


















In this chapter, we will cover:
Creating a new project
Reading CSV data into Incanter datasets
Reading JSON data into Incanter datasets
Reading data from Excel with Incanter
Reading data from JDBC databases
Reading XML data into Incanter datasets
Scraping data from tables in web pages
Scraping textual data from web pages
Reading RDF data
Reading RDF data with SPARQL
Aggregating data from different formats
There's not a lot of data analysis that we can do without data, so the first step in any project is evaluating what data we have and what we need. And once we have some idea of what we'll need, we have to figure out how to get it.
Many of the recipes in this chapter and in this book use Incanter (http://incanter.org/) to import the data and target Incanter datasets. Incanter is a library for doing statistical analysis and graphics in Clojure, similar to R. Incanter may not be suitable for every task—later we'll use the Weka library for clustering and machine learning—but it is still an important part of our toolkit for doing data analysis in Clojure. This chapter has a collection of recipes for gathering data and making it accessible to Clojure. For the very first recipe, we'll look at how to start a new project. We'll start with very simple formats like comma-separated values (CSV) and move into reading data from relational databases using JDBC. Then we'll examine more complicated data sources, such as web scraping and linked data (RDF).
Over the course of this book, we're going to use a number of third-party libraries and external dependencies. We need a tool to download them and track them. We also need a tool to set up the environment and start a read-eval-print-loop ( REPL, or interactive interpreter), which can access our code, or to execute our program.
We'll use Leiningen for that (http://leiningen.org/). This has become a standard package automation and management system.
Visit the Leiningen site (http://leiningen.org/) and download the lein script. This will download the Leiningen JAR file. The instructions are clear, and it's a simple process.
To generate a new project, use the
lein new command, passing it the name of the project:
$ lein new getting-data Generating a project called getting-data based on the 'default' template. To see other templates (app, lein plugin, etc), try 'lein help new'.
Now, there will be a new subdirectory named getting-data. It will contain files with stubs for the
getting-data.core namespace and for tests.
Tip
Downloading the example code
You can download the example code files for all Packt books you have purchased from your account at http://www.packtpub.com. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
The new project directory also contains a file named project.clj. This file contains metadata about the project: its name, version, and license. It also contains a list of dependencies that our code will use. The specifications it uses allows it to search Maven repositories and directories of Clojure libraries (Clojars, https://clojars.org/) to download the project's dependencies.
(defproject getting-data "0.1.0-SNAPSHOT"
:description "FIXME: write description"
:url "http://example.com/FIXME"
:license {:name "Eclipse Public License"
:url "http://www.eclipse.org/legal/epl-v10.html"}
:dependencies [[org.clojure/clojure "1.4.0"]])In the Getting ready section of each recipe, we'll see what libraries we need to list in the :dependencies section of this file.
One of the simplest data formats is comma-separated values (CSV). And it's everywhere. Excel reads and writes CSV directly, as do most databases. And because it's really just plain text, it's easy to generate or access it using any programming language.
First, let's make sure we have the correct libraries loaded. The project file of Leiningen (https://github.com/technomancy/leiningen), the project.clj file, should contain these dependencies (although you may be able to use more up-to-date versions):
:dependencies [[org.clojure/clojure "1.4.0"]
[incanter/incanter-core "1.4.1"]
[incanter/incanter-io "1.4.1"]]Also, in your REPL or in your file, include these lines:
(use 'incanter.core
'incanter.io)Finally, I have a file named data/small-sample.csv that contains the following data:
Gomez,Addams,father Morticia,Addams,mother Pugsley,Addams,brother Wednesday,Addams,sister …
You can download this file from http://www.ericrochester.com/clj-data-analysis/data/small-sample.csv. There's a version with a header row at http://www.ericrochester.com/clj-data-analysis/data/small-sample-header.csv.
Use the
incanter.io/read-datasetfunction:user=> (read-dataset "data/small-sample.csv") [:col0 :col1 :col2] ["Gomez" "Addams" "father"] ["Morticia" "Addams" "mother"] ["Pugsley" "Addams" "brother"] ["Wednesday" "Addams" "sister"] …
If we have a header row in the CSV file, then we include
:header truein the call toread-dataset:user=> (read-dataset "data/small-sample-header.csv" :header true) [:given-name :surname :relation] ["Gomez" "Addams" "father"] ["Morticia" "Addams" "mother"] ["Pugsley" "Addams" "brother"]
Using Clojure and Incanter makes a lot of common tasks easy. This is a good example of that.
We've taken some external data, in this case from a CSV file, and loaded it into an Incanter dataset. In Incanter, a dataset is a table, similar to a sheet in a spreadsheet or a database table. Each column has one field of data, and each row has an observation of data. Some columns will contain string data (all of the columns in this example did), some will contain dates, some numeric data. Incanter tries to detect automatically when a column contains numeric data and coverts it to a Java int or double. Incanter takes away a lot of the pain of importing data.
If we don't want to involve Incanter—when you don't want the added dependency, for instance—data.csv is also simple (https://github.com/clojure/data.csv). We'll use this library in later chapters, for example, in the
recipe Lazily processing very large datasets of Chapter 2, Cleaning and Validating Data.
Chapter 6, Working with Incanter Datasets
Another data format that's becoming increasingly popular is JavaScript Object Notation (JSON, http://json.org/). Like CSV, this is a plain-text format, so it's easy for programs to work with. It provides more information about the data than CSV does, but at the cost of being more verbose. It also allows the data to be structured in more complicated ways, such as hierarchies or sequences of hierarchies.
Because JSON is a much fuller data model than CSV, we may need to transform the data. In that case, we can pull out just the information we're interested in and flatten the nested maps before we pass it to Incanter. In this recipe, however, we'll just work with fairly simple data structures.
First, include these dependencies in the Leiningen project.clj file:
:dependencies [[org.clojure/clojure "1.4.0"]
[incanter/incanter-core "1.4.1"]
[org.clojure/data.json "0.2.1"]]Use these libraries in our REPL interpreter or in our program:
(use 'incanter.core
'clojure.data.json)And have some data. For this, I have a file named data/small-sample.json that looks like the following:
[{"given_name": "Gomez",
"surname": "Addams",
"relation": "father"},
{"given_name": "Morticia",
"surname": "Addams",
"relation": "mother"}, …
]You can download this data file from http://www.ericrochester.com/clj-data-analysis/data/small-sample.json.
Once everything's in place, this is just a one-liner, which we can execute at the REPL interpreter:
user=> (to-dataset (read-json (slurp "data/small-sample.json"))) [:given_name :surname :relation] ["Gomez" "Addams" "father"] ["Morticia" "Addams" "mother"] ["Pugsley" "Addams" "brother"] …
Like all Lisps, Clojure is usually read from inside out, from right to left. Let's break it down. clojure.core/slurp reads in the contents of the file and returns it as a string. This is obviously a bad idea for very large files, but for small ones it's handy. clojure.data.json/read-json takes the data from slurp, parses it as JSON, and returns native Clojure data structures. In this case, it returns a vector of maps. maps.incanter.core/to-dataset takes a sequence of maps and returns an Incanter dataset. This will use the keys in the maps as column names and will convert the data values into a matrix. Actually, to-dataset can accept many different data structures. Try (doc to-dataset) in the REPL interpreter or see the Incanter documentation at http://data-sorcery.org/contents/ for more information.
We've seen how Incanter makes a lot of common data-processing tasks very simple; reading an Excel spreadsheet is another example of this.
First, make sure that our Leiningen project.clj file contains the right dependencies:
:dependencies [[org.clojure/clojure "1.4.0"]
[incanter/incanter-core "1.4.1"]
[incanter/incanter-excel "1.4.1"]]Also, make sure that we've loaded those packages into the REPL interpreter or script:
(use 'incanter.core
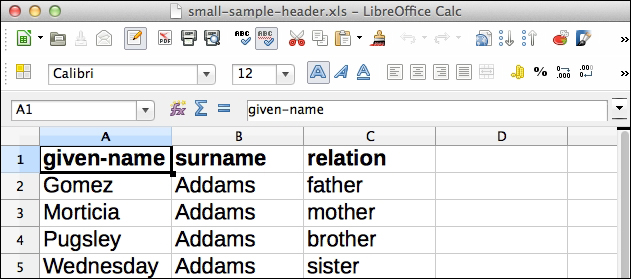
'incanter.excel)And find the Excel spreadsheet we want to work on. I've
named mine data/small-sample-header.xls. You can download this from http://www.ericrochester.com/clj-data-analysis/data/small-sample-header.xls.
Reading data from a relational database is only slightly more complicated than reading from Excel. And much of the extra complication is involved in connecting to the database.
Fortunately, there's a Clojure-contributed package that sits on top of JDBC and makes working with databases much easier. In this example, we'll load a table from an SQLite database (http://www.sqlite.org/).
First, list the dependencies in our Leiningen project.clj file. We also need to include the database driver library. For this example that's org.xerial/sqlite-jdbc.
:dependencies [[org.clojure/clojure "1.4.0"]
[incanter/incanter-core "1.4.1"]
[org.clojure/java.jdbc "0.2.3"]
[org.xerial/sqlite-jdbc "3.7.2"]]Then load the modules into our REPL interpreter or script file:
(use '[clojure.java.jdbc :exclude (resultset-seq)]
'incanter.core)Finally, get the database connection information. I have my data in a SQLite database file named data/small-sample.sqlite. You can download this from http://www.ericrochester.com/clj-data-analysis/data/small-sample.sqlite.

Loading the data is not complicated, but we'll make it even easier with a wrapper function.
Create a function that takes a database connection map and a table name and returns a dataset created from that table:
(defn load-table-data "This loads the data from a database table." [db table-name] (let [sql (str "SELECT * FROM " table-name ";")] (with-connection db (with-query-results rs [sql] (to-dataset (doall rs))))))Next, define a database map with the connection parameters suitable for our database:
(def db {:subprotocol "sqlite" :subname "data/small-sample.sqlite" :classname "org.sqlite.JDBC"})Finally, call
load-table-datawithdband a table name as a symbol or string:user=> (load-table-data db 'people) [:relation :surname :given_name] ["father" "Addams" "Gomez"] ["mother" "Addams" "Morticia"] ["brother" "Addams" "Pugsley"] …
The load-table-data function sets up a database connection using clojure.java.jdbc/with-connection. It creates a SQL
query that queries all the fields of the table passed in. It then retrieves the results using clojure.java.jdbc/with-query-results. Each result row is a sequence of maps of column names to values. This sequence is wrapped in a dataset by incanter.core/to-dataset.
Connecting to different database systems using JDBC isn't necessarily a difficult task, but it's very dependent on what database we wish to connect to. Oracle has a tutorial for working with JDBC at http://docs.oracle.com/javase/tutorial/jdbc/basics/, and the documentation for the clojure.java.jdbc library has some good information also (http://clojure.github.com/java.jdbc/). If you're trying to find out what the connection string looks like for a database system, there are lists online. This one, http://www.java2s.com/Tutorial/Java/0340__Database/AListofJDBCDriversconnectionstringdrivername.htm, includes the major drivers.
One of the most popular formats for data is XML. Some people love it, some hate it. But almost everyone has to deal with it at some point. Clojure can use Java's XML libraries, but it also has its own package, which provides a more natural way of working with XML in Clojure.
First, include these dependencies in our Leiningen project.clj file:
:dependencies [[org.clojure/clojure "1.4.0"]
[incanter/incanter-core "1.4.1"]]Use these libraries in our REPL interpreter or program:
(use 'incanter.core
'clojure.xml
'[clojure.zip :exclude [next replace remove]])And find a data file. I have a file named data/small-sample.xml that looks like the following:
<?xml version="1.0" encoding="utf-8"?>
<data>
<person>
<given-name>Gomez</given-name>
<surname>Addams</surname>
<relation>father</relation>
</person>
…You can download this data file from http://www.ericrochester.com/clj-data-analysis/data/small-sample.xml.
The solution for this recipe is a little more complicated, so we'll wrap it into a function:
(defn load-xml-data [xml-file first-data next-data] (let [data-map (fn [node] [(:tag node) (first (:content node))])] (->> ;; 1. Parse the XML data file; (parse xml-file) xml-zip ;; 2. Walk it to extract the data nodes; first-data (iterate next-data) (take-while #(not (nil? %))) (map children) ;; 3. Convert them into a sequence of maps; and (map #(mapcat data-map %)) (map #(apply array-map %)) ;; 4. Finally convert that into an Incanter dataset to-dataset)))Which we call in the following manner:
user=> (load-xml-data "data/small-sample.xml" down right) [:given-name :surname :relation] ["Gomez" "Addams" "father"] ["Morticia" "Addams" "mother"] ["Pugsley" "Addams" "brother"] …
This recipe follows a typical pipeline for working with XML:
It parses an XML data file.
It walks it to extract the data nodes.
It converts them into a sequence of maps representing the data.
And finally, it converts that into an Incanter dataset.
load-xml-data implements this process. It takes three parameters. The input file name, a function that takes the root node of the parsed XML and returns the first data node, and a function that takes a data node and returns the next data node or nil, if there are no more nodes.
First, the function parses the XML file and wraps it in a zipper (we'll discuss more about zippers in a later section). Then it uses the two functions passed in to extract all the data nodes as a sequence. For each data node, it gets its child nodes and converts them into a series of tag-name/content pairs. The pairs for each data node are converted into a map, and the sequence of maps is converted into an Incanter dataset.
We used a couple of interesting data structures or constructs in this recipe. Both are common in functional programming or Lisp, but neither has made their way into more mainstream programming. We should spend a minute with them.
The first thing that happens to the parsed XML file is it gets passed to clojure.zip/xml-zip. This takes Clojure's native XML data structure and turns it into something that can be navigated quickly using commands such as clojure.zip/down and clojure.zip/right. Being a functional programming language, Clojure prefers immutable data structures; and zippers provide an efficient, natural way to navigate and modify a tree-like structure, such as an XML document.
Zippers are very useful and interesting, and understanding them can help you understand how to work with immutable data structures. For more information on zippers, the Clojure-doc page for this is helpful (http://clojure-doc.org/articles/tutorials/parsing_xml_with_zippers.html). But if you rather like diving into the deep end, see Gerard Huet's paper, The Zipper (http://www.st.cs.uni-saarland.de/edu/seminare/2005/advanced-fp/docs/huet-zipper.pdf).
Also, we've used the ->> macro to express our process as a pipeline. For deeply nested function calls, this macro lets us read it from right to left, and this makes the process's data flow and series of transformations much more clear.
We can do this in Clojure because of its macro system. ->> simply rewrites the calls into Clojure's native, nested format, as the form is read. The first parameter to the macro is inserted into the next expression as the last parameter. That structure is inserted into the third expression as the last parameter and so on, until the end of the form. Let's trace this through a few steps. Say we start off with the (->> x first (map length) (apply +)) expression. The following is a list of each intermediate step that occurs as Clojure builds the final expression (the elements to be combined are highlighted at each stage):
(->> x first (map length) (apply +))(->> (first x) (map length) (apply +))(->> (map length (first x)) (apply +))(apply + (map length (first x)))
XML and JSON (from the Reading JSON data into Incanter datasets recipe) are very similar. Arguably, much of the popularity of JSON is driven by disillusionment with XML's verboseness.
When we're dealing with these formats in Clojure, the biggest difference is that JSON is converted directly to native Clojure data structures that mirror the data, such as maps and vectors. XML, meanwhile, is read into record types that reflect the structure of XML, not the structure of the data.
In other words, the keys of the maps for JSON will come from the domain, first_name or age, for instance. However, the keys of the maps for XML will come from the data format, tag, attribute, or children, say, and the tag and attribute names will come from the domain. This extra level of abstraction makes XML more unwieldy.
There's data everywhere on the Internet. Unfortunately, a lot of it is difficult to get to. It's buried in tables, or articles, or deeply nested div tags. Web scraping is brittle and laborious, but it's often the only way to free this data so we can use it in our analyses. This recipe describes how to load a web page and dig down into its contents so you can pull the data out.
To do this, we're going to use the Enlive library (https://github.com/cgrand/enlive/wiki). This uses a domain-specific language (DSL) based on CSS selectors for locating elements within a web page. This library can also be used for templating. In this case, we'll just use it to get data back out of a web page.
First we have to add Enlive to the dependencies of the project:
:dependencies [[org.clojure/clojure "1.4.0"]
[incanter/incanter-core "1.4.1"]
[enlive "1.0.1"]]Next, we use those packages in our REPL interpreter or script:
(require '(clojure [string :as string])) (require '(net.cgrand [enlive-html :as html])) (use 'incanter.core) (import [java.net URL])
Finally, identify the file to scrape the data from. I've put up a file at http://www.ericrochester.com/clj-data-analysis/data/small-sample-table.html, which looks like the following:

It's intentionally stripped down, and it makes use of tables for layout (hence the comment about 1999).
Since this task is a little complicated, let's pull the steps out into several functions:
(defn to-keyword "This takes a string and returns a normalized keyword." [input] (-> input string/lower-case (string/replace \space \-) keyword)) (defn load-data "This loads the data from a table at a URL." [url] (let [html (html/html-resource (URL. url)) table (html/select html [:table#data]) headers (->> (html/select table [:tr :th]) (map html/text) (map to-keyword) vec) rows (->> (html/select table [:tr]) (map #(html/select % [:td])) (map #(map html/text %)) (filter seq))] (dataset headers rows)))Now, call
load-datawith the URL you want to load data from:user=> (load-data (str "http://www.ericrochester.com/" #_=> "clj-data-analysis/data/small-sample-table.html ")) [:given-name :surname :relation] ["Gomez" "Addams" "father"] ["Morticia" "Addams" "mother"] ["Pugsley" "Addams" "brother"] ["Wednesday" "Addams" "sister"] …
The let bindings in load-data tell the story here. Let's take them one by one.
The first binding has Enlive download the resource and parse it into its internal representation:
(let [html (html/html-resource (URL. url))
The next binding selects the table with the ID data:
table (html/select html [:table#data])
Now, we select all header cells from the table, extract the text from them, convert each to a keyword, and then the whole sequence into a vector. This gives us our headers for the dataset:
headers (->>
(html/select table [:tr :th])
(map html/text)
(map to-keyword)
vec)We first select each row individually. The next two steps are wrapped in map so that the cells in each row stay grouped together. In those steps, we select the data cells in each row and extract the text from each. And lastly, we filter using seq, which removes any rows with no data, such as the header row:
rows (->> (html/select table [:tr])
(map #(html/select % [:td]))
(map #(map html/text %))
(filter seq))]Here is another view of this data. In the following screenshot, we can see some of the code from this web page. The variable names and the select expressions are placed beside the HTML structures that they match. Hopefully, this makes it more clear how the select expressions correspond to the HTML elements.

Finally, we convert everything to a dataset. incanter.core/dataset is a lower-level constructor than incanter.core/to-dataset. It requires us to pass in the column names and data matrix as separate sequences:
(dataset headers rows)))
It's important to realize that the code, as presented here, is the result of a lot of trial and error. Screen scraping usually is. Generally I download the page and save it, so I don't have to keep requesting it from the web server. Then I start REPL and parse the web page there. Then, I can look at the web page and HTML with the browser's "view source" functionality, and I can examine the data from the web page interactively in the REPL interpreter. While working, I copy and paste the code back and forth between the REPL interpreter and my text editor, as it's convenient. This workflow and environment makes screen scraping—a fiddly, difficult task even when all goes well—almost enjoyable.
Not all of the data in the web are in tables. In general, the process to access this non-tabular data may be more complicated, depending on how the page is structured.
First, we'll use the same dependencies and require statements as we did in the last recipe.
Next, we'll identify the file to scrape the data from. I've put up a file at http://www.ericrochester.com/clj-data-analysis/data/small-sample-list.html.
This is a much more modern example of a web page. Instead of using tables, it marks up the text with the section and article tags and other features of HTML5.

Since this is more complicated, we'll break the task down into a set of smaller functions.
(defn get-family "This takes an article element and returns the family name." ([article] (string/join (map html/text (html/select article [:header :h2]))))) (defn get-person "This takes a list item and returns a map of the persons' name and relationship." ([li] (let [[{pnames :content} rel] (:content li)] {:name (apply str pnames) :relationship (string/trim rel)}))) (defn get-rows "This takes an article and returns the person mappings, with the family name added." ([article] (let [family (get-family article)] (map #(assoc % :family family) (map get-person (html/select article [:ul :li])))))) (defn load-data "This downloads the HTML page and pulls the data out of it." [html-url] (let [html (html/html-resource (URL. html-url)) articles (html/select html [:article])] (to-dataset (mapcat get-rows articles))))Now that those are defined, we just call
load-datawith the URL that we want to scrape.user=> (load-data (str "http://www.ericrochester.com/" #_=> "clj-data-analysis/data/small-sample-list.html ") [:family :name :relationship] ["Addam's Family" "Gomez Addams" "— father"] ["Addam's Family" "Morticia Addams" "— mother"] ["Addam's Family" "Pugsley Addams" "— brother"] ["Addam's Family" "Wednesday Addams" "— sister"] …
After examining the web page, we find that each family is wrapped in an article tag that contains a header with an h2 tag. get-family pulls that tag out and returns its text.
get-person processes each person. The people in each family are in an unordered list (ul) and each person is in an li tag. The person's name itself is in an em tag. The let gets the contents of the li tag and decomposes it in order to pull out the name and relationship strings. get-person puts both pieces of information into a map and returns it.
get-rows processes each article tag. It calls get-family to get that information from the header, gets the list item for each person, calls get-person on that list item, and adds the family to each person's mapping.
Here's how the HTML structures correspond to the functions that process them. Each function name is beside the element it parses:

Finally, load-data ties the process together by downloading and parsing the HTML file and pulling the article tags from it. It then calls get-rows to create the data mappings, and converts the output to a dataset.
More and more data is going up on the Internet using linked data in a variety of formats: microformats, RDFa, and RDF/XML are a few common ones. Linked data adds a lot of flexibility and power, but it also introduces more complexity. Often, to work effectively with linked data, we'll need to start a triple store of some kind. In this recipe and the next three, we'll use Sesame (http://www.openrdf.org/) and the kr Clojure library (https://github.com/drlivingston/kr).
First, we need to make sure the dependencies are listed in our project.clj file:
:dependencies [[org.clojure/clojure "1.4.0"]
[incanter/incanter-core "1.4.1"]
[edu.ucdenver.ccp/kr-sesame-core "1.4.5"]
[org.clojure/tools.logging "0.2.4"]
[org.slf4j/slf4j-simple "1.7.2"]]And we'll execute this to have these loaded into our script or REPL:
(use 'incanter.core
'edu.ucdenver.ccp.kr.kb
'edu.ucdenver.ccp.kr.rdf
'edu.ucdenver.ccp.kr.sparql
'edu.ucdenver.ccp.kr.sesame.kb
'clojure.set)
(import [java.io File])For this example, we'll get data from the Telegraphis Linked Data assets. We'll pull down the database of currencies at http://telegraphis.net/data/currencies/currencies.ttl. Just to be safe, I've downloaded that file and saved it as data/currencies.ttl, and we'll access it from there.
The longest part of this process will be defining the data. The libraries we're using do all the heavy lifting.
First, we will create the triple store and register the namespaces that the data uses. We'll bind that triple store to the name
tstore.(defn kb-memstore "This creates a Sesame triple store in memory." [] (kb :sesame-mem)) (def tele-ont "http://telegraphis.net/ontology/") (defn init-kb "This creates an in-memory knowledge base and initializes it with a default set of namespaces." [kb-store] (register-namespaces kb-store '(("geographis" (str tele-ont "geography/geography#")) ("code" (str tele-ont "measurement/code#")) ("money" (str tele-ont "money/money#")) ("owl" "http://www.w3.org/2002/07/owl#") ("rdf" (str "http://www.w3.org/" "1999/02/22-rdf-syntax-ns#")) ("xsd" "http://www.w3.org/2001/XMLSchema#") ("currency" (str "http://telegraphis.net/" "data/currencies/")) ("dbpedia" "http://dbpedia.org/resource/") ("dbpedia-ont" "http://dbpedia.org/ontology/") ("dbpedia-prop" "http://dbpedia.org/property/") ("err" "http://ericrochester.com/")))) (def tstore (init-kb (kb-memstore)))After looking at some more data, we can identify what data we want to pull out and start to formulate a query. We'll use kr's query DSL and bind it to the name
q:(def q '((?/c rdf/type money/Currency) (?/c money/name ?/full_name) (?/c money/shortName ?/name) (?/c money/symbol ?/symbol) (?/c money/minorName ?/minor_name) (?/c money/minorExponent ?/minor_exp) (?/c money/isoAlpha ?/iso) (?/c money/currencyOf ?/country)))Now we need a function that takes a result map and converts the variable names in the query into column names in the output dataset. The
header-keywordandfix-headersfunctions will do that:(defn header-keyword "This converts a query symbol to a keyword." [header-symbol] (keyword (.replace (name header-symbol) \_ \-))) (defn fix-headers "This changes all the keys in the map to make them valid header keywords." [coll] (into {} (map (fn [[k v]] [(header-keyword k) v]) coll)))As usual, once all the pieces are in place, the function that ties everything together is short:
(defn load-data [k rdf-file q] (load-rdf-file k rdf-file) (to-dataset (map fix-headers (query k q))))
And using this function is just as simple:
user=> (load-data t-store (File. "data/currencies.xml") q) [:symbol :country :name :minor-exp :iso :minor-name :fullname] ["إ.د" http://telegraphis.net/data/countries/AE#AE "dirham" "2" "AED" "fils" "United Arab Emirates dirham"] ["؋" http://telegraphis.net/data/countries/AF#AF "afghani" "2" "AFN" "pul" "Afghan afghani"] …
First, some background: Resource Description Format (RDF) isn't an XML format, although it's often written using XML (there are other formats as well, such as N3 and Turtle). RDF sees the world as a set of statements. Each statement has at least three parts (a triple): the subject, the predicate, and the object. The subject and the predicate have to be URIs. (URIs are like URLs, only more general. uri:7890 is a valid URI, for instance.) Objects can be a literal or a URI. The URIs form a graph. They link to each other and make statements about each other. This is where the linked-in linked data comes from.
If you want more information about linked data, http://linkeddata.org/guides-and-tutorials has some good recommendations.
Now about our recipe: From a high level, the process we used here is pretty simple:
Create the triple store (
kb-memstoreandinit-kb).Load the data (
load-data).Query it to pull out only what we want (
qandload-data).Transform it into a format Incanter can ingest easily (
rekeyandcol-map).Create the Incanter dataset (
load-data).
The newest thing here is the query format. kb uses a nice SPARQL-like DSL to express the queries. In fact, it's so easy to use that we'll deal with it instead of working with raw RDF. The items starting with ?/ are variables; these will be used as keys for the result maps. The other items look like rdf-namespace/value. The namespace is taken from the registered namespaces defined in init-kb. These are different from Clojure's namespaces, although they serve a similar function for your data: to partition and provide context.
For the previous recipe, the embedded domain-specific language (EDSL) used for the query gets converted to SPARQL, the query language for many linked data systems. If you squint just right at the query, it looks kind of like a
SPARQL WHERE clause. It's a simple query, but one nevertheless.
And this worked great when we had access to the raw data in our own triple store. However, if we need to access a remote SPARQL end-point directly, it's more complicated.
For this recipe, we'll query DBPedia (http://dbpedia.org) for information about the United Arab Emirates' currency, the dirham. DBPedia extracts structured information from Wikipedia (the summary boxes) and re-publishes it as RDF. Just as Wikipedia is a useful first-stop for humans to get information about something, DBPedia is a good starting point for computer programs gathering data about a domain.
First, we need to make sure the dependencies are listed in our project.clj file:
:dependencies [[org.clojure/clojure "1.4.0"]
[incanter/incanter-core "1.4.1"]
[edu.ucdenver.ccp/kr-sesame-core "1.4.5"]
[org.clojure/tools.logging "0.2.4"]
[org.slf4j/slf4j-simple "1.7.2"]]Then, load the Clojure and Java libraries that we'll use.
(require '(clojure.java [io :as io]))
(require '(clojure [xml :as xml]
[pprint :as pp]
[zip :as zip]))
(use 'incanter.core
'[clojure.set :only (rename-keys)]
'edu.ucdenver.ccp.kr.kb
'edu.ucdenver.ccp.kr.rdf
'edu.ucdenver.ccp.kr.sparql
'edu.ucdenver.ccp.kr.sesame.kb)
(import [java.io File]
[java.net URL URLEncoder]) As we work through this, we'll define a series of functions. Finally, we'll create one function, load-data, to orchestrate everything, and we'll finish by calling it.
We have to create a Sesame triple store and initialize it with the namespaces that we'll use. For both of these we'll use the
kb-memstoreandinit-kbfunctions that we discussed in the previous recipe. We define a function that takes a URI for a subject in the triple store and constructs a SPARQL query that returns at most 200 statements about that. It filters out any statements with non-English strings for objects, but it allows everything else through:(defn make-query "This creates a query that returns all the triples related to a subject URI. It does filter out non-English strings." ([subject kb] (binding [*kb* kb *select-limit* 200] (sparql-select-query (list '(~subject ?/p ?/o) '(:or (:not (:isLiteral ?/o)) (!= (:datatype ?/o) rdf/langString) (= (:lang ?/o) ["en"])))))))Now that we have the query, we'll need to encode it into a URL to retrieve the results:
(defn make-query-uri "This constructs a URI for the query." ([base-uri query] (URL. (str base-uri "?format=" (URLEncoder/encode "text/xml") "&query=" (URLEncoder/encode query)))))Once we get a result, we'll parse the XML file, wrap it in a zipper, and navigate to the first result. All this will be in a function that we'll write in a minute. Right now, the next function will take that first result node and return a list of all of the results:
(defn result-seq "This takes the first result and returns a sequence of this node, plus all the nodes to the right of it." ([first-result] (cons (zip/node first-result) (zip/rights first-result))))The following set of functions takes each result node and returns a key-value pair (
result-to-kv). It usesbinding-strto pull the results out of the XML file. Thenaccum-hashfunction pushes those key-value pairs into a map. Keys that occur more than once have their values accumulated in a vector.(defn binding-str "This takes a binding, pulls out the first tag's content, and concatenates it into a string." ([b] (apply str (:content (first (:content b)))))) (defn result-to-kv "This takes a result node and creates a key-value vector pair from it." ([r] (let [[p o] (:content r)] [(binding-str p) (binding-str o)]))) (defn accum-hash "This takes a map and key-value vector pair and adds the pair to the map. If the key is already in the map, the current value is converted to a vector and the new value is added to it." ([m [k v]] (if-let [current (m k)] (assoc m k (conj current v)) (assoc m k [v]))))For the last utility function, we'll define
rekey. This will convert the keys of a map based on another map:(defn rekey "This just flips the arguments for clojure.set/rename-keys to make it more convenient." ([k-map map] (rename-keys (select-keys map (keys k-map)) k-map)))Now, let's add a function that takes a SPARQL endpoint and a subject, and returns a sequence of result nodes. This will use several of the functions we've just defined.
(defn query-sparql-results "This queries a SPARQL endpoint and returns a sequence of result nodes." ([sparql-uri subject kb] (->> kb ;; Build the URI query string. (make-query subject) (make-query-uri sparql-uri) ;; Get the results, parse the XML, ;; and return the zipper. io/input-stream xml/parse zip/xml-zip ;; Find the first child. zip/down zip/right zip/down ;; Convert all children into a sequence. result-seq)))Finally, we can pull everything together. Here's
load-data:(defn load-data "This loads the data about a currency for the given URI." [sparql-uri subject col-map] (->> ;; Initialize the triple store. (kb-memstore) init-kb ;; Get the results. (query-sparql-results sparql-uri subject) ;; Generate a mapping. (map result-to-kv) (reduce accum-hash {}) ;; Translate the keys in the map. (rekey col-map) ;; And create a dataset. to-dataset))Now let's use it. We can define a set of variables to make it easier to reference the namespaces that we'll use. We'll use them to create a mapping to column names:
(def rdfs "http://www.w3.org/2000/01/rdf-schema#") (def dbpedia "http://dbpedia.org/resource/") (def dbpedia-ont "http://dbpedia.org/ontology/") (def dbpedia-prop "http://dbpedia.org/property/") (def col-map {(str rdfs 'label) :name, (str dbpedia-prop 'usingCountries) :country (str dbpedia-prop 'peggedWith) :pegged-with (str dbpedia-prop 'symbol) :symbol (str dbpedia-prop 'usedBanknotes) :used-banknotes (str dbpedia-prop 'usedCoins) :used-coins (str dbpedia-prop 'inflationRate) :inflation})We call
load-datawith the DBPedia SPARQL endpoint, the resource we want information about (as a symbol), and the column map:user=> (load-data "http://dbpedia.org/sparql" #_=> (symbol (str dbpedia "/United_Arab_Emirates_dirham")) #_=> col-map) [:used-coins :symbol :pegged-with :country :inflation :name :used-banknotes] ["2550" "إ.د" "U.S. dollar = 3.6725 dirhams" "United Arab Emirates" "14" "United Arab Emirates dirham" "9223372036854775807"]
The only part of this recipe that has to do with SPARQL, really, is the function make-query. It uses the function sparql-select-query to generate a SPARQL query string from the query pattern. This pattern has to be interpreted in the context of the triple store that has the namespaces defined. This context is set using the binding command. We can see how this function works by calling it from the REPL by itself:
user=> (println
#_=> (make-query
#_=> (symbol (str dbpedia "/United_Arab_Emirates_dirham"))
#_=> (init-kb (kb-memstore))))
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
SELECT ?p ?o
WHERE { <http://dbpedia.org/resource/United_Arab_Emirates_dirham> ?p ?o .
FILTER ( ( ! isLiteral(?o)
|| ( datatype(?o) != <http://www.w3.org/1999/02/22-rdf-syntax-ns#langString> )
|| ( lang(?o) = "en" ) )
)
} LIMIT 200The rest of the recipe is concerned with parsing the XML format of the results, and in many ways it's similar to the last recipe.
Being able to aggregate data from many linked data sources is nice, but most data isn't already formatted for the semantic web. Fortunately, linked data's flexible and dynamic data model facilitates integrating data from multiple sources.
For this recipe, we'll combine several previous ones. We'll load currency data from RDF, as we did in the Reading RDF data recipe, and we'll scrape exchange rate data from X-Rates (http://www.x-rates.com) to get information out of a table, just as we did in the Scraping data from tables in web pages recipe. Finally, we'll dump everything into a triple store and pull it back out, as we did in the last recipe.
First, make sure your project.clj file has the right dependencies:
:dependencies [[org.clojure/clojure "1.4.0"]
[incanter/incanter-core "1.4.1"]
[enlive "1.0.1"]
[edu.ucdenver.ccp/kr-sesame-core "1.4.5"]
[org.clojure/tools.logging "0.2.4"]
[org.slf4j/slf4j-simple "1.7.2"]
[clj-time "0.4.4"]]And we need to declare that we'll use these libraries in our script or REPL:
(require '(clojure.java [io :as io]))
(require '(clojure [xml :as xml]
[string :as string]
[zip :as zip]))
(require '(net.cgrand [enlive-html :as html])
(use 'incanter.core
'clj-time.coerce
'[clj-time.format :only (formatter formatters parse unparse)]
'edu.ucdenver.ccp.kr.kb
'edu.ucdenver.ccp.kr.rdf
'edu.ucdenver.ccp.kr.sparql
'edu.ucdenver.ccp.kr.sesame.kb)
(import [java.io File]
[java.net URL URLEncoder])Finally, make sure
that you have the file, data/currencies.ttl, which we've been using since the Reading RDF data recipe.
Since this is a longer recipe, we'll build it up in segments. At the end, we'll tie everything together.
To begin with, we'll create the triple store. This has become pretty standard. In fact, we'll use the same version of kb-memstore and init-kb that we've been using from the Reading RDF data recipe.
This is where things get interesting. We'll pull out the timestamp. The first function finds it. The second function normalizes it into a standard format:
(defn find-time-stamp ([module-content] (second (map html/text (html/select module-content [:span.ratesTimestamp]))))) (def time-stamp-format (formatter "MMM dd, yyyy HH:mm 'UTC'")) (defn normalize-date ([date-time] (unparse (formatters :date-time) (parse time-stamp-format date-time))))We'll drill down to get the countries and their exchange rates:
(defn find-data ([module-content] (html/select module-content [:table.tablesorter.ratesTable :tbody :tr]))) (defn td->code ([td] (let [code (-> td (html/select [:a]) first :attrs :href (string/split #"=") last)] (symbol "currency" (str code "#" code))))) (defn get-td-a ([td] (->> td :content (mapcat :content) string/join read-string))) (defn get-data ([row] (let [[td-header td-to td-from] (filter map? (:content row))] {:currency (td->code td-to) :exchange-to (get-td-a td-to) :exchange-from (get-td-a td-from)})))This function takes the data extracted from the HTML page and generates a list of RDF triples:
(defn data->statements ([time-stamp data] (let [{:keys [currency exchange-to]} data] (list [currency 'err/exchangeRate exchange-to] [currency 'err/exchangeWith 'currency/USD#USD] [currency 'err/exchangeRateDate [time-stamp 'xsd/dateTime]]))))And this function ties those two groups of functions together by pulling the data out of the web page, converting it to triples, and adding them to the database:
(defn load-exchange-data "This downloads the HTML page and pulls the data out of it." [kb html-url] (let [html (html/html-resource html-url) div (html/select html [:div.moduleContent]) time-stamp (normalize-date (find-time-stamp div))] (add-statements kb (mapcat (partial data->statements time-stamp) (map get-data (find-data div))))))
That's a mouthful, but now that we can get all the data into a triple store, we just need to pull everything back out and into Incanter.
Bringing the two data sources together and exporting it to Incanter is fairly easy at this point:
(defn aggregate-data "This controls the process and returns the aggregated data." [kb data-file data-url q col-map] (load-rdf-file kb (File. data-file)) (load-exchange-data kb (URL. data-url)) (to-dataset (map (partial rekey col-map) (query kb q))))
We'll need to do a lot of the setup we've done before. Here we'll bind the triple store, the query, and the column map to names, so that we can refer to them easily:
(def t-store (init-kb (kb-memstore)))
(def q
'((?/c rdf/type money/Currency)
(?/c money/name ?/name)
(?/c money/shortName ?/shortName)
(?/c money/isoAlpha ?/iso)
(?/c money/minorName ?/minorName)
(?/c money/minorExponent ?/minorExponent)
(:optional
((?/c err/exchangeRate ?/exchangeRate)
(?/c err/exchangeWith ?/exchangeWith)
(?/c err/exchangeRateDate ?/exchangeRateDate)))))
(def col-map {'?/name :fullname
'?/iso :iso
'?/shortName :name
'?/minorName :minor-name
'?/minorExponent :minor-exp
'?/exchangeRate :exchange-rate
'?/exchangeWith :exchange-with
'?/exchangeRateDate :exchange-date})The specific URL that we're going to scrape is http://www.x-rates.com/table/?from=USD&amount=1.00. Let's go ahead and put everything together:
user=> (aggregate-data t-store "data/currencies.ttl" #_=> "http://www.x-rates.com/table/?from=USD&amount=1.00" #_=> q col-map) [:exchange-date :name :exchange-with :minor-exp :iso :exchange-rate :minor-name :fullname] [#<XMLGregorianCalendarImpl 2012-10-03T10:35:00.000Z> "dirham" currency/USD#USD "2" "AED" 3.672981 "fils" "United Arab Emirates dirham"] [nil "afghani" nil "2" "AFN" nil "pul" "Afghan afghani"] [nil "lek" nil "2" "ALL" nil "qindarkë" "Albanian lek"] [nil "dram" nil "0" "AMD" nil "luma" "Armenian dram"] …
As you can see, some of the data from currencies.ttl doesn't have exchange data (the ones that start with nil). We can look in other sources for that, or decide that some of those currencies don't matter for our project.
A lot of this is just a slightly more complicated version of what we've seen before, pulled together into one recipe. The complicated part is scraping the web page, and that's driven by the structure of the page itself.
After looking at the source of the page and playing with it on the REPL the page's structure was clear. First, we needed to pull the timestamp off the top of the table that lists the exchange rates. Then we walked over the table and pulled the data from each row. Both data tables (the short one and the long one) are in a div tag with a class moduleContent, so everything began there.
Next, we drilled down from the module content into the rows of the rates table. Inside each row, we pulled out the currency code and returned it as a symbol in the currency namespace. We also drilled down to the exchange rates and returned them as floats. Then we put everything into a map and converted that to triple vectors, which we added to the triple store.
If you have questions about how we pulled in the main currency data and worked with the triple store, refer to the Reading RDF data recipe.
If you have questions about how we scraped the data from the web page, refer to the Scraping data from tables in web pages recipe.
If you have questions about the SPARQL query, refer to the Reading RDF data with SPARQL recipe.