


















Chapter 1: What Is DataRobot and Why You Need It?
Machine learning (ML) and AI are all the rage these days, and it is clear that these technologies will play a critical role in the success and competitiveness of most organizations. This will create considerable demand for people with data science skills.
This chapter describes the current practices and processes of building and deploying ML models and some of the challenges in scaling these approaches to meet the expected demand. The chapter then describes what DataRobot is and how DataRobot addresses many of these challenges, thus allowing analysts and data scientists to quickly add value to their organizations. This chapter also helps executives understand how they can use DataRobot to efficiently scale their data science practice without the need to hire a large staff with hard-to-find skills, and how DataRobot can be leveraged to increase the effectiveness of your existing data science team. This chapter covers various components of DataRobot, how it is architected, how it integrates with other tools, and different options to set it up on-premises or in the cloud. It also describes, at a high level, various user interface components and what they signify.
By the end of this chapter, you will have learned about the core functions and architecture of DataRobot and why it is a great enabler for data analysts as well as experienced data scientists for solving the most critical challenges facing organizations as they try to extract value from data.
In this chapter, we're going to cover the following topics:
- Data science practices and processes
- Challenges associated with data science
- DataRobot architecture
- DataRobot features and how to use them
- How DataRobot addresses data science challenges
Technical requirements
This book requires that you have access to DataRobot. DataRobot is a commercial piece of software, and you will need to purchase a license for it. Most likely your organization has already purchased DataRobot licenses, and your administrator can set up your account on a DataRobot instance and provide you with the appropriate URL to access DataRobot.
A trial version is available, at the time of the writing of this book, that you can access from DataRobot's website: https://www.datarobot.com/trial/. Please be aware that the trial version does not provide all of the functionality of the commercial version, and what it provides may change over time.
Data science processes for generating business value
Data science is an emerging practice that has seen a lot of hype. Much of what it means is under debate and the practice is evolving rapidly. Regardless of these debates, there is no doubt that data science methods can provide business benefits if used properly. While following a process is no guarantee of success, it can certainly improve the odds of success and allow for improvement. Data science processes are inherently iterative, and it is important to not get stuck in a specific step for too long. People looking for predictable and predetermined timelines and results are bound to be disappointed. By all means, create a plan, but be ready to be nimble and agile as you proceed. A data science project is also a discovery project: you are never sure of what you will find. Your expectations or your hypotheses might turn out to be false and you might uncover interesting insights from unexpected sources.
There are many known applications of data science and new ones are being discovered every day. Some example applications are listed here:
- Predicting which customer is most likely to buy a product
- Predicting which customer will come back
- Predicting what a customer will want next
- Predicting which customer might default on a loan
- Predicting which customer is likely to have an accident
- Predicting which component of a machine might fail
- Forecasting how many items will be sold in a store
- Forecasting how many calls the call center will receive tomorrow
- Forecasting how much energy will be consumed next month
Figure 1.1 shows a high-level process that describes how a data science project might go from concept to value generation:

Figure 1.1 – Typical process steps with details about what happens during each step
Following these steps is critical for a successful machine learning project. Sometimes these steps get skipped due to deadlines or issues that inevitably surface during development and debugging. We will show how using DataRobot helps you avoid some of the problems and ensure that your teams are following best practices. These steps will be covered in great detail, with examples, in other chapters of this book, but let's get familiar with them at a high level.
Problem understanding
This is perhaps the most important step and also the step that is given the least attention. Most data science projects fail because this step is rushed. This is also the task where you have the least methods and tools available from the data science disciplines. This step involves the following:
- Understanding the business problem from a systemic perspective
- Understanding what it is that the end users or consumers of the model's results expect
- Understanding what the stakeholders will do with the results
- Understanding what the potential sources of data are and how the data is captured and modified before it reaches you
- Assessing whether there are any legal concerns regarding the use of data and data sources
- Developing a detailed understanding of what various features of the datasets mean
Data preparation
This step is well known in the data science community as data science teams typically spend most of their time in this step. This is a task where DataRobot's capabilities start coming into play, but not completely. There is still a lot of work that the data science or data engineering teams have to do using SQL, Python, or R. There are also many tasks in this step that require a data scientist's skill and experience (for example, feature engineering), even though DataRobot is beginning to provide capabilities in this area. For example, DataRobot provides a lot of useful data visualizations and notifications about data quality, but it is up to the analyst to make sense out of them and take appropriate actions.
This step also involves defining the expected result (such as predicting how many items will be sold next week or determining the probability of default on a loan) of the model and how the quality of results will be measured during model development, validation, and testing stages.
Model development
This step involves the development of several models using different algorithms and optimizing or tuning hyperparameters of the algorithms. Results produced by the models are then evaluated to narrow down the model list, potentially drop some of the features, and fine-tune the hyperparameters.
It is also common to look at feature effects, feature importance, and partial dependence plots to engineer additional features. Once you are satisfied with the results, you start thinking about how to turn the predictions and explanations into useable and actionable information.
Model deployment
Upon completion of model development, the model results are reviewed with users and stakeholders. This is the point at which you should carefully assess how the results will be turned into actions. What will the consequences of those actions be, and are there any unintended consequences that could emerge? This is also the time to assess any fairness or bias issues resulting from the models. Make sure to discuss any concerns with the users and business leaders.
DataRobot provides several mechanisms to rapidly deploy the models as REST APIs or executable Java objects that can be deployed anywhere in the organization's infrastructure or in the cloud. Once the model is operational as an API, the hard part of change management starts. Here you have to make sure that the organization is ready for the change associated with the new way of doing business. This is typically hard on people who are used to doing things a certain way. Communicating why this is necessary, why it is better, and how to perform new functions are important aspects that frequently get missed.
Model maintenance
Once the model is successfully deployed and operating, the focus shifts to managing the model operations and maintenance. This includes identifying data gaps and other recommendations to improve the model over time as well as refining and retraining the models as needed. Monitoring involves evaluating incoming data to see whether the data has drifted and whether the drift requires action, monitoring the health of the prediction services, and monitoring the results and accuracy of the model outputs. It is also important to periodically meet with users to understand what the model does well and where it can be improved. It is also common to sometimes employ champion and challenger models to see whether a different model is able to perform better in the production setting.
As we outlined before, although these steps are presented in a linear fashion, in practice these steps do not occur in this exact sequence and there is typically plenty of iteration before you get to the final result. ML model development is a challenging process, and we will now discuss what some of the challenges are and how to address them.
Challenges associated with data science
It is no secret that getting value from data science projects is hard, and many projects end in failure. While some of the reasons are common to any type of project, there are some unique challenges associated with data science projects. Data science is still a relatively young and immature discipline and therefore suffers from problems that any emerging discipline encounters. Data science practitioners can learn from other mature disciplines to avoid some of the mistakes that others have learned to avoid. Let's review some of the key issues that make data science projects challenging:
- Lack of good-quality data: This is a common refrain, but this is a problem that is not likely to go away anytime soon. The key reason is that most organizations are used to collecting data for reporting. This tends to be aggregate, success-oriented information. Data needed for building models, on the other hand, needs to be detailed and should capture all outcomes. Many organizations invest heavily in data and data warehouses in response to the need for data; the mistake they make is collecting it from the perspective of reporting rather than modeling. Hence, even after all the time and costs spent, they end up in a place where enough useable data is not available. This leads to frustration in senior leadership as to why their teams cannot make use of these large data warehouses built at enormous expense. Taking some time in developing a systemic understanding of the business can help mitigate this problem, as discussed in the following chapters.
- Explosion of data: Data is being generated and collected on an exponential scale. As more data is collected, the scale of the data makes it harder to be analyzed and understood through traditional reporting methods. New data also spawns new use cases that were previously not possible. The scaling of data also increases noise. This makes it increasingly difficult to extract meaningful insights with traditional methods.
- Shortage of experienced data scientists: This is another topic that gets a lot of press. The reason for the shortage is that it is a relatively new field where techniques and methods are still rapidly evolving. Another factor is that data science is a multi-disciplinary field that requires expertise in multiple areas, such as statistics, computer science, and business, as well as knowledge of the domain where it is to be applied. Most of the talent pool today is relatively inexperienced and therefore most data scientists have not had a chance to work on a variety of use cases with a broad range of methods and data types. Best practices are still evolving and are not in widespread use. As more and more jobs become data-driven, it will also become important for a broad range of employees to become data-savvy.
- Immature tools and environments: Most of the tools and environments being used are relatively immature, and that makes it difficult to efficiently build and deploy models. Most of a data scientist's time is spent wrestling with data and infrastructure issues, which limits the time spent understanding the business problem and evaluating the business and ethical implications of models. This in turn increases the odds of failure to produce lasting business value.
- Black box models: As the complexity of models rises, our ability to understand what they are doing goes down. This lack of transparency creates many problems and can lead to models producing nonsensical results or, at worst, dangerous results. To make matters worse, these models tend to have better accuracy on training and validation datasets. Black box models tend to be difficult to explain to stakeholders and are therefore less likely to be adopted by users.
- Bias and fairness: The issue of ML models being biased and unfair has been raised recently and it is a key concern for anyone looking to develop and deploy ML models. The biases can creep into the models via biased data, biased processes, or even biased decision-making using model results. The use of black box models makes this problem much harder to track and manage. Bias and fairness are hard to detect but will be increasingly important not only for an organization's reputation but also with regard to the regulatory or legal problems that they can create.
Before we discuss how to address these challenges, we need to introduce you to DataRobot because, as you might have guessed, DataRobot helps in addressing many of these challenges.
DataRobot architecture
DataRobot is one of the most well-known commercial tools for automated ML (AutoML). It only seems appropriate that the technology meant to automate everything should itself benefit from automation. As you go through the data science process, you will realize that there are many tasks that are repetitive in nature and standardized enough to warrant automation. DataRobot has done an excellent job of capturing such tasks to increase the speed, scale, and efficiency of building and deploying ML models. We will cover these aspects in great detail in this book. Having said that, there are still many tasks and aspects of this process that still require decisions, actions, and tradeoffs to be done by data scientists and data analysts. We will highlight these as well. The following figure shows a high-level view of the DataRobot architecture:

Figure 1.2 – Key components of the DataRobot architecture
The figure shows five key layers of the architecture and the corresponding components. In the following sections, we will describe each layer and how it enables a data science project.
Hosting platform
The DataRobot environment is accessed via a web browser. The environment itself can be hosted on an organization's servers, or within an organization's server instances on a cloud platform, such as AWS or DataRobot's cloud. There are pros and cons to each hosting option and which option you should choose depends on your organization's needs. Some of these are discussed at a high level in Table 1.1:
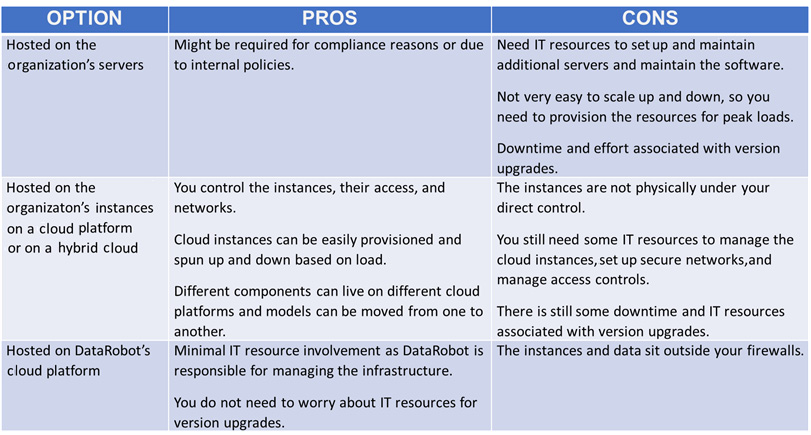
Figure 1.3 – Pros and cons of various hosting options
As you can gather from this table, DataRobot offers you a lot of choices, and you can pick the option that suits your environment the best. It is important to get your IT, information security, and legal teams involved in this conversation. Let's now look at how data comes into DataRobot.
Data sources
Datasets can be brought into DataRobot via local files (csv, xlsx, and more), by connecting to a relational database, from a URL, or from Hadoop Distributed File System (HDFS) (if it is set up for your environment). The datasets can be brought directly into a project or can be placed into an AI catalog. The datasets in the catalog can be shared across multiple projects. DataRobot has integrations and technology alliances with several data management system providers.
Core functions
DataRobot provides a fairly comprehensive set of capabilities to support the entire ML process, either through the core product or through add-on components such as Paxata, which provides easy-to-use data preparation and Exploratory Data Analysis (EDA) capabilities. Discussion of Paxata is beyond the scope of this book, so we will provide details of the capabilities of the core product. DataRobot automatically performs several EDA analyses that are presented to the user for gaining insights into the datasets and catching any data quality issues that may need to be fixed.
The automated modeling functions are the most critical capability offered by DataRobot. This includes determining the algorithms to be tried on the selected problem, performing basic feature engineering, automatically building models, tuning hyperparameters, building ensemble models, and presenting results. It must be noted that DataRobot mostly supports supervised ML algorithms and time series algorithms. Although there are capabilities to perform Natural Language Processing (NLP) and image processing, these functions are not comprehensive. DataRobot has also been adding to MLOps capabilities recently by providing functions for rapidly deploying models as REST APIs, monitoring data drift and service health, and tracking model performance. DataRobot continues to add capabilities such as support for geospatial data and bias detection.
These tasks are normally done by using programming languages such as R and Python and can be fairly time-consuming. The time spent coding up data analysis, model building, output analysis, and deployment can be significant. Typically, a lot of time is also spent debugging and fixing errors and making the code robust. Depending on the size and complexity of the model, this can take anywhere from weeks to months. DataRobot can reduce this time to days. This time can in turn be used to deliver projects faster, build more robust models, and better understand the problem being solved.
External interactions
DataRobot functions can be accessed via a comprehensive user interface (which we will describe in the next section), a client library that can be used in a Python or R framework to programmatically access DataRobot capabilities via an API, and a REST API for use by external applications. DataRobot also provides the ability to create applications that can be used by business users to enable them to make data-driven decisions.
Users
While most people believe that DataRobot is for data analysts and data scientists who do not like to code, it offers significant capabilities for data scientists who can code and can significantly increase the productivity of any data science team. There is also some support for business users for some specific use cases. Other systems can integrate with DataRobot models via the API, and this can be used to add intelligence to external systems or to store predictions in external databases. Several tool integrations exist through their partners program.
Navigating and using DataRobot features
Now that you have some familiarity with the core functions, let's take a quick tour of what DataRobot looks like and how you navigate the various functions. This section will introduce DataRobot at a high level, but don't worry: we will get into details in subsequent chapters. This section is only meant to familiarize you with DataRobot functionality.
Your DataRobot administrator will provide you with the appropriate URL and a username and password to access your DataRobot instance. In my experience, Google Chrome seems to work best with DataRobot, but you can certainly try other browsers as you see fit.
Note
Please note that the screens and options you see depend on the products you have the license for and the privileges granted to you by your admin. For most part, it will not affect the flow of this book. Since we will be focusing on the ML development core of DataRobot, you should be able to follow along.
So, let's go ahead and launch the browser and go to your DataRobot URL. You will see a login screen as shown in the following figure:
Figure 1.4 – DataRobot login screen
Go ahead and log in using your credentials. Once you have logged in, you will be presented with a welcome screen (Figure 1.4) that prompts you to select what you want to do next. It is also possible that (depending on your setup) you will be directly taken to the data input screen (Figure 1.5):
Figure 1.5 – Welcome screen
At this point, we will select the ML Development option and click the Continue button. This prompts you to provide the dataset that you wish to build models with (Figure 1.5):
Figure 1.6 – New project/drag dataset screen
At this point, you can drag a dataset file from your local machine onto the screen (or select one of the other choices) and DataRobot will start the process of analyzing your data. You can click on the View dataset requirements link to see the file format options available (Figure 1.6). The file size requirements for your instance might be different from what you see here:
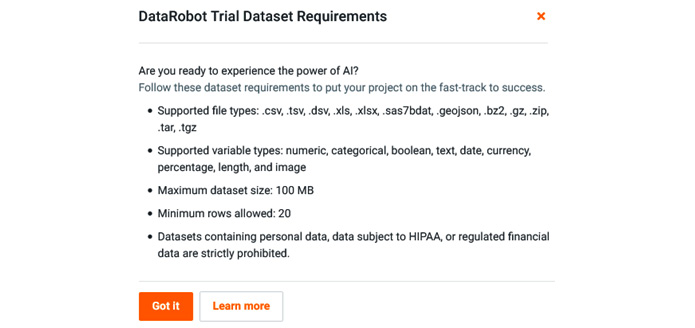
Figure 1.7 – Dataset requirements
At this point, you can upload any test dataset from your local drive. DataRobot will immediately start evaluating your data (Figure 1.7):
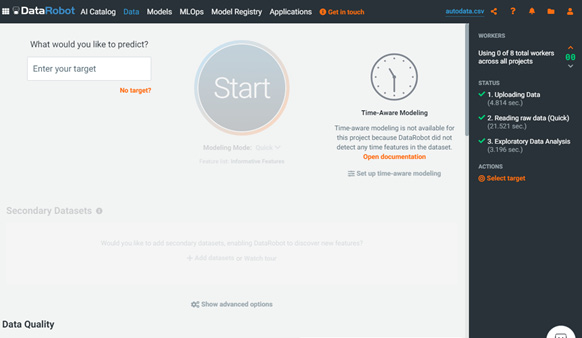
Figure 1.8 – EDA
We will cover the process of building the project and associated models in later chapters; for now, let's cover what other options we have. If you click on the ? icon in the top right, you will see the DOCUMENTATION drop-down menu (Figure 1.8):
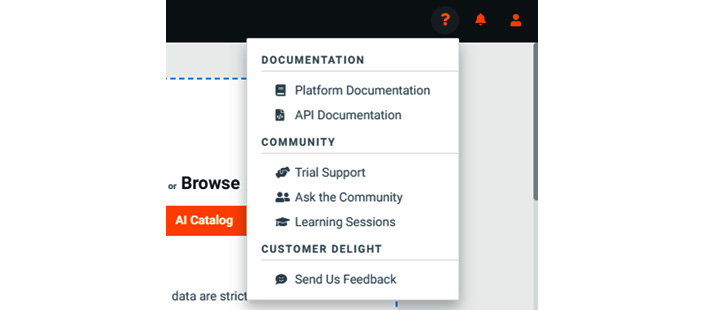
Figure 1.9 – DOCUMENTATION drop-down menu
Here you see various options to learn more about different functions, contact customer support, or interact with the DataRobot community. I highly recommend joining the community to interact with and learn from other community members. You can reach the community via https://community.datarobot.com. If you select Platform Documentation from the dropdown, you will see extensive documentation on DataRobot functions (Figure 1.9):
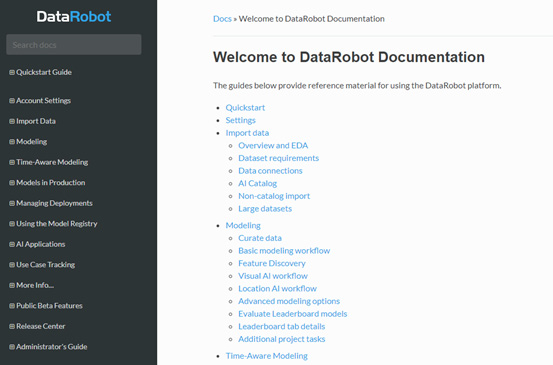
Figure 1.10 – DataRobot platform documentation
You can review the various topics at your leisure or come back to a specific topic as needed according to the task you are working on. Let's click on the ? icon in the top right again and this time select API Documentation from the dropdown. You will now see the documentation for the DataRobot API (Figure 1.10):
Figure 1.11 – DataRobot API Documentation
We will cover the API in the advanced topics in later chapters. If you are not familiar with programming or are relatively new to programming, you can ignore this part for now. If you are an experienced data scientist with expertise in Python or R, you can start reviewing the various functions available to you to automate your model-building tasks even further.
Let's go back to the main DataRobot page and this time select the folder icon in the top right of the page (Figure 1.11):
Figure 1.12 – Project drop-down menu
If you do not see the folder icon, it simply means that you do not have any projects defined. We will describe creating projects in more detail later. For now, just familiarize yourself with different options and what they look like. Here you will see options to create a new project or manage existing projects. In here, you will also see some details about the currently active project as well as a list of recent projects.
The Create New Project option takes you back to the new project page that we saw before in Figure 1.5. If you select the Manage Projects menu, it will show all of your projects listed by create date (Figure 1.12). Here you are able to select a project to see more details, clone a project, share the project with other users, or delete a project as needed, as shown in the following figure:
Figure 1.13 – Manage projects page
If you click on the very last menu item in the top right of the page that looks like a person, you will see a dropdown (Figure 1.13):
Figure 1.14 – User account management dropdown
From here you can manage your profile and adjust your account settings. If you have admin privileges, you can view and manage other users and groups. You can also sign out of DataRobot if needed.
If you select the Profile menu, you will see details of your account (Figure 1.14):
Figure 1.15 – User profile page
Here you can update some of your information. You will also see some new menu choices on the second menu row at the top. This allows you to change settings or access some developer options, and so on. If you select the Settings menu, you will see the following (Figure 1.15):
Figure 1.16 – User Settings
On this page, you can change your password, set up two-factor authentication, change the theme, and set up notifications (you will see different options available to you based on how your account was set up by your administrator).
If you select Developer Tools, you will see the following (Figure 1.16):
Figure 1.17 – Developer Tools screen
Here you can create an API key associated with your account. This key is useful for authentication if you will be using the DataRobot API. You can also download the API package to set up a portable prediction server to deploy models within your organization's infrastructure.
If you click on the AI Catalog menu at the top, you will see a catalog of shareable datasets available within DataRobot (Figure 1.17):
Figure 1.18 – AI Catalog
This page shows you a list of datasets available. If you do not see any datasets, you can upload a test dataset here by clicking on the Add new data button (Figure 1.18). You can also click on a dataset to explore the data available. You can search and sort by sources, user-defined tags, or owner/creator:
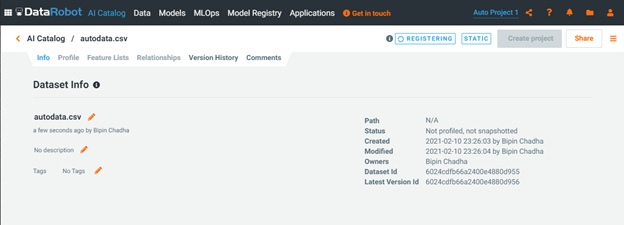
Figure 1.19 – Dataset information page
Normally a dataset is only available within a project. If you want to share datasets across projects or iterations of projects, you can create the dataset within this catalog. This allows you to share these datasets across projects and users. The datasets can be static, or they can be dynamically created using a SQL query as needed. Datasets can also be modified or blended via Spark SQL if you need data from multiple tables or sources for a project.
If you click on the Profile button, you will see profile-level information about the dataset (Figure 1.19). This information is automatically compiled for you. We will describe these capabilities and how to use them in more detail later:
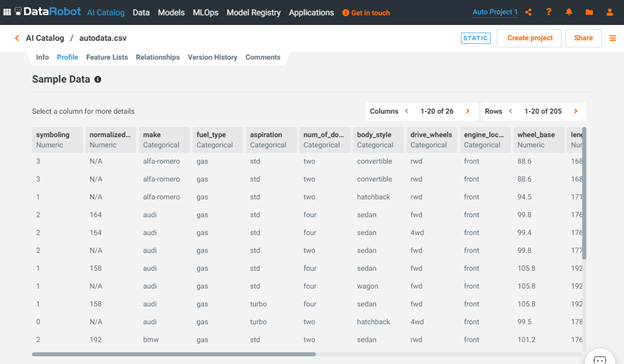
Figure 1.20 – Dataset information page
This page shows details of the dataset that is part of the project that is active at that time. This page is one of the key components of the DataRobot capability. The page shows summary information as well as any data quality issues that DataRobot has detected. Below that, it shows summaries of data features as well as a feature's importance relative to the target feature. We will cover these capabilities in more detail in subsequent chapters.
Let's now click on the Data menu at the top left of the page. This page (Figure 1.20) shows a detailed analysis of the dataset for your currently active project:
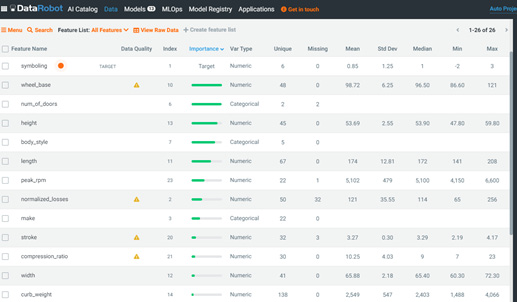
Figure 1.21 – Project data page
This page shows the results of the analysis of your datasets, provides any warnings, relative importance of the features, and the feature lists for use in your project. We will review the functionality of this page in great detail in later chapters.
Let's now click on the Models menu item at the top. This shows the model leaderboard for the active project (Figure 1.21):
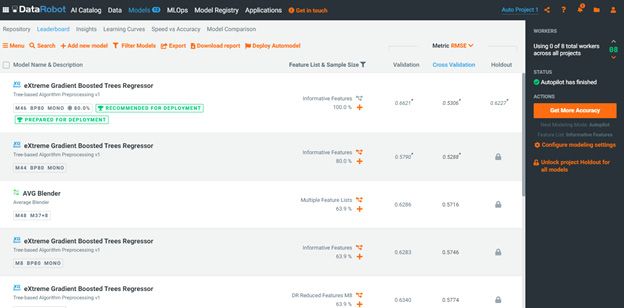
Figure 1.22 – Model leaderboard
This is another critical page where you will spend a lot of your time during the modeling process. Here you can see the top-performing models that DataRobot has built and their performance metrics for validation, cross-validation, and holdout samples. You can drill down into the details of any selected model. It is important to note that DataRobot mostly works with supervised learning problems; currently, it does not have support for unsupervised learning (except for some anomaly detection) or reinforcement learning. Also, support for NLP and image processing problems is limited. Similarly, there are situations where either due to data limitations or extreme scales, you will find that the automation adds a level of overhead that makes it impractical to use DataRobot. If your project requires advanced capabilities in these areas, you will need to work in Python or R directly. More on this in subsequent chapters.
Let's now move to the next menu item, MLOps. When you click on MLOps, you will see the screen shown in Figure 1.22:
Figure 1.23 – MLOps page
The MLOps page shows you your active deployments and their health. You can set up alerts relating to data drift or model accuracy as needed for your use cases.
The next menu item is Model Registry. Now, Model registry is the mechanism by which you can bring externally developed models into DataRobot. This capability is an add-on that your organization may or may not have purchased. This aspect is an advanced topic that is beyond the scope of this book.
Let's click on the next menu item, Applications. You will now see what's shown in Figure 1.23:
Figure 1.24 – Applications page
Applications is a relatively new functionality in DataRobot that is meant to allow business users to easily access model results without needing to get DataRobot user licenses.
This concludes our quick tour of what DataRobot is and what it looks like. We will revisit many of these components in great detail and see examples of how these are used to take a data science project from start to finish.
Addressing data science challenges with DataRobot
Now that you know what DataRobot offers, let's revisit the data science process and challenges to see how DataRobot helps in addressing these challenges and why this is a valuable tool in your toolkit.
Lack of good-quality data
While DataRobot cannot do much to address this challenge, it does offer some capabilities to handle data with quality problems:
- Automatically highlights data quality problems.
- Automated EDA and data visualization expose issues that could be missed.
- Handles and imputes missing values.
- Detection of data drift.
Explosion of data
While it is unlikely that the increase in the volume and variety will slow down any time soon, DataRobot offers several capabilities to address these challenges:
- Support for SparkSQL enables the efficient pre-processing of large datasets.
- Automatically handles categorical data encodings and selects appropriate model blueprints.
- Automatically handles geospatial features, text features, and image features.
Shortage of experienced data scientists
This is a key challenge for most organizations and data science teams, and DataRobot is well positioned to address this challenge:
- Provides capabilities that cover most of the data science process steps.
- Significant automation of several routine tasks by providing pre-built blueprints encoded with best practices.
- Experienced data scientists can build and deploy models much faster.
- Data analysts or data scientists who are not very comfortable coding can utilize DataRobot capabilities without having to write a lot of code.
- Experienced data scientists who are comfortable with coding can utilize the APIs to automatically build and deploy an order of magnitude more models than otherwise feasible without the support of other data engineering or IT staff.
- Even experienced data scientists do not know all the possible algorithms and typically do not have the time to try out many of the combinations and build analysis visualizations and explanations for all models. DataRobot takes care of many of these tasks for them, enabling them to focus more time on understanding the problem and analyzing results.
Immature tools and environments
This is a key barrier to the productivity and effectiveness of any data science organization. DataRobot clearly addresses this key challenge by offering the following:
- Ease of deployment of any model as a REST API.
- Ease of use in developing multiple competing models and selecting the best ones without worrying about the underlying infrastructure, installation of compatible versions, and without coding and debugging. These tasks can take up a lot of time that would be better spent on understanding and solving the business problem.
- DataRobot encodes many of the best practices into their development process so as to prevent mistakes. DataRobot automatically takes care of many small details that can be overlooked even by experienced data scientists, leading to flawed models or rework.
- DataRobot provides automated documentation of models and modeling steps that could otherwise be glossed over or forgotten. This becomes valuable at a later time when a data scientist has to revisit an old model built by them or someone else.
Black box models
This is a key challenge that DataRobot has done extensive work on to provide methods to help make models more explainable, such as the following:
- Automated generation of feature importance (using Shapley values and other methods) and partial dependence plots for models
- Automated generation of explanations for specific predictions
- Automated generation of simpler models that could be used to explain the complex models
- Ability to create models that inherently more explainable such as Generalized Additive Models (GAMs)
Bias and fairness
Recently, DataRobot has added capabilities to help detect bias and fairness issues in models. This is no guarantee of a complete lack of bias, but it's a good starting point to ensure positive movement in this direction. Some of the capabilities added are listed here:
- Specify protected features that need to be checked for bias.
- Specify bias metrics that you want to use to check for fairness.
- Evaluate your models using metrics for protected features.
- Use of model explanations to investigate whether there is potential for unfairness.
While many people believe that with these automated tools, you no longer need data scientists, nothing could be further from the truth. It is, however, obvious that such tools will make data science teams a lot more valuable to their organizations by unlocking more value faster and by making these organizations more competitive. It is therefore likely that tools such as DataRobot will become increasingly commonplace and see widespread use.
Summary
Most data scientists today are bogged down in the implementation details or are implementing suboptimal algorithms. This leaves them with less time to understand the problem and to search for optimal algorithms or their hyperparameters. This book will show you how to take your game to the next level and let the software do the repetitive work.
In this chapter, we covered what a typical data science process is and how DataRobot supports this process. We discussed steps in the process where DataRobot offers a lot of capability and we also highlighted areas where a data scientist's expertise and domain understanding is critical (areas such as problem understanding and analyzing the impacts of deploying a model on the overall system). This highlights an important point in that success comes from the combination of skilled data scientists and analysts and appropriate tools (such as DataRobot). By themselves, they cannot be as effective as the combination. DataRobot enables relatively new data scientists to quickly develop and deploy robust models. At the same time, experienced data scientists can use DataRobot to rapidly explore and build a broader range of models than they would be able to build on their own.
We covered some of the key data science challenges and how DataRobot helps you overcome some of the specific challenges. This should help guide leaders on how to craft the right combination of data scientists and the tools and infrastructure they need. We also covered the DataRobot architecture, its components, and what DataRobot looks like. You got a taste of what you will see when you start using it and where to go to find specific functions and help.
Hopefully, this chapter has shown you why DataRobot could be an important tool in your toolbox regardless of your experience or how comfortable you are with coding. In the following chapters, we will use hands-on examples to show how to use DataRobot in detail and how to move your projects into a higher gear. But before we do that, we need to cover some ML basics in the next chapter.
