



















 Download code from GitHub
Download code from GitHub
Natural Language Understanding, Related Technologies, and Natural Language Applications
Natural language, in the form of both speech and writing, is how we communicate with other people. The ability to communicate with others using natural language is an important part of what makes us full members of our communities. The first words of young children are universally celebrated. Understanding natural language usually appears effortless, unless something goes wrong. When we have difficulty using language, either because of illness, injury, or just by being in a foreign country, it brings home how important language is in our lives.
In this chapter, we will describe natural language and the kinds of useful results that can be obtained from processing it. We will also situate natural language processing (NLP) within the ecosystem of related conversational AI technologies. We will discuss where natural language occurs (documents, speech, free text fields of databases, etc.), talk about specific natural languages (English, Chinese, Spanish, etc.), and describe the technology of NLP, introducing Python for NLP.
The following topics will be covered in this chapter:
- Understanding the basics of natural language
- Global considerations
- The relationship between conversational AI and NLP
- Exploring interactive applications
- Exploring non-interactive applications
- A look ahead – Python for NLP
Learning these topics will give you a general understanding of the field of NLP. You will learn what it can be used for, how it is related to other conversational AI topics, and the kinds of problems it can address. You will also learn about the many potential benefits of NLP applications for both end users and organizations.
After reading this chapter, you will be prepared to identify areas of NLP technology that are applicable to problems that you’re interested in. Whether you are an entrepreneur, a developer for an organization, a student, or a researcher, you will be able to apply NLP to your specific needs.
Understanding the basics of natural language
We don’t yet have any technologies that can extract the rich meaning that humans experience when they understand natural language; however, given specific goals and applications, we will find that the current state of the art can help us achieve many practical, useful, and socially beneficial results through NLP.
Both spoken and written languages are ubiquitous and abundant. Spoken language is found in ordinary conversations between people and intelligent systems, as well as in media such as broadcasts, films, and podcasts. Written language is found on the web, in books, and in communications between people such as emails. Written language is also found in the free text fields of forms and databases that may be available online but are not indexed by search engines (the invisible web).
All of these forms of language, when analyzed, can form the basis of countless types of applications. This book will lay the basis for the fundamental analysis techniques that will enable you to make use of natural language in many different applications.
Global considerations – languages, encodings, and translations
There are thousands of natural languages, both spoken and written, in the world, although the majority of people in the world speak one of the top 10 languages, according to Babbel.com (https://www.babbel.com/en/magazine/the-10-most-spoken-languages-in-the-world). In this book, we will focus on major world languages, but it is important to be aware that different languages can raise different challenges for NLP applications. For example, the written form of Chinese does not include spaces between words, which most NLP tools use to identify words in a text. This means that to process Chinese language, additional steps beyond recognizing whitespace are necessary to separate Chinese words. This can be seen in the following example, translated by Google Translate, where there are no spaces between the Chinese words:

Figure 1.1 – Written Chinese does not separate words with spaces, unlike most Western languages
Another consideration to keep in mind is that some languages have many different forms of the same word, with different endings that provide information about its specific properties, such as the role the word plays in a sentence. If you primarily speak English, you might be used to words with very few endings. This makes it relatively easy for applications to detect multiple occurrences of the same word. However, this does not apply to all languages.
For example, in English, the word walked can be used in different contexts with the same form but different meanings, such as I walked, they walked, or she has walked, while in Spanish, the same verb (caminar) would have different forms, such as Yo caminé, ellos caminaron, or ella ha caminado. The consequence of this for NLP is that additional preprocessing steps might be required to successfully analyze text in these languages. We will discuss how to add these preprocessing steps for languages that require them in Chapter 5.
Another thing to keep in mind is that the availability and quality of processing tools can vary greatly across languages. There are generally reasonably good tools available for major world languages such as Western European and East Asian languages. However, languages with fewer than 10 million speakers or so may not have any tools, or the available tools might not be very good. This is due to factors such as the availability of training data as well as reduced commercial interest in processing these languages.
Languages with relatively few development resources are referred to as low-resourced languages. For these languages, there are not enough examples of the written language available to train large machine learning models in standard ways. There may also be very few speakers who can provide insights into how the language works. Perhaps the languages are endangered, or they are simply spoken by a small population. Techniques to develop natural language technology for these languages are actively being researched, although it may not be possible or may be prohibitively expensive to develop natural language technology for some of these languages.
Finally, many widely spoken languages do not use Roman characters, such as Chinese, Russian, Arabic, Thai, Greek, and Hindi, among many others. In dealing with languages that use non-Roman alphabets, it’s important to recognize that tools have to be able to accept different character encodings. Character encodings are used to represent the characters in different writing systems. In many cases, the functions in text processing libraries have parameters that allow developers to specify the appropriate encoding for the texts they intend to process. In selecting tools for use with languages that use non-Roman alphabets, the ability to handle the required encodings must be taken into account.
The relationship between conversational AI and NLP
Conversational artificial intelligence is the broad label for an ecosystem of cooperating technologies that enable systems to conduct spoken and text-based conversations with people. These technologies include speech recognition, NLP, dialog management, natural language generation, and text-to-speech generation. It is important to distinguish these technologies, since they are frequently confused. While this book will focus on NLP, we will briefly define the other related technologies so that we can see how they all fit together:
- Speech recognition: This is also referred to as speech-to-text or automatic speech recognition (ASR). Speech recognition is the technology that starts with spoken audio and converts it to text.
- NLP: This starts with written language and produces a structured representation that can be processed by a computer. The input written language can either be the result of speech recognition or text that was originally produced in written form. The structured format can be said to express a user’s intent or purpose.
- Dialog management: This starts with the structured output of NLP and determines how a system should react. System reactions can include such actions as providing information, playing media, or getting more information from a user in order to address their intent.
- Natural language generation: This is the process of creating textual information that expresses the dialog manager’s feedback to a user in response to their utterance.
- Text-to-speech: Based on the textural input created by the natural language generation process, the text-to-speech component generates spoken audio output when given text.
The relationships among these components are shown in the following diagram of a complete spoken dialog system. This book focuses on the NLP component. However, because many natural language applications use other components, such as speech recognition, text-to-speech, natural language generation, and dialog management, we will occasionally refer to them:

Figure 1.2 – A complete spoken dialog system
In the next two sections, we’ll summarize some important natural language applications. This will give you a taste of the potential of the technologies that will be covered in this book, and it will hopefully get you excited about the results that you can achieve with widely available tools.
Exploring interactive applications – chatbots and voice assistants
We can broadly categorize NLP applications into two categories, namely interactive applications, where the fundamental unit of analysis is most typically a conversation, and non-interactive applications, where the unit of analysis is a document or set of documents.
Interactive applications include those where a user and a system are talking or texting to each other in real time. Familiar interactive applications include chatbots and voice assistants, such as smart speakers and customer service applications. Because of their interactive nature, these applications require very fast, almost immediate, responses from a system because the user is present and waiting for a response. Users will typically not tolerate more than a couple of seconds’ delay, since this is what they’re used to when talking with other people. Another characteristic of these applications is that the user inputs are normally quite short, only a few words or a few seconds long in the case of spoken interaction. This means that analysis techniques that depend on having a large amount of text available will not work well for these applications.
An implementation of an interactive application will most likely need one or more of the other components from the preceding system diagram, in addition to NLP itself. Clearly, applications with spoken input will need speech recognition, and applications that respond to users with speech or text will require natural language generation and text-to-speech (if the system’s responses are spoken). Any application that does more than answer single questions will need some form of dialog management as well so that it can keep track of what the user has said in previous utterances, taking that information into account when interpreting later utterances.
Intent recognition is an important aspect of interactive natural language applications, which we will be discussing in detail in Chapter 9 and Chapter 14. An intent is essentially a user’s goal or purpose in making an utterance. Clearly, knowing what the user intended is central to providing the user with correct information. In addition to the intent, interactive applications normally have a requirement to also identify entities in user inputs, where entities are pieces of additional information that the system needs in order to address the user’s intent. For example, if a user says, “I want to book a flight from Boston to Philadelphia,” the intent would be make a flight reservation, and the relevant entities are the departure and destination cities. Since the travel dates are also required in order to book a flight, these are also entities. Because the user didn’t mention the travel dates in this utterance, the system should then ask the user about the dates, in a process called slot filling, which will be discussed in Chapter 8. The relationships between entities, intents, and utterances can be seen graphically in Figure 1.3:
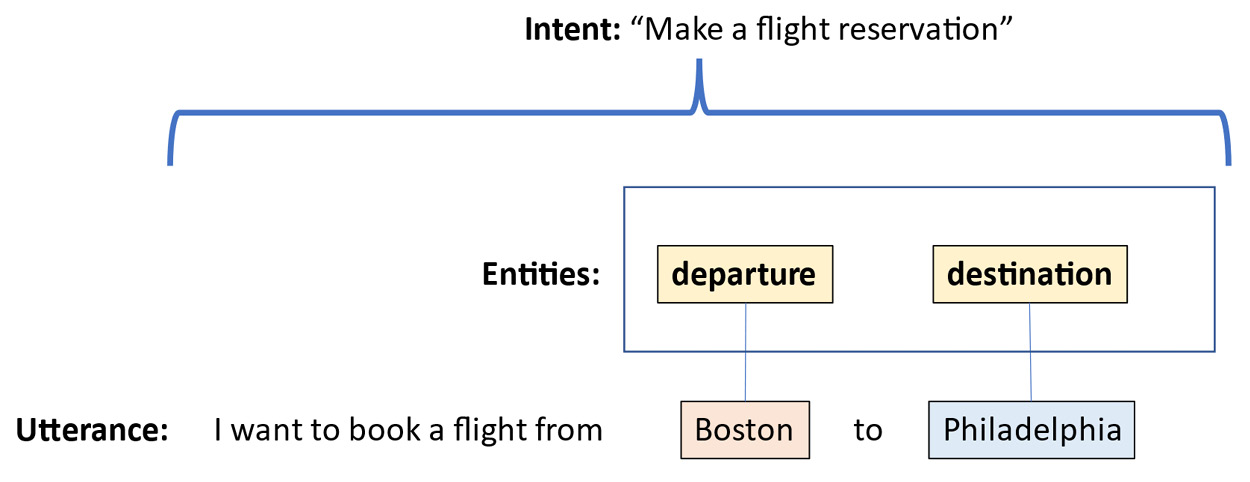
Figure 1.3 – The intent and entities for a travel planning utterance
Note that the intent applies to the overall meaning of the utterance, but the entities represent the meanings of only specific pieces of the utterance. This distinction is important because it affects the choice of machine learning techniques used to process these kinds of utterances. Chapter 9, will go into this topic in more detail.
Generic voice assistants
The generic voice assistants that are accessed through smart speakers or mobile phones, such as Amazon Alexa, Apple Siri, and Google Assistant, are familiar to most people. Generic assistants are able to provide users with general information, including sports scores, news, weather, and information about prominent public figures. They can also play music and control the home environment. Corresponding to these functions, the kinds of intents that generic assistants recognize are intents such as get weather forecast for <location>, where <location> represents an entity that helps fill out the get weather forecast intent. Similarly, “What was the score for <team name> game?” has the intent get game score, with the particular team’s name as the entity. These applications have broad but generally shallow knowledge. For the most part, their interactions with users are just based on one or, at most, a couple of related inputs – that is, for the most part, they aren’t capable of carrying on an extended conversation.
Generic voice assistants are mainly closed and proprietary. This means that there is very little scope for developers to add general capabilities to the assistant, such as adding a new language. However, in addition to the aforementioned proprietary assistants, an open source assistant called Mycroft is also available, which allows developers to add capabilities to the underlying system, not just use the tools that the platforms provide.
Enterprise assistants
In contrast to the generic voice assistants, some interactive applications have deep information about a specific company or other organization. These are enterprise assistants. They’re designed to perform tasks specific to a company, such as customer service, or to provide information about a government or educational organization. They can do things such as check the status of an order, give bank customers account information, or let utility customers find out about outages. They are often connected to extensive databases of customer or product information; consequently, based on this information, they can provide deep but mainly narrow information about their areas of expertise. For example, they can tell you whether a particular company’s products are in stock, but they don’t know the outcome of your favorite sports team’s latest game, which generic assistants are very good at.
Enterprise voice assistants are typically developed with toolkits such as the Alexa Skills Kit, Microsoft LUIS, Google Dialogflow, or Nuance Mix, although there are open source toolkits such as RASA (https://rasa.com/). These toolkits are very powerful and easy to use. They only require developers to give toolkits examples of the intents and entities that the application will need to find in users’ utterances in order to understand what they want to do.
Similarly, text-based chatbots can perform the same kinds of tasks that voice assistants perform, but they get their information from users in the form of text rather than voice. Chatbots are becoming increasingly common on websites. They can supply much of the information available on the website, but because the user can simply state what they’re interested in, they save the user from having to search through a possibly very complex website. The same toolkits that are used for voice assistants can also be used in many cases to develop text-based chatbots.
In this book, we will not spend too much time on the commercial toolkits because there is very little coding needed to create usable applications. Instead, we’ll focus on the technologies that underly the commercial toolkits, which will enable developers to implement applications without relying on commercial systems.
Translation
The third major category of an interactive application is translation. Unlike the assistants described in the previous sections, translation applications are used to assist users to communicate with other people – that is, the user isn’t having a conversation with the assistant but with another person. In effect, the applications perform the role of an interpreter. The application translates between two different human languages in order to enable two people who don’t speak a common language to talk with each other. These applications can be based on either spoken or typed input. Although spoken input is faster and more natural, if speech recognition errors (which are common) occur, this can significantly interfere with the smoothness of communication between people.
Interactive translation applications are most practical when the conversation is about simple topics such as tourist information. More complex topics – for example, business negotiations – are less likely to be successful because their complexity leads to more speech recognition and translation errors.
Education
Finally, education is an important application of interactive NLP. Language learning is probably the most natural educational application. For example, there are applications that help students converse in a new language that they’re learning. These applications have advantages over the alternative of practicing conversations with other people because applications don’t get bored, they’re consistent, and users won’t be as embarrassed if they make mistakes. Other educational applications include assisting students with learning to read, learning grammar, or tutoring in any subject.
Figure 1.4 is a graphical summary of the different kinds of interactive applications and their relationships:
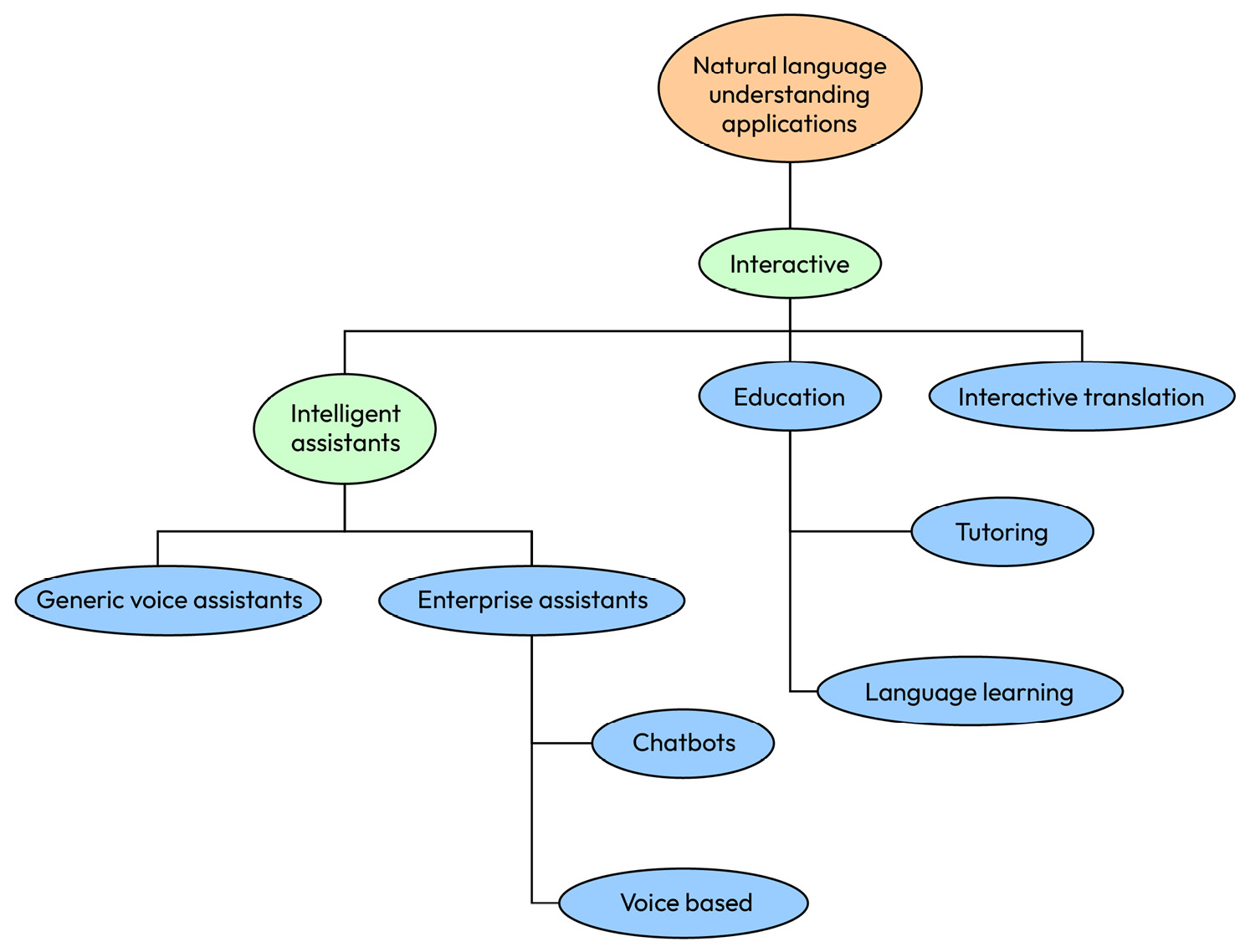
Figure 1.4 – A hierarchy of interactive applications
So far, we’ve covered interaction applications, where an end user is directly speaking to an NLP system, or typing into it, in real time. These applications are characterized by short user inputs that need quick responses. Now, we will turn to non-interactive applications, where speech or text is analyzed when there is no user present. The material to be analyzed can be arbitrarily long, but the processing time does not have to be immediate.
Exploring non-interactive applications
The other major type of natural language application is non-interactive, or offline applications. The primary work done in these applications is done by an NLP component. The other components in the preceding system diagram are not normally needed. These applications are performed on existing text, without a user being present. This means that real-time processing is not necessary because the user isn’t waiting for an answer. Similarly, the system doesn’t have to wait for the user to decide what to say so that, in many cases, processing can occur much more quickly than in the case of an interactive application.
Classification
A very important and widely used class of non-interactive natural language applications is document classification, or assigning documents to categories based on their content. Classification has been a major application area in NLP for many years and has been addressed with a wide variety of approaches.
One simple example of classification is a web application that answers customers’ frequently asked questions (FAQs) by classifying a query into one of a set of given categories and then providing answers that have been previously prepared for each category. For this application, a classification system would be a better solution than simply allowing customers to select their questions from a list because an application could sort questions into hundreds of FAQ categories automatically, saving the customer from having to scroll through a huge list of categories. Another example of an interesting classification problem is automatically assigning genres to movies – for example, based on reviews or plot summaries.
Sentiment analysis
Sentiment analysis is a specialized type of classification where the goal is to classify texts such as product reviews into those that express positive and negative sentiments. It might seem that just looking for positive or negative words would work for sentiment analysis, but in this example, we can see that despite many negative words and phrases (concern, break, problem, issues, send back, and hurt my back), the review is actually positive:
“I was concerned that this chair, although comfortable, might break before I had it for very long because the legs were so thin. This didn’t turn out to be a problem. I thought I might have to send it back. I haven’t had any issues, and it’s the one chair I have that doesn’t hurt my back.”
More sophisticated NLP techniques, taking context into account, are needed to recognize that this is a positive review. Sentiment analysis is a very valuable application because it is difficult for companies to do this manually if there are thousands of existing product reviews and new product reviews are constantly being added. Not only do companies want to see how their products are viewed by customers, but it is also very valuable for them to know how reviews of competing products compare to reviews of their own products. If there are dozens of similar products, this greatly increases the number of reviews relevant to the classification. A text classification application can automate a lot of this process. This is a very active area of investigation in the academic NLP community.
Spam and phishing detection
Spam detection is another very useful classification application, where the goal is to sort email messages into messages that the user wants to see and spam that should be discarded. This application is not only useful but also challenging because spammers are constantly trying to circumvent spam detection algorithms. This means that spam detection techniques have to evolve along with new ways of creating spam. For example, spammers often misspell keywords that might normally indicate spam by substituting the numeral 1 for the letter l, or substituting the numeral 0 for the letter o. While humans have no trouble reading words that are misspelled in this way, keywords that the computer is looking for will no longer match, so spam detection techniques must be developed to find these tricks.
Closely related to spam detection is detecting messages attempting to phish a user or get them to click on a link or open a document that will cause malware to be loaded onto their system. Spam is, in most cases, just an annoyance, but phishing is more serious, since there can be extremely destructive consequences if the user clicks on a phishing link. Any techniques that improve the detection of phishing messages will, therefore, be very beneficial.
Fake news detection
Another very important classification application is fake news detection. Fake news refers to documents that look very much like real news but contain information that isn’t factual and is intended to mislead readers. Like spam detection and phishing detection, fake news detection is challenging because people who generate fake news are actively trying to avoid detection. Detecting fake news is not only important for safeguarding reasons but also from a platform perspective, as users will begin to distrust platforms that consistently report fake news.
Document retrieval
Document retrieval is the task of finding documents that address a user’s search query. The best example of this is a routine web search of the kind most of us do many times a day. Web searches are the most well-known example of document retrieval, but document retrieval techniques are also used in finding information in any set of documents – for example, in the free-text fields of databases or forms.
Document retrieval is based on finding good matches between users’ queries and the stored documents, so analyzing both users’ queries and documents is required. Document retrieval can be implemented as a keyword search, but simple keyword searches are vulnerable to two kinds of errors. First, keywords in a query might be intended in a different sense than the matching keywords in documents. For example, if a user is looking for a new pair of glasses, thinking of eyeglasses, they don’t want to see results for drinking glasses. The other type of error is where relevant results are not found because keywords don’t match. This might happen if a user uses just the keyword glasses, and results that might have been found with the keywords spectacles or eyewear might be missed, even if the user is interested in those. Using NLP technology instead of simple keywords can help provide more precise results.
Analytics
Another important and broad area of natural language applications is analytics. Analytics is an umbrella term for NLP applications that attempt to gain insights from text, often the transcribed text from spoken interactions. A good example is looking at the transcriptions of interactions between customers and call center agents to find cases where the agent was confused by the customer’s question or provided wrong information. The results of analytics can be used in the training of call center agents. Analytics can also be used to examine social media posts to find trending topics.
Information extraction
Information extraction is a type of application where structured information, such as the kind of information that could be used to populate a database, is derived from text such as newspaper articles. Important information about an event, such as the date, time, participants, and locations, can be extracted from texts reporting news. This information is quite similar to the intents and entities discussed previously when we talked about chatbots and voice assistants, and we will find that many of the same processing techniques are relevant to both types of applications.
An extra problem that occurs in information extraction applications is named entity recognition (NER), where references to real people, organizations, and locations are recognized. In extended texts such as newspaper articles, there are often multiple ways of referring to the same individual. For example, Joe Biden might be referred to as the president, Mr. Biden, he, or even the former vice-president. In identifying references to Joe Biden, an information extraction application would also have to avoid misinterpreting a reference to Dr. Biden as a reference to Joe Biden, since that would be a reference to his wife.
Translation
Translation between languages, also known as machine translation, has been one of the most important NLP applications since the field began. Machine translation hasn’t been solved in general, but it has made enormous progress in the past few years. Familiar web applications such as Google Translate and Bing Translate usually do a very good job on text such as web pages, although there is definitely room for improvement.
Machine translation applications such as Google and Bing are less effective on other types of text, such as technical text that contains a great deal of specialized vocabulary or colloquial text of the kind that might be used between friends. According to Wikipedia (https://en.wikipedia.org/wiki/Google_Translate), Google Translate can translate 109 languages. However, it should be kept in mind that the accuracy for the less widely spoken languages is lower than that for the more commonly spoken languages, as discussed in the Global considerations section.
Summarization, authorship, correcting grammar, and other applications
Just as there are many reasons for humans to read and understand texts, there are also many applications where systems that are able to read and understand text can be helpful. Detecting plagiarism, correcting grammar, scoring student essays, and determining the authorship of texts are just a few. Summarizing long texts is also very useful, as is simplifying complex texts. Summarizing and simplifying text can also be applied when the original input is non-interactive speech, such as podcasts, YouTube videos, or broadcasts.
Figure 1.5 is a graphical summary of the discussion of non-interactive applications:
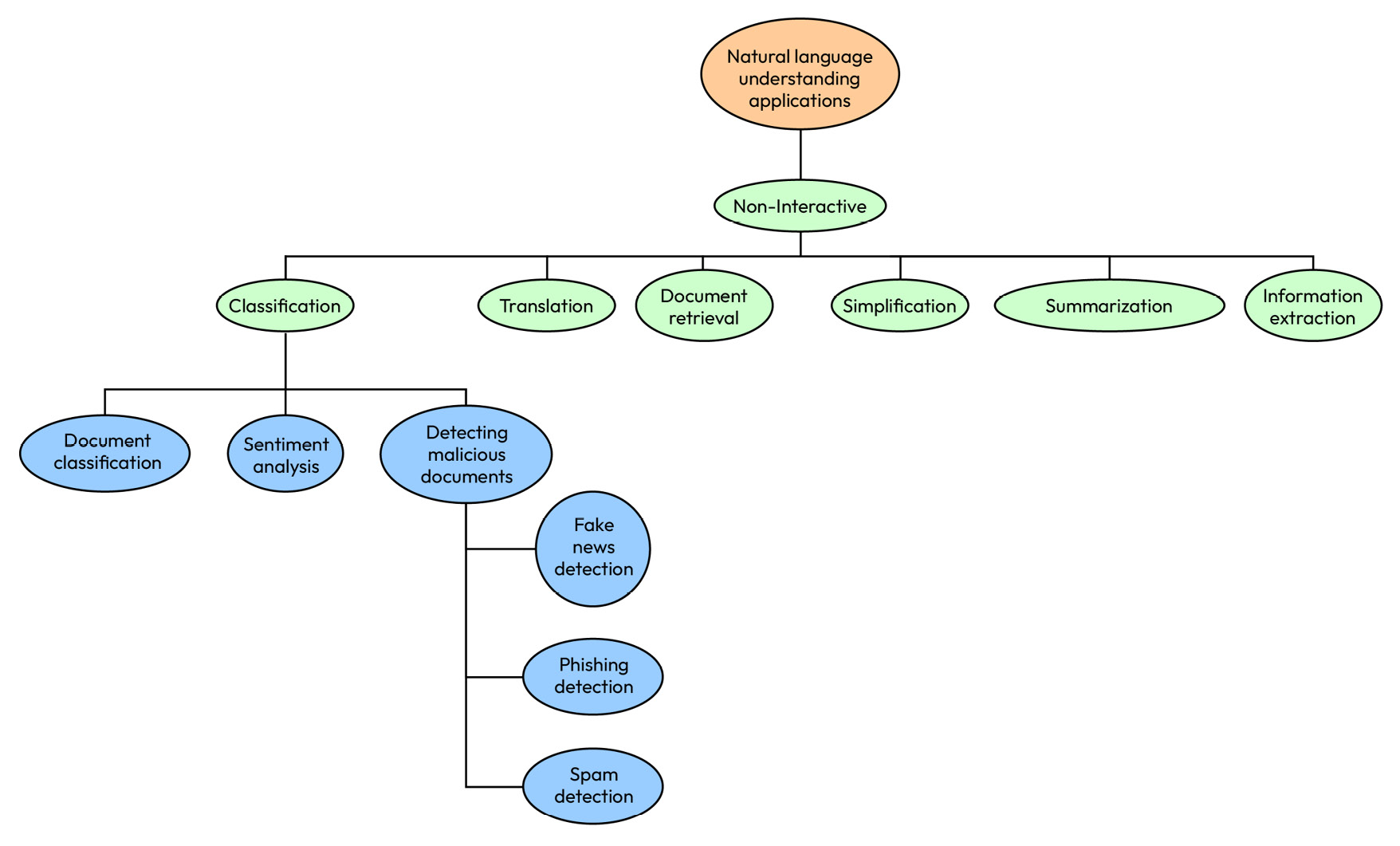
Figure 1.5 – A hierarchy of non-interactive applications
Figure 1.5 shows how the non-interactive NLP applications we’ve been discussing are related to each other. It’s clear that classification is a major application area, and we will look at it in depth in Chapter 9, Chapter 10, and Chapter 11.
A summary of the types of applications
In the previous sections, we saw how the different types of interactive and non-interactive applications we have discussed relate to each other. It is apparent that NLP can be applied to solving many different and important problems. In the rest of the book, we’ll dive into the specific techniques that are appropriate for solving different kinds of problems, and you’ll learn how to select the most effective technologies for each problem.
A look ahead – Python for NLP
Traditionally, NLP has been accomplished with a variety of computer languages, from early, special-purpose languages, such as Lisp and Prolog, to more modern languages, such as Java and now Python. Currently, Python is probably the most popular language for NLP, in part because interesting applications can be implemented relatively quickly and developers can rapidly get feedback on the results of their ideas.
Another major advantage of Python is the very large number of useful, well-tested, and well-documented Python libraries that can be applied to NLP problems. Some of these libraries are NLTK, spaCy, scikit-learn, and Keras, to name only a few. We will be exploring these libraries in detail in the chapters to come. In addition to these libraries, we will also be working with development tools such as JupyterLab. You will also find other resources such as Stack Overflow and GitHub to be extremely valuable.
Summary
In this chapter, we learned about the basics of natural language and global considerations. We also looked at the relationship between conversational AI and NLP and explored interactive and non-interactive applications.
In the next chapter, we will be covering considerations concerning selecting applications of NLP. Although there are many ways that this technology can be applied, some possible applications are too difficult for the state of the art. Other applications that seem like good applications for NLP can actually be solved by simpler technologies. In the next chapter, you will learn how to identify these.

