


















 Download code from GitHub
Download code from GitHub
Chapter 1: Amazon SageMaker Overview
This chapter will provide a high-level overview of the Amazon SageMaker capabilities that map to the various phases of the machine learning (ML) process. This will set a foundation for the best practices discussion of using SageMaker capabilities in order to handle various data science challenges.
In this chapter, we're going to cover the following main topics:
- Preparing, building, training and tuning, deploying, and managing ML models
- Discussion of data preparation capabilities
- Feature tour of model-building capabilities
- Feature tour of training and tuning capabilities
- Feature tour of model management and deployment capabilities
Technical requirements
All notebooks with coding exercises will be available at the following GitHub link:
https://github.com/PacktPublishing/Amazon-SageMaker-Best-Practices
Preparing, building, training and tuning, deploying, and managing ML models
First, let's review the ML life cycle. By the end of this section, you should understand how SageMaker's capabilities map to the key phases of the ML life cycle. The following diagram shows you what the ML life cycle looks like:
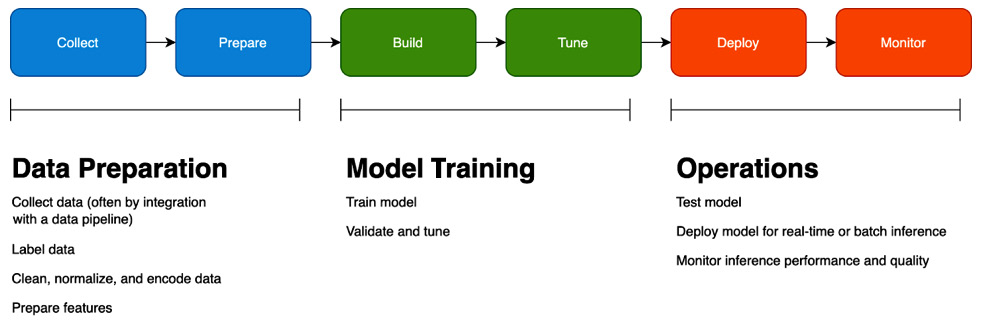
Figure 1.1 – Machine learning life cycle
As you can see, there are three phases of the ML life cycle at a high level:
- In the Data Preparation phase, you collect and explore data, label a ground truth dataset, and prepare your features. Feature engineering, in turn, has several steps, including data normalization, encoding, and calculating embeddings, depending on the ML algorithm you choose.
- In the Model Training phase, you build your model and tune it until you achieve a reasonable validation score that aligns with your business objective.
- In the Operations phase, you test how well your model performs against real-world data, deploy it, and monitor how well it performs. We will cover model monitoring in more detail in Chapter 11, Monitoring Production Models with Amazon SageMaker Model Monitor and Clarify.
This diagram is purposely simplified; in reality, each phase may have multiple smaller steps, and the whole life cycle is iterative. You're never really done with ML; as you gather data on how your model performs in production, you'll likely try to improve it by collecting more data, changing your features, or tuning the model.
So how do SageMaker capabilities map to the ML life cycle? Before we answer that question, let's take a look at the SageMaker console (Figure 1.2):
Figure 1.2 – Navigation pane in the SageMaker console
The appearance of the console changes frequently and the preceding screenshot shows the current appearance of the console at the time of writing.
These capability groups align to the ML life cycle, shown as follows:
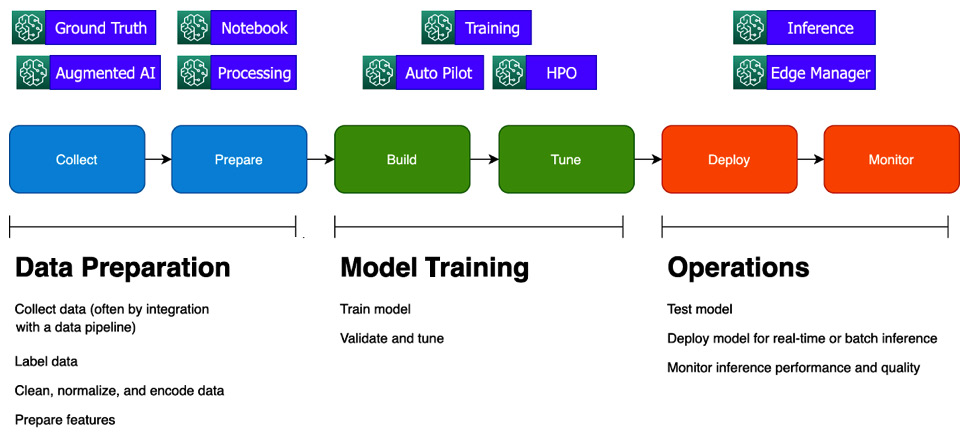
Figure 1.3 – Mapping of SageMaker capabilities to the ML life cycle
SageMaker Studio is not shown here, as it is an integrated workbench that provides a user interface for many SageMaker capabilities. The marketplace provides both data and algorithms that can be used across the life cycle.
Now that we have had a look at the console, let's dive deeper into the individual capabilities of SageMaker in each life cycle phase.
Discussion of data preparation capabilities
In this section, we'll dive into SageMaker's data preparation and feature engineering capabilities. By the end of this section, you should understand when to use SageMaker Ground Truth, Data Wrangler, Processing, Feature Store, and Clarify.
SageMaker Ground Truth
Obtaining labeled data for classification, regression, and other tasks is often the biggest barrier to ML projects, as many companies have a lot of data but have not explicitly labeled it according to business properties such as anomalous and high lifetime value. SageMaker Ground Truth helps you systematically label data by defining a labeling workflow and assigning labeling tasks to a human workforce.
Over time, Ground Truth can learn how to label data automatically, while still sending low-confidence results to humans for review. For advanced datasets such as 3D point clouds, which represent data points like shape coordinates, Ground Truth offers assistive labeling features, such as adding bounding boxes to the middle frames of a sequence once you label the start and end frames. The following diagram shows an example of labels applied to a dataset:

Figure 1.4 – SageMaker Ground Truth showing the labels applied to sentiment reviews
The data is sourced from the UCI Machine Learning Repository (https://archive.ics.uci.edu/ml/datasets/Sentiment+Labelled+Sentences). To counteract individual worker bias or error, a data object can be sent to multiple workers. In this example, we only have one worker, so the confidence score is not used.
Note that you can also use Ground Truth in other phases of the ML life cycle; for example, you may use it to check the labels generated by a production model.
SageMaker Data Wrangler
Data Wrangler helps you understand your data and perform feature engineering. Data Wrangler works with data stored in S3 (optionally accessed via Athena) and Redshift and performs typical visualization and transformations, such as correlation plots and categorical encoding. You can combine a series of transformations into a data flow and export that flow into an MLOps pipeline. The following screenshot shows an example of Data Wrangler information for a dataset:

Figure 1.5 – Data Wrangler displaying summary table information regarding a dataset
You may also use Data Wrangler in the operations phase of the ML life cycle if you want to analyze the data coming into an ML model for production inference.
SageMaker Processing
SageMaker Processing jobs help you run data processing and feature engineering tasks on your datasets. By providing your own Docker image containing your code, or using a pre-built Spark or sklearn container, you can normalize and transform data to prepare your features. The following diagram shows the logical flow of a SageMaker Processing job:

Figure 1.6 – Conceptual overview of a Spark processing job. Spark jobs are particularly handy for processing larger datasets
You may also use processing jobs to evaluate the performance of ML models during the Model Training phase and to check data and model quality in the Model Operations phase.
SageMaker Feature Store
SageMaker Feature Store helps you organize and share your prepared features. Using a feature store improves quality and saves time by letting you reuse features rather than duplicate complex feature engineering code and computations that have already been done. Feature Store supports both batch and stream storage and retrieval. The following screenshot shows an example of feature group information:

Figure 1.7 – Feature Store showing a feature group with a set of related features
Feature Store also helps during the Model Operations phase, as you can quickly look up complex feature vectors to help obtain real-time predictions.
SageMaker Clarify
SageMaker Clarify helps you understand model behavior and calculate bias metrics from your model. It checks for imbalance in the dataset, models that give different results based on certain attributes, and bias that appears due to data drift. It can also use leading explainability algorithms such as SHAP to help you explain individual predictions to get a sense of which features drive model behavior. The following figure shows an example of class imbalance scores for a dataset, where we have many more samples from the Gift Card category than the other categories:

Figure 1.8 – Clarify showing class imbalance scores in a dataset. Class imbalance can lead to biased results in an ML model
Clarify can be used throughout the entire ML life cycle, but consider using it early in the life cycle to detect imbalanced data (datasets that have many examples of one class but few of another).
Now that we've introduced several SageMaker capabilities for data preparation, let's move on to model-building capabilities.
Feature tour of model-building capabilities
In this section, we'll dive into SageMaker's model-building capabilities. By the end of this section, you should understand when to use SageMaker Studio or SageMaker notebook instances, and how to choose between SageMaker's built-in algorithms, frameworks, and libraries, versus a bring your own (BYO) approach.
SageMaker Studio
SageMaker Studio is an integrated development environment (IDE) for ML. It brings together Jupyter notebooks, experiment management, and other tools into a unified user interface. You can easily share notebooks and notebook snapshots with other team members using Git or a shared filesystem. The following screenshot shows an example of one of SageMaker Studio's built-in visualizations:

Figure 1.9 – SageMaker Studio showing an experiment graph
SageMaker Studio can be used in all phases of the ML life cycle.
SageMaker notebook instances
If you prefer a more traditional Jupyter or JupyterLab experience, and you don't need the additional integrations and collaboration tools that Studio provides, you can use a regular SageMaker notebook instance. You choose the notebook instance compute capacity (that is, whether you want GPUs and how much storage you need), and SageMaker provisions the environment with the Jupyter Notebook and JupyterLab and several of the common ML frameworks and libraries installed.
The notebook instance also supports Docker in case you want to build and test containers with ML code locally. Best of all, the notebook instances come bundled with over 100 example notebooks. The following figure shows an example of the JupyterLab interface in a notebook:

Figure 1.10 – JupyterLab interface in a SageMaker notebook, showing a list of example notebooks
Similar to SageMaker Studio, you can perform almost any part of the ML life cycle in a notebook instance.
SageMaker algorithms
SageMaker bundles open source and proprietary algorithms for many common ML use cases. These algorithms are a good starting point as they are tuned for performance, often supporting distributed training. The following table lists the SageMaker algorithms provided for different types of ML problems:

Figure 1.11 – SageMaker algorithms for various ML scenarios
BYO algorithms and scripts
If you prefer to write your own training and inference code, you can work with a supported ML, graph, or RL framework, or bundle your own code into a Docker image. The BYO approach works well if you already have a library of model code, or if you need to build a model for a use case where a pre-built algorithm doesn't work well. Data scientists who use R like to use this approach. SageMaker supports the following frameworks:
- Supported machine learning frameworks: XGBoost, sklearn
- Supported deep learning frameworks: TensorFlow, PyTorch, MXNet, Chainer
- Supported reinforcement learning frameworks: Ray RLLib, Coach
- Supporting graph frameworks: Deep Graph Library
Now that we've introduced several SageMaker capabilities for model building, let's move on to training and tuning capabilities.
Feature tour of training and tuning capabilities
In this section, we'll dive into SageMaker's model training capabilities. By the end of this section, you should understand the basics of SageMaker training jobs, Autopilot and Hyperparameter Optimization (HPO), SageMaker Debugger, and SageMaker Experiments.
SageMaker training jobs
When you launch a model training job, SageMaker manages a series of steps for you. It launches one or more training instances, transfers training data from S3 or other supported storage systems to the instances, gets your training code from a Docker image repository, and starts the job. It monitors job progress and collects model artifacts and metrics from the job. The following screenshot shows an example of the hyperparameters tracked in a training job:

Figure 1.12 – SageMaker training jobs capture data such as input hyperparameter values
For larger training datasets, SageMaker manages distributed training. It will distribute subsets of data from storage to different training instances and manage the inter-node communication during the training job. The specifics vary based on the ML framework you're using, but note that most of the supported frameworks and several of the SageMaker built-in algorithms support distributed training.
Autopilot
If you are working with tabular data and solving regression or classification problems, you may find that you're performing a lot of repetitive work. You may have settled on XGBoost as a high-performing algorithm, always one-hot encoding for low-cardinality categorical features, normalizing numeric features, and so on. Autopilot performs many of these routine steps for you. In the following diagram, you can see the logical steps for an Autopilot job:

Figure 1.13 – Autopilot process
Autopilot saves you time by automating a lot of that routine process. It will run normal feature preparation tasks, try the three supported algorithms (Linear Learner, XGBoost, and a multilayer perceptron), and run hyperparameter tuning. Autopilot is a great place to start even if you end up needing to refine the output, as it generates a notebook with the code used for the entire process.
HPO
Some ML algorithms accept tens of hyperparameters as inputs. Tuning these by hand is time-consuming. Hyperparameter Optimization (HPO) simplifies that process by letting you define the hyperparameters you want to experiment with, the ranges to work over, and the metric you want to optimize. The following screenshot shows example output for an HPO job:

Figure 1.14 – Hyperparameter tuning jobs showing the objective metric of interest
SageMaker Debugger
SageMaker Debugger helps you debug and, depending on your ML framework, profile your training jobs. While making training jobs run faster is always helpful, debugging is particularly useful if you are writing your own deep learning code with neural networks. Problems such as exploding gradients or mysterious NaN in your tensors are quite tough to track down, particularly in distributed training jobs. Debugger can effectively help you set breakpoints to see where things are going wrong. The following figure shows an example of the training and validation loss captured by SageMaker Debugger:

Figure 1.15 – Visualization of tensors captured by SageMaker Debugger
SageMaker Experiments
ML is an iterative process. When you're tuning a model, you may try several variations of hyperparameters, features, and even algorithms. It's important to track that work systematically so you can reproduce your results later on. That's where SageMaker Experiments comes into the picture. It helps you track, organize, and compare different trials. The following screenshot shows an example of SageMaker Experiments information:

Figure 1.16 – Trial results in SageMaker Experiments
Now that we've introduced several SageMaker capabilities for training and tuning, let's move on to model management and deployment capabilities.
Feature tour of model management and deployment capabilities
In this section, we'll dive into SageMaker's model hosting and monitoring capabilities. By the end of this section, you should understand the basics of SageMaker model endpoints along with the use of SageMaker Model Monitor. You'll also learn about deploying models on edge devices with SageMaker Edge Manager.
Model Monitor
In some organizations, the gap between the ML team and the operations team causes real problems. Operations teams may not understand how to monitor an ML system in production, and ML teams don't always have deep operational expertise.
Model Monitor tries to solve that problem: it will instrument a model endpoint and collect data about the inputs to, and outputs from, an ML model used for inference. It can then analyze that data for data drift and other quality problems, as well as model accuracy or quality problems. The following diagram shows an example of model monitoring data captured for an inference endpoint:

Figure 1.17 – Model Monitor checking data quality on inference inputs
Model endpoints
In some cases, you need to get a large number of inferences at once, in which case SageMaker provides a batch inference capability. But if you need to get inferences closer to real time, you can host your model in a SageMaker managed endpoint. SageMaker handles the deployment and scaling of your endpoints. Just as important, SageMaker lets you host multiple models in a single endpoint. That's useful both for A/B testing (that is, you can direct some percentage of traffic to a newer model) and for hosting multiple models that are tuned for different traffic segments.
You can also host an inference pipeline with multiple containers chained together, which is convenient if you need to preprocess inputs before performing inference. The following screenshot shows a model endpoint with two models serving different percentages of traffic:
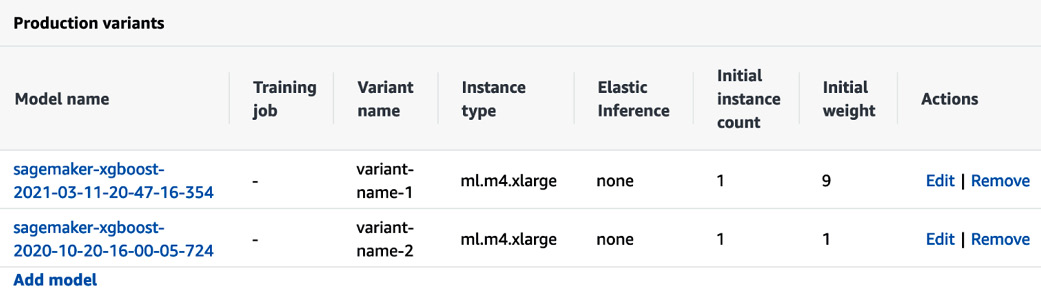
Figure 1.18 – Multiple models configured behind a single inference endpoint
Edge Manager
In some cases, you need to get model inferences on a device rather than from the cloud. You may need a lower response time that doesn't allow for an API call to the cloud, or you may have intermittent network connectivity. In video use cases, it's not always feasible to stream data to the cloud for inference. In such cases, Edge Manager and related tools such as SageMaker Neo help you compile models optimized to run on devices, deploy them, manage them, and get operational metrics back to the cloud. The following screenshot shows an example of a virtual device managed by Edge Manager:
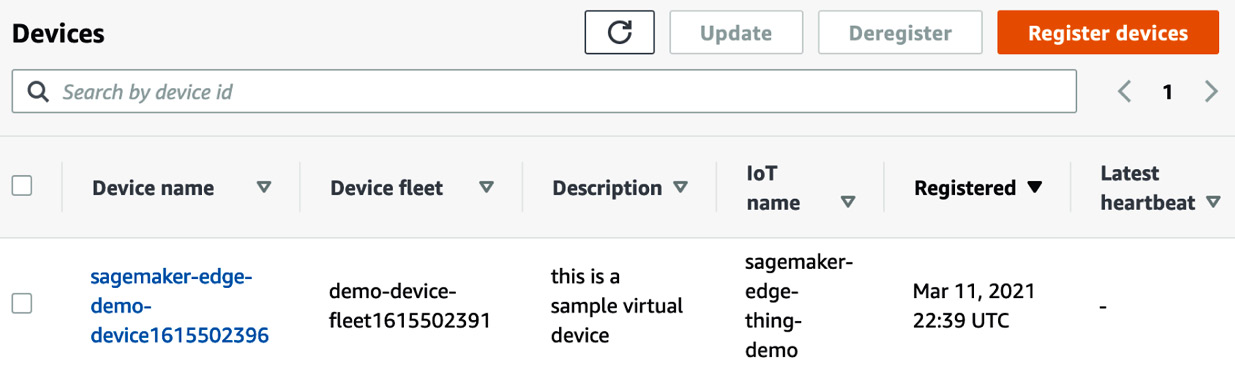
Figure 1.19 – A device registered to an Edge Manager device fleet
Before we conclude with the summary, let's have a recap of the SageMaker capabilities provided for the following primary ML phases:
- For data preparation:
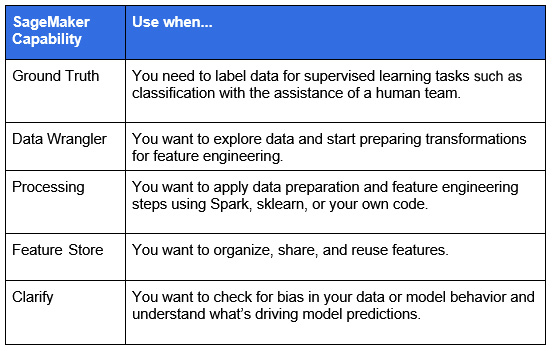
Figure 1.20 – SageMaker capabilities for data preparation

Figure 1.21 – SageMaker capabilities for operations
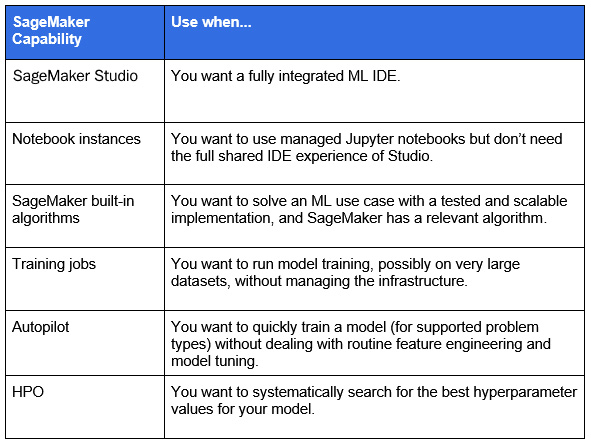
Figure 1.22 – SageMaker capabilities for model training
With this, we have come to the end of this chapter.
Summary
In this chapter, you saw how to map SageMaker capabilities to different phases of the ML life cycle. You got a quick look at important SageMaker capabilities. In the next chapter, you will learn about the technical requirements and the use case that will be used throughout. You'll also learn about setting up managed data science environments for scaling model-building activities.
