


















 Download code from GitHub
Download code from GitHub
Testing and Designing Tests
In the Preface section, we mentioned three levels of testing – checking the obvious, testing intensely (which might never end), and, finally, looking at testing as a risk management activity. We’ll start with the obvious, demonstrate the forever, and then talk about the ways to look at testing as risk management – that is, how can we spend a little time now to save time and money and avoid frustrated users and damaged reputations later? To do that, we must select a few of the most powerful test ideas, with a bias toward the most important parts of the software, and then determine something of meaning from them. Risk management also includes a variety of techniques with some overlap, so that if one approach fails to find a problem, others might succeed. We’ll cover that in Part 2 of this book.
These ideas apply to both unit and customer-facing tests; they also apply to the specialized testing that we’ll discuss in Chapter 5. To start, the examples will be customer-facing, only because we find that the most approachable to the widest audience.
This chapter will focus on the following areas:
- Understanding and explaining the impossibility of complete testing
- Learning and developing the theory of error to find defects
- Understand how a real-time unscripted test session might run
- How to perform unscripted testing
- Creating test ideas, including boundaries, equivalence classes, and the pairwise approach to testing
- Understanding other methods, such as model-driven, soak, and soap opera, as well as other alternative test approaches
Jumping into testing
Let’s start with the happy path. This refers to the primary path and/or workflow that the software developers intend for the application to follow to do its work or provide its results. To do that, we’ll look at a web application that will take some text as input and tell the user if the text is a palindrome or not. Feel free to play along at https://www.xndev.com/palindrome. (This exercise is free and open to the public. It was proposed at WhatDat, the Workshop on Teaching Test Design, an Excelon Event, in 2016, with initial code by Justin Rohrman and Paul Harju).
For our purposes, a palindrome is a word that is the same both forward and backward. Thus, bob is a palindrome, while robert is not, because robert spelled backward is trebor. To determine if the text is a palindrome or not, we can create a very simple application with one input, one button, and one output. This user interface can be seen in Figure 1.1. Here, the user has typed in bob, clicked SUBMIT, and the answer came back as Yes! bob reversed is bob:

Figure 1.1 – The palindrome problem
The happy path test here is the process where we type in bob and we see that it is a palindrome. We then check the same for robert, see that it is not, and then declare the testing done. After dozens of times running this exercise for job interviews, we have seen veteran testers stop at the happy path and declare victory perhaps 10% of the time. These are people with years of experience on their resumes.
Most people can come up with the happy path; it may be where we get the idea that testing is easy. The focus of this book is doing better. To do that, we need to open our eyes to all the possible risks, and then figure out how to reduce them.
The impossibility of complete testing
Let’s say for a moment you are hired by a company that is implementing palindrome software. The Executive Vice President (EVP) for new business explains that the software represents a huge contract with the Teachers Union of Canada, the first of many. As such, there must be no risk within the product. None. To make sure there is no risk, the software must be tested completely.
What is the EVP asking for?
Let’s see just how many risks a palindrome has, starting with the first test that is not completely obvious: uppercase letters. We’ll start by typing a capital B for Bob in the text box and clicking SUBMIT (https://www.xndev.com/palindrome).
This run of the code tells us that Bob is not a palindrome, because Bob is not the same as boB. To someone with a writing background, this might be a bug, because it bugs them. However, to the programmer who wrote the software, the feature is working as designed. All the software does is reverse the thing and compare it, and it shows that Bob and boB are different. This is an especially interesting bug because the programmer and some customers disagree on what the software should do. This type of problem can be addressed earlier through communication and conversation – finding a bug like this so far along means fixing the code and retesting. Possibly, it also means a long series of discussions, arguments, and conflict, ending in no change. Once the end customer sees the software, the team might face another set of arguments. Getting involved earlier and working together to create a shared understanding of what the software should do are helpful things. We’ll touch on them in Part 3, Practicing Politics. For now, our focus is testing, and the product owner was convinced that the simple reversal comparison was good enough.
Speaking of testing, if you run the software on a mobile device such as a phone or tablet, the first letter of the word is capitalized. To make most palindromes work, the user has to downshift the first letter every time. This might be a bug. And certainly, mobile devices should be tested. This means duplicating every test in four platforms, including Chrome, Firefox, Safari (Mac), or Edge (Windows) for each of the five devices, including laptop, tablet, and perhaps three or four different phones, which makes it five combinations in each of the Linux, Mac, and PC ecosystems (three combinations). This means you don’t run one test – you run 60 (4*5*3). An argument can be made that the underlying technology of these is norming, so there is much less risk. Yet once you see the combinatorics problem in one place, you’ll see it everywhere – for example, with versions of the Android operating system and mobile devices.
Meanwhile, we’ve barely scratched the surface of palindromes. An experienced tester will, at the very least, test spaces (if you do, you’ll find multiple spaces at the front or back are truncated) and special characters such as !@#$%^&*()<>,/?[]{}\|; they are likely to test embedding special characters that might have meaning under the hood, such as database code (SQL), JavaScript, and raw HTML. An open question is how the browser handles long strings. One way to test this is to go to Project Gutenberg (https://www.gutenberg.org/, an online library of free electronic books, or eBooks, most of which are in the public domain), find a large bit of text, then search for a string reversal tool online. Next, you can add the first string to the reversed second one and run it. A good open question is, How large a string should the code accept?
Strings are collections of text. At the time of writing, when you google classic palindrome sentence, the first search results include the following:
- Mr. Owl ate my metal worm
- Do geese see God?
- Was it a car or a cat I saw?
All of these will fail in the palindrome converter because they are not the same forward and backward. A literature review will find that a palindrome sentence is allowed to have capitalization, punctuation, and spaces that are ignored on reversal.
Did anyone else notice the Anagram section at the bottom of the page shown in Figure 1.1? All that functionality is part of the next release. Anyone testing it is told to “not test it” and “not worry about it” because it is part of the next release. Yet unless the tester explicitly reminds the team, that untested code will go out in the next build!
We could also check all these browsers and devices to see if they resize appropriately. We haven’t considered the new challenges of mobile devices, such as heat, power, loss of network while working, or running while low on memory. If you are not exhausted yet, consider one more: just because a test passes once does not mean it will pass the next time. This could be because of a memory leak or a programmer optimization. As a young programmer, Matt once wrote a joke into a tool called the document repository, where there was a 1% chance it would rename itself on load, picking a random thesaurus entry for document and one for repository. A graphic designer, offended by the term Archive Swag Bag, insisted Matt change it. He replied, “Just click refresh.” While the story was based on a joke from the game Wizardry V, it did happen. This kind of problem does happen in software – for example, in projects that store frequently used data and have a longer lookup for rare data. Errors can happen when the data is read from longer-term storage and when it is written out, and when those happen can be unpredictable.
Now, consider that this is the code for the palindrome that is doing all the heavy lifting:
original = document.getElementById("originalWord").value;
var palindrome = original.split("").reverse().join("");
if ( original === palindrome) {
document.getElementById("palindromeResult").innerHTML = "Yes! " + original + " reversed is " + palindrome;
} else {
document.getElementById("palindromeResult").innerHTML = "No! " + original + " reserved is " + palindrome;
} All these tests are for one textbox, one button, six lines of code, and one output. Most software projects are considerably more complex than this, and that additional complexity adds more combinations. In many cases, if we double the size of the code, we don’t double the number of possible tests; we square the number of possible tests.
Given an essentially unlimited input space and an unlimited number of ways to walk through a dynamic application, and that the same test repeated a second time could always yield different results, we run into a problem: complete testing is impossible.
Note
One of our earlier reviewers, Dr Lee Hawkins, argues that we haven’t quite made our point that complete testing is impossible. So, here’s mathematical proof:
1. We must consider that the coverage of our input space is a function, such as f(x)
2. A demonstration of f(n) does not demonstrate that f(n+1) is correct
3. A complex test would test from f(orig) to f(∞)
4. If f(n) does not imply f(n+1), proof by induction is impossible
5. If the input space goes to f(∞), or infinity, dynamic testing is impossible
Thus, complete testing is impossible.
As complete testing is impossible, we are still tasked with finding out the status of the software anyway. Some experts, people we respect as peers, say this cannot be done. All testing can do is find errors. The best a tester can say is, “The software appeared to perform under some very specific conditions at some specific point in time.”
Like happy path testing, anyone can do and say that. It might technically be true, but it is unlikely to be seen as much more than a low-value dodge.
When Matt was a Cadet in the Civil Air Patrolin Frederick Composite Squadron, there was a scroll that hung on a nail in the cadet office. This is what it said:
That is what we are tasked to do: the impossible for the (often) ungrateful. By this, we mean that we must find the most powerful tests that reveal the most information about the software under test and then figure out what information the tests reveal.
Part of doing that is figuring out for ourselves, in our project, where the bugs come from so that we can find them in their lair with minimal effort.
If you aren’t convinced yet, well, we ran out of room – but consider the number of combinations of possible tests in a calculator. Now, consider if the calculator might have a small memory leak, and try to detect that leak with tests. Complete testing is impossible. Say it again: complete testing is impossible.
Before we move on to a theory of error, we hope you’ve explored the software yourself and have a list of bugs to write up. Save them and use Chapter 5 to practice writing them up. Our favorite defect is likely HTML injection; you can use an IMG tag or HR tag to embed HTML in the page.
Toward a theory of error
When people talk about bugs in software, they tend to have one root cause in mind – the programmer screwed up. The palindrome problem demonstrates a few types of a much wider theory of error. A few of these are as follows:
- Missed requirement: It would be really easy to do an operation I logically want to do… but there is no button for it.
- Unintended consequences of interactions between two or more requirements: On the Mars rover project, one input took meters and the other yards. Those measurements are close, but they don’t work for astrophysics.
- Common failure modes of the platform: On a mobile app, losing internet signal or a draining battery is suddenly a much bigger deal.
- Vague or unclear requirements: “The input device” could be a keyboard, a mouse, or a Nintendo Wii controller.
- Clear but incorrect requirements: “Yes, we said it should do that. Now that we’ve seen it, we don’t like it.”
- Missed implicit requirements: Everyone just knows that the (F)ile menu should be the first in an editing program, with (N)ew immediately below that and (C)lose at the bottom.
- Programmer error: This is the one we understand and tend to assume.
- The software doesn’t match customer expectations: Imagine building and testing the Anagram function as if it were written for elementary English teachers to use with students, when in fact it was for extremely picky Scrabble players – or the other way around. This might bug someone, or a group large enough to matter. Thus requirements and specifications are less what the software will do, and more a generally shared agreement as to what the software should do, made at some point in time.
Even this quick, sloppy list is much wider and deeper than the idea of the simple happy path of testing the obvious. The list is sloppy by design. Instead of presenting it as final, we suggest that, over time, testers build their own lists. More important than the list are the things in the list, and the weights attached to them – that is, the percentage of effort that corresponds to each category of error. Once you have a list and have gone past the happy path and requirements-driven approaches, you can create scenarios that drive the software to where these failures might be. Those are tests.
The list of categories, what is in them, and their weights will change over time as you find more bugs, and as the technical staff, product, and platform change. Our goal with this book is to accelerate that learning process for you and provide ideas that help you develop those powerful test ideas.
Testing software – an example
There are plenty of books that say the person doing the testing should be involved up-front. Our example will go the other way. In this example, the software engineering group does not create the “consistent, correct, complete, clear” requirements that are idealized. Their requirements did not decompose nicely into stories that have clear acceptance criteria that can be objectively evaluated. The stories did not have a “kick-off” meeting where the developers, the person doing testing, and the product owner got together to build a shared mental model.
Instead, someone plunked us down at a keyboard and said, “Test this.” As an example, we can use the old Grand Rapids Airport Parking Calculator, which, at the time of writing, Markus Gärtner has copied and placed on his website at https://www.shino.de/parkcalc/. Looking at the following figure; it is a piece of software that allows you to predict the cost of your airport parking:
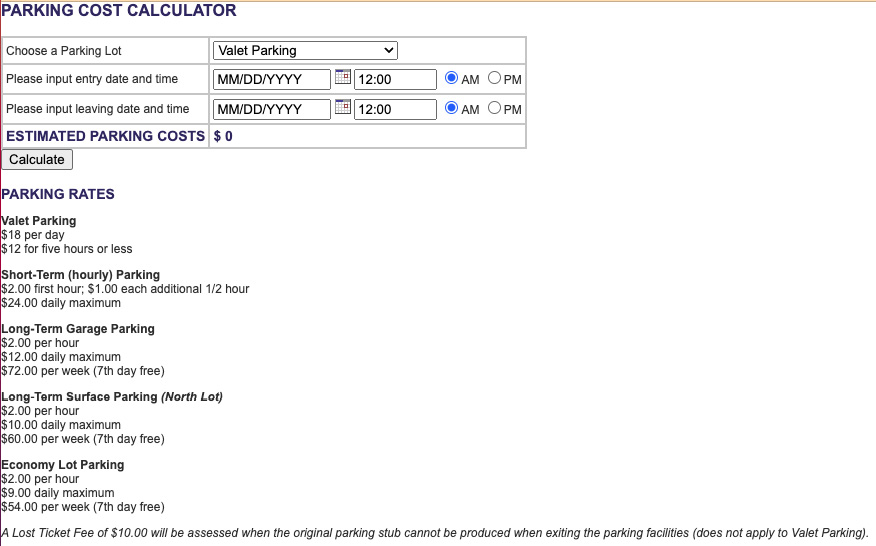
Figure 1.2 – ParcCalc from Markus’s website
The techniques we are about to list have been quickly determined and are rapid-fire, with questions to learn how they behave under different conditions. This thinking applies to unit tests, specialized tests, application programming interface (API) tests, and other risk management approaches. As Matt tested ParkCalc seriously for the first time in years, he wrote down what he was thinking and doing; you could look at it almost like a chess game that was documented for your benefit.
During testing, he was asking questions about the software, as an attorney might ask a suspect under examination in court. The answers led him to the next question. Instead of trying to build the software up, as a programmer does, he was trying to figure out what makes it work, a different style of thought. This thinking can apply to requirements, the API’s performance, or accessibility.
Start of test notes
This is a little more complex than a palindrome – more inputs, more outputs, and many more equivalence classes, which are categories to break things into that “should” be treated the same. We might hypothesize, for example, that the difference between 10/1/2024 at 1:05 P.M. and 10/1/2024 at 1:07 P.M. is not worth testing. This shrinks the number of potential tests a bit as we can test one thing for the “bucket” of, say, 1 minute to 59 minutes. Boundary values point out that the errors tend to be around the transitions – at 59 minutes, 60, or 61. This happens when a programmer types, for example, less than (<); in this case, they should type less than or equal to (<=). These are sometimes called off-by-one errors. Unit tests, which we’ll explore later, can radically decrease how often these sorts of errors occur. For now, though, we don’t know if the programmers wrote unit tests.
When we run these sorts of simulations, it’s common for the person performing the test to want to get the customer involved, to get some sort of customer feedback, or to try some sort of mind-meld with the product owner. These approaches can be incredibly powerful, and we’ll discuss them in this book, particularly in the Agile testing section. For now, however, we’ll strip everything down to the raw bug hunt. This is unfair for many reasons. After all, how can you assess if the software is “good enough” if no one tells you what “good enough” means?
And yet we press on...
In this example, we have a single screen and a single interaction. Later in this book, in Chapter 9, we’ll talk about how to measure how well the software is tested when it is more complex. For now, the thing to do is “dive in.” The place to dive in with no other information is likely the user interface. When Markus created the page, he did us the great favor of adding requirements in the text below the buttons. Note those requirements hinge on “choose a parking lot,” which is the first drop-down element:
|
A software tester walks into a bar: They run into it They crawl into it. They dance into it They fly into it They jump into it |
The tester orders: A beer 2 beers 0 beers 999,999,999 beers A goldfish in a beer glass (test: water or beer?) -1 beer A “qwerty” beers |
The tester declares that testing is complete |
A real customer walks into the bar and asks where the bathroom is The bar goes up in flames |
Table 1.1 – A tester’s view of the world
Faced with an interface like this, I tend to interleave two ideas: using the software while overwhelming the input fields with invalid, blank, out-of-range, or nonsensical data. This provides a quick and shallow assessment. The tradeoff here is coverage (checking all the combinations) with speed (getting fast results).
So, when I tested it at the time of writing, these tests looked like this:
|
Test Number |
Type |
Date Start |
Date End |
Time Start |
Time End |
Expected |
|
1 |
Valet |
7/29/22 |
7/29/22 |
2:00 P.M. |
3:00 P.M. |
$12.00 |
|
2 |
Valet |
7/22/22 |
7/22/22 |
2:00 P.M. |
7:00 P.M. |
$12.00 |
|
3 |
Valet |
7/22/22 |
7/22/22 |
2:00 P.M. |
7:01 P.M. |
$18.00 |
Table 1.2 – Valet parking test examples
You can build a similar table like this for your tests:
|
Test Number |
Type |
Date Start |
Date End |
Time Start |
Time End |
Expected |
|
4 |
Valet |
7/29/22 |
7/29/22 |
2:00 P.M. |
2:59 P.M. |
$12.00 |
Table 1.3 – Sample table for your own tests
Now, we find a second issue. After we return to the main page, the drop box defaults back to Valet. This means the correct dollar amount shows, but it looks to the reader like it was selected for valet parking.
At this point, I started clicking the calendar to find the datetime picker:
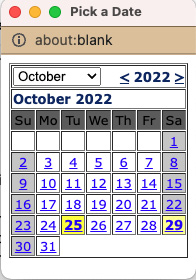
Figure 1.3 – Datetime picker
Notice that the picker says about:blank, which likely means an optional parameter for about is not populated. Beyond that, if you click away from the picker and back to the page, it gives the page focus. In older browser versions, the popup would not stay at the front focus but would stay behind the page with focus. This is fixed in current browsers. This led to testing maximizing the page and filling the entire screen.
Another bug is that, if the screen is maximized and you click the popup, it appears as a strange maximized new tab:

Figure 1.4 – Maximized new tab.The intent of this screenshot is to show the maximized layout; text readability is not required.
If you start to look at the requirements, you’ll see a lot of valid combinations for each type. We could decompose all the possibilities. When you look at that appendix, you will realize that the list is just too long. Exploring short-term just a little more yields these combinations:
30 minutes, 60 minutes, 90 minutes, 120 minutes, 121 minutes, 119 minutes 23 hours and 59 minutes, 24 hours, 24 hours and 1 minute
Leap years. Three interesting ideas to test are to see if the datetime picker realizes that 2024 contains February 29 but 2023 and 2022 do not, to see if the tool correctly realizes that February 28 to March 1 2023 is 1 day in 2023 and 2 days in 2024, and to hard-code, say, 2/29/2023 to 3/1/2023 as a date and see if the software realizes the date is in error.
While the first two scenarios work, the period from 2/29/2023 at 14:00 to 3/1/2023 at 13:59 seems to be -1 days, 23 hours, and 59 minutes. This is the same calculation as 3/1/2023 to 3/1/2023 14:00 to 13:59. The software seems to be calculating the date as days_since_something; numbers beyond the end of the month just get added on. Also, if you think about it, “-1 days PLUS 23 hours PLUS 59 minutes” is the same as 0 days, 0 hours, and -1 minutes:
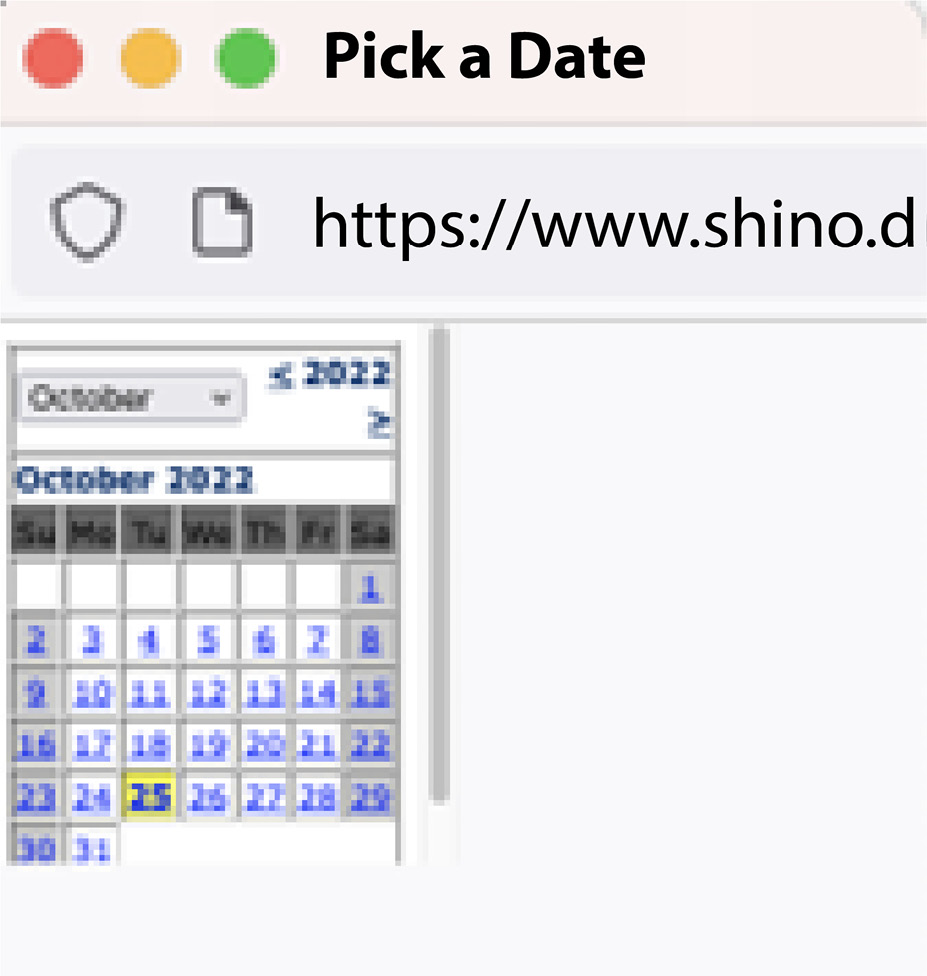
Figure 1.5 – Highlighted date picker
While this is probably a bug, exactly how the software should work is a little less clear. It might be better to print an error message, such as Departure date from parking cannot be before arrival.
My next move is to switch over to Firefox and mess with the popup. On two monitors, I see the popup appear in the center of my first monitor, apparently with fonts selected for the second. I also see the same maximize causes popup to open in a new tab problem.
Note that today’s date appears in the date picker with a yellow background. If the month has 31 days in it, then the last day is also yellow. Why we would want that, I’m not sure. I moused over the button to find the name of the JavaScript function, which is NewCal(). Then, I right-clicked and chose View source to find the web page code. Not finding a definition for NewCal in the source, I found the following include, which pointed to the JavaScript file name that might include NewCal:
<script language="JavaScript" type="text/JavaScript" src="datetimepicker.js"></script>
Looking at that code (https://www.shino.de/parkcalc/datetimepicker.js) it appears to be someone else’s custom date time picker, not anything from the operating system. Here’s the beginning of the source code:
//Javascript name: My Date Time Picker //Date created: 16-Nov-2003 23:19 //Scripter: TengYong Ng //Website: http://www.rainforestnet.com //Copyright (c) 2003 TengYong Ng //FileName: DateTimePicker.js //Version: 0.8 //Contact: contact@rainforestnet.com
This code appears to be from 2003 and likely hasn’t kept up as people started to use more monitors, smartphones, and so on. I tried the app on my iPhone and the interface was hard to read, and the date picker was even more awkward. I could have spent a great deal of time looking at this JavaScript code if I wanted to.
With no specific goals on risks or effort, the JavaScript code for DatePicker is just one of many directions I could speed off in, with no plans or governance of where to invest my time. While the things I have found so far bug me, I don’t know that the product owner would care. So, again, I’d try to find a person with the authority to make final decisions to talk about the expectations for the software and test process. This will guide my testing. If I know the decision maker just does not care about entire categories of defects, I won’t waste time testing them. Let’s say the person in charge of the product made a common reasonable decision: “Spend about an hour on a bug hunt, don’t get too focused on any one thing, and then we’ll decide what to do next.”
This statement isn’t that far-fetched. A few years ago, Matt worked with a team that had made a corporate decision not to support tablets for their web application. Of course, the customer used them anyway, to the tune of several million dollars a month and growing exponentially. Instead of saying “We don’t support tablets,” which was no longer a choice, a proposal was made to go into an empty office for a day and figure out what the largest blocking issues were. It might have been that we just needed a half-dozen bug fixes; it might have been so bad that a total rewrite was needed. Without actually using the software on a tablet, no one knew.
Timing work to an hour, it was determined that each action from the dropdown would take about 3 minutes minus 15 minutes total. That would be 15 more minutes for each platform (different browsers, different screen resolutions, different devices), then 15 minutes exploring incorrect data, and 15 minutes to double-check and document findings.
Speaking of overwhelming, the next test is to examine data that looks correct but is not. An example is short-term parking from 10/32/2022 to 11/3/2022, or valet from 12:00 P.M. to 70:00 P.M. Both of those return results that fit the mental model of how the software is performing – that is, the expectation is to convert complex dates into a simpler format and subtract them. 1:00 P.M. becomes 13:00 A.M., so the software can subtract and get elapsed time. Thus, 10/32 is the same as 11/1 and 70:00 P.M. is 10:00 P.M. plus 2 days (48 hours).
It’s time for a new test: I tried short-term, 12:00 A.M. to 13:00 A.M. The time should be 1 hour, and the rate should be $2.00. Instead, the software says $24.00, which is the day-rate maximum. Looking at the time, I can see that this is treated as 12:00 A.M. (midnight) to 1:00 P.M., or 13 hours, at $2.00 per hour, with a daily max of $24.00 – that is, 12:00 A.M. is midnight, to be followed by 12:01 A.M., with 1:00 A.M. 1 hour after midnight.
End of test notes
After a few pages of reading how I test, you’ve probably realized a few things. A lot of details have been included but nowhere near as much as was performed (this example was shortened for printing purposes and yet was still full of information). In the next section, we will break down the steps we performed and analyze how and why we performed the tests listed. Let’s examine what we accomplished here and see how we can use these techniques in our testing process.
Testing software – an analysis
First of all, note how messy the process is. Instead of planning my time, I jumped in. Planning happened about 15 minutes in, where I planned only the first hour. My style was to jump in and out, back and forth, quickly. Fundamentally, I skipped between three modes:
- Testing the user journey
- Testing for common platform errors
- Testing for invalid formats
If all of the notes had been included, you would have seen more elaboration on each dropdown, plus invalid format attacks on every field. The invalid format attacks are either data that looks correct but is out of bounds (The 50th of October), data that looks entirely wrong (a date of “HELLOMA”), or data that is blank. Another way to do this is to do things out of order: click buttons that would not be in the normal order, perhaps delete a comment on one device, and attempt to reply on another after it has been deleted.
It’s easy to dismiss these kinds of invalid data approaches as “garbage in, garbage out,” but they provide valuable information quickly. If the programmer makes small attention-to-detail errors on input, they probably make larger attention-to-detail errors in the logic of the program. As we’ll learn later, accepting invalid inputs can create security vulnerabilities.
Thus, if I find a large number of “quick attack” errors, it tells me to look more closely at the valid exception conditions in the software. Having conversations about what is valid and not with the technical staff is one way I force conversations about the requirements. For example, I can ask what the software should do under certain conditions. When the answer is, “That’s interesting. Huh. I hadn’t thought about that,” we enter the realm of defects from unintended consequences or missed expectations.
Let’s put this together to figure out how to be an airdropped tester, then step back to a few formal techniques.
Quick attacks – the airdropped tester
If you read the example that we discussed earlier, and you don’t have a background in formal documented test techniques, then it looks like I’m just goofing around, just taking a tour. Michael Kelly introduced the tour metaphor and James Whittaker wrote a book on it. If you have seen documented test cases with each step laid out, it might look more like foolishness – where is the structure, where is the planning?
With this style of testing, the results of the previous test inform the next. The first question is “What should I test first?”, after that “What did that test result tell me?”, and after that “What should I test next?” It may seem impossible, but this is exactly how strategy games such as chess are played. As the situation unfolds, the experienced player adjusts their strategy to fit what they have found. I outlined the general style previously – explore the user journey while pushing the platform to failure, and particularly pushing the inputs to failure. And, as I mentioned previously, more information about the team, platform, and history of the software will inform better tests.
On the outside, a game of chess looks like chaos. Where is the strategy? Where is the structure, the planning? Isn’t it irresponsible to not write things down?
A different aspect of the code changes each time we test it. That is different from an assembly line, where each item should be the same with the same dimensions – a quality control specialist can check every part the same way, or develop a tool to do it, perhaps by the case. With software, the risks of each build are very different. Given the limited time to test and an infinite number of possibilities, it makes sense for us to customize every test session to squeeze the most value. Later in this book, in Chapter 9, we’ll discuss how to create just enough documentation to guide and document decisions, especially for larger software. This lesson is on the airdropped tester – the person who drops in with little knowledge of the system.
Most people working in software realize they cannot do an airdropped tester role. We know because we have challenged people at conferences and run simulations. Instead, people “wiggle on the hook,” asking for documents, asking to speak to the product owner, to talk to customers. Those are all good things. The airdropped tester does it anyway, without any of that help.
After reading this entire chapter, you should be able to do something. For this section, we’ll tell you a few secrets.
First, the ignorance of being an outsider is your friend. Employees of the company, filling out the same form year after year, might know that phone numbers are to be input in a particular format, such as (888) 868 7194, but you don’t. So, you’ll try without the parentheses and get an error. We call this the consultant’s gambit: there are probably obvious problems you can’t see because of your company culture.
Here’s an example of time-and-date attacks:
Timeouts
Time Difference between Machines
Crossing Time Zones
Leap Days
Always Invalid Days (Feb 30, Sept 31)
Feb 29 in Non-Leap Years
Different Formats (June 5, 2001; 06/05/2001; 06/05/01; 06-05-01; 6/5/2001 12:34) Internationalization dd.mm.yyyy, mm/dd/yyyy
A.M/P.M. 24 Hours
Daylight Savings Changeover Reset Clock Backward or Forward
For any given input field, throw in some of these invalid dates. We’d add dates that are too early or too late, such as in ParkCalc when we tried to park a car in the past, or far in the future. Most variables are stored in an internal representation, a data type (such as an integer or a float), and these usually have a size limit. In ParkCalc, one good attack is to try the type of parking that will grow the fastest (valet) with the largest possible period to see if you can get the result to be too large. It could be too large to fit the screen, too large for the formatting tool, or too large for the internet item. Because of how they are structured, floating-point numbers are especially bad when adding numbers that contain both large and small elements. A float in C++, for example, has only 6 to 9 digits of precision. This means that storing 0.0025 is easy, as is storing 25,000, but storing 25,000.0025 will be a problem. Most programming languages these days can store at least twice as many numbers, but at the same time, a great deal of software is still built on top of older, legacy systems.
Going back to the consultant’s gambit, we typically try to change the operational use. If the programmers all use phones to edit and test their mobile applications, we’ll use a tablet – and turn it sideways. If all the work is done on at-home strong networks, we’ll take a walk in the woods on a weak cell connection. If the answer comes back that this kind of testing isn’t useful, that’s good; we’ve gone from airdropped to actually learning about the software and the customers.
After doing this professionally for over a decade, Matt has always been able to find a serious defect that would stop release within 1 day. While the team works on fixing that bug, Matt can dive into all the other important things we’ve implied, such as requirements, talking to customers, talking to the team, gathering old test documents, and so on.
Generally, business software takes input through a transformation, creating output. In our ParkCalc example, there are all sorts of hidden rules such as the seventh day free. Without those requirements on the initial splash screen, it will be very difficult to know what the correct answer should be. Moreover, there are hidden things to test (such as a 6-day stay, 7-day stay, and 8-day stay) that you don’t know to test without those requirements.
Once you’ve found the first few important bugs and the programmers are busy fixing them and have found enough documents to understand how the software should work, it’s time to analyze and create deeper test ideas.
Next, we’ll talk about designing tests to cover combinations of inputs.
Test design – input space coverage
In early elementary school, Matt wrote a little program that would take your name and echo back hello. It was in the back of computer programming magazines. Sometimes, we would do something a little cheeky; if you entered a special code, you’d get a special answer. We’ll cheat a bit and show you the relevant bits of code:
print "Enter your name " propername = gets.chomp(); if (propername == "victor") puts "Congratulations on your win!"; else puts "hello, " + propername + "\n\n"; end
Given this sort of requirement, there are two obvious tests – the top and bottom of the input statement. Type in victor, type in Matthew, see both sides execute, and we are done testing. We tend to think of this as myopic testing, or testing with blinders on – reducing the testing to the most trivial examples possible. What about Victor or VICTOR? Let’s modify the assignment, like this:
propername = gets.chomp().downcase()
That gives us at least three test ideas – Victor, victor, and Matthew. As a tester, a blank string, a really long string, and special characters – foreign languages and such – would be good parameters to test with.
You could think of this as trying to come up with test ideas, and that’s certainly true. On the other hand, what we are doing here is reducing the number of possible tests from an infinite set to a manageable set. One core idea is the equivalence class – if we’ve tested for Matt, we likely don’t need to test for Matthew, Robert, or anything else that is not “victor”-ish. Looking at the code, we likely have three equivalence classes: “victor”-ish, Matt, and “special cases”, such as really long strings, really short strings, foreign languages, emojis, and special ASCII codes. We’re a fan of char(7) – the ASCII “bell” sound.
In the old days, we would have programs that rejected non-standard character codes; we’d have to worry if the text we entered exceeded the memory allowed for that bit of text. Ruby takes care of a great deal of that for us. Many modern applications are still built on top of those old systems, where data structure size matters or appears on a phone screen with a limited amount of room. By knowing the code and programming language, we can reduce (or increase) the amount of testing we do. Another way to do that is by understanding the operational use – business customers are much less likely to paste in the newest form of emotional representative object, and, when they do, are unlikely to view their pasting of an animated picture as a fail.
Still, these three test ideas miss the point.
Notice \n\n at the end of the else statement. That is a carriage return. The output of victor looks like this:
mheusser@Matthews-MBP-2 Chapter01 % ruby TestDesign01.rb Enter your name victor Congratulations on your win! mheusser@Matthews-MBP-2 Chapter01 %
On the other hand, the output of Matt looks like this:
mheusser@Matthews-MBP-2 Chapter01 % ruby TestDesign01.rb Enter your name Matt hello, matt mheusser@Matthews-MBP-2 Chapter01 %
Those \n characters are the carriage returns. That is what a typewriter does when the author wants to finish a line and go to the next. The extra \n\n creates the extra whitespace between matt and the next line. This is an inconsistency.
You could argue that this sort of inconsistency doesn’t matter; this is a silly children’s game. Yet if you train yourself to spot the inconsistencies, you’ll notice when they do matter.
Here’s another: By down-casing the propername method, it is also printed out in lowercase. “Matt” becomes “Hello, matt.” downcase() should probably only go inside the comparison, which is the criterion that’s used for the if statement. That way, the variable printed out exactly matches what was typed in.
Thus, we have Heusser’s Maxim of documented testing:
In Chapter 2, we’ll discuss why we are not excited about test cases, and other ways to plan, visualize, and think about testing. It would be fair to write down a list of inputs and expected results, especially in later examples when the software becomes more complex. The problem comes when we fixate on one thing (the if statement’s correctness) instead of the entire application. This becomes especially true after the programmers give fixes; it is too easy to re-test just the fix, instead of elements around the fix. Get four, five, six, or seven builds that aren’t quite good enough and you can get tester fatigue. Each build can lead to less and less testing. When this happens, the “little errors”, such as the capitalization mentioned previously, can get missed. We’ll also discuss a formula for reducing these problems through programmer tests, acceptance tests (that can be automated), and human exploration.
Looking at the code, we can see another way to test – statement coverage. Statement coverage has us measure, as a percentage, the number of lines of code that are executed by the tests. We can achieve 100% statement coverage by testing matt and victor, neither of which would trip the capitalization bug. Being able to see the code and consider it is something called white box or clear box testing, while only viewing the program as it is running is sometimes called black box testing. Focusing on the code can also be myopic; it doesn’t consider resizing the window of a windowed application or if hitting the Enter key on a web form will click the submit button. Looking at coverage from a clear box can be helpful, and we’ll cover it when we consider programmer-facing testing in Chapter 3.
Often, we want to come up with test ideas before the code is created, or as it is created. In those cases, the clear/black-box distinction doesn’t matter. Let’s look at a second example that is a little more complex.
To do that, we’ll build up an application, micro-feature by micro-feature, in ways that allow us to demonstrate some classic test techniques.
Equivalence classes and boundaries
In this section, we will look at a sample auto insurance premium calculation app.
Story 1 – minimal insurance application
The software is designed to calculate or quote the cost of auto insurance for potential customers in the United States. The first story drops just one input (Age), and one button (Calculate, or Submit). Here’s the breakdown of insurance costs and the screen mock-up:

Figure 1.6 – Insurance application screen
From here, we can select the age brackets and the appropriate level of coverage:
|
Age |
Cost |
|
0 to 15 |
No insurance |
|
16 to 20 |
$800 per month |
|
21 to 30 |
$600 per month |
|
30 to 40 |
$500 per month |
|
41 to 50 |
$400 per month |
|
51 to 70 |
$500 per month |
|
71 to 99 |
$700 per month |
Table 1.4 – Insurance rates based on age
Given what we’ve written so far, get a piece of paper and write down your test ideas. Recognize that every test has a cost and time is limited, so you want to run the most powerful tests as quickly as possible.
We aren’t going to propose a single “right” answer. How much time you invest in testing, and how deep you go, will depend on how much time you have, what you would rather be doing, and how comfortable you are introducing errors into the wild. What we are doing in this chapter is providing you with some techniques to come up with test ideas. Chapters 9 and 10 include ideas to help you balance risk and effort. So keep your list, finish the chapter, then review if you missed anything. For that matter, read Chapters 9 and 10 , then consider your own organizational context, try this exercise again, and compare your lists. Another option is to work with a peer to come up with two different lists and compare them.
Now let’s talk about test ideas. First of all, there is a problem with the requirements. How much do we charge a 30-year-old, again? This is a requirements error; the transition is 21-30 and 31-40. Once you get past that, you would likely ask how much to charge a 100-year-old. Assuming the company has worked out the legal problems and the answer is “error,” we can look at categories of input that should be treated the same. So, for example, if 45 “passes,” yielding a correct answer of $40, then we would not need to test 44, 46, or 47. Here’s what that looks like on a number line, where it yields eight test ideas. The numbers on top are the specific bracket numbers, while the arrows represent the test values that we can use:

Figure 1.7 – Age brackets and example numbers to test
As it turns out, this is terrible testing. The most common error when creating programs like this one is called the off-by-one error, and it looks like this:
if (age<16) puts "Unable to purchase insurance"; elsif (age>16 && age<20) puts "$600/month"; elsif (age>=20 && age<30) puts "$500/month";
The preceding code block has two errors. First, 16 is never processed because the first if is less than 16 and the second is greater than 16. 20 is processed along with the people leading up to 20, instead of with 16 to 20, where it should be. Including (or failing to include) the equals sign when using greater/less than can lead to errors around the boundaries. Errors in boundaries can also creep in when boundaries are calculated. For example, if we input Fahrenheit and then convert it into Celsius, a round-off error could miscalculate freezing or boiling by just enough that 100 degrees Celsius calculates to 99.999 Celsius. This is “not boiling.” In the same case, a print statement might truncate 99.999 and print “99” when it should round to 100. We also see these kinds of errors in loops, when a loop is executed one time too many or one time too few.
The test examples listed are all smack dab in the middle, unlikely to trip any boundary condition. So, let’s try again:

Figure 1.8 - Highlighting the possible edge conditions
The preceding example has 22 conditions out of a possible 85. It combines at least four approaches:
- Equivalence classes: Right in the middle of each category. 25, 35, and 45.
- Boundaries: Around the transitions between values. 20 and 21, 40 and 41.
- Robust boundaries: One above and below a boundary condition. 19, 22, 39, 42, and so on.
- Magic numbers: Once we’ve tested 100, there is nothing particularly new or special about 101. Likewise, nothing special is supposed to happen between 29 and 21. Yet we added a test at 101 and another at 29. These are robust boundaries, but they are also the boundaries of big, logical numbers – remember our code example where 16 itself was missed.
In addition to these, we might wonder what would happen if the field is left blank or text is typed in, such as special characters, (how do we process 30.5?), very large numbers, and all the other unique characters we’ve talked about before, or the security things we’ll talk about later. It’s worth noting that the best fix for this is likely to put a mask on the input, so you simply cannot type in anything except whole numbers from 16 to 99.
Even with an input mask, the only way to “know” that every line is correct is to test all the values from 16 to 99. Even that does not guarantee some sort of memory leak or programmer easter egg if a certain combination is entered. Video game fans may think of test flags, such as the “Up Up Down Down Left Right Left Right B A Start” in some console games. Simple requirements techniques will fail to find these edge cases.
This example is just too simple. It is the first feature, cranked out in a week to satisfy an executive. Let’s add some spice.
Decision tables
In this section, we’ll look at our next story.
Story 2 – adding a type of insurance dropdown
It should have the following coverage:
- Comprehensive /w No Deductible 3x Cost
- Comprehensive /w Deductible 2x Cost
- Minimal Coverage 1x Cost
Here’s the user interface:

Figure 1.9 – Expanded insurance quote screen example
Notice that the UI has changed a bit; the button has now changed from Submit to Calculate, and the button does not appear to be centered. Likewise, Age and Coverage look “off.” We don’t even know if this is a Windows or Mac application, runs in a browser, or on a native mobile app. If it is for Windows, the UI does not tell us if the screen should have a minimize or medium-sized button or be resizable. None of these ideas come up when we look at the pure algorithm, yet we have both worked on projects where exact pixel position and font size mattered, so part of the testing was making sure the screen matched the exact appearance in a mockup. Matt once worked on an eCommerce web project where a mini-shopping cart, on the right-hand side, was too high. When it was moved down, the buttons were cut off!
Still, focusing on the algorithm, we have a problem. Our little number line now has two dimensions. To solve this, we can make a table and arrange the values using equivalence classes:
|
Coverage Type |
|||
|
Age |
Minimal |
Comprehensive, deductible |
Comprehensive, not deductible |
|
0-15 |
N/A |
N/A |
N/A |
|
16-20 |
800 |
1,600 |
2,400 |
|
21-30 |
600 |
1,200 |
1,800 |
|
31-40 |
500 |
1,000 |
1,500 |
|
41-50 |
400 |
800 |
1,200 |
|
51-70 |
500 |
1,000 |
1,500 |
|
71-99 |
700 |
1,400 |
2,100 |
|
100 |
NA |
N/A |
N/A |
Table 1.5 – Insurance quotes presented in equivalence classes
This is sometimes called a decision table. If every combination is one thing we “should” test, our number of combinations shoots up from 8 to 24. That gives us 100% requirements coverage and generates our test ideas to run for us. If you want to get fancy, you could put this in a web-based spreadsheet and color the cells green or red when they pass or fail – an instant dashboard!
Sadly, based on our application of boundaries, robust boundaries, and magic numbers, it’s more like 22 times 3 or 66. It still could be modeled in a table – it would just be long, ugly, and hard to test.
Don’t worry. That’s nothing – it’s about to get a lot harder.
Decision trees
In this section, we’ll consider adding a vehicle’s value.
Story 3 – adding a vehicle’s value
Users will use an offline tool (for now) to calculate the vehicle’s value, then apply the following guidelines to change the insurance quote:

Figure 1.10 – Quote percentage changes based on the cost of the vehicle
The 10% increase for a low-priced vehicle is correct as the data shows that “cheap” vehicles are more likely to be involved in accidents. At this point, our two-dimensional table fails us, and we have to move to a decision tree. Here’s one way to model that decision tree; note that it is painful and brings us to 198 possible tests if we use robust testing, or a mere 76 with “just” equivalence class testing:

Figure 1.11 – Decision tree example
But there is a bigger issue – shouldn’t the price also be tested with robust boundary conditions? Instead of seven possibilities, that’s more like 20 or a total of (22 * 3* 20) 1,320 things to test in three stories that, realistically, might take a total of 30 minutes to code.
This is a problem.
In a real organization, Matt would suggest that instead of typing in the vehicle price, we select from a dropdown. If these are true equivalence classes, we could make the code handle them equally. That’ll help… a little. Yet when Matt does training on this, he makes it harder, adding a “driving record” dropdown for speeding tickets (four choices) and a “years with no accident” dropdown (five more choices). That is 1,520 equivalence class tests; 26,400 with robust boundaries.
We call this the “combinatorics problem,” and once you look for it, it is everywhere. When Android devices were young, it was common for manufacturers to “fork” the operating system, leaving native applications to be tested hundreds of ways on top of any existing testing. The same problem came when tablets appeared, and the possible number of screen resolutions exploded. Plus, of course, there is the logic in our own code.
The earlier example is contrived. The programmers likely used a pattern where each additional requirement functioned independently of the other. A little knowledge of what goes on under the hood might allow the testers to test each requirement once, leading to a combination like this:
- All the ages tested robustly one time (22 tests)
- All the coverage types tested once (3 tests)
- All the price of the vehicle ranges tests tested once (7 tests)
- All the driving record options tested once (4 tests)
- All the years with no accident choices tested once (5 tests)
This is 41 tests. If you think about it, though, each of the ages could also be used to test one of the coverage types, one of the vehicle ranges, one of the record options, and one of the accident choices. In seven tests, we could have tested everything except for 15 of the ages. Some companies put the test combinations on the first column of a spreadsheet, the equivalence classes on the other columns, and the tests in rows, and put an X every time a combination is hit. This is called a traceability matrix. These kinds of tests are more useful when dealing with complex equipment that might take a significant time to set up, where the interaction of the components could cause unexpected errors. It could also happen if the preceding program were coded in a naive way by someone using a great deal of if statements and a cut-and-paste coding style. As a tester, identifying where the real risk is, and what we can afford to skip, is a significant part of the job.
So, what do you do when there are just too many combinations? We can use a technique that allows us to make a more manageable set of parameters by making sets of combinations, combining two variables at a time. This is referred to as all-pairs or pairwise testing.
All-pairs and pairwise testing
The giant decision tree we mentioned earlier implies that we need to test everything. After all, a specific combination of insurance, coverage, vehicle sale price, and driving record might have an error the others do not, so we need to test all 9,240 combinations (that is, the number of possible test cases if every option is tested with every other option for an exhaustive listing).
Except, of course, no one is testing that by hand. Even if we did and found, say, three bugs that only occurred in their specific circumstances, those defects would impact about 0.03% of all cases. By covering every scenario once, we run just 22 test cases; after the seventh, we can weigh the scenarios, testing the ones we think are most likely. This should provide us with pretty good coverage, right? The question is how much.
As it turns out, the USA-based National Institute of Standards and Technology (NIST) ran a study on the combinatorics problem (web.archive.org/web/20201001171643/https:/csrc.nist.gov/publications/detail/journal-article/2001/failure-modes-in-medical-device-software-an-analysis-of-15-year), first published in 2001, that discovered something interesting. According to the study, 66% percent of defects in a medical device could be found through testing all the possible pairs, or two-way combinations between components, 99% could be found through all three-way interactions, and 100% through all four-way interactions. Here’s the relevant table from that study, from their 2004 publication in IEEE Transactions:

Table 1.6 – Percent of faults triggered by n-way conditions
Source: IEEE TRANSACTIONS ON SOFTWARE ENGINEERING, VOL. 30, NO. 6, JUNE 2004. Fair Use applies.
It’s an overstatement to say this set the testing world on fire, but it is fair to say this was kind of a big deal. The challenge of the day was creating test labs that had combinations of operating systems, browsers, browser versions, JavaScript enabled (or not), and so on. Mobile phones and tablets made this problem much worse. By testing pairwise, or all-pairs, it was possible to radically reduce the number of combinations. Mathematicians had done their part, developing tables to identify the pairs in a given set of interactions, called Orthogonal arrays. These were based on algorithms that could be put into code. In 2006, James Bach released a free and open all-pairs generator under the Gnu public license.
In 2009, a friend of ours, Justin Hunter, founded a company to make all-pairs generation available to everyone, easily, online, through a web browser. More than just all-pairs, Justin was interested in going the other way, to create additional coverage beyond all-pairs, to all-triples, all-quadruples, and up to six-way combinations. He called his company Hexawise (The company is now a division of Idera). It took less than 10 minutes for us to model the insurance problem in Hexawise; here is a partial screen capture of the table it generates:

Figure 1.12 – Hexawise example of testing variations
Here’s a sample of the output:

Figure 1.13 – Sample output from the Hexawise configuration
The thing that was most interesting to us was the slider, which allows you to select less than 57 all-pairs and visualize the amount of coverage. With this option, you can see the red elements and decide if they matter or whether you should change the ratings:

Figure 1.14 – Visualization of Hexawise test coverage
Like any of the test ideas in this book, when you see a new technique, it’s easy to get enamored with it and overly focus on it. This is something we call test myopia. While we have both run into testing projects where all-pairs was incredibly valuable, such as financial services and social media, after 15 years of having the tools at our disposal, we find Pairwise testing only useful some of the time. That is sort of the lesson of this book – we are climbing up Bloom’s Taxonomy – that is, this book creates knowledge (what the techniques are), comprehension (restate them in other words), and application (actually use them) before moving to analyze, synthesize, and finally evaluate – picking the best combination of test ideas to use in limited time and under conditions of uncertainty.
Pairwise testing has a place, but it isn’t a universal one and doesn’t tell us when to automate versus human test, where to stop on the “slider”, how to integrate the work with the developers, how to handle re-testing when a new feature might change existing functionality… there is a lot more to examine.
In the fourth edition of Software Testing: A Craftsman’s Approach, Matt’s old professor Dr. Paul C. Jorgensen discusses static applications (where you enter a value, a transaction runs, and an answer pops out) versus dynamic applications. In a dynamic application, such as a website, you might make a post, scroll down, make a comment, upload an image, and so on. Dr. Jorgesen concludes that all-pairs is more helpful for the former scenario. As the behavior of browsers and operating systems have standardized, cross-compiling tools have evolved, and responsive design frameworks have emerged. We also see less use of all-pairs on the test environment side.
Let’s talk about another approach to solving the combinatorics problem – that is, using high volume – along with some less popular test techniques.
High volume automated approaches
One company had a legacy system with all kinds of tweaks and problems. Users were handled differently according to rules long forgotten. Data setup could either be by creating flat text files and importing them into a database, or tweaking the database so known users looked like valid test scenarios. The system did work in batch; it would run and “pick up” new users and put them into a second data set. This kind of work is called extract, transform, load (ETL). Testing took weeks, which encouraged the organization to make many changes and test rarely. As a result, releases were infrequent, slow, and buggy.
The tech lead, Ross Beehler, had a brilliant idea. What if we had two databases where, using the previous version of the software and the current change, we ran huge files in them and compared the output? Here’s how it worked:

Figure 1.15 – A/B flow example from two databases
- First, we set up two identical source databases that are empty (A and B), along with two downstream databases that are empty (a and b).
- Next, we get a huge text file that can be used to populate the database. Our database system had export/import capabilities, so we could export from production, clean it up, and import the data in a few lines of code. That text file could contain live customer data for unregulated environments, or anonymized data if regulated. It is possible to use truly random data, but that will not have the same impact as live data. In our case, we would test a month of realistic customer data, or tens of thousands of tests, in about 3 hours.
- Run the ETL. This will iterate over the data in the database (A and B) and send the results to databases a and b. Note that B will use the second “new, changed” version of the ETL. At the end of this process, we’ll have a version of database a as it would exist from today’s program running live, and a version of database b as we are expecting to test it.
We would use the database utility to export databases a and b as text files and use a simple diff function to compare text files.
The differences between the two were interesting. We would expect to see the planned differences and no unplanned differences.
For example, early on in the process, we had a change where diagnostic code should change; we were now supporting French users, so instead of going from French to Category 999 (unsupportable), it would go to French, 6. Running for tens of thousands of users, there were now a handful of 6s. Tying those back to UserID and searching the database, all of the 6s had a country language of FR, and none of them had a country code other than FR, and that was the only change.
Of course, some very odd combination of data could trip some other change. By using a great deal of realistic customer-like data, we were able to say with some confidence that if such an error existed, we could not have tripped it in the past month of data over so many thousands of users. If management wanted more data, we could go further back, pulling older records and simulating them. This made the tradeoff of risk and effort explicit, providing management with a dial to adjust.
We find having live data in test for this type of work to be compelling. With very little work, a company can scramble birthdates, names, and important identifying codes. Due to regulations, some companies protect the data, and de-identifying data can be expensive – we’ll talk about regulated testing in Chapter 5. For now, if using live data is impossible, it’s usually possible to simulate with randomization. When the system is an event-based, dynamic system, and we generate random steps, we sometimes call this model-based testing.
Other approaches
A variety of testing methodologies can be used to help get a handle on the testing problem and approach it from a variety of angles:
- Model-driven testing: Assuming you have a dynamic system, such as the editable web pages in a wiki, with some options (new, edit, save, comment, tag a page), you could draw circles and arrows between states, then use a tool to automate the program running, recording every step. Let it run overnight, then export the result and compare it to what you expect to see.
- Soak testing: Let a system sit in a corner and run for an extended period. A tool might drive the user interface to do the same thing, over and over, to see if the 10,000th time is different than the first. You can also do this with multiple users or randomization. Once a problem does occur, though, it can be difficult to figure out the root cause.
- Data flow diagrams and control flow: This is similar to model-driven testing without randomization. The idea is to make sure we cover all the possible transitions. One easy example of this is applications where we enter information and then come back and have to re-enter it; the programmer likely did not consider that state transition.
- Soap opera testing: These are a few incredibly powerful and rare scenarios. When Matt was at the insurance company, for example, he would test a claim turned in 21 days after the event happened, where the event happened the day before the end of the plan year, the family became ineligible for service, the child turned 27 and ineligible for insurance the next day, and the bill pushed the family two dollars over their deductible for the year. He also tested “just barely rejected” scenarios and looked for the reason why. Hans Buwalda calls this soap opera testing.
- Use/abuse case testing: Use cases are a way of writing down requirements; they are how the customers will use the software. Abuse cases go the other way; they assume the customer will misuse the software and plan on what the software will do in that situation.
- Exploratory approaches: If you’ve noticed, this chapter has “bounced around” quite a bit. We introduced ideas, explored them, offered to come back to them, and provided you with more information in the notes. You might be frustrated by this approach. Still, we find the best results are exploratory. A few years ago, we would do training on this, splitting the class into three groups. The first group was given a requirements document and told to design tests. The second group was given the requirements document and a tour of the user interface, while the third group was freed from the need for a requirements document or a previous tour and could design their approach as they went. Invariably, the third group, which combined test design, execution, reporting, and learning, who had new test ideas developed out of their work, both found more bugs that were more important, but also reported higher satisfaction in the work. Even with documents telling you what to test, humans that find something odd go “off script,” and, once the bug is found, return to a different place. Thus, we’d argue that all good testing has an exploratory component, and the techniques listed here can inform and improve test approaches.
We’ll discuss other kinds of testing not directly related to functionality, such as security and load/performance, in Chapter 5.
Data and predictability – the oracle problem
Once you’ve randomly created a wiki page with a bunch of comments and tags, how do you know what the correct page should look like? In practice, you dump the text to something called wikimarkup and, as the test runs, generate what the wikimarkup should be. Another term for that is an oracle, which Dr. Cem Kaner describes (https://kaner.com/?p=190) as a tool that helps you decide whether the program passed your test:

Figure 1.16 – Example insurance app
Google’s mortgage calculator, for example, takes four inputs: Loan amount, Loan term, Interest, and Include taxes & fees, and spits out the monthly payment. It might be possible to loop through thousands of inputs and get the answers. To know they are correct, you might have someone else code up a second version of the system. Comparing the answers doesn’t prove correctness (nothing can), but it might at least demonstrate that if a mistake were made, it was reasonable to make such a mistake.
When we’ve made such automated oracles, we generally try to have them separated as much as possible. Have a second person write the oracle, someone with a different background, using a different programming language. This prevents the “made the same round-off error” sorts of mistakes. In our experience, when oracles make the same mistake as the software, there are often interpretation errors in the requirements, or elements left blank by the requirements. Truly random data will tend to help find the hidden equivalence classes in the data.
Oracles can come from anywhere. Your knowledge, dictionary spellings, the knowledge that the (E)dit menu should be to the right of (F)ile, prior experience, the specification… all of these can be oracles. Oracles can also be incorrect. Candidates who run the palindrome problem and are well-educated often cite palindrome sentences, such as, “Was it a car or a cat I saw?” and expect the spaces and punctuation to be ignored. Their oracle spots a problem, but the customer wants to just reverse the text and compare, so the sentence “should” fail.
These ideas of a fallible method to solve a problem are sometimes called heuristic. Heuristics, or, as we joke, “Heusseristics” are integral to testing because we combine a large variety of techniques and timing aspects to figure out if the software is correct.
The final problem this chapter will introduce is test data. The act of running the test generally pollutes the database the test runs over. In many cases, running the test a second time will create a new and different result. Clearing out the database before each run is tempting; it is the approach we usually take for programmer’s units or micro-tests. Yet there are often problems that only occur as data builds over time. To save time, some companies like to run more than one test at the same time, or more than one tester, and these tests can step on each other. That means separating the data used in testing, tracking it, and coming up with a strategy to optimize between simple/repeating and powerful/longer-running can make or break a test effort. We’ll come back to test data in Chapter 7.
Summary
In this chapter, we explained how complete testing is impossible, then showed a handful of ways to come up with a few powerful tests. We discussed a few ways of looking at testing but haven’t looked at user interfaces in depth. Once you find your domain, you’ll want to dive deep into it. There is a great deal more to testing than we could cover in this chapter, which just gives a feel for the depth of the work, plus some approaches worth considering.
While we touched on the idea of user interfaces, it is Michael Hunter and his 32-page treatise testing Windows applications, You Are Not Done Yet, that hits on how to test Windows applications. As he was at Microsoft working on systems that would be used by hundreds of millions of people with a higher cost to ship updates, we found reproducing his work here beyond our scope.
In the next chapter, we will discuss how to use tools to help us.
Further reading
To learn more about the topics that were covered in this chapter, take a look at the following resources:
- Pairwise Testing: A Best Practice That Isn’t, by James Bach.
- Software Testing: A Craftsman’s Approach. 4th Edition, CRC Publications: https://www.oreilly.com/library/view/software-testing-4th/9781466560680/.
- Use Soap Opera Testing to Twist Real-Life Stories into Test Ideas, by Hans Buwalda: https://www.agileconnection.com/sites/default/files/presentation/file/2018/W11_14.pdf.
- The Oracle Problem and the Teaching of Software Testing, Cem Kaner: https://kaner.com/?p=190.
- A PDF version of You Are Not Done Yet is available at https://www.thebraidytester.com/downloads/YouAreNotDoneYet.pdf).
- You can download the Allpairs generator from https://www.satisfice.com/download/allpairs. There is a command line (MS-DOS-like) version that is a
.exefile and also a script written in Perl that runs on most Unix machines, including Mac. - James also teamed up with Danny Faught on PerlClip, which generates structured test data: https://www.agileconnection.com/sites/default/files/magazine/file/2012/XDD9687filelistfilename1_0.pdf.
