


















In this chapter, we will introduce some firewalling and networking concepts in enough detail to provide a refresher to those who've encountered them already, but in as minimal a fashion as possible, since understanding networking concepts is not the focus of this book. We feel that some of these concepts are important, and that a broader picture of how these technologies are used and where they come from serves to better our understanding of the way in which IT works—however, for the reader who is challenged for time, we have tried, wherever possible, to provide italicized summaries of the knowledge that we feel is important to have about these concepts.
Don't worry if you don't understand all of the concepts we discuss—equally, readers more comfortable with networking concepts should be able to skip ahead. IPCop makes explicit understanding of many of these concepts irrelevant, as it attempts to make administration simple and automated wherever possible. However, if you do feel inclined to learn about these topics in more depth, the introduction given here and some of the URLs and links to other resources that we provide should hopefully be of use. Understanding networking, routing, and how some common protocols work, although not a requirement, will also help you immeasurably if you intend to keep working with systems such as IPCop on a regular basis.
During the early 1970s, as data networks became more common, the number of different ways in which to build them increased exponentially. To a number of people, the concept of internetworking (IBM TCP/IP Tutorial and Technical Overview, Martin W. Murhammer, Orcun Atakan, Stefan Bretz, Larry R. Pugh, Kazunari Suzuki, David H. Wood, October 1998, pp3), or connecting multiple networks to each other, became extremely important as connecting together disparate and contrasting networks built around different sets of technology started causing pain.
A protocol, within the context of IT and Computer Science, is generally speaking a common format in which computers interchange data for a certain purpose. In networking, a protocol is best compared to a language—the networking situation in the 1970s was one in which there were many different languages and very few interpreters readily available to translate for people.
The resulting research, and most importantly that carried out and funded by the American Department of Defense's Defense Advanced Research Projects Agency (http://www.darpa.mil), gave birth not only to a range of network protocols designed for interoperability (that is to say, in order to allow easy, platform-neutral communications between a range of devices), but a network, ARPANet, set up for this express purpose. The best comparison for this within language is the development of the language Esperanto—although the proliferation of this international language has been fairly minimal, computers have the advantage of not taking years to learn a particular protocol!
This ARPANet was first experimented with using TCP/IP in 1976, and in January of 1983, its use was mandated for all computers participating in the network. By the late 1970s, many organizations besides the military were granted access to the ARPANet as well, such as NASA, the National Science Foundation (NSF), and eventually universities and other academic entities.
After the military broke away from the ARPANet to form its own, separate network for military use (MILNET), the network became the responsibility of the NSF, which came to create its own high-speed backbone, called NSFNet, for the facilitation of internetworking.
When the Acceptable Usage Policy for NSFNet began to permit non-academic traffic, the NSFNet began, in combination with other (commercial and private) networks (such as those operated via CIX), to form the entity we now know as the Internet. By the NSF's exit from the management of the Internet and the shutdown of the NSFNet in April 1995, the Internet was populated by an ever-growing population of commercial, academic, and private users.
The standards upon which the Internet is based have become the staple of modern networking, and nowadays when anyone says 'networking' they tend to be referring to something built with (and around) TCP/IP, the set of layered protocols originally developed for use on ARPANet, along with other standards upon which TCP/IP is implemented, such as 802.3 or Ethernet, which defines how one of the most popular standards over which TCP/IP runs across in network segments works.
These layered protocols, apart from being interesting to us for historical and anecdotal reasons, have several important implications for us. The most notable implication is that any device built around them is entirely interoperable with any other device. The consequence of this, then, is that we can buy networking components built by any vendor—our Dell laptop running Microsoft Windows can freely communicate, via TCP/IP, over an Ethernet network using a Linksys switch, plugged into a Cisco Router, and view a web page hosted on an IBM server running AIX, also talking TCP/IP.
More standardized protocols, running on top of TCP/IP, such as HTTP, actually carry the information itself, and thanks to the layering of these protocols, we can have a vast and disparate set of networks connected that appear transparent to devices such as web browsers and web servers, that speak protocols such as HTTP. Between our Dell laptop and our IBM server, we may have a dial-up connection, a frame relay network segment, a portion of the internet backbone, and a wireless network link—none of which concern TCP/IP or HTTP, which sit 'above' these layers of the network, and travel freely above them. If only a coach load of children on a school tour could use air travel, ferries, cycle paths, and cable cars, all without stepping from their vehicle or being aware of the changing transport medium beneath them! Layered communication of the type that TCP/IP is capable of in this sense is incredibly powerful and really allows our communications infrastructure to scale.
During the early 1970s, as data networks became more common, the number of different ways in which to build them increased exponentially. To a number of people, the concept of internetworking (IBM TCP/IP Tutorial and Technical Overview, Martin W. Murhammer, Orcun Atakan, Stefan Bretz, Larry R. Pugh, Kazunari Suzuki, David H. Wood, October 1998, pp3), or connecting multiple networks to each other, became extremely important as connecting together disparate and contrasting networks built around different sets of technology started causing pain.
A protocol, within the context of IT and Computer Science, is generally speaking a common format in which computers interchange data for a certain purpose. In networking, a protocol is best compared to a language—the networking situation in the 1970s was one in which there were many different languages and very few interpreters readily available to translate for people.
The resulting research, and most importantly that carried out and funded by the American Department of Defense's Defense Advanced Research Projects Agency (http://www.darpa.mil), gave birth not only to a range of network protocols designed for interoperability (that is to say, in order to allow easy, platform-neutral communications between a range of devices), but a network, ARPANet, set up for this express purpose. The best comparison for this within language is the development of the language Esperanto—although the proliferation of this international language has been fairly minimal, computers have the advantage of not taking years to learn a particular protocol!
This ARPANet was first experimented with using TCP/IP in 1976, and in January of 1983, its use was mandated for all computers participating in the network. By the late 1970s, many organizations besides the military were granted access to the ARPANet as well, such as NASA, the National Science Foundation (NSF), and eventually universities and other academic entities.
After the military broke away from the ARPANet to form its own, separate network for military use (MILNET), the network became the responsibility of the NSF, which came to create its own high-speed backbone, called NSFNet, for the facilitation of internetworking.
When the Acceptable Usage Policy for NSFNet began to permit non-academic traffic, the NSFNet began, in combination with other (commercial and private) networks (such as those operated via CIX), to form the entity we now know as the Internet. By the NSF's exit from the management of the Internet and the shutdown of the NSFNet in April 1995, the Internet was populated by an ever-growing population of commercial, academic, and private users.
The standards upon which the Internet is based have become the staple of modern networking, and nowadays when anyone says 'networking' they tend to be referring to something built with (and around) TCP/IP, the set of layered protocols originally developed for use on ARPANet, along with other standards upon which TCP/IP is implemented, such as 802.3 or Ethernet, which defines how one of the most popular standards over which TCP/IP runs across in network segments works.
These layered protocols, apart from being interesting to us for historical and anecdotal reasons, have several important implications for us. The most notable implication is that any device built around them is entirely interoperable with any other device. The consequence of this, then, is that we can buy networking components built by any vendor—our Dell laptop running Microsoft Windows can freely communicate, via TCP/IP, over an Ethernet network using a Linksys switch, plugged into a Cisco Router, and view a web page hosted on an IBM server running AIX, also talking TCP/IP.
More standardized protocols, running on top of TCP/IP, such as HTTP, actually carry the information itself, and thanks to the layering of these protocols, we can have a vast and disparate set of networks connected that appear transparent to devices such as web browsers and web servers, that speak protocols such as HTTP. Between our Dell laptop and our IBM server, we may have a dial-up connection, a frame relay network segment, a portion of the internet backbone, and a wireless network link—none of which concern TCP/IP or HTTP, which sit 'above' these layers of the network, and travel freely above them. If only a coach load of children on a school tour could use air travel, ferries, cycle paths, and cable cars, all without stepping from their vehicle or being aware of the changing transport medium beneath them! Layered communication of the type that TCP/IP is capable of in this sense is incredibly powerful and really allows our communications infrastructure to scale.
This network and the research underpinning it, originally funded based on the utility for military purposes in one country, has far surpassed its original aims, and through international research and uptake, spawned a phenomenon that is shaping (and will shape) generations to come. Networking is now a core activity not just to governments and research organizations, but also to companies small and large, and even home users. Further developments such as the inception of wireless technology have served to make this technology even more accessible (and relevant) to people at home, on the go, and in the imminent future, virtually anywhere on the surface of the planet!
Many of these networking protocols were originally designed in an environment in which the word 'hacker' had not yet come to have the (negative) meaning that it nowadays has, and implemented upon a network in which there was a culture of mutual trust and respect. IPv4, the foundation of all communications via the Internet (and the majority of private networks) and SMTP (the protocol used to send electronic mail and relay it from to server to server) are two prime examples of this. Neither protocol, in its initial incarnation, was designed with features designed to maintain the three qualities that nowadays are synonymous with effective communication, Confidentiality, Integrity, and Availability (called the CIA triad). The CIA triad is often defined as the aim of information security— http://en.wikipedia.org/wiki/CIA_triad. Spam and Denial of Service attacks are just two examples of (malicious) exploitations of some of the weaknesses in these two protocols.
As networking technologies grew and were adopted by governments and large organizations that relied upon them, the need for these three qualities increased, and network firewalls became a necessity. In short, the need for network security sprung into existence. The Internet has come a long way too from its humble beginnings. As the barrier for entry has decreased, and knowledge of the technologies underpinning it has become more accessible, it has become a decreasingly friendly place.
With growing reliance on the Internet for communications, firewalls have, at time of writing, become almost universally deployed as a primary line of defense against unauthorized network activity, automated attacks, and inside abuse. They are deployed everywhere, and the term 'firewall' is used in this context to refer to anything from a software stack built into commonly used operating systems (such as the Windows firewall built into Service Pack 2 of Microsoft's Windows Operating System (http://www.microsoft.com/windowsxp/using/security/internet/sp2_wfintro.mspx)) protecting only the computer it is running on, to devices costing significant sums of money deployed in banks, datacenters, and government facilities (such as Cisco's PIX line of firewall products (http://www.cisco.com/en/US/products/hw/vpndevc/ps2030/)). Such high-end devices may govern and restrict network traffic between hundreds of thousands of individual computers.
Given this increase in the use of the term 'firewall', and with so many qualifiers added to the word to distinguish between different types of firewall (such as the terms stateful, proxy, application, packet filter, hardware, software, circuit-level, and many more), it becomes very difficult to know what someone means when they tell you that their network "has a firewall". Our exploration of IPCop, therefore, must begin with an exploration of what a firewall actually is, and armed with this knowledge, we can then relate IPCop to this knowledge and understand what function it is that IPCop can fulfill for us.
In order to improve our network security, we need to first identify the problems we need to solve, and determine whether this firewall is the solution to them. Implementing a firewall for the sake of satisfying the buzzword requirement is a common mistake in security design.
The term firewall refers, generally, to a collection of technologies and devices all designed to do one thing—stop unauthorized network activity. A firewall acts as a choke point between more than one network (or network segment), and uses a (hopefully) strictly defined set of rules in order to allow, or disallow, certain types of traffic to traverse to the other side of the firewall. Most importantly, it is a security boundary between two or more networks.

In the diagram above, a web server connected to the Internet is protected by a firewall, which sits in between it and the Internet, filtering all incoming and outgoing traffic. In this scenario, illegitimate traffic from the attacker is blocked by the firewall. This could be for any number of reasons, such as the service the attacker has attempted to connect is blocked by the firewall from the Internet, because the attacker's network address is blacklisted, or because the type of traffic the attacker is sending is recognized by the firewall as being part of a Denial of Service attack.
In this scenario, the network that the web server sits on (which in a scenario such as this would probably contain multiple web servers) is segmented from the Internet by the firewall, effectively implementing a security policy dictating what can go from one network (or collection of networks) to the other. If our firewall disallowed the attacker from connecting to a file-sharing port on the web server, for instance, while the 'user' was free to access the web server on port 80, the other servers behind the firewall might be allowed access to the file sharing ports in order to synchronize content or make backups.
Layered protocols are generally explained using the Open System Interconnection (OSI) layers. Knowledge of this is extremely useful to anyone working in networking or with firewalls in particular, as so many of the concepts pertaining to it require knowledge of the way in which this layering works.
The OSI layers divide traffic and data into seven layers each of which in theory falls into a protocol. Although excellent in theory, networking and IT applications do not always strictly adhere to the OSI Layers, and it is worth considering them to be guidelines rather than a strict framework. That said, they are extremely useful for visualizing connectivity, and in general the vision of layers, each utilizing hardware and software designed by different vendors, each interoperating with the layers above and below is not unrealistic.
The OSI model is shown in the following figure:

The physical layer encompasses the physical medium on which a network is built. Specifications that operate within the physical layer include physical interfaces such as ports, voltages, pin specifications, cable design, and materials. A network hub is a layer-one device.
The data link layer provides connectivity between hosts on the same network segment. MAC addresses are used at the physical layer to distinguish between different physical network adapters and allow them to communicate. Ethernet is a layer-two standard.
The network layer provides connectivity between hosts on different networks, and it is at this layer that routing occurs. Internet Protocol (IP) and Address Resolution Protocol (ARP) exist at this layer. ARP serves an important purpose, as it intermediates between layer two and layer three by ascertaining the layer-two (MAC) address for a given layer-three (IP) address.
The transport layer, generally, acts as the layer that ensures data integrity. TCP, the protocol most frequently used at this layer, is a stateful protocol that, by maintaining connections with a remote host, can retransmit data that does not reach the destination. UDP, another (slightly less common) protocol also operates at this layer, but is not stateful—each message it sends is not part of a 'connection' as such, and is treated as entirely separate to a reply (if one is required) or any messages previously passed between two hosts.
Note
IP, TCP/IP, UDP, and other Layer four protocols
As we can see from the examination of the OSI Layers, TCP is a protocol running on top of IP, forming the abbreviation TCP/IP. Unfortunately, when people use the term TCP/IP, this specific pair of protocols is not always what they mean—the 'TCP/IP Protocol Suite' is quite frequently defined to be IP, TCP, and other protocols such as UDP and ICMP that are used along with it. This is a distinction that it is worth being aware of, and which is particularly common amongst IT professionals, and in the documentation for operating systems such as Microsoft's Windows.
The upper three layers in the OSI model are no longer concerned with (inter-) networking issues as such, and have more to do with the practicalities of software and applications that use connectivity. The session layer is where mechanisms for setting up sessions live, such as the NetBIOS protocol.
The presentation layer handles data-specific issues such as encoding, compression, and encryption. SNMP and XML are standards often used, which exist at this layer.
The application layer is the layer at which common protocols used for communication live, such as HTTP, FTP, and SMTP.
Generally, Layers three and four, are the ones most commonly dealt with by firewalls, with a small (but increasing) number, generally referred to as 'proxy firewalls' or 'application-layer firewalls' sitting at layers above this (and being aware of protocols like HTTP, DNS, RCP, and NetBIOS). It is worth noting that many firewalls (incorrectly) classify all layers above layer three as application layers.
For our purposes, a thorough understanding (and explanation) of OSI layers and some of the more conceptual and technical aspects of networking are unnecessary—although we have tried to provide some outline of these, this is more for familiarity and in order to give you some idea as to what you may want to learn in future.
For our purposes a knowledge that layering exists is sufficient. If you feel the need (or are otherwise so inclined) to learn more about these topics, some of the URLs given in this chapter serve as good starting points for this. You don't necessarily have to understand, agree with, or like the OSI layers in order to work with firewalls (in fact, many TCP/IP stacks do not strictly adhere to segment handling of traffic based on them), but knowing that they exist and understanding approximately what they're designed to do and how the technologies built around them interact is important to anyone serious about understanding firewalls or networking or for anyone who regularly works with these technologies.
In many instances, Wikipedia (http://www.wikipedia.org) serves as a good starting reference for technical concepts where the (ostensibly well versed in IT) audience of wikipedia really shine at providing comprehensive coverage of topics! The wikipedia OSI Layer page is well referenced and has technically accurate content. This can be found at http://en.wikipedia.org/wiki/OSI_seven-layer_model.
Another excellent online resource for information on all things on TCP/IP is http://tcpipguide.com/.
The IBM "TCP/IP Tutorial and Technical Overview" referenced earlier in this chapter, by Martin W. Murhammer, Orcun Atakan, Stefan Bretz, Larry R. Pugh, Kazunari Suzuki, and David H. Wood, is another good (and free) guide to the world of TCP/IP networking. Although slightly out of date (the last iteration was published in October 1998), many of the standards surrounding TCP/IP have not changed in over 20 years, so the date should not put you off too much. This guide, and many others pertaining to open standards and IBM products can be found at the excellent 'IBM Redbooks' site at http://www.redbooks.ibm.com/.
For a published introduction to TCP/IP, the three "TCP/IP Illustrated" books by Richard W. Stevens are generally considered to be the authoritative source on the topic. The ISBN number for the complete set is 0-201-77631-6, and it can be found at any good major bookstore or online book retailer.
Whether you know it or not, the chances are that any network that you use is build on top of IP, Internet Protocol. IP and the protocols that are built on top of it (such as TCP, UDP, and ICMP, all of which use IP datagrams) are the foundation of almost every network presently deployed. The components that such networks are built out of are interoperable, and for these reasons their roles are well defined and well understood. We will, briefly, talk about these devices and—particularly—how they interconnect with firewalls.
Ethernet, as the underlying technology on top of which most of these protocols are generally layered, forms the basis of these devices. As such network devices, peripherals, and appliances are often referred to as LAN, Ethernet, or TCP/IP equipment (or more commonly, just "Network" equipment). There are other networking standards in use, two of them being Token Ring and SNA networks that have fairly specific uses. Many of theses standards including the two mentioned above, are generally considered outdated. It is commonly the case that in scenarios in which they are still deployed for legacy reasons, such networks, are hallmarked for replacement or are effectively change-frozen.
As a point of interest, Token Ring and SNA are often deployed in larger organizations, the latter almost unilaterally in communication with a mainframe such as IBM zSeries. Other specialized IT environments, such as clustering, have specific networking requirements that draw them towards other forms of networking also.
Here, however, we shall consider the following (Ethernet/IP) network devices:
The server/client relationship is the cornerstone of the TCP/IP protocol and it is necessary to have some understanding of it in order to be able to effectively administer, implement, and think about it. Put very simply, a client is any device that initiates a connection (i.e. commences sending data) to another computer, and a server is any device that listens for such a connection in order to allow others to connect to it.
Within the context of TCP/IP, all devices on a network are servers and clients, irrespective of whether or not they are specifically assigned the role of server (such as a corporate mail server) or client (such as a desktop computer). This is for two reasons: firstly, many higher-level protocols initiate connections back to clients from the server itself; secondly, a TCP/IP connection actually involves data being sent to listening ports in both connections—initially from the client to the server in order to commence the transaction, connecting (generally) to a well-known port on the server in order to access a specific service (such as port 80 for HTTP, port 25 for SMTP, or port 21 for FTP) with traffic coming from a (generally) random ephemeral (i.e. greater than 1024) port on the client.
Once this data arrives, the server sends data to the client (and in this connection, the server is a client!) from the service port and to the (random) port on the client that was used as the source port for the initial connection. Traffic from the service port on the server to the client is used in order for the server to reply to the client. Data flowing in both directions, from client to server and server to client, constitutes a 'whole' TCP/IP connection. This particular distinction becomes important later on when we discuss traffic filtering.
Within the context of a network, a server is a device that provides a fixed service to hosts on that network. Generally this involves some form of centraliszed resource; although a 'firewall' may be described as a server it doesn't necessarily have to accept connections to itself (but rather facilitates connections to other locations and/or servers).
A server may serve files, email, or web pages, provide network configuration information via DHCP, provide translation between Domain Names and Host Names and IP addresses acting as a DNS server, or even provide other, more complex services, which facilitate single sign on or provide security services (such as Kerberos servers, radius servers, intrusion detection systems, etc.). For the purposes of this book, we will—generally—consider a server to be a device that provides services and data to other computers and devices on a network.
Clients are generally used directly by users and will be situated on desks and have monitors and input devices plugged into them, or are laptops (servers frequently either share such peripherals or don't have them at all). They are directly used to access resources and information that is sometimes stored elsewhere (such as web pages or files from a file server) or locally (such as documents stored on a local My Documents folder). For the purposes of this book, we will, generally, consider a client to be a device that a user uses to access services on other computers (and access data stored on them) on a network or on the Internet.
Note
For more information on the client/server relationship, see http://en.wikipedia.org/wiki/Client-server.
The hub is a networking device that allows multiple clients to be plugged into the network segment, within the context of which they can communicate with each other. A hub is, logically, very simple, and essentially acts as a logical connector for all devices attached to the device, allowing traffic to freely flow from port to port, such that in a four-port device, if the client attached to port 1 sends data to the client attached to port 4, the hub (unaware of the concept of 'clients') simply allows this traffic to flow to all ports on this device—clients 2 and 3 ignore the traffic not destined for them.

Switches address several shortcomings of hubs and are typically deployed in preference to them. Increasingly, in addition, hubs are becoming a relic of a previous age, and are becoming very hard to purchase at retail outlets and online.

Switches work by keeping a table in memory correlating ports with MAC addresses, such that the switch knows which computers are plugged into which port. Some switches, which can be 'stacked', apply this to the entire network segment, although in a network in which unmanaged or un-stacked switches were simply connected to each other by crossover cabling, a given switch would simply see a large number of MAC addresses on a particular port.
Since traffic on local segments (even traffic being routed through that segment and destined for another network) is passed from host to host (router to router, router to client, client to server, etc.) directly by MAC address, the switch can make a decision based on the ports it has, as to for which port a particular datagram is intended. As processing is required, switches have historically been more expensive than hubs, as the electronics required to perform such processing costs more than the 'stupid' components inside a hub.
In terms of their advantages, switches are faster, since any two ports may use a large quantity of bandwidth without affecting the bandwidth available to other ports on the device. On an unswitched network, if clients 1 and 4 are generating traffic at 90% of the available bandwidth, there is only 10% of the bandwidth (or, practically, less, when dealing with overhead imposed by IP) available for the rest of the network. On a switched network, each port, logically, has a significantly increased bandwidth limit, typically up to the limit of the hardware of the switch.
It is worth noting that many switches will have an overall bandwidth limit for traffic through all ports, and most medium to higher-end switches have an 'uplink' port, which in addition to providing MDI-X ability (the ability to sense whether a crossover link is required, and if so, perform the necessary modification in the switch, so a normal 'patch' cable can be used for a switch-to-switch connection) is also a higher bandwidth port (gigabit on a 100 megabit switch), or is a GBIC interface enabling a modular uplink.
Switches are also inherently slightly more secure as it is harder for any device to arbitrarily listen to network traffic, which may contain private data or authentication information such as passwords. Switches understand which clients are plugged into which socket on the switch, and will under normal circumstances move data from one port to another without passing unrelated traffic to computers not acting as the destination.
This is not, however, an absolute security measure, and may be circumvented using a technique known as ARP Spoofing or ARP Poisoning (http://www.node99.org/projects/arpspoof/). ARP Spoofing is a very well-known technique, with several tools existing for multiple platforms in order to allow people to perform it. On a local segment, ARP spoofing allows any user with administrator or system-level access to a PC (administrator credentials, a spare network socket into which to plug a laptop, or just a computer configured to boot from CD or floppy disk) to intercept any and all traffic sent by other computers on the same segment, and redirect it transparently to the Internet (or another destination) without any visible disruption to the user. Once this layer-two protocol is compromised, every other protocol at every other layer (with the exception of strong cryptographic protocols involving handshakes that are hard to attack, or using certificates) must be considered to be compromised as well.
Modern switches often have many forms of advanced functionality. Traditional switches, although more intelligent than hubs, are described (in the form in which they were described above) as 'unmanaged' switches. Newer, 'managed' switches (which generally have larger microprocessors, more memory, and increased throughput (the amount of data that can traverse the network in a given timeframe)) offer more functionality. Some examples of this are the ability to provide added security features such as MAC address filtering, DHCP snooping, and monitoring ports. Other such new features may address security and network structure such as vLANs. As mentioned earlier, some 'managed' switches offer a stacking capability, whereby using a proprietary link cable (such as the 'Matrix' cable with 3com Superstack switches), or a plain patch/crossover cable between the uplink ports of the switches, a 'stack' of switches can be managed as one, effectively sharing configuration and management interface.
Some very high-end switches, such as the Cisco 6500 series and the 3com Corebuilder switches also have 'routing engines', which allow them to fulfill some of the functionality of routers. This, again, leads to more 'blur' between the OSI Layers when we come to apply them to 'real life'.
Switches range from small four-port units often integrated with other network devices, and sold as consumer appliances (such as the Linksys WRT54G) to large, high-availability units designed for use in data centers, which support many hundreds of concurrent clients and have an extremely high throughput.
Within the context of this book, we will consider switches in a fairly simple context, and ignore functionality such as vLANs and routing engines, which are outside the scope of what we can reasonably deal with while talking about IPCop (such discussion would more be suited to a book on networking). For the purposes of this book, although a knowledge of switches is useful, it should suffice to understand that switches are devices that allow all clients plugged into a network socket to talk to every other host on the switch, and as such, provide connectivity for a number of hosts to each other, to a network, and to shared resources stored on servers.
If a series of switches and hubs connect together our client devices in order to form a network, routers are, very simply, devices that connect those networks together (put another way, routers are the foundation of inter-networking). A small router (such as a 1700-series Cisco router) may link a branch office to a main office via an ISDN or broadband link, while at the other end of the scale, an expensive high-end router from Cisco, Juniper, or Nortel (or based on an operating system like Windows 2003 or Linux) may have several network links and be responsible for linking a smaller ISP with several larger ISPs it uses to connect to the internet backbone. At the high end of the scale, dedicated devices, although based on architectures similar to PCs, can handle far more traffic than a 'normal' computer running an OS such as Windows or Linux, and as such, these 'backbone' routers are very rarely anything but dedicated devices.
On a TCP/IP network, computers on the same 'subnet' (i.e. plugged into the same hub/switch, or series of hubs/switches) will communicate directly with each other, using ARP (Address Resolution Protocol) to find out the hardware (or MAC) address of the destination computer (as we mentioned when discussing OSI Layers, ARP is used to essentially step between layers two and three), and then sending data directly to this MAC address on the local network segment. It is for this reason that a 'subnet mask' is important; it allows a device to calculate which network addresses are 'local', and which are not. If our network uses the (private) address range 192.168.0.1, and our subnet mask is 255.255.255.0 (or one class C network or a /24 CIDR address space), then any network address not starting with 192.168.0. will be considered as a remote address, and rather than attempting to connect to it directly (via layer two), the device will consult a 'routing table' to see which 'router' should be used to send the data through (via layer three), as an intermediary to another network.
A fairly typical configuration for clients on smaller networks (or well-structured larger networks) is that there is only one router—the 'default' router—through which traffic goes. Using the previous example, if our device attempts to connect to another device at network address 192.0.2.17, the operating system—seeing that this is not a local device according to the network address and subnet of the network adapter—will send data for this destination to the 'default gateway', which then 'routes' the traffic to the correct destination. Although it is possible to configure a client to use different routers for different network segments, this is a more advanced and less common configuration option.
One may want to configure clients with multiple routes if, for instance, a network uses a fast network connection such as an ADSL router as the default gateway (for Internet access), and a slower network connection with a separate router to access another subnet of the internal network (for instance, a branch office of a company that has multiple sites). A preferable scenario for this in a smaller company would be to provide the internal and internet connectivity through one router that handled both, making client configuration and administration simpler (with all traffic via a default gateway, rather than static routing tables on every client pointing to different routers), but this may not always be possible or desirable.

In the above illustration, we consider a company with a head office building. The Head Office LAN Infrastructure (represented here by the colonnaded building at the bottom left-hand corner) contains internally accessed servers such as file, mail, print, and directory servers, as well as clients. Situated in between this network and both the Internet and the non-trusted network segment, or DMZ (in which are contained the externally accessible corporate web/mail systems, hosting the corporate website and accepting incoming email) is a firewall.
In addition to clients at the head office situated behind the firewall, we also have a Secondary Office, in the same town as the head office—opened when the head office ran out of space for expansion. This office has both server and client systems on the same logical network infrastructure as the Head Office, but in its own (routed) subnet, connected to the head office network via a building-to-building wireless link, possibly working by either microwave or laser link.
A Branch Office (perhaps for sales staff in another part of the country with a high density of customers for our fictitious business) also uses resources on the Head Office network. Due to the distance, this office also has its own servers (most likely file, print, and email systems with content and information being synchronized to the corresponding systems in Head Office). In a subnet of its own, this network is linked via VPN, with the route from Secondary Office segment to Head Office segment tunneled over the Internet and through firewalls due to the prohibitive cost of a leased line or similar connection.
Due to web/mail services being made available to the Internet, our Head Office has multiple Internet connections for redundancy. In a scenario like this, there would frequently be several more routers employed both for the Head Office infrastructure (which may be fairly large) and for the Internet service provision (and the Head Office firewall itself would most likely be, or be accompanied by, another router). These have been omitted for simplicity!
For our purposes, we will consider a router to be a device that forwards packets across a wide area network or inter-network to their correct destination.
Although it is easy to talk about networks in such cut and dry terms—separate networks based on layers, and network devices as isolated, well-defined items, this is quite frequently not the case. For many reasons, including network topology and limited resources, roles are quite frequently combined, particularly in smaller networks. Frequently, the first of these to be combined are the roles of 'firewall' and 'router'.
As networks are frequently joined together by routers, this natural choke point can seem a convenient place to firewall as well. This in itself is good networking theory, but frequently this is implemented by adding firewalling functionality or rule sets to the existing router without any change to the network. Although on a small network this makes some sense, it can cause problems in handling load, and adds complexity to a device (router) that should be kept as simple as possible. In general, it is a good idea to split roles wherever possible, by utilizing separate routers, firewalls, proxy servers, etc.
This also applies to other infrastructure roles on servers—DNS servers, Kerberos Domain Controllers, DHCP servers, web servers, and so on, should be kept apart as far as possible, in the interests of performance, reliability, and security.
Unfortunately, as we've already mentioned, this isn't always possible, and there are several network roles that are frequently combined, such as firewalls and routers. Particularly in organizations that do not have their own routable IP addresses for every network device (which is virtually every SME (Small and Medium Enterprise)), there is a need for Network Address Translation. NAT is a process whereby (in order to alleviate the increasing shortage of IP addresses available for use on the Internet), a local network will not use IP addresses that work (are 'routable') on the Internet.
Network Address Translation is another consequence of the way in which the Internet and the protocols it is built upon were designed. Much as protocols such as DNS, SMTP, and TCP/IP were designed in an environment in which security was frequently an afterthought, so too was the extent to which (what would become) the Internet would grow. The IPv4 addressing scheme, which we should be familiar with, uses four octets of numbers, each with a range of 0 to 255, a hypothetical maximum of just over four billion addresses (255^4, to be precise).
Given the wide proliferation of internet connectivity and the vast number of personal computers, mobile telephones, PDAs, and other devices that use IP addresses (of which routers, non-mobile IP telephones, and even appliances such as fridges and microwaves are just a few), this address space although initially probably considered huge, is beginning to run out. For this reason, and as a result of the long timeframe for deployment of IPv6 (which aside from many other functional improvements upon IPv4 includes a larger address space), an interim method was required in order to reduce the rate at which IP addresses were being consumed—this is NAT.
As an example of how NAT is used in practice, consider the following hypothetical scenario:

Consider the diagram above—a fictional ISP and four of its customers. Each customer is allocated one IP address by the ISP, assigned to the computer or device directly attached to the connection provided by the ISP.
Customer A is a medium-sized solicitors firm—Customer A has a firewall based on IPCop, several servers, and several clients in its private network segment. It uses the 10.0.1.0/24 (class C) subnet for its internal clients, but its external IP is actually used by several dozen computers.
Customer B is a home user—customer B has only one computer, a laptop, which is directly attached to the ISP's internet connection. Customer B's external IP is used by one computer, and has no NAT and no private internal network.
Customer C is a larger manufacturing company—customer C has a high-end firewall attached to its internet connection, and a large number of diverse devices in its internal network. Customer C uses the 172.16.5.0/24 subnet for the network segment directly behind its firewall, and has a phone system, clients, server systems, and a midrange mainframe system in its internal network.
Customer D is a home with several computers for members of the family, and a tablet PC—they have a handful of clients attached to a wireless network provided by an all-in-one switch/router/firewall device (possibly the Linksys WAP54G mentioned earlier) purchased at a local computer store.
Just four IP addresses actually represent hundreds of clients on the Internet—through clever use of technology, clients using Internet Service Providers to provide access to the Internet reduce IP wastage by not allocating an IP address for every host.
If your computer exists as a host on a network on which the default gateway is performing Network Address Translation, and you visit a website, your computer will initiate a connection to port 80 on the web server you are connecting to, your computer will send a packet of data from the IP address it has (in the case of NAT, a private address like 192.168.1.23) to the destination. The destination will, in the case of a website on the Internet, be an internet-routable IP address such as 72.14.207.99 (one of Google's IP addresses).
If your gateway simply forwarded this packet to Google, it would be unlikely to get there in the first place, as a router between your computer and Google would almost certainly be configured to 'drop' packets from addresses like the 192.168.0.0/16 address range, which are not valid for internet communications. Instead, therefore, your router rewrites the packet before forwarding it, and swaps the 192.168.1.23 for the external address of your router, given to you temporarily by your ISP.
When replies come back from the host at the other end, the router, having made a note of the translation process, consults a table in memory, establishes based on the sequence number of the connection that 192.168.1.23 was the originating host, and rewrites the packet back again. Effectively, your clients are masquerading as the device attached to the Internet (or it is masquerading as them), and indeed, 'masquerading' is the technical term used for NAT in the iptables/netfilter firewalling components in Linux. Although the NAT process breaks some more complicated protocols, it is an extremely effective way of having many hundreds or thousands of devices online behind one internet-routable (public) IP address.
For the clients, the setup appears as if their address range existed as a normal, routed segment of the Internet, whereas in actual fact, the 'default gateway' is performing Network Address Translation. In this manner, the worldwide shortage of IP addresses is alleviated at the expense of some convenience. Small and home office devices in particular, such as any of those marketed by D-Link, Linksys et al., almost always use Network Address Translation to provide connectivity to their clients, and IPCop uses it too.
Note
Private Address Ranges
These 'private' IP address ranges are set out in RFC 1918 (http://www.rfc-archive.org/getrfc.php?rfc=1918). RFCs, or Requests For Comment, while not technical standards, are "technical and organizational notes about the Internet (originally the ARPANET), beginning in 1969. Memos in the RFC series discuss many aspects of computer networking, including protocols, procedures, programs, and concepts, as well as meeting notes, opinions, and sometimes humor." (http://www.rfc-editor.org/, front page, November 20, 2005). For protocols, standards, and convention, they make an excellent first line of reference, although (often depending upon the authors and intended audience) they are usually fairly technical.
The most recognizable of the private IP ranges is probably the 192.168.0.0/16 range, which constitutes 255 class C 'subnets', of which the two most commonly used are the 192.168.0.1/24 and the 192.168.1.1/24 subnets. This address range is very frequently used as the default private address range for Small Office Home Office (SOHO) routers. There are also two other private address ranges for these purposes, the 10.0.0.0/8 and 172.16.0.0/12 ranges.
As a result of NAT, devices at the border of Small Office Home Office Networks, therefore, are almost always combined-role, and although typically marketed as router/firewalls or simply routers, often perform all of the following roles:
Router (performing Network Address Translation)
Firewall
DHCP server
Caching / Resolving DNS server
Some such devices (including IPCop) may also provide some of the following pieces of functionality, most of which are generally more commonly found in enterprise products:
Proxy server
Content Filtering
File server
Intrusion Detection
VPN/IPSec server
Due to the complex nature of some of these tasks, it is often the case that the 'embedded' combined devices are difficult to configure and interoperating some of the more complex functions (such as IPSec and File Serving) with other devices (such as an IPSec/VPN device from another vendor) can be very difficult. Although the price and size of these devices makes them a very attractive prospect for smaller networks, networks requiring some of the more advanced functionality should look at them quite carefully and evaluate whether or not, economically and technically, they will meet their needs.
When combined roles are required, larger, more fully designed solutions (such as a firewall appliance from Borderware, Checkpoint, Cisco, et al.) or commercial piece of software (such as Microsoft's ISA server) often do the job more effectively and in a manner more configurable and interoperable than their smaller, cheaper SOHO cousins. Obviously, we believe that not only does IPCop do a better job at the tasks it is intended for than embedded devices, but than some of the commercial firewall and gateway packages as well!
Knowing what firewalls are intended to do and why their function is important to us, it is now necessary to explore, briefly, how it is that firewalls accomplish the broad purpose we've assigned for them.
Personal firewalls have become increasingly common in the last five years. With the inclusion of personal firewalling technology in Windows XP Service Pack 2 (and augmented technology in the upcoming Windows Vista), as well as firewalling stacks in the OSX and Linux operating systems, it is now a fairly normal occurrence for workstations and desktops to be running firewalling software.
Generally, this comes in one of two forms—either firewalling software built into the operating system (as in the case of OSX, Linux, and XP's Windows Firewall), or one of the many third-party firewalls from software vendors who write such software. Two relatively well regarded examples of such packages are Agnitum's Outpost package and ZoneLabs ZoneAlarm package.
Personal firewalling software cannot be a true firewall. As we have discussed earlier, a firewall is a security boundary between one side of the firewall and another. By definition, a personal firewall must accept data onto a computer before making the decision as to whether it is allowed to be there or not. Many forms of exploit involve the misinterpretation of maliciously crafted data while parsing and evaluating that data. Since a firewall is performing these tasks on the host it is supposed to be protecting, there is no way in which it can effectively isolate the portions of the software that are doing the protecting from the portions of the software that are being protected. Even for a smaller network, a personal firewall can never offer the degree of segregation that a network firewall provides.
Although personal firewalling software is relatively effective against inbound (ingress) traffic, such software cannot offer protection against unauthorized outbound (or egress) traffic, since an application generating such traffic on the workstation will typically have some degree of access to the firewall's internals. If the logged on user is an administrator of the workstation (or if there exists a security flaw in the operating system allowing a non-administrative application to gain system or administrative privileges), it is quite possible to circumvent software/personal firewalls using the operating system (http://www.vigilantminds.com/files/defeating_windows_personal_firewalls.pdf) in a way that simply isn't possible with a firewall distinct from the client itself.
Many personal firewall packages, such as ZoneAlarm, step beyond the services offered solely by a packet filtering firewall, and serve as a Host-based Intrusion Detection System (HIDS) or Host-based Intrusion Prevention System (HIPS). These systems actively monitor, and in the case of a HIPS, prevent, alterations to the operating system and its components. Such functions cannot be provided by a network firewall such as IPCop for obvious reasons, but the same criticisms apply to a HIPS as to a Personal Firewall—ultimately, if the host it is running on is compromised, the accuracy of the Intrusion Prevention System is compromised also.
Recent developments in security include rootkit software, which is capable of providing a 'backdoor' into a host operating system using virtualization software (such as VMware) and hardware-based virtualization support (such as that in AMD and Intel's newest processors). Such software, like VMware and Virtual PC themselves, literally acts as a container (or hypervisor) for the OS running inside it, the consequence of which is that such backdoors literally exist outside the OS that installed them. In light of these concepts being demonstrated publicly, the role of host-based firewall and IPS software is redoubled—part of a security solution, but not a 'killer app'. Fundamentally, what we can take from this that is for sure is that different packages have different strengths, and we shouldn't ever rely on one in particular.
Although an important part of an overall stance on security, not all firewalls are created equal, and a personal firewall should never be considered to be a substitute for well-designed, well-maintained perimeter and segment firewalling as part of a network's overall security strategy.
'Packet filtering' is a term generally used to describe a firewall, acting at the network layer, which decides where data should go based on criteria from the data packet. Generally, this will include the source and destination ports and source and destination addresses—so, for instance, an organization may allow connections to its remote access server from a business partner's IP address range but not from the Internet in general. Other criteria may include the time of day at which the connection is made.
Although fast and historically effective, 'stateless' packet filters operate solely at the network layer and provide no inspection of data traveling through them at all—a stateless packet filter configured to allow traffic from the Internet to port 80 in an organization's DMZ will allow such traffic, irrespective of what the data going to port 80 is, and more importantly whether or not that data is actually part of an established connection.
A packet filter that is stateful understands the state of a TCP connection that is in progress through it. When a TCP Connection is set up a very specific process known as a 'three-way handshake' takes place between the source and the target hosts.
This is a very basic, simplistic explanation of stateful firewalling—it would be out of scope for this text to cover the entire topic of stateful firewalling (there are other resources such as http://en.wikipedia.org/wiki/Stateful_inspection that cover this), but a basic explanation of the topic is useful:
Firstly, the client in the connection issues a TCP SYN packet to the destination. For the firewall, this is considered a 'new' connection, and at this point the firewall will allocate memory to track the status of the connection as it progresses.
Secondly, the server—if the connection proceeds as expected—replies by sending back a packet with the correct sequence number, source, and destination ports, with both SYN and ACK flags set.
Thirdly, the client, upon receiving the SYN ACK packet, returns a third packet with solely the ACK packet set. Frequently, this packet will also contain some of the first bits of data pertaining to the connection in it. At this point, the firewall considers the connection to be 'established', and will allow data associated with this connection (that is to say, data to and from the source/destination addresses, going to and from the correct ports, with the correct sequence number) to freely pass through the firewall.
In the event that this is not completed, the firewall will forget about the details of the connection either after a specific time period or when the available memory to remember such connections is exhausted, depending upon how the firewall works. This added use of memory makes 'stateful' packet inspection more processor and memory intensive, although as it only inspects the header of our data, it is still not as processor or memory-intensive as a firewall that inspects data all of the way up to the application layer and so unpacks the payload of data packets traversing it also.
The principle advantage of a stateful firewall, however, stems from the understanding it has of 'established' connections. In a network with several clients with a non-stateful firewall that allows those clients to connect to external sites on port 80, any traffic with a destination port of 80 will be allowed out of the network, but more importantly, any host on the Internet will be able to bypass the firewall completely and connect to internal clients simply by sending their traffic from a source port of 80. Because responses from web servers will come from port 80, without the firewall checking to see if connections from outside the network from port 80 are responses to internal clients (i.e. without acting statefully), there is no way to prevent this.
A stateful firewall, however, will only allow data to traverse the firewall if it is part of an 'established' connection. Since there should be no payload allowed through for packets that are sent before the three-way handshake, this minimizes what an attacker could actually do to a target system without fully connecting to it in a way allowed by the firewall.
Although stateful packet firewalls can very effectively restrict where traffic can go to and from on a network, it cannot control what exactly that traffic is. The actual data inside data packets themselves exists at a higher level than packet firewalls, which as network-layer devices are unaware of the application layer.
As an example of this, consider a simple office network with a gateway that allows connections outbound to port 80 (HTTP) in order to allow clients on the network to browse the Internet. The network administrator has denied connections to all other ports such as 443 and 25, as the company policy dictates that staff should not be able to access external mail (via 25) or sites that require HTTPS login (as many of these are sites such as eBay and webmail sites, which the company does not want its staff to access). It uses a stateful firewall in order to prevent traffic coming into its network with a source port of 80, which might be used to attack, probe, or scan clients on its network.
This firewall, however, does not prevent staff from accessing other resources on port 80—one of the staff might, for instance, have set up a mail server listening on port 80 and be using this to read his or her mail. Another might have the SSH service or a VPN server running on a server outside the company or at home listening to port 80 and use this connection to 'tunnel' other traffic through in order to connect to services (such as mail, IRC, etc.) that the IT policy denies.
This is extremely hard to prevent unless the administrator has a firewall that understands the application layer, because only then can he or she restrict traffic based specifically on what sort of traffic it is. Such firewalls are often called 'proxy firewalls', because the way in which they function is frequently by proxying traffic—accepting the connection on behalf of the client, unpacking it and inspecting the data, and then forwarding it on to the destination if it is allowed by whatever access control the firewall has in place. As with stateful firewalls, an application-layer firewall or proxy server may restrict traffic based on destination, time, content, (in this case), and many other factors. Squid, the open-source proxy server that ships with IPCop, is very powerful in this respect, and has the ability to enforce powerful access control, particularly in conjunction with the Squidguard add-on.
Web proxy servers, debatably, are a frequently deployed application-layer firewall—although not often considered as such, many proxy servers have functionality that approximates that of a full-fledged application-layer firewall, and by blocking normal connections to port 80 and forcing connections to the Internet through a proxy server, organizations ensure that requests made to port 80 are HTTP, and no other protocol is allowed over that port. Unfortunately, many protocols (such as SSL on port 443) are very hard to proxy due to their use of cryptography, and for this reason these ports are frequently unprotected and therefore are good candidates for a malicious intruder (or errant employee) to use for nefarious purposes.
Consider border control as an object lesson—we restrict cross-border travel by using passports to verify whether someone is authorized to go to and from a source and destination country—this is analogous to stateless packet filtering, as passports are similar in nature to packet headers; they contain information about the bearer (or payload). We then use visas to verify the state of someone during their travel—that is to say, whether they are in the state of being at the end of their legitimate stay, having no legitimate reason to enter the country (even though by law they may be entitled to), and so on. The passport (and inspection of it) by itself does not restrict travel based on who someone is and what they are doing, as well as whether they are on a blacklist or not for security reasons. This is analogous to application-layer firewalling. Further, through passports and lists, governments inspect the people themselves who travel cross-border, and examine their bags (their payload) to verify whether it is legitimately carried (or contains contraband, such as explosives or munitions)—this could be compared both to application-layer firewalls and Intrusion Detection / Prevention Systems.
Proxy servers, then, can be a form of application-layer firewalling. A proxy server is, very simply, a device that accepts a request from one computer, and passes it to another. In passing the request along, a proxy server may also levy certain restrictions upon exactly what that request can be. Most importantly, however, as a proxy server understands the concept of a 'request', it provides security over and above simply allowing a client to connect to the destination server or service itself, as a proxy server will not allow just anything to traverse the firewall.
Consider our earlier example—the small network that wishes to allow clients to access the Internet, while preventing them from accessing certain resources (such as mail, online auction sites, games, etc.). The network administrator, deciding that the present firewalling strategy is inadequate, installs a proxy server, and configures the web browser for clients on the network (either by hand, or automatically using a script or a centralized configuration method such as Red Hat Directory server or Microsoft's Active Directory) to point to the proxy server for Internet access.
The network administrator then configures the firewall to drop all outbound connections from workstations on the network (allowing connections to the Internet from the proxy server). At this point, if anyone is using the gateway/firewall to connect to the Internet, such as a hypothetical employee connecting to an SSH server on port 80 for nefarious purposes, those connections will be dropped by the firewall (and possibly logged). From this point onwards, whenever an employee initiates a connection to a website using his or her web browser, the web browser does not do what it had done previously and attempt to connect to the website in question and retrieve content for the user. Instead, the web browser connects to the proxy server it has been configured with, and requests that the proxy server give it the webpage in question.
It is at this point that a proxy server enacting any form of access control would determine whether the user in question was allowed to access the requested resource it. Dan's Guardian is an example of a package for IPCop that allows the filtering of inappropriate websites.
Another advantage of proxy servers is that as they act as a chokepoint for the requests for content, they can check to see if a webpage has been requested already, and if it has, then give the client a local (cached) copy of the page, instead of retrieving another copy of the same content. Such proxy servers are referred to as caching web proxies. Microsoft's ISA server, and the Open Source package Squid are both examples of these.
Having established that there is no local copy of the content (if the proxy server is caching) and that the user is authorized to view the content (if there is access control in effect), the proxy server will attempt to retrieve the content itself, either from an upstream proxy server, or (more likely) from the Internet itself. The proxy server may return an error to the user if the destination site does not exist, or give an error returned from the remote site to the user.
Transparent proxies (which IPCop has support for), or 'intercepting proxies' (http://www.rfc.org.uk/cgi-bin/lookup.cgi?rfc=rfc3040)' perform this via NAT without the need for reconfiguration (and without the required participation of the client), taking advantage of chokepoints to impose network policy upon traffic.

In the example above, our transparent proxy server fetches www.google.com for a laptop client. Hypothetically, we allow access to most internet sites (such as Google) but block access to sites with keywords such as "pornography" or which are contained on a blacklist. In this situation, the proxy server accomplishes the goals of our IT Policy by providing content filtering. It also sanitizes the content to ensure that only valid HTTP traffic is allowed, and not connections for arbitrary applications (such as Skype or MSN), which our IT Policy disallows. If a second client now requests the same page, the proxy server can deliver the cached copy (eliminating step 3) significantly quicker than the first time around, delivering a better service for clients and reducing the load on the internet connection. The proxy server essentially does the 'heavy lifting' for the client itself.
In a firewalling role, the principle advantage of a proxy server, aside from the ability to more effectively restrict users from accessing certain resources, is the fact that it sanitizes, to a certain degree, data going into and out of the network. Since in order for traffic to go out of, or come into, the network it must conform to the standards pertaining to web pages, which a web proxy understands, 'out of band' or non-standard data is significantly harder to get into/out of the security perimeter.
Some packages, such as the open-source package Zorp and Microsoft's ISA server, will also proxy other protocols, such as RPC—this is a relatively new entrant to the firewalling world, and it is less common to see firewalls deployed with this sort of functionality outside enterprise networks.
Although in enterprise scenarios (such as the example of network topology listed earlier in this chapter) firewalls, routers, and proxy servers are generally separate devices, in smaller networks (and even some larger ones), roles are very frequently combined. Even in a large enterprise, in our branch office, it might not make economic sense to have three network infrastructure servers (firewall, router, proxy server) and three desktop infrastructure servers (fileserver, mail server, print server) if the office only has a staff of 50! By putting all of our network tasks on one host running something such as IPCop, and handling our desktop services off one server, we cut our equipment by 2/3, and possibly improve performance (since we can put those services on higher-specification machines). Our easier-to-manage environment requires less electricity, reduced air conditioning, and takes up less space.
DNS, the Domain Name System (http://www.dns.net/dnsrd/rfc/), is the system used across the Internet (and on private networks) to translate hostnames into IP addresses. As with previous topics, this is a very basic, simplistic explanation of what DNS does—this is designed to give a basic understanding of the topic, and not breed DNS experts. There have been many books written on the theory and practicalities of DNS (http://www.packtpub.com/DNS/book being one such example), and it is outside our scope to recreate them here.
In addition to a default gateway and/or proxy server for internet access, clients are assigned a DNS server, which allows them to look up an Internet Protocol address for any given DNS domain name. When a connection is made to another host, a network client will issue a lookup request to the first DNS server that it has been assigned, asking for an A record (unless it is connecting to a service such as SMTP, which uses its own specific record, in this instance MX, for configuration).
The DNS server returns to the client an IP address, or more than one IP address, which the client then uses to connect to the site via the default gateway or to issue a request to the proxy server for connectivity. In many instances there is one IP address defined as the A record for a website, which the client will connect to, but in some instances, typically for larger sites, there are several—in these instances, they will be returned in a random order by the responding DNS server each time they are requested, using this order to balance traffic across all of the IP addresses. This technique is known as "round-robin DNS", and a prime example of a site using this is Google.
Email uses MX records to indicate where email for a particular domain should go to. Each MX record listed for a domain will typically have its own 'preference number'—convention is that the lowest preference number is the most important mail server, so it is quite a frequent occurrence for a domain name to have two (or more) MX records set up, a primary (with a priority of, for instance, 10) for a main mail server, and a secondary (with a priority of, for instance, 50) pointing to a backup MX server in case the primary is down.
Using the dig or host commands on a Unix or Linux system (or a Windows system with the cygwin toolkit installed), or using the nslookup command in Windows (or Unix/Linux), we can retrieve the IP addresses listed for a given domain name and (with a recent version of the host command) the MX records for it, like so:
james@horus: ~ $ host google.com DNSIP address, retrievinggoogle.com has address 72.14.207.99 google.com has address 64.233.187.99 google.com mail is handled by 10 smtp2.google.com. google.com mail is handled by 10 smtp3.google.com. google.com mail is handled by 10 smtp4.google.com. google.com mail is handled by 10 smtp1.google.com. james@horus: ~ $
The dig command (which takes as input the type of record to retrieve as the first argument) can also be used to troubleshoot this, as follows:
james@horus: ~ $ dig mx google.com ; <<>> DiG 9.3.1 <<>> mx google.com ;; global options: printcmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 64387 ;; flags: qr rd ra; QUERY: 1, ANSWER: 4, AUTHORITY: 0, ADDITIONAL: 1 ;; QUESTION SECTION: ;google.com. IN MX ;; ANSWER SECTION: google.com. 118 IN MX 10 smtp3.google.com. google.com. 118 IN MX 10 smtp4.google.com. google.com. 118 IN MX 10 smtp1.google.com. google.com. 118 IN MX 10 smtp2.google.com. ;; ADDITIONAL SECTION: smtp3.google.com. 209 IN A 64.233.183.25 ;; Query time: 21 msec ;; SERVER: 10.1.1.6#53(10.1.1.6) ;; WHEN: Sun Nov 20 19:59:24 2005 ;; MSG SIZE rcvd: 132 james@horus: ~ $
As a perfect demonstration of round-robin DNS, we can see that the MX records were returned in a different order (2341, 3412) each time we queried for them, spreading out the load among them.
The nslookup command in Windows may be used as follows in interactive mode to look up MX records (or A records, which are the default, without setting an explicit record type) as follows:
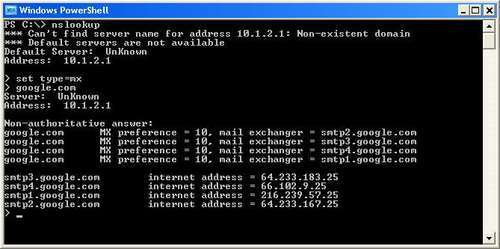
This knowledge can often be useful when troubleshooting firewall and networking problems, as DNS failure is one of many problems that can prevent connectivity (and is virtually the number one cause of malfunctions in misconfigured Active Directory environments). Knowledge of DNS (and how to look up DNS records manually) and knowing how to use the ping command are the first two tools in the IT Professional's toolkit for debugging connectivity issues. The ping command is often useful for troubleshooting connectivity, although frequently the layer-four protocol that ping uses, icmp, is firewalled either at the client side or at the destination (www.microsoft.com is an example of a website that drops ICMP packets), so the lack of a ping response cannot always be relied upon as a clear indicator of connectivity issues.
IPCop includes a DNS server, which, set up by default, acts as a resolving name server—that is to say, it will accept DNS requests from clients and resolve them externally, passing the results back to clients on the local network. As with a web proxy server, this can speed up requests when the resolving name server has a cached copy of the domain/IP correlation, which it can pass back to a client without the added milliseconds of resolving it fully. Clients can also be configured to make their own DNS queries through the firewall to an external DNS server, but this is inefficient, opens unnecessary ports through the firewall, and is generally not a recommended configuration.
DHCP, the Dynamic Host Configuration Protocol, is a descendant of BOOTP, an earlier protocol, and is used to configure hosts on a network automatically with network addresses and other configuration information, such as gateway and DNS server information. DHCP works using broadcast traffic—very simply, a client configured to use DHCP sends out a UDP packet with a DHCPDISCOVER message to the address 255.255.255.255 (a broadcast address, forwarded to every host in the same subnet) when it connects to a network, requesting a DHCP server.
Based on the client's request, a DHCP server on the network segment will send a DHCPOFFER request back, specifying an IP address it offers to the client. Generally speaking, a client will only be offered one IP address by one server (it's fairly rare for more than one DHCP server to be running on the same network segment), but in the event that there is more than one server, the client will pick one of the offered IP addresses. The client then returns a DHCPREQUEST message to the broadcast address, requesting the configuration it has picked. All things going well, the server returns a DHCPACK message to the client to confirm that it can have the assigned configuration information.
DHCP, in addition to an IP address, is also capable of assigning a variety of other configuration information, the most common few options being DNS servers, WINS servers, Gateway, Subnet Mask, NTP servers, and DNS Domain Name. IPCop includes a DHCP implementation configured by default to hand out the requisite information to use the IPCop server for internet access, and uses Dynamic DNS to populate the DNS server with hostnames sent out by DHCP requests, such that there are DNS entries set up for clients on the network when they request configuration via DHCP.
DHCP configuration (or static network configuration) can be viewed on a client device in Windows using the 'ipconfig /a' command or, in Unix/Linux, using the 'ifconfig -a' command. In Windows, the ipconfig command also allows the user to release and renew DHCP information.
In this chapter, we have covered topics like where the Internet came from, some of the design considerations that went into it, and why firewalls are important and fit into the grand scheme of things. We also took a look at basic networking, including how network layers are significant and what they do, some different types of firewall, and some other services firewalls may operate.
We should by this point have a relatively good understanding of the scope of the protocols and technology used in IPCop. We may also have identified some technologies that you hadn't heard of or didn't understand—don't worry, this is a good thing! If so inclined, there is plenty of scope to learn about these technologies based on the information summarized here and the links given to other resources.
