


















1.1. Introduction
1.1.1. The rise of NoSQL systems and languages
Managing, querying and making sense of data have become major aspects of our society. In the past 40 years, advances in technology have allowed computer systems to store vast amounts of data. For the better part of this period, relational database management systems (RDBMS) have reigned supreme, almost unchallenged, in their role of sole keepers of our data sets. RDBMS owe their success to several key factors. First, they stand on very solid theoretical foundations, namely the relational algebra introduced by Edgar F. Codd [COD 70], which gave a clear framework to express, in rigorous terms, the limit of systems, their soundness and even their efficiency. Second, RDBMS used one of the most natural representations to model data: tables. Indeed, tables of various sorts have been used since antiquity to represent scales, account ledgers, and so on. Third, a domain-specific language, SQL, was introduced almost immediately to relieve the database user from the burden of low-level programming. Its syntax was designed to be close to natural language, already highlighting an important aspect of data manipulation: people who can best make sense of data are not necessarily computer experts, and vice versa. Finally, in sharp contrast to the high level of data presentation and programming interface, RDBMS have always thrived to offer the best possible performances for a given piece of hardware, while at the same time ensuring consistency of the stored data at all times.
At the turn of the year 2000 with the advances in high speed and mobile networks, and the increase in storage and computing capacity, the amount of data produced by humans became massive, and new usages were discovered that were impractical previously. This increase in both data volumes and computing power gave rise to two distinct but related concepts: “Cloud Computing” and “Big Data”. Broadly speaking, the Cloud Computing paradigm consists of having data processing performed remotely in data centers (which collectively form the so-called cloud) and having end-user devices serve as terminals for information display and input. Data is accessed on demand and continuously updated. The umbrella term “Big Data” characterizes data sets with the so-called three “V”s [LAN 01]: Volume, Variety and Velocity. More precisely, “Big Data” data sets must be large (at least several terabytes), heterogeneous (containing both structured and unstructured textual data, as well as media files), and produced and processed at high speed. The concepts of both Cloud Computing and Big Data intermingle. The sheer size of the data sets requires some form of distribution (at least at the architecture if not at the logical level), preventing it from being stored close to the end-user. Having data stored remotely in a distributed fashion means the only realistic way of extracting information from it is to execute computation close to the data (i.e. remotely) to only retrieve the fraction that is relevant to the end-user. Finally, the ubiquity of literally billions of connected end-points that continuously capture various inputs feed the ever growing data sets.
In this setting, RDBMS, which were the be-all and end-all of data management, could not cope with these new usages. In particular, the so-called ACID (Atomicity, Consistency, Isolation and Durability) properties enjoyed by RDBMS transactions since their inception (IBM Information Management System already supported ACID transactions in 1973) proved too great a burden in the context of massively distributed and frequently updated data sets, and therefore more and more data started to be stored outside of RDBMS, in massively distributed systems. In order to scale, these systems traded the ACID properties for performance. A milestone in this area was the MapReduce paradigm introduced by Google engineers in 2004 [DEA 04]. This programming model consists of decomposing a high-level data operation into two phases, namely the map phase where the data is transformed locally on each node of the distributed system where it resides, and the reduce phase where the outputs of the map phase are exchanged and migrated between nodes according to a partition key – all groups with the same key being migrated to the same (set of) nodes – and where an aggregation of the group is performed. Interestingly, such low-level operations where known both from the functional programming language community (usually under the name map and fold) and from the database community where the map phase can be used to implement selection and projection, and the reduce phase roughly corresponds to aggregation, grouping and ordering.
At the same time as the Big Data systems became prevalent, the so-called CAP theorem was conjectured [BRE 00] and proved [GIL 02]. In a nutshell, this formal result states that no distributed data store can ensure, at the same time, optimal Consistency, Availability and Partition tolerance. In the context of distributed data stores, consistency is the guarantee that a read operation will return the result of the most recent global write to the system (or an error). Availability is the property that every request receives a response that is not an error (however, the answer can be outdated). Finally, partition tolerance is the ability for the system to remain responsive when part of its components are isolated (due to network failures, for instance). In the context of the CAP theorem, the ACID properties enjoyed by RDBMS consist of favoring consistency over availability. With the rise of Big Data and associated applications, new systems emerged that favored availability over consistency. Such systems follow the BASE principles (Basically Available, Soft state and Eventual consistency). The basic tenets of the approach is that operations on the systems (queries as well as updates) must be as fast as possible and therefore no global synchronization between nodes of the system should occur at the time of operation. This, in turn, implies that after an operation, the system may be in an inconsistent state (where several nodes have different views of the global data set). The system is only required to eventually correct this inconsistency (the resolution method is part of the system design and varies from system to system). The wide design space in that central aspect of implementation gave rise to a large number of systems, each having its own programming interface. Such systems are often referred to with the umbrella term Not only SQL (NoSQL). While, generally speaking, NoSQL can also characterize XML databases and Graph databases, these define their own field of research. We therefore focus our study on various kinds of lower-level data stores.
1.1.2. Overview of NoSQL concepts
Before discussing the current trends in research on NoSQL languages and systems, it is important to highlight some of the technical concepts of such systems. In fact, it is their departure from well understood relational traits that fostered new research and development in this area. The aspects which we focus on are mainly centered around computational paradigms and data models.
1.1.2.1. Distributed computations with MapReduce
As explained previously, the MapReduce paradigm consists of decomposing a generic, high-level computation into a sequence of lower-level, distributed, map and reduce operations. Assuming some data elements are distributed over several nodes, the map operation is applied to each element individually, locally on the node where the element resides. When applied to such an element e, the map function may decide to either discard it (by not returning any result) or transform it into a new element e′, to which is associated a grouping key, k, thus returning the pair (k, e′). More generally, given some input, the map operation may output any number of key-value pairs. At the end of the map phase, output pairs are exchanged between nodes so that pairs with the same key are grouped on the same node of the distributed cluster. This phase is commonly referred to as the shuffle phase. Finally, the reduce function is called once for each distinct key value, and takes as input a pair  of a key and all the outputs of the map function that were associated with that key. The reduce function can then either discard its input or perform an operation on the set of values to compute a partial result of the transformation (e.g. by aggregating the elements in its input). The result of the reduce function is a pair (k′, r) of an output key k′ and a result r. The results are then returned to the user, sorted according to the k′ key. The user may choose to feed such a result to a new pair of map/reduce functions to perform further computations. The whole MapReduce process is shown in Figure 1.1.
of a key and all the outputs of the map function that were associated with that key. The reduce function can then either discard its input or perform an operation on the set of values to compute a partial result of the transformation (e.g. by aggregating the elements in its input). The result of the reduce function is a pair (k′, r) of an output key k′ and a result r. The results are then returned to the user, sorted according to the k′ key. The user may choose to feed such a result to a new pair of map/reduce functions to perform further computations. The whole MapReduce process is shown in Figure 1.1.
This basic processing can be optimized if the operation computed by the reduce phase is associative and commutative. Indeed, in such a case, it is possible to start the reduce operations on subsets of values present locally on nodes after the map phase, before running the shuffle phase. Such an operation is usually called a combine operation. In some cases, it can drastically improve performance since it reduces the amount of data moved around during the shuffle phase. This optimization works particularly well in practice since the reduce operations are often aggregates which enjoy the commutativity and associativity properties (e.g. sum and average).
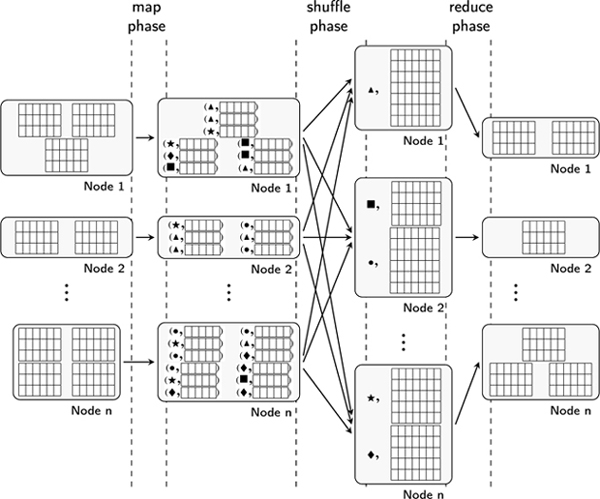
Figure 1.1. MapReduce
The most commonly used MapReduce implementation is certainly the Apache Hadoop framework [WHI 15]. This framework provides a Java API to the programmer, allowing us to express map and reduce transformations as Java methods. The framework heavily relies on the Hadoop Distributed File System (HDFS) as an abstraction for data exchange. The map and reduce transformations just read their input and write their output to the file system, which handle the lower-level aspects of distributing chunks of the files to the components of the clusters, and handle failures of nodes and replication of data.
1.1.2.2. NoSQL databases
A common trait of the most popular NoSQL databases in use is their nature as key-value stores. A key-value store is a database where collections are inherently dictionaries in which each entry is associated with a key that is unique to the collection. While it seems similar to a relational database where tables may have primary keys, key-value stores differ in a fundamental way from relational tables in that they do not rely on – nor enforce – a fixed schema for a given collection. Another striking aspect of all these databases is the relatively small set of operations that is supported natively. Updates are usually performed one element at a time (using the key to denote the element to be added, modified or deleted). Data processing operations generally consist of filtering, aggregation and grouping and exposing a MapReduce-like interface. Interestingly, most NoSQL databases do not support join operations, rather they rely on data denormalization (or materialized joins) to achieve similar results, at the cost of more storage usage and more maintenance effort. Finally, some databases expose a high-level, user-friendly query language (sometimes using an SQL compatible syntax) where queries are translated into combinations of lower-level operations.
1.1.3. Current trends of French research in NoSQL languages
NoSQL database research covers several domains of computer science, from system programming, networking and distributed algorithms, to databases and programming languages. We focus our study on the language aspect of NoSQL systems, and highlight two main trends in French research that pertains to NoSQL languages and systems.
The first trend aims to add support for well-known, relational operations to NoSQL databases. In particular, we survey the extensive body of work that has been done to add support for join operations between collections stored in NoSQL databases. We first describe how join operations are implemented in NoSQL systems (and in particular how joins can be decomposed into sequences of MapReduce operations).
The second trend of research is aimed at unifying NoSQL systems, in particular their query languages. Indeed, current applications routinely interact with several data stores (both relational and NoSQL), using high-level programming languages (PHP, Java, Ruby or JavaScript for Web applications, Python and R for data analytics, etc.). We will survey some of the most advanced work in the area, particularly the definition of common, intermediate query language that can map to various data stores.
1.2. Join implementations on top of MapReduce
While NoSQL databases generally support a more flexible data model than relational ones, many users of NoSQL databases still use a somewhat flat and homogeneous encoding of data (i.e. what is stored in NoSQL databases is still mostly relational tables). In this respect, the join operation is still of paramount importance. Indeed, although denormalization is possible, it increases the cost of writing to the database (since the join must be maintained) and furthermore, such writes may leave the system inconsistent for a while (since, in general, no notion of transaction exists in NoSQL databases). As a result, a large body of work has been done recently to compute joins effectively on top of MapReduce primitives.
Before exploring some of the most prevalent work in this area, we recall the definition of the join operator. Let R and S be two collections1, the join operation between R and S is defined as:

where θ is a Boolean predicate over r and s called the join condition. When θ is an equality condition between (parts of) r and s, the join is called an equijoin. Joins can be generalized to an arbitrary number of collections (n-way joins) and several variations of the basic join operator exist.
A straightforward way to implement joins is the so-called nested loop: which iterates over all r elements in R, and for each r, performs an iteration over all s elements in S, and tests whether θ(r, s) holds (for instance, see [RAM 03], Chapter 14). While this technique is often used by relational databases to evaluate joins, it cannot be used in the context of a MapReduce evaluation, since it is impossible to iterate over the whole collection (which is distributed over several nodes). In the context of equijoins, however, a distributed solution can be devised easily and is given in Algorithm 1.1.
To perform the join, we assume that the MAP function is applied to each element of either collection, together with a tag indicating its origin (a simple string with the name of the collection, for instance). The MAP function outputs a pair of a key and the original element and its origin. The key must be the result of a hashing (or partition) function that is compatible with the θ condition of the join, that is:

During the shuffle phase of the MapReduce process, the elements are exchanged between nodes and all elements yielding the same hash value end up on the same node. The REDUCE function is then called on the key (the hash value) and the sequence of all elements that have this key. It then separates this input sequence with respect to the origin of the elements and can perform, on these two sequences, a nested loop to compute the join. This straightforward scheme is reminiscent of the Hash Join (e.g. see [RAM 03], Chapter 14) used in RDBMS. It suffers however from two drawbacks. The first is that it requires a hashing function that is compatible with the θ condition, which may prove difficult for conditions other than equality. Second, and more importantly, the cost of data exchange in the shuffle phase may be prohibitive. These two drawbacks have given rise to a lot of research in recent years. A first area of research is to reduce the data exchange by filtering bad join candidates early, during the map phase. The second area is to develop ad-hoc MapReduce implementations for particular joins (where the particular semantics of the θ condition is used).
In [PHA 16] and [PHA 14], Phan et al. reviewed and extended the state of the art on filter-based joins. Filter-based joins discard non-joinable tuples early by using Bloom filters (named after their inventor, Burton H. Bloom [BLO 70]). A Bloom filter is a compact data structure that soundly approximates a set interface. Given a set S of elements and a Bloom filter F constructed from S, the Bloom filter can tell whether an element e is not part of the set or if it is present with a high probability, that is, the Bloom filter F is sound (it will never answer that an element not in S belongs to F) but not complete (an element present in F may be absent from S). The advantage of Bloom filters is their great compactness and small query time (which is a fixed parameter k that only depends on the precision of the filter, and not on the number of elements stored in it). The work of Phan et al. extends existing approaches by introducing intersection filter-based joins in which Bloom filters are used to compute equijoins (as well as other related operators such as semi-joins). Their technique consists of two phases. Given two collections R and S that must be joined on a common attribute x, a first pre-processing phase projects each collection on attribute x, collects both results in two Bloom filters FRx and FSx and computes the intersection filter Fx = FRx ∩ FSx which is very quick and easy. In practice, this filter is small enough to be distributed to all nodes. In a second phase, computing the distributed join, we may test during the map phase if the x attribute of the given tuple is in Fx, and, if not, discard it from the join candidates early. Phan et al. further extend their approach for multi-way joins and even recursive joins (which compute the transitive closure of the joined relations). Finally, they provide a complete cost analysis of their techniques, as well as others that can be used as a foundation for a MapReduce-based optimizer (they take particular care evaluating the cost of the initial pre-processing).
One reason why join algorithms may perform poorly is the presence of data skew. Such bias may be due to the original data, e.g. when the join attribute is not uniformly distributed, but may also be due to a bad distribution of the tuples among the existing nodes of the cluster. This observation was made early on in the context of MapReduce-based joins by Hassan in his PhD thesis [ALH 09]. Hassan introduced special algorithms for a particular form of queries, namely GroupBy-Join queries, or SQL queries of the form:
SELECT R.x, R.y, S.z, f(S.u)
FROM R,S
WHERE R.x = S.x
GROUP BY R.y, R.z
Hassan gives variants of the algorithm for the case where the joined on attribute x is also part of the GROUP BY clause. While Hassan’s work initially targeted distributed architectures, it was later adapted and specialized to the MapReduce paradigm (e.g. see [ALH 15]). While a detailed description of Hassan et al.’s algorithm (dubbed MRFAG-Join in their work) is outside of the scope of this survey, we give a high-level overview of the concepts involved. First, as for the reduce side join of Algorithm 1.1, the collections to be joined are distributed over all the nodes, and each tuple is tagged with its relation name. The algorithm then proceeds in three phases. The first phase uses one MapReduce operation to compute local histograms for the x values of R and S (recall that x is the joined on attribute). The histograms are local in the sense that they only take into account the tuples that are present on a given node. In the second phase, another MapReduce iteration is used to circulate the local histograms among the nodes and compute a global histogram of the frequencies of the pairs (R.x, S.x). While this step incurs some data movements, histograms are merely a summary of the original data and are therefore much smaller in size. Finally, based on the global distribution that is known to all the nodes at the end of the second step, the third step performs the join as usual. However, the information about the global distribution is used cleverly in two ways: first, it makes it possible to filter out join candidates that never occur (in this regard, the global histogram plays the same role as the Bloom filter of Phan et al.); but second, the distribution is also used to counteract any data skew that would be present and distribute the set of sub-relations to be joined evenly among the nodes. In practice, Hassan et al. showed that early filtering coupled with good load balancing properties allowed their MRFAG-join algorithm to outperform the default evaluation strategies of a state-of-the-art system by a factor of 10.
Improving joins over MapReduce is not limited to equijoins. Indeed, in many cases, domain-specific information can be used to prune non-joinable candidates early in the MapReduce process. For instance, in [PIL 16], Pilourdault et al. considered the problem of computing top-k temporal joins. In the context of their work, relations R and S are joined over an attribute x denoting a time interval. Furthermore, the join conditions involve high-level time functions such as meet(R.x, S.x) (the R.x interval finishes exactly when the S.x interval starts), overlaps(R.x, S.x) (the two interval intersects), and so on. Finally, the time functions are not interpreted as Boolean predicates, but rather as scoring functions, and the joins must return the top k scoring pairs of intervals for a given time function. The solution which they adopt consists of an initial offline, query-independent pre-processing step, followed by two MapReduce phases that answer the query. The offline pre-processing phase partitions the time into consecutive granules (time intervals), and collects statistics over the distribution of the time intervals to be joined among each granule. At query time, a first MapReduce process distributes the data using the statistics computed in the pre-processing phase. In a nutshell, granules are used as reducers’ input keys, which allows a reducer to process all intervals that occurred during the same granule together. Second, bounds for the scoring time function used in the query are computed and intervals that have no chance of being in the top-k results are discarded early. Finally, a final MapReduce step is used to compute the actual join among the reduced set of candidates.
In the same spirit, Fang et al. considered the problem of nearest-neighbor joins in [FAN 16]. The objects considered in this work are trajectories, that is, sequences of triple (x, y, t) where (x, y) are coordinates in the Euclidean plane and t a time stamp (indicating that a moving object was at position (x, y) at a time t). The authors focus on k nearest-neighbor joins, that is, given two sets of trajectories R and S, and find for each element of R, the set of k closest trajectories of S. The solution proposed by the authors is similar in spirit to the work of Pilourdault et al. on temporal joins. An initial pre-processing step first partitions the time in discrete consecutive intervals and then the space in rectangles. Trajectories are discretized and each is associated with the list of time interval and rectangles it intersects. At query time, the pair of an interval and rectangle is used as a partition key to assign pieces of trajectories to reducers. Four MapReduce stages are used, the first three collect statistics, perform early pruning of non-joinable objects and distribution over nodes, and the last step is – as in previously presented work – used to perform the join properly.
Apart from the previously presented works which focus on binary joins (and sometimes provide algorithms for ternary joins), Graux et al. studied the problem of n-ary equijoins [GRA 16] in the context of SPARQL [PRU 08] queries. SPARQL is the standard query language for the so-called semantic Web. More precisely, SPARQL is a W3C standardized query language that can query data expressed in the Resource Description Framework (RDF) [W3C 14]. Informally, the RDF data are structured into the so-called triples of a subject, a predicate and an object. These triples allow facts about the World to be described. For instance, a triple could be ("John", "lives in", "Paris") and another one could be ("Paris", "is in", "France"). Graux et al. focused on the query part of SPARQL (which also allows new triple sets to be reconstructed). SPARQL queries rely heavily on joins of triples. For instance, the query:
SELECT
?name ?townWHERE {
?name "lives in" ?town .
?town "is in" "France"
}
returns the pair of the name of a person and the city they live in, for all cities located in France (the “.” operator in the query acts as a conjunction). As we can see, the more triples with free variables in the query, the more joins there are to process. Graux et al. showed in their work how to efficiently store such triple sets on a distributed file system and how to translate a subset of SPARQL into Apache Spark code. While they use Spark’s built-in join operator (which implements roughly the reduce side join of Algorithm 1.1), Graux et al. made a clever use of statistics to find an optimal order for join evaluations. This results in an implementation that outperforms both state-of-the-art native SPARQL evaluators as well as other NoSQL-based SPARQL implementations on popular SPARQL benchmarks. Finally, they show how to extend their fragment of SPARQL with other operators such as union.
1.3. Models for NoSQL languages and systems
A striking aspect of the NoSQL ecosystem is its diversity. Concerning data stores, we find at least a dozen heavily used solutions (MongoDB, Apache Cassandra, Apache HBase, Apache CouchDB, Redis, Microsoft CosmosDB to name a few). Each of these solutions comes with its integrated query interface (some with high-level query languages, others with a low-level operator API). But besides data store, we also find processing engines such as Apache Hadoop (providing a MapReduce interface), Apache Spark (general cluster computing) or Apache Flink (stream-oriented framework), and each of these frameworks can target several of the aforementioned stores. This diversity of solutions translates to ever more complex application code, requiring careful and often brittle or inefficient abstractions to shield application business logic from the specificities of every data store. Reasoning about such programs, and in particular about their properties with respect to data access has become much more complex. This state of affairs has prompted a need for unifying approaches allowing us to target multiple data stores uniformly.
A first solution is to consider SQL as the unifying query language. Indeed, SQL is a well-known and established query language, and being able to query NoSQL data stores with the SQL language seems natural. This is the solution proposed by Curé et al. [CUR 11]. In this work, the database user queries a “virtual relational database” which can be seen as a relational view of different NoSQL stores. The approach consists of two complementary components. The first one is a data mapping which describes which part of a NoSQL data store is used to populate a virtual relation. The second is the Bridge Query Language (BQL), an intermediate query representation that bridges the gap between the high-level, declarative SQL, and the low-level programming API exposed by various data stores. The BQL makes some operations, such as iteration or sorting, explicit. In particular, BQL exposes a foreach construct that is used to implement the SQL join operator (using nested loops). A BQL program is then translated into the appropriate dialect. In [CUR 11], the authors give two translations: one targeting MongoDB and the other targeting Apache Cassandra, using their respective Java API.
While satisfactory from a design perspective, the solution of Curé et al. may lead to sub-optimal query evaluation, in particular in the case of joins. Indeed, in most frameworks (with the notable exception of Apache Spark), performing a double nested loop to implement a join implies that the join is actually performed on the client side of the application, that is, both collections to be joined are retrieved from the data store and joined in main memory. The most advanced contribution to date that provides not only a unified query language and data model, but also a robust query planner is the work of Kolev et al. on CloudMdsQL [KOL 16b]. At its heart, CloudMdsQL is a query language based on SQL, which is extended in two ways. First, a CloudMdsQL program may reference a table from a NoSQL store using the store’s native query language. Second, a CloudMdsQL program may contain blocks of Python code that can either produce synthetic tables or be used as user-defined functions (UDFs) to perform application logic. A programmer may query several data stores using SELECT statements (the full range of SQL’s SELECT syntax is supported, including joins, grouping, ordering and windowing constructs) that can be arbitrarily nested. One of the main contributions of Kolev et al. is a modular query planner that takes each data store’s capability into account and furthermore provides some cross data store optimizations. For instance, the planner may decide to use bind joins (see [HAA 97]) to efficiently compute a join between two collections stored in different data stores. With a bind join, rather than retrieving both collections on the client side and performing the join in main memory, one of the collections is migrated to the other data store where the join computation takes place. Another example of optimization performed by the CloudMdsQL planner is the rewriting of Python for each loops into plain database queries. The CloudMdsQL approach is validated by a prototype and an extensive benchmark [KOL 16a].
One aspect of CloudMdsQL that may still be improved is that even in such a framework, reasoning about programs is still difficult. In particular, CloudMdsQL is not so much a unified query language than the juxtaposition of SQL’s SELECT statement, Python code and a myriad of ad-hoc foreign expressions (since every data manipulation language can be used inside quotations). A more unifying solution, from the point of view of the intermediate query representation, is the Hop.js framework of Serrano et al. [SER 16]. Hop.js is a multi-tier programming environment for Web application. From a single JavaScript source file, the framework deduces both the view (HTML code), the client code (client-side JavaScript code) and the server code (server-side JavaScript code with database calls), as well as automatically generating server/client communications in the form of asynchronous HTTP requests. More precisely, in [COU 15], Serrano et al. applied the work of Cheney et al. [CHE 13b, CHE 13a, CHE 14] on language-integrated queries to Hop.js. In [COU 15], list comprehension is used as a common query language to denote queries to different data stores. More precisely, borrowing the Array comprehension syntax2 of the Ecmascript 2017 proposal, the author can write queries as:
[ for ( x of table )if ( x.age >= 18 ) { name: x.name, age: x.age } ]
which mimics the mathematical notation of set comprehension:

In this framework, joins may be written as nested for loops. However, unlike the work of Curé et al., array comprehension is compiled into more efficient operations if the target back-end supports them.
Despite their variety of data models, execution strategies and query languages, NoSQL systems seem to agree on one point: their lack of support for schema! As is well-known, the lack of schema is detrimental to both readability and performance (for instance, see the experimental study of the performance and readability impact of data modeling in MongoDB by Gómez et al. [GÓM 16]). This might come as a surprise, database systems have a long tradition of taking types seriously (from the schema and constraints of RDBMS to the various schema standards for XML documents and the large body of work on type-checking XML programs). To tackle this problem, Benzaken et al. [BEN 13] proposed a core calculus of operators, dubbed filters. Filters reuse previous work on semantic sub-typing (developed in the context of static type checking of XML transformations [FRI 08]) and make it possible to: (i) model NoSQL databases using regular types and extensible records, (ii) give a formal semantics to NoSQL query languages and (iii) perform type checking of queries and programs accessing data. In particular, the work in [BEN 13] gives a formal semantics of the JaQL query language (originally introduced in [BEY 11] and now part of IBM BigInsights) as well as a precise type-checking algorithm for JaQL programs. In essence, JaQL programs are expressed as sets of mutually recursive functions and such functions are symbolically executed over the schema of the data to compute an output type of the query. The filter calculus was generic enough to encode not only JaQL but also MongoDB’s query language (see [HUS 14]). One of the downsides of the filter approach, however, is that to be generic enough to express any kind of operator, filters rely on low-level building blocks (such as recursive functions and pattern matching) which are not well-suited for efficient evaluation.
1.4. New challenges for database research
Since their appearance at the turn of the year 2000, NoSQL databases have become ubiquitous and collectively store a large amount of data. In contrast with XML databases, which rose in popularity in the mid-1990s to settle on specific, document-centric applications, it seems safe to assume that NoSQL databases are here to stay, alongside relational ones. After a first decade of fruitful research in several directions, it seems that it is now time to unify all these research efforts.
First and foremost, in our sense, a formal model of NoSQL databases and queries is yet to be defined. The model should play the same role that relational algebra played as a foundation for SQL. This model should in particular allow us to:
- – describe the data-model precisely;
- – express complex queries;
- – reason about queries and their semantics. In particular, it should allow us to reason about query equivalence;
- – describe the cost model of queries;
- – reason about meta-properties of queries (type soundness, security properties, for instance, non-interference, access control or data provenance);
- – characterize high-level optimization.
Finding such a model is challenging in many ways. First, it must allow us to model data as it exists in current – and future – NoSQL systems, from the simple key-value store, to the more complex document store, while at the same time retaining compatibility with the relational model. While at first sight the nested relational algebra seems to be an ideal candidate (see, for instance, [ABI 84, FIS 85, PAR 92]), it does not allow us to easily model heterogeneous collections which are common in NoSQL data stores. Perhaps an algebra based on nested data types with extensible records similar to [BEN 13] could be of use. In particular, it has already been used successfully to model collections of (nested) heterogeneous JSON objects.
Second, if a realistic cost model is to be devised, the model might have to make the distributed nature of data explicit. This distribution happens at several levels: first, collections are stored in a distributed fashion, and second, computations may also be performed in a distributed fashion. While process calculi have existed for a long time (for instance, the one introduced by Milner et al. [MIL 92]), they do not seem to tackle the data aspect of the problem at hand.
Another challenge to be overcome is the interaction with high-level programming languages. Indeed, for database-oriented applications (such as Web applications), programmers still favor directly using a query language (such as SQL) with a language API (such as Java’s JDBC) or higher-level abstractions such as Object Relational Mappings, for instance. However, data analytic oriented applications favor idiomatic R or Python code [GRE 15, VAN 17, BES 17]. This leads to inefficient idioms (such as retrieving the bulk of data on the client side to filter it with R or Python code). Defining efficient, truly language-integrated queries remains an unsolved problem. One critical aspect is the server-side evaluation of user-defined functions, written in Python or R, close to the data and in a distributed fashion. Frameworks such as Apache Spark [ZAH 10], which enable data scientists to write efficient idiomatic R or Python code, do not allow us to easily reason about security, provenance or performance (in other words, they lack formal foundations). A first step toward a unifying solution may be the work of Benzaken et al. [BEN 18]. In this work, following the tradition of compiler design, an intermediate representation for queries is formally defined. This representation is an extension of the λ-calculus, or equivalently of a small, pure functional programming language, extended with data operators (e.g. joins and grouping). This intermediate representation is used as a common compilation target for high-level languages (such as Python and R). Intermediate terms are then translated into various back-ends ranging from SQL to MapReduce-based databases. This preliminary work seems to provide a good framework to explore the design space and address the problems mentioned in this conclusion.
Finally, while some progress has been made in implementing high-level operators on top of distributed primitives such as MapReduce, and while all these approaches seem to fit a similar template (in the case of join: prune non-joinable items early and regroup likely candidates while avoiding duplication as much as possible), it seems that some avenues must be explored to unify and formally describe such low-level algorithms, and to express their cost in a way that can be reused by high-level optimizers.
In conclusion, while relational databases started both from a formal foundation and solid implementations, NoSQL databases have developed rapidly as implementation artifacts. This situation highlights its limits and, as such, database and programming language research aims to ‘correct’ it in this respect.
1.5. Bibliography
[ABI 84] ABITEBOUL S., BIDOIT N., “Non first normal form relations to represent hierarchically organized data”, Proceedings of the 3rd ACM SIGACT-SIGMOD Symposium on Principles of Database Systems, PODS’84, New York, USA, pp. 191–200, 1984.
[ALH 09] AL HAJJ HASSAN M., Parallelism and load balancing in the treatment of the join on distributed architectures, PhD thesis, University of Orléans, December 2009.
[ALH 15] AL HAJJ HASSAN M., BAMHA M., “Towards scalability and data skew handling in group by-joins using map reduce model”, International Conference On Computational Science - ICCS 2015, 51, Procedia Computer Science, Reykjavik, Iceland, pp. 70–79, June 2015.
[APA 17a] APACHE SOFTWARE FOUNDATION, Apache Hadoop 2.8, 2017.
[APA 17b] APACHE SOFTWARE FOUNDATION, Apache Spark, 2017.
[BEN 13] BENZAKEN V., CASTAGNA G., NGUYỄN K. et al., “Static and dynamic semantics of NoSQL languages”, SIGPLAN Not., ACM, vol. 48, no. 1, pp. 101–114, January 2013.
[BEN 18] BENZAKEN V., CASTAGNA G., DAYNÈS L. et al., “Language-integrated queries: a BOLDR approach”, The Web Conference 2018, Lyon, France, April 2018.
[BES 17] BESSE P., GUILLOUET B., LOUBES J.-M., “Big data analytics. Three use cases with R, Python and Spark”, in MAUMY-BERTRAND M., SAPORTA G., THOMAS-AGNAN C. (eds), Apprentissage Statistique et Données Massives, Journées d’Etudes en Statistisque, Technip, 2017.
[BEY 11] BEYER K.S., ERCEGOVAC V., GEMULLA R. et al., “Jaql: a scripting language for large scale semistructured data analysis”, PVLDB, vol. 4, no. 12, pp. 1272–1283, 2011.
[BLO 70] BLOOM B.H., “Space/time trade-offs in hash coding with allowable errors”, Communication ACM, ACM, vol. 13, no. 7, pp. 422–426, July 1970.
[BRE 00] BREWER E.A., “Towards robust distributed systems (abstract)”, Proceedings of the Nineteenth Annual ACM Symposium on Principles of Distributed Computing, ACM, New York, USA, p. 7, 2000.
[CHE 13a] CHENEY J., LINDLEY S., RADANNE G. et al., “Effective quotation”, CoRR, vol. abs/1310.4780, 2013.
[CHE 13b] CHENEY J., LINDLEY S., WADLER P., “A practical theory of language-integrated query”, SIGPLAN Not., ACM, vol. 48, no. 9, pp. 403–416, September 2013.
[CHE 14] CHENEY J., LINDLEY S., WADLER P., “Query shredding: Efficient relational evaluation of queries over nested multisets (extended version)”, CoRR, vol. abs/1404.7078, 2014.
[COD 70] CODD E.F., “A relational model of data for large shared data banks”, Communication ACM, ACM, vol. 13, no. 6, pp. 377–387, June 1970.
[COU 15] COUILLEC Y., SERRANO M., “Requesting heterogeneous data sources with array comprehensions in Hop.js”, Proceedings of the 15th Symposium on Database Programming Languages, ACM, Pittsburgh, United States, p. 4, October 2015.
[CUR 11] CURÉ O., HECHT R., LE DUC C. et al., “Data integration over NoSQL stores using access path based mappings”, DEXA 2012, 6860 Lecture Notes in Computer Science, Toulouse, France, pp. 481–495, August 2011.
[DEA 04] DEAN J., GHEMAWAT S., “MapReduce: simplified data processing on large clusters”, Proceedings of the 6th Conference on Symposium on Opearting Systems Design & Implementation - Volume 6, USENIX Association, Berkeley, USA, p. 10, 2004.
[FAN 16] FANG Y., CHENG R., TANG W. et al., “Scalable algorithms for nearest-neighbor joins on big trajectory data”, IEEE Transactions on Knowledge and Data Engineering, Institute of Electrical and Electronics Engineers, vol. 28, no. 3, 2016.
[FIS 85] FISCHER P.C., SAXTON L.V., THOMAS S.J. et al., “Interactions between dependencies and nested relational structures”, Journal of Computer and System Sciences, vol. 31, no. 3, pp. 343–354, 1985.
[FRI 08] FRISCH A., CASTAGNA G., BENZAKEN V., “Semantic subtyping: dealing set-theoretically with function, union, intersection, and negation types”, Journal ACM, vol. 55, no. 4, pp. 19:1–19:64, September 2008.
[GIL 02] GILBERT S., LYNCH N., “Brewer’s conjecture and the feasibility of consistent, available, partition-tolerant web services”, SIGACT News, vol. 33, no. 2, pp. 51–59, June 2002.
[GÓM 16] GÓMEZ P., CASALLAS R., RONCANCIO C., “Data schema does matter, even in NoSQL systems!”, 2016 IEEE Tenth International Conference on Research Challenges in Information Science (RCIS), Grenoble, France, June 2016.
[GRA 16] GRAUX D., JACHIET L., GENEVÈS P. et al., “SPARQLGX: efficient distributed evaluation of SPARQL with apache spark”, The 15th International Semantic Web Conference, Kobe, Japan, October 2016.
[GRE 15] GREENFIELD P., Keynote speech at PyData 2015: How Python Found its way into Astronomy, New York, USA, 2015.
[HAA 97] HAAS L.M., KOSSMANN D., WIMMERS E.L. et al., “Optimizing queries across diverse data sources”, Proceedings of the 23rd International Conference on Very Large Data Bases, VLDB’97, San Francisco, USA, pp. 276–285, 1997.
[HUS 14] HUSSON A., “Une sémantique statique pour MongoDB”, Journées francophones des langages applicatifs 25, Fréjus, France, pp. 77–92, January 8–11 2014.
[KOL 16a] KOLEV B., PAU R., LEVCHENKO O. et al., “Benchmarking polystores: the CloudMdsQL experience”, in GADEPALLY V. (ed.), IEEE BigData 2016: Workshop on Methods to Manage Heterogeneous Big Data and Polystore Databases, IEEE Computing Society, Washington D.C., United States, December 2016.
[KOL 16b] KOLEV B., VALDURIEZ P., BONDIOMBOUY C. et al., “CloudMdsQL: querying heterogeneous cloud data stores with a common language”, Distributed and Parallel Databases, vol. 34, no. 4, pp. 463–503, December 2016.
[LAN 01] LANEY D., 3D Data Management: Controlling Data Volume, Velocity, and Variety, Report, META Group, February 2001.
[MIL 92] MILNER R., PARROW J., WALKER D., “A calculus of mobile processes, I”, Information and Computation, vol. 100, no. 1, pp. 1–40, 1992.
[PAR 92] PAREDAENS J., VAN GUCHT D., “Converting nested algebra expressions into flat algebra expressions”, ACM Transaction Database Systems, vol. 17, no. 1, pp. 65–93, March 1992.
[PHA 14] PHAN T.-C., Optimization for big joins and recursive query evaluation using intersection and difference filters in MapReduce, Thesis, Blaise Pascal University, July 2014.
[PHA 16] PHAN T.-C., D’ORAZIO L., RIGAUX P., “A theoretical and experimental comparison of filter-based equijoins in MapReduce”, Transactions on Large-Scale Data-and Knowledge-Centered Systems XXV, 9620 Lecture Notes in Computer Science, pp. 33–70, 2016.
[PIL 16] PILOURDAULT J., LEROY V., AMER-YAHIA S., “Distributed evaluation of top-k temporal joins”, Proceedings of the 2016 International Conference on Management of Data, SIGMOD’16, New York, USA, pp. 1027–1039, 2016.
[RAM 03] RAMAKRISHNAN R., GEHRKE J., Database Management Systems, McGraw-Hill, New York, 3rd ed., 2003.
[SER 16] SERRANO M., PRUNET V., “A Glimpse of Hopjs”, International Conference on Functional Programming (ICFP), ACM, Nara, Japan, p. 12, September 2016.
[VAN 17] VANDERPLAS J., Keynote speech at PyCon 2017, 2017.
[W3C 13] W3C, SPARQL 1.1 overview, 2013.
[W3C 14] W3C, RDF 1.1 Concepts and Abstract Syntax, 2014.
Chapter written by Kim NGUYỄN.
