























































Piping patterns
As in real-life plumbing, Node.js streams can also be piped together by following different patterns. We can, in fact, merge the flow of two different streams into one, split the flow of one stream into two or more pipes, or redirect the flow based on a condition. In this section, we are going to explore the most important plumbing patterns that can be applied to Node.js streams.
Combining streams
In this chapter, we have stressed the fact that streams provide a simple infrastructure to modularize and reuse our code, but there is one last piece missing from this puzzle: what if we want to modularize and reuse an entire pipeline? What if we want to combine multiple streams so that they look like one from the outside? The following figure shows what this means:
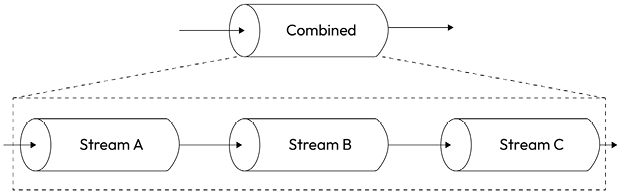
Figure 6.6: Combining streams
From Figure 6.6, we should already get a hint of how this works:
- When we write into the combined stream, we are writing into the first stream of the pipeline.
- When we read from the combined stream, we are reading from the last stream of the pipeline.
A combined stream is usually a Duplex stream, which is built by connecting the first stream to its Writable side and the last stream to its Readable side.
To create a Duplex stream out of two different streams, one Writable and one Readable, we can use an npm module such as duplexer3 (nodejsdp.link/duplexer3) or duplexify (nodejsdp.link/duplexify).
But that’s not enough. In fact, another important characteristic of a combined stream is that it must capture and propagate all the errors that are emitted from any stream inside the pipeline. As we already mentioned, any error event is not automatically propagated down the pipeline when we use pipe(), and we should explicitly attach an error listener to each stream. We saw that we could use the pipeline() helper function to overcome the limitations of pipe() with error management, but the issue with both pipe() and the pipeline() helper is that the two functions return only the last stream of the pipeline, so we only get the (last) Readable component and not the (first) Writable component.
We can verify this very easily with the following snippet of code:
import { createReadStream, createWriteStream } from 'node:fs'
import { Transform, pipeline } from 'node:stream'
import assert from 'node:assert/strict'
const streamA = createReadStream('package.json')
const streamB = new Transform({
transform(chunk, _enc, done) {
this.push(chunk.toString().toUpperCase())
done()
},
})
const streamC = createWriteStream('package-uppercase.json')
const pipelineReturn = pipeline(streamA, streamB, streamC, () => {
// handle errors here
})
assert.equal(streamC, pipelineReturn) // valid
const pipeReturn = streamA.pipe(streamB).pipe(streamC)
assert.equal(streamC, pipeReturn) // valid
From the preceding code, it should be clear that with just pipe() or pipeline(), it would not be trivial to construct a combined stream.
To recap, a combined stream has two major advantages:
- We can redistribute it as a black box by hiding its internal pipeline.
- We have simplified error management, as we don’t have to attach an error listener to each stream in the pipeline, but just to the combined stream itself.
Combining streams is common in Node.js, and node:stream exposes compose() to make it clean. It merges two or more streams into a single Duplex: writes you perform on the composite enter the first stream in the chain, reads come from the last. Backpressure is preserved end to end, and if any inner stream errors, the composite emits error and the whole chain is destroyed.
import { compose } from 'node:stream'
// ... define streamA, streamB, streamC
const combinedStream = compose(streamA, streamB, streamC)
When we do something like this, compose will create a pipeline out of our streams, return a new combined stream that abstracts away the complexity of our pipeline, and provide the advantages discussed previously.
Unlike .pipe() or pipeline(), compose() is lazy: it just builds the chain and does not start any data flow, so you still need to pipe the returned Duplex to a source and/or destination to move data. Use it when you want to package a reusable processing pipeline as one stream; use pipeline() when you want to wire a source to a destination and wait for completion.
Implementing a combined stream
To illustrate a simple example of combining streams, let’s consider the case of the following two Transform streams:
- One that both compresses and encrypts the data
- One that both decrypts and decompresses the data
Using compose, we can easily build these streams (in a file called combined-streams.js) by combining some of the streams that we already have available from the core libraries:
import { createGzip, createGunzip } from 'node:zlib'
import { createCipheriv, createDecipheriv, scryptSync } from 'node:crypto'
import { compose } from 'node:stream'
function createKey(password) {
return scryptSync(password, 'salt', 24)
}
export function createCompressAndEncrypt(password, iv) {
const key = createKey(password)
const combinedStream = compose(
createGzip(),
createCipheriv('aes192', key, iv)
)
combinedStream.iv = iv
return combinedStream
}
export function createDecryptAndDecompress(password, iv) {
const key = createKey(password)
return compose(createDecipheriv('aes192', key, iv), createGunzip())
}
We can now use these combined streams as if they were black boxes, for example, to create a small application that archives a file by compressing and encrypting it. Let’s do that in a new module named archive.js:
import { createReadStream, createWriteStream } from 'node:fs'
import { pipeline } from 'node:stream'
import { randomBytes } from 'node:crypto'
import { createCompressAndEncrypt } from './combined-streams.js'
const [, , password, source] = process.argv
const iv = randomBytes(16)
const destination = `${source}.gz.enc`
pipeline(
createReadStream(source),
createCompressAndEncrypt(password, iv),
createWriteStream(destination),
err => {
if (err) {
console.error(err)
process.exit(1)
}
console.log(`${destination} created with iv: ${iv.toString('hex')}`)
}
)
Note how we don’t have to worry about how many steps there are within archive.js. In fact, we just treat it as a single stream within our current pipeline. This makes our combined stream easily reusable in other contexts.
Now, to run the archive module, simply specify a password and a file in the command-line arguments:
node archive.js mypassword /path/to/a/file.txt
This command will create a file called /path/to/a/file.txt.gz.enc, and it will print the generated initialization vector to the console.
Now, as an exercise, you could use the createDecryptAndDecompress() function to create a similar script that takes a password, an initialization vector, and an archived file and unarchives it. Don’t worry, if you get stuck, we will have a solution implemented in this book’s code repository under the file unarchive.js.
In real-life applications, it is generally preferable to include the initialization vector as part of the encrypted data, rather than requiring the user to pass it around. One way to implement this is by having the first 16 bytes emitted by the archive stream represent the initialization vector. The unarchive utility would need to be updated accordingly to consume the first 16 bytes before starting to process the data in a streaming fashion. This approach would add some additional complexity, which is outside the scope of this example; therefore, we opted for a simpler solution. Once you feel comfortable with streams, we encourage you to try to implement, as an exercise, a solution where the initialization vector doesn’t have to be passed around by the user.
With this example, we have clearly demonstrated how important it is to combine streams. On one side, it allows us to create reusable compositions of streams, and on the other, it simplifies the error management of a pipeline.
Forking streams
We can perform a fork of a stream by piping a single Readable stream into multiple Writable streams. This is useful when we want to send the same data to different destinations; for example, two different sockets or two different files. It can also be used when we want to perform different transformations on the same data, or when we want to split the data based on some criteria. If you are familiar with the Unix command tee (nodejsdp.link/tee), this is exactly the same concept applied to Node.js streams!
Figure 6.7 gives us a graphical representation of this pattern:
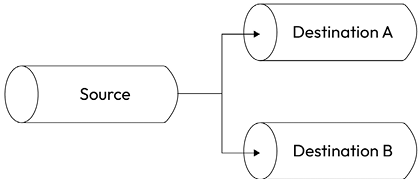
Figure 6.7: Forking a stream
Forking a stream in Node.js is quite easy, but there are a few caveats to keep in mind. Let’s start by discussing this pattern with an example. It will be easier to appreciate the caveats of this pattern once we have an example at hand.
Implementing a multiple checksum generator
Let’s create a small utility that outputs both the sha1 and md5 hashes of a given file. Let’s call this new module generate-hashes.js:
import { createReadStream, createWriteStream } from 'node:fs'
import { createHash } from 'node:crypto'
const filename = process.argv[2]
const sha1Stream = createHash('sha1').setEncoding('hex')
const md5Stream = createHash('md5').setEncoding('hex')
const inputStream = createReadStream(filename)
inputStream.pipe(sha1Stream).pipe(createWriteStream(`${filename}.sha1`))
inputStream.pipe(md5Stream).pipe(createWriteStream(`${filename}.md5`))
Very simple, right? The inputStream variable is piped into sha1Stream on one side and md5Stream on the other. There are a few things to note that happen behind the scenes:
- Both
md5Streamandsha1Streamwill be ended automatically wheninputStreamends, unless we specify{ end: false }as an option when invokingpipe(). - The two forks of the stream will receive a reference to the same data chunks, so we must be very careful when performing side-effect operations on the data, as that would affect every stream that we are sending data to.
- Backpressure will work out of the box; the flow coming from
inputStreamwill go as fast as the slowest branch of the fork. In other words, if one destination pauses the source stream to handle backpressure for a long time, all the other destinations will be waiting as well. Also, one destination blocking indefinitely will block the entire pipeline! - If we pipe to an additional stream after we’ve started consuming the data at source (async piping), the new stream will only receive new chunks of data. In those cases, we can use a
PassThroughinstance as a placeholder to collect all the data from the moment we start consuming the stream. Then, thePassThroughstream can be read at any future time without the risk of losing any data. Just be aware that this approach might generate backpressure and block the entire pipeline, as discussed in the previous point.
Merging streams
Merging is the opposite operation to forking and involves piping a set of Readable streams into a single Writable stream, as shown in Figure 6.8:
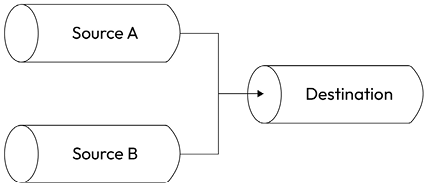
Figure 6.8: Merging streams
Merging multiple streams into one is, in general, a simple operation; however, we have to pay attention to the way we handle the end event, as piping using the default options (whereby { end: true }) causes the destination stream to end as soon as one of the sources ends. This can often lead to an error, as the other active sources continue to write to an already terminated stream.
The solution to this problem is to use the option { end: false } when piping multiple sources to a single destination and then invoke end() on the destination only when all the sources have completed reading.
Merging text files
To make a simple example, let’s implement a small program that takes an output path and an arbitrary number of text files, and then merges the lines of every file into the destination file. Our new module is going to be called merge-lines.js. Let’s define its contents, starting from some initialization steps:
import { createReadStream, createWriteStream } from 'node:fs'
import { Readable, Transform } from 'node:stream'
import { createInterface } from 'node:readline'
const [, , dest, ...sources] = process.argv
In the preceding code, we are just loading all the dependencies and initializing the variables that contain the name of the destination (dest) file and all the source files (sources).
Next, we will create the destination stream:
const destStream = createWriteStream(dest)
Now, it’s time to initialize the source streams:
let endCount = 0
for (const source of sources) {
const sourceStream = createReadStream(source, { highWaterMark: 16 })
const linesStream = Readable.from(createInterface({ input: sourceStream }))
const addLineEnd = new Transform({
transform(chunk, _encoding, cb) {
cb(null, `${chunk}\n`)
},
})
sourceStream.on('end', () => {
if (++endCount === sources.length) {
destStream.end()
console.log(`${dest} created`)
}
})
linesStream
.pipe(addLineEnd)
.pipe(destStream, { end: false })
}
In this code, we initialize a source stream for each file in the sources array. Each source is read using createReadStream().
The createInterface() function from the node:readline module is used to process each source file line by line, producing a linesStream that emits individual lines of the source file.
To ensure each emitted line ends with a newline character, we use a simple Transform stream (addLineEnd). This transform appends \n to each chunk of data.
We also attach an end event listener to each source stream. This listener increments a counter (endCount) each time a source stream finishes. When all source streams have been read, it ensures the destination stream (destStream) is closed, signaling the completion of the streaming pipeline.
Finally, each linesStream is piped through the addLineEnd transform and into the destination stream. During this last step, we use the { end: false } option to keep the destination stream open even when one of the sources ends. The destination stream is only closed when all source streams have finished, ensuring no data is lost during the merge. This last step is where the merge happens, because we are effectively piping multiple independent streams into the same destination stream.
We can now execute this code with the following command:
node merge-lines.js <destination> <source1> <source2> <source3> ...
If you run this code with large enough files, you will notice that the destination file will contain lines that are randomly intermingled from all the source files (a low highWaterMark of 16 bytes makes this property even more apparent). This kind of behavior can be acceptable in some types of object streams and some text streams split by line (as in our current example), but it is often undesirable when dealing with most binary streams.
There is one variation of the pattern that allows us to merge streams in order; it consists of consuming the source streams one after the other. When the previous one ends, the next one starts emitting chunks (it is like concatenating the output of all the sources). As always, on npm, we can find some packages that also deal with this situation. One of them is multistream (https://npmjs.org/package/multistream).
Multiplexing and demultiplexing
There is a particular variation of the merge stream pattern in which we don’t really want to just join multiple streams together, but instead, use a shared channel to deliver the data of a set of streams. This is a conceptually different operation because the source streams remain logically separated inside the shared channel, which allows us to split the stream again once the data reaches the other end of the shared channel. Figure 6.9 clarifies this situation:
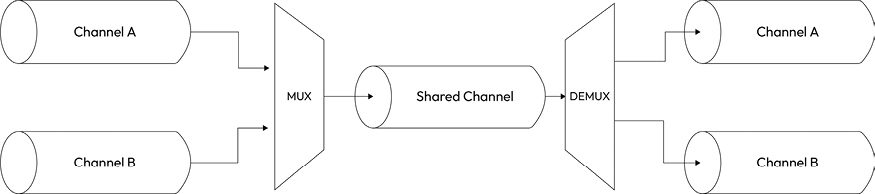
Figure 6.9: Multiplexing and demultiplexing streams
The operation of combining multiple streams (in this case, also known as channels) to allow transmission over a single stream is called multiplexing, while the opposite operation, namely reconstructing the original streams from the data received from a shared stream, is called demultiplexing. The devices that perform these operations are called multiplexer (or mux) and demultiplexer (or demux), respectively. This is a widely studied area in computer science and telecommunications in general, as it is one of the foundations of almost any type of communication media, such as telephony, radio, TV, and, of course, the Internet itself. For the scope of this book, we will not go too far with the explanations, as this is a vast topic.
What we want to demonstrate in this section is how it’s possible to use a shared Node.js stream to transmit multiple logically separated streams that are then separated again at the other end of the shared stream.
Building a remote logger
Let’s use an example to drive our discussion. We want a small program that starts a child process and redirects both its standard output and standard error to a remote server, which, in turn, saves the two streams in two separate files. So, in this case, the shared medium is a TCP connection, while the two channels to be multiplexed are the stdout and stderr of a child process. We will leverage a technique called packet switching, the same technique that is used by protocols such as IP, TCP, and UDP. Packet switching involves wrapping the data into packets, allowing us to specify various meta information that’s useful for multiplexing, routing, controlling the flow, checking for corrupted data, and so on. The protocol that we are implementing in our example is very minimalist. We wrap our data into simple packets, as illustrated in Figure 6.10:

Figure 6.10: Byte structure of the data packet for our remote logger
As shown in Figure 6.10, the packet contains the actual data, but also a header (Channel ID + Data length), which will make it possible to differentiate the data of each stream and enable the demultiplexer to route the packet to the right channel.
Client side – multiplexing
Let’s start to build our application from the client side. With a lot of creativity, we will call the module client.js. This represents the part of the application that is responsible for starting a child process and multiplexing its streams.
So, let’s start by defining the module. First, we need some dependencies:
import { fork } from 'node:child_process'
import { connect } from 'node:net'
Now, let’s implement a function that performs the multiplexing of a list of sources:
function multiplexChannels(sources, destination) {
let openChannels = sources.length
for (let i = 0; i < sources.length; i++) {
sources[i]
.on('readable', function () { // 1
let chunk
while ((chunk = this.read()) !== null) {
const outBuff = Buffer.alloc(1 + 4 + chunk.length) // 2
outBuff.writeUInt8(i, 0)
outBuff.writeUInt32BE(chunk.length, 1)
chunk.copy(outBuff, 5)
console.log(`Sending packet to channel: ${i}`)
destination.write(outBuff) // 3
}
})
.on('end', () => { // 4
if (--openChannels === 0) {
destination.end()
}
})
}
}
The multiplexChannels() function accepts the source streams to be multiplexed and the destination channel as input, and then it performs the following steps:
- For each source stream, it registers a listener for the
readableevent, where we read the data from the stream using the non-flowing mode (the use of the non-flowing mode will give us more flexibility on reading a specific number of bytes, as we get to write the demultiplexing code). - When a chunk is read, we wrap it into a packet called
outBuffthat contains, in order, 1 byte (UInt8) for the channel ID (offset 0), 4 bytes (UInt32BE) for the packet size (offset 1), and then the actual data (offset 5). - When the packet is ready, we write it into the destination stream.
- Finally, we register a listener for the
endevent so that we can terminate the destination stream when all the source streams have ended.
Our protocol is capable of multiplexing up to 256 different source streams because we have 1 byte to identify the channel. This is probably enough for most use cases, but if you need more, you can use more bytes to identify the channel.
Now, the last part of our client becomes very easy:
const socket = connect(3000, () => { // 1
const child = fork( // 2
process.argv[2],
process.argv.slice(3),
{ silent: true }
)
multiplexChannels([child.stdout, child.stderr], socket) // 3
})
In this last code fragment, we perform the following operations:
- We create a new TCP client connection to the address
localhost:3000. - We start the child process by using the first command-line argument as the path, while we provide the rest of the
process.argvarray as arguments for the child process. We specify the option{silent: true}so that the child process does not inheritstdoutandstderrof the parent. - Finally, we take
stdoutandstderrof the child process and we multiplex them into the socket’sWritablestream using themutiplexChannels()function.
Server side – demultiplexing
Now, we can take care of creating the server side of the application (server.js), where we demultiplex the streams from the remote connection and pipe them into two different files.
Let’s start by creating a function called demultiplexChannel():
import { createWriteStream } from 'node:fs'
import { createServer } from 'node:net'
function demultiplexChannel(source, destinations) {
let currentChannel = null
let currentLength = null
source
.on('readable', () => { // 1
let chunk
if (currentChannel === null) { // 2
chunk = source.read(1)
currentChannel = chunk?.readUInt8(0)
}
if (currentLength === null) { // 3
chunk = source.read(4)
currentLength = chunk?.readUInt32BE(0)
if (currentLength === null) {
return null
}
}
chunk = source.read(currentLength) // 4
if (chunk === null) {
return null
}
console.log(`Received packet from: ${currentChannel}`)
destinations[currentChannel].write(chunk) // 5
currentChannel = null
currentLength = null
})
.on('end', () => { // 6
for (const destination of destinations) {
destination.end()
}
console.log('Source channel closed')
})
}
The preceding code might look complicated, but it is not. Thanks to the features of Node.js Readable streams, we can easily implement the demultiplexing of our little protocol as follows:
- We start reading from the stream using the non-flowing mode (as you can see, now we can easily read as many bytes as we need for every part of the received message).
- First, if we have not read the channel ID yet, we try to read 1 byte from the stream and then transform it into a number.
- The next step is to read the length of the data. We need 4 bytes for that, so it’s possible (even if unlikely) that we don’t have enough data in the internal buffer, which will cause the
this.read()invocation to returnnull. In such a case, we simply interrupt the parsing and retry at the nextreadableevent. - When we can finally also read the data size, we know how much data to pull from the internal buffer, so we try to read it all. Again, if this operation returns
null, we don’t yet have all the data in the buffer, so we returnnulland retry on the nextreadableevent. - When we read all the data, we can write it to the right destination channel, making sure that we reset the
currentChannelandcurrentLengthvariables (these will be used to parse the next packet). - Lastly, we make sure to end all the destination channels when the source channel ends.
Now that we can demultiplex the source stream, let’s put our new function to work:
const server = createServer(socket => {
const stdoutStream = createWriteStream('stdout.log')
const stderrStream = createWriteStream('stderr.log')
demultiplexChannel(socket, [stdoutStream, stderrStream])
})
server.listen(3000, () => console.log('Server started'))
In the preceding code, we first start a TCP server on port 3000; then, for each connection that we receive, we create two Writable streams pointing to two different files: one for the standard output and the other for the standard error. These are our destination channels. Finally, we use demultiplexChannel() to demultiplex the socket stream into stdoutStream and stderrStream.
Running the mux/demux application
Now, we are ready to try our new mux/demux application, but first, let’s create a small Node.js program to produce some sample output:
// generate-data.js
console.log('out1')
console.log('out2')
console.error('err1')
console.log('out3')
console.error('err2')
Okay, now we are ready to try our remote logging application. First, let’s start the server:
node server.js
Then, we’ll start the client by providing the file that we want to start as a child process:
node client.js generateData.js
The client will run almost immediately, but at the end of the process, the standard input and standard output of the generate-data.js application will have traveled through one single TCP connection and been demultiplexed on the server into two separate files.
Please make a note that, as we are using child_process.fork() (nodejsdp.link/fork), our client will only be able to launch other Node.js modules.
Multiplexing and demultiplexing object streams
The example that we have just shown demonstrates how to multiplex and demultiplex a binary/text stream, but it’s worth mentioning that the same rules apply to object streams. The biggest difference is that when using objects, we already have a way to transmit the data using atomic messages (the objects), so multiplexing would be as easy as setting a channelID property in each object. Demultiplexing would simply involve reading the channelID property and routing each object toward the right destination stream.
Another pattern involving only demultiplexing is routing the data coming from a source depending on some condition. With this pattern, we can implement complex flows, such as the one shown in Figure 6.11:
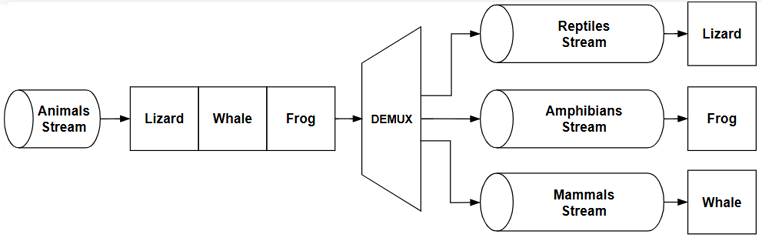
Figure 6.11: Demultiplexing an object stream
The demultiplexer used in the system in Figure 6.11 takes a stream of objects representing animals and distributes each of them to the right destination stream based on the class of the animal: reptiles, amphibians, or mammals.
Using the same principle, we can also implement an if...else statement for streams. For some inspiration, take a look at the ternary-stream package (nodejsdp.link/ternary-stream), which allows us to do exactly that.












