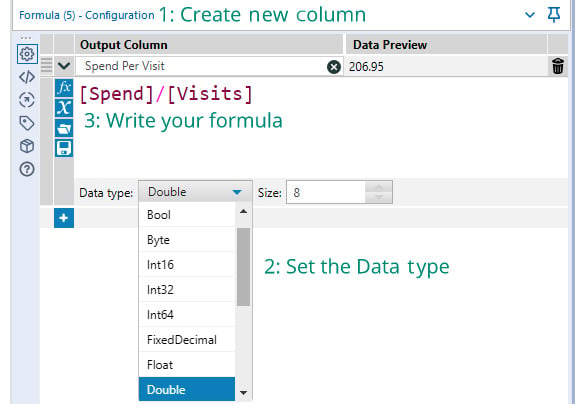
Figure 1.3 – Steps for creating a formula
The third step in the process is to summarize the results to find the average speed per customer in each city as follows:
- Choose any grouping fields: Select any fields that we are grouping by, such as
City, and then add the action ofGroup Byfor that field. - Choose any aggregation fields: Select the field that we want to aggregate,
Spend Per Visit, and apply the aggregation we want to action (Numeric action menu | Average option)
The configuration for the summary described is shown in the following screenshot:
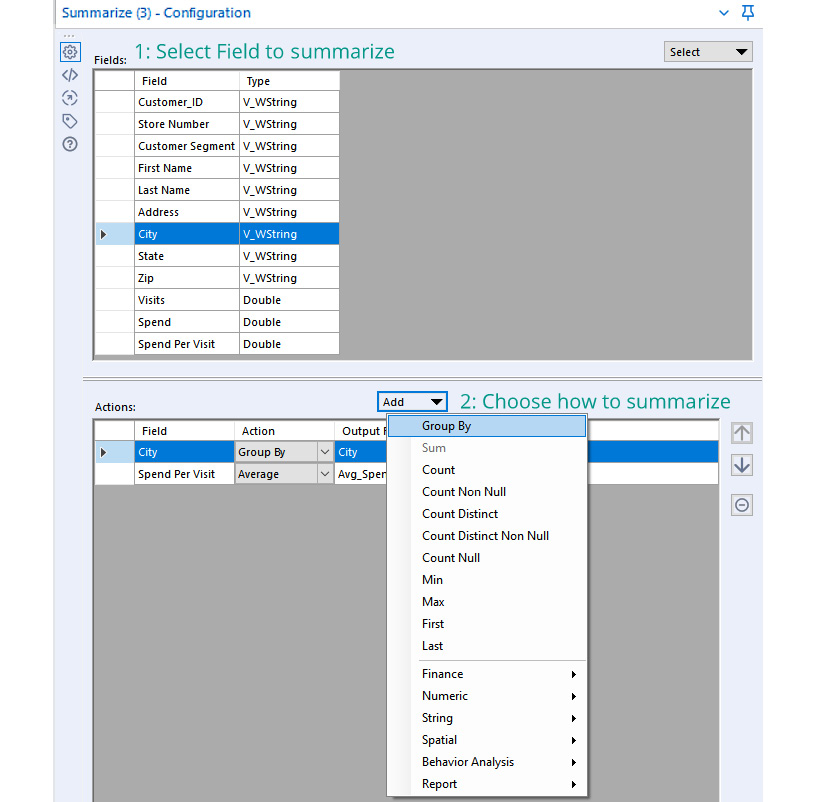
Figure 1.4 – Summarize configuration
The final step in our workflow is to view the results of the processing. We can use the Browse tool to view all the records in a dataset and see the full results.
The process we have looked at works well on smaller datasets or data in local files. It is less effective when working with large data sources or when the data is already in a database. In those situations, using InDB tools is a better toolset to use. We will get an understanding of how to use those tools in the next section.
What can the InDB tools do?
The InDB tools are a great way to process datasets without copying the data across the network to your local machine. In the following screenshot, we have an example workflow that uses a sample Snowflake database to process 4.1 GB of data in less than 2 minutes:
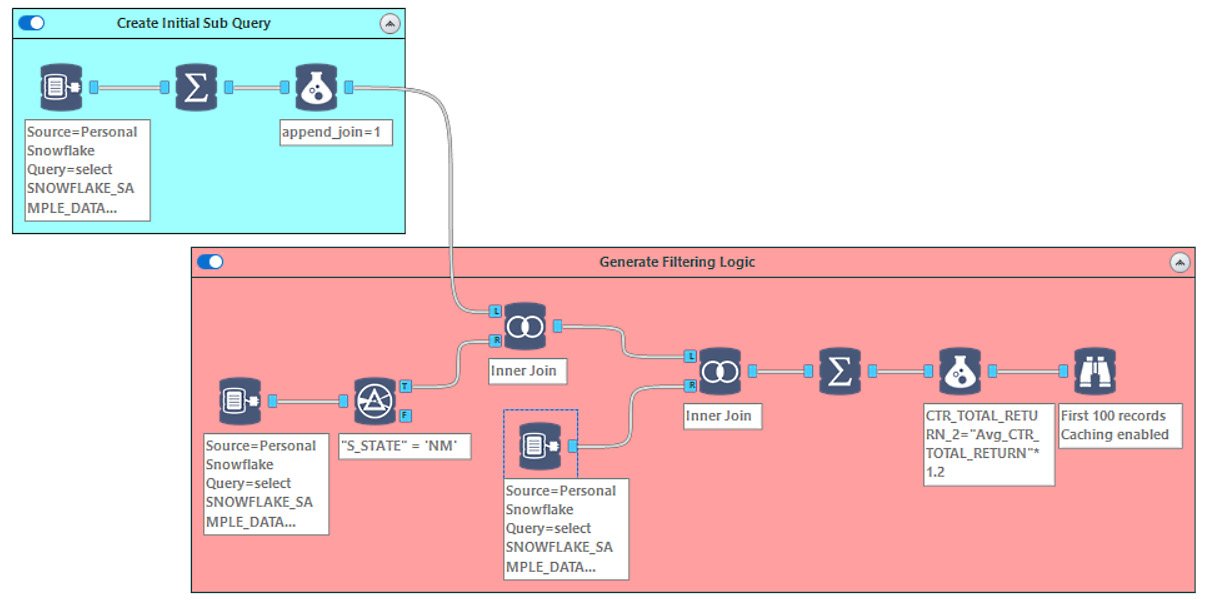
Figure 1.5 – Example workflow using InDB tools
You can look at the example workflow in the book's GitHub repository here: https://github.com/PacktPublishing/Data-Engineering-with-Alteryx/tree/main/Chapter%2001.
This workflow entails three steps:
- Generate an initial query for the target data.
- Produce a subquery off that data to generate the filtering logic.
- Apply the filtering logic to the primary query.
When looking at the visual layout, we see the generation of the query, where the logic branches off, and how we merge the logic back onto the dataset. The automated annotations all provide information about what is happening at each step. At the same time, the tool containers group the individual logic steps together.
We will look at how to use the InDB tools in more detail in later chapters, but this workflow shows how complicated queries are run on large datasets while still providing good performance in your workflow.
Building better documentation into your workflow improves the usability of the workflow. Therefore, adding this documentation is considered the best practice to employ when developing a workflow. We will explore how we can apply the documentation in the next section.
Best practices for Designer workflows
Applying Designer best practices makes your data engineering more usable for you and other team members. Having the documentation and best practices implemented throughout a workflow embeds the knowledge of what the workflow components are doing in context. It means that additional team members, or you in the future, will be able to open a workflow and understand what each small section is trying to achieve.
The best practices fall into three areas:
- Supplementing the automatic annotations: The automatic annotations that Alteryx creates for individual tools provide basic information about what has happened in a tool. The annotations do not offer an explanation or justification of the logic. Additionally, the default naming of each tool doesn't provide any context for the log outputs. We can add more information in both of these areas. We can update the tool name to describe what is happening in that tool and expand the annotation to include more detail.
- Using tool containers to group logic: Adding tool containers to a workflow is a simple way of visually grouping processes on the canvas. You can also use specific colors for the containers to highlight different functions. For example, you can color input functions green and logic calculations in orange. These particular color examples don't matter as long as the colors are consistent across workflows and your organization.
- Adding comment and explorer box tools for external context: Often, you will need to add more context to a workflow, and this context won't fit in an annotation or color grouping. You can supplement the automatic documentation with Comment tools for text-based notes or an explorer box to reference external sources. Those external sources could be web pages, local HTML files, or folder directories. For example, you can include web documentation or a README file in the workflow, thereby providing deeper context.
These three areas all focus on making a workflow decipherable at a glance and quickly understandable. They give new data engineers the information they need to understand the workflow when adopting or reviewing a project.
With a completed workflow, the next step will be making the workflow run automatically. We also need to make the datasets that the workflow creates searchable and the lineage traceable. We will use Alteryx Server and Alteryx Connect to achieve this, which we will look at next.
Leveraging Alteryx Server and Alteryx Connect
Once you have successfully created a data pipeline, the following process is to automate its use. In this section, we will use Alteryx to automate a pipeline and create discoverability and trust in the data.
The two products we will focus on are Alteryx Server and Alteryx Connect. Server is the workflow automation, scaling, and sharing platform, while Connect is for data cataloging, trust, and discoverability.
Server has three main capabilities that are of benefit to a data engineer:
- Time-based automation of workflows: Relying on a single person to run a workflow that is key to any system is a recipe for failure. So, having a schedule-based system for running those workflows makes it more robust and reliable.
- Scaling of capacity for running workflows: Running multiple workflows on Designer Desktop is not a good experience for most people. Having Server run more workflows will also free up local resources for other jobs.
- Sharing workflows via a central location: The Server is the central location where workflows are published to and discovered by users around the organization.
Connect is a service for data cataloging and discovery. Data assets can be labeled by what the data represents, the field contents, or the source. This catalog enables the discovery of new resources. Additionally, the Data Nexus allows a data field's lineage to be traced and builds trust with users to know where a field originated from and what transformations have taken place.
How can you use Alteryx Server to orchestrate a data pipeline?
Once we have created a pipeline, we may want to have the dataset extracted on a regular schedule. Having this process automated allows for more robust implementation and makes using the dataset simpler to use.
Orchestrating a data pipeline with Alteryx Server is a three-step process:
- Create a pipeline in Alteryx Designer and publish it to Alteryx Server.
- Set a time frame to run the workflow.
- Monitor the running of the workflow.
This three-step process is deceptively simple and, for this introduction, only covers the most straightforward use cases. Later, in Chapter 10, Monitoring DataOps and Managing Changes, we will walk through some techniques to orchestrate more complex, multistep data pipelines. Still, those examples fundamentally come back to these three steps mentioned above.
In the following screenshot, we can see how we can define the time frame for our schedule on the Server Schedule page:

Figure 1.6 – The Alteryx Server scheduling page
On this page, we can define the frequency of a schedule, the time the schedule will occur, and provide a reference name for the schedule.
How does Connect help with discoverability?
The final piece of your data engineering puzzle is how will users find and trust the dataset you have created? While you will often generate datasets on request, you also find that users will come to you looking for datasets you have already made, and they don't know they exist.
Connect is a data cataloging and discoverability tool for you to surface the datasets in your organization and allow users to find them, request access, and understand what the fields are. It is a central place for data definitions and allows searching in terms of how content is defined.
Using this book in your data engineering work
Now that you know the basics of using Alteryx, we can investigate how Alteryx applies to data engineering. Data engineering is a broad topic and has many different definitions, depending on who is using it. So, for the context of this book, here is how I define data engineering:
Data engineering is the process of taking data from any number of disparate sources and transforming them into a usable format for an end user.
It sounds simple enough, but this definition encapsulates many variables and complexity:
- Where is the data, and how many sources are there?
- What transformations are needed?
- What is a usable state?
- How should the data be accessed?
- Who is the end user?
Chapter 2, Data Engineering with Alteryx, will expand on what this definition means. It will also explain how Alteryx products cover all the steps needed to deliver that definition.
How does the Alteryx platform come together for data engineering?
So far in this introduction, we have talked about how the parts of Alteryx can help the data engineering process independently. However, each Alteryx element also works together to build a complete, end-to-end data engineering process.
There is a common set of processes that are required when completing a data engineering project. These processes are shown in the next diagram along with what Alteryx software is usually associated with that process:

Figure 1.7 – The aspects of the data engineering process
The preceding screenshot shows Designer overlapping the data sources and transformation aspects of the processes, Server overlays the automation (which performs some of the transformations), and Connect covers the discovery section of the process.
Chapter 2, Data Engineering with Alteryx, will introduce a complete data engineering example and the DataOps principles that support data engineering in Alteryx. Finally, Chapter 3, DataOps and Its Benefits, will take the principles introduced and expand on why those principles will benefit data engineering and your organization.
Examples where Alteryx is used for data engineering
I want to share two example use cases where Alteryx provides an excellent platform for data engineering from my consulting work.
In the first example, my client uses Alteryx Designer to create a series of workflows to collect reference information from a third party. They automate this process on Server to extract the information from the source text files and load them into their data warehouse daily. These resources are then shared with people throughout the company and made discoverable.
The other use case is where a medium-sized business uses Alteryx to collect the core company information from scattered business APIs; finance and billing, social media and web analytics, CRM, and customer engagement. Next, the company automatically consolidates the business resources into the core reporting database. The company then discovers the centralized data sources in Connect while Alteryx populates an additional data catalog for the Business Intelligence tool.
Summary
In this chapter, we have learned the parts that make up the Alteryx platform. We have also learned how they can benefit you as a data engineer with faster development, an iterative workflow, and extendable self-documentation.
We examined an example of how to build a workflow with Designer and learned what the InDB tools can do. Finally, we introduced Server and Connect. We learned how Server can automate and scale your data engineering developments. Then we learned that Connect provides a place for user discovery of the datasets you have created.
In the next chapter, we will expand on what a data engineer is for Alteryx and how you can use Alteryx products for data engineering. Then we will introduce DataOps and why this is a guiding principle for data engineering in Alteryx.
