


















 Download code from GitHub
Download code from GitHub
Chapter 1: An Introduction to Google Cloud for Architects
Is the "cloud” just someone else's data center? Some may see it that way, but there is much more to cloud computing than that. Cloud computing builds on infrastructure virtualization technologies to deliver services on demand, enabling not only a technological but a cultural shift in the way we work with IT systems. Furthermore, cloud computing has facilitated a new economic model for infrastructure services and has lowered the entry barrier for highly demanding applications, particularly in the areas of big data and artificial intelligence (AI), making it easier for smaller players to join the data-driven market. Foundational knowledge of cloud business and Google Cloud is a fundamental first step in a cloud architect's journey toward designing solutions with confidence using Google Cloud, so this is where we will start. In this chapter, you will learn about the enabling technologies of cloud computing and the motivations for its adoption, as well as develop a basic understanding of cloud economics and different cloud delivery models. You will then be provided with an overview of Google Cloud services and learn about some of its competitive advantages and best-of-breed technologies. Finally, you will get hands-on with Google Cloud by setting up an account, installing the SDK, and running a minor deployment.
In this chapter, we're going to cover the following main topics:
- Understanding the motivations and economics of cloud computing
- Making the business case for cloud adoption (and Google Cloud)
- Learning about Google Cloud's key differentiators – big data and AI
- Getting an overview of Google Cloud for cloud architects
- Getting started with Google Cloud Platform (GCP)
Technical requirements
Check out the following link to see the Code in Action video: https://bit.ly/3bYNoEv
Understanding the motivations and economics of cloud computing
At what point do we stop calling it just a data center, and start calling it the "cloud”? The National Institute of Standards and Technology (NIST) defines the following five essential traits that characterize cloud computing:
- On-demand, self-service
- Broad network access
- Resource pooling
- Rapid elasticity or expansion
- Measured service
The ability to deliver elastic services that can scale to adapt to varying demand, while paying only for the resources that you use, is what makes cloud computing so appealing and powerful.
The main enabling technology is that of infrastructure virtualization (or cloudification, as it is sometimes referred to), which has been made possible in the past few decades by the commoditization of hardware and new paradigms such as software-defined networking (SDN), in which the system's "intelligence” (control plane) is decoupled from the system's underlying hardware processing functions (the data plane).
These new technologies have allowed for increased levels of programmability of the infrastructure, where provisioned infrastructure resources can be abstracted and services can be exposed through application programming interfaces (APIs), in the same way that software applications' resources are. For example, with a few REST API calls, you can deploy a virtual network environment with virtual machines and public IP addresses. This has made cloud computing much more accessible to professionals working in roles beyond those of traditional enterprise IT or solution architects. It has also facilitated the emergence of the Infrastructure-as-Code (IaC) paradigm and the DevOps culture.
It has done this by enabling infrastructure resources to be defined in text-based declarative language and source-controlled in a code repository, and deployments to be streamlined via pipelines. At the time of writing, there is nothing standing between a team of developers and a complete infrastructure ready to run application workloads at any scale, except perhaps the required budget for doing so.
The NIST definition also lists four cloud deployment models:
- Private
- Community
- Public
- Hybrid
These models relate to the ownership of the hosting infrastructure. This book is about Google Cloud, which is owned and operated by Google as the cloud service provider and delivered over the internet through the public cloud model. In a public cloud, the infrastructure resources are shared between organizations (or cloud "tenants”), which means that within the same physical hosting infrastructure, several different virtualized systems from different customers may be running alongside each other. This, along with the lack of control and visibility over the underlying physical infrastructure, is one of the most criticized aspects of the public cloud model since it raises security and privacy concerns. It is the reason some organizations are reluctant to seriously consider migrating their infrastructure to the public cloud, and also the reason several others settle "somewhere in the middle” with a hybrid cloud deployment, in which only part of their infrastructure is hosted in a public cloud environment (the remaining part being privately hosted).
What makes cloud computing so disruptive and appealing, however, is not solely the new technological model that's enabled by virtualization technologies and commodity hardware, but the economic model that ensues (at least for the players in the market with deep enough pockets), which is that of economies of scale and global reach. While IT systems are generally expensive to purchase and maintain, being able to buy resources in massive quantities and build several data centers across the globe enables you to reduce and amortize those costs greatly, and then pass those savings on to your customers, who themselves can benefit from the consumption-based model and avoid large upfront investments and commitments. It's a win-win situation.
This is the shift from Capital Expenditures (CAPEX) to Operational Expenditures (OPEX) that we hear about so often, and is one of the tenets of cloud computing.
CAPEX versus OPEX
Instead of purchasing your own expensive infrastructure with a large upfront investment (the CAPEX model), you can benefit from the pay-as-you-go pricing model offered in the public cloud as a monthly consumption fee with no termination penalty (the OPEX model). Pay-as-you-go simply means you pay only for the resources you consume, while you consume them, and it's a bundled price that includes everything from any potential software licenses down to maintenance costs of the physical infrastructure running the service. This is in contrast to acquiring your own private infrastructure (or private cloud), in which case you would size it for the expected maximum demand and commit with a large upfront investment to this full available capacity, even if you only utilize a fraction of that capacity most of the time.
For organizations whose line-of-business applications have varying demands based on, for example, day of the week or time of the year (indeed, this is the case for most web-based applications today), the ability to only pay for extra resource allocation only during the few hours or days that those extra resources are needed is very beneficial financially. Resource utilization efficiency is maximized. What is even better is that such scaling events can be done automatically, and they require no on-call operations personnel to handle them.
The shift from CAPEX to OPEX also has implications on cash flow. Rather than having to pay a large, upfront infrastructure cost (the price commitment for which may go beyond the budget of smaller organizations, which would force them to borrow money and deal with interest costs), organizations can smooth out cash flows over time and drive improved average margin per user. In addition, it offers a much lower financial "penalty” for start - ups that pivot their business in a way that would drive major changes in the infrastructure architecture (in other words, it costs less to "pull the plug” on infrastructure "purchase” decisions).
Technology enablement
Cloud technologies are also powering a new range of applications that require immense distributed computing power and AI capabilities. The possibility to scale compute needs on-demand and pay only for what you use means that many more companies can benefit from this powerful and virtually limitless capacity, as they don't need to rely on prohibitively expensive infrastructure of their own to support such high-demand workloads.
Google has invested heavily over the years in their infrastructure and machine learning models since services such as Google Search, Google Maps, and YouTube – some of the most powerful data-driven services at the highest scale you can think of today – run on the same infrastructure and use the same technologies that Google now makes available for Google Cloud customers for consumption.
The NIST definition for cloud computing also lists three "service models” that, together with the deployment models, characterize the ways services are delivered in the cloud:
- Software-as-a-Service, also known as SaaS
- Platform-as-a-Service, also known as PaaS
- Infrastructure-as-a-Service, also known as IaaS
These relate to which layers of the infrastructure are managed and operated by the cloud provider (or the infrastructure owner) and which are your responsibility as a consumer.
In a public cloud, such as Google Cloud, the delivery models are easy to reason about when you're visualizing the stack of infrastructure layers against your – and the cloud provider's – responsibility for managing and operating each layer:

Figure 1.1 – Difference in management responsibilities (on-premises versus IaaS versus PaaS versus SaaS)
Organizations with a medium to large digital estate and several different types of workloads will typically acquire not one but a mix of services across different models, based on the specific requirements and technical constraints of each workload. For example, you may have a stateless application that you developed with a standard programming language and framework hosted on a PaaS service, while you may have another application in the same cloud environment that relies heavily on custom libraries and features, and is therefore hosted on a virtual machine (IaaS). As we will see throughout this book, there are several considerations and design trade-offs to take into account when choosing which delivery model is best, but typically, it comes down to a tug of war between control over the underlying platform (things such as patch and update schedules, the configurability of the application runtime and framework, access to the operating system's filesystem, custom VM images, and so on) and low management overhead (low to no platform operation, smaller and more independent application teams).
Cloud-native or cloud-first organizations will typically consume more of the PaaS and SaaS services, and rely less on IaaS VMs. This reduces dependencies on infrastructure teams and allows development-focused teams to quickly and easily deploy code to a platform whose infrastructure management is delegated to the cloud provider. This is one reason why the public cloud has a very strong appeal to smaller organizations and start - up software companies.
For other organizations, you may need to make a convincing case for the public cloud to get executive buy-in. Next, we'll explore how to make the business case for cloud adoption.
Making the business case for cloud adoption (and Google Cloud)
An important decision-making tool for companies considering cloud adoption is the Return on Investment (ROI) calculation, which can be obtained as follows:

Let's take a look at this calculation in more detail:
- The gain from investment is the net positive cost savings obtained by migrating on-premises infrastructure to the cloud. This can be estimated by obtaining a quote (for instance, from the Google Cloud Pricing Calculator) and subtracting it from the Total Cost of Ownership (TCO) of the on-premises data center. This includes capital costs of equipment, labor costs, and other maintenance and operational costs, such as software license fees.
- The initial investment is the sum of costs involved in the migration project itself. This involves primarily labor and training costs.
A positive ROI will help you make a stronger case for the business value of cloud adoption to the executives in the organization you're working with. A cloud solution architect will often be involved in this financial exercise.
It is also useful (and even more important) to identify, as a cloud architect, the main motivations and business drivers behind a cloud adoption project beyond cost savings, as this knowledge will help shape the solution's design. Each organization is unique and has different needs, but some of the most common motivations for enterprises are as follows:
- You can avoid large capital expenditures and infrastructure maintenance in order to focus on application development.
- You can reduce technical complexity and integrate complex IT portfolios.
- You can optimize and increase the productivity of internal operations.
- You can improve the reliability and stability of online applications.
- You can increase business agility and innovation with self-service environments.
- You can scale to meet market demands.
Once you have identified these motivations, the next thing you must do is align those motivations with your expected business outcomes. These are observable and measurable results, such as increased profitability, improved customer satisfaction, improved team productivity, and so on. For each business outcome, success metrics should be defined that describe how such benefits are going to be measured. The ROI we discussed earlier is one example of such a metric, but there could be several others that measure, in some way or another, the degree of success of the cloud adoption (which, of course, depends on the organization's own definition of success). The following diagram shows an example of a motivation + outcome + metric triad:

Figure 1.2 – Sample motivation, outcome, and metric triad as a cloud adoption strategy
This exercise is not just something to wind up on a slide presentation at a meeting room full of executives during a boring Tuesday afternoon. It should be taken seriously and become an integral part of the organization's overall strategy. In fact, in a recent Unisys' Cloud Success Barometer report (https://www.unisys.com/cloudbarometer), it has been shown that, globally, one in three cloud migrations fail because the cloud is not part of the business' core strategy. On the other hand, organizations that make the cloud a part of a broader business transformation strategy are substantially more likely to succeed. Let that sink in.
Establishing a cloud adoption business strategy is outside the scope of this book, but Google's Cloud Adoption Framework (https://cloud.google.com/adoption-framework) was developed to provide a streamlined framework to guide organizations throughout their cloud adoption efforts. It is freely available online and is based on four themes (Learn, Lead, Scale, and Secure) and three phases that reflect the organization's maturity level (Tactical, Strategic, and Transformational).
Deciding whether or not to migrate to the public cloud may not be a very difficult decision to make. We are well past the phase of early adoption and uncertainty, and the public cloud model is now very mature and well into its adulthood. A perhaps more difficult question, however, is: why Google Cloud?
You've learned about the economics of cloud computing and how to make the business case for cloud adoption. Now, let's see where Google fits into the picture and the reasons you can present to organizations as to why they should choose Google Cloud.
Learning about Google Cloud's key differentiators – big data and AI
The cloud business is a real fight of titans, with the "titans” being Microsoft, Amazon, Google, Alibaba, and a few others. They are among the biggest organizations in the world in terms of network and infrastructure footprint. Competition is good for any business, of course, but for us customers, it can make it difficult for us to decide between the options we have when they are all seemingly great.
Why Google?
Google Cloud was late to the cloud business. And it didn't speak to the early adopters when it decided to focus on PaaS services primarily (as opposed to the more familiar IaaS option), something the world wasn't yet ready for in the early days of cloud computing. But things are now changing. Google Cloud offers some of the best-of-breed services for the development of modern, containerized applications, using sophisticated analytics and AI capabilities that are cost-competitive. Google is the inventor of Kubernetes and some of the cutting-edge big data technology innovations such as TensorFlow, MapReduce, and BigTable. Google knows how to handle large-scale distributed applications and very large amounts of data probably better than anyone, because this is exactly what it has been doing (and doing really well) for about two decades now. It also knows how complex these systems are, which is why it is presenting them to its customers as a friendly, serverless, and easy-to-consume service in the cloud.
The reluctance of many enterprises to consider Google Cloud is understandable. Amazon's AWS is very mature and reliable, and their client portfolio certainly speaks for the success and maturity of their platform. Microsoft's Azure is a natural best choice too if all your existing IT systems are based on Microsoft products and services, such as Active Directory, Windows Servers, and Microsoft (MS) Office applications. Microsoft has dominated the enterprise IT business for years (and probably still does, with its strong appeal to enterprise customers due to existing relationships and its level of maturity), and they are certainly making sure that a transition to the Azure cloud would be as seamless as possible. Plus, they understand the needs of enterprises deeply, their security and compliance concerns, their need for protecting users' identities, and their need for reliability and strong Service-Level Agreements. This is all very true, but an unfair assumption that's often made in that line of reasoning is that Google does not have any of that expertise or credibility themselves. People will often say Google Cloud is "cool," but it is not as safe a bet as AWS or Azure. That might have been true once, but now, that is an assumption that you, as a cloud architect, can learn to challenge.
Firstly, Google Cloud has a growing list of high-profile customers, some of which are:
- PayPal
- HSBC
- Target
- eBay
- Verizon
- Spotify
- Deutsche Bank
These are just a few. They have all reported that they have realized benefits with Google Cloud, especially around big data and AI capabilities, but not exclusively so. PayPal's CTO Sri Shivananda has stated that PayPal turned to Google as their cloud provider "because it has the fastest network in terms of throughput, bandwidth, and latency." It's not very difficult to understand why Google's global network is hard to beat: it powers latency- and bandwidth-sensitive services such as Google Search and YouTube. Twitter runs on a distributed Hadoop system that hosts more than 300 PB of data across tens of thousands of servers on Google Cloud. Parag Agrawal, CTO of Twitter, said "Google Cloud Platform provides the infrastructure that can support this and the advanced security that well serves not just our company but also our users. This peace of mind is invaluable."
Multi-cloud friendly
More and more companies are also evaluating so-called multi-cloud strategies to benefit from the best of two or more cloud platforms. Google seems very much on board with this, facilitating multi-cloud strategies and even developing products that work on multiple cloud platforms. Organizations that would like to leverage, for example, Microsoft Azure to migrate their existing Windows-based systems and Active Directory identities can still do so, while more modern applications can be migrated to Google Cloud to reap the benefits of modern capabilities. You can have yet another piece of your application in AWS too, should you consider that platform to be best suited for it. The one drawback of multi-cloud deployments is the higher management overhead and the more diverse skillset required within the organization to manage multiple platforms, which may increase the needs for internal training and/or hiring (and therefore drive costs).
Once again, however, the strategic discussions around business motivations and business outcomes become very relevant in identifying ways to actually obtain a higher ROI through a multi-cloud deployment model, by aiming to explore the best of what each cloud provider has to offer. With the right strategy and the right execution, multi-cloud certainly pays off.
Big data and AI
One important consideration when it comes to making the case for Google Cloud is to adopt an innovation-led development mindset and understand industry trends. We may be in a moment now where big data and AI are somewhat what cloud computing itself used to be in its early days: a shiny new object, a cool-but-maybe-not-for-me-yet technology. Now, nearly everyone is in a rush to get to the cloud, and some probably regret not being among the early adopters. The same could happen with AI and big data: this may likely be the right window to get in, and should you decide to do so, it is hard to dispute the fact that Google Cloud is leading the way and offering the very best you can get in that arena. Google firmly believes in the saying that "every company is a data company," or at least that this will eventually be true, because it seems to be seeding the ground for a future where the best big data capabilities will be the deciding factor on who's going to win the war for cloud market share.
In a 2019 PwC study, it was estimated that AI will provide a potential contribution of $15.7 trillion to the global economy by 2030, with high potential use cases across several different industries. What is already a reality in 2020, however, is that companies are investing heavily in cognitive software capabilities to analyze data and inform decision-making or to build more personalized and profitable products and campaigns. Other areas of focus of AI currently include supply chain optimizations, mobile features (such as real-time speech translation), enhancing customer experience (by providing, for example, always-on chat bots or contact center AI), and improved security (with features such as fraud and threat detection).
The common theme underlying these use cases is not old technologies being replaced (or people, at least not for the time being), but rather the improvement, enhancement, or augmentation of existing ones to provide more value and profitability. The field of AI has many aspirations and ambitions for the future, and those are the ones we tend to hear about the most in the press, which gives us the impression that AI still only belongs to the realm of imagination and research. But it is very real already, and companies have been reaping its benefits for years. Jumping on the AI and big data bandwagon is likely one of the safest bets tech organizations can place today, especially considering the entry barrier has never been this low, with easy-to-consume, pay-as-you-go AI services that are on the bleeding edge of the field.
And it gets better. You don't need to lock yourself in with Google Cloud products if you want to leverage these capabilities – you can simply build your applications on open source tools you might already be familiar with.
Open source
If you work with an organization involved in the open source world (be it as a contributor, or purely as a consumer), Google's heavy involvement and strategic partnerships with leading open source companies may appeal to them. These partnerships have allowed Google to integrate open source tooling and services into Google Cloud, making it easy for enterprise customers to build and use apps by using those services in ways that feel very similar to the experience of using cloud-native resources. If vendor lock-in is a concern in your organization, you can see how Google Cloud embraces not only the open software culture, but also the multi-cloud model, by allowing several of these services to seamless integrate with systems that are hosted in other public clouds or on-premises data centers (in a hybrid cloud model). And because open source software does not rely on proprietary libraries and technologies, they are easier to port to another cloud provider, should you decide to do so. One of the best examples is Kubernetes, an open source container orchestration platform where you can run service-oriented applications completely agnostic to the underlying infrastructure. In fact, one of Google's latest developments is Anthos, a new and also open platform service that lets you run applications anywhere inside Kubernetes clusters, unmodified, across different clouds and/or private on-premises environments. It is a fully fledged hybrid- and multi-cloud solution for modern application development.
You have now gotten a better understanding of the many strengths of Google Cloud and some reasons why organizations should consider it, as well as how you can make a convincing case for it. Next, let's dive into Google Cloud and its technologies.
Getting an overview of Google Cloud
As we discussed in the previous section, some of Google Cloud's key market differentiators are its democratized big data and AI innovations and its open source friendly ecosystem. Data-driven businesses that already work with open source tools and frameworks such as Kubernetes, TensorFlow, Apache Spark, and Apache Beam will find Google to be a well-suited cloud provider as these services are first-class citizens on Google Cloud Platform (GCP). Although you can technically deploy open source software on any cloud platform using VMs, Google has gone to some greater lengths than its competitors have by offering several of these services through a cloud-native experience with its PaaS offerings.
GCP also has one of the world's largest high-speed software-defined networks. At the time of writing, Google Cloud is available in over 200 countries and territories, with 24 cloud regions and 144 network edge locations. It would come as no surprise, however, if by the time you're reading this that these numbers have increased.
In this section, we're going to explore how GCP is structured into regions and zones, what its core services are, and how it approaches the security of the platform and its resource hierarchy.
Regions and zones
GCP is organized into regions and zones. Regions are independent and broad geographic areas, such as europe-west1 or us-east4, while zones are more specific locations that may or may not correspond to a single physical data center, but which can be thought of as single failure domains. Networked locations within a region typically have round-trip network latencies under 5ms, often under 1ms.
Most regions have three or more zones, which are specified with a letter suffix added to the region name. For example, region us-east4 has three zones: us-east4-a, us-east4-b, and us-east4-c. Mapping a zone to a physical location is not the same for every organization. In other words, there's not a location Google calls "zone A” within the us-east4 region. There are typically at least three different physical locations, and what a zone letter corresponds to will be different for each organization since these mappings are done independently and dynamically. The main reason for this is to ensure there's a resource balance within a region.
Certain services in Google Cloud can be deployed as multi-regional resources (spanning several regions). Throughout this book, we will look at the options and design considerations for regional or multi-regional deployments for various services.
Core Google Cloud services
In this section, we'll present a bird's-eye overview of the core GCP services across four different major categories: compute, storage, big data, and machine learning. The purpose is not to present an in-depth description of these services (which will happen in the chapters in section two as we learn how to design solutions), but to provide a quick rundown of the various services in Google Cloud and what they do. Let's take a look at them:
- Compute
Compute Engine: A service for deploying IaaS virtual machines.
Kubernetes Engine: A platform for deploying Kubernetes container clusters.
App Engine: A compute platform for applications written in Java, Python, PHP, Go, or Node.js.
Cloud Functions: A serverless compute platform for executing code written in Java, Python, Go, or Node.js.
- Storage
Bigtable: A fully managed NoSQL database service for large analytical and operational workloads with high volumes and low latency.
Cloud Storage: A highly durable and global object storage.
Cloud SQL: A fully managed relational database service for MySQL, PostgreSQL, and SQL Server.
Cloud Spanner: A fully managed and highly scalable relational database with strong consistency.
Cloud Datastore: A highly scalable NoSQL database for web and mobile applications.
- Big Data
BigQuery: A highly scalable data warehouse service with serverless analytics.
Pub/Sub: A real-time messaging service.
Data Fusion: A fully managed, cloud-native data integration service.
Data Catalog: A fully managed, highly scalable data discovery service.
Dataflow: A serverless stream and batch data processing program based on Apache Beam.
Dataproc: A data analytics service for building Apache Spark, Apache Hadoop, Presto, and other OSS clusters.
- Machine Learning
Natural Language API: A service that provides natural language understanding.
Vision API: A service with pre-trained machine learning models for classifying images and detecting objects and faces, as well as printed and handwritten text.
Speech API: A service that converts audio into text by applying neural network models.
Translation API: A service that translates text between thousands of language pairs.
AutoML: A suite of machine learning products for developing machine learning models with little to no coding.
AI Platform: A code-based development platform with an integrated tool chain that can help you run your own machine learning applications.
Naturally, similar services to the ones presented here could be deployed to virtual machines with the full power of customization that comes with them. However, a self-hosted IaaS-based service is evidently not managed nor offered any service-level guarantees (beyond that of the virtual machines themselves) by the cloud provider, although they are viable options when migrating applications – sometimes the only option – as will be discussed in later chapters.
Multi-layered security
Security is a legitimate concern for many organizations when considering cloud adoption. For many, it may feel like they're taking a strong business risk in handing over their data and line-of-business applications to some other company to host within their data centers. Cloud providers know about such concerns very well, which is why they have gone to great lengths to ensure that they're designing security into their technical infrastructure. After all, the major cloud providers in the market (Google, Amazon, and Microsoft) are themselves consumer technology companies that have to deal with security attacks and penetration attempts on a daily basis. In fact, these organizations have years of experience safeguarding their infrastructure against Denial-of-Service (DoS) attacks and even things such as social engineering. In fact, an argument could be made that security concerns over hosting private data and intellectual property by a third party is somewhat offset by the fact that the third party's infrastructure is likely to be more secure and impenetrable than a typical private data center facility. The infrastructure security personnel of a cloud service provider certainly outnumbers that of a typical organization, offering more manpower and more concentrated effort toward preventing and mitigating security incidents at the infrastructure layer.
The following are some of the measures taken by Google with its multi-layered security approach to cloud infrastructure:

Because of the sheer scale of Google, it can deliver a higher level of security at the lower layers of the infrastructure than most of its customers could even afford to. Several measures are taken to protect users against unauthorized access, and Google's systems are monitored 24 hours a day, 365 days a year by a global operations team.
With that being said, it is important to recognize that security in the cloud is a shared responsibility. Customers are still responsible for securing their data properly, even for PaaS and SaaS services.
Security is a fundamental skill for cloud architects, and incorporating security into any design will be a central theme throughout this book.
Resource hierarchy
Resources in GCP are structured similar to how you would structure artifacts when working in any other types of projects.
The project level is where you enable and manage GCP capabilities such as specific APIs to be used, billing, and other Google services, and is also where you can add or remove collaborators. Any resources that are created are connected to a project and belong to exactly one project. A project can have multiple owners and users, and multiple projects can be organized into folders. Folders can nest other folders (sub-folders) up to 10 levels deep, and contain a combination of projects and folders.
One common way to define a folder hierarchy is to have each folder represent a department within the company, with sub-folders representing different teams within the department, each with their own sub-folders representing different applications managed by the team. These will then contain one or more projects that will host the actual cloud resources. At the top level of the hierarchy is the organization node.
If this sounds a little confusing, then take a look at the following diagram, which helps illustrate an example hierarchy. Hopefully, this will make things a little clearer to you:
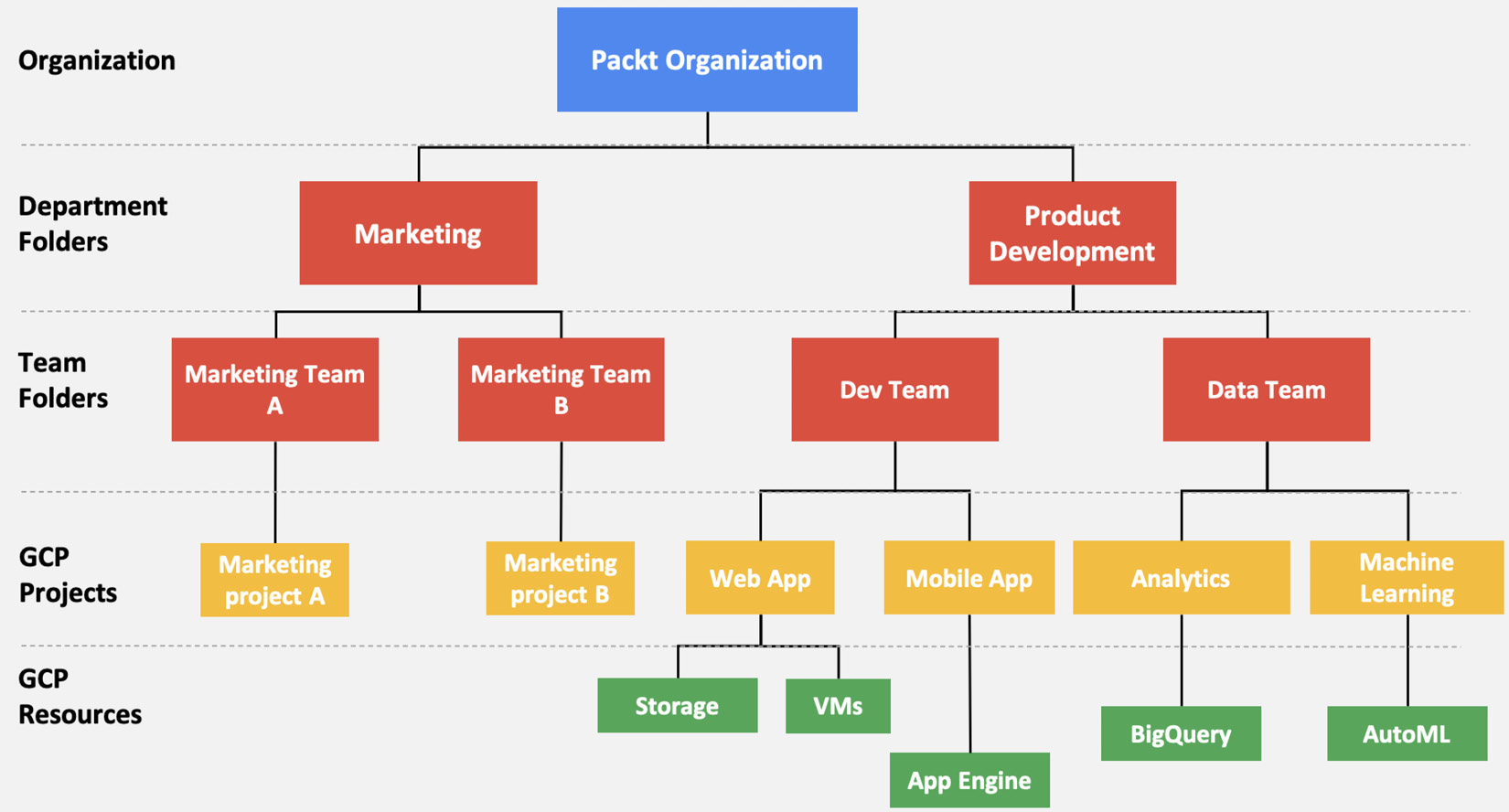
Figure 1.3 – Resource hierarchy in GCP
At every level in this hierarchy (and down to the cloud resources for certain types of resources), Identity and Access Management (IAM) policies can be defined, which are inherited by the nodes down the hierarchy. For example, a policy applied at the organization node level will be automatically inherited by all folders, projects, and resources under it.
Folders can also be used to isolate requirements for different environments, such as production and development. You are not required to organize projects into folders, but it is a recommended best practice that will greatly facilitate management (and access management in particular) for your projects. An organization node is also not a requirement, and not necessarily something you have to obtain if, for example, you have a GCP project for your own personal use and experimentation.
One important thing to note is that an access policy, when applied at a level in the hierarchy, cannot take away access that's been granted at a lower level. For example, a policy applied at project A granting user John editing access will take effect even if, at the organization node (the project's parent level), view-only access is granted. The less restrictive (that is, more permissive) access is applied in this case, and user John will be able to edit resources under project A (but still not under other projects belonging to the same organization).
Getting started with Google Cloud Platform
In this section, we will get started with GCP by setting up an account and a project, installing the Software Development Kit (SDK), and using BigQuery to query Wikipedia articles and get you warmed up with big data in Google Cloud.
Setting up a GCP account and project
From a web browser, navigate to https://console.cloud.google.com/ and sign in with your personal Gmail account (if you don't have one, go ahead and create one before continuing). If you're a first-time user, you will be asked to select your country and agree with the Terms of Service, and you will also see a prompt for activating a free trial so that you can get $300 to explore Google Cloud. This may be a banner on the top, or a button on the Home page. Activate your trial, keeping in mind that you will be asked for a valid credit card number. But don't worry – you won't be charged even after the trial ends, unless you manually upgrade to a paid account. There should be a clarifying statement on the trial activation page that confirms this.
Once you've gone through that so that your account has been set up and your trial has been activated, you should be directed to the Google Cloud console. A project named My First Project (or something similar) will be automatically created for you. On the top bar within the console, you can see which project you're currently working under from the top-left corner:

Figure 1.4 – GCP console project view
If you click on the small down arrow next to the name of the project, it will open the project selection menu, as shown in the following screenshot. This is where you can choose which project to work on (for now, there will only be one listed). You can also create a new project from here if you wish to do so:
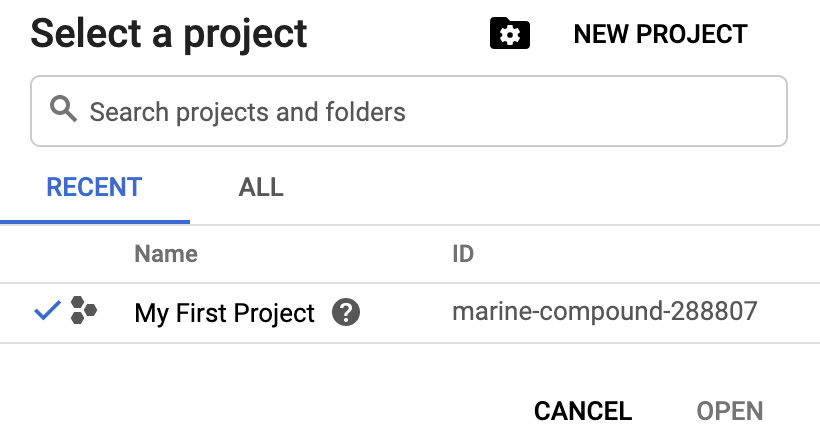
Figure 1.5 – GCP project selection menu
For every project in GCP, the following must be defined:
- Project Name: Set by you and doesn't need to be globally unique. Can be changed after project creation.
- Project ID: Can be set by you but needs to be globally unique and cannot be changed.
- Project Number: Assigned by GCP. It is globally unique and cannot be changed.
For now, however, we don't need to create a new project (we will do that in Chapter 2, Mastering the Basics of Google Cloud, as well as handling things such as billing and IAM policies. If you're already somewhat familiar with the platform, feel free to skip ahead to the next chapter!).
Installing the Google Cloud SDK and using gcloud
The Google Cloud Software Development Kit (SDK) is a set of tools for interacting with the platform. This includes the gcloud, gsutil, and bq command-line tools, as well as client libraries and local emulators for developing with Google Cloud.
Go to https://cloud.google.com/sdk/install and follow the installation instructions specific to your operating system. Make sure that you complete the last step, which is to run the following on a terminal:
$ gcloud init
If you're a Windows user, after running this command, there will be an option to select at the end of the installation process. This command will initialize gcloud and set some default configurations. You will be asked to sign in to Google Cloud and choose a project.
If you want to see what the active configuration is, you can run the following command:
$ gcloud config list
This command should list your active configurations, such as the account and project currently being used.
The gcloud CLI commands are organized into a nested hierarchy of command groups, each one representing a specific service or feature of the platform or their functional subgroups. So, for example, if you want to run commands against virtual machines, you would start with gcloud compute instances. That's how you "drill down” the hierarchy of command groups: you simply append the respective command group name. This is, of course, a very long list to memorize, but you don't have to. As you type in commands, if you're unsure what options are available for the next level, you can simply add the --help command suffix flag and you will see the sub-groups and commands you can use from that point on.
For example, if you want to see what you can do with compute instances, you can type in the following:
$ gcloud compute instances --help
In the output, you should see something similar to the following:
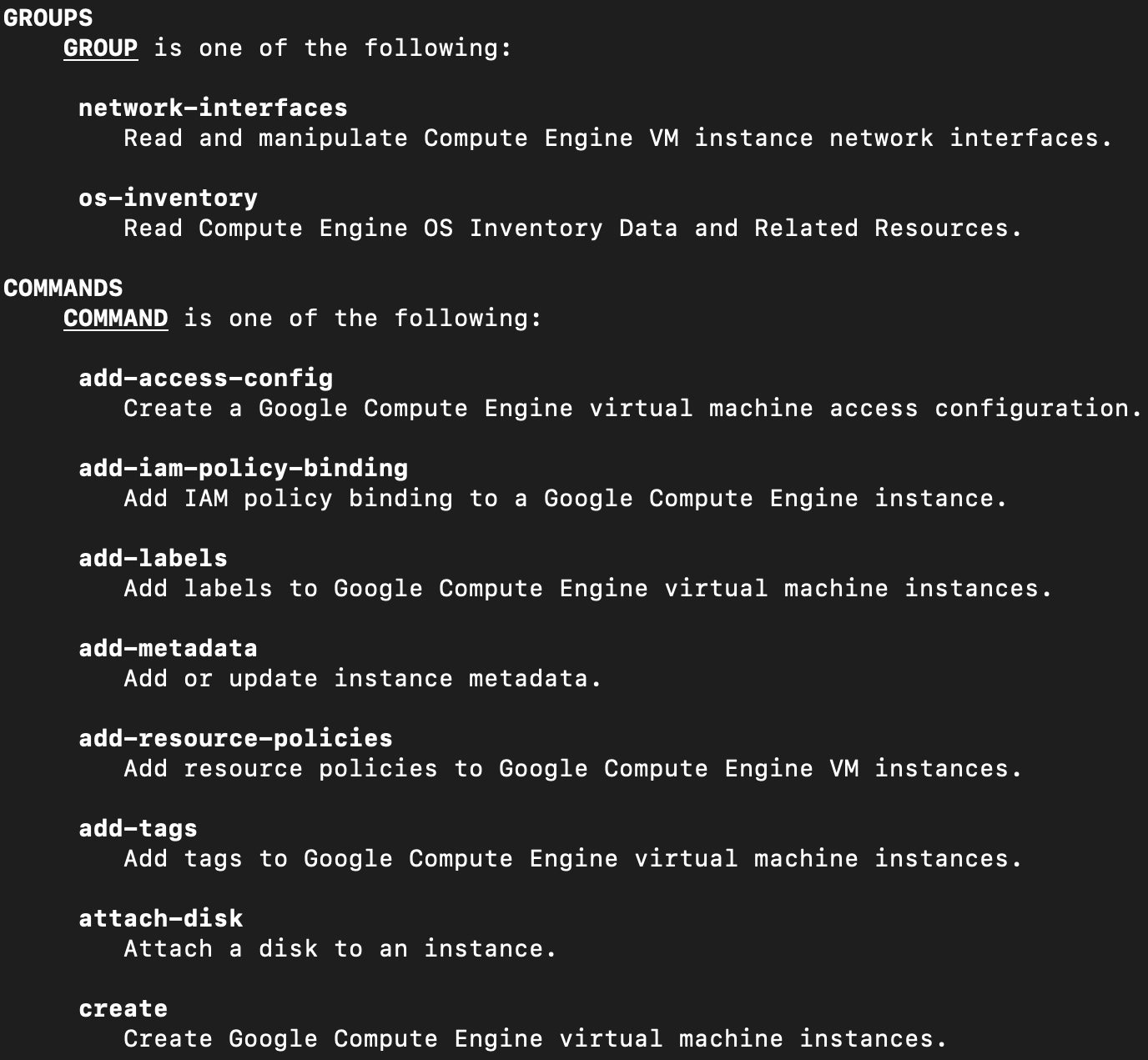
Figure 1.6 – gcloud help command output for compute instances
The GROUPS section lists the command sub-groups available "under” gcloud compute instances. We can see here that we can drill further down into the VM network interfaces or the VM OS inventory data and run commands against those resources.
The COMMANDS section lists the commands that can be applied at the level that you are in (in this case, compute instances). In this example, this include things such as creating a VM, attaching a disk, adding tags, and several others not shown in the preceding screenshot.
It is also a good idea to bookmark the cheat sheet from Google so that you can quickly look up commonly used commands:
https://cloud.google.com/sdk/docs/cheatsheet.
Using the bq command-line tool and a primer on BigQuery
The bq command-line tool is a Python-based CLI for BigQuery.
BigQuery is a petabyte-scale analytics data warehouse. It is actually two services in one:
- SQL Query Engine
- Managed Storage
It therefore provides both a serverless analytics engine and storage space for data, and you don't have to manage any of the underlying infrastructure for that. Google also provides a number of publicly available datasets that are ready to consume, so it's very easy to get started. So, let's run a query right away to count the number of Wikipedia articles whose titles contain the word cloud or variations of it. Open a terminal and run the following:
$ bq query --use_legacy_sql=false \ 'SELECT DISTINCT title FROM `bigquery-public-data`.samples.wikipedia WHERE title LIKE "%cloud%”'
The first time you run the bq command, you may be asked to select a GCP project to be the default one to work with. Simply select the same project you've been working on so far.
This command is simply running a SQL query that selects the title column from the Wikipedia table (under the public dataset called samples), where the title text includes the substring cloud. In other words, we're asking to see all the Wikipedia article titles that include the word cloud in some way.
Your output should look like this:
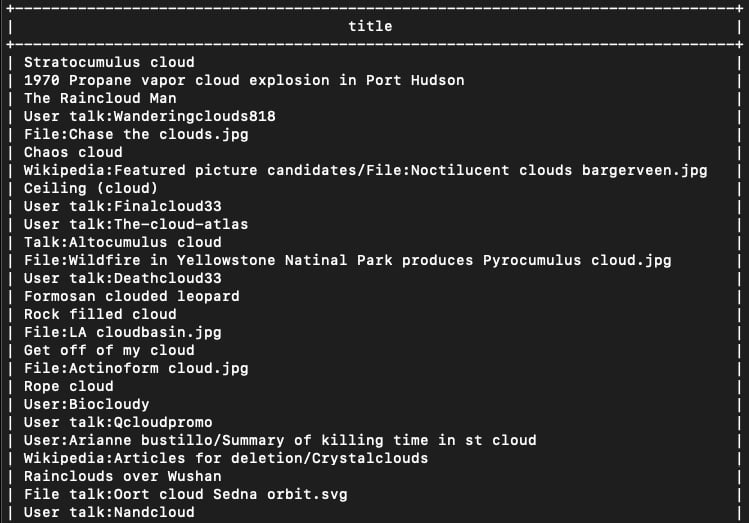
Figure 1.7 – bq query output
The preceding screenshot only shows a part of the full output. As you can see, there are quite a few cloud-related articles on Wikipedia.
In this section, you signed up for GCP, installed the SDK, got up and running with the platform, and with just a short CLI command, you queried the entire Wikipedia dataset in a matter of just a few seconds, without spinning up a single VM or database – and without even paying for it. This was just a taste of the power of Google Cloud. With that, you have gotten up to speed with how to interact with the platform and what some of its capabilities are.
Summary
In this first chapter, you learned about the appeal of cloud computing and how to make the case for cloud adoption and for Google Cloud in particular. You also learned about some of Google Cloud's key differentiators, such as its fast network and its cutting-edge big data and AI services. We had a look at the core services of the platform and things such as regions and zones, the resource hierarchy, and other GCP concepts. Finally, we got started with the platform by setting up an account and installing the Cloud SDK, before teasing out BigQuery's powerful capabilities by running a fast serverless query on a sample public dataset.
In the next chapter, we will get into IAM in Google Cloud and look at ways to improve the cost discipline. To help you truly master the basics, we will end the next chapter with a case study and a small hands-on project.






