


















 Download code from GitHub
Download code from GitHub
From Cloud to Cloud Native and Kubernetes
In this chapter, you’ll see how computing has evolved over the past 20 or so years, what the cloud is and how it appeared, and how IT landscapes have changed with the introduction of containers. You’ll learn about fundamentals such as Infrastructure-as-a-Service (IaaS), Platform-as-a-Service (PaaS), Software-as-a-Service (SaaS), and Function-as-a-Service (FaaS), as well as learning about the transition from monolithic to microservice architectures and getting a first glimpse at Kubernetes.
This chapter does not map directly to a specific KCNA exam objective, but these topics are crucial for anyone who’d like to tie their career to modern infrastructures. If you are already familiar with the basic terms, feel free to quickly verify your knowledge by going directly to the recap questions. If not, don’t be surprised that things are not covered in great detail, as this is an introductory chapter, and we’ll dive deeper into all of the topics in later chapters.
We’re going to cover the following topics in this chapter:
- The cloud and Before Cloud (B.C.)
- Evolution of the cloud and cloud-native
- Containers and container orchestration
- Monolithic versus microservices applications
- Kubernetes and its origins
Let’s get started!
The cloud and Before Cloud (B.C.)
The cloud has triggered a major revolution and accelerated innovation, but before we learn about the cloud, let’s see how things were done before the era of the cloud.
In the times before the term cloud computing was used, one physical server would only be able to run a single operating system (OS) at a time. These systems would typically host a single application, meaning two things:
- If an application was not used, the computing resources of the server where it ran were wasted
- If an application was used very actively and needed a larger server or more servers, it would take days or even weeks to get new hardware procured, delivered, cabled, and installed
Moving on, let’s have a look at an important aspect of computing – virtualization.
Virtualization
Virtualization technology and virtual machines (VMs) first appeared back in the 1960s, but it was not until the early 2000s that virtualization technologies such as XEN and Kernel-based Virtual Machines (KVMs) started to become mainstream.
Virtualization would allow us to run multiple VMs on a single physical server using hypervisors, where a hypervisor is a software that acts as an emulator of the hardware resources, such as the CPU and RAM. Effectively, it allows you to share the processor time and memory of the underlying physical server by slicing it between multiple VMs.
It means that each VM will be very similar to the physical server, but with a virtual CPU, memory, disks, and network cards instead of physical ones. Each VM will also have an OS on which you can install applications. The following figure demonstrates a virtualized deployment with two VMs running on the same physical server:

Figure 1.1 – Comparison of traditional and virtualized deployments
This concept of sharing hardware resources between the so-called guest VMs is what made it possible to utilize hardware more effectively and reduce any waste of computing resources. It means we might not need to purchase a whole new server in order to run another application.
The obvious benefits that came along with virtualization are as follows:
- Less physical hardware required
- Fewer data center personnel required
- Lower acquisition and maintenance costs
- Lower power consumption
Besides, provisioning a new VM would take minutes and not days or weeks of waiting for new hardware. However, to scale beyond the capacities of the hardware already installed in the corporate data center, we would still need to order, configure, and cable new physical servers and network equipment – and that has all changed with the introduction of cloud computing.
The cloud
At a very basic level, the cloud is virtualization on demand. It allows us to spawn VMs accessible over the network as a service, when requested by the customers.
Cloud computing
This is the delivery of computational resources as a service, where the actual hardware is owned and managed by the cloud provider rather than a corporate IT department.
The cloud has ignited a major revolution in computing. It became unnecessary to buy and manage your own hardware anymore to build and run applications and VMs. The cloud provider takes full care of hardware procurement, installation, and maintenance and ensures the efficient utilization of resources by serving hundreds and thousands of customers on shared hardware securely. Each customer will only pay for the resources they use. Today, it is common to distinguish the following three cloud types:
- Public – The most popular type. A public cloud is operated by a third-party company and available for use by any paying customer. Public clouds are typically used by thousands of organizations at the same time. Examples of public cloud providers include Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP).
- Private – Used by one typically large organization or an enterprise. The operations and maintenance might be done by the organization itself or a private cloud provider. Examples include Rackspace Private Cloud and VMware Private Cloud.
- Hybrid – This is the combination of a public and private cloud, in a case where an organization has a private cloud but uses some of the services from a public cloud at the same time.
However, the cloud is not just VMs reachable over the network. There are tens and hundreds of services offered by cloud providers. Today, you can request and use network-attached storage, virtual network devices, firewalls, load balancers, VMs with GPUs or specialized hardware, managed databases, and more almost immediately.
Now, let’s see in more detail how cloud services can be delivered and consumed.
Evolution of the cloud and cloud-native
Besides the huge variety of cloud services you can find today, there is also a difference in how the services are offered. It is common to distinguish between four cloud service delivery models that help meet different needs:
- IaaS – The most flexible model with the basic services provided: VMs, virtual routers, block devices, load balancers, and so on. This model also assumes the most customer responsibility. Users of IaaS have access to their VMs and must configure their OS, install updates, and set up, manage, and secure their applications. AWS Elastic Compute Cloud (EC2), AWS Elastic Block Store (EBS), and Google Compute Engine VMs are all examples of IaaS.
- PaaS – This helps to focus on the development and management of applications by taking away the need to install OS upgrades or do any lower-level maintenance. As a PaaS customer, you are still responsible for your data, identity and access, and your application life cycle. Examples include Heroku and Google App Engine.
- SaaS – Takes the responsibilities even further away from the customers. Typically, these are fully managed applications that just work, such as Slack or Gmail.
- FaaS – A newer delivery model that appeared around 2010. It is also known as Serverless today. A FaaS customer is responsible for defining the functions that are triggered by the events. Functions can be written in one of the popular programming languages and customers don’t have to worry about server or OS management, deployment, or scaling. Examples of FaaS include AWS Lambda, Google Cloud Functions, and Microsoft Azure Functions.
These models might sound a bit complicated, so let’s draw a simple analogy with cars and transportation.
On-premises, traditional data centers are like having your own car. You are buying it, and you are responsible for its insurance and maintenance, the replacement of broken parts, passing regular inspections, and so on.
IaaS is more like leasing a car for some period of time. You pay monthly lease payments, you drive it, you fill it with gas, and you wash it, but you don’t actually own the car and you can give it back when you don’t need it anymore.
PaaS can be compared with car-sharing. You don’t own the car, you don’t need to wash it, do any maintenance, or even refill it most of the time, but you still drive it yourself.
Following the analogy, SaaS is like calling a taxi. You don’t need to own the car or even drive it.
Finally, Serverless or FaaS can be compared to a bus from a user perspective. You just hop on and ride to your destination – no maintenance, no driving, and no ownership.
Hopefully, this makes things clearer. The big difference between traditional on-premises setups where a company is solely responsible for the organization, hardware maintenance, data security, and more is that a so-called shared responsibility model applies in the cloud.
Shared responsibility model
Defines the obligations of the cloud provider and the cloud customer. These responsibilities depend on the service provided – in the case of an IaaS service, the customer has more responsibility compared to PaaS or SaaS. For example, the cloud provider is always responsible for preventing unauthorized access to data center facilities and the stability of the power supply and underlying network connectivity.
The following figure visually demonstrates the difference between the responsibilities:
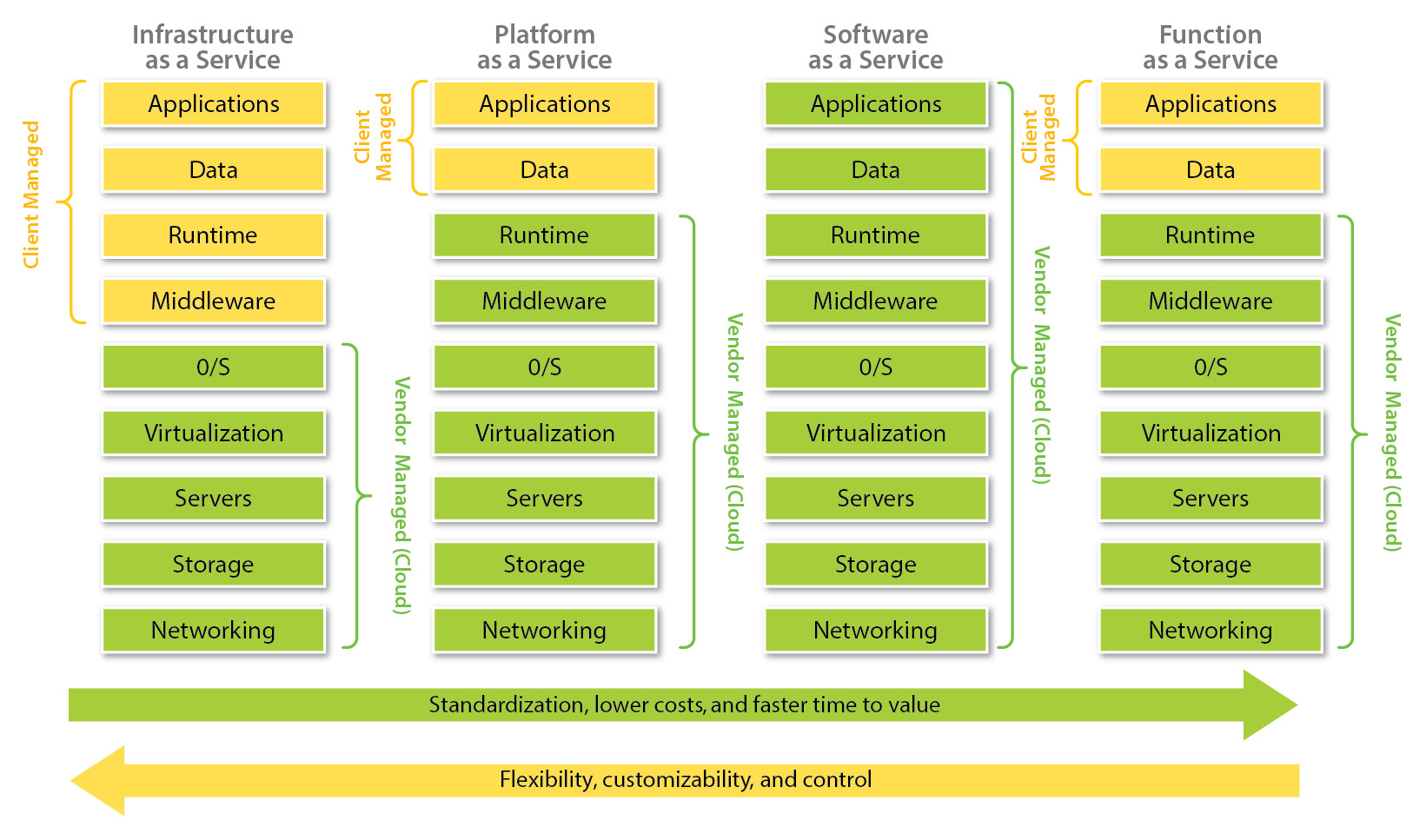
Figure 1.2 – Comparison of cloud delivery models
As cloud technologies and providers evolved over the past 20 years, so did the architectures of the applications that run on the cloud; a new term has emerged – cloud-native. Most of the time, it refers to the architectural approach, but you will often encounter cloud-native applications or cloud-native software as well.
Cloud-native
Is an approach to building and running applications on modern, dynamic infrastructures such as clouds. It is emphasizing application workloads with high resiliency, scalability, high degree of automation, ease of management, and observability.
Despite the presence of the word cloud, it does not mean that a cloud-native application must run strictly in a public, private, or hybrid cloud. You can develop a cloud-native application and run it on-premises with Kubernetes as an example.
Cloud-native should not be confused with Cloud Service Providers (CSPs), or simply cloud providers, and cloud-native is also not the same as cloud-first, so remember the following:
Cloud-native ≠ CSP ≠ cloud-first
For the sake of completeness, let’s define the other two.
A CSP is a third-party company offering cloud computing services such as IaaS, PaaS, SaaS, or FaaS. Cloud-first simply stands for a strategy where the cloud is the default choice for either optimizing existing IT infrastructure or for launching new applications.
Don’t worry if those definitions do not make total sense just yet – we will dedicate a whole section to cloud-native that explains all its aspects in detail. For now, let’s have a quick introduction to containers and their orchestration.
Containers and container orchestration
At a very high level, containers are another form of lightweight virtualization, also known as OS-level virtualization. However, containers are different from VMs with their own advantages and disadvantages.
The major difference is that with VMs, we can slice and share one physical server between many VMs, each running their own OS. With containers, we can slice and share an OS kernel between multiple containers and each container will have its own virtual OS. Let’s see this in more detail.
Containers
These are portable units of software that include application code with runtimes, dependencies, and system libraries. Containers share one OS kernel, but each container can have its own isolated OS environment with different packages, system libraries, tools, its own storage, networking, users, processes, and groups.
Portable is important and needs to be elaborated. An application packaged into a container image is guaranteed to run on another host because the container includes its own isolated environment. Starting a container on another host does not interfere with its environment or the application containerized.
A major advantage is also that containers are a lot more lightweight and efficient compared to VMs. They consume less resources (the CPU and RAM) than VMs and start almost instantly because they don’t need to bootstrap a complete OS with a kernel. For example, if a physical server is capable of running 10 VMs, then the same physical server might be able to run 30, 40, or possibly even more containers, each with its own application (the exact number depends on many factors, including the type of workload, so those values are for demonstration purposes only and do not represent any formula).
Containers are also much smaller than VMs in disk size, because they don’t package a full OS with thousands of libraries. Only applications with dependencies and a minimal set of OS packages are included in container images. That makes container images small, portable, and easy to download or share.
Container images
These are essentially templates of container OS environments that we can use to create multiple containers with the same application and environment. Every time we execute an image, a container is created.
Speaking in numbers, a container image of a popular Linux distribution such as Ubuntu Server 20.04 weighs about 70 MB, whereas a KVM QCOW2 virtual machine image of the same Ubuntu Server will weigh roughly 500 MB. Specialized Linux container images such as Alpine can be as small as 5 to 10 MB and provide the bare minimum functionality to install and run applications.
Containers are also agnostic to where they run – whether on physical servers, on-premises VMs, or the cloud, containers can run in any of these locations with the help of container runtimes.
Container runtimes
A container runtime is a special software needed to run containers on a host OS. It is responsible for creating, starting, stopping, and deleting containers based on the container images it downloads. Examples of container runtimes include containerd, CRI-O, and Docker Engine.
Figure 1.3 demonstrates the differences between virtualized and containerized deployments:
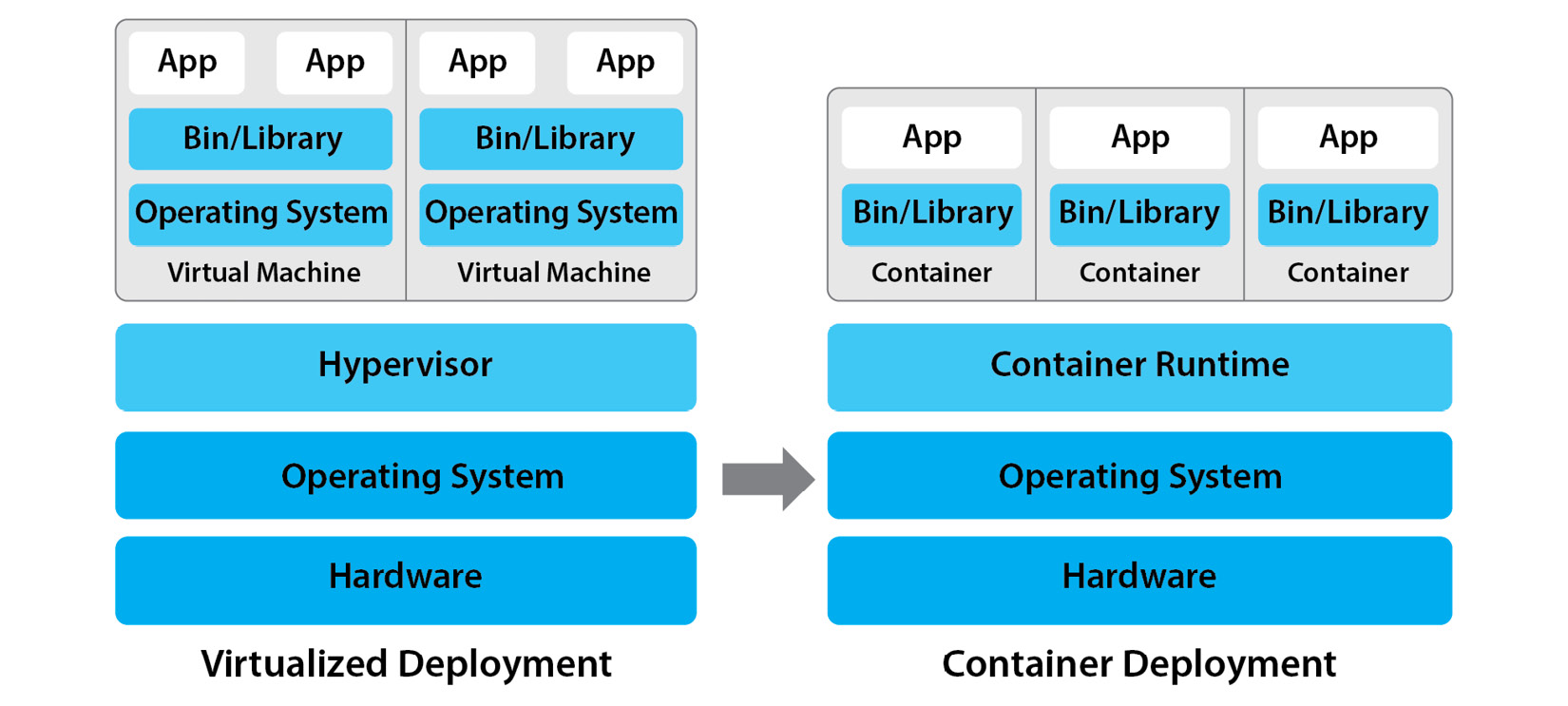
Figure 1.3 – Comparison of virtualized and container deployments
Now, a question you might be asking yourself is if containers are so great, why would anyone use VMs and why do cloud providers still offer so many VM types?
Here is the scenario where VMs have an advantage over containers: they provide better security due to stronger isolation because they don’t directly share the same host kernel. That means if an application running in a container has been breached by a hacker, the chances that they can get to all the other containers on the same host are much higher than compared to regular VMs.
We will dive deeper into the technology behind OS-level virtualization and explore the low-level differences between VMs and containers in later chapters.
As containers gained momentum and received wider adoption over the years, it quickly became apparent that managing containers on a large scale can be quite a challenge. The industry needed tools to orchestrate and manage the life cycle of container-based applications.
This had to do with the increasing number of containers that companies and teams had to operate because as the infrastructure tools evolved, so did the application architectures too, transforming from large monolithic architectures into small, distributed, and loosely coupled microservices.
Monolithic versus microservices applications
To understand the difference between monolithic and microservice-based applications, let us reflect on a real-world example. Imagine that a company runs an online hotel booking business. All reservations are made and paid for by the customers via a corporate web service.
The traditional monolithic architecture for this kind of web application would have bundled all the functionality into one single, complex software that might have included the following:
- Customer dashboard
- Customer identity and access management
- Search engine for hotels based on criteria
- Billing and integration with payment providers
- Reservation system for hotels
- Ticketing and support chat
A monolithic application will be tightly coupled (bundled) with all the business and user logic and must be developed and updated at once. That means if a change to a billing code has to be made, the entire application will have to be updated with the changes. After that, it should be carefully tested and released to the production environment. Each (even a small) change could potentially break the whole application and impact business by making it unavailable for a longer time.
With a microservices architecture, this very same application could be split into several smaller pieces communicating with each other over the network and fulfilling its own purpose. Billing, for example, can be performed by four smaller services:
- Currency converter
- Credit card provider integration
- Bank wire transfer processing
- Refund processing
Essentially, microservices are a group of small applications where each is responsible for its own small task. These small applications communicate with each other over the network and work together as a part of a larger application.
The following figure demonstrates the differences between monolithic and microservice architectures:
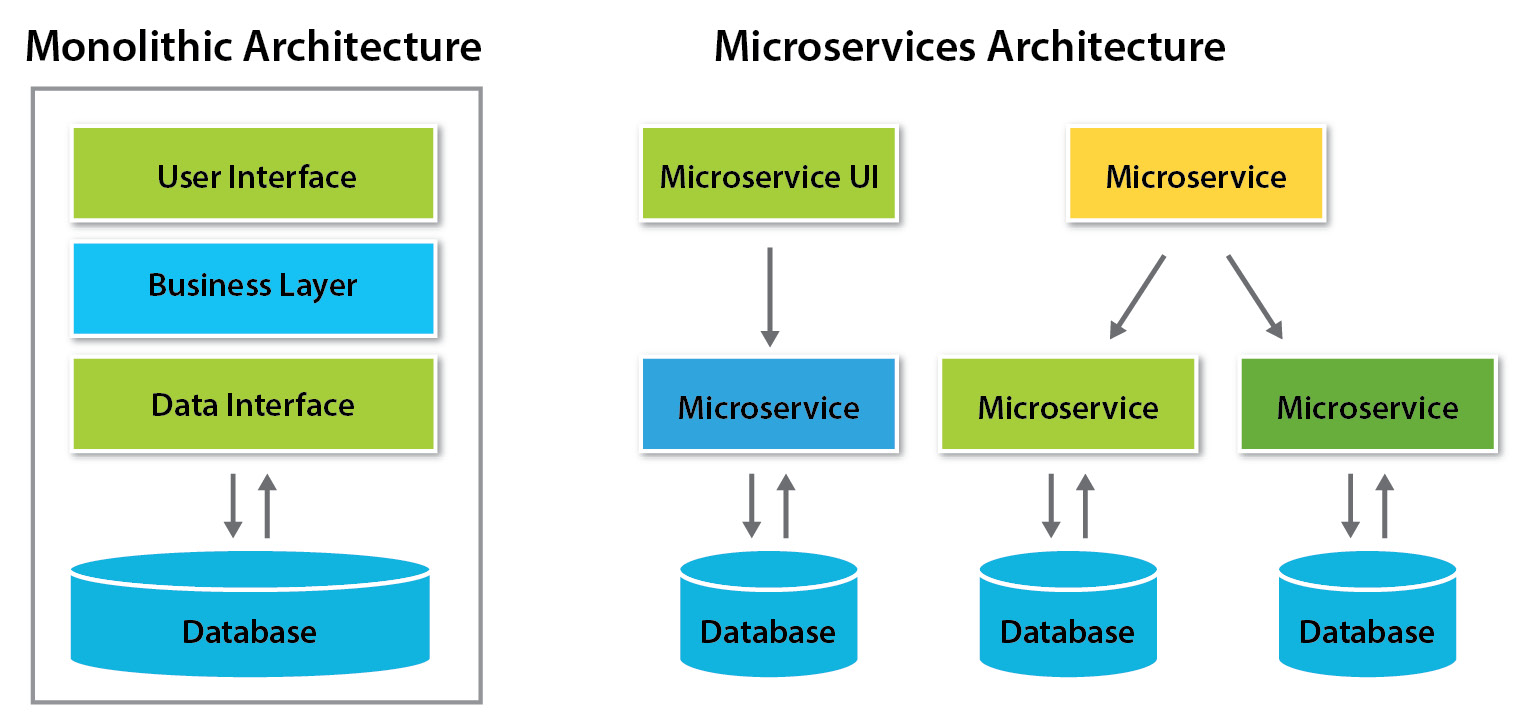
Figure 1.4 – Comparison of monolithic and microservice architectures
This way, all other parts of the web application can also be split into multiple smaller independent applications (microservices) communicating over the network. The advantages of this approach include the following:
- Each microservice can be developed by its own team
- Each microservice can be released and updated separately
- Each microservice can be deployed and scaled independently of others
- A single microservice outage will only impact a small part of the overall functionality of the app
Microservices are an important part of cloud-native architectures, and we will review in detail the benefits as well as the challenges associated with microservices in Chapter 9, Understanding Cloud Native Architectures. For the moment, let’s get back to containers and why they need to be orchestrated.
When each microservice is packaged into a container, the total number of containers can easily reach tens or even hundreds for especially large and complex applications. In such a complex distributed environment, things can quickly get out of our control.
A container orchestration system is what helps us to keep control over a large number of containers. It simplifies the management of containers by grouping application containers into deployments and automating operations such as the following:
- Scaling microservices depending on the workload
- Releasing new versions of microservices and their updates
- Scheduling containers based on host utilizations and requirements
- Automatically restarting containers that fail or failing over the traffic
As of today, there are many container and workload orchestration systems available, including these:
- Kubernetes
- OpenShift (also known as Open Kubernetes Distribution (OKD))
- Hashicorp Nomad
- Docker Swarm
- Apache Mesos
As you already know from the book title, we will only focus on Kubernetes and there won’t be any sort of comparison made between these five. In fact, Kubernetes has overwhelmingly higher market shares and over the years, has become the de facto platform for orchestrating containers. With a high degree of confidence, you can concentrate on learning about Kubernetes and forget about the others, at least for the moment.
Kubernetes and its origins
Let’s start with a brief history first. The name Kubernetes originates from Greek and means pilot or helmsman – a person steering a ship (that is why there is a steering wheel in the logo). The steering wheel has seven bars and the number seven has a special meaning for Kubernetes. The team originally working on Kubernetes called it Project Seven – named after seven of nine characters from the well-known TV series, Star Trek.

Figure 1.5 – The Kubernetes logo
Kubernetes was initially developed by Google and released as an open source project in 2014. Google has been a pioneer, having run its services in containers already for more than a decade by that time, and the release of Kubernetes triggered another small revolution in the industry. By that time, many businesses had realized the benefits of using containers and were in need of a solution that would simplify container orchestration at scale. Kubernetes turned out to be this solution, as we will see soon.
Kubernetes (K8s)
Kubernetes is an open source platform for container orchestration. Kubernetes features an extensible and declarative API that allows you to automatically reach the desired state of resources. It allows flexible scheduling, autoscaling, rolling update, and self-healing of container-based payloads.
(Online and in documentation, a shorter abbreviation, K8s, can often be encountered – where eight is the number of letters between “K” and “s”.)
Kubernetes has inherited many of its features and best ideas from Borg – an internal container cluster management system powering thousands of different applications at Google. Many Borg engineers participated in the development of Kubernetes and were able to address relevant pain points based on their experience of operating a huge fleet of containers over the years.
Soon after its initial release, Kubernetes rapidly gained the attention of the open source community and attracted many talented contributors from all over the world. Today, Kubernetes is among the top three biggest open source projects on GitHub (https://github.com/kubernetes) with more than 80,000 stars and 3,000 contributors. It was also the first project to graduate from the Cloud Native Computing Foundation (CNCF), a non-profit organization that split off from the Linux Foundation created with the goal of advancing container and cloud-native technologies.
One of the most important features of Kubernetes is the concept of the desired state. Kubernetes operates in a way where we define the state of the application containers we want to have, and Kubernetes will automatically ensure the state is reached. Kubernetes constantly observes the state of all deployed containers and makes sure this state matches what we’ve requested.
Let’s consider the following example. Imagine that we run a simple microservice-based application on Kubernetes cluster with three hosts. We define a specification that requires Kubernetes to run these:
- Two identical containers for the frontend
- Three identical containers for the backend
- Two containers with volumes serving the data persistence
Unexpectedly, one of the three hosts fails, and two containers running on the frontend and backend become unavailable. Kubernetes observes the changed number of hosts in the cluster and reduced number of containers responsible for the frontend and the backend. Kubernetes automatically starts one frontend and one backend container on the other two operational hosts to bring the system back to its desired state. This process is known as self-healing.
Kubernetes can do way more than scheduling and restarting failed containers – we can also define a Kubernetes specification that requires the number of microservice containers to automatically increase based on the current demand. For example, in the preceding example, we can specify that with an increased workload, we want to run five replicas of the frontend and five replicas of the backend. Alternatively, in case of low application demand, we can automatically decrease the number of each microservice containers to two. This process is known as autoscaling.
This example demonstrates the basic capabilities of Kubernetes. In Part 3, we will explore more Kubernetes features and try some of them firsthand.
Important note
While being a container orchestrator, Kubernetes does not have its own container runtime. Instead, it has integration with popular container runtimes such as containerd and can work with multiple runtimes within a Kubernetes cluster.
You often see references to Kubernetes clusters because a typical Kubernetes installation will be used to manage hundreds of containers spread across multiple hosts. Single-host Kubernetes installations are only suitable for learning or local development, but not for production usage.
To sum up, Kubernetes has laid down the path for massive container adoption and is a thriving open source ecosystem that is still growing with new projects graduating from the CNCF every year. In this book, we will cover the Kubernetes API, components, resources, features, and operational aspects in depth, and learn more about projects that can be used with Kubernetes to extend its functionality.
Summary
In this chapter, we learned about the concepts of the cloud and containers, and the evolution of computing over the last 20 to 30 years. In the era before the cloud, traditional deployments with one or a few applications per physical server caused a lot of inefficiency and wasted resources with underutilized hardware and high costs of ownership.
When virtualization technologies came along, it became possible to run many applications per physical server using VMs. This addressed the pitfalls of traditional deployments and allowed us to deliver new applications more quickly and with significantly lower costs.
Virtualization paved the way for the cloud services that are delivered via four different models today: IaaS, PaaS, SaaS, and FaaS or Serverless. Customer responsibilities differ by cloud service and delivery model.
This progress never stopped – now, cloud-native as an approach to building and running applications has emerged. Cloud-native applications are designed and built with an emphasis on scalability, resilience, ease of management, and a high degree of automation.
Over recent years, container technology has developed and gained momentum. Containers use virtualization at the OS level and each container represents a virtual OS environment. Containers are faster, more efficient, and more portable compared to VMs.
Containers enabled us to develop and manage modern applications based on a microservices architecture. Microservices were a step ahead compared to traditional monoliths – all-in-one, behemoth applications.
While containers are one of the most efficient ways to run cloud-native applications, it becomes hard to manage large numbers of containers. Therefore, containers are best managed using an orchestrator such as Kubernetes.
Kubernetes is an open source container orchestration system that originated from Google and automates many operational aspects of containers. Kubernetes will schedule, start, stop, and restart containers and increase or decrease the number of containers based on the provided specification automatically. Kubernetes makes it possible to implement self-healing and autoscaling based on the current demand.
Questions
At the end of each chapter, you’ll find recap questions that allow to test your understanding. Questions might have multiple correct answers. Correct answers can be found in the Assessment section of the Appendix:
- Which of the following describes traditional deployments on physical servers (pick two)?
- Easy maintenance
- Underutilized hardware
- Low energy consumption
- High upfront costs
- Which advantages do VMs have compared to containers?
- They are more reliable
- They are more portable
- They are more secure
- They are more lightweight
- What describes the difference between VMs and containers (pick two)?
- VM images are small and container images are large
- VM images are large and container images are small
- VMs share the OS kernel and containers don’t
- Containers share the OS kernel and VMs don’t
- At which level do containers operate?
- The orchestrator level
- The hypervisor level
- The programming language level
- The OS level
- What is typically included in a container image (pick two)?
- An OS kernel
- A minimal set of OS libraries and packages
- A graphical desktop environment
- A packaged microservice
- Which advantages do containers have compared to VMs (pick multiple)?
- They are more secure
- They are more lightweight
- They are more portable
- They are faster to start
- Which software is needed to start and run containers?
- A container runtime
- A hypervisor
- Kubernetes
- VirtualBox
- Which of the following can be used to orchestrate containers?
- containerd
- CRI-O
- Kubernetes
- Serverless
- Which of the following is a cloud service delivery model (pick multiple)?
- IaaS, PaaS
- SaaS, FaaS
- DBaaS
- Serverless
- Which of the following statements about cloud-native is true?
- It is an architectural approach
- It is the same as a cloud provider
- It is similar to cloud-first
- It is software that only runs in the cloud
- Which of the following descriptors applies to cloud-native applications (pick two)?
- High degree of automation
- High scalability and resiliency
- Can only run in a private cloud
- Can only run in a public cloud
- Which of the following statements is true about monolithic applications?
- They are easy to update
- Their components communicate with each other over the network
- They include all the business logic and interfaces
- They can be scaled easily
- Which of the following statements is true for microservices (pick multiple)?
- They can only be used for the backend
- They work together as a part of a bigger application
- They can be developed by multiple teams
- They can be deployed independently
- Which of the following can be done with Kubernetes (pick multiple)?
- Self-healing in case of failure
- Autoscaling containers
- Spawning VMs
- Scheduling containers on different hosts
- Which project served as an inspiration for Kubernetes?
- OpenStack
- Docker
- Borg
- OpenShift
