



















 Download code from GitHub
Download code from GitHub
Chapter 1: Introduction to Reinforcement Learning
Reinforcement Learning (RL) aims to create Artificial Intelligence (AI) agents that can make decisions in complex and uncertain environments, with the goal of maximizing their long-term benefit. These agents learn how to do it through interacting with their environments, which mimics the way we as humans learn from experience. As such, RL has an incredibly broad and adaptable set of applications, with the potential to disrupt and revolutionize global industries.
This book will give you an advanced level understanding of this field. We will go deeper into the theory behind the algorithms you may already know, and cover state-of-the art RL. Moreover, this is a practical book. You will see examples inspired by real-world industry problems and learn expert tips along the way. By its conclusion, you will be able to model and solve your own sequential decision-making problems using Python.
So, let's start our journey with refreshing your mind on RL concepts and get you set up for the advanced material upcoming in the following chapters. Specifically, this chapter covers:
- Why reinforcement learning?
- The three paradigms of ML
- RL application areas and success stories
- Elements of a RL problem
- Setting up your RL environment
Why reinforcement learning?
Creating intelligent machines that make decisions at or superior to human level is a dream of many scientist and engineers, and one which is gradually becoming closer to reality. In the seven decades since the Turing test, AI research and development has been on a roller coaster. The expectations were very high initially: In the 1960s, for example, Herbert Simon (who later received the Nobel Prize in Economics) predicted that machines would be capable of doing any work humans can do within twenty years. It was this excitement that attracted big government and corporate funding flowing into AI research, only to be followed by big disappointments and a period called the "AI winter." Decades later, thanks to the incredible developments in computing, data, and algorithms, humankind is again very excited, more than ever before, in its pursuit of the AI dream.
Note
If you're not familiar with Alan Turing's instrumental work on the foundations of AI in 1950, it's worth learning more about the Turing Test here: https://youtu.be/3wLqsRLvV-c
The AI dream is certainly one of grandiosity. After all, the potential in intelligent autonomous systems is enormous. Think about how we are limited in terms of specialist medical doctors in the world. It takes years and significant intellectual and financial resources to educate them, which many countries don't have at sufficient levels. In addition, even after years of education, it is nearly impossible for a specialist to stay up-to-date with all of the scientific developments in her field, learn from the outcomes of the tens of thousands of treatments around the world, and effectively incorporate all this knowledge into practice.
Conversely, an AI model could process and learn from all this data and combine it with a rich set of information about a patient (medical history, lab results, presenting symptoms, health profile) to make diagnosis and suggest treatments. Such a model could serve even in the most rural parts of the world (as far as an internet connection and computer are available) and direct the local health personnel about the treatment. No doubt that it would revolutionize international healthcare and improve the lives of millions of people.
Note
AI is already transforming the healthcare industry. In a recent article, Google published results from an AI system surpassing human experts in breast cancer prediction using mammography readings (McKinney et al. 2020). Microsoft is collaborating with one of India's largest healthcare providers to detect cardiac illnesses using AI (Agrawal, 2018). IBM Watson for Clinical Trial Matching uses natural language processing to recommend potential treatments for patients from medical databases (https://youtu.be/grDWR7hMQQQ).
On our quest to develop AI systems that are at or superior to human level, which is -sometimes controversially- called Artificial General Intelligence (AGI), it makes sense to develop a model that can learn from its own experience - without necessarily needing a supervisor. RL is the computational framework that enables us to create such intelligent agents. To better understand the value of RL, it is important to compare it with the other ML paradigms, which we'll look into next.
The three paradigms of ML
RL is a separate paradigm in Machine Learning (ML) along supervised learning (SL) and unsupervised learning (UL). It goes beyond what the other two paradigms involve – perception, classification, regression and clustering – and makes decisions. Importantly however, RL utilizes the supervised and unsupervised ML methods in doing so. Therefore, RL is a distinct yet a closely related field to supervised and UL, and it's important to have a grasp of them.
Supervised learning
SL is about learning a mathematical function that maps a set of inputs to the corresponding outputs/labels as accurately as possible. The idea is that we don't know the dynamics of the process that generates the output, but we try to figure it out using the data coming out of it. Consider the following examples:
- An image recognition model that classifies the objects on the camera of a self-driving car as pedestrian, stop sign, truck
- A forecasting model that predicts the customer demand of a product for a particular holiday season using past sales data.
It is extremely difficult to come up with the precise rules to visually differentiate objects, or what factors lead to customers demanding a product. Therefore, SL models infer them from labeled data. Here are some key points about how it works:
- During training, models learn from ground truth labels/output provided by a supervisor (which could be a human expert or a process),
- During inference, models make predictions about what the output might be given the input,
- Models use function approximators to represent the dynamics of the processes that generate the outputs.
Unsupervised learning
UL algorithms identify patterns in data that were previously unknown. While using such models, we might have an idea of what to expect as a result, but we don't supply the models with labels. For example:
- Identifying homogenous segments on an image provided by the camera of a self-driving car. The model is likely to separate the sky, road and buildings based on the textures on the image.
- Clustering weekly sales data into 3 groups based on sales volume. The output is likely to be weeks with low, medium, and high sales volume.
As you can tell, this is quite different than how SL works, namely:
- UL models don't know what the ground truth is, and there is no label to map the input to. They just identify the different patterns in the data. Even after doing so, for example, the model would not be aware that it separated sky from road, or a holiday week from a regular week.
- During inference, the model would cluster the input into one of the groups it had identified, again, without knowing what that group represents.
- Function approximators, such as neural networks, are used in some UL algorithms, but not always.
With supervised and UL reintroduced, we'll now compare them with RL.
Reinforcement learning
RL is a framework to learn how to make decisions under uncertainty to maximize a long-term benefit through trial and error. These decisions are made sequentially, and earlier decisions affect the situations and benefits that will be encountered later. This separates RL from both supervised and UL, which don't involve any decision-making. Let's revisit the examples we provided earlier to see how a RL model would differ from supervised and UL models in terms of what it tries to find out.
- For a self-driving car, given the types and positions of all the objects on the camera, and the edges of the lanes on the road, the model might learn how to steer the wheel and what the speed of the car should be to pass the car ahead safely and as quickly as possible.
- Given the historical sales numbers for a product and the time it takes to bring the inventory from the supplier to the store, the model might learn when and how many units to order from the supplier, so that seasonal customer demand is satisfied with high likelihood while the inventory and transportation costs are minimized.
As you will have noticed, the tasks that RL is trying to accomplish are of different nature and more complex than those simply addressed by SL and UL alone. Let's elaborate on how RL is different:
- The output of an RL model is a decision given the situation, not a prediction or clustering.
- There are no ground truth decisions provided by a supervisor that tell what the ideal decisions are in different situations. Instead, the model learns the best decisions from the feedback from its own experience and the decisions it made in the past. For example, through trial and error, an RL model would learn that speeding too much while passing a car may lead to accidents; and ordering too much inventory before holidays will cause excess inventory later.
- RL models often use outputs of SL models as inputs to make decisions. For example, the output of an image recognition model in a self-driving car could be used to make driving decisions. Similarly, the output of a forecasting model is often an input to an RL model that makes inventory replenishment decisions.
- Even in the absence of such an input from an auxiliary model, RL models, either implicitly or explicitly, predict what situations its decisions will lead to in the future.
- RL utilizes many methods developed for supervised and UL, such as various types of neural networks as function approximators.
So, what differentiates RL from other ML methods is that it is a decision-making framework. What makes it exciting and powerful, though, is its similarities to how we learn as humans to make decisions from experience. Imagine a toddler learning how to build a tower from toy blocks. Usually, the taller the tower, the happier the toddler is. Every increment in height is a success. Every collapse is a failure. She quickly discovers that the closer the next block is to the center of the one beneath, the more stable the tower is. This is reinforced when a block placed too close to the edge more readily topples. With practice, she manages to stack several blocks on top of each other. She realizes how she stacks the earlier blocks creates a foundation which determines how tall of a tower she can build. Thus, she learns.
Of course, the toddler did not learn these architectural principles from a blueprint. She learnt from the commonalities in her failure and success. The increasing height of the tower or its collapse provided a feedback signal upon which she refined her strategy accordingly. Learning from experience, rather than a blueprint is at the center of RL. Just as the toddler discovers which block positions lead to taller towers, an RL agent identifies the actions with the highest long-term rewards through trial and error. This is what makes RL such a profound form of AI; it's unmistakably human.
Over the past several years, there have been many amazing success stories proving the potential in RL. Moreover, there are many industries it is about to transform. So, before diving into the technical aspects of RL, let's further motivate ourselves by looking into what RL can do in practice.
RL application areas and success stories
RL is not a new field. Many of the fundamental ideas in RL were introduced in the context of dynamic programming and optimal control throughout the past seven decades. However, successful RL implementations have taken off recently thanks to the breakthroughs in deep learning and more powerful computational resources. In this section, we talk about some of the application areas of RL together with some famous success stories. We will go deeper into the algorithms behind these implementations in the following chapters.
Games
Board and video games have been a research lab for RL, leading to many famous success stories in this area. The reasons of why games make good RL problems are as follows:
- Games are naturally about sequential decision-making with uncertainty involved.
- They are available as computer software, making it possible for RL models to flexibly interact with them and generate billions of data points for training. Also, trained RL models are then also tested in the same computer environment. This is as opposed to many physical processes for which it is too complex to create accurate and fast simulators.
- The natural benchmark in games are the best human players, making it an appealing battlefield for AI vs. human comparisons.
After this introduction, let's go into some of the most exciting RL work that made to the headlines.
TD-Gammon
The first famous RL implementation is TD-Gammon, a model that learned how to play super-human level backgammon - a two-player board game with 1020 possible configurations. The model was developed by Gerald Tesauro at the IBM Research in 1992. TD-Gammon was so successful that it created a great excitement in the backgammon community back then with the novel strategies it taught humans. Many methods used in that model (temporal-difference, self-play, use of neural networks) are still at the center of the modern RL implementations.
Super-human performance in Atari games
One of the most impressive and seminal works in RL was that of Volodymry Mnih and his colleagues at Google DeepMind that came out in 2015. The researchers trained RL agents that learned how to play Atari games better than humans by only using screen input and game scores, without any hand-crafted or game-specific features through deep neural networks. They named their algorithm deep Q-network (DQN), which is one of the most popular RL algorithms today.
Beating the world champions in Go, chess and Shogi
The RL implementation that perhaps brought the most fame to RL was Google DeepMind's AlphaGo. It was the first computer program to beat a professional player in the ancient board game of Go in 2015, and later the world champion Lee Sedol in 2016. This story was later turned into a documentary film with the same name. The AlphaGo model was trained using data from human expert moves as well as with RL through self-play. The later version, AlphaGo Zero reached a performance of defeating the original AlphaGo 100-0, which was trained via just self-play and without any human knowledge inserted to the model. Finally, the company released AlphaZero in 2018 that was able to learn the games of chess, shogi (Japanese chess) and Go to become the strongest player in history for each, without any prior information about the games except the game rules. AlphaZero reached this performance after only several hours of training on tensor processing units (TPUs). AlphaZero's unconventional strategies were praised by world-famous players such as Garry Kasparov (chess) and Yoshiharu Habu (shogi).
Victories in complex strategy games
RL's success later went beyond just Atari and board games, into Mario, Quake III Arena, Capture the Flag, Dota 2 and StarCraft II. Some of these games are exceptionally challenging for AI programs with the need for strategic planning, involvement of game theory between multiple decision makers, imperfect information and large number of possible actions and game states. Due to this complexity, it took enormous amount of resources to train those models. For example, OpenAI trained the Dota 2 model using 256 GPUs and 128,000 CPU cores for months, giving 900 years of game experience to the model per day. Google DeepMind's AlphaStar, which defeated top professional players in StarCraft II in 2019, required training hundreds of copies of a sophisticated model with 200 years of real-time game experience for each, although those models were initially trained on real game data of human players.
Robotics and autonomous systems
Robotics and physical autonomous systems are challenging fields for RL. This is because RL agents are trained in simulation to gather enough data; but a simulation environment cannot reflect all the complexities of the real-world. Therefore, those agents often fail in the actual task, which is especially problematic if the task is safety critical. In addition, these applications often involve continuous actions, which require different types of algorithms than DQN. Despite these challenges, on the other hand, there are numerous RL success stories in these fields. In addition, there is a lot of research on using RL in exciting applications such autonomous ground and air vehicles.
Elevator optimization
An early success story that proved RL can create value for real-world applications was about elevator optimization in 1996 by Robert Crites and Andrew Barto. The researchers developed an RL model to optimize elevator dispatching in a 10-story building with 4 elevator cars. This was a much more challenging problem than the earlier TD-gammon due to the possible number of situations the model can encounter, partial observability (the number of people waiting at different floors was not observable to the RL model), and the possible number of decisions to choose from. The RL model substantially improved the best elevator control heuristics of the time across various metrics such as average passenger wait-time and travel-time.
Humanoid robots and dexterous manipulation
In 2017, Nicolas Heess et al. of Google DeepMind were able to teach different types of bodies (humanoid ) various locomotion behaviors such as how to run, jump in a computer simulation. In 2018, Marcin Andrychowicz et al. of OpenAI trained a five-fingered humanoid hand that is able to manipulate a block from an initial configuration to a goal configuration. And in 2019, again researchers from OpenAI, Ilge Akkaya et al. were able to train a robot hand that can solve a Rubik's cube.

Figure 1.1 – OpenAI's RL model that solved Rubik's cube is trained in simulation (a) and deployed on a physical robot (b). (Image source: OpenAI Blog, 2019)
Both of the latter two models were trained in simulation and successfully transferred to physical implementation using domain randomization techniques (Figure 1.1).
Emergency response robots
In the aftermath of a disaster, using robots could be extremely helpful especially when operating in dangerous conditions. For example, robots could locate survivors in damaged structures, turn off gas valves Creating intelligent robots that operate autonomously would allow to scale emergency response operations and provide the necessary support to many more people than it is possible with manual operations.
Self-driving vehicles
Although a full self-driving car is too complex to solve with an RL model alone, some of the tasks could be handled by RL. For example, we can train RL agents for self-parking, and making decisions for when and how to pass a car on a highway. Similarly, we can use RL agents to execute certain tasks in an autonomous drone, such as how to take off, land, avoid collusions
Info
In a phenomenal success story that came in late 2020, Loon and Google AI deployed a superpressure balloon in the stratosphere that is controlled by a RL agent. You can read about this story at https://bit.ly/33RqQCh.
As in many areas, we see RL appearing as a competitive alternative to traditional controllers for vehicles.
Supply chain
Many decisions in supply chain are of sequential nature and involve uncertainty, for which RL is a natural approach. Some of these problems are as follows:
- Inventory planning is about deciding when to place a purchase order to replenish the inventory of an item and at what quantity. Ordering less than necessary causes shortages and ordering more than necessary causes excess inventory costs, product spoilage and inventory removal at reduced prices. RL models are used to make inventory planning decisions to decrease the cost of these operations.
- Bin packing is a common problem in manufacturing and supply chain where items arriving at a station are placed into containers to minimize the number of containers used, and to ensure smooth operations in the facility. This is a difficult problem that can be solved using RL.
Manufacturing
An area where RL will have a great impact is manufacturing, where a lot of manual tasks can potentially be carried out by autonomous agents at reduced costs and increased quality. As a result, many companies are looking into bringing RL to their manufacturing environment. Here are some example RL applications in manufacturing.
- Machine calibration is a task that is often handled by human experts in manufacturing environments, which is inefficient and error prone. RL models are often capable of achieving these tasks at reduced costs and increased quality.
- Chemical plant operations often involve sequential decision making, which are often handled by human experts or heuristics. RL agents are shown to be effectively controlling these processes with better final product quality and less equipment wear and tear.
- Equipment maintenance requires planning down-times to avoid costly breakdowns. RL models can effectively balance the cost of downtime and cost of a potential breakdown.
- In addition to the examples above, many successful RL applications in robotics can be transferred to manufacturing solutions.
Personalization and recommender systems
Personalization is arguably the area where RL has created the most business value so far. Big tech companies provide personalization as a service with RL algorithms running under the hood. Here are some examples.
- In advertising, the order and content of promotional materials delivered to (potential) customers is a sequential decision-making problem that can be solved using RL, leading to increased customer satisfaction and conversion.
- News recommendation is an area where Microsoft News has famously applied RL and increased visitor engagement by improving the article selection and the order of recommendation.
- Personalization of the artwork that you see for the titles on Netflix is handled by RL algorithms. With that, the viewers better identify the titles relevant to their interests.
- Personalized healthcare is becoming increasingly important as it provides more effective treatments at reduced costs. There are many successful applications of RL picking the right treatment for patients.
Smart cities
There are many areas RL can help improve how cities operate. Below are couple examples.
- In a traffic network with multiple intersections, the traffic lights should work in harmony to ensure the smooth flow of the traffic. It turns out that this problem can be modeled as a multi-agent RL problem and improve the existing systems for traffic light control.
- Balancing the generation and demand in electricity grids in real-time is an important problem to ensure the grid safety. One way of achieving this is to control the demand, such as charging electric vehicles and turning on air conditioning systems when there is enough generation, without sacrificing the service quality, to which RL methods have successfully been applied.
This list can go on for pages, but it should be enough to demonstrate the huge potential in RL. What Andrew Ng, a pioneer in the field, says about AI is very much true for RL as well.
Just as electricity transformed almost everything 100 years ago, today I actually have a hard time thinking of an industry that I don't think AI will transform in the next several years. ("Andrew Ng: Why AI is the new electricity;" Stanford News; March 15, 2017)
RL today is only at the beginning of its prime time; and you are making a great investment by putting effort to understand what RL is and what it has to offer. Now, it is time to get more technical and formally define the elements in a RL problem.
Elements of a RL problem
So far, we have covered the types of problems that can be modeled using RL. In the next chapters, we will dive into state-of-the-art algorithms that will solve those problems. However, in between, we need to formally define the elements in an RL problem. This will lay the ground for the more technical material by establishing our vocabulary. After providing these definitions, we then look into what these concepts correspond to in a tic-tac-toe example.
RL concepts
Let's start with defining the most fundamental components in an RL problem.
- At the center of a RL problem, there is the learner, which is called the agent in RL terminology. Most of the problem classes we deal with has a single agent. On the other hand, if there are more than one agent, that problem class is called a multi-agent RL, or MARL for short. In MARL, the relationship between the agents could be cooperative, competitive or the mix of the two.
- The essence of an RL problem is the agent learning what to do, that is which action to take, in different situations in the world it lives in. We call this world the environment and it refers to everything outside of the agent.
- The set of all the information that precisely and sufficiently describes the situation in the environment is called the state. So, if the environment is in the same state at different points in time, it means everything about the environment is exactly the same - like a copy-paste.
- In some problems, the knowledge of the state is fully available to the agent. In a lot of other problems, and especially in more realistic ones, the agent does not fully observe the state, but only part of it (or a derivation of a part of the state). In such cases, the agent uses its observation to take actions. When this is the case, we say that the problem is partially observable. Unless we say otherwise, we assume that the agent is able to fully observe the state that the environment is in and is basing its actions on the state.
Info
The term state and its notation
 is more commonly used during abstract discussions, especially when the environment is assumed to be fully observable, although observation is a more general term: What the agent receives is always an observation, which is sometimes just the state itself, and sometimes a part of or a derivation from the state, depending on the environment. Don't get confused if you see them used interchangeably in some contexts.
is more commonly used during abstract discussions, especially when the environment is assumed to be fully observable, although observation is a more general term: What the agent receives is always an observation, which is sometimes just the state itself, and sometimes a part of or a derivation from the state, depending on the environment. Don't get confused if you see them used interchangeably in some contexts.
So far, we have not really defined what makes an action good or bad. In RL, every time the agent takes an action, it receives a reward from the environment (albeit it is sometimes zero). Reward could mean many things in general, but in RL terminology, its meaning is very specific: it is a scalar number. The greater the number is, the higher also is the reward. In an iteration of an RL problem, the agent observes the state the environment is in (fully or partially) and takes an action based on its observation. As a result, the agent receives a reward and the environment transitions into a new state. This process is described in Figure 2 below, which is probably familiar to you.
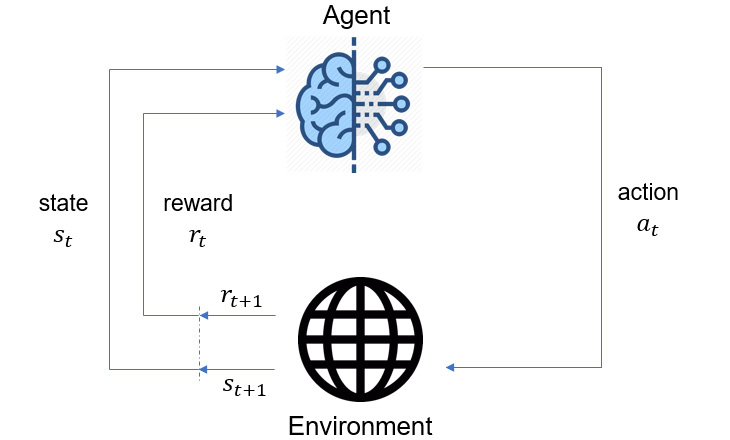
Figure 1.2 – RL process diagram
Remember that in RL, the agent is interested in actions that will be beneficial over the long term. This means the agent must consider the long-term consequences of its actions. Some actions might lead the agent to immediate high rewards only to be followed by very low rewards. The opposite might also be true. So, the agent's goal is to maximize the cumulative reward it receives. The natural follow up question is over what time horizon? The answer depends on whether the problem of interest is defined over a finite or an infinite horizon.
- If it is the former, the problem is described as an episodic task where an episode is defined as the sequence of interactions from an initial state to a terminal state. In episodic tasks, the agent's goal is to maximize the expected total cumulative reward collected over an episode.
- If problem is defined over an infinite horizon, it is called a continuing task. In that case, the agent will try to maximize the average reward since the total reward would go up to infinity.
- So, how does an agent achieve this objective? The agent identifies the best action(s) to take given its observation of the environment. In other words, the RL problem is all about finding a policy, which maps a given observation to one (or more) of the actions, that maximizes the expected cumulative reward.
All these concepts have concrete mathematical definitions, which we will cover in detail in later chapters. But for now, let's try to understand what these concepts would correspond to in a concrete example.
Casting Tic-Tac-Toe as a RL problem
Tic-tac-toe is a simple game, in which two players take turns to mark the empty spaces in a  grid. We now cast this as a RL problem to map the definitions provided above to the concepts in the game. The goal for a player is to place three of their marks in a vertical, horizontal or diagonal row to become the winner. If none of the players are able to achieve this before running out of the empty spaces on the grid, the game ends in a draw. Mid-game, a tic-tac-toe board might look like this:
grid. We now cast this as a RL problem to map the definitions provided above to the concepts in the game. The goal for a player is to place three of their marks in a vertical, horizontal or diagonal row to become the winner. If none of the players are able to achieve this before running out of the empty spaces on the grid, the game ends in a draw. Mid-game, a tic-tac-toe board might look like this:
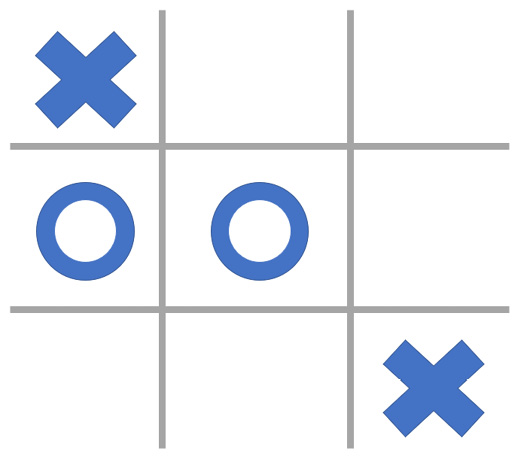
Figure 1.3 – An example board configuration in tic-tac-toe
Now, imagine that we have an RL agent playing against a human player.
- The action the agent takes is to place its mark (say a cross) in one of the empty spaces on the board when it is the agent's turn.
- Here, the board is the entire environment; and the position of the marks on the board is the state, which is fully observable to the agent.
- In a 3x3 tic-tac-toe game, there are 765 states (unique board positions, excluding rotations and reflections) and the agent's goal is to learn a policy that will suggest an action for each of these states so as to maximize the chance of winning.
- The game can be defined as an episodic RL task. Why? Because the game will last for a maximum 9 turns and the environment will reach a terminal state. A terminal state is one where either three Xs or Os make a row; or one where no single mark makes a row and there is no space left on the board (a draw).
- Note that no reward is given as the players make their moves during the game, except at the very end if a player wins. So, the agent receives +1 reward if it wins, -1 if it loses and 0 if the game is a draw. In all the iterations until the end, the agent receives 0 reward.
- We can turn this into a multi-agent RL problem by replacing the human player with another RL agent to compete with the first one.
Hopefully, this refreshes your mind on what agent, state, action, observation, policy and reward mean. This was just a toy example and rest assured that it will get much more advanced later. With this introductory context out of the way, what we need to do is to setup our computer environment to be able to run the RL algorithms we will cover in the following chapters.
Setting up your RL environment
RL algorithms utilize state-of-the-art ML libraries that require some sophisticated hardware. To follow along the examples we will solve throughout the book, you will need to set up your computer environment. Let's go over the hardware and software you will need in your setup.
Hardware requirements
As mentioned previously, state-of-the-art RL models are usually trained on hundreds of GPUs and thousands of CPUs. We certainly don't expect you to have access to those resources. However, having multiple CPU cores will help you simultaneously simulate many agents and environments to collect data more quickly. Having a GPU will speed up training deep neural networks that are used in modern RL algorithms. In addition, to be able to efficiently process all that data, having enough RAM resources is important. But don't worry, work with what you have, and you will still get a lot out of this book. For your reference, here are some specifications of the desktop we used to run the experiments:
- AMD Ryzen Threadripper 2990WX CPU with 32 cores
- NVIDIA GeForce RTX 2080 Ti GPU
- 128 GB RAM
As an alternative to building a desktop with expensive hardware, you can use Virtual Machines (VM) with similar capabilities provided by various companies. The most famous ones are:
- Amazon AWS
- Microsoft Azure
- Google Cloud
These cloud providers also provide data science images for your virtual machines during the setup and it saves the user from installing the necessary software for deep learning (CUDA, TensorFlow ). They also provide detailed guidelines on how to setup your VMs, to which we defer the details of the setup.
A final option that would allow small-scale deep learning experiments with TensorFlow is Google's Colab, which provides VM instances readily accessible from your browser with the necessary software installed. You can start experimenting on a Jupyter Notebook-like environment right away, which is a very convenient option for quick experimentation.
Operating system
When you develop data science models for educational purposes, there is often not a lot of difference between Windows, Linux or MacOS. However, we plan to do a bit more than that in this book with advanced RL libraries running on a GPU. This setting is best supported on Linux, of which we use Ubuntu 18.04.3 LTS distribution. Another option is macOS, but that often does not come with a GPU on the machine. Finally, although the setup could be a bit convoluted, Windows Subsystem for Linux (WSL) 2 is an option you could explore.
Software toolbox
One of the first things people do while setting up the software environment for data science projects is to install Anaconda, which gives you a Python platform along with many useful libraries.
Tip
The CLI tool called virtualenv is a lighter weight tool compared to Anaconda to create virtual environments for Python, and preferable in most production environments. We, too, will use it in certain chapters. You can find the installation instructions for virtualenv at https://virtualenv.pypa.io/en/latest/installation.html.
We will particularly need the following packages:
- Python 3.7: Python is the lingua franca of data science today. We will use version 3.7.
- NumPy: It is one of the most fundamental libraries used in scientific computing in Python.
- Pandas: Pandas is a widely used library that provides powerful data structures and analysis tools.
- Jupyter Notebook: This is a very convenient tool to run Python code especially for small-scale tasks. It usually comes with your Anaconda installation by default.
- TensorFlow 2.x: This will be our choice as the deep learning framework. We use version 2.3.0 in the book. Occasionally, we will refer to repos that use TF 1.x as well.
- Ray & RLlib: Ray is a framework for building and running distributed applications and it is getting increasingly popular. RLlib is a library running on Ray that includes many popular RL algorithms. At the time of writing this book, Ray supports only Linux and macOS for production, and Windows support is in alpha phase. We will use version 1.0.1, unless noted otherwise.
- Gym: This is an RL framework created by OpenAI that you have probably interacted with before if you ever touched RL. It allows us to define RL environments in a standard way and let them communicate with algorithms in packages like RLlib.
- OpenCV Python Bindings: We need this for some image processing tasks.
- Plotly: This is a very convenient library for data visualization. We will use Plotly together with the Cufflinks package to bind it to pandas.
You can use one of the following commands on your terminal to install a specific package. With Anaconda:
conda install pandas==0.20.3
With virtualenv (Also works with Anaconda in most cases)
pip install pandas==0.20.3
Sometimes, you are flexible with the version of the package, in which case you can omit the equal sign and what comes after.
Tip
It is always a good idea to create a virtual environment specific to your experiments for this book and install all these packages in that environment. This way, you will not break dependencies for your other Python projects. There is a comprehensive online documentation on how to manage your environments provided by Anaconda available at https://bit.ly/2QwbpJt.
That's it! With that, you are ready to start coding RL!
Summary
This was our refresher on RL fundamentals! We began this chapter by discussing what RL is, and why it is such a hot topic and the next frontier in AI. We talked about some of the many possible applications of RL and the success stories that made it to the news headlines over the past several years. We defined the fundamental concepts we will use throughout the book. Finally, we covered the hardware and software you need to run the algorithms we will introduce in the next sections. Everything so far was to refresh your mind about RL, motivate and set you up for what is upcoming next: Implementing advanced RL algorithms to solve challenging real-world problems. In the next chapter, we will dive right into it with multi-armed bandit problems, an important class of RL algorithms that has many applications in personalization and advertising.
References
- Sutton, R. S., Barto, A. G. (2018). RL: An Introduction. The MIT Press.
- Tesauro, G. (1992). Practical issues in temporal difference learning. ML 8, 257–277.
- Tesauro, G. (1995). Temporal difference learning and TD-Gammon. Commun. ACM 38, 3, 58-68.
- Silver, D. (2018). Success Stories of Deep RL. Retrieved from https://youtu.be/N8_gVrIPLQM.
- Crites, R. H., Barto, A.G. (1995). Improving elevator performance using RL. In Proceedings of the 8th International Conference on Neural Information Processing Systems (NIPS'95).
- Mnih, V. et al. (2015). Human-level control through deep RL. Nature, 518(7540), 529–533.
- Silver, D. et al. (2018). A general RL algorithm that masters chess, shogi, and Go through self-play. Science, 362(6419), 1140–1144.
- Vinyals, O. et al. (2019). Grandmaster level in StarCraft II using multi-agent RL.
- OpenAI. (2018). OpenAI Five. Retrieved from https://blog.openai.com/openai-five/.
- Heess, N. et al. (2017). Emergence of Locomotion Behaviours in Rich Environments. ArXiv, abs/1707.02286.
- OpenAI et al. (2018). Learning Dexterous In-Hand Manipulation. ArXiv, abs/1808.00177.
- OpenAI et al. (2019). Solving Rubik's Cube with a Robot Hand. ArXiv, abs/1910.07113.
- OpenAI Blog (2019). Solving Rubik's Cube with a Robot Hand. URL: https://openai.com/blog/solving-rubiks-cube/
- Zheng, G. et al. (2018). DRN: A Deep RL Framework for News Recommendation. In Proceedings of the 2018 World Wide Web Conference (WWW '18). International World Wide Web Conferences Steering Committee, Republic and Canton of Geneva, CHE, 167–176. DOI: https://doi.org/10.1145/3178876.3185994
- Chandrashekar, A. et al. (2017). Artwork Personalization at Netflix. The Netflix Tech Blog. URL: https://medium.com/netflix-techblog/artwork-personalization-c589f074ad76
- McKinney, S. M. et al. (2020). International evaluation of an AI system for breast cancer screening. Nature, 89-94.
- Agrawal, R. (2018, March 8). Microsoft News Center India. Retrieved from https://news.microsoft.com/en-in/features/microsoft-ai-network-healthcare-apollo-hospitals-cardiac-disease-prediction/






