"As an architect you design for the present, with an awareness of the past for a future which is essentially unknown."
– Herman Foster
In this article by James Pogran, author of the book Learning Powershell DSC, we will cover the following topics:
- Push and pull management
- General workflow
- Local Configuration Manager
- DSC Pull Server
- Deployment considerations
(For more resources related to this topic, see here.)
Overview
DSC enables you to ensure that the components of your server environment have the correct state and configuration. It enables declarative, autonomous, and idempotent deployment, as well as configuration and conformance of standards-based managed elements.
By its simplest definition, DSC is a Windows service, a set of configuration files, and a set of PowerShell modules and scripts. Of course, there is more to this; there's push and pull modes, MOF compilation, and module packaging, but this is really all you need to describe DSC architecture at a high level.
At a lower level, DSC is much more complex. It has to be complex to handle all the different variations of operations you can throw at it. Something so flexible has to have some complicated inner workings. The beauty of DSC is that these complex inner workings are abstracted away from you most of the time, so you can focus on getting the job done. And if you need to, you can access the complex inner workings and tune them to your needs.
To ensure we are all on the same page about the concepts we are going to cover, let's cover some terms. This won't be an exhaustive list, but it will be enough to get us started.
|
Term
|
Description
|
|
Idempotent
|
An operation that can be performed multiple times with the same result.
|
|
DSC configuration file
|
A PowerShell script file that contains the DSC DSL syntax and list of DSC Resources to execute.
|
|
DSC configuration data
|
A PowerShell data file or separate code block that defines data that can change on target nodes.
|
|
DSC Resource
|
A PowerShell module that contains idempotent functions that brings a target node to a desired state.
|
|
DSC Cmdlets
|
PowerShell Cmdlets specially made for DSC operations.
|
|
MOF file
|
Contains the machine-readable version of a DSC configuration file.
|
|
LCM
|
The DSC engine, which controls all execution of DSC configurations.
|
|
CM
|
The process of managing configuration on the servers in your environment.
|
|
Drift
|
A bucket term to indicate the difference between the desired state of a machine and the current state.
|
|
Compilation
|
Generally a programming term, in this case it refers to the process of turning a DSC configuration file into an MOF file
|
|
Metadata
|
Data that describes other data. Summarizes basic information about other data in a machine-readable format.
|
Push and pull modes
First and foremost, you must understand how DSC gets the information needed to configure a target node from the place it's currently stored to the target node. This may sound counterintuitive; you may be thinking we should be covering syntax or the different file formats in use first. Before we get to where we're going, we have to know how we are getting there.
The more established CM products available on the market have coalesced into two approaches: push and pull. Push and pull refer to the directions and methods used to move information from the place where it is stored to the target nodes. It also describes the direction commands being sent to or received by the target nodes.
Most CM products primarily use the pull method, which means they rely on agents to schedule, distribute, and rectify configurations on target nodes, but have a central server that holds configuration information and data. The server maintains the current state of all the target nodes, while the agent periodically executes configuration runs on the target nodes. This is a simplistic but effective approach, as it enables several highly important features. Because the server has the state of every machine, a query-able record of all servers exists that a user can utilize. At any one point in time, you can see the state of your entire infrastructure at a glance or in granular detail. Configuration runs can be executed on demand against a set of nodes or all nodes. Other popular management products that use this model are Puppet and Chef.
Other CM products primarily use the push method, where a single workstation or user calls the agent directly. The user is solely responsible for scheduling executions and resolving all dependencies that the agent needs. It's a loose but flexible network as it allows the agents to operate even if there isn't a central server to report the status to. This is called a master-less deployment, in that there isn't anything keeping track of things.
The benefit of this model largely depends on your specific use cases. Some environments need granularity in scheduling and a high level of control over how and when agents perform actions, so they benefit highly from the push model. They choose when to check for drift and when to correct drift on a server-to-server basis or an entire environment. Common uses for this approach are test and QA environments, where software configurations change frequently and there is a high expectation of customization.
Other environments are less concerned with low-level customization and control and are more focused on ensuring a common state for a large environment (thousands and thousands of servers). Scheduling and controlling each individual server among thousands is less important than knowing that eventually, all severs will be in the same state, no matter how new or old they are. These environments want new a server quickly that conforms to an exacting specification without human intervention, so new severs are automatically pointed to a pull sever for a configuration assignment.
Both DSC and other management products like Puppet and Chef can operate with and without a central server. Products like Ansible only support this method of agent management. Choosing which product to use is more a choice of which approach fits your environment best, rather than which product is best.
The push management model
DSC offers a push-based approach that is controlled by a user workstation initiating an execution on agents on target nodes, but there isn't a central server orchestrating things. Push management is very much an interactive process, where the user directly initiates and executes a specified configuration.
The following diagram shows the push deployment model:
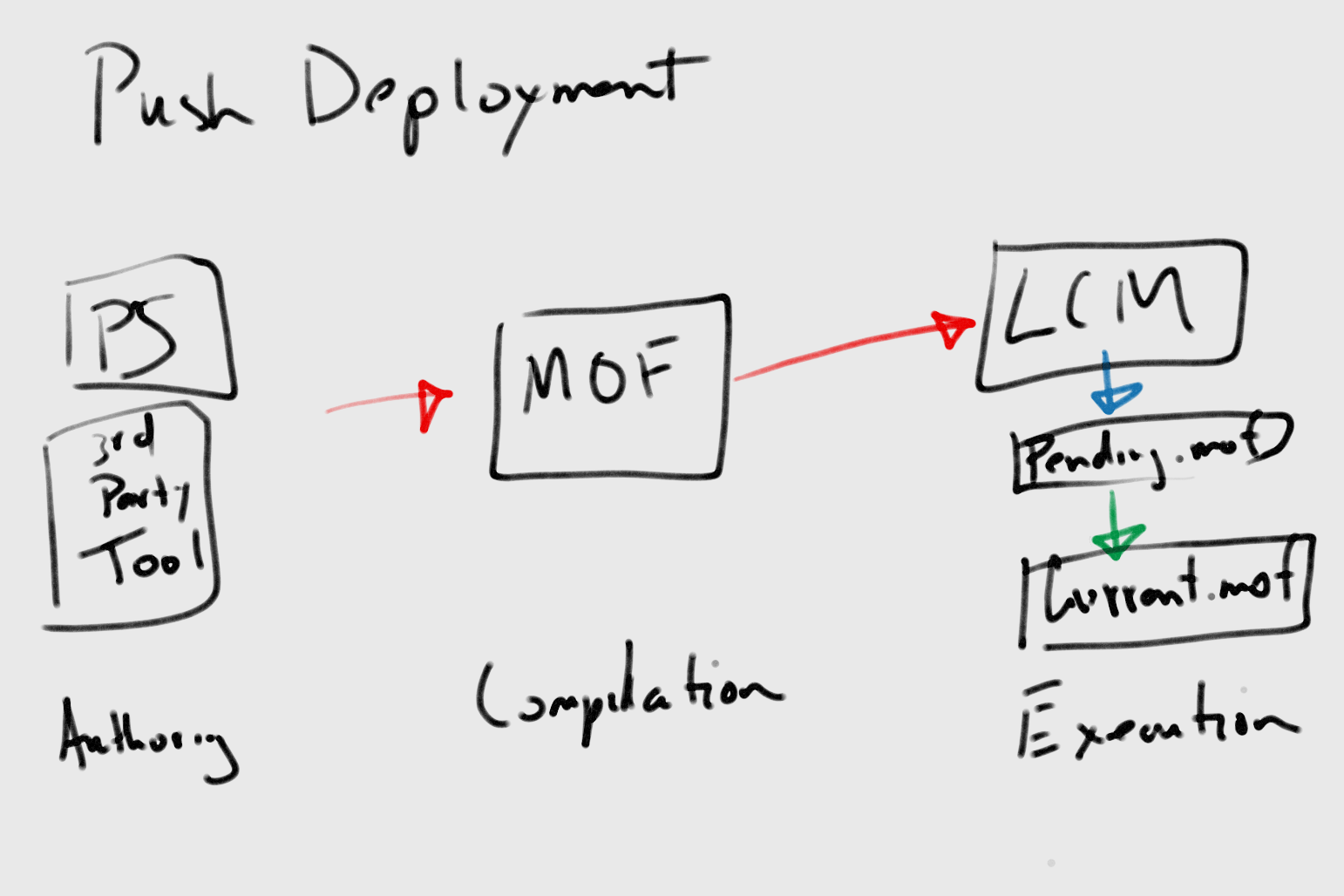
This diagram shows the steps to perform a push deployment. The next section discusses the DSC workflow, where these steps will be covered, but for now, we see that a push deployment is comprised of three steps: authoring a configuration file, compiling the file to an MOF file, and then finally, executing the MOF on the target node.
DSC operates in a push scenario when configurations are manually pushed to target nodes using the Start-DscConfiguration Cmdlet. It can be executed interactively, where the configuration is executed and the status is reported back to the user as it is running. It can also be initiated in a fire and forget manner as a job on the target node, where the configuration will be executed without reporting the status back to the user directly, but instead is logged to the DSC event log.
Pushing configurations allow a great deal of flexibility. It's the primary way you will test your configurations. Run interactively with the Verbose and Wait parameter, the Start-DscConfiguration Cmdlet shows you a log of every step taken by the LCM, the DSC Resources it executes, and the entire DSC configuration run. A push-based approach also gives you an absolute time when the target node will have a configuration applied, instead of waiting on a schedule. This is useful in server environments when servers are set up once and stay around for a long time.
This is easiest to set up and the most flexible of the two DSC methods, but is the hardest to maintain in large quantities and in the long term.
The pull management model
DSC offers a pull-based approach that is controlled by agents on target nodes, but there is a central server providing configuration files. This is a marked difference from the push models offered by other CM products.
The following diagram shows the pull deployment model. The diagram shows the steps in a pull deployment and also shows how the status is reported for the compliance server. Refer back to following diagram when we cover pull servers later on in this article:

DSC operates in a pull scenario when configurations are stored on a DSC Pull Server and pulled by LCM on each target node. The Pull Server is the harder of the two DSC methods to set up, but the easiest to maintain in large node quantities and in the long term.
Pull management works great in server environments that have a lot of transient machines, like cloud or datacenter environments. These kinds of servers are created and destroyed frequently, and DSC will apply on a triggered basis. Pull Servers are also more scalable, as they can work against thousands of hosts in parallel. This seems counterintuitive, as with most Pull Servers we have a central point of drift detection, scheduling, and so on. This isn't the case with a DSC Pull Server; however, as it does not detect drift, compile MOFs, or other high cost actions. Compilation and the like happens on the author workstation or Converged infrastructure (CI) and the drift detection and scheduling happens on the agent, so the load is distributed across agents and not on the Pull Server.
The general workflow
The following diagram shows the authoring, staging, and execution phases of the DSC workflow. You will notice it does not look much different than the push or pull model diagrams. This similarity is on purpose, as the architecture of DSC allows the usage of it in either a push or pull deployment to be the same until the execution phase. This reduces the complexity of your configuration files and allows them to be used in either deployment mode without modification. Let's have a look at the entire DSC workflow:

Authoring
In order to tell DSC what state the target node should be in, you have to describe that state in the DSC DSL syntax. The end goal of the DSL syntax is to create an MOF file. This listing and compilation process comprises the entirety of the authoring phase. Even so, you will not be creating the MOF files directly yourself. The MOF syntax and format is very verbose and detailed, too much so for a human to reliably produce it. You can create an MOF file using a number of different methods―anything from Notepad to third-party tools, not just DSC tooling. The third-party vendors other than Microsoft will eventually implement their own compilers, as the operations to compile MOF is standardized and open for all to use, enabling authoring DSC files on any operating system.
Syntax
DSC provides a DSL to help you create MOF files. We call the file that holds the DSL syntax the DSC configuration file. Even though it is a PowerShell script file (a text file with a .ps1 extension), it can't do anything on its own. You can try to execute a configuration file all you want; it won't do anything to the system by itself. A DSC configuration file holds the information for the desired state, not the execution code to bring the node to a desired state. We talked about this separation of configuration information and execution logic before, and we are going to keep seeing this repeatedly throughout our use of DSC.
The DSC DSL allows both imperative and declarative commands. What this means is that configuration files can both describe what has to be done (declarative) as well as have a PowerShell code that is executed inline (imperative).
Declarative code will typically be DSC functions and resource declarations, and will make up the majority of code inside your DSC configuration file. Remember, the purpose of DSC is to express the expected state of the system, which you do by declaring it in these files in the human-readable language.
Imperative code will typically make decisions based on metadata provided inside the configuration file, for example, choosing whether to apply a configuration to a target node inside the $AllNodes variable or deciding which files or modules to apply based on some algorithm. You will find that putting a lot of imperative code inside your configuration files will cause maintenance and troubleshooting problems in the future. Generally, a lot of imperative code indicates that you are performing actions or deciding on logic that should be in a DSC Resource, which is the best place to put imperative code.
Compilation
The DSC configuration file is compiled to an MOF format by invoking the declared DSC configuration block inside the DSC configuration file. When this is done, it creates a folder and one or more MOF files inside it. Each MOF file is for a single target node, containing all configuration information needed to ensure the desired state on the target machine.
If at this point you are looking for example code of what this looks like, The example workflow has what you are looking for. We will continue explaining MOF compilation here, but if you want to jump ahead and take a look at the example and come back here when you are done, that's fine.
You can only have one MOF file applied to any target node at any given time. Why one MOF file per target node? This is a good question. Due to the architecture of DSC, an MOF file is the one source of truth for that server. It holds everything that can describe that server so that nothing is missed.
With DSC partial configurations, you can have separate DSC configuration blocks to delineate different parts of your installation or environment. This enables multiple teams to collaborate and participate in defining configurations for the environment instead of forcing all teams to use one DSC configuration script to track. For example, you can have a DSC partial configuration for an SQL server that is handled by the SQL team and another DSC partial configuration for the base operating system configuration that is handled by the operations team. Both partial configurations are used to produce one MOF file for a target node while allowing either DSC partial configuration to be worked on separately.
In some cases, it's easier to have a single DSC configuration script that has the logic to determine what a target node needs installed or configured rather than a set of DSC partial configuration files that have to be tracked together by different people. Whichever one you choose is largely determined by your environment.
Staging
After authoring the configuration files and compiling them into MOF files, the next step is the staging phase. This phase slightly varies if you are using a push or pull model of deployment.
When using the push model, the MOF files are pushed to the target node and executed immediately. There isn't much staging with push, as the whole point is to be interactive and immediate. In PowerShell v4, if a target node is managed by a DSC Pull Server, you cannot push the MOF file to it by using the Start-DscConfiguration Cmdlet. In PowerShell v4, a target node is either managed by a DSC Pull Server or not. This distinction is somewhat blurred in PowerShell v5, as a new DSC mode allows a target node to both be managed by a DSC Pull Server and have MOF files pushed to it.
When using the pull model, the MOF files are pushed to the DSC Pull Server by the user and then pulled down to target nodes by DSC agents. Because the local LCMs on each target node pull the MOF when they hit the correct interval, MOF files are not immediately processed, and thus are staged. They are only processed when the LCM pulls the MOF from the Pull Server. When attached to a Pull Server, the LCM performs other actions to stage or prepare the target node. The LCM will request all required DSC resources from the Pull Server in order to execute the MOF in the next phase.
Whatever process the MOF file uses to get to the target node, the LCM processes the MOF file by naming it pending.mof file and placing it inside the $env:systemRoot/system32/configuration path. If there was an existing MOF file executed before, it takes that file and renames it the previous.mof file.
Execution
After staging, the MOF files are ready for execution on the target node. An MOF is always executed as soon as it is delivered to a target node, regardless of whether the target node is configured for push or pull management. The LCM does run on a configurable schedule, but this schedule controls when the LCM pulls the new MOFs from the DSC Pull Server and when it checks the system state against the described desired state in the MOF file. When the LCM executes the MOF successfully, it renames the pending.mof file to current.mof file.
The following diagram shows the execution phase:

The execution phase operates the same no matter which deployment mode is in use, push or pull. However, different operations are started in the pull mode in comparison to the push mode, besides the obvious interactive nature of the push mode.
Push executions
In the push mode, the LCM expects all DSC resources to be present on the target node. Since the LCM doesn't have a way to know where to get the DSC resources used by the MOF file, it can't get them for you. Before running any push deployment on a target node, you must put all DSC resources needed there first. If they are not present, then the execution will fail.
Using the Start-DscConfiguration Cmdlet, the MOF files are executed immediately. This kind of execution only happens when the user initiates it. The user can opt for the execution caused by the Start-DscConfiguration Cmdlet to happen interactively and see the output as it happens, or have it happen in the background and complete without any user interaction.
The execution can happen again if the LCM ConfigurationMode mode is set to ApplyAndMonitor or ApplyAndAutoCorrect mode, but will only be applied once if ConfigurationMode is set to ApplyOnly.
Pull executions
In the pull mode, the LCM contacts the Pull Server for a new configuration, and the LCM downloads a new one if present. The LCM will parse the MOF and download any DSC resources that are specified in the configuration file, respecting the version number specified there.
The MOF file is executed on a schedule that is set on each target node's LCM configuration. The same LCM schedule rules apply to a target node that is attached to a Pull Server as one that is not attached. The ApplyAndMonitor and ApplyAndAutoCorrect modes will continue to monitor the system state and change it if necessary. If it is set to the ApplyOnly mode, then LCM will check with the Pull Server to see if there are new MOF files to download, but will only apply them if the last execution failed. The execution happens continuously on a schedule that the LCM was set to use. In the next section, we will cover exactly how the LCM schedules configuration executions.
The example workflow
At this point, a simple example of the workflow you will use will be helpful to explain what we just covered. We will first create an example DSC configuration file. Then, we will compile it to an MOF file and show an example execution using the push deployment model.
A short note about composing configuration files: if you use the built-in PowerShell Integrated Script Environment (ISE), then you will have intellisense provided as you type. This is useful as you start learning; the popup information can help you as you type things without having to look back at the documentation. The PowerShell ISE also provides on-demand syntax checking, and will look for errors as you type.
The following text would be saved as a TestExample.ps1 file. You will notice this is a standalone file and contains no configuration data. Let's look at the following code snippet, which is a complete example of a DSC configuration file:
# First we declare the configuration
Configuration TestExample
{
# Then we declare the node we are targeting
Node "localhost"
{
# Then we declare the action we want to perform
Log ImportantMessage
{
Message = "This has done something important"
}
}
}
# Compile the Configuration function
TestExample
We can see the Configuration keyword, which holds all the node statements and DSC Resources statements. Then, the Node keyword is used to declare the target node we are operating on. This can either be hardcoded like in the example, or be passed in using the configuration data. And finally, the resource declaration for the action we want to take is added. In this example, we will output a message to the DSC event log when this is run on the localhost.
We use the term keyword here to describe Configuration and Node. This is slightly inaccurate, as the actual definitions of Configuration and Node are PowerShell functions in the PSDesiredStateConfiguration module. PowerShell functions can also be defined as Cmdlets. This interchangeability of terms here is partly due to PowerShell's naming flexibility and partly due to informal conventions. It's sometimes a hot topic of contention.
To compile this DSC configuration file into an MOF, we run the following script from the PowerShell console:
PS C:\Examples> .\TestExample.ps1
Directory: C:\Examples\TestExample
Mode LastWriteTime Length Name
---- ------------- ------ ----
-a--- 5/20/2015 7:28 PM 1136 localhost.mof
As we can see from the result, compiling the configuration file to an MOF resulted in a folder with the name of the configuration block we just created and with one file called the localhost.mof file.
Don't worry too much about reading or understanding the MOF syntax right now. For the most part, you won't be reading or dealing with it directly in your everyday use, but it is useful to know how the configuration block format looks in the MOF format.
Let's try the following snippet:
/*
@TargetNode='localhost'
@GeneratedBy=James
@GenerationDate=05/20/2015 19:28:50
@GenerationHost=BLUEBOX
*/
instance of MSFT_LogResource as $MSFT_LogResource1ref
{
SourceInfo = "C:\\Examples\\TestExample.ps1::8::9::Log";
ModuleName = "PSDesiredStateConfiguration";
ModuleVersion = "1.0";
ResourceID = "[Log]ImportantMessage";
Message = "This has done something important";
};
instance of OMI_ConfigurationDocument
{
Version="1.0.0";
Author="James";
GenerationDate="05/20/2015 19:28:50";
GenerationHost="BLUEBOX";
};
We can see from this MOF that not only do we programmatically state the intent of this configuration (log a message), but we also note the computer it was compiled on as well as the user that did it. This metadata is used by the DSC engine when applying configurations and reporting statuses back to a Pull Server.
Then, we execute this configuration on a target node using the push deployment model by calling the Start-DscConfiguration Cmdlet:
PS C:\Examples> Start-DscConfiguration –Path C:\Examples\TestExample –Wait –Verbose
VERBOSE: Perform operation 'Invoke CimMethod' with following parameters, ''methodName' =
SendConfigurationApply,'className' = MSFT_DSCLocalConfigurationManager,'namespaceName' =
root/Microsoft/Windows/DesiredStateConfiguration'.
VERBOSE: An LCM method call arrived from computer BLUEBOX with user sid ************.
VERBOSE: [BLUEBOX]: LCM: [ Start Set ]
VERBOSE: [BLUEBOX]: LCM: [ Start Resource ] [[Log]ImportantMessage]
VERBOSE: [BLUEBOX]: LCM: [ Start Test ] [[Log]ImportantMessage]
VERBOSE: [BLUEBOX]: LCM: [ End Test ] [[Log]ImportantMessage] in 0.0000 seconds.
VERBOSE: [BLUEBOX]: LCM: [ Start Set ] [[Log]ImportantMessage]
VERBOSE: [BLUEBOX]: [[Log]ImportantMessage] This has done something important
VERBOSE: [BLUEBOX]: LCM: [ End Set ] [[Log]ImportantMessage] in 0.0000 seconds.
VERBOSE: [BLUEBOX]: LCM: [ End Resource ] [[Log]ImportantMessage]
VERBOSE: [BLUEBOX]: LCM: [ End Set ] in 0.3162 seconds.
VERBOSE: Operation 'Invoke CimMethod' complete.
VERBOSE: Time taken for configuration job to complete is 0.36 seconds
Notice the logging here. We used the Verbose parameter, so we see listed before us every step that DSC took. Each line represents an action DSC is executing, and each has a Start and End word in it, signifying the start and end of each execution even though an execution may span multiple lines.
Each INFO, VERBOSE, DEBUG, or ERROR parameter is written both to the console in front of us and also to the DSC event log. Everything done is logged for auditing and historical purposes. An important thing to note is that while everything is logged, not everything is logged to the same place. There are several DSC event logs: Microsoft-Windows-DSC/Operational, Microsoft-Windows-DSC/Analytical, and Microsoft-Windows-DSC/Debug. However, only the Microsoft-Windows-DSC/Operational event log is logged to by default; you have to enable the Microsoft-Windows-DSC/Analytical and Microsoft-Windows-DSC/Debug event log in order to see any events logged there. Any verbose messages are logged in Microsoft-Windows-DSC/Analytical, so beware if you use the Log DSC Resource extensively and intend to find those messages in the logs.
A configuration data
Now that we have covered how deployments work (push and pull) in DSC and covered the workflow (authoring, staging, and execution) for using DSC, we will pause here for a moment to discuss the differences between configuration files and configuration data.
The DSC configuration blocks contain the entirety of the expected state of the target node. The DSL syntax used to describe the state is expressed in one configuration file in a near list format. It expresses all configuration points of the target system and is able to express dependencies between configuration points.
DSC configuration data is separated from DSC configuration files to reduce variance and duplication. Some points that are considered data are software version numbers, file path locations, registry setting values, and domain-specific information like server roles or department names.
You may be thinking, what is the difference between the data you put in a configuration file and a configuration data file? The data we put in a configuration file is structural data, data that does not change based on the environment. The data we put in configuration data files is environmental. For example, no matter the environment, a server needs IIS installed in order to serve webpages. The location of the source files for the webpage may change depending on whether the environment is the development environment or the production environment.
The structural information (that we need IIS for) is contained in the DSC configuration file and the environmental information (source file locations) is stored in the configuration data file.
Configuration data can be expressed in DSC in several ways.
A hardcoded data
Configuration data can be hardcoded inside DSC configuration files, but this is not optimal in most cases. You will mostly use this for static sets of information or to reduce redundant code as shown in the following code snippet:
configuration FooBar
{
$features = @('Web-Server', 'Web-Asp-Net45')
Foreach($feature in $features){
WindowsFeature "Install$($feature)"
{
Name = $feature
}
}
}
A parameter-based data
A parameter-based data can be passed as parameters to a configuration block, like so:
configuration FooBar
{
param([switch]$foo,$bar)
if($foo){
WindowsFeature InstallIIS
{
Name = "Web-Server"
}
}elseif($bar){
WindowsFeature InstallHyperV
{
Name = "Microsoft-Hyper-V"
}
}
}
FooBar –Foo
A hashtable data
The most flexible and preferred method is to use the ConfigurationData hashtable. This specifically structured hashtable provides a flexible way of declaring frequently changing data in a format that DSC will be able to read and then insert into the MOF file as it compiles it. Don't worry too much if the importance of this feature is not readily apparent. With following command lines, we define a specifically formatted hashtable called $data:
$data = @{
# Node specific data
# Note that is an array of hashes. It's easy to miss
# the array designation here
AllNodes = @(
# All the WebServers have this identical config
@{
NodeName = "*"
WebsiteName = "FooWeb"
SourcePath = "C:\FooBar\"
DestinationPath = "C:\inetpub\FooBar"
DefaultWebSitePath = "C:\inetpub\wwwroot"
},
@{
NodeName = "web1.foobar.com"
Role = "Web"
},
@{
NodeName = "web2.foobar.com"
Role = "Web"
},
@{
NodeName = "sql.foobar.com"
Role = "Sql"
}
);
}
configuration FooBar
{
# Dynamically find the web nodes from configuration data
Node $AllNodes.where{$_.Role -eq "Web"}.NodeName
{
# Install the IIS role
WindowsFeature IIS
{
Ensure = "Present"
Name = "Web-Server"
}
}
}
# Pass the configuration data to configuration as follows:
FooBar -ConfigurationData $data
The first item's key is called $AllNodes key, the value of which is an array of hashtables. The content of these hashtables are free form, and can be whatever we need them to be, but they are meant to express the data on each target node. Here, we specify the roles of each node so that inside the configuration, we can perform a where clause and filter for only the nodes that have a web role.
If you look back at the $AllNodes definition, you'll see the three nodes we defined (web1, web2, and sql) but also notice one where we just put an * sign in the NodeName field. This is a special convention that tells DSC that all the information in this hashtable is available to all the nodes defined in this AllNodes array. This is an easy way to specify defaults or properties that apply to all nodes being worked on.
Local Configuration Manager
Now that we have covered how deployments work (push and pull) in DSC and covered the workflow (authoring, staging, and execution) for using DSC, we will talk about how the execution happens on a target node.
Unlock access to the largest independent learning library in Tech for FREE!
Get unlimited access to 7500+ expert-authored eBooks and video courses covering every tech area you can think of.
Renews at $19.99/month. Cancel anytime
The LCM is the PowerShell DSC engine. It is the heart and soul of DSC. It runs on all target nodes and controls the execution of DSC configurations and resources whether you are using a push or pull deployment model. It is a Windows service, but is part of the WMI service host, so there is no direct service named LCM for you to look at.
The LCM has a large range of settings that control everything from the scheduling of executions to how the LCM handles configuration drift. LCM settings are settable by DSC itself, although using a slightly different syntax. This allows the LCM settings to be deployed just like DSC configurations, in an automatable and repeatable manner.
These settings are applied separately from your DSC configurations, so you will have configuration files for your LCM and separate files for your DSC configurations. This separation means that LCM settings can be applied per server or on all servers, so not all your target nodes have to have the same settings. This is useful if some servers have to have a stricter scheduler and control over their drift, whereas others can be checked less often or be more relaxed in their drift.
Since the LCM settings are different from DSC settings but describe how DSC operates, they are considered DSC metadata. You will sometimes see them referred to as metadata instead of settings, because they describe the entirety of the process and not just LCM-specific operations. These pieces of information are stored in a separate MOF file than what the DSC configuration block compiles to. These files are named with the NodeName field you gave them and appended with meta.mof as the file extension. Anytime you configure the LCM, the *.meta.mof files will be generated.
LCM settings
Common settings that you will configure are listed in the following table. There are more settings available, but these are the ones that are most useful to know right away.
|
Setting
|
Description
|
|
AllowModuleOverwrite
|
Allows or disallows DSC resources to be overwritten on the target node. This applies to DSC Pull Server use only.
|
|
ConfigurationMode
|
Determines the type of operations to perform on this host. For example, if set to ApplyAndAutoCorrect and if the current state does not match the desired state, then DSC applies the corrections needed.
|
|
ConfigurationModeFrequencyMins
|
The interval in minutes to check if there is configuration drift.
|
|
RebootNodeIfNeeded
|
Automatically reboot server if configuration requires it when applied.
|
|
RefreshFrequencyMins
|
How often to check for a new configuration when LCM is attached to a Pull Server.
|
|
RefreshMode
|
Determines which deployment mode the target is in, push or pull.
|
The LCM comes with most of these settings set to logical defaults to allow DSC to operate out of the box. You can check what is currently set by issuing the following Get-DscLocalConfigurationManager Cmdlet:
PS C:\Examples> Get-DscLocalConfigurationManager
ActionAfterReboot : ContinueConfiguration
AllowModuleOverwrite : False
CertificateID :
ConfigurationID :
ConfigurationMode : ApplyAndMonitor
ConfigurationModeFrequencyMins : 15
Credential :
DebugMode : {NONE}
DownloadManagerCustomData :
DownloadManagerName :
LCMCompatibleVersions : {1.0}
LCMState : Idle
LCMVersion : 1.0
RebootNodeIfNeeded : False
RefreshFrequencyMins : 30
RefreshMode : PUSH
PSComputerName :
Configuration modes
An important setting to call out is the LCM ConfigurationMode setting. As stated earlier, this setting controls how DSC applies the configuration to the target node. There are three available settings: ApplyOnly, ApplyAndMonitor, and ApplyAndAutoCorrect. These settings will allow you to control how the LCM behaves and when it operates. This controls the actions taken when applying the configuration as well as how it handles drift occurring on the target node.
ApplyOnly
When the ApplyOnly mode is set, DSC will apply the configuration and do nothing further unless a new configuration is deployed to the target node. Note that this is a completely new configuration, not a refresh of the currently applied configuration. If the target node's configuration drifts or changes, no action will be taken by DSC. This is useful for a one time configuration of a target node or in cases where it is expected that a new configuration will be pushed at a later point, but some initial setup needs to be done now. This is not a commonly used setting.
ApplyAndMonitor
When the ApplyAndMonitor mode is set, DSC behaves exactly like ApplyOnly, except after the deployment, DSC will monitor the current state for configuration drift. This is the default setting for all DSC agents. It will report back any drift to the DSC logs or Pull Server, but will not act to rectify the drift. This is useful when you want to control when change happens on your servers, but reduces the autonomy DSC can have to correct changes in your infrastructure.
ApplyAndAutoCorrect
When the ApplyAndAutoCorrect mode is set, DSC will apply the configuration to the target node and continue to monitor for configuration drift. If any drift is detected, it will be logged and the configuration will be reapplied to the target node to bring it back into compliance. This gives DSC the greatest autonomy to ensure your environment is valid and act on any changes that may occur without your direct input. This is great for fully locked down environments where variance is not allowed, but must also be corrected on the next scheduled run and without fail.
Refresh modes
While the ConfigurationMode mode determines how DSC behaves in regard to configuration drift, the RefreshMode setting determines how DSC gets the configuration information. In the beginning of this article, we covered the push and pull deployment models, and this setting allows you to change which model the target node uses.
By default, all installs are set to the push RefreshMode, which makes sense when you want DSC to work out of the box. Setting it to the pull RefreshMode allows the LCM to work with a central Pull Server.
The LCM configuration
Configuring the LCM is done by authoring an LCM configuration block with the desired settings specified. When compiled, the LCM configuration block produces a file with the extension meta.mof. Applying the meta.mof file is done by using the Set-DscLocalConfigurationManager Cmdlet.
You are not required to write your LCM configuration block in a file; it can alternately be placed inside the DSC configuration file. There are several reasons to separate them. Your settings for the LCM could potentially change more often than your DSC configuration files, and keeping them separated reduces changes to your core files. You could also have different settings for different servers, which you may not want to express or tie down inside your DSC configuration files. It's up to you how you want to organize things.
Compiling the LCM configuration block to MOF is done just like a DSC configuration block, by invoking the name of the LCM configuration you defined. You apply the resulting meta.mof file to the target node using the Set-DscLocalConfigurationManager Cmdlet.
An example LCM configuration
An example LCM configuration is as follows, saved as ExampleLCMConfig.ps1. We could have put this inside a regular DSC configuration file, but it was separated for a clearer example as shown:
#Declare the configuration
Configuration SetTheLCM
{
# Declare the settings we want configured
LocalConfigurationManager
{
ConfigurationMode = "ApplyAndAutoCorrect"
ConfigurationModeFrequencyMins = 120
RefreshMode = "Push"
RebootNodeIfNeeded = $true
}
}
SetTheLCM
To compile this configuration into an MOF file, you execute the following configuration file in the PowerShell console:
PS C:\Examples> .\ExampleLCMConfig.ps1
Directory: C:\Users\James\Desktop\Examples\SetTheLCM
Mode LastWriteTime Length Name
---- ------------- ------ ----
-a--- 5/20/2015 7:28 PM 984 localhost.meta.mof
As we can see from the output, a localhost.meta.mof file was created inside a folder named for the configuration, as a SetTheLCM folder. The filename reminds us again that the LCM settings are considered DSC metadata, so any files or operations on LCM get the "meta" moniker.
Looking at the contents of the MOF file, we see the same syntax as the MOF file generated by the DSC configuration file. Let's have a look at the following snippet:
/*
@TargetNode='localhost'
@GeneratedBy=James
@GenerationDate=05/20/2015 19:28:50
@GenerationHost=BLUEBOX
*/
instance of MSFT_DSCMetaConfiguration as $MSFT_DSCMetaConfiguration1ref
{
RefreshMode = "Push";
ConfigurationModeFrequencyMins = 120;
ConfigurationMode = "ApplyAndAutoCorrect";
RebootNodeIfNeeded = True;
};
instance of OMI_ConfigurationDocument
{
Version="1.0.0";
Author="James";
GenerationDate="05/20/2015 19:28:50";
GenerationHost="BLUEBOX";
};
We then execute the LCM configuration by using the Set-DscLocalConfigurationManager cmdlet:
PS C:\Examples> Set-DscLocalConfigurationManager -Path .\SetTheLCM\ -Verbose
VERBOSE: Performing the operation "Start-DscConfiguration: SendMetaConfigurationApply" on target
"MSFT_DSCLocalConfigurationManager".
VERBOSE: Perform operation 'Invoke CimMethod' with following parameters, ''methodName' =
SendMetaConfigurationApply,'className' = MSFT_DSCLocalConfigurationManager,'namespaceName' =
root/Microsoft/Windows/DesiredStateConfiguration'.
VERBOSE: An LCM method call arrived from computer BLUEBOX with user sid *********************.
VERBOSE: [BLUEBOX]: LCM: [ Start Set ]
VERBOSE: [BLUEBOX]: LCM: [ Start Resource ] [MSFT_DSCMetaConfiguration]
VERBOSE: [BLUEBOX]: LCM: [ Start Set ] [MSFT_DSCMetaConfiguration]
VERBOSE: [BLUEBOX]: LCM: [ End Set ] [MSFT_DSCMetaConfiguration] in 0.0520 seconds.
VERBOSE: [BLUEBOX]: LCM: [ End Resource ] [MSFT_DSCMetaConfiguration]
VERBOSE: [BLUEBOX]: LCM: [ End Set ] in 0.2555 seconds.
VERBOSE: Operation 'Invoke CimMethod' complete.
VERBOSE: Set-DscLocalConfigurationManager finished in 0.235 seconds.
The DSC Pull Server
The DSC Pull Server is your one stop central solution for managing a large environment using DSC. In the beginning of this article, we talked about the two deployment modes of DSC: push and pull. A DSC Pull Server operates with target nodes configured to be in the pull deployment mode.
What is a DSC Pull Server?
A DSC Pull Server is an IIS website that exposes an OData endpoint that responds to requests from the LCM configured on each target node and provides DSC configuration files and DSC Resources for download. That was a lot of acronyms and buzzwords, so let's take this one by one.
IIS is an acronym for Internet Information Services, which is the set of components that allow you to host websites on a Windows server. OData is an acronym for Open Data Protocol, which defines a standard for querying and consuming RESTful APIs. One last thing to cover before we move on. A DSC pull server can be configured to use Server Message Block (SMB) shares instead of HTTP to distribute MOF files and DSC resources. This changes the distribution mechanism, but not much more internally to the DSC server.
What does the Pull Server do for us?
Since the LCM handles the scheduling and executing of the MOF files, what does the Pull Server do? The Pull Server operates as a single management point for all DSC operations. By deploying MOF files to the Pull Server, you control the configuration of any target node attached to it.
Automatic and continuous configuration
As a central location for all target nodes to report to, a Pull Server provides an automatic deployment of configurations. Once a target node's LCM is configured, it automatically will pull configurations and dependent files without requiring input from you. It will also do this continuously and on schedule, without requiring extra input from you.
Repository
The Pull Server is the central repository for all the MOF files and DSC Resources that the LCM uses to schedule and execute. With the push model, you are responsible for distributing the DSC Resources and MOF files to the target nodes yourself. A DSC pull server provides them to the target nodes on demand and ensures they have the correct version.
Reporting
The Pull Server tracks the status of every target node that uses it, so it also has another role called a reporting server. You can query the server for the status of all the nodes in your environment and the Pull Server will return information on their last run. A reporting server stores the pull operation status and configuration and node information in a database. Reporting endpoints can be used to periodically check the status of the nodes to see if their configurations are in sync with the Pull Server or not.
The PowerShell team has transitioned from calling this a compliance server to a reporting server during the PowerShell v5 development cycle.
Security
A Pull Server can be set up to use HTTPS or SMB with NTFS permissions for the MOF and DSC Resource repositories. This controls access to the DSC configuration files and DSC Resources but also encrypts them over the wire.
You will most likely at some point have to provide credentials for one of your settings or DSC Resources. Certificates can be used to encrypt the credentials being used in the DSC configurations. It would be foolish to enter in the credentials inside the DSC configuration files, as it would be in plain text that anyone could read. By setting up and using certificates to encrypt the credentials, only the servers with the correct certificates can read the credentials.
Setting up a DSC Pull Server
You would think with so many dependencies that setting up a DSC Pull Server would be hard. Actually, it's a perfect example of using DSC to configure a server! Again, don't worry if some of this is still not clear; we will cover making DSC configuration files in more detail later.
Pull Server settings
A Pull Server has several configuration points for each of the roles it performs. These can either be set manually or through DSC itself, as discussed in the following table:
|
Name
|
Description
|
|
EndpointName
|
Configures the name of the OData endpoint.
|
|
Port
|
The port the service listens on.
|
|
CertificateThumbPrint
|
The SSL certificate thumbprint the web service uses.
|
|
PhysicalPath
|
The install path of the DSC service.
|
|
ModulePath
|
The path to the DSC Resources and modules.
|
|
ConfigurationPath
|
The working directory for the DSC service.
|
The compliance server settings are as discussed in the following table:
|
Name
|
Description
|
|
EndpointName
|
Configures the name of the OData endpoint.
|
|
Port
|
The port the service listens on.
|
|
CertificateThumbPrint
|
The SSL certificate thumbprint the web service uses.
|
|
PhysicalPath
|
The install path of the DSC service.
|
Installing the DSC server
The following example is taken from the example provided by the PowerShell team in the xPSDesiredStateConfiguration module. Just as when we showed an example DSC configuration in the authoring phase, don't get too caught up on the following syntax. Examine the structure and how much this looks like a list for what we need. Running this on a target node sets up everything needed to make it a Pull Server, ready to go from the moment it is finished.
The first step is to make a text file called the SetupPullServer.ps1 file with the following content:
# Declare our configuration here
Configuration SetupPullServer
{
Import-DSCResource -ModuleName xPSDesiredStateConfiguration
# Declare the node we are targeting
Node "localhost"
{
# Declare we need the DSC-Service installed
WindowsFeature DSCServiceFeature
{
Ensure = "Present"
Name = "DSC-Service"
}
# Declare what settings the Pull Server should have
xDscWebService PSDSCPullServer
{
Ensure = "Present"
State = "Started"
EndpointName = "PSDSCPullServer"
Port = 8080
CertificateThumbPrint = "AllowUnencryptedTraffic"
PhysicalPath = "$env:SystemDrive\inetpub\wwwroot\PSDSCPullServer"
ModulePath = "$env:PROGRAMFILES\WindowsPowerShell\DscService\Modules"
ConfigurationPath = "$env:PROGRAMFILES\WindowsPowerShell\DscService\Configuration"
DependsOn = "[WindowsFeature]DSCServiceFeature"
}
# Declare what settings the Compliance Server should have
xDscWebService PSDSCComplianceServer
{
Ensure = "Present"
State = "Started"
EndpointName = "PSDSCComplianceServer"
Port = 9080
PhysicalPath = "$env:SystemDrive\inetpub\wwwroot\PSDSCComplianceServer"
CertificateThumbPrint = "AllowUnencryptedTraffic"
IsComplianceServer = $true
DependsOn = @("[WindowsFeature]DSCServiceFeature","[xDSCWebService]PSDSCPullServer")
}
}
}
The next step is to invoke the DSC Configuration Cmdlet to produce an MOF file. By now, we don't need to show the output MOF file as we have covered that already. We then run the Start-DscConfiguration Cmdlet against the resulting folder and the Pull Server is set up.
A good thing to remember when you eventually try to use this DSC configuration script to make a DSC Pull Server is that you can't make a client operating system a Pull Server. If you are working on a Windows 8.1 or 10 desktop while trying out these examples, some of them might not work for you because you are on a desktop OS. For example, the WindowsFeature DSC Resource only works on the server OS, whereas the WindowsOptionalFeature DSC Resource operates on the desktop OS. You will have to check each DSC resource to find out what OS or platforms they support, just like you would have to check the release notes of software to find out supported system requirements.
Adding MOF files to a Pull Server
Adding an MOF file to a Pull Server is slightly more involved than using an MOF with the push mode. You still compile the MOF with the same steps we outlined in the Authoring section earlier in this article.
Pull Servers require MOFs to use checksums to determine when an MOF has changed for a given target node. They also require the MOF filename to be the ConfigurationID file of the target node. A unique identifier is much easier to work with than the names a given target node is using. This is typically done only once per server, and is kept for the lifetime of the server. It is usually decided when configuring the LCM for that target node.
The first step is to take the compiled MOF and rename it with the unique identifier we assigned it when we were creating the configuration for it. In this example, we will assign a newly created GUID as shown:
PS C:\Examples> Rename-Item -Path .\TestExample\localhost.mof -NewName "$([GUID]::NewGuid().ToString()).mof"
PS C:\Examples> ls .\TestExample\
Directory: C:\TestExample
Mode LastWriteTime Length Name
---- ------------- ------ ----
-a--- 5/20/2015 10:52 PM 1136 b1948d2b-2b80-4c4a-9913-ae6dcbf23a4d.mof
The next step is to run the New-DSCCheckSum Cmdlet to generate a checksum for the MOF files in the TestExample folder as shown:
PS C:\Examples> New-DSCCheckSum -ConfigurationPath .\TestExample\ -OutPath .\TestExample\ -Verbose
VERBOSE: Create checksum file 'C:\Examples\TestExample\\b1948d2b-2b80-4c4a-9913-ae6dcbf23a4d.mof.checksum'
PS C:\Examples> ls .\TestExample\
Directory: C:\TestExample
Mode LastWriteTime Length Name
---- ------------- ------ ----
-a--- 5/21/2015 10:52 PM 1136 b1948d2b-2b80-4c4a-9913-ae6dcbf23a4d.mof
-a--- 5/22/2015 10:52 PM 64 b1948d2b-2b80-4c4a-9913-ae6dcbf23a4d.mof.checksum
PS C:\Examples> gc .\TestExample\b1948d2b-2b80-4c4a-9913-ae6dcbf23a4d.mof.checksum
A62701D45833CEB2A39FE1917B527D983329CA8698951DC094335E6654FD37A6
The next step is to copy the checksum file and MOF file to the Pull Server MOF directory. This is typically located in C:\Program Files\WindowsPowerShell\DscService\Configuration path on the Pull Server, although it's configurable so it might have been changed in your deployment.
Adding DSC Resources to a Pull Server
In push mode, you can place a DSC Resource module folder in a PowerShell module path (any of the paths defined in the $env:PSModulePath path) and things will work out fine. A Pull Server requires that DSC Resources be placed in a specific directory and compressed into a ZIP format with a specific name in order for the Pull Server to recognize and be able to transfer the resource to the target node.
Here is our example DSC Resource in a folder on our system. We are using the experimental xPSDesiredStateConfiguration resource provided by Microsoft, but these steps can apply to your custom resources, as well as shown in the following command:
PS C:\Examples> ls .
Directory: C:\Examples
Mode LastWriteTime Length Name
---- ------------- ------ ----
d---- 5/20/2015 10:52 PM xPSDesiredStateConfiguration
The first step is to compress the DSC Resource folder into a ZIP file. You may be tempted to use the .NET System.IO.Compression.Zip file classes to compress the folder to a ZIP file. In DSC v4, you cannot use these classes, as they create a ZIP file that the LCM cannot read correctly. This is a fault in the DSC code that reads the archive files However, in DSC v5, they have fixed this so that you can still use System.IO.Compression.zip file. A potentially easier option in PowerShell v5 is to use the built-in Compress-Archive Cmdlet to accomplish this. The only way to make a ZIP file for DSC v4 is either to use the built-in compression facility in Windows Explorer, a third-party utility like 7zip, or the COM Shell.Application object in a script.
PS C:\Examples> ls .
Directory: C:\Examples
Mode LastWriteTime Length Name
---- ------------- ------ ----
d---- 5/20/2015 10:52 PM xPSDesiredStateConfiguration
d---- 5/20/2015 10:52 PM xPSDesiredStateConfiguration.zip
Once you have your ZIP file, we rename the file to MODULENAME_#.#.#.#.zip, where MODULENAME is the official name of the module and the #.#.#.# refers to the version of the DSC resource module we are working with. This version is not the version of the DSC Resource inside the module, but the version of the DSC Resource root module. You will find the correct version in the top-level psd1 file inside the root directory of the module.
Let's have a look at the following example:
PS C:\Examples> ls .
Directory: C:\Examples
Mode LastWriteTime Length Name
---- ------------- ------ ----
d---- 5/20/2015 10:52 PM xPSDesiredStateConfiguration
d---- 5/20/2015 10:52 PM xPSDesiredStateConfiguration_3.2.0.0.zip
As with MOF files, DSC needs a checksum in order to identify each DSC Resource. The next step is to run the New-DscCheckSum Cmdlet against our ZIP file and receive our checksum:
PS C:\Examples> New-DSCCheckSum -ConfigurationPath .\xPSDesiredStateConfiguration_3.2.0.0.zip -OutPath . -Verbose
VERBOSE: Create checksum file 'C:\Examples\xPSDesiredStateConfiguration _3.2.0.0.zip.checksum'
PS C:\Examples> ls .
Directory: C:\TestExample
Mode LastWriteTime Length Name
---- ------------- ------ ----
-a--- 5/21/2015 10:52 PM 1136 xPSDesiredStateConfiguration _3.2.0.0.zip
-a--- 5/22/2015 10:52 PM 64 xPSDesiredStateConfiguration _3.2.0.0.zip.checksum
The final step is to copy the ZIP file and checksum file up to the C:\Program Files\WindowsPowerShell\DscService\Modules path on the Pull Server.
Once completed, the previous steps provide a working Pull Server. You configure your target nodes using the steps outlined in the previous section on LCM and your target nodes will start pulling configurations.
Deployment considerations
By this point, we have covered the architecture and the two different ways that we can deploy DSC in your environment. When choosing the deployment method, you should be aware of some additional considerations and observations that have come through experience using DSC in production.
General observations
You will generally use the DSC push mode deployments to test new configurations or perform one off configurations of servers. While you can use the push mode against several servers at once, you lose the benefits of the Pull Server.
Setting up a DSC Pull Server is the best option for a large set of nodes or environments that frequently build and destroy servers. It does have a significant learning curve in setting up the DSC resources and MOF files, but once done it is reliably repeatable without additional effort.
When using Pull Servers, each target node is assigned a configuration ID that is required to be unique and is expected to stay with that server for its lifetime. There is currently no built-in tracking of configuration IDs inside DSC or in the Pull Server, and there are no checks to avoid duplicate collisions. This is by design, as it allows greater deployment flexibility.
You can choose to have a unique ID for every target node in your environment or have one single ID for a group of systems. An example of sharing a configuration ID is a web farm that creates and destroys VMs based on demand during certain time periods. Since they all have the same configuration ID, they all get the same configuration with significantly less work on your part (not having to make multiple MOF files and maintain lists of IDs for temporary nodes).
Maintaining a list of used IDs and which targets they refer to is currently up to you. Some have used the active directory IDs for the target node as an identifier. This is awkward to support as often we are running configurations on target nodes before they are joined to an AD domain. We recommend using a GUID as an identifier and keeping the configuration data files where the node identifiers are kept: in a source control system.
LCM gotchas
The LCM service runs under the system account and so has a high privilege access to the system. However, the system account is not a user account, which causes trouble when you assume DSC can perform an action just like you did a moment ago. Common gotchas include accessing network file shares or accessing parts of the system that require user credentials. These will typically fail with a generic Access Denied, which will most likely lead you down the wrong path when troubleshooting. Unfortunately, the only way to know this beforehand is to hope that the DSC Resource or application you are executing documented the permissions they needed to run. Some DSC Resources have parameters that accept a PSCredential object for this very purpose, so be sure to inspect examples or the DSC Resource itself to find out how to best handle access permissions. Trial and error will prove things one way or the other for you here.
As described in the execution phase in The General workflow, when first deploying using push or pull and trying out new configurations, or troubleshooting existing ones, the frequent executions often cause problems. If the configuration run was interrupted or stopped mid-run, a pending.mof file is often left in place. This signals to DSC that a configuration is either in flight or that something else occurred and it should not run. When you try to run another configuration, you get an error saying that a configuration is currently in flight. To solve this, you need to delete the pending.mof file before running the Update-DscConfiguration or Start-DscConfiguration -Force Cmdlet.
Deployment mode differences
When used with a DSC Pull Server, the LCM does a lot of work for you. It will pull down the required DSC Resources for your DSC configuration file automatically, instead of you having to copy them there yourself. It will also report the status back to the Pull Server, so you can see the status of all your targets in one place.
When used in the push mode, the LCM does all the work of applying your DSC configuration file for you, but does not do as much when in the pull mode. It does not auto download dependent DSC Resources for you.
Summary
In this article, we have identified the three phases of DSC use and the two different deployment models. We then covered how the phases and models work together to comprise the architecture of DSC. And lastly, we covered how the LCM and Pull Server work separately and together.
Resources for Article:
Further resources on this subject:

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Singapore
Singapore
 Canary Islands
Canary Islands
 Hungary
Hungary
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 South Korea
South Korea
 Turkey
Turkey
 Switzerland
Switzerland
 Colombia
Colombia
 Taiwan
Taiwan
 Chile
Chile
 Norway
Norway
 Ecuador
Ecuador
 Indonesia
Indonesia
 New Zealand
New Zealand
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 Austria
Austria
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 South Africa
South Africa
 Malaysia
Malaysia
 Japan
Japan
 Slovakia
Slovakia
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand













