


















 Download code from GitHub
Download code from GitHub
Become an Adaptive Thinker
In May 2017, Google revealed AutoML, an automated machine learning system that could create an artificial intelligence solution without the assistance of a human engineer. IBM Cloud and Amazon Web Services (AWS) offer machine learning solutions that do not require AI developers. GitHub and other cloud platforms already provide thousands of machine learning programs, reducing the need of having an AI expert at hand. These cloud platforms will slowly but surely reduce the need for artificial intelligence developers. Google Cloud's AI provides intuitive machine learning services. Microsoft Azure offers user-friendly machine learning interfaces.
At the same time, Massive Open Online Courses (MOOC) are flourishing everywhere. Anybody anywhere can pick up a machine learning solution on GitHub, follow a MOOC without even going to college, and beat any engineer to the job.
Today, artificial intelligence is mostly mathematics translated into source code which makes it difficult to learn for traditional developers. That is the main reason why Google, IBM, Amazon, Microsoft, and others have ready-made cloud solutions that will require fewer engineers in the future.
As you will see, starting with this chapter, you can occupy a central role in this new world as an adaptive thinker. There is no time to waste. In this chapter, we are going to dive quickly and directly into reinforcement learning, one of the pillars of Google Alphabet's DeepMind asset (the other being neural networks). Reinforcement learning often uses the Markov Decision Process (MDP). MDP contains a memoryless and unlabeled action-reward equation with a learning parameter. This equation, the Bellman equation (often coined as the Q function), was used to beat world-class Atari gamers.
The goal here is not to simply take the easy route. We're striving to break complexity into understandable parts and confront them with reality. You are going to find out right from the start how to apply an adaptive thinker's process that will lead you from an idea to a solution in reinforcement learning, and right into the center of gravity of Google's DeepMind projects.
The following topics will be covered in this chapter:
- A three-dimensional method to implement AI, ML, and DL
- Reinforcement learning
- MDP
- Unsupervised learning
- Stochastic learning
- Memoryless learning
- The Bellman equation
- Convergence
- A Python example of reinforcement learning with the Q action-value function
- Applying reinforcement learning to a delivery example
Technical requirements
- Python 3.6x 64-bit from https://www.python.org/
- NumPy for Python 3.6x
- Program on Github, Chapter01 MDP.py
Check out the following video to see the code in action:
How to be an adaptive thinker
Reinforcement learning, one of the foundations of machine learning, supposes learning through trial and error by interacting with an environment. This sounds familiar, right? That is what we humans do all our lives—in pain! Try things, evaluate, and then continue; or try something else.
In real life, you are the agent of your thought process. In a machine learning model, the agent is the function calculating through this trial-and-error process. This thought process in machine learning is the MDP. This form of action-value learning is sometimes called Q.
To master the outcomes of MDP in theory and practice, a three-dimensional method is a prerequisite.
The three-dimensional approach that will make you an artificial expert, in general terms, means:
- Starting by describing a problem to solve with real-life cases
- Then, building a mathematical model
- Then, write source code and/or using a cloud platform solution
It is a way for you to enter any project with an adaptive attitude from the outset.
Addressing real-life issues before coding a solution
In this chapter, we are going to tackle Markov's Decision Process (Q function) and apply it to reinforcement learning with the Bellman equation. You can find tons of source code and examples on the web. However, most of them are toy experiments that have nothing to do with real life. For example, reinforcement learning can be applied to an e-commerce business delivery person, self-driving vehicle, or a drone. You will find a program that calculates a drone delivery. However, it has many limits that need to be overcome. You as an adaptive thinker are going to ask some questions:
- What if there are 5,000 drones over a major city at the same time?
- Is a drone-jam legal? What about the noise over the city? What about tourism?
- What about the weather? Weather forecasts are difficult to make, so how is this scheduled?
In just a few minutes, you will be at the center of attention, among theoreticians who know more than you on one side and angry managers who want solutions they cannot get on the other side. Your real-life approach will solve these problems.
A foolproof method is the practical three-dimensional approach:
- Be a subject matter expert (SME): First, you have to be an SME. If a theoretician geek comes up with a hundred Google DeepMind TensorFlow functions to solve a drone trajectory problem, you now know it is going to be a tough ride if real-life parameters are taken into account.
An SME knows the subject and thus can quickly identify the critical factors of a given field. Artificial intelligence often requires finding a solution to a hard problem that even an expert in a given field cannot express mathematically. Machine learning sometimes means finding a solution to a problem that humans do not know how to explain. Deep learning, involving complex networks, solves even more difficult problems. - Have enough mathematical knowledge to understand AI concepts: Once you have the proper natural language analysis, you need to build your abstract representation quickly. The best way is to look around at your everyday life and make a mathematical model of it. Mathematics is not an option in AI, but a prerequisite. The effort is worthwhile. Then, you can start writing solid source code or start implementing a cloud platform ML solution.
- Know what source code is about as well as its potential and limits: MDP is an excellent way to go and start working in the three dimensions that will make you adaptive: describing what is around you in detail in words, translating that into mathematical representations, and then implementing the result in your source code.
Step 1 – MDP in natural language
Step 1 of any artificial intelligence problem is to transpose it into something you know in your everyday life (work or personal). Something you are an SME in. If you have a driver's license, then you are an SME of driving. You are certified. If you do not have a driver's license or never drive, you can easily replace moving around in a car by moving around on foot.
Let's say you are an e-commerce business driver delivering a package in an area you do not know. You are the operator of a self-driving vehicle. You have a GPS system with a beautiful color map on it. The areas around you are represented by the letters A to F, as shown in the simplified map in the following diagram. You are presently at F. Your goal is to reach area C. You are happy, listening to the radio. Everything is going smoothly, and it looks like you are going to be there on time. The following graph represents the locations and routes that you can possibly cover.

The guiding system's state indicates the complete path to reach C. It is telling you that you are going to go from F to B to D and then to C. It looks good!
To break things down further, let's say:
- The present state is the letter s.
- Your next action is the letter a (action). This action a is not location A.
- The next action a (not location A) is to go to location B. You look at your guiding system; it tells you there is no traffic, and that to go from your present state F to your next state B will take you only a few minutes. Let's say that the next state B is the letter B.
At this point, you are still quite happy, and we can sum up your situation with the following sequence of events:

The letter s is your present state, your present situation. The letter a is the action you're deciding, which is to go to the next area; there you will be in another state, s'. We can say that thanks to the action a, you will go from s to s'.
Now, imagine that the driver is not you anymore. You are tired for some reason. That is when a self-driving vehicle comes in handy. You set your car to autopilot. Now you are not driving anymore; the system is. Let's call that system the agent. At point F, you set your car to autopilot and let the self-driving agent take over.
The agent now sees what you have asked it to do and checks its mapping environment, which represents all the areas in the previous diagram from A to F.
In the meantime, you are rightly worried. Is the agent going to make it or not? You are wondering if its strategy meets yours. You have your policy P—your way of thinking—which is to take the shortest paths possible. Will the agent agree? What's going on in its mind? You observe and begin to realize things you never noticed before. Since this is the first time you are using this car and guiding system, the agent is memoryless, which is an MDP feature. This means the agent just doesn't know anything about what went on before. It seems to be happy with just calculating from this state s at area F. It will use machine power to run as many calculations as necessary to reach its goal.
Another thing you are watching is the total distance from F to C to check whether things are OK. That means that the agent is calculating all the states from F to C.
In this case, state F is state 1, which we can simplify by writing s1. B is state 2, which we can simplify by write s2. D is s3 and C is s4. The agent is calculating all of these possible states to make a decision.
The agent knows that when it reaches D, C will be better because the reward will be higher to go to C than anywhere else. Since it cannot eat a piece of cake to reward itself, the agent uses numbers. Our agent is a real number cruncher. When it is wrong, it gets a poor reward or nothing in this model. When it's right, it gets a reward represented by the letter R. This action-value (reward) transition, often named the Q function, is the core of many reinforcement learning algorithms.
When our agent goes from one state to another, it performs a transition and gets a reward. For example, the transition can be from F to B, state 1 to state 2, or s1 to s2.
You are feeling great and are going to be on time. You are beginning to understand how the machine learning agent in your self-driving car is thinking. Suddenly your guiding system breaks down. All you can see on the screen is that static image of the areas of the last calculation. You look up and see that a traffic jam is building up. Area D is still far away, and now you do not know whether it would be good to go from D to C or D to E to get a taxi that can take special lanes. You are going to need your agent!
The agent takes the traffic jam into account, is stubborn, and increases its reward to get to C by the shortest way. Its policy is to stick to the initial plan. You do not agree. You have another policy.
You stop the car. You both have to agree before continuing. You have your opinion and policy; the agent does not agree. Before continuing, your views need to converge. Convergence is the key to making sure that your calculations are correct. This is the kind of problem that persons, or soon, self-driving vehicles (not to speak about drone air jams), delivering parcels encounter all day long to get the workload done. The number of parcels to delivery per hour is an example of the workload that needs to be taken into account when making a decision.
To represent the problem at this point, the best way is to express this whole process mathematically.
Step 2 – the mathematical representation of the Bellman equation and MDP
Mathematics involves a whole change in your perspective of a problem. You are going from words to functions, the pillars of source coding.
Expressing problems in mathematical notation does not mean getting lost in academic math to the point of never writing a single line of code. Mathematics is viewed in the perspective of getting a job done. Skipping mathematical representation will fast-track a few functions in the early stages of an AI project. However, when the real problems that occur in all AI projects surface, solving them with source code only will prove virtually impossible. The goal here is to pick up enough mathematics to implement a solution in real-life companies.
It is necessary to think of a problem through by finding something familiar around us, such as the delivery itinerary example covered before. It is a good thing to write it down with some abstract letters and symbols as described before, with a meaning an action and s meaning a state. Once you have understood the problem and expressed the parameters in a way you are used to, you can proceed further.
Now, mathematics well help clarify the situation by shorter descriptions. With the main ideas in mind, it is time to convert them into equations.
From MDP to the Bellman equation
In the previous step 1, the agent went from F or state 1 or s to B, which was state 2 or s'.
To do that, there was a strategy—a policy represented by P. All of this can be shown in one mathematical expression, the MDP state transition function:
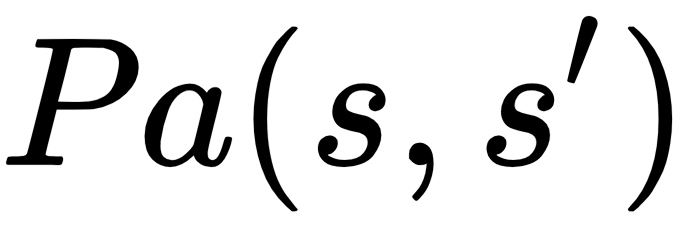
P is the policy, the strategy made by the agent to go from F to B through action a. When going from F to B, this state transition is called state transition function:
- a is the action
- s is state 1 (F) and s' is state 2 (B)
This is the basis of MDP. The reward (right or wrong) is represented in the same way:
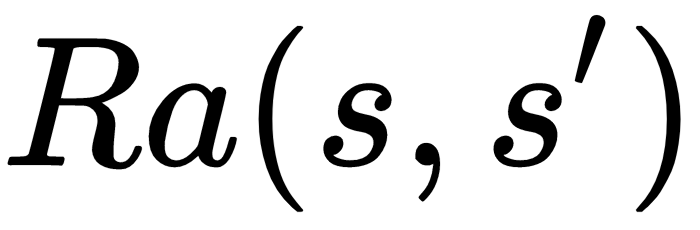
That means R is the reward for the action of going from state s to state s'. Going from one state to another will be a random process. This means that potentially, all states can go to another state.
The example we will be working on inputs a reward matrix so that the program can choose its best course of action. Then, the agent will go from state to state, learning the best trajectories for every possible starting location point. The goal of the MDP is to go to C (line 3, column 3 in the reward matrix), which has a starting value of 100 in the following Python code.
# Markov Decision Process (MDP) - The Bellman equations adapted to
# Reinforcement Learning
# R is The Reward Matrix for each state
R = ql.matrix([ [0,0,0,0,1,0],
[0,0,0,1,0,1],
[0,0,100,1,0,0],
[0,1,1,0,1,0],
[1,0,0,1,0,0],
[0,1,0,0,0,0] ])
Each line in the matrix in the example represents a letter from A to F, and each column represents a letter from A to F. All possible states are represented. The 1 values represent the nodes (vertices) of the graph. Those are the possible locations. For example, line 1 represents the possible moves for letter A, line 2 for letter B, and line 6 for letter F. On the first line, A cannot go to C directly, so a 0 value is entered. But, it can go to E, so a 1 value is added.
Some models start with -1 for impossible choices, such as B going directly to C and 0 values to define the locations. This model starts with 0 and 1 values. It sometimes takes weeks to design functions that will create a reward matrix (see Chapter 2, Think like a Machine).
There are several properties of this decision process. A few of them are mentioned here:
- The Markov property: The process is applied when the past is not taken into account. It is the memoryless property of this decision process, just as you do in a car with a guiding system. You move forward to reach your goal. This is called the Markov property.
- Unsupervised learning: From this memoryless Markov property, it is safe to say that the MDP is not supervised learning. Supervised learning would mean that we would have all the labels of the trip. We would know exactly what A means and use that property to make a decision. We would be in the future looking at the past. MDP does not take these labels into account. This means that this is unsupervised learning. A decision has to be made in each state without knowing the past states or what they signify. It means that the car, for example, was on its own at each location, which is represented by each of its states.
- Stochastic process: In step 1, when state B was reached, the agent controlling the mapping system and the driver didn't agree on where to go. A random choice could be made in a trial-and-error way, just like a coin toss. It is going to be a heads-or-tails process. The agent will toss the coin thousands of times and measure the outcomes. That's precisely how MDP works and how the agent will learn.
- Reinforcement learning: Repeating a trial and error process with feedback from the agent's environment.
- Markov chain: The process of going from state to state with no history in a random, stochastic way is called a Markov chain.
To sum it up, we have three tools:
- Pa(s,s'): A policy, P, or strategy to move from one state to another
- Ta(s,s'): A T, or stochastic (random) transition, function to carry out that action
- Ra(s,s'): An R, or reward, for that action, which can be negative, null, or positive
T is the transition function, which makes the agent decide to go from one point to another with a policy. In this case, it will be random. That's what machine power is for, and that's how reinforcement learning is often implemented.
Randomness is a property of MDP.
The following code describes the choice the agent is going to make.
next_action = int(ql.random.choice(PossibleAction,1))
return next_action
Once the code has been run, a new random action (state) has been chosen.
Bellman's equation completes the MDP. To calculate the value of a state, let's use Q, for the Q action-reward (or value) function. The pre-source code of Bellman's equation can be expressed as follows for one individual state:

The source code then translates the equation into a machine representation as in the following code:
# The Bellman equation
Q[current_state, action] = R[current_state, action] + gamma * MaxValue
The source code variables of the Bellman equation are as follows:
- Q(s): This is the value calculated for this state—the total reward. In step 1 when the agent went from F to B, the driver had to be happy. Maybe she/he had a crunch in a candy bar to feel good, which is the human counterpart of the reward matrix. The automatic driver maybe ate (reward matrix) some electricity, renewable energy of course! The reward is a number such as 50 or 100 to show the agent that it's on the right track. It's like when a student gets a good grade in an exam.
- R(s): This is the sum of the values up to there. It's the total reward at that point.
- ϒ = gamma: This is here to remind us that trial and error has a price. We're wasting time, money, and energy. Furthermore, we don't even know whether the next step is right or wrong since we're in a trial-and-error mode. Gamma is often set to 0.8. What does that mean? Suppose you're taking an exam. You study and study, but you don't really know the outcome. You might have 80 out of 100 (0.8) chances of clearing it. That's painful, but that's life. This is what makes Bellman's equation and MDP realistic and efficient.
- max(s'): s' is one of the possible states that can be reached with Pa (s,s'); max is the highest value on the line of that state (location line in the reward matrix).
Step 3 – implementing the solution in Python
In step 1, a problem was described in natural language to be able to talk to experts and understand what was expected. In step 2, an essential mathematical bridge was built between natural language and source coding. Step 3 is the software implementation phase.
When a problem comes up—and rest assured that one always does—it will be possible to go back over the mathematical bridge with the customer or company team, and even further back to the natural language process if necessary.
This method guarantees success for any project. The code in this chapter is in Python 3.6. It is a reinforcement learning program using the Q function with the following reward matrix:
import numpy as ql
R = ql.matrix([ [0,0,0,0,1,0],
[0,0,0,1,0,1],
[0,0,100,1,0,0],
[0,1,1,0,1,0],
[1,0,0,1,0,0],
[0,1,0,0,0,0] ])
Q = ql.matrix(ql.zeros([6,6]))
gamma = 0.8
R is the reward matrix described in the mathematical analysis.
Q inherits the same structure as R, but all values are set to 0 since this is a learning matrix. It will progressively contain the results of the decision process. The gamma variable is a double reminder that the system is learning and that its decisions have only an 80% chance of being correct each time. As the following code shows, the system explores the possible actions during the process.
agent_s_state = 1
# The possible "a" actions when the agent is in a given state
def possible_actions(state):
current_state_row = R[state,]
possible_act = ql.where(current_state_row >0)[1]
return possible_act
# Get available actions in the current state
PossibleAction = possible_actions(agent_s_state)
The agent starts in state 1, for example. You can start wherever you want because it's a random process. Note that only values > 0 are taken into account. They represent the possible moves (decisions).
The current state goes through an analysis process to find possible actions (next possible states). You will note that there is no algorithm in the traditional sense with many rules. It's a pure random calculation, as the following random.choice function shows.
def ActionChoice(available_actions_range):
next_action = int(ql.random.choice(PossibleAction,1))
return next_action
# Sample next action to be performed
action = ActionChoice(PossibleAction)
Now comes the core of the system containing Bellman's equation, translated into the following source code:
def reward(current_state, action, gamma):
Max_State = ql.where(Q[action,] == ql.max(Q[action,]))[1]
if Max_State.shape[0] > 1:
Max_State = int(ql.random.choice(Max_State, size = 1))
else:
Max_State = int(Max_State)
MaxValue = Q[action, Max_State]
# Q function
Q[current_state, action] = R[current_state, action] + gamma * MaxValue
# Rewarding Q matrix
reward(agent_s_state,action,gamma)
You can see that the agent looks for the maximum value of the next possible state chosen at random.
The best way to understand this is to run the program in your Python environment and print() the intermediate values. I suggest that you open a spreadsheet and note the values. It will give you a clear view of the process.
The last part is simply about running the learning process 50,000 times, just to be sure that the system learns everything there is to find. During each iteration, the agent will detect its present state, choose a course of action, and update the Q function matrix:
for i in range(50000):
current_state = ql.random.randint(0, int(Q.shape[0]))
PossibleAction = possible_actions(current_state)
action = ActionChoice(PossibleAction)
reward(current_state,action,gamma)
# Displaying Q before the norm of Q phase
print("Q :")
print(Q)
# Norm of Q
print("Normed Q :")
print(Q/ql.max(Q)*100)
After the process is repeated and until the learning process is over, the program will print the result in Q and the normed result. The normed result is the process of dividing all values by the sum of the values found. The result comes out as a normed percentage.
View the Python program at https://github.com/PacktPublishing/Artificial-Intelligence-By-Example/blob/master/Chapter01/MDP.py.
The lessons of reinforcement learning
Unsupervised reinforcement machine learning, such as MDP and Bellman's equation, will topple traditional decision-making software in the next few years. Memoryless reinforcement learning requires few to no business rules and thus doesn't require human knowledge to run.
Being an adaptive AI thinker involves three requisites—the effort to be an SME, working on mathematical models, and understanding source code's potential and limits:
- Lesson 1: Machine learning through reinforcement learning can beat human intelligence in many cases. No use fighting! The technology and solutions are already here.
- Lesson 2: Machine learning has no emotions, but you do. And so do the people around you. Human emotions and teamwork are an essential asset. Become an SME for your team. Learn how to understand what they're trying to say intuitively and make a mathematical representation of it for them. This job will never go away, even if you're setting up solutions such as Google's AutoML that don't require much development.
Reinforcement learning shows that no human can solve a problem the way a machine does; 50,000 iterations with random searching is not an option. The days of neuroscience imitating humans are over. Cheap, powerful computers have all the leisure it takes to compute millions of possibilities and choose the best trajectories.
Humans need to be more intuitive, make a few decisions, and see what happens because humans cannot try 50,000 ways of doing something. Reinforcement learning marks a new era for human thinking by surpassing human reasoning power.
On the other hand, reinforcement learning requires mathematical models to function. Humans excel in mathematical abstraction, providing powerful intellectual fuel to those powerful machines.
The boundaries between humans and machines have changed. Humans' ability to build mathematical models and every-growing cloud platforms will serve online machine learning services.
Finding out how to use the outputs of the reinforcement learning program we just studied shows how a human will always remain at the center of artificial intelligence.
How to use the outputs
The reinforcement program we studied contains no trace of a specific field, as in traditional software. The program contains Bellman's equation with stochastic (random) choices based on the reward matrix. The goal is to find a route to C (line 3, column 3), which has an attractive reward (100):
# Markov Decision Process (MDP) - Bellman's equations adapted to
# Reinforcement Learning with the Q action-value(reward) matrix
# R is The Reward Matrix for each state
R = ql.matrix([ [0,0,0,0,1,0],
[0,0,0,1,0,1],
[0,0,100,1,0,0],
[0,1,1,0,1,0],
[1,0,0,1,0,0],
[0,1,0,0,0,0] ])
That reward matrix goes through Bellman's equation and produces a result in Python:
Q :
[[ 0. 0. 0. 0. 258.44 0. ]
[ 0. 0. 0. 321.8 0. 207.752]
[ 0. 0. 500. 321.8 0. 0. ]
[ 0. 258.44 401. 0. 258.44 0. ]
[ 207.752 0. 0. 321.8 0. 0. ]
[ 0. 258.44 0. 0. 0. 0. ]]
Normed Q :
[[ 0. 0. 0. 0. 51.688 0. ]
[ 0. 0. 0. 64.36 0. 41.5504]
[ 0. 0. 100. 64.36 0. 0. ]
[ 0. 51.688 80.2 0. 51.688 0. ]
[ 41.5504 0. 0. 64.36 0. 0. ]
[ 0. 51.688 0. 0. 0. 0. ]]
The result contains the values of each state produced by the reinforced learning process, and also a normed Q (highest value divided by other values).
As Python geeks, we are overjoyed. We made something rather difficult to work, namely reinforcement learning. As mathematical amateurs, we are elated. We know what MDP and Bellman's equation mean.
However, as natural language thinkers, we have made little progress. No customer or user can read that data and make sense of it. Furthermore, we cannot explain how we implemented an intelligent version of his/her job in the machine. We didn't.
We hardly dare say that reinforcement learning can beat anybody in the company making random choices 50,000 times until the right answer came up.
Furthermore, we got the program to work but hardly know what to do with the result ourselves. The consultant on the project cannot help because of the matrix format of the solution.
Being an adaptive thinker means knowing how to be good in all the dimensions of a subject. To solve this new problem, let's go back to step 1 with the result.
By formatting the result in Python, a graphics tool, or a spreadsheet, the result that is displayed as follows:
| A | B | C | D | E | F | |
| A | - | - | - | - | 258.44 | - |
| B | - | - | - | 321.8 | - | 207.752 |
| C | - | - | 500 | 321.8 | - | - |
| D | - | 258.44 | 401. | - | 258.44 | - |
| E | 207.752 | - | - | 321.8 | - | - |
| F | - | 258.44 | - | - | - | - |
Now, we can start reading the solution:
- Choose a starting state. Take F for example.
- The F line represents the state. Since the maximum value is 258.44 in the B column, we go to state B, the second line.
- The maximum value in state B in the second line leads us to the D state in the fourth column.
- The highest maximum of the D state (fourth line) leads us to the C state.
Note that if you start at the C state and decide not to stay at C, the D state becomes the maximum value, which will lead you to back to C. However, the MDP will never do this naturally. You will have to force the system to do it.
You have now obtained a sequence: F->B->D->C. By choosing other points of departure, you can obtain other sequences by simply sorting the table.
The most useful way of putting it remains the normalized version in percentages. This reflects the stochastic (random) property of the solution, which produces probabilities and not certainties, as shown in the following matrix:
| A | B | C | D | E | F | |
| A | - | - | - | - | 51.68% | - |
| B | - | - | - | 64.36% | - | 41.55% |
| C | - | - | 100% | 64.36% | - | - |
| D | - | 51.68% | 80.2% | - | 51.68% | - |
| E | 41.55% | - | - | 64.36% | - | - |
| F | - | 51.68% | - | - | - | - |
Now comes the very tricky part. We started the chapter with a trip on a road. But I made no mention of it in the result analysis.
An important property of reinforcement learning comes from the fact that we are working with a mathematical model that can be applied to anything. No human rules are needed. This means we can use this program for many other subjects without writing thousands of lines of code.
Case 1: Optimizing a delivery for a driver, human or not
This model was described in this chapter.
Case 2: Optimizing warehouse flows
The same reward matrix can apply to going from point F to C in a warehouse, as shown in the following diagram:

In this warehouse, the F->B->D->C sequence makes visual sense. If somebody goes from point F to C, then this physical path makes sense without going through walls.
It can be used for a video game, a factory, or any form of layout.
Case 3: Automated planning and scheduling (APS)
By converting the system into a scheduling vector, the whole scenery changes. We have left the more comfortable world of physical processing of letters, faces, and trips. Though fantastic, those applications are social media's tip of the iceberg. The real challenge of artificial intelligence begins in the abstract universe of human thinking.
Every single company, person, or system requires automatic planning and scheduling (see Chapter 12, Automated Planning and Scheduling). The six A to F steps in the example of this chapter could well be six tasks to perform in a given unknown order represented by the following vector x:

The reward matrix then reflects the weights of constraints of the tasks of vector x to perform. For example, in a factory, you cannot assemble the parts of a product before manufacturing them.
In this case, the sequence obtained represents the schedule of the manufacturing process.
Case 4 and more: Your imagination
By using physical layouts or abstract decision-making vectors, matrices, and tensors, you can build a world of solutions in a mathematical reinforcement learning model. Naturally, the following chapters will enhance your toolbox with many other concepts.
Machine learning versus traditional applications
Reinforcement learning based on stochastic (random) processes will evolve beyond traditional approaches. In the past, we would sit down and listen to future users to understand their way of thinking.
We would then go back to our keyboard and try to imitate the human way of thinking. Those days are over. We need proper datasets and ML/DL equations to move forward. Applied mathematics has taken reinforcement learning to the next level. Traditional software will soon be in the museum of computer science.
An artificial adaptive thinker sees the world through applied mathematics translated into machine representations.
Summary
Presently, artificial intelligence is predominantly a branch of applied mathematics, not of neurosciences. You must master the basics of linear algebra and probabilities. That's a difficult task for a developer used to intuitive creativity. With that knowledge, you will see that humans cannot rival with machines that have CPU and mathematical functions. You will also understand that machines, contrary to the hype around you, don't have emotions although we can represent them to a scary point (See Chapter 16, Improve the Emotional Intelligence Deficiencies of Chatbots, and Chapter 17, Quantum Computers That Think) in chatbots.
That being said, a multi-dimensional approach is a requisite in an AI/ML/DL project—first talk and write about the project, then make a mathematical representation, and finally go for software production (setting up an existing platform and/or writing code). In real-life, AI solutions do not just grow spontaneously in companies like trees. You need to talk to the teams and work with them. That part is the real fulfilling aspect of a project—imagining it first and then implementing it with a group of real-life people.
MDP, a stochastic random action-reward (value) system enhanced by Bellman's equation, will provide effective solutions to many AI problems. These mathematical tools fit perfectly in corporate environments.
Reinforcement learning using the Q action-value function is memoryless (no past) and unsupervised (the data is not labeled or classified). This provides endless avenues to solve real-life problems without spending hours trying to invent rules to make a system work.
Now that you are at the heart of Google's DeepMind approach, it is time to go to Chapter 2, Think Like a Machine, and discover how to create the reward matrix in the first place through explanations and source code.
Questions
- Is reinforcement learning memoryless? (Yes | No)
- Does reinforcement learning use stochastic (random) functions? (Yes | No)
- Is MDP based on a rule base? (Yes | No)
- Is the Q function based on the MDP? (Yes | No)
- Is mathematics essential to artificial intelligence? (Yes | No)
- Can the Bellman-MDP process in this chapter apply to many problems? (Yes | No)
- Is it impossible for a machine learning program to create another program by itself? (Yes | No)
- Is a consultant required to enter business rules in a reinforcement learning program? (Yes | No)
- Is reinforcement learning supervised or unsupervised? (Supervised | Unsupervised)
- Can Q Learning run without a reward matrix? (Yes | No)
Further reading
Andrey Markov: https://www.britannica.com/biography/Andrey-Andreyevich-Markov
The Markov Process: https://www.britannica.com/science/Markov-process


