





















































Preface
Apache Camel is a Java framework for building system integrations.
Why, you may well ask, does anyone need such a framework? System integration is pretty much a solved problem. After all, we have been connecting various frontends to web services, message brokers, and databases for years! Surely this is a well-understood domain that requires no further abstractions.
Not quite.
Apache Camel, since its release in 2007, has disrupted the integration market much like the Spring Framework disrupted the Java EE market back in 2003. Camel enables a new way of doing, and thinking about, system integrations that results in much cleaner, easier to understand code, which in turn results in less work, less bugs, and easier maintenance. These are big claims, and to validate them you only need to look at the large and active Apache Camel community, the growing number of commercial integration products based on Camel, and the talks on Camel that appear at most middleware developer conferences to feel that there is a good buzz around Camel, and for very good reason.
This book is targeted at readers who already have some familiarity with Camel, and are looking for tips on how Camel may be able to better help them solve more complex integration challenges. This book is structured as a series of over 100 how-to recipes, including step-by-step instructions on using Camel to solve common integration tasks. Each recipe includes a brief explanation of what Camel is doing internally, and references on where to find more information for those who want to dig deeper.
This book may not be a good introduction/beginner book about Camel, though if you have familiarity with other integration technologies, and learn well by doing, you may find this book's recipe approach helpful. This book does not spend a lot of time explaining Camel concepts in great depth.
For readers looking for more conceptual coverage of Camel (with lots of code examples), we would recommend reading the excellent book Camel in Action by Claus Ibsen and Jonathan Anstey, published by Manning. For a more introductory guide, look at Instant Apache Camel Message Routing by Bilgin Ibryam, published by Packt Publishing. The Apache Camel website (http://camel.apache.org) is the authoritative site on Camel, with a long list of articles and documentation that will help you on your journey of using Camel.
What is Camel?
This section provides a quick overview of what Camel is, and why it was created. Its goal is to help remind the reader of the core concepts used within Camel, and to help the reader understand how the authors define those concepts. It is not intended as a comprehensive introduction to Camel. Hopefully, it will act as a quick reference for Camel concepts as you use the various recipes contained within this book.
Integrating systems is hard work. It is hard because the developers doing the integration work must understand and how the endpoint systems expose themselves to external systems, how to transform and route the data records (messages) from each of the systems. They must also have a working knowledge of the ever growing number of technologies used in transporting, routing, and manipulating those messages. What makes it more challenging is that the systems you are integrating with were probably written by different teams of developers, at different times, and are probably still changing even while you are trying to integrate them. This is equivalent to connecting two cars while they are driving down the highway.
Traditional system integrations, in the way that we have built them in the past decades, require a lot of code to be created that has absolutely nothing to do with the higher-level integration problem trying to be solved. The vast majority of this is boilerplate code dealing with common, repetitive tasks of setting up and tearing down libraries for the messaging transports and processing technologies such as filesystems, SOAP, JMS, JDBC, socket-level I/O, XSLT, templating libraries, among others. These mechanical concerns are repeated over and over again in every single integration project's code base.
In early 2000, there were many people researching and cataloging software patterns within many of these projects, and this resulted in the excellent book Enterprise Integration Patterns: Designing, Building, and Deploying Messaging Solutions by Gregor Hohpe and Bobby Woolf, published by Addison Wesley. This catalog of integration patterns, EIPs for short, can be viewed at http://www.enterpriseintegrationpatterns.com. These patterns include classics such as the Content Based Router, Splitter, and Filter. The EIP book also introduces a model of how data moves from one system to another that is independent of the technology doing the work. These named concepts have become a common language for all integration architects and developers making it easier to express what an integration should do without getting lost in how to implement that integration.
Camel embraces these EIP concepts as core constructs within its framework, providing an executable version of those concepts that are independent of the mechanics of the underlying technology actually doing the work. Camel adds in abstractions such as Endpoint URIs (Uniform Resource Identifier) that work with Components (Endpoint factories), which allows developers to specify the desired technology to be used in connecting to an endpoint system without getting lost in the boilerplate code required to use that technology. Camel provides an integration, domain-specific language (DSL) for defining integration logic that is adapted to many programming languages (Java, Groovy, Scala, and so on) and frameworks (Spring, OSGi Blueprint, and so on), so that the developer can write code that is an English-like expression of the integration using EIP concepts. For example:
consume from some endpoint, split the messages based on an expression, and send those split messages to some other endpoint
Let us look at a concrete example to show you how to use Camel.
Imagine that your boss comes to you, asking you to solve an integration problem for your project. You are asked to: poll a specific directory for new XML files every minute, split those XML files that contain many repeating elements into individual records/messages (think line items), and send each of those individual records to a JMS queue for processing by another system. Oh, and make sure that the code can retry if it hits any issues. Also, it is likely the systems will change shortly, so make sure the code is flexible enough to handle changes, but we do not know what those changes might look like. Sound familiar?
Before Camel, you would be looking at writing hundreds of lines of code, searching the Internet for code snippets of how best to do reliable directory polling, parsing XML, using XPath libraries to help you split those XML files, setting up a JMS connection, and so forth. Camel hides all of that routine complexity into well-tested components so you just need to specify your integration problem as per the following example using the Spring XML DSL:
<route>
<from uri="file://someDirectory?delay=60000"/>
<split>
<xpath>/xpath/to/record</xpath>
<to uri="jms:queue:myProcessingQueue"/>
</split>
</route>Wow! We still remember when we first saw some Camel code, and were taken aback by how such a small amount of code could be so incredibly expressive.
This Camel example shows a Route, a definition (recipe) of a graph of channels to message processors, that says: consume files from someDirectory every 60,000 milliseconds; split that data based on an XPath expression; and send the resulting messages to a JMS queue named myProcessingQueue. That is exactly the problem we were asked to solve, and the Camel code effectively says just that. This not only makes it easy to create integration code, it makes it easy for others (including your future self) to look at this code and understand what it is doing.
What is not obvious in this example is that this code also has default behaviors for handling errors (including retrying the processing of files), data type transformation such as File object to XML Document object, and connecting and packaging data to be sent on a JMS queue.
But what about when we need to use different endpoint technologies? How does Camel handle that? Very well, thank you very much. If our boss told us that now we need to pick up the files from a remote FTP server instead of a directory, we can make a simple change from the File Component to the FTP Component, and leave the rest of the integration logic alone:
<route>
<from uri="ftp://scott@remotehost/someDirectory?delay=60000"/>
<split>
<xpath>/xpath/to/record</xpath>
<to uri="jms:queue:myProcessingQueue"/>
</split>
</route>This simple change from file: to ftp: tells Camel to switch from using the hundreds of lines of well-tested code doing local directory polling to the hundreds of lines of well-tested FTP directory polling code. Plus, your core record-processing logic to split and forward on to a JMS queue remains unchanged.
At the time of writing, there are over 160 components within the Camel community dealing with everything; from files, FTP, and JMS, to distributed registries such as Apache Zookeeper, low-level wire formats such as FIX and HL7, monitoring systems such as Nagios, and higher-level system abstractions that include Facebook, Twitter, SAP, and Salesforce. Many of these components were written by the team that created the technology you are trying to use, so they generally reflect best practices on using that technology. Camel allows you to leverage the best practices of hundreds of the best integration technologists in the world, all in an easy to use, open source framework.
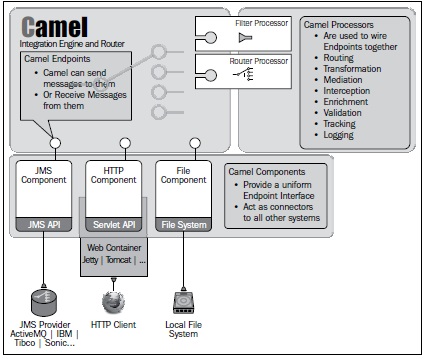
Another big innovation with Camel is that it does not require the messages flowing through its processing channels (routes) to be of any fixed/canonical data type. Instead, Camel tracks the current data type of the message, and includes an extensible data type conversation capability that allows Camel to try to convert the message to the data type required by the next step in the processing chain. This also helps Camel in providing seamless integration with your existing Java libraries, as Camel can type convert to and from your Java methods that you call as part of your Camel route. This all combines into an extremely flexible mechanism where you can quickly and easily extend almost any part of Camel with some highly focused Java code.
There is so much more to Camel than what can be covered in this very brief overview.
Camel Concepts
A number of Camel architectural concepts are used throughout this book and are briefly explained here to provide a quick reference. Full details can be found on the Apache Camel website at http://camel.apache.org.
A Camel Exchange is a holder object that encapsulates the state of a conversation between systems. It contains properties, a variety of flags, a message exchange pattern or MEP (InOnly or InOut), and two messages (an In message and an Out message). Properties are expressed as a map of Strings to Objects, and are typically used by Camel and its components to store information pertaining to the processing of the exchange.
A message contains the payload to be processed by a processing step, as well as headers that are expressed as a map of Strings to Objects. You use headers to pass additional information about the message between processors. Headers are commonly used to override endpoint defaults.
An In message is always present on an exchange as it enters a processor. The processor may modify the In message or prepare a new payload and set it on the Out message. If a processor sets the Out message, the Camel context will move it to the In message of the exchange before handing it to the next processor. For more, see http://camel.apache.org/exchange.html and http://camel.apache.org/message.html.
A Camel Processor is the base interface for all message-processing steps. Processors include predefined EIPs such as a Splitter, calls to endpoints, or custom processors that you have created implementing the org.apache.camel.Processor interface. For more, see http://camel.apache.org/processor.html.
A Camel Route is a series of message processing steps defined using Camel's DSL. A Route always starts with one consumer endpoint within a from() statement, and contains one or more processor steps. The processing steps within a route are loosely coupled, and do not invoke each other, relying on the Camel context instead to pass messages between them. For more, see http://camel.apache.org/routes.html.
The Camel Context is the engine that processes exchanges along the steps defined through routes. Messages are fed into a route based on a threading model appropriate to the component technologies being consumed from. Subsequent threading depends on the processors defined on the route.
A Camel Component is a library that encapsulates the communication with a transport or technology behind a common set of Camel interfaces. Camel uses these components to produce messages to or consume messages from those technologies. For a full list of components, see http://camel.apache.org/components.html.
A Camel Endpoint is an address that is interpreted by a component to identify a target resource, such as a directory, message queue, or database table that the component will consume messages from or send messages to. An endpoint used in a from() block is known as a Consumer endpoint, while an endpoint used in a to() block is known as a Producer endpoint. Endpoints are expressed as URIs, whose attributes are specific to their corresponding component. For more, see http://camel.apache.org/endpoint.html.
A Camel Expression is a way to script up Route in-line code that will operate on the message. For example, you can use the Groovy Expression Language to write inline Groovy code that can be evaluated on the in-flight message. Expressions are used within many EIPs to provide data to influence the routing of messages, such as providing the list of endpoints to route a message to as part of a Routing Slip EIP. For more, see http://camel.apache.org/expression.html.
The Camel DSL
All integration routes are defined in Camel through its own domain-specific language (DSL). This book presents the two main DSL flavors when discussing routing, the Java DSL, and the Spring XML DSL. OSGi Blueprint XML DSL is modeled after Spring, and is touched on lightly in this book. The Spring and OSGi Blueprint XML DSLs are collectively referred to as the XML DSL). There are other DSL variants available for defining Camel routes, including Groovy and Scala. For details on these see the following links:
Groovy DSL: http://camel.apache.org/groovy-dsl.html
Scala DSL: http://camel.apache.org/scala-dsl.html
Here is an example of a classic Content Based Router configured in Camel using both the XML and Java DSLs. You can find out more details on this in the Content Based Router recipe in Chapter 2, Message Routing.
In the XML DSL, you would write the routing logic as:
<route>
<from uri="direct:start"/>
<choice>
<when>
<simple>${body} contains 'Camel'</simple>
<log message="Camel ${body}"/>
</when>
<otherwise>
<log message="Other ${body}"/>
</otherwise>
</choice>
<log message="Message ${body}"/>
</route>In the Java DSL, the same route is expressed as:
from("direct:start")
.choice()
.when().simple("${body} contains 'Camel'")
.log("Camel ${body}")
.otherwise()
.log("Other ${body}")
.end()
.log("Message ${body}");The decision of which flavor of DSL to use is largely a personal one, and using one does not rule out using another alongside it. There are pros and cons to each, though none are functional. All of the DSL variants allow you to fully use Camel's features.
|
DSL |
Pros |
Cons |
|---|---|---|
|
Java |
|
|
|
XML |
|
|
What this book covers
Chapter 1, Structuring Routes, introduces you to the fundamentals of structuring Camel integrations; getting the framework running inside Java and Spring applications, using Camel components, and breaking down and reusing routing logic.
Chapter 2, Message Routing, details the use of the main EIPs used to route messages within Camel integrations; everything from if-else style content-based routing to more complex, dynamic options.
Chapter 3, Routing to Your Code, describes how to interact with a Camel runtime from your Java code, and how your Java code can be used from within Camel routes.
Chapter 4, Transformation, provides some off-the-shelf strategies for converting between and manipulating common message formats such as Java objects, XML, JSON, and CSV.
Chapter 5, Splitting and Aggregating, takes a deep dive into the related Splitter and Aggregator EIPs. It details the impacts of completion conditions, parallel processing options, and using the EIPs in combination with each other.
Chapter 6, Parallel Processing, outlines Camel's support for scaling out processing through the use of thread pools, profiles, and asynchronous processors.
Chapter 7, Error Handling and Compensation, details the mechanisms provided by the Camel DSLs for dealing with failure, including capabilities for triggering compensating routing steps for non-transactional interactions that have already completed.
Chapter 8, Transactions and Idempotency, presents a number of variations for dealing with transactional resources (JDBC and JMS). It additionally details the handling of non-transactional resources (such as web services) in such a way that they will only ever be invoked once in the event of message replay or duplicates.
Chapter 9, Testing, outlines Camel's test support that allows you to verify your routes' behavior without the need for backend systems. It also presents ways to manipulate routes with additional steps for testing purposes, without altering the code used at runtime.
Chapter 10, Monitoring and Debugging, describes Camel's support for logging, tracing, and debugging. Monitoring is examined through Camel's support for JMX, which includes the ability to define your own attributes and operations.
Chapter 11, Security, covers encrypting communication between systems, hiding sensitive configuration information, non-repudiation using certificates, and applying authentication and authorization to your routes.
Chapter 12, Web Services, shows you how to use Camel to invoke, act as a backend to, and proxy SOAP web services.
What you need for this book
This book is best used in conjunction with the example sources found at http://github.com/CamelCookbook/camel-cookbook-examples. You can also get a copy of the code through your account at http://www.packtpub.com.
Tip
From the start we set out with the goal that working code should back up every single recipe. As a result the supporting code base supports multiple variants of each example, all backed up by working unit tests. In fact, if you printed out all of the source code, you would end up with a book nearly four times as thick as the one you are holding!
All of the examples are driven through JUnit tests, and are collectively structured as a set of Apache Maven projects. To execute them, you will need a copy of the Java 6 or 7 JDK (http://www.oracle.com/technetwork/java/javase/downloads/index.html) and an Apache Maven 3 installation (http://maven.apache.org/). Maven will download all of the appropriate project dependencies.
Note
Maven has become the build tool of choice over the last few years within the broader Java community for a number of reasons, including:
Standard way of laying out projects, leading to a quicker comprehension of a project layout by new developers.
A set of standard, customizable build plugins that allow the developer to declare what build steps need to be performed at various stages of the build, without worrying about explaining the details.
A mechanism for working with library dependencies. This has been Maven's largest success, and has become the gold standard approach for dependency management, being reused by numerous other build systems, such as Ant (via the Ivy dependency management extension), Groovy's Gradle, Scala's SBT, and others.
A full coverage of Maven is beyond the scope of this book, but interested readers should take a look at Better Builds with Maven by MaestroDev (http://www.maestrodev.com/better-builds-with-maven/about-this-guide/) for an excellent walkthrough.
Who this book is for
This book is for programmers working with Apache Camel who just want to get things done, without learning the entire framework up front. Those who are new to Camel and need a starting point will find it particularly useful in building up momentum with the framework.
We intended this book to be read as a set of individual how-to recipes to be accessed when needed. It is possible to read the book from cover to cover, but you should feel free to jump around between recipes; most are entirely self-contained, and those that are not reference the required prerequisites. Each recipe contains links to in-depth background reading, and pointers to other recipes that may come in handy when building system integrations using the techniques being discussed.
Conventions
In this book, you will find a number of styles of text that distinguish between different kinds of information. Here are some examples of these styles, and an explanation of their meaning.
Code words in text, Camel endpoint URIs, folder names, filenames, file extensions, pathnames, and dummy URLs are shown as follows: "In both cases ${spring-version} is a property that you define in the properties section of your POM that states which version of Spring you are using."
A block of code is set as follows:
from("direct:processXml")
.choice()
.when()
.xpath("/order[@units > 100]")
.to("direct:priorityXmlOrder")
.otherwise()
.to("direct:normalXmlOrder")
.end();When we wish to draw your attention to a particular part of a code block, the relevant lines or items are set in bold:
from("direct:processXml")
.choice()
.when()
.xpath("/order[@units > 100]")
.to("direct:priorityXmlOrder")
.otherwise()
.to("direct:normalXmlOrder")
.end();Any command-line input or output is written as follows:
# java -jar camel-jasypt-2.12.2.jar -c encrypt -p encryptionPassword -i myDatabasePassword
New terms and important words are shown in bold.
Note
Warnings or important notes appear in a box like this.
Tip
Tips and tricks appear like this.
Reader feedback
Feedback from our readers is always welcome. Let us know what you think about this book—what you liked or may have disliked. Reader feedback is important for us to develop titles that you really get the most out of.
To send us general feedback, simply send an e-mail to <feedback@packtpub.com>, and mention the book title via the subject of your message.
If there is a topic that you have expertise in and you are interested in either writing or contributing to a book, see our author guide on www.packtpub.com/authors.
Customer support
Now that you are the proud owner of a Packt book, we have a number of things to help you to get the most from your purchase.
Downloading the example code
The latest version of the example code for this book can be found at http://github.com/CamelCookbook/camel-cookbook-examples.
You can also download the example code files for all Packt books you have purchased from your account at http://www.packtpub.com. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
Errata
Although we have taken every care to ensure the accuracy of our content, mistakes do happen. If you find a mistake in one of our books—maybe a mistake in the text or the code—we would be grateful if you would report this to us. By doing so, you can save other readers from frustration and help us improve subsequent versions of this book. If you find any errata, please report them by visiting http://www.packtpub.com/submit-errata, selecting your book, clicking on the errata submission form link, and entering the details of your errata. Once your errata are verified, your submission will be accepted and the errata will be uploaded on our website, or added to any list of existing errata, under the Errata section of that title. Any existing errata can be viewed by selecting your title from http://www.packtpub.com/support.
Piracy
Piracy of copyright material on the Internet is an ongoing problem across all media. At Packt, we take the protection of our copyright and licenses very seriously. If you come across any illegal copies of our works, in any form, on the Internet, please provide us with the location address or website name immediately so that we can pursue a remedy.
Please contact us at <copyright@packtpub.com> with a link to the suspected pirated material.
We appreciate your help in protecting our authors, and our ability to bring you valuable content.
Questions
You can contact us at <questions@packtpub.com> if you are having a problem with any aspect of the book, and we will do our best to address it.









