


















Storage technology is improving day by day, and the more storage that becomes available at a low cost, the more data appears to fill it up. Managing high volumes of data becomes impractical if we take the traditional export/import approach, as this tool is very limited. Let's remember that export/import has been available in Oracle for a very long time, it dates back to Oracle Release 5, and it has been adapted to incorporate some meaningful new features. When 10g first appeared, a complete re-engineering took place and a new product was conceived to meet today's data management requirements. It was the Data Pump.
Data Pump allows better manageability, and performance; it can be parameterized to meet particular data management requirements, such as direct export/import operations between different databases (or even different versions, starting with 10g Release 1). It can remap data object definitions, and access them by means of either a Command Line Interface(CLI) batch or interactive interface. In turn, the data pump Application Programming Interface(API) allows a programmer to embed data pump code inside a regular PL/SQL application so that it manages its own data without requiring a direct Database Administrator (DBA) or Database Owner(DBO) intervention.
Data Pump provides these features:
Better performance and more manageability than the old export/import
It is a server side tool
Resume / suspend control
Network Mode
Restartable
Fine grained object Selection
Provides a Metadata API
Oracle Data Pump is a facility available since Oracle 10g Release 1. It first appeared back in 2003. It enables high speed data and metadata transfers. It is an efficient, manageable, adaptive tool that can be used in more than one mode; namely, the regular command line interface, the suspended mode, the network mode, and the PL/SQL API mode. Besides the CLI interface, it is used by Enterprise Manager, SQL*Loader (by means of the external data pump table driver), the PL/SQL API, and other clients.
Data Pump is a productive tool designed to make the DBA's life easier. It can be easily set to a suspended mode and brought back to work wherever it was stopped. A session does not need an interactive connection to perform data management, so it can leave an unattended job and it can be resumed any time. This tool doesn't need to generate a file to transfer data in a database-to-database mode; it is the so called network mode, which is very useful when a single load is performed. When this data transfer mode is used, data does not have to be erased afterwards as there is no intermediate file created to move the data. The network mode is similar to the conventional named pipes which are used to perform data transfers on the fly; however, this traditional approach is not available on all Operating Systems(OSes) (Windows does not support named pipes). If a task is launched, even if a degree of parallelism hasn't been specified, it can be modified at run time, so resource consumption can be increased or decreased at will.
Data Pump allows high speed data movement from one database to another. The expdp command exports data and metadata to a set of OS files known as a dump file set. Compared with the traditional export/import tool set, Data Pump allows a DBA to easily clone accounts, move objects between tablespaces and change other object features at load time without being required to generate an SQL script to have the object modified, rebuilt and loaded. This kind of on-the-fly object redefinition is known as the remap feature. Data Pump performance is significantly better than that of the old export/import tools.
Data Pump provides these features:
Better performance and more manageability than the old export/import
It is a server side tool
Resume / suspend control
Network Mode
Restartable
Fine grained object Selection
Provides a Metadata API
Oracle Data Pump is a facility available since Oracle 10g Release 1. It first appeared back in 2003. It enables high speed data and metadata transfers. It is an efficient, manageable, adaptive tool that can be used in more than one mode; namely, the regular command line interface, the suspended mode, the network mode, and the PL/SQL API mode. Besides the CLI interface, it is used by Enterprise Manager, SQL*Loader (by means of the external data pump table driver), the PL/SQL API, and other clients.
Data Pump is a productive tool designed to make the DBA's life easier. It can be easily set to a suspended mode and brought back to work wherever it was stopped. A session does not need an interactive connection to perform data management, so it can leave an unattended job and it can be resumed any time. This tool doesn't need to generate a file to transfer data in a database-to-database mode; it is the so called network mode, which is very useful when a single load is performed. When this data transfer mode is used, data does not have to be erased afterwards as there is no intermediate file created to move the data. The network mode is similar to the conventional named pipes which are used to perform data transfers on the fly; however, this traditional approach is not available on all Operating Systems(OSes) (Windows does not support named pipes). If a task is launched, even if a degree of parallelism hasn't been specified, it can be modified at run time, so resource consumption can be increased or decreased at will.
Data Pump allows high speed data movement from one database to another. The expdp command exports data and metadata to a set of OS files known as a dump file set. Compared with the traditional export/import tool set, Data Pump allows a DBA to easily clone accounts, move objects between tablespaces and change other object features at load time without being required to generate an SQL script to have the object modified, rebuilt and loaded. This kind of on-the-fly object redefinition is known as the remap feature. Data Pump performance is significantly better than that of the old export/import tools.
Data Pump is a server side tool; even if it is remotely invoked, all the command actions and file generation will take place on the host where the database resides, and all directory objects refer to paths in the server. Oracle Data Pump requires a Master Table which is created in the user's schema when a Data Pump session is open. This table records the Data Pump's session status and if the job has to be stopped (either on purpose or due to an unexpected failure), the Data Pump knows where it was when it is brought back to work. This table is automatically purged once the job is finished. The master table will match the job name given, by means of the command line parameter job_name, or Oracle can choose to generate a name for it, in case this parameter hasn't been defined.

Oracle Data Pump has a master process that is responsible for orchestrating the data pump work. This master process is automatically created when either an impdp or expdp is started. Among other things, this process is responsible for populating the master table and spawning several worker processes (in case Data Pump has been directed to work in parallel mode).
Data Pump is a server side tool. In order for it to work with the remote file system it requires an access to the file by means of Oracle directory objects. On the database you must create directory objects and make sure the physical paths at the OS level are readable and writable by the oracle user. The examples provided assume a default database was created with the default oracle demo schemas; we'll be using the SCOTT, HR, SH, and OE demo schemas; when the database is created make sure the default demo accounts are selected.
Let's connect with the SYS administrative account by means of a regular SQL command line interface session, in this example the SYS user is used only for demonstration purposes, and the goal of SYS is to create the directory objects and grant privileges on these directories to the demo users. You can use any user who has been granted privileges to read and write on a directory object.
$ sqlplus / as sysdba
Let's create two directories, one for the default dump files and the other for the default log dest:
SQL> create directory default_dp_dest
2 as '/home/oracle/default_dp_dest';
SQL> create directory default_log_dest
2 as '/home/oracle/default_log_dest';
Some privileges are required for the users to have access to these oracle directories:
grant read, write on directory default_dp_dest to scott; grant read, write on directory default_dp_dest to hr; grant read, write on directory default_dp_dest to sh; grant read, write on directory default_dp_dest to oe; grant read, write on directory default_log_dest to scott; grant read, write on directory default_log_dest to hr; grant read, write on directory default_log_dest to sh; grant read, write on directory default_log_dest to oe; grant create database link to scott; grant create database link to hr, oe, sh; grant exp_full_database to scott, hr, sh, oe;
In this example, the exp_full_database privilege is granted to the demo accounts. This is done to allow the users to work on the database, but you can restrict them to only manage the data that belongs to their schemas.
Data Pump export (expdp) is the database utility used to export data, it generates a file in a proprietary format. The generated file format is not compatible with the one generated by the old export (exp) utility.
Data Pump export modes define the different operations that are performed with Data Pump. The mode is specified on the command line using the appropriate parameters. Data Pump has the following modes:
Full export mode: This mode exports the whole database; this requires the user to have the
exp_full_databaserole granted.Schema mode: This mode selects only specific schemas, all objects belonging to the listed schemas are exported. When using this mode you should be careful, if you direct a table to be exported and there are objects such as triggers which were defined using a different schema, and this schema is not explicitly selected then the objects belonging to this schema are not exported.
Table mode: The tables listed here are exported, the list of tables, partitions, and dependent objects are exported. You may export tables belonging to different schemas, but if this is the case then you must have the
exp_full_databaserole explicitly granted to be able to export tables belonging to different schemas.Tablespace mode: This mode allows you to export all tables belonging to the defined tablespace set. The tables along with the dependent objects are dumped. You must have the
exp_full_databaserole granted to be able to use this mode.Transportable tablespace mode: This mode is used to transport a tablespace to another database, this mode exports only the metadata of the objects belonging to the target set of listed tablespaces. Unlike tablespace mode, transportable tablespace mode requires that the specified tables be completely self-contained.
Data Pump Export provides different working interfaces such as:
Command line interface: The command line interface is the default and the most commonly used interface. Here the user must provide all required parameters from the OS command line.
Parameter file interface: In this mode the parameters are written in a plain text file. The user must specify the parameter file to be used for the session.
Interactive command line interface. This is not the same interactive command line most users know from the regular exp command. This interactive command line is used to manage and configure the running jobs.
Now let's start with our first simple Data Pump export session. This will show us some initial and important features of this tool.
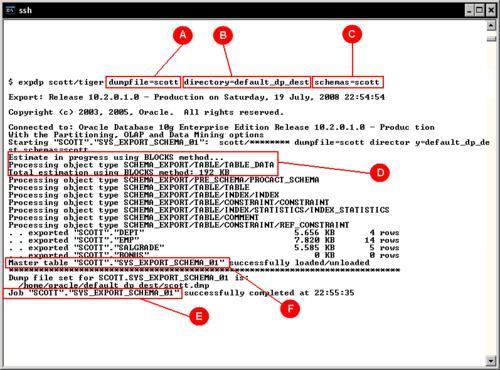
Here we will start with a basic Data Pump session to perform a simple logical backup. The command expdp has the following arguments:
Initially we define a Dumpfile(A) . As it will be managed by means of a database directory object(B) it is not necessary to define the path where the dump file will be stored. Remember, the directory objects were previously defined at the database level. This session will export a user's Schema(C) . No other parameters are defined at the command prompt and the session begins.
It can be seen from the command output that an estimation(D) takes place; this estimates the size of the file at the file system, and as no other option for the estimation was defined at the command line it is assumed the BLOCKS method will be used. The estimation by means of the BLOCKS method isn't always accurate, as it depends on the blocks sampled. Block density is a meaningful error factor for this estimation, it is better to use STATISTICS as the estimation method.
At the output log, the Master table(F) where the job running information is temporarily stored can be seen. The job name takes a default name(E) . It is a good practice to define the job name and not let Oracle define it at execution time, if a DBA names the Job, it will be easier to reference it at a later time.
At the command line, filtering options can be specified. In this example, it is used to define the tables to export, but we can also specify whether the dump file will (or will not) include all other dependent objects.
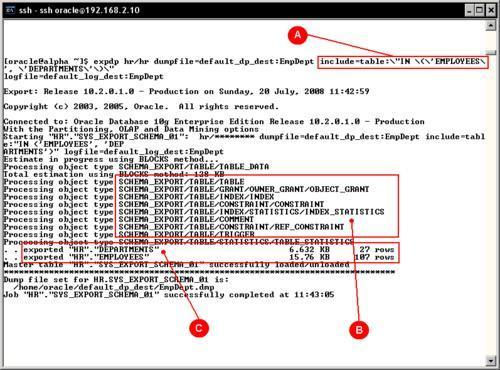
The include (A) and exclude options are mutually exclusive, and in this case as include was declared at the command line and it requires special characters, those must be escaped so the OS doesn't try to interpret them. When a longer include or exclude option is required, it is better to use a parameter file, where the escape characters are not required.
All the filtered objects (C) to be exported were saved in the dump file along with their dependent objects (B). If you change the command line with the following, it will prevent all the indexes being exported:
$ expdp hr/hr dumpfile=default_dp_dest:EmpDeptNoIndexes tables=EMPLOYEES,DEPARTMENTS exclude=INDEX:\"LIKE \'\%\'\" logfile=default_log_dest:EmpDeptNoIndexes
As can be seen, the exclude or include clause is actually a where predicate.
Using a parameter file simplifies an otherwise complex to write command line, it also allows the user to define a library of repeatable operations, even for simple exports. As previously seen, if a filtering (object or row) clause is used—some extra operating system escape characters are required. By writing the filtering clauses inside a parameter file, the command line can be greatly simplified.
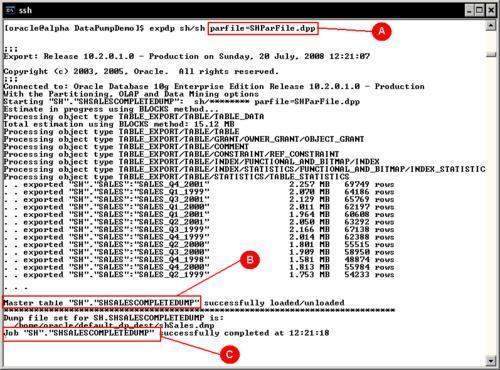
Comparing this command line (A) against the previously exposed command lines, it can be seen that it is more readable and manageable. The SHParFile.dpp file from the example contains these command options:
USERID=sh/sh DUMPFILE=shSales DIRECTORY=default_dp_dest JOB_NAME=shSalesCompleteDump TABLES=SALES LOGFILE=default_log_dest:shSales
The parameter file is a plain text format file. You may use your own naming conventions. Oracle regularly uses .par for the parameter files, in this case it used .dpp to denote a Data Pump parameter file. The file name can be dynamically defined using environment variables, but this file name formatting is beyond the scope of Oracle and it exclusively depends on the OS variable management.
JOBNAME (C) is the option to specify a non-default job name, otherwise oracle will use a name for it. It is good practice to have the job name explicitly defined so the user can ATTACH to it at a later time, and related objects such as the Master table (B) can be more easily identified.
In some circumstances, it may be useful to export the image of a table the way it existed before a change was committed. If the database is properly configured, the database flashback query facility—also integrated with dpexp—may be used. It is useful for obtaining a consistent exported table image.
In this example a copy of the original HR.EMPLOYEES table is made (HR.BAK_EMPLOYEES), and all the tasks will update the BAK_EMPLOYEES table contents. A Restore Point is created so that you can easily find out the exact time stamp when this change took place:
SQL> CREATE RESTORE POINT ORIGINAL_EMPLOYEES;
Restore point created.
SQL> SELECT SCN, NAME FROM V$RESTORE_POINT;
SCN NAME
---------- --------------------------------
621254 ORIGINAL_EMPLOYEES
SQL> SELECT SUM(SALARY) FROM EMPLOYEES;
SUM(SALARY)
-----------
691400
This is the way data was, at the referred SCN. This number will be used later, to perform the expdp operation and retrieve data as it was, at this point in time.
Next a non-reversible update on the data takes place.
SQL> UPDATE BAK_EMPLOYEES SET SALARY=SALARY*1.1;
107 rows updated.
SQL> COMMIT;
Commit complete.
SQL> SELECT SUM(SALARY) FROM BAK_EMPLOYEES
SUM(SALARY)
-----------
760540
Here we have a time reference and the goal is to restore data as it was.
Below are the contents of the data pump parameter file used to retrieve data.
USERID=hr/hr DIRECTORY=default_dp_dest DUMPFILE=hrExpAtRestorePoint JOB_NAME=hrExpAtRestorePoint TABLES=BAK_EMPLOYEES LOGFILE=default_log_dest:hrExpAtRestorePoint FLASHBACK_SCN=621254
The parameter FLASHBACK_SCN states the point in time from when the table is to be retrieved.
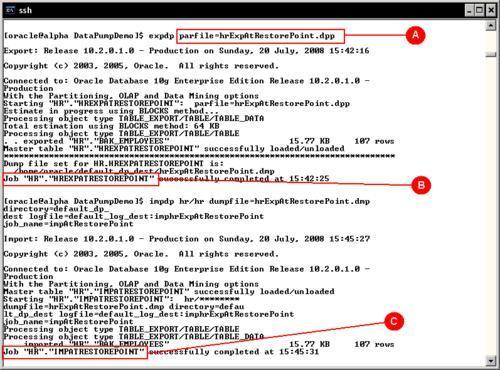
Once the backup is taken, the current table is dropped. When the import takes place it rebuilds the table with the data, as it was before. The import parameter file has been temporarily modified so it defines the log file name, and it includes only the minimum required parameters for the impdp task (C).
USERID=hr/hr DIRECTORY=default_dp_dest DUMPFILE=hrExpAtRestorePoint JOB_NAME=ImpAtRestorePoint TABLES=BAK_EMPLOYEES LOGFILE=default_log_dest:hrImpAtRestorePoint
Once the import job is finished, a query to the current table shows the data 'as it was', prior to the update command.
SQL> select sum(salary) from bak_employees;
SUM(SALARY)
-----------
691400
Proactively estimating the amount of space required by an export file prevents physical disk space shortages. Data Pump has two methods to estimate the space requirements: Estimation by block sampling (BLOCKS) or estimation by object statistics (STATISTICS).
ESTIMATE={BLOCKS | STATISTICS}
BLOCKS—The estimate is calculated by multiplying the number of database blocks used by the target objects times the appropriate block sizes.
STATISTICS—The estimate is calculated using statistics for each table. For this method to be as accurate as possible, all tables should have been analyzed recently.
The second method leads to more accurate results and can be performed in a more efficient way than the BLOCKS method; this method requires reliable table statistics.
It can be seen from an export execution, that space estimation is always carried out, and the default estimation method is BLOCKS. The BLOCKS method is used by default as data blocks will always be present at the table, while the presence of reliable statistics cannot be taken for granted. From performance and accuracy perspectives it is not the best choice. It takes longer to read through the whole table, scanning the data block to estimate the space required by the dump file. This method may not be accurate as it depends on the block data distribution. This means that it assumes all block data is evenly distributed throughout all the blocks, which may not be true in every case, leading to inaccurate results. If the STATISTICS keyword is used, it is faster; it only has to estimate the file size from the information already gathered by the statistics analysis processes.
Taking the export of the SH schema with the ESTIMATE_ONLY option and the option BLOCKS, the estimation may not be as accurate as the STATISTICS method. As these test results shows:
|
ESTIMATE_ONLY |
Reported Estimated Dump File Size |
|---|---|
|
BLOCKS |
15.12 MB |
|
STATISTICS |
25.52 MB |
|
ACTUAL FILE SIZE |
29.98 MB |
From the above results, it can be seen how important it is to have reliable statistics at the database tables, so any estimation performed by data pump can be as accurate as possible.
Data Pump export is an exporting method that is faster than the old exp utility. Export speed can between 15 and 45 times faster than the conventional export utility. This is because the original export utility uses only conventional mode inserts, whereas Data Pump export uses the direct path method of loading, but in order for it to reach the maximum possible speed it is important to perform the parallel operations on spindles other than those where the database is located. There should be enough I/O bandwidth for the export operation to take advantage of the dump file multiplexing feature.
The options used to generate an export dump in parallel with multiplexed dump files are:
USERID=sh/sh DUMPFILE=shParallelExp01%u,shParallelExp02%u DIRECTORY=default_dp_dest JOB_NAME=shParallelExp TABLES=SALES LOGFILE=default_log_dest:shParallelExp ESTIMATE=statistics PARALLEL=4
Notice the %u flag, which will append a two digit suffix to the Data Pump file. These options will direct export data pump to generate four dump files which will be accessed in a round robin fashion, so they get uniformly filled.
The resulting export dump files are:
shParallelExp0101.dmp shParallelExp0102.dmp shParallelExp0201.dmp shParallelExp0202.dmp
Data Pump allows data transfers among different Oracle versions that support the feature. (Note the feature was introduced in Oracle Database 10g Release. 1). The database must be configured for compatibility of 9.2.0 or higher. This feature simplifies data transfer tasks. In order for this to work it is important to consider the source version versus the destination version. It works in an ascending compatible mode, so a Data Pump export taken from a lower release can always be read by the higher release, but an export taken from a higher release must be taken with the VERSION parameter declaring the compatibility mode. This parameter can either take the value of COMPATIBLE (default) which equals the compatible instance parameter value, LATEST, which equals the metadata version or any valid database version greater than 9.2.0. This last statement doesn't mean Data Pump can be imported on a 9.2.0 database. Rather, it stands for the recently migrated 10g databases which still hold the compatible instance parameter value set to 9.2.0.
If the COMPATIBLE parameter is not declared an export taken from a higher release won't be read by a lower release and a run time error will be displayed.
When performing data transfers among different database versions, you should be aware of the Data Pump compatibility matrix:
Data Pump client and server compatibility:
|
|
10.1.0.X |
10.2.0.X |
11.1.0.X |
|---|---|---|---|
|
10.1.0.X |
Supported |
Supported |
Supported |
|
10.2.0.X |
NO |
Supported |
Supported |
|
11.1.0.X |
NO |
NO |
Supported |
Each Oracle version produces a different Data Pump file version, when performing expdp/impdp operations using different Data Pump file versions you should be aware of the file version compatibility.
|
Version Data Pump Dumpfile Set |
Written by database with compatibility |
Can be imported into Target | ||
|---|---|---|---|---|
|
10.1.0.X |
10.2.0.X |
11.1.0.X | ||
|
0.1 |
10.1.X |
Supported |
Supported |
Supported |
|
1.1 |
10.2.X |
No |
Supported |
Supported |
|
2.1 |
11.1.X |
No |
No |
Supported |
Data Pump is meant to work as a batch utility, but it also has a prompt mode, which is known as the interactive mode. It should be emphasized that the data pump interactive mode is conceptually different from the old interactive export/import mode. In this release, the interactive mode doesn't interfere with the currently running job, it is used to control some parameter of the running job, such as the degree of parallelism, kill the running job, or resume job execution in case of a temporary stop due to lack of disk space.
In order for the user to ATTACH to a running job in interactive mode, the user must issue the Ctrl-C keystroke sequence from an attached client. If the user is running on a terminal different from the one where the job is running, it is still possible to attach to the running job by means of the explicit ATTACH parameter. It is because of this feature that it is useful to not let Oracle define the job name.
Once attached there are several commands that can be issued from the open Data Pump prompt:
|
Command |
Description (Default) |
|---|---|
|
|
Return to logging mode. Job will be re-started if idle |
|
|
Quit client session and leave the job running |
|
|
Summarize interactive commands |
|
|
Detach and delete job |
|
|
Change the number of active workers for current job |
|
|
Start/resume current job. |
|
|
Frequency (seconds) job status is to be monitored where the default (0) will show new status when available |
|
|
Orderly shutdown of job execution and exits the client. |
In this scenario the expdp
Command Line Interface (CLI) is accessed to manage a running job. First a simple session is started using the command:
expdp system/oracle dumpfile=alphaFull directory=default_dp_dest full=y job_name=alphaFull
The JOB_NAME parameter provides a means to quickly identify the running job.
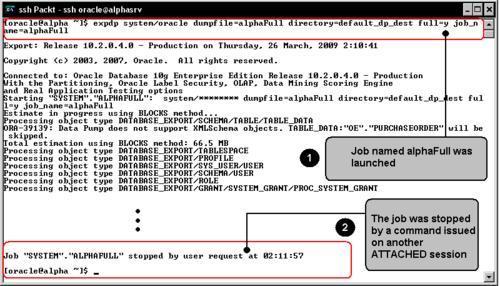
Once the job is running on a second OS session a new expdp command instance is started, this time using the ATTACH command. This will open a prompt that will allow the user to manage the running job.
expdp system/oracle attach=alphaFull
After showing the job status it enters the prompt mode where the user can issue the previously listed commands.
In this case a STOP_JOB command has been issued. This notifies the running session that the command execution has been stopped, the job output is stopped and the OS prompt is displayed. After a while the user reattaches to the running job, this time the START_JOB command is issued, this resumes the job activity, but as the expdp session was exited no more command output is displayed. The only way the user can realize the job is running is by querying the DBA_DATAPUMP_JOBS view or by browsing the log file contents.
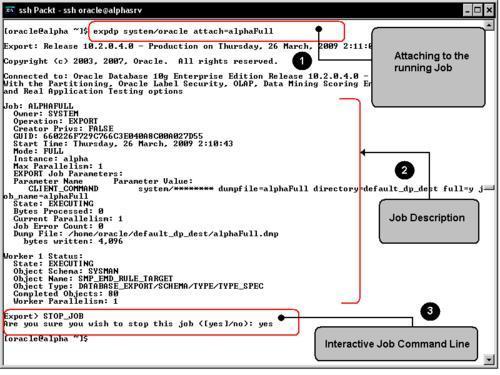
In case of failure or any other circumstances that prevent the Data Pump job from successfully ending its work, an implicit recommencing feature is activated. The job enters a suspended mode that allows the DBA to attach this feature to the job. It is important to emphasize that the master job table must positively identify the interrupted job, otherwise it won't be possible to restart the job once the circumstance behind the failure has been properly corrected.
In order for the user to attach to the job, it must be connected with the ATTACH command line option properly set. At this point, it becomes evident why it is a good practice to have a name for the data pump job, other than the default system generated name.
When a Data Pump task takes place, it can be monitored to find out if everything is running fine with it. A view named DBA_DATAPUMP_JOBS can be queried to check the task status.
SQL> select * from dba_datapump_jobs;

In this query it can be seen that a FULL(C) EXPORT(B) data pump job named SYS_EXPORT_FULL_01(A) is in Executing State(D) . It is executing with a default parallel degree of 1(E) . In case of trouble, the status changes and it would be time to work with the CLI mode to ATTACH to the job and take corrective action.
Data Pump import (impdp) is the tool used to perform the data import operation, it reads the data from a file created by Data Pump export. This tool can work in different modes such as:
Full import mode: This is the default operation mode. This mode imports the entire contents of the source dump file, and you must have the
IMP_FULL_DATABASErole granted if the export operation required theEXP_FULL_DATABASErole.Schema mode: A schema import is specified using the
SCHEMASparameter. In a schema import, only objects owned by the current user are loaded. You must have theIMP_FULL_DATABASErole in case you are planning to import schemas you don't own.Table mode: This mode specifies the tables, table partitions and the dependent objects to be imported. If the
expdpcommand required theEXP_FULL_DATABASEprivilege to generate the dump file, then you will require theIMP_FULL_DATABASEto perform the import operation.Tablespace mode: In this mode all objects contained within the specified set of tablespaces are loaded.
Transportable tablespace mode: The transportable tablespace mode imports the previously exported metadata to the target database; this allows you to plug in a set of data files to the destination database.
Network mode: This mode allows the user to perform an import operation on the fly with no intermediate dump file generated; this operation mode is useful for the one time load operations.
The Data Pump import tool provides three different interfaces:
Command Line Interface: This is the default operation mode. In this mode the user provides no further parameters once the job is started. The only way to manage or modify running parameters afterwards is by entering interactive mode from another Data Pump session.
Interactive Command Interface: This prompt is similar to the interactive
expdpprompt, this allows you to manage and modify the parameters of a running job.Parameter File Interface: This enables you to specify command-line parameters in a parameter file. The
PARFILEparameter must be specified in the command line.
One of the most interesting import data pump features is the REMAP function. This function allows the user to easily redefine how an object will be stored in the database. It allows us, amongst many other things, to specify if the tables to be loaded will be remapped against another schema (REMAP_SCHEMA). It also changes the tablespace where the segment will be stored (REMAP_TABLESPACE). In case of a full data pump import, the function can also remap where the database files will be created by means of the REMAP_DATAFILE keyword.
Let's show the REMAP_SCHEMA facility. It is common practice to have a user's schema cloned for testing or development environments. So let's assume the HR schema is to be used by a recently created HRDEV user, and it requires all the HR schema objects mapped in its schema.
Create the HRDEV user. In this case the user HRDEV is created with the RESOURCE role granted. This is only for demonstration purposes, you should only grant the minimum required privileges for your production users.
SQL> create user HRDEV ident
2 identified by ORACLE
3 default tablespace USERS;
User created.
SQL> grant CONNECT, RESOURCE to HRDEV;
Grant succeeded.
Export the HR Schema objects using the following command:
$ expdp system/oracle schemas=HR dumpfile=DEFAULT_DP_DEST:hrSchema logfile=DEFAULT_LOG_DEST:hrSchema

Import the HR Schema objects and remap them to the HRDEV user's schema. Using the following command:
$ impdp system/oracle \
dumpfile=DEFAULT_DP_DEST:hrSchema \
logfile=DEFAULT_LOG_DEST:hrSchema \ REMAP_SCHEMA=HR:HRDEV
The import session runs as follows:

The HRDEV schema automatically inherits, by means of a cloning process (REMAP_SCHEMA), 35 objects from the HR schema, which includes tables, views, sequences, triggers, procedures, and indexes.
One of the most interesting data pump features is the network mode, which allows a database to receive the data directly from the source without generating an intermediate dump file. This is convenient as it saves space and allows a networked pipeline communication between the source and the destination database.
The network import mode is started when the parameter NETWORK_LINK is added to the impdp command, this parameter references a valid database link that points to the source database. This link is used to perform the connection with a valid user against the source database. A simple CREATE DATABASE LINK command is required to setup the source database link at the target database.

.It can be seen that the import operation takes place at the 11g database; meanwhile the export is taken from a 10g Release 1 database by network mode using a database link created on the 11g side. This example is a classical data migration from a lower to a higher version using a one-time export operation.
The source database is 10.1.0.5.0 (A), and the destination database version is 11.1.0.6.0 (C). There is a database link named db10gR1 (B) on the 11g database. In order for this export to work it is important to consider version compatibility. In network mode the source database must be an equal or lower version than the destination database, and the database link can be either public, fixed user, or connected user, but not current user. Another restriction of the data pump network mode is the filtering option; only full tables can be transferred, not partial table contents.
At the target site a new database link is created:
CREATE DATABASE LINK DB10GR1 CONNECT TO <username> IDENTIFIED BY <password> using <TNSAlias>;
This alias is used at import time:
impdp <username>/<password> network_link=<DBLink> tables=<List of Tables to Import> logfile=<Directory Object>:file_name
The network import mode provides a practical approach for one-time data transfers. It is convenient and reduces the intermediate file management that is usually required.
There are some considerations the user should pay attention, in order to take full advantage of this tool. When performing a data pump export operation it can perform faster if using parallelism, but if this is not used properly, the process may end up serializing, which is very likely to happen if the dump files are written to the same disk location.
When performing a data pump import operation, we should consider the same parallelism issue. If using an enterprise edition, the degree of parallelism can be set and can be tuned so that there will be several parallel processes carrying out the import process. It is advisable to ensure the number of processes does not exceed twice the number of available CPU's.
Also, the tablespace features are important. The tablespace should be locally managed with Automatic Segment Space Management(ASSM); this will allow the insert process to perform faster.
Other features that should be considered are related to database block checking. Both db_block_ckecking and db_block_checksum impose a performance penalty. It has been reported by some users that this penalty is meaningful when batch loading takes place. It is advisable to either disable these parameters or reduce the emphasis. Those instance parameters are dynamic, so they can be modified during the operation.
Other instance parameters to consider are those related to parallelism, the parallel_max_servers, and parallel_execution_message_size. When using parallelism, the large_pool_size region should be properly configured.
The Data Pump API allows the PL/SQL programmer to gain access to the data pump facility from inside PL/SQL code. All the features are available, so an export/import operation can be coded inside a stored procedure, thus allowing applications to perform their own programmed logical exports.
The stored program unit that leverages the data pump power is DBMS_DATAPUMP.
This code shows a simple export data pump job programmed with the DBMS_DATAPUMP API.
This sample code required the DBMS_DATAPUMP program units to perform the following tasks:
FUNCTION OPEN
PROCEDURE ADD_FILE
PROCEDURE METADATA_FILTER
PROCEDURE START_JOB
PROCEDURE DETACH
PROCEDURE STOP_JOB
The account used in the next example is used merely for demonstration purposes. In a practical scenario you can use any user that has the execute privilege granted on the DBMS_DATAPUMP package and the appropriate privileges on the working directories and target objects.
conn / as sysdba
set serveroutput on
DECLARE
dp_id NUMBER; -- job id
BEGIN
-- Defining an export DP job name and scope
dp_id := dbms_datapump.open('EXPORT','SCHEMA',NULL,'DP_API_EXP_DEMO','COMPATIBLE');
-- Adding the dump file
dbms_datapump.add_file(dp_id, 'shSchemaAPIDemo.dmp', 'DEFAULT_DP_DEST',
filetype => DBMS_DATAPUMP.KU$_FILE_TYPE_DUMP_FILE);
-- Adding the log file
dbms_datapump.add_file(dp_id, 'shSchemaAPIDemo.log', 'DEFAULT_LOG_DEST',
filetype => DBMS_DATAPUMP.KU$_FILE_TYPE_LOG_FILE);
-- Specifying schema to export
dbms_datapump.metadata_filter(dp_id, 'SCHEMA_EXPR', 'IN (''SH'')');
-- Once defined, the job starts
dbms_datapump.start_job(dp_id);
-- Once the jobs has been started, the session is dettached. Progress can be monitored from dbms_datapump.get_status.
-- in case it is required, the job can be attached by means of the dbms_datapump.attach() function.
-- Detaching the Job, it will continue to work in background.
dbms_output.put_line('Detaching Job, it will run in background');
dbms_datapump.detach(dp_id);
-- In case an error is raise, the exception
-- is captured and processed.
EXCEPTION
WHEN OTHERS THEN
dbms_datapump.stop_job(dp_id);
END;
/
'The features described so far are valid in both 10g and 11g, but there are specific features available only in 11g such as:
Compression
Encrypted dump file sets
Enhancements for Data Pump external table management
Support for XML data types
The compression feature in 10g is related to the metadata, not the actual data part of the dump files. With 11g, this feature was improved to allow either the metadata, the row data or the complete dump file set to be compressed. This shrinks the dump file set by 10 to 15 percent.
In 11g it is possible to use the encrypted dump file sets feature to have the dump set encrypted. Data Pump in 11g includes other keywords to manage encryption, such as ENCRYPTION_ALGORITHM, and ENCRYPTION_MODE which requires the Transparent Data Encryption(TDE) feature to perform the encryption process. This feature will be addressed in more depth in the security chapter
In 10g, when a row in an external table was corrupted, it led to the entire process being aborted. Data Pump 11g is more tolerant under these circumstances, allowing the process to continue with the rest of the data.
With this feature, it is possible to move just one partition or sub partition between databases without having the need to move the whole table. A partition can be added as part of an existing table or as an independent table.
Data Pump is one of the least known and under-exploited data management tools in Oracle, in part due to the widely used regular export/import utility. Most user's are used to the old tool and as the data pump export dump file is not compatible with the old utilities, there is a point of no return when starting to use the Data Pump utility. However, when the user gets acquainted with the Data Pump features and feels more comfortable using this alternative for regular data management processes, they will notice how productivity and manageability improve.
Data Pump allows more flexible data management scenarios than its predecessor, the regular export/import utilities. Once the power of Data Pump is deployed by the user on the DBA's day-to-day tasks, Data Pump will automatically be positioned as the de-facto data management tool. It is available in all Oracle editions starting from 10g Release 1. Getting to know this tool allows the DBA to plan much more flexible scenarios.
In the next chapter another useful data management tool will be addressed, SQL*Loader, a tool that is used to perform plain file loads to the database.
