


















Content Management Interoperability Services (CMIS) is a new interface to talk to Content Management Systems (CMS) in a standard way. This chapter will introduce you to the CMIS standard, explain why it is important, and see how it came about. We will cover the different parts of the CMIS standard, the benefits of using it, and some example use cases for CMIS.
CMIS is an effort toward standardization and is managed by the Organization for the Advancement of Structured Information Standards (OASIS) body. The latest version is 1.1 (http://docs.oasis-open.org/cmis/CMIS/v1.1/CMIS-v1.1.html), which was approved in May 2013. Version 1.0 specifies most of the functionalities and is quite developed being approved in May 2010. Some content servers might not yet support Version 1.1, so we will point out when a feature is only available in Version 1.1. CMIS is all about being able to access and manage content in a so-called content repository in a standard way. You can think of a content repository as something that can be used to store files in a folder hierarchy.
The CMIS interface consists of two parts: a number of repository services for things such as content navigation and content creation, and a repository query language for content search. The standard also defines what protocols can be used to communicate with a repository and what formats should be used in requests and responses via these protocols.
To really explain what CMIS is, and the background to why it came about, one has to look at how the implementation of content management systems has evolved. If we go back 15-20 years, most companies (that are large corporations) had one content management system installed for Document Management (DM) and workflow. This meant that all the content was available in one system via a single Application Programming Interface (API), making it easy for other enterprise systems to integrate with it and access content. For example, the Swedish nuclear power plant that I worked for in the mid 90s had one big installation of Documentum that everyone used.
In the last 5-10 years, there has been an explosion in the number of content management systems used by companies; most companies now have multiple content management systems in use, sometimes running into double digits.
Note
So you are thinking that this cannot be true; companies having five content management systems? This is true alright. According to the Association for Information and Image Management (AIIM), which is the main Enterprise Content Management (ECM) industry organization, 72 percent of large organizations have three or more ECM, Document Management, or Record Management systems, while 25 percent have five or more (as mentioned in State of the ECM Industry, AIIM, 2011).
This is because these days we not only manage documents, but we also manage records (known as Record Management), images and media files (known as Digital Asset Management), advanced workflows, web content (known as Web Content Management), and many other types of content. It is quite often that one content management system is better than the other in handling one type of content such as records or web content, so a company ends up buying multiple content management systems to manage different types of content.
A new type of content management system has also emerged, which is open source and easily accessible for everyone to try out. Each one of these systems have different APIs and can be implemented in a different language and on a different type of platform. All this means that a lot of companies have ended up with many content silos/islands that are not communicating with each other, sometimes having duplicated content.
What this means is that when it comes to implementing the following kind of services, we might have a problem choosing what API to work with:
Enterprise service that should aggregate content from several of these systems
Content transfer from one system to another
UI client that should display content from more than one of these systems
It would then be necessary to learn about a whole lot of APIs and platforms. Most of the proprietary APIs were also not based on HTTP, so if you wanted a service or client to be outside the firewall, you would have to open up new ports in the firewall to take care of security and so on.
Any company that wants to develop tools or clients to access content management systems would also have to support many different protocols and formats, making it difficult to work with more than a handful of the seasoned CMS players. This leads to people thinking about some sort of standard interface and protocol to access CMS systems.
The first established standard covering the content management area is Web Distributed Authoring and Versioning (WebDAV), which was proposed in February 1999 with RFC 2518 (refer to ftp://ftp.isi.edu/in-notes/rfc2518.txt). It is supported by most content management systems, including Alfresco, and is usually used to map a drive to access the content management system via, for example, Windows Explorer or Mac Finder. The problem with this way of accessing content is that most of the valuable features of a content management system cannot be used, such as setting custom metadata, managing versions, setting fine grained permissions, controlling relationships, and searching for content.
So this led to more comprehensive standards such as the Java Content Repository (JCR) API, which is managed by the Java Community Process as JSR-170 (https://www.jcp.org/en/jsr/detail?id=170) and JSR-283 (https://www.jcp.org/en/jsr/detail?id=283) and was first developed in 2002. The JCR standard has been supported by Alfresco for a long time, but it has never really taken off as it is Java centric and excludes content management systems such as SharePoint and Drupal.
Something needed to be done to come up with a new standard that would be easy to learn and adopt. This is where CMIS comes into the picture. CMIS provides a standard API and query language that can be used to talk to any CMS system that implements the CMIS standard. The following figure illustrates how a client application that adheres to the CMIS standard can talk to many different content management systems through one standard service-oriented interface:

The preceding figure shows how each one of the content management systems offers access to their proprietary content and metadata via the standard CMIS service interface. The CMIS interface is web-based, which means that it can be accessed via HTTP through the Internet. Even cloud-based content management systems such as the Alfresco Cloud installation can be accessed via CMIS.
There are quite a few companies that support the CMIS standard. The participants in the standards process include Adobe Systems Incorporated, Alfresco, EMC, eXo, FatWire, HP, IBM, ISIS Papyrus, Liferay, Microsoft, Nuxeo, OpenText, Oracle, Newgen, OmniDocs, and SAP.
To get an idea of how widespread the CMIS standard is, we can have a look at the following products, clients, and libraries that support it:
CMS servers: Alfresco, Documentum, HP Interwoven, IBM Content Manager and FileNet, Lotus Quickr, Microsoft SharePoint, OpenText, and SAP
WCM systems: Magnolia, Liferay, Drupal, Hippo, TYPE3, and dotCMS
Blogging: Wordpress
Clients: Libre Office, Adobe Drive, Atlassian Confluence, SAP ECM Integration, Pentaho Data Integration, SugarCRM, Trac, Kofax, and Salesforce Files
SOA: Mule ESB and Spring Integration
Libraries: Apache Chemistry (which includes Java, Python, PHP, .NET, and Objective-C)
So we can see there is no doubt that the CMIS standard has been very well received and adopted.
The benefits of using CMIS might be quite clear to you now, but let's walk through some of them:
Language neutral: Any language can be used to access a CMS system that implements the CMIS service interface, as long as the language has the functionality for making HTTP requests and can handle XML or JSON. So you could have a C++ application accessing a content management system written in PHP.
Platform independence: It doesn't matter what platform the CMS system is implemented on top of. As long as it supports the CMIS standard any client application can talk to it if it has the capability to make HTTP calls and parse XML or JSON.
Standard service API: Clients need to use only one API to access content management systems and they have a much better chance of not being limited to only one vendor's API and platform. This is probably a great benefit as it means that you can work with any CMS system after you learn to work with the first one, thus saving time and money. It will also be easier to find people who can work on new CMS projects.
Standard and easy-to-learn query language: The CMIS query language is easy to learn and adopt as it is based on the ANSI SQL-92 standard. So you can use SQL syntax such as
SELECT * FROM cmis:document WHERE cmis:name LIKE '*alfresco*';.One application to access them all: End users can now use one application and user interface to access all content management systems, and do not have to learn about a new user interface for each and every CMS system that the organization has deployed.
Easy workflow integration: It is now much easier for a company to deploy an enterprise workflow that interacts with content managed by multiple content management systems.
Repository vendors get more applications: CMS vendors are more likely to get many more client applications using their server as any application that uses the CMIS API can access any CMIS repository.
Applications get a bigger customer base: Applications that are written to support the CMIS interface are more likely to get a bigger customer base as they will work with a multitude of CMIS-compliant content management systems.
There are a number of content management use cases that can benefit from using CMIS. A couple of them are explored as follows:
R2R is the use case when content management systems talk directly to each other. The following figure illustrates a typical scenario when content in the enterprise content management system such as Alfresco should be displayed on a website via a web content management system such as Drupal:

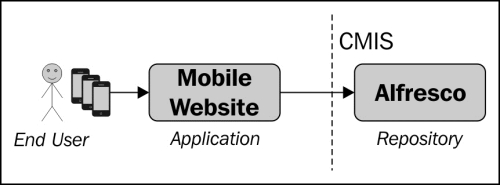
A2R is probably the most common use case. You have an application such as a collaboration application, records management application, enterprise CRM system, business process application, web application, portal, design tool, or Office package that wants to work with content in your CMS system. This is now easy with the CMIS interface. The following figure shows a mobile web application, getting its content from an Alfresco repository via CMIS:
A2MR is quite a common use case and handles the case when you want to aggregate content from multiple repositories in an application such as a user interface, or for example a broker application. The following figure illustrates a typical scenario that represents this use case when you have an Enterprise Service Bus (ESB), fetching content from multiple repositories, processing it, and then serving it to an enterprise application:
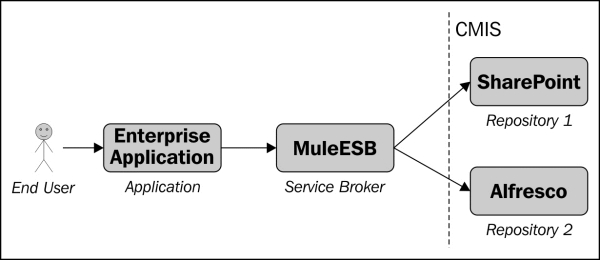
Another common scenario applicable to this use case is federated search, which is something that is really useful for end users. Instead of going into multiple applications to search for content in a disparate content management system, they can now just go into one search application that is hooked up to all the CMS systems.
This section will dig deeper into the CMIS standard and explore its domain model and the different services that it provides. It will also present the different protocol bindings that we can work with.
All CMS vendors have their own definitions of a content model, also called an object model. For example, in Alfresco, there is a folder type (cm:folder), a generic content type (cm:content), associations described as aspects (for example, cm:contains, rn:rendition, and cm:references), and so on. These are available out of the box and are used when you create folders and upload files into the repository. In Alfresco, these types and aspects have properties and they can inherit definitions from other types and aspects. Each property has a datatype and other behavior attributes such as multi-valued and required. When you work with Alfresco in a specific domain, such as legal, it is possible to create domain-specific subtypes that extend the generic types. For example, you could create a legal case type that extends the generic folder type.
Now, as you can imagine, other vendors would not necessarily have the same definitions for their content model. If we take Documentum as an example, its generic content type is named dm_document and not cm:content. Some content management systems also do not have the concept of an aspect.
So what the CMIS Standardization group had to do was come up with an object model that was generic enough for most CMS vendors to be able to implement it. And it had to be specific enough for the implementations to be meaningful and usable. So, the group came up with something called the CMIS domain model.
The CMIS domain model defines a repository as a container and an entry point to all the content items, called objects from now on. All objects are classified by an object type, which describes a common set of properties (such as type ID, parent, and display name). There are five base types of objects: Document, Folder, Relationship, Policy, and Item (CMIS 1.1), and they all inherit from the Object type as shown in the following figure:

Besides these base object types, there are a number of property types that can be used when defining new properties for an object type. They are, as can be seen in the preceding figure, String, Boolean, Decimal, Integer, and DateTime. Besides these property types, there are also the URI, ID, and HTML property types, which are not shown in the preceding figure.
Let's take a closer look at each one of the following base types:
Document: This base type is almost always the same as a file, although it doesn't need to have any content (when you upload a file via, for example, the AtomPub binding—explained in the RESTful AtomPub binding section—the metadata is created with the first request and the content for the file is posted with the second request). The base document type is automatically assigned to any file, such as an MS Office document or an image, when it is uploaded to the repository.
Folder: This is self-explanatory; it is a container for fileable objects such as folders and documents. As soon as a folder or document is filed in a folder, an implicit parent-child relationship is automatically created, which is different from the relationship base object type that has to be created manually. Whether an object is fileable or not is specified in the object type definition with the
fileableproperty.Relationship: This object defines a relationship between two objects (the target and source). An object can have multiple relationships with other objects. The support for relationship objects is optional.
Policy: This is a way of defining administrative policies to manage objects. An object to which a policy may be applied is called a controllable object (the
controllablePolicyproperty has to be set totrue). For example, you can use a CMIS policy to define which documents are subject to retention policies. A policy is opaque and means nothing to the repository. You would have to implement and enforce the behavior for your policy in a repository-specific way. For example, in Alfresco, you could use rules to enforce the policy. The support for policy objects is optional.Item (available from CMIS v1.1): This object represents a generic type of a CMIS information asset. This could be, for example, a user or group object. Item objects are not versionable and do not have content streams like documents, but they have properties like all other CMIS objects. The support for item objects is optional.
Additional object types can be defined in a repository as custom subtypes of these base types, such as the Legal Case type in the preceding figure. CMIS services are provided for the discovery of object types that are defined in a repository. However, object type management services, such as the creation, modification, and deletion of an object type, are not covered by the CMIS standard.
An object has one primary base object type, such as document or folder, which cannot be changed. An object can also have secondary object types applied to it (CMIS 1.1). A secondary type is a named class that may add properties to an object in addition to the properties defined by the object's primary base object type (if you are familiar with Alfresco, you can think of secondary object types to be the same as aspects; for example, emailed, versionable, published, and more).
Every CMIS object has an opaque and immutable object identity (ID), which is assigned by the repository when the object is created. In the case of Alfresco, a so-called node reference is created, which becomes the object ID. An ID uniquely identifies an object within a repository regardless of the type of the object.
All CMIS objects have a set of named, but not explicitly ordered, properties. Within an object, each property is uniquely identified by its property ID. In addition, a document object can have a content stream, which is then used to hold the actual byte content for the file representing, for example, an image or a Word document. A document can also have one or more renditions associated with it. A rendition can be a thumbnail or an alternate representation of the content stream, such as a different size of an image.
Document or folder objects can have one Access Control List (ACL), which then controls the access to the document or folder. An ACL is made up of a list of ACEs. An Access Control Entry (ACE) in turn represents one or more permissions being granted to a principal, such as a user, group, role, or something similar.
Now, we may ask the questions such as, what does a document object look like?, what properties does it have?, what namespace is used?, and so on. The following figure shows you how the document object and the other objects are defined with properties:

All the objects and properties are defined in the cmis namespace. From now on, we'll refer to the different objects and properties by their fully qualified names, for example, cmis:document or cmis:name.
The CMIS specification also defines the following set of services to access and manage the CMIS objects in the content repository:
Repository services: These services are used to discover information about the repository, including repository IDs (could be more than one repository managed by the endpoint), capabilities (many features are optional and this is the way to find out if they are supported or not), available object types, and descendants. If we are working with a CMIS v1.1-compliant repository, then it could also support creating new types dynamically on the fly. The repository service methods are
getRepositories,getRepositoryInfo,getTypeChildren,getTypeDescendants,getTypeDefinition,createType(CMIS 1.1),updateType(CMIS 1.1), anddeleteType(CMIS 1.1).Navigation services: These services are used to navigate the folder hierarchy in a CMIS repository, and to locate documents that are checked out. The navigation service methods are
getChildren,getDescendants,getFolderTree,getFolderParent,getObjectParents, andgetCheckedOutDocs.Object services: These services provide ID-based CRUD (Create, Read, Update, and Delete) operations on the objects in a repository. The object service methods are
createDocument,createDocumentFromSource,createFolder,createRelationship,createPolicy,createItem(CMIS 1.1),getAllowableActions,getObject,getProperties,getObjectByPath,getContentStream,getRenditions,updateProperties,bulkUpdateProperties(CMIS 1.1),moveObject,deleteObject,deleteTree,setContentStream,appendContentStream(CMIS 1.1), anddeleteContentStream.Multifiling services: These services are optional; they make it possible to put an object into several folders (multifiling) or outside the folder hierarchy (unfiling). This service is not used to create or delete objects. The multifiling service methods are
addObjectToFolderandremoveObjectFromFolder.Discovery services: These services are used to look for queryable objects within the repository (objects with the property
queryableset totrue). The discovery service methods arequeryandgetContentChanges.Versioning services: These services are used to manage versioning of document objects, other objects not being versionable. Whether or not a document can be versioned is controlled by the
versionableproperty in the object type. The versioning service methods arecheckOut,cancelCheckOut,checkIn,getObjectOfLatestVersion,getPropertiesOfLatestVersion, andgetAllVersions.Relationship services: These services are optional and are used to retrieve the relationships in which an object is participating. The relationship service method is
getObjectRelationships.Policy services: These services are optional and are used to apply or remove a policy object to an object which has the property
controllablePolicyset totrue. The policy service methods areapplyPolicy,removePolicy, andgetAppliedPolicies.ACL services: These services are used to discover and manage the access control list (ACL) for an object, if the object has one. The ACL service methods are
applyACLandgetACL.
As we can see, there are quite a few services at our disposal and we will see how they are used in the upcoming chapters. Note that when working with the different types of protocols and formats that the CMIS standard supports, the preceding method names might not be used. For example, if you wanted to get the children objects for an object, you would use the getChildren method from the navigation service. However, if we are using the AtomPub binding, this method would be referred to as the Folder Children Collection and can be accessed via a URL that looked similar to the following: .../children?id=....
The query method of the discovery service uses a query language that is based on a subset of the well known SQL-92 standard for database queries. It also has some ECM-specific extensions added to it. Each object type is treated as a logical relational table and joins are supported between these, creating a relational view of the CMIS model. The query language supports metadata and/or a full-text search (FTS is optional).
The CMIS object type definitions contain some properties that are related to searching, which are as follows:
The
queryableproperty should be set totrueif the object type should be searchable. Non-queryable object types are excluded from the relational view and cannot appear in theFROMclause of a query statement.The
queryNameproperty of a queryable object type is used to identify the object type in theFROMclause of a query statement.The
includedInSuperTypeproperty determines if an object subtype is included in a query for any of its supertypes. So, it may be possible that all subtypes are not included in the query for a type. If an object type is notincludedInSuperType, a direct query for the type is still supported if it is defined asqueryable. For example, Alfresco internally models renditions as a subtype ofcmis:document. Renditions are not marked asincludedInSuperTypeand so will not appear in queries forcmis:document.
The following example selects all properties for all documents but does not include thumbnails (cm:thumbnail):
SELECT * FROM cmis:document
On the other hand, the following example includes cm:thumbnail and any subtypes that are set as includedInSuperType=true:
SELECT * FROM cm:thumbnail
To select specific properties for all documents, use the following query:
SELECT cmis:name, cmis:description FROM cmis:document
To select all documents that have a name containing the text alfresco, we can use the following:
SELECT cmis:name FROM cmis:document WHERE cmis:name LIKE '%alfresco%'
To perform a Full-Text Search (FTS), we need to use the SQL-92 CMIS extension CONTAINS() to look for any document with the text alfresco in it as follows:
SELECT * FROM cmis:document WHERE CONTAINS('alfresco')The previous query will return all properties (columns) as we have used the wildcard *. There are also some folder-related SQL-92 CMIS extensions to search in a folder (IN_FOLDER) or folder tree (IN_TREE):
SELECT cmis:name FROM cmis:document WHERE IN_FOLDER('folder id')The preceding query returns all documents in the folder with the identifier folder id. A folder identifier would be the same as a node reference in the Alfresco world. The following query returns all objects beneath the folder with folder id:
SELECT cmis:name FROM cmis:folder WHERE IN_TREE('folder id')We have covered the object model and the available repository services. We also need to have a look at how we can actually communicate with the repository from a remote client over the wire. This is where protocol bindings come into the picture. There are three of them available: RESTful AtomPub, SOAP Web Services, and RESTful Browser (CMIS 1.1). CMIS-compliant repositories must provide a service endpoint (that is, the starting URL) for each of the bindings. The service URL and an understanding of the CMIS specifications is all that a client needs to discover both the capabilities and content of a repository.
The REST binding is built on the Atom Publishing Protocol—based on XML (refer to http://tools.ietf.org/html/rfc5023)—with CMIS-specific extensions. In this binding, the client interacts with the repository by acquiring the service document. The client will request the service document using the URI provided by the vendor; in the case of Alfresco, this URL has the format http://<hostname>:<port>/alfresco/api/-default-/public/cmis/versions/1.1/atom (swap 1.1 with 1.0 to use that version). From the returned service document XML, the client will choose a CMIS collection, represented by a URI, and start accessing the repository by following the links in returned XML documents. There are a number of collections of objects that we can use in the service document. You can think of a collection as a URI pointing to a place in the repository. The following are the service collections:
Root collection: An HTTP GET for this collection will give us information about all the objects at the top level in the repository (in Alfresco, that would be all the content under
/Company Home). Making an HTTP POST to this collection adds objects to the top folder in the repository.Query collection: An HTTP POST to this collection executes a search.
Checked-Out collection: An HTTP GET for this collection will give us a list of all checked-out documents. To check-out a document, we POST to this collection.
Unfiled collection: This is a collection described in the service document to manage unfiled documents, policies, and item objects.
Type Children collection: This collection can be used to GET all base types in the repository. One can then continue to navigate to the subtype hierarchy from a base type and so on.
Bulk Update collection (CMIS 1.1): This collection is used to upload multiple objects to the repository at the same time.
Requests and responses made via the AtomPub binding are in the form of an Atom XML feed or an Atom XML entry. Usually, the response is extended to include CMIS-specific tags within one of the CMIS-specific namespaces.
The Web Service binding uses the SOAP protocol (http://www.w3.org/TR/soap/) and maps directly to the CMIS domain model, services, and methods defined in the specification. When using Alfresco, we can access a summary page with all the services and their WSDL document links via the http://<hostname>:<port>/alfresco/cmis URL. There are two types of XSD documents that make up the WSDL for the services: one defines the data model and the other defines the message formats. For authentication, the repository should support WS-Security 1.1 for Username Token Profile 1.1 and has the option of supporting other authentication mechanisms. A CMIS-compliant repository may grant access to some or all of its services to unauthenticated clients. For content transfer, the repository should support Message Transmission Optimization Mechanism (MTOM) and must accept Base64 encoded content.
The Browser binding was introduced in Version 1.1 to make it easier to work with CMIS from HTML and JavaScript within a web browser. Content can be managed directly from HTML forms and responses from AJAX calls to CMIS services can be fed directly into JavaScript widgets.
The Browser binding also uses a REST-based approach, but instead of AtomPub feed and entry XML, it uses JavaScript Object Notation (JSON). (To learn more about JSON, refer to http://tools.ietf.org/html/rfc4627). This binding is specifically designed to support applications running in a web browser but is not restricted to them. It is based on technologies such as HTML, HTML Forms, JavaScript, and JSON. Importantly, it does not require a specific JavaScript library, but takes advantage of the existing built-in capabilities of modern browsers.
While this binding is optimized for use in browser applications, it can also serve as an easy-to-use binding in other application models. To access Alfresco repository information via the Browser binding, use the http://<hostname>:<port>/alfresco/api/-default-/public/cmis/versions/1.1/browser URL.
In this chapter, we introduced the CMIS standard and how it came about. A couple of use cases, such as one client accessing multiple repositories, were presented, which illustrated the need for the standard. Then we covered the CMIS domain model with its five base object types: document, folder, relationship, policy, and item (CMIS 1.1.). We also learned that the CMIS standard defines a number of services, such as navigation and discovery, which makes it possible to manipulate objects in a content management system repository. And finally, we looked at how we can communicate over the wire with a CMIS-compliant repository; this can be done with, for example, a REST-based approach over HTTP.
So now that we know what CMIS is, let's take it for a spin. In the next chapter, we will start using it and see how we can manipulate objects in a CMIS-compliant repository.


