


















 Download code from GitHub
Download code from GitHub
Nowadays, it seems like everyone is talking about the term big data. However, a majority of them are not sure what it is and how they will make the most out of it. Apart from a few companies, most of them are still confused about the concept and are not ready to adopt the idea. Even when we hear the term big data, so many questions come to our minds. It is very important to understand these concepts. These questions include:
- What is big data?
- Why is there so much hype about it?
- Does it just mean huge volumes of data or is there something else to it?
- Does big data have any characteristics and what are these?
- Why do we need big data architects and what are the design considerations we have to consider to architect any big data solutions?
In this chapter, we will focus on answering these questions and building a strong foundation toward understanding the world of big data world. Mainly, we will be covering the following topics:
- Big data
- The characteristics of big data
- The different design considerations to big data solutions
- The key terminology used in the world of big data
Let's now start with the first and the most important question: what is big data?
What is big data?
If we take a simpler definition, it can basically be stated as a huge volume of data that cannot be stored and processed using the traditional approach. As this data may contain valuable information, it needs to be processed in a short span of time. This valuable information can be used to make predictive analyses, as well as for marketing and many other purposes. If we use the traditional approach, we will not be able to accomplish this task within the given time frame, as the storage and processing capacity would not be sufficient for these types of tasks.
That was a simpler definition in order to understand the concept of big data. The more precise version is as follows:
Data that is massive in volume, with respect to the processing system, with a variety of structured and unstructured data containing different data patterns to be analyzed.
From traffic patterns and music downloads, to web history and medical records, data is recorded, stored, and analyzed to enable technology and services to produce the meaningful output that the world relies on every day. If we just keep holding on to the data without processing it, or if we don't store the data, considering it of no value, this may be to the company's disadvantage.
Have you ever considered how YouTube is suggesting to you the videos that you are most likely to watch? How Google is serving you localized ads, specifically targeted to you as ones that you are going to open, or of the product you are looking for? These companies are keeping all of the activities you do on their website and utilizing them for an overall better user experience, as well as for their benefit, to generate revenue. There are many examples available of this type of behavior and it is increasing as more and more companies are realizing the power of data. This raises a challenge for technology researchers: coming up with more robust and efficient solutions that can cater to new challenges and requirements.
Now, as we have some understanding of what big data is, we will move ahead and discuss its different characteristics.
Characteristics of big data
These are also known as the dimensions of big data. In 2001, Doug Laney first presented what became known as the three Vs of big data to describe some of the characteristics that make big data different from other data processing. These three Vs are volume, velocity, and variety. This the era of technological advancement and loads of research is going on. As a result of this reaches and advancements, these three Vs have become the six Vs of big data as of now. It may also increase in future. As of now, the six Vs of big data are volume, velocity, variety, veracity, variability, and value, as illustrated in the following diagram. These characteristics will be discussed in detailed later in the chapter:

Different computer memory sizes are listed in the following table to give you an idea of the conversions between different units. It will let you understand the size of the data in upcoming examples in this book:
|
1 Bit |
Binary digit |
|
8 Bits |
1 byte |
|
1,024 Bytes |
1 KB (kilobyte) |
|
1,024 KB |
1 MB (megabyte) |
|
1,024 MB |
1 GB (gigabyte) |
|
1,024 GB |
1 TB (terabyte) |
|
1,024 TB |
1 PB (petabyte) |
|
1,024 PB |
1 EB (exabyte) |
|
1,024 EB |
1 ZB (zettabyte) |
|
1,024 ZB |
1 YB (yottabyte) |
|
1,024 YB |
1 brontobyte |
|
1,024 brontobyte |
1 geopbyte |
Now that we have established our basis for subsequent discussions, let's move on to discuss the first characteristics of big data.
Volume
In earlier years, company data only referred to the data created by their employees. Now, as the use of technology increases, it is not only data created by employees but also the data generated by machines used by the companies and their customers. Additionally, with the evolution of social media and other internet resources, people are posting and uploading so much content, videos, photos, tweets, and so on. Just imagine; the world's population is 7 billion, and almost 6 billion of them have cell phones. A cell phone itself contains many sensors, such as a gyro-meter, which generates data for each event, which is now being collected and analyzed.
When we talk about volume in a big data context, it is an amount of data that is massive with respect to the processing system that cannot be gathered, stored, and processed using traditional approaches. It is data at rest that is already collected and streaming data that is continuously being generated.
Take the example of Facebook. They have 2 billion active users who are continuously using this social networking site to share their statuses, photos, videos, commenting on each other's posts, likes, dislikes, and many more activities. As per the statistics provided by Facebook, a daily 600 TB of data is being ingested into the database of Facebook. The following graph represents the data that was there in previous years, the current situation and where it is headed in future:

Take another example of a jet airplane. One statistic shows that it generates 10 TB of data for every hour of flight time. Now imagine, with thousands of flights each day, how the amount of data generated may reach many petabytes every day.
In the last two years, the amount of data generated is equal to 90% of the data ever created. The world's data is doubling every 1.2 years. One survey states that 40 zettabytes of data will be created by 2020.
Not so long ago, the generation of such massive amount of data was considered to be a problem as the storage cost was very high. But now, as the storage cost is decreasing, it is no longer a problem. Also, solutions such as Hadoop and different algorithms that help in ingesting and processing this massive amount of data make it even appear resourceful.
The second characteristic of big data is velocity. Let's find out what this is.
Velocity
Velocity is the rate at which the data is being generated, or how fast the data is coming in. In simpler words, we can call it data in motion. Imagine the amount of data Facebook, YouTube, or any social networking site is receiving per day. They have to store it, process it, and somehow later be able to retrieve it. Here are a few examples of how quickly data is increasing:
- The New York stock exchange captures 1 TB of data during each trading session.
- 120 hours of videos are being uploaded to YouTube every minute.
- Data generated by modern cars; they have almost 100 sensors to monitor each item from fuel and tire pressure to surrounding obstacles.
- 200 million emails are sent every minute.
If we take the example of social media trends, more data means more revealing information about groups of people in different territories:
The preceding chart shows the amount of time users are spending on the popular social networking websites. Imagine the frequency of data being generated based on these user activities. This is just a glimpse of what's happening out there.
Another dimension of velocity is the period of time during which data will make sense and be valuable. Will it age and lose value over time, or will it be permanently valuable? This analysis is also very important because if the data ages and loses value over time, then maybe over time it will mislead you.
Till now, we have discussed two characteristics of big data. The third one is variety. Let's explore it now.
Variety
In this section, we study the classification of data. It can be structured or unstructured data. Structured data is preferred for information that has a predefined schema or that has a data model with predefined columns, data types, and so on, whereas unstructured data doesn't have any of these characteristics. These include a long list of data such, as documents, emails, social media text messages, videos, still images, audio, graphs, the output from all types of machine-generated data from sensors, devices, RFID tags, machine logs, and cell phone GPS signals, and more. We will learn more details about structured and unstructured data in separate chapters in this book:
Let's take an example; 30 billion pieces of content are shared on Facebook each month. 400 million Tweets are sent per day. 4 billion hours of videos are watched on YouTube every month. These are all examples of unstructured data being generated that needs to be processed, either for a better user experience or to generate revenue for the companies itself.
The fourth characteristic of big data is veracity. It's time to find out all about it.
Veracity
This vector deals with the uncertainty of data. It may be because of poor data quality or because of the noise in data. It's human behavior that we don't trust the information provided. This is one of the reasons that one in three business leaders don't trust the information they use for making decisions.
We can consider in a way that velocity and variety are dependent on the clean data prior to analysis and making decisions, whereas veracity is the opposite to these characteristics as it is derived from the uncertainty of data. Let's take the example of apples, where you have to decide whether they are of good quality. Perhaps a few of them are average or below average quality. Once you start checking them in huge quantities, perhaps your decision will be based on the condition of the majority, and you will make an assumption regarding the rest, because if you start checking each and every apple, the remaining good-quality ones may lose their freshness. The following diagram is an illustration of the example of apples:

The main challenge is that you don't get time to clean streaming data or high-velocity data to eliminate uncertainty. Data such as events data is generated by machines and sensors and if you wait to first clean and process it, that data might lose value. So you must process it as is, taking account of uncertainty.
Veracity is all about uncertainty and how much trust you have in your data, but when we use it in terms of the big data context, it may be that we have to redefine trusted data with a different definition. In my opinion, it is the way you are using data or analyzing it to make decisions. Because of the trust you have in your data, it influences the value and impact of the decisions you make.
Let's now look at the fifth characteristic of big data, which is variability.
Variability
This vector of big data derives from the lack of consistency or fixed patterns in data. It is different from variety. Let's take an example of a cake shop. It may have many different flavors. Now, if you take the same flavor every day, but you find it different in taste every time, this is variability. Consider the same for data; if the meaning and understanding of data keeps on changing, it will have a huge impact on your analysis and attempts to identify patterns.
Now comes the final and an important characteristic of big data—value.
Value
This is the most important vector in terms of big data, but is not particularly associated with big data, and it is equally true for small data as well. After addressing all the other Vs, volume, velocity, variety, variability, and veracity, which takes a lot of time, effort, and resources, now it's time to decide whether it's worth storing that data and investing in infrastructure, either on premises or in the cloud. One aspect of value is that you have to store a huge amount of data before you can utilize it in order to give valuable information in return. Previously, storing this volume of data lumbered you with huge costs, but now storage and retrieval technology is so much less expensive. You want to be sure that your organization gets value from the data. The analysis needs to be performed to meet ethical considerations.
Now that we have discussed and understand the six Vs of big data, it's time to broaden our scope of understanding and find out what to do with data having these characteristics. Companies may still think that their traditional systems are sufficient for data having these characteristics, but if they remain under this influence, they may lose in the long run. Now that we have understood the importance of data and its characteristics, the primary focus should be how to store it, how to process it, which data to store, how quickly an output is expected as a result of analysis and so on. Different solutions for handling this type of data, each with their own pros and cons, are available on the market, while new ones are continually being developed. As a big data architect, remember the following key points in your decision making that will eventually lead you to adopt one of them and leave the others.
Solution-based approach for data
Increasing revenue and profit is the key focus of any organization. Targeting this requires efficiency and effectiveness from employees, while minimizing the risks that affect overall growth. Every organization has a competitor and, in order to compete with them, you have to think and act quickly and effectively before your competitor does. Most decision-makers depend on the statistics made available to them and raise the following issues:
- What if you get analytic reports faster compared to traditional systems?
- What if you can predict how customers behave, different trends, and various opportunities to grow your business, in close to real time?
- What if you have automated systems that can initiate critical tasks automatically?
- What if automated activities clean your data and you can make your decisions based on reliable data?
- What if you can predict the risk and quantify them?
Any manager, if they can get the answers to these questions, can act effectively to increase the revenue and growth of any organization, but getting all these answers is just an ideal scenario.
Data – the most valuable asset
Almost a decade ago, people started realizing the power of data: how important it can be and how it can help organizations to grow. It can help them to improve their businesses based on the actual facts rather than their instincts. There were few sources of data to collect from, and analyzing this data in its raw form was not an easy task.
Now that the amount of data is increasing exponentially, at least doubling every year, big data solutions are required to make the most of your assets. Continuous research is being conducted to come up with new solutions and regular improvements are taking place in order to cater to requirements, following realization of the important fact that data is everything.
Traditional approaches to data storage
Human-intensive processes only work to make sense of data that doesn't scale as data volume increases. For example, people used to put each and every record of the company record in some sort of spreadsheet, and then it is very difficult to find and analyze that information once the volume or velocity of information increases.
Traditional systems use batch jobs, scheduling them on daily, weekly, or monthly bases to migrate data into separate servers or into data warehouses. This data has schema and is categorized as structured data. It will then go through the processing and analysis cycle to create datasets and extract meaningful information. These data warehouses are optimized for reporting and analytics purposes only. This is the core concept of business intelligence (BI) systems. BI systems store this data in relational database systems. The following diagram illustrates an architecture of a traditional BI system:
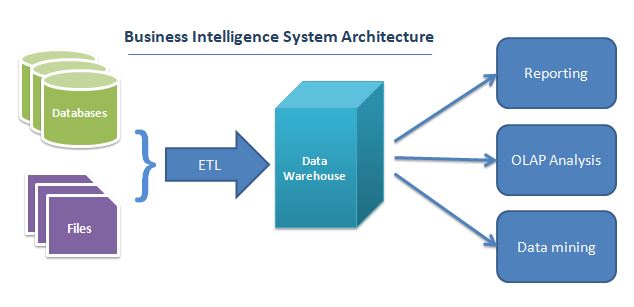
The main issue with this approach is the latency rate. The reports made available for the decision makers are not real-time and are mostly days or weeks old, dependent on fewer sources having static data models.
This is an era of technological advancement and everything is moving very rapidly. The faster you respond to your customer, the happier your customer will be and it will help your business to grow. Nowadays, the source of information is not just your transactional databases or a few other data models; there are many other data sources that can affect your business directly and if you don't capture them and include them in your analysis, it will hit you hard. These sources include blog posts and web reviews, social media sources, posts, tweets, photos, videos, and audio. And it is not just these sources; logs generated by sensors, commonly known as IoTs (Internet of Things), in your smartphone, appliances, robot and autonomous systems, smart grids, and any devices that are collecting data, can now be utilized to study different behaviors and patterns, something that was unimaginable in the past.
It is a fact that every type of data is increasing, but especially IoTs, which generate logs of each and every event automatically and continuously. For example, a report shared by Intel states that an autonomous car generates and consumes 4 TB of data each day, and this is from just an hour of driving. This is just one source of information; if we consider all the previously mentioned sources, such as blogs and social media, it will not just make a few terabytes. Here, we are talking about exabytes, zettabytes, or even yottabytes of data.
We have talked about data that is increasing, but it is not just that; the types of data are also growing. Fewer than 20% of the types have definite schema. The other 80% is just raw data without any specific pattern which cannot reside in traditional relational database systems. This 80% of data includes videos, photos, and textual data including posts, articles, and emails.
Now, if we consider all these characteristics of data and try to implement this in a traditional BI solution, it will only be able to utilize 20% of your data, because the other 80% is just raw data, making it outreached for relational database systems. In today's world, people have realized that the data that they considered to be of no use can actually make a big difference to decision making and to understanding different behaviors. Traditional business solutions, however, are not the correct approach to analyze data with these characteristics, as they mostly work with definite schema and on batch jobs that produce results after a day, week or month.
Clustered computing
Before we take a further dive into big data, let us understand clustered computing. This is a set of computers connected to each other in such a way that they act as a single server to the end user. It can be configured to work with different characteristics that enable high availability, load balancing, and parallel processing. Each computer in these configurations is called a node. They work together to execute any task or application and behave as a single machine. The following diagram illustrates a computer cluster environment:
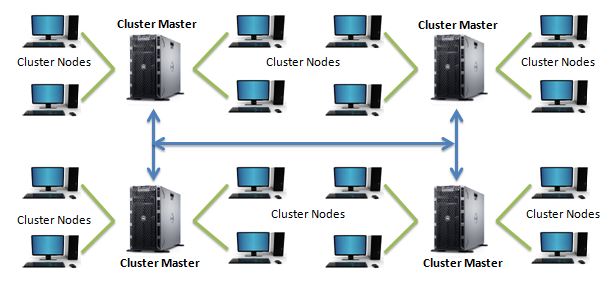
The volume of data is increasing, as we have already stated; it is now beyond the capabilities of a single computer to do the analysis all by itself. Clustered computing combines the resources of many smaller low — cost machines, to achieve many greater benefits. Some of them are listed here in the following sections
High availability
It is very important for all companies that their data and content must be available at all times and that when any hardware or software failure occurs, it must not constitute a disaster for them. Cluster computing provides fault tolerance tools and mechanisms to provide maximum uptime without affecting performance, so that everyone has their data ready for analysis and processing.
Resource pooling
In clustered computing, multiple computers are connected to each other to act as a single computer. It is not just that their data storage capacity is shared; CPU and memory pooling can also be utilized in individual computers to process different tasks independently and then merge outputs to produce a result. To execute large datasets, this setup provides more efficient processing power.
Easy scalability
Scaling is very straightforward in clustered computing. To add additional storage capacity or computational power, just add new machines with the required hardware to the group. It will start utilizing additional resources with minimum setup, with no need to physically expand the resources in any of the existing machines.
Big data – how does it make a difference?
We have established an understanding regarding traditional systems, such as BI, how they work, what their focused areas are, and where they are lagging in terms of the different characteristics of data. Let's now talk about big data solutions. Big data solutions are focused on combining all the data dimensions that were previously ignored or considered of minimum value, taking all the available sources and types into consideration and analyzing them for different and difficult-to-identify patterns.
Big data solutions are not just about the data itself or other characteristics of data; it is also about affordability, making it easier for organizations to store all of their data for analysis and in real time, if required. You may discover different insights and facts regarding your suppliers, customers, and other business competitors, or you may find the root cause of different issues and potential risks your organization might be faced with.
Big data comprises structured and unstructured datasets, which also eliminates the need for any other relational database management solutions, as they don't have the capability to store unstructured data or to analyze it.
Another aspect is that scaling up a server is also not a solution, no matter how powerful it might be; there will always be a hard limit for each resource type. These limits will undoubtedly move upward, but the rate of data increase will grow much faster. Most importantly, the cost of this high-end server and resources will be relatively high. Big data solutions comprise clustered computing mechanisms, which involve commodity hardware with no high-end servers or resources and can easily be scaled up and down. You can start with a few servers and can easily scale without any limits.
If we talk about just data itself, in big data solutions, data is replicated to multiple servers, commonly known as data nodes, based on the configurations done to make them fault tolerant. If any of the data nodes fail, the respective task will continue to run on the replica server where the copy of same data resides. This is handled by the big data solution without additional software development and operation. To keep the data intact, all the data copies need to be updated accordingly.
Distributed computing comprises commodity hardware, with reasonable storage and computation power, which is considered much less expensive compared to a dedicated processing server with powerful hardware. This led to extremely cost-effective solutions that enabled big data solutions to evolve, something that was not possible a couple of years ago.
Big data solutions – cloud versus on-premises infrastructure
Since the time when people started realizing the power of data, researchers have been working to utilize it to extract meaningful information and identify different patterns. With big data technology enhancements, more and more companies have started using big data and many are now on the verge of using big data solutions. There are different infrastructural ways to deploy a big data setup. Until some time ago, the only option for companies was to establish the setup on site. But now they have another option: a cloud setup. Many big companies, such as Microsoft, Google, and Amazon, are now providing a large amount of services based on company requirements. It can be based on server hardware configuration, and can be for computation power utilization or just storage space.
Later in this book, we will discuss these services in detail.
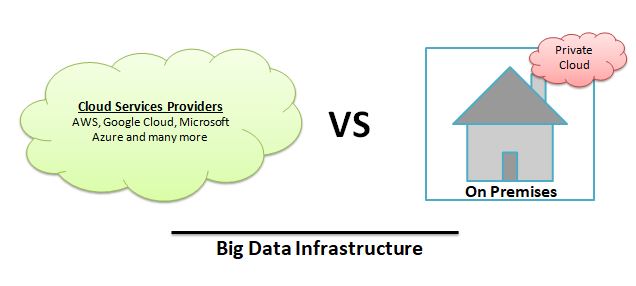
Every company's requirements are different; they have different approaches to different things. They do their analysis and feasibility before adopting any big changes, especially in the technology department. If your company is one of them and you are working on adopting any big data solution, make sure to bear the following in mind.
Cost
This is a very important factor, not just for small companies but also for big companies. Sometimes, it is the only deciding factor in finalizing any solution.
Setting up infrastructure on site has a big start up costs. It involves high-end servers and network setup to store and analyze information. Normally, it's a multimillion dollar setup, which is very difficult for small companies to bear; that would lead them to stay on a traditional approach. Now, with the emergence of technology, these companies have the option to opt for a cloud setup. In this way, they have the option to have an escape route from the start up costs, while utilizing the full potential of big data analytics. Companies offering cloud setup have very flexible plans, such as users having the option to just have a server and increase them as required. On the other hand, setup on site requires network engineers and experts to monitor full-time activity of the setup and maintain it. In a cloud setup, there is less hassle for companies; they just need to worry about how much storage capacity they need and how much computational power is required for analysis purposes.
Security
This is one of the main concerns for companies, because their establishment depends on it. Infrastructure setup on premises gives companies a sense of more security. It also gives them control over who is accessing their data, when it is used, and for what purpose it is being used. They can do their due diligence to make sure the data is secure.
On the other hand, data in the cloud has its inherent risks. Many questions arise with respect to data security when you don't know the whereabouts of your data. How is it being managed? Which team members from the cloud infrastructure provider can access the data? What, if any, unauthorized access was made to copy that data? That being said, reputable cloud infrastructure providers are taking serious measures to make sure that every bit of information you put on the cloud is safe and secure. Many encrypting mechanisms are being deployed so that even if any unauthorized access is made, the data will be useless for that person. Secondly, additional copies of your data are being backed up on entirely different facilities to make sure that you don't lose your data. Measures such as these are making cloud infrastructure almost as safe and secure as on-site setup.
Current capabilities
Another important factor to consider while implementing big data solutions in terms of on-premises setup versus cloud setup is whether you currently have big data personnel to manage your implementation on site. Do you already have a team to support and oversee all aspects of big data? Is it with your budget, or can you afford to hire them? If you are starting from scratch, the staff required for on-site setup will be significant, from big data architects to network support engineers. It doesn't mean that you don't need a team if you opt for cloud setup. You will still need big data architects to implement your solution so that companies can focus on what's important, making sense of the information gathered and effecting implementation in order to improve the business.
Scalability
When you install infrastructures for big data on site, you must have done some analysis about how much data will be gathered, how much storage capacity is required to store it, and how much computation power is required for analysis purposes. Accordingly, you must decide on the hardware required in this setup. Now in future, if your data analysis requirement changes, you may start receiving data from more sources or need more computation power to perform analysis on it. In order to fulfil this requirement, you need more servers or for additional hardware to be installed in your on-site setup.
Another aspect will be this: let's suppose you did the analysis that you will gather this much data, but after implementation, you are not receiving that much, or before, you assumed that you would need this much computational power but now, after implementation, you realize that you don't. In both cases, you will end up with expensive server hardware of no use to manage. In a cloud setup, you will have the option to scale your hardware up and down, without worrying about the negative financial implications, and doing so is incredibly easy.
We will now move on to briefly discuss some of the key concepts and terminologies that you will encounter in your day-to-day life while working in the world of big data.
Big data glossary
The section includes some key definitions to sum up the core concepts of big data. These will help you to keep key definitions in mind as we move further into the book, to help you understand what we have learned so far, and what lies ahead of us.
Big data
Data that is massive in volume, with respect to the processing system, with a variety of structured and unstructured data containing different data patterns to be analyzed.
Batch processing
A process of analyzing large datasets, which is typically scheduled and executes in bulk when no other processes are running. This is typically ideal for non-time-sensitive work that operates on very large datasets. Once the process has finished executing the task, it will return results typically as an output file or as a database entry.
Cluster computing
Cluster computing is the practice of combining the resources of multiple commodity low-cost hardwares and managing their collective processing and storage capabilities to execute different tasks. It requires a software layer to handle communication between different individual nodes in order to effectively manage and coordinate the execution of assigned work.
Data warehouse
A large repository of structured data for analysis and reporting purposes. It is composed of data that is already cleaned, with a definite schema and well integrated with sources. It is normally referred to in the context of traditional systems, such as BI.
Data lake
Similar to a data warehouse, for storing large datasets, but it comprises unstructured data. This is a commonly used term in the context of big data solutions that store information such as blogs, posts, videos, photos, and more.
Data mining
Data mining is the process of trying to process a mass of data into a more understandable and visual medium. It is a broad term for the practice of trying to find hidden patterns in large datasets.
ETL
ETL stands for extract, transform, and load. This mainly refers to traditional systems such as BI, which take raw data and process it for analytical and reporting purposes. It is mainly associated with data warehouses, but characteristics of this process are also found in the ingestion pipelines of big data systems.
Hadoop
An open source software platform for processing very large datasets in a distributed environment with respect to storage and computational power, mainly built on low-cost commodity hardware. It is designed for easy scale up from a few to thousands of servers. It will help to process locally stored data in an overall parallel processing setup. It comprises different modules–Hadoop Distributed File System (HDFS), Hadoop MapReduce, and Hadoop YARN (Yet Another Resource Negotiator).
In-memory computing
A strategy that involves moving the working datasets entirely within a cluster's collective memory instead of reading it from hard disk, to reduce the processing time while omitting I/O bound operations. Intermediate calculations are not written to disk and are instead held in memory. This is the fundamental idea of projects such as Apache Spark. Because of this, it has huge advantages in speed over I/O bound systems such as MapReduce.
Machine learning
The study that involves designing a system that can learn without being explicitly programmed. It can have the ability to adjust and improve itself based on the data fed to it. It involves the implementation of predictive and statistical algorithms that can continually zero in on correct behavior and insights as more data flows through the system.
MapReduce
MapReduce is a framework for processing any task in a distributed environment. It works on a Master/Slave principle similar to HDFS. It involves splitting a problem set into different nodes available in a clustered computing environment and produces intermediate results. It then shuffles the results to align like sets, and then reduces them by producing a single value for each set.
NoSQL
NoSQL provides a mechanism for storage and retrieval of data that is not in tabular form, such as what we store in relational database systems. It is also called non-SQL or a non-relational database. It is well suited to big data as it is mostly used with unstructured data and can work in distributed environments.
Stream processing
The practice of processing individual data items as they move through a system. This will help with real-time analysis of the data as it is being fed to the system. It is useful for time-sensitive operations using high velocity metrics.
Summary
In this chapter, we have learned about big data, its characteristics, the six Vs of big data, and the different aspects of big data. We have also discussed clustered computing and how to approach it for big data solutions. We also compared big data infrastructure on site versus the on-cloud setup. At the end, we briefly described some commonly used terms that you maybe already have encountered and will encounter, whenever you deal with big data. In the next chapter, we will go through the step-by-step setup of creating our own Hadoop environment, from a single node server to a clustered environment.





