



















 Download code from GitHub
Download code from GitHub
The Impact of Data Quality on Organizations
Data quality is often one of the most neglected topics in organizations. It becomes part of the culture of the organization to make statements such as The data for that report comes from our CRM system – but be warned: the data quality isn’t great or Sorry, I can’t answer that question because our data just isn’t good enough to support it. How often do you hear these statements repeated month after month – and even year after year?
When data quality is neglected in this way, it impacts the following:
- The effectiveness of business and compliance processes
- The ability to make high-quality decisions from reporting
- The ability to differentiate your organization from the competition
- The reputation of the organization with customers, suppliers, and employees
Organizations cannot leverage new technologies, such as AI and ML, to get the most out of their data. Those lofty ambitions to monetize data as a product all too often must be shelved.
Poor data quality is also an invisible drain on productivity. Every employee in an organization is impacted by poor data quality in some way – whether it is a report that doesn’t include all the information they need or a business process that they can’t complete because key data is missing. Eventually, people stop reporting the issues and create new (often highly complex) processes to deliver the required outcome despite the data quality problems. The problem of data quality is often considered to be too complex and too costly to resolve – leading to people searching for ways around the problems.
Take the example of a manufacturing organization with a highly automated product master data creation process. The products needed to be extended to the various manufacturing plants and sales organizations. This was done using tables containing rules (for example, field X should contain value Y for Italy and value Z for Germany). The process of creating products took just seconds but the underlying tables of rules had not been kept up to date, so this systematically created incorrect data for three products in one country. The incorrect data was carried over into sales invoices that reached customers. The product master data had a flag that, if ticked, meant an additional charge needed to be made for packaging. This flag was incorrectly left blank for the three products. A total of more than ten thousand invoices were distributed in six weeks without the additional packaging fee. A small issue had a substantial impact!
After reporting the product data issue consistently for many weeks – with no action taken to resolve the issue – the sales team established a process to manually correct each invoice before it reached the customer. This work was so repetitive that employee attrition became an issue. This was one of a raft of similar issues within this organization that was invisibly draining away its potential.
Does this sound like a familiar story in your organization? If so, I hope that this book helps you find a path forward.
The value of this book
I realize it is never easy to find the time to read a book like this one. There are so many business books you could read to improve your performance and that of your organization. Most people have started to read a number of similar business books and never made it all the way through.
So, why invest your valuable time in this one? I hope that I will help you understand which of your data is bad, which of that data matters, how to get that data quickly from bad to good enough – and to keep it there. This is the meaning of Practical Data Quality.
The approach outlined in this book helped take an organization that had such poor data that it was literally struggling to keep the lights on in its premises, to a point where data quality was considered a strength. (This organization had such poor data that it could not get payments to its utility providers and very nearly had a power supply suspension.)
The rate of progression was high. In just weeks, data quality improvements were made for the highest priority issues. Within 6 months, an automated data quality tool was in place to identify data that did not meet business needs, and processes were in place to correct the data. After two years, data quality was fully embedded in organizational processes, with new employees given training on the topic and data quality scores close to 100% of the targets. If you follow the approach in this book and you have the right support from your organization, you should be able to achieve similar results.
Importance of executive support
I firmly believe that the approach in this book is the right one. However, even the right approach can fail without the right support from executives.
In the example organization, the support that was required was relatively easy to obtain. The situation had been so bad that the leadership team could see that data quality was a major issue that was affecting revenue, costs, and compliance matters – the three topic areas that typically capture the interest of executive boards.
The data quality team was asked to report on data quality monthly to the board and every time a concern or blocker was raised, actions were immediately defined to move them out of the way.
In most organizations, data quality issues are not so severe that their impact is plain to see right up to the executive level. The issues are well known to those on the front line of the business, but people work hard to smooth the rough edges of the data before it reaches the executives. Processes and compliance activities are impacted, but not severely enough to cause a complete breakdown that executives will become aware of. Business and IT executives often have different priorities and different languages when talking about data and data teams must often bridge these divides.
The following chapters will outline an approach that will help you surface these issues in a way that will influence executives to support data quality initiatives.
The remainder of this chapter will cover the following main topics:
- What is bad data?
- The impacts of bad data quality
- The typical causes of bad data quality
What is bad data?
The first topic is about defining what is meant by bad data. It rarely makes sense to aim for what people might consider perfect data (every record is complete, accurate, and up to date). The investment required is usually prohibitive, and the gains made for the last 1% of data quality improvement effort become far too marginal.
Detailed definition of bad data
What do I mean by bad data?
In summary, this is the point where the data no longer supports the objectives of the business. To drill into this in more detail, it is where the following occurs:
- Data issues prevent business processes from being completed in the following ways:
- Data issues mean key information is not available to support business decisions at the time it is required. This can be because of the following challenges:
- Missing or delayed information (for example, selecting products to discontinue based on profit margins, but no margins are available for key products in reporting)
- Incorrect information (for example, competitor margin is presumed to be X% but is 5% lower than this presumption in reality, due to an error in data aggregation)
- Data issues cause a compliance risk – this can be where the following occurs:
- Data does not allow the business to differentiate itself from its competitors where data is sold as a product (for example, a database of customer data) or as part of a differentiated customer experience.
Data that contributes to any of these types of issues to the point that business objectives cannot be met would be considered bad by this definition.
The level of data quality is rarely consistent across business units and locations within a company. There are usually pockets of excellence and areas where data has become a major problem. Often, the overall progress of a business toward its objectives can be seriously impacted by significant failures within just one business unit or location.
One organization I worked with had a strongly differentiated product that was achieved through great R&D and thoughtful acquisition activity. The R&D team carefully managed their data and kept the quality high enough to achieve their business objectives. The Operations team was less mature in their management of data, but their data quality issues were not severe enough to prevent them from meeting their main objectives. They still managed to produce enough of their differentiated product for the organization to predict extremely high sales growth. However, the Commercial team had inherited low-quality customer master data (heavily duplicated, incorrect, or missing shipping details primarily) from an acquisition, and some of the possible sales growth was not achieved. As part of a customer experience review, a major customer commented, “you can have the best products in the marketplace, but if it becomes hard to do business with you, it doesn’t matter.”
Bad data versus perfect data
We already mentioned that the investment to get to perfect data rarely makes economic sense. Having bad data does not make economic sense either. So, how should organizations decide on what standard of data is fit for purpose?
The answer is complex and will be covered in more depth in Chapter 6, in the Key features of data quality rules section, but in summary, you must define a threshold at which you deem the data to be fit for purpose. This is the point where the data allows you to achieve your business objectives.
The trick is to make sure that the thresholds you define are highly specific. For example, most people would consider a tax ID for a supplier to be a mandatory element of data. It is tempting to target a data quality score of 100% (in other words, every row of data is perfect) for data like this, but in reality, thinking must be much more nuanced.
In many countries, small organizations will not have a tax ID. In the UK, for example, it is optional to register for VAT until company revenue reaches £85,000 (as of 2022). This means that the field in a system that contains this data cannot be made mandatory when collecting the data. A data quality threshold has to be set at which data will be considered fit for purpose.
Note
To manage this truly effectively, you would segregate the vendors into large enterprises and smaller organizations. You would set a high threshold (for example, 95%) for large enterprises, and a much lower threshold (for example, 60%) for smaller organizations.
To get this rule perfect, you might even try to capture (or import from a source such as the Dun and Bradstreet database) the average annual revenue for the past 3 years for a supplier when adding them to your system. You would then specify a high threshold for those who had revenue over the tax registration level. This would be a time-consuming rule to create and manage because you would need to capture a lot of additional data and the thresholds would change over time. This is where judgment comes in when defining data quality rules – is the benefit you will gain on making the rule specific worth the effort to obtain/maintain the information you need?
If you are not specific enough with your targets, data may be flagged as bad inappropriately. When tasked with correcting it, your colleagues will notice false negatives and lose faith in the data quality reporting you are providing them with. In this example, a supplier is being chased for a tax ID, only to find they do not have one. These false negatives are damaging because the people involved in your data quality initiative start to feel they can ignore the data failures – it is the classic “boy who cried wolf” tale in a data quality context.
Now that we have introduced the basics of bad data, let's understand how this bad data can impact an organization.
Impact of bad data quality
In November 2018, a Gartner survey found that “Poor data quality costs organizations an average of $11.8M per year.” The same survey also found that “57% of organizations don’t know what bad data quality is costing them.”
Quantification of the impact of bad data
It is usually incredibly difficult to be this precise when thinking about the monetary impact of data quality issues. When looking at these two quotes together, there is a further curiosity. Presumably, the number of $11.8m per year comes from the 43% of organizations that did calculate what bad data quality was costing them. By implication, then, we do not get from this survey what the organizations who are not measuring this suffer in terms of losses from poor data quality. To quote Donald Rumsfeld from 2002, these organizations are operating with “unknown unknowns.”
Those that do not even measure the impact of poor data quality ironically are likely to have the worst data quality issues – they are completely ignoring the topic. It is like in education – the student who constantly worries about their test results and fears failure is usually more successful in the end than their more relaxed counterparts who rarely (if ever) bother the teacher.
The measurement also lacks sophistication. It would be helpful, for example, to understand how this number changes for large organizations and in different geographies. $11.8m is almost irrelevant for a company with tens of billions of dollars in revenue but is a make-or-break figure for more modestly sized organizations.
The other challenge with this number (which will also be discussed in Chapter 2) is that the dollar cost of data quality issues is inherently difficult to accurately and completely measure. For example, it might be possible to identify the personnel cost of the effort expended while contacting suppliers to collect missing email addresses. However, this is just one data quality issue of an unknown number. Do you really have time to identify the effort being expended on all these manual data correction activities in your company today and quantify them? What about the missed revenue from situations where a customer is impacted by poor data quality and decides not to trade with you again? Do you even know that is why they chose to stop trading with you? The reality is that there is rarely time to get holistic answers to these kinds of questions when working to get a data quality initiative off the ground. At best, illustrative examples are provided to show the known impacts of data quality. This is typically not what senior executives expect and this often means data quality initiatives fail before they can even begin.
In truth, no one knows how much bad data quality costs a company – even companies with mature data quality initiatives in place, who are measuring hundreds of data points for their quality struggle to accurately measure quantitative impact. This is often a deal-breaker for senior leaders when trying to get approval for a budget for data quality work. Data quality initiatives often seek substantial budgets and are up against projects with more tangible benefits.
At an investment board meeting in a previous organization, a project in which I was involved was seeking approval for a data quality initiative. In the same meeting, there was a project seeking approval to implement an e-invoicing solution. This was an online portal for suppliers to log onto and submit invoices electronically against purchase orders and track their payments from the company. This project had a clear business case – it was expected to reduce supplier queries about payments by 50% and allow a reduction in the number of full-time employees in that area. The board was challenging and, in the end, approved the e-invoicing project and rejected our initiative.
Six months later (and with irony that was not lost on the team), the e-invoicing project was not able to go live on time because it was identified that the supplier master data quality was too low. The go-live would have caused chaos because basic system functionality required the email and VAT fields for suppliers to be populated with a much higher level of completeness and accuracy than was available.
Both fields were in the scope of the data quality initiative, and our team had raised these concerns previously with the e-invoicing project team. The outcome was that the project had to be delayed by three months and the resources (costly consultants) had to be paid to complete the testing activities again.
What were the learnings from this experience?
Firstly, it is critical to start small. Pick one type of data (for example, customer or product data) where you know there are issues. The type of data you choose should be one where you can give tangible examples of the issues and what they mean to the company – in terms of revenue, costs, or compliance risks. Request a modest budget and show the value of what you have delivered through the issues that you have detected and resolved.
Secondly, make it part of your strategy when trying to obtain approvals to explain to key stakeholders (for example, business sponsors) why it is hard to quantify the benefits of data quality. Remember that they are used to seeing projects with quantitative business cases and they need a mindset shift before considering your data quality initiative. Meet with decision-makers individually before an approval board and make sure they understand this. Not everyone will be supportive, but in taking this approach, hopefully, enough debate is sparked to give you a better chance of approval.
Impacts of bad data in depth
We will now explore each element of our bad data definition in more depth. This section aims to outline in depth how poor data quality can affect organizations to help you look for these impacts in your own organization.
Process and efficiency impacts
Many organizations introduce SLAs for key processes – for example, 24 hours to create a new account for a new employee. These SLAs are critical because other processes are designed with an expectation that the SLA is met. For example, a hiring manager might be told that an employee can be onboarded within two weeks from the initial request. If one of the sub-processes (for example, new account creation) is delayed, this can lead to an employee arriving on site and being unable to be effective. Poor data quality can often cause SLAs to be missed. For example, if a new employee record is incorrectly assigned to an old organizational unit, the relevant approvals may not be triggered by the hiring manager and other leaders. This is surprisingly common – when re-organizations take place, legacy organizational units are often left in place.
Note
Every organization I have worked with asks for a response to a similar statement in their employee survey: “Processes at the organization allow me to be effective at work.” This statement always received the most negative response in the survey. When studying the text comments in response to this statement, I found that a significant percentage (around 30%) related to issues with data quality.
Here are further typical impacts on the organization when bad data causes SLAs to be missed:
|
Example(s) |
|
|
The impacts are diverse. They can include the following:
|
A contract is signed with a supplier to start providing a service. The supplier has been used for many contracts in the past and there are multiple versions of this supplier in the system already. Procurement has to work out which version of the supplier record to associate the contract to, and this takes 2 weeks, against an SLA of 48 hours. The supplier is not able to provide resources on time as there is no purchase order, and resources are assigned to another project. It takes a further 4 weeks for appropriately skilled staff from the supplier to become available, leading to a 6 week delay in a critical project. |
Table 1.1 - Impacts and examples of missing SLAs
When bad data quality causes issues with processes, another impact can be on the budget for running that process. The organization of teams running processes is based on a certain level of expectation for process efficiency. Often, leaders and Human Resources professionals do not check the level of data quality before establishing teams. There is an assumption that data is of high enough quality to be used in the process and there is no resourcing allowance for remedial work. When data quality is not fit for purpose, then the team may not be correctly sized, resulting in the following impacts:
|
Typical Impacts |
Example(s) |
|
The accounts payable team for one business unit discover that invoices are routinely coded to another business unit by mistake. Invoices must be manually re-coded to the correct business unit before month-end processes can start. The month-end deadline is not adjusted; therefore, the team effort level is higher. |
Table 1.2 – Impacts and examples of incorrectly sized teas
When processes are unexpectedly impacted by data quality issues, it may not be possible to rapidly augment the team. In these situations, the focus of the team running the process is split. They must manage data quality issues on top of their usual tasks:
|
Typical Impacts |
Example(s) |
|
If a team cannot be augmented, the following can occur:
|
The accounts payable team can process payments for key suppliers. Key suppliers include those who provide raw materials for manufacturing. However, utility suppliers are not included in the priority list and are not paid on time, leading to facility utility outages. Manufacturing is halted while the issue is resolved. |
Table 1.3 – Impacts and examples of poor data quality on teams that cannot be augmented
Tables 1.1, 1.2, and 1.3 provide many of the typical impacts of data quality in the area of processes and efficiency. Many of those who are impacted by these will also be impacted again when they start to use reporting and analytics.
Reporting and analytics impacts
The main purpose of reports is to provide summarized data in a way that quickly conveys relevant information to a user and allows them to make a decision or help them with their day-to-day activities. Summarizing data can often mean that end users of reports are not best placed to detect data quality issues. The more senior the stakeholder, the more difficult it is for them to detect gaps in the data because they are looking at the highest level of summarized data.
For example, the following simple column chart shows the count of road traffic collisions in the UK in 2010 (source: https://www.kaggle.com/datasets/salmankhaliq22/road-traffic-collision-dataset).
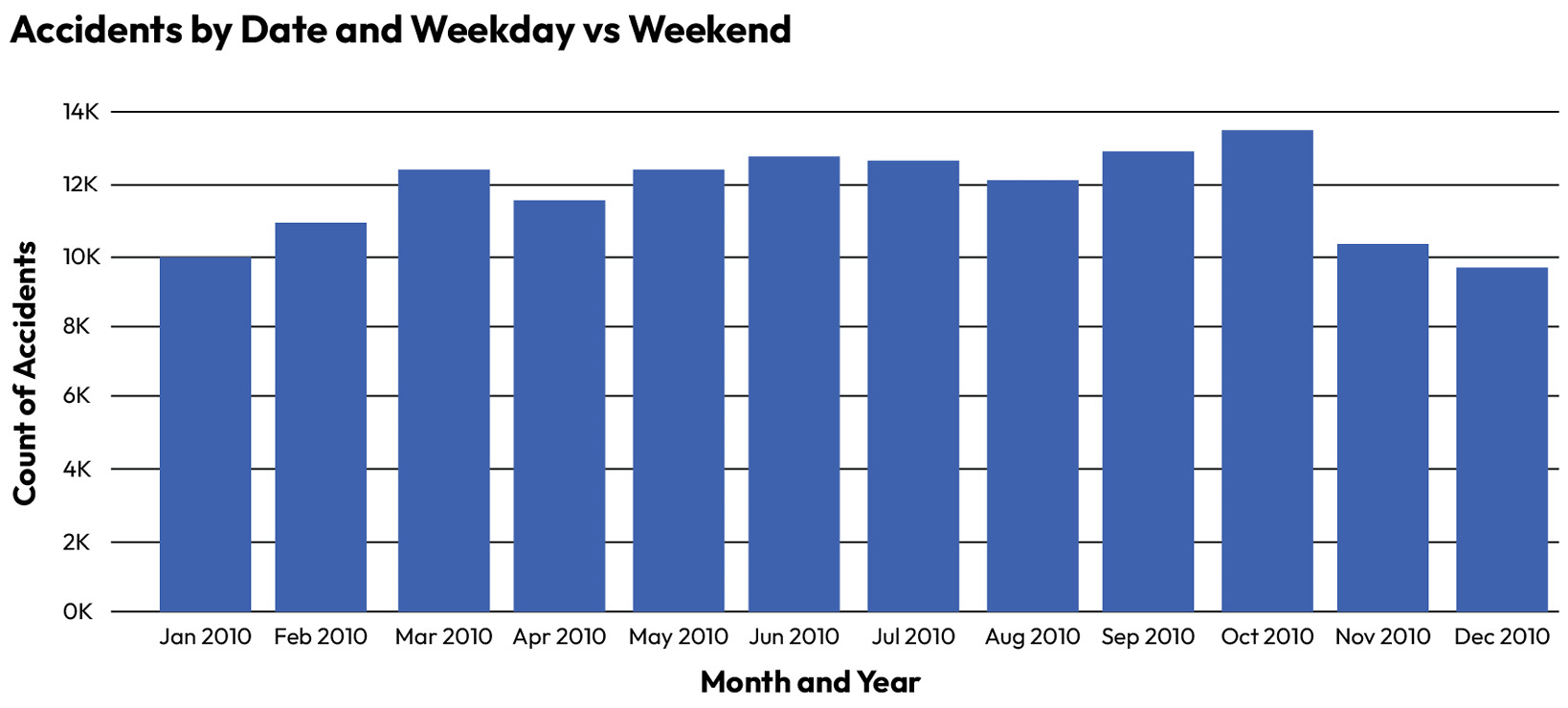
Figure 1.1 – Road traffic collision chart with missing data in November 2010
November 2010 looks like one of the best months in terms of collisions. Only December is better. However, a full week of data has been removed from November 2010 – but there is no way that the end user of this report could know that. Here is the correct chart:
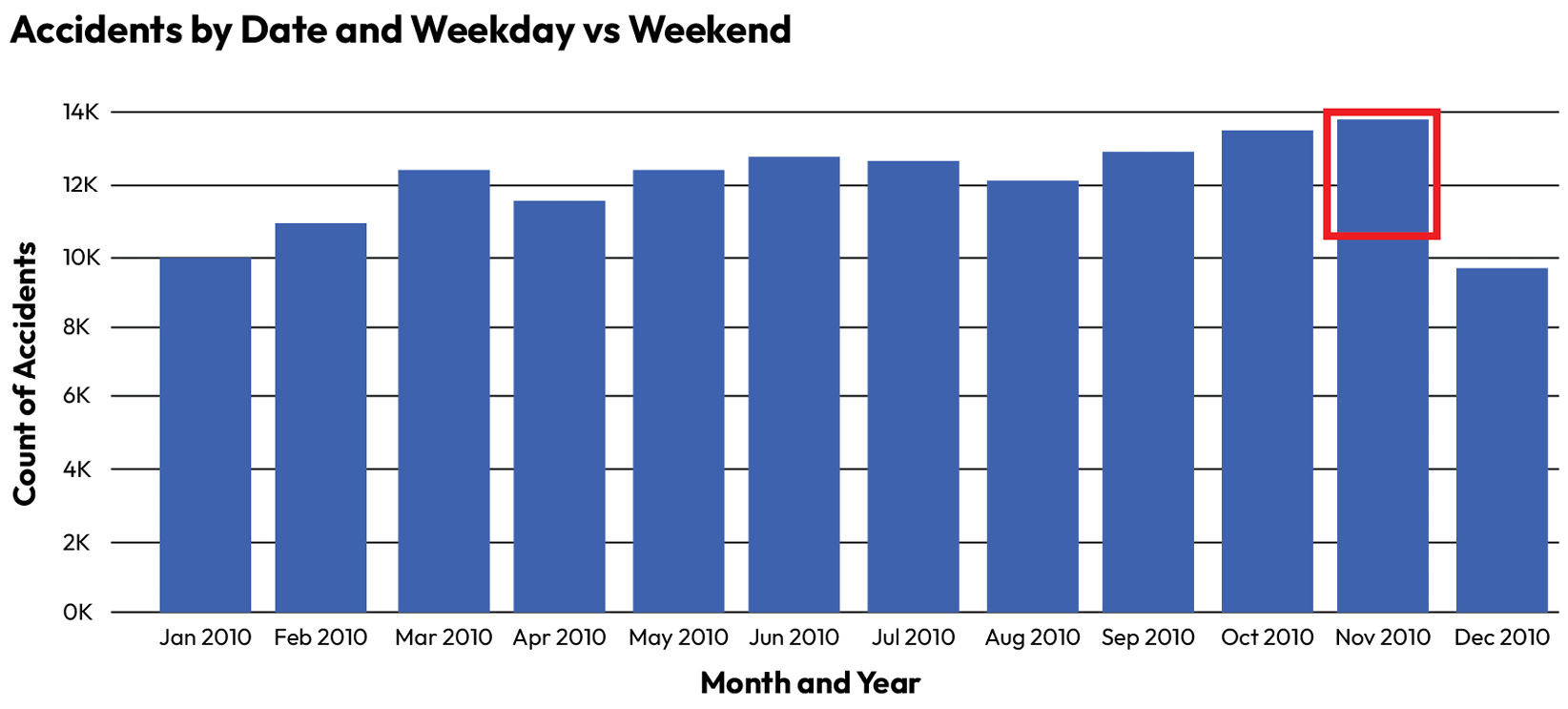
Figure 1.2 – Corrected road traffic collision chart
Here, we can see that November is actually the worst month of the year. There could be other major data quality issues in this dataset that an end user would find hard to detect – a whole region of the United Kingdom could be missing, for example. Some collisions could be misclassified into the wrong region.
All of these issues could drive incorrect decision-making. For example, the Department of Transport in the UK could decide to ban certain types of roadworks on major roads in October every year with a catch-up activity in November. In reality, this could drive a major increase in collisions in a month that is already the worst in the year.
In addition to the process and reporting impacts I've described so far, bad data can mean that an organization struggles to remain compliant with local laws and regulations. Let's explore the impacts and risks that can arise from issues with compliance.
Compliance impacts
Data quality issues can impact compliance for any organization – even those outside of regulated industries. Most companies have a financial audit every year and those with data quality issues will find that process challenging. The modern approach of external auditors is to assess internal systems, processes, and controls and, wherever possible, rely on those controls. The auditor tests that controls were in operation instead of checking the underlying records.
Historically, auditors would perform what they called a substantive audit where they would try to observe documents to support a high enough percentage of a particular number in the accounts. For example, if accounts receivable (amounts owed to the company by other companies) was £1m, the auditor would look for invoices to the total of around £600k and check that they had been properly accounted for (that is, they were unpaid at the period end). This would give them confidence about the whole balance of £1m.
In modern auditing, where controls are found to not be operating effectively, the auditor will exit from the controls-based approach and return to the substantive audit. This increases the audit fee substantially because of the time involved; it also consumes time from your internal resources. In the worst cases, auditors may actually qualify their audit opinion where there is an inability to obtain sufficient appropriate audit evidence. This qualified opinion appears in the company’s financial statements and is a huge red flag to investors.
However, companies in regulated industries have another set of challenges to face.
In Financial Services, the regulators request submissions of data in a particular taxonomy so that they can compare different financial institutions. The goal (particularly following the Lehmann Brothers collapse and resulting global financial crisis) is to ensure that institutions are being prudent enough in their lending to avoid future financial disruption. When the data is received by the regulator, it must meet stringent quality checks and submissions are frequently returned with required changes. Regulators will strengthen their oversight of an organization if they see poor practices in place. Strengthened oversight can even lead to institutions being required to retain more capital on their balance sheets (that is, reduce the amount they are lending and making a profit with!) if they lack confidence in management. Banking regulators have even introduced specific regulations for their industry about data governance. In Europe, the Basel Committee for Banking Supervision wrote a standard (BCBS 239) with the subject “Principles for effective risk data aggregation and risk reporting.” It includes principles such as “Governance, accuracy and integrity, completeness, timeliness,” and many more. See https://en.wikipedia.org/wiki/BCBS_239.
In pharmaceutical companies, medicinal products and devices are highly regulated by bodies such as the FDA in the United States and the MHRA in the United Kingdom. These regulators examine many aspects of a pharmaceutical company business – manufacturing, commercial, R&D, quality assurance, and quality control to name a few. Regulators expect to be able to inspect a site of the company with little to no warning and a data review would be a key part of this.
For example, deviations are a critical part of the pharmaceutical company data model. These are issues that are raised with any part of the company’s operations that can contribute to patient outcomes. They can be raised when something goes wrong in manufacturing, in a clinical trial, or even when an IT project does not go to plan. Regulators will inspect deviations, and if data quality is poor, the regulator may choose to apply their statutory powers to remedy the situation. The most serious issues can result in sites being shut down until improvements can be made. This has financial and reputational consequences for organizations, but the ultimate goal of regulation is to keep human beings safe. Data quality in pharmaceutical companies can be a matter of life and death!
The level of scrutiny and the risk of managing data poorly is so high for companies in these industries that investment in data governance in general tends to be higher. However, it should be noted that data initiatives in these organizations tend to move slowly because of the level of documentation and compliance required for implementation work.
More and more organizations are going beyond using data just for processes, reporting, and compliance in modern economies. We’ve already covered how these areas are impacted by bad data. If an organization is aiming to create or enhance streams of revenue by including data in their products or by making data itself the product, bad data can be disastrous.
Data differentiation impacts
There has been a major growth in businesses that use data to drive a revenue stream. An example of this is where data is a product in its own right (or part of a product), such as a database of doctor's offices (GP practices) in the UK, that is kept up to date by the owning company and sold to pharmaceutical companies to help with their sales pipelines and contact details.
Data is also often used by organizations as part of a differentiated customer experience. For example, online retailers use algorithms based partly on purchase history to present relevant recommendations to customers. If this purchase history were incomplete, the recommendations would lose relevance and fewer people would be enticed into their next purchase.
In these cases where the data itself is the product or part of the product, data quality is under the greatest scrutiny. It is no longer just your organization that is impacted by the quality issues – your customer is directly impacted now as well, leading to complaints, loss of revenue, and reputational damage. If you sell a range of data products, the low quality of one product might affect the sales of all data products!
Finally, and probably most seriously, there is the risk that where business partners (customers, suppliers, or employees) are exposed to poor data from your organization, the issue enters the public domain. With the prevalence of social media, a relatively isolated data quality issue posted by an influential person can harm the reputation of your company and give the impression that you are hard to do business with. At one organization the commercial team was talking to multiple customers about pricing for the year – which varied across different customers. The data quality of the source system was poor and was exported and combined with spreadsheet data to make it complete. This export was broken down into different spreadsheets to be shared with each customer. Unfortunately, one of the master data analysts made a mistake and sent the whole export to one of the customers – revealing other customers’ prices to that customer. This was a significant data breach and led to the employee being dismissed and the customer relationship breaking down as they saw that other customers were paying less for the same products, and they lost confidence in the organization’s ability to manage their data. This did not reach social media channels but became widely known in the industry and I saw it quoted as an example of poor practice in another company’s data training. It would just take a similar mistake to occur on data about individuals and there could be a GDPR breach with accompanying financial penalties and unwanted press attention. Data quality issues lead to workarounds with data, and workarounds lead to mistakes. Mistakes like these can destroy a business.
With all the negative impacts we have described, it can sometimes be hard to understand how organizations reach a point of having bad data in the first place. It is important to understand how this has occurred in your organization so that meaningful change can be made to avoid future re-occurrences.
Causes of bad data
Any of these impacts can cause critical damage to an organization. No organization deliberately plans for data quality to be poor enough to be impacted in these ways. So, how do organizations end up impacted in this way? How does an organization neglect data sufficiently so that it can no longer achieve its objectives?
Lack of a data culture
Successful organizations try to put a holistic data culture in place. Everyone is educated on the basics of looking after data and the importance of having good data. They consider what they have learned when performing their day-to-day tasks. This is often referred to as the promotion of good data literacy.
Putting a strong data culture in place is a key building block when trying to ensure data remains at an acceptable level of quality for the business to succeed in its objectives. The data culture includes how everyone thinks about data. Many leaders will say that they treat data like an asset, but this can be quite superficial. Doug Laney’s book, Infonomics, explains this best:
“Consider your company’s well-honed supply chain and asset management practices for physical assets, or your financial management and reporting discipline. Do you have similar accounting and asset management practices in place for your “information assets?” Most organizations do not.” (Laney, 2017)
Laney makes an interesting point. Accounting standards allow organizations to value intangible assets – for example, patents, copywrites, and goodwill. These are logged on an asset register and are depreciated over time as their value diminishes. Why do we not do this with data as well? If data had a value attributed to it, then initiatives to eliminate practices that eroded that value would be better received.
We will return to this in later chapters, but for now, suffice it to say that having a data culture is a key building block when striving for good data quality. Many organizations make statements about treating data as an asset and having a data culture, without really taking practical steps to make this so.
Prioritizing process speed over data governance
There is always a contention between the speed of a business process and the level of data governance involved in the steps of that process. Efforts to govern and manage data can often be seen as red tape.
Sometimes, a desire for a high process speed comes into conflict with the enforcement of these rules. There may even be financial incentives for process owners to keep processes shorter than a certain number of days/hours. In these cases, process owners may ask for the data entry process to be simplified and the rules removed.
In the short term, this may result in an improved end-to-end process speed – for example, in procurement, initial requests may be turned into purchase orders more quickly than before. However, as shown in Figure 1.3, a fast process with few data entry rules will result in poor data quality (box 1) and this is unsustainable.
In all these cases, the organization experiences what we call data and process breakdown – the dreaded box 2 in Figure 1.3. The initial data entry process is now rapid, but the follow-on processes are seriously and negatively impacted. For example, if supplier bank details are not collected accurately in the initial process, then the payment process will not be completed successfully. The accounts payable team will have to contact the supplier to request the correct details. If the contact details have also not been collected properly, then the team will have a mystery to solve before they can do their job! For one supplier, this can be frustrating, but for large organizations with thousands of suppliers and potentially millions of payments, processes are usually highly automated, and gaps like these become showstopping issues:

Figure 1.3 – Balance of process speed and data quality – avoiding data and process breakdown
When establishing new processes, most organizations start in box 3, where the rules have been established but they are inefficient. For example, rules are applied in spreadsheet-based forms, but the form must be approved by three different people before data can be entered into a system. Some organizations (typically those in regulated industries) move further to the right into box 6 – where the data governance is so complex that process owners feel compelled to act. This often leads to a move back to box 1 – where the process owner instructs their team to depart from the data governance rules, sacrificing data quality for process speed. Again, this brings the data and process breakdown scenario into sharp focus.
Through technology, organizations tend to move to box 4 – for example, a web-based form is added for data input that validates data, connects to the underlying system to save the valid data, and automatically orchestrates approvals as appropriate. As these processes are improved over time, there is the opportunity to move to box 5 – for example, by adding lookups to databases of companies (for example, Dun and Bradstreet) to collect externally validated supplier data, including additional attributes such as details of the supplier risk and company ownership details. In the best cases, good master data management can contribute to a higher process speed than would otherwise have been possible.
There can be significant shifts in an organization’s position within this model when there is great organizational change. This might include a re-organization which might remove roles relating to data management, or a merger with another organization.
Mergers and acquisitions
Often, in merger and acquisition scenarios, two different datasets need to be brought together from different systems – for example, datasets from two different ERP systems are migrated to a single ERP. Often, these projects have extremely aggressive timelines because of the difficulties of running a newly combined business across multiple systems of record and the cost of maintaining the legacy systems.
When data is migrated in an aggressive timeline, the typical problems are as follows:
- Data is not de-duplicated across the two different source systems (for example, the same supplier exists for both former organizations and two copies get created in the new system)
- Data is migrated as-is without being adjusted to work in the new system – which may have different data requirements
- Data was of poor quality in one or more of the legacy systems, but there is no time to enhance it in the project timeline
After a merger, there is usually a significant investment in the harmonization of systems and processes that cover the migration process. If the migration process encounters these problems and bad data is created in the new systems, a budget is rarely set aside to resolve the problems in a business-as-usual context.
Summary
In this chapter, I began to explore how bad data can impact an organization and the people who work within it. I started to explain how organizations unintentionally reach an unfavorable position in terms of data quality. I hope that these topics resonate with you and help you understand how your organization got to this point and what barriers it might be experiencing to its current and future success.
Chapter 2 will outline the key concepts which need to be understood about data quality prior to embarking on improving it. It will also outline the book's approach to managing data quality. This is used to structure much of the rest of the book - with each chapter representing a part of the approach.
References
The following reference was provided in this chapter:
- https://www.gartner.com/smarterwithgartner/how-to-improve-your-data-quality: Gartner predicts that by 2022, 70% of organizations will rigorously track data quality levels via metrics. This sounds positive, but it means that 30% of companies are not even tracking problems. It is also likely that many of the 70% only do this tracking in certain business units or geographies or are at an early stage.
