In this section, we’ll learn about two important concepts: microservices and decentralized architecture.
Microservices is an architectural style and approach to building software applications as a collection of small, loosely coupled, and independently deployable services. Meanwhile, in decentralized architecture, components or services are distributed across multiple nodes or entities.
Both microservices architecture and decentralized architecture promote modularity, scalability, fault tolerance, and autonomy. While microservices focus on building applications as a collection of small services, decentralized architecture focuses on distributing processing and decision making across multiple nodes. These architectural approaches can be combined to build highly scalable, resilient, and flexible systems that can adapt to changing requirements and handle complex workloads.
Let’s start with the microservices architecture.
Microservices architecture
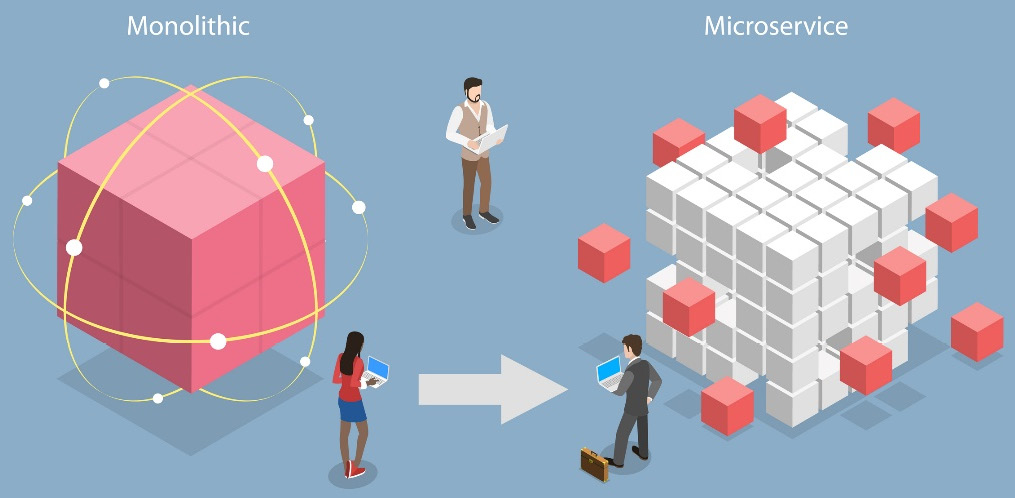
In a microservices architecture, the application is broken down into multiple small services, each responsible for a specific business capability. These services are developed, deployed, and managed independently, communicating with one another through well-defined application programming interfaces (APIs) or message-based protocols.
Figure 1.1 shows a typical microservices architecture compared to a typical monolithic architecture.
Figure 1.1: A typical microservices architecture
In Node.js, microservices are typically developed using lightweight frameworks such as Express.js or Fastify. Each microservice is a separate application with its own code base and can be developed, deployed, and scaled independently. Microservices can be written in different programming languages such as Java and Python, but Node.js is often chosen due to its efficiency, event-driven nature, and large ecosystem of modules.
The key characteristics of microservices include the following:
- Modularity: Microservices promote a modular approach, where each service is self-contained and focuses on a specific business functionality. Services can be developed, updated, and scaled independently, allowing for flexibility and easy maintenance.
- Loose coupling: Microservices are loosely coupled, meaning they have minimal dependencies on one another. They communicate through well-defined interfaces, typically using lightweight protocols such as RESTful APIs or messaging systems. This loose coupling enables services to evolve and scale independently without affecting the entire system.
- Independently deployable: Each microservice can be deployed independently of other services. This allows for rapid deployment and reduces the risk of system-wide failures. It also enables teams to work on different services simultaneously, promoting faster development cycles and continuous deployment practices.
- Polyglot architecture: Microservices architecture allows for the use of different technologies, programming languages, and frameworks for each service. This flexibility allows teams to select the most appropriate technology stack for a specific service, based on its requirements and characteristics.
- Resilience and fault isolation: Failure in one microservice does not bring down the entire system. Faults or errors in one service are isolated and do not propagate to other services. This enhances the overall resilience and fault tolerance of the system.
Understanding these key characteristics is essential for designing, developing, and maintaining successful microservices architectures. Embracing these principles can lead to more scalable, resilient, and agile software systems that meet the demands of modern application development.
Now that you’ve been introduced to the concept of microservices architecture and learned about its key characteristics, let’s dive into the next concept: decentralized architecture.
Decentralized architecture
Decentralized architecture, also known as distributed architecture, refers to an architectural approach where components or services are distributed across multiple nodes or entities rather than being centrally managed. This promotes autonomy, scalability, and fault tolerance by distributing processing, data, and decision making across multiple nodes.
Centralized architectures have a single point of control, making them easier to manage but potentially less scalable and more vulnerable to failures. Decentralized architectures distribute control and data, offering better scalability, fault tolerance, and performance, especially in large and dynamic systems.
Examples of centralized architectures include traditional client-server architectures, where clients communicate with a central server. Mainframes and many early computing systems followed centralized architectures.
Examples of decentralized architectures include blockchain networks, peer-to-peer file-sharing systems, and certain types of distributed databases. Also, some modern microservices architectures follow decentralized principles where services can function independently.
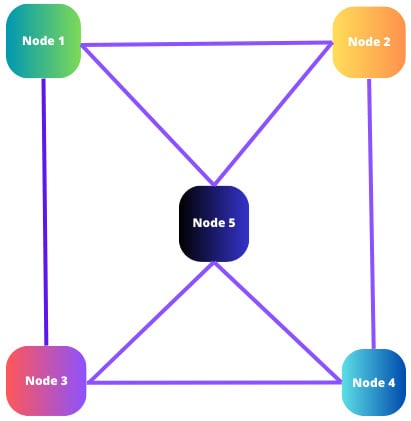
Figure 1.2 shows a typical decentralized architecture:
Figure 1.2: A typical decentralized architecture
The key aspects of a decentralized architecture include the following:
- Distribution of responsibilities: In a decentralized architecture, responsibilities and tasks are distributed across multiple nodes or entities. Each node operates independently and is responsible for specific functions or services. This distribution allows for better resource utilization and can improve fault tolerance and performance.
- Autonomy and independence: Nodes in a decentralized architecture have a certain degree of autonomy and can operate independently. They can make decisions, process data, and provide services without relying on central coordination. This autonomy allows the system to function even if connectivity to other nodes is disrupted.
- Peer-to-peer communication: Decentralized architectures often rely on peer-to-peer communication between nodes. Nodes can interact directly with each other, exchanging messages, data, or resources without the need for a centralized intermediary. Peer-to-peer communication enables decentralized decision making, data sharing, and collaboration.
- Scalability and load distribution: Decentralized architectures can scale horizontally by adding more nodes to handle increased workloads. As the system grows, new nodes can be added, distributing the load and allowing for improved scalability and performance. This scalability makes decentralized architectures well suited for handling large-scale applications or systems with dynamic resource demands.
- Resilience and fault tolerance: Decentralized architectures offer better resilience and fault tolerance compared to centralized architectures. If one node fails or becomes unavailable, the system can continue to function by routing requests or tasks to other available nodes. Nodes can recover independently, and failures are less likely to affect the entire system.
- Security and privacy: Decentralized architectures can provide enhanced security and privacy compared to centralized architectures. Distributed data storage and communication patterns make it more challenging for attackers to compromise the system or gain unauthorized access to sensitive information. Additionally, decentralized systems can allow users to maintain more control over their data and identities.
Understanding these key aspects is crucial when designing and implementing decentralized architectures. By leveraging the benefits of distribution, autonomy, and scalability, organizations can build robust and flexible systems capable of handling modern computing challenges.
In the next section, we’ll explore the principles of service boundaries and loose coupling.
 Argentina
Argentina
 Australia
Australia
 Austria
Austria
 Belgium
Belgium
 Brazil
Brazil
 Bulgaria
Bulgaria
 Canada
Canada
 Chile
Chile
 Colombia
Colombia
 Cyprus
Cyprus
 Czechia
Czechia
 Denmark
Denmark
 Ecuador
Ecuador
 Egypt
Egypt
 Estonia
Estonia
 Finland
Finland
 France
France
 Germany
Germany
 Great Britain
Great Britain
 Greece
Greece
 Hungary
Hungary
 India
India
 Indonesia
Indonesia
 Ireland
Ireland
 Italy
Italy
 Japan
Japan
 Latvia
Latvia
 Lithuania
Lithuania
 Luxembourg
Luxembourg
 Malaysia
Malaysia
 Malta
Malta
 Mexico
Mexico
 Netherlands
Netherlands
 New Zealand
New Zealand
 Norway
Norway
 Philippines
Philippines
 Poland
Poland
 Portugal
Portugal
 Romania
Romania
 Russia
Russia
 Singapore
Singapore
 Slovakia
Slovakia
 Slovenia
Slovenia
 South Africa
South Africa
 South Korea
South Korea
 Spain
Spain
 Sweden
Sweden
 Switzerland
Switzerland
 Taiwan
Taiwan
 Thailand
Thailand
 Turkey
Turkey
 Ukraine
Ukraine
 United States
United States