


















DynamoDB is a NoSQL database fully managed by Amazon, and it is made freely available (to a certain limit) as a web service. The meaning of fully managed is that all the patch installation, updates, data backup, replication, and all other security measures are taken care of by Amazon itself. Almost every NoSQL database has its own data model. A programmer or application designer always evaluates the strengths and weaknesses of a database by looking at its data model. This is the reason why we have taken DynamoDB data modeling for our primary discussion.
In this chapter we are going to discuss the basics of DynamoDB. The chapter is divided into four sections:
Discussing DynamoDB data model concepts, such as tables, items, and attributes
Continuing to discuss primary key creation and usage
Using secondary indexes
The different data types in DynamoDB
The following table makes understanding the data model easier. In RDBMS, a table is organized into rows and columns, but in DynamoDB we will never use these two words (except in this paragraph). Even if it is used mistakenly, please understand that rows are called items and columns are called attributes in DynamoDB, as shown in the following table:

Having said that, let's go and look at realizing a table in DynamoDB. Throughout this book, we are going to use a common illustration. The common illustration is that of a library catalogue, and we are going to discuss examples related to it. Let's take a look at the library catalogue table:

Tip
If you wish to know how to create a table with the attributes mentioned in Table 1.1, read the DynamoDB data types section first. During the creation of a DynamoDB table, it is only possible to specify secondary index attributes, and hash and range key attributes. It is not possible to specify other attributes (previously mentioned as optional attributes) during the creation of the table. In fact, except for hash and range key attributes, all other attributes are part of the items (rows); that is the reason why we don't specify these optional attributes while creating the table.
Let's call the table Tbl_Book. The table has seven attributes. The first two attributes act as a compound primary key. We set the first attribute BookTitle as the hash key and the second attribute Author as the range key. Except for the primary key attributes, all other attributes are optional and we need not specify nonprimary key attributes while creating the table.
Therefore, during the creation of the Tbl_Book table in DynamoDB, we will specify only the BookTitle and Author attributes. All other attributes can be specified while inserting an item into this table.
Let's assume that Tbl_Book has been created in DynamoDB with BookTitle and Author attributes as the hash and range key. We will now insert four items into the table as shown:

One quick question: while inserting the first item into the table, do we need to specify the PubDate attribute as null? The answer is no; every item can have its own attributes, along with mandatory primary key attributes specified during table creation. In fact, if we want to insert a fifth item with a new attribute named CoverPhoto, we can do it without affecting the previous four items.
Tip
Unlike RDBMS tables, the attributes (that is, what we call columns in RDBMS) of DynamoDB tables are stored in the item itself as a key-value pair. The attribute name becomes the key and the attribute value becomes the value. So every item will have its own attributes. There is a tradeoff here. Fetching a record will not only fetch the attribute value, but also its attribute name. So if you choose very long attribute names, then the efficiency will decrease.
Let's take a look at a few valid table schema that are supported by DynamoDB:

Let's take a look at a few invalid table schema:

The schema for Table 1.7 is invalid, because it doesn't have the hash key attribute that is mandatory to create the table. Table 1.8 is invalid because of the same reason. The schemas for Table 1.9 and Table 1.10 are invalid because the hash and range keys must be either String, Number, or Binary. It cannot be Set. We will discuss the Set data type at the end of this chapter.
Once you have had a good look at a valid table schema, you will have the following questions for sure:
What is the difference between the hash key and the range key?
What is the difference between
Stringdata type andStringSetdata type?Apart from
Set, is there any other data type that I should know about?During table creation, what mandatory information should I provide?
Let us discuss the answers to these questions, which will help us understand the DynamoDB data model better. Here comes the answer to the first question. With the hash and range keys, hash and range are two attributes that act like a (compound) primary key. The range key must be accompanied by the hash key, but the hash key can optionally be accompanied by the range key. The hash key is an attribute that every table must have. It is an unordered collection of items; this means that items with the same hash key values will go to the same partition, but there won't be any ordering based on these hash key values, whereas items will always be ordered on range key values (but grouped on hash key values). After applying the previous statements to the already-created table, its order will look as follows:

So there is no guarantee that the table data will be sorted by the hash key (that is BookTitle), but it will be hashed or grouped based on the hash key attribute value. That is the reason why Item1 and Item4 are placed close together. On the other hand, the records are ordered on the range key (that is, Author). That is the reason why the book SCJP authored by Kathy is first, followed by the book authored by Khalid. This answers the first question.
An attribute of the type String can hold only a simple string. For example, in the previous table we have two attributes (Language and Language2) to store the edition language of the book. If a book has 10 different language editions, then we would be left with too many attributes in an item (which will reduce fetch efficiency as discussed on the previous page). So a better solution is to change the Language attribute from a simple String type to StringSet as shown in the following table:

The same cannot be done for the Author attribute. Can you guess why? If not, you can go back and take a look at Table 1.9 and Table 1.10. Can you guess now? It's because neither the hash key nor the range key can be of the Set type.
At present there are only six data types in DynamoDB, namely String, Number, Binary, StringSet, NumberSet, and BinarySet. We will discuss this at the end of this chapter.
During table creation, there are two scenarios that decide the mandatory parameters needed to create a DynamoDB table.
Hash primary key: In this scenario we must (and we can only) provide two parameters. The first parameter is the table name, and the second parameter is the name and type of hash key.
Hash and range primary key: In this scenario, we must (and we can only) provide three parameters. The first parameter is the table name, the second parameter is the name and type of hash key, and the third parameter is the name and type of range key.
There are different interfaces available to interact with DynamoDB. Take a look at Chapter 2, DynamoDB Interfaces, to know more about the interfaces. We are now done with the basics of this chapter.
As DynamoDB is a NoSQL database and is used with scalable applications, table data might grow exponentially. This might reduce data read and write throughput (the number of 1 KB read or write requests per second) if not managed efficiently. This management starts right from choosing the correct primary key and its parameters. Take a look at the following table:

As soon as the table is created, the table data is partitioned on the hash key attribute. What this means is that if the table has three partitions, then the first two items will go to the first partition, the third item will go to the second partition and the last item will go to the third partition. This partition is based purely on hash logic, which we are not going to discuss here.
In our library catalogue example, we are always looking for a certain book, with the assumption that the first thing that comes to our mind when identifying a book is its title. That is why we decided to set the BookTitle attribute as the hash key. Another reason why we chose this specific attribute as the hash key is the assumption that most of the scan operations for the table will include the BookTitle attribute.
DynamoDB does not allow duplication of the hash key (provided that the table does not have a range attribute), so if the primary key is a simple hash key, then we are enforcing that an entry cannot be made into the previous table with the same book title. But in a real-world scenario this is not the case. So we are in need of a range key attribute as well. The next decision to be taken is what should be made the range attribute. We will assume that the second attribute that comes to mind when identifying a book is the name of its author. Unlike the hash key attribute, range key attributes are ordered (also grouped on the hash key attribute). Here also we are enforcing upon DynamoDB that the same author will never write a book on the same title.
Take a look at the following table (which is incorrect and is shown only to understand the concept):

But this might fail in several cases because the later editions of the book might have been authored by the same author. In this case, the second item insertion will simply overwrite the first item because the primary key is duplicated. As a solution, at this point in time I'd recommend you to concatenate the Author attribute along with the Edition attribute separated by # (or any other acceptable delimiter). So the table will look as follows:

Observe the String range key attribute Author#Edition. Even if some of the items don't have the edition included in the range key attribute, it will not create any trouble at the DynamoDB end (but we have to take care from the application programming front).
Some of you might have thought of making the range key attribute type as StringSet, but remember that hash or range key attributes cannot be a Set type.
There are a few things to be kept in mind before choosing the correct hash and range attributes:
Since the table is partitioned based on the hash key attribute, do not choose repeating attributes that will have only single-digit (very few) unique values. For example, the
Languageattribute of our table has only three identical values. Choosing this attribute will eat up a lot of throughput.Give the most restricted data type. For example, if we decide to make some number attributes as primary key attributes, then (even though
Stringcan also store numbers) we must use theNumberdata type only, because the hash and ordering logic will differ for each data type. Other advantages will be discussed in Chapter 5, Query and Scan Operations in DynamoDB, while discussing query and scan.Do not put too many attributes or too lengthy attributes (using delimiter as discussed formerly) into the primary key attributes, because it becomes mandatory that every item must have these attributes and all the attributes will become part of the query operation, which is inefficient.
Make the attribute to be ordered as the range key attribute.
Make the attribute to be grouped (or partitioned) as the hash key attribute.
Just imagine that we are entering a hypermarket to purchase a few grocery items, which we have already noted on a piece of paper. It's a multistorey store. Being a hypermarket, it has almost all the products, such as grocery items, home appliances, electronics, footwear, and lifestyle items. Since our intention is to purchase grocery items, we start with olive oil, and we find it located on the first floor, but the cookware is not available on the same floor; it's available on the top floor (let's say the tenth floor). After dragging ourselves from the bottom floor to the top floor, we find that we were especially looking to buy a microwave oven, but guess what? It is available on the fifth floor. So we are thinking of getting the elevator and going to the fifth floor. In spite of the badly-arranged items (not only with grocery items), almost all the people are using the elevator, because of which we couldn't purchase the microwave oven (along with some other items). So it's a loss of money for the store as well as a waste of time for the customers.
We are entering another hypermarket, that has all the grocery items placed on the first floor. Along with the items noted on the paper, we are purchasing a few more items that we missed out while writing. In this way both the customer and the store will benefit. Which store will you choose to shop in the next time? If you say that I love the first store and I will always choose to purchase items only from that store, then please read Chapter 4, Working with Secondary Indexes, which covers the usage of secondary index.
So you can call a store or hypermarket perfectly managed only if it helps the customer complete his/her purchase easily. This can be done by organizing the items properly. Similarly you can call a database properly managed only if the elements or items are organized in such a way that it allows easy and fast retrieval of items in the table (in NoSQL, we don't care much about insertion speed, since the data is read multiple times when it is written or updated).
Indexes make retrieval much faster and minimize your billing in many ways. We are going to discuss a few secondary index basics here, and a much more detailed discussion will continue in Chapter 4, Working with Secondary Indexes.
Do you know that whenever you create a DynamoDB table, an index is also created? That index is called as primary index. This primary index will include the primary key attributes (both hash and range keys). The index created over a hash key is an unordered hash index. What it means is that the items with the same hash key will be grouped together and placed adjacent to each other, which helps in faster retrieval of items with the same hash key attributes (using the scan operation), but there will not be any ordering in the item on the hash key attribute.
Just for illustration purposes, let's go back to the Tbl_Book table:

Here, you can see that the items with the same BookTitle attribute (which is the hash key attribute) are placed adjacent to each other, because as soon as the table is created, this index will be created, and whenever an insertion takes place it will hash this attribute using some hash logic and place it in the correct location. If you look at the ASCII code or the English alphabetical order, L as in Let us C comes before S as in SCJP. Since the index created on the hash key is unordered, the items will not be sorted on this attribute.
Another noticeable concept is the index created on the Author#Edition attribute (which is the range key attribute); it works deeper on the tree created by the hash key index. This index will order the items that have the same hash key (but of course with different range key values) either in descending or ascending order. To put it in RDBMS terms, the hash key index will perform GROUP BY and the range key index will perform the ORDER BY action.
Primary indexes are created by DynamoDB by default. Along with those indexes, the user can create up to five secondary indexes for a table. There are two kinds of secondary indexes:
In both of these secondary index types, the range key can be a field, which the user needs to create the index for.
In the case of the local secondary index, the grouping will always take place on the hash key attribute, whereas the ordering takes place on the nonprimary key attribute. A quick question: in DynamoDB, except for primary key attributes, all other attributes are optional for an item. So where do these index attributes fall, in optional attributes or mandatory attributes? The answer is that local secondary index attributes are also optional attributes. If an item does not include this attribute, then that item will not be indexed, it's as simple as that.
We will take a look at an example in the following table:
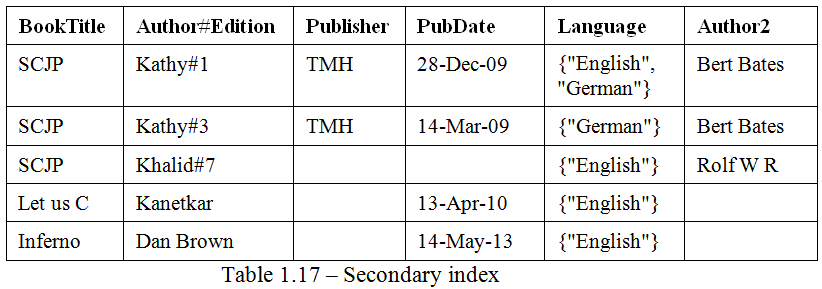
Let's say that we are creating a local secondary index on the PubDate attribute. Let's name this index Idx_PubDate. The index will look as shown in the next table. This is the smallest local secondary index we can create (we are not going to discuss projections yet. We will discuss them in Chapter 4, Working with Secondary Indexes). Take a look at the following table:

You will quickly notice that the third item did not have the secondary index attribute, so that item is not available in the index. One more change is that the index is sorted on the PubDate attribute, so the first item became the second item.
In the case of the local secondary index, there is a restriction that the hash key of the table must be the hash key of the index too. In order to overcome this, we can also specify the user-defined (non-primary key attribute) attribute as the hash key attribute of the secondary index. Then this index will be called the global secondary index.
Let's take a scenario in which we need to count the number of unique languages a publisher has published the book in. In this case, the publisher name will become the GROUP BY column (index hash key) and the Language column will become the ORDER BY column (index range key). Take a look at the following tables:

In this case, the item will be put into the index only if both the attributes of the index are available in the item. That is the reason why two items are not available in the global secondary index.
DynamoDB supports six data types, namely String, Number, Binary, StringSet, NumberSet, and BinarySet. To understand this better, we will get some help from the AWS management console. Once we have signed up with AWS, our management console will look for an icon to work with DynamoDB, as shown in the following screenshot:

Clicking on the DynamoDB icon for the first time will take us to a getting started page, which has guidelines on starting with DynamoDB. We should click on the Create Table button to create our first table. We are now going to create the Tbl_Book table, which we have seen enough times. We are also going to insert only one item into this table. The table and its item are as shown:

After clicking on Create Table, you will see the following page. Here you have to provide Table Name, Hash Attribute Name, and Range Attribute Name. After providing the necessary parameters, you can proceed further.

As we discussed, during the creation of the table we need to specify only the primary key attributes along with the table name. In this table, both the key elements are of type String.
If we need to create a simple hash (without range key) primary key, then we can select the Hash radio button instead of Hash and Range.
The next page will provide an option to create secondary indexes, which we need not bother about now. Once we proceed with all the command buttons in the browser, we will see the page in the following screenshot:

Initially, the status will be CREATING. Once it becomes ACTIVE, we can click on Explore Table (as shown in the previous screenshot) to insert (or scan) items into the table.
Once we have clicked on Explore Table, we should again click on the New Item button to insert an item. Clicking on this button will open the window in the following screenshot (we have already populated it to save paper):

The mandatory attributes, name and type, will be already populated and we cannot change them. But we can add the attribute values (which must be unique).
In addition to that, we can simple click on empty textboxes (under hash and range key attribute name) to add item-specific attribute name, type, and value.
Here the first four attributes are of the type String, so we can enter the corresponding values in the attribute value field.
While entering multivalued data for a Set data type (StringSet for the Language field), specify multiple strings or numbers by clicking on the plus sign to the right of the value textbox. Once all the attributes are entered, click on the Put Item button, which will put this item into the Tbl_Book table.
To view the inserted item, click on the Browse Items tab, select the Scan radio button, and click on the Go button. Now we will be able to see the table content as shown in the following screenshot:

The String attribute values are enclosed in double quotes, and the Set attribute values are enclosed by set brackets. The number attribute values won't be enclosed by any character.
There are a few rules while using the Set data type. These rules are as follows:
Setmust have a nonzero number of elements (that is, empty sets are not permitted)Setmust not have duplicate values (that is, theLanguageset will not takeEnglish,English)
There is a special kind of data type, called Binary, which is capable of storing Base64 encoded values. It is also used to store images or pictures in the Base64 encoded format. We will see it in Chapter 6, Working with the DynamoDB API.
In this chapter, we learned about data model concepts, including tables, items and attributes, primary key, and indexes and their design patterns.
We started the chapter by discussing the DynamoDB data model where we understood the importance of primary keys. We then took a look at a few valid and invalid table schema. We understood the basic significance of DynamoDB indexes. Finally, there was some explanation of the DynamoDB data types that we have used so far in the chapter. This is a basic chapter and we are going to cover similar topics in the upcoming chapters in greater detail.
In this chapter we took a look at the AWS management console. But along with the management console we can interact with DynamoDB in numerous ways, which we are going to see in the next chapter along with the installation and configuration details. We will learn how to access DynamoDB in the management console, command line, and the Eclipse plugin.


