


















In this chapter, we will discuss how Service-oriented Architecture (SOA) as a design approach allows us to achieve certain goals and the characteristics that have to be maintained to make these benefits feasible. The practical ways of attaining these characteristics are based on a concrete balance of very well-defined principles, and we will closely look at each one of them. This balance is maintained in specific areas of relevance and is formed in a structure of frameworks. Here, we will discuss issues that are frequently encountered within and across these frameworks, and the common patterns employed as a publicly approved way of solving these recurring problems. One of the main purposes of this chapter is to give developers and architects a matrix of the design rules (patterns) in relation to the corresponding frameworks, all based on SOA principles.
As an evolutionary approach, comprising the best of the architectural and technical solutions designed in the last forty years (arguably even more), SOA nowadays in many ways is quite well standardized with a well laid out vocabulary of meanings of technical terms. Along the course of the entire book, we will stick to the definition of SOA, summarized by Thomas Erl in Service-Oriented Architecture: Concepts, Technology, and Design, Prentice Hall / PearsonPTR Publishing.
This is also available at http://serviceorientation.com/whatissoa/service_oriented_architecture. The complete SOA Manifesto that was developed as a result of systematic collaboration of many experts' groups can be found at http://serviceorientation.com/soamanifesto/annotated.
Still, it's quite fascinating to see that debates are still being sparked and raged worldwide regarding proper terms and their meanings. We are not going to judge or participate in any form in these discussions. That's not the purpose of this book. Obviously, there is one good way to avoid that, which is to stay focused on the practical targets that SOA helps us to achieve. No wonder these goals and benefits are quite well defined and are the sole purposes and reasons why the SOA approach was proposed in the first place. Any practicing architect who has been through several projects (even if not defined as being SOA-based) could easily recollect the common requirements stated by both sides: Business and IT. Let's just quickly recollect them. So, any concrete solution should have the following properties:
They should be kept as simple as possible while still meeting the business needs [R 1]
They should be kept flexible and consistent to support the changing enterprise-wide business needs and enable the evolution of the company [R 2]
They should be based on open industry standards [R 3]
Systems and components within the proposed IT domain (architecture) will be viewed as a set of independent and reusable assets that can be composed to provide a solution for the company [R 4]
They should be based on clearly defined, well-partitioned, and loosely-coupled components, processes, and roles [R 5]
They should be designed for ease of testing [R 6]
They should be based on a proven, reliable technology that is used as originally intended [R 7]
They should be designed and developed, focusing on nonfunctional requirements right from the start [R 8]
They should be secure; able to protect confidentiality and the privacy of all underlying resources and communications [R 9]
They should be resilient to faults, that is, capable of staying operational even in the event of catastrophic failure of the internal components [R 10]
We could really continue on, but in general, these are the top-ten points of any requirements list, and it will be hard to go further without repeating them. Therefore, any list that is similar to this cannot be consistent with more than 15 unique statements within it. We suggest keeping these points up your sleeve until the end of this chapter. This is because at the end of the chapter, we will do some practical exercises of matching listed declarations to the capabilities of SOA. Quite often, these requirements are based on pure common sense, and some people declare them as design principles. It is hard to argue that real design principles should at least be based on common sense, but compliance to this simple fact is not enough to talk about elements from the previous list as principles. At the moment, they are just declarations of good intentions, and we, after several implementations of complex projects, know quite well what road is paved with them. We will talk about the definition of principles a bit later in a considerable amount of detail, but now it's important to analyze these wishes and find what's common there and how it is relevant to the service-oriented approach. It is quite simple to see that the whole list (with one small exception, which is just to confirm the general rule) can be divided into two categories. These categories are related to effort (first, third, fourth, fifth, sixth, seventh, and eighth items) and time (second and seventh items), with the seventh item equally relevant to both effort and time.
Standing a bit aside, the ninth item, generally described as compliance by security policies, is nothing more than pure money, as almost no one these days seeks fun in simple informational vandalism. All security breaches aim to steal your information, that is, money, and therefore, put you out of business. As a consequence, it's needless to say that time and effort can essentially be compared to money as well. So, unsurprisingly, everything boils down to the same logical end, that is, money, which is the key; we have learned this many times, when talking to the bosses (CIO, CEO, project manager, and so on). As stated previously, in IT, money comes in two general ways: either we consistently shorten the delivery cycle or reduce operational costs.
Firstly, we would like to place strong affectation on the word consistently, otherwise, all delivered solutions will tend to be quick and dirty with rocketing operational costs. The two ways (mentioned previously) don't need to be exactly inversely proportional, and proper balance can be found, as we will see later.
A shortened delivery cycle simply means that we will strive to employ the existing reusable components if feasible. Also, every new component or element of the infrastructure that we will add to our inventory will be designed, keeping reusability features in mind. The good rate of return from previous investments (that is, ROI) is the main direction of implementation for new products. At the same time, a higher level of reuse denotes a lower number of heterogeneous components and elements in the infrastructure.
A less diverse technical infrastructure with more standardized components tends to be more predictable and consequently more manageable, and the lowering Total Cost of Ownership (TCO), which is the key part of operational costs, becomes more attainable. With higher ROI and lower TCO, an organization becomes more adaptable to market changes. This is because with them, we will maintain a more transparent and understandable application portfolio with a high level of reuse, and at the same time, reserve more money for creating new and best-of-breed products in the areas of our business expansion.
How can these strategic business benefits be achieved from a components' development standpoint? We have already mentioned that to make our components more interoperable, we should reduce the level of disparity, but at what level? By building components on the same platforms using the same languages, versions, protocols, and so on? This will be unrealistic even within a single department, not to mention a decent-sized enterprise. Our development and implementation processes must be focused on reducing the integration efforts between components, aiming to standardize interfaces. Taking this standardization further onto higher levels, we could achieve a certain abstraction level that will be comprehensible to business analysts yet present enough technical details to be sufficient for IT personnel. The long time benefits promised (which may not be entirely directed) by object-oriented programming (OOP) are quite rarely achieved due to the complexity of inheritance and encapsulation concepts.
The Agile developing approach is the solid basis on which business analysts and technical leads can find mutual areas for fostering reusable components with minimal interaction cycles. Still, the Agile methodology in place is not the main prerequisite for achieving this, and if correctly maintained, the level of interface abstraction allows people from both business and technology fields to speak the same language. The main outcome of this exercise should be to provide a description of a component's interface with business-related capabilities that is desirable for the expected level of reuse. What is inside the component, that is, its technical implementation, is completely out of discussion, and it's up to the technical lead to decide which way to go.
Thus, various technical platforms can leverage their best sides where it's needed (or where it's inevitable due to specific skill sets in place of physical implementation) by staying interconnected without affecting each other's premises and project deadlines. Finally, the federated approach gives the opportunity to choose the best products from various vendors and assemble them in the business flows, abstracted and architected in the previous steps. Of course, these products must stay in compliance with the interface specifications and the operational requirements that we put in place. The opposite is also true, that is, setting standards from our business standpoint will help vendors to adjust their products and offerings in such a way that integration efforts will be minimal.
So, it's all about money, as the logical sequence mentioned earlier demonstrates. Have you noticed that in that logical exercise, we didn't use the abbreviation SOA at all? So far, we are just trying to convert the previously presented list of intentions derived from various project-design documents, such as request for informations (RFIs) and request for proposals (RFPs), into a concise list of benefits. Our next step will be to assess how attainable they are. Although that will be the purpose of the entire book, the key criterion will be defined here shortly. Before proceeding with this, we would like to stress again that the basic terminology around business benefits and design characteristics is based on the widely accepted structure presented by Thomas Erl as mentioned earlier. Also, we do not want to reinvent the wheel for the thousandth time and then participate in terminology wars, which will lead us nowhere. Thomas Erl has described the obvious benefits that we would like to achieve in a logical sequence, and you can see the proposed sequence for implementing the listed-out goals in the following table:
|
Goals and benefits |
Common solutions' requirements |
|---|---|
|
1, 8 | |
|
Reduced IT burden (low TCO) |
1, 3 |
|
Increased organizational agility (shorter time to market) |
4, 8, 10 |
|
Increased intrinsic interoperability (reduce integration efforts) |
2, 4, 6 |
|
3 | |
|
Increased federation |
5, 6 |
|
Increased business and technology alignment |
1, 2 |
It is also obvious from the previous requirements list that some of the requirements are very contradictory, and in most practical implementations, there could be quite a few natural enemies present, such as:
Security and performance (always blood enemies).
Reliability factors and highly reusable components (for example, having a single point of failure).
Resilience achieved by Redundant Implementation and IT costs, independent reusable assets and governance costs (for example, preventing the component logic from getting scattered over several implementations).
Flexibility and reuse-by-design and development costs (for example, in the initial phase of development). Higher flexibility denotes that more execution paths are required, which requires more testing.
This list can go on as the previously mentioned points are just the obvious ones. Thus, the benefits summarized in the table are comparably more consistent as the most contradicting parts are abstracted. However, we must keep in mind that they are still there, and we will focus on them in more detail while discussing the implementation of design principles. What is important now is to distill the most common characteristics that any architectural approach will ensure in every application to attain these benefits.
It is clear that one of the primary requirements for reducing time to market is to improve communication between the technical leads and business analysts. If the ways of expressing the business and technical requirements are kept abstracted from the analysts, and at the same time, the essential technical specifications are kept in place for the developers, then this architectural model could be truly business-driven. The other way around is also valid. If IT provides a managed collection of reusable business-related services, then it's quite possible that new business opportunities can be spotted and proposed by business analysts; this is because new workflows are composed out of the existing services. The response time to the new challenges will be lowered as the change in the implementation's task force will be business-driven and IT will be resource-oriented at the same time.
Components, especially developed with a business recomposition option in mind, will gradually form some kind of components library. With strong sponsorship from architects, this library will become attractive for more and more extensive reuse in various business domains, depending on the business context of the components of course. This library has a name. Traditionally, it's called repository, and we will spend a lot of time discussing its purpose and architecture a bit further. However, from the characteristics standpoint, let's depict it as a technical platform that is capable of hosting these components and providing runtime and design-time visibility, which will be discussed further. Simplistically, this will be any application server with a management console, available for all enterprise developers and architects; it will present all reusable components as the sole enterprise-centric assets.
This second characteristic would be possible only when the presented components are designed with the highest level of composability in mind. This means that when integration efforts, including regression test requirements, platform performance enforcements, and activity monitoring are tamed enough to a level where the reusability option becomes so attractive for all the technical and business teams, the idea of reinventing the wheel would never come as a plausible option. Surely, these characteristics could have more governance efforts in the background than purely technical ones. Still, with proper planning based on honest and realistic maturity assessment and with evasion of the big bang's "all-or-nothing" approach, when SOA becomes more religion than the practical "one step at the time" approach, it’s quite achievable.
Components developed as reusable assets should follow commonly accepted standards; otherwise, reusability will be severely limited to one technology domain. Another alternative would be to reinvent the already existing standards, which is always a waste of time. It doesn't mean that any published standard must be followed blindly; the adoption of standards must be carefully planned. An enterprise's maturity analysis combined with marketing research on top products in a particular area will guide an architect towards common models, describing the component's behavior and implementation technique with minimal integration efforts. Thus, by achieving the first three characteristics, we will open the highly desirable option of maintaining the hot-pluggable infrastructure where best-of-breed products from various vendors could be combined into well-turned fabric based on common standards. It is an architect's responsibility to stay watchful, analyze standards' specifications, and deduct the crucial parts and to be focused on increasing the desirable characteristics.
This design characteristic of making it possible for all components in a repository to stay vendor-neutral has an extra significance for us in the context of this book; it is dedicated to the realization of certain design patterns on the Oracle platform. Actually, there is no contradiction here. This is because we will strive to present concrete solutions in a vendor-neutral way first, if possible, and then demonstrate how Oracle tools could address the same issue. We will do this here and try to demonstrate the maturity of the Oracle platform, which is capable of delivering hot-pluggable solutions that could potentially pose fewer burdens for the enterprise IT domain.
So, now it's a good time to sum up the short descriptions given previously in the table of architectural characteristics, in the way they have been defined by Thomas Erl. Here, we will again repeat our exercise, trying to map the supporting core characteristics to most of our requirements (if not all).
|
Characteristics |
Requirements [R 1] to [R 8] |
|---|---|
|
Business-driven |
2 |
|
Composition-centric |
1, 5, 8 |
|
Enterprise-centric |
4 |
|
Vendor-neutral |
7 |
We have selected the most obvious characteristics, which directly support the most common requirements, summarized at the beginning of this chapter. There is no need to elaborate on this further, as we can easily see that other requirements are supported directly or indirectly. However, we would strongly recommend that you repeat this exercise every time you analyze the requirements for new products, systems, or components in the RFI scope or at any other stage of the project.
The following figure summarizes all that we have learned so far:
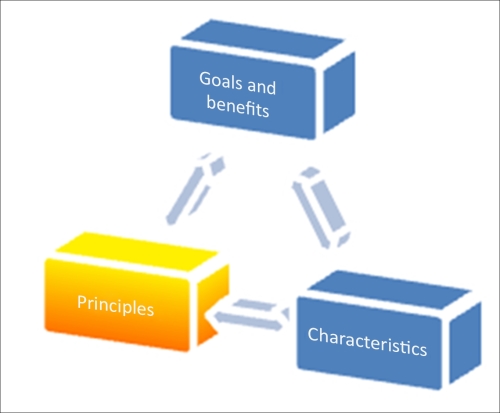
Until now, we have intentionally avoided mentioning the term SOA during this short exercise of outlining the keystones of the requirements analysis. The purpose is quite straightforward: if you could clearly define your goals in a very precise way and declare concise characteristics in support of these objectives, it really doesn't matter what the name of your design approach is. Some can call it common sense, and that's perfectly fine. Nothing could be better than a design approach based on common sense, which is easily comprehendible by business and IT. However, apparently something else is needed, and that would be the design principles as a strong foundation for the first two keystones.
In the following paragraphs, we will outline this foundation again using the classification provided by a best-selling SOA author and founder of the SOA School, Thomas Erl, which is accepted by Oracle. This time, we will strongly focus on SOA and Service-Oriented Computing (SOC) as the best technical implementation of common sense depicted earlier. There is no reason to evade it further—if it looks like a duck, swims like a duck, and quacks like a duck, then it is probably a duck. Goals and characteristics mentioned previously are exactly how the SOA declares them. How they will be achieved and supported is a matter of the principles' implementation. They are all interconnected, so the balance is also part of common sense, and as is usually put, it must be applied in a meaningful context. The extent of this is the level of realization of tactical and strategic goals and technical capabilities of the principles' implementation.
Tip
Please be forewarned as the following example is a recipe for a perfect disaster. We have to put this disclaimer as some could take it as direct architectural advice. It is also sadly realistic, since all that we have described next was taken from real implementations. We will use this example in the later chapters.
So, what are the tactical goals? The essence here is time, usually limited by a timeframe of a project or several milestones of non-correlated projects. It is always good to stay on budget and deliver on time what was promised. This is a common scenario for a component or a single application development process. Isolation, focus on performance, and reliability as primary targets have their obvious benefits. As a solution architect, do not bother your team much with interoperability, as you probably have another enterprise application integration (EAI) team that is especially dedicated to this purpose; they are somewhere nearby and are capable of performing the tricks. Skillful EAI means that some integration platforms are in place already, providing hub-and-spoke capabilities with all the necessary transformations, translations, protocol bridges, and so on. Honestly, nothing's wrong with that. At least, not yet.
All that you need is a capable integration team and be lucky enough not to be at the end in the row of endless regression tests. Also, it would be prudent to maintain a very thorough events/error log for your product, just in case you need to identify where all your inbound/outbound messages have gone. You must be able to prove that you (your application) have sent all the required outgoing messages, and they are definitely now on the integration platform's side (just search better); alternatively, if you haven't received what you need, the flaw is definitely on the part of the EAI's design.
As time is of the essence, moving further, you can take the liberty to define all your APIs and XSDs as close to your technical implementations as possible, based on the DB structure and the logic of the classes. Modern development platforms and SDK/XDK are truly advanced, so this task can really be done in no time by a right-mouse click. Following this path, you can provide newer versions of your application almost instantly after receiving new requirements, and it's purely EAI's responsibility to maintain concurrent APIs published on an integration platform. Again, just be the first in the list of regression tests.
As performance is declared to be one of the primary objectives, always demand for direct access to the resources you need. A direct DB access or Remote Method Invocation (RMI) is much faster than the hub-and-spoke integration approach. At the same time, do not let anyone access your internal resources, as it potentially could affect the third characteristic declared prime, that is, reliability. On second thoughts, it would be good to hide all your implementation details and keep them hidden from everyone. It will prevent any unauthorized access into your backend resources.
Strengthening security is a positive side effect of this isolation. The obvious fact that all technical details and data structures are already exposed via your autogenerated Web Services Description Languages (WSDLs) are just Web Services (WS) collaterals and must be handled again by EAI. This is because we follow a common principle of separation of concerns by delegating security operations to the middleware. By helping middleware handle error situations, you could provide a full-stack trace from your entire web-based API, leaving the standard SOAP Fault message by default. The EAI team will have to find all the necessary details and handle them according to their understanding of business logic, as we will keep our internal logic secluded for the reasons explained previously (security and resource protection).
As you already have direct connections to the resources in other systems, you could potentially implement some extra logic on your side in order to speed up the external processes and get the necessary results without waiting. Why not? We are endorsing distributed computing! You can go even further; you can include your public API's capabilities from other systems, as you already have access to them. So, it's a mashup, isn't it? For the sake of clarity, you just inform the EAI team that these new capabilities are foreign and not covered by your original SLA, as you cannot guarantee that the design of other systems would be good; however, you welcome everyone to use them. Speaking of SLA, quite soon you will spot that the autogenerated XSDs are a bit elaborate, causing some latency on the API side and extra processing overhead on the EAI platform. As an architect, you would propose quite a simple workaround (remember that performance is the essence): switch off the XSD validation at the EAI platform's end. It certainly helped a bit, but not enough. Later, you will discover the original cause, that is, the standard JAXB library responsible for message marshaling/demarshaling is way too slow.
The implementation of custom marshaling would certainly be helpful not only for your application, but also for others' as well. Why not help other teams by supplying them with a more robust and reliable XDK? In parallel, you can make some improvements to the XML structure, presenting custom elements within the message body for parsing acceleration. For instance, if you have several addresses in the message (billing, postal, and corporate), you could implement special predicates to indicate which one is to be used in a particular business case and when others should be suppressed. You can really dedicate some time to these tasks so that developing and adapting your components is not so burdensome.
Our tactical goals have been well achieved. All that's left is to explain to your CIO why the consolidated IT costs after three years of tactical architecting are almost equal to corporate revenues.
If you think the presented scenario is a bit artificial, please suspect not. On the contrary, some unnecessary technical details had been omitted to make it less chilling. However, we would like to make one thing clear: we are not against tactical goals at all; they are chunks of iterative development and essential parts of SCRUM sprints. We just believe that tactical goals and benefits must be a native part of some bigger strategy; otherwise, you could win a battle or two but lose the war very badly. The temptation to achieve your target instantly by buying another magic pill is always high but usually leads to a spaghetti-like infrastructure. In best case scenarios, you will get a lasagna-style infrastructure if your integration efforts are consistent (another term for expensive). So now, we are going to discuss the principles that could make our strategy capable of supporting declared goals and characteristics.
Don't worry, we will not be reinventing the terms here again. After more than ten years of implementation, the principles are quite well declared and explained. The consolidation done by Thomas Erl has been accepted de facto by most of the top market players, and what is most important for this exercise is that it has been accepted even by Oracle. You can refer to it at http://serviceorientation.com/serviceorientation/index.
Here, we will mostly focus on the relation of the principles and characteristics and the consequences that will follow if the principles are neglected. Jumping ahead, it would be right to say that the patterns are really needed when principles are not implemented as they are intended. The reasons for this could be different, which are mentioned as follows:
The already existing burden of legacy systems prevents us from implementing more reusable solutions immediately. We really do not want any revolutions.
The obvious political reasons of all kinds, usually caused by strong focus on tactical goals, temptation to pick the low-hanging fruit, and show quick results even if they are based on another silo in the app's stack.
Most interestingly, patterns would be required to resolve the conflicts that arise during the implementation of different principles from the same technological area. Yes, principles can contradict and must be applied in a meaningful context.
It is also important to recognize that all these architectural principles are generic, common, and universal for the selected technological area (SOA in this case). Principles are also tangible, well recognized, and limited in number.
Some may say that our top-ten requirements can be perceived as principles as well. Even all illities could be principles because of their universality and simplicity. Unfortunately, simplicity here cannot help. We, as architects, should give strict, precise, and most importantly, tangible guidance to developers, and be able to follow our own recommendations.
The measurable outcome is the result of proper guidance, and the principles here are closest to the physical implementation and must be understood and followed. Some principles could be less tangible than others and could just present the results for collective implementation principles with lesser abstraction, but still the results of the implementations can be measured. Let's take the most common illities such as reliability or flexibility and try to explain to your developers (or yourself) in just few words how to code your components in order to achieve them.
Depending on the technology platform, the explanation could take up to a couple of pages or several chapters. Still, they should seem obvious and even quite measurable. (Reliability is usually the Mean Time Between Failure (MTBF) and flexibility is also a time-based characteristic that displays how fast a system can be reconfigured for other business requirements.) So, NFRs are also precise technical requirements and not a guide in technical terms. Looking forward, let's propose a logical hierarchy of the terms, one way or another related to principles and their areas of application. By the end of this chapter, we will cover all of them. Your benefit from this exercise will be a clear outline that will guide you on how to analyze requirements and apply design rules for most of your SOA-related projects. The following table illustrates the principles and patterns discussed:
|
Principles and patterns |
Quantity |
|---|---|
|
Even being highly generic, the characteristics of generic illities have certain practical implications and materialize in at least six architectural frameworks. |
7 |
|
Technology stack's architectural principles (for SOA design principles) states that every application consists of several technology areas, the sharing or reuse of components, and composites. For every application, an individual and balanced combination of the universal principles is the key for successful implementation. |
8 |
|
Architectural patterns form a pattern catalog, commonly approved as open standard ( |
>85 |
The following figure explains the preceding principles and patterns:
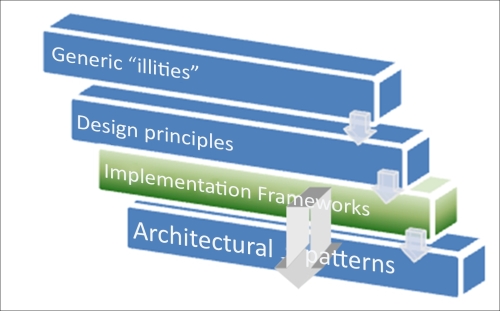
So let's start with the obvious ones that were already mentioned earlier.
In a standardized service contract, we really believe that the word service here is a bit of an overkill. Services today are strongly associated with the web service's technical implementations, so naturally, the first thing that comes to our mind would be WSDL with schemas, optionally, with policies. Nothing's wrong with that; it's truly the most common service implementation (or REST maybe), but the fact that any WSDL and XSD can be easily autogenerated compromises this idea. Autogeneration doesn't turn it into a standard. An autogenerated service contract is nothing but trouble, and if you haven't got it after the first exercise dedicated to tactical goals, we will have plenty of opportunities to convince you.
By doing so, you are just forcing everyone to adapt to your specifications, which include existing applications. Surely, if you are an architect in a big bank, this approach might work; we're hesitant about the stub's implementation time at the remote end.
The second point here is that we can build a very robust service-oriented system without a single web service. The Oracle PL/SQL will do it beautifully, and we will demonstrate it in the next chapters. So, the contract could be anything that declares public operations, available protocols, and data structures such as the PL/SQL package header .pks, C++ class header .h, and the Java interfaces (also called contracts). Component-based development is a completely valid approach in SOA if it's approved by all the members of the implementation domain. Interactions between different domains will require some integration efforts even if the technology is the same, but that would be true for web services as well, so that's not a major drawback of using components as SOA's building blocks.
The problem here is that all components' contracts are nondetachable compared to WSDLs. The true beauty of WS interfaces is that we can sit in a quiet corner along with developers and business analysts and by using just a pen and a napkin describe the prototype of service compositions, go back to our stations, and start coding right away. Talking seriously, by describing the detachable contract as WSDL, we can really provide a parallel development process and work on an iterative development in a reasonably painless manner. Simply speaking, you can compile the service logic (Java) without WSDL and try to do the same with a PL/SQL package body without the package specification. Finally, the most important thing is that this contract-first approach allows us to generate the code based on an initially defined and mutually accepted contract, and Oracle is really good at it. Practically, you can generate skeletons on any platform that you want to be your logic carrier, such as Java, BPEL, and Mediators.
A standard contract is the primary means of presenting your service as a corporate asset to maintain at least two main SOA characteristics: Composition-centric and Enterprise-centric. With the WS-based approach, you will achieve vendor neutrality as well.
This principle is probably the most well-comprehended principle. Everybody knows that tight coupling is bad. Is it really? To discuss this, let's first describe what kind of couplings we could get. You'll be able to understand this from the realization of service anatomy. Basically, we have the following:
Service resources, presented as DB, file structures, and so on
Technology platform (Java, .NET)
Service logic implementation
Parent service logic
Anything that links your contract or, even worse, your consumer to one of those service resources can obstruct the core SOA characteristics we are trying to maintain. So, all links going from contract to service resources or bypassing the contract are bad. The opposite direction is not much better because providing details of the technology platform or excessive resource demonstrations is not good, as it can provoke the service consumers to build their consumption logic based on these details. However, what about the contract-first principle? Yes, it's a positive thing, so coupling your service logic to the declared contract is a natural and decent way of implementing the service. However, neither the service logic nor the service contract has been set in stone—business is evolving, and so are our services. Quite soon, a new contract version will be published or the core service logic will be patched. It will eventually turn out that this positive coupling also has its deficiencies. No reason to despair though; it's life. All of us are evolving, and customers connected to our contract are always welcome. How to deal with this situation using various Oracle SOA patterns will be discussed further.
In addition to this, we would like to emphasize that coupling from customer to contract is the second positive coupling, although it is susceptible to the same problem like the one with contract evolution. All other couplings must be prohibited if possible. This statement is not as strong as you would expect. We have touched upon the reason for this earlier in the tactical goal's architecture example, that is, performance. Standard contract denotes the message processing overhead, some milliseconds (or more) in addition to the total processing time, CPU utilization, and memory consumption. Is it worthy enough to jump over the service contract and utilize service resources directly? Only you know what these milliseconds of overhead mean for your business, and the decision on what to sacrifice is yours. In general, the answer is no. Please look at your contract first. Is it truly standard? Assess your needs using the following logic:
Do you clearly define your data structures with the required elements only?
Do you avoid autogeneration, especially for operations with CLOB fields without
CDATAor<any>elements? (Memory leaks during marshaling is a common outcome of this approach.)Can a concurrent contract with more lightweight technology (REST instead of SOAP) possibly solve the problem? (Concurrent contracts will be discussed further in the Chapter 4, From Traditional Integration to Composition – Enterprise Business Services.)
How about a platform-specific SOAP/XML acceleration? Oracle's WLS T3 protocol could be useful as it has proven many times
The tuning of the execution environment and proactive monitoring.
If platform-neutral contracts (WSDL / REST-based) do not help, could we employ a component-based concurrent contract?
Always think what price you will pay to break this principle for gaining ten or fifty milliseconds of processing time. This principle directly supports the composition's centricity and vendor neutrality's SOA characteristics.
The logical outcome from the implementation of the first two principles is standard, preferably (but not mandatory) a detachable service contract as a declaration of our capabilities, processing requirements, and input expectations. Still, the word standard is a bit vague. Let's put the discussion about existing standards aside for a moment and focus on the areas of standardization. The bottom line is that standardization is the way of generalizing information, a process of making it more abstract in order for it to be more multipurpose in predefined technical boundaries. Some of the elements of abstraction in service-orientation boundaries that we have already mentioned during the discussion of Loose Coupling are as follows:
Do not reveal in your service contract the specifications of your technical platform (such as the coding language, SDK's details, and XDK properties)
Do not expose details regarding your underlying resources (such as the DB structure, constraints, and especially the foreign keys)
Be reasonably reserved regarding services-composition members that comprises your service
Why would you do that? It is because of the same reasons we mentioned while discussing the previous principle. Excessive information can provoke negative coupling to service resources, making the service less adaptive and reducing its reusability options.
For example, you have a lot of useful functions in your service logic. Obviously, you can fall into the trap of promising extra features in addition to the already agreed one. (Okay, not you, your new project manager.) It literally costs almost nothing at the beginning. Most probably, it will not even affect the level of standardization of your contract at first glance, which is shown as follows:
Who can give you a warrant that the business logic, encapsulated in your service, will not change tomorrow and that an auxiliary-declared operation becomes a burden or even an unwanted shortcut in the business process? How about a number of consumers who become dependent on your extra feature? Migration in SOA is not an easy task, even with certain SOA patterns applied.
On the other hand, even in a relatively static business ecosystem, this new feature could become so popular that all of the hardware power dedicated to your service scope will be consumed by only this one operation.
So, do not promise anything and keep everything for ourselves? Let's not blow this out of proportion. SOA is full of promises; it was designed in this way, and luckily, we have enough methods to keep these promises. If service capabilities (that is, operations) are correctly planned from the beginning and used unevenly, then maybe we have put too much on a single service's plate. What is the functional scope of this service? If this service handles one single business entity (such as invoice), then all our operations should be bound to its functional context, which is abstracted to the level of a functionally completed environment. You would hardly keep salt, sugar, and flour in one jar in your kitchen just because all of them are white. Still, it's rather amazing how this simple thing called granularity is neglected in the real life of service development.
Functional granularity is based on the understanding of service models. Entity services that are already mentioned are the first and closest abstracts to the atomic data representations in an enterprise, for example, invoice, order, cargo unit, and customer. All operations would be naturally based on the DB CRUD model but not limited by them. The number of truly unique entity services is rarely more than 20 in any enterprise. The functional granularity here is usually based on the OLAP/OLTP segregation:
Online transaction processing (OLTP) as very short, real-time, CRUD-like operations with high demands for response time are naturally the primary capabilities of the entity services, and their operational time slot is frequently within the standard business hours (that is, 08:00-17:00)
Online analytical processing (OLAP) operations are not that demanding when it comes to response times, but data volumes are usually higher and operational time slots are either evenly distributed around the clock or tend to be close to the regular nightly batch-operations time.
As you can see, mixing them together would not be a good idea if we have an overlapping operational time slot. The possible conflict between high volumes and high throughput will require your attention at the very early stages of service modeling. Should we abstract OLAP operations to DWH-specific services?
The second service model is the utility that usually presents the most reusable and supplemental logic, consumed by all other services. The level of functional abstraction here is really high and business-independent. Your transformation, translation, or measure-unit conversion services are typical representatives of this model. The level of functional granularity can be easily defined and operations can be tuned for high-usage demands. Migration issues are not that frequent here, so functional abstraction is fairly simple.
The last model or task service is what we usually know as workflow, which is the composition of other services combined together in order to fulfill one single task such as OrderProcurement and BookingRequest.
Distinctive properties of this service model comprise one task, one operation, and one business context. Functional abstraction should not be a big puzzle, but still we can see a lot of misinterpretation caused by the deceptive simplicity of modern development tools, providing neat visualization of service compositions, plus very mature resource adapter frameworks starting from order fulfillment (many thanks to Oracle for providing an extremely detailed Fusion Order Demo (FOD), available at http://www.oracle.com/technetwork/developer-tools/jdev/learnmore/fod1111-407812.html). An enthusiastic developer can soon include Invoice, Booking, and General Ledger flows into one monster. Entity services are commonly neglected, as we do not need them anymore; a DB adapter can provide us with the perfect result in five clicks. Additional interfaces that were constructed while composing this task service can be easily exposed to external consumers. The problem here is that this service is not a task anymore; it's a hybrid with the worst possible functional granularity, combining business-specific and business-agnostic capabilities. A thorough application of the abstraction principle from the very beginning could prevent this problem.
The deceptive simplicity of development can hoodwink developers, who are left alone without architectural guidance. This fact provokes developers to use it everywhere, whether it's appropriate or not. Some industry-specific forums and advisory boards quite often produce rather vague frameworks and business process specifications that are in fact not more than business heat maps. Following them too directly can easily result in such hybrid services with unclear abstraction levels.
Data granularity is the next level of granularity we should take into consideration when applying the abstraction principle. Processing one single order line or a complete bunch of orders received in one message in reality makes a difference; however, in your design of an Order XSD, all that it takes is to set minOccurs to greater than 1 for the Order node right under the
OrderHeader element.
The data constraints granularity or constraints granularity in general is the next logical level of granularity. Again, talking about XSD, you could be really restrictive with your data type definitions while determining whether they are necessary by declaring a simple type using XSD patterns, explained as follows:
|
Fine-grained |
Coarse-grained | |
|---|---|---|
|
<xsd:simpleType name="imageType">
<xsd:restriction base="xsd:string">
<xsd:pattern value="(.)+\.(gif|jpg|jpeg|bmp)"/>
</xsd:restriction>
</xsd:simpleType> |
xsd:string |
xsd:any |

Here, you want to be sure that the image's filename provided in a message is safe (at least not executable). This could not be achieved by the most popular xsd:string data type alone in the service contract. The xsd:any element is at the upper level in this hierarchy, which in OOP has equivalent Object. All these levels of abstraction have full rights to exist, but you must clearly realize which part of your SOA infrastructure should employ these different levels of granularity. The other means of data granularity already mentioned are minOccurs, maxOccurs, and nillable that are applicable for the elements and xsd: attributes. Terms usually used for different levels of detailing are the fine- and coarse-grained granularity, and they are quite self-explanatory. The levels of declared granularity directly impact the location of the service-processing logic. This means that with a more fine-grained XSD, you will put more processing demands on the contract's message processing logic—XDK marshalers (serializers). With a more coarse-grained granularity, you inevitably put the big chunk of message parsing and validation logic into the service's component logic behind the contract. It could also make service difficult to test, as highly abstracted contract will not reflect any changes that are supposed to be presented to the Consumer.
Other abstractions include the abstraction of technical details hidden behind the service contract, and programming language aims to increase the federation of our heterogeneous service infrastructure. Abstracting contract-related parts of SLA, such as quality of service, availability information, and performance metrics also helps to standardize service profiles within a service inventory.
We have deliberately put aside the security considerations related to the abstraction principle until now. By declaring more precise data types, you could reveal technical information necessary for data-oriented attacks. When using the data type casts features, the attacker could trigger the error, revealing internal data structures associated with the element (the point of the attack) and exploit them. An element with the type <any> reveals nothing, but at the same time allows it to send any types of data, including the harmful code. With such a high level of abstraction, presenting the service contract with the operation Process and data model Any, you literally open the door for all kinds of parser-related attacks, memory leaks, and buffer overflows. Possible ways of balancing the granularity and abstraction levels for services that operate on different technology layers will be discussed further in Chapter 7, Gotcha! Implementing Security Layers.
The ultimate purpose of principles' implementation in SOA is to increase the service composability options as a direct method of increasing ROI. A less abstract service contract where more information is revealed tends to be more attractive for developers as they are more interpretable.
The implementation of this principle directly affects SOA characteristics such as composition centricity and vendor neutrality. This principle directly supports Loose Coupling. Abstraction from excessively expressed technical details will certainly increase the business value of the service (business-driven).
The first three fundamental principles combined together will lead us to the declaration of the first really tangible design principle, that is, reusability. One can say that this is the essence of all the SOA principles. Still, we will not crown it above all others, as it cannot be maintained alone without proper foundation of the first three. In the book dedicated to the Java EE enterprise architecture, Sun Certified Enterprise Architect for Java EE Study Guide (2nd Edition) by Mark Cade, Humphrey Sheil, Prentice Hall Publishing, this principle is not included in the requirements for the component's architecture. The first three include performance, scalability, and reliability, and that's absolutely true. No one needs reusable components that are unreliable and cannot perform as intended.
We just have to realize that these illities here are applied to the service logic, presented by Java components. If it's not reliable, and we would like to put that first, we must not present this logic as a public service. In traditional component architecture, the reusability support is delegated to the integration layer. In SOA, we strive to make services reusable by means of the following:
Defining the standard contract, exposing canonical data and canonical operations.
Making internal service logic more universal (another synonym for abstract) and suitable for reutilization by other services. As discussed earlier, only one service model is allowed to be highly specific, that is, task, as a composition of other services, fulfilling the specific operation.
Preventing negative couplings by promoting the technical contract as only one way of accessing the service logic.
The level of reusability is really easy to assess: just count the number of compositions where this service participates. The implementation of this principle directly promotes composability and the enterprise's centricity. Let's now look at the two pure technical principles that support reusability.
An service can maintain the required level of reliability (measured by MTBF as time, or percentage as an availability) necessary for consistent reuse only if it can possess and control its own underlying resources. Database, file objects, physical realization of the service logic, and so on should not be shared or delegated to other services. The service should be perceived as an atomic unit of concrete logic, functioning in a dedicated technical environment. In this case, the service behavior will be predictable, fulfilling scalability requirements, and making it possible to relocate the service into a similar technical environment with reasonably low efforts. This last illity is highly desirable for a cloud-based implementation.
Unfortunately, this principle is probably the hardest to implement. We all know that most commonly used databases are shared resources. License costs, bundles of legacy applications, common network infrastructure, and so on are the reasons why this principle is very hard to achieve without significant investment or considerable maintenance efforts.
This principle is quite often mistaken for Loose Coupling. Indeed, they are very similar with regards to the negative impact on service reusability, although we can draw a distinct line between them as mentioned as follows:
Loose Coupling is the ratio between iterations, carrying through the service contract from consumer and service resources (relatively positive coupling) and iterations bypassing the contract (negative coupling). In fact, the service is always coupled if it's in use, positively and negatively. Service-oriented architecture based on components is more prone to negative coupling, as their APIs are more technology-specific.
Service autonomy is the measure of service independence. A business usually has quite a limited number of data warehouses (DWHs) (usually one per business domain and ideally—only one). Therefore, all analytical services (InvoiceHistory, OrderHistory, and so on) using a single DWH DB will not be autonomous. Present them as one service (this is not an advice), move into a private cloud, and you will get a perfectly autonomous service. Now the question is the price.
The implementation of this principle directly promotes the composition and enterprise centricity and vendor neutrality.
There are no negative impacts on other principles, but as we have said, true service autonomy is the nirvana that is really hard to reach.
This second technical and very tangible design principle is the support of the service reusability.
It's defined as an ability of a service to maintain low-resource consumption when needed, namely between service activities, while waiting for a response, and so on.
At first glance, it's more applicable to the long running asynchronous services, which could run for days or weeks. The deferring service state is vital here. We have to store execution scope variables and preinvocation data in a special database with all necessary information for waking it up when the response arrives. In this Hibernation DB (dehydration store in Oracle terms), we will have a chain of defer-awake records that are equal to the number of asynchronous invocations. Moving further, we can defer the information at any stage of the long running process for legal or compensative activities. This type of storage is compulsory for all task-orchestrated services and is usually provided centrally by an orchestration platform.
This fact makes all task orchestrated services far less autonomic than other service models. Surely, you can implement individual partial state deferral for every task-orchestrated service (task service hosted within an orchestration platform), making them ultimately autonomous. In that case, we truly admire the grandiosity of your project's budget, not to mention the infrastructure and support.
Asynchronous services are not the only ones that need to maintain their state. A poorly designed synchronous service with a lot of global variables, excessive looping or branching logic, and a lot of calls to underlying storage resources will consume a lot of memory and CPU. There is no remedy for this scenario that is provided by the SOA technology platform; you can only rebuild it from scratch. You could technically turn this service into an asynchronous process and set the queues as transport means; however, that's not what consumers expect, and the level of potential reuse drops considerably. Only services with predictable state management will have predictable behavior and scale well when necessary.
This principle addresses the same benefits as autonomy but has negative impact on the autonomy itself.
Despite its obvious meaning, this is arguably the most-neglected principle. The main reason for such negligence is the misunderstanding of service governance boundaries. For some, governance starts after the service deployment process in production. Although it's been said many times before, we would like to repeat it again—governance starts long before the first line of code is written. You must plan for the following:
Which service trace records will be left in your audit/trace log under the different logging settings
How service activities will be perceived by different operational policies
How a service could be dynamically invoked by different consumers and controllers
These items among many others form the so-called runtime discoverability. It is in your best interests to expose your service to all who can potentially use it. This is possible if you follow these points:
Service operations and functional boundaries are well defined according to the service contract
Service particulars presented in the form of service metadata help everyone understand possible service runtime roles, model, composability potential, and limitations
Quality of service information describing service availability, reliability, and performance is guaranteed
Supplementary information regarding all test results and test conditions are in support of declared performance
Policy standards to which services adhere to mandatorily or optionally
All these items are elements of design-time discoverability. As part of governance efforts, special layers of service infrastructure will be established in order to support these two types of discoverability. We will dedicate a whole chapter to this challenge, as we reckon lack of discoverability is probably the main problem in the implementation of SOA. However, even if a technical platform is capable of supporting dynamic discovery and invocation, and the service metadata storage is full of service details down to the particular engines in use and rule types employed, we could still jeopardize potential reuse by keeping interpretability of discovered information below the comprehension level. Information that is too abstract (see the Implementation of Service Abstraction principle) will prevent the demonstration of full service potentials. A methodology in support of service taxonomy and metadata ontology (discussed in Chapter 5, Maintaining the Core – the Service Repository in great detail) will be not only established, but also conveyed to all individuals responsible for SOA governance from the very beginning to the end.
How do we measure service discoverability? What questions should you ask your developers and architects (including yourself) in order to understand the level of principle adoption? Refer to the following questions:
Do we have an inventory for all enterprise assets acting as service consumers and service providers? In other words, what are the enterprise/domain boundaries?
Do we have individual service profiles?
What are the key elements of service metadata available from the service profile that we will use for a service lookup?
From which service infrastructure layers will we perform the lookup and for what purpose? In other words, who is allowed to discover this information and when (security)?
Can we perform reverse search metadata by service?
How will these metadata elements be presented in a service message, in which parts, and at what level of detail?
Are these metadata elements in the service messages covered by the existing SOA standards? Can we keep them vendor-neutral and minimalistic?
Believe it or not, a simple Excel spreadsheet will do the trick, and the explanation will be provided shortly. How many times have we witnessed the situation when without a well-structured and understandable taxonomy, even the most powerful harvesters (SOA artifacts introspection tools) with marvelous graphical representation of discovered relations just turn the situation from bad to worse?
This principle undoubtedly supports all four desirable SOA characteristics. This principle conflicts with the service abstraction and can negatively impact security when poorly implemented.
Finally, we come to the last principle that completes the foundation of SOA. This principle is in fact the paramount realization of SOA, as it's the closest thing to money, the universal entity that is understandable by any members of an enterprise.
Next, we compose and recompose the new business applications and processes out of the existing building blocks; the less we waste, the more we gain through reuse. However, is there any overlap between composability and the reusability principles discussed before? Yes, but only at first glance, as the key here is in the measure of "waste" we would like to prevent. Almost everything in IT could be reused; the question is how much effort (time) it could cost for doing this.
The composability principle defines the measure of how easily any service from a particular service inventory could be involved in a new composition, regardless of the composition's size or complexity. Of course, a service should be involved in the operations it was designed for and in the roles it can support. Thus, the common quantifier for this principle is time. When designing a service from the very beginning, you should speculate on how hard it would be to implement composed capabilities using your service along with others, and how many compositions a single instance of your service can support from the performance standpoint. Yes, the statement regardless of the composition's size or complexity has its own limits, and these limits will be thoroughly tested during the unit stress test and properly documented in the individual service profile.
The quantification of this principle is roughly similar to the measure of flexibility of hub-and-spoke integration platform. For hub-and-spoke, with all enterprise applications connected to it, you have the canonical data models for all entities presented by the application. When a new application with its own data representation arrives, all that you need is to perform the following:
Transform the newly received application data model to a canonical model
Establish routing rules for message flows in a hub for this application
For simplicity, we assume that a unified canonical protocol is in place. With this simplistic model, we can estimate that a new XSLT (actually, two of them) with a reasonable level of complexity could be built in four hours, and the routing rules in a static table can be maintained in another two. Allocate a day for testing and we are ready for production in less than 16 business hours! Theoretically. Let's now recall how reality typically bends our plans.
|
No. |
How do we see it |
What it means |
|---|---|---|
|
1 |
Yes, it's not a problem to build XSLT or XQuery in four hours. Obtaining the mapping instruction and understanding the meaning of field names and data types can take week(s). |
Discoverability and Abstraction |
|
2 |
Not all data elements needed for CDM and other applications in the farm are available via a public API. |
Standardized contract |
|
3 |
To extract necessary data, we have to bypass the API and reach out for internal resources. |
Loose Coupling |
|
4 |
The extraction of additional data inevitably implements call-back interchange patterns, which are not always positive. This could disrupt performance of the main app functions and put some logic outside the app boundaries. |
Autonomy |
|
5 |
Quite often, internal logic of a new application is more complex than what a simple request-response interchange pattern can provide, thus requiring the hub atomic transaction coordinator's (ATCs) capabilities. We have to put more logic on the hub. |
Loose Coupling |
This shortlist of five items is only the tip of the iceberg; usually, it's more than a page long. The bottom line is that the total time required for making a new application composable via the hub-and-spoke approach is usually from two to six months.
With the service-oriented approach, the result will be quite similar if any of the previously discussed principles are neglected or put off-balance. The following figure explains the general relations between principles and their importance for composability. Loose Coupling and Abstraction together with Composability are the regulatory principles, shaping and governing the implementation of others. Despite their regulatory status, only Abstraction is quite difficult to quantify, although it's still quite possible by assessing the amount of message-processing logic in marshaler / contract parser and core service logic.
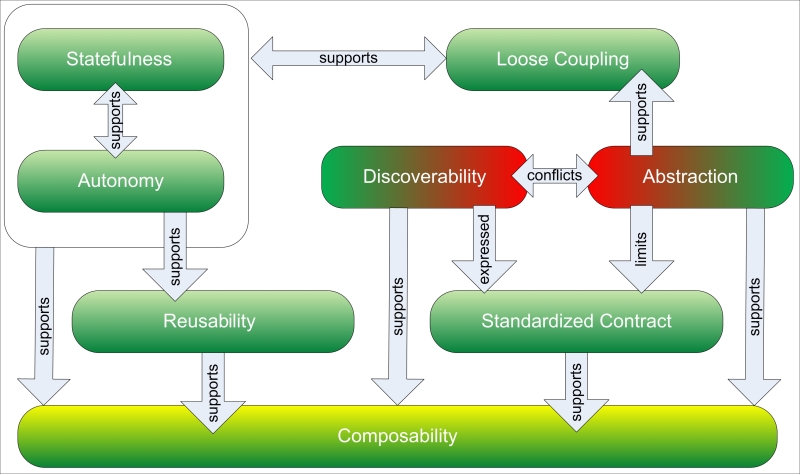
The Statefulness and Autonomy services are pure technical principles and directly affect Reusability. It would be quite right to say that Reusability and Discoverability together have a major impact on Composability, but other principles also must be accounted for.
We would like to advise you to keep this relation matrix in front of you every time you are given the task to analyze an existing design or propose a new one based on expressed illities, or analyze what's behind the illities, which is promoted as design guidance. It will prevent you from establishing rules that are too vague for understanding and following. For the final exercise dedicated to principles alone, let's get back to our list of top ten generic wishes and analyze the sixth item; refer to the following table:
|
Designed for testing |
Meaning |
Requirement |
|---|---|---|
|
Valid (we are testing what we are supposed to test) |
Service / Component APIs can be easily exposed to any existing testing tool (JMeter, SoapUI, LoadUI, and so on) and all the test operations generated with low efforts. |
Standardized Contract |
|
Verifiable (we must be able to recreate the results) |
Test results, achieved in one environment (JIT, for instance) can be easily recreated in any other environment in testing hierarchy. This means no surprises in production! |
Autonomy, Statefulness |
|
Reliable (we will trust test results) |
Service with acceptable characteristics achieved initially must not be obscured by later amendments/implementations breaking services, technical consistency. |
Autonomy, Statefulness, Loose Coupling |
|
Comprehendible (we must be able to understand the results) |
Test results, sometime together with test suites must be stored in a place where it can be reached, accessed, comprehended by any concerned party and re-implemented if necessary. |
Discoverability (Beware of Abstraction) |
This simple exercise demonstrates that there's neither any need to invent new principles out of wishes or abstract illities, nor to multiply unnecessary entities:
Entia non sunt multiplicanda praeter necessitatem | ||
| --Ockham | ||
Principles here act as precise technical guidance. Elaborative lists of more than 50 items, produced as a collective effort of several departments in some enterprises, usually leave only one question: how are you supposed to enforce all of them? A principle is the direct order, and it is only good if you can control its fulfillment.
For good measure, may we suggest that you repeat this exercise for the remaining nine requirements in that list?
The deceptive simplicity of SOA as an architectural approach made it attractive twelve years ago, and this deception (actually, the misunderstanding) caused its downfall after two to three years of initial implementations. Initially, the idea was pure and simply brilliant; it is mentioned as follows:
Quickly maturing XML, as the most universal standard and foundation for practically everything: messaging, transformations, protocols, data representation, the way you name it
Emergence of web services, as the next logical step in object-orientation and procedural programming with the highest level of encapsulation and standard detachable API expressed via the WSDL contract
SOAP presented in 1998 promised some transport-independent (to a certain extent) messaging protocol that was simple enough to gain popularity in the blink of an eye
In addition to the UDDI standard, employing lots of XML features has also been presented in order to support service discoverability. Thus, we got our first so-called Contemporary SOA representation in the shape of a triangle: Service Consumer (Sender), Service Provider (Receiver), and Service Registry (UDDI) shown as follows:

Message is always SOAP-based synchronous request/response; contract is WSDL with number of operations abstracted to be reasonable minimum. Service Consumer is displayed in a different color in order to stress the fact that it doesn't have to be a web service. This means that a service can be called from any program, interface, and device if WSDL can be understood and SOAP request-response can be supported.
This model will work (and more importantly it works) perfectly within designated boundaries for simple compositions or compositions based on multiple sequential invocations. We will discuss the obvious limitation of the contemporary model shortly; now, let's focus on core technologies, which are the core of all SOA models.
As stated before, we do not intend to cover all SOA standards, as we simply have no room for this in a single chapter. We will briefly touch only those which we will be using in the following chapters. The book Web Service Contract Design and Versioning for SOA, Prentice Hall Publishing, by Thomas Erl, could be a good reference in addition to the web recourses from standard authorities for SAML, OAuth, and so on. This section is just a technical recap of the absolute bare minimum requirements to link previous paragraphs dedicated to SOA principles with the soon-to-arrive SOA design rules based on patterns applied in particular SOA frameworks.
As an experienced architect, you are certainly quite familiar with all the technologies we will briefly touch on now.
This is the foundation of most of the standards and applications, not only SOA. Please note that you do not have to use XML to make your platform service-oriented in order to achieve goals of service-orientation, but you will find it rather difficult not to do so. You will have to replace quite a sizeable amount of movable and static elements of your infrastructure (configuration files, interchange messages, transformation mappings, contracts, and so on) with some similar but older formats such as CSV, EDIFACT, and X12 with lots of unexpected consequences. Modern standards such as JSON are also not entirely XML-free. So, we would like to suggest something for your own architectural benefits. Please look at the simple W3C School XML quiz (http://www.w3schools.com/xml/xml_quiz.asp); it will only take five minutes. If your score is less than 100 percent, we suggest you refresh yourself by reading a good XML book.
If service is an atomic building block of the whole SOA, then web services are the most popular variant of these building blocks. The reason for this is in an object/XML serializer, which is the native part of any WS and the link between a detached WSDL-based service contract and core service logic. For the Oracle platform (but not only), quite naturally employed Java marshaling/unmarshaling, Java-WS (or JWS) technology would be based on one of the following serialization APIs:
Java architecture for XML binding: JAXB (exists on multiple implementations but is not always fully compatible).
A more advanced JiBX. This can inject the conversion code directly into Java classes during the post-compilation process, and by doing so, improve the performance considerably when compared to JAXB. Also, it has its own runtime-binding component.
Simplified mapping-free version of marshaler: XStream.
JAXB is still the most popular one because of the number of characteristics it offers:
Runtime message validation
XPath-oriented
No post compilation required for code injection
Can support very complex message structures
The JAXB API is part of Java SE and EE package bundles, but still it is better to check for the latest release if performance is an issue. If serialization performance is the major concern, look at the JiBX more closely as it could be up to five times (some claim more) faster.
Here again, the reliability and predictability of parser should be balanced with reasonable performance; otherwise, you will have to rebuild your services from scratch every time the XSD specifications change.
So, in the JWS specification, JAXB is responsible for mapping a Java class to the message's XSD using customizable annotations. Java API for XML Web Services (JAX-WS) is the technology that is responsible for mapping Java parameters to the WSDL declaration. These two specifications conclude
service endpoint interface (SEI) as the representation of a standardized contract. Of course, just using them alone doesn't guarantee that contract will be truly standardized, but they are the two essential technical WS specs. The last and the most important part of the WS spec is the web container; it is responsible for performing basic HTTP operations: POST and GET. It's related to the handling of transport protocols, and we will discuss it right away.
XML-based SOAP-messaging protocol handled by the web container is typically implemented as a servlet if you need to utilize the HTTP transport protocol, which is most common for JWS. SOAP is a type of XML structure, serving as a container for service message interactions. There are two mandatory parts: soap:Envelope as a root and soap:Body that acts as a business payload container. Two optional elements can also be present: soap:Header and soap:Fault. Although the header element is optional, its role for providing transport and processing-related metadata is enormous. Most of the WS-* extensions followed after the first publication of initial WS specs are related to the SOAP headers. There are some which could be equally distributed between the header and body. For instance, WS-Security naturally relates to the body and header via encrypted and signed elements and WS-MetadataExchange provides and distributes WSDL-related data necessary for establishing service interactions, which can also be done via the SOAP body.
Most commonly, the Java web container will probably use a servlet as the front controller, and it is responsible for parsing the header elements and invoking the JAXB mapping to Java objects to process the SOAP body.
We will discuss UDDI-related protocols as part of contemporary SOA further when we approach the Service Registry architecture.
There are no drawbacks in the contemporary SOA model. Every single technical element is mature and proven to be reliable after dozen of years of evolution and improvements. Actually, it was pretty acceptable from the very beginning, but its broad usage was severely limited by the initial constraints set by the simplified service interaction model: synchronous request-response between limited numbers of composition members (usually two). At the time of the first implementation, it was apparent that a substantial number of complex real-life requirements needed be addressed by the SOA technology platform to make it capable of fulfilling its promises; they are as follows:
There is more than one simple message exchange pattern (MEP). We can count one-way MEPs, two-ways, callback MEP types along with all possible types of acknowledgements (responses), such as mandatory, only on errors, and so on.
Asynchronous MEPs are equally popular and must be covered by the technology platform in a common way. The ability to maintain sync-async communication bridges for complex service interactions was the prerequisite for further SOA proliferation.
Even synchronous service compositions could be far more complex than the basic request-response method with all elements of distributed transactions and two-phase commits requiring a transparent level of transaction coordination.
Long-running transactions also need common and reliable methods of controlling process execution with a lot of callbacks and numerous activation-deactivation phases. First of all, this involves transparent coordination based on the correlation ID and correlations sets, and the ability to compensate unsuccessful transactions.
Services must be able to reliably communicate in cases where we have infrastructure breakdowns or slow responses from other parties.
Service messages must be equipped with information that is sufficient for supporting complex routings and distributions.
Services and service registries are extremely vulnerable to security breaches due to high exposure to potential consumers (implementation of the Discoverability principle). This issue will be addressed with minimal impact on services intrinsic's interoperability.
These are only the most obvious requirements, which had to be fulfilled in order to make service orientation capable to serve its purpose and achieve the goals we discussed in the beginning of this chapter. It is apparent that all these issues must be addressed in a standard way; otherwise, proprietary implementations will be put across service environments' federation and vendor neutrality.
Most of the standards in the form of recommendations and profiles are provided by three main standardization committees, as shown in the following table:
|
About |
OASIS |
W3C |
WS-I |
|---|---|---|---|
|
URL | |||
|
Established |
1993 as SGML Open |
1994 by Tim Berners-Lee |
2002 |
|
Approximate membership |
600 |
About 390 |
200 |
|
Overall goal (as it relates to SOA) |
OASIS promotes industry consensus and produces worldwide standards for security, Cloud computing, SOA, web services, Smart Grid, electronic publishing, emergency management, and other areas. OASIS's open standards offer the potential to lower the cost, stimulate innovation, grow global markets, and protect the right of free choice of technology. (From official site) |
W3C's primary activity is to develop protocols and guidelines that ensure long-term growth for the Web. W3C's standards define key parts of what makes the World Wide Web work. (From official site) |
The Web Services Interoperability Organization (WS-I) is an open industry organization chartered to establish best practices for the web services interoperability. It is for selected groups of web services standards across platforms, operating systems, and programming languages |
|
Delivered Standards/ Specifications |
UDDI, ebXML, SAML, XACML, WS-BPEL, WS-Security |
XML, XML Schema, XQuery, XML Encryption, XML Signature XPath, XSLT, WSDL, SOAP, WS-CDL, WS-Addressing, Web Services Architecture WS-Eventing |
Basic Profile, Basic Security Profile |
In this section, we will group and discuss the service orientation standards and their roles in establishing framework-based infrastructure. Every standard deserves at least a single dedicated chapter, so we advise you to follow the links to the provided standardizations committee technical pages for more details on the latest versions.
Standards that define service repository taxonomy and semantics are explained in the following sections.
The details on S-RAMP are given in the following table:
|
Authority |
Primarily addresses |
Latest release |
|---|---|---|
|
OASIS |
Discoverability |
https://www.oasis-open.org/committees/tc_home.php?wg_abbrev=s-ramp |
The S-RAMP technical specification defines a common data model for SOA repositories as well as an interaction protocol to facilitate the use of common tooling and sharing of data. S-RAMP is not intended to define general purpose ontology for SOA. Instead, the specification references the work of The Open Group (http://www.opengroup.org/), defining how it is integrated and used in the context of S-RAMP. S-RAMP is focused on publication and query of documents based on their content and metadata.
This specification will be used together with Service-Aware Interoperability Framework (SAIF) further for defining lightweight service repository taxonomy, which is suitable for service lookup and dynamic invocation by agnostic composition controllers.
The core standards that define services' contracts and reliable communications will be covered in the following sections.
The details of WSDL are as shown in the following table:
|
Authority |
Primarily addresses |
Latest release |
|---|---|---|
|
W3C |
Reusability, Loose Coupling, and Discoverability, Composability |
Web Services Description Language Version 2.0 (WSDL 2.0) provides a model and an XML format for describing web services. Description has abstract and concrete parts. In the abstract part, we can define what messages can participate in which operations; consequently, in request and response, we can define what fault message can be generated. The concrete part binds operations with related messages to the physical service endpoint shown as follows:
<!-- WSDL definition structure --> <definitions name="cargoBooking" targetNamespace="http://erikredshipping.com/booking/" xmlns="http://schemas.xmlsoap.org/wsdl/"> <!-- abstract definitions --> <types> ... <message> ... <portType> ... <!-- concrete definitions --> <binding> ... <service> ... </definition>
Tip
Downloading the example code
You can download the example code files for all Packt books you have purchased from your account at http://www.packtpub.com. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
WSDL is equally important for implementing the WS-* specification as SOAP. Practically, all elements can be linked to the WS policy statements, describing behavior, data requirements, or QoS declarations. One of the most important pieces of information along with the declared data models / types (XSD) and operations (via declared canonical expressions such as get, process, and so on) is to bind the message exchange pattern.
The WSDL Message Exchange Patterns (MEPs) 2.0 are as follows:
The in-out pattern, which is the standard request-response operation. This is the most common pattern.
The out-in pattern, where a service provider initiates the interchange.
The in-only pattern, which is the regular fire-and-forget MEP.
The out-only pattern, which is the reverse of the in-only pattern.
The robust in-only pattern is similar to the previous one, but it comes with the capability to provide the fault response message back if there is an error.
The robust out-only pattern is similar to the out-only pattern, but it provides the optional fault message.
The in-optional-out pattern is similar to the in-out pattern, but here, the response message is optional. This pattern also supports the generation of a fault message.
The out-optional-in pattern is the reverse of the in-optional-out pattern, where the incoming message is optional. Here, generation of a fault message is supported.
We will touch upon some of these MEPs later, discussing the WS-* specification's roadmap.
The details of WS-Addressing are as shown in the following table:
This standard is the keystone for the whole WS-* stack, as all other standards are actively using it. It provides a neutral way of distributing messages. The SOAP header is the placeholder for all key elements, and they are presented in the following table:
|
wsa: Element |
Description |
|---|---|
|
|
This property presents the ID of a message that can be used to uniquely identify a message. |
|
|
This property provides the destination URI, and it indicates where the message will be sent to. If not specified, the destination defaults to http://www.w3.org/2005/08/addressing/anonymous. |
|
|
This property provides the source endpoint reference, and it indicates where the message came from. |
|
|
This property provides the reply endpoint reference, and it indicates where the reply for the request message should be sent. If not specified, the reply endpoint defaults to http://www.w3.org/2005/08/addressing/anonymous. |
|
|
This property conveys the message ID of a related message along with the relationship type. |
|
|
This property provides the fault endpoint reference. It indicates where the fault message should be sent to if there is a fault. If this is not present, usually the fault will be sent back to the endpoint where the request came from. |
|
|
This property displays the action related to a message. For example, the |
|
|
This property references parameters that need to be communicated. |
WS-Addressing allows the sending of messages to the specific instance of a service, which is not possible by WSDL concrete bindings alone. The SOAP request and response implementation is as follows:
|
Request |
Response |
|---|---|
|
The code for request implementation is as follows:
<soapenv:Envelope xmlns:soapenv ="http://www.w3.org/2003/05/soap-envelope" xmlns:wsa="http://www.w3.org/2005/08/addressing/">
<soapenv:Header>
<wsa:MessageID>
http://example.com/someuniquestring
</wsa:MessageID>
<wsa:ReplyTo> <wsa:Address>http://example.com/Myclient</wsa:Address>
</wsa:ReplyTo>
<wsa:To>
http://example.com/fabrikam/Purchasing
</wsa:To>
<wsa:Action>
http://example.com/fabrikam/SubmitPO
</wsa:Action>
<soapenv:Header>
<soapenv:Body>
...
</soapenv:Body>
</soapenv:Envelope> |
The code for request implementation is as follows:
< soapenv:Envelope
xmlns:soapenv ="http://www.w3.org/2003/05/soap-envelope"
xmlns:wsa="http://www.w3.org/2005/08/addressing">
<soapenv:Header>
<wsa:MessageID>http://example.com/someotheruniquestring</wsa:MessageID>
<wsa:RelatesTo>http://example.com/someuniquestring</wsa:RelatesTo>
<wsa:To>http://example.com/MyClient/wsa:To>
<wsa:Action>
http://example.com/fabrikam/SubmitPOAck
</wsa:Action>
</soapenv:Header>
<soapenv:Body>
...
</soapenv:Body>
</soapenv:Envelope> |
Requirements for addressing in WSDL are presented in the following fragment:
<binding name="cargoBookingPortBinding" type="tns:cargoBooking">
<wsaw:UsingAddressing wsdl:required="true" />
......
<soap:binding transport="http://schemas.xmlsoap.org/soap/http"
style="document"/>
<operation name="bookCargoUnit">
<soap:operation soapAction=""/>
<input>
<soap:body use="literal"/>
</input>
<output>
<soap:body use="literal"/>
</output>
<fault name="missingCargoId">
<soap:fault name=" missingCargoId" use="literal"/>
</fault>
</operation>
</binding>WS-ReliableMessaging provides an interoperable protocol that a Reliable Messaging (RM) source and RM destination are used to provide the application source and destination with a guarantee that a message that is sent will be delivered:
|
Authority |
Primarily addresses |
Latest release |
|---|---|---|
|
OASIS |
Composability, Loose Coupling, |
The guarantee is specified as a delivery assurance. The protocol supports the endpoints by providing these delivery assurances. It is the responsibility of the RM source and the RM destination to fulfill the delivery assurances or raise an error. It would be right to see the analogy between WSRM and JMS in the Java world in terms of delivery assurance. The key differences are that JMS is highly platform-specific with a standard API, whereas WSRM is platform-independent by means of SOAP (and WSDL). Of course, WSRM agents (handlers) must be implemented behind services WSDLs and also on the client side to retransmit the message if necessary or provide the acknowledgement; however, these agents are invisible at the service/application's interaction levels. WSRM is an extension of SOAP, and all of its protocols are based on the concept of sequence. Sequence is the number of predefined steps, shown as follows:
CreateSequenceCreateSequenceResponseCloseSequenceCloseSequenceResponseTerminateSequenceTerminateSequenceResponse
You can see the latest specification on the official OASIS site.
Reliable messaging in a WSDL implementation is as shown in the following code snippet:
<?xml version="1.0" encoding="utf-8"?>
<wsdl:definitions xmlns:wsdl="http://schemas.xmlsoap.org/wsdl/"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:wsa="http://www.w3.org/2005/08/addressing"
xmlns:wsam="http://www.w3.org/2007/05/addressing/metadata"
xmlns:rm="http://docs.oasis-open.org/ws-rx/wsrm/200702"
xmlns:tns="http://docs.oasis-open.org/ws-rx/wsrm/200702/wsdl"
targetNamespace="http://docs.oasis-open.org/ws-rx/wsrm/200702/wsdl">
<wsdl:types>
<xs:schema>
<xs:import namespace="http://docs.oasis-open.org/ws-rx/wsrm/200702"
schemaLocation="http://docs.oasis-open.org/ws-rx/wsrm/200702/wsrm-1.1-schema-200702.xsd"/>
</xs:schema>
</wsdl:types>
<wsdl:message name="CreateSequence">
<wsdl:part name="create" element="rm:CreateSequence"/>
</wsdl:message>
<wsdl:message name="CreateSequenceResponse">
<wsdl:part name="createResponse" element="rm:CreateSequenceResponse"/>
</wsdl:message>
....
<wsdl:message name="TerminateSequence">
<wsdl:part name="terminate" element="rm:TerminateSequence"/>
</wsdl:message>
<wsdl:message name="TerminateSequenceResponse">
<wsdl:part name="terminateResponse" element="rm:TerminateSequenceResponse"/>
</wsdl:message>
<wsdl:portType name="SequenceAbstractPortType">
<wsdl:operation name="CreateSequence">
<wsdl:input message="tns:CreateSequence" wsam:Action="http://docs.oasis-open.org/ws-rx/wsrm/200702/CreateSequence"/>
<wsdl:output message="tns:CreateSequenceResponse" wsam:Action="http://docs.oasis-open.org/ws-rx/wsrm/200702/CreateSequenceResponse"/>
</wsdl:operation>
....
<wsdl:operation name="TerminateSequence">
<wsdl:input message="tns:TerminateSequence" wsam:Action="http://docs.oasis-open.org/ws-rx/wsrm/200702/TerminateSequence"/>
<wsdl:output message="tns:TerminateSequenceResponse" wsam:Action="http://docs.oasis-open.org/ws-rx/wsrm/200702/TerminateSequenceResponse"/>
</wsdl:operation>
</wsdl:portType>
</wsdl:definitions>The service metadata describes what is needed for the service consumers, including composition controllers to establish successful interchange sessions with service provider(s). Some of the WS specifications are described in the following sections.
Almost all elements of WSDL can be perceived as metadata: XSD structures, and also as message data types, policies, provider's capabilities, requirements for transaction control, or reliable messaging. The details of WS-MetadataExchange are as shown in the following table:
|
Authority |
Primarily addresses |
Latest release |
|---|---|---|
|
W3C |
Discoverability, Composability, Loose Coupling |
These metadata elements can be pushed or pulled as a whole or partially from the service provider's contract. In general, these standards describe the way of encapsulating this data and the extraction protocols. Some elements responsible for pulling or pushing data and its encapsulation are presented in the following table:
The SBDH standard provides a document header that identifies a key data about a specific business document. The details of SBDH are shown in the following table:
|
Authority |
Primarily addresses |
Latest release |
|---|---|---|
|
UN/CEFACT GS1 |
Discoverability |
http://www.gs1tw.org/twct/gs1w/download/SBDH_v1.3_Technical_Implementation_Guide.pdf |
Since SBDH standardizes the way data is presented, the data elements within SBDH can be easily located and leveraged by multiple applications. SBDH is a business document header and should not be confused with a transport header. It is created before the transport routing header is applied to the document and is retained after the transport header is removed.
Although SBDH is not the transport header, data in it can be used by transport applications to determine the routing header since it does contain the sender, receiver, and document details. It can also be used by business applications to determine the appropriate process that is to be performed on the business document. The specifications are explained in the following section.
This very wide specification establishes conditions and restrictions for a service's invocation and consequently for all compositions it may participate in. The details of WS-Policy are as follows:
|
Authority |
W3C |
|---|---|
|
Primarily addresses |
Composability, Loose Coupling, and Abstraction |
|
Latest release |
Most importantly, when compared with human-readable SLAs, these conditions are expressed in a machine-readable form. In fact, this specification has a lot of common features with the metadata exchange standard, but it's far wider as it expresses service requirements and preferences regarding all other WS-* specifications in a detachable form, presented as an XML policy file. This separation allows you to centralize all policies and present them in a hierarchical way, simplifying attachment to the provider's WSDL.
Some delivery assurance elements along with their descriptions are as follows:
The WS-Policy delivery assurance elements are typically used together with other WS-* specifications for enforcing certain operational requirements, such as reliable messaging timeout and acknowledgement interval, as shown in the next code snippet.
The following code will help us understand how the policy is defined as a child element of the wsdl:definitions element:
<wsp:Policy wsu:Id="RMAcknowledge_policy">
<wsp:ExactlyOne>
<wsp:All>
<wsaw:UsingAddressing/>
<wsrm:RMAssertion>
<wsrm:AcknowledgementInterval Milliseconds="500"/>
<wsrm:InactivityTimeout Milliseconds="100000"/>
</wsrm:RMAssertion>
</wsp:All>
</wsp:ExactlyOne>
</wsp:Policy>The last step will be the referencing of the policy with the child element of the wsdl:binding element shown as follows:
<wsdl:binding name="testWsRmBinding" type="tns:TestWSRM">
<wsp:PolicyReference URI="# RMAcknowledge_policy "/>
…...The specifications of transaction control and activity coordination are explained in detail in the following sections.
The details of WS-Coordination are as shown in the following table:
|
Authority |
Primarily addresses |
Latest release |
|---|---|---|
|
OASIS |
Reusability, Composability |
http://docs.oasis-open.org/ws-tx/wstx-wscoor-1.1-spec-errata-os/wstx-wscoor-1.1-spec-errata-os.html |
This specification is the foundation for the service federation, allowing services from different business and technology domains to coordinate their interoperability operations, both long- and short-term living. According to this specification, it's realized in two stages:
In the first phase, all participants registered in one unified coordination context and communication protocols are agreed upon
In the second phase, all registered participants exchange messages according to the protocols and rules of engagement established during the registration phase
This specification is responsible for the following:
Creating and formatting
CoordinationContextthat contains registration information, which is mandatory for all participantsEstablishing a coordination protocol based on
CoordinationContext, and the ways of distributing this context between participantsEstablishing a registration protocol
CoordinationContext in the header of a SOAP message can be seen in the following code snippet:
<wscoor:CoordinationContext>
<wsu:Expires>2014-03-21T00:00:00.0000000-05:00</wsu:Expires>
<wsu:Identifier>
uuid:0d13748c-7a09-8520-a911-17c73f09ac82
</wsu:Identifier>
<wscoor:CoordinationType>
http://schemas.xmlsoap.org/ws/2003/09/wsat
</wscoor:CoordinationType>
<wscoor:RegistrationService>
<wsa:Address>
http://erikredshipping.com/ShcheduleCoordinationService/RegistrationCoordinator
</wsa:Address>
<wsa:ReferenceParameters >
....
<refApp:App1> ... </refApp:App1>
<refApp:App2> ... </refApp:App2>
....
</wsa:ReferenceParameters >
</wscoor:RegistrationService>
</wscoor:CoordinationContext>The WS-Coordination specification is the foundation for other specifications, setting the standards for complex coordinated activities: WS-AtomicTransaction and WS-BusinessActivity. Both of these define a type of agreement coordination that addresses the needs of complementary classes of activities, ACID- and BASE-type requirements, as discussed later in this chapter.
To understand how
WS-* standards could help solve some problems that are not addressed by the simple model of contemporary SOA, we will walk through the process-identification flow diagram shown in the next figure. This diagram is based on the interactions of web-based services as native areas of the WS-* standards implementation. We will start with the definition of the process as a number of services invocations, sequential or parallel, with different durational and transactional requirements.
First, let's identify whether it is a long or short running process. Longevity is the subject of technical and/or business timeouts. The first one is related to a time slot; here, your services in composition could hold on to the active state without draining too many resources. The second is set by business requirements and can be quite substantial (days, weeks, and so on). Moving by the left lane, we will first look at the synchronous services and the standards associated with them. In common cases, we could assemble service compositions from different domains, so a Service Broker will be compulsory; it will help us resolve the disparity of the data models, formats, and protocol bridging as well.
Also, brokering means that routing and mediation could be necessary for complex service activities when more than two services are involved. In these cases, Service Broker will act as a Composition Controller. Both of them are SOA patterns, arguably most-commonly used, and we will see their implementation in detail soon. If it's just a synchronous single interaction between a service consumer and a service provider, it's called a primitive activity. In general, the following two major standards must be taken into consideration:
WSDL should have a binding to a proper MEP; otherwise, communication simply will not be possible.
The
WS-ReliableMessagingservice must be implemented if a feeble connection or slow response from a service message-receiver could affect service activities. The application of this standard will ensure that the message is delivered or at least provide an acknowledgement about the state of the delivery.
Let's move on to the middle lane. If more than two participants in a synchronous composition can be expected, for example, one composition initiator and two or more composition members, the number of WS-* standards and specifications involved will be doubled. Composition Controller becomes mandatory in this scenario. In addition to WSDL MEPs and WS-RM from primitive activities, the transaction coordination based on WS-AtomicTransaction arguably will be one of the most important specifications for these types of composition. It will address typical ACID requirements related to multiphase commits:
At design time, define all the Atomic Transaction Coordinators (ATC) phases in WSDL with specific messages such as
wsat:Prepare,wsat:Prepared,wsat:Aborted,wsat:Commit,wsat:Rollback,wsat:Commited, andwsat:Reply. Bind ATC messages to the operations.At runtime, initiate the transaction, send messages, collect votes, commit if all participants have voted positively, send the rollback signal if any vote is not received in the designated time slot or is negative, repeat operations if necessary, and propagate the response to the initial sender.
With many services involved in this complex activity, some from different domains with different data models (which is common in the adapter technology layer), requirements for complex transformations could be anticipated. The transformation technique could be different, of course; sometimes, you may come across a proprietary technique. However, here we will discuss the standard XSLT/XQuery approaches. Most common complex transformations that we will be coming across in our designs are as follows:
The message aggregations design: Here, we combine several messages in one that are further processed by a service that can accept only coarse-grained data models. If messages arrive sequentially, XSLT alone will not be enough; some transformation's intermediate store will be necessary if we do not want to keep the messages in.
The message debatching or splitting design: Here, we separate one message that contains a batch of similar messages into a sequence of messages suitable for processing by a service with a fine-grained data model. This task is very common; inbound messages usually in a non-XML format and whole processing will require a
WS-RMimplementation, as ordered sequential processing is involved in providing possible acknowledgements for batch or individual messages.
Finally, for the middle lane, the most common standard WS-Addressing will be compulsory if message mediation is required for complex service activities. Usually, it's presented as a content-based routing, sometimes based on rules handled by the rule engine; static routing tables are also common.
This concludes the mapping of synchronous service activities to the technology standards and WS-* specifications.
Asynchronous services are more complex, as more infrastructural technical elements are required as follows:
Asynchronous queuing will require server resources such as topics and/or queues
State repository will be required for resource hibernation during the composition's inactive state
Their realization is not covered by any particular WS-* specification, but their presence is significant for the WS-BusinessActivity specification's implementation. The WS-BusinessActivity specification together with WS-AtomicTransaction and support from WS-Coordination has presented the mechanism controlling service activities over a long period of time. The
Business Activity coordination protocol can be perceived as a chain of discrete over-the-time atomic coordinations. As it is clear from the context, rollback actions are virtually impossible between different stages of business activities, so the possibility to have an arbitrary compensative transaction is the essential part of this protocol. Using compensation, it is possible to return the data of an application's participant to a consistent state, but not exactly to the state before the transaction, such as the Atomic Coordination. The complexity of compensative transactions could be very high, allowing you to correct the changes happened many steps before the actual error.
Further implementation of standards and recommendations in the right lane is similar to implementing complex synchronous activities; this confirms the fact that an asynchronous business activity is a chain of complex synchronous activities. A special significance of asynchronous transactions is that it has a WS-Coordination specification for its role of establishing a coordinator service model we mentioned earlier.
The composition of a coordinator service model consists of the following services:
The activation service, which creates new coordination contexts and associates them with the planning activity
The registration service, which registers a service's participant and distributes coordination contexts among them
Protocol-specific services, which represent the protocols supported by the coordinator's coordination type
The coordinator controller service of this composition, also known as the coordination service
A key element of the coordination context is the correlation key, which is common for all activities in a particular composition. WS-Addressing's elements wsa:ReferenceParameters and wsa:ReplyTo could be employed as a container for correlation ID and address, where the response will be sent:
<soap:Header>
<wsa:MessageID>uuid:35f19ca8-c9fe</wsa:MessageID>
<wsa:Action>http://erikredcarrier.com/ship</wsa:Action>
<wsa:To>http://www.portaquaba.com:7070/ShippingService</wsa:To>
<wsa:ReplyTo>
<wsa:Address>
http://www.portbremen.com:7777/response
</wsa:Address>
<wsa:ReferenceParameters>
<customHeader>correlationKey</customHeader>
</wsa:ReferenceParameters>
</wsa:ReplyTo>
...Combined together, these elements form the SOA pattern called Service Callback, which is most commonly used in asynchronous communications.
Another pattern that is common to all types of service interactions related to the service is the Policy Centralization
SOA pattern. The WS-Policy specification is a machine-readable language for representing these web service capabilities and requirements as policies. A policy makes it possible for providers to represent such capabilities and requirements in a machine-readable form. A separate policy file such as policy.xml can contain several policy expressions that are grouped under different WS-Utility identifiers (wsu:Id) for simplified referencing, both external (http://erikredcarrier.shipping.com/policy.xml#common) and internal (just #common); please see the PolicyReference examples shown in the following code snippet:
<Policy wsu:Id="common"> <wsap:UsingAddressing /> .... <!-- other policies with usage attributes : wsp:Optional="true" --> </Policy>
The representation Policy to the service consumers is designed by binding policy expressions to WSDL elements, to service operation, for example as shown in the following code:
<wsdl:binding name="AddressingBinding" type="tns:RealTimeDataInterface" > <PolicyReference URI="#common" /> <wsdl:operation name="getCargoStatus" >...</wsdl:operation> ... </wsdl:binding>
The last standards, presented as optional for all lanes are related to complex event processing specifications: WS-Notifications (OASIS) and WS-Eventing (W3C). In a nutshell, both of them describe the publish-subscribe protocols with the propagation of events that follow right from the publisher to the subscriber, some sort of fire-and-forget messaging patterns. It is important to remember that both subscribers and consumers are not always the same actors; most interestingly, for Brokered Notification, some form of Service Broker called Event Broker will be employed for distributing events between multiple consumers.
SOA Standards and Patterns implementation roadmap
We didn't cover all the existing WS-* specifications, but the ones described earlier are quite capable of dealing with challenges, something that the contemporary SOA is unable to address. These specifications were under development during the last ten years, and some of them are still evolving; however, overall, the technology stack based on WS-* is very mature. Although some of the specifications are a bit complex, the fact that all of them are based on clearly defined principles has made them commonly acceptable and adoptable not only by main market players/sponsors of standardization committees, but also by open source communities, acting as some of the most valuable contributors toward the proliferation of these standards.
Abstract principles and vendor-neutral standards do not exist in a vacuum; they have practical service boundaries as we have seen during the discussion of the standards' implementation roadmap. We even touched upon some roles of patterns discussing principle-standards relations. These relations could have many forms and dependencies with regards to the infrastructural areas of service implementation. Every area has its own distinctive characteristics, a proprietary for every single step of service's lifecycle such as analysis, modeling, development, testing, and implementation.
Collectively, they are shaping service boundaries in the form of complex building blocks that connect internal information assets with external consumers of those assets.
Distinctive characteristics of these blocks are formalized in a collection of design rules, one for each particular area; however, collectively, they aim at the same goal of maintaining a desirable level of composability for services that exist in these ecosystems.
Framework is one of the most commonly used terms, not just only in IT (probably, together with pattern). It is also commonly said that SOA is a framework in itself. This means that the SOA framework is dedicated to the technological and operational areas for the implementation of SOA Principles in order to achieve the predefined goals. One problem here though is that it's too often mentioned that principles must be applied in a meaningful context.
Too much about framework, which by its dictionary definition should show some precision as mentioned in The American Heritage® Dictionary of the English Language, Fourth Edition copyright ©2000 by the Houghton Mifflin Company:
A structure for supporting or enclosing something else, especially a skeletal support used as the basis for something being constructed.
A fundamental structure, as for a written work.
A set of assumptions, concepts, values, and practices that constitutes a way of viewing reality.
So, maybe from reviewing SOA realities, we could identify the number of frameworks it consists of and their distinguishing characteristics, as we can see in the following figure:
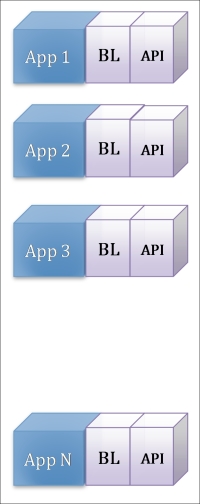
The starting point would be the realization of the ultimate goal of any business application's infrastructure to have a hot-pluggable collection of business applications (App1 to App N), each providing and effectively serving its own functional context. All functional contexts have strictly defined non-overlapping boundaries; physical realization of applications has a high level of technical autonomy, which in fact makes these applications hot-pluggable. At any given point in time, an application that becomes technically obsolete or functionally irrelevant can be replaced with its more modern and cost-efficient equivalent.
As long as all functional boundaries are precise and individual, business logic (BL) encapsulated within each application is transpired and comprehendible. It can be clearly separated from application resources and modeled/remodeled using platform-independent means as there are no parasitic couplings between separated elements of business logic of any kind. Every application presents public operations and related data models via standardized APIs using common notations, available for all involved parties in a comprehendible way.
A number of communication protocols and exchange patterns have been reduced to reasonable minimum with well defined timeouts and compensation activities if there are occasional miscommunications.
What we just described is a collection of services, as they should be designed from the beginning. A service can be perceived as an application if a functional context permits this without affecting Loose Coupling and Abstraction negatively.
The following two assumptions are distinctive:
Assumption 1: Services have non-overlapping functional boundaries, encapsulating the logic that is specific only for this service.
Assumption 2: Services allow you to access the service logic only via a publicly available service contract, which is expressed using the canonical data model and canonical expressions for capabilities. Canonical protocols complete the picture.

In this case, the implementation of a new business process would be achieved by simply recomposing existing service capabilities in the sequence and duration as per the new functional context.
We will need some hypothetical area where this recomposition will be possible technically. There shouldn't be any problem, as the protocol, data, and interfaces stay homogenous. Any programming language or platform will do if the result of the recomposition—the new service—follows the initially declared standards for the services.
The fact that a newly composed application is also the service is important, as this composition could potentially be part of an even bigger composition; therefore, all strict standards must be applied all the way. This idealistic picture is pretty close to the contemporary SOA model. We have only one solid framework here that is used for business service composition, and with this, we practically accomplish very little. All our compositions would be just invocations of existing APIs' capabilities with values' assignments in between. No transformation is required as all data models are CDM-compliant, and a unified protocol eliminates the necessity of the bridging protocol.
The first real wake-up call would come from the realization that not all our APIs really are parts of the canonical Federated Endpoint Layer (as explained in Chapter 6, Finding the Compromise – the Adapter Framework). The Assumption 2 item mentioned in the previous bullet list is quite often too optimistic in real life; this means that:
Data model transformation and data format transformation (translation) could be needed.
There could be no APIs at all. Even worse, data required for a new composite service will be pulled from various sources, sometimes with multiple data cleansing and filtering routines extended over a period of time.
Complex transformations will be performed to maintain the initially declared data granularity on service composition, such as aggregation or debatching.
Messaging and/or transport protocols are not canonical, and this disparity must be harmonized.
Following the principle of separation of concerns, we must preserve our Business Service Composition's hypothetical area that is free from all disparities; this is suitable only for fast and clean compositions. Thus, the implementation of Application Business Connector Services is compulsory. This is the first concrete framework in the list of SOA frameworks we are going to discuss. The sole purpose of this framework is to compensate for the lack of the service(s) to present a standardized contract, suitable for repeatable reuse and utilization. Services residing in this framework are special forms of wrappers, designed to receive/extract, translate, transform, filter, validate, and propagate (route) further information required for business compositions, that is, implement the VETRO pattern (http://www.oracle.com/technetwork/articles/soa/jellema-esb-pattern-1385306.html). You can see the required functionalities, implementation techniques, and service models for this framework in the following list of requirements:
Implementation technique:
Synchronous implementation for simple MEPs
Asynchronous transaction coordinator for adapters (data-collectors), handling long-running data aggregation transactions
Service models:
Adapter services (Legacy Wrappers, File Gateways, FTP Hotels, and so on) are utility services in general
Required functionalities:
Availability of Protocol adapters such as SOAP.
Availability of Transport Adapters available such as JMS/MQ, AQ, and HTTP.
Availability of Application adapters such as OEBS, Siebel, and so on.
Availability of Component adapters such as DBs for instance.
Presence of Atomic Transaction Coordinator at the adapter level, and the implementation of the voting mechanism.
WS-ReliableMessaging support.
Data model and data format transformations support (types and engines) and protocol bridges (
SOAP<->REST).Automated fault handlers (retry mechanisms) for southbound adapters mostly.
Implementation of the FTP(S) Gateway pattern.
Implementation of the File Gateway pattern.
Filesystem objects' (FSO) replication such as files and folders/subfolders.
Reverse proxy realization for security reasons.
API for JCA adapters that provides the possibility to create your own adapters.
Reliable store-and-forward queue mechanisms with full message traceability and no message losses.
Message filtering mechanisms, suppressing unwanted responses.
Multiconsumer queues' support.
Implementation of the high-availability reliable adapters.
The following figure explains the presented list:
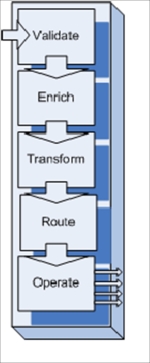
This framework is kind of special. Ideally, it is not supposed to exist; yet, it is one of the most common and, at the same time, heavy frameworks in use. It's heavy with embedded functionalities, practically all WS-* standards employed here in order to support the VETRO pattern's implementation.
There is a strong reason for viewing these types of services as temporary services, exiting only during the time of the transition of incapable application to a consistent service state with all SOA principles properly applied. This transition could be very time consuming, so some characteristics should be observed constantly in order to not create hybrid services and make the situation worse.
The ABCS design rules usually are as follows:
Northbound ABCS receives any type of messages and produces a canonical model (CDM) for the service composition layer. Inbound Debatching/Aggregation is performed here.
Southbound ABCS gets CDM and reliably delivers application-related messages.
ABCS is responsible for consistently maintaining all message header elements.
Error occurring in the active (poller) northbound ABCS will be not propagated further. Acknowledge the message returned to the northbound application if necessary, and a record is usually created in the audit log. Numbers of extraction retries could be unlimited, as a business transaction is not started yet. Still, limiting the number of retries can be wise.
Error occurring in southbound ABCS is reported back to the composition controller or actual service worker. The number of retries allowed is limited and policy-based. Depending on the type of transaction (sync-async), ATC rules are applied.
ABCS is highly tailored to the endpoint application service. It is not recommended to have one terminal adapter for several endpoints. It would be quite right to say that the adapter belongs more to a service-enabled application than an SOA inventory.
If the number of identical adapters is substantial, the Adapter Factory pattern could be applied for instantiating particular adapters of similar types (only the actual endpoint is different and looked up from the registry). Adapter Factory Service acts as a coordinator and does not belong to the ABCS technology layer.
Transaction Coordinator is a valid SOA pattern for ABCS if data extraction procedures require transactional control. For instance, some of the data must be extracted from the first DB and the extraction flags subsequently updated, then another portion of data extracted from second DB, and values changed again and after that consolidated and validated following the final update. We must remember that data extraction routines must not be mixed with business logic; otherwise, we unconsciously introduce a hybrid service on an adapter layer, scattering the logic over and making this solution very hard to maintain.
Again, from pure logic, ABCS's have no right to exist. If your application is not capable of being a reliable composition member, it is better to something about it, such as redesign, rewrite, retest, and reimplement. Alas, it doesn't work this way in real life. From the version control standpoint, ABCS's are inevitable; however, how many times did we witness that adapter services with complexities are compared to the application logic it tried to isolate and abstract. From very beginning though, it meant presenting a lightweight wrapper only. In most cases, that's the result of the second dissonance with reality, that is, Assumption 1 is wrong and our application, even with proper WS API, is too bulky, sluggish, and not reliable to act as a composition member. Yes, implementation of ABCS could potentially help, but some SOA principles have to be sacrificed (original applications such as Autonomy, Loose Coupling, and Abstraction), which makes the situation even worse. Thus, a service must be redesigned in this scenario, as an adapter alone cannot improve its composability.
Obviously, two new linked frameworks have to be introduced, although there is nothing new about them; they are as follows:
The Object Modeling and Design framework must be adopted for proper implementation of the separation of concerns principle. As a practical outcome of its application, functional boundaries of the services must be rearranged; autonomy of the services improved due to resource isolation, if it's possible; and the negative couplings resolved by the application of logic-to-contract positive coupling.
The XML Design framework as a support of canonical business model must be presented. XML message is a serialized transportable representation of the business object, encapsulated in service logic. Therefore, this framework in general is the extension of objects' modeling and design.
It is hard to say which one of these two frameworks is the primary one as both of them have a particular purpose, that is, to promote the Contract-First design rule as much as possible. Surely, this design rule is more applicable in the top-down approach when we have the possibility to design a service from scratch. Redesigning a bulky legacy application significantly limits our options, but functional decomposition together with the discussed ABCS's layer still makes it possible.
The details of the GF02: Object Modeling and Design framework are as shown in the following table:
|
Implementation technique |
Service models |
Required functionality |
|---|---|---|
|
Avoid the generation of a contract (WSDL) from the service logic |
All service models that include Utility services, Entity Services, Task Services, and so on (with some limitations for orchestrated services) |
Object-to-XML mappings |
|
Identify all service metadata elements |
Flexible XML marshalling | |
|
Register metadata elements in an individual service profile |
Support of WS-Security | |
|
Persistence support (mapping relational data to XML and object model) | ||
|
Complete support of object- and aspect-oriented programming (by default) |
The following figure explains the table:
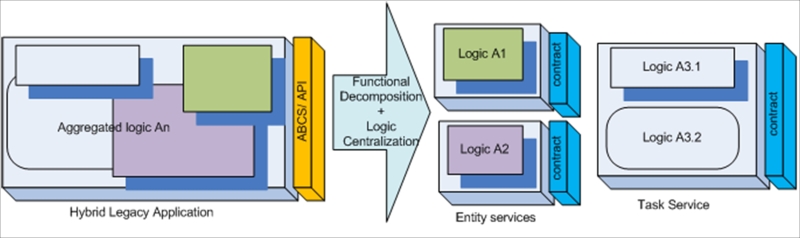
This framework is vendor-specific and is only related to the component/service implementation. Anything will do really, such as Spring Web Services / MVC, the .NET framework, and so on.
For functional decomposition, we will the need combined efforts of business analysts, service architects, and technical infrastructure experts for balancing SOA principles discussed previously with technical feasibility of redesigned services (in order to understand the physical level of decomposition required). To follow the Contract-First principle, any SDK is good.
The third related framework, XML Design, is interrelated to Object Design and primarily concerned with establishing a canonical business model for the service inventory. This model is not a single entity; it's a collection of enterprise entities in the form of Enterprise Business Objects closely related to the existing DB models that describe primary enterprise assets such as Order, Invoice, and CargoUnit. One possible source of them is already mentioned in functional decomposition, which is the oldie but goodie reverse engineering fashion that can harvest these entities for us. With the top-down approach, these entities can be acquired from technology-specific forums that are related to business functional areas such as telecommunication, transportation, and healthcare. However, you must be quite skeptical about the amount of data presented on these resources; these specifications are some sort of all-weather cases that are oversized and over-bloated with elements you could never use in your business. By following them blindly, you can end up with a simple purchase order with two or three order lines of 3 Meg size. Another problem is that these models are quite illogically partitioned, mixing together all essential building blocks:
Qualified data types (QDT)
Qualified data object (QDO)
Message header and process header elements
Message tracking data
Amazingly, through some international projects, we also witnessed the implementation of regional data models using local languages. Yes, you won't believe it. An entire local messaging hierarchy (XML elements, attributes, documentation, and constraints) has been implemented in one Scandinavian language—so much for discoverability and composability, without mentioning the encoding issues.
The foundation for the XML framework has been well set by the UN/CEFACT Document XML Naming and Design Rules draft version published in August 2004. Please acquire the latest version and follow the design rules section (see Appendix C, Naming and Designing the Rules List). They are all important, from [R 1] to [R 185]; we just would like to quote the most important part from our point of view.
The following table lists the implementation techniques, service models, and some selected design rules using the contract-first approach, as follows:
|
Implementation technique |
Service models |
Selected Design rules (out of 185) |
|---|---|---|
|
Avoid XSD generation from DB model |
All: Utility Services, Entity Services, and Task Services |
[R 4] ELEMENT, ATTRIBUTE AND TYPE NAMES MUST BE IN THE ENGLISH LANGUAGE, USING THE PRIMARY ENGLISH SPELLINGS PROVIDED IN THE OXFORD ENGLISH DICTIONARY. |
|
Identify all EBO/EBM elements |
[R 5] LOWER-CAMEL-CASE (LCC) MUST BE USED FOR NAMING ATTRIBUTES. | |
|
Follow Naming and Design Rules List |
[R 6] UPPER-CAMEL-CASE (UCC) MUST BE USED FOR NAMING ELEMENTS AND TYPES. | |
|
Register message-related metadata elements in service repository |
[R 13] A ROOT SCHEMA MUST BE CREATED FOR EACH UNIQUE BUSINESS INFORMATION EXCHANGE. | |
|
[R 23] A QUALIFIED DATA TYPE SCHEMA MODULE MUST BE CREATED |
The figure explaining the table is as follows:

Needless to say, these rules also must be applied wisely with proper understanding of all consequences. For example, following the rule [R 60], that is, THE XSD: ANY ELEMENT MUST NOT BE USED, we would not be able to implement an agnostic composition controller using the message container concept. However, this rule is highly important for security reasons and must be strictly followed for ABCSs and in Perimeter Gateways implementations.
For now, we have identified three frameworks that are responsible for shaping and creating a service, establishing communication, and resolving interchange disparities. The Hypothetical Business Service Composition area remains untouched, but now it is the time to find out what is it, really. From the standards roadmap diagram, we realized that complex compositions could be synchronous with elements of atomic transaction coordination and asynchronous with running chains of complex communications, lasting for very extended period of time. Different technical standards and operational requirements delineate two new frameworks, each dedicated to its own type of service interactions, mostly based on time metrics. We will start with asynchronous service compositions, as they are more technically demanding.
Firstly, the presence of State Repository is a very distinctive feature, a proprietary for this framework. It will allow all business flows to be consolidated under this technical platform, deferring the transactional state while waiting for a response. It can be done by any form of DB such as Relational, XML, or NoSQL, depending on types of messages running in these flows. The Relational type is still one of the most common; it allows you to conduct a quick search of hibernated instances and associations with the designated Correlation ID. Possible glitches, resulting in leaving orphan-hibernated records, can also be more easily dealt with in a relational environment. The storage overhead, which is common for relational models, must be taken into consideration during the planning phase. Also, it's important to realize a unified Enterprise Business Flow framework's state repository can present a single point of failure and/or a performance bottleneck, so proper DBA administration, replication, and maintenance is one of the highest demands for this framework.
To make business flows more manageable and centralized, another element of technical infrastructure should be observed as a decision service is based on rules engine. We deliberately segregate the rules, associated with pure business logic and centralize them in one location, thus making it possible to employ dynamic message routing and process invocation, value mapping, and data sorting processes. Of course, taking some logic away from the compound process reduces its autonomy and also could present a single point of failure, but this calculated risk makes business flows more agile and quickly adaptable to the shifting business conditions.
Task-orchestrated services are most commonly composed using languages based on WS-BPEL specifications (Business Process Execution Language). Common requirements (such as the implementation techniques, service models, and required functionalities) for the GF04: EBF framework are given in the following following list of requirements:
Implementation technique:
WS-BPEL, Orchestration
Service models:
Task Orchestrated Services
Required functionalities:
Level of WS-BPEL support (versions, extensions) with full orchestration features, which include branching, parallel processing, conditions, looping, scoping, and so on.
Correlations and correlations sets, which include native support for long running processes. Native transition for different protocols, that is,
SOAP/HTTP <->JMS.Implicit Correlation support.
Support of standard BPEL Faults, the ability to assign recovery operations dynamically or statically, and fault handling in long-running compositions using compensations.
Custom activity implementation and custom variable assignment extensions. BPEL 2.0 extensibility mechanism implementation.
Embedded Java support (or any other high-level language).
Level of XPath support (XPath versions).
SOAP/Message Header support, that is, the ability to reassign the whole header to the new message.
Level of XQuery support (XQuery version).
Level of REST support in BPEL. Native support REST and SOAP resources (partner links).
The
forEachlooping and branching support for the XML nodes with various interactions technique.Assigning data by default to the missing/empty nodes.
Supporting transport and message processing metadata (Message Tracking Data or Process context metadata).
SBDH support (optionally).
Dynamic partner links invocation.
Rule-based invocation/mediation. Limitations for MEPs and data transformation.
Orchestration engine's capability to clean-up orphan/obsolete data in hibernation store automatically or by schedule.
Transport protocol accelerators.
Possibility to use external transformation engines for complex callouts in transformation.
Runtime optimization of message size in order to avoid possible memory leak.
Various compensation flows implementation technique.
Possibility to dynamically invoke different compensation flows by rules/types of failures.
Asynchronous Service Broker implementation.
WSIF support (implementations, extensions).
Human task workflow support.
WS-Policy support.
Availability of High Availability (HA) patterns tested for EBF.
Level of CEP support (signals, probes, sensors, patterns analyzers, event language, and so on).
Common J2EE patterns/artifacts support SpringBeans, EJB, and so on.
The figure explaining the previous list is as follows:
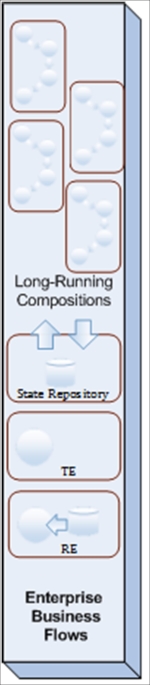
Business services with high throughput demands, participating in quick running compositions are naturally interconnected in the Enterprise Business Services (EBS) framework. Let's not get confused by the naming. The GF05: ESB framework in itself provides tools and methods to address the required functionalities, which are listed as follows in terms of implementation techniques and required functionalities:
Implementation technique:
Service Broker as composition controller
Mediators
Asynchronous message queues
Required functionality:
Atomic Transaction Coordinator implementation.
WS-RM support (versions, implementations, and extensions).
WS-Addressing support (versions, implementations, and extensions).
Native WS-Coordination support (versions, implementations, and extensions).
Supported transport protocols.
Supported messaging protocols.
Supported protocol's sync-async bridging.
Supported MEPS (for WSDL1.1 - 4; for WSDL 2.0-8).
Concurrent Contract support (contact versioning, by proxy or by other means, such as agents/facades).
Supported adapters (including JCA).
Process pipes orchestration: looping, branching, termination, and service chaining.
Basic security support: encryption, digital signature, and authorization/authentication.
Types of data model transformation (XQuery, XSLT).
Types of message objects transformation (
XSD<->JSON, and so on.).Content based routing, dynamic rule-based routing.
Types of message validation (complete, partial, nodes, security screening by regular expression/pattern, and so on).
Federated heterogeneous ESB support (native links to other vendors using the
WS-*standard), such as coexistence with Mule or GlassfishESB (ESB grids, snowflakes).WS-Policy, WS-SecurityPolicy, WS-PolicyAttachment support.
Big message volume / throughput native support, such as message throttling, internal component balancing, if any.
Possibility support sticky sessions (WS-Correlation), in a cluster as well, together or without LBs.
Scalability and clusters (number of nodes supported, dynamic scaling, dynamic cloud burst).
JCache (jsr-107) support or other caching support technique for distributed in-memory operations with message's zero-loss tolerance. Number of transactions achieved in reference architecture.
Available Rile Engines, rule types, ruleflows, RETE support, and available APIs.
HA patterns tested for ESB.
The figure explaining the previous list is as follows:
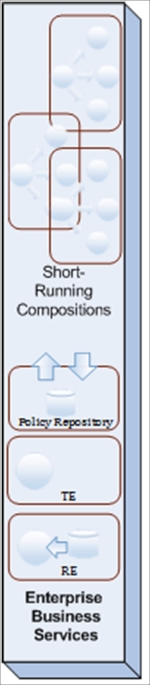
Service Bus as a pattern provides structural ways to solve the problems we most probably have while applying these programmatic and methodological tools in order to fulfill the requirements. First, similar to enterprise business flows, we will also deal with composition controllers, managing complex transaction, but in Atomic, Consistent, Isolated, and Durable way (so called ACID), compared to EBF's tolerant way, abbreviated as BASE for Basic Availability, Soft-state, and Eventual consistency. Therefore, the ATC implementation is the one of the top requirements, usually fulfilled by composition controllers and transaction registration services.
Synchronous service brokers together with message mediators are the natural elements of ESB. Similar to the EBF framework, EBS has to consolidate and centralize the business rules, as the magnitude of tasks is similar to asynchronous compositions:
Rule-based routing and transformations
Rule-based invocation and computation
It doesn't mean that rule stores must be separate for synchronous and asynchronous frameworks. Decentralization must be conducted on technical requirements: performance and the level of reliability. It is possible to have two (or more) rule engines and one centralized rule store implemented with high availability options.
The same is true for the Policy store and Policy centralization itself, as they are vital parts of EBS and service buses. The point here is that due to its more lightweight nature when compared to EBF, service buses act as service gateways and service perimeter guards, at least the core components of ESB such as Service Brokers do this. Security policies, message mediation and invocation policies, and QoS policies are attached to the service contracts, and most importantly, they are globally enforced through the implementation of policy declaration and policy enforcement points on ESB.
We already mentioned several shared stores required for process-related entities and message metadata. Looking at the broader picture, the physical service implementation requires some sort of logical structure, providing a segregation of the services by types, runtime roles, models, engines required for service executions, failover types, and so on. Actually, we already segregated the Enterprise Business Flow framework for long running services from the fast-spinning Enterprise Service Bus. It is simply inevitable, as technical requirements for platforms holding and running these services are quite opposite, and this fact is obvious enough to start this segregation from the modeling and analysis phase of a service's lifecycle. That's a purely governance matter and will be addressed by a separate framework.
As service governance is a never-ending process that begins before a service is created and doesn't finish until it is decommissioned, shaping and defining the service inventory should be addressed at the beginning, before other frameworks. Nevertheless, we would prefer to come to this point at the end of frameworks' discussion, when high demands for it become clear and obvious. Yet, this is probably the most misunderstood and obscured framework. Even naming can be confusing, so we need to explain the difference between repositories and inventories first.
The service repository is the centralized store of service-related artifacts and metadata that (possibly) include service code, test results and metrics, and services message attributes. This store is organized as a container with clearly defined metadata taxonomy and service ontology, supporting fast search and lookup. This container is mostly of the design-time nature, but can be actively used on runtime as well; it is usually supplied with elaborative human-readable interface in support of design-time discoverability, allowing artifact harvesting out of exiting implementations and expanding the arbitrary service taxonomy.
The service inventory is the runtime-accessible list of service artifacts mostly related to a service contract that supports fast search and dynamic service invocations. These are supported by machine-readable APIs, which are capable of registering newly deployed services, and search by different elements of service contract (WSDL and tModels).
Both support discoverability, that is, runtime and design-time, and therefore should not be implemented separately. One just supports the other. The role of this framework is immense; the UDDI mechanism was declared as an essential part of contemporary SOA from the very beginning. We would risk assuming that initially slow acceptance of SOA was also caused by immature or complex taxonomies of service inventories. Simply put, it's rather hard to invoke and reuse something that is difficult to find or comprehend. At the present moment, most standards related to the service taxonomy are under development and still maturing.
Common frameworks' requirements for GF06: ESR are consolidated as follows:
The Service Repository tool available with links to EBS and EBF
An Object Harvesting mechanism for existing objects/installations (service/objects discovery in designtime)
UDDI support for ESR, automatic registration on deployment
Automatic service discovery in runtime (ESR unified)
Service templates available for ESR (tModels, or something more human readable)
BPMN2.0 support for all stages of service development—modeling, analysis, and conversion:
UML->XML->XDD->SRL
The following figure explains the Common frameworks' requirements for GF06: ESR:
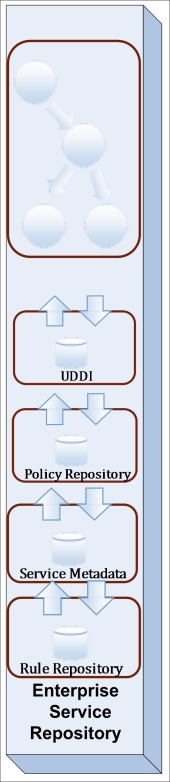
The role of this framework is to position services as an enterprise asset during design time, collect all necessary service metadata and store it in a well-partitioned repository, and provide runtime search capabilities for a dynamic invocation of the service and service-related artifacts. The results of invocation should be properly logged using elements of this framework for further business analysis and usage monitoring. One of the most challenging tasks here is the establishment of the mentioned well-partitioned repository, and we will dedicate a whole chapter for defining its possible taxonomy.
Now is the time to put all the discussed frameworks together and identify the role of patterns in every framework. Six core frameworks are identified, but some more should be explored to complete the picture:
Security framework: Reliable security is a result of diligent measures that are applied to all elements of all frameworks, and it's impossible to say where it is more or less important to have a secure design in place. Still, from the application of principle separation of concerns, a considerable amount of security features are usually dedicated to Secure Perimeter and most commonly implemented as Enterprise Service Bus. So, the security framework has a lot of similarities to the EBS framework.
Automated Testing framework: This requires technical infrastructure elements for supporting continuous integration or other forms of automated build and testing.
Automated Deployment: This framework is strongly related to the previous test automation framework and are usually used together.
Governance framework: This acts as a combination of precepts and standards with relations to processes and roles. This framework is based on proper ESR implementation, but it is much wider than the service's metadata taxonomy.

One could extend this list of framework, adding more fragmentation; however, from any practical point of view, these ten frameworks (that is, 6 + 4) are pretty adequate for dividing the entire technical infrastructure into distinguished and consistent areas of implementation principles, standards, and patterns. However, what are patterns, the main subject of this book?
Through the examples we already explored, we can agree on some of the most frequent problems that are well known to any practicing architect. These problems are common, and so will the solutions be. Thus, commonly approved solutions for regular problems have a common name pattern. The history of patterns in distributed computing is quite similar to the history of the SOA itself. It was a stiff curve from love and passion to hate and disbelief, and there is a very simple explanation for it; that is, the pattern is not a panacea and not an ultimate purpose of your solution design. It would be prudent if from now on you exclude the following questions from your architectural vocabulary:
What kind of pattern will we apply here?
Is this design according to the approved pattern catalog?
Is it pattern or anti-pattern (http://www.oracle.com/technetwork/topics/entarch/oea-soa-antipatterns-133388.pdf)?
A pattern is a stick for the lame, a remedy for the disease, not the other way around. A clear realization of the problem must be identified first; otherwise, you'll be left looking out for a suitable lame for the stick. This is usually unsuccessful and is followed by the amputation of the healthy application's part, just for making use of the patented remedy from the catalogue with some catchy name. If fact, the patterns' catalogues should be seen as common problems' catalogues. The implementation of the pattern as a working solution could be in jeopardy if:
You misunderstand the problem on hands, its location (as a framework), root cause, and its relation with the execution environment
You misinterpret the existing standards, their areas of application, and, as a result, attempt to reinvent it
You misinterpret the design principles, the balance between them, and the areas of their application
We already gave you a map of the frameworks and standards in relation to the principles, so it's time now to list all the frameworks we mentioned in this chapter and structure them for further discussion, as shown in the following table:
The following figure explains the preceding table:
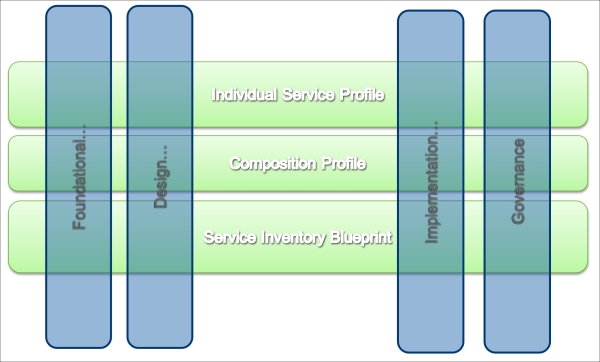
All these patterns will be discussed during the implementation of three already mentioned main SOA compound patterns: Enterprise Service Bus, Orchestration, and Federated Endpoint Layer.
Services are the functionally consistent atomic units of work with technical boundaries, providing the required level of autonomy where principles of the service orientation are applied in order to maintain characteristics that are essential for achieving the goals of service orientation.
Service orientation is the architectural approach that is based on the recognition of a service as a unified business block.
One of the key roles of the independent standards (WS-* specifications) is to ensure that service-oriented solutions based on these standards stay truly vendor-neutral.
The SOA framework is a structured and technically independent area where design principles and standards can be repeatedly applied together in a measured balance during various stages of analysis, modeling, development, implementation, testing, and governing in order to achieve the desired technical characteristics. As some WS-* specifications can be seen as a framework as well, most of the SOA frameworks have a compound nature.
SOA patterns are commonly accepted and approved solutions to repeatable and recognizable problems usually occurring in different frameworks, while implementing combinations of standards and principles.
