


















 Download code from GitHub
Download code from GitHub
Chapter 1: Background Concepts
In this chapter, you will gain an understanding of the basic types of databases and how people tend to use them. You will learn how MySQL implements specific concepts such as database structures, layers, organization, and what its architecture looks like. You will explore what a relational database management system such as MySQL is, and how it differs from a standard database management system. You will also learn about data normalization and data modeling.
By the end of this chapter, you will have a good overview of what a database is and its different components. You will also learn what makes MySQL special and how it fits into this ecosystem.
This chapter covers the following topics:
- Introducing databases
- Exploring MySQL
- Exercise 1.01: Organizing data in a relational format
- Exploring MySQL architecture
- Storage engines (InnoDB and MyRocks)
- Data modeling
- Normalization
- Activity 1.01: Creating an optimized table for an employee project
Introducing databases
Information is abundant, an ever-growing pile of little bits of data that drives every aspect of your life, and the bigger that pile of data grows, the more valuable it becomes to yourself or others. For example, consider a situation where you need to search the internet for a specific piece of information, such as how to create a MySQL database. To do this, you would send a query to a search engine, which then parses large sets of data to find the relevant results. Putting all that data into some form of useful context manually, such as inputting it into spreadsheet software, is time-consuming.
Using databases, it is easier to automate the input and processing of data. Now you can store all that data into ever-growing databases and push, pull, squeeze, and tug on the data to get information from it that you could never dream of getting before, and in the blink of an eye. A database is an organized collection of structured data. The data becomes information once it is processed. For example, you have a database to store servers and their information, such as processor count, memory, storage, and location. Alone, this data is not immediately useable for business decisions and analysis. However, detailed reports about the utilization of servers at specific locations contain the information that can be fetched from the database.
To ensure fast and accurate access and to protect all the valuable data, the database is usually housed in an external application specifically designed to efficiently store and manage large volumes of data. MySQL is one such application. In almost all cases, the database management system or database server is installed on a dedicated computer. This way, many users can connect to a centralized database server at the same time. Irrespective of the number of users, both the data and the database are important—as sensitive data and useful insights are stored in it—and must be suitably protected and efficiently used. For example, a database can be used to store log information or the revenue of a company.
In this book, you will build up your knowledge to manage your database. You will also learn how to deploy, manage, and query the database as you progress in the book.
The following section will describe databases in greater depth.
Database architecture
A database is a collection of related data that has been gathered and stored for easy access and management. Each discrete item of data in a database is, in itself, not very useful or valuable, but the entire collection of data as a whole (when coupled with ease of use and fast access) provides an exceptionally powerful tool for business and personal use. For example, if you have a set of data that shows how much time a user spends on a specific page, you can track user experience on your application. As the volume of data grows and its historical content stretches further back in time, the data becomes more useful in identifying and predicting past and future trends, and the value of the data to its owner increases. Databases allow the user to logically separate data and store it in a well-structured format that allows them to create reports and identify trends.
To understand the advantage of databases, consider a telephone book that is used to store people's names, addresses, and phone numbers. A phone book is a good example of a manual data store, in which data is organized alphabetically to find the information easily (albeit, manually). With a phone book, storing large sets of data creates a bulky physical object, which must be manually searched to find the data we want. The process of searching the data is time-consuming, and we can only search the data by name since this is how it is organized.
To help improve this process, you can utilize computer-based information systems to store the data either in tables or flat files. Flat files store data in a plain text format. Files with the extensions .csv or .txt are usually flat files.

Figure 1.1 – An example of a flat file
Tables store data in rows and columns, allowing you to logically separate data and store them.

Figure 1.2 – An example of a table
You use databases in almost everything you do in your life. Whenever you connect to a website, the screen layout and the information displayed in front of the screen are fetched from the database. The cell phone you use in your day-to-day life stores the contact numbers in a database. When you watch a show on a streaming service, your login details, the information about the show, and the show itself are stored in a database.
There are many different types of database systems out there. Most are quite similar in some ways, though quite different in others. Some are geared toward a specific type of activity, and others are more general in their application. You will look at the two most common database management systems used by businesses today, DBMS and RDBMS, in the upcoming sections.
A centralized database is one that is located, stored, and maintained at a single site. The simplest example of a centralized database is an MS Access file stored on SharePoint that is used by multiple people. A distributed database is more complex as the data is not stored in a single place, but rather at multiple locations. A distributed database helps users to fetch the information quickly as the data is stored closer to the end users.
For example, if you have a database that is distributed across America, Europe, and Asia, American users will access the database stored in America, European users will access the one stored in Europe, and so on. However, this does not mean that Americans cannot access data in Europe or Asia. It's just that accessing data closer to them is faster.
Relational and object-based databases are ideas as to how the data is stored behind the scenes. Relational databases include databases such as MySQL and MSSQL, whereas object databases include databases such as PostgreSQL. Relational databases use the concept of the relational database model explained in this chapter, while object-based databases use the concept of intelligent objects and object-oriented programming, where the elements know what their purpose is and what they are intended to be used for.
In the next section, you will look at a few examples of common database management solutions used by developers.
MS Access as a database
MS Access is a database application from Microsoft. It is one of the simplest examples of a database. It allows users to manipulate data with macro functions, queries, and reports, to be able to share it via different visualization techniques, such as graphs and Venn diagrams. It is a number cruncher and is excellent for analyzing numbers, forecasting, and performing what-if scenarios.

Figure 1.3 – MS Access file
However, MS Access is not the best database available, due to certain limitations in terms of functionality. For example, if offices of your company are present at multiple locations, it is possible to share an Access database. However, there is a limit to the number of users who can connect at a single time. In addition, there are limitations on the size of Access database files, making it only possible to store limited datasets. Access works best in situations where the groups accessing the database are small, and also the dataset is small, within the range of 1 million records or less.
Take, for example, a situation where an insurance company is creating a database for customer service to access customer data for insurance policies. If the team starts small, with 3 customer service agents and 300 records, MS Access works well, since the scope of usage is limited. However, as the company grows, more customer service agents may be added, and more records may be created. As the database grows, MS Access becomes less practical and eventually, Access will no longer work for the application.
Because of these limitations, alternative database management systems are preferred.
Database management system
A database management systems (DBMSs) aim to provide its end users with fine-tuned access to data based in a controlled environment. These systems allow you to define and manage data in a more structured manner. There are many different types of DBMSs used in applications, each with distinct pros and cons. When selecting a DBMS, it is important to determine the best choice for a given problem.
Take the previous example of an insurance company creating a database for customer service agents. If the developers wanted to transition away from MS Access, they could store data within a generic DBMS. These systems can help to organize data in a similar fashion to the Access database, while removing the size and connection caps created by Access. This solves the problem of the database system being limited; however, there are still limitations in terms of the data's structure based on the generic DBMS solution. Some DBMS solutions will simply organize data in tabular formats without any structural advantages. These situations are less ideal for large sets of data. These issues can be eliminated by relational database management systems (RDBMSs).
Examples of DBMS include your computer's filesystem, FoxPro, and the Windows Registry.
Figure 1.4 – Windows Registry is an example of a basic DBMS
RDBMS
A relational database stores data in a well-structured format of rows, columns, and tables. A row contains a set of data related to a single entity. A column contains data about a single field or descriptor of the data point. Take, for example, a table that contains user data. Each row will contain data about a single user. Each column will describe the user, storing data points such as their username, password, and similar information. Different types of relationships can be defined between tables, and specific rules enforced on columns. This is an improved version of the DBMS concept and was introduced in 1970. It was designed to support client-server hierarchy, multiple concurrent users or application access, security features, transactions, and other facilities that make working with data from these systems not just safe but efficient as well.
An RDBMS is more robust than a general DBMS or MS Access database. With the insurance database example, you can now create a structure around the data being stored for the customer service representatives. This structure represents the relationships between different datasets, making it easier to draw conclusions from related data. Additionally, you still get all the advantages of a DBMS, giving you the best system to fit your needs.
The following figure is an example of a database in MySQL. As you can see, the database has multiple tables (countrylanguage, country, and city), and these tables are linked to each other. You will learn how to link different tables later in Chapter 10, MS Access, Part 2.
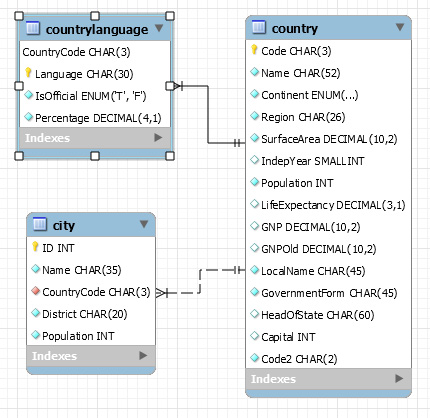
Figure 1.5 – RDBMS entity relationship diagram
Some popular RDBMS systems are MySQL, Microsoft SQL Server, and MariaDB. You will learn about MySQL in the following section.
Exploring MySQL
MySQL is an open source RDBMS that uses intuitive keywords such as SELECT, INSERT INTO, and DELETE to communicate with the database. These keywords are used in queries that instruct the server on how to handle data, how to read and write the data, or to perform operations on the database objects or the server, such as creating or modifying tables, stored procedures, functions, and views. The database objects are defined and manipulated using SQL commands and all communication and instructions issued to the database by the client applications are done using SQL code.
MySQL has a wide range of applications in business. This includes data warehousing, inventory management, logging user sessions on web pages, and storing employee records.
MySQL is based on the client-server model. The client-server model makes it possible for MySQL to handle concurrent connections from multiple users and host a great number of databases, each with their own tables and fine-tuned security permissions to ensure the data is only accessed by the appropriate users.
In the next section, you will explore some of the data types that are used in MySQL for storing data.
Data types
Each column in a database table requires a data type to identify the type of data that will be stored in it. MySQL uses the assigned data type to determine how it will work with the data.
In MySQL version 8.0, there are three main data types. These data types are known as string, numeric, and date and time. The following table describes these types in more detail.
string: Strings are text-based representations of data. There are various types of string data types, includingCHAR,VARCHAR,BINARY,VARBINARY,BLOB,TEXT,ENUM, andSET. These data types can represent data from single text characters inCHARtypes to full strings of text inVARCHARtypes. The size of string variables can vary from 1 byte to 4 GB, depending on the type and size of the data being stored. To learn more about these data types, you can visit https://dev.mysql.com/doc/refman/8.0/en/string-types.html.numeric: Numeric data types store numeric values only. There are various types of numeric data, includingINTEGER,INT,SMALLINT,TINYINT,MEDIUMINT,BIGINT,DECIMAL,NUMERIC,FLOAT,DOUBLE, andBIT. These data types can represent numbers of various formats. Types such asDECIMALandFLOATrepresent decimal values, whereasINTEGERtypes can only represent integer values. The size range stored is dependent on the numeric data type assigned to the field and can range from 1 to 8 bytes, depending on whether the data is signed, and whether the type supports decimal values. To learn more about these data types, you can visit https://dev.mysql.com/doc/refman/8.0/en/numeric-types.html.dateandtime: There are five date and time data types:Date,Time,Year,DateTime, andTimeStamp.Date,Time, andYearstore different components of date in separate columns,DateTimewill record a combined date and time, andTimestampwill indicate how many seconds have passed from a fixed point in time. Date-based data types typically take up around 8 bytes in size, depending on whether they store the time as well as the date. Visit the following link for further details: https://dev.mysql.com/doc/refman/8.0/en/date-and-time-types.html.
As the developer, it is your responsibility to select the appropriate data type and size for the information you will be storing in the column. If you know a field is only going to use 5 characters, define its size as 5.
In the next exercise, you will learn how to organize a set of data in a relational format, with proper data types for each field.
Exercise 1.01: Organizing data in a relational format
Suppose you are working for a company, ABC Corp. Your manager would like to develop a database that stores clients' contact information, as well as the orders a client has made. You have been asked to determine how to organize the data in a relational format. In addition, the company would like you to define the data types that are appropriate for each field. The following is a list of properties that are to be stored in the relational model:
- Customer Data:
- Customer ID
- Customer Name
- Customer Address
- Customer Phone Number
- Order Data:
Perform the following steps to create a relational database structure:
- First, determine the data types that are appropriate for the data. The ID fields should be
intdata type, since IDs are typically numeric. For fields containing names, addresses, and phone numbers, avarchardata type is appropriate since it can store general text. Finally, a price can be defined asdouble, since it needs to be able to store decimal values. - Determine how many tables you should have. In this case, you have two sets of data, which means you should have two tables –
CustomerDataandOrderData. - Consider how tables are related to each other. Since a customer can have an order in the order data, you can conclude that customers and orders are related to one another.
- Next, look at what columns are the same between the two sets of data. In this case, both tables contain the
CustomerIDcolumn.
Finally, combine all the information. You have two tables, CustomerData and OrderData. You can relate them by using the column they share, which is CustomerID. The relational model would look like the following:
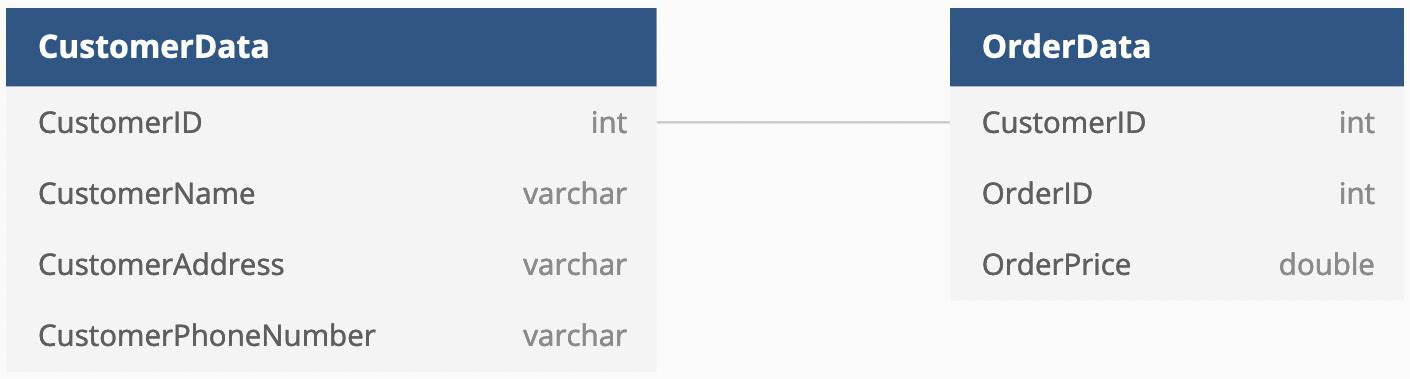
Figure 1.6 – The data for customers and orders organized in a relational format
With this, you now have a fully defined relational structure for your data. This structure with data types can be used to construct a proper relational database.
Now, you will delve into the architecture of MySQL in the following section.
Exploring MySQL architecture
Under the hood, all computer systems consist of several layers. Each layer has a specific role to play within the system's overall design. A layer is responsible for one or more tasks. The tasks are broken down into smaller modules dedicated to one aspect of the layer's role. An operation needs to get through all the layers to succeed. If it fails at one, it cannot proceed to the next and an error occurs.
MySQL server also has several layers. The physical layer is responsible for storing the actual data in an optimized format. The physical layer is then accessed through the logical layer. The logical layer is responsible for structuring data in a sensible format, with all required permissions and structures applied. The highest layer is the application layer, which provides an interface for web applications, scripts, or any kind of applications that have the API to talk to the database.
As discussed before, an RDBMS system typically has a client-server architecture. You and your application are the client, and MySQL is the server.
The MySQL layers
There are three layers in the MySQL server:
- Application layer
- Storage layer
- Physical layer
These layers are essential for understanding which part is responsible for how your data is treated. The following is a graphical representation of the basic architecture of a MySQL server. It shows how the different components within the MySQL system relate to each other.
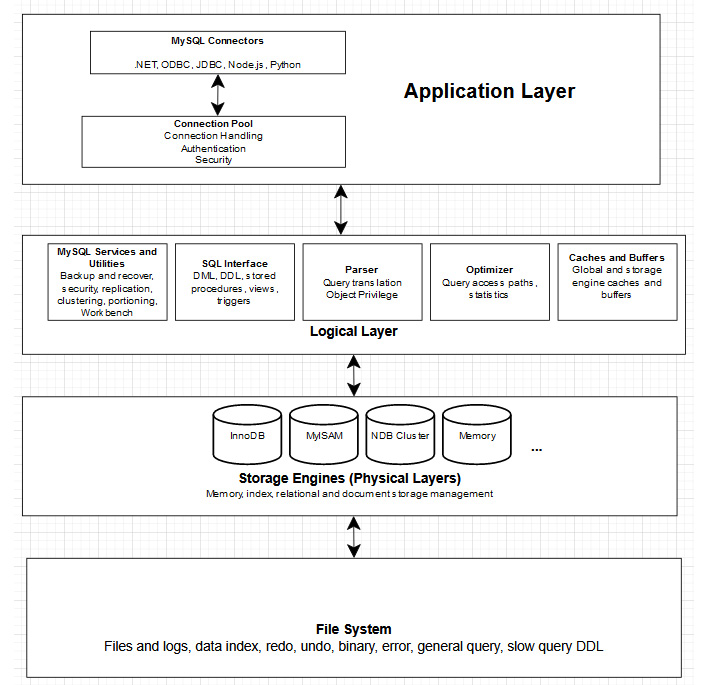
Figure 1.7 – MySQL architecture
Application layer – Client connection
The application layer accepts a connection using any one of the client technologies (JDBC, ODBC, .NET, PHP). It has a connection pool that represents the API for the application layer that handles communication with different consumers of the data, including applications and web servers. It performs the following tasks:
- Connection handling: The client is allocated a thread while creating a connection; think of it as a pipeline into the server. Everything the client does will be over this thread. The thread is cached so the client does not need to log in each time they send a request. The thread is destroyed when the client breaks the connection. All clients have their own threads. When a client wants to connect to a database, they will start by sending a request to the database server using their credentials. Typically, the requests will also include details about which database they specifically wish to connect to on the server. The server will then validate their request, establish a session with the server, and return a connection to the user.
- Authentication: When the connection is established, the server will then authenticate the client using the username and password details sent with the request. If the login details are incorrect, the client will not be allowed to proceed any further. If the login details are correct, the client will move to the security checks.
- Security: When the client has successfully connected, MySQL will check what the user account is permitted to do in it. It will check their read/write/update/delete status, and the security level for the thread will be set for all requests performed on this connection and thread.
When a client connects to the server, several services activate in the connection pool of the server layer.
MySQL server layer (logical layer)
This layer has all the logic and functionality of the MySQL RDBMS. Its first layer is the connection pool, which accepts and authenticates client connections. If the client connects successfully, the rest of the MySQL server layers will be available to them within the constraints. It has the following components:
- MySQL services and utilities: This layer provides services and utilities to administer and maintain the MySQL system. Additional services and utilities can be added as required; this is one of the main reasons why MySQL is so popular. Some of the services and utilities include backup and recovery, security, replication, clustering, portioning, and MySQL Workbench.
- SQL interface: SQL is a tool to provide interaction between the MySQL client and the MySQL server. The SQL tools provided by the SQL interface layer include, but are not limited to, Data Manipulation Language (DML), Data Definition Language (DDL), stored procedures, views, and triggers. These concepts will be taught thoroughly throughout the course of this book.
- Parser: MySQL has its own internal language to process data requests. When a SQL statement is passed into the MySQL server, it will first check the cache. If it finds that an identical statement has previously been run by any client, it will simply return the cached results. If it does not find the query that has been previously run, MySQL parses the statement and compiles it into the MySQL internal language.
The parser has three main operations it will perform on the SQL statement:
- A lexical analysis takes the stream of characters (SQL statement) and builds a word list making up the statement.
- A syntactic analysis takes the words and creates a structured representation of the syntax, verifying that the syntax is correctly defined.
- Code generation converts the syntax generated in Step 2 into the internal language of MySQL, which is a translation from syntactically correct queries to the internal language of MySQL.
- Optimizer: The internal code from the parser is then passed into the optimizer layer, which will work out to be the best and most efficient way to execute the code. It may rewrite the query, determine the order of scanning the tables, and select the correct indexes that should be used.
- Caches: MySQL will then cache the complete result set for the
SELECTstatements. The cached results are kept in case any client, including yourself, runs the same query. If they do so, the parsing is skipped, and the cached results are returned. You will notice this in action if you run a query twice. The first time will take longer for the results to be returned; subsequent runs will be faster.
Storage engine layer (physical layer)
The storage engine layer handles all the insert, read, and update operations with the data. MySQL uses pluggable storage engines technology. This means that you can add storage engines to better suit your needs. Storage engines are often optimized for certain tasks or types of storage and will perform better than others at their "specialty."
Now, you will look into different types of storage engines in the following section.
Storage engines (InnoDB and MyRocks)
MySQL storage engines are software modules that MySQL server uses to write, read, and update data in the database. There are two types of storage engines – transactional and non-transactional:
- Transactional storage engines permit write operations to be rolled back if it fails; thus, the original data remains unchanged. A transaction may encompass several write operations. Imagine the transfer of funds from one account to another in the company accounting system; debiting funds from one account and crediting them to another is a single transaction. If the failure happens near the end of the transaction, all preceding operations will be rolled back, and nothing in the transaction will be committed. If all write tasks were successful, the transaction would be committed, and all changes will be made permanent. Most storage engines are transactional, like InnoDB.
- Non-Transactional storage engines commit the data immediately on execution. If a write operation fails toward the end of a series of write operations, the preceding operations will need to be rolled back manually by code. To do so, the user will likely need to have recorded the old values elsewhere to know what they were. With the accounting example, imagine that the funds were debited from the first account but failed to be credited to the second, and the initial debit was not reversed. In this case, the funds would simply disappear. An example of this type of engine is MyISAM.
Another consideration when selecting a storage engine is if it is ACID-compliant.
ACID compliance
ACID compliance ensures data integrity in case of intermittent failures on different layers, such as broken connectivity, storage failure, and server process crash:
- Atomicity ensures all distinct operations within a transaction are treated as a single unit, meaning that if one fails, they all fail. This ensures no transaction is left partially done. If the transaction is successful, the changes are committed to the storage layer, and data is guaranteed to be correct.
- Consistency ensures a transaction cannot bring the database to an invalid state. Any data written must comply with all defined rules in the database, including constraints, cascades, triggers, and the referential integrity of the primary and foreign keys. This will prevent the corruption of data caused by an illegal transaction.
- Isolation ensures that no part of the transaction is visible to other users or processes until the entire transaction is completed.
- Durability ensures that once the transaction is committed, it will remain committed even in the event of a system failure, or power failure. The transaction is recorded in a logon store that is non-volatile.
The default storage engine of MySQL is InnoDB, and it is ACID-compliant. There are other types of storage engines as well that store and manipulate the data differently. If you are interested in learning more about what type of storage engines are available for MySQL, you can refer to the following link: https://dev.mysql.com/doc/refman/8.0/en/storage-engines.html.
In the next section, you will take a look at how different applications can connect to your database through the application layer
Data modeling
Data modeling is the conceptual and logical representation of the proposed physical database provided in a visual format using entity relationship (ER) diagrams. An ER diagram represents all the database entities in a way that defines their relationships and properties. The goal of the ER diagram is to lay out the structure of the entities such that they are easy to understand and are implemented later in the database system.
To understand data modeling, there are two crucial concepts you need to be aware of. The first is the primary key. Primary keys are used to uniquely identify a specific record or row in your database. For now, you should know that it enforces the table to have no duplicate rows with the same key. The other concept is the foreign key. The foreign key allows you to link tables together with a field or collection of fields that refer to a primary key of another table.
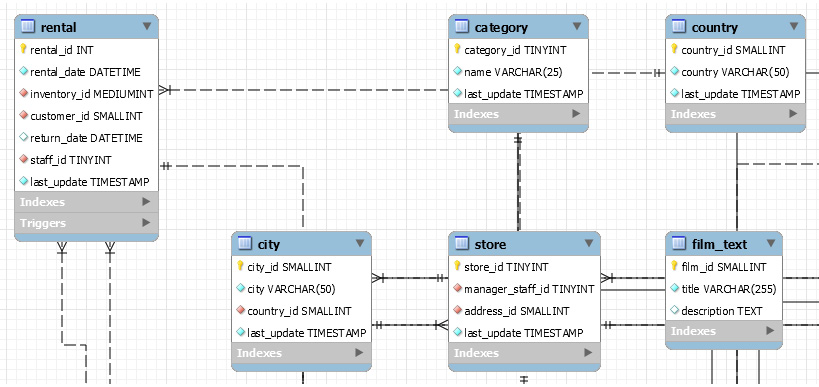
Figure 1.8 – Data model of the sakila database
The preceding screenshot shows you parts of the data model for the sakila database. It shows how different tables are connected and what their relationships are. You can read the relationships through the fields shared between the connected tables. For example, the rental table and category table are connected by the last_update field. The category table is then connected to the country table through the same last_update field. This demonstrates the general structure of the table relationships.
The data model ensures that all the required data objects (including tables, primary keys, foreign keys, and stored procedures) are represented and that the relationships between them are correctly defined. The data model also helps to identify missing or redundant data.
MySQL offers an Enhanced Entity Relationship Diagram for data modeling with which you can interact directly to add, modify, and remove the database objects and set the relationships and indexes. This can be accessed through the Workbench (this is explained in detail in the next chapter). When the model is completed, it can then be used to create the physical database if it does not exist or update an existing physical database.
The following steps describe the process by which a database comes into existence:
- Someone gets an idea for a database and application creation.
- A database analyst or developer is hired to create the database.
- An analysis is performed to determine what data must be stored. This source information could come from another system, documents, or verbal requirements.
- The analyst then normalizes the data to define the tables.
- The database is modeled using the normalized tables.
- The database is created.
- Applications that use the database for reporting, processing, and computation are developed.
- The database goes live.
For example, suppose that you are working on a system that stores videos for users. First, you need to determine how the database will be structured. This includes determining what data needs to be stored, what fields are relevant, what data types the fields should have, and the relationships between the data. For your video database example, you may want to store the video's location on the server, the name of the video, and a description of the video. This might link into a database table that contains ratings and comments for the video. Once this is produced, you can create a database that matches the proposed structure. Finally, you can place the database on a server so that it is live and accessible for users.
In the next section, you will learn about database normalization, which is the act of creating an optimized database schema with as few redundancies as possible with the help of constraints and removing functional dependency by breaking up the database into smaller tables.
Normalization
Normalization is one of the most crucial skills for anyone planning to design and maintain databases. It's a design technique that helps eliminate undesirable characteristics such as insert, update, and delete anomalies and reduces data redundancy. Insert anomalies can come from the lack of primary keys, or the presence of functional dependency. Simply put, you will have duplicate records when there should be none.
If you have a big table with millions of records, the lookup, update, and deletion operations are very time-consuming. The first thing you can do is to give more resources to the server, but that does not scale well. The next thing to do is to normalize the table. This means you try to break up the big table you have into smaller ones and link the smaller tables by relationships using the primary and foreign keys.
This technique was first invented by Edgar Codd, and it has seven distinct forms called normal forms. The list goes from First Normal Form (1NF) to Sixth Normal Form (6NF), and one extra one, which is Boyce-Codd Normal Form (BCNF).
The first normal form states that each cell should contain a single value and each record should be unique. For example, suppose you have a database that stores information about employees. The first normal form implies that each column in your table contains a single piece of information, as shown here.
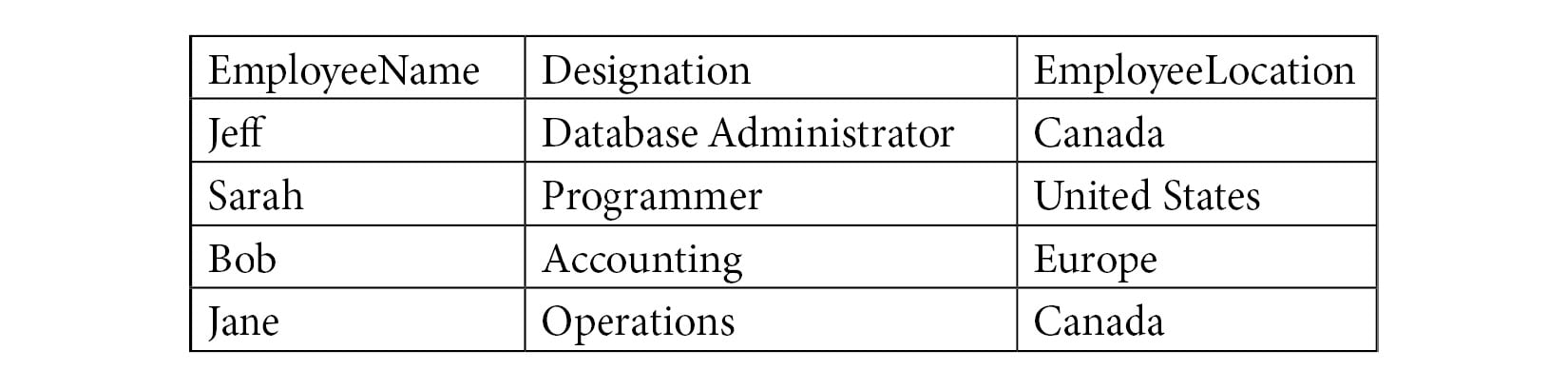
Figure 1.9 – Example of a table in 1NF
The second normal form means the database is in first normal, and it must also have a single-column primary key. With the previous example, you don't currently have a single unique column, since the employee name could duplicate, as well as the title and location. To convert it into a second normal form, you can add an ID as a unique identifier.

Figure 1.10 – Example of a table in 2NF
The third normal form requires the database to be in the second normal form and it is forbidden to have transitive functional dependencies. A transitive functional dependency is when a column in one table is dependent on a different column that is not a primary key. This means that every relationship in the database is between primary keys only. A database is considered normalized if it reaches the third normal form. The table here is in the third normal form, as it has a primary key that can be used to relate to any other tables, without the need for a non-key field:
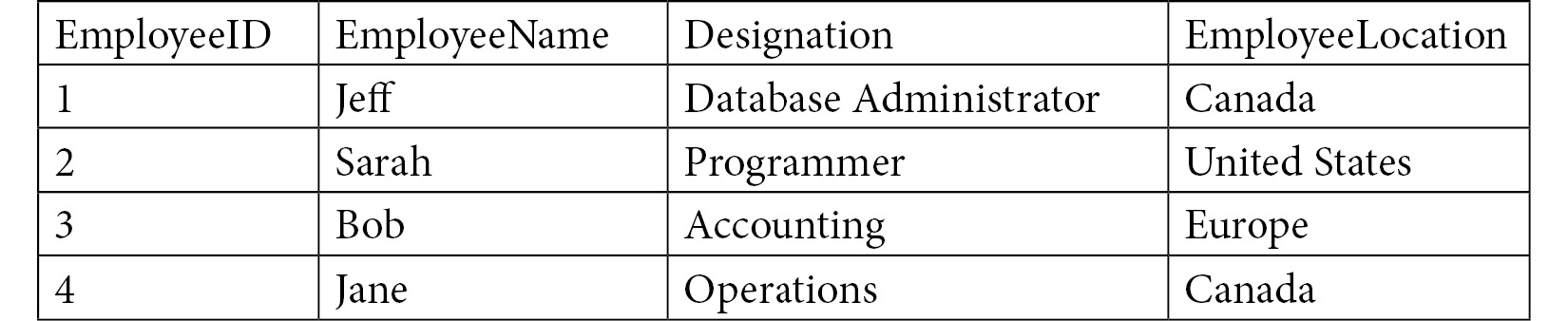
Figure 1.11 – Example of a table in 3NF
For further details, you can visit the following site: https://docs.microsoft.com/en-us/office/troubleshoot/access/database-normalization-description.
Now that you have learned all about working with datasets, let's perform an activity to recap everything we have learned so far in this chapter.
Activity 1.01: Creating an optimized table for an employee project
Your manager asked you to create a database that holds information about network devices in your corporate network site. You may have multiple devices with the same name in the same location. You are required to make the tables conform to the 3NF to make them as efficient as possible. In addition to this, you need to determine the proper data types for each column in the table. Finally, you are required to determine which columns should be primary keys, such that 3NF is satisfied. You have decided to perform the following steps.
- Analyze the following table:

Figure 1.12 – A table of devices on the network
- Identify patterns to determine the data types and possible primary keys. You may need to add a column to the table if an appropriate primary key does not already exist. Next, bring the table to 1NF
- Bring it to 2NF, break down the table, and try to bring it to the 2NF form according to the rule.
- Bring it to 3NF, break it down even further, and bring it to 3NF so the table is in 2NF with the appropriate constraints.
Note
The solution to this activity can be found in the Appendix.
Now you have an optimized table set up, you will be able to use this technique to efficiently optimize your database before you start filling it up with data and deploying it in production.
Summary
In this chapter, you have learned what a relational database is and what the differences are between a DBMS database and an RDBMS database. You learned about the client-server model used by MySQL and had a brief introduction to the MySQL architecture to see how MySQL works.
You then explored what layers make up MySQL, how to define different data models, and added tables to those data models. You also went through the basic concepts of ACID and how to initialize your database.
In the next chapter, you will further improve your knowledge of data modeling, entity relationships, and how to use the MySQL Workbench to set up/configure databases.






