


















Querying a graph database using the Java API can be very tedious; you would need to visit the whole graph and skip nodes that don't match what you are searching for. Any changes to the query will result in rethinking the code, changing it, and building it all over again. Why? The reason is that we are using an imperative language to do pattern matching, and traditional imperative languages don't work well in this task. Cypher is the declarative query language used to query a Neo4j database. Declarative means that it focuses on the aspects of the result rather than on methods or ways to get the result so that it is human-readable and expressive.
In this chapter, we will cover the following topics:
Setting up a Neo4j database
Querying the database in a simpler way than using the Java API
If you already have experience in creating a Neo4j database, you can skip this and jump to the next section.
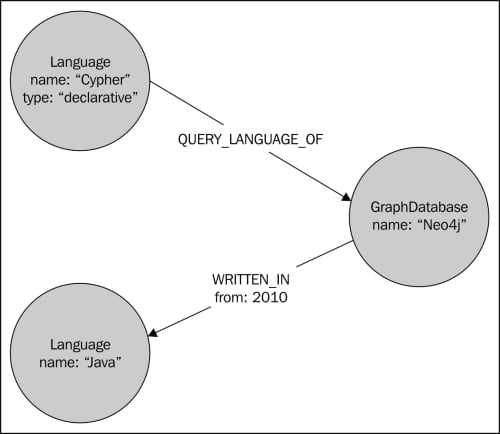
Neo4j is a graph database, which means that it does not use tables and rows to represent data logically; instead, it uses nodes and relationships. Both nodes and relationships can have a number of properties. While relationships must have one direction and one type, nodes can have a number of labels. For example, the following diagram shows three nodes and their relationships, where every node has a label (language or graph database), while relationships have a type (QUERY_LANGUAGE_OF and WRITTEN_IN).
The properties used in the graph shown in the following diagram are name, type, and from. Note that every relation must have exactly one type and one direction, whereas labels for nodes are optional and can be multiple.
Neo4j can be run in two modes:
An embedded database in a Java application
A standalone server via REST
In any case, this choice does not affect the way you query and work with the database. It's an architectural choice driven by the nature of the application (whether a standalone server or a client server), performance, monitoring, and safety of data.
Neo4j Server is the best choice for interoperability, safety, and monitoring. In fact, the REST interface allows all modern platforms and programming languages to interoperate with it. Also, being a standalone application, it is safer than the embedded configuration (a potential crash in the client wouldn't affect the server), and it is easier to monitor. If we choose to use this mode, our application will act as a client of the Neo4j server.
To start Neo4j Server on Windows, download the package from the official website (http://www.neo4j.org/download/windows), install it, and launch it from the command line using the following command:
C:\Neo4jHome\bin\Neo4j.bat
You can also use the frontend, which is bundled with the Neo4j package, as shown in the following screenshot:
To start the server on Linux, you can either install the package using the Debian package management system, or you can download the appropriate package from the official website (http://www.neo4j.org/download) and unpack it with the following command:
# tar -cf <package>
After this, you can go to the new directory and run the following command:
# ./bin/neo4j console
Anyway, when we deploy the application, we will install the server as a Windows service or as a daemon on Linux. This can be done easily using the Neo4j installer tool.
On the Windows command launch interface, use the following command:
# bin\Neo4jInstaller.bat install
When installing it from the Linux console, use the following command:
# neo4j-installer install
To connect to Neo4j Server, you have to use the REST API so that you can use any REST library of any programming language to access the database. Though any programming language that can send HTTP requests can be used, you can also use online libraries written in many languages and platforms that wrap REST calls, for example, Python, .NET, PHP, Ruby, Node.js, and others.
An embedded Neo4j database is the best choice for performance. It runs in the same process of the client application that hosts it and stores data in the given path. Thus, an embedded database must be created programmatically. We choose an embedded database for the following reasons:
When we use Java as the programming language for our project
When our application is standalone
For testing purposes, all Java code examples provided with this book are made using an embedded database.
The fastest way to prepare the IDE for Neo4j is using Maven. Maven is a dependency management as well as an automated building tool. In the following procedure, we will use NetBeans 7.4, but it works in a very similar way with the other IDEs (for Eclipse, you will need the m2eclipse plugin). The procedure is described as follows:
Create a new Maven project as shown in the following screenshot:

In the next page of the wizard, name the project, set a valid project location, and then click on Finish.
After NetBeans has created the project, expand Project Files in the project tree and open the
pom.xmlfile. In the<dependencies>tag, insert the following XML code:<dependencies> <dependency> <groupId>org.neo4j</groupId> <artifactId>neo4j</artifactId> <version>2.0.1</version> </dependency> </dependencies> <repositories> <repository> <id>neo4j</id> <url>http://m2.neo4j.org/content/repositories/releases/</url> <releases> <enabled>true</enabled> </releases> </repository> </repositories>
This code informs Maven about the dependency we are using on our project, that is, Neo4j. The version we have used here is 2.0.1. Of course, you can specify the latest available version.
If you are going to use Java 7, and the following section is not present in the file, then you'll need to add the following code to instruct Maven to compile Java 7:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>Once saved, the Maven file resolves the dependency, downloads the JAR files needed, and updates the Java build path. Now, the project is ready to use Neo4j and Cypher.
Creating an embedded database is straightforward. First of all, to create a database, we need a GraphDatabaseFactory class, which can be done with the following code:
GraphDatabaseFactory graphDbFactory = new GraphDatabaseFactory();
Then, we can invoke the newEmbeddedDatabase method with the following code:
GraphDatabaseService graphDb = graphDbFactory
.newEmbeddedDatabase("data/dbName");Now, with the GraphDatabaseService class, we can fully interact with the database, create nodes, create relationships, and set properties and indexes.
Neo4j allows you to pass a set of configuration options for performance tuning, caching, logging, file system usage, and other low-level behaviors. The following code sets the size of the memory allocated for mapping the node store to 20 MB:
import org.neo4j.graphdb.factory.GraphDatabaseSettings;
// ...
GraphDatabaseService db = graphDbFactory
.newEmbeddedDatabaseBuilder(DB_PATH)
.setConfig(GraphDatabaseSettings
.nodestore_mapped_memory_size, "20M")
.newGraphDatabase();You will find all the available configuration settings in the GraphDatabaseSettings class (they are all static final members).
Note that the same result can be achieved using the properties file. Clearly, reading the configuration settings from a properties file comes in handy when the application is deployed because any modification to the configuration won't require a new build. To replace the preceding code, create a file and name it, for example, neo4j.properties. Open it with a text editor and write the following code in it:
neostore.nodestore.db.mapped_memory=20M
Then, create the database service with the following code:
GraphDatabaseService db = graphDbFactory
.newEmbeddedDatabaseBuilder(DB_PATH)
.loadPropertiesFromFile("neo4j.properties")
.newGraphDatabase();For the first example in this book, I chose an enterprise application, such as human resource (HR) management, because I think Neo4j is a great persistence tool for enterprise applications. In fact, they are famous for having very complex schemas with a lot of relationships and entities and requirements that often change during the life of the software; therefore, the queries are also complicated and prone to change frequently.
Tip
Downloading the example code
You can download the example code files for all Packt books you have purchased from your account at http://www.packtpub.com. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
In our human resources tool, we have two kinds of nodes: employees and cost centers. So, we can define the two labels with the following code:
public enum HrLabels implements Label {
Employee,
CostCenter
}Labels are usually defined using an enumeration, but Neo4j just requires those labels that implement the Label interface.
Tip
Labels are a very useful feature introduced in Neo4j 2.0 that allow us to label a node and make it easier to find them later. A node can have one or more labels, so you can express complex domain concepts. Labels can be indexed to improve the performance of a search as well.
We have three types of relationships:
Employees that belong to cost centers
Employees that report to other employees
Employees that can be managers of a cost center
So, we have to define the relationships. This is usually done using the enum function, as shown in the following code snippet:
public enum EmployeeRelationship implements RelationshipType {
REPORTS_TO,
BELONGS_TO,
MANAGER_OF;
public static final String FROM = "from";
}The FROM constant represents the name of a property. We will use it to store the start date of the validity of the relationship. Clearly, a real-world HR application would have a lot of relationships and properties; here we have just a subset.
The next step is to fill in the database. First of all, to work with Neo4j using the Java API, we always need a transaction created from the GraphDatabaseService class. While building with Java 7, you can use the following syntax:
import org.neo4j.graphdb.Transaction;
import org.neo4j.graphdb.GraphDatabaseService;
// ...
try (Transaction tx = graphDb.beginTx()) {
// work with the graph...
tx.success();
}The first line in the preceding code creates a transaction named tx. The call to success marks the transaction successful; every change will be committed once the transaction is closed. If an exception is thrown from inside the try statement, the transaction automatically ends with a rollback. When you use Java 6, the code is a little longer because you have to close the transaction explicitly within a finally clause, as shown in the following code:
Transaction tx = graphDb.beginTx();
try {
// work with the graph...
tx.success();
} finally {
tx.close();
}Now, in our application, cost centers are identified only by their code, while employees can have the following properties:
Name
Surname
Middle name
Our relationships (REPORTS_TO, BELONGS_TO, and MANAGER_OF) can have a property (From) that specifies the dates of validity. The following code creates some examples of nodes and the relationships between them, and then sets the property values of nodes and some relationships:
import java.util.GregorianCalendar;
import org.neo4j.graphdb.GraphDatabaseService;
import org.neo4j.graphdb.Node;
import org.neo4j.graphdb.Transaction;
import org.neo4j.graphdb.factory.GraphDatabaseFactory;
public class DatabaseSetup {
/**
* Properties of a cost center
*/
public static class CostCenter {
public static final String CODE = "code";
}
/**
* Properties of an employee
*/
public static class Employee {
public static final String NAME = "name";
public static final String MIDDLE_NAME = "middleName";
public static final String SURNAME = "surname";
}
Public static void setup(GraphDatabaseService graphDb) {
try (Transaction tx = graphDb.beginTx()) {
// set up of center costs
Node cc1 = graphDb.createNode(HrLabels.CostCenter);
cc1.setProperty(CostCenter.CODE, "CC1");
Node cc2 = graphDb.createNode(HrLabels.CostCenter);
cc2.setProperty(CostCenter. CODE, "CC2");
Node davies = graphDb.createNode(HrLabels.Employee);
davies.setProperty(Employee.NAME, "Nathan");
davies.setProperty(Employee.SURNAME, "Davies");
Node taylor = graphDb.createNode(HrLabels.Employee);
taylor.setProperty(Employee.NAME, "Rose");
taylor.setProperty(Employee.SURNAME, "Taylor");
Node underwood = graphDb.createNode(HrLabels.Employee);
underwood.setProperty(Employee.NAME, "Heather");
underwood.setProperty(Employee.MIDDLE_NAME, "Mary");
underwood.setProperty(Employee.SURNAME, "Underwood");
Node smith = graphDb.createNode(HrLabels.Employee);
smith.setProperty(Employee.NAME, "John");
smith.setProperty(Employee.SURNAME, "Smith");
// There is a vacant post in the company
Node vacantPost = graphDb.createNode();
// davies belongs to CC1
davies.createRelationshipTo(cc1, EmployeeRelationship.BELONGS_TO)
.setProperty(EmployeeRelationship.FROM,
new GregorianCalendar(2011, 1, 10).getTimeInMillis());
// .. and reports to Taylor
davies.createRelationshipTo(taylor, EmployeeRelationship.REPORTS_TO);
// Taylor is the manager of CC1
taylor.createRelationshipTo(cc1, EmployeeRelationship.MANAGER_OF)
.setProperty(EmployeeRelationship.FROM,
new GregorianCalendar(2010, 2, 8).getTimeInMillis());
// Smith belongs to CC2 from 2008
smith.createRelationshipTo(cc2, EmployeeRelationship.BELONGS_TO)
.setProperty(EmployeeRelationship.FROM,
new GregorianCalendar(2008, 9, 20).getTimeInMillis());
// Smith reports to underwood
smith.createRelationshipTo(underwood, EmployeeRelationship.REPORTS_TO);
// Underwood belongs to CC2
underwood.createRelationshipTo(cc2, EmployeeRelationship.BELONGS_TO);
// Underwood will report to an employee not yet hired
underwood.createRelationshipTo(vacantPost, EmployeeRelationship.REPORTS_TO);
// But the vacant post will belong to CC2
vacantPost.createRelationshipTo(cc2, EmployeeRelationship.BELONGS_TO);
tx.success();
}
}
}In the preceding code, we used the following functions of the GraphDatabaseService class:
createNode: This creates a node and then returns it as result. The node will be created with a long, unique ID.createRelationshipTo: This creates a relationship between two nodes and returns that relationship in a relationship instance. This one too will have a long, unique ID.setProperty: This sets the value of a property of a node or a relationship.
We put the time in milliseconds in the property because Neo4j supports only the following types or an array of one of the following types:
booleanbyteshortintlongfloatdoubleString
To store complex types of arrays, we can code them using the primitive types, as seen in the preceding list, but more often than not, the best approach is to create nodes. For example, if we have to store a property such as the entire address of a person, we can convert the address in JSON and store it as a string.
This way of storing data in a JSON format is common in document-oriented DBs, such as MongoDB, but since Neo4j isn't a document database, it won't build indexes on the properties of the document. So, for example, it would be difficult or very slow to query people by filtering on any field of the address, such as the ZIP code or the country. In other words, you should use this approach only for raw data that won't be filtered or processed with Cypher; in other cases, creating nodes is a better approach.
A typical report of our application is a list of all the employees. In our database, an employee is a node labeled Employee, so we have to find all nodes that match with the label Employee pattern. In Cypher, this can be expressed with the following query:
MATCH (e:Employee) RETURN e
The MATCH clause introduces the pattern we are looking for. The e:Employee expression matches all e nodes that have the label Employee; this expression is within round brackets because e is a node. So, we have the first rule of matching expressions—node expressions must be within round brackets.
With the RETURN clause, we can specify what we want; for example, we can write a query to return the whole node with all its properties. In this clause, we can use any variable used in the MATCH clause. In the preceding query, we have specified that we want the whole node (with all its properties). If we are interested only in the name and the surname of the employees, we can make changes only in the RETURN clause:
MATCH (e:Employee) RETURN e.name,e.surname
If any node does not have either of the properties, a null value is returned. This is a general rule for properties from version 2 of Cypher; missing properties are evaluated as null values.
The next question is how to invoke Cypher from Java.
To execute Cypher queries on a Neo4j database, you need an instance of ExecutionEngine; this class is responsible for parsing and running Cypher queries, returning results in a ExecutionResult instance:
import org.neo4j.cypher.javacompat.ExecutionEngine;
import org.neo4j.cypher.javacompat.ExecutionResult;
// ...
ExecutionEngine engine =
new ExecutionEngine(graphDb);
ExecutionResult result =
engine.execute("MATCH (e:Employee) RETURN e");Note that we use the org.neo4j.cypher.javacompat package and not the org.neo4j.cypher package even though they are almost the same. The reason is that Cypher is written in Scala, and Cypher authors provide us with the former package for better Java compatibility.
Now with the results, we can do one of the following options:
Dumping to a string value
Converting to a single column iterator
Iterating over the full row
Dumping to a string is useful for testing purposes:
String dumped = result.dumpToString();
If we print the dumped string to the standard output stream, we will get the following result:

Here, we have a single column (e) that contains the nodes. Each node is dumped with all its properties. The numbers between the square brackets are the node IDs, which are the long and unique values assigned by Neo4j on the creation of the node.
When the result is a single column, or we need only one column of our result, we can get an iterator over one column with the following code:
import org.neo4j.graphdb.ResourceIterator;
// ...
ResourceIterator<Node> nodes = result.columnAs("e");Then, we can iterate that column in the usual way, as shown in the following code:
while(nodes.hasNext()) {
Node node = nodes.next();
// do something with node
}However, Neo4j provides a syntax-sugar utility to shorten the code that is to be iterated:
import org.neo4j.helpers.collection.IteratorUtil;
// ...
for (Node node : IteratorUtil.asIterable(nodes)) {
// do something with node
}If we need to iterate over a multiple-column result, we will write this code in the following way:
ResourceIterator<Map<String, Object>> rows = result.iterator();
for(Map<String,Object> row : IteratorUtil.asIterable(rows)) {
Node n = (Node) row.get("e");
try(Transaction t = n.getGraphDatabase().beginTx()) {
// do something with node
}
}The iterator function returns an iterator of maps, where keys are the names of the columns. Note that when we have to work with nodes, even if they are returned by a Cypher query, we have to work in transaction. In fact, Neo4j requires that every time we work with the database, either reading or writing to the database, we must be in a transaction. The only exception is when we launch a Cypher query. If we launch the query within an existing transaction, Cypher will work as any other operation. No change will be persisted on the database until we commit the transaction, but if we run the query outside any transaction, Cypher will open a transaction for us and will commit changes at the end of the query.
If you have ever used the Neo4j Java API, you might wonder why we should write the following code:
ExecutionEngine engine =
new ExecutionEngine(graphDb, StringLogger.SYSTEM);
ExecutionResult result =
engine.execute("MATCH (e:Employee) RETURN e");
ResourceIterator<Node> nodes = result.columnAs("e");You can get the same result with the Java API with a single line of code:
import org.neo4j.tooling.GlobalGraphOperations;
// ...
ResourceIterable<Node> empl = GlobalGraphOperations.at(graphDb)
.getAllNodesWithLabel(HrLabels.Employee);However, pattern matching is much more powerful. By making slight changes to the query, we can get very important and different results; for example, we can find nodes that have relationships with other nodes. The query is as follows:
MATCH (n:Employee) --> (cc:CostCenter) RETURN cc,n
The preceding query returns all employees that have a relation with any cost center:

Again, as you can see, both n and cc are within round brackets. Here, the RETURN clause specifies both n and cc, which are the two columns returned. The result would be the same if we specified an asterisk instead of n and cc in the RETURN clause:
MATCH (n:Employee) --> (cc:CostCenter)
RETURN *
In fact, similar to SQL, the asterisk implies all the variables referenced in the patterns, but unlike SQL, not all properties of the entities are involved, just those of the referenced ones. In the previous query, relationships were not returned because we didn't put a variable in square brackets.
By making another slight change to the query, we can get all the employees that have a relation with a specific cost center, for example CC1. We have to filter the code property as shown in the following code:
MATCH (n:Employee) --> (:CostCenter { code: 'CC1' })
RETURN nIf we compare this query with the previous one, we can note three differences, which are listed as follows:
The query returns only the employee node
nbecause we don't care about the center cost here.Here, we omitted the
ccvariable. This is possible because we don't need to give a name to the cost center that matches the expression.In the second query, we added curly brackets in the cost center node to specify the property we are looking for. So, this is another rule of pattern-matching expressions: properties are expressed within curly brackets.
The --> symbol specifies the direction of the relation; in this case, outgoing from n. In the case of MATCH expressions, we can also use the <-- symbol for inverse direction. The following expression is exactly equivalent to the previous expression:
MATCH (:CostCenter { code: 'CC1' } ) <-- (n:Employee)
RETURN nThe preceding expression will give the same result:
+-----------------------------------------+
| n |
+-----------------------------------------+
| Node[2]{name:"Nathan",surname:"Davies"} |
| Node[3]{name:"Rose",surname:"Taylor"} |
+-----------------------------------------+If we don't have a preferred direction, we will use the -- symbol:
MATCH (n:Employee) -- (:CostCenter { code: 'CC1' } )
RETURN nIn our example, the latter query will return the same result as the previous one because in our model, relationships go from employees to cost centers.
If we wish to know the existing relationships between the employees and cost centers, we will have to introduce another variable:
MATCH (n:Employee) -[r]- (:CostCenter { code: 'CC1' })
RETURN n.surname,n.name,rThe variable r matches any relationship that exists between the employees and cost center CC1 and is returned in a new column:
+-----------------------------------------------------------+
| n.surname | n.name | r |
+-----------------------------------------------------------+
| "Davies" | "Nathan" | :BELONGS_TO[0]{from:1297292400000} |
| "Taylor" | "Rose" | :MANAGER_OF[2]{from:1268002800000} |
+-----------------------------------------------------------+So, here we have the last rule: relationship expressions must be specified in square brackets.
To filter the employees who belong to a specific cost centre, we have to specify the relationship type:
MATCH (n) -[:BELONGS_TO]-> (:CostCenter { code: 'CC1' } )
RETURN nThis query matches any node n, which has a relation of the BELONGS_TO type with any node cc that has the value CC1 as a property code:
+-----------------------------------------+
| n |
+-----------------------------------------+
| Node[2]{name:"Nathan",surname:"Davies"} |
+-----------------------------------------+We can specify multiple relationships using the | operator. The following query will search for all employees who belong to or are managers of the cost center CC1:
MATCH (n) -[r:BELONGS_TO|MANAGER_OF]-> (:CostCenter{code: 'CC1'})
RETURN n.name,n.surname,rThis time we returned only the name and surname, while the relationship is returned in the second column:
+-----------------------------------------------------------+
| n.name | n.surname | r |
+-----------------------------------------------------------+
| "Nathan" | "Davies" | :BELONGS_TO[0]{from:1297292400000} |
| "Rose" | "Taylor" | :MANAGER_OF[2]{from:1268002800000} |
+-----------------------------------------------------------+By making a slight change to the query in the preceding code, we can return the manager as well as the employees of the cost center as the result. This can be implemented as shown in the following query:
MATCH (n) -[:BELONGS_TO]-> (cc:CostCenter) <-[:MANAGER_OF]- (m) RETURN n.surname,m.surname,cc.code
In this query, we can see the expressivity of Cypher—a very intuitive syntax to translate the "node n belonging to the cost center having a manager m" pattern. The result is the following code:
+---------------------------------+ | n.surname | m.surname | cc.code | +---------------------------------+ | "Davies" | "Taylor" | "CC1" | +---------------------------------+
Of course, we can chain an increasing number of relationship expressions to describe very complex patterns:
MATCH (n) -[:BELONGS_TO]->
(cc:CostCenter) <-[:MANAGER_OF]- (m) <-[:REPORTS_TO]- (k)
RETURN n.surname,m.surname,cc.code, k.surnameAnother query that is very useful in real-world applications is finding nodes reachable from one node with a certain number of steps and a certain depth. The ability to execute this kind of query, and search the neighborhood, is one of the strong points of graph databases:
MATCH (:Employee {surname: 'Smith'}) -[*2]- (neighborhood)
RETURN neighborhoodThis query returns the nodes that you can reach, starting from the Davies node, by visiting exactly two relationships of the graph. The result contains duplicated nodes because we have several paths to reach each of them:
+---------------------------------------------------------------+
| neighborhood |
+---------------------------------------------------------------+
| Node[4]{name:"Heather",surname:"Underwood",middleName:"Mary"} |
| Node[6]{} |
| Node[1]{code:"CC2"} |
| Node[6]{} |
+---------------------------------------------------------------+
4 rowsTip
To get different values, we can use the DISTINCT keyword:
MATCH (:Employee {surname: 'Smith'}) -[ *2]- (neighborhood)
RETURN DISTINCT neighborhoodThis time, we haven't specified any relationship type in the square brackets, so it matches any type. The expression *2 means exactly two steps. With a little change, we can also ask for the relationships we visited:
MATCH (:Employee {surname: 'Davies'}) -[r*2]- (neighborhood)
RETURN neighborhood, rOf course, by changing the number in the expression, we can get the query to navigate any number of relationships. However, we could also want all the nodes that are reachable from a number of relationships in a range of step numbers, for example, from two to three:
MATCH (:Employee {surname: 'Smith'}) -[r*2..3]- (neighborhood)
RETURN neighborhood,r
This is very useful in real-world applications such as social networks because it can be used to build lists, for example, a list of people you may know.
If we also want the starting node in the result, we can modify the range to start from 0:
MATCH (:Employee{surname: 'Smith'}) -[r*0..2]- (neighborhood)
RETURN neighborhood,r
In our applications, we often need to get some information related to something that could be missing. For example, if we want to get a list of all employees who have a specific number of employees reporting to them, then we must deal with those employees too who have no employees reporting to them. In fact, we can write:
MATCH (e:Employee) <-[:REPORTS_TO]- (m:Employee) RETURN e.surname,m.surname
From this, the following result is obtained:
+-------------------------+ | e.surname | m.surname | +-------------------------+ | "Taylor" | "Davies" | | "Underwood" | "Smith" | +-------------------------+
However, this is not what we are looking for. In fact, we want all the employees, with all the employees that report to them as an option. This type of relation is similar to the OUTER JOIN clause of SQL and can be done in Cypher using OPTIONAL MATCH. This keyword allows us to use any pattern expression that can be used in the MATCH clause, but it describes only a pattern that could match. If the pattern does not match, the OPTIONAL MATCH clause sets any variable to null variable:
MATCH (e:Employee) OPTIONAL MATCH (e) <-[:REPORTS_TO]- (m:Employee) RETURN e.surname,m.surname, c.code
In this query, we slightly changed the previous one; we just inserted OPTIONAL MATCH (e). The effect is that the first part (e:Employee) must match, but the pattern following OPTIONAL MATCH may or may not match. So, this query returns any employee e, and if e has a relationship of the REPORTS_TO type with any other employee, this query is returned in m; otherwise, m will be a null value. The result is as follows:
+-------------------------+ | e.surname | m.surname | +-------------------------+ | "Davies" | <null> | | "Taylor" | "Davies" | | "Underwood" | "Smith" | | "Smith" | <null> | +-------------------------+
Note
Unlike object-oriented languages where referencing any property of a null object will result in a null-reference exception, in Cypher referencing, which is a property of the null node, we get a null value again.
Now, let's say that we also want to know whether the employee is the manager of any center cost, and if so, which one. Also, we want to know the cost center of any employee. For this, we can write the following code:
MATCH (e:Employee) OPTIONAL MATCH (c:CostCenter) <–[:MANAGER_OF]- (e) <-[:REPORTS_TO]- (m:Employee) RETURN e.surname,m.surname
The preceding code returns the following result:
+----------------------------------+ | e.surname | m.surname | c.code | +----------------------------------+ | "Davies" | <null> | <null> | | "Taylor" | "Davies" | "CC1" | | "Underwood" | <null> | <null> | | "Smith" | <null> | <null> | +----------------------------------+
What happened? Does it look like Smith does not report to Underwood anymore? This weird result is due to the fact that the whole pattern in OPTIONAL MATCH must match. We can't have partially matched patterns. Since we can add as many OPTIONAL MATCH expressions as we want to, we have to write the following code to get the result we are looking for:
MATCH (e:Employee) OPTIONAL MATCH (e) <-[:REPORTS_TO]- (m:Employee) OPTIONAL MATCH (e) -[:MANAGER_OF]-> (c:CostCenter) RETURN e.surname, m.surname, c.code
In fact, the result is the following code:
+----------------------------------+ | e.surname | m.surname | c.code | +----------------------------------+ | "Davies" | <null> | <null> | | "Taylor" | "Davies" | "CC1" | | "Underwood" | "Smith" | <null> | | "Smith" | <null> | <null> | +----------------------------------+
This query works because we have two OPTIONAL MATCH clauses that can independently generate a successful match.
As we have seen earlier, graph databases are useful to find paths between two nodes:
MATCH path = (a{surname:'Davies'}) -[*]- (b{surname:'Taylor'})
RETURN pathThis query uses a construct which we have not used so far—the path assignment, path =. The assignment of variables can be done only with paths. Note that the query in the preceding code returns all the possible paths from two nodes. Here, the result is two paths in our database:
[Node[2]{name:"Nathan",surname:"Davies"},:BELONGS_TO[0]{from:1297292400000},Node[0]{code:"CC1"},:MANAGER_OF[2]{from:1268002800000},Node[3]{name:"Rose",surname:"Taylor"}] |
[Node[2]{name:"Nathan",surname:"Davies"},:REPORTS_TO[1]{},Node[3]{name:"Rose",surname:"Taylor"}]However, what if we need the shortest path between them? The shortest path is the path with the least number of nodes visited. Clearly, we could iterate over all the paths and take the shortest, but Cypher provides a function that does the work for us:
MATCH (a{surname:'Davies'}), (b{surname:'Taylor'})
RETURN allShortestPaths((a)-[*]-(b)) as pathLet's see what is new in this query:
MATCH: In this clause, we have two node expressions (in round brackets) separated by a comma. These expressions,aandb, match any node independently, just like a Cartesian product.RETURN: In this clause, we have to call theallShortestPathfunction that takes an expression as a parameter. The expression is a variable length relation (this is the asterisk between the square brackets). Here, we don't care about relationship types and the direction, but we can filter properties, relation types involved, and so on, if necessary.RETURN: In this clause, we have an alias. An alias must be defined using the keywordAS. It just specifies the name of the column returned.
When we execute a query like the previous code, Cypher must find the nodes and relationships that match the pattern. However, to do so, it must start to search from a set of nodes or relationships. We can let Cypher find the starting points of a query on its own, but we can also specify them because we want to search a pattern that starts from a specific node, or a specific relation resulting in an important improvement in the performances of the query.
We can assign starting points to variables in the query using the START keyword. The previous query, for example, could be rewritten in the following way:
START a=node(2), b=node(3) RETURN allShortestPaths((a)-[*]-(b)) AS path
If we execute this query, and compare the time elapsed in executing this query and the previous one, we can easily prove that the latter is dramatically faster. The drawback is that we need to know the ID of the node.
In real-world applications, you often need to execute a query multiple times, changing a value in the query every time. For example, you need to find an employee by the surname, but the surname is typed by the application user from the keyboard. Cypher allows us to use parameters, just like in SQL. The names of the parameters must be between curly brackets:
MATCH (n:Employee {surname: {inputSurname} })
RETURN nIn this query, we have a parameter (inputSurname), whose value must be provided while executing the query.
The Cypher Java API wants us to pass all the parameters in the map. The following code is a class example that has a public method to find all employees by their surname:
import java.util.Map;
import java.util.HashMap;
import org.neo4j.cypher.javacompat.ExecutionEngine;
import org.neo4j.cypher.javacompat.ExecutionResult;
import org.neo4j.graphdb.Node;
import org.neo4j.helpers.collection.IteratorUtil;
public class EmployeeRepository {
public Iterator<Node> bySurname(String surname) {
Map<String, Object> params = new HashMap<>();
params.put("inputSurname", surname);
ExecutionResult result = engine
.execute("MATCH (n:Employee {surname: {inputSurname}})" +
"RETURN n",
params);
Iterator<Node> nodes = result.columnAs("n");
return nodes;
}
}The bySurname method takes the surname of the employees as a parameter to search, and it creates a new HashMap and puts the parameter in the map. Finally, the map is passed to the execute method of ExecutionEngine, and the result is treated in the usual way.
In this chapter, you first created a Neo4j database using the Java API. It details how Neo4j works with nodes and relationships.
Then, you queried that database to learn Cypher pattern matching. You learned about the MATCH keyword. You also learned that node expressions must go between round brackets, while relationships must be expressed in square brackets, and property expressions must be written between curly brackets.
You also learned how to use the RETURN clause to select which matched values we want the query to return. We wrote the Java code needed to use the result, even using query parameters. The OPTIONAL MATCH keyword allows us to match parts of the graph that could be missing. You also learned how to find paths from one node to another, and the shortest path between them, using the allShortestPaths function.
In the next chapter, you will learn how to filter and aggregate data and how to page through a query result.


