


















 Download code from GitHub
Download code from GitHub
Enterprise Data Architecture Principles
Traditionally, enterprises have embraced data warehouses to store, process, and access large volumes of data. These warehouses are typically large RDBMS databases capable of storing a very-large-scale variety of datasets. As the data complexity, volume, and access patterns have increased, many enterprises have started adopting big data as a model to redesign their data organization and define the necessary policies around it.
This figure depicts how a typical data warehouse looks in an Enterprise:

As Enterprises have many different departments, organizations, and geographies, each one tends to own a warehouse of their own and presents a variety of challenges to the Enterprise as a whole. For example:
- Multiple sources and destinations of data
- Data duplication and redundancy
- Data access regulatory issues
- Non-standard data definitions across the Enterprise.
- Software and hardware scalability and reliability issues
- Data movement and auditing
- Integration between various warehouses
It is becoming very easy to build very-large-scale systems at less costs compared to what it was a few decades ago due to several advancements in technology, such as:
- Cost per terabyte
- Computation power per nanometer
- Gigabits of network bandwidth
- Cloud
With globalization, markets have gone global and the consumers are also global. This has increased the reach manifold. These advancements also pose several challenges to the Enterprises in terms of:
- Human capital management
- Warehouse management
- Logistics management
- Data privacy and security
- Sales and billing management
- Understanding demand and supply
In order to stay on top of the demands of the market, Enterprises have started collecting more and more metrics about themselves; thereby, there is an increase in the dimensions data is playing with in the current situation.
In this chapter, we will learn:
- Data architecture principles
- The importance of metadata
- Data governance
- Data security
- Data as a Service
- Data architecture evolution with Hadoop
Data architecture principles
Data at the current state can be defined in the following four dimensions (four Vs).
Volume
The volume of data is an important measure needed to design a big data system. This is an important factor that decides the investment an Enterprise has to make to cater to the present and future storage requirements.
Different types of data in an enterprise need different capacities to store, archive, and process. Petabyte storage systems are a very common in the industry today, which was almost impossible to reach a few decades ago.
Velocity
This is another dimension of the data that decides the mobility of data. There exist varieties of data within organizations that fall under the following categories:
- Streaming data:
- Real-time/near-real-time data
- Data at rest:
- Immutable data
- Mutable data
This dimension has some impact on the network architecture that Enterprise uses to consume and process data.
Variety
This dimension talks about the form and shape of the data. We can further classify this into the following categories:
- Streaming data:
- On-wire data format (for example, JSON, MPEG, and Avro)
- Data At Rest:
- Immutable data (for example, media files and customer invoices)
- Mutable data (for example, customer details, product inventory, and employee data)
- Application data:
- Configuration files, secrets, passwords, and so on
As an organization, it's very important to embrace very few technologies to reduce the variety of data. Having many different types of data poses a very big challenge to an Enterprise in terms of managing and consuming it all.
Veracity
This dimension talks about the accuracy of the data. Without having a solid understanding of the guarantee that each system within an Enterprise provides to keep the data safe, available, and reliable, it becomes very difficult to understand the Analytics generated out of this data and to further generate insights.
Necessary auditing should be in place to make sure that the data that flows through the system passes all the quality checks and finally goes through the big data system.
Let's see how a typical big data system looks:

As you can see, many different types of applications are interacting with the big data system to store, process, and generate analytics.
The importance of metadata
Before we try to understand the importance of Metadata, let's try to understand what metadata is. Metadata is simply data about data. This sounds confusing as we are defining the definition in a recursive way.
In a typical big data system, we have these three levels of verticals:
- Applications writing data to a big data system
- Organizing data within the big data system
- Applications consuming data from the big data system
This brings up a few challenges as we are talking about millions (even billions) of data files/segments that are stored in the big data system. We should be able to correctly identify the ownership, usage of these data files across the Enterprise.
Let's take an example of a TV broadcasting company that owns a TV channel; it creates television shows and broadcasts it to all the target audience over wired cable networks, satellite networks, the internet, and so on. If we look carefully, the source of content is only one. But it's traveling through all possible mediums and finally reaching the user’s Location for viewing on TV, mobile phone, tablets, and so on.
Since the viewers are accessing this TV content on a variety of devices, the applications running on these devices can generate several messages to indicate various user actions and preferences, and send them back to the application server. This data is pretty huge and is stored in a big data system.
Depending on how the data is organized within the big data system, it's almost impossible for outside applications or peer applications to know about the different types of data being stored within the system. In order to make this process easier, we need to describe and define how data organization takes place within the big data system. This will help us better understand the data organization and access within the big data system.
Let's extend this example even further and say there is another application that reads from the big data system to understand the best times to advertise in a given TV series. This application should have a better understanding of all other data that is available within the big data system. So, without having a well-defined metadata system, it's very difficult to do the following things:
- Understand the diversity of data that is stored, accessed, and processed
- Build interfaces across different types of datasets
- Correctly tag the data from a security perspective as highly sensitive or insensitive data
- Connect the dots between the given sets of systems in the big data ecosystem
- Audit and troubleshoot issues that might arise because of data inconsistency
Data governance
Having very large volumes of data is not enough to make very good decisions that have a positive impact on the success of a business. It's very important to make sure that only quality data should be collected, preserved, and maintained. The data collection process also goes through evolution as new types of data are required to be collected. During this process, we might break a few interfaces that read from the previous generation of data. Without having a well-defined process and people, handling data becomes a big challenge for all sizes of organization.
To excel in managing data, we should consider the following qualities:
- Good policies and processes
- Accountability
- Formal decision structures
- Enforcement of rules in management
The implementation of these types of qualities is called data governance. At a high level, we'll define data governance as data that is managed well. This definition also helps us to clarify that data management and data governance are not the same thing. Managing data is concerned with the use of data to make good business decisions and ultimately run organizations. Data governance is concerned with the degree to which we use disciplined behavior across our entire organization in how we manage that data.
It's an important distinction. So what's the bottom line? Most organizations manage data, but far fewer govern those management techniques well.
Fundamentals of data governance
Let's try to understand the fundamentals of data governance:
- Accountability
- Standardization
- Transparency
Transparency ensures that all the employees within an organization and outside the organization understand their role when interacting with the data that is related to the organization. This will ensure the following things:
- Building trust
- Avoiding surprises
Accountability makes sure that teams and employees who have access to data describe what they can do and cannot do with the data.
Standardization deals with how the data is properly labeled, describe, and categorized. One example is how to generate email address to the employees within the organization. One way is to use firstname-lastname@company.com, or any other combination of these. This will ensure that everyone who has access to these email address understands which one is first and which one is last, without anybody explaining those in person.
Standardization improves the quality of data and brings order to multiple data dimensions.
Data security
Security is not a new concept. It's been adopted since the early UNIX time-sharing operating system design. In the recent past, security awareness has increased among individuals and organizations on this security front due to the widespread data breaches that led to a lot of revenue loss to organizations.
Security, as a general concept, can be applied to many different things. When it comes to data security, we need to understand the following fundamental questions:
- What types of data exist?
- Who owns the data?
- Who has access to the data?
- When does the data exit the system?
- Is the data physically secured?
Let's have a look at a simple big data system and try to understand these questions in more detail. The scale of the systems makes security a nightmare for everyone. So, we should have proper policies in place to keep everyone on the same page:
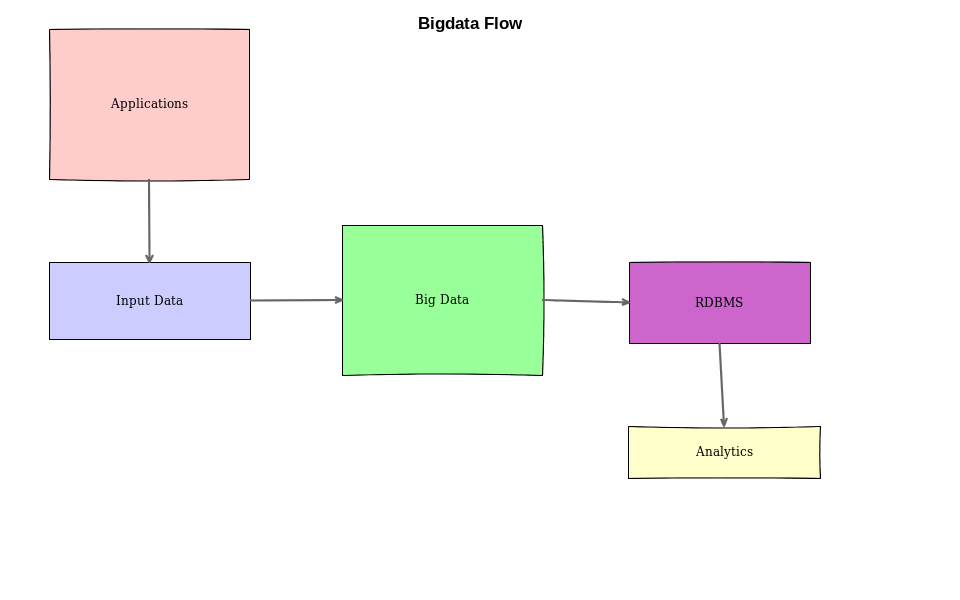
In this example, we have the following components:
- Heterogeneous applications running across the globe in multiple geographical regions.
- Large volume and variety of input data is generated by the applications.
- All the data is ingested into a big data system.
- ETL/ELT applications consume the data from a big data system and put the consumable results into RDBMS (this is optional).
- Business intelligence applications read from this storage and further generate insights into the data. These are the ones that power the leadership team's decisions.
You can imagine the scale and volume of data that flows through this system. We can also see that the number of servers, applications, and employees that participate in this whole ecosystem is very large in number. If we do not have proper policies in place, its not a very easy task to secure such a complicated system.
Also, if an attacker uses social engineering to gain access to the system, we should make sure that the data access is limited only to the lowest possible level. When poor security implementations are in place, attackers can have access to virtually all the business secrets, which could be a serious loss to the business.
Just to think of an example, a start-up is building a next-generation computing device to host all its data on the cloud and does not have proper security policies in place. When an attacker compromises the security of the servers that are on the cloud, they can easily figure out what is being built by this start-up and can steal the intelligence. Once the intelligence is stolen, we can imagine how hackers use this for their personal benefit.
With this understanding of security's importance, let's define what needs to be secured.
Application security
Applications are the front line of product-based organizations, since consumers use these applications to interact with the products and services provided by the applications. We have to ensure that proper security standards are followed while programming these application interfaces.
Since these applications generate data to the backend system, we should make sure only proper access mechanisms are allowed in terms of firewalls.
Also, these applications interact with many other backend systems, we have to ensure that the correct data related to the user is shown. This boils down to implementing proper authentication and authorization, not only for the user but also for the application when accessing different types of an organization's resources.
Without proper auditing in place, it is very difficult to analyze the data access patterns by the applications. All the logs should be collected at a central place away from the application servers and can be further ingested into the big data system.
Input data
Once the applications generate several metrics, they can be temporarily stored locally that are further consumed by periodic processes or they are further pushed to streaming systems like Kafka.
In this case, we should carefully think through and design where the data is stores and which uses can have access to this data. If we are further writing this data to systems like Kafka or MQ, we have to make sure that further authentication, authorization, and access controls are in place.
Here we can leverage the operating-system-provided security measures such as process user ID, process group ID, filesystem user ID, group ID, and also advanced systems (such as SELinux) to further restrict access to the input data.
Big data security
Depending on which data warehouse solution is chosen, we have to ensure that authorized applications and users can write to and read from the data warehouse. Proper security policies and auditing should be in place to make sure that this large scale of data is not easily accessible to everyone.
In order to implement all these access policies, we can use the operating system provided mechanisms like file access controls and use access controls. Since we're talking about geographically distributed big data systems, we have to think and design centralized authentication systems to provide a seamless experience for employees when interacting with these big data systems.
RDBMS security
Many RDBMSes are highly secure and can provide the following access levels to users:
- Database
- Table
- Usage pattern
They also have built-in auditing mechanisms to tell which users have accessed what types of data and when. This data is vital to keeping the systems secure, and proper monitoring should be in place to keep a watch on these system's health and safety.
BI security
These can be applications built in-house for specific needs of the company, or external applications that can power the insights that business teams are looking for. These applications should also be properly secured by practicing single sign-on, role-based access control, and network-based access control.
Since the amount of insights these applications provide is very much crucial to the success of the organization, proper security measures should be taken to protect them.
So far, we have seen the different parts of an enterprise system and understood what things can be followed to improve the security of the overall enterprise data design. Let's talk about some of the common things that can be applied everywhere in the data design.
Physical security
This deals with physical device access, data center access, server access, and network access. If an unauthorized person gains access to the equipment owned by an Enterprise, they can gain access to all the data that is present in it.
As we have seen in the previous sections, when an operating system is running, we are able to protect the resources by leveraging the security features of the operating system. When an intruder gains physical access to the devices (or even decommissioned servers), they can connect these devices to another operating system that's in their control and access all the data that is present on our servers.
Care must be taken when we decommission servers, as there are ways in which data that's written to these devices (even after formatting) can be recovered. So we should follow industry-standard device erasing techniques to properly clean all of the data that is owned by enterprises.
In order to prevent those, we should consider encrypting data.
Data encryption
Encrypting data will ensure that even when authorized persons gain access to the devices, they will not be able to recover the data. This is a standard practice that is followed nowadays due to the increase in mobility of data and employees. Many big Enterprises encrypt hard disks on laptops and mobile phones.
Secure key management
If you have worked with any applications that need authentication, you will have used a combination of username and password to access the services. Typically these secrets are stored within the source code itself. This poses a challenge for programs which are non-compiled, as attackers can easily access the username and password to gain access to our resources.
Many enterprises started adopting centralized key management, using which applications can query these services to gain access to the resources that are authentication protected. All these access patterns are properly audited by the KMS
Employees should also access these systems with their own credentials to access the resources. This makes sure that secret keys are protected and accessible only to the authorized applications.
Data as a Service
Data as a Service (DaaS) is a concept that has become popular in recent times due to the increase in adoption of cloud. When it comes to data. It might some a little confusing that how can data be added to as a service model?
DaaS offers great flexibility to users of the service in terms of not worrying about the scale, performance, and maintenance of the underlying infrastructure that the service is being run on. The infrastructure automatically takes care of it for us, but given that we are dealing with a cloud model, we have all the benefits of the cloud such as pay as you go, capacity planning, and so on. This will reduce the burden of data management.
If we try to understand this carefully we are taking out the data management part alone. But data governance should be well-defined here as well or else we will lose all the benefits of the service model.
So far, we are talking about the Service in the cloud concept. Does it mean that we cannot use this within the Enterprise or even smaller organizations? The answer is No. Because this is a generic concept that tells us the following things.
When we are talking about a service model, we should keep in mind the following things, or else chaos will ensue:
- Authentication
- Authorization
- Auditing
This will guarantee that only well-defined users, IP addresses, and services can access the data exposed as a service.
Let's take an example of an organization that has the following data:
- Employees
- Servers and data centers
- Applications
- Intranet documentation sites
As you can see, all these are independent datasets. But, as a whole when we want the organization to succeed. There is lot of overlap and we should try to embrace the DaaS model here so that all these applications that are authoritative for the data will still manage the data. But for other applications, they are exposed as a simple service using REST API; therefore, this increases collaboration and fosters innovation within the organization.
Let's take further examples of how this is possible:
- The team that manages all the employee data in the form of a database can provide a simple Data Service. All other applications can use this dataset without worrying about the underlying infrastructure on which this employee data is stored:
- This will free the consumers of the data services in such a way that the consumers:
- Need not worry about the underlying infrastructure
- Need not worry about the protocols that are used to communicate with these data servers
- Can just focus on the REST model to design the application
- Typical examples of this would be:
- Storing the employee data in a database like LDAP or the Microsoft Active directory
- This will free the consumers of the data services in such a way that the consumers:
- The team that manages the infrastructure for the entire organization can design their own system to keep off the entire hardware inventory of the organization, and can provide a simple data service. The rest of the organization can use this to build applications that are of interest to them:
- This will make the Enterprise more agile
- It ensures there is a single source of truth for the data about the entire hardware of the organization
- It improves trust in the data and increases confidence in the applications that are built on top of this data
- Every team in the organization might use different technology to build and deploy their applications on to the servers. Following this, they also need to build a data store that keeps track of the active versions of software that are deployed on the servers. Having a data source like this helps the organization in the following ways:
- Services that are built using this data can constantly monitor and see where the software deployments are happening more often
- The services can also figure out which applications are vulnerable and are actively deployed in production so that further action can be taken to fix the loopholes, either by upgrading the OS or the software
- Understanding the challenges in the overall software deployment life cycle
- Provides a single platform for the entire organization to do things in a standard way, which promotes a sense of ownership
- Documentation is one of the very important things for an organization. Instead of running their own infrastructure, with the DaaS model, organizations and teams can focus on the documents that are related to their company and pay only for those. Here, services such as Google Docs and Microsoft Office Online are very popular as they give us flexibility to pay as we go and, most importantly, not worry about the technology required to build these.
- Having such a service model for data will help us do the following:
- Pay only for the service that is used
- Increase or decrease the scale of storage as needed
- Access the data from anywhere if the service is on the Cloud and connected to the internet
- Access corporate resources when connected via VPN as decided by the Enterprise policy
- Having such a service model for data will help us do the following:
In the preceding examples, we have seen a variety of applications that are used in Enterprises and how data as a model can help Enterprises in variety of ways to bring collaboration, innovation, and trust.
But, when it comes to big data, what can DaaS Do?
Just like all other data pieces, big data can also be fit into a DaaS model and provides the same flexibility as we saw previously:
- No worry about the underlying hardware and technology
- Scale the infrastructure as needed
- Pay only for the data that is owned by the Enterprise
- Operational and maintenance challenges are taken away
- Data can be made geographically available for high availability
- Integrated backup and recovery for DR requirements
With these few advantages, enterprises can be more agile and build applications that can leverage this data as service.
Evolution data architecture with Hadoop
Hadoop is a software that helps in scalable and distributed computing. Before Hadoop came into existence, there were many technologies that were used by the industry to take care of their data needs. Let's classify these storage mechanisms:
- Hierarchical database
- Network database
- Relational database
Let's understand what these data architectures are.
Hierarchical database architecture
This model of storing Enterprise data was invented by IBM in the early 60s and was used in their applications. The basic concept of hierarchical databases is that the data is organized in the form of a rooted tree. The root node is the beginning of the tree and then all the children are linked only to one of its parent nodes. This is a very unique way of storing and retrieving things.
If you have some background in computer science, trees are one of the unique ways of storing data so that it has some relation with each other (like a parent and child relationship).
This picture illustrates how data is organized in a typical HDBMS:
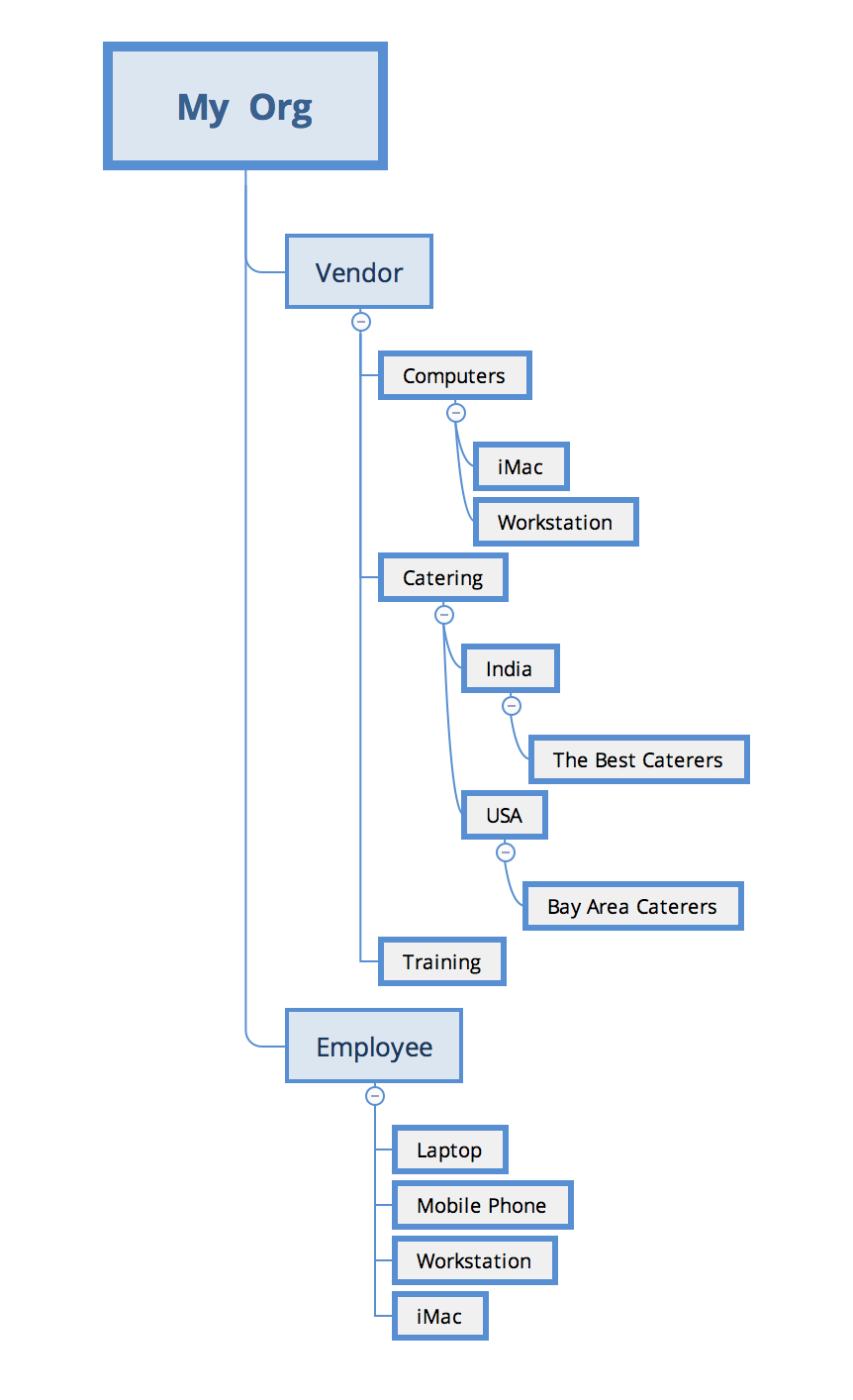
As we can see, the root node is the organization itself and all the data associated with the organization follows a tree structure which depicts several relationships. These relationships can be understood like this:
- Employee owns Laptop, Mobile phone, Workstation, and iMac
- Employee belongs to organization
- Many vendors supply different requirements:
- Computer vendors supply iMac and Workstation
- Catering is in both India and USA; two vendors, The Best Caterers and Bay Area Caterers, serve these
Even though we have expressed multiple types of relationships in this one gigantic data store, we can see that the data gets duplicated and also querying data for different types of needs becomes a challenge.
Let's take a simple question like: Which vendor supplied the iMac owned by Employee-391?
In order to do this, we need to traverse the tree and find information from two different sub-trees.
Network database architecture
The network database management system also has its roots in computer science: graph theory, where there are a vast and different types of nodes and relationships connect them together. There is no specific root node in this structure. It was invented in the early 70s:
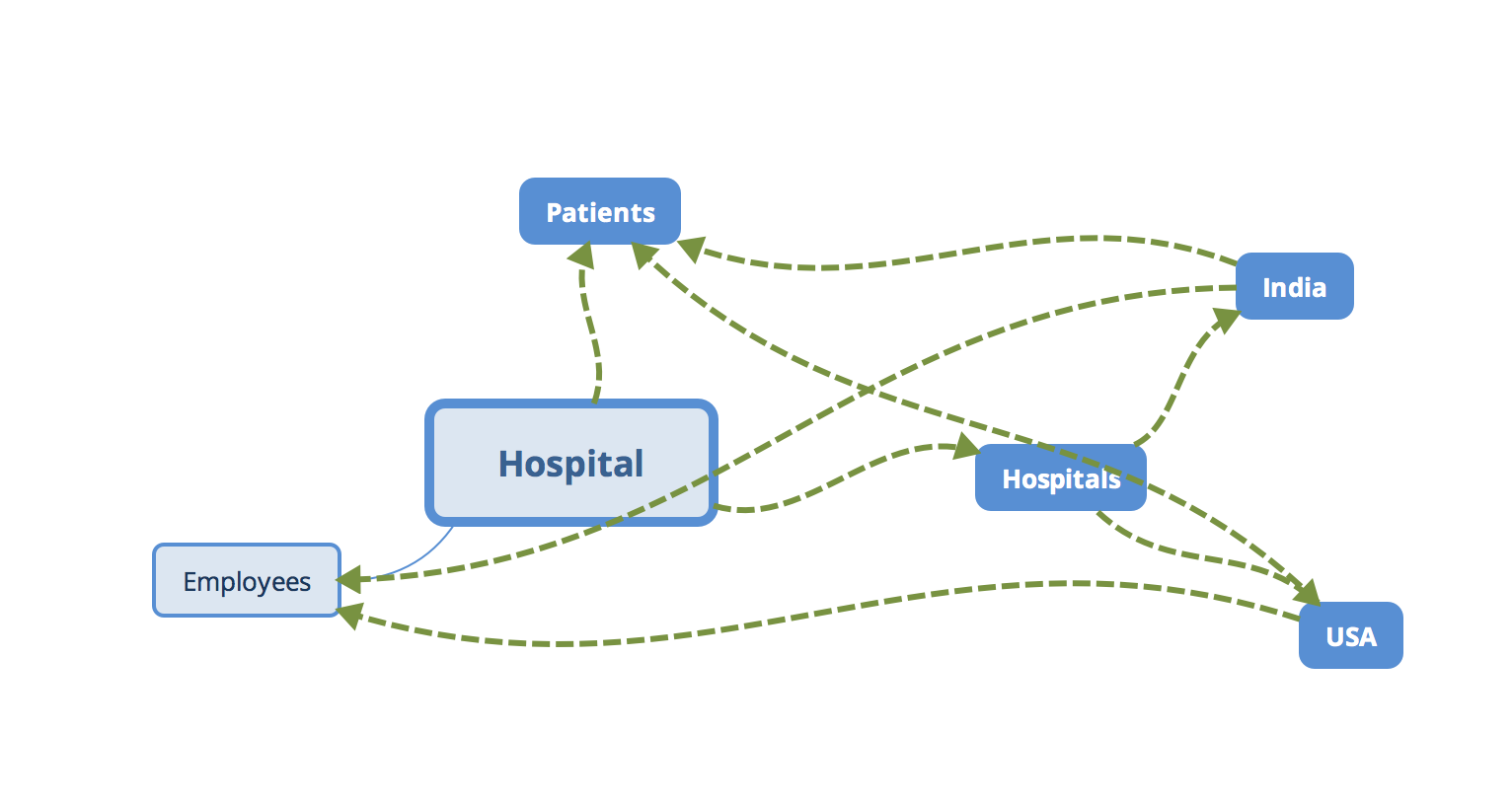
As we can see, in this structure, there are a few core datasets and there are other datasets linked with the core datasets.
This is how we can understand it:
- The main hospital is defined
- It has many subhospitals
- Subhospitals are in India and USA
- The Indian hospital uses the data in patients
- The USA hospital uses the data in patients
- The patients store is linked to the main hospital
- Employees belong to the hospital and are linked with other organizations
In this structure, depending upon the design we come up with, the data is represented as a network of elements.
Relational database architecture
This system was developed again in IBM in the early 80s and is considered one of the most reputed database systems to date. A few notable examples of the software that adopted this style are Oracle and MySQL.
In this model, data is stored in the form of records where each record in turn has several attributes. All the record collections are stored in a table. Relationships exist between the data attributes across tables. Sets of related tables are stored in a database.
Let's see a typical example of how this RDBMS table looks:
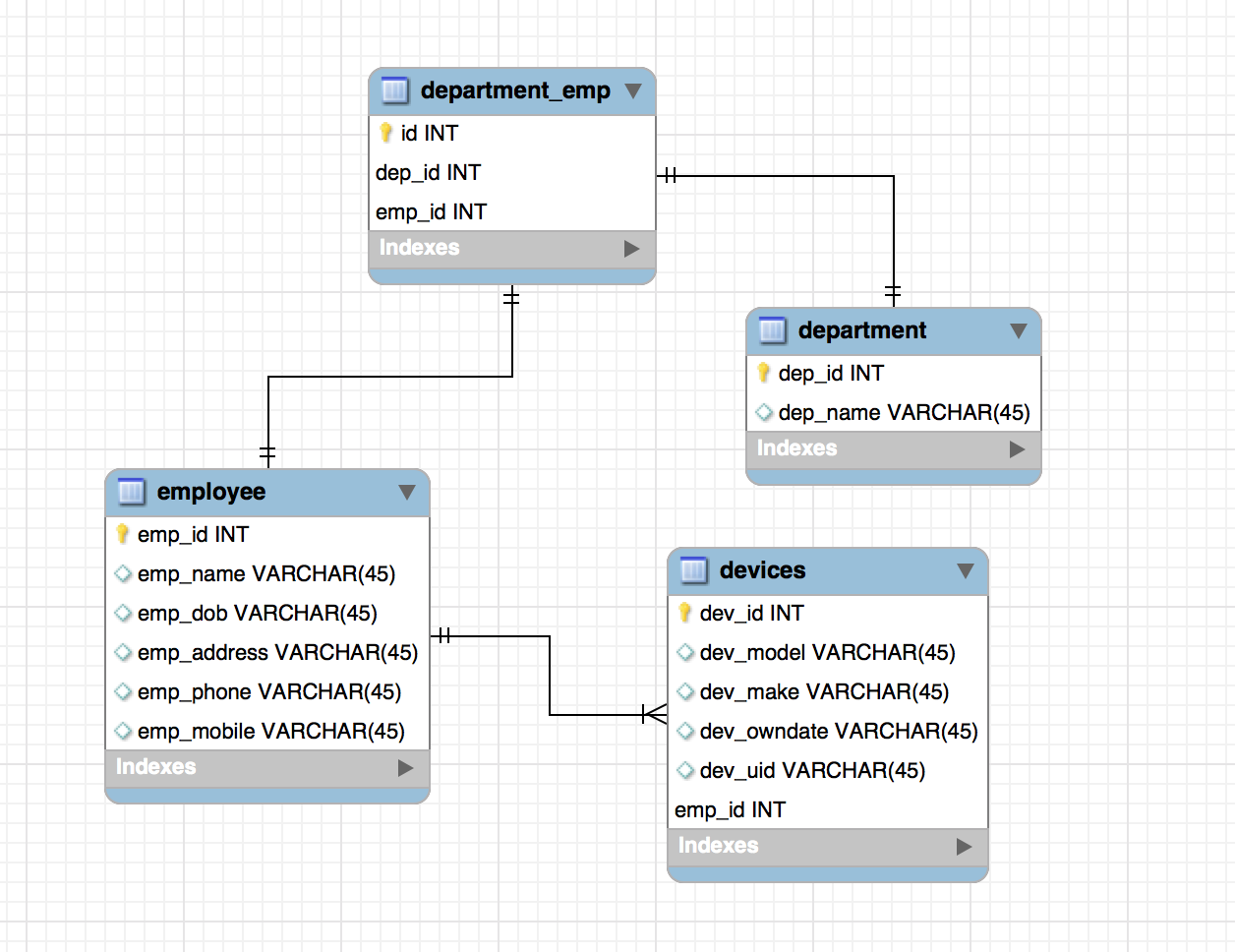
We are defining the following types of tables and relationships
Employees
- The table consists of all the employee records
- Each record is defined in terms of:
- Employee unique identifier
- Employee name
- Employee date of birth
- Employee address
- Employee phone
- Employee mobile
Devices
- The table consists of all the devices that are owned by employees
- Each ownership record is defined in terms of the following:
- Device ownership identifier
- Device model
- Device manufacturer
- Device ownership date
- Device unique number
- Employee ID
Department
A table consisting of all the departments in the organization:
- Unique department ID
- Unique department name
Department and employee mapping table
This is a special table that consists of only the relationships between the department and employee using their unique identifiers:
- Unique department ID
- Unique employee ID
Hadoop data architecture
So far, we have explored several types of data architectures that have been in use by Enterprises. In this section, we will understand how the data architecture is made in Hadoop.
Just to give a quick introduction, Hadoop has multiple components:
- Data
- Data management
- Platform to run jobs on data
Data layer
This is the layer where all of the data is stored in the form of files. These files are internally split by the Hadoop system into multiple parts and replicated across the servers for high availability.
Since we are talking about the data stored in terms of files, it is very important to understand how these files are organized for better governance.
The next diagram shows how the data can be organized in one of the Hadoop storage layers. The content of the data can be in any form as Hadoop does not enforce them to be in a specific structure. So, we can safely store Blu-Ray™ Movies, CSV (Comma Separated Value) Files, AVRO Encoded Files, and so on inside this data layer.
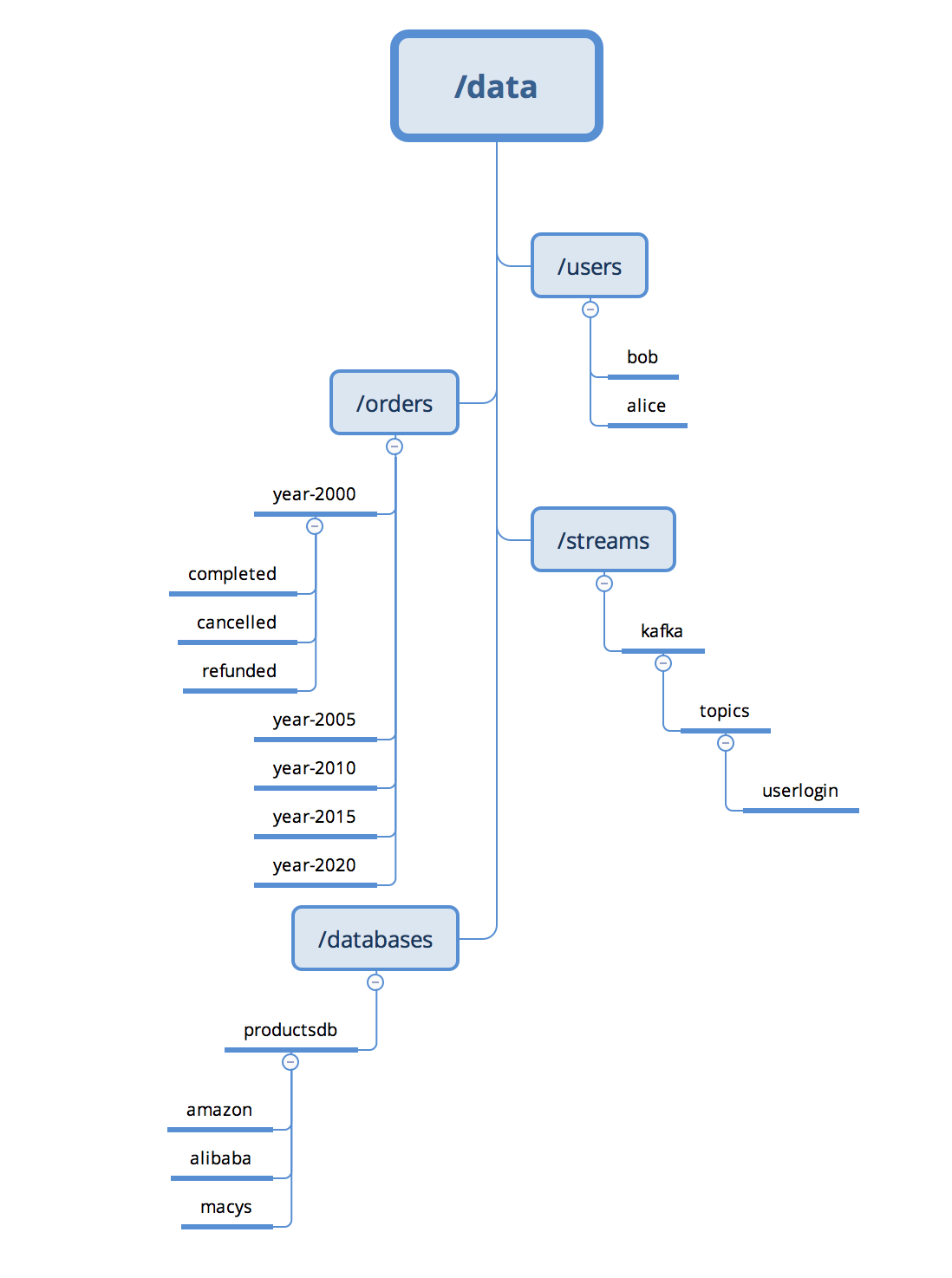
Data management layer
This layer is responsible for keeping track of where the data is stored for a given file or path (in terms of servers, offsets, and so on). Since this is just a bookkeeping layer, it's very important that the contents of this layer are protected with high reliability and durability. Any corruption of the data in this layer will cause the entire data files to be lost forever.
In Hadoop terminology, this is also called NameNode.
Job execution layer
Once we have the data problem sorted out, next come the programs that read and write data. When we talk about data on a single server or a laptop, we are well aware where the data is and accordingly we can write programs that read and write data to the corresponding locations.
In a similar fashion, the Hadoop storage layer has made it very easy for applications to give file paths to read and write data to the storage as part of the computation. This is a very big win for the programming community as they need not worry about the underlying semantics about where the data is physically stored across the distributed Hadoop cluster.
Since Hadoop promotes the compute near the data model, which gives very high performance and throughput, the programs that were run can be scheduled and executed by the Hadoop engine closer to where the data is in the entire cluster. The entire transport of data and movement of the software execution is all taken care of by Hadoop.
So, end users of Hadoop see the system as a simple one with massive computing power and storage. This abstraction has won everyone’s requirements and has become the standard in big data computing today.
Summary
In this chapter, we have seen how many organizations have adopted data warehouses to store, process, and access large volumes of data they possess. We learned about data architecture principles, their governance, and security. In the next chapter, we will take a look at some concepts of data pre-processing.


